Embed Size (px)
Citation preview

Building Reliable Distributed Information Spaces
Carl Lagoze
CS 430
10/22/2002

Characteristics of a library
• Functions– Selection– Access– Organization– User support– Preservation
• Characteristics– Standardized– Professionalized– Service-oriented– In it for the long-haul– Conservative– Trustworthy– Expensive (human
centric)

Perspective on the Budget

Library in current environment
• “I don’t do libraries” – anonymous Cornell undergrad to Bob Constable
• How do you use the library?– Go to the library to study?– Go to the library to do research?
• Talked to a reference librarian?
– Use the library gateway or electronic resources?

Characteristics of the Web
• Decentralized/Anarchic/Illegal• Agreements are technical (at best)• Roles are undefined and fluid• Immediate• Ephemeral • Integrity not established• Anonymous (or “no one knows you are a
dog”)

What is a Digital Library?
Evolutionary perspective: digital libraries as institutions that are the continuation of libraries (library automation and digitization as the link between libraries and digital libraries).
Revolutionary perspective: digital libraries as technical/organizational/economic/legal layers on top of networked information (the Web) that render existing libraries obsolete.

What is a Digital Library?
A digital library is a managed collection of information, with associated services, where the information is stored in digital formats and is accessible over a network. [Arms CS502 sp00]

Many facets of the problem/solution
technology
law
economy
sociology

Technical Trade-offsCost
Functionality

National Science Digital Library(NSDL)
• Goal: Reform science education in the US in the digital age
• $25M in funding 2002-2006• Over 80 institutional grants for collections,
services, core infrastructure (technical, economic, organizational)
• Cornell is primary technical development partner – Carl Lagoze, Director of Technology
• http://www.nsdl.org
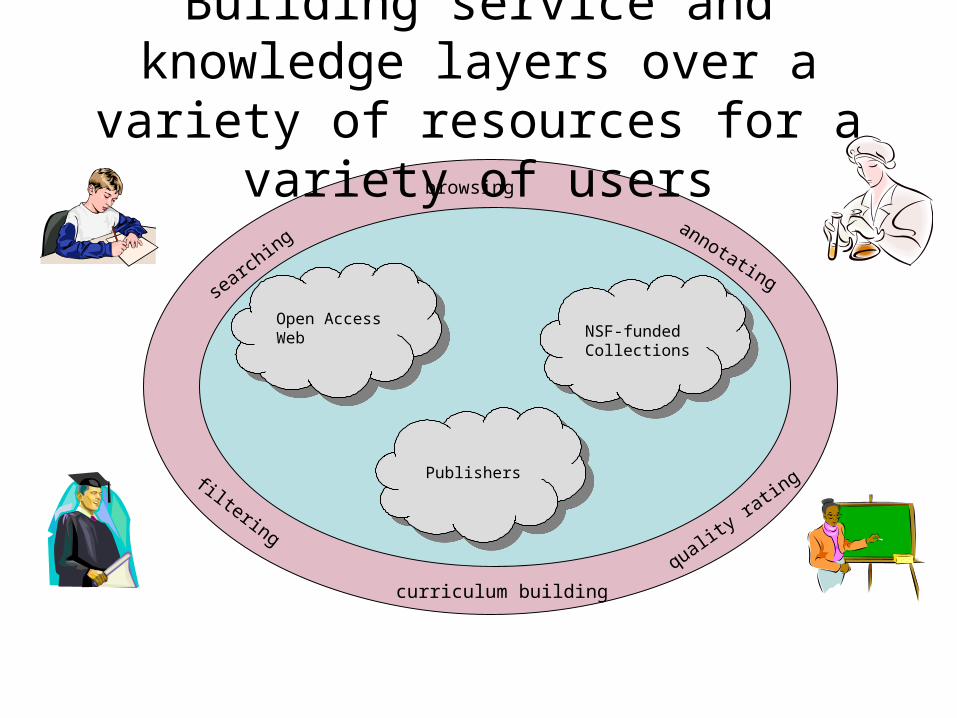
browsing
search
ingannotating
curriculum building
filtering
quality ra
ting
Building service and knowledge layers over a variety of resources for a
variety of users
Open Access Web
Open Access Web
PublishersPublishers
NSF-funded Collections
NSF-funded Collections

All branches of science, all levels of education, very broadly defined:
Five year targets
1,000,000 different users
10,000,000 digital objects
10,000 to 100,000 independent sites
How Big might the NSDL be?

It is possible to build a very large digital library with a small staff.
But ...
Every aspect of the library must be planned with scalability in mind.
Some compromises will be made.
Lots of standard library functions must be automated.
Core Integration Philosophy

Resources for Core Integration
Core Integration
Budget $4-6 million
Staff 25 - 30
Management Diffuse How can a small team, without direct management control, create a very large-scale digital library?

Collections: the Basic AssumptionThe Core Integration team will not manage any collections
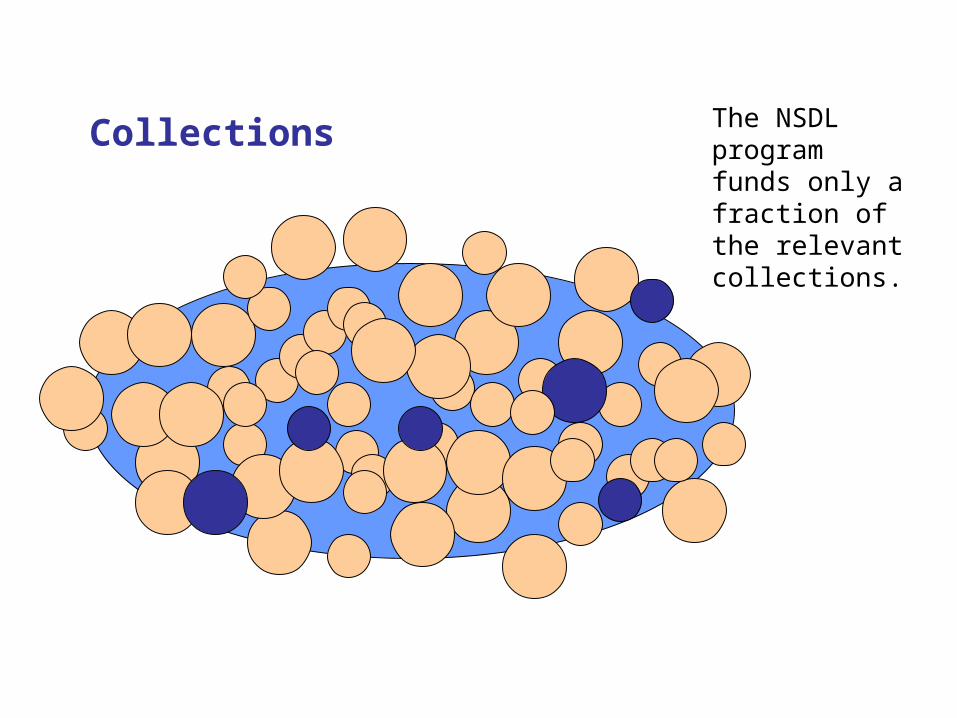
Collections The NSDL program funds only a fraction of the relevant collections.

Every Collection is Different
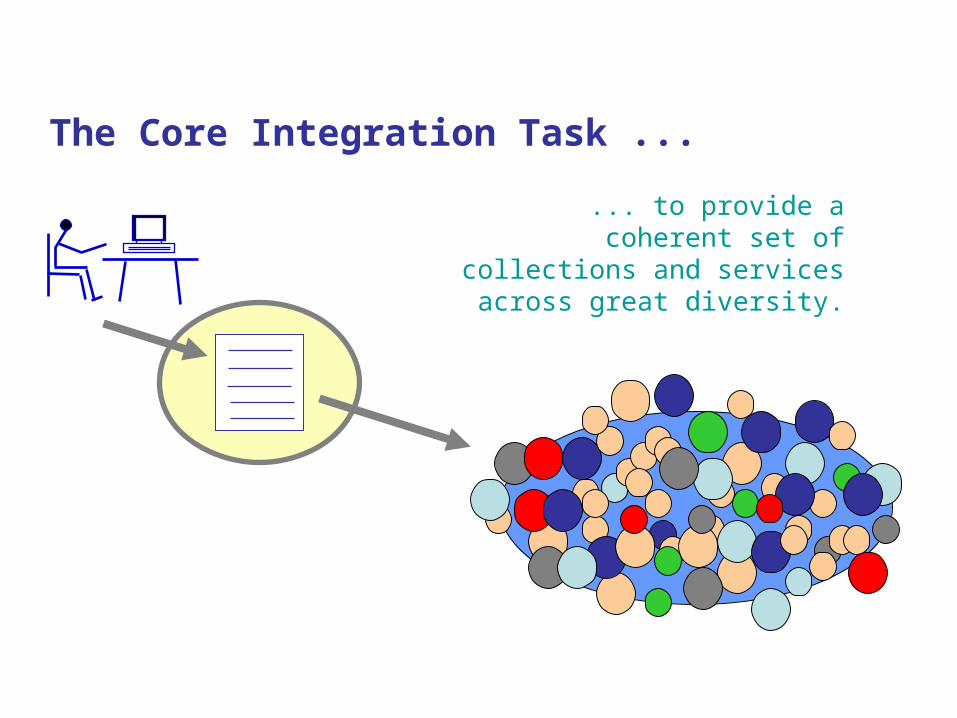
... to provide a coherent set of collections and services across
great diversity.
The Core Integration Task ...

Interoperability
The Problem
Conventional approaches to interoperability require partners to support agreements (technical, content, and business
But NSDL needs thousands of very different partners
... most of whom are not directly part of the NSDL program
The Approach
A spectrum of interoperability

Levels of interoperability
Level Agreements Example
Federation Strict use of standards AACR, MARC(syntax, semantic, Z 39.50and business)
Harvesting Digital libraries expose Open Archivesmetadata; simple metadata harvesting
protocol and registry
Gathering Digital libraries do not Web crawlerscooperate; services must and search enginesseek out information

What to Index?
When possible, full text indexing is excellent, but full text indexing is not possible for all materials (non-textual, no access for indexing).
Comprehensive metadata is an alternative, but available for very few of the materials.
What Architecture to Use?
Few collections support an established search protocol (e.g., Z39.50)
Searching

Function versus cost of acceptance
Function
Cost of acceptance
Metadata Harvesting
SDLIP
Z39.50

Z39.50 principles
• Servers store a set of databases with searchable indexes
• Interactions are based on a session
• The client opens a connection with the server(s), carries out a sequence of interactions and then closes the connection.
• During the course of the session, both the server and the client remember the state of their interaction.

State
Z39.50
• The server carries out the search and builds a results set
• Server saves the results set.
• Subsequent message from the client can reference the result set.
• Thus the client can modify a large set by increasingly precise requests, or can request a presentation of any record in the set, without searching entire database.
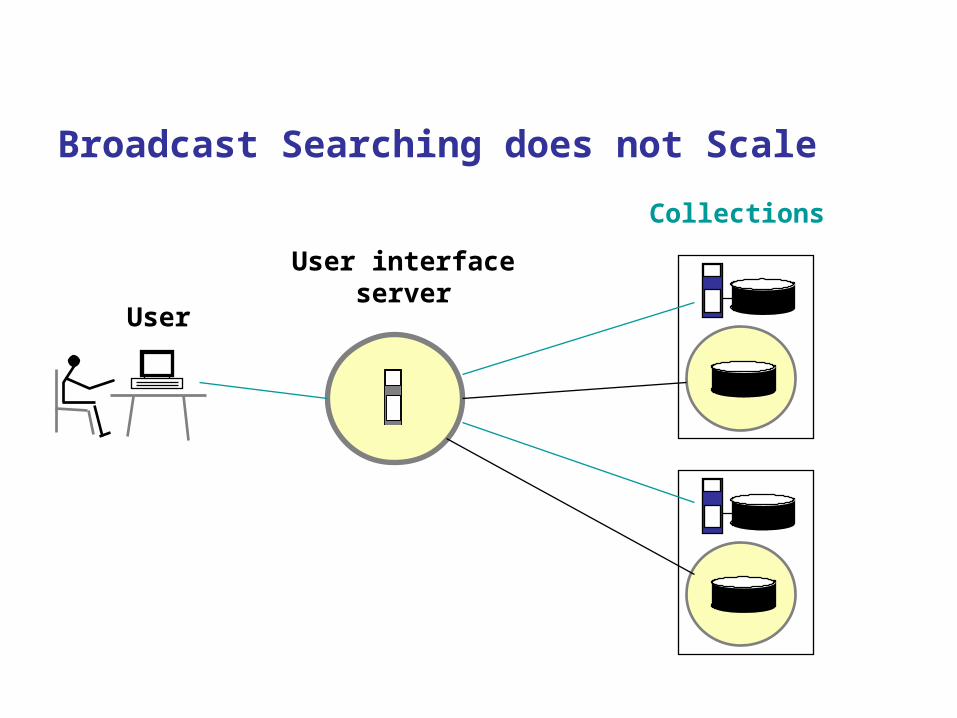
Broadcast Searching does not Scale
User interfaceserver
User
Collections

Open Archives Initiative Protocol for Metadata Harvesting
• Low-barrier protocol for exposing structured information (metadata) from cooperating repositories
• Provides opportunity for building comprehensive service network
• http://www.openarchives.org

DiscoveryCurrent
AwarenessPreservation
Service Providers
Data Providers
Meta
data
harv
estin
g
OAI-PMH: A simple two party model for sharing structured information
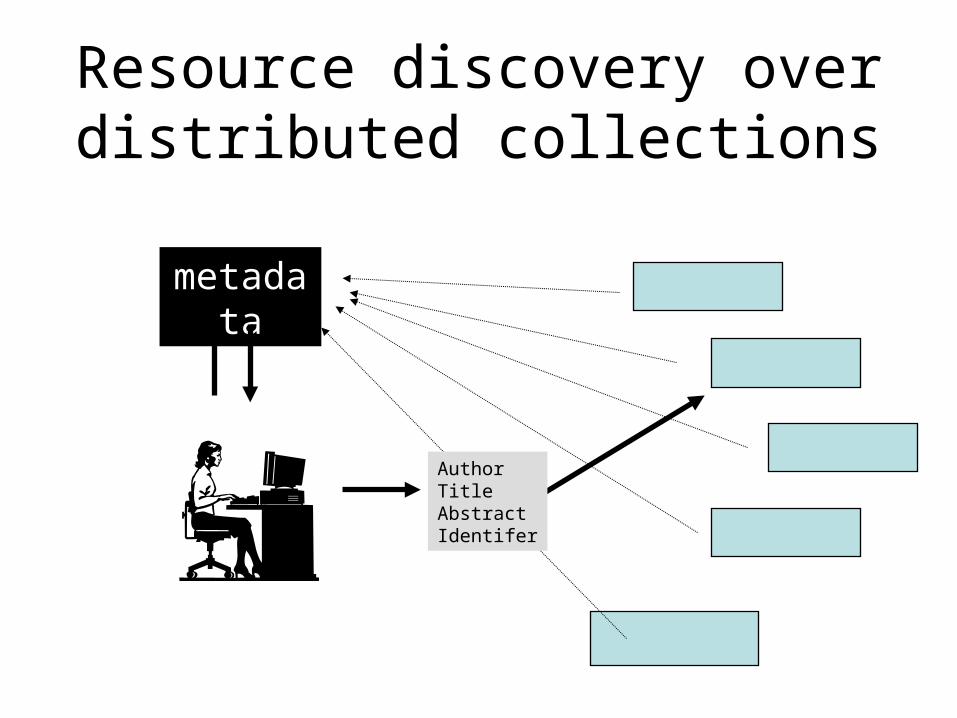
Resource discovery over distributed collections
metadata
AuthorTitleAbstractIdentifer

OAI-PMH Key technical features
• Deploy now technology – 80/20 rule• Simple HTTP encoding• Foundation of established XML standards• Multiple metadata formats• Repository partitioning (sets)• Selective harvesting (sets and dates)• Clean partition between core and
implementation-specific extensions – Multiple item-level metadata– Collection level metadata

OAI Verbs
• Identify – repository characteristics
• ListMetadataFormats – DC required
• ListSets – repository paritioning
• ListRecords – (selectively) harvest metadata
• ListIdentifiers – (selectively) harvest metadata identifiers
• GetRecord – known item retrieval

Users
Collections
Metadata repository
The Metadata Repository
Services
The metadata repository is a resource for service providers.
It holds information about every collection and item known to the NSDL.

• Central storage of all metadata about all resources in the NSDL– Defines the extent of NSDL collection
– Metadata includes collections, items, annotations, etc.
• MR main functions– Aggregation
– Normalization
– redistribution
• Ingest of metadata by various means– Harvesting, manual, automatic, cross-walking
• Open access to MR contents for service builders via OAI-PMH
Metadata Repository

Importing metadata into the MR
Collections
Harvest
Staging area
Cleanup and
crosswalks
Database load
Metadata Repository
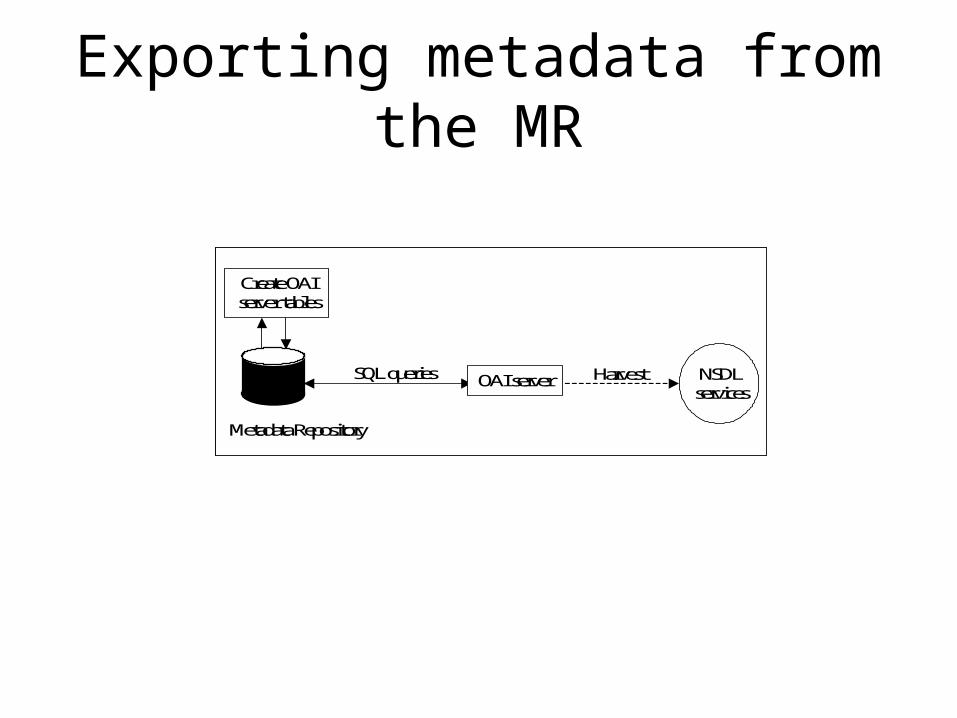
Exporting metadata from the MR
NSDL services
Create OAI server tables
Metadata Repository
SQL queries OAI server Harvest NSDL services
Create OAI server tables
Metadata Repository
SQL queries OAI server Harvest
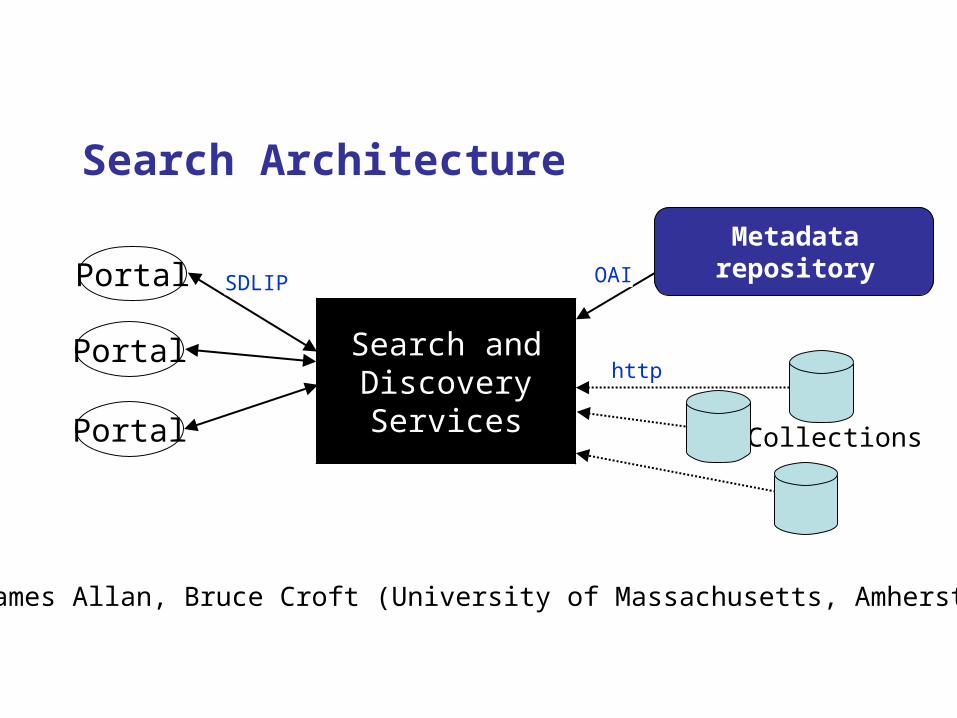
Search Architecture
Portal
Portal
Portal
Search andDiscoveryServices Collections
SDLIP OAI
http
Metadata repository
James Allan, Bruce Croft (University of Massachusetts, Amherst)

The Metadata Repository as a ResourceRecords are exposed through Open Archives Initiative harvesting protocol.
Core Integration team will provide some services based on the metadata repository.
The architecture encourages others to build services.
Support for Service Providers

Building on the basics
• Gathering resources from the open web– Automated collection aggregation– Automated metadata generation
• Content of resource• Context of resource
– Automated quality assessment
• Annotation, review, and aggregation environment

If you find this all interesting
• CS502 – Architecture of Web information Systems






























