Embed Size (px)
Citation preview

���®IBM® Rational® Data Architect
Best Practices Information Modeling with Rational
Data Architect Version 7
Steven Tsounis IT Specialist Information Management
Der Ping Chou Development Manager Information Management

Rational Data Architect Page 2
Executive summary............................................................................................. 5
Introduction to information modeling ........................................................... 6
Assumptions about the reader ..................................................................... 6
Attributes of high quality database designs.................................................. 8
General best practices ........................................................................................ 9
Eclipse and the general Rational Data Architect user experience.......... 9
Defragment your hard drive ............................................................................. 9 Apply the latest fix packs................................................................................... 9 Create an easy to find workspace..................................................................... 9 Save often ............................................................................................................. 9 Minimize the number of open projects and model in the data project explorer............................................................................................................... 10 Learn and update shortcut keys ..................................................................... 10 Create customized perspectives for your specific tasks .............................. 10 Always start clean............................................................................................. 11 Align diagrams for printing during initial diagram creation..................... 11
Additional tips on Printing ............................................................................14 Use local history for comparison and model restoration ............................ 15
How to compare a data model resource with a prior state from the local history ......................................................................................................15 How to restore a workbench or model resource from a prior a historical state ..................................................................................................16
Increase virtual memory available to Rational Data Architect: ................. 16 Increase virtual memory available to the data model import/export bridge in Rational Data Architect: .................................................................. 16 Update import/export bridges to enable or disable the bridges that are available in Rational Data Architect ........................................................ 17 Leverage the model import function to speed up modeling ...................... 18
Best practices for Eclipse and the general Rational Data Architect user experience ...................................................................................................... 20
Establishing standards..................................................................................... 21
Naming standards ....................................................................................... 21
How to define naming standards – Name component ordering in Rational Data Architect .................................................................................... 23 How to define naming standards – Physical object naming standards template.............................................................................................................. 24

Rational Data Architect Page 3
Best practices for naming standards......................................................... 25
Additional commentary on best practices for naming standards.............. 25 Understanding the structure of a glossary model in Rational Data Architect ............................................................................................................. 27 How to create a glossary model...................................................................... 28 Populating a glossary model in Rational Data Architect: Important points of interest................................................................................................ 29 Analyzing a model using a glossary .............................................................. 31
Best practices for glossary models............................................................ 34
Domain standards ....................................................................................... 34
How to create a domain: .................................................................................. 34 Best practices for domains: ........................................................................ 37
Logical data modeling in Rational Data Architect ..................................... 38
Table normalization and denormalization ............................................. 38
Complying with first normal form................................................................. 39 Complying with second normal form............................................................ 40 Complying with third normal form ............................................................... 41 Denormalization ............................................................................................... 42
Best practices for normalization in logical data models ...................... 43
Generalization relationships ..................................................................... 43
Best practices for generalization relationships ...................................... 45
Team sharing ................................................................................................ 45
Separate logical entities using packages........................................................ 45 Create submodels from packages................................................................... 46
How to create a submodel from a package..................................................46 Best practices for team sharing ................................................................. 47
Physical data modeling in Rational Data Architect ................................... 48
Normalization and denormalization ....................................................... 48
Best practices for normalization and denormalization ........................ 49
Index design .................................................................................................. 49
Best practices for index design................................................................... 50
Referential integrity .................................................................................... 50
Best practices for referential integrity...................................................... 51

Rational Data Architect Page 4
Model transformation and deployment ....................................................... 52
Model transformation and physical model deployment ....................... 52
Model validation and analysis ........................................................................ 52 Traceability ........................................................................................................ 54 Impact analysis.................................................................................................. 55
Best practices for model transformation ................................................. 56
Best practices for deploying a physical data model............................... 56
Lifecycle management...................................................................................... 56
Comparison................................................................................................... 56
Object comparison ............................................................................................ 56 Best practice for comparing objects.......................................................... 56
Mapping models........................................................................................... 57
Create mapping models even if transformation logic is ignored .............57 Leverage mapping discovery algorithms.....................................................60
Best practices for mapping models ........................................................... 62
Education ............................................................................................................ 63
Best practices for user education............................................................... 63
Check developerWorks for newest articles on Rational Data Architect ........................................................................................................... 63 Check for updates to this document: ...................................................... 63 Participate in the wiki for this document: ................................................ 64
Best practices summary.................................................................................... 65
Conclusion.......................................................................................................... 70
Further reading.................................................................................................. 71
Contributors ................................................................................................. 72
Notices................................................................................................................. 73
Trademarks ................................................................................................... 74

Rational Data Architect Page 5
Executive summary
Database and Information design is a very important, yet commonly overlooked part of the system development lifecycle. By establishing and employing standards in design and using proven design methodologies, organizations can create highly reusable models that satisfy business requirements. Rational Data Architect is an information modeling tool that can be used to facilitate communication and understanding between business and IT associates in an organization. Leveraging Rational Data Architect and the modeling best practices from this paper can help organizations experience benefits, such as:
Improving efficiency of IT organization members:
o Business analyst
o Data modeler or data architect
o Database administrator
o Data governance steward
Providing a structured, standardized form of communication between business and IT departments
Leveraging and reusing existing investments
Reducing data duplication
Improving the documentation of systems
Streamlining the standardization processes by employing naming and domain standards
Reducing of syntax errors
Providing foresight—the ability to model the future before implementing it
Data modeling is a very interesting skill because there are always different ways to model the same requirements, and each method will often have its own advantages and disadvantages. While it is difficult to say that one way of creating a model is better than another way, there are some basic rules that can lead to flexible models that can accommodate future requirements.
The document shares insights gained from the experiences of a team of data modelers using Rational Data Architect within IBM.

Rational Data Architect Page 6
Introduction to information modeling
Information modeling is the end-to-end design effort required to transform business requirements into a business model and ultimately into a database platform–specific technology model. Business data models are called logical models, whereas the platform specific models are called physical models.
Logical model design includes the following items:
Establishing naming and domain standards
Designing a normalized model (at least third normal form)
Definition of entities, their attributes, and the relationships between them.
Physical model design includes the following items:
Table denormalization
Performance objects such as indexes, materialized query tables, and partitioning
Database storage object allocation
Ultimately, you can use physical models to generate code to deploy the model into a database system. Rational Data Architect can compare and synchronize models and the databases resulting from the models, thus supporting the full database lifecycle capabilities.
Rational Data Architect goes beyond traditional data modeling by supporting XML schema modeling functionality. However, this paper focuses only on database modeling best practices.
Assumptions about the reader
This paper assumes you are familiar with data modeling and the associated concepts. Therefore, only a very brief description is provided for each concept. This paper focuses on the best practices for applying these concepts and features within Rational Data Architect. For details on the product features, refer to the Rational Data Architect documentation.
People who are familiar with physical data models sometimes confuse entities and attributes, and tables and columns. Entities and attributes are logical constructs in a logical data model, and their counterparts in a physical model are tables and columns. This document assumes that readers are familiar with the differences between logical and physical data modeling and the terminology associated with each discipline.
This paper refers to Rational Data Architect Version 7. IBM has recently released Rational Data Architect Version 7.5, and the best practices described in this

Rational Data Architect Page 7
document might not be best practices in Rational Data Architect 7.5 or future releases of Rational Data Architect.

Rational Data Architect Page 8
Attributes of high quality database designs
The goals of database design are to produce high quality logical and physical data models.
High quality logical data models have the following traits:
They are in third normal form (3NF).
They comply with naming and domain standards
They are documented appropriately using diagrams that convey the model clearly to interested parties
They are created from and correlated to specific business requirements
High quality physical data models have the following traits:
They minimizes I/O
They balance design features used for the efficiency of query performance with the overhead of transaction and maintenance operations
They improve the efficiency of database management, such as roll-in and roll-out of data.

Rational Data Architect Page 9
General best practices
This section describes some basic principles of using any software tool that should be followed when using Rational Data Architect.
Eclipse and the general Rational Data Architect user experience
Defragment your hard drive Like most applications, Rational Data Architect can create fragmented files on your hard drive over time. Maintain optimal performance of all of your desktop applications by periodically defragmenting your hard drive.
This is very important to do after the initial installation along with the application of subsequent fixpacks.
Apply the latest fix packs A new fix pack for Rational Data Architect is released about every three months. Be sure to check for updates periodically.
If you use the IBM Installation Manager, click the update packages icon in the Installation Manager to apply updates.
However, if a silent installation was used to install the product, contact your installation administrator to work out the details of a fixpack schedule.
Information on the latest fixpacks can be found at the Rational Data Architect Support website:
http://www.ibm.com/software/data/integration/support/rda/
Create an easy to find workspace The workspace contains all of your project files that are created using Rational Data Architect. Some of the workspace customizations that you make are stored in an important metadata folder.
If you want to examine project log file, you will need to know the location of this folder.
To make the metadata folder easier to find, you might want to move your active workspace from the default directory to something easier to find such as C:\Workspace\Workspace_Name.
Save often Saving often prevents lost work. Rational Data Architect is context specific when using Ctrl+S to save a modeling artifact. If you click on a diagram, it saves the

Rational Data Architect Page 10
diagram, if you are in a glossary model, it saves the glossary model. To save all of the changes you made in a workspace, use Ctrl+Shift+S.
If you accidentally save unwanted work, Rational Data Architect provides many methods of backtracking and undoing saved changes. For one method, see the section called “Use local history for comparison and model restoration”
Minimize the number of open projects and model in the data project explorer Whenever you open a project or model in Rational Data Architect, memory is allocated to processes that handle the objects. If too much memory is used, the memory will start paging and have a negative impact on the performance of your system. If you have a lot of models or projects in your workspace and you are only working on one of them, close the rest of the objects. When a model is opened, Rational Data Architect will prompt the user to open related resources, so you don’t have to worry about remembering which models have related objects between them.
Learn and update shortcut keys As with most desktop applications, keyboard shortcut keys can help improve your efficiency.
You can customize the shortcut keys in Rational Data Architect. To see the list of shortcut keys, select Window > Preferences > General > Keys. You see a screen similar to one shown below:
Create customized perspectives for your specific tasks
In Rational Data Architect, you can customize the layout of a perspective. You can undock views and move them around or even close them. Open additional views by selecting Windows > Show View. You can also use this menu option to find a view if you accidentally close a view that you need in a perspective.
When the layout of the perspective meets your needs, save the perspective and give it a name that you will remember.
Rational Data Architect Page 11
For more information, view the video tutorial in the Rational Data Architect Information Center: http://publib.boulder.ibm.com/infocenter/rdahelp/v7r5/topic/com.ibm.etools.workbench.tutorial.doc/topics/wbt_lesson4.html
Always start clean Always start Rational Data Architect using the –clean option. This option cleans cached data used by the OSGi framework and the Eclipse runtime environment and helps avoid rare startup errors caused by anomalies in the cached data after install, update, or when using a shared configuration. Modify the properties of the Rational Data Architect shortcut to include the –clean option (For example, "C:\Program Files\IBM\SDP70\eclipse.exe" -clean -product com.ibm.rational.rda.product.ide). In Microsoft Windows®, right click the shortcut, choose properties, then add the ‘-clean’ parameter to the end of the Target.
Align diagrams for printing during initial diagram creation
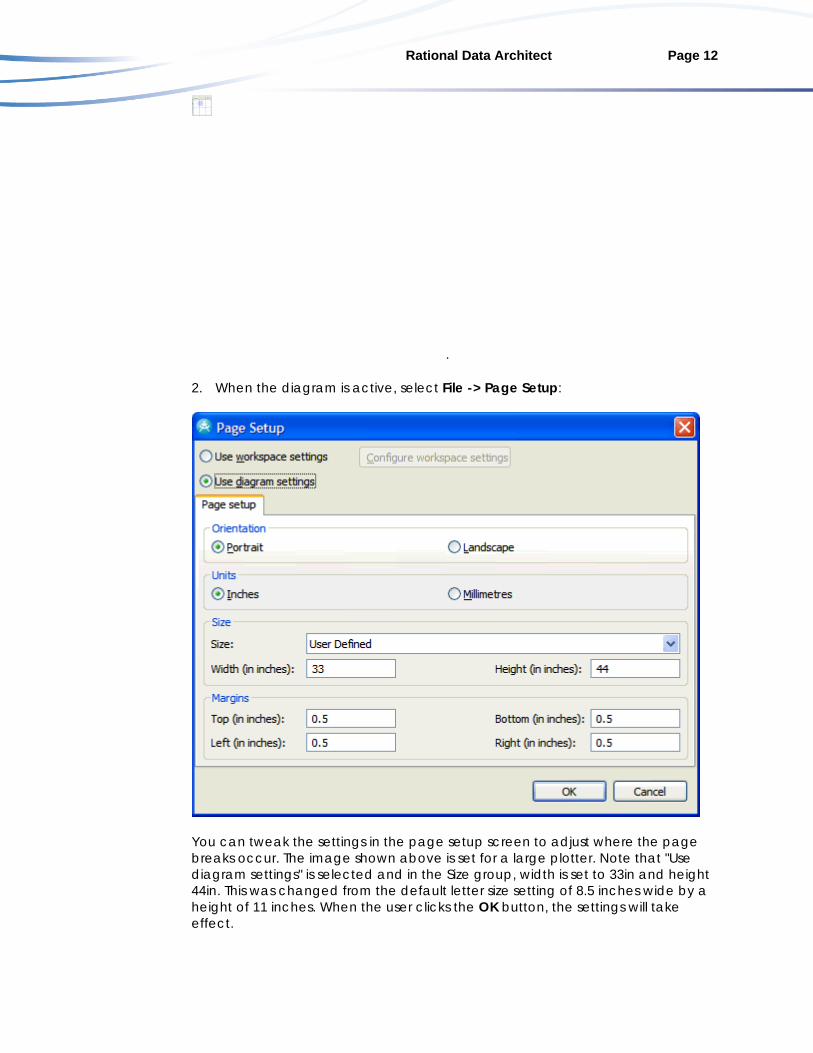
When you start to build a diagram of your data model, you should take future printouts into consideration. This will enable you to avoid having to redesign the diagram again in the future. In order to understand how the diagram will be printed while you are building the diagram, use the following productivity tips for printing or plotting a Rational Data Architect diagram: 1. Right-click the diagram surface area and select View -> Page Breaks. The
outline view of your diagram shows lines indicating how the diagram is split across pages:
Rational Data Architect Page 12
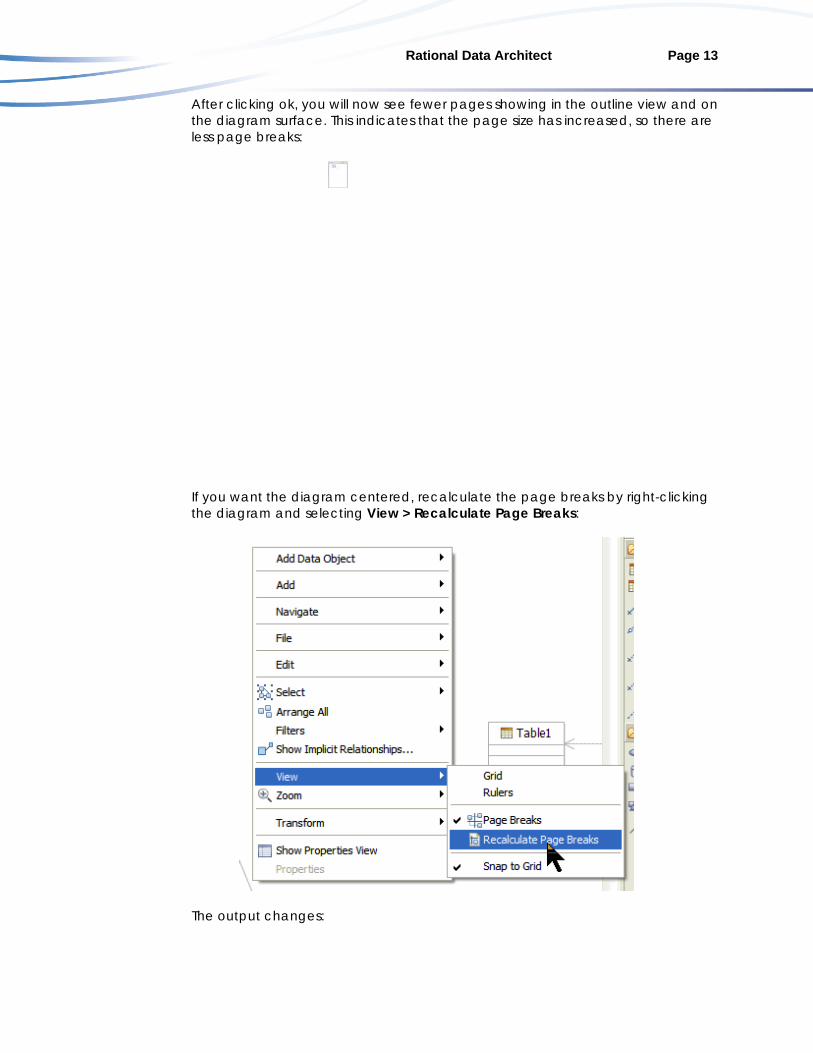
. 2. When the diagram is active, select File -> Page Setup:
You can tweak the settings in the page setup screen to adjust where the page breaks occur. The image shown above is set for a large plotter. Note that "Use diagram settings" is selected and in the Size group, width is set to 33in and height 44in. This was changed from the default letter size setting of 8.5 inches wide by a height of 11 inches. When the user clicks the OK button, the settings will take effect.
Rational Data Architect Page 13
After clicking ok, you will now see fewer pages showing in the outline view and on the diagram surface. This indicates that the page size has increased, so there are less page breaks:
If you want the diagram centered, recalculate the page breaks by right-clicking the diagram and selecting View > Recalculate Page Breaks:
The output changes:
Rational Data Architect Page 14
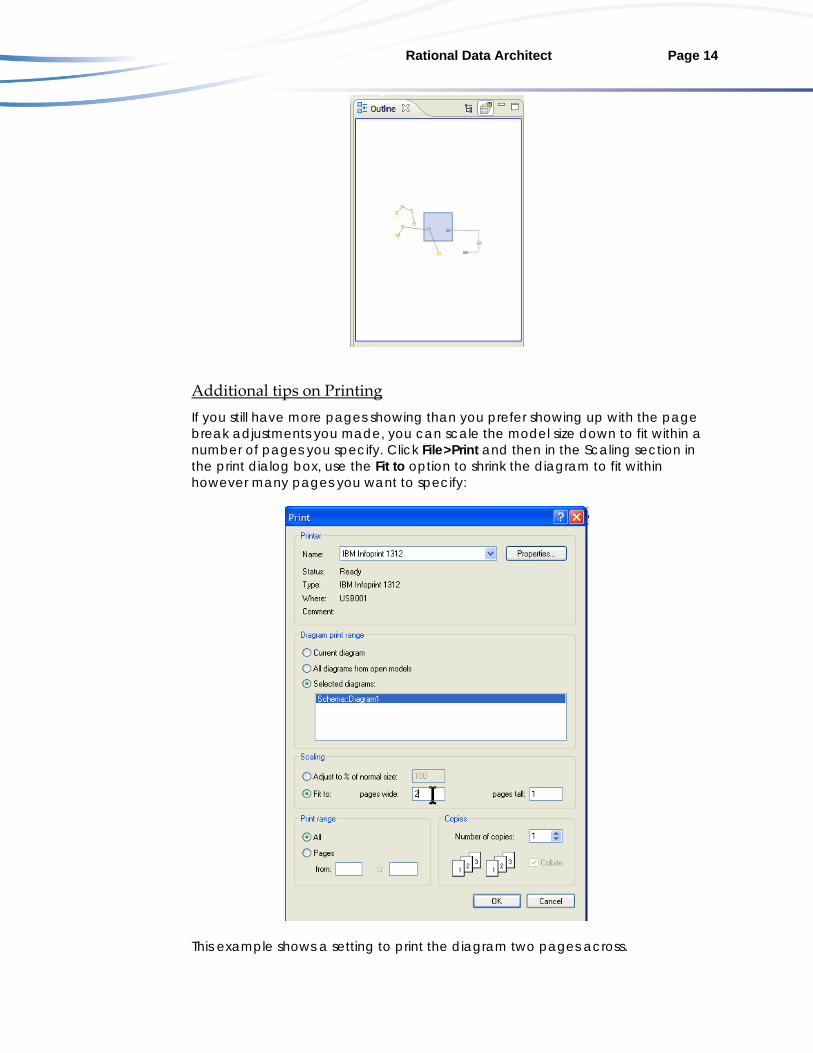
Additional tips on Printing If you still have more pages showing than you prefer showing up with the page break adjustments you made, you can scale the model size down to fit within a number of pages you specify. Click File>Print and then in the Scaling section in the print dialog box, use the Fit to option to shrink the diagram to fit within however many pages you want to specify:
This example shows a setting to print the diagram two pages across.

Rational Data Architect Page 15
Use local history for comparison and model restoration A local edit history of model files (for example, .pdm or .ldm) is maintained when you create or modify a file in Rational Data Architect. Each time you edit and save the file, a snapshot copy is saved. You can use this snapshot copy to replace the current file with a previous edit or even restore a deleted file. You can also compare the contents of all the local edits. Each edit in the local history is represented uniquely by the date and time the file was saved. Use the "Replace with Local History" function to recover prior versions of your files. This would restore some of the work you might have saved while working on your project. If you want to see the difference between different versions that have been saved, use the “Compare with Local History” function. The details on using these functions are explained in the next two sections starting on the next page of this document. You can configure your workbench preferences to specify how many days to keep files, or how many entries per file you want to keep, or the maximum file size for files to be kept. Select Window > Preferences and then click General > Workspace > Local History to change these settings. To increase the maximum file size of your local history, select Window > Preferences and then click General > Workspace > Local History. You can set the options for how long you want to keep history and how large your history file can be. The default history files size is 1 MB, which is relatively small. The maximum file size allowed is 100 MB. As a best practice, increase the file size to the largest size you can afford. You also might want to keep the history for a longer period of time than the default 7 days—set Days to keep files to a longer period of time. There are no obvious drawbacks to keeping changes in models for a long period of time, except that the file size grows to the maximum file size that is specified. The recommendation is to set it to a minimum of 183 days (approximately six months).
How to compare a data model resource with a prior state from the local history 1. In the data project explorer view, select a model that you want to
compare with the local history. 2. If you select a specific data model, you can right click on the data model
and choose Compare With > Local History. The Compare From Local History dialog box opens showing the history of edits between the current version of the resource selected and a historical version of the resource, which is determined by the timestamp that you click on (Rational Data Architect defaults to the most recent historical version). This functionality can help you to determine which version of a model you want to restore from. This is explained in the next section.

Rational Data Architect Page 16
3. Click Ok to close the dialog box.
How to restore a workbench or model resource from a prior a historical state 1. In one of the navigation views, select the folder or project into which you
want to restore a local history state. 2. If you are on the project level, right click on the resource and select
Restore from Local History… If you select a specific data model, you can right click on the data model and choose Replace With > Local History…. The Restore From Local History dialog box opens showing the history of edits to the resources.
3. Select the files that you want to restore. If you do not want to restore the
last state of a file, select any other state of the file from the Local History list in the dialog box. The bottom pane of the dialog shows the contents of the state.
4. Click Replace.
Increase virtual memory available to Rational Data Architect: If you are working with large models and want to improve the performance of Rational Data Architect, increase the memory available to the Rational Data Architect Eclipse instance. If you installed Rational Data Architect in the default directory specified the first time you use the IBM Installation Manager, you would need to follow these instructions: 1. Close Rational Data Architect. 2. Go to C:\Program Files\IBM\SDP70\eclipse.ini 3. Change the value(@@@) in the –Xmx@@@m line, to the amount of
memory that you want to allocate to Rational Data Architect. For example, if you want 768 MB of memory to be used, the value to the following: -Xmx768m
4. Save and close the file. 5. Start Rational Data Architect.
Increase virtual memory available to the data model import/export bridge in Rational Data Architect: The import/export bridge might fail if the model is too big and the memory settings are too low. You can improve the performance of the import/export bridge by increasing its available virtual memory. Warning: Do not allocate more than 768MB of memory to the import bridge. In Rational Data Architect version 7, if you increase the memory for this bridge beyond 768MB of memory, the bridge will fail to execute properly. To increase the amount of virtual memory available to the Rational Data

Rational Data Architect Page 17
1. For Rational Data Architect V7, open the MIRsetup.xml file in a plain text editor, like Notepad. The path to MIRsetup.xml is similar to the following path: C:\Program Files\IBM\SDP70Shared\plugins\com.ibm.datatools.metadata.wizards.miti.win32_1.variable_part\MetaIntegration\conf\MIRSetup.xml, where variable_part varies depending on your version of Rational Data Architect.
2. Go to the section that has the following text:
Purpose: JRE or JDK execution Options Value: Run time option string (optional) Default: "-Xmx256m" to allocate more memory --> <Options></Options>\
3. Enter the amount of memory that you want to allow the import/export bridge to use in between the Options tags(in this example, we boosted the bridge to use 768 Mb of RAM):
<Options>-Xmx768m </Options>
Warning: Do not allocate more than 768MB of memory to the import bridge. In Rational Data Architect version 7, if you increase the memory for this bridge beyond 768MB of memory, the bridge will fail to execute properly.
4. Save and close the file. Open Rational Data Architect and the bridge will now
use more memory.
Update import/export bridges to enable or disable the bridges that are available in Rational Data Architect Rational Data Architect includes a significant number of import and export bridges that can be used share metadata between various products. Due to the large number of bridges available, Rational Data Architect only includes the most commonly requested bridges as part of the product installation. However, you can manually update the bridges that are available to the product by locating the MIRModelBridges.xml file and updating the bridges. The default directory for the MIRModelBridges.xml file is C:\Program Files\IBM\SDP70Shared\plugins\com.ibm.datatools.metadata.wizards.miti.win32_1.0.1.vYYYYMMDDHHMM\MetaIntegration\conf YYYMMDDHHMM differs depending on the version and fix pack level of Rational Data Architect being used. It represents the Year, Month, Day, Hour, and Minutes using YYYYMMDDHHMM format. The higher the date, the newer the fix pack level that the folder contains plug-ins for. Therefore, if you are on the newest fix pack, you want to choose the highest date. There are two major sections in the XML document. The Import section contains the import bridges and begins with the <Import> tag and ends with the </Import> tag. The export section contains the export bridge and begins with the <Export> tag and ends with the </Export> tag.
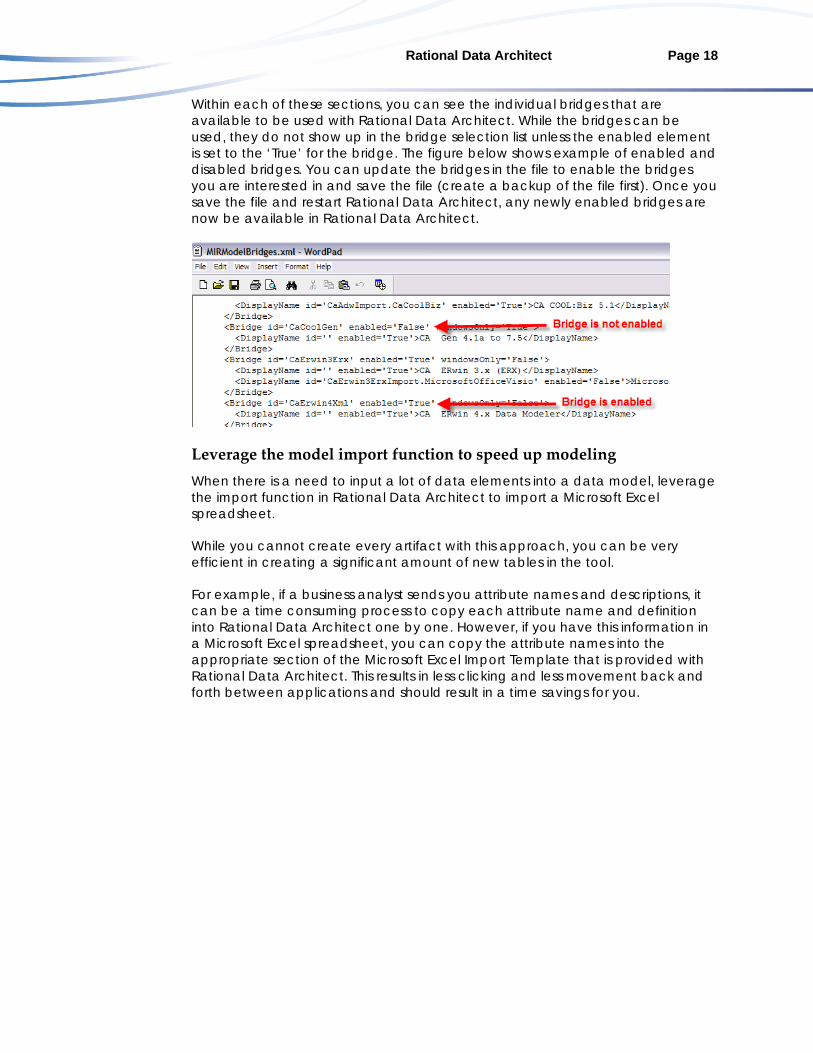
Rational Data Architect Page 18
Within each of these sections, you can see the individual bridges that are available to be used with Rational Data Architect. While the bridges can be used, they do not show up in the bridge selection list unless the enabled element is set to the ‘True’ for the bridge. The figure below shows example of enabled and disabled bridges. You can update the bridges in the file to enable the bridges you are interested in and save the file (create a backup of the file first). Once you save the file and restart Rational Data Architect, any newly enabled bridges are now be available in Rational Data Architect.
Leverage the model import function to speed up modeling When there is a need to input a lot of data elements into a data model, leverage the import function in Rational Data Architect to import a Microsoft Excel spreadsheet.
While you cannot create every artifact with this approach, you can be very efficient in creating a significant amount of new tables in the tool.
For example, if a business analyst sends you attribute names and descriptions, it can be a time consuming process to copy each attribute name and definition into Rational Data Architect one by one. However, if you have this information in a Microsoft Excel spreadsheet, you can copy the attribute names into the appropriate section of the Microsoft Excel Import Template that is provided with Rational Data Architect. This results in less clicking and less movement back and forth between applications and should result in a time savings for you.
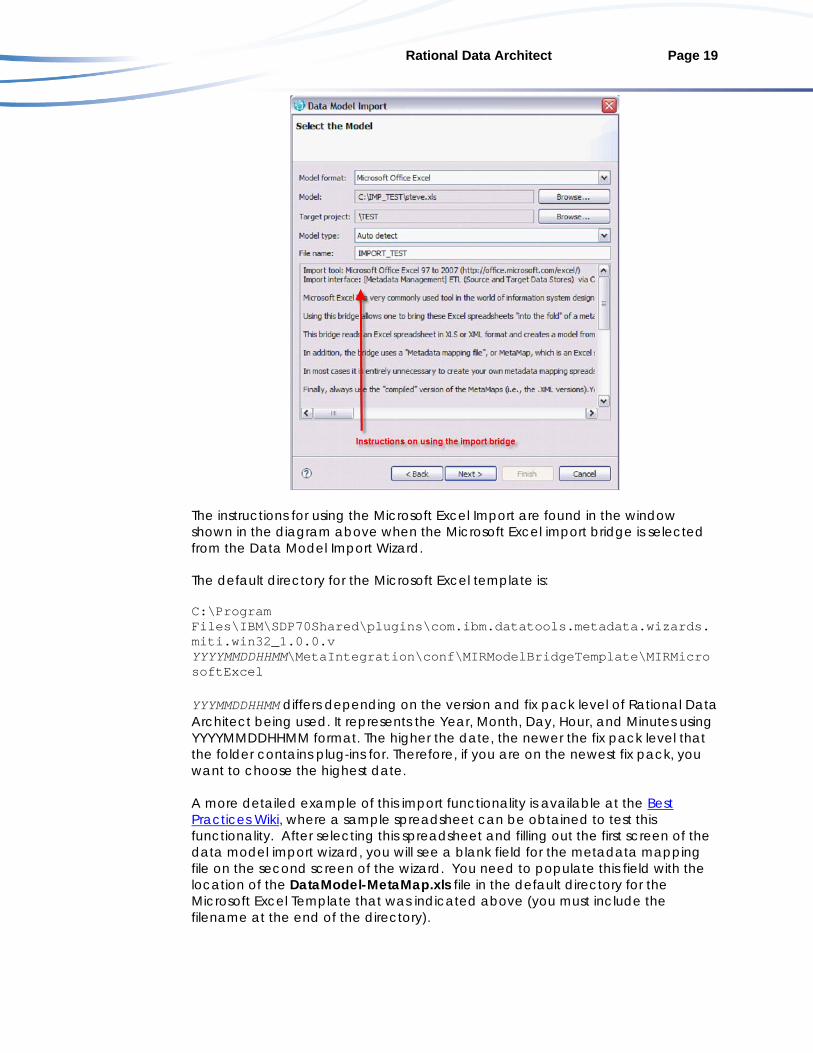
Rational Data Architect Page 19
The instructions for using the Microsoft Excel Import are found in the window shown in the diagram above when the Microsoft Excel import bridge is selected from the Data Model Import Wizard.
The default directory for the Microsoft Excel template is:
C:\Program Files\IBM\SDP70Shared\plugins\com.ibm.datatools.metadata.wizards.miti.win32_1.0.0.v YYYYMMDDHHMM\MetaIntegration\conf\MIRModelBridgeTemplate\MIRMicrosoftExcel YYYMMDDHHMM differs depending on the version and fix pack level of Rational Data Architect being used. It represents the Year, Month, Day, Hour, and Minutes using YYYYMMDDHHMM format. The higher the date, the newer the fix pack level that the folder contains plug-ins for. Therefore, if you are on the newest fix pack, you want to choose the highest date. A more detailed example of this import functionality is available at the Best Practices Wiki, where a sample spreadsheet can be obtained to test this functionality. After selecting this spreadsheet and filling out the first screen of the data model import wizard, you will see a blank field for the metadata mapping file on the second screen of the wizard. You need to populate this field with the location of the DataModel-MetaMap.xls file in the default directory for the Microsoft Excel Template that was indicated above (you must include the filename at the end of the directory).

Rational Data Architect Page 20
Best practices for Eclipse and the general Rational Data Architect user experience
Defragment your hard drive.
Apply the latest fix pack.
Create a directory that is easy to find to store workspace information.
o For example: C:\Workspace
Save often.
o For a single model use Ctrl+S
o For all changes use Ctrl+Shift+S
Minimize the number of open projects and model in the Data Project Explorer to free up system resources.
Learn and update shortcut keys
Create customized perspectives for specific tasks that you work on.
Always start Rational Data Architect using the –clean option.
Align diagrams for printing during the initial diagram creation
o Use the diagram layout functions to help line up a diagram for printing.
Increase the size of the history file.
Increase memory available to eclipse.
Increase memory to the data model import/export bridge.
Update import/export bridges to enable or disable the bridges that show up in the drop-down list in Rational Data Architect.
Use Microsoft Excel (or any compatible spreadsheet program) to quickly create a large number of data model objects in a spreadsheet and use the model import function to import the spreadsheet into a data model.

Rational Data Architect Page 21
Establishing standards
From a logical data modeling perspective, Rational Data Architect supports the following standardization capabilities:
o Naming standards, enforced using a glossary model and validation engine o Domain standards, enforced using a domain model o Normalization standards, enforced via a validation engine
If you already have standards in place, leverage the standards in Rational Data Architect. You can import standards into Rational Data Architect from a variety of tools. You can copy naming standards from Microsoft Excel or Lotus Symphony Spreadsheets directly into Rational Data Architect, so there are a few ways to leverage what you might already have in place. These are two types of standards that users can define in Rational Data Architect: glossary (naming) standards and domain standards: Naming standards provide a common abbreviation and definition for a single component of a logical (business) term or word. The abbreviation is used when transforming a logical model into a physical model to maintain consistent naming of physical model objects. Domain standards enforce business rules in the logical data model design. Domains can be created so that a specific datatype is used and provides context to the values of data that can be stored in a field. For example, if a domain was created to maintain rules around values that can be populated in a United States state field, the business rule might be that the datatype can only be two characters (using standard state abbreviations) and then a list of the abbreviations for state may be provided along with the full name of the state. Once a domain is created, it can be reused in any modeling effort moving forward, so this reusable domain can help to speed up your work on future efforts. Often organizations might have multiple standards in place due to legacy standards and new enterprise standards that have been developed or maybe they have a different standard for each deployment environment. Rational Data Architect supports the use multiple standards on a single effort. The standards can be placed in order of priority for how they should be used for an effort.
Naming standards
Naming standards are important in enabling different parties to look at the same words the same way, while deriving the same meaning from them. The words will have a consistent representation throughout IT systems. Database platforms have limitations on how long an attribute name could be and often words have to

Rational Data Architect Page 22
often be abbreviated in order to meet the constraints of the database. The problem is that different people often use different abbreviations for the same words. If you leave abbreviations up to each data modeler or system designer, you could wind up having multiple systems with different representations of basic words. This lack of consistency can lead to longer development times and the inability to correlate two fields that mean the same thing in two different systems. In order to develop naming standards for data architecture efforts, a basic understanding of the naming conventions used in Rational Data Architect is needed. Rational Data Architect was designed enable users to use industry best practices in data design projects; the naming standards are a feature that is no exception to this. Components or elements of a name are broken down into three groups:
o Prime word o Class word o Modifiers
Prime words: Think of prime words as an object, entity, or concept. They are the entities that are the center of focus in the system that is being developed. These are generally the primary entities that are going to appear in a data model. Examples of prime words:
o Account o Office/Location o Client o Employee o State
To understand each component of an attribute name, a consistent attribute name will be used:
o Account Last Accessed Date In the word above, Account is the center of focus in the attribute name and is therefore the prime word. Class words: Class words are descriptive words that describe the primary classification of data that is associated with a data element. They can help to describe general characteristics that can be expected of the object or concept that is being named. Class words describe how an element will be used and are very closely correlated with the datatype that is going to be used for the given attribute that is being named. Examples of class words:
o Amount o Name o Rank o Code

Rational Data Architect Page 23
o Price o Rate o Date o Time
Using our previous attribute name example:
o Account Last Accessed Date In the word above, Date described the classification of the element and is also a very good indicator of the data type that should be associated with the name (a date data type), therefore it is the class word.
Modifiers: Modifiers are words that provide additional descriptive information about an element, however they are not the classifying word that describes the use of the element. Basically, these words are all of the other words that make up an attribute name that are not prime words or the class word. They help to provide better readability and meaning from an attribute name. Considering that any word could be a modifier, a list of examples will not be provided.
Using our previous attribute name example:
o Account Last Accessed Date In the word above, Last and Accessed are words that provide additional meaning to the attribute name outside of the prime word, Account, and the class word, Date. Therefore, these words are the modifiers.
How to define naming standards – Name component ordering in Rational Data Architect To view and edit the name component ordering that is used in your naming standards in Rational Data Architect, select Window>Preferences. Under Data, you see Naming Standard:
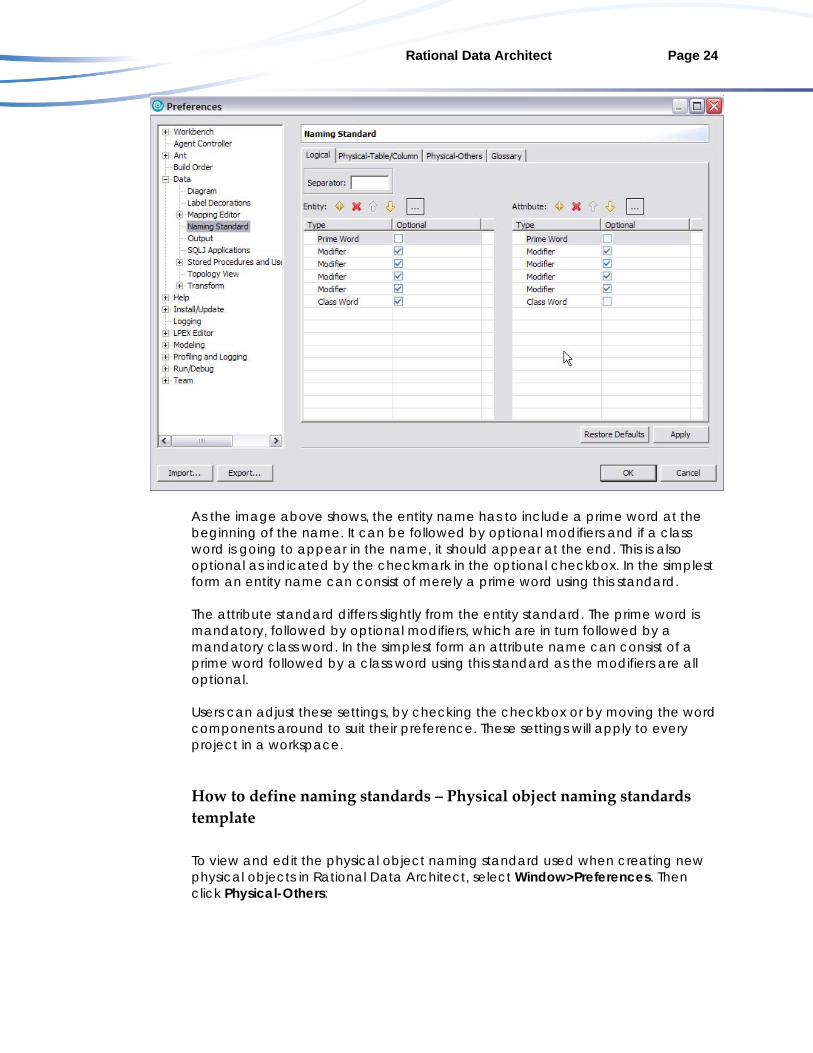
Rational Data Architect Page 24
As the image above shows, the entity name has to include a prime word at the beginning of the name. It can be followed by optional modifiers and if a class word is going to appear in the name, it should appear at the end. This is also optional as indicated by the checkmark in the optional checkbox. In the simplest form an entity name can consist of merely a prime word using this standard. The attribute standard differs slightly from the entity standard. The prime word is mandatory, followed by optional modifiers, which are in turn followed by a mandatory class word. In the simplest form an attribute name can consist of a prime word followed by a class word using this standard as the modifiers are all optional. Users can adjust these settings, by checking the checkbox or by moving the word components around to suit their preference. These settings will apply to every project in a workspace.
How to define naming standards – Physical object naming standards template To view and edit the physical object naming standard used when creating new physical objects in Rational Data Architect, select Window>Preferences. Then click Physical-Others:
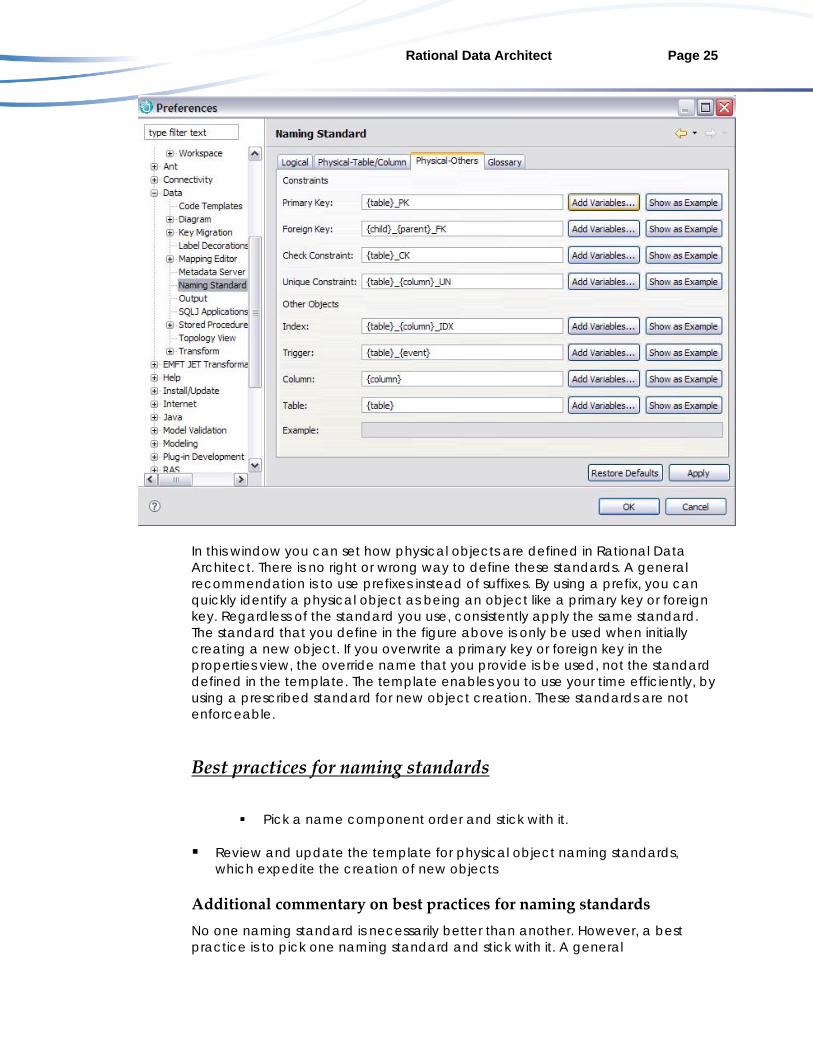
Rational Data Architect Page 25
In this window you can set how physical objects are defined in Rational Data Architect. There is no right or wrong way to define these standards. A general recommendation is to use prefixes instead of suffixes. By using a prefix, you can quickly identify a physical object as being an object like a primary key or foreign key. Regardless of the standard you use, consistently apply the same standard. The standard that you define in the figure above is only be used when initially creating a new object. If you overwrite a primary key or foreign key in the properties view, the override name that you provide is be used, not the standard defined in the template. The template enables you to use your time efficiently, by using a prescribed standard for new object creation. These standards are not enforceable.
Best practices for naming standards
Pick a name component order and stick with it.
Review and update the template for physical object naming standards, which expedite the creation of new objects
Additional commentary on best practices for naming standards No one naming standard is necessarily better than another. However, a best practice is to pick one naming standard and stick with it. A general

Rational Data Architect Page 26
recommendation is to use the naming standard that was exhibited in the example for the name component ordering. In the past, we have seen naming standards where the class word used in the logical data model is always transposed to be used at the beginning of a physical column name. Others might place the class word at the end of the physical column name. Placing a class word at the beginning or end of a physical column name is more descriptive of the type of data that is being used rather than using the class word somewhere in the middle of the column name. For example, if the class word is a monetary amount, an organization might use the abbreviation MNY to represent money. If an attribute was named Total Asset Monetary Amount, the physical column name would look like MNY_TOT_ASSET if the class word was used as the first part of the physical name. If your enterprise standard is that monetary amount are always decimal (13,2), a developer knows what the data type of this field is without having to look past the prefix. If the class word was used at the end of the physical column name, then the column name would be TOT_ASSET_MNY. Similarly, a developer can quickly figure out the datatype of this column because they know to always look at the last part of the column name to determine the classword. If the column name placed the class word in the middle of the column name, such as TOT_MNY_ASSET, it is not as easy to quickly identify the class word. It may seem simple with a name with three parts such as this example, but if the name had four parts in it, it would not be as easy to figure out. To further validate this point, if an attribute, the total future value of monetary assets was given the column name TOT_FUT_VAL_MNY_ASSET, it wouldn’t be as easy to quickly identify MNY as the class word. Regardless of whether you prefer a class word at the beginning or end of a column name, a best practice is to pick one of these standards and stick to it. Another argument that often comes up is whether or not the name of the entity should be included in all of the attribute names within the entity. For example, if the client entity requires a field that holds the first name of a client, some people will say that you should only name the attribute “First Name” as the attribute belongs to the entity. Even though it is redundant, you should name the attribute Client First Name. There are two reasons for this. First, it eliminates any confusion about the column. Always try to be more descriptive to make your metadata more valuable. If a business analyst were to do a search on “Client First Name”. They can quickly find this column. If the column was only called “First Name”, it might not show up forcing the analyst to use “First Name” in their search. The search could result in a number of columns called “First Name” across a significant number of tables, such as the Advisor table, the Client table, or the Employee table. Now they will have to deal with more complexity in analyzing their search results to find exactly what they are looking for. The second reason has to do the transformation of names into the physical model. If you are using a naming glossary to enforce standardized abbreviations during the transformation of logical to physical data models in Rational Data Architect, you could run into a potential issue, depending on how you define your standards. If you always want a prime word first, and you eliminate “Client”

Rational Data Architect Page 27
from the attribute “Client First Name”, you either have to make the prime word optional to start the name or you have to make “First” a prime word. Making “First” a prime word does not seem to conform to the definition of prime words as stated in an earlier section of this document.
Understanding the structure of a glossary model in Rational Data Architect Rational Data Architect provides users with the ability to organize the glossary model into logical branches. The model itself can contain one or many glossaries, which are groupings of terms into logical categories:
In the image above, a glossary model called “Enterprise Naming Standards.ndm” was created. It is contained within a project called “Enterprise Standards”. The glossary model itself contains a naming standard field, which can be used to enter any name that you want for the naming standard in this model. In this example, the name is “Enterprise Naming Standard”. The naming standard can contain one or more glossaries. Terminology can be created in a glossary; it cannot be created at the naming standard level. A
Rational Data Architect Page 28
glossary can be created within a glossary to continue to allow users to categorize terminology appropriately. Glossaries become even more valuable when you start to leverage the integration between Rational Data Architect and Websphere Business Glossary. When using Websphere Business Glossary, different business units within an organization might be the data stewards for different data. Therefore, they might each have their own glossary models, which are defined in Websphere Business Glossary. The rules can be defined within Websphere Business Glossary to only allow the stewards of a specific glossary to create and update terminology within a glossary. Therefore, multiple glossaries might exist to support different stewards. Rational Data Architect can consume each of these glossaries, so that the enterprise terminology that has been defined can be reused throughout any data modeling efforts.
How to create a glossary model In order to create a glossary like the one you see above, you can follow one of two approaches: Method 1: 1. Select File > New > Glossary Model:
2. Choose the project that the glossary belongs to (if you have not created a
project, you cannot create a glossary). 3. Give your glossary a meaningful name. 4. If you want to attach this glossary to the project it is created in, select Add to
project properties as project naming standard. 5. Click Finish.
Rational Data Architect Page 29
Method 2: 1. In the Data Project Explorer, go to the project where you want to create the
glossary and right-click Data Models and select New > Glossary Model:
2. Choose the project that the glossary belongs to (if you have not created a
project, you cannot create a glossary). 3. Give your glossary a meaningful name 4. If you want to attach this glossary to the project it is created in, select Add to
project properties as project naming standard. 5. Click Finish.
Populating a glossary model in Rational Data Architect: Important points of interest Now that you have created a glossary model, you can open the model and populate it with your glossary information. There are a few important points worth noting when creating a glossary in Rational Data Architect. 1. Names in the glossary model are case sensitive. If your names are in all-
capital letters in your data model, but the glossary model is all lower case, every column will fail validation when the model is analyzed.
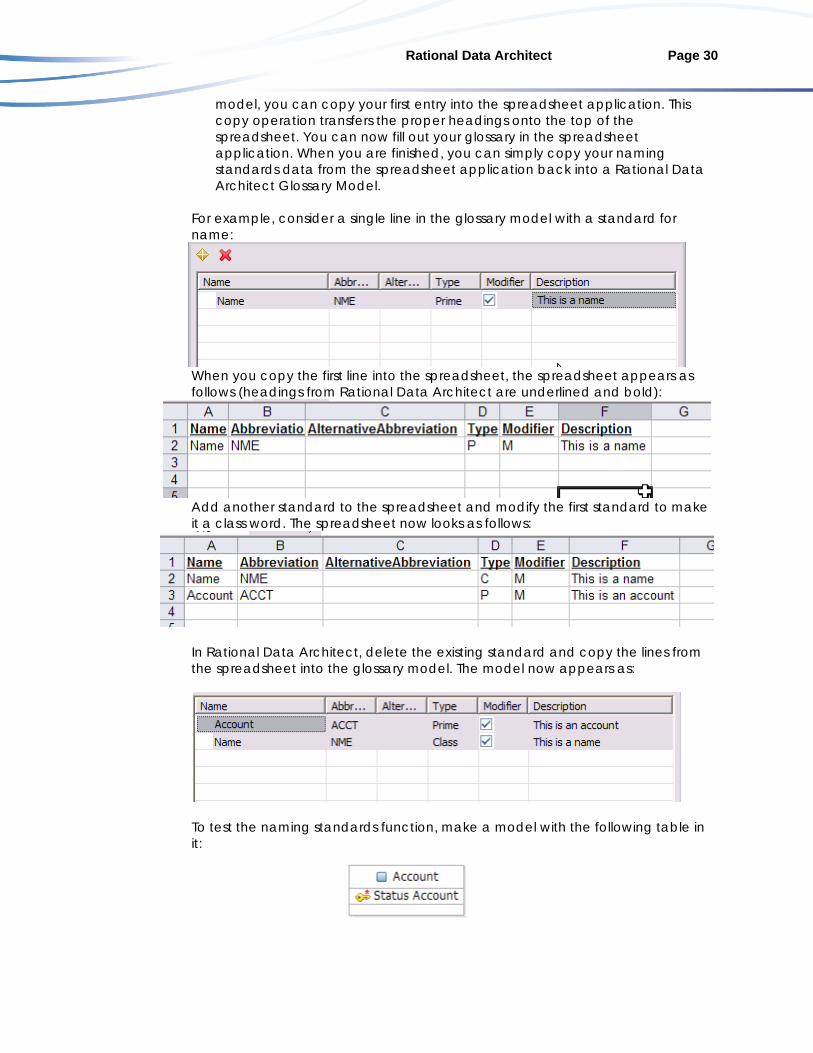
As an example, consider the following glossary:
2. If you want to quickly populate a glossary, use a spreadsheet application,
such as Lotus Symphony or Microsoft Excel. If you open up your glossary
Rational Data Architect Page 30
model, you can copy your first entry into the spreadsheet application. This copy operation transfers the proper headings onto the top of the spreadsheet. You can now fill out your glossary in the spreadsheet application. When you are finished, you can simply copy your naming standards data from the spreadsheet application back into a Rational Data Architect Glossary Model.
For example, consider a single line in the glossary model with a standard for name:
When you copy the first line into the spreadsheet, the spreadsheet appears as follows (headings from Rational Data Architect are underlined and bold):
Add another standard to the spreadsheet and modify the first standard to make it a class word. The spreadsheet now looks as follows:
In Rational Data Architect, delete the existing standard and copy the lines from the spreadsheet into the glossary model. The model now appears as:
To test the naming standards function, make a model with the following table in it:

Rational Data Architect Page 31
Analyzing a model using a glossary Before you analyze a data model using a glossary, decide if you want to attach a glossary model to an entire workspace to be used for analysis with every model in the workspace or attach a naming standards model to a specific project to be used only against objects in that project. Therefore, if you want to attach the naming standards to a specific data model, you have to attach the glossary model to the project that the data model belongs to. When you create a new project, you have the option of creating references to existing projects. If you already have naming standards that exist from another existing project, create the reference to that project at this time. If you have standards that will be shared across multiple projects, consider creating a separate project for “Enterprise Standards” in which you create an enterprise glossary model and an enterprise domain model. This makes it easier to attach standards to multiple projects without having to search through each project to find out where you created your standards. If there is a need for a project specific glossary or domain model, keep them within the project that they apply to. Creating project-specific glossary models is generally not recommended; however there are scenarios where this is necessary. For example, if you are reverse engineering an existing database into a data model, you might have to create a project specific glossary that does not conform to the enterprise standards. In this case, you still want the standards that were used in this database to be documented, so you would create a project specific glossary. To attach a new glossary to an existing project:
1. In the Data Project Explorer, click the project name. 2. On the Properties tab for the project, click Naming Standard. 3. Click Add. 4. Select the Glossary model (ending in .ndm) that you will apply to the
project. 5. Click Ok.
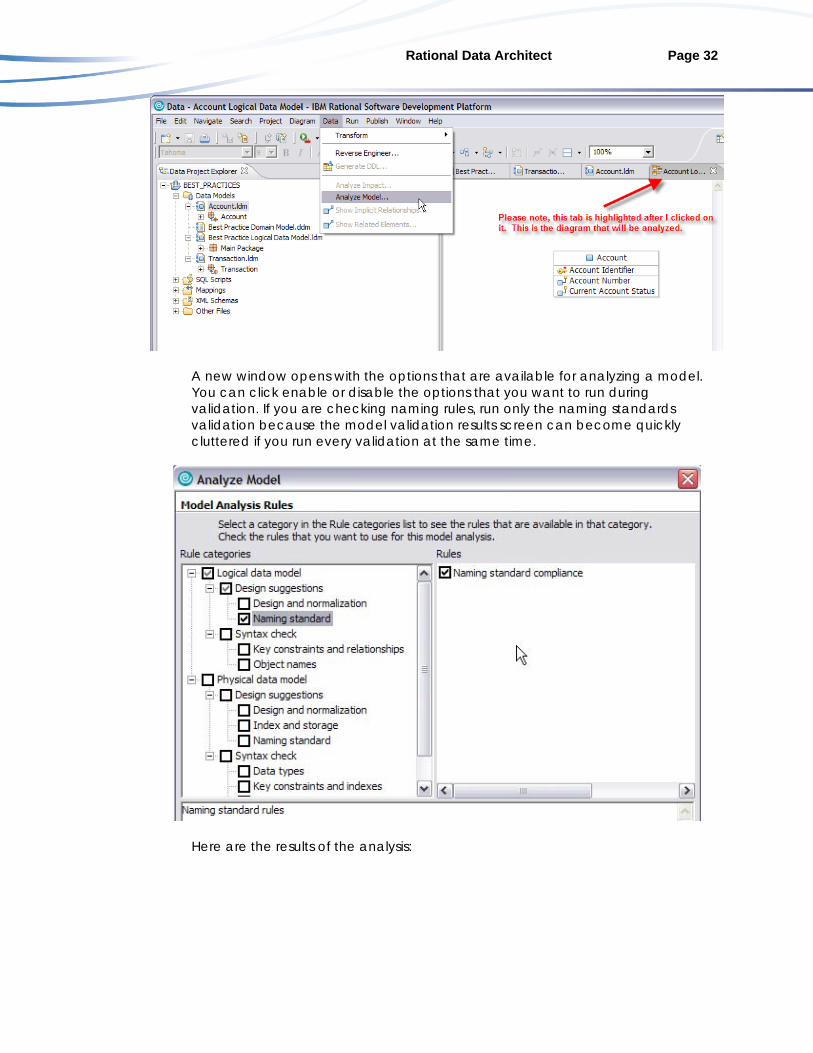
Now this glossary model is always be applied to any objects or diagrams in this project. Once a glossary is attached, there are a few ways to analyze data model artifacts in Rational Data Architect. This section of the document is going to focus on analyzing the objects within a diagram. To analyze a data model diagram, open a data model diagram. Click the tab with the diagram that you want to analyze or click on an empty space in the diagram itself. Now select Data > Analyze Model:
Rational Data Architect Page 32
A new window opens with the options that are available for analyzing a model. You can click enable or disable the options that you want to run during validation. If you are checking naming rules, run only the naming standards validation because the model validation results screen can become quickly cluttered if you run every validation at the same time.
Here are the results of the analysis:
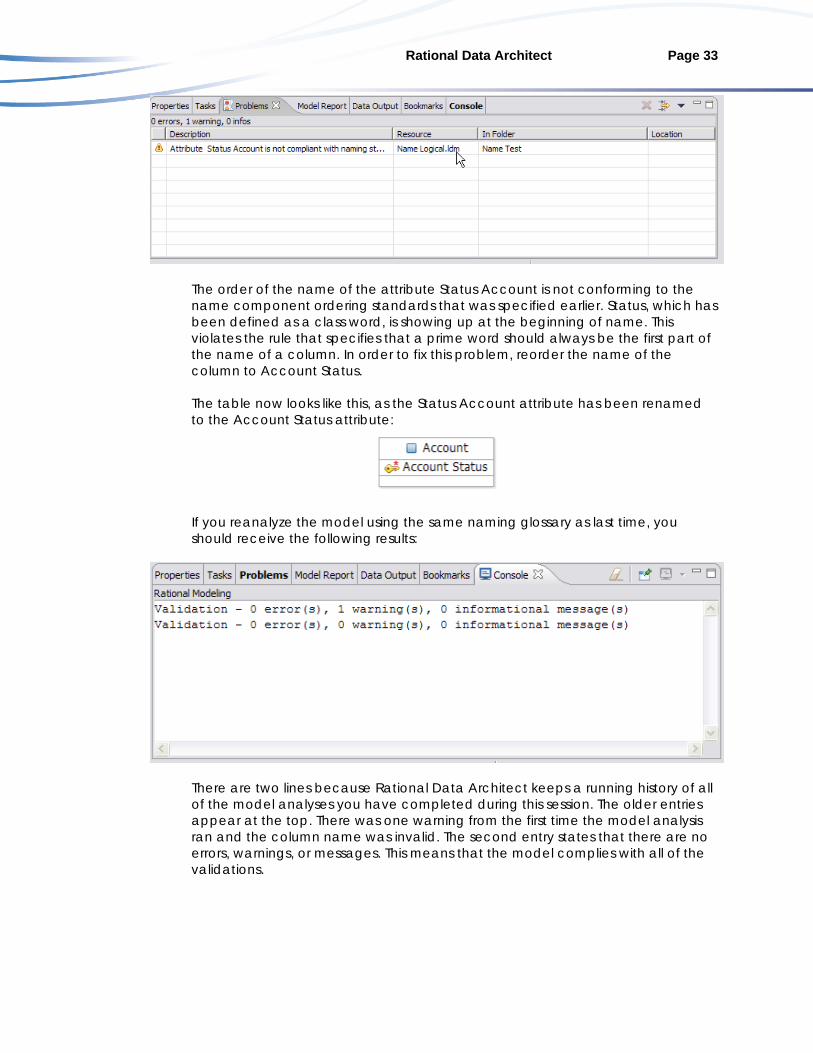
Rational Data Architect Page 33
The order of the name of the attribute Status Account is not conforming to the name component ordering standards that was specified earlier. Status, which has been defined as a class word, is showing up at the beginning of name. This violates the rule that specifies that a prime word should always be the first part of the name of a column. In order to fix this problem, reorder the name of the column to Account Status. The table now looks like this, as the Status Account attribute has been renamed to the Account Status attribute:
If you reanalyze the model using the same naming glossary as last time, you should receive the following results:
There are two lines because Rational Data Architect keeps a running history of all of the model analyses you have completed during this session. The older entries appear at the top. There was one warning from the first time the model analysis ran and the column name was invalid. The second entry states that there are no errors, warnings, or messages. This means that the model complies with all of the validations.

Rational Data Architect Page 34
Best practices for glossary models
When creating glossary models, consider the following best practices:
Create a separate enterprise standard project that contains any glossary or domain model that be universally shared throughout the organization.
Create a glossary model within a specific project for legacy models that might have terminology that was created before the enterprise glossary and may use different definitions.
Give the glossary model a meaningful name. Create multiple glossaries within a naming standard to logical group
terminology into categories that make sense from a business perspective and a data stewardship perspective.
Create nested glossaries to provide a logical grouping of terminology within a specific business subject area.
Create a subglossary that contains class words only to reduce the time you spend looking through an entire glossary to understand these terms.
If possible, Use a spreadsheet to enter data more efficiently. Copy terminology to a spreadsheet application such as Lotus Symphony or Microsoft Excel to quickly update and edit terminology and then copy it back into Rational Data Architect
Domain standards
Domain standards can have different meanings to different organizations. It is important to clearly establish what domain standards mean to your dictionary. In some organizations, domains are used only to represent a data type. In others, domains represent the enterprise data dictionary.
How to create a domain: In order to start using domains, you must first create a new domain model:
1. If you have not done so already, create a data design project. 2. Under the project, right-click Data Models and select New > Domain
Model:
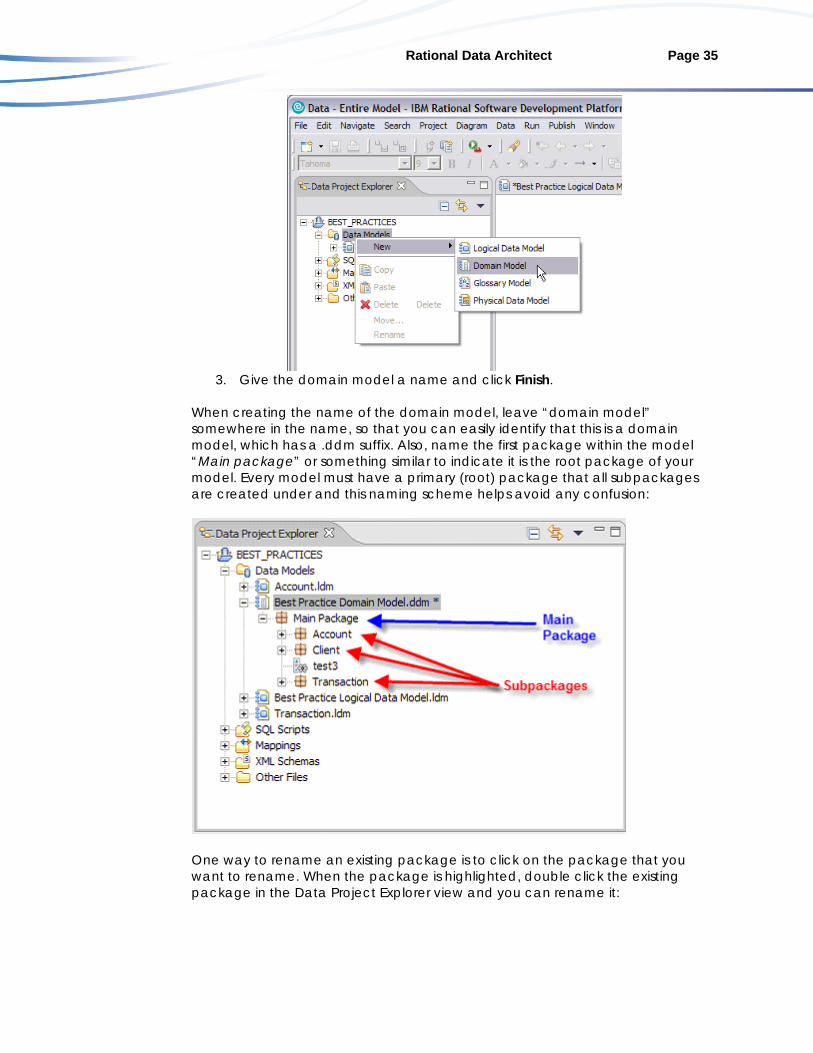
Rational Data Architect Page 35
3. Give the domain model a name and click Finish.
When creating the name of the domain model, leave “domain model” somewhere in the name, so that you can easily identify that this is a domain model, which has a .ddm suffix. Also, name the first package within the model “Main package” or something similar to indicate it is the root package of your model. Every model must have a primary (root) package that all subpackages are created under and this naming scheme helps avoid any confusion:
One way to rename an existing package is to click on the package that you want to rename. When the package is highlighted, double click the existing package in the Data Project Explorer view and you can rename it:
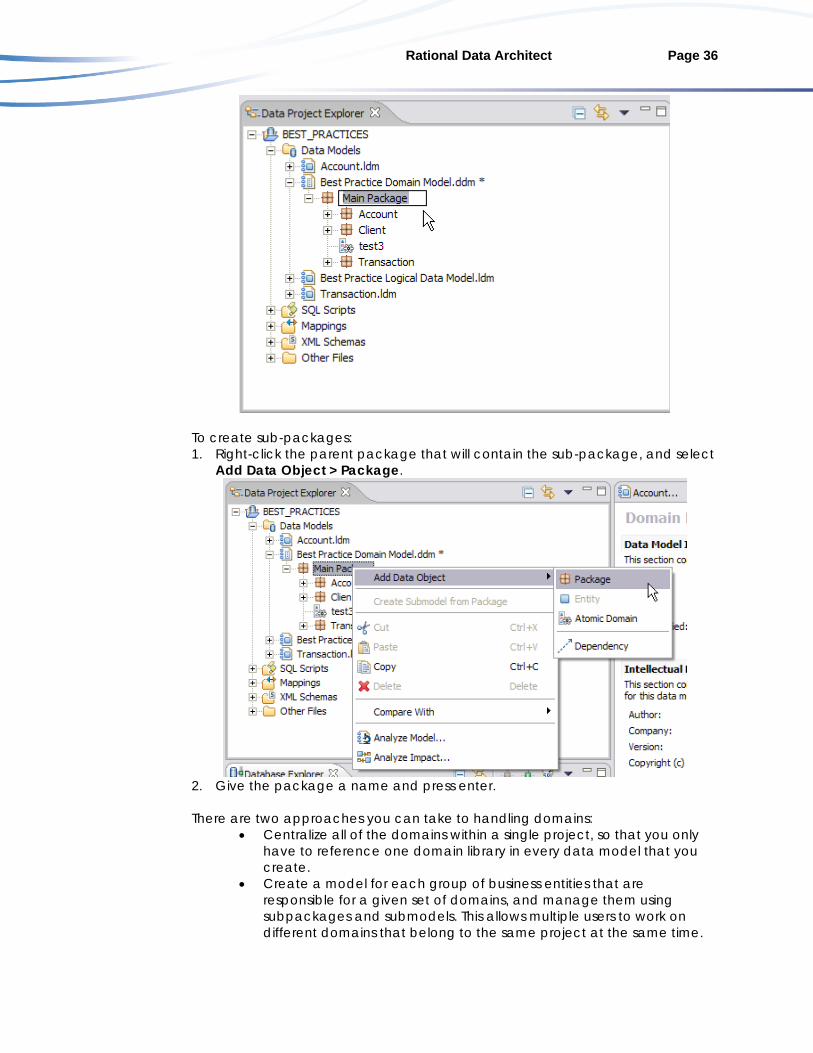
Rational Data Architect Page 36
To create sub-packages: 1. Right-click the parent package that will contain the sub-package, and select
Add Data Object > Package.
2. Give the package a name and press enter.
There are two approaches you can take to handling domains:
• Centralize all of the domains within a single project, so that you only have to reference one domain library in every data model that you create.
• Create a model for each group of business entities that are responsible for a given set of domains, and manage them using subpackages and submodels. This allows multiple users to work on different domains that belong to the same project at the same time.

Rational Data Architect Page 37
Using subpackages is generally preferred because it enables the creation of submodel to enable more efficient team-sharing capabilities.
When creating domains, it is important to keep in mind that a specific set of domains is applied to an entire project, which can consist of multiple models. Therefore, if there are certain domains that are specific to an operating environment, such as a data warehouse, or a transactional system, separating these domains into two separate models, one for each environment, is appropriate. However, if the domains are going to be universally applied, then it makes sense to keep them within a single model. In an ideal world, you could use the same domains in all of your efforts for consistency reasons. However, due to legacy systems or having separate modeling teams for your operational and reporting environments, you might already have different standards. The effort to consolidate the domains into a single model might not be worth the time if both sets of standards have been followed thoroughly. It might make more sense to continue to implement each existing standard. Rational Data Architect is flexible enough to allow you to follow either approach.
Best practices for domains:
Create a separate enterprise standard project that contains any glossary or domain model that is universally shared throughout the organization.
Create a domain model within a specific project for legacy models that might have domains that were created before any enterprise domains if they do not conform to the newer enterprise standard.
Give the domain model a meaningful name. You might want to include “domain” as part of the model name to easily identify the domain model in the Data Project Explorer view
Create nested domains to provide a logical grouping of domains within a specific business subject area.

Rational Data Architect Page 38
Logical data modeling in Rational Data Architect
Table normalization and denormalization
Table normalization is the process of dividing entities into multiple physical tables. Normalization is usually a logical data modeling exercise. There are a few goals in doing so:
Eliminate redundant data. Enforce valid data dependencies, Maximize the flexibility of the system for future growth in data structures.
Third normal form (3NF) is a combination of the rules for first normal form and second normal form, combined with rules unique to 3NF. Briefly the rules for 3NF are as follows:
Eliminate repeating groups - Make a separate table for each set of related attributes, and give each table a primary key.
o Eliminate duplicate columns from the same table. o Create separate tables for each group of related data and
identify each row with a unique column or set of columns (the primary key)
o Eliminate redundant data - If an attribute depends on only part of a multi-valued key, remove it to a separate table.
Remove subsets of columnar data that apply to multiple rows of a table and move them into separate tables.
Create valid relationships between the tables through the use of foreign keys.
Eliminate columns that are not dependent on the primary key o If attributes do not contribute to a description of the key, they
should be moved to a separate table. When creating logical data models, the models should be in third normal form (3NF). This design methodology provides users with flexible models that can continue to grow and expand as business requirements evolve and change. While third normal form is recommended for logical models, models often may not performance efficiently when they are deployed physically in third normal form.

Rational Data Architect Page 39
Normalization example The following example is meant to help you understand the process of normalization. There are many ways to model a solution to a problem, but the purpose of this section is to provide an understanding of normalization.
For example, some people might argue that you should never normalize names from a table, while others will say that names should be normalized because if a middle name column was to be created you could have a situation where many people do not in fact have a middle name. Therefore, you would have many records with nulls in them. As this example shows, data modeling is a skill that often does not provide a definitive solution. For the remainder of this normalization example, the assumption is that normalization is occurring in a logical data model. The same principles can be applied to a physical data model, but terminology substitutions are necessary, where the term entity is substituted with table and attribute with column. In this example, there is a denormalized entity created after reviewing some basic requirements:
Denormalized model:
Complying with first normal form In order to comply with first normal form (1NF), eliminate any repeating groups from entities. To eliminate repeating groups, create a new entity for each repeating group and establish a primary key for each entity . To maintain a relationship between the data moved into separate entities, define foreign key relationships. An example of a repeating group is a manager with multiple employees that report to them. The number of employees that report to a manager can be different for each manager. For example, one manager has only two employees reporting to them while another manager has ten employees reporting to them. If the manager entity contained an attribute for each employee that reported to them, the manager entity would require ten employee attributes to accommodate the second manager. The second manager would have a value populated in all ten of the attributes, while the first manager, with only two

Rational Data Architect Page 40
employees, would have eight attributes containing a null value. This results in an inefficient use of storage space. Using our previous denormalized model, achieve first normal form by eliminating the following repeating groups:
Address Line 1, Address Line 2, and Address Line 3 Customer First name, Customer Last Name
First normal form:
To make the denormalized model comply with 1NF, the repeating groups of data elements were normalized into separate entities. The customer names are normalized because if a middle name field is required in the future, there could be much redundant data due to nulls as many people do not have middle names. Also, normalizing the names could eliminate the need to keep adding additional name related attributes to the entity, such as name suffixes (for example, Jr., Sr., or III) or name prefixes (for example, Mr. , Mrs. , or Ms.).
Complying with second normal form To comply with second normal form (2NF), the model must be in first normal form and then you must remove subsets of columnar data that apply to multiple rows of an entity and move them into separate entities. This might result in the creation of new entities, in which each new entity must have a primary key defined. To maintain a relationship between the data that has been moved from the entity into a separate entity, a foreign key relationship must be defined. An example of a subset of data is that a city and state always have the same postal code. If an address entity contains a city attribute, a state attribute, and a postal code attribute, there is always be a pattern between city, state, and postal code. The data for these three attributes is consistently repeated for any address in the same postal code. This results in an inefficient use of storage space.

Rational Data Architect Page 41
Therefore, these three attributes, city, state, and postal code can be removed from the entity and placed in a separate entity where postal code would be the primary key. A relationship can then be made between the postal code entity and the current address entity using the postal code column as the foreign key. Using our previous denormalized model, to achieve 2NF, eliminate the following potential data redundancies
Customer Names Customer Addresses
Second normal form:
To make the model comply with 2NF, it must comply with 1NF and any attributes have to be fully dependent on any part of a composite key.
Complying with third normal form In order to comply with third normal form (3NF), a model must be in second normal form (and inherently first normal form), and then you must move any attributes that are not fully dependent on the key to a separate entity. When an attribute is dependent on another attribute that is not part of the primary key, it is known as a transitive dependency. This can result in the creation of new entities, in which each new entity must have a primary key defined. To maintain a relationship between the data that has been moved into separate entities, a foreign key relationship must be defined.
Third normal form:

Rational Data Architect Page 42
To comply with 3NF, any transitive dependencies must be eliminated. Transitive dependencies occur when a value in non-key field is determined by the value of another non-key field (that is, not part of a candidate key).
Denormalization For the remainder of this denormalization section, the assumption is that denormalization is occurring in a physical data model, as denormalization is typically a physical data modeling exercise. The same principles can be applied to a logical data model, but terminology substitutions are necessary. Star schema and snowflake designs have become quite popular for data warehousing (business intelligence) systems. The primary concept of star schema is to separate the “facts” of the system from its “dimensions”. Dimensions are defined as attributes of the data, such as location, or customer, or parts, while the facts of the system refer to the time specific events of the data. For example, a part description does not typically change with time, so it can be designed as a dimension. Conversely the number of parts sold each day is time variant and is therefore a fact. The resulting schema is called a star schema because it is usually characterized by a large central fact table that holds the time variant events, surrounded (conceptually) by a set of dimension tables holding the meta-attributes of items that are referenced within the fact events. A snowflake is basically an extension of a star schema. In a snowflake design, the low-cardinality columns are often moved from a dimension table in a star schema into another dimension table and then a relationship is created between the two dimensions. Denormalization is the process of collapsing tables and therefore possibly increasing redundancy of data within the database. Denormalization can be useful to reduce the complexity of a database or reduce the number of joins

Rational Data Architect Page 43
required to get to the data that you want. The complexity of the database is reduced by reducing the number of tables. The primary goal of denormalization is to maximize performance of a system and reduce the complexity in administering the system. While some users may use denormalization in their logical data models, this is generally not recommended. Denormalization could reduce the flexibility of the data model, which is one of the goals of logical data model design. Denormalization should be a physical data modeling task used to meet performance requirements or to reduce complexity in administering and developing systems for a particular database environment.
Best practices for normalization in logical data models
A logical data model should always be in third normal form (3NF).
Generalization relationships
Generalization relationships are special relationships between parent entities and child entities that help to derive additional meaning while looking at a logical data model. The parent known as the supertype and the child is a subtype. The subtype is a type of the parent, which is why generalized relationships are sometimes called supertype-subtype relationships
For example, a closed account is a type of an account. An open account is also a type of an account. They each might have their own unique attributes, but the parent has common attributes. So an open account might have a balance. A closed account might have a closed date. The parent might have an account open date because all accounts, whether open or closed, required a date when they were opened. By representing the generalization relationships described above, a user can derive more meaning from a logical diagram. If all of these attributes were in a single account entity, there could be some confusion as to why every account needs to have a closed date, even if they were never closed. The entity would not look as clear in a diagram:
Account entity without generalization relationship

Rational Data Architect Page 44
Account entity with generalization relationship
The second diagram provides more value because it more clearly explains which attributes belong to specific types of account.
Generalization relationships are special relationships not only because they provide added value by conveying a better understanding of a model, but you can also choose how to transform them when creating a physical model. What looks good in the logical model might not be the best physical design.
For example, in a physical model, you might prefer to have a single account table for performance reasons. You can easily roll up the subtypes into the parent table. A second option is to push the parent table down into the child tables. The same columns (attributes from the logical model) of the parent table would then exist in every child table. A third option is to simply leave the tables as is. To provide better insight, the results of these types of transformations are shown as follows:
Generalization rollup transformation

Rational Data Architect Page 45
Generalization roll-down transformation
Generalization separate table transformation
Best practices for generalization relationships
Use the generalization and subtype relationships to provide a more meaningful logical data model for business analysts.
Team sharing
Team sharing is an important concept in the design of data models. A data model provides little value to an organization if it is not widely available to a community of interested users. Rational Data Architect incorporates a few concepts to make team sharing an easy and efficient task.
Separate logical entities using packages Separating logical entities into packages can help reduce the complexity in a large model, making it easier to understand. This is useful with both domain and logical data models.

Rational Data Architect Page 46
Create submodels from packages The ability to create submodels from packages is very powerful concept as it can greatly reduce the time that you have to spend merging multiple changes into a team sharing repository. When you use a team sharing repository, you typically have to check models in and out. In Rational Data Architect, an entire model is checked in and checked out. Therefore even if a change in only made to an entity, the whole model is checked in. A problem can arise if two users check out the same model and both make changes and check them back in. The first user can save their changes with no issue. When the second user checks in their changes, they must compare their changes with the updated version from the first users in the team sharing repository and choose which changes they want to migrate into the repository. This can become time consuming as the model grows. One solution is to use a repository that supports branching. With branching, you can have your own branch in the repository where you can check out and check in only the model you are working on. When you are done with your changes, the changes then must be merged into an integration (or master) stream for the project in the repository. While this saves you from having to deal with dealing with the model merge, the integration or project manager is now responsible for merging the various branches into the master stream. This is a powerful concept, but many organizations do not want to invest the resources to set up such a repository. A second solution is to use the submodel functionality within Rational Data Architect as a mean to handle this situation. Submodeling lets you break off pieces of a large model into smaller models. Anyone accessing the large model can access the smaller models. If you want to making changes to one of the smaller models (a submodel), you have to check out only the smaller model. After you make your changes, you have to check in only the small model. This can help to reduce model check-in collisions that require model merging because if two people are each working on separate submodels, they can check in both of their changes without impacting the other person. If the larger model was not divided into submodels, the second user to check in their changes would have to manually merge their changes back into the repository using the compare feature. By using submodels, users can save time by avoiding merging changes into the repository manually. There can be instances where collisions occur, but the sub-models are much smaller, making the merge much easier and faster than a merge of the full model.
How to create a submodel from a package In order to create a submodel from a package, you must already have an existing subpackage. Submodels cannot be created from the primary (root)

Rational Data Architect Page 47
package in a model. Once you have at least one subpackage, you can create a submodel from it. To create a submodel:
1. In the Data Project Explorer, right -click the existing package and select Create Submodel from package.
Best practices for team sharing
Use packages to separate logical entities.
Create submodels from packages to minimize the impact of team sharing.

Rational Data Architect Page 48
Physical data modeling in Rational Data Architect
Physical data modeling is the process of creating a database-specific data model to fulfill application performance requirement needs. It can be a daunting task as it is often difficult to project the growth of a database system, especially when working in a business intelligence environment, where the success of an initial deployment could lead to requests for more data sources to be included in the data store.
There are some best practices that can be followed in physical database design that apply to most databases. While IBM has already published a best practices paper on physical database design for DB2® databases, Rational Data Architect is an enterprise information modeling tool that supports many databases, so some of the same best practices apply to database design in general.
You can obtain the DB2 best practice paper “Physical Database Design” at the following URL: http://www.ibm.com/developerworks/db2/bestpractices/.
Normalization and denormalization
While normalization and denormalization were discussed in the section discussing logical data model design, physical model design is guided by different principles. Often it is more important to meet the demands of a SLA (Service Level Agreement) rather than to maintain a flexible design for future growth. Therefore, when physical modeling a few approaches tend be suited for specific situations: Use 3NF for most OLTP and general purpose database designs. In general use
3NF whenever possible to maintain flexibility in design of the system. For warehouses and data marts that require very high performance, a star
schema or snowflake model is usually optimal for dimensional query processing. However, any star schema model should be verified to conform to the relationships that are designed in a normalized logical data model.
For broad based data warehousing that is used for several purposes, such as operational data stores, reporting, OLAP, and cubing, IBM recommends a layered data architecture that is illustrated by the diagram on the next page. The layered data architecture is a powerful paradigm too detailed to describe at length here. See the Further reading section at the end of this document for more information on this approach to data warehousing. Not all databases support this approach if they lack certain features that the layered data architecture relies on when building the performance level (Floor 3 in the diagram).
Consider denormalizing very narrow tables. The extra tables in the database increase query complexity and complicate administration. Look for tables that are very narrow (where each record is 30 bytes or less) as candidates.

Rational Data Architect Page 49
OperationalDecision Making
Tactical Decision Making
StrategicDecision Making
Staging, detail, denormalized, Raw SourceDuration: 60, 120, 180, etc days
Near 3rd Normal Form, Subject Area, code and Reference tables. Duration: Years
Summarized DataPerformance and rolled up Data
Duration: Years
Dimensional, Data Mart,Cubes, Duration: Years
Floor 1
Floor 5
Floor 4
Floor 3
Floor 2
Dashboard Static reports, Fixed Periods
The IBM layered data architecture
Best practices for normalization and denormalization
Normalize your tables to third normal form (3NF) for most general-purpose databases; use a star schema or snowflake model for dimensional queries; and the IBM layered data architecture for broad-based data warehousing, online analytical processing (OLAP), and business intelligence (BI).
Index design
Indexes provide fast lookup for the location of data in the database. They are absolutely critical for performance.
They are used by the database for the following things:
Applying predicates, especially as start or stop keys Inducing order (for example, ORDER BY, GROUP BY, or joins) Providing index-only access (saving accessing data pages) Enforcing uniqueness
However, indexes do have a down side:
Indexes add cost to UPDATE, INSERT, DELETE, and LOAD operations Indexes add cost to compilation (more choices for the optimizer) Indexes can consume significant storage
Consider the following best practices for index design:
Index every primary key and most foreign keys in the database. o Most joins occur between primary keys (PKs) and foreign keys (FKs), so
it is important to build indexes on all PKs and FKs whenever possible.

Rational Data Architect Page 50
Consider indexing attributes frequently referenced in SQL WHERE clauses. o An exception to this rule occurs when the predicate is an inequality
like “WHERE cost <> 4”. Indexes are seldom useful for inequalities because of the high selectivity involved.
Use an index for both equality and range queries.
Add indexes only when absolutely necessary. Remember that indexes significant impact INSERT UPDATE and DELETE performance, and require storage.
Choose carefully one clustered index for each table. o Clustering indexes attempts to cluster data as much as possible, but
over time the index may still become unclustered.
Avoid or remove redundant indexes. Indexes that use the same or similar columns make query optimization more complicated; consume storage; seriously impact INSERT, UPDATE, and DELETE performance; and often add very marginal benefit. An example of a redundant index is an index containing a single column such as account number with another index comprised of one of more columns that also has the same account number column as the first column in that index. Rational Data Architect can help to identify these overused indices when analyzing the model and running validations against it.
Best practices for index design
Design a basic set of indexes using workload predicates and primary keys (PKs) and foreign keys (FKs).
Perform a model validation to check for index overuse.
Referential integrity
In a physical database, referential integrity is typically used to force a constraint on data in the database. It stops users from entering inconsistent data between two tables where a join is commonly performed.
For example, if a customer table has a customer identifier as a primary key, this key is carried over into the customer address table in order to join the two tables together. By defining referential integrity between the two tables on the customer identifier columns, you can enforce a restriction stating that a customer address cannot exist without a corresponding record in the customer table.
There is overhead associated with checking the relationship when inserting a record into the customer address table. In a high transaction database, this overhead might be unacceptable. In addition, overall maintenance of the database can become more difficult as database administrators need to be

Rational Data Architect Page 51
aware of the referential integrity in situations such as loading data into tables or when setting up backup and recovery procedures.
In data modeling, relationships are the key to understanding a visual diagram that helps users to understand a system. If the referential integrity was missing from the diagram, you could end up with a diagram with many tables and no idea how they work together. Therefore, it is a best practice to create referential integrity in a physical model whether it exists in the database or not. Rational Data Architect can help users to streamline this process by inferring implicit relationships.
Use unenforced referential integrity in a database if you are not going to use enforced referential integrity. Unenforced referential integrity avoids the overhead of checking that the data entered into a table is valid. However, unenforced referential integrity can provide additional insight to the database query optimizer when it is chooses an appropriate plan to execute a query. Therefore, it is a best practice to deploy unenforced referential integrity if the database being used permits it.
Best practices for referential integrity
Always model referential integrity even if it is not created in the database definition.
Create unenforced referential integrity in situations where you do not want to create a hard constraint on the database.

Rational Data Architect Page 52
Model transformation and deployment
Model transformation and physical model deployment
When getting ready to deploy a physical model to a database or transforming a logical model to a physical model, or vice versa, there are best practices that can help you to eliminate potential errors in design and also help you with object lineage.
Model validation and analysis Modeling data from requirements to deployment is a time consuming task. With all of the factors that are involved, it can be very easy to overlook something as simple as the spelling of an attribute name, or the length of the name given to a foreign key. To help you to create models that always comply with standards and conventions, Rational Data Architect can validate a data model against general best practices, such as normalization and against user-defined standards, such as naming standards.
In order to validate naming standards, the glossary model which contains the naming standards must be attached to the project containing the model being analyzed resides. To attach a glossary model to a project:
1. In the Data Project Explorer, click the project name. 2. On the Properties view(tab) for the project, click Naming Standard. 3. Click Add. 4. Select the Glossary model (ending in .ndm) that you will apply to the
project. 5. Click OK.
Alternatively, you can attach the glossary to the workspace so that the glossary can be used to validate every model in every project in the workspace. To attach a glossary model to the workspace:
1. Select Window > Preferences. 2. In the Preferences view, select Data > Naming Standards. 3. Click the Glossary tab 4. Click Add. 5. Select the Glossary model (ending in .ndm) that you will apply to the
project. 6. Click OK to close the File Selection window. 7. Click Apply 8. Click OK to close the preferences window.
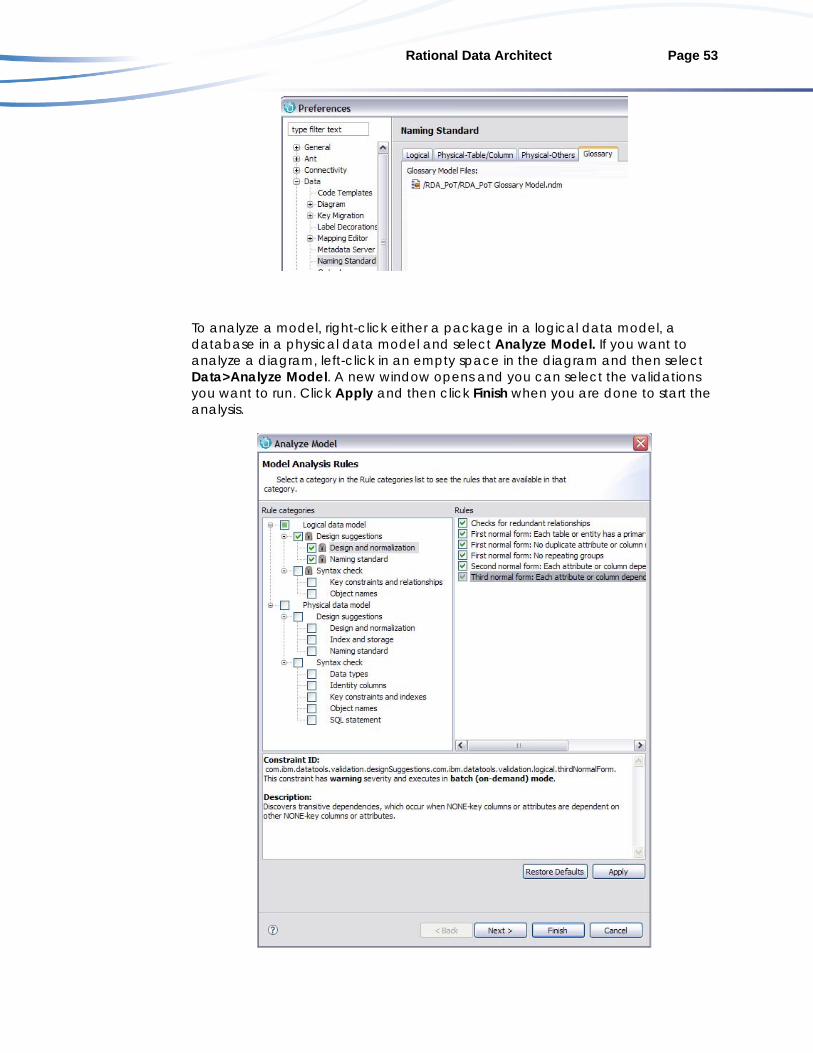
Rational Data Architect Page 53
To analyze a model, right-click either a package in a logical data model, a database in a physical data model and select Analyze Model. If you want to analyze a diagram, left-click in an empty space in the diagram and then select Data>Analyze Model. A new window opens and you can select the validations you want to run. Click Apply and then click Finish when you are done to start the analysis.
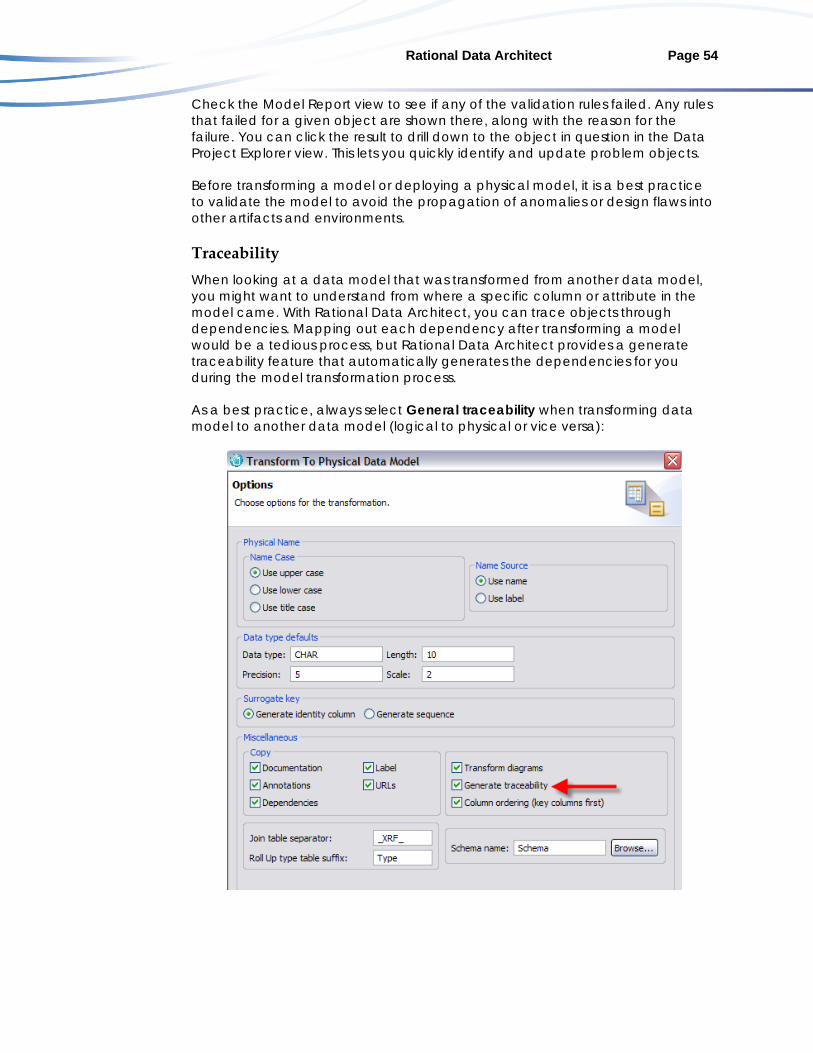
Rational Data Architect Page 54
Check the Model Report view to see if any of the validation rules failed. Any rules that failed for a given object are shown there, along with the reason for the failure. You can click the result to drill down to the object in question in the Data Project Explorer view. This lets you quickly identify and update problem objects.
Before transforming a model or deploying a physical model, it is a best practice to validate the model to avoid the propagation of anomalies or design flaws into other artifacts and environments.
Traceability When looking at a data model that was transformed from another data model, you might want to understand from where a specific column or attribute in the model came. With Rational Data Architect, you can trace objects through dependencies. Mapping out each dependency after transforming a model would be a tedious process, but Rational Data Architect provides a generate traceability feature that automatically generates the dependencies for you during the model transformation process.
As a best practice, always select General traceability when transforming data model to another data model (logical to physical or vice versa):
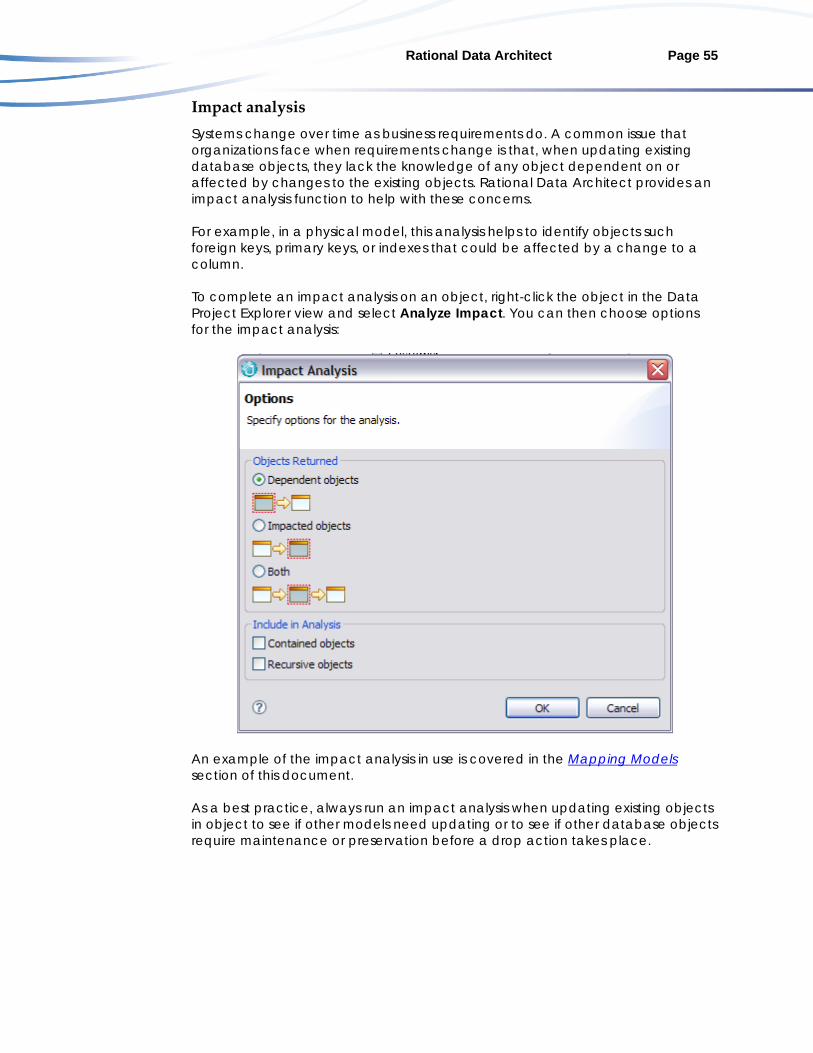
Rational Data Architect Page 55
Impact analysis Systems change over time as business requirements do. A common issue that organizations face when requirements change is that, when updating existing database objects, they lack the knowledge of any object dependent on or affected by changes to the existing objects. Rational Data Architect provides an impact analysis function to help with these concerns. For example, in a physical model, this analysis helps to identify objects such foreign keys, primary keys, or indexes that could be affected by a change to a column. To complete an impact analysis on an object, right-click the object in the Data Project Explorer view and select Analyze Impact. You can then choose options for the impact analysis:
An example of the impact analysis in use is covered in the Mapping Models section of this document. As a best practice, always run an impact analysis when updating existing objects in object to see if other models need updating or to see if other database objects require maintenance or preservation before a drop action takes place.

Rational Data Architect Page 56
Best practices for model transformation
Analyze and validate models before transforming or deploying them
Always select Generate traceability in the Transformation wizard.
Best practices for deploying a physical data model
Always analyze the impact of a change before deploying it.
To save time, use DDL templates when generating DDL.
Lifecycle management
Comparison
Object comparison
A key feature of Rational Data Architect is the ability to compare a data model to a database to migrate a difference in one to the other. If you are only making a change to a specific table, it would not be efficient to compare an entire database model against the actual physical database. This would require Rational Data Architect to read the entire metadata catalog of the database to compare against an entire physical data model when you are only looking to compare a single table. This is a time consuming process when working with large databases. In addition, the comparison window shows all of the objects on both sides of the compare. If there are many tables, it might take some time to find the specific difference you want to migrate from one environment to another.
You can avoid these issues if you do the comparison at the table level. Rational Data Architect is catalog aware and issues a query to the database catalog using predicates. When the compare is done at the table level, it passes a query to the database to retrieve the contents of the only the table that was specified.
Best practice for comparing objects
Always do a compare at the lowest level possible to minimize the amount of metadata required for the comparison.

Rational Data Architect Page 57
Mapping models
Create mapping models even if transformation logic is ignored Rational Data Architect provides mapping capabilities which serve many purposes. The mappings can be used to understand how objects are related from one system to another. They can also be used to generate code depending on the artifact types that are being mapped.
For example, if a physical data model is mapped to a XML schema and transformation logic is provided, Rational Data Architect can generate the SQL/XML code, which can be used to query a source database and return a result with XML tags that are compliant with the structure defined by the XML schema.
If a database model is mapped to a database or another physical data model and transformation logic is provided, Rational Data Architect can generate the SQL code to query the source and return a result set that meets the structure of the target in the mapping. This can be very helpful in federation scenarios.
One last purpose of mapping models, and perhaps the most valuable, is to provide lineage analysis capabilities. When any object is mapped to another object, Rational Data Architect users can use the impact analysis feature to see if an object has any objects that it is a dependent of or Rational Data Architect can identify any downstream objects that are dependent on the object being analyzed. For example:
As this is an example, naming standards were ignored, hence the differences in the three environments. The Account_ID column in the Account table in an operational database is a source to the ACT_ID column in the ACT table in an operational data store. The ACT_ID in the operational data store is in turn a source for the ACCT_ID column in the ACCT table of the data warehouse.
A relationship is defined between the column in operational database and the operational data store and is stored in a mapping model and the same is done for the relationship between the columns in the operational data store and the data warehouse.

Rational Data Architect Page 58
Mapping from Operational Database to Operational Data Store
Mapping from Operational Data Store to Data Warehouse
A change is required for the Account_ID column in the operational database. A user can right click on the column in the data project explorer in Rational Data Architect and perform an impact analysis.
When completing an impact analysis on the ACCOUNT_ID in the operational database, if Impacted objects is selected, Rational Data Architect identifies any objects that might be impacted, such as the ACT_ID in the operational data store. However, the impact analysis does not traverse the second mapping to identify ACCT_ID in the data warehouse as an impacted object at this time.
If you also choose to include recursive objects in the impact analysis, Rational Data Architect also identifies the ACCT_ID column in the data warehouse as an impacted object because Rational Data Architect will recursively traverse multiple mappings to identify impacted objects. Here is an example of the Impact analysis setting described:
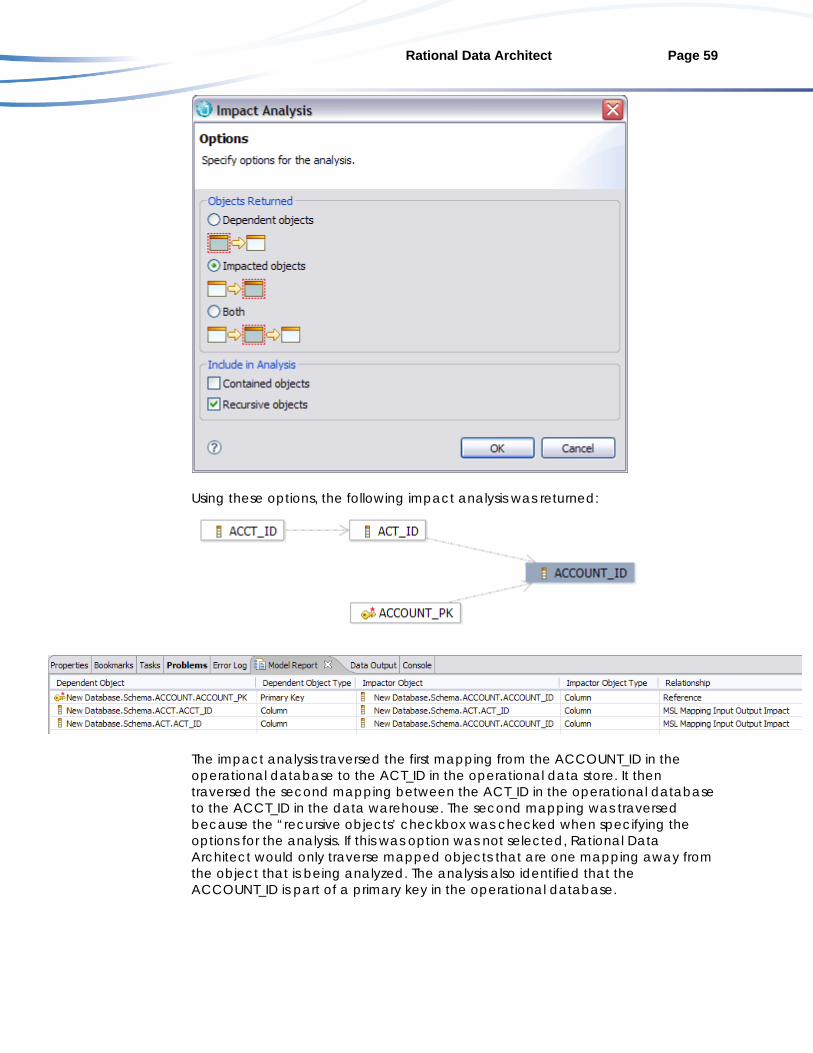
Rational Data Architect Page 59
Using these options, the following impact analysis was returned:
The impact analysis traversed the first mapping from the ACCOUNT_ID in the operational database to the ACT_ID in the operational data store. It then traversed the second mapping between the ACT_ID in the operational database to the ACCT_ID in the data warehouse. The second mapping was traversed because the “recursive objects’ checkbox was checked when specifying the options for the analysis. If this was option was not selected, Rational Data Architect would only traverse mapped objects that are one mapping away from the object that is being analyzed. The analysis also identified that the ACCOUNT_ID is part of a primary key in the operational database.
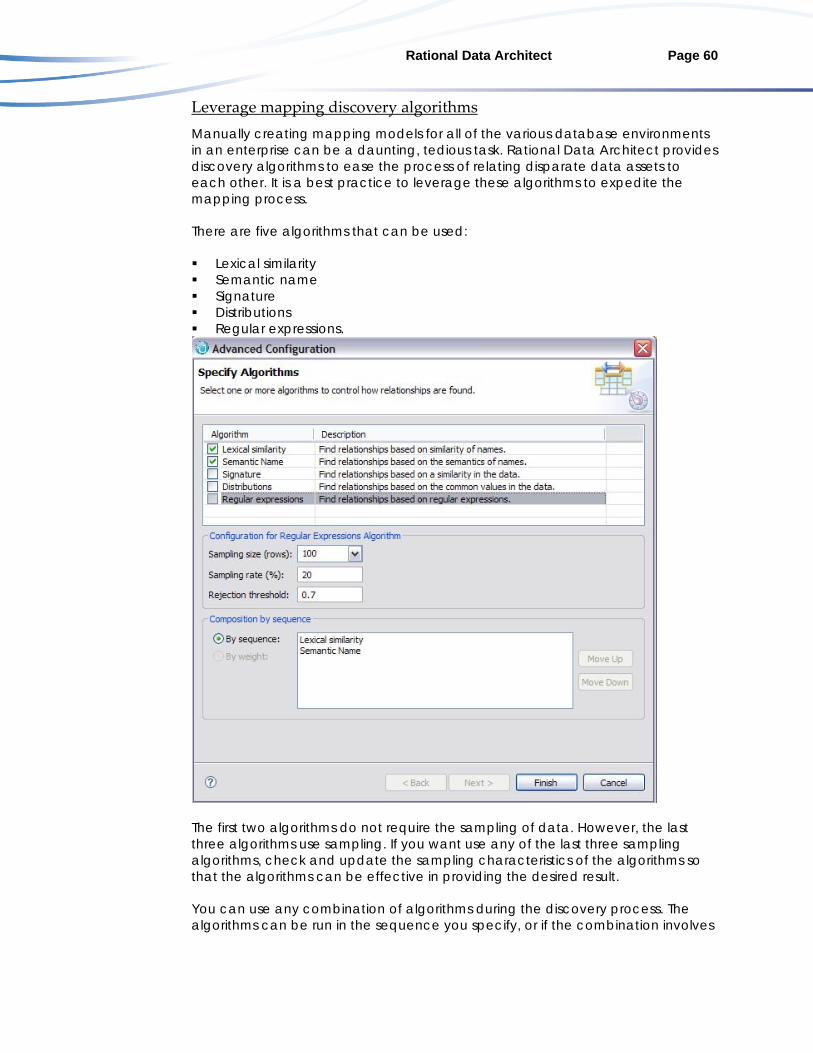
Rational Data Architect Page 60
Leverage mapping discovery algorithms Manually creating mapping models for all of the various database environments in an enterprise can be a daunting, tedious task. Rational Data Architect provides discovery algorithms to ease the process of relating disparate data assets to each other. It is a best practice to leverage these algorithms to expedite the mapping process.
There are five algorithms that can be used:
Lexical similarity Semantic name Signature Distributions Regular expressions.
The first two algorithms do not require the sampling of data. However, the last three algorithms use sampling. If you want use any of the last three sampling algorithms, check and update the sampling characteristics of the algorithms so that the algorithms can be effective in providing the desired result.
You can use any combination of algorithms during the discovery process. The algorithms can be run in the sequence you specify, or if the combination involves

Rational Data Architect Page 61
any of the last three algorithms, a weight can be assigned each of the algorithms to be used during the discovery process.
It is also possible to leverage enterprise naming standards to help discover the appropriate mappings. The glossary model that should be used for each schema in the mapping must be attached when selecting the Enterprise Naming Standard option for Discover Relationships as shown below.
There are two primary options for discovering relationships in mapping models.
• Use the Find Similar option to get multiple mappings from either the source or the target side for each element on the opposite side. For example, you can specify that you want each source element to have five columns that it maps to on the target side. Rational Data Architect always chooses the number of matches specified, so a significant amount of time might be spent validating mappings and removing invalid ones.
• Use the Find Best Fit option to identify a single match on the target side for each element on the source side. This approach could potentially miss valid mappings, but in general it takes less time to validate the mappings that are inferred.

Rational Data Architect Page 62
It is a best practice to leverage the discovery functionality as it can result in a significant time savings when creating mapping models.
Best practices for mapping models
Always try to create a mapping model if there are any relationships between two models. Even if transformation logic is ignored the mappings can be used in an impact analysis.
Leverage the discovery algorithms in Rational Data Architect to rapidly create mapping models.

Rational Data Architect Page 63
Education
Best practices for user education
Consider formal training:
IBM offers training courses on using Rational Data Architect. These courses might be of value to new data architects, or even experienced architects who are transitioning from other tools or want to make sure they are maximizing their use Rational Data Architect. For more information about training course, see the following URL: http://www-304.ibm.com/jct03001c/services/learning/ites.wss/zz/en?pageType=page&c=a0011023 At the time of publishing, the US based courses on Rational Data Architect are:
Course description: Using Rational Data Architect
http://www-304.ibm.com/jct03001c/services/learning/ites.wss/us/en?pageType=course_description&courseCode=CE820
Course description: Using Rational Data Architect - Instructor Led Online
http://www-304.ibm.com/jct03001c/services/learning/ites.wss/us/en?pageType=course_description&courseCode=3E820
Check developerWorks for newest articles on Rational Data Architect
There are many technical articles available that provide tutorials on functionality in Rational Data Architect as well as general insight to being successful with the product. These articles can be found at the following URL: http://www.ibm.com/developerworks/views/db2/libraryview.jsp?sort_by=Date&show_abstract=true&show_all=false&search_flag=&product_by=P:Rational+Data+Architect&topic_by=All+Topics&type_by=All+Types
Check for updates to this document:
This document will be updated periodically as new functionality becomes available in Rational Data Architect. Check the IBM DB2 Best Practices Web page for updates to this document:
http://www.ibm.com/developerworks/db2/bestpractices/

Rational Data Architect Page 64
Participate in the wiki for this document:
In order to obtain feedback on best practices from the user community, IBM has created the IBM database wiki on developerWorks. This document is included on the wiki with other best practices, On the wiki, you can suggest changes to the document and enhance the value of this document for all users of Rational Data Architect. The wiki is located at the following URL:
http://www.ibm.com/developerworks/wikis/display/data/Home

Rational Data Architect Page 65
Best practices summary
General best practices
Eclipse and the general Rational Data Architect user experience
Save often o Use Ctrl+S to save a single object o Use Ctrl+Shift+S to save everything
Apply the latest fix pack Minimize the number of open projects and model in
the Data Project Explorer view to free up system resources.
Defragment the hard drive Customize the user experience
o Create customized perspectives for specific tasks that you work on.
Create a workspace that is easy to find Start clean
o Always start Rational Data Architect using the -clean option.
Use shortcut keys o Learn and update shortcut keys in the eclipse
preferences window. Align diagrams for printing during initial diagram
creation o Use the diagram layout functions to help line up a
diagram for printing. History
o Increase the size of the history file, so you can compare and replace current models with historical versions.
Memory o Increase the amount of virtual memory available
to eclipse to improve performance of Rational

Rational Data Architect Page 66
Data Architect o Increase the amount of memory available to the
import export bride to improve the performance of the bridge and to import very large models.
Rapid modeling o Use Microsoft Excel to create data model objects
in a spreadsheet and use the model import function to import the spreadsheet into a data model.
Establish standards
Project standards
Create a single project for enterprise standards, which can be shared with all users in the organization.
Store project specific standards with the project that they belong to.
Naming standards
Define name component ordering. Create a glossary model and define naming standards.
o Define multiple glossaries within a naming standard model to logically group terminology in a meaningful way to the organization.
o Copy glossary models to and from spreadsheet applications to enter glossary entries more efficiently.
Update object naming standards.
Domain standards
Establish domain standards. Consider storing domain value definitions in a physical
database table, where the definitions can be joined to values to provide context.

Rational Data Architect Page 67
Logical data modeling
Normalization
A logical data model should always be in at least third normal form (3NF).
Generalization relationships
Use generalization and subtype relationships to provide a more meaningful logical data model for business analysts.
Use a two tiered subtype if there are exclusive subtypes.
Team sharing
Use packages to separate logical entities. Create submodels from packages to minimize the
impact of team sharing.
Physical model design
Table normalization and denormalization
Normalize your tables using third normal form (3NF) for most general-purpose databases
Use a star schema or snowflake model for dimensional queries
Use the IBM layered data architecture for broad-based data warehousing, online analytical processing (OLAP), and business intelligence (BI) if the database in use can support this methodology.
Index design
Design a basic set of indexes using workload predicates, primary keys (PKs), and foreign keys (FKs).

Rational Data Architect Page 68
Referential integrity
Always model referential integrity even if it is not going to be physically created.
Create unenforced referential integrity instead in situations where you do not want to create a hard constraint on the database.
Model transformation
Analyze and validate models
Analyze and validate models before transforming or deploying them.
Traceability
Always select the Generate traceability option in the Transformation wizard.
Deployment
Impact analysis
Always analyze the impact of a change before deploying it.
Use templates
Use DDL templates when generating DDL to save time.
Lifecycle management
Object comparison
Always do a compare at the lowest level possible to minimize the amount of metadata required for the comparison.

Rational Data Architect Page 69
Mapping models
Always try to create a mapping model if there are any relationships between two models. Even if transformation logic is ignored the mappings can be used in an impact analysis.
Leverage the discovery algorithms in Rational Data Architect to rapidly create mapping models.

Rational Data Architect Page 70
Conclusion
Data model design is a vital step in achieving successful database implementations. The design affects the scalability, efficiency, maintainability and extensibility of a database as well as the quality and information that can be derived from the data contained within the database. Although database design can be complex, a good design is extensible, improves performance, and reduces operational risk. While there is no perfect design for a given problem, mastery of data modeling is vital in achieving successful enterprise architecture.

Rational Data Architect Page 71
Further reading
• DB2 Best Practices http://www.ibm.com/developerworks/db2/bestpractices/
• Best Practices for Physical Database Design http://download.boulder.ibm.com/ibmdl/pub/software/dw/dm/db2/bestpractices/DB2BP_Physical_Design_0508I.pdf
• Rational Data Architect V7.5 Information Center http://publib.boulder.ibm.com/infocenter/rdahelp/v7r5/index.jsp
• developerWorks articles on Rational Data Architect http://www.ibm.com/developerworks/views/db2/libraryview.jsp?sort_by=Date&show_abstract=true&show_all=false&search_flag=&product_by=P:Rational+Data+Architect&topic_by=All+Topics&type_by=All+Types
• S. Lightstone, T. Teorey, T. Nadeau, “Physical Database Design: the database professional's guide to exploiting indexes, views, storage, and more”, Morgan Kaufmann Press, 2007. ISBN: 0123693896
• T. Teorey, S. Lightstone, T. Nadeau, “Database Modeling & Design: Logical Design, 4th edition”, Morgan Kaufmann Press, 2005. ISBN: 0-12-685352-5

Rational Data Architect Page 72
Contributors
Norma Mullin Consulting IT Specialist Information Management
Paul Rockwood IT Specialist Information Management
Sam Lightstone Program Director and Senior Technical Staff Member Information Management
Christopher Tsounis Executive IT Specialist Information Management
Eric Koeck Technical Editor Information Management
Agatha Colangelo DB2 Information Development

Rational Data Architect Page 73
Notices
This information was developed for products and services offered in the U.S.A.
IBM may not offer the products, services, or features discussed in this document in other countries. Consult your local IBM representative for information on the products and services currently available in your area. Any reference to an IBM product, program, or service is not intended to state or imply that only that IBM product, program, or service may be used. Any functionally equivalent product, program, or service that does not infringe any IBM intellectual property right may be used instead. However, it is the user's responsibility to evaluate and verify the operation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matter described in this document. The furnishing of this document does not grant you any license to these patents. You can send license inquiries, in writing, to:
IBM Director of Licensing IBM Corporation North Castle Drive Armonk, NY 10504-1785 U.S.A.
The following paragraph does not apply to the United Kingdom or any other country where such provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES CORPORATION PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer of express or implied warranties in certain transactions, therefore, this statement may not apply to you.
Without limiting the above disclaimers, IBM provides no representations or warranties regarding the accuracy, reliability or serviceability of any information or recommendations provided in this publication, or with respect to any results that may be obtained by the use of the information or observance of any recommendations provided herein. The information contained in this document has not been submitted to any formal IBM test and is distributed AS IS. The use of this information or the implementation of any recommendations or techniques herein is a customer responsibility and depends on the customer’s ability to evaluate and integrate them into the customer’s operational environment. While each item may have been reviewed by IBM for accuracy in a specific situation, there is no guarantee that the same or similar results will be obtained elsewhere. Anyone attempting to adapt these techniques to their own environment do so at their own risk.
This document and the information contained herein may be used solely in connection with the IBM products discussed in this document.
This information could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in new editions of the publication. IBM may make improvements and/or changes in the product(s) and/or the program(s) described in this publication at any time without notice.
Any references in this information to non-IBM Web sites are provided for convenience only and do not in any manner serve as an endorsement of those Web sites. The materials at those Web sites are not part of the materials for this IBM product and use of those Web sites is at your own risk.
IBM may use or distribute any of the information you supply in any way it believes appropriate without incurring any obligation to you.
Any performance data contained herein was determined in a controlled environment. Therefore, the results obtained in other operating environments may vary significantly. Some measurements may have been made on development-level systems and there is no guarantee that these measurements will be the same on generally available systems. Furthermore, some measurements may have been estimated through extrapolation. Actual

Rational Data Architect Page 74
results may vary. Users of this document should verify the applicable data for their specific environment.
Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products.
All statements regarding IBM's future direction or intent are subject to change or withdrawal without notice, and represent goals and objectives only.
This information contains examples of data and reports used in daily business operations. To illustrate them as completely as possible, the examples include the names of individuals, companies, brands, and products. All of these names are fictitious and any similarity to the names and addresses used by an actual business enterprise is entirely coincidental.
COPYRIGHT LICENSE: © Copyright IBM Corporation 2008. All Rights Reserved.
This information contains sample application programs in source language, which illustrate programming techniques on various operating platforms. You may copy, modify, and distribute these sample programs in any form without payment to IBM, for the purposes of developing, using, marketing or distributing application programs conforming to the application programming interface for the operating platform for which the sample programs are written. These examples have not been thoroughly tested under all conditions. IBM, therefore, cannot guarantee or imply reliability, serviceability, or function of these programs. The sample programs are provided "AS IS", without warranty of any kind. IBM shall not be liable for any damages arising out of your use of the sample programs.
Trademarks IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information with a trademark symbol (® or ™), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at “Copyright and trademark information” at www.ibm.com/legal/copytrade.shtml
Microsoft and Windows are trademarks of Microsoft Corporation in the United States, other countries, or both.
Other company, product, or service names may be trademarks or service marks of others.