Embed Size (px)
Citation preview

Big Data on Kubernetes
Maciej Bryński

● Introduction to Kubernetes
● Helm and its ecosystem
● Big Data technologies on Kubernetes:
○ Kafka
○ HDFS
○ Spark
○ Flink
● Live Demo
Contents

Introduction to Kubernetes

● Kubernetes is an open-source system for automating deployment, scaling, and management
of containerized applications.
● The name Kubernetes originates from Greek, meaning "helmsman" or "pilot"
● K8s is an abbreviation derived by replacing the 8 letters "ubernete" with 8
● Based on Google’s Borg
Kubernetes

Different competitors:
● Docker Swarm and Compose
● Mesos (DC/OS)
● Nomad
Why Kubernetes?

● Most active GitHub project
Why Kubernetes?

Support from every main Cloud Provider:
● GKE – Google Kubernetes Engine
● EKS - Amazon Elastic Container Service
● AKS - Azure Kubernetes Service
● Alibaba Container Service for Kubernetes
Why Kubernetes?

Main concepts

● Logical "host"
● Group of one or more containers
● Shared storage (volumes)
● Shared network
Pod

● Problem: pods are not durable
● Solution: Deployment – mechanism which ensures that a specified number of pod replicas
are running at any given time
● Features:
○ Ability to upgrade (and rollback) pods
○ Ability to control scaling (change number of Pods)
● Pods created with deployment have random name
Deployment
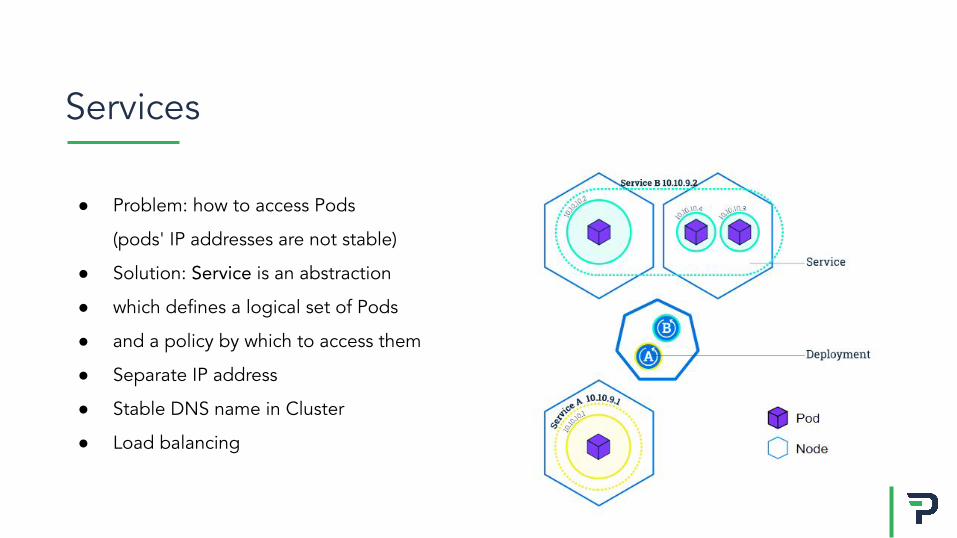
● Problem: how to access Pods
(pods' IP addresses are not stable)
● Solution: Service is an abstraction
● which defines a logical set of Pods
● and a policy by which to access them
● Separate IP address
● Stable DNS name in Cluster
● Load balancing
Services

● Problem: Storage abilities for Pods
● Solution: Persistent Volume – storage resources in the cluster
● Some PV providers:
○ AWSElasticBlockStore
○ AzureDisk
○ GCEPersistentDisk
○ CephFS
● Persistent Volumes are bound to Pod by pod's name
Persistent Volume

● Problem: how to create PV in deployments
● Solution: StatefulSet - API object used to manage stateful applications
● Features:
○ Stable, unique network identifiers ({name}-{index}).
○ Stable, persistent storage.
○ Ordered, graceful deployment and scaling.
○ Ordered, automated rolling updates.
StatefulSet

● Problem: One Pod per Node
● Solution: DaemonSet ensures that all (or some) Nodes run exactly one copy of a Pod.
● As nodes are added to the cluster, Pods are added to them. As nodes are removed from the
cluster, those Pods are garbage collected
● Use cases:
○ Logging (fluentd, logstash)
○ Monitoring (Prometheus exporter)
○ Cluster storage (Ceph, HDFS (?))
DaemonSet

● Pod – ephemeral applications
● Deployments – stateless applications
● StatefulSets – stateful applications
● DaemonSets – app per node – monitoring, logging, cluster storage
Deployment options - summary

● Problem: store configuration and separate from Pod
● Solutions:
○ ConfigMaps – store configuration files, command-line arguments, environmental
variables, port numbers etc.
○ Secrets – objects intended to hold sensitive information
● ConfigMaps and Secrets can be binded to Pod as:
○ Environmental variable
○ Regular file
ConfigMap and Secret

● Namespaces – way to divide cluster into parts
● Ability to divide cluster resources between multiple users
● Three initial namespaces:
○ default The default namespace for objects with no other namespace
○ kube-system The namespace for objects created by the Kubernetes system
○ kube-public This namespace is created automatically and is readable by all users
Namespaces

Helm and its ecosystem

● Package manager for Kubernetes
● Chart – Helm package
● Features:
○ Way to deploy complicated application into K8s
○ De facto standard for managing apps on K8s
○ More than 300 ready to use deployments in official repo
○ Many unofficial repos available
● Two official repositories:
○ Stable
○ Incubator
Helm

● MySQL, PostgreSQL
● Elasticsearch + Kibana + Fluentd
● Prometheus
● Vault
● Nginx, HAProxy, Traefik
● Jenkins
● Gitlab
Sample charts

● Problem: how to manage helm charts
● Solution – Helmfile – declarative spec for deploying helm charts
● Helm plugins:
○ Helm-diff – Ability to see the changes before upgrade
○ Helm-secrets + sops – managing secrets in helm
○ Helm-s3 – private charts repositories on S3
Helm ecosystem

Big Data on Kubernetes

Kafka

Components:
● Zookeeper
● Kafka Server
● Schema Registry
● Kafka REST
● Kafka Connect
What building blocks to use ?
Kafka

Components:
● Zookeeper - StatefulSet
● Kafka Server
● Schema Registry
● Kafka REST
● Kafka Connect
Kafka

Components:
● Zookeeper - StatefulSet
● Kafka Server - StatefulSet
● Schema Registry
● Kafka REST
● Kafka Connect
Kafka

Components:
● Zookeeper - StatefulSet
● Kafka Server - StatefulSet
● Schema Registry - Deployment
● Kafka REST
● Kafka Connect
Kafka

Components:
● Zookeeper - StatefulSet
● Kafka Server - StatefulSet
● Schema Registry - Deployment
● Kafka REST - Deployment
● Kafka Connect - Deployment
Kafka

Official Helm Charts:
● Zookeeper - incubator/zookeeper
● Kafka Server - incubator/kafka
● Schema Registry - incubator/schema-registry
● Kafka REST - nope
● Kafka Connect - nope
Kafka

● Problems:
○ Official charts are maintained by different people and not playing super well together
○ There is no charts for Kafka REST and Connect
● Solution: Confluent Helm Charts
○ Still beta, but better than official charts
○ Includes all components
○ Maintained by one organization
○ https://github.com/confluentinc/cp-helm-charts/
Kafka

HDFS

● Main features
○ Data locality
○ Performance
○ HA
● Competitors
○ Ceph
○ S3
○ GlusterFS
HDFS

● Components:
○ Namenode - StatefulSet
○ Datanode - StatefulSet / DaemonSet
● HA components:
○ Zookeeper - StatefulSet
○ ZKFC - same pod as Namenode
○ JournalNode - StatefulSet
HDFS

● Official Chart:
○ No HA
○ HDFS + Yarn (without ability to turn off Yarn)
○ Datanodes as Statefulset
● apache-spark-on-k8s/kubernetes-HDFS
○ High Availability
○ Only HDFS
○ Datanodes as DaemonSet
○ Only local storage used by Datanodes
HDFS

Processing Engines

● Active Mode
○ App is aware about cluster manager that it is running on and interacts with it.
○ Samples – almost every Big Data deployment:
■ Spark on Yarn / Mesos / Kubernetes
■ Flink on Yarn / Mesos
Deployment Modes

● Active Mode
○ App is aware about cluster manager that it is running on and interacts with it.
○ Samples – almost every Big Data deployment:
■ Spark on Yarn / Mesos / Kubernetes
■ Flink on Yarn / Mesos
● Reactive Mode
○ App is oblivious to its environment
○ App may react to new resource when job is scaled
○ Samples:
■ Kafka Streams
Deployment Modes

● Active Mode
○ App is aware about cluster manager that it is running on and interacts with it.
● Reactive Mode
○ App is oblivious to its environment
○ App may react to new resource when job is scaled
● Standalone Mode
○ App is deployed to the cluster in standalone mode
Deployment Modes

Apache Spark

Work in progress
● Spark on Kubernetes fork
○ Many features working
○ Discontinued
● Spark 2.4
○ Continuously merging features from fork into main Spark branch
Apache Spark

Spark 2.4 – features:
● Active Mode
● PySpark and SparkR support
● Client Mode support (interactive tools)
Apache Spark

Spark 2.4 – things that's not working:
● Dynamic Resource Allocation
● Shuffle service
● Data locality with HDFS
All those features were supported in Spark on Kubernetes fork
Apache Spark

Apache Flink

Current state - two modes of running on Kubernetes:
● Standalone
○ Needs to deploy standalone Flink cluster on Kubernetes (including task manager
and job managers)
○ Job managers are using cluster resource even when there is no jobs running
● "Single shot"
○ Cluster for single job
○ Difficult to maintain
Apache Flink

Future
● Active and Reactive Mode
● Reactive Mode - Flink as a Library
● Ability to use Kubernetes Horizontal Pod Autoscaler
Apache Flink

Live Demo

Live Demo

Live Demo

Thank you






























