Embed Size (px)
Citation preview

By Makinen, Navarro and Ukkonen

Abstract
Let A and B be two run-length encoded strings of encoded lengths m’ and n’, respectively. we will show an O(m’n+n’m) time algorithmthat compute their edit distance.
Let A be a short pattern, a B be a long text and a threshold parameter K. We will show an algorithm that will report all the approximate occurrences of A in B Which are at an edit distance K or less from the pattern.

Example of simple edit distance:
A= aaabbcB= abbdb
aaabbc
0123456
a1
b2
b3
d4
b5

Example of simple edit distance:
A= aaabbcB= abbdb
aaabbc
0123456
a1012345
b2
b3
d4
b5

Example of simple edit distance:
A= aaabbcB= abbdb
aaabbc
0123456
a1012345
b2112233
b3
d4
b5

Example of simple edit distance:
A= aaabbcB= abbdb
aaabbc
0123456
a1012345
b2112233
b3222223
d4333334
b5444334

Example of simple edit distance:
A= aaabbcB= abbdb
aaabbc
0123456
a1012345
b2112233
b3222223
d4333334
b5444334

We distinct between three kinds of edit distance:
Levenshtein distance - DL (A,B) : Insertion =1 ,Deletion =1,Substitution=1.distance - DID (A,B) : Insertion =1 ,Deletion =1,Substitution=∞ (no Substitution).Global distance - DG (A,B) : Arbitrary coast for Insertion ,Deletion ,Substitution.

KeyWords
• Run-Length compressed
aaaabbcccaab = (a,4),(b,2),(c,3),(a,2),(b,1).
• White Box
• Black Box
aaaa
a
a
a
aaaa
B
B
B

Dividing the Edit Distance matrix into boxes
aaaabbbbbbcccccbb
a
a
a
b
b
b
b
b
a
a
a
a
a
a
b
b

Dividing the Edit Distance matrix into boxes
aaaabbbbbbcccccbb
a
a
a
b
b
b
b
b
a
a
a
a
a
a
b
b

An O(mn’ + m’n) Algorithm for DL
• Equal Letter Box (White):– “Copying” the values from the upper left borders to
the bottom right borders, using as much diagonal moves as possible.
78889
7
8
98 7 7 8
8
8
•In an Equal letter box, DID = DL because no substitutions are needed.

An O(mn’ + m’n) Algorithm for DL
• Different Letter Box (Black):– Filling only the borders: – 1 + min (t-1 + min relevant upper border ,
s-1 + min relevant left border ).

(3,5)
t > s
(5,3)
t < s
(5,5)
t = s

78889
7
8
99 9 10
11
10
9
1+min( 3-1 + min(7,8) , 1-1 + min(8,9)) = 91+min( 3-1 + min(7,8,8) , 2-1 + min(7,8,9)) = 91+min( 3-1 + min(7,8,8,8) , 3-1 + min(7,7,8,9)) = 101+min( 3-1 + min(8,8,8,9) , 4-1 + min(7,7,8,9)) = 111+min( 2-1 + min(8,8,9) , 4-1 + min(7,7,8)) = 101+min( 1-1 + min(8,9) , 4-1 + min(7,7)) = 9
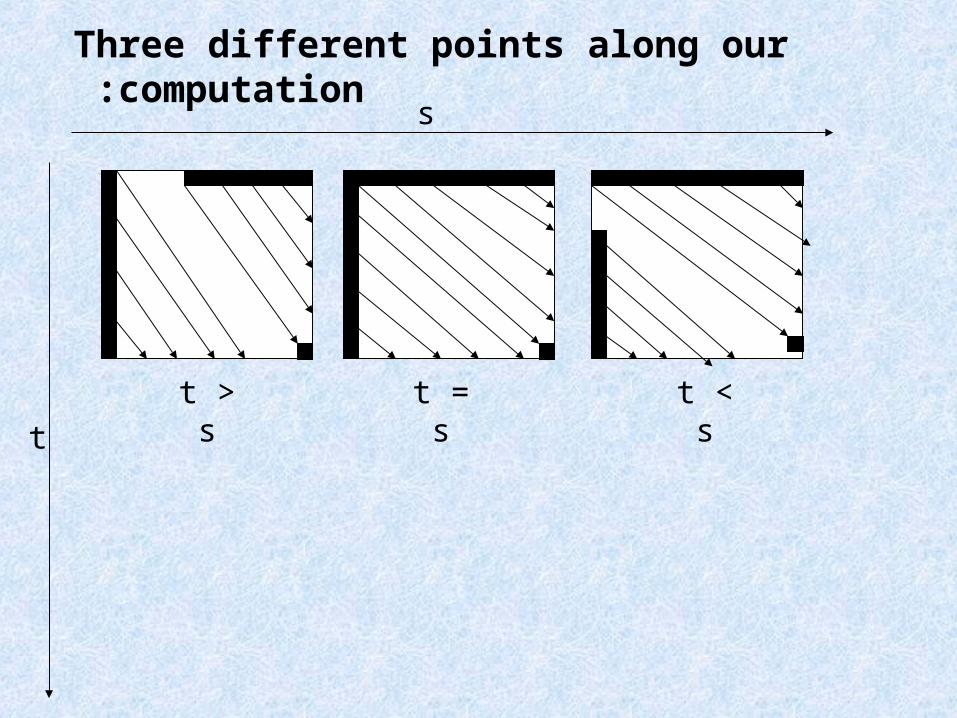
Three different points along our computation:
t > s
t = s
t < st
s

Extending the Algorithm to Global Edit Distance.
Inside a given box there are only three different costs involved :
CI - insertion cost.CD - deletion cost.CS substitution cost.
Since the triangle inequity holds : CS < CI + CD we will not differentiate between white box and black box.
We assume without loss of generality that the cost CI and CD are the same in all boxes

Filling the borders:For each cell (s,t) in the border :
cell(s,t) = min(upper triangle values, leftmost triangle values)
triangle values = min( relevant border cells + each cell’s path to
(s,t) )path = CS * number of diagonal moves +
CI * number of insertions +CD * number of deletions.
example
An O(mn’ + m’n) Algorithm for DG

Example 78889
7
8
9
CI = 7CD = 4CS = 10
2016 2120
13
17
min ( min(9+1*7 , 8+1*10) , min(7+1*10 + 2*4 , 8+3*4)) =16min (min(9+2*7 , 8+1*10+1*7 , 7+2*10) , min(7+2*10 + 1*4 , 8+2*4+1*10 , 8+3*4)) =20min (min(9+3*7 , 8+1*10+2*7 , 7+2*10+1*7 , 7+3*10) , min(7+3*10 , 8+2*10+1*4 , 8+1*10+2*4 , 8+3*4)) =20min (min(9+4*7 , 8+1*10+3*7 , 7+2*10+2*7 , 7+3*10+1*7) , min(8+3*10 , 8+2*10+1*4 , 8+1*10+2*4 , 9+3*4)) =21min(min(8+3*7 , 7+1*10+2*7 , 7+2*10+1*7) , min(8+2*10 , 8+1*10+1*4,9+2*4)) =17min (min(7+3*7 , 7+1*10+2*7) , min( 8+1*10 ,9+1*4)) =13

Complexity:
Stays O(m’n + n’m) same as the Levenshtein algorithm because we only add constant time calculations (multiplications)
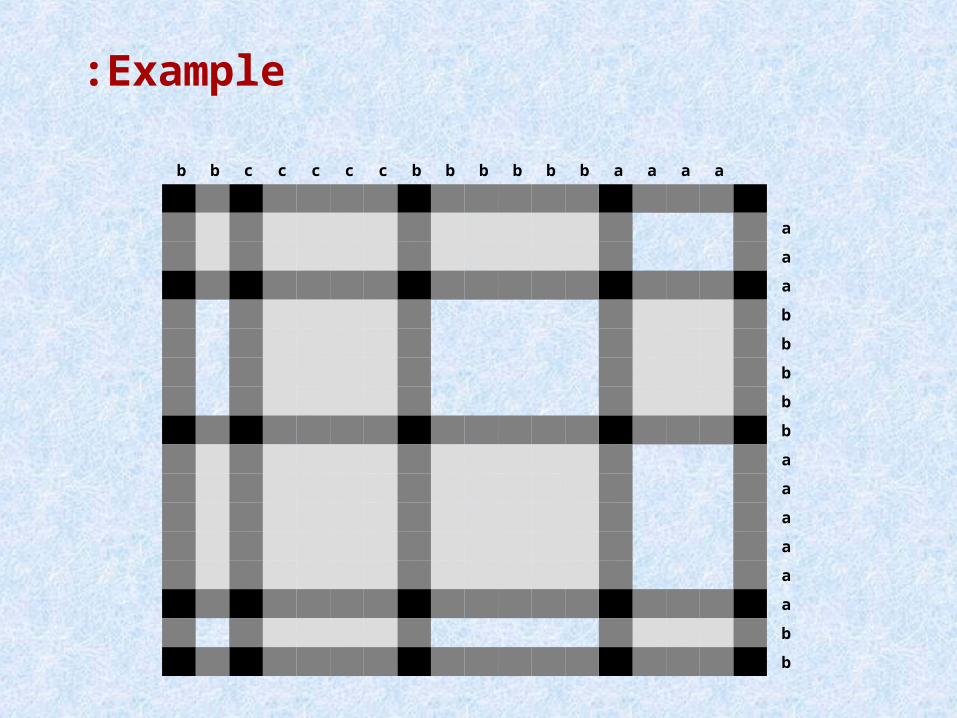
Example:
aaaabbbbbbcccccbb
a
a
a
b
b
b
b
b
a
a
a
a
a
a
b
b

Example:
aaaabbbbbbcccccbb
012345678910
a1
a2
a3
b4
b5
b6
b7
b8
a
a
a
a
a
a
b
b
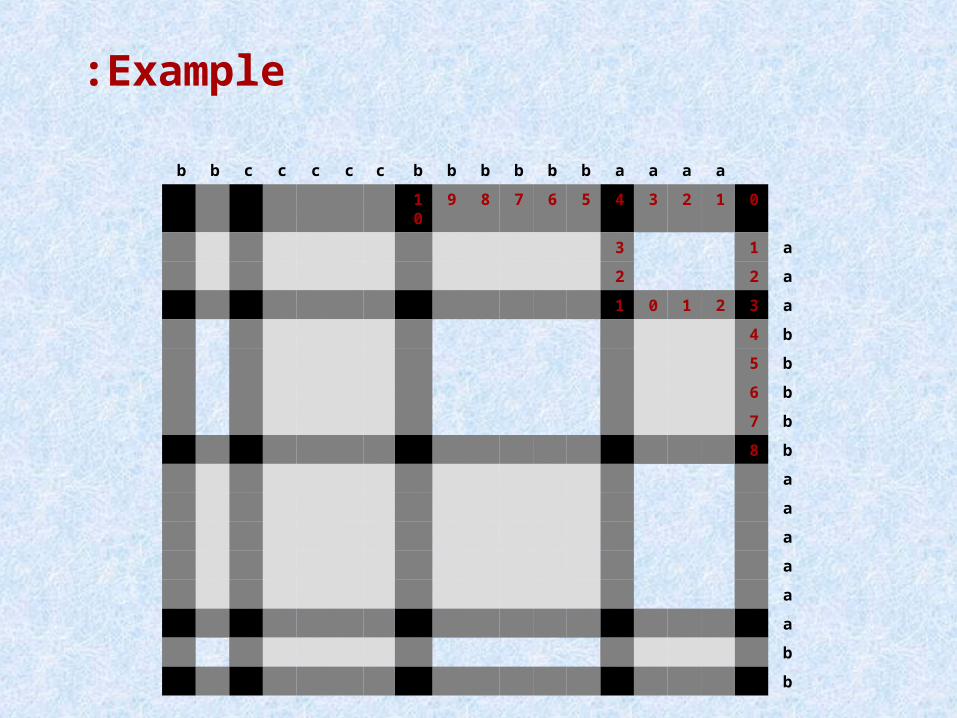
Example:
aaaabbbbbbcccccbb
012345678910
a13
a22
a32101
b4
b5
b6
b7
b8
a
a
a
a
a
a
b
b
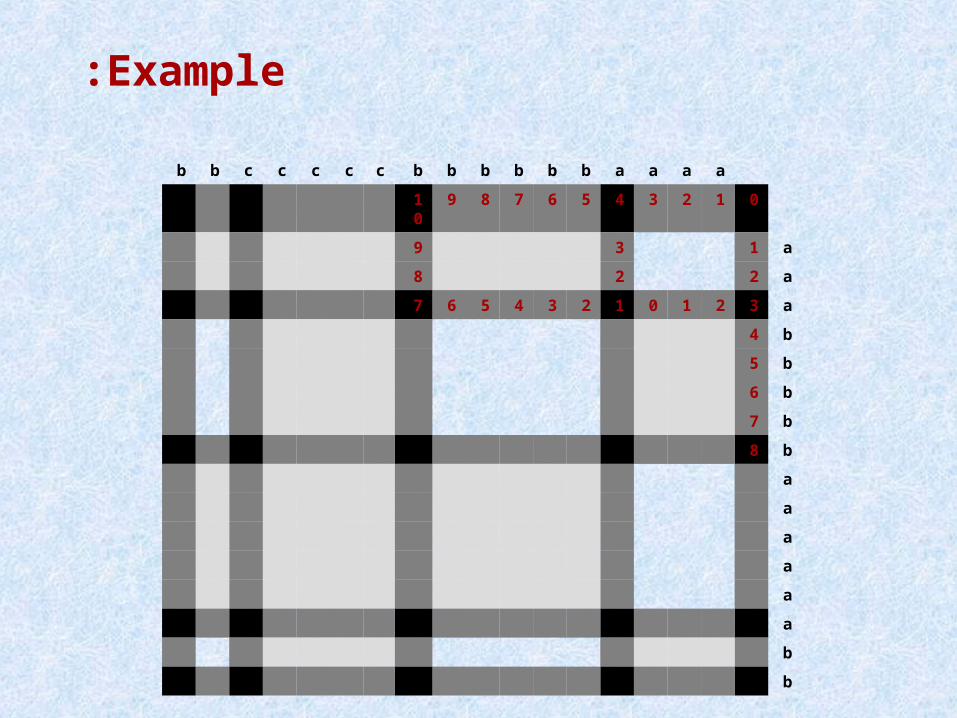
Example:
aaaabbbbbbcccccbb
012345678910
a139
a228
a32101234567
b4
b5
b6
b7
b8
a
a
a
a
a
a
b
b
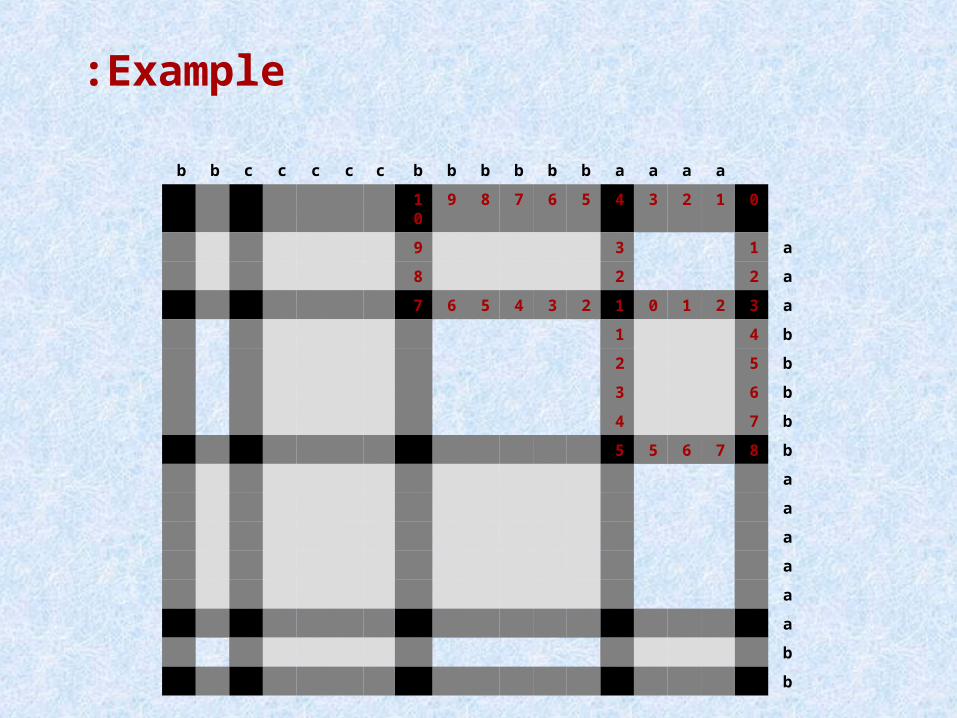
Example:
aaaabbbbbbcccccbb
012345678910
a139
a228
a32101234567
b41
b52
b63
b74
b87655
a
a
a
a
a
a
b
b

Example:
aaaabbbbbbcccccbb
012345678910
a139
a228
a32101234567
b416
b525
b634
b743
b87655432112
a
a
a
a
a
a
b
b

Notice There are two cases computing the borders:
1 .cell(s,t) gets its minimum value from the left border.2 .cell(s,t) gets its minimum value from the top border.
In case 1, the minimum path cost to cell(s,t) can be written as CellValue = BorderCellValue + PathCost(BorderCell, Cell) = BorderCellValue + Diagonal * CS + (Position – Diagonal) * CI = BorderCellValue + Diagonal * (CS – CI) + Position * CI.
BORDERCELLVALUE + DIAGONAL * (CS – CI) is not dependant on Position! Hence it can be calculated in advance, and kept in an array for all border cells, allowing each CellValue calculation to spend only constant time.
Same applies for case 2, by changing CI to CD.

Approximate SearchingGiven a string A (short pattern ) ,a string B ( long text ) and a threshold parameter K ,we are interested reporting all the “approximate occurrences “ of A in B using K errors or less.
)the position of substrings in B that are at distance K or less from the pattern A (.
A = aabca
B = aaeeeeeebbbbbbbaaaaaabbbbbbcccaaaccccabcdcdcdeeeaaab
K = 3

Classical algorithm to find the “matches”
Computes a matrix exactly like previous algorithm with the only difference that the first row of the matrix I initialized with zeros.
The last row of the matrix is examined ,and every text position which is smaller then K is reported as a match .
aabbbbaaacbbbbcca
a
a
b

Classical algorithm to find the “matches”
Computes a matrix exactly like previous algorithm with the only difference that the first row of the matrix I initialized with zeros.
The last row of the matrix is examined ,and every text position which is smaller then K is reported as a match .
aabbbbaaacbbbbcca
00000000000000000
a
a
b

Classical algorithm to find the “matches”
Computes a matrix exactly like previous algorithm with the only difference that the first row of the matrix I initialized with zeros.
The last row of the matrix is examined ,and every text position which is smaller then K is reported as a match .
aabbbbaaacbbbbcca
00000000000000000
a00111100011111110
a10122210012222221
b21012221111222332

More efficient algorithm – pattern and text are run-length compressed:Fill the matrix only at beginning of text runs.Complete the first m columns only.
aabbbbaaacbbbbcca
00000000000000000
a00111100011111110
a10122210012222221
b21012221111222332
Complexity = O(m2n’+R) For each run – m*m, there are n’ runs, R is the size of the output.

Improving the trivial algorithm
Problem: We would have wanted to apply DL, but if the text is very large, m’n may be a
lot bigger than m2n.’
Solution: Combine the two. Evaluating only the borders of the runs, and only the first m cells of each run, yields an O(m’m + m +m) per run of the text, multiplying by n’ to the final O(m’mn’ + R) complexity. דוגמה






![Árvores de Ukkonen - USP · de su xos [AJS99 ] e árvores de k-fatores [AS04] como casos particulares das árvores de Ukkonen e propomos novos algoritmos ótimos para cada um destes](https://img.pdfslide.net/doc/110x75/5f56ad30b5cf6e5cfb189ba6/rvores-de-ukkonen-de-su-xos-ajs99-e-rvores-de-k-fatores-as04-como-casos.jpg)
























