Embed Size (px)
Citation preview

CAP6412AdvancedComputerVision
http://www.cs.ucf.edu/~bgong/CAP6412.html
Boqing GongFeb11,2016

Today
• Administrivia• Neuralnetworks&Backpropagation(PartVII)• Edgedetection,byGoran

Nextweek:CNN&videos
Tuesday(02/16)
Abdullah Jamal
[Opticalflow] Fischer,Philipp,AlexeyDosovitskiy,EddyIlg,PhilipHäusser,CanerHazırbaş,VladimirGolkov,PatrickvanderSmagt,DanielCremers,andThomasBrox."Flownet:Learningopticalflowwithconvolutionalnetworks."arXiv preprintarXiv:1504.06852 (2015).& Secondary papers
Thursday(02/18)
Amar Kelu Nair
[Pose estimation] Pfister, Tomas, James Charles, and Andrew Zisserman.“Flowing convnets for human pose estimation in videos.” In Proceedingsof the IEEE International Conference on Computer Vision, pp. 1913-1921.2015.& Secondary papers

Project1:Dueintwoweeks(02/28)
• Ifyouchooseoption2,yourownproject
• Deadlinefordiscussion&approval:02/11/2016(ThisThursday)
• Seeinstructionsonhowtopreparetheslidesfordiscussion
• http://www.cs.ucf.edu/~bgong/CAP6412/proj1.pdf

Uploadslidesbeforeorafterclass
• See“PaperPresentation”onUCFwebcourse
• Sharingyourslides• Refertotheoriginalssourcesofimages,figures,etc.inyourslides• ConvertthemtoaPDFfile• UploadthePDFfileto“PaperPresentation”afteryourpresentation

Today
• Administrivia• Neuralnetworks&Backpropagation(PartVI)• Imagesuper-resolution,byJose

Trainingalgorithm
• INPUT:BSD(trainingimageXn,edgeannotationsYn1,…Yn5 ),n=1,2,…N• Configuratenetwork:
• TrimVGG-net• (Seerightfornetworkspecification)
• Generate”gold”targetYn foreachimageXn:• Majorityvote:5annotatededgemapsYn1,…Yn5 à oneedgemapYn• DuplicateYn tohave“gold”sideoutput
• Augmentdata:• Rotateimagesby16angles• Flipimages
• Tunehyper-parameters:• mini-batchsize(10),learningrate(1e-6),lossweight(1),momentum(0.9),initializationfilter(0),initialization
fusion(1/5),weightdecay(2e-4),#iteration10,000
• Traintheneuralnetworkwiththosehyper-parametersandaugmenteddata• OUTPUT:Awell-trainednetwork

Test
• INPUT:Anaturalimage,thetrainednetwork
• OUTPUT:Predictededgemaps

Holistically-Nested Edge Detection
Authors: Saining Xie, Zhuowen Tu, UC San Diego In Proceedings of the IEEE International Conference on Computer Vision, December 2015. Presented at UCF Advance Computer Vision Class by: Goran Igic, [email protected] February 11th 2016.

About Paper and important links
Paper was presented on ICCV 2015 conference which was held December 11-18th 2015 In Santiago Chile. It was announced on the second day (TUE DEC 15th ) that paper got Marr Prize honorable mention. The author Xie’s web site: http://vcl.ucsd.edu/~sxie/research/ The code used in the paper is open sourced and published at: https://github.com/s9xie/hed The same page has links to other repositories including CAFFE, modified-caffe for HED. The paper used Piotr's Structured Forest matlab toolbox available here https://github.com/pdollar/edges

Content
▪ Motivation of Research
▪ Problem Statement
▪ Main Contributions of the paper
▪ Approach Outline
▪ Details of Proposed Approach
▪ Experiments
▪ Related Work
▪ Conclusion – Strengths and Weakness of the
Paper
– Overall Rating
– Future Directions

Motivation of Research
To address fundamental and important vision problem: The Edge Detection The problem was studied for years in Image Processing, Camera Vision, 3D Camera Vision and Robotics There are plenty of solutions : • Early Pioneering Methods: Sobel, Zerro Crossing, and Canny detector; • Information Theory Implementation: Statistical Edges, Pb, and gPb; • Learning Based Methods: BEL, Multiscale, Sketch Tokens, and structured Edges • The newest wave of CNN based methods: N4-fields, Deep-Contour, Deep Edge, and CSCNN

Edge Detection – Classic Approach
There are three basic types of intensity discontinuities in digital images: points, lines, and edges. The most common way to look for discontinuities is to run a mask through the image. The response R of the mask in any point of the image is given by:
The isolated point is detected when
Line detection
Points and lines are important in the image segmentation, edge detection is the most common approach.
9
1
, for the 3x3 mask;i i
i
R w z
, where is treshold;R T T
, for all ;i jR R j i
Convolution and Edge Detection. 15-463: Computational Photography. Alexei Efros, CMU, Fall 2005.
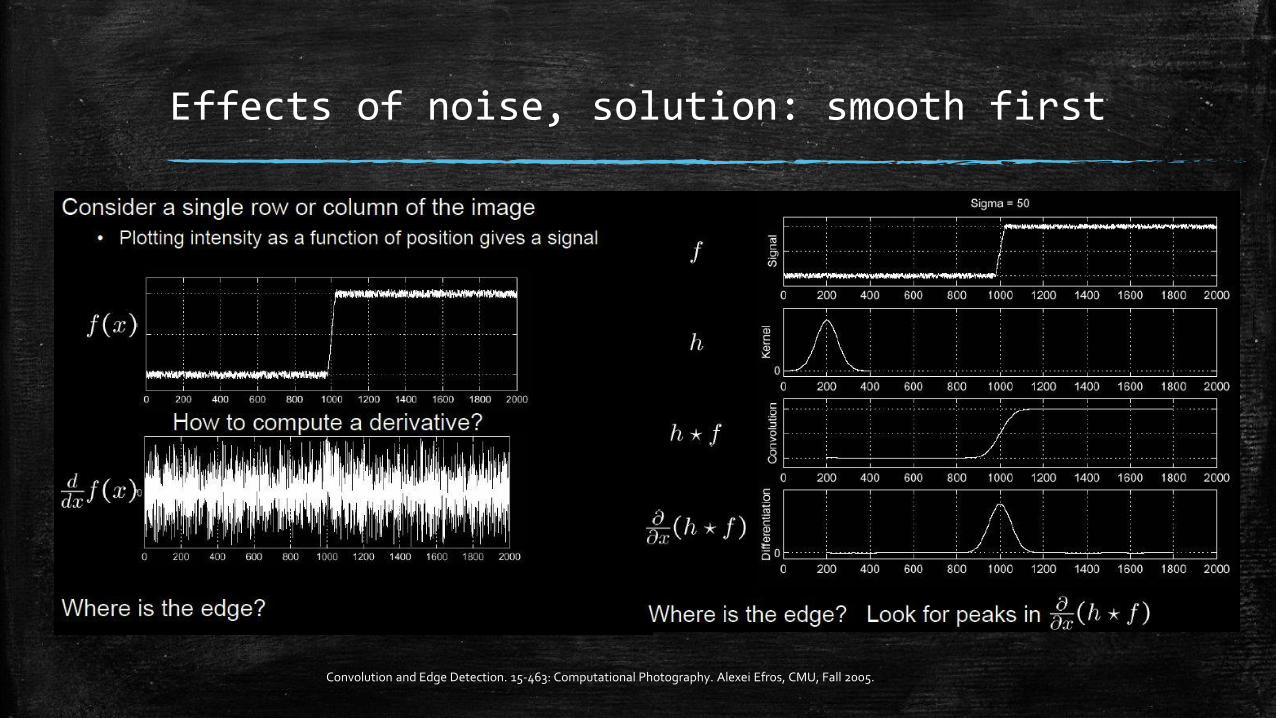
Effects of noise, solution: smooth first
Convolution and Edge Detection. 15-463: Computational Photography. Alexei Efros, CMU, Fall 2005.
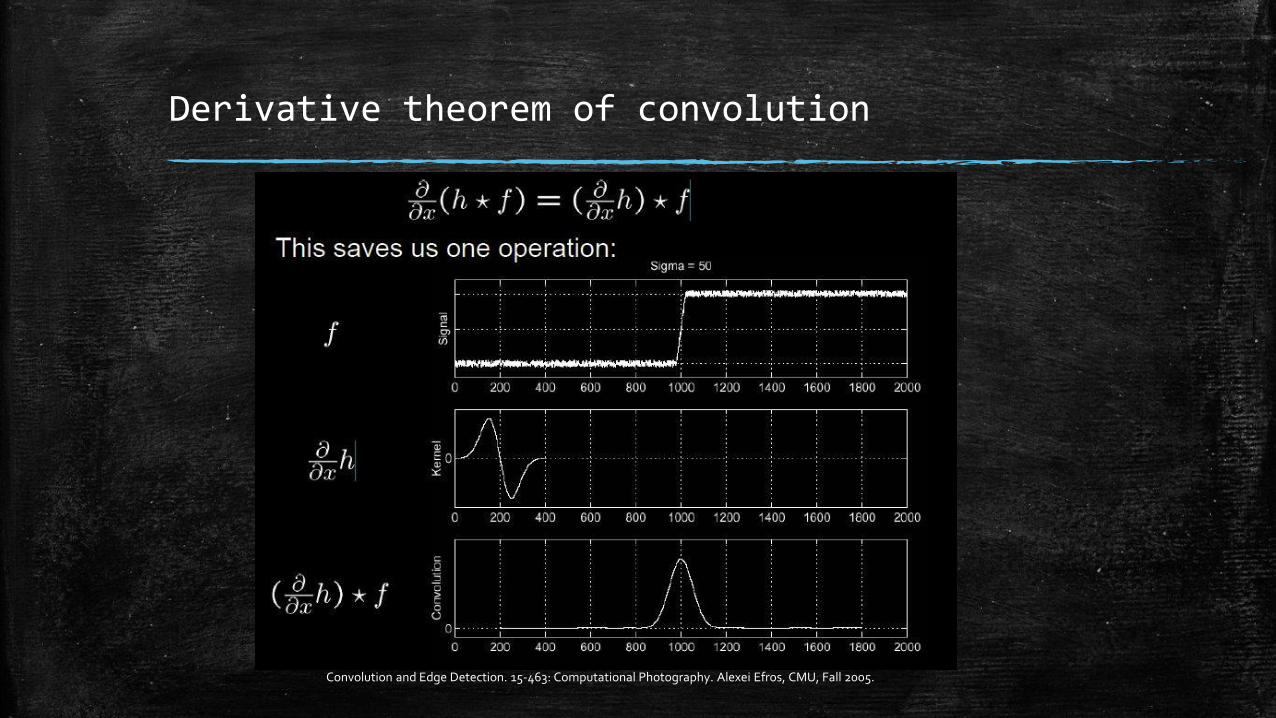
Derivative theorem of convolution
Convolution and Edge Detection. 15-463: Computational Photography. Alexei Efros, CMU, Fall 2005.
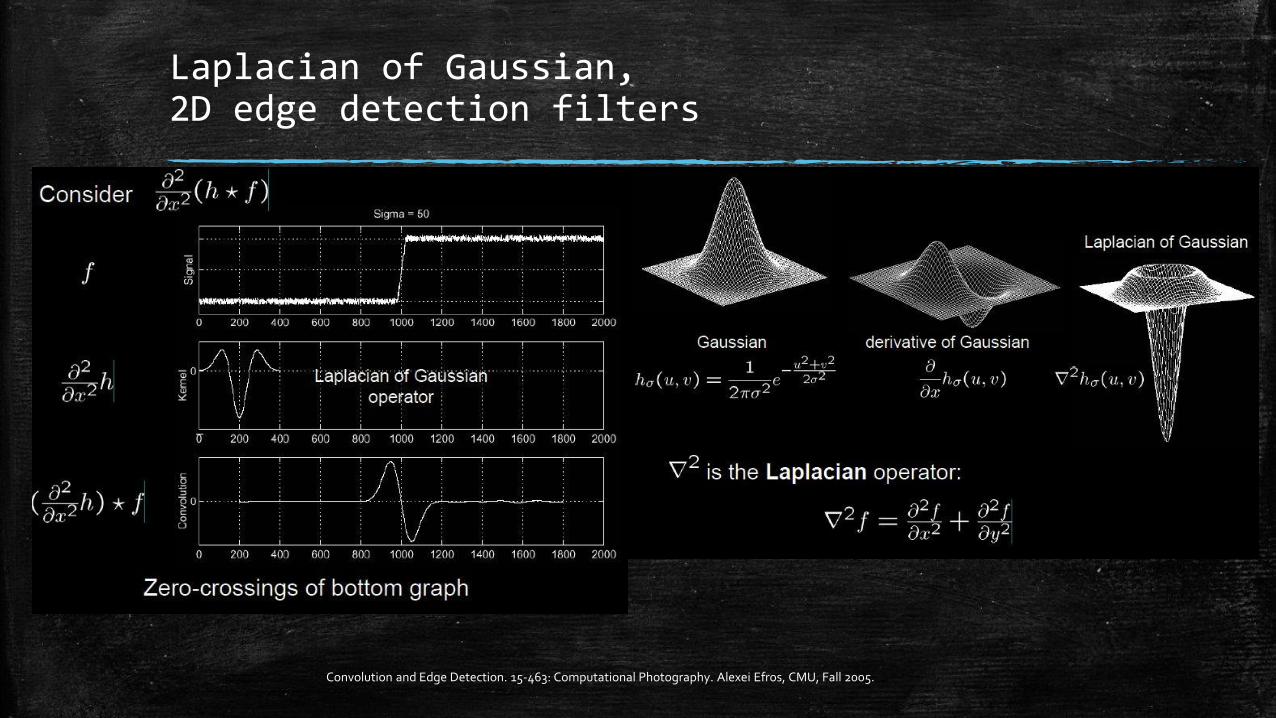
Laplacian of Gaussian, 2D edge detection filters
Convolution and Edge Detection. 15-463: Computational Photography. Alexei Efros, CMU, Fall 2005.

Canny Edge Detector (1)
Authors compare their work to the 1986 edge detector CANNY
First image needs to be converted to gray scale:

Canny Edge Detector (2) The threshold is auto-detected T=[0.05,0.125]
Standard deviation of smoothing filter is =2.0
=4.0
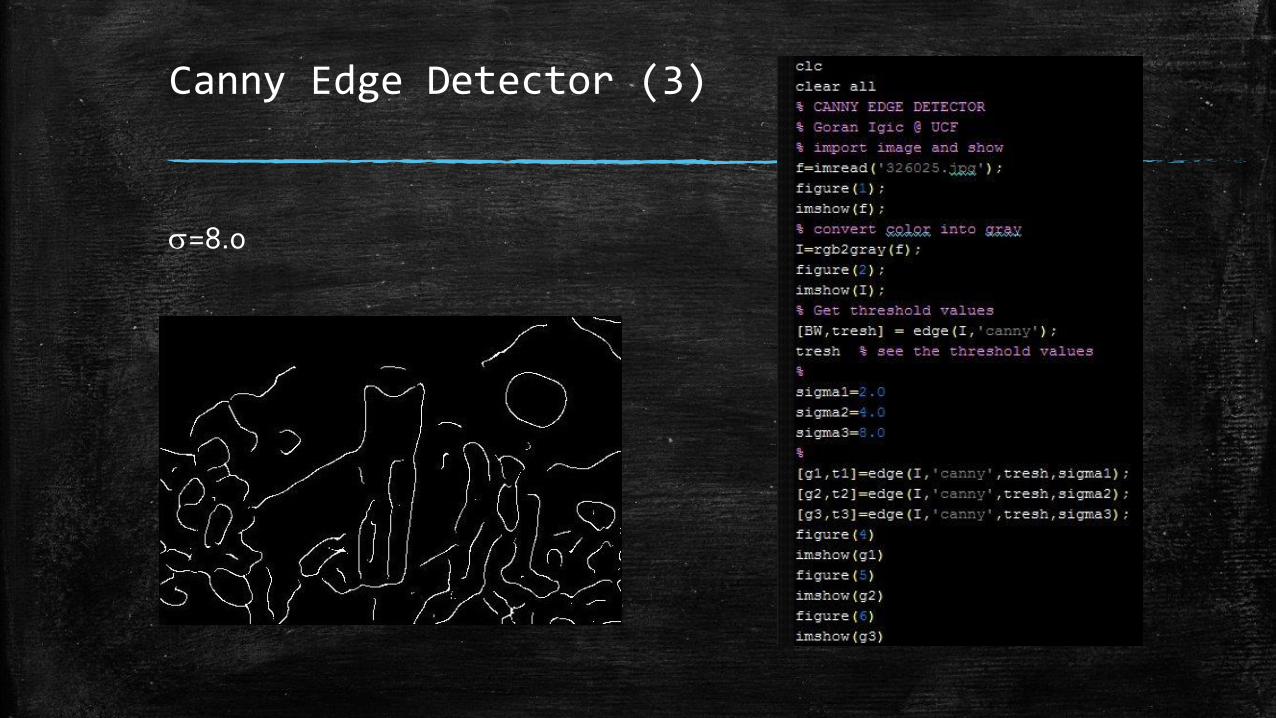
Canny Edge Detector (3)
=8.0

Classical Methods
For more information in regards with classical methods see chapter 10 of the book:
E.C.Gonzalez, R.E.Woods, S.L.Eddins, “Digital Image Processing Using Matlab”, 2nd edition 2010
On Canny Edge Detector from Matlab Help: The Canny method, finds edges by looking for local maxima of the gradient of I. The gradient is calculated using the derivative of a Gaussian filter. The method uses two thresholds, to detect strong and weak edges, and includes the weak edges in the output only if they are connected to strong edges.

Information Theory on the top of features
Methods, statistical edges, Pb and gPb: 1. P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik. Contour detection and hierarchical image segmentation. PAMI,2011, • Contour detector combines multiple local cues into a globalization
framework based on spectral clustering. • It utilize segmentation algorithm for transforming the output of any
contour detector into a hierarchical region tree. • This paper is also important because introduces contour benchmark test.
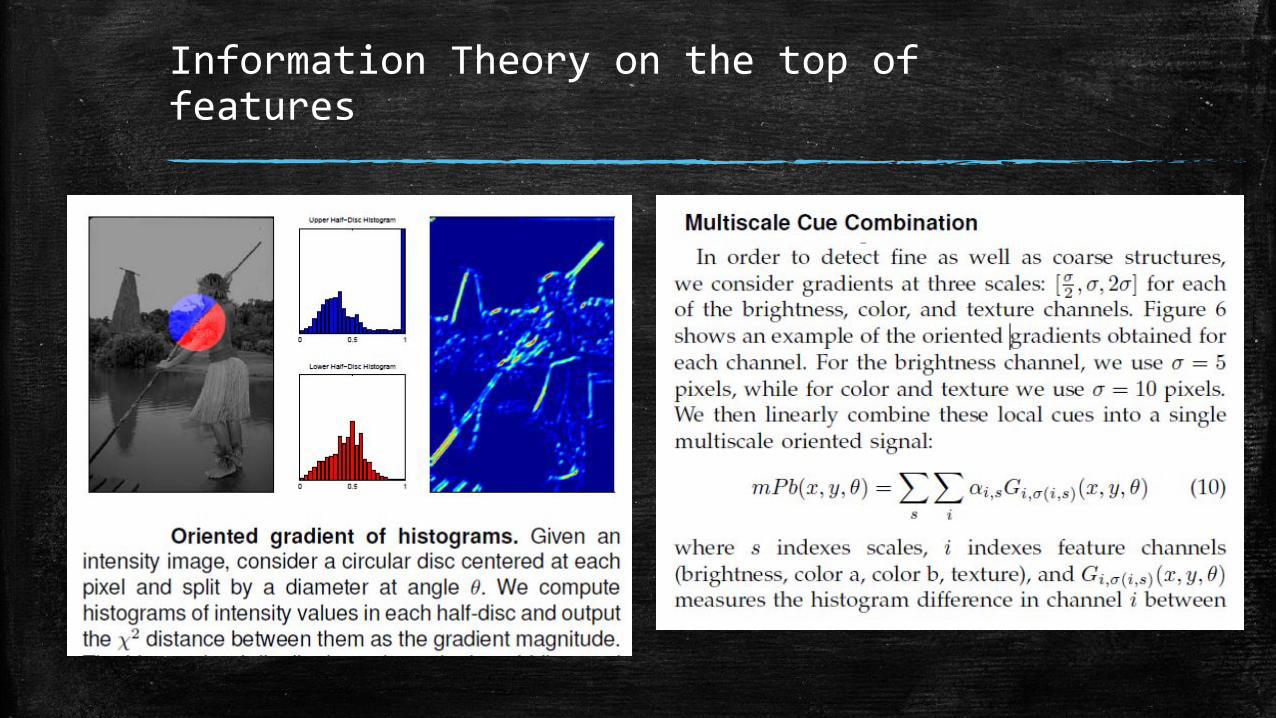
Information Theory on the top of features

Learning Based Models
Structured edges, SE: P. Doll´ar and C. L. Zitnick. Fast edge detection using structured forests. PAMI, 2015. Patches of edges exhibit well-known forms of local structure, such as straight lines or T-junctions. This paper takes advantage of the structure present in local image patches to learn both an accurate and computationally efficient edge detector. The paper formulates the problem of predicting local edge masks in a structured learning framework applied to random decision forests.
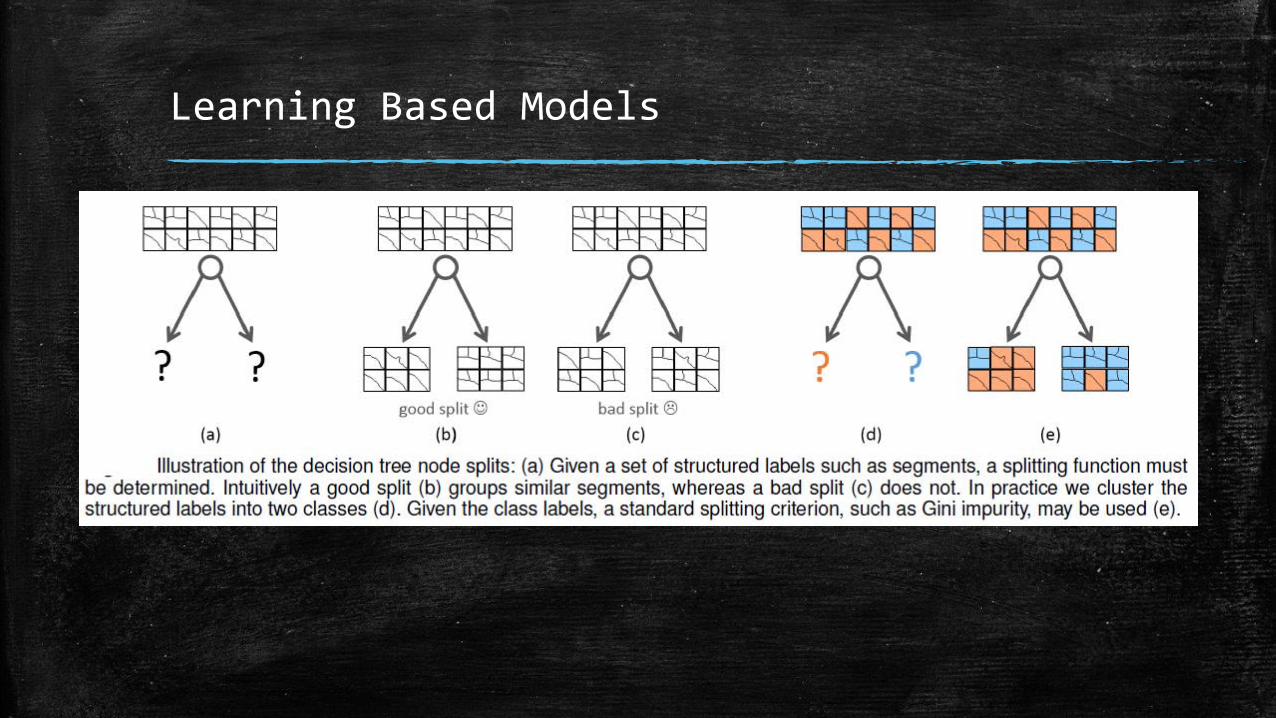
Learning Based Models

Learning Based Models
• As input, the method takes an image that may contain multiple channels, such as an RGB or RGBD image. The task is to label each pixel with a binary variable indicating whether the pixel contains an edge or not. The labels within a small image patch are highly interdependent, providing a promising candidate problem for our structured forest approach.
• Method needs segmented training images, in which the boundaries between the segments correspond to contours.
• To train decision trees, the mapping is defined: • Ensemble model, Random forests achieve robust results by combining the
output of multiple trees.
:Y Z

Models based on Convolutional Neural Networks
Models with Integrated Automatic hierarchical feature learning, N4-fields, Deep Contour, Deep Edge, CSCNN Holistically-nested Edge Detection (HED) Holistic – the system takes an image as input and directly produces the edge map as output. Nested – the system produces edge maps as side outputs,

Content
▪ Motivation of Research
▪ Problem Statement
▪ Main Contributions of the paper
▪ Approach Outline
▪ Details of Proposed Approach
▪ Experiments
▪ Related Work
▪ Conclusion – Strengths and Weakness of the
Paper
– Overall Rating
– Future Directions

Problem Statement
▪ Paper needs to address two important issues of edge detection vision problem:
1. Holistic Image Training and Prediction, used in image –to-image classification, CNN
2. Nested Multiscale and Multilevel Feature learning, deeply-supervised nets – to guide early predictions, deep layer supervision to ‘guide’ early classification results.

Content
▪ Motivation of Research
▪ Problem Statement
▪ Main Contributions of the paper
▪ Approach Outline
▪ Details of Proposed Approach
▪ Experiments
▪ Related Work
▪ Conclusion – Strengths and Weakness of the
Paper
– Overall Rating
– Future Directions

Main Contributions of the paper
,
• Develops an end-to-end edge detection system, holistically-nested edge detection system (HED) • Holistic – it aims to train and predict edges in an image-to-
image fashion; • Nested – the path along with each prediction is common to
each of these edge maps; • The system has integrated learning of hierarchical features

Content
▪ Motivation of Research
▪ Problem Statement
▪ Main Contributions of the paper
▪ Approach Outline
▪ Details of Proposed Approach
▪ Experiments
▪ Related Work
▪ Conclusion – Strengths and Weakness of the
Paper
– Overall Rating
– Future Directions

Approach Outline
HED (Holistic Edge Detection) uses DSN (Deep Supervised Network) training to fine tune the VGG network (Visual Geometry Group – Oxford University) for the task of boundary detection. The principle behind DSN is classifier stacking adapted to deep learning, where each layer is informed about the final objective. VGG Net has great depth (16 convolutional layers), great density (stride-1 convolutional kernels), and multiple stages (five 2-sttrade down sampling layers).
J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014.
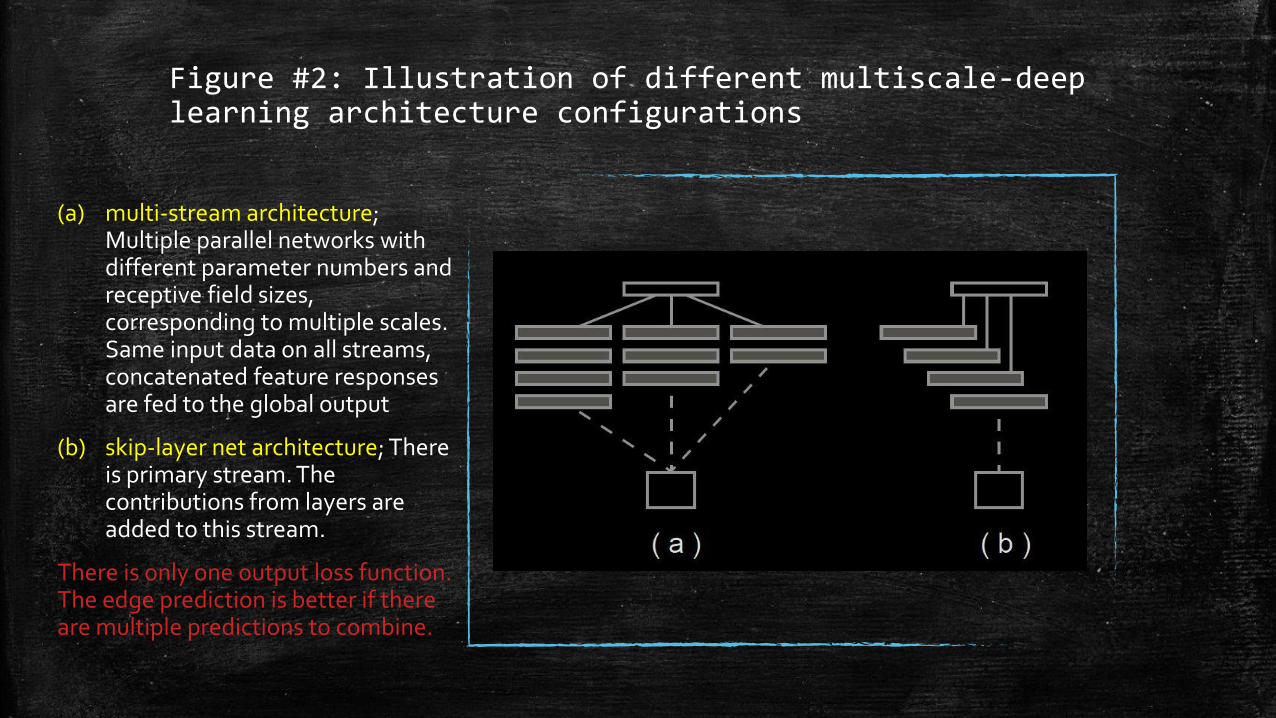
Figure #2: Illustration of different multiscale-deep learning architecture configurations
(a) multi-stream architecture; Multiple parallel networks with different parameter numbers and receptive field sizes, corresponding to multiple scales. Same input data on all streams, concatenated feature responses are fed to the global output
(b) skip-layer net architecture; There is primary stream. The contributions from layers are added to this stream.
There is only one output loss function. The edge prediction is better if there are multiple predictions to combine.
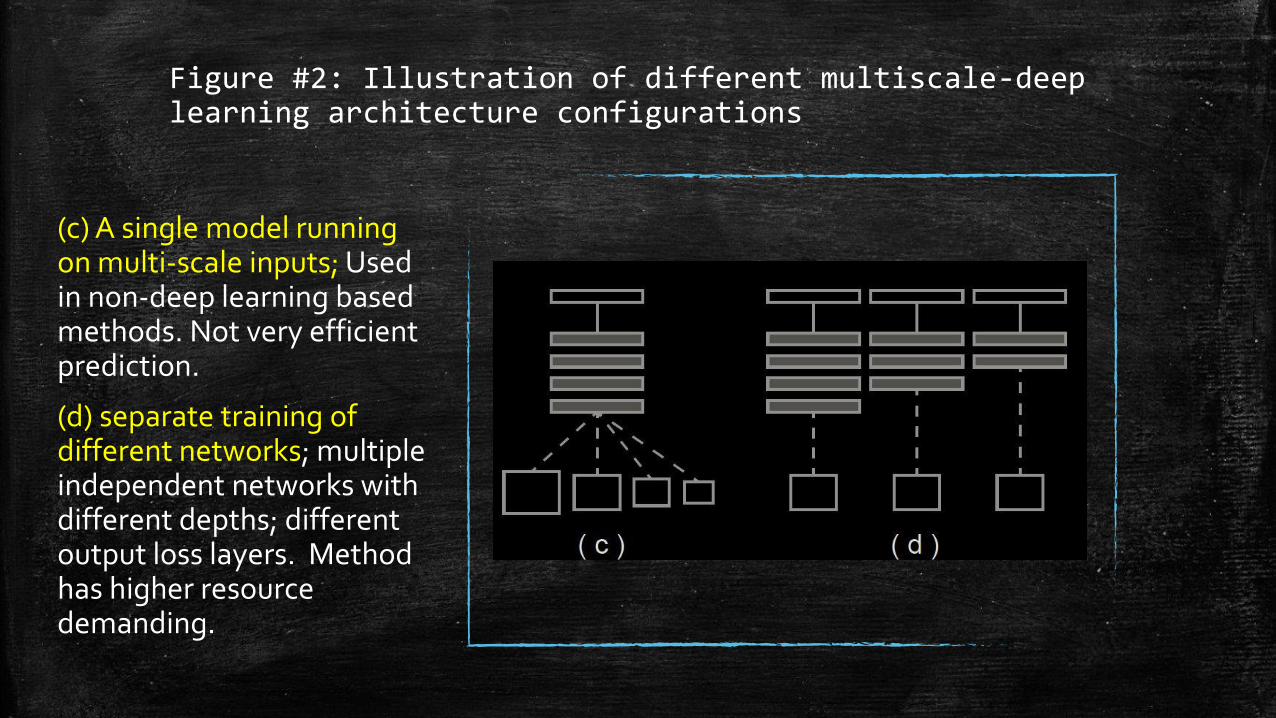
Figure #2: Illustration of different multiscale-deep learning architecture configurations
(c) A single model running on multi-scale inputs; Used in non-deep learning based methods. Not very efficient prediction.
(d) separate training of different networks; multiple independent networks with different depths; different output loss layers. Method has higher resource demanding.
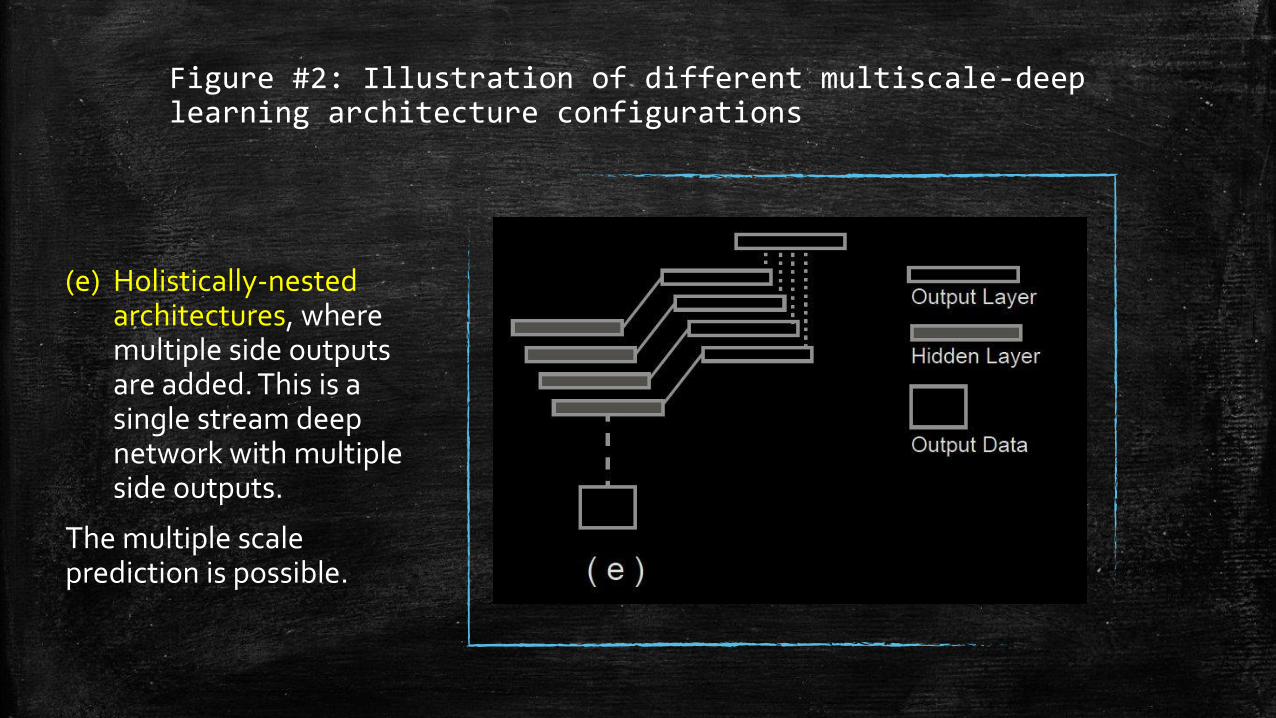
Figure #2: Illustration of different multiscale-deep learning architecture configurations
(e) Holistically-nested architectures, where multiple side outputs are added. This is a single stream deep network with multiple side outputs.
The multiple scale prediction is possible.
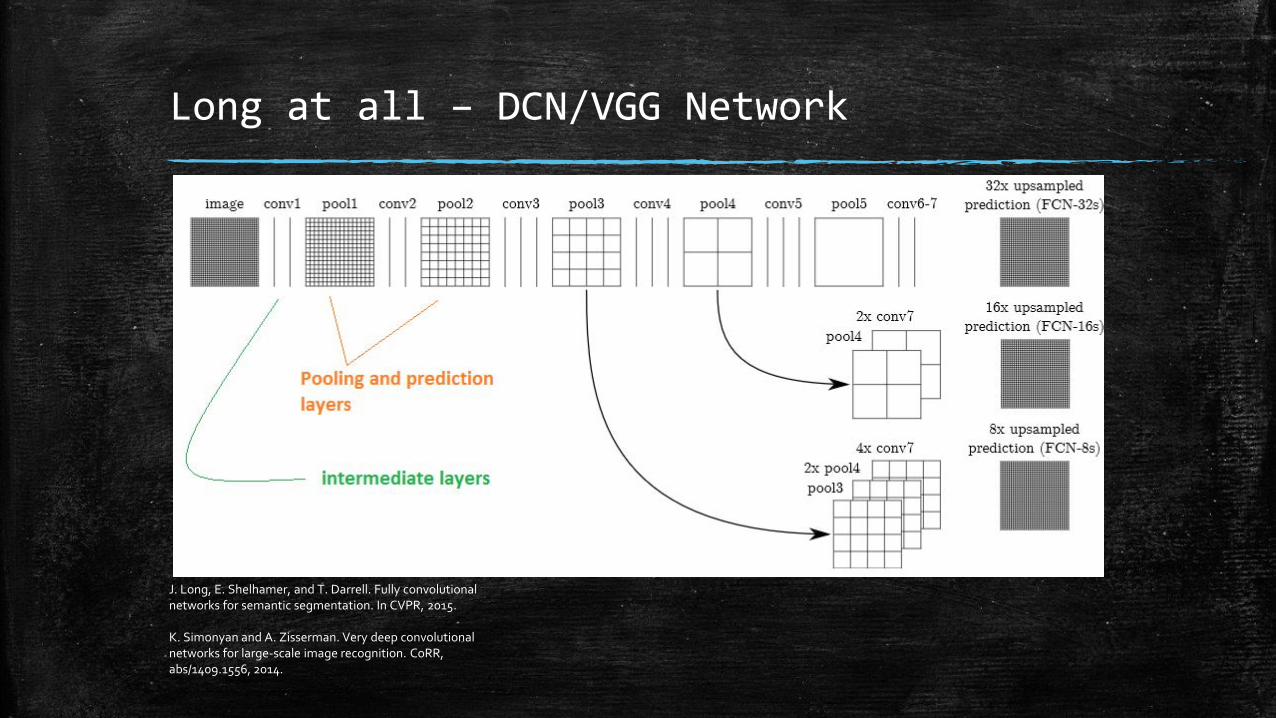
Long at all – DCN/VGG Network
J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014.

Approach Outline
Authors of the paper changed net: • Side output layer is connected to the last convolutional layer • The last stage of VGGN is cut out including 5th pooling layer
J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014.

Content
▪ Motivation of Research
▪ Problem Statement
▪ Main Contributions of the paper
▪ Approach Outline
▪ Details of Proposed Approach
▪ Experiments
▪ Related Work
▪ Conclusion – Strengths and Weakness of the
Paper
– Overall Rating
– Future Directions

Details of Proposed Approach
• Training Phase • Input training data set:
, , 1,..,
where raw image sample is , 1,..., ;
coresponding ground truth binary edge map for image :
, 1,..., , 0,1 ;
Each image is treated holistically and independently, so s
n n
n
n j n
n
n n
n j n j
S X Y n N
X x j X
X
Y y j X y
ufix can be omitted.
The goal is to have a network that learns the features from witch
it is possible to produce edge map approaching the ground truth.
n

Details of Proposed Approach
• W is collection of all standard network layer parameters. • Network has M side-output layers, each of them is associated with the
classifier , with corresponding weights: • The objective function of HED:
• Loss function is computed over all pixels in training image.
𝑋 = 𝑥𝑗
𝑛, 𝑗 = 1, . . . , |𝑋| ;
𝑌 = 𝑦𝑗𝑛, 𝑗 = 1, . . . , |𝑋𝑛| , 𝑦𝑗
𝑛 ∈ 0,1 ;
(1) ,...,M
w w w
1
W,w W,w , where is the image-level loss function for side outputs,M
m m
side m side side
m
L l l

Details of Proposed Approach
• The typical natural image, has the distribution of edge / non-edge pixels as that 90% of pixels is non-edge.
• Simpler strategy (vs other papers) is used here to automatically balance loss between positive / negative classes, class balancing weight b on per-pixel term basis. Class-balanced cross-entropy loss function:
W,w log Pr 1 ; W,w (1 ) log Pr 0 ; W,wm m m m
side j j
j Y j Y
y X y Xb b
l
Where / ; and 1 / ;
is edge ground truth label set; is non-edge ground truth label set;
Pr 1 ; W,w 0,1 is computed using sigmoid function
. on the activation value at pixel j ;
m m
j j
Y Y Y Y
Y Y
y X a
b b

Details of Proposed Approach
• Edge map predictions on each side output layer:
• To directly utilize side output prediction, ‘weighted-fusion’ layer is added. The fusion weight is leaned during the training. The fusion layer loss function:
^ ^ ^
, where , 1,..., ,
are activations of the side output of layer
m m mm
side side side jY A A a j Y
m
^ ^ ^
1
1
W,w,h , ; ;
The fusion weight ,..., ,
mM
fuse fuse sidefuse mm
M
Dist Y Y Y h A
h h h
L

Details of Proposed Approach
^
*
, is the distance between the fused prediction and
the ground truth label map; it is cross entropy loss;
Minimized O
W,w
bjective Functi
,h
on:
arg min( W,w)+ W,w, ;side fuse
fuseDist Y Y
h
L L

Details of Proposed Approach
• Testing phase:
1^ ^ ^
*
^ ^ ^
is given image, edge-map prediction is obtain from both the side output layers
and the weight fusion layer
, ,..., , W,w,h ,
The final unified output:
,
M
fuse side side
HED fuse s
X
Y Y Y CNN X
Y Average Y Y
1 ^
,..., .M
ide sideY
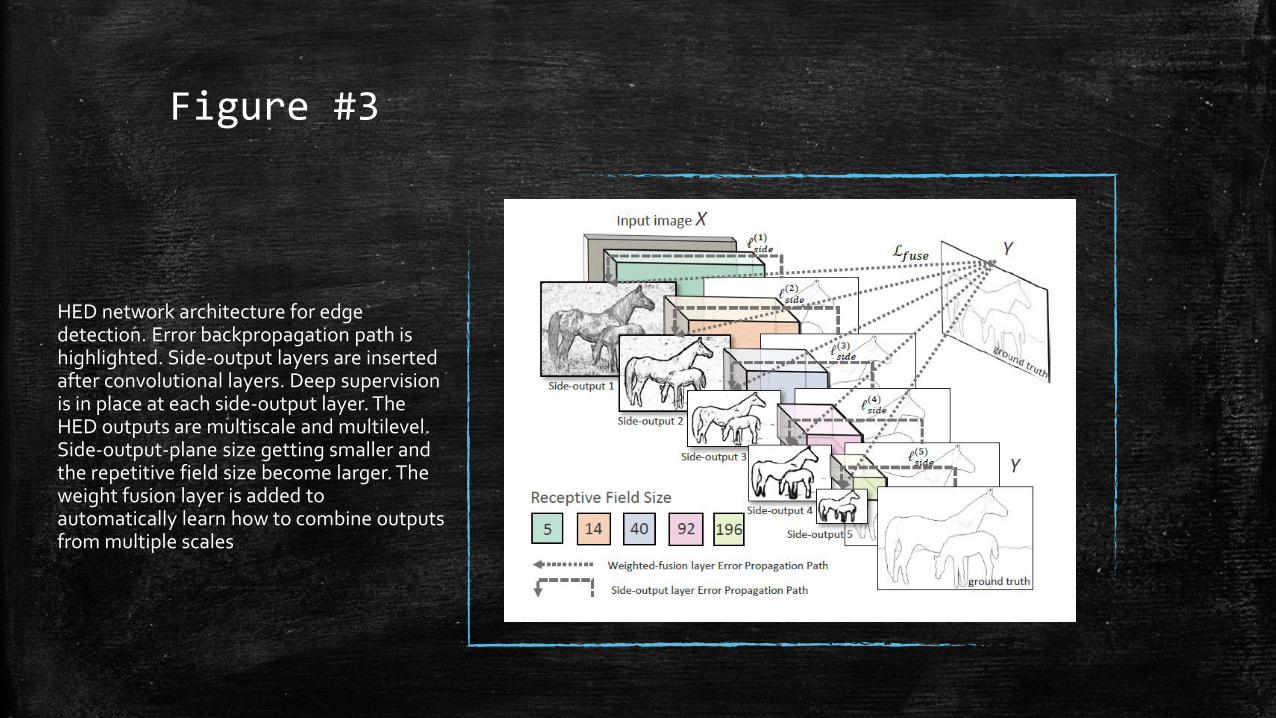
Figure #3
HED network architecture for edge detection. Error backpropagation path is highlighted. Side-output layers are inserted after convolutional layers. Deep supervision is in place at each side-output layer. The HED outputs are multiscale and multilevel. Side-output-plane size getting smaller and the repetitive field size become larger. The weight fusion layer is added to automatically learn how to combine outputs from multiple scales
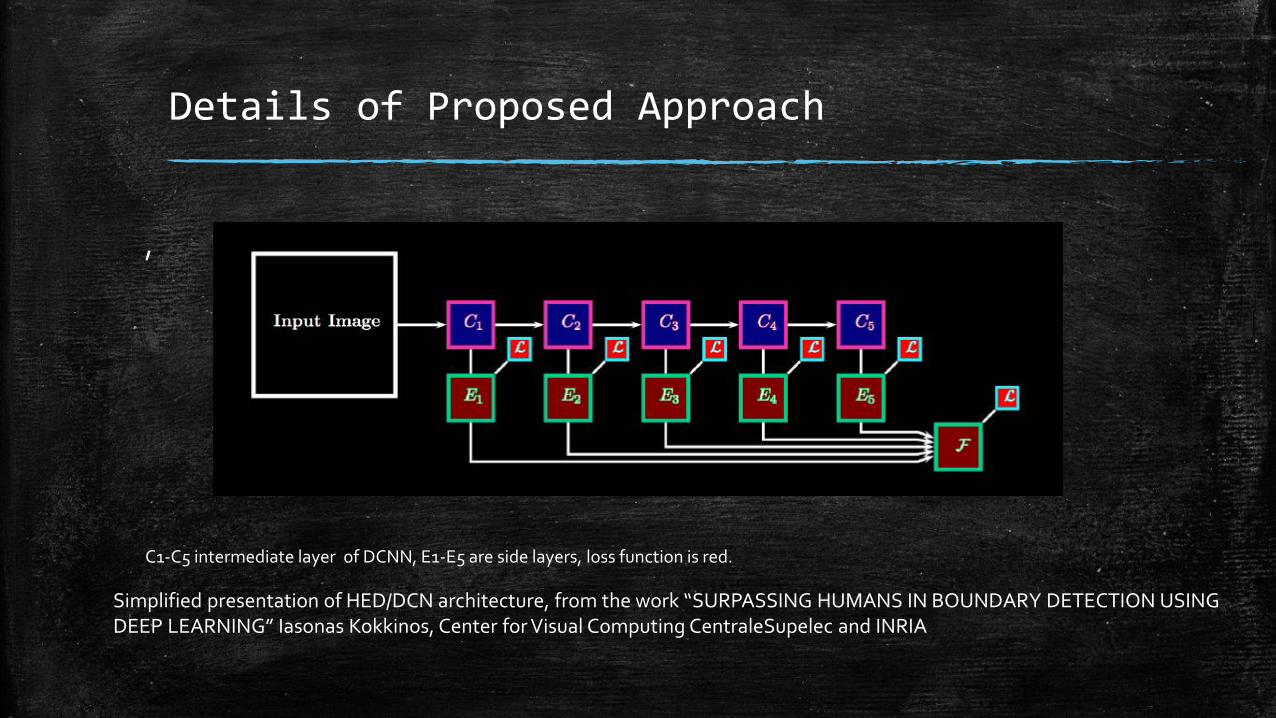
Details of Proposed Approach
,
Simplified presentation of HED/DCN architecture, from the work “SURPASSING HUMANS IN BOUNDARY DETECTION USING DEEP LEARNING” Iasonas Kokkinos, Center for Visual Computing CentraleSupelec and INRIA
C1-C5 intermediate layer of DCNN, E1-E5 are side layers, loss function is red.

Figure #2, results from HED

Content
▪ Motivation of Research
▪ Problem Statement
▪ Main Contributions of the paper
▪ Approach Outline
▪ Details of Proposed Approach
▪ Experiments
▪ Related Work
▪ Conclusion – Strengths and Weakness of the
Paper
– Overall Rating
– Future Directions

Experiments
• The work uses publically available Caffe Library, publically available implementation of FCN and DSN. The whole network is fine tuned from an initialization with the pre-trained VGG-16 Net model
• The hyper-parameters (mini-batch size, learning rate, loss-weight for each side-output layer) are tuned.
• Data augmentation, different pooling functions, in-network bilinear interpolation is used with no much improvement.
• Running time, training takes about 7 hours on a single NVIDIA K40 GPU. From an image 320x480 pixels, HED produces the final edge map for about 400mS
m

Arbelaez at all..
P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik. Contour detection and hierarchical image segmentation. PAMI, 33(5):898–916, 2011.
This paper proposed benchmark test: One option is to regard the segment boundaries as contours and evaluate them as such. One might argue that the boundary benchmark favors contour detectors over segmentation methods, since the former are not burdened with the constraint of producing closed curves. Leading contour detection approaches are ranked according to their maximum F-measure with respect to human ground-truth boundaries. ODS – fixed threshold contour - measure Boundary quality. Detector performance are measured in terms of precision, the fraction of true positives, and recall, the fraction of ground-truth boundary pixels detected. The global F measure, or harmonic mean of precision and recall at the optimal detector threshold, provides a summary score. ODS is for entire data set, OIS is per image, AP ia average precision.
2 Precision Recall
Precision+Recall
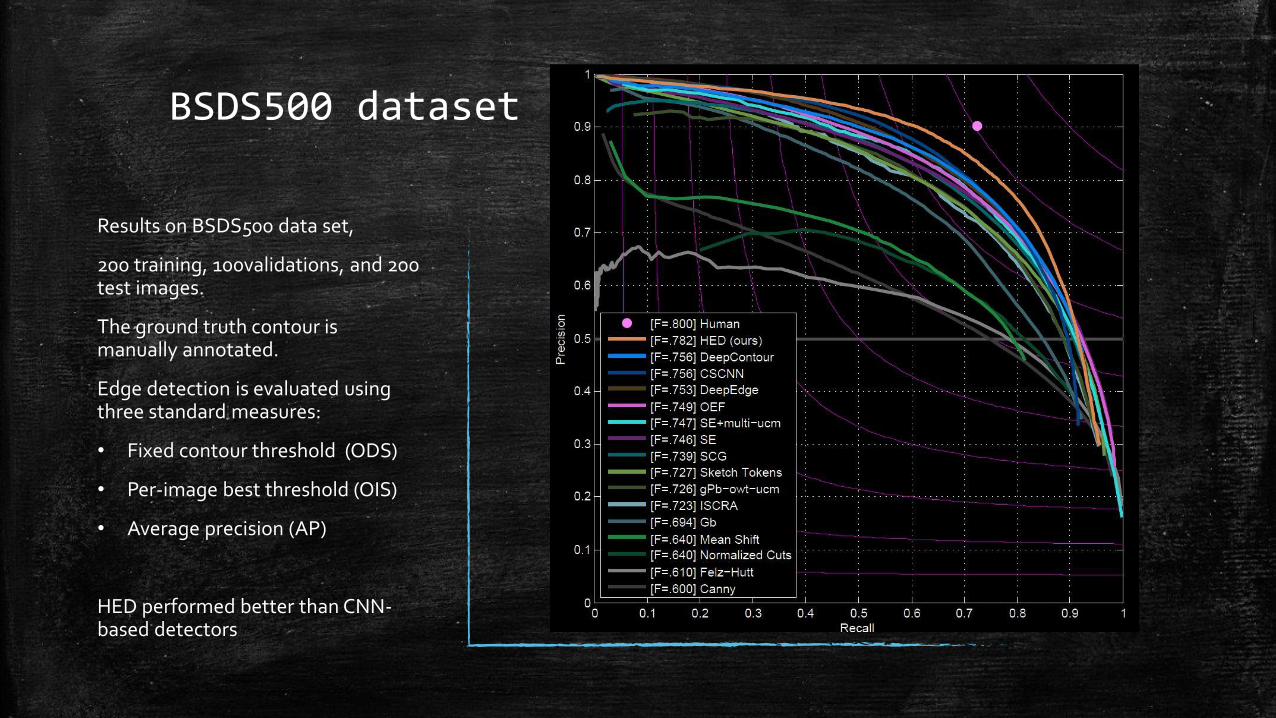
BSDS500 dataset
Results on BSDS500 data set,
200 training, 100validations, and 200 test images.
The ground truth contour is manually annotated.
Edge detection is evaluated using three standard measures:
• Fixed contour threshold (ODS)
• Per-image best threshold (OIS)
• Average precision (AP)
HED performed better than CNN-based detectors
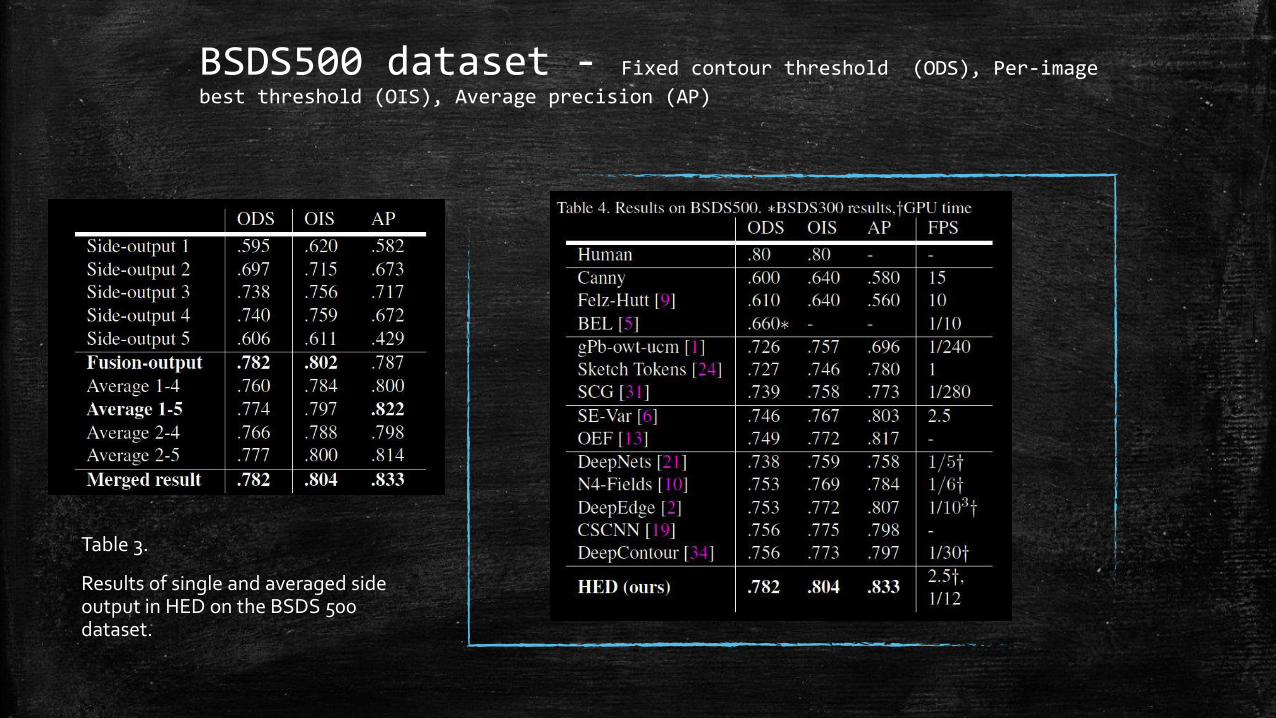
BSDS500 dataset - Fixed contour threshold (ODS), Per-image
best threshold (OIS), Average precision (AP)
Table 3.
Results of single and averaged side output in HED on the BSDS 500 dataset.
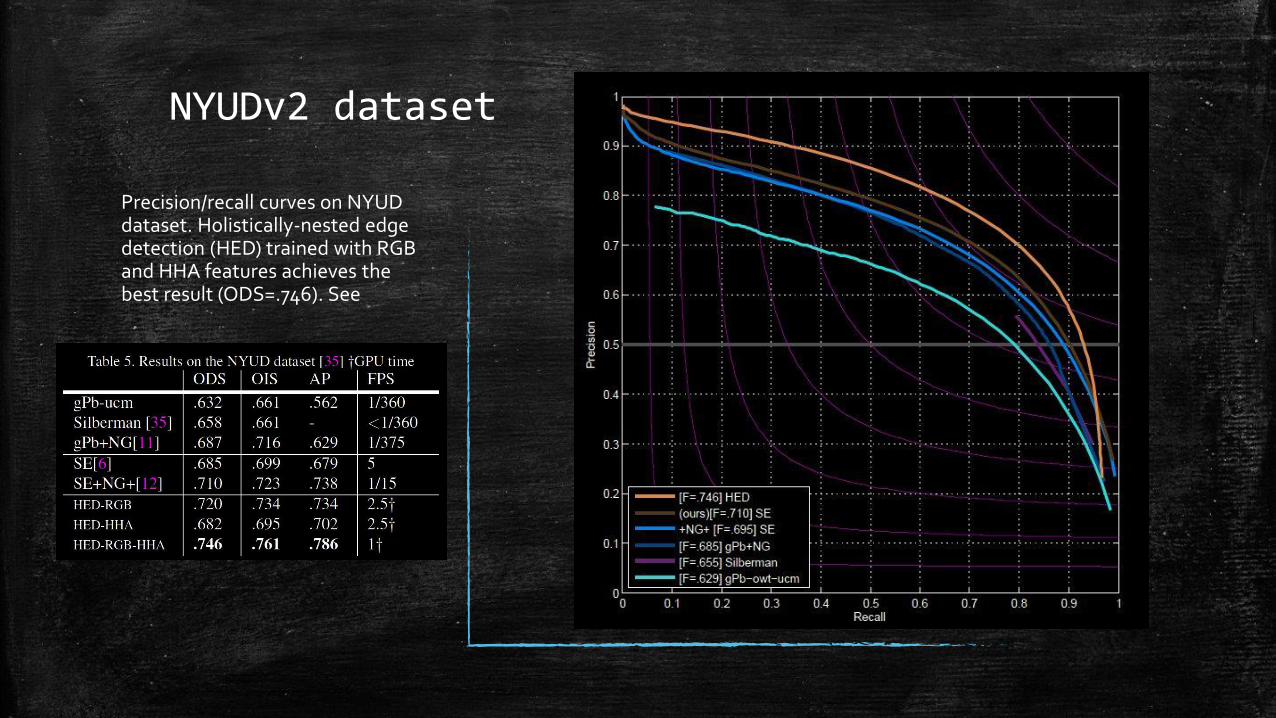
NYUDv2 dataset
Precision/recall curves on NYUD dataset. Holistically-nested edge detection (HED) trained with RGB and HHA features achieves the best result (ODS=.746). See

Content
▪ Motivation of Research
▪ Problem Statement
▪ Main Contributions of the paper
▪ Approach Outline
▪ Details of Proposed Approach
▪ Experiments
▪ Related Work
▪ Conclusion – Strengths and Weakness of the
Paper
– Overall Rating
– Future Directions

Related Work
• Lee, Chen-Yu, Xie, Saining, Gallagher, Patrick W., Zhang, Zhengyou, and Tu, Zhuowen. “Deeply-supervised nets.” In Proc. AISTATS, 2015.
• Iasonas Kokkinos "SURPASSING HUMANS IN BOUNDARY DETECTION USING DEEP LEARNING“
• Liu, Ziwei, Li, Xiaoxiao, Luo, Ping, Loy, Chen Change, and Tang, Xiaoou. “Semantic image segmentation via deep parsing network.” arXiv preprint arXiv:1509.02634, 2015.
• Yizhou, Yu, Chaowei, Fang, Zicheng, Liao, “Piecewise Flat Embedding for
Image Segmentation”

Content
▪ Motivation of Research
▪ Problem Statement
▪ Main Contributions of the paper
▪ Approach Outline
▪ Details of Proposed Approach
▪ Experiments
▪ Related Work
▪ Conclusion – Strengths and Weakness of the
Paper
– Overall Rating
– Future Directions

Conclusion - Strength and Weakness
The known problem is:
Consensus sampling, the ground truth is duplicated at each side-output layer and side output is down sampled to its original scale. The mismatch exist and noise may cause convergence issue in the high-level side outputs even with the help of pre-trained model.
• Develops an end-to-end edge detection system, holistically-nested edge detection system (HED) • Holistic – it aims to train and predict
edges in an image-to-image fashion; • Nested – the path along with each
prediction is common to each of these edge maps;
• The system has integrated learning of hierarchical features
• Experimental work done well

Conclusion – Overall Rating
The paper got Marr Prize honorable mention at the last ICCV 2015 conference which was held December 11-18th 2015 In Santiago Chile.
The paper is very fresh and novel, it is the major part of the current wave of CNN implementations, and machine learning in Vision
I have read the following works for ICCV 2016
The experimental results showing step forward
The code is publically available
Illustration of different multiscale-deep learning architecture configurations is given
My rating is 0

Conclusion - Future Directions
▪ DCN can outperform humans (Iasonas Kokkinos said). There is certainly a great potential in usage of DCN. The system idea is not very complex.
▪ The training can be improved.
▪ There are works with including multiresolution architecture.

![CAP 6412 Advanced Computer Vision - UCF CRCV · Email --- the best way to reach me • Put [CAP6412] in subject line • Summarize message in subject line • Ex: [CAP6412] Meeting](https://img.pdfslide.net/doc/110x75/5f0cd1657e708231d43747fc/cap-6412-advanced-computer-vision-ucf-crcv-email-the-best-way-to-reach-me.jpg)








![CAP 6412 Advanced Computer Vision - CS Departmentbgong/CAP6412/lec1.pdfEmail --- the best way to reach me • Put [CAP6412] in subject line • Summarize message in subject line •](https://img.pdfslide.net/doc/110x75/5f0cd1657e708231d43747fa/cap-6412-advanced-computer-vision-cs-bgongcap6412lec1pdf-email-the-best.jpg)


















![IS 10990-2 (1992): Technical drawings - Simplified ... ISO 6412-2 1994.pdfIS 10990 ( Part 2 ] :1992 ISO 6412-2:1989 ‘wTwfh mm (Reaffirmed1998)Indian Standard TECHNICAL DRAWINGS —](https://img.pdfslide.net/doc/110x75/6142c598b7accd31ec0ee9dd/is-10990-2-1992-technical-drawings-simplified-iso-6412-2-1994pdf-is-10990.jpg)