Embed Size (px)
Citation preview

Bulut, Singh #Bulut, Singh #
Selecting the Right Selecting the Right Interestingness Measure for Interestingness Measure for
Association Patterns Association Patterns Pang-Ning Tan, Vipin Kumar, and Jaideep Srivastava
Department of Computer Science and Engineering
University of Minnesota
Presented by Ahmet Bulut

2Bulut, Singh #Bulut, Singh #
MotivationMotivation• Major Data mining problem: analysis of
relationships among variables
• Finding sets of binary variables that co-
occur together
– Association Rule Mining [Agrawal et al.]
• How to find a suitable metric to capture
the dependencies between variables
(defined in terms of contingency
tables)
• Many metrics provide conflicting
information
• Goal: Automated way of choosing the
best metric for an application domain

3Bulut, Singh #Bulut, Singh #
)().(
)(
BPAP
BAP

4Bulut, Singh #Bulut, Singh #
Justification for ConflictsJustification for Conflicts• E10 is ranked highest by I
measure but lowest according to
coefficient.
• Recognize intrinsic properties of
the existing measures

5Bulut, Singh #Bulut, Singh #
Analysis of a MeasureAnalysis of a Measure• The relationship between the gender of a student and the grade
obtained in a course
• Number of male students X 2, Number of female students X 10
• One expects scale-invariance in this particular application
• Most measures are sensitive to scaling of rows and columns
such as: gini index, interest, mutual information etc.

6Bulut, Singh #Bulut, Singh #
Solutions to zero-inSolutions to zero-in
• Support based pruning
– Eliminate uncorrelated and poorly correlated patterns
• Table Standardization
– To modify contingency tables to have uniform margins
– Many measures provide non-conflicting information
• Expectation of domain experts
– Choose the measure that agrees with the expectations the
most.
– Number of contingency tables, |T|, is high
– It is possible to extract a small set, S, of contingency tables
– Find the best measure for S to approximate for T

7Bulut, Singh #Bulut, Singh #
PreliminariesPreliminaries
• The similarity between any two measures M1 and M2: the
similarity between OM1(T) and OM2(T)
• The similarity metric used is correlation coefficient
corr(OM1(T), OM2(T) ) > threshold then similar
},...,,{)(
},...,,{)(
:
},...,,{)(
21
21
21
NM
N
N
oooTO
mmmTM
M
measures
tttDT
P
P

8Bulut, Singh #Bulut, Singh #
Desired Properties of a Measure MDesired Properties of a Measure M

9Bulut, Singh #Bulut, Singh #
Properties of a Measure M cont’d.Properties of a Measure M cont’d.
• Denote 2X2 contingency table as a contingency matrix
• Interestingness measure is a matrix operator, O such that
– OM = k where k is a scalar.
– For instance for Coefficient as the interestingness measure
k equals to normalized form of the determinant operator
Det(M) = f11f00 – f01f10
Statistical Independence
a singular matrix M whose determinant equal to 0.
];[ 00011011 ffffM

10Bulut, Singh #Bulut, Singh #
Properties of a Measure M cont’d.Properties of a Measure M cont’d.
• Property 1: Symmetry under
variable permutation: O(MT) =
O(M)
– cosine (IS), interest factor(I), odds
ratio ( )
• Property 2: Row/Column Scaling
Invariance: R=C=[k1 0; 0 k2]
– R x M is row scaling and M x R is
column scaling
– If O(RM) = O(M) and O(MR) =
O(M), then M is row/scale invariant
– odds ratio ( ) satisfies this
property along with Yule’s Q and Y
• Property 3: Antisymmetry under
row/column permutation
– S = [0 1;1 0]
– If O(SM) = -O(M), antisymmetric
under row permutation
– If O(MS) = -O(M), antisymmetric
under column permutation
– Measures that are symmetric
under the row and column
permutation operations: no
distinction between positive and
negative correlations of a table
For example: gini index
• Property 4: Inversion Invariance
– S=[0 1;1 0]
– row and column permutation
together
– If O(SMS)=O(M), inversion
invariant
– Insight: flip presence with
absence and vice versa for
binary variables.
– coefficient, odds ratio,
collective strength are
symmetric binary measures
– Jaccard measure is asymmetric

11Bulut, Singh #Bulut, Singh #
Property 4 and Property 5Property 4 and Property 5
• Market Basket analysis requires unequal treatment of binary values of a variable
– A symmetric measure like the one above is not suitable
• Property 5: Null Invariance: If O(M+C) = O(M) where C=[0 0;0 k] and k is a positive constant
– For binary variables; more records added that do not contain the two variables under consideration: Co-occurrence emphasized
12Bulut, Singh #Bulut, Singh #
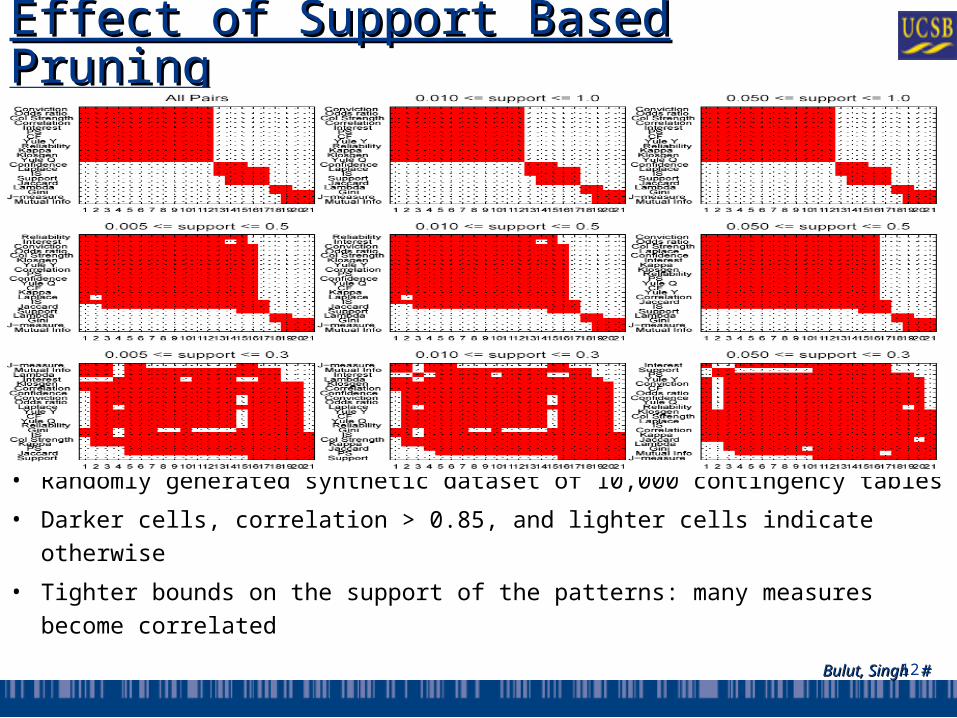
Effect of Support Based Effect of Support Based PruningPruning
• Randomly generated synthetic dataset of 10,000 contingency tables
• Darker cells, correlation > 0.85, and lighter cells indicate otherwise
• Tighter bounds on the support of the patterns: many measures become correlated

13Bulut, Singh #Bulut, Singh #
Elimination of poorly correlated Elimination of poorly correlated tables using Support-based tables using Support-based PruningPruning• Minimum support threshold to prune out the low support patterns
• Having a maximum support threshold: equal elimination of uncorrelated, negatively correlated and positively correlated tables
• Having a lower bound of support will prune out the negatively correlated or uncorrelated tables.

14Bulut, Singh #Bulut, Singh #
Table standardizationTable standardization
• A standardized table: visual
depiction of the disjoint
distribution of two variables after
elimination of non-uniform
marginals

15Bulut, Singh #Bulut, Singh #
Implications of standardizationImplications of standardization• The rankings from different measures become identical

16Bulut, Singh #Bulut, Singh #
Implications of standardization Implications of standardization cont’dcont’d• After standardization, a matrix has [x y ; y x] where
y = N/2-x and x = f*11
• If you consider monotonically increasing functions of x (nearly all of the measures are)– Identical rankings on standardized, positively correlated tables
– Some measures do not satisfy this property
• Consider the values of x where N/4 < x < N/2
• IPF favors “odds ratio” measure, therefore final rankings agree with odds ratio rankings before standardization
• Leave with: Different standardization techniques may be more appropriate for different application domains

17Bulut, Singh #Bulut, Singh #
Measure Selection Based on Measure Selection Based on Rankings by ExpertsRankings by Experts• Ideally, experts rank all the contingency tables, choose the best
measure accordingly
• Laborious task if the number of tables is too large
• Provide a smaller set of tables to decide the best measure

18Bulut, Singh #Bulut, Singh #
Table Selection via Disjoint Table Selection via Disjoint AlgorithmAlgorithm• Use Disjoint algorithm to
choose a subset of tables of
cardinality k.
• Rank tables according to
various measures
• Compute the similarity
between different measures
• A good table selection scheme
minimizes
),(),(max),( jiSjiSSSD STTS

19Bulut, Singh #Bulut, Singh #
Experimental ResultsExperimental Results

20Bulut, Singh #Bulut, Singh #
ConclusionsConclusions
• Key properties to consider for selecting the right
measure
• No measure is consistently better than others
• Situations where most measures provide correlated info
• Choosing the right measure on a non-biased small set
of all the tables give good estimates to the ideal
solution
• As a future work
– Extension to k-way contingency tables
– Association between mixed data types