Embed Size (px)
Citation preview

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Business Intelligence
Alberi decisionali
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Examples of Classification Task
● Predicting tumor cells as benign or malignant
● Classifying credit card transactions as legitimate or fraudulent
● Classifying secondary structures of protein as alpha-helix, beta-sheet, or random coil
● Categorizing news stories as finance, weather, entertainment, sports, etc

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Classification Techniques
● Decision Tree based Methods● Rule-based Methods● Memory based reasoning● Neural Networks● Naïve Bayes and Bayesian Belief Networks● Support Vector Machines
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Alberi Decisionali
L’Albero Decisionale è una tecnica di classificazione o di regressione ad albero.
● Tecnica di data mining prescrittivo (cluster: descrittivo, impossibile uso automatico dei risultato)
● Tecnica di classificazione a priori
(-) descrive bene i casi per cui è costruito, difficile generalizzare (problema overfitting)
(+) semplice interpretazione dei risultati

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Alberi Decisionali
● Nodi (escluse le foglie): domande (decisioni da prendere)● Foglie: decisioni● Rami: valori degli attributi● Cammino: regola
● Albero: È una sequenza di regole, di condizioni:Se .. à allora.. Se età > 18 allora decisione: si
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Alberi Decisionali
● Quando l’albero viene applicato ai dati di ingresso, ogni dato viene analizzato dall’albero lungo un percorso stabilito da una serie di test sugli attributi (features) del dato stesso, finchè il dato non raggiunge un nodo foglia
● Ogni nodo è associato ad una classe. Quando arriva alla foglia, al dato viene assegnata:– una etichetta di classe (class label) nel caso di
alberi di classificazione,– un valore numerico alla sua variabile target
nel caso di alberi di regressione

7
● Dato un’insieme di classi con descrizione di un insieme di feature
● Dato un oggetto stabilire a che classe appartiene
No. di ruote2 4
motore
si no
moto bici
auto
C1 ruote=4, motore=si classificazione=autoC2 ruote=2, motore= si classificazione=motoC3 ruote=2, motore= no classificazione=bici
Alberi di classificazione
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›8
● Esempio [Russel, Norvig]: entrare in un ristorante?
no. clienti
stima attesa
alternative fame
prenotazione Ven/Sab
Bar
alternative
piove
no si
nessuno alcuni pieno
no si
0-10>60 30-60 10-30
sino
no si
sinosino
si
no si
sino
no
si
si
no
si
si
no si
sino
si e no sono le due classi di decisione

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›9
● Apprendimento: costruire l’albero a partire da esempi
– esempi di decisioniusi/no nel caso di decisioni binarie
– esempi delle varie classi corrispondenti alle fogli:
attributiEs.alt. bar V/S fame noC prez piov pren tipo att
Dec
x1 si no no si alc £££ no si F 0-10 Six2 si no no si pieno £ no no Thai 30-60 Nox3 no si no no alc £ no no hamb 0-10 Six4 si no si si pieno £ no no Thai 10-30 Six5 si no si no pieno £££ no si F >60 Nox6 no si no si alc ££ si si I 0-10 Six7 no si no no ness £ si no hamb 0-10 Nox8 no no no si alc ££ si si Thai 0-10 Six9 no si si no pieno £ si no hamb >60 Nox10 si si si si pieno £££ no si I 10-30 Nox11 no no no no ness £ no no Thai 0-10 Nox12 si si si si pieno £ no no hamb 30-60 Si
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›10
● Una soluzione banale– costruire un ramo per ognuno degli esempi
● Obiettivo– costruire un albero “semplice”– Occam’s razor: il più semplice tra quelli
consistenti con gli esempi

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Decision Tree Induction
● Many Algorithms:– Hunt’s Algorithm – CART– ID3, C4.5– SLIQ,SPRINT
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›12
Algoritmo ID3[Quinlan]
if non ci sono esempi then terminaif tutti gli esempi hanno la stessa classificazione
then etichetta il nodo con la classificazioneelse if nessun attrubuto rimasto then termina
seleziona attributo ai che discrimina megliodividi gli esempi in base ai valori di aicostruisci un nodo etichettato con ai e con un ramoin uscita per ogni valore vj di airichiama ricorsivamente per ogni vj con gli esempi

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›13
● Attributo ideale ai da selezionare ad ogni passo– discrimina completamente tra gli esempi, ossia
udati valori v1, …, vkuper ogni vj, tutti gli esempi con lo stesso valore vj hanno la stessa classificazione
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›14
● Esempio– attributo noClienti: per due valori discrimina completamente
noClientinessuno
pieno alcuni
si: ---no: x7, x11 si: x4, x12
no: x2, x5, x9, x10
si: x1, x3, x6, x8no: ---
– attributo tipo: discrimina male per tutti i valori
tipoburg
I Thai
si: x1no: x5
si: x3, x12no: x7, x19
Fsi: x6no: x10
si: x4, x8no: x2, x11
– Tra i due noClienti è la scelta migliore– in generale tra tutti è quello con entropia più bassa
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›15
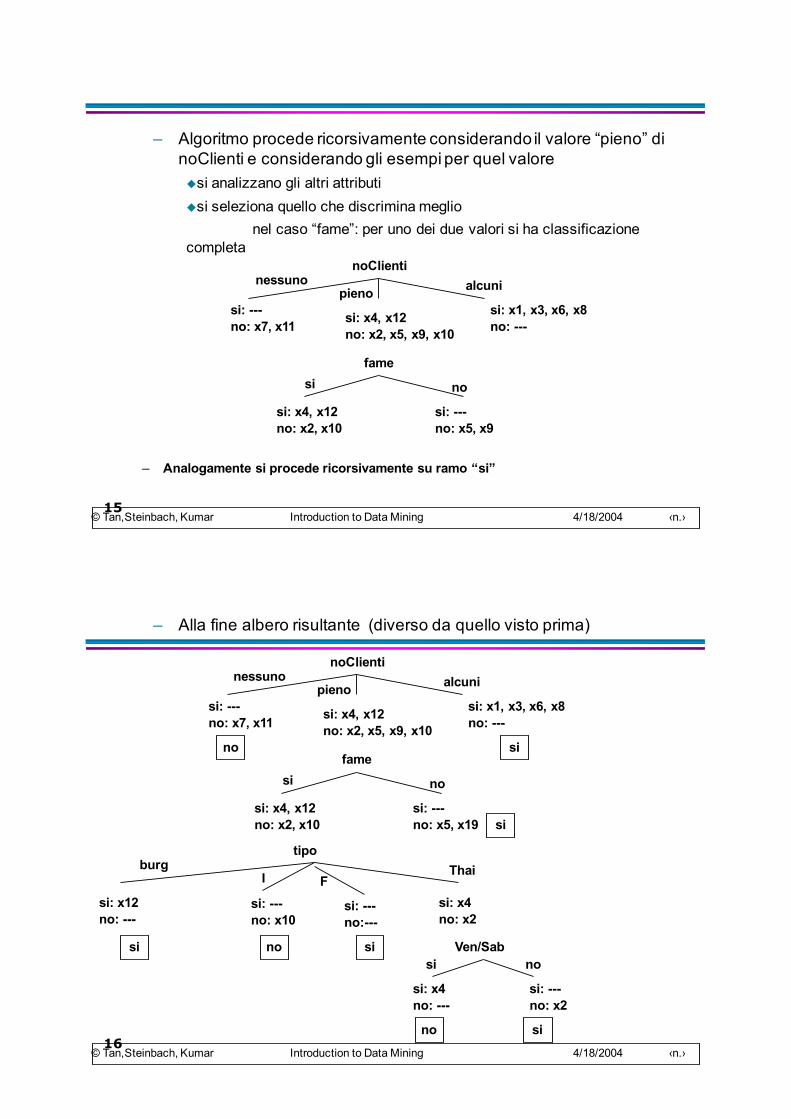
– Algoritmo procede ricorsivamente considerando il valore “pieno” di noClienti e considerando gli esempi per quel valoreusi analizzano gli altri attributiusi seleziona quello che discrimina meglio
nel caso “fame”: per uno dei due valori si ha classificazione completa
noClientinessuno
pieno alcuni
si: ---no: x7, x11 si: x4, x12
no: x2, x5, x9, x10
si: x1, x3, x6, x8no: ---
famesi no
si: x4, x12no: x2, x10
si: ---no: x5, x9
– Analogamente si procede ricorsivamente su ramo “si”
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›16
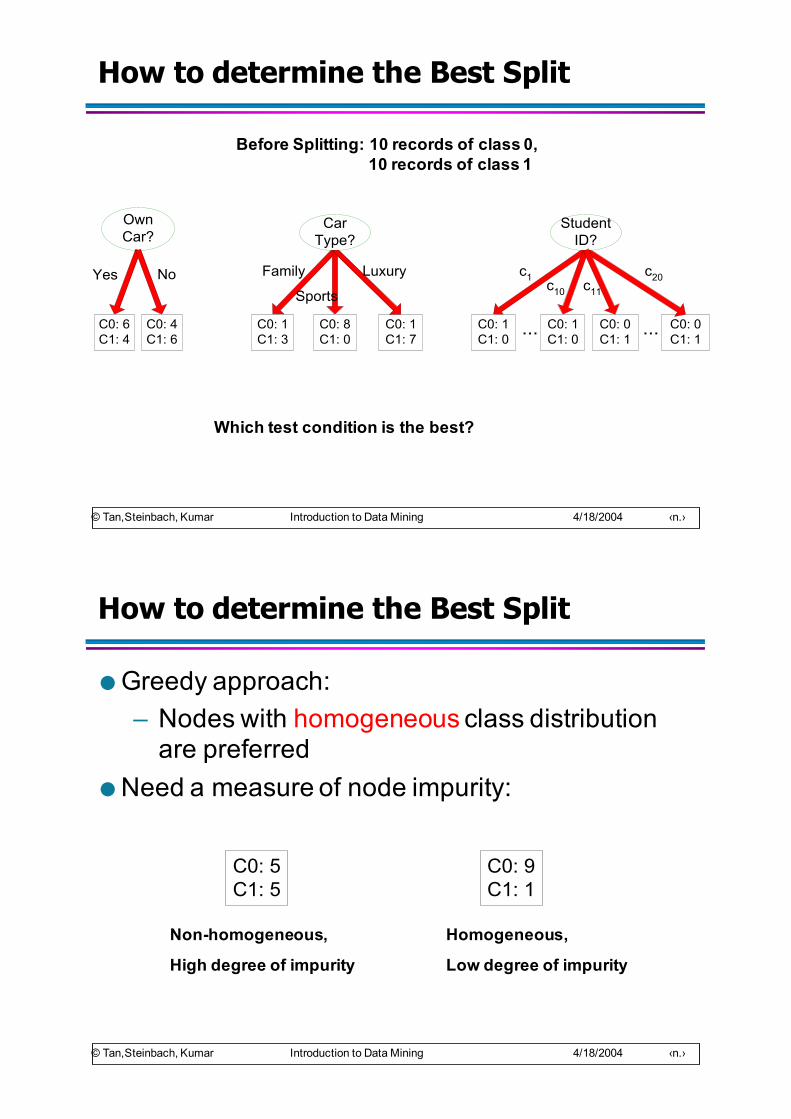
– Alla fine albero risultante (diverso da quello visto prima)
noClientinessuno
pieno alcuni
si: ---no: x7, x11 si: x4, x12
no: x2, x5, x9, x10
si: x1, x3, x6, x8no: ---
famesi no
si: x4, x12no: x2, x10
si: ---no: x5, x19
tipoburg
I Thai
si: ---no:---
si: x12no: ---
Fsi: ---no: x10
si: x4no: x2
no si
si
si no si Ven/Sabsi no
si: x4no: ---
si: ---no: x2
sino
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
How to determine the Best Split
OwnCar?
C0: 6C1: 4
C0: 4C1: 6
C0: 1C1: 3
C0: 8C1: 0
C0: 1C1: 7
CarType?
C0: 1C1: 0
C0: 1C1: 0
C0: 0C1: 1
StudentID?
...
Yes No Family
Sports
Luxury c1 c10
c20
C0: 0C1: 1
...
c11
Before Splitting: 10 records of class 0,10 records of class 1
Which test condition is the best?
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
How to determine the Best Split
● Greedy approach: – Nodes with homogeneous class distribution
are preferred● Need a measure of node impurity:
C0: 5C1: 5
C0: 9C1: 1
Non-homogeneous,
High degree of impurity
Homogeneous,
Low degree of impurity

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Measures of Node Impurity
● Entropy● Gini Index● Misclassification error
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Measure of Impurity: GINI
● Gini Index for a given node t :
(NOTE: p( j | t) is the relative frequency of class j at node t).
– Maximum (1 - 1/nc) when records are equally distributed among all classes, implying least interesting information
– Minimum (0.0) when all records belong to one class, implying most interesting information
∑−=j
tjptGINI 2)]|([1)(
C1 0C2 6Gini=0.000
C1 2C2 4Gini=0.444
C1 3C2 3Gini=0.500
C1 1C2 5Gini=0.278

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Splitting Criteria based on INFO
● Entropy at a given node t:
(NOTE: p( j | t) is the relative frequency of class j at node t).
– Measures homogeneity of a node. uMaximum (log nc) when records are equally distributed
among all classes implying least informationuMinimum (0.0) when all records belong to one class,
implying most information
∑−=j
tjptjptEntropy )|(log)|()(
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Classification task
● Given a collection of records (training set )– Each record contains a set of attributes, one of the
attributes is the class.● Find a model for class attribute as a function
of the values of other attributes.● Goal: previously unseen records should be
assigned a class as accurately as possible.– A test set is used to determine the accuracy of the
model. Usually, the given data set is divided into training and test sets, with training set used to build the model and test set used to validate it.

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Illustrating Classification Task
Apply Model
Induction
Deduction
Learn Model
Model
Tid Attrib1 Attrib2 Attrib3 Class
1 Yes Large 125K No
2 No Medium 100K No
3 No Small 70K No
4 Yes Medium 120K No
5 No Large 95K Yes
6 No Medium 60K No
7 Yes Large 220K No
8 No Small 85K Yes
9 No Medium 75K No
10 No Small 90K Yes 10
Tid Attrib1 Attrib2 Attrib3 Class
11 No Small 55K ?
12 Yes Medium 80K ?
13 Yes Large 110K ?
14 No Small 95K ?
15 No Large 67K ? 10
Test Set
Learningalgorithm
Training Set
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Example of a Decision Tree
Tid Refund MaritalStatus
TaxableIncome Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes10
Refund
MarSt
TaxInc
YESNO
NO
NO
Yes No
MarriedSingle, Divorced
< 80K ³80K
Splitting Attributes
Training Data Model: Decision Tree

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Another Example of Decision Tree
Tid Refund MaritalStatus
TaxableIncome Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes10
MarSt
Refund
TaxInc
YESNO
NO
NO
Yes No
MarriedSingle,
Divorced
< 80K ³80K
There could be more than one tree that fits the same data!
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Decision Tree Classification Task
Apply Model
Induction
Deduction
Learn Model
Model
Tid Attrib1 Attrib2 Attrib3 Class
1 Yes Large 125K No
2 No Medium 100K No
3 No Small 70K No
4 Yes Medium 120K No
5 No Large 95K Yes
6 No Medium 60K No
7 Yes Large 220K No
8 No Small 85K Yes
9 No Medium 75K No
10 No Small 90K Yes 10
Tid Attrib1 Attrib2 Attrib3 Class
11 No Small 55K ?
12 Yes Medium 80K ?
13 Yes Large 110K ?
14 No Small 95K ?
15 No Large 67K ? 10
Test Set
TreeInductionalgorithm
Training SetDecision Tree

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Apply Model to Test Data
Refund
MarSt
TaxInc
YESNO
NO
NO
Yes No
MarriedSingle, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
Test DataStart from the root of tree.
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Apply Model to Test Data
Refund
MarSt
TaxInc
YESNO
NO
NO
Yes No
MarriedSingle, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
Test Data

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Apply Model to Test Data
Refund
MarSt
TaxInc
YESNO
NO
NO
Yes No
MarriedSingle, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
Test Data
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Apply Model to Test Data
Refund
MarSt
TaxInc
YESNO
NO
NO
Yes No
MarriedSingle, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
Test Data

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Apply Model to Test Data
Refund
MarSt
TaxInc
YESNO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
Test Data
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Apply Model to Test Data
Refund
MarSt
TaxInc
YESNO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Refund Marital Status
Taxable Income Cheat
No Married 80K ? 10
Test Data
Assign Cheat to “No”

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Decision Tree Classification Task
Apply Model
Induction
Deduction
Learn Model
Model
Tid Attrib1 Attrib2 Attrib3 Class
1 Yes Large 125K No
2 No Medium 100K No
3 No Small 70K No
4 Yes Medium 120K No
5 No Large 95K Yes
6 No Medium 60K No
7 Yes Large 220K No
8 No Small 85K Yes
9 No Medium 75K No
10 No Small 90K Yes 10
Tid Attrib1 Attrib2 Attrib3 Class
11 No Small 55K ?
12 Yes Medium 80K ?
13 Yes Large 110K ?
14 No Small 95K ?
15 No Large 67K ? 10
Test Set
TreeInductionalgorithm
Training Set
Decision Tree
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Decision Tree Based Classification
● Advantages:– Inexpensive to construct– Extremely fast at classifying unknown records– Easy to interpret for small-sized trees– Accuracy is comparable to other classification
techniques for many simple data sets

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›35
● Conoscenza appresa influenzata dagli esempi– potrebbe classificare in modo sbagliato nuove
istanze– esempi devono essere un buon campione della
popolazione
Valutazione delle prestazioni
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Alberi Decisionali
● È importante sottolineare che in questo contesto è già noto a priori il tipo di classificazione che si vuole realizzare: si vuole classificare tra le classi predefinite dal training set e dal test set.
● Questo tipo di classificatori sono molto utili per applicazioni tipo diagnosi di malattie, ma non permettono di individuare cluster di record che definiscono una nuova classe (ad es. una nuova malattia).

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Alberi Decisionali● La parte più intensa, dal punto di vista computazionale, risulta la
generazione dell’albero, problema di trovare il più piccolo albero decisionale.
● Fortunatamente, con delle semplici euristiche si riescono a trovare alberi di decisione capaci di descrivere un gran numero di casi in maniera concisa.
● L’idea fondamentale alla base di questi algoritmi consiste nel cercare di verificare per primi gli attributi più importanti (attributi discriminativo).
● Per più “importanti” si intende quelli che fanno più differenza nella classificazione dei dati (la quale differenza viene misurata, con opportuni indici detti indici di diversità come entropia). In questo modo possiamo sperare di arrivare alla classificazione corretta con un piccolo numero di test.
© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
I decision tree sono relativamente veloci, confrontati con altri metodi di classificazione e regressione, e sono di semplice interpretazione.
Questa proprietà ne indica il campo di applicazione nel Data Mining: vengono impiegati quando lo scopo che ci si prefigge è la generazione di regole (di classificazione o regressione) chiare e semplici.

© Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 ‹n.›
Bibliography
● Survey: W. Buntine. Learning classification trees. In Artificial Intelligence Frontiers in Statistics. Chapman & Hall, 1993.
● CART: L. Breiman, J.H. Friedman, R. Olshen, C.J. Stone. Classification and regression trees. Chapman & Hall, 1984.
● ID3: J.R.Quinlan. Discovering rules by induction from large collection of examples. In Expert Systems in the Micro Electronic Age. 1979.
● C. Schaffer. Overfitting avoidance as bias. Machine Learning, #10. 1993.
● R.Kohavi. A study on cross-validation and boostrap for accuracy estimation and model selection. In Proc. IJCAI, 1995.
● M.Mehta, R.Agrawal, J. Rissanen. SLIQ: A fast scalable classifier for data mining. In Proc. EDBT, 1996.
● H.Wang, C.Zaniolo. CMP: A fast decision tree classifier using multivariate predictions. In Proc. ICDE, 2000.
● J. Gehrke, R.Ramakrishnan, V.Ganti. RainForest: A framework for fast decision tree construction of large datasets. DAMI (4-2/3), 2000.








![IBMCognos BusinessIntelligencepublic.dhe.ibm.com/software/data/cognos/documentation/docs/th/1… · ˝(3˙˝) ˜#˘˛ ˘˛IBM ®Cognos BusinessIntelligence ˘&’ (=\( #3 ˜ #) ˜$35]](https://img.pdfslide.net/doc/110x75/5f72a6951f67b42af406470a/ibmcognos-busine-3-oe-ibm-cognos-businessintelligence-a.jpg)




















