Embed Size (px)
Citation preview

Biological Databases

Biologists Collect Lots of Data
• Hundreds of thousands of species• Millions of articles in scientific journals• Genetic information:
– gene names– phenotype of mutants– location of genes/mutations on chromosmes– linkage (distances between genes)

• High Throughput technology– Rapid inexpensive DNA sequencing– Many methods of collecting genotype data
• Assays for specific polymorphisms• Genome-wide SNP chips
• Must have data quality assessment prior to analysis

What is a Database?• Organized data• Information is stored in
"records" and "fields"• Fields are categories
– Must contain contain data of the same type
• Records contain data that is related to one object

A Spreadsheet can be a Database
• columns are Fields • Rows are Records• Can search for a term
within just one field• Or combine searches
across several fields
SNP ID SNPSeq ID
Gene +primer -primer Hap A Hap B Hap C
D1Mit160_1 10.MMHAP67FLD1.seq
lymphocyte antigen 84
AAGGTAAAAGGCAATCAGCACAGCC
TCAACCTGGAGTCAGAGGCT
C — A
M-05554_1 12.MMHAP31FLD3.seq
procollagen, type III, alpha
TGCGCAGAAGCTGAAGTCTA
TTTTGAGGTGTTAATGGTTCT
C — A
M-05554_2 X60184 complement component factor i
ACTTCCAGCCCTGGCTCT
ATATGCCACCAAGAAGCA
A C —
M-09947_3 AF067835 caspase 8 TCACAGAGGGAAACATGAAG
CTCCACATTGAACCAAAGCA
G C T
M-11415_1 U02023 insulin-like growth factor binding protein
GGGAAAAGCCTGAAAGAAGC
AGCTGAAACCGGACATCAAT
T G —
D1Mit284_3
J05234 nucleolin TGTTGGAACCGACTTCTTCA
AAGAGTCAAAGAATTTATGGAATGA
G T T

Structured Data
• Repository of information
• managed and accessed differently
• Flat-file (text)• Relational (key)• “talk” to each other

Standard Data Formats• DNA sequence = ACGT, but what about
gaps, unknown letters, etc.– How many letters per line ???– ?? Spaces, numbers, headers, etc.– Store as a string, code as binary numbers, etc.
• Use a completely different format for proteins?
Need standard formats!!

FASTA Format• William Pearson (1985)
• The FASTA format is now universal for all databases and software that handles DNA and protein sequences
>URO1 uro1.seq Length: 2018 November 9, 2000 11:50 Type: N Check: 3854 ..CGCAGAAAGAGGAGGCGCTTGCCTTCAGCTTGTGGGAAATCCCGAAGATGGCCAAAGACAACTCAACTGTTCGTTGCTTCCAGGGCCTGCTGATTTTTGGAAATGTGATTATTGGTTGTTGCGGCATTGCCCTGACTGCGGAGTGCATCTTCTTTGTATCTGACCAACACAGCCTCTACCCACTGCTTGAAGCCACCGACAACGATGACATCTATGGGGCTGCCTGGATCGGCATATTTGTGGGCATCTGCCTCTTCTGCCTGTCTGTTCTAGGCATTGTAGGCATCATGAAGTCCAGCAGGAAAATTCTTCTGGCGTATTTCATTCTGATGTTTATAGTATATGCCTTTGAAGTGGCATCTTGTATCACAGCAGCAACACAACAAGACTTTTTCACACCCAACCTCTTCCTGAAGCAGATGCTAGAGAGGTACCAAAACAACAGCCCTCCAAACAATGATGACCAGTGGAAAAACAATG
One header line, starts with > with a [return] at end
All other characters are part of sequence.

Multi-Sequence FASTA file>FBpp0074027 type=protein; loc=X:complement(16159413..16159860,16160061..16160497); ID=FBpp0074027; name=CG12507-PA;
parent=FBgn0030729,FBtr0074248; dbxref=FlyBase:FBpp0074027,FlyBase_Annotation_IDs:CG12507 PA,GB_protein:AAF48569.1,GB_protein:AAF48569; MD5=123b97d79d04a06c66e12fa665e6d801; release=r5.1; species=Dmel; length=294;
MRCLMPLLLANCIAANPSFEDPDRSLDMEAKDSSVVDTMGMGMGVLDPTQPKQMNYQKPPLGYKDYDYYLGSRRMADPYGADNDLSASSAIKIHGEGNLASLNRPVSGVAHKPLPWYGDYSGKLLASAPPMYPSRSYDPYIRRYDRYDEQYHRNYPQYFEDMYMHRQRFDPYDSYSPRIPQYPEPYVMYPDRYPDAPPLRDYPKLRRGYIGEPMAPIDSYSSSKYVSSKQSDLSFPVRNERIVYYAHLPEIVRTPYDSGSPEDRNSAPYKLNKKKIKNIQRPLANNSTTYKMTL>FBpp0082232 type=protein; loc=3R:complement(9207109..9207225,9207285..9207431); ID=FBpp0082232; name=mRpS21-PA;
parent=FBgn0044511,FBtr0082764; dbxref=FlyBase:FBpp0082232,FlyBase_Annotation_IDs:CG32854-PA,GB_protein:AAN13563.1,GB_protein:AAN13563; MD5=dcf91821f75ffab320491d124a0d816c; release=r5.1; species=Dmel; length=87;
MRHVQFLARTVLVQNNNVEEACRLLNRVLGKEELLDQFRRTRFYEKPYQVRRRINFEKCKAIYNEDMNRKIQFVLRKNRAEPFPGCS>FBpp0091159 type=protein; loc=2R:complement(2511337..2511531,2511594..2511767,2511824..2511979,2512032..2512082); ID=FBpp0091159;
name=CG33919-PA; parent=FBgn0053919,FBtr0091923; dbxref=FlyBase:FBpp0091159,FlyBase_Annotation_IDs:CG33919-PA,GB_protein:AAZ52801.1,GB_protein:AAZ52801; MD5=c91d880b654cd612d7292676f95038c5; release=r5.1; species=Dmel; length=191;
MKLVLVVLLGCCFIGQLTNTQLVYKLKKIECLVNRTRVSNVSCHVKAINWNLAVVNMDCFMIVPLHNPIIRMQVFTKDYSNQYKPFLVDVKIRICEVIERRNFIPYGVIMWKLFKRYTNVNHSCPFSGHLIARDGFLDTSLLPPFPQGFYQVSLVVTDTNSTSTDYVGTMKFFLQAMEHIKSKKTHNLVHN>FBpp0070770 type=protein; loc=X:join(5584802..5585021,5585925..5586137,5586198..5586342,5586410..5586605); ID=FBpp0070770; name=cv-PA;
parent=FBgn0000394,FBtr0070804; dbxref=FlyBase:FBpp0070770,FlyBase_Annotation_IDs:CG12410-PA,GB_protein:AAF46063.1,GB_protein:AAF46063; MD5=0626ee34a518f248bbdda11a211f9b14; release=r5.1; species=Dmel; length=257;
MEIWRSLTVGTIVLLAIVCFYGTVESCNEVVCASIVSKCMLTQSCKCELKNCSCCKECLKCLGKNYEECCSCVELCPKPNDTRNSLSKKSHVEDFDGVPELFNAVATPDEGDSFGYNWNVFTFQVDFDKYLKGPKLEKDGHYFLRTNDKNLDEAIQERDNIVTVNCTVIYLDQCVSWNKCRTSCQTTGASSTRWFHDGCCECVGSTCINYGVNESRCRKCPESKGELGDELDDPMEEEMQDFGESMGPFDGPVNNNY…

Reformatting Data Files
• Much of the routine (yet annoying) work of bioinformatics involves messing around with data files to get them into formats that will work with various software
• Then messing around with the results produced by that software to create a useful summary…

Public Sequence Databases
• Three major repositories:– NCBI (www.ncbi.nlm.nih.gov)– EBI (www.ebi.ac.uk)– DDBJ (www.dbj.nig.ac.jp)
• Same sequence information in all three, but different tools for searching and retrieval

GenBank• Contains all DNA and protein sequences described
in the scientific literature or collected in publicly funded research
• Flatfile: Composed entirely of text• Each submitted sequence is a record• Had fields for Organism, Date, Author, etc.• Unique identifier for each sequence
– Locus and Accession #

Fields

Accession Numbers!!• Databases are designed to be searched by
accession numbers (and locus IDs)• These are guaranteed to be non-redundant,
accurate, and not to change.• Searching by gene names and keywords is
doomed to frustration and probable failure
• Neither scientists nor computers can be trusted to accurately and consistently annotate database entries!!

http://www.ncbi.nlm.nih.gov/Genbank
• Once upon a time, GenBank mailed out sequences on CD-ROM disks a few times per year.
• At least doubles in size every 18 months
• There are approximately 106,533,156,756 bases in 108,431,692 sequence records in the traditional GenBank divisions and 148,165,117,763 bases in 48,443,067 sequence records in the WGS division as of August 2009.

A few words about RefSeq• Many sequences in GenBank correspond to the same
gene• genomic clones, full length mRNA, various kinds of ESTs,
submitted by different investigators
• RefSeq is the “Reference Sequence” for a gene - as determined by GenBank curators– best guess given the current evidence, can change– usually based on the longest mRNA– usually has both 5’ and 3’ UTR
• Not necessarily reliable– A lot is not yet known… eg, alternative splicing

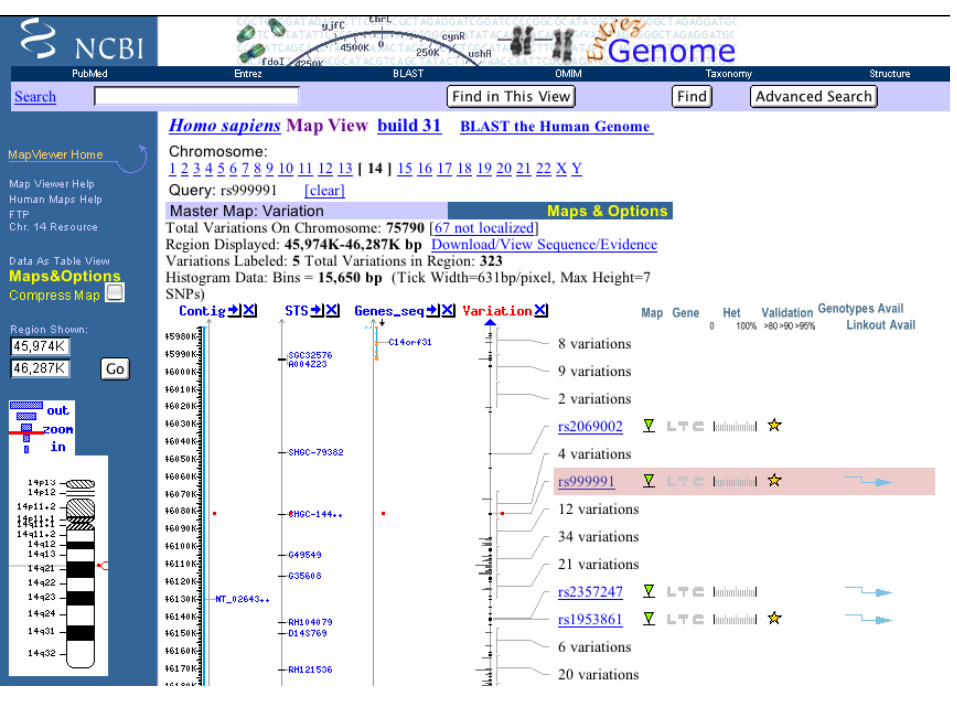
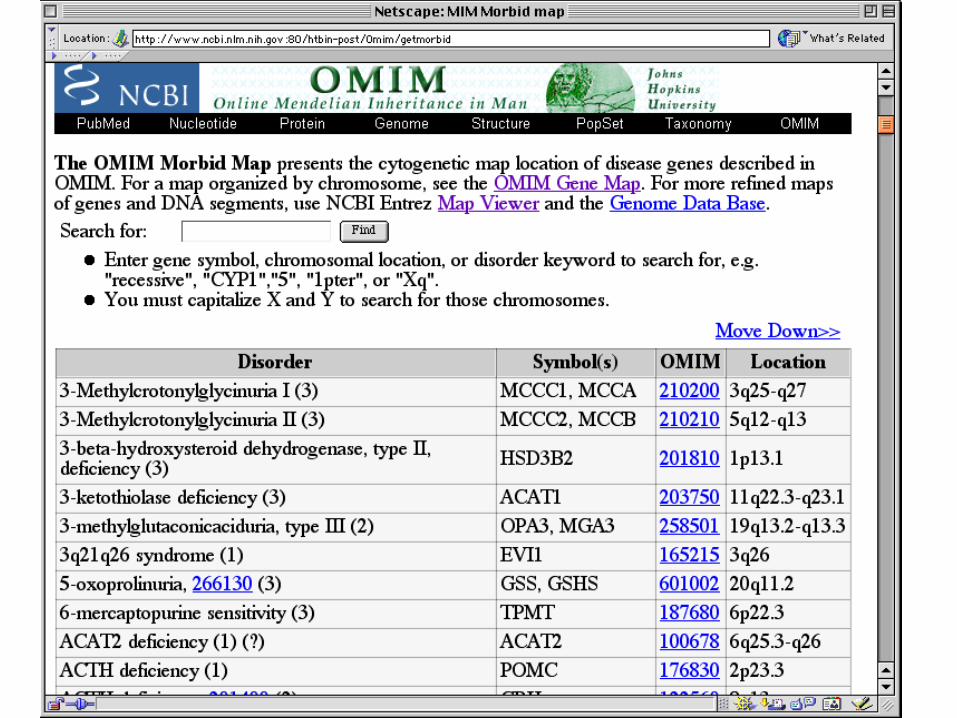
Many Datasets at NCBI• The NCBI hosts a huge interconnected
database system that, in addition to DNA and protein, includes:– Journal Articles (PubMed)– Genetic Diseases (OMIM)– Polymorphisms (dbSNP)– Cytogenetics (CGH/SKY/FISH & CGAP)– Gene Expression (GEO)– Taxonomy– Chemistry (PubChem)

Web Query
• Most databases have a web-based query tool
• It may be simple…
… or complex
ENTREZ is the GenBank web query tool
Advanced query
interface:

ENTREZ has pre-computed links between Tables
•Relationships between sequences are computed with BLAST
•Relationships between articles are computed with "MESH" terms (shared keywords)
•Relationships between DNA and protein sequences rely on accession numbers
•Relationships between sequences and PubMed articles rely on both shared keywords and the mention of accession numbers in the articles.
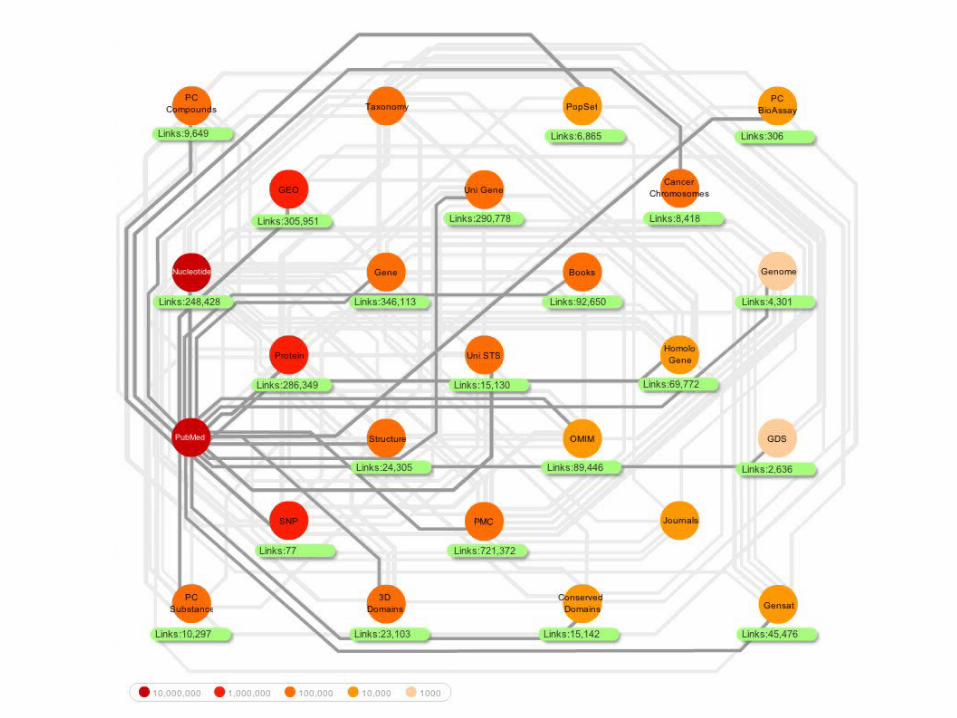

NAR Database Issue
• Online collection of biological databases:http://www3.oup.co.uk/nar/database/c/
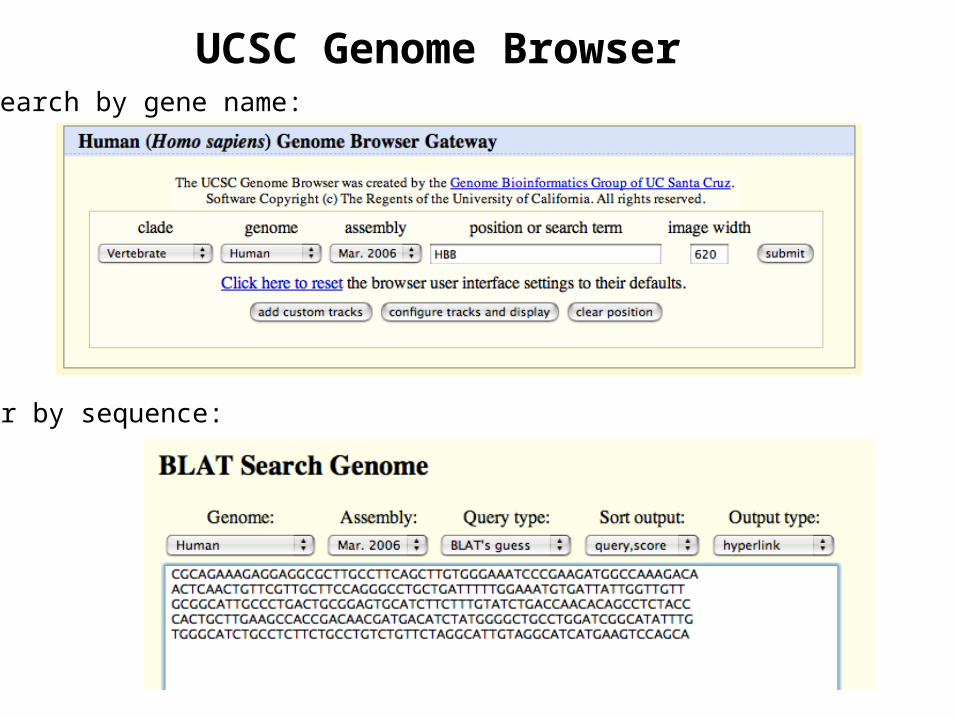
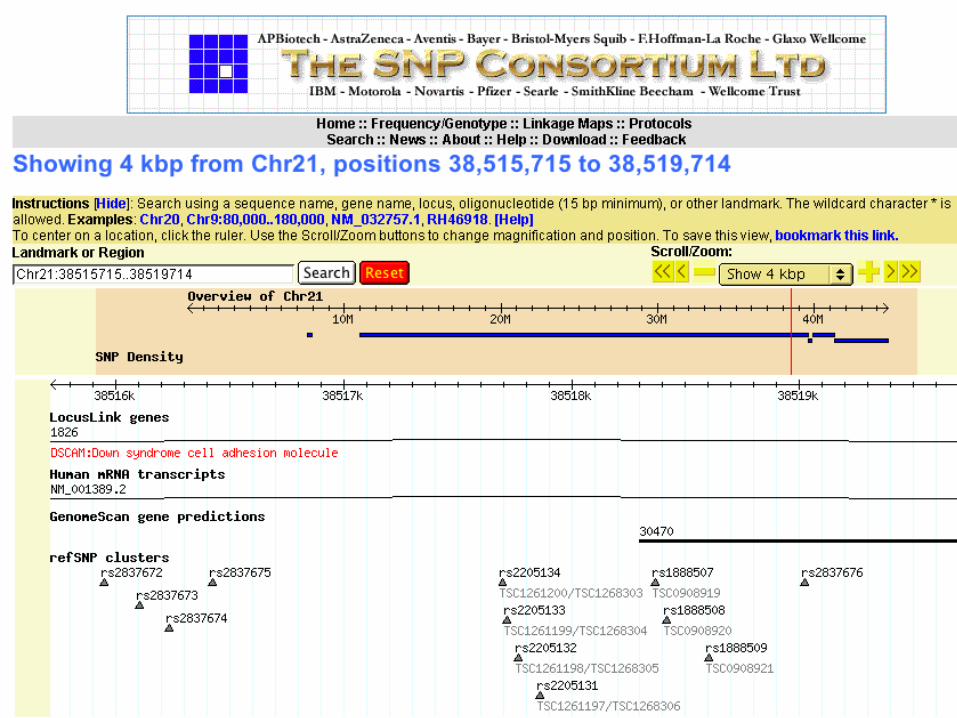
UCSC Genome BrowserSearch by gene name:
or by sequence:


Lots of additional data can be added as optional "tracks"
- anything that can be mapped to locations on the genome
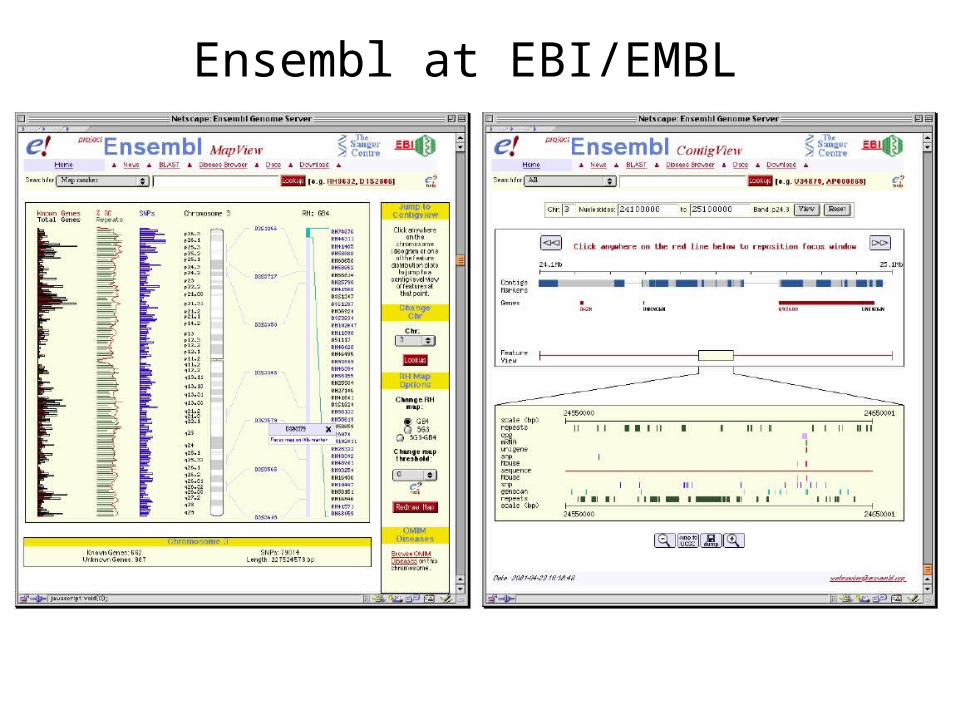
Ensembl at EBI/EMBL

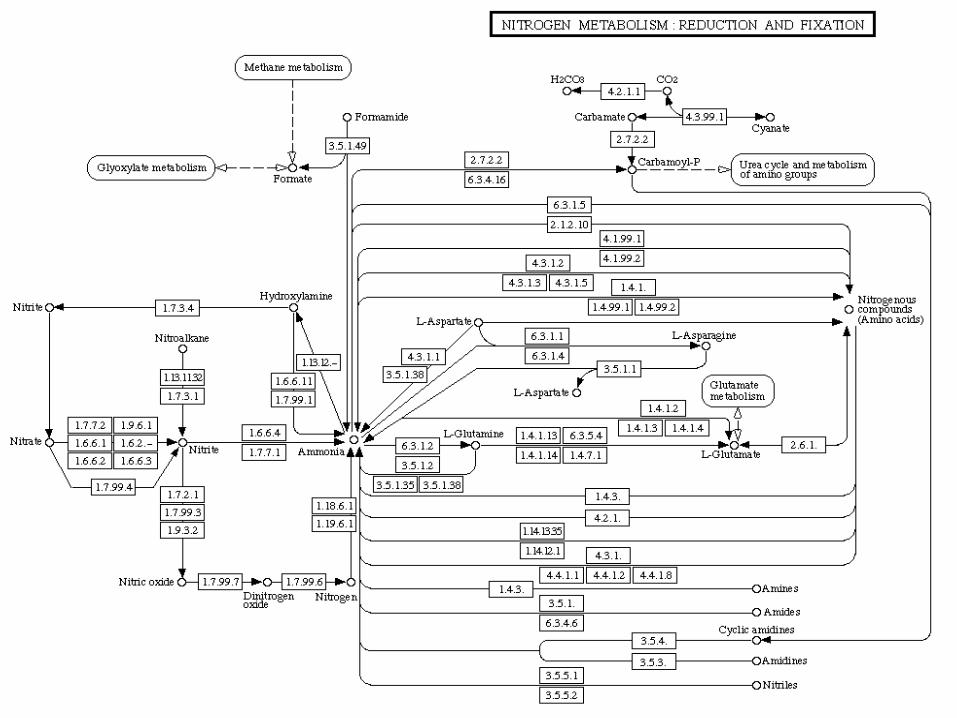
KEGG: Kyoto Encylopedia of Genes and Genomes
• Enzymatic and regulatory pathways• Mapped out by EC number and cross-
referenced to genes in all known organisms(wherever sequence information exits)
• Parallel maps of regulatory pathways

Genome Ontology• Biology is a messy science
• Assortment of names, mutants, odd phenotypes– “sonic hedgehog”
• Genome Ontology– Molecular function (specific tasks)– Biological process (broad biological goal)– Cellular component (location)

Database SearchingA database can only be searched in ways that
it was designed to be searched
Boolean: "AND" and "OR" searches
Bad to search for "human hemoglobin" in a 'Description' field
Much better to search for "homo sapiens in 'Organism' AND "HBB" in 'gene name'

Strategies
• Use accession numbers whenever possible
• Start with broad keywords and narrow the search using more specific terms
• Try variants of spelling, numbers, etc.
• Search all relevant databases
• Be persistent!!

Golden Rules
• Use published databases and methods– Supported, maintained, trusted by community
• Document what you have done !!!– Sequence identification numbers– Server, database, program VERSION– Program parameters
• Assess reliability of results