Embed Size (px)
Citation preview

Big Fast SQL on OpenShift
Kamil Bajda-Pawlikowski Co-founder / CTO @prestosql @starburstdata
OpenShift Commons 2019 @ San Francisco
Kyle Bader Principal Solutions Architect

2
Presto: SQL-on-Anything
Deploy Anywhere, Query Anything

Why Presto?
Community-driven open source project
High performance ANSI SQL engine• New Cost-Based Query Optimizer• Proven scalability• High concurrency
Separation of compute and storage• Scale storage and compute
independently• No ETL or data integration
necessary to get to insights• SQL-on-anything
No vendor lock-in• No Hadoop distro vendor lock-in• No storage engine vendor lock-in• No cloud vendor lock-in

Enterprise edition
© 2019 5
Founded by Presto committers:● Over 4 years of contributions to Presto● Presto distro for on-prem and cloud env● Supporting large customers in production● Enterprise subscription add-ons (ODBC,
Ranger, Sentry, Oracle, Teradata, K8S)
Notable features contributed:● ANSI SQL syntax enhancements● Execution engine improvements● Security integrations● Spill to disk● Cost-Based Optimizer
https://www.starburstdata.com/presto-enterprise/

Built for PerformanceQuery Execution Engine:
● MPP-style pipelined in-memory execution● Columnar and vectorized data processing● Runtime query bytecode compilation● Memory efficient data structures● Multi-threaded multi-core execution● Optimized readers for columnar formats (ORC and Parquet)● Predicate and column projection pushdown● Now also Cost-Based Optimizer
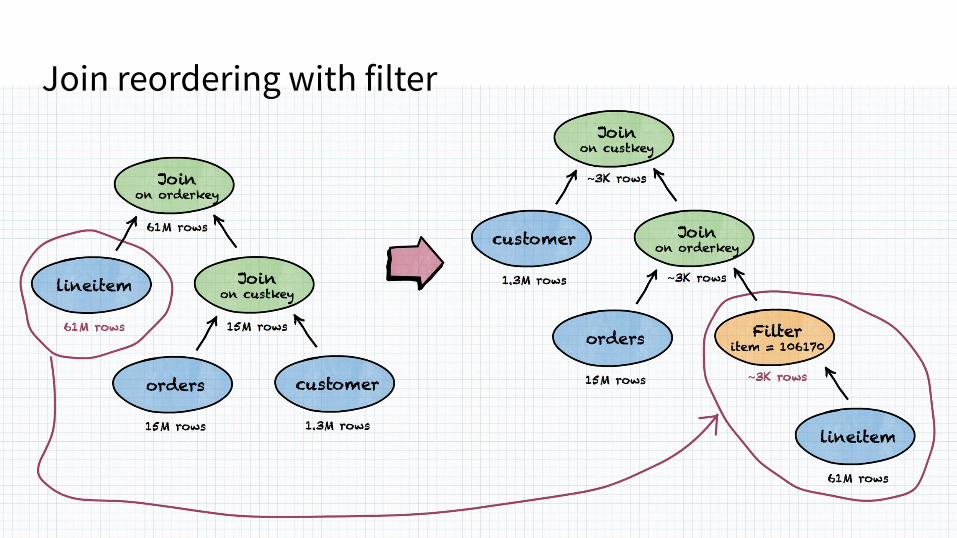
Join reordering with filter

CBO off
CBO on
https://www.starburstdata.com/presto-benchmarks/
Benchmark results

© 2019

Administrative challenges
● Configuring and managing clusters● Autotuning properties based on the hardware provisioned● High Availability for Presto Coordinator● Scaling cluster elastically based on query load● Gracefully decommissioning Presto Workers to avoid killing queries● Monitoring of hardware and software layers
https://www.starburstdata.com/technical-blog/presto-on-kubernetes/

https://docs.starburstdata.com/latest/kubernetes.html
Presto on OpenShift
Presto WorkerPod
Presto WorkerPod
11
Presto CoordinatorPod
Presto WorkerPod
Horizontal Pod Autoscaler (HPA)
Presto OperatorK8s Operator
PrestoService
Hive Metastore ServicePod
Hadoop / Hive
RDBMS

Now available in OpenShift Catalog!

● Massively scalable○ 10’s-100’s of PBs○ Billions of objects○ 100’s of gigabits
● Erasure coding drives storage efficiency● High level of fidelity with S3 API● Open source software - LGPL 2.1 / 3

Red HatOpenShift Container Storage
● Rook-Ceph operator● Ceph for block (RWO), file (RWO/RWX), object (S3)● Noobaa for multi-cloud gateway

Hive connector configuration example (hive.properties)
connector.name=hive-hadoop2
hive.metastore.uri=thrift://metastore.example.com:9083
hive.s3.endpoint=s3.example.com
hive.s3.aws-access-key=ACCESS_KEY
hive.s3.aws-secret-key=SECRET_KEY
hive.s3.use-instance-credentials=false
hive.s3.staging-directory=/tmp
hive.s3.ssl.enabled=true

presto> CREATE SCHEMA hive.s3_export WITH (location =
's3://my_bucket/some/path');
presto> CREATE TABLE hive.s3_export.my_table
WITH (format = 'ORC')
AS <source query>;

Demo at ODSC West 12:30PM Thursday 10/31

Thank You!
18
Twitter: @starburstdata @prestosqlBlog: www.starburstdata.com/technical-blog/Newsletter: www.starburstdata.com/newsletter
© 2019






























