Embed Size (px)
Citation preview

Beijing, 31 October─3 November 2010
Bioinformatics and computational tools
Etienne P. de Villiers (PhD)
International Livestock Research InstituteNairobi, Kenya

Beijing, 31 October─3 November 2010
International Livestock Research InstituteNairobi, Kenya
• ILRI works at the crossroads of livestock and poverty, bringing high‐quality science and capacity building to bear on poverty reduction and sustainable development.
• It is one of 15 centers supported by the Consultative Group on International Agricultural Research (CGIAR) that conduct food and environmental research to help alleviate poverty and increase food security.
• ILRI biotech facilities:– Molecular biology Laboratories (>6,000 sqm)– State‐of‐the‐art biosciences equipment
• 2 ABI sequencers (3130, 3730)• 1 Roche 454 GS FLX
– Bioinformatics unit• 64 CPU high performance compute cluster
– BSL3 laboratory– Flow cytometry and microscopy– Diagnostics (nucleotide‐ and protein‐based)– Vaccine technology/Immunology– Small and Large Animal units
http://www.ilri.org http://hub.africabiosciences.org/

Beijing, 31 October─3 November 2010
Central dogma of molecular biology

Beijing, 31 October─3 November 2010
Bioinformatics
• Bioinformatics is the application of information technology and computer science to the field of molecular biology.

Beijing, 31 October─3 November 2010
Bioinformatics
ACGGTGCGTAACGTCAGTCAGGTCAGTCAGGenome (DNA) sequence
Bioinformatics or computational biology
Gene or proteinproperties
Comparative analysisProtein structure and function prediction

Beijing, 31 October─3 November 2010
The Sequencing RevolutionNext Generation Sequencing
High‐Throughput Sequencing2000
High‐Throughput Sequencing2010
2.6 million sequences per hour96 sequences per hour
Beijing, 31 October─3 November 2010
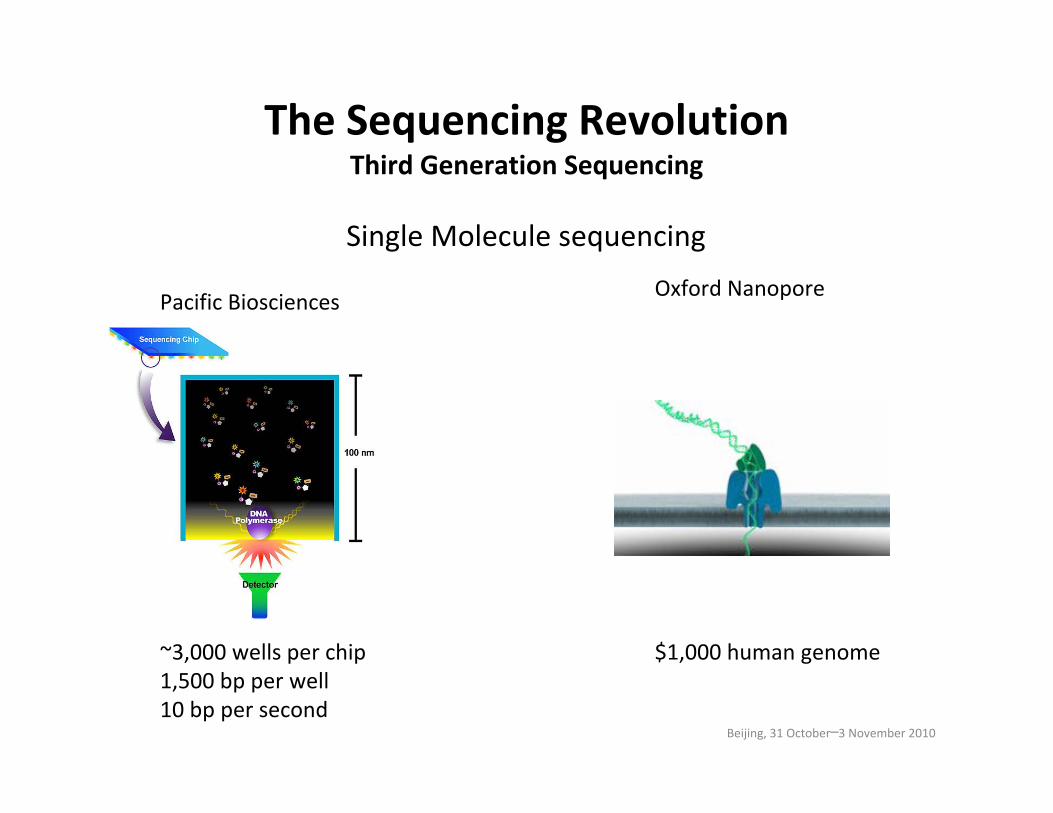
The Sequencing RevolutionThird Generation Sequencing
Oxford NanoporePacific Biosciences
Single Molecule sequencing
~3,000 wells per chip1,500 bp per well10 bp per second
$1,000 human genome

Beijing, 31 October─3 November 2010
Sequencing the Human Genome
Year
Log 1
0(price)
2010: 5K$, a few days
2009: Illumina40-50K$
201020052000
10
8
6
4
2
2008: ABI SOLiD60K$, 2 weeks
2007: 4541M$, 3 months
2001: Celera100 Million $ 3 years
2001: Human Genome Project3 billion $, 11 years

Beijing, 31 October─3 November 2010
Next Generation SequencingCurrent Projects
• 1000 Genomes project (www.1000genomes.org)
– Sequence genomes from 2500 people from divers backgrounds to 4x coverage to identify human genetic variation.
• Ensembl genomes (www.ensemblgenomes.org)
– 234 species sequenced from mammalians, birds to parasites.
– >400 bacterial species sequenced.
• Plant genomes – 18 sequenced (www.phytozome.org/)
• BGI (China) (www.genomics.cn) ‐ 1,000 plant and animal reference genome project.
Beijing, 31 October─3 November 2010
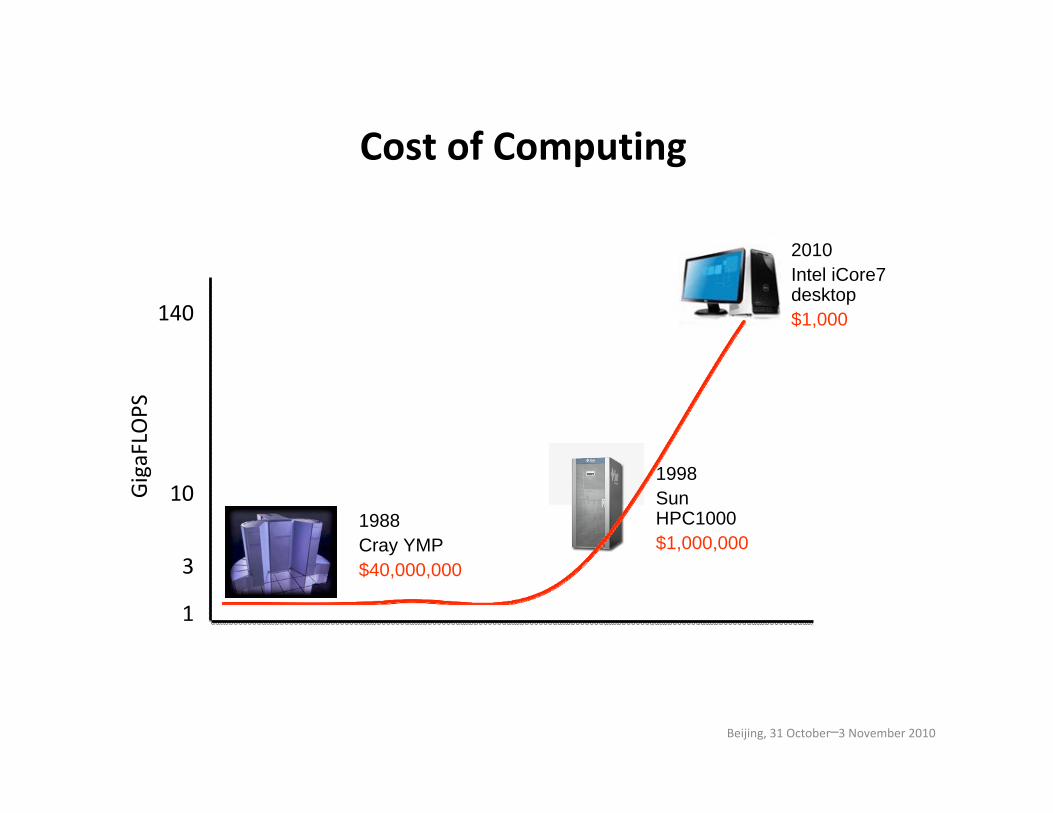
2010Intel iCore7 desktop$1,000
1998Sun HPC1000$1,000,000
1988Cray YMP $40,000,000
GigaFLO
PS
1
3
140
Cost of Computing
10

Beijing, 31 October─3 November 2010
World Internet Connections

Beijing, 31 October─3 November 2010
Cloud Computing
• Cloud computing is a general term for computation‐as‐a‐service.
• Computation‐as‐a‐service means that customers rent the hardware and the storage only for the time needed to achieve their goals
• Amazon Elastic Compute Cloud (Amazon EC2) provides resizable compute capacity in the cloud including,
• High Performance computing (HPC) on demand• 23 GB of memory
• 64 Compute nodes
• 1.7 Terabytes storage
• $1.60 per hour or
• $5,000 per year

Beijing, 31 October─3 November 2010
Distributed computing
The client uses the spare CPU cycles on a user’s computer to run the simulation algorithm on the assigned structure.
Results are automatically returned and exchanged for a new work unit on a daily basis. lab/office…home… anywhere
A central server sends and receives the work units (essentially just protein structures and sequences).
• Distributed computing is any computing that involves multiple computers remote from each other.

Beijing, 31 October─3 November 2010
Distributed computingFolding @home
• Understand how existing proteins attain their specific, functional three‐dimensional structures.
• Use distributed computing through installation of “screensaver” on user computer.
• In 2009 was running on 40,000 CPUs or 5 PFLOPS• Fastest standalone supercomputer is "Tianhe‐1A” at 2.5
PFLOPS
Beijing, 31 October─3 November 2010
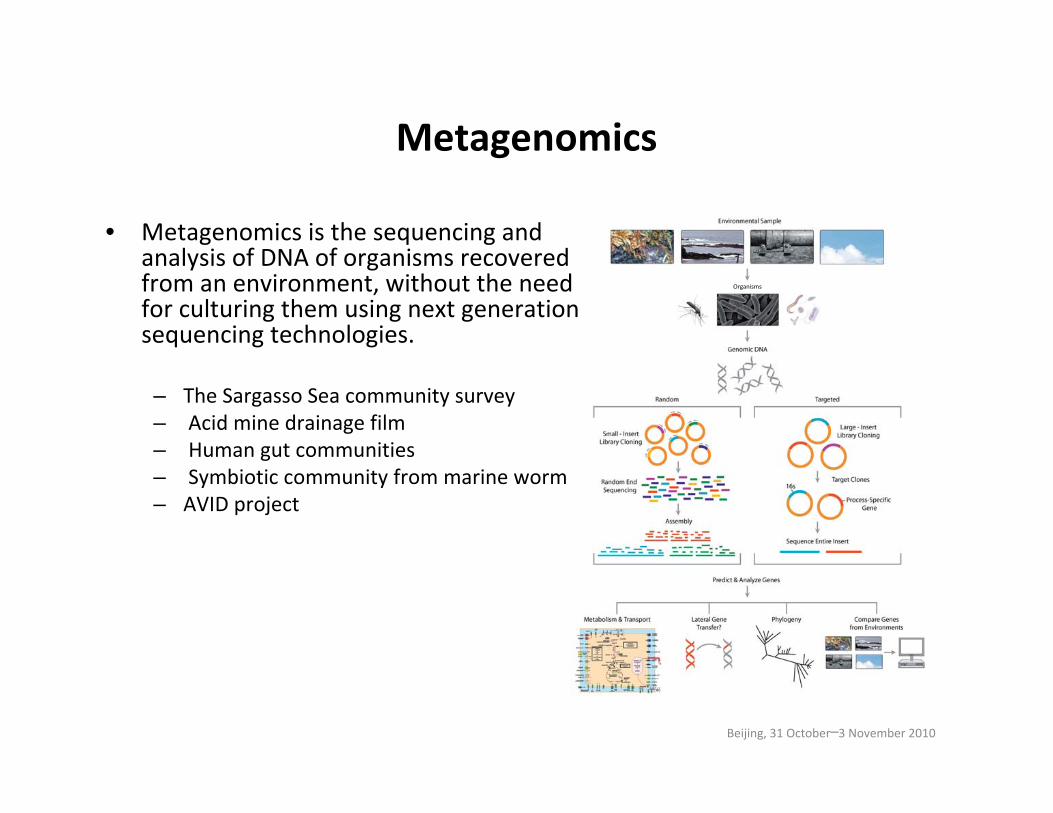
Metagenomics
• Metagenomics is the sequencing and analysis of DNA of organisms recovered from an environment, without the need for culturing them using next generation sequencing technologies.
– The Sargasso Sea community survey– Acid mine drainage film– Human gut communities– Symbiotic community from marine worm– AVID project
Organisms

Beijing, 31 October─3 November 2010
Compilation of complete genomes, metagenomes,
annotation and curation of metadata
(meta)genome sequencing
Extraction of important biological
information
Vaccine dvlpmt
Diagnostics
Global diseases surveillance
Drug dvlpmt
Better control tools
geographical mapping
sequence variation analysis
Primer,microarray
phylogeneticanalysis
proteinmodelingDatabases
Improved drug selection
From Sequence (genomics/metagenomics) to impact
discovery of new micro‐
organisms and pathways
Environmentalsustainability

Beijing, 31 October─3 November 2010
AVIDArbovirus Incident & Diversity project
• Google.org ‐ Predict and Prevent funded project.
• Pilot project on Rift Valley Fever virus.• virus is transmitted by mosquitoes and infect both animals and humans
• deadly to both humans and livestock
• outbreaks occur every 5‐6 years
A complex mix of species, sub species, populations.
Can we understand its dynamics ?

Beijing, 31 October─3 November 2010
AVID ‐ Questions
• “Where” is the virus (between “outbreaks”) ?– Environment– Vectors– Reservoirs
• What is the diversity of ?– Virus– Vector– Reservoir
• And how do these interact ?• Distribution of other pathogens ?• Novel pathogens and variants ?
For example:Does a particular virus variant occur in a particular vector variant associated with a particular mammalian variant ?
Viral Geneflow

Beijing, 31 October─3 November 2010
AVID ‐ Strategy
• Samples are collected in specific areas:– Human blood, livestock, wildlife, mosquitoes, water, soil
• Each sample collected with a full meta data description (location, date/time, eco‐geo‐socio descriptors).
• Amplify sequences from multiple points on multiple possible genomes – virus, insect, mammal, others.
• Sequence these amplicons simultaneously from 1,000s of samples using next generation sequencing.
• Analyse sequences – look for distribution and co‐occurrence.• Refine primers for a ‘simple’ (RT)‐PCR approach.• Move diagnostic sequences on to high throughput PCR
diagnostics.

Beijing, 31 October─3 November 2010

Beijing, 31 October─3 November 2010
AVID – Data management and BioBANK
• Data management is one of the biggest challenges. – The project cannot achieve its goals without great data
integration.
• All samples are biobanked with full data descriptors
• Opportunity to share samples across projects ?
• Wildlife samples are very expensive and everyone is collecting them for their own purposes!!

Beijing, 31 October─3 November 2010
Thank You





























