Embed Size (px)
Citation preview

Beyond Mindless Labeling: Really Leveraging Humans to Build Intelligent
Machines
Devi ParikhVirginia Tech

Image Understanding
Slide credit: Devi Parikh
“Color College Avenue”, Blacksburg, VA, May 2012
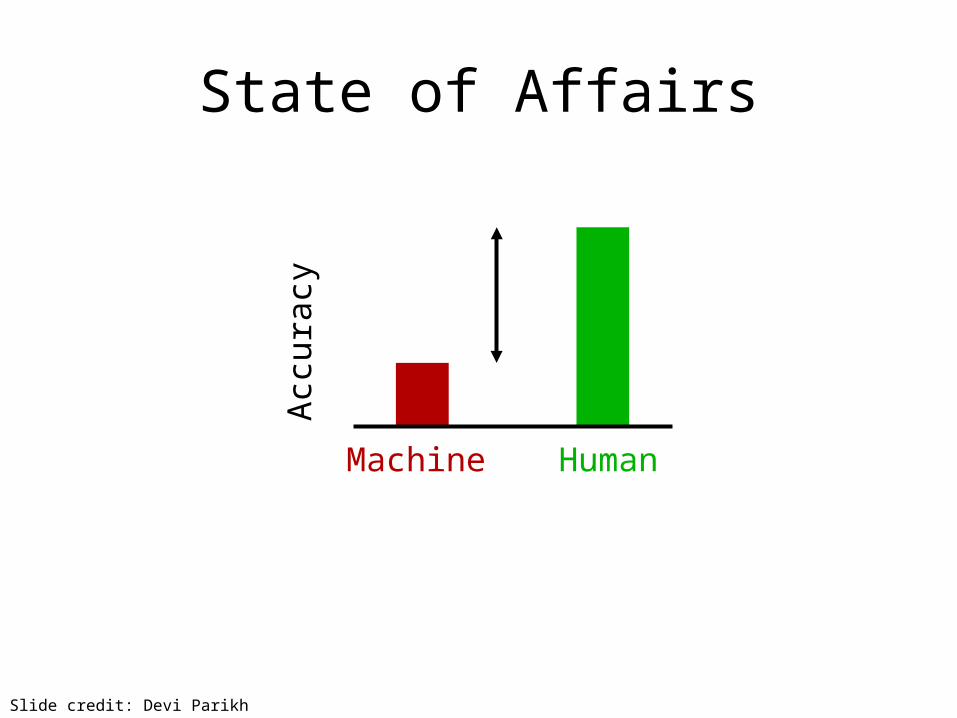
Accu
racy
Machine Human
State of Affairs
Slide credit: Devi Parikh

How do we teach machines today?
Slide credit: Devi Parikh

Slide credit: Devi Parikh

Slide credit: Devi Parikh

Slide credit: Devi Parikh

Slide credit: Devi Parikh

Slide credit: Devi Parikh

Slide credit: Devi Parikh

Slide credit: Devi Parikh

And on, and on, and on…
Slide credit: Devi Parikh

Slide credit: Devi Parikh

How do machines behave?
Slide credit: Devi Parikh

Airplane Cabin Amusement Park
Aquarium Badminton Court
Bedroom
Xiao et al., CVPR 2010Slide credit: Devi Parikh
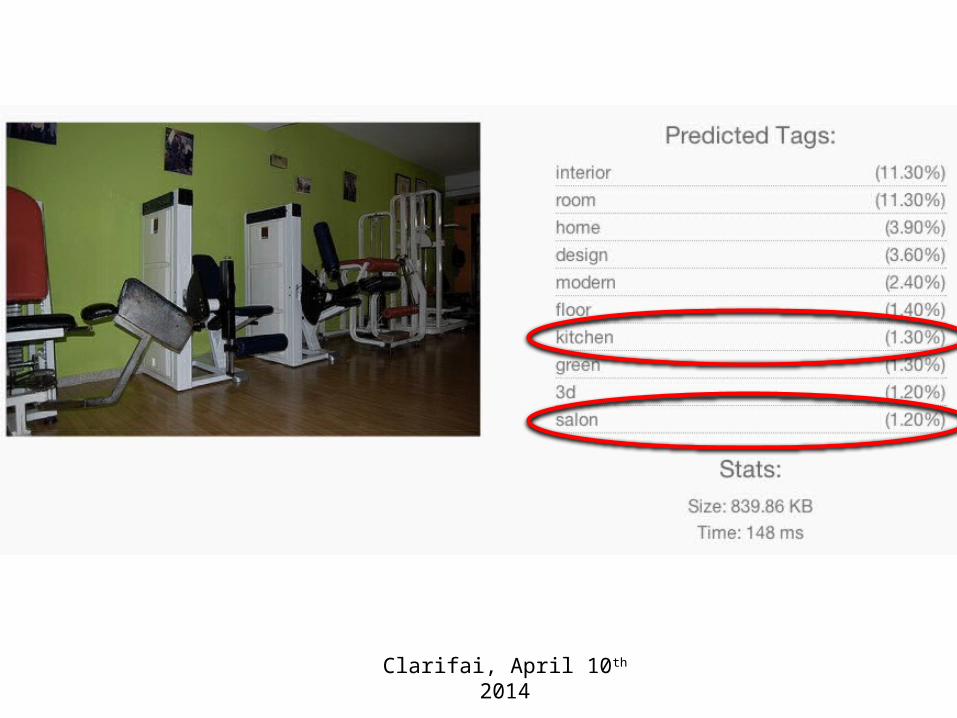
Clarifai, April 10th 2014

Slide credit: Devi Parikh
Need a better mode of communication!
Interacting with Vision Systems

Attributes
• Examples: furry, natural, young, etc.• Mid-level• Shareable across concepts• Human understandable• Machine detectable• Allow for human-machine communication
Slide credit: Devi Parikh
[Parikh and Grauman, ICCV 2011]
[Parkash and Parikh, ECCV 2012]
[Biswas and Parikh, CVPR 2013]
[Lad and Parikh, ECCV 2014]
[Kovashka, Parikh and Grauman, CVPR 2012][Parikh and Grauman,
ICCV 2013]
[Bansal, Farhadi and
Parikh, ECCV 2014]
Supervisor
User
User
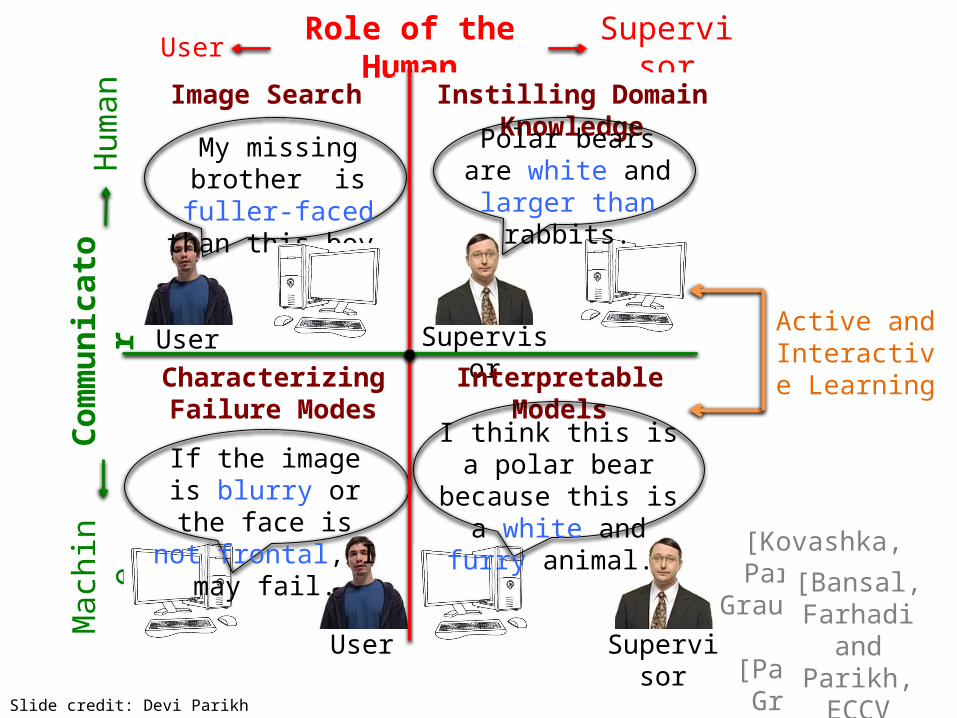
Role of the Human
Com
mun
icat
or
SupervisorUser
Hum
anM
achi
neImage Search Instilling Domain Knowledge
Characterizing Failure Modes
Interpretable Models
My missing brother is fuller-faced than
this boy.
Polar bears are white and larger
than rabbits.
If the image is blurry or the face is not frontal, I may fail.
Active and Interactive Learning
Slide credit: Devi Parikh
Supervisor
I think this is a polar bear because this is a
white and furry animal.

Accessing Common Sense
• Direct communication
• Learn by observing structure in our visual world?
Slide credit: Devi Parikh

Two professors converse in front of a blackboard.
Slide credit: Larry Zitnick

Two professors stand in front of a blackboard.
Slide credit: Larry Zitnick

Two professors converse in front of a blackboard.
Slide credit: Larry Zitnick

Challenges
• Lacking visual density• Annotations are expensive (and boring)• Computer vision doesn’t work well enough
Slide credit: Devi Parikh

Is photorealism necessary?
Slide credit: Larry Zitnick

Jenny Mike
Slide credit: Larry Zitnick

Slide credit: Larry Zitnick
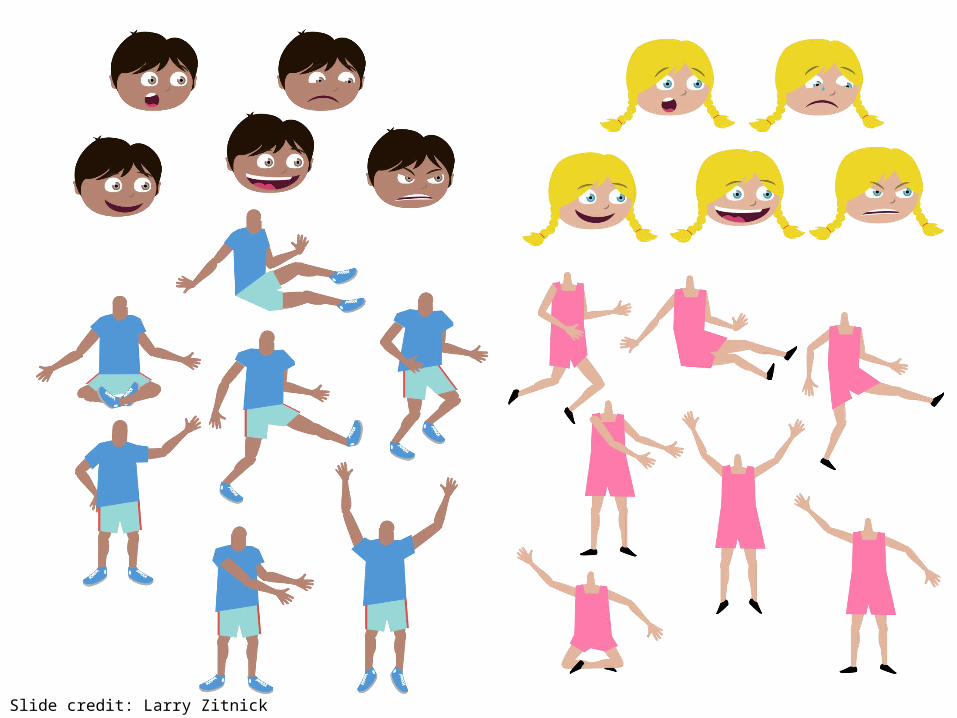
Slide credit: Larry Zitnick

Interface
2x

Mike fights off a bear by giving him a hotdog while Jenny runs away.
Slide credit: Larry Zitnick

1,000 classes of semantically similar scenes:
Class 1 Class 2 Class 1,000
1,000 classes x 10 scenes per class = 10,000 scenes
Slide credit: Larry Zitnick
Dataset
Dataset online[Zitnick and Parikh, CVPR 2013]

Slide credit: Larry Zitnick
Visual Features
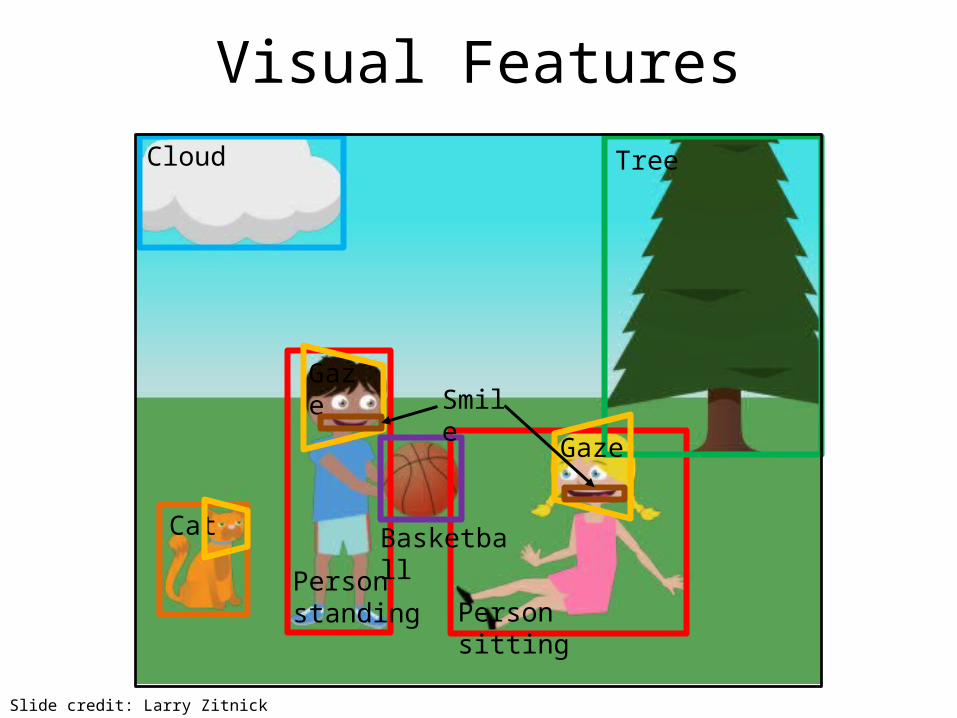
Cloud
Cat Basketball
Smile
Gaze
Gaze
Person sitting
Tree
Person standing
Slide credit: Larry Zitnick
Visual Features
Cloud
Cat Basketball
Smile
Gaze
Gaze
Person sitting
Tree
Person standing
Slide credit: Devi Parikh
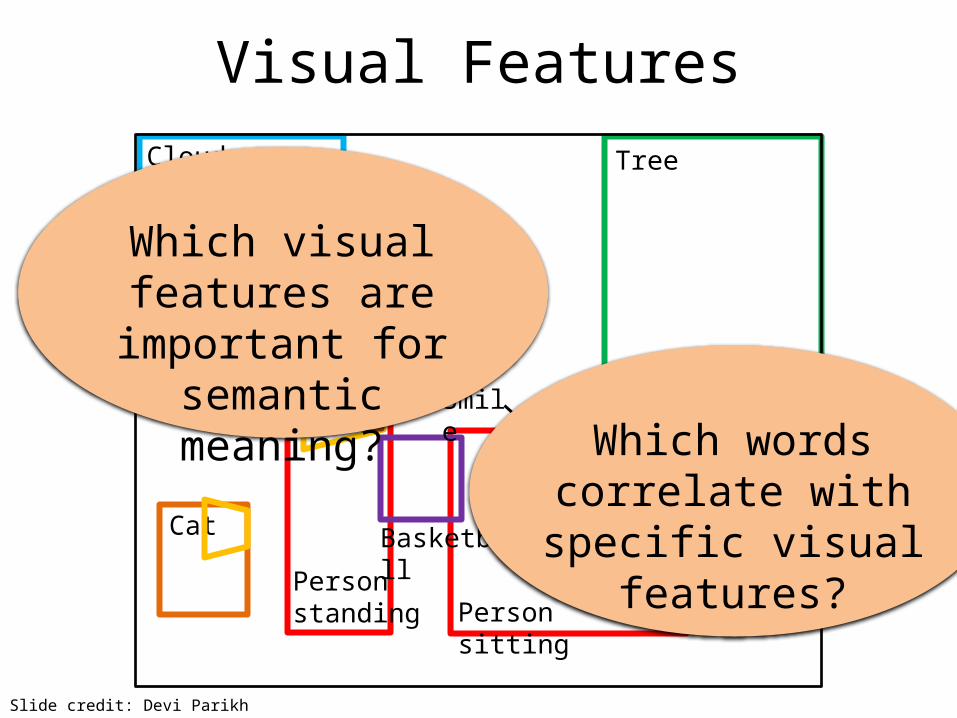
Visual Features
Which visual features are important for
semantic meaning?
Which words correlate with specific visual
features?

Generate and Retrieve ScenesInput: Jenny is catching the ball. Mike is kicking the ball. The table is next to the tree.
Tuples: <<Jenny>,<catch>,<ball>> <<Mike>,<kick>,<ball>> <<table>,<be>,<>>
Slide credit: Devi Parikh [Zitnick, Parikh and Vanderwende, ICCV 2013]
Automatically Generated Human Generated
Retrieval: score a database of scenes
Slide credit: Devi Parikh [Antol, Zitnick and Parikh, ECCV 2014]
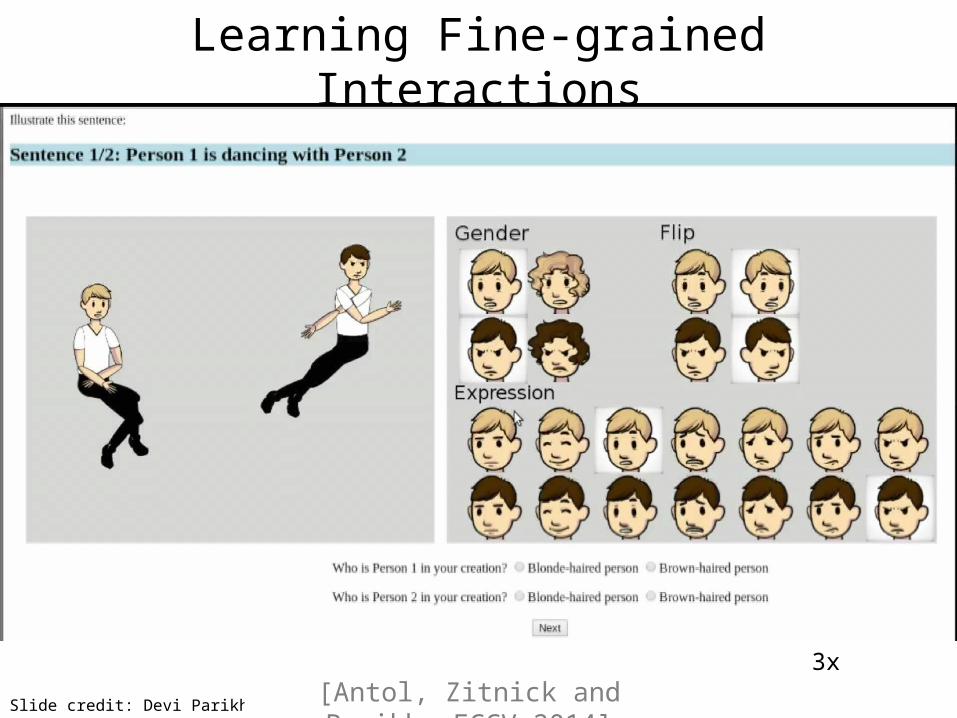
Learning Fine-grained Interactions
3x

Learning Fine-grained Interactions
Train on abstract, test on real
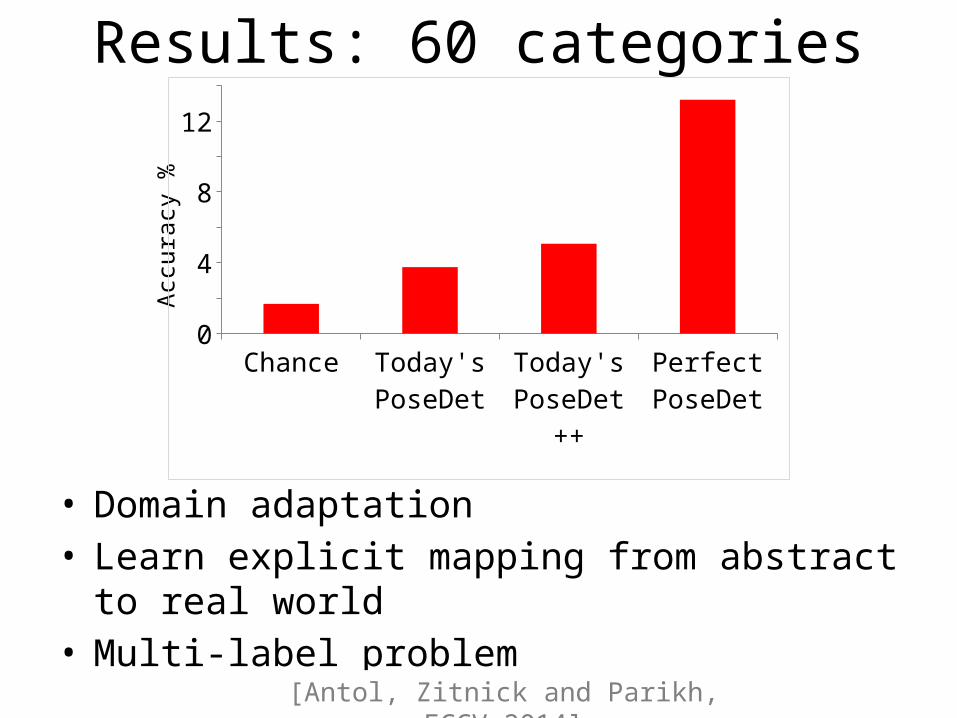
Results: 60 categories
Accu
racy
%
Chance Today's PoseDet
Today's PoseDet ++
Perfect PoseDet
0
2
4
6
8
10
12
14
• Domain adaptation• Learn explicit mapping from abstract to real world• Multi-label problem
[Antol, Zitnick and Parikh, ECCV 2014]

Visual Abstraction For…• Studying mappings between images and text• Zero-shot learning• Studying image memorability, specificity, etc.
• Learning common sense knowledge
• Rich annotation modality– Ask for descriptions– Ask for scenes– Show scene and ask for modification
Goes beyond “Jenny and Mike.”
Study high-level image understanding
tasks without waiting for lower-level
vision tasks to be solved

[Xinlei Chen]
Accu
racy
Machine Human
Conclusion
• Give computer vision systems access to common-sense knowledge– Communication with humans via attributes (text)– Visual abstraction
• Use humans for more than just “labels”Slide credit: Devi Parikh

Thank you.
Slide credit: Devi Parikh





























