Embed Size (px)
Citation preview

Berkley Data Analysis Stack (BDAS)
Mesos, Spark, Shark, Spark Streaming
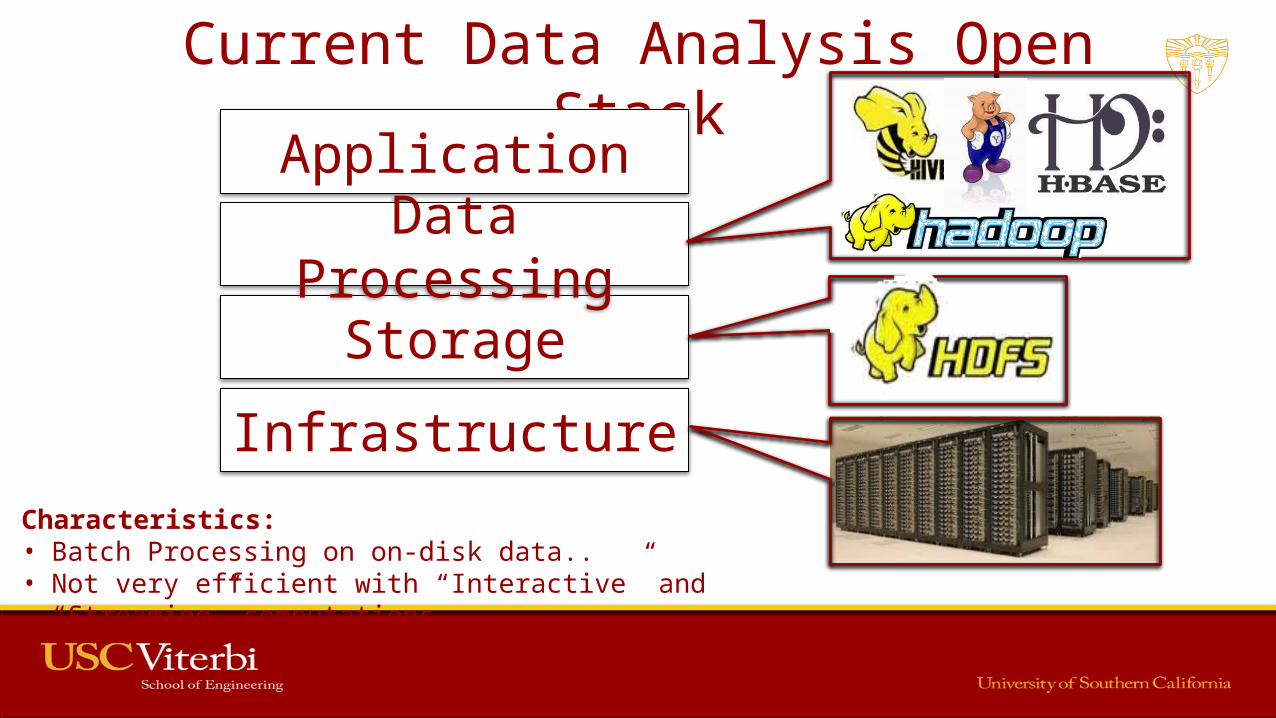
Current Data Analysis Open Stack
Application
Storage
Data Processing
InfrastructureCharacteristics: • Batch Processing on on-disk data..• Not very efficient with “Interactive” and “Streaming” computations.
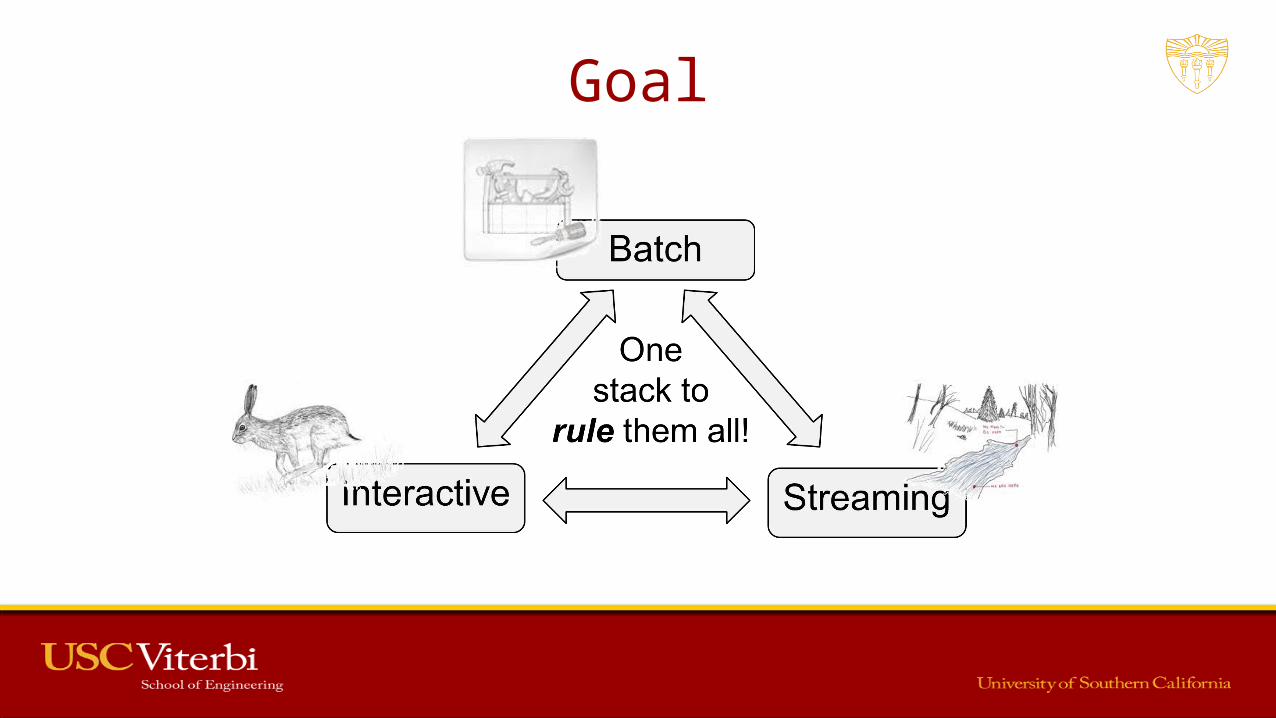
Goal
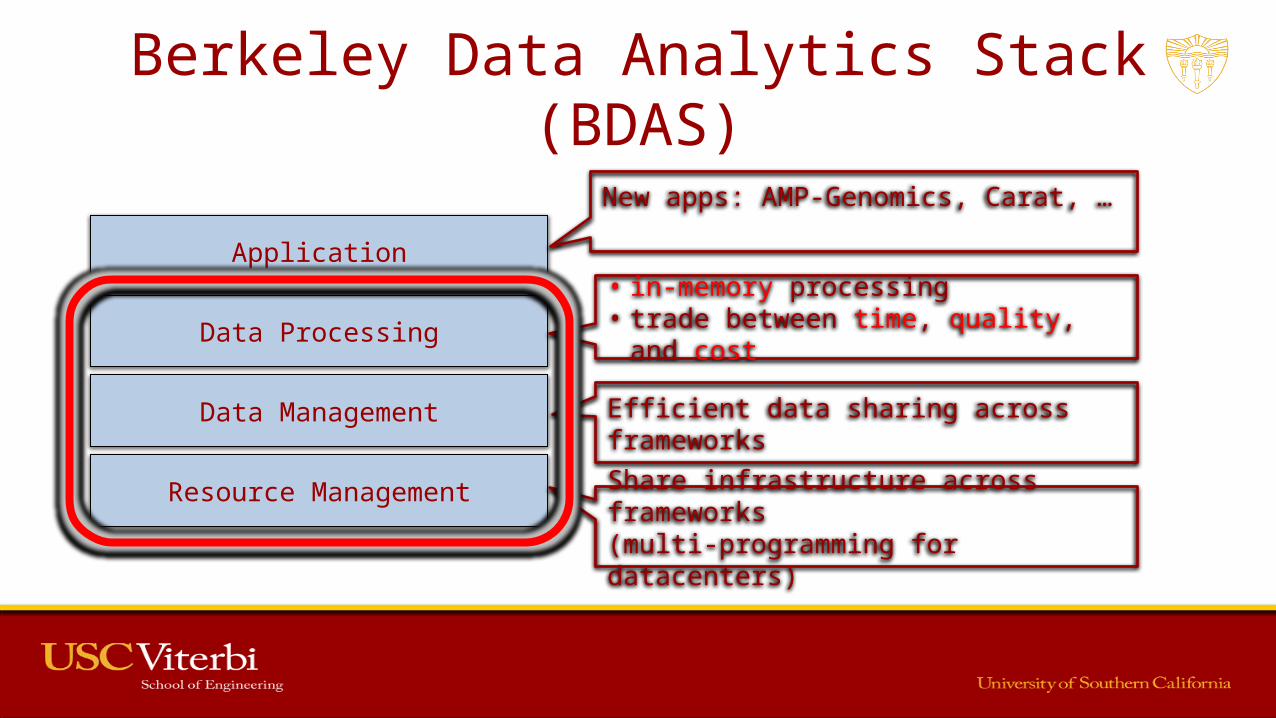
Berkeley Data Analytics Stack (BDAS)
Infrastructure
Storage
Data Processing
Application
Resource Management
Data Management
Share infrastructure across frameworks(multi-programming for datacenters)
Efficient data sharing across frameworks
Data Processing• in-memory processing • trade between time, quality, and cost
ApplicationNew apps: AMP-Genomics, Carat, …

BDAS Components
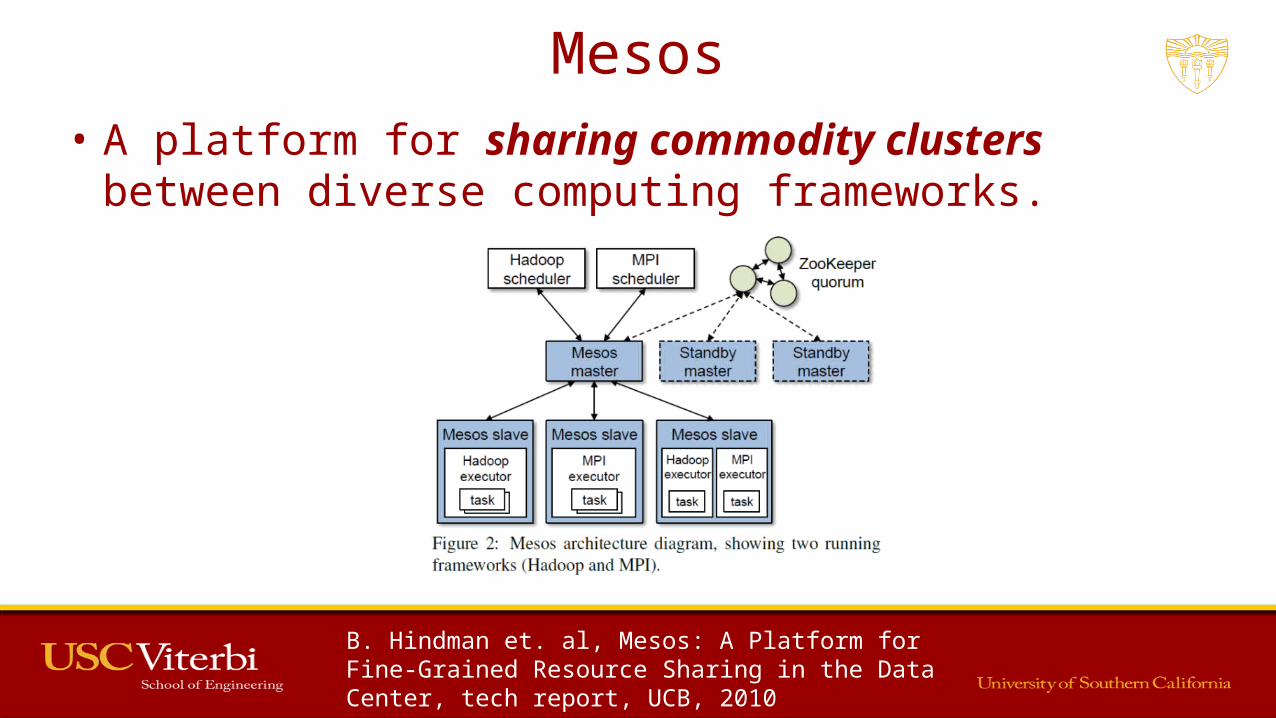
Mesos• A platform for sharing commodity clusters between diverse
computing frameworks.
B. Hindman et. al, Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center, tech report, UCB, 2010

Mesos• “Resource Offers” to publish available resources
B. Hindman et. al, Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center, tech report, UCB, 2010
• Has to deal with “framework” specific constraints (without knowing the specific constraints).
• e.g. data locality.• Allows the framework scheduler to “reject
offer” if constraints are not met.

Mesos• Other Issues:
• Resource Allocation Strategies: Pluggable • fair sharing plugin implemented
• Revocation• Isolation:
• “Existing OS isolation techniques: Linux Containers”.
• Fault Tolerance: • Master: stand by master nodes and zoo keeper • Slaves: Reports task/slave failures to the framework, the latter handles.• Framework scheduler failure: Replicate
B. Hindman et. al, Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center, tech report, UCB, 2010
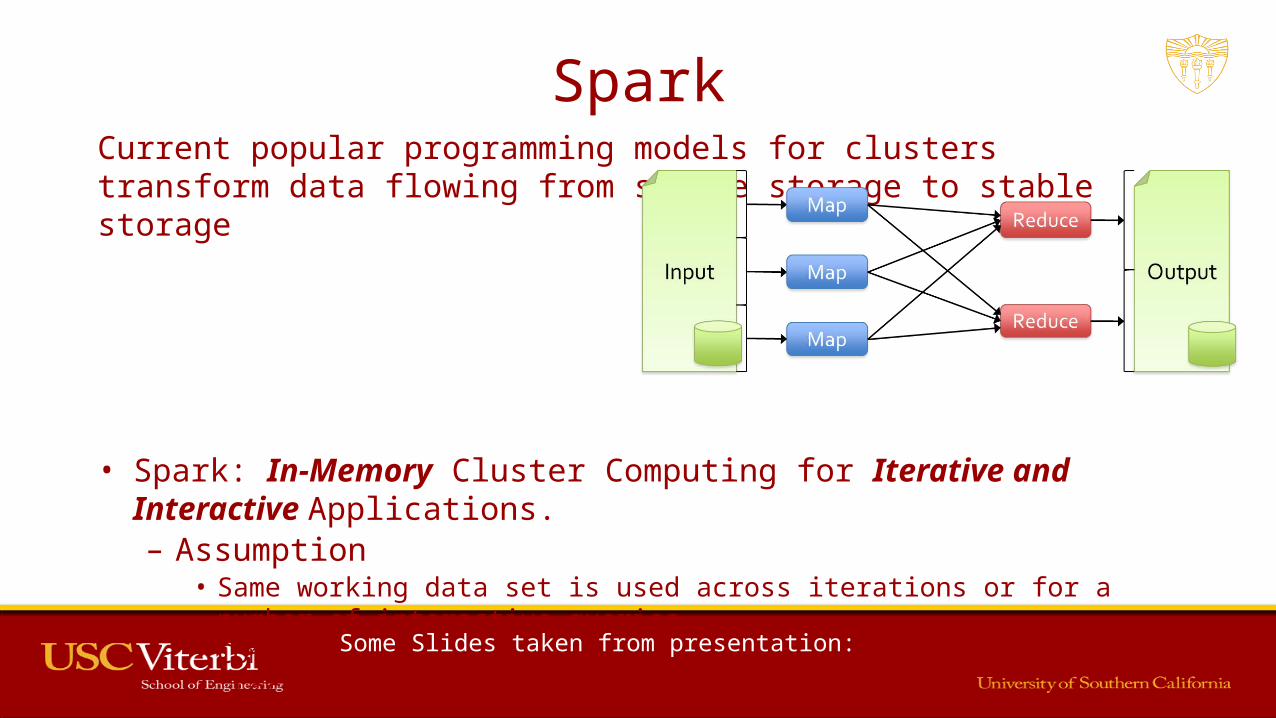
SparkCurrent popular programming models for clusters transform data flowing from stable storage to stable storage
• Spark: In-Memory Cluster Computing for Iterative and Interactive Applications. – Assumption
• Same working data set is used across iterations or for a number of interactive queries.• Commodity Cluster• Local Data partitions fit in Memory
Some Slides taken from presentation:

Spark
• Acyclic data flows – powerful abstractions– But not efficient for Iterative/interactive applications that
repeatedly use the same “working data set”.
Solution: augment data flow model with in-memory “resilient distributed datasets”
(RDDs)

RDDs
• An RDD is an immutable, partitioned, logical collection of records– Need not be materialized, but rather contains information to rebuild a
dataset from stable storage (lazy-loading and lineage)– can be rebuilt if a partition is lost (Transform once read many)
• Partitioning can be based on a key in each record (using hash or range partitioning)
• Created by transforming data in stable storage using data flow operators (map, filter, group-by, …)
• Can be cached for future reuse

Generality of RDDs• Claim: Spark’s combination of data flow with RDDs
unifies many proposed cluster programming models– General data flow models: MapReduce, Dryad, SQL– Specialized models for stateful apps: Pregel (BSP), HaLoop
(iterative MR), Continuous Bulk Processing
• Instead of specialized APIs for one type of app, give user first-class control of distributed datasets

Programming ModelTransformations(define a new RDD)
mapfiltersampleuniongroupByKeyreduceByKeyjoincache…
Parallel operations(return a result to
driver)reducecollectcountsavelookupKey…

Example: Log Mining• Load error messages from a log into memory,
then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(_.startsWith(“ERROR”))
messages = errors.map(_.split(‘\t’)(2))
cachedMsgs = messages.cache()Block 1
Block 2
Block 3
Worker
Worker
Worker
Driver
cachedMsgs.filter(_.contains(“foo”)).count
cachedMsgs.filter(_.contains(“bar”)).count
. . .
tasks
results
Cache 1
Cache 2
Cache 3
Base RDDTransformed RDD
Cached RDDParallel operation
Result: full-text search of Wikipedia in <1 sec (vs 20 sec for on-disk data)

RDD Fault Tolerance
• RDDs maintain lineage information that can be used to reconstruct lost partitions
• Ex: cachedMsgs = textFile(...).filter(_.contains(“error”)) .map(_.split(‘\t’)(2)) .cache()
HdfsRDDpath: hdfs://…
FilteredRDDfunc: contains(...)
MappedRDDfunc: split(…)
CachedRDD

Benefits of RDD Model• Consistency is easy due to immutability• Inexpensive fault tolerance (log lineage rather than
replicating/checkpointing data)• Locality-aware scheduling of tasks on partitions• Despite being restricted, model seems applicable to a broad
variety of applications

Example: Logistic Regression
• Goal: find best line separating two sets of points
+
–
++
+
+
+
++ +
– ––
–
–
–
––
+
target
–
random initial line

Logistic Regression Code
val data = spark.textFile(...).map(readPoint).cache()
var w = Vector.random(D)
for (i <- 1 to ITERATIONS) { val gradient = data.map(p => (1 / (1 + exp(-p.y*(w dot p.x))) - 1) * p.y * p.x ).reduce(_ + _) w -= gradient}
println("Final w: " + w)
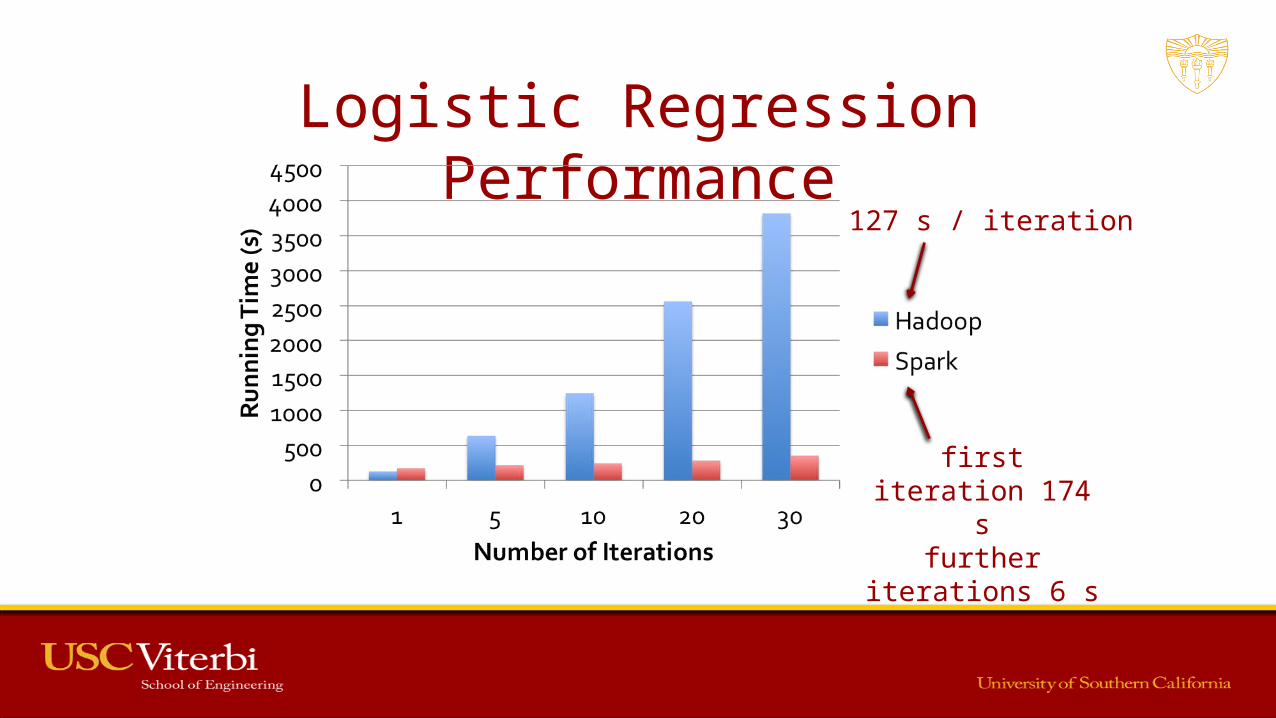
Logistic Regression Performance
127 s / iteration
first iteration 174 s
further iterations 6 s

Page Rank: Scala Implementation
val links = // RDD of (url, neighbors) pairsvar ranks = // RDD of (url, rank) pairs
for (i <- 1 to ITERATIONS) { val contribs = links.join(ranks).flatMap { case (url, (links, rank)) => links.map(dest => (dest, rank/links.size)) } ranks = contribs.reduceByKey(_ + _) .mapValues(0.15 + 0.85 * _)}
ranks.saveAsTextFile(...)

• Fast, expressive cluster computing system compatible with Apache Hadoop– Works with any Hadoop-supported storage system (HDFS, S3, Avro, …)
• Improves efficiency through:– In-memory computing primitives– General computation graphs
• Improves usability through:– Rich APIs in Java, Scala, Python– Interactive shell
Up to 100× faster
Often 2-10× less code
Spark Summary

Spark Streaming
• Framework for large scale stream processing – Scales to 100s of nodes– Can achieve second scale latencies– Integrates with Spark’s batch and interactive processing– Provides a simple batch-like API for implementing complex algorithm– Can absorb live data streams from Kafka, Flume, ZeroMQ, etc.

Requirements
Scalable to large clusters
Second-scale latencies
Simple programming model
Integrated with batch & interactive processing
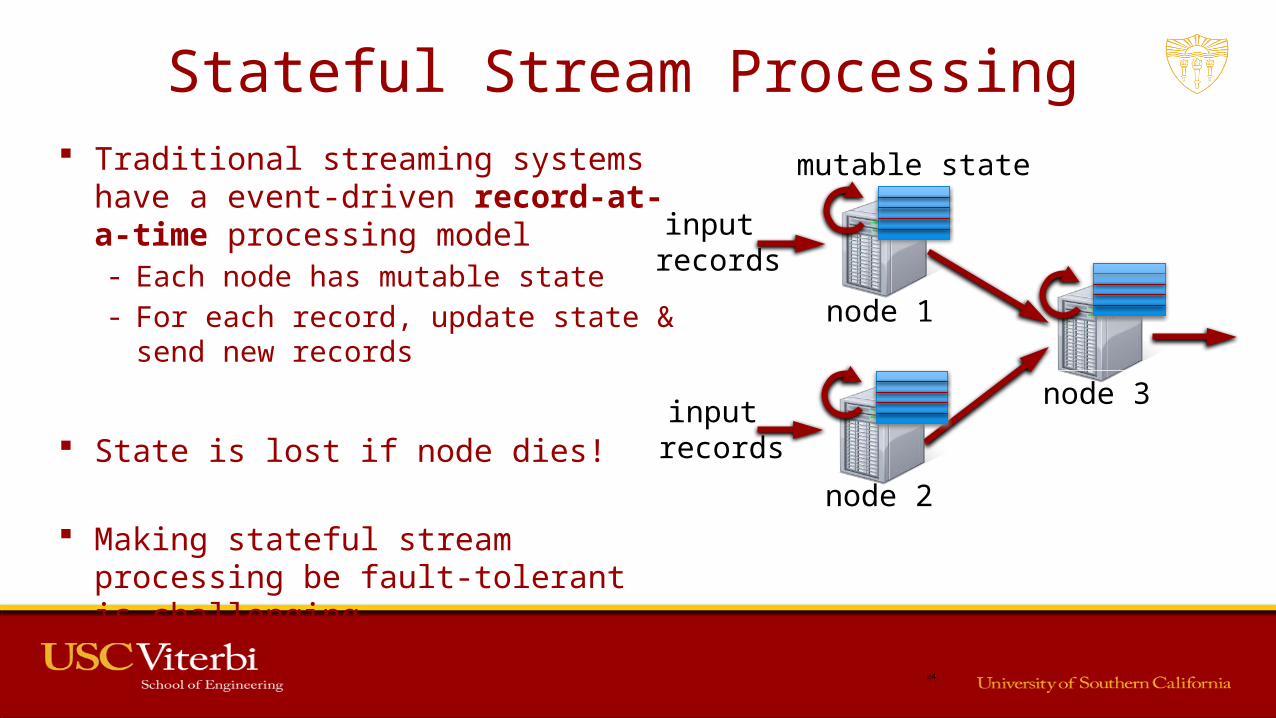
Stateful Stream Processing Traditional streaming systems have a event-
driven record-at-a-time processing model- Each node has mutable state- For each record, update state & send new
records
State is lost if node dies!
Making stateful stream processing be fault-tolerant is challenging
mutable state
node 1
node 3
input records
node 2
input records
24

Discretized Stream Processing
Run a streaming computation as a series of very small, deterministic batch jobs
25
Spark
SparkStreaming
batches of X seconds
live data stream
processed results
Chop up the live stream into batches of X seconds
Spark treats each batch of data as RDDs and processes them using RDD operations
Finally, the processed results of the RDD operations are returned in batches

Example 1 – Get hashtags from Twitter val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)
DStream: a sequence of RDD representing a stream of data
batch @ t+1batch @ t batch @ t+2
tweets DStream
stored in memory as an RDD (immutable, distributed)
Twitter Streaming API
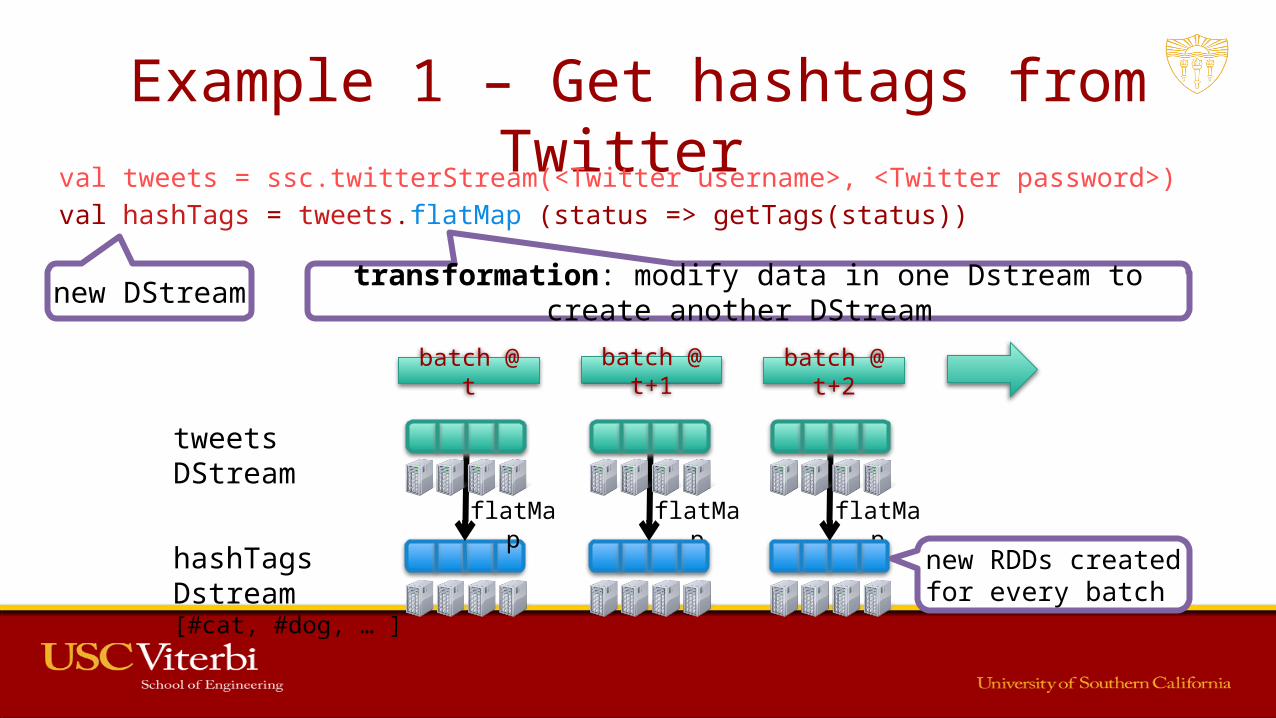
Example 1 – Get hashtags from Twitter val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)val hashTags = tweets.flatMap (status => getTags(status))
flatMap flatMap flatMap
…
transformation: modify data in one Dstream to create another DStream new DStream
new RDDs created for every batch
batch @ t+1batch @ t batch @ t+2
tweets DStream
hashTags Dstream[#cat, #dog, … ]
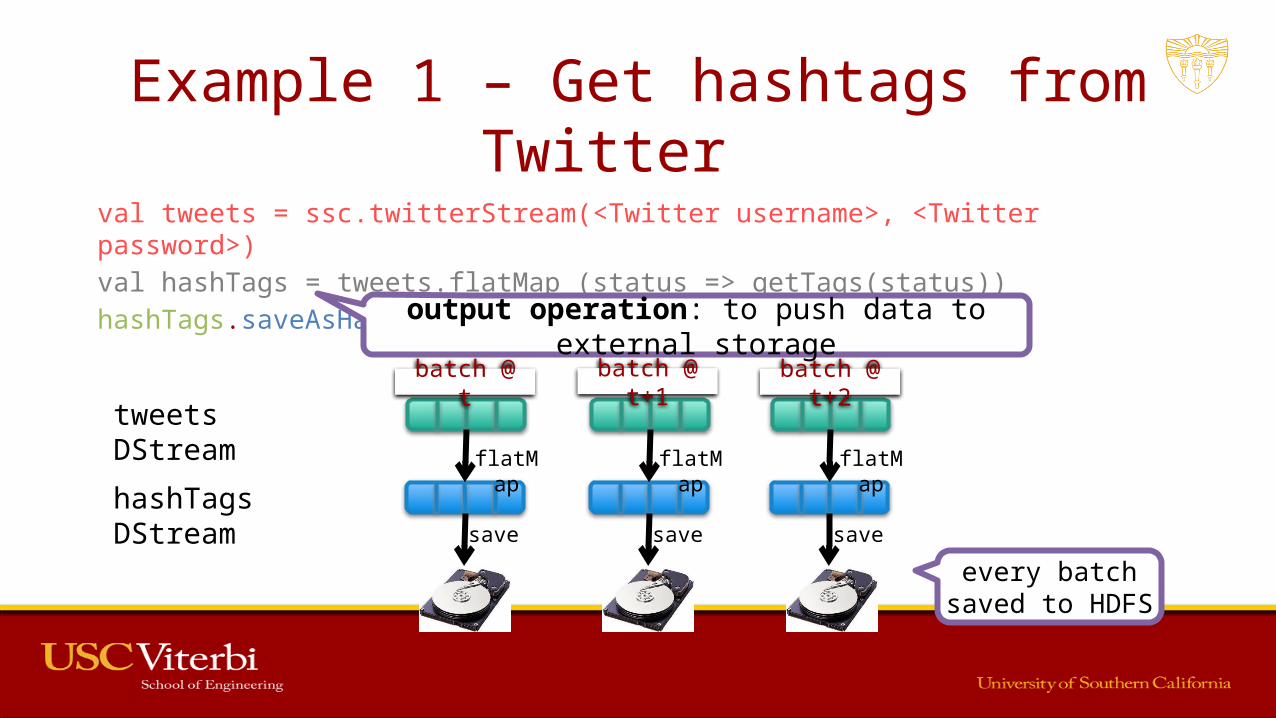
Example 1 – Get hashtags from Twitter
val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)val hashTags = tweets.flatMap (status => getTags(status))hashTags.saveAsHadoopFiles("hdfs://...")output operation: to push data to external storage
flatMap
flatMap
flatMap
save save save
batch @ t+1batch @ t batch @ t+2tweets DStream
hashTags DStream
every batch saved to HDFS
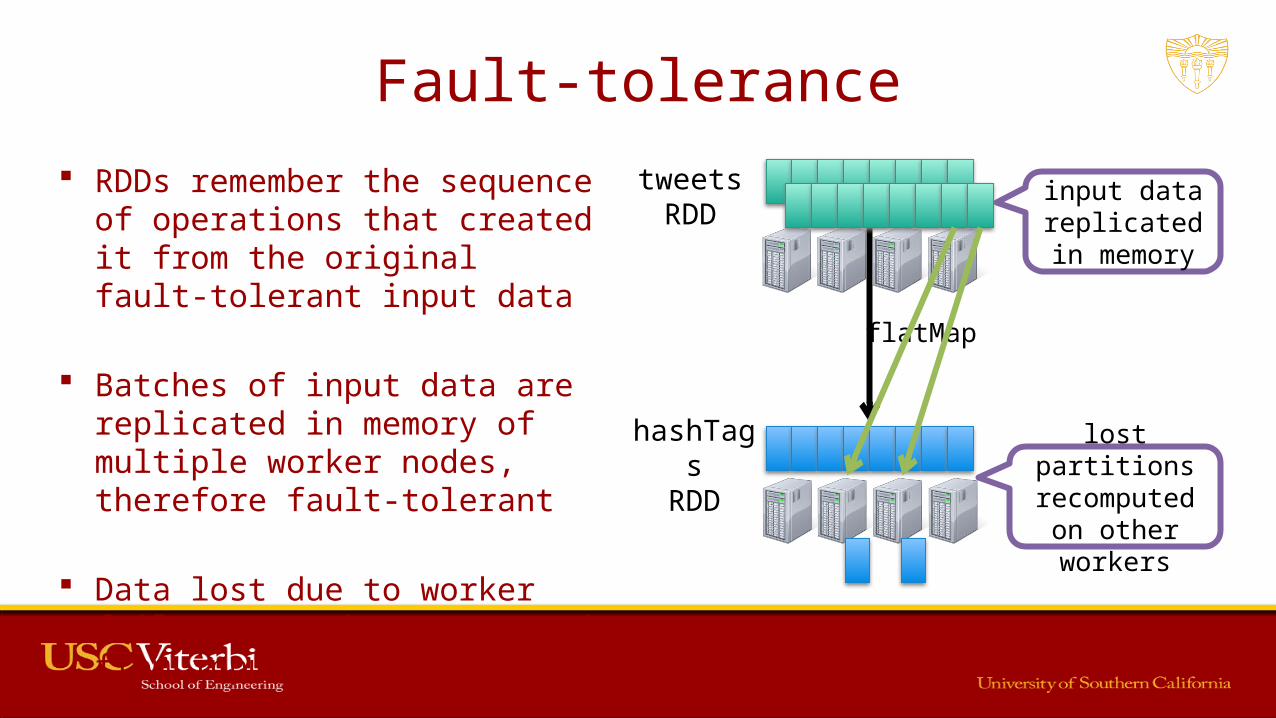
Fault-tolerance RDDs remember the sequence of
operations that created it from the original fault-tolerant input data
Batches of input data are replicated in memory of multiple worker nodes, therefore fault-tolerant
Data lost due to worker failure, can be recomputed from input data
input data replicatedin memory
flatMap
lost partitions recomputed on other workers
tweetsRDD
hashTagsRDD

Key concepts• DStream – sequence of RDDs representing a stream of data
– Twitter, HDFS, Kafka, Flume, ZeroMQ, Akka Actor, TCP sockets
• Transformations – modify data from on DStream to another– Standard RDD operations – map, countByValue, reduce, join, …– Stateful operations – window, countByValueAndWindow, …
• Output Operations – send data to external entity– saveAsHadoopFiles – saves to HDFS– foreach – do anything with each batch of results
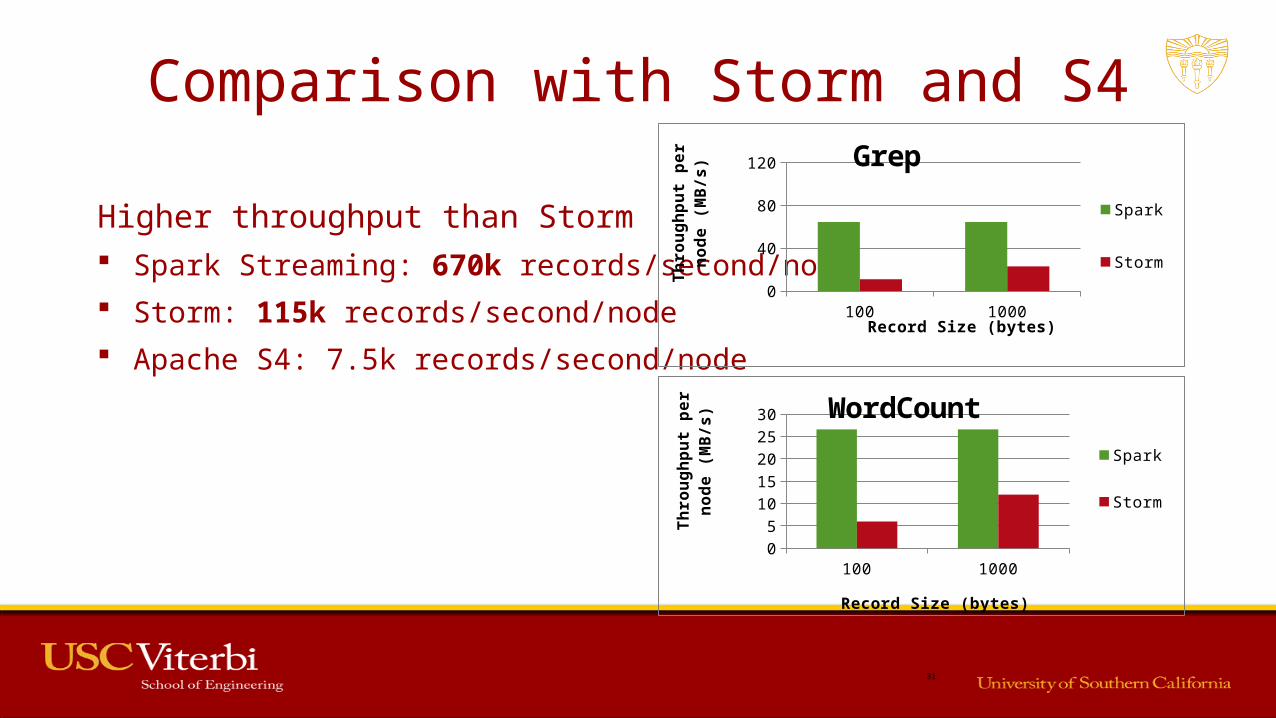
Comparison with Storm and S4
Higher throughput than Storm Spark Streaming: 670k records/second/node Storm: 115k records/second/node Apache S4: 7.5k records/second/node
100 100005
1015202530 WordCount
Spark
Storm
Record Size (bytes)
Thro
ughp
ut p
er n
ode
(MB/
s)
100 10000
40
80
120 Grep
Spark
Storm
Record Size (bytes)
Thro
ughp
ut p
er n
ode
(MB/
s)31





























