Embed Size (px)
Citation preview

共通生物学実験 資料
bit.ly/2Ey3dPq

データの視覚化 Data visualization
集めたデータ(標本)の概要を理解する上で、グ
ラフを描くのは有効な手段。特に、データの分布
を把握するために、頻度分布(histogram)は有用。
小 大
多
少
小 大
多
少
1bit.ly/2Ey3dPq

頻度分布 Histogramデータ(標本)を階級分けして、各階級に含まれるデータ
の数(頻度)を棒グラフとして描く。http://bit.ly/2IGFDTr
①に数値
を入力。
①2bit.ly/2Ey3dPq

頻度分布 Histogramスクロールして、”Compute”②を押す。
③
②
3bit.ly/2Ey3dPq
更にスクロールして、
グラフ③を右クリッ
クして画像(PNG形
式)として保存する。

推 定 Estimation
生物の調査では、全ての個体(母集団
全体)を調べることは通常不可能。
例)犬の平均体重を求めるのに、地球上
にいる全ての犬の体重を測定する。
そこで、母集団から抽出した標
本(サンプル)から、母集団の特徴
や性質を推測する。
例)視聴率(600/約1,600万世帯)
アンケート
母集団
標本
4
bit.ly/2Ey3dPq

代表値 Central tendency
・平均(average):データ(xi)の合
計を、サンプル数(n)で割った値。
☞最も一般的な代表値。
・中央値(median):全データを小さ
い順に並べた時に、ちょうど真ん中
にある値。サンプル数が偶数の場合
には、真ん中の2値の平均を採用。
☞分布から極端に外れた少数の
データの影響を軽減。
1,②,3
1,2,3,4
2.5
xi平均(x) =
n
i=1
n
5bit.ly/2Ey3dPq

検定 Statistical Test
複数のサンプル集団間には
差が観察されても、たまたま
偏ってサンプルを集めただけ
で、母集団には差がない可能
性もある。
そこで、観察された差
が偶然に生じる確率を求
めて、本当に差があるの
か判断する。
小 大
小 大
6bit.ly/2Ey3dPq

帰無仮説・対立仮説
検定では、2つの仮説を立てて、どちらかを採用する。
帰無仮説 Null hypothesis
観察された現象は、たまたま生じたと考える。
☞母集団には差がない
対立仮説 Alternative hypothesis
必然性があって、観察した現象が生じたと考える。
☞母集団に差がある
検定では、帰無仮説に基づいて、観察した現象が偶然生じる確
率を計算する。その確率があまりに小さい場合は、帰無仮説を
棄却し、対立仮説を採用する。観察した現象を、有意
(Significant)なものと判断する。 7bit.ly/2Ey3dPq

帰無仮説・対立仮説例❶ ある犬が、メスばかり3頭産んだ。
帰無仮説:たまたま♀ばかり産んだだけで、平均性比は1:1。
対立仮説:この犬は♀を産みやすい体質(状態)。
帰無仮説の通りメスが生まれる確率が0.5だとすると、3頭続け
て、メスが生まれる確率は 0.53 = 0.125。
☞偶然でも8(=23)回に1回観察される現象であり、帰無仮説を棄
却できない。
例➋ ある犬が、メスばかり10頭産んだ。
10頭続けて、メスが生まれる確率は 0.510 ≈ 0.001。
☞偶然だと1024(=210)回に1回しか観察されない現象であり、帰
無仮説を棄却できる。つまり、♀を産みやすいという対立仮説が
採用される。 8bit.ly/2Ey3dPq

棄却率・有意水準
・帰無仮説を棄却する基準を、有意水準という。
一般的に有意水準は、5%に設定されることが多い。
例) ♀ばかり4頭産んだ:0.54 = 6.25% ☞帰無仮説を採用
♀ばかり5頭産んだ:0.55 = 3.125% ☞対立仮説を採用=有意
・しかし5%水準では、20人が同じ実験を独立に行った場合、実
際には帰無仮説が正しくても、1人は偶然に対立仮説を採用し
てしまう(第1種の誤り=本当は偶然に生じた現象なのに、有意
な現象と誤認すること)。そのため、有意水準を別名で(第1種の
誤りをおかす)危険率とも呼ぶ。そのため危険率を下げるため
に、有意水準をより低い値(1%、0.5%、0.1%など)に設定する場
合もある。 9
bit.ly/2Ey3dPq

Mann-Whitney検定①
◎使えるデータのタイプ:順位尺度 (間隔・比率変数)
◎使う目的:観察した2群の母集団の分布の位置が、異なるかどうか調べる。
Mann-Whitney検定では、U値を統計量と
して用いるが、U値は以下のように求める。
①観察した値を、小さい順に並べる。
②各群ごとに、それぞれのデータについて、
自分より大きな他群のデータの数を数える。
その数を各群ごとに合計し、より小さい合計をU値として採用する(両側検定)。
右の例のA群では、1と2は4個、4と6は3個ずつあるので、合計14個。B群では、3は2
個、7と9と10は0個なので、合計2個。2より14が小さいので、U=2とする。
※小さな(大きな)データが、一方の群に偏ってい
るほど、U値は大きくなる(最大で、nAnB)。
両群のデータに差がないほど、U値は小さくなる。
A 6
2 1
4
B 7
3
10 9
1 2 3 4 6 7 9 10
A A B A A B B B
小 A A A A B B B B 大☞ U=0
小 A B A B BA B A 大☞ U=8 10
bit.ly/2Ey3dPq

Mann-Whitney検定③
◎この検定でも、
帰無仮説:2つの群は同じ母集団に由来する。
※観察されたU値が示す両群の差は偶然の産物。
対立仮説:2つの群が属する母集団は異なる。
とおく。観察値以上に大きなU値が偶然生じる確率が低ければ、
帰無仮説を棄却する。
A 6
2 1
4
B 7
3
10 9
①A: 1 2 3 4 ☞ U=0
B: 6 7 9 10
②A: 1 2 3 6 ☞ U=1
B: 4 7 9 10
③A: 2 4 6 7 ☞ U=7
B: 1 3 9 10
③A: 1 3 6 9 ☞ U=6
B: 2 4 7 10
:
:
6 7
2 1 3
4 10 9
帰無仮説
対立仮説
◎様々なU値が生じる確率を計
算するには、観察データが1つの
母集団に属すると見立てた上で、
採集したのと同じサイズの2つの
群にあらゆる組み合わせで、振り
分けてみる。その上で、各組み合
わせでU値を計算して、各U値の
相対頻度を割り出すことができる。
U組み合わせ数
累積頻度
累積相対頻度
0 2 2 0.029
1 2 4 0.057
2 4 8 0.114
3 6 14 0.200
4 10 24 0.343
5 10 34 0.486
6 14 48 0.686
7 14 62 0.886
8 8 70 1.000
合計 70 = 8C4
11
bit.ly/2Ey3dPq
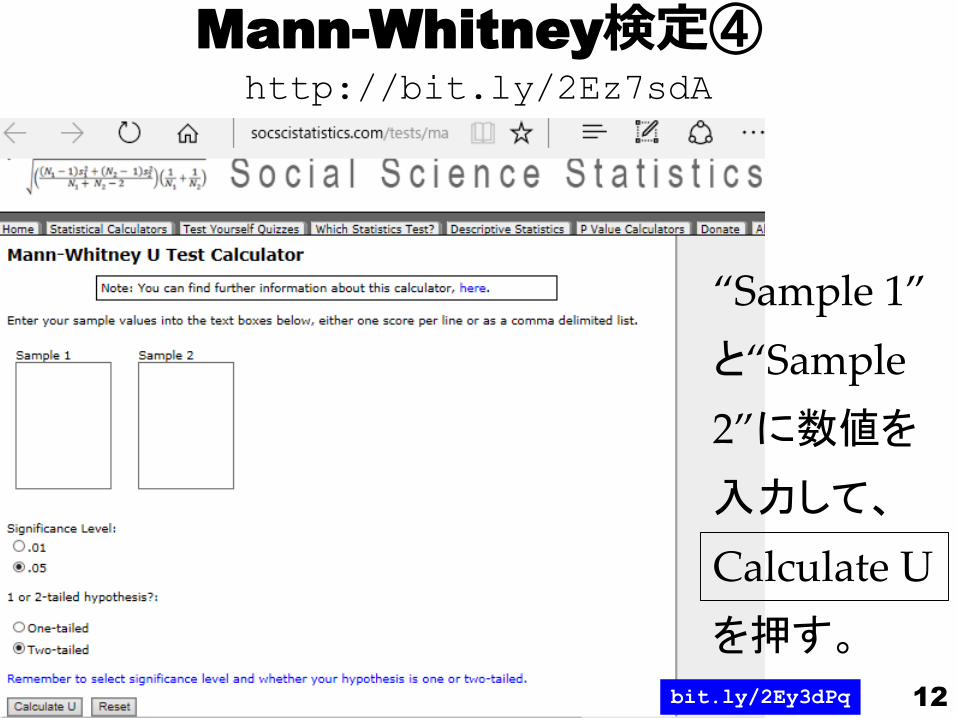
Mann-Whitney検定④
“Sample 1”
と“Sample
2”に数値を
入力して、
Calculate U
を押す。
http://bit.ly/2Ez7sdA
12bit.ly/2Ey3dPq

Mann-Whitney検定⑤
Ⓐの “p-value” が、0.05以下の場合、
有意に差があると判断できる。
Ⓐ
13bit.ly/2Ey3dPq

実習課題①本日の学生の身長を調べる。
※自己申告。男女別。
②身長のヒストグラムを描く。
※男女別。自身の値を矢印で書き込む。
③男女の身長差を
Mann-Whitney検定で比較。
④ ヒストグラム(男女別)、身長の平均値(男女別)
と中央値(男女別) 、U値とp値を報告(来週まで)。
※提出先: [email protected]
学籍番号・氏名は、メールの表題にも明記。 14
bit.ly/2Ey3dPq





























![資料3-1 風向・風速の異常年検定 [本編p.77参照] 「窒素酸化 ...4以上 5.5以上 6.4 9.5 3.8 3.0 1.3 1.9 3.5 5.0 8.7 9.7 8.6 14.1 6.3 2:風力階級4~9までのそれぞれの出現頻度の合計と風力階級4以上の出現頻度の値は、端数処理を行っているため一致しない。](https://img.pdfslide.net/doc/110x75/603812deeedcab35a766ae99/e3i1-efeecoe-oecp77c-oecceoe.jpg)