Embed Size (px)
Citation preview

121
Capitolul 3 Managementul resurselor logice ale unei reţele de calculatoare
3.1. Componentele logice ale reţelei
Componentele logice (software) ale reţelei care permit calculatoarelor şi perifericelor să
comunice sunt: sistemul de operare, aplicaţiile, aplicaţiile pentru comunicaţie şi protocoalele. Aceste componente conectează în mod logic reţeaua. Componentele logice corespund nivelelor de deasupra nivelului fizic din stratificarea reţelelor. Toate aceste resurse logice influenţează funcţionarea reţelei. Fiecare dintre aceste resurse logice vor fi analizate în subcapitolele următoare referitor la administrare şi performanţe.
Sistemul de operare include sistemul de operare de pe calculator şi sistemul de operare pentru reţea, care de obicei se instalează pe server. Categoria de aplicaţii oarecare nu face obiectul prezentei lucrări. Aplicaţiile pentru comunicaţie sunt prezentate separat fiind direct legate de reţelele de calculatoare. Protocoalele sunt şi ele tratate separat.
Pentru a înţelege relaţia optimă între hardware şi software, acest lucru implică analiza performanţelor direct asupra tuturor elementelor platformei: procesele din calculator, procesorul, memoria, interfaţa de I/O şi rutarea. 3.2. Sistemul de operare
Dacă privim reţelele prin prisma sistemelor de operare ce pot fi folosite, vom putea clasifica aceste reţele în reţele de-la-egal-la–egal (peer-to-peer) şi reţele bazate pe server sau tip client-server.
În reţelele de-la-egal-la-egal fiecare dintre calculatoarele reţelei poate îndeplini şi funcţia de server, sistemul de operare în reţea fiind instalat pe fiecare din calculatoarele reţelei. Acest model de reţea este avantajos pentru reţele de dimensiune mică. Există programe avansate instalate peste sistemul de operare în reţea care partajează mai bine resursele şi securizează mai bine calculatorul. Ca dezavantaj al acestor reţele: partajarea informaţiei este dificilă pentru că nu există un calculator central care să păstreze informaţiile pentru toţi utilizatori. O reţea de la-egal-la-egal se poate uşor transforma într-o reţea client-server.
Tehnologia egal-la-egal este tehnologia în care fiecare din staţiile cooperante realizează funcţiile necasere de administrare, procesare, control şi prezentare date. Tehnologia egal-la-egal se foloseşte pe larg în reţelele locale mici.
Pentru reţelele client-server sistemul de operare în reţea rulează pe un server. Aceste reţele sunt mai complexe şi de aceea necesită adminitrare. Pentru aceste reţele resursele care trebuie partajate vor fi gestionate de server, precum şi securitatea reţelei poate fi gestionată centralizat.
Tehnologia client-server contribuie esenţial la dezvoltarea sistemelor deschise, realizând accesul pentru diverse staţii-client la unul şi acelaşi server din mai multe posibile. Ea asigură performanţe mai înalte decât tehnologia server-de-fişiere.
Sistemul de operare cuprinde următoarele elemente logice: • interfaţa utilizator (interpretorul de comenzi); • interfaţa de programare (apelurile sistem);

122
• manevrarea întreruperilor; • administrarea proceselor; • administrarea procesorului; • administrarea memoriei; • administrarea sistemului de fişiere; • administrarea driverelor dispozitivelor periferice; • administrarea securităţii. Alegerea folosirii unui sistem de operare trebuie să ţină seama de performanţele
componentelor sus amintite. Există sisteme de operare pentru mainframe, servere, calculatoare personale, PDA şi alte
dispozitive de control, smart-carduri, sisteme în timp-real şi pentru alte categorii de echipamente IT. Interfaţa utilizator, interfaţa de programare şi manevrarea întreruperilor sunt 3
componente care influenţează prea puţin performanţa reţelei. În schimb, numărul comenzilor, al apelurilor de sistem şi al întreruperilor diferenţiază sistemele de operare între ele şi pot influenţa performanţa în sensul că pot oferii o administrare mai bună a informaţiei, a memoriei, a proceselor şi a procesorului. Administrarea resurselor şi a proceselor nu face partre din această lucrare, ci este obiectul unui studiu legat de sistemele de operar, de aceea sunt prezentate sumar.
Administrarea procesorului, a memoriei, a fişierelor şi a perifericelor sunt părţi componente ale administrării resurselor hardware care se realizează prin intermediul sistemului de operare. Procesorul, memoria şi dispozitivele de I/O sunt resurse care produc gâtuire în sistem. Procesorul şi memoria sunt resurse care se pot planifica.
Driverul dispozitivelor reprezintă un program la nivel hardware cunoscut drept microcod, care controlează modul de funcţionare al unui anumit dispozitiv individual (de exemplu, placa de interfaţă cu reţeaua).
Un driver de dispozitiv poate fi privit ca un sistem de operare în miniatură pentru o singură componentă hardware. Fiecare driver conţine toată logica şi toate datele necesare pentru a asigura funcţionarea corectă a dispozitivului respectiv. În cazul unei plăci de interfaţă cu reţeaua (NIC), driverul include furnizarea unei interfeţe pentru sistemul de operare al gazdei. 3.3. Administrarea proceselor
Administrarea proceselor presupune: • alocarea resurselor la procese; • contorizarea pentru a cunoaşte care proces ce resurse foloseşte; • planificarea proceselor pentru a folosi resursele; • protecţia resurselor pentru ca procesul să acceseze doar resursa care îi este permisă. Administrarea proceselor ţine seama de: • timpul de calcul (generat de cod); • timpul de încărcare (generat de tabele de adrese); • timpul de execuţie (generat de procesor). Pentru marea majoritate a proceselor, cantitatea de memorie folosită este fixată în timpul
compilării (alocare continuă), excepţie făcând recursivitatea şi structurile dinamice de date.

123
3.3.1. Modurile de execuţie ale proceselor Un proces poate fi executat în:
• modul utilizator: pentru programe restricţionate la instrucţiuni de nivel utilizator şi spaţiu de adresă.
Excepţie: apeluri sistem şi instrucţiuni capcană (trap) care cauzează o întrerupere sau o schimbare a modului de lucru al procesorului.
• modul supervizor sau privilegiat sau sistem: toate instrucţiunile inclusiv cele privilegiate şi spaţiul de adrese.
În modul utilizator, programul are acces doar la spaţiul propriu de adrese. În modul supervizor, sistemul de operare are acces complet la toată memoria. 3.3.2. Încărcarea cu lucrări a sistemului
Lucrările pot fi clasificate astfel: • multiutilizator: mai mulţi utilizatori lucrează prin terminale individuale, trebuie
maximizată viteza de lucru a sistemului pentru a preveni timpul de răspuns slab; • server: încărcarea cu lucrări constă în cereri de la mai multe sisteme. Sarcinile
serverului trebuie împărţite în funcţie de aplicaţiile care trebuie să le îndeplinească: server de mail, server de baze de date, server de aplicaţii şi programe, etc.
• staţii de lucru: un singur utilizator pe respectivul sistem. Diferenţe în încărcarea cu lucrări (procese) a sistemului poate cauza mari variaţii în
măsurarea performanţelor sistemului care se diferenţiază în viteza UCP şi dimensiunea RAM. Este important să ţinem seama şi de activitatea din spate (fundal) a sistemului. 3.3.3. Etapele de utilizare a resursei de către procese
Resursele hardware folosite de procese sunt: fişierele (spaţiul pe disc), memoria RAM, procesorul şi dispozitivele de I/O. Cele trei etape de utilizare a resursei sunt:
1. cererea şi aşteptarea pentru acapararea resursei; 2. utilizarea resursei; 3. eliberarea resursei. O resursă preemptivă este o resursă care poate fi preluată nu numai de procesul căreia
îi aparţine fără să afecteze UCP şi memoria. O resursă non-preemptabilă este resursa care poate fi folosită doar de un proces la un
moment dat, de exemplu imprimanta, discheta, intrarea în tabela de i-noduri, Ethernet-ul, înregistrarea într-o bază de date. 3.3.4. Ierarhia de execuţie a procesului Execuţia unui proces este legată atât de resurse hardware cât şi de resurse software.
Ierarhia execuţiei procesului (programului) este prezentată în figura următoare.

124
Hardware Sistem de operare (nivel fizic) (nivel logic)
registrele şi pipeline-urile instrucţiune procesorului curentă cache secvenţă de program
trimisă spre execuţie
tampon de translatere secvenţă de program executată
memoria reală stări de aşteptare
sau manevrarea întreruperi
discul programe
executabile Pentru a rula, un program trebuie să parcurgă în paralel unele ierarhii hardware
(componente fizice) şi ierarhii software (sistemele de operare). Fiecare element hardware din ierarhie este mai scump decât elementul de sub el. În cazul în care programul concurează cu alt program pentru fiecare resursă, tranziţia de la un nivel la următorul consumă timp. Pentru a înţelege dinamica execuţiei programului trebuie înţeles fiecare nivel din ierarhie.
3.3.4.1. Ierarhia hardware
Ierarhia hardware face obiectul capitolului 2, dar ceea ce este prezentat aici în continuare are legatură cu administrarea acestor componente de către sistemul de operare. Piramida de stocare
Piramida prezintă relaţia între toate formele de stocare, capacitatea şi timpul de acces crescând spre baza piramidei, în timp ce lăţimea de bandă creşte spre vârf şi de asemenea şi costul per octet.
Discurile fixe
Cele mai lente operaţii în rularea unui program sunt obţinerea codului şi a datelor de pe disc. Timpul de răspuns, numit şi întârziere, reprezintă durata scursă de la momentul lansării
cererii până la apariţia primului bit din data respectivă. Componentele hardware ale discului introduc următoarele întârzieri: • întârzierea de coadă de aşteptare, reprezintă timpul cât controlorul de disc este
direcţionat să acceseze blocurile specificate; • întârzierea de căutare, reprezintă timpul cât braţul discului caută cilindrul corect;

125
• întârzierea rotaţională, reprezintă timpul cât capetele de citire/scriere trebuie să aştepte până când blocul corect se roteşte sub el;
• timpul de transmisie, reprezintă timpul cât datele trebuie să fie transmise la controlor; • timpul de manevrare a întreruperii, reprezintă timpul cât datele sunt conduse de la
controler la programul de aplicaţie.
Memoria RAM Memoria RAM (Random Access Memory) este mai rapidă decât discul, dar mult mai
scumpă per octet. Sistemul de operare încearcă să ţină în RAM doar codul şi datele care sunt folosite (în momentul respectiv), stocând orice exces pe disc. În general, întârzierea introdusă de RAM este de cicluri de memorie şi apare între momentul în care hardware-ul reorganizează necesarul pentru accesul la RAM şi momentul în care datele şi instrucţiunile sunt disponibile la procesor.
Tampon de translatare
În cazul în care codul programului are nevoie de memorie multă, sistemul translatează adresele virtuale ale programului pentru instrucţiuni şi date în adrese reale care sunt necesare pentru a prelua instrucţiunile şi datele de la RAM. Deoarece procesul de translatare a adreselor consumă timp, sistemul păstrează adresele reale ale paginilor de memorie virtuală accesate recent într-un cache numit tampon de translatare într-o parte (TLB – Translation Lookaside Buffer).
Dacă apare o eroare de pagină, execuţia programului este suspendată până când pagina este citită de la disc.
Cache
Pentru a minimiza timpul pe care programul îl consumă cu întârzierea pentru transferul în RAM, sistemul foloseşte o zonă de memorie cu acces rapid (cache) pentru instrucţiuni şi date, astfel acestea sunt disponibile pentru procesor în următorul ciclu fără întârziere (dacă lipseşte memoria cache apare întârzierea datorată memoriei RAM).
Există mai multe nivele cache: L1, L2, L3. Dacă nivelul L1 lipseşte este căutat L2 şi tot aşa dacă nu există nici L3 se foloseşte RAM. Structura şi dimensiunea cache variază de la model la model.
Există memorii cache pentru calculatoare, harddiscuri, rutoare, etc.
Instrucţiunile curente ale maşinii Marea majoritate a instrucţiunilor maşină sunt capabile să se execute într-un singur ciclu
de procesor dacă nu lipsesc TLB sau cache. În contrast, dacă programul se împarte rapid la diferite zone de program şi accesează date de la un număr mare de zone diferite cauzează un TLB ridicat şi frecvente absenţe ale cache, astfel numărul de cicluri de proces per instrucţiune (CPI) executate poate fi mai mare decât 1.
Programele trebuie să folosească un număr minim de instrucţiuni necesare pentru a îndeplini acea activitate, pentru a nu consuma ineficient număr mare de cicluri.
Pipeline şi registre
Folosite pentru a procesa simultan mai multe instrucţiuni. Numeroase registre folosite în scop general şi registre de virgulă-mobilă pot păstra cantităţi considerabile de date de program în registre, chiar dacă stocarea şi reîncărcarea datelor este continuă.
Funcţiile de optimizare a compilatoarelor trebuie folosite întotdeauna când generăm programe productive.

126
3.3.4.2. Ierarhia software
Pentru a rula un program, acesta trebuie să parcurgă paşii ierarhiei din figura din pag 4. Programe executabile
Când cereţi execuţia unui program, sistemul de operare produce un număr de operaţii care transformă programul executabil de pe disc în program rulabil. Întâi se găseşte pe calea indicată programul de executat. Apoi, încărcătorul trebuie să rezolve orice referinţă externă de la program pentru a partaja resursele, librăriile. Sistemul de operare crează un proces sau un set de resurse, care sunt cerute de către orice rulare de program.
Un thread este o stare curentă de execuţie a unei singure instanţe a programului. Multiple astfel de stări pot fi create într-un proces de către programul de aplicaţie. Aceste stări curente partajează resursele proprii procesului în care acestea rulează.
Manevrarea întreruperilor
Mecanismul de avertizare a sistemului de operare asupra unui eveniment extern are loc în întreruperea stării curentă de rulare şi transferarea controlului către un mânuitor de întreruperi (handler).
Înainte ca mânuitorul de întrerupere să poată rula trebuie să fie salvată starea hardware pentru a asigura faptul că sistemul poate restaura contextul stării curente după ce manevrarea înteruperii este completă.
Stare curentă de aşteptare
Reprezintă cererea care nu poate fi satisfăcută imediat este o operaţie sincronă de I/O. 3.4. Administrarea procesorului
Instrucţiuni privilegiate pe care le execută procesorul sunt: • instrucţiuni pentru schimbarea modului de lucru al procesorului; • instrucţiuni de administrare a memoriei; • instrucţiuni pentru cronometrare; • instrucţiuni care setează alţi registrii hardware importanţi.
3.4.1. Modelarea utilizării unităţii centrale de prelucrare
Modelarea utilizării unităţii centrale de prelucrare poate fi făcută după: • modelul nativ: dacă un proces calculează p% din timp un sistem cu 100/p procesoare
va calcula 100% din timp; • modelul probabilistic: dacă procesul petrece o fracţiune p din timpul său într-o stare de
aşteptare pentru I/O, un sistem cu n procese va avea utilizarea UCP egală cu 1 - pn; • teoria cozilor: este un model mai exact (de acurateţe).
3.4.2. Planificarea unităţii centrare de prelucrare
Unitatea centrală de prelucrare trebuie planificată, deoarece este o resursă care produce gâtuire în reţea.
Un proces poate fi într-una din stările: proces nou, gata de execuţie, în rulare, gata

127
(suspendat, aşteptând procesorul), blocat, blocat (în aşteptare, amânat), terminat. Planificarea deciziilor are loc când procesele comută de la rulare la aşteptare, rulare la
gata, aşteptare la gata şi rulare la terminare. Selectarea unui proces din coadă este realizată din planificator pe baza algoritmilor de
planificare. Aceste aspecte ţin de sistemul de operare. Planificarea non-preemptivă nu necesită hard special (de exemplu timer) şi procesorul
curent foloseşte unitatea centrală de prelucrare până o eliberează. Planificare preemptivă rularea procesului curent poate fi întreruptă şi mutată în starea
gata de către sistemul de operare. Necesită hard special (timer - pentru sincronizare), mecanisme pentru coordonarea accesului la datele partajate, nucleul (de sistem) protejat pentru a proteja integritatea structurilor de date proprii. Majoritatea sistemelor de operare UNIX aşteaptă apeluri sistem pentru a rezolva I/O. În viitor întreruperile vor fi dezactivate. 3.4.3. Planificarea mai multor procesoare
În cazul mai multor procesoare ele trebuie grupate pentru a executa procese astfel: • set eterogen de procesoare: procesele pot fi un set de instrucţiuni specific - poate fi
cazul în calcul distribuit (procesarea distribuită); • set omogen de procesoare: încărcare partajată (sharing).
• coadă separată pentru fiecare procesor; • coadă comună; • multiprocesare asimetrică: procesoare distincte pentru planificare, pentru procesarea intrărilor/ieşirilor şi pentru alte activităţi ale sistemului; • multiprocesare simetrică: fiecare procesor se autoplanifică sau există o structură de tip stăpân-aservit (master-slave).
3.4.4. Monitorizarea unităţii centrale de prelucrare
O unitate centrală de prelucrare care este mult încărcată trebuie să partajeze execuţia ciclurilor între toate procesele şi fiecare proces aşteaptă pentru execuţie într-o coadă. Timpii lungi de aşteptare pentru execuţie pot afecta abilitatea procesului de a oferi timp de răspuns adecvat, aceasta introducând gâtuirea.
Puteţi monitoriza folosirea unităţii centrale de prelucrare prin comanda sar (system activity resourcer) (vezi cap. 3 subcap. „Monitorizarea resurselor interne ale calculatorului”).
Pentru a determina dacă există o gâtuire a unităţii centrale de prelucrare este necesar să monitorizaţi şi lungimea cozii de aşteptare a proceselor pentru execuţie folosind aceeaşi comandă, dar cu altă opţiune.
Această comandă arată şi câte procese sunt în coada de aşteptare pentru execuţie. Pentru comanda vmstat se indică numărul proceselor care nu pot fi executate deoarece
ele aşteaptă discul, terminalul sau operaţii de I/O cu reţeaua. La testele prezentate în lucrare am determinat în ce condiţii apare gâtuirea unităţii
centrale de prelucrare.

128
3.5. Administrarea memoriei Funcţia sistemului de operare dedicată administrării memoriei implică: • alocarea memoriei corespunzătoare la procese; • partejarea memoriei între procesele active; • protecţia memorie pentru ca un proces să nu afecteze zona de memorie a altui proces; • utilizarea procesorului într-un mod eficient funcţie de politica de planificare; • dezvoltarea programelor să nu restricţioneze dimensiunea memoriei; • pentru optimizare în memoria principală trebuie să existe un număr mare de procese.
Administrarea spaţiului de memorie se realizează de către sistemul de operare prin: • paginare (alocare necontinuă): minimizează fragmentarea externă şi simplifică alocarea. Memoria fizică este împărţită în zone de dimensiune fixată. Dimensiunea va determina
gradul de fragmentare internă. Memoria logică este împărţită în blocuri de aceeaşi dimensiune numite pagini. Fiecare
proces are o tabelă a paginilor, iar sistemul de operare menţine o tabelă a paginilor (pentru fiecare pagină liberă sau alocată şi cărui proces). Adresa efectivă este dată de formula:
numărul de pagină + deplasament în pagină
Pentru protecţie sunt asociaţi biţi de protecţie la fiecare pagină (citire, scriere, citire-scriere). Paginarea multinivel este întâlnită în cazul spaţiilor mari de adresă, pentru care tabela
paginilor este mare şi trebuie şi aceasta la rândul ei să fie paginată. • segmentare: (în caz extrem fiecare subrutină are propriul segment). Metoda se bazează pe adresa logică (adică număr de segment şi deplasament în cadrul
segmentului) şi pe tabela segmentelor. Dacă segmentele au lungime variabilă se fragmentează. • segmentare cu paginare: îmbină avantajele celor 2 metode.
3.5.1. Organizarea ierarhică a memoriei
Memoria este organizată ierarhic în următoarele categorii: • registre; • memoria cache; • memorie principală; • memoria cache a discului; • discul; • memorii de stocare externe, eventual reutilizabile (CD-ROM, flash, etc.).
O parte a acestei ierarhizări a fost prezentată şi în subcapitolul “Ierarhia de execuţie a procesului”. 3.5.2. Performanţa memoriei
Dacă o unitate centrală de prelucrare accesează date direct din memorie, mai degrabă decât de la disc, performanţa este ridicată, deoarece accesul la memorie este cu câteva ordine mai rapid decât accesul la disc (viteza memoriei este măsurată în nanosecunde în timp ce viteza discului este măsurată în milisecunde).

129
Creşterea accesului discului în schimbul accesului la memorie reduce performanţa. La achiziţionarea sistemelor, nu economisiţi RAM. În general sistemele sunt subconfigurate (subdimensionate) din punctul de vedere al memoriei RAM pentru a menţine scăzut costul de achiziţie.
Comanda sar cu opţiunea -r va raporta paginile de memorie nefolosite şi spaţiul de salvare (swap) pe disc în pagini de 4 Kocteţi sau blocuri de 512 Kocteţi (vezi cap.3). freemem indică numărul de pagini din RAM care sunt imediat gata de a fi folosite când un proces demarează sau are nevoie de mai multă memorie. O utilizare redusă şi continuă (mai puţin de 6% din memoria instalată) a valorilor freemem poate indica o diminuare a memoriei disponibile şi o gâtuire potenţială. 3.6. Administrarea sistemului de fişiere
Funcţiile administrării fişierelor sunt: • identifică şi localizează fişierul selectat; • foloseşte un director pentru a descrie locaţia fişierelor şi atributele acestora; • pe un sistem partajat descrie controlul accesului utilizatorilor; • blochează accesul la fişiere; • alocă fişierele la blocurile libere; • administrează spaţiul de stocare liber. Directorul este un fişier proprietate a sistemului de operare. Pentru accesul partajat la fişiere pentru a se evita accesul simultan se foloseşte
excluderea mutuală şi blocarea. 3.6.1. Implementarea sistemului de fişiere
Sistemul de fişiere poate avea structura: • secvenţe de octeţi; • secvenţe de înregistrări; • arbore de înregistrări. Cererile I/O de transfer de blocuri trebuie să fie eficiente. Sectoarele discului au în mod uzual o dimensiune de la 32 la 4096 octeţi, iar valoarea 512
este cea mai frecventă. Sistemul de fişiere de pe disc suportă acces direct sau secvenţial, precum şi rescriere în acelaşi loc.
3.6.2. Organizarea sistemului de fişiere
Sistemul de fişiere are o arhitectură stratificată după cum urmează: • control I/O prin driverele dispozitivelor şi întreruperi; • sistemul de fişiere de bază prin comenzi pentru driverele dispozitivelor pentru
poziţionare pe unitate, cilindru, platan, sector; • modul de organizare a datelor în fişiere şi blocuri logice; blocuri fizice translatează
structura logică în structură fizică şi organizează spaţiile goale; • sistemul de fişiere logic folosit pentru protecţie şi securitate. Sistemele de operare UNIX şi MacOS pentru a avea acces la fişiere trebuie întâi să
monteze sistemul de fişiere respectiv.

130
3.6.3. Metode de alocare a spaţiului pentru date
Alocarea poate fi: • alocare continuă - performanţă bună, dar apare fragmentarea; • alocare legată - administrare eficientă, dar cere spaţiu pentru punctatori; slabă
performanţă pentru acces aleator la date. Dacă sistemul de fişiere are organizare sub formă arborescentă, unele din problemele de mai sus se rezolvă;
• alocare indexată - oferă administrarea eficientă a memoriei şi acces cu ajutorul unui index bloc, dar risipeşte spaţiu.
La UNIX se foloseşte o schemă combinată cu index multinivel şi scheme legate şi apare inodul. Pentru performanţe bune se combină metoda contiguă cu alocarea indexată şi în plus
UCP trebuie să aibă viteză la fel şi timpul de acces al discului să fie bun. De aceste aspecte trebuie ţinut seama în alegerea unui disc şi a unui sistem de fişiere.
3.6.4. Probleme ale sistemului de fişiere
Sistemul de operare nu scrie imediat pe disc când un fişier este modificat. Pentru a salva timp el scrie într-un tampon cache care este mult mai rapid.
Sistemul de fişiere este corupt din cauza opririlor/pornirilor improprii sau a erorilor de scriere a NFS sau a problemelor hardware.
Nu opriţi calculatorul direct de la buton. Pornirea incorectă nu va verifica sistemul de fişiere. Problemele hard pot fi blocuri defecte pe harddisc, controlere defecte ale harddiscurilor, fluctuaţii de tensiune, deconectare accidentală de la curent.
Dacă sistemul este întrerupt înainte ca memoria-tampon să fie golită pe harddisc, sistemul de fişiere de pe disc poate fi afectat.
Pentru ca unii utilizatori să nu monopolizeze harddiscul, aceştia pot folosi doar o cotă din capacitatea totală a harddiscului. Spaţiul folosit de un utilizator, grupuri de utilizatori sau aplicaţii poate fi limitat prin cote hard sau soft. Cotele hardware pot afecta negativ performanţa sistemului I/O.
Salvarea transparentă trebuie făcut săptămânal (cel complet) pentru fiecare sistem de fişiere în parte.
Atenţie! Compresia fişierelor în general salvează de la 1/2 până la 2/3 din spaţiul fişierului iniţial. Un fişier compresat este un fişier binar. 3.7. Administrarea dispozitivelor periferice. Statistici pentru sistemul de intrare/ieşire
Sistemul de I/O lucrează cu: • procesele utilizatorilor; • sistemul de fişiere (dispozitive independente de aplicaţie); • drivere; • sistemul de întreruperi; • componente hardware (controlele, driverele discurilor, etc.).
Sistemul de intrare/ieşire este un prim candidat pentru a reprezenta gâtuirea sistemului.
De exemplu, gâtuirea discurilor apare când sistemul nu poate citi şi/sau scrie date pe disc

131
suficient de repede. Aceasta reprezintă o problemă frecventă pe serverele de fişiere care au clienţi care cer date care sunt localizate în diferite locaţii fizice pe discul serverului de fişiere.
Putem verifica dacă discul este supraîncărcat prin comanda iostat. Discurile care sunt ocupate mai mult de 30% şi care au un timp de servire a
intrărilor/ieşirilor (valoare svc_entry din ieşirea comenzii) mai mare de 50 ms sunt considerate lente. Timpul serverului este timpul care se scurge pentru un proces al utilizatorului (de exemplu comanda de citire şi efectuarea completă a citirii).
Tot comenda iostat însumează statistici I/O de când sistemul a fost pentru prima dată butat. Discurile sunt comparate pentru o perioadă de test de 5 secunde pentru a vedea care dintre ele este folosit mult mai mult decât celelalte. Dacă aceasta este situaţia, singura soluţie este transferarea unei părţi din sistemul de fişiere pe alt disc mai puţin încărcat. Dacă discurile încărcate au zone de date de tip swap, creaţi zone suplimentare de swap pe unul sau mai multe discuri din cele mai puţin încărcate.
3.8. Probleme de performanţă pentru resurse
Probleme posibile de performanţă: a) un program particular rulează mai încet; b) totul rulează mai încet într-o perioadă a zilei; c) totul rulează mai încet la intervale imprevizibile; d) tot ce rulează un utilizator individual merge lent; e) un număr de sisteme conectate la reţeaua locală se depreciază în funcţionare simultan; f) totul pentru un serviciu particular sau dispozitiv încetineşte la un moment dat. g) totul rulează mai încet când ne conectăm la distanţă.
Cauze şi soluţii Pentru punctul a) limbajul interpretativ nu este optimizat de către compilator. Pentru punctul b) identificaţi programele care rulează în UCP în perioada respectivă. Pentru punctul c) problemele apar la transmisia de la sisteme independente la sisteme distribuite. Folosiţi statistici de reţea pentru a vă asigura dacă nu există probleme fizice de reţea.
Comanda netstat -v nu raportează erori sau coliziuni în exces pe adaptor. Pentru punctele d) şi e) diferite probleme de software sau firmware pot satura sporadic
reţeaua locală cu difuzare sau alte pachete. Când apar rafale de difuzare, chiar sistemele care nu folosesc în mod activ reţeaua pot fi
încetinite de neîncetatele întreruperi şi de către resursa UCP consumată în recepţia şi procesarea pachetelor. Aceste probleme sunt mai bine detectate şi localizate cu dispozitive de analiza (analizoare) de reţea locală decât cu utilitare de performanţă.
Dacă aveţi 2 reţele locale conectate printr-un sistem (folosind un sistem drept rutor), se consumă mult timp din activitatea UCP pentru a procesa şi copia pachete. Rutoarele hardware dedicate şi punţile reprezintă o soluţie mai robustă, dar cu un cost mai mare.
Accesul la fişiere prin NFS determină un cost considerabil în traficul reţelei locale, în timpul UCP pentru client şi server şi în timpul de răspuns al utilizatorului final.
Pentru punctul f) monitorizaţi performanţa UCP, a memoriei, a volumului fizic şi logic, a sistemului de fişiere, a reţelei.
Pentru punctul g) autentificarea pe un sistem aflat la distanţă are un timp de răspuns mai mare. (vezi capitolul 4)

132
3.9. Administrarea securităţii din perspectiva sistemului de operare
Pentru funcţia de securitate, sistemul de operare: • controlează accesul la fişiere (autorizare); • autentifică utilizatorul (stabileşte identitatea sigură a utilizatorului); • asigură comunicaţii sigure (criptare).
3.10. Criterii pentru alegerea sistemului de operare
Administratorul de reţea are doar obligaţia de a alege cel mai performant sistem de operare pentru reţeaua ce o va administra, ţinând seama în modul de alegere de:
• eficienţă; • robusteţe; • flexibilitate; • portabilitate; • compatibilitate; • facilităţi în utilizare; • să asigure administrarea proceselor; • să asigure administrarea resurselor; • să asigure protecţia şi securitatea resurselor.
Pentru a alege un sistem de operare care planifică eficient procesele trebuie să avem în
vedere următoarele criterii de planificare: • echilibrare: fiecare proces are propria partajare; • eficienţă: eficienţa utilizării unităţii centrale de prelucrare; • viteza de execuţie: numărul de procese/unitatea de timp; • durată de execuţie: timpul consumat cu executarea unui proces de la început până la sfârşit; • timp de aşteptare: timpul total petrecut în coada gata pentru execuţie; • timp de răspuns: cantitatea (medie) de timp pentru care o comandă lansată primeşte
răspunsul.
3.11. Parametrii de performanţă pentru alegerea sistemului de operare
După ce definiţi activităţile pe care sistemul dvs. de calcul le va executa, puteţi alege criteriile de performanţă şi obiectivele de performanţe bazate pe aceste criterii. Parametrii principali de performanţă pentru calculatorul dvs. sunt timpul de răspuns şi viteza de execuţie.
Timpul de răspuns reprezintă timpul scurs între momentul când o cerere este preluată şi până când răspunsul la cerere este returnat.
Exemple de timpi de răspuns: timpul pentru a interoga o bază de date, timpul pentru a accesa o pagină Web, timpul pentru a vedea caracterele apăsate pe ecran. Aceştia variază funcţie de aplicaţia (procesul) rulat de către sistemul de operare. De exemplu, timpul de răspuns variază al protocolului HTTP este 2 RTT + timpul de transmisie (nu şi retransmisie) pentru fiecare obiect (pagini mici). Pentru imagini timpul de răspuns = 3 RTT + timpul de transmisie (cel mai bun).

133
Viteza de execuţie este o măsură a cantităţii de „muncă” care poate fi realizată de-a lungul unor unităţi de timp.
De exemplu, tranzacţii per minut cu baza de date, kiloocteţi transferaţi per secundă dintr-un fişier, kiloocteţi citiţi/scrieţi per secundă dintr-un fişier, accesări per minut la serverul Web.
O performanţă acceptabilă se bazează pe o viteză de execuţie rezonabilă combinată cu un timp de răspuns rezonabil.
În planificarea unui sistem fiţi siguri că aveţi obiective clare atât pentru timpul de răspuns cât şi pentru viteza de execuţie când procesaţi o încărcare specifică.
Algoritmii de evaluare definesc criteriul care trebuie folosit ţinând seama de: utilizarea UCP, timpul de răspuns, viteza de execuţie.
Este de preferat ca să asigurăm tuturor proceselor timpul de execuţie al UCP de care au
nevoie şi să maximizăm utilizarea unităţii centrale de preluare şi a vitezei şi să minimizăm timpul de execuţie, timpul de aşteptare şi timpul de răspuns.
Observaţie: 1. Deoarece serverele pot avea 2 sau mai multe procesoare trebuie ca sistemul de
operare să poată planifica mai multe procesoare. 2. 80% din încărcările UCP trebuie să fie mai mici dacă cuanta de timp.
În prezent sistemele de operare trebuie să poată planifica şi în timp real procesele. Se
folosesc pentru multimedia, grafică interactivă la viteză mare de procesare şi alte tascuri critice. Planificarea în timp real necesită hardware pentru timp real şi rezolvă complet procesul
critic într-un timp garantat (nu poate avea capacitate de stocare secundară sau memorie virtuală). Planificarea politicii şi procesele în timp real au cel mai mare grad de prioritate.
3.12. Aplicaţii pentru comunicaţie
Componentele hardware şi software de reţea nu au capacitatea de a-i permite unui utilizator să folosească efectiv reţeaua. Ele nu fac decât să asigure infrastructura şi mecanismele care permit utilizarea acesteia. Sarcina utilizării efective a reţelei cade în seama programelor specializate, care controlează comunicaţiile.
Acestea se instalează peste sistemul de operare şi reprezintă o interfaţă între sistemul de operare şi protocoale.
Aplicaţiile pentru comunicaţie sau aplicaţiile de comunicaţie implementează protocoalele. Exemple de aplicaţii pentru comunicaţie: aplicaţii pentru transfer informaţie, navigatoarele, motoarele de căutare.
Aplicaţiile de comunicaţie mai pot fi împărţite în aplicaţii cu misiune critică şi aplicaţii fără misiune critică. Aplicaţiile cu misiune critică sunt protejate şi aplicaţiile fără misiune critică sunt administrate.
Exemple de aplicaţii cu misiune critică (lista este deschisă): • web (tip http, https); • transfer de fişier (ftp); • porţi (SMTP, POP, IMAP); • filme video (Real, Quick Time, Windows Media, RTSP, etc.); • video interactiv (H323, SIP, RTP, etc.);

134
• emulare terminal (telnet, ssh); • VPN; • mesagerie (AIM, MSM, etc.). De exemplu, transferul prin ftp este de fapt o aplicaţie din cadrul sistemului de operare,
care permite transferul de fişiere mari fără a folosi discul şi fără a memora în cache tot fişierul, folosind doar /dev/zero ca intrare şi /dev/null ca ieşire.
Aplicaţii fără misiune critică nu sunt blocate de reţeaua locală, dar sunt restricţionate cu privire la cantitatea de lăţimea de bandă din reţeaua externă pe care o poate consuma.
Aplicaţiile fără misiune critică sunt aplicaţii de la egal-la-egal (P2P pear-to-pear) şi permit utilizatorilor să împartă mediul de transmisie al reţelei respectiv în audio, video, documente şi chiar aplicaţii de-a lungul reţelei. Aceste aplicaţii permit utilizatorilor să descarce (upload) fişiere între ei însuşi şi nu sunt dependente de un server centralizat. Exemplu de aplicaţii P2P: DirectConnect, iTunes, Audiogalaxy, etc. şi jocurile.
În perioada de vârf de utilizare (dimineaţa şi după-amiaza), aplicaţiile fără misiune critică se porduc cu timp redus. Volumul traficului P2P poate consuma aproape toată capacitatea Internet disponibilă dacă nu sunt administrate.
Când acest volum atinge capacitatea maximă care a fost definită pentru politici QoS fără misiune critică, viteza de transfer va începe să se diminueze şi să devină imprevizibilă. 3.12.1. Clasificarea aplicaţiilor de comunicaţie
Infrastructura reţelelor actuale oferă aplicaţii de comunicaţie precum: • aplicaţii utilizator-la-utitlizator; • aplicaţii utilizator-la-server de informaţii; • aplicaţii în timp real; • aplicaţii de mesagerie; • aplicaţii de la egal-la-egal (între terminale pereche); • aplicaţii client-server (între terminalul clientului şi server).
În continuare, vor fi prezentate câteva măsurători pentru aplicaţiile de comunicaţie şi un
exemplu particular de aplicaţie de comunicaţie. 3.13. Măsurători pentru aplicaţiile de reţea 3.13.1. Studiu de caz pentru aplicaţii de mesagerie: Poşta electronică
Măsurătorile cu privire la frecvenţa utilizării poştei analizează: a) procentul celor mai frecvenţi utilizatori de poştă; b) procentul celor mai puţin frecvenţi utilizatori de poştă. a) Sunt utilizatorii care trimit şi/sau primesc un număr predeterminat de mesaje într-un interval de timp. b) Sunt utilizatorii care trimit şi/sau recepţionează un număr predeterminat de mesaje sau mai puţin în acelaşi interval de timp. Se poate alege un număr de mesaje, de exemplu, 50 sau mai multe pentru utilizatorii frecvenţi şi mai puţin de 50 pentru utilizatorii mai puţin frecvenţi. Această valoare depinde de la un caz de reţea la altul de numărul mediu de mesaje trimise şi recepţionate de o persoană.

135
Următoarele formule calculează valorile ce vor fi analizate: • numărul utilizatorilor frecvenţi de reţea împărţit la numărul utilizatorilor de reţea; • numărul de utilizatori mai puţin frecvenţi împărţit la numărul utilizatorilor de reţea. Analizăm numărul utilizatorilor de reţea comparativ numărului utilizatorilor de poştă. În general toţi utilizatorii care au un cont au dreptul să-l folosească şi pentru poştă. În general, reţelele au un server central care poate analiza traficul de poştă sau poate exista un server special dedicat pentru acest serviciu. Alegem o perioadă de teste de 2 săptămâni, iar în această perioadă alegem eşantioane de 3 zile. Repetăm testele de 2 sau 3 ori pe an pentru a observa tendinţele. Alte informaţii adiţionale pot fi incluse în test, precum: • cât timp a fost poşta accesată; • numărul de mesaje trimise şi recepţionate; • tipul mesajelor (personale, de servici, etc.). Instalaţi o aplicaţie de administrare care monitorizează traficul de poştă la serverul central şi dacă se doreşte la fiecare server distribuit. Unele servere de poştă menţin automat tranzacţiile de conectare (la contul de poştă). Aplicaţia trebuie să numere de câte ori fiecare utilizator (sau grup de utilizatori) a trimis şi/sau recepţionat mesaje de poştă în perioada de testare. Dacă se foloseşte activitatea de conectare la cont, utilizatorii pot fi împărţiţi pe zone de lucru (departamente). Se calculează numărul celor mai frecvenţi utilizatori, respectiv al celor mai puţin frecvenţi pentru fiecare categorie de utilizatori. Aceste date ne ajută să evaluăm distribuţia utilizatorilor pentru a-i putea include în fiecare grup. Dacă 75% din totalul datelor sunt utilizatori frecvenţi, pentru evaluare trebuie redefinite criteriile care trebuie luate în considerare în analiză pentru respectiva reţea. Cunoscând numărul de utilizatori frecvenţi şi mai puţin frecvenţi putem dezvolta reţeaua folosind ca linie de bază (baseline) numărul de utilizatori frecvenţi.
Acest număr trebuie actualizat şi poate fi folosit şi pentru împărţirea utilizatorilor pe categorii. Folosirea unui e-mail directory (pentru reţea) poate fi calea cea mai bună de identificare a utilizatorilor comparativ cu celelalte 2 modalităţi. O altă mărime interesantă este raportul între numărul de mesaje de poştă trimise de către utilizatori reţelei şi numărul de mesaje de poştă recepţionate în timpul aceleiaşi perioade de timp. O astfel de măsură oferă un indicator extern pentru reţea cu privire la gradul în care poşta de la utilizatori din afara reţelei afectează încărcarea în întregime a traficului. 3.13.2. Măsurători pentru managementul aplicaţiilor de reţea Se vor analiza: • numărul de aplicaţii active; • utilizarea aplicaţiilor de către un grup de utilizatori specific. Acestea analiză arată cât de des sunt folosite aplicaţiile specifice într-o perioadă dată de timp. Aplicaţiile pot fi disponibile pentru utilizatori pe calculatoarele de birou individuale de la un server prin reţeaua locală. Tipul de aplicaţie de care are serverul nevoie pentru a contoriza aplicaţiile folosite şi pentru a le ordona într-un top depinde de sistemul de operare care

136
controlează serverul. Dar, mulţi utilizatori primesc aplicaţiile de pe mai multe servere sau supercalculatoare şi în acest caz este dificil să obţinem cu acurateţe numărul de aplicaţii folosite în întreaga reţea. Totuşi, pentru contorizare se aplică 2 metode:
• software pentru măsurarea aplicaţiilor; • activitatea de conectare a utilizatorilor. Posibilitatea serverului sau supercalculatorului să ruleze un program care să contorizeze
numărul de utilizări a aplicaţiilor (topul), depinde de mulţi factori de configurare a reţelei. Determinaţi care servere/mainframe-uri oferă acces la aceste aplicaţii. Determinaţi ce sisteme de operare se găsesc pe aceste servere. Alegeţi o perioadă de test care să fie o perioadă tipică de folosire a reţelei.
Notă: Această metodă nu poate măsura ce aplicaţii folosesc utilizatorii de pe harddiscurile locale şi nu poate să măsoare utilizarea tuturor aplicaţiilor disponibile în reţea, ci doar de pe serverele pe care este instalat programul.
Programul nu poate face distincţie între cine utilizează aplicaţia sau câţi utilizatori diferiţi folosesc aplicaţia, dar poate spune cât timp a fost utilizată aplicaţia. Atenţie! Rularea programului de monitorizare a aplicaţiilor poate reduce performanţa pe server! 3.13.3. Monitorizare prin acces distribuit la aplicaţii
Deoarece arhitectura majorităţii reţelelor LAN este distribuită, aceleaşi aplicaţii pot fi rezidente pe mai multe servere diferite din reţea.
Plasând astfel de programe în toate serverele care oferă aplicaţiile în discuţie putem cere o cooperare a unităţilor de calcul distribuit care controlează aceste servere.
Selectaţi serverele de analizat. O metodă poate fi doar măsurarea cererii de aplicaţii de pe serverele care servesc
clusterele publice. Altă metodă ar fi selectarea aleatoare a unui număr dat de servere din reţea sau
selectarea câtorva servere din cele mai importante categorii de servere şi apoi măsurarea aplicaţiilor cerute de acestea.
Pot fi chestionaţi şi utilizatorii conectaţi în legătură cu ce aplicaţii folosesc în perioada de timp de test pentru cât timp folosesc aplicaţia şi în ce scop (cercetare, învăţare, etc.). Trebuie selectat un grup de utilizatori care au un spectru larg de activităţi.
Odată obţinute datele, acestea pot fi analizate pentru calcularea numărului de câte ori o aplicaţie particulară este folosită în perioada de timp de către un utilizator. Apoi stabilesc de câte ori pe zi au fost cerute aplicaţiile respective.
De aceea, prima metodă de testare (program de administrare a sistemului) oferă informaţii cantitative cu privire la numărul total de utilizări a aplicaţiei (topul aplicaţiilor) pentru o perioadă de timp stabilită, în timp ce a 2-a metodă de testare al unei utilizari (conectarea utilizatorilor) putem obţine informaţii cu privire la numărul de aplicaţii folosite pe categorii de utilizatori, pe ce durată de timp şi scopul folosirii aplicaţiei respective.
Aceste rezultate combinate cu opiniile şi percepţiile utilizatorilor cu privire la importanţa aplicaţiilor ne dau informaţii despre aplicaţiile din reţea şi ce ar trebui sporit ca număr de licenţe sau în sens contrar. Dacă este necesară creşterea numărului de licenţe, performanţa reţelei sporeşte, deoarece numărul de cerinţe de utilizare a unei aplicaţii nu este subdimensionat. Putem

137
alcătui un top cu aplicaţiile pe care utilizatorii le consideră cele mai importante pentru activităţile desfăşurate de aceştia.
Aceste 2 abordări (cantitative şi calitative) oferă sprijin în planificarea căror aplicaţii să fie oferite în viitor. 3.13.4. Măsurători pentru folosirea clusterelor sau site-urilor publice pentru a accesa reţeaua
Se vor analiza: a) raportul utilizatorilor reţelei de la terminale publice; b) frecvenţa ocupării de către site-urile publice. a) cluster public (grup public) este definit ca o locaţie creată pentru folosire publică a
reţelei de către utilizatori care au acces autorizat folosind identificatorul şi parola. Aceştia pot fi chiar utilizatori ai reţelei.
Aceste terminale tip cluster public oferă acces la aplicaţii ca poştă, Internet, procesare de text, baze de date, aplicaţii diverse, etc.
Măsurătorile sunt utile pentru reţelele care oferă un astfel de acces pentru o utilizare de bază şi pentru statistici ale utilizării per terminal pentru a determina tendinţele şi a cunoaşte actuala utilizare. Pentru analiză trebuie obţinut numărul de utilizatori ai reţelei şi numărul de utilizatori activi ai reţelei. Trebuie obţinut şi numărul de clustere publice şi numărul de terminale sau staţii de lucru ale fiecărui cluster. Pentru fiecare cluster obţinem un grafic al orelor de operare în timpul unei săptămâni. În cele mai multe cazuri fiecare cluster are un supervizor în timpul orelor de operare. Aceastei persoane poate să i se dea responsabilitatea de menţinere a conectărilor manuale a staţiilor de lucru în perioada de test (de preferinţă 2 spătămâni). Se verifică ocuparea staţiei de lucru la intervale de 30 de minute. Această perioadă de teste trebuie să fie aceeaşi pentru toate clusterele. Dacă nu este posibilă monitorizarea, alternativa înregistrării ocupării este folosirea semnalului IN şi OUT al conectării (adică login, logout). Pentru fiecare cluster procentul de ocupare poate fi calculat la fiecare 30 minute în timpul perioadei de test. Statisticile ocupării pot fi prezentate grafic pentru fiecare cluster şi pentru toate clusterele. Extinderea clusterelor publice este direct legată de planurile pentru accesul individual la reţea. 3.13.5. Măsurători pentru acces la Internet prin servere partajate
Se vor analiza: • numărul de accesări prin furnizorii de servicii; • numărul de accesări prin conexiune telefonică.
Aceasta măsoară predicţiile pentru ca aplicaţiile de administrare ale sistemului de operare al serverului să permită cererea accesului pentru o colecţie de adrese IP ale calculatoarelor care cer accesul.
Serverele bazate pe UNIX păstrează un fişier de conectare (log file) pentru fiecare activitate.

138
Pot fi create fişiere batch ale tuturor adreselor IP care accesează serverul partajat. Un program de administrare poate grupa după adresa IP, dacă aceasta este din reţea, dacă sunt de la furnizori de servicii Internet sau dacă sunt adrese IP temporare atribuite prin conectare telefonică.
Poate fi contactat furnizorul de servicii (local) pentru a şti dacă aceştia oferă un cont pentru un număr de conexiune sau număr de utilizatori, accesând adresa IP a respectivei reţele testate prin serviciile lor.
Majoritatea sistemelor de operare includ aplicaţii de administrare care înregistrează adresa IP a calculatoarelor care cer acces la el.
Aceste adrese trebuie sortate după: • acces prin furnizorii de servicii Internet; • acces prin conexiune telefonică; • acces din respectiva reţea. Cu aceste date se determină 2 rapoarte folosind formulele:
acces la serverul partajat prin furnizorul de servicii
acces furnizor = -------------------------------------------------------------------------- accesul total la serverul partajat
acces la serverul partajat prin conexiune telefonică acces telefon = --------------------------------------------------------------------------
accesul total la serverul partajat Folosind aceste 2 rapoarte putem observa în timp câţi utilizatori accesează informaţii sau servicii de pe serverul partajat.
Un alt raport care se calculează este:
numărul total de conexiuni de la distanţă conx = -----------------------------------------------------------
numărul total de conexiuni
Prin scădere din 100 % obţinem procentul conexiunilor care nu sunt de la distanţă. 3.13.6. Măsurarea performanţei LAN în cazul adăugării de noi aplicaţii
Performanţa LAN cere modele sofisticate de analiză şi unelte de simulare. Acestea sunt în general fie prea complexe, fie prea costisitoare.
Formula prezentată poate fi folosită pentru proiectarea unui nou LAN sau pentru estimarea performanţelor rezultate din adăugarea unei noi aplicaţii într-un LAN existent.
Formula are la bază cei mai esenţiali parametrii de performanţă: • viteza de transmisie a reţelei LAN; • capacitatea totală cerută, ca medie de-a lungul unei perioade stabilite; • maximul vitezei minime de transfer cerută pe aplicaţie (viteza cea mai mică de transfer
cerută pe aplicaţie). Se poate aplica pentru probleme de lăţimea de bandă disponibilă cum ar fi:

139
• Pot transmite un fişier de n Mocteţi în x secunde prin Ethernet care operează cu o încărcare medie de t Mo pe secundă ?
• Câţi utilizatori pot partaja acelaşi segment LAN dacă ei au de transmis fişiere de n Mo în x secunde şi generează o încărcarea medie de t Mo pe secundă ?
VLAN ≥ Cc + V Cm = VLAN - V sau VM = VLAN - Cc unde VLAN = viteza de transfer a reţelei LAN Cc = capacitatea medie cerută V = viteza de transfer minimă cerută Cm = capacitatea medie disponibilă VM = cea mai mare viteză de transfer disponibilă La stabilirea acestor formule s-a pornit de la ideea că viteza maximă la care o cantitate
sigură de date poate fi transmisă prin LAN este în medie egală cu diferenţa dintre capacitatea totală a reţelei şi media capacităţii folosite de celelalte segmente. Cu alte cuvinte la un moment dat o cantitate de date dată poate fi transmisă la o viteză minimă Vm, capacitatea disponibilă pentru alte staţii va fi egală cu diferenţa între capacitatea totală netă a reţelei CLAN şi Vm.
Ca = CLAN - Vm, unde Ca = capacitatea disponibilă pentru alţi utilizatori Folosind modelare matematică, reţeaua poate fi privită ca un sistem cu cozi de aşteptare
cu disturbări (terminalele generează trafic în rafală şi nu doar unul singur influenţează încărcarea medie) şi model închis cu cozi de aşteptare a unui sistem de divizare a cuantei, dacă staţiile au aceeaşi încărcare. 3.13.7. Efectele resurselor hardware asupra aplicaţiilor Lăţimea de bandă disponibilă şi latenţa au efecte diferite asupra aplicaţiilor de reţea. Lăţimea de bandă disponibilă va afecta aplicaţiile care cer acces susţinut la mari cantităţi de lăţime de bandă, precum FTP-ul. O lăţime de bandă disponibilă mică creşte timpul pe care fiecare aplicaţie îl foloseşte pentru a se executa. Latenţa are un mare impact asupra aplicaţiilor în timp real precum VoIP sau streaming video, iar creşterea sa va reduce calitatea şi utilizabilitatea acestor servicii.
Rutorul coloanei vertebrale are efecte dramatice pentru lăţimea de bandă FTP disponibilă. 3.14. Protocoale de comunicaţie Definiţie
Protocolul este definit ca un set de reguli şi convenţii cu ajutorul cărora este guvernat schimbul de informaţii între echipamentele unei reţele.
Protocoalele de reţea sunt standarde ce permit calculatoarelor să comunice între ele. Un protocol este o descriere formală a unui set de reguli şi convenţii care guvernează un
aspect particular despre cum componentele de reţea comunică între ele. Protocoalele determină formatul, secvenţa de timp şi controlul erorilor în comunicaţii. Protocoalele controlează toate aspectele comunicării de date, care includ următoarele:

140
• cum este construită reţeaua fizică; • cum se conectează calculatoarele la reţea; • cum sunt formatate şi transmise datele; • cum sunt propagate datele; • cum sunt interpretate erorile.
Aceste reguli ale reţelei sunt create şi intreţinute de mai multe organizaţii şi comitete internaţionale: IEEE, ANSI, EIA, TIA şi ITU.
Pot exista mai multe protocoale diferite în aceleaşi mediu de lucru. TCP/IP (pentru UNIX, Windows NT, Windows 95), IPX (pentru Novell Net Ware), DECnet (pentu retele Digital Equipment Corp.), AppleTalk (pentru calculatoare Macintosh) şi NetBIOS/NetBEUI (reţele Windows NT) sunt principalele tipuri de protocoale de reţea folosite azi.
Protocolul, prin ansamblul de convenţii stabilite, ajută la cooperarea mai multor entităţi în
realizarea unei activităţi. Acestea acţionează la mai multe niveluri. Un nivel cuprinde un ansamblu de funcţii, care, la cererea utilizatorilor, realizează servicii. Serviciul reprezintă un ansamblu de primitive (operaţii), pe care un nivel îl furnizează nivelului superior.
Ansamblul de niveluri şi protocoale poartă numele de arhitectura reţelei. Stiva de protocoale Internet cuprinde: • nivelul aplicaţie: suportă aplicaţii de reţea folosind protocoalele FTP, SMTP, HTTP; • nivelul transport: transferă datele de la calculator la calculator folosind protocoalele
TCP, UDP; • nivelul reţea: rutează datagramele de la sursă la destinaţie folosind protocolul IP şi alte
protocoale de rutare; • nivelul legătură de date: transferă date între elementele vecine de reţea folosind
Ethernet, PPP. Protocolul PPP (Point - to - Point Protocol) este folosit pentru a crea o conexiune cu providerul Internet prin (via) modem.
• nivelul fizic: reprezintă biţii pe fir. Nivelul reţea fiind un nivel unde se decide direcţia în care merge informaţia are următoarele funcţii de bază:
• determinarea căii: ruta aleasă de pachete de la sursă la destinaţie folosind algoritmi de rutare; • retransmisia: deplasarea pachetelor de la intrarea rutorului la cea mai apropiată ieşire (output) a rutorului; • setarea apelului: numeroase arhitecturi de reţea solicită setări ale apelului (cale) rutorului de-a lungul căii înainte de a trimite date (flux de date).
3.14.1. Modelul TCP/IP pentru arhitectura inter-reţelelor de calculatoare
O reţea universală, bazată pe o unică tehnologie hardware, este imposibil de construit, căci nici un tip de reţea de calculatoare nu ar putea satisface toate necesităţile tuturor utilizatorilor.

141
De la începutul anilor 1980 a apărut o nouă tehnologie care a dat posibilitatea conectării unor reţele realizate fizic diferit, făcându-le să funcţioneze ca o unitate coordonată. Această tehnologie, numită interconectare (internetworking), permite adaptarea a numeroase şi diferite tehnologii hardware, oferind o modalitate de interconectare a unor reţele eterogene şi stabilirea unei mulţimi coerente şi nu prea numeroase de convenţii de comunicare.
TCP/IP reprezintă de fapt este o denumire colocvială pentru mai mult de 100 de protocoale diferite, dar care au fost înglobate sub aceeaşi denumire. TCP/IP are două niveluri cu acelaşi nume ca la modelul OSI (nivelul fizic şi nivelul reţea) şi nu trebuie confundate cu acelea pentru că fiecare nivel are funcţii total diferite. Ca utilizatori finali avem de a face numai cu nivelul aplicaţie, dar cunoaşterea detaliată a nivelurilor este vitală pentru realizarea unei reţele.
Din punct de vedere al datelor acestea poartă denumiri diferite funcţie de nivel.
Denumire nivel Denumire date Nivelul aplicaţie datele sunt împărţite în mesaje sau fluxuri de octeţi Nivelul transport datele sunt împărţite în pachete Nivelul reţea datele sunt împărţite în datagrame Nivelul interfaţă la reţea datele sunt împărţite în cadre Nivelul fizic datele sunt împărţite în şiruri de biţi
Nivelul reţea utilizează algoritmul de dirijare pentru a determina dacă să livreze
datagrama direct sau să o trimită unui ruter şi pasează datagrama interfeţei de reţea corespunzătoare pentru a fi transmisă.
Pentru dezvoltatorii de soft, modelul TCP/IP oferă flexibilitate maximă prin nivelul aplicaţie. Pentru TCP/IP fiabilitatea este o problemă între utilizatorii finali. Sistemul de operare conţine protocoalele TCP/IP, acestea fiind rulate automat de
aplicaţiile care folosesc reţeaua Internetul. 3.14.2. Avantaje TCP/IP Avantajele arhitecturii TCP/IP sunt: • independenţa de platformă. Protocolul TCP/IP nu a fost conceput pentru utilizarea într-un mediu destinat unui anumit tip de hardware sau software. De aceea este utilizat în reţele de toate tipurile.
• adresare absolută. TCP/IP asigură modalitatea de identificare în mod unic a fiecarei maşini din Intemet
• standarde deschise. Specificaţiile TCP/IP sunt disponibile în mod public utilizatorilor şi dezvoltatorilor. În continuare sunt exemplificate 2 protocale folosite în comunicaţia din reţele. Marea majoritate a protocoalelor de comunicaţie TCP/IP au fost prezentate în referatul autoarei “Analiza comparativă a modelului OSI şi TCP/IP” dat la bibliografie.

142
3.14.3. Exemple de protocoale din modelul TCP/IP Protocolul ARP
Protocolul ARP (Address Resolution Protocol) este un protocol folosit pentru a mapa adresele IP v4 pe 32 biţi în adresă de 48 biţi a adaptorului calculatorului gazdă cerută de către protocolul legăturii de date. ARP este manevrat în mod transparent de către sistem. Sistemul menţine un cache pentru ARP, care este un tabel cu adrese IP pe 32 biţi şi adresele corespunzătoare calculatoarelor gazdă pe 48 de biţi.
Pachetele TCP şi UDP aşteaptă la coadă în timp ce protocolul ARP schimbă aceste informaţii. În cazul în care coada de aşteptare ARP de ieşire poate fi supraîncărcată, aceasta poate cauza pierderea pachetelor. Aceste tabele se construiesc la pornire (butare) sau în timpul încărcării TCP/IP.
Comanda netstat -p arp afişează statistici ARP, care arată câte cereri ARP au fost trimise şi câte pachete au fost scoase din tabel când o intrare este ştearsă pentru a face loc alteia. Protocol RPC (Remote Procedure Call)
RPC este o bibliotecă de proceduri. Procedurile permit unui proces (proces server) să conducă alt proces (proces client) pentru a executa apeluri de procedură ca şi cum procesul client ar executa apeluri în propriul spaţiu de adrese. Deoarece clientul şi serverul sunt 2 procese separate, nu este necesar ca ele să existe pe acelaşi sistem fizic (deşi ar putea).
Fiecare aplicaţie RPC a fost asociată cu un număr de program şi un număr de versiune. Aceste numele sunt folosite pentru a comunica cu o aplicaţie/serverul de aplicaţie de pe serverul din sistem. Clientul, când face o cerere la server, este necesar să cunoască numărul de port prin care serverul îi acceptă cererea. Acest număr de port este asociat cu protocolul UDP sau TCP care va fi folosit de serviciu.
Portul logic este un număr pe 16 biţi care identifică în mod unic procesele care rulează pe un anumit calculator care are o singură adresă IP pentru toate procesele din calculator. Orice aplicaţie care realizează o conexiune în reţea va trebui să ataşeze un număr de port acelei conexiuni.
Clientul cunoaşte numărul programului, numărul versiunii şi numărul calculatorului şi numele sistemului sau numele calculatorului gazdă unde rezidă serviciul. 3.15. Protocoale de rutare 3.15.1. Rutarea. Algoritmi de rutare.
Drumul ales de un pachet de la sursă la destinaţie poartă denumirea de rută (route). Operaţia de alegere a unei căi pentru un pachet se numeşte rutare (routing). Un ruter este, în general, un calculator conectat simultan la mai multe reţele. Adresele în Intemet sunt ierarhice. Asta înseamnă că o adresă dă şi o oarecare indicaţie
despre traseul care trebuie urmat pînă la acea adresă. Rutarea statică este configurată de către administratorul de reţea şi nu se pot face
modificări în reţea fără intervenţia administratorului. La rutarea dinamică modificările circumstanţelor reţelei se fac prin analiza datelor din mesajele de rutare fără intervenţia administratorului.

143
3.15.2. Clasificarea algoritmilor de rutare
Clasificarea algoritmilor de rutare se poate face după: • tip: static saudinamic; • cale: cale unică sau căi multiple;
• structură: plană sau ierarhică; • locul algoritmului: la nivel de calculator gazdă saula nivel de rutor; • informaţia analizată: starea legăturii sau vector-distanţă; • domeniu: domeniu intern saudomeniu extern. Administratorul de reţea trebuie să studieze criteriile ce analizează fiecare tip de algoritm
de rutare pentru a cunoaşte ce algoritm de rutare să aplice şi ce protocol de rutare foloseşte respectivul algoritm de rutare. 3.15.3. Metrici de rutare Metricile folosite pentru rutare:
• lungimea căii; • fiabilitatea/siguranţa algoritmului de rutare; • întârzierea de rutare; • lăţimea de bandă (capacitatea disponibilă); • încărcarea de trafic disponibilă pe o legătură; • costul comunicării.
3.15.4. Tabelele de rutare
Când se doreşte comunicarea cu un calculator care nu este conectat în aceeaşi reţea locală, pachetul va trebui să treacă prin mai multe gateway-uri pînă la destinaţie. Informatia de acest gen este menţinută de nivelul IP într-o tabelă de rutare. Această tabelă descrie pentru fiecare grup de adrese interfaţa care trebuie folosită pentru a ajunge la ele şi primul ruter căruia datele trebuie să-i fie trimise următorul salt (next hop). Tabela de rutare cuprinde informaţii utilizate de către software-ul de comutare pentru a selecta calea cea mai bună.
Cum arată tabela de rutare şi de unde vin informaţiîle din ea depinde de importanţa ruterului (rutere mici sau rutere de coloană vertebrală – vezi în capitolul 2). 3.15.5. Protocoale de rutare
Protocoalele de rutare pot fi: • protocoale interne - fac schimb de informaţii între ruterele din acelaşi sistem autonom.
Din această categorie fac parte: ■ IGRP (Interior Gateway Routing Protocol) - este un protocol de rutare bazat pe vectorul de distanţă, proprietate CISCO. A fost creat pentru a elimina limitările RIP în reţelele mari. Metrica include: lărgimea de bandă, încărcarea, întârzierile, fiabilitatea. Numărul maxim de hop-uri: 255. ■ EIGRP (Enhanced Interior Gateway Routing Protocol) - tot proprietate CISCO, utilizează "starea legăturii". Datele colectate sunt memorate în trei tabele:

144
♦ tabela vecinilor - stochează informaţii despre interfeţele dispozitivelor direct conectate; ♦ tabela topologiilor - memorează graful aferent topologiei reţelei (este componenta "starea legăturii"); ♦ tabela de rutare – memorează calea cea mai scurtă (shortest path) la toate reţelelede destinaţie (componenta "vectorul distanţă"). ■ OSPF (Open Shortest Path First) – bayat pe starea legăturii şi utilizează cunoscutul algoritm (pentru rutare) Dijkstra pentru calculul arborelui căilor cele mai scurte.Utilizează ca metrică costul. Este succesorul lui RIP pe Intemet şi baza de date "link state" este construită pentru topologia reţelei, care este identică pentru toate destinaţiile. OSPFv3 suportă Ipv6 ■ RIP (Routing Internet Protocol) - este unul dintre cele mai răspândite protocoale IGP în reţele interne şi mai puţin pe Intemet. Asigură schimbul de informaţii de rutare, astfel încât ruterele să-şi poată modifica dinamic informaţiile despre conexiunile la reţele - care reţea poate fi accesată, de care ruter şi cât de departe este (numărul de hop-uri). Deşi este încă activ, este considerat depăşit de către protocoalele "link state": OSPF şi EIGRP. RIP, dezvoltat în 1969, ca parte a ARPANET, utilizează algoritmul bazat pe "vectorul distanţă". Metrica utilizată: numărul de hop-uri (numărul maxim permis: 15). Fiecare ruter RIP transmite la fiecare 30 sec (valoare implicită) toate informaţiile de actualizare, deci generează un volum mare de trafic. Rulează deasupra nivelului de reţea şi utilizează UDP portul 520 pentru a-şi transmite datele. Există RIPvl şi RIPv2 (1994) - ambele utilizează rutarea pe baza adreselor IP, dar RIPv2 proiectat pentru CIDR, îşi menţine compatibilitatea cu RIPvl.
• protocoale externe - lucrează între ruterele din diferite sisteme autonome. Cele mai cunoscute sunt:
■ EGP (External Gateway Protocol), care era utilizat pentru conectarea coloanei vertebrale a Intemetului, declarat acum depăşit şi treptat înlocuit cu BGP; ■ BGP (Border Gateway Protocol) - BGPv4 (2002). El menţine tabelele de adrese de reţele IP sau „prefixe", care definesc reţelele ce pot fi accesate între sistemele autonome. Este un protocol ce utilizează algoritmul bazat pe „vector de distanţă". Suportă CIDR şi utilizează agregarea rutelor pentru scăderea dimensiunii tabelelor de rutare. BGP asigură rutarea descentralizată pentru ca Internetul să devină sistem descentralizat.
Explicaţie
Protocoale de rutare bazate pe vectorul distanţă (Distance-Vector Routing Protocols)
Acest tip de protocoale cere ca fiecare ruter pur şi simplu să-şi informeze vecinii despre tabela sa de rutare. Pentru fiecare cale de rutare, ruterele receptoare captează informaţia de la vecin la costul cel mai mic şi adaugă această intrare propriei tabele de rutare, pentru re-avertizare. Hello şi RIP sunt protocoalele de rutare cele mai uzuale, care folosesc rutarea pe baza vectorului de distanţă.

145
Protocoale de rutare bazate pe starea legăturii (Link State Routing Protocols)
Acest tip de protocoale cere ca fiecare ruter să întreţină cel puţin o hartă (graf) parţială a reţelei. Când legătura (conexiunea) la o reţea îşi schimbă starea (up to down, or vice versa), reţeaua este „inundată" cu o notificare, denumită LSA (link state advertisement). Toate ruterele iau act de modificare şi-şi reconstruiesc rutele corespunzător. Această metodă este mult mai fiabilă mai uşor de depanat şi mai puţin consumatoare de lărgime de bandă decât în protocoalele bazate pe vectori de distanţă. De asemenea, este mult mai complexă şi consumă mai multă memorie şi calcule. De exemplu, OSPF este un protocol de rutare pe bază de starea legăturii. 3.15.6. Metrici folosite pentru evaluarea performanţei protocoalelor de rutare
Pentru evaluarea performanţelor protocoalelor de rutare se analizează următoarele metrici:
• rutare încărcată (peste limită); Numită şi suprasarcina rutării, reprezintă numărul total de pachete rutate transmise în
timpul testelor pentru măsurarea scalarităţii protocolului. Controlul pachetelor nu consumă o mare cantitate de lăţime de bandă, dar pot interfera în
mare măsură cu transmisia. Rutarea încărcată se exprimă în octeţi şi număr de pachete. • numărul de abateri de la calea optimă; Acest număr reprezintă diferenţa între numărul de salturi pe calea cea mai scurtă şi pe
calea stabilită de rutare pe care circulă de fapt pachetele şi se măsoară în număr de salturi (hopuri). • puterea medie disipată; Această mărime indică implicit puterea de utilizare a protocolului şi se exprimă în Joule. • pachete livrate cu succes sau rata de pierdere a pachetelor; Reprezintă raportul:
numărul de pachete transmise de la sursă pachete livrate cu succes = ----------------------------------------------------------------- numărul de pachete recepţionate la destinaţie
Această mărime se exprimă în procente. • lăţimea de bandă disponibilă; Această mărime reprezintă cantitatea de date transmise cu succes pe secundă în reţea şi
se exprimă în Kocteţi/sec. • întârzierea medie a reţelei; Este întârzierea medie cap-la-cap a părţilor care comunică şi se exprimă în milisecunde.
3.16. Comenzi pentru administrarea reţelei, a componentelor sale, precum şi a performanţei reţelei
Comenzile de sistem pot măsura statistici de reţea şi să prezinte informaţii variate. În continuare este prezentat modul în care le folosim pentru administrarea reţelei şi cum interpretăm statisticile de reţea generate de acestea. Statisticile oferite trebuie interpretate cunoscând configuraţia reţelei şi aplicaţiile ce rulează.
Aceste comenzi fac parte din sistemul de operare şi marea majoritate a acestora sunt comune mai multor sistemele de operare. Ele se pot utiliza pentru administrarea zilnică a reţelei.

146
Cele mai uzuale vor fi prezentate în continuare detaliat. Sunt comenzi care în funcţie de opţiune oferă informaţii variate care pot aduce precizări în problemele de funcţionare ale reţelei, acestea fiind mai uşor de administrat.
În afara comenzilor de monitirizare care aparţin sistemului de operare, există posibilitatea de monitorizare a reţelei prin Java. Cele mai importante unelte Java pentru monitorizarea şi identificarea problemelor de performanţă care se pot folosi în aplicaţiile Java sunt:
vmstat - oferă informaţii despre câteva resurse ale sistemului. Raportează statistici despre utilizarea memoriei, spaţiul de paginare, I/O pe disc, întreruperile, apelurile sistem, activitatea unităţii centrale de prelucrare.
iostat raportează informaţii detaliate despre I/O pe disc topas - raportează activitatea unităţii centrale de prelucrare a reţelei, I/O pe disc şi a
procesului. Desigur există şi utilitare pentru monitorizarea reţelei, dar lucrarea nu prezintă varianta
comercială a administrării reţelei.
3.17. Monitorizarea resurselor interne ale calculatorului şi a performanţelor acestora 3.17.1. Monitorizarea procesorului, a memoriei, a discului şi a sistemului de fişiere şi interpretarea statisticilor obţinute
Comanda sar oferă informaţii de performanţă şi se foloseşte pentru a determina utilizarea UCP şi gâtuirile.
# sar -q 5 3 19:31:42 runq-sz %runocc swpq-sz %swpocc 19:31:47 1.0 100 1.0 100 19:31:52 2.0 100 1.0 100 19:31:57 1.0 100 1.0 100 Average 1.3 95 1.0 95
În exemplu de mai sus variabila runq-sz (numărul de stări curente ale procesului în
memorie aşteptând execuţia) nu trebuie să fie mai mare de 4 pentru o unitate centrală de prelucrare. În mod consistent, caz contrar aceasta indică o gâtuire a unităţii centrale de prelucrare.
Dacă totuşi sistemul funcţionează lent şi asta nu se datorează unităţii centrale de prelucrare trebuie examinate ale componente (subsistemele).
Utilitarul cel mai bun pentru o privire de ansamblu a utilizării resurselor când rulează lucrări ale mai multor utilizatori este comanda vmstat. Aceasta raportează activitatea UCP, a I/O, cum folosesc datele memoria şi paginarea. Ieşirea comenzii # vmstat 5 pentru o perioad• de test de 5 secunde este următoarea: kthr memory page faults UCP ----- ----------- ------------------------ ------------ ----------- r b avm fre re pi po fr sr cy in sy cs us sy id wa 0 0 8793 81 0 0 0 1 7 0 125 42 30 1 2 95 2 0 0 8793 80 0 0 0 0 0 0 155 113 79 14 8 78 0 0 0 8793 57 0 3 0 0 0 0 178 28 69 1 12 81 6 0 0 9192 66 0 0 16 81 167 0 151 32 34 1 6 77 16 0 0 9193 65 0 0 0 0 0 0 117 29 26 1 3 96 0 0 0 9193 65 0 0 0 0 0 0 120 30 31 1 3 95 0 0 0 9693 69 0 0 53 100 216 0 168 27 57 1 4 63 33

147
0 0 9693 69 0 0 0 0 0 0 134 96 60 12 4 84 0 0 0 10193 57 0 0 0 0 0 0 124 29 32 1 3 94 2 0 0 11194 64 0 0 38 201 1080 0 168 29 57 2 8 62 29 0 0 11194 63 0 0 0 0 0 0 141 111 65 12 7 81 0 0 0 5480 755 3 1 0 0 0 0 154 107 71 13 8 78 2 0 0 5467 5747 0 3 0 0 0 0 167 39 68 1 16 79 5 0 1 4797 5821 0 21 0 0 0 0 191 192 125 20 5 42 33 0 1 3778 6119 0 24 0 0 0 0 188 170 98 5 8 41 46 0 0 3751 6139 0 0 0 0 0 0 145 24 54 1 10 89 0
Pentru comanda vmstat 5, intrarea b indică numărul proceselor care nu pot fi executate
deoarece ele aşteaptă discul, terminalul sau operaţii de I/O cu reţeaua. Valori continue, scăzute, (mai puţin de 10) care apar în câmpul id (idle) de pe coloane
UCP indică faptul că unitatea centrală de prelucrare este foarte ocupată, dar nu reprezintă neapărat o gâtuire. La testele prezentate în lucrare am determinat în ce condiţii apare gâtuirea unităţii centrale de prelucrare.
Dacă prin comanda vmstat obţinem timpi de aşteptare mari pentru operaţiile de I/O, folosim comanda iostat pentru a avea informaţii detaliate despre folosirea UCP şi discului.
Comanda iostat 5 2, raportează activitatea I/O şi utilizarea UCP la fiecare 5 secunde şi statisticile afişate se vor opri după a 2-lea raport.
# iostat 5 2 tty: tin tout avg-UCP: % user % sys % idle % iowait 0.1 102.3 0.5 0.2 99.3 0.1 " Disk history since boot not available. "
tty: tin tout avg-UCP: % user % sys % idle % iowait 0.2 79594.4 0.6 6.6 73.7 19.2 Disks: % tm_act Kbps tps Kb_read Kb_wrtn hdisk1 0.0 0.0 0.0 0 0 hdisk0 78.2 1129.6 282.4 5648 0 cd1 0.0 0.0 0.0 0 0
Prima linie a rezultatului comenzii iostat -D 5 însumează statistici I/O de când sistemul a
fost pentru prima dată butat. Discurile sunt comparate 5 secunde pentru a vedea care dintre ele este folosit în mod semnificativ mai mult decât altele. Dacă aceasta este situaţia, atunci soluţia este posibilitatea de a muta părţi din sistemul de fişiere pe alt disc mai puţin încărcat. Dacă discurile încărcate conţin zone de schimb de date (swap), creaţi zone suplimentare de schimb pe unul sau mai multe discuri din cele neîncărcate.
Pentru disc putem verifica dacă este supraîncărcat prin comanda iostat -x 30. Dacă sunteţi singurul utilizator al sistemului puteţi folosi comanda time pentru a raporta I/O şi UCP.
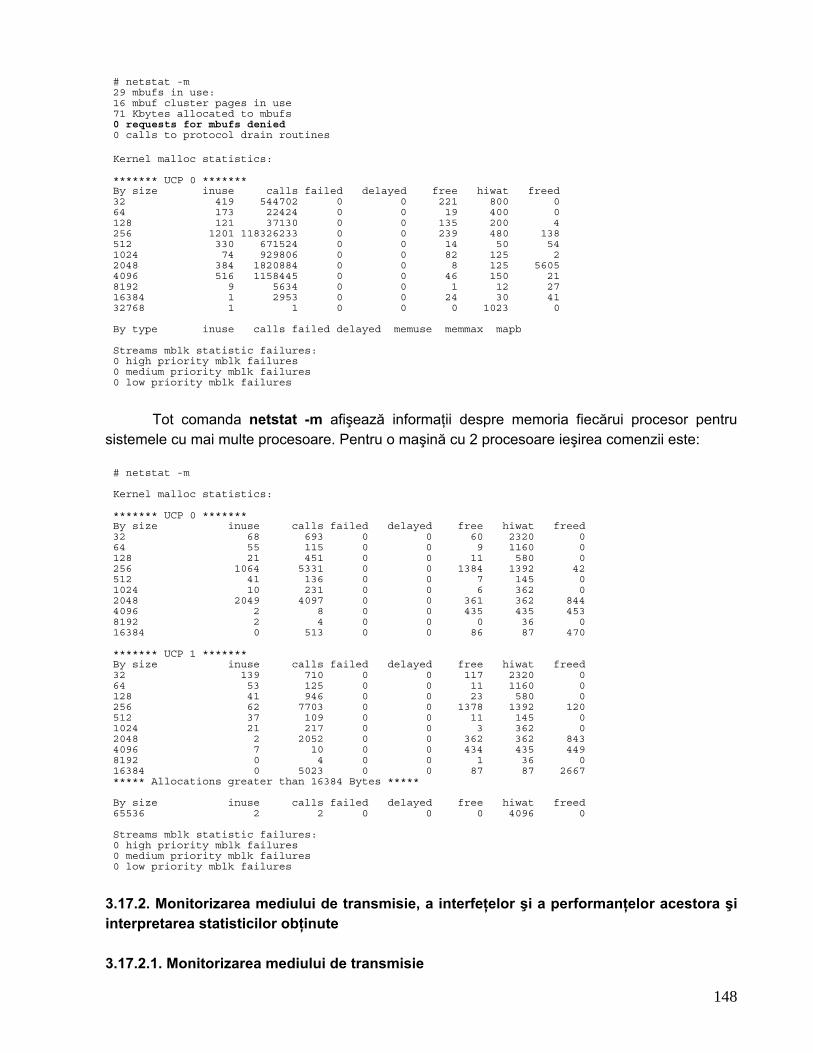
Comanda netstat -m afişează statistici înregistrate de către rutinele de administrare a memoriei (mbuf sau clustere).
Există un set predefinit de memorii-tampon din fiecare mărime cu care sistemul porneşte după fiecare rebutare şi numărul de memorii-tampon creşte dacă este necesar.
Dacă memoriile-tampon nu sunt disponibile imediat când o cerere este recepţionată, cererea este cel mai adesea pierdută, la fel şi pachetele. Dacă numărul de cereri cu probleme este în creştere, sistemul poate avea o pierdere de memorie-tampon (mbuf).
Dacă doar o porţiune mare din memorie este disponibilă pentru a stoca în memorii-tampon fişiere, spaţiul de pagini al sistemului este disponibil ca stocare temporară pentru programe care lucrează date care au fost scoase forţat din RAM.
148
# netstat -m 29 mbufs in use: 16 mbuf cluster pages in use 71 Kbytes allocated to mbufs 0 requests for mbufs denied 0 calls to protocol drain routines Kernel malloc statistics: ******* UCP 0 ******* By size inuse calls failed delayed free hiwat freed 32 419 544702 0 0 221 800 0 64 173 22424 0 0 19 400 0 128 121 37130 0 0 135 200 4 256 1201 118326233 0 0 239 480 138 512 330 671524 0 0 14 50 54 1024 74 929806 0 0 82 125 2 2048 384 1820884 0 0 8 125 5605 4096 516 1158445 0 0 46 150 21 8192 9 5634 0 0 1 12 27 16384 1 2953 0 0 24 30 41 32768 1 1 0 0 0 1023 0 By type inuse calls failed delayed memuse memmax mapb Streams mblk statistic failures: 0 high priority mblk failures 0 medium priority mblk failures 0 low priority mblk failures
Tot comanda netstat -m afişează informaţii despre memoria fiecărui procesor pentru
sistemele cu mai multe procesoare. Pentru o maşină cu 2 procesoare ieşirea comenzii este:
# netstat -m Kernel malloc statistics: ******* UCP 0 ******* By size inuse calls failed delayed free hiwat freed 32 68 693 0 0 60 2320 0 64 55 115 0 0 9 1160 0 128 21 451 0 0 11 580 0 256 1064 5331 0 0 1384 1392 42 512 41 136 0 0 7 145 0 1024 10 231 0 0 6 362 0 2048 2049 4097 0 0 361 362 844 4096 2 8 0 0 435 435 453 8192 2 4 0 0 0 36 0 16384 0 513 0 0 86 87 470
******* UCP 1 ******* By size inuse calls failed delayed free hiwat freed 32 139 710 0 0 117 2320 0 64 53 125 0 0 11 1160 0 128 41 946 0 0 23 580 0 256 62 7703 0 0 1378 1392 120 512 37 109 0 0 11 145 0 1024 21 217 0 0 3 362 0 2048 2 2052 0 0 362 362 843 4096 7 10 0 0 434 435 449 8192 0 4 0 0 1 36 0 16384 0 5023 0 0 87 87 2667 ***** Allocations greater than 16384 Bytes ***** By size inuse calls failed delayed free hiwat freed 65536 2 2 0 0 0 4096 0 Streams mblk statistic failures: 0 high priority mblk failures 0 medium priority mblk failures 0 low priority mblk failures
3.17.2. Monitorizarea mediului de transmisie, a interfeţelor şi a performanţelor acestora şi interpretarea statisticilor obţinute 3.17.2.1. Monitorizarea mediului de transmisie

149
Cel mai simplu test pentru disponibilitatea (conectivitatea) reţelei este comanda ping
(între server şi calculatorul client). Tot comanda ping se foloseşte pentru a determina starea reţelei, pentru a găsi şi izola probleme hardware şi software şi pentru a testa, măsura şi administra reţelele. Oferă informaţii generale privind pierderea pachetelor şi timpul dus-întors (întârzierea).
Programul ping se bazează pe protocolul ICMP (Internet Control Message Protocol) şi trimite un pachet ECHO-REQUEST la calculatorul gazdă destinaţie, solicitând un ECHO-RESPONSE (prin aceasta creând un şir de biţi dus-întors). Când pachetul-ecou este recepţionat, calculatorul gazdă îndepărtat trimite înapoi tot un pachet-ecou către dispozitivul emiţător.
Primul pas în măsurarea performanţei de reţea este să determinăm dacă reţeaua chiar
lucrează. Dacă traficul nu traversează reţeaua nu putem vorbi de performanţă. Dacă vreţi să testaţi probleme de comunicaţie folosind ping, începeţi prin a verifica
calculatorul local pentru a vă asigura că interfaţa de reţea locală este operaţională, şi apoi creşteţi raza de acţiune a testului la calculatoarele gazdă îndepărtate şi la porţi.
Comanda ping testează dacă un calculator gazdă de la distanţă este activ. Dacă ping nu afişează ieşiri, atunci calculatorul de la distanţă este deconectat sau este defect.
Recepţionând un pachet de la calculatorul gazdă îndepărtat înseamnă că reţeaua este disponibilă pe calea dintre clientul şi serverul care au comunicat. În caz contrar există probleme cu un dispozitiv al reţelei sau cu legătura dintre dispozitive. Dacă serverul comunică spre alţi clienţi înseamnă că acesta este funcţional şi celelalte legături funcţionează.
Se ia calculatorul gazdă care nu a răspuns la testul ping şi se conectează pe o altă legătură funcţională. Dacă nu răspunde la ping problema este de la dispozitivul de reţea al acestui calculator, în caz contrar de la legătura iniţială.
Pentru a determina problemele dispozitivului de reţea sunt necesare alte teste. Folosiţi comanda netstat -i pentru a monotoriza starea interfeţei de reţea în timpul experimentului (vedeţi dacă sistemul pierde pachete). Testaţi şi monitorizaţi şi alte sisteme pentru comparaţie, deoarece rutorul sau reţeaua pot avea probleme.
Trimiţând doar un singur pachet ping la calculatorul gazdă îndepărtat determinăm disponibilitatea reţelei. În schimb, dacă trimitem un şir de pachete prin ping determinăm performanţa reţelei pentru conexiunile între client şi server.
Testul ping folosind pachete de dimensiuni mari este exemplificat în subcapitolul „Monitorizarea datelor care circulă prin reţea”.
Formatul comenzii ping este: ping [-dfnqrvR][-c numărător][-i aşteptare][-l preîncărcare][-p şablon][-s dimensiune pachet]
Puteţi folosi diferite opţiuni şi parametrii pentru ping, care pot fi utilizaţi pentru a testa avansat reţeaua. Pentru opţiunile şi parametrii impliciţi informaţiile despre disponibilitate sunt suficiente.
Opţiuni pentru comanda ping: -c specifică numărul de pachete pe care îl trimitem. Dacă nu folosiţi opţiunea -c (de la
count=număr) ping transmite încontinuu datagrame până este oprit şi nu poate fi folosit în scripturi.
-s specifică lungimea pachetelor; puteţi folosi această opţiune pentru a verifica

150
fragmentarea şi reasamblarea; -f trimite pachetele la intervale de 10 ms sau imediat după fiecare răspuns. Doar
superutilizatorul poate folosi această opţiune. Această opţiune încarcă reţeaua şi de aceea trebuie folosită cu precauţie.
Exemplul următor foloseşte ping cu opţiunea -c pentru a limita numărul de datagrame
trimise şi recepţionate. Ping testează şi măsoară traficul între sistemul local şi sistemul testat.
$ ping -c5 pluto PING pluto (193.226.34.186): 56 data bytes 64 bytes from 193.226.34.186: icmp_seq=0 ttl=249 time=157.229 ms 64 bytes from 193.226.34.186: icmp_seq=1 ttl=249 time=29.371 ms 64 bytes from 193.226.34.186: icmp_seq=2 ttl=249 time=45.086 ms 64 bytes from 193.226.34.186: icmp_seq=3 ttl=249 time=49.171 ms 64 bytes from 193.226.34.186: icmp_seq=4 ttl=249 time=136.825 ms ----pluto PING Statistics---- 5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max = 29.371/83.536/157.229 ms
Folosiţi opţiunea -s pentru a prezenta datagrame de mărime dată şi timpul de tranzit RTT
(timpul dus-întors) şi pierderea de pachete. 3.17.2.2. Pierderea pachetelor
Pachetele pot fi scăpate în orice nod de-a lungul căii. Pierderea pachetelor este o condiţie de eroare în care pachetele de date sunt transmise
corect la un capăt al conexiunii, dar nu ajung niciodată, deoarece: • reţeaua are probleme şi pachetele se defectează în timpul transmisiei; • pachetele sunt scăpate la un rutor, deoarece reţeaua internă se congestionează.
Ce efect are pierderea pachetelor ? Principalul efect observabil al pierderii pachetelor este slaba performanţă a vitezei de
transport a datelor. Dar pierderea pachetelor nu este singura cauză a unei performanţe scăzute. Pierderea pachetelor se manifestă în diferite moduri funcţie de protocolul care este testat.
Anumite condiţii de eroare pot afecta un protocol, dar nu şi pe altele.
Dacă pierderea pachetelor este peste 0,1% (persistă), trebuie făcute alte investigaţii. Pachetele deteriorate sunt uneori un indiciu al problemelor (erorilor) hardware (conectori, terminatori, urmărirea continuităţii cablurilor).
Pierderea pachetelor poate fi sporadică, caz în care poate fi util un script pentru ping la intervale specificate, rezultatele fiind salvate într-un fişier. Dacă ping răspunde la test, dar telnet şi ftp nu, poate fi vorba de o eroare din cauza expirării timpului TTL. Puteţi extinde timpul TTL pentru datagramă cu opţiunea -T. 3.17.2.3. Statistici obţinute cu ping
Pentru pachete multiple trimise prin ping la calculatorul gazdă îndepărtat rezultatul este

151
afişat ca procent de pachete care nu au fost recepţionate. Un program de performanţă de reţea poate utiliza statistici ping pentru a obţine informaţii
de bază referitoare la starea reţelei între 2 puncte finale. În UNIX programul ping trimite continuu pachete la calculatorul destinaţie până când
utilizatorul apasă tastele CTRL-C. Exemplu de comandă ping care foloseşte pachete multiple.
$ ping 193.226.34.186 PING 193.226.34.186 (193.226.34.186):56 data bytes 64 bytes from 193.226.34.186:icmp_seq=0 ttl=255 time=0.703 ms 64 bytes from 193.226.34.186:icmp_seq=1 ttl=255 time=0.661 ms 64 bytes from 193.226.34.186:icmp_seq=2 ttl=255 time=0.647 ms 64 bytes from 193.226.34.186:icmp_seq=3 ttl=255 time=0.623 ms 64 bytes from 193.226.34.186:icmp_seq=4 ttl=255 time=0.695 ms ^C ---193.226.34.186 ping statistics --- 5 packets transmitted,5 packets received,0%packet loss round-trip min/avg/max/stddev =0.623/0.665/0.703/0.031 ms
$ În acest exemplu s-a primit răspuns de la toate pachetele care au fost trimise, ceea ce
înseamnă că nu există probleme cu reţeaua. În caz contrar, ceva pe reţea a provocat pierderea de pachete.
Dacă sunt pachete pierdute după ce s-a încheiat testarea cu ping trebuie determinată cauza pierderii pachetelor. Pot fi două cauze majore ale acestui fenomen:
• coliziunea pe acel segment de reţea; • pachetele sunt pierdute de un dispozitiv de reţea. Într-un segment Ethernet doar unei singure staţii îi este permis să trimită la un moment
dat. Dacă mai mult de o staţie încearcă să transmită în acelaşi timp apare coliziune. Coliziunile sunt normale pentru reţelele Ethernet şi nu trebuie ca administratorul reţelei să se îngrijoreze.
În schimb, dacă segmentul Ethernet este supraîncărcat, coliziunile vor fi în exces în reţea. Cu cât mai mult trafic este generat în reţea, cu atât mai multe coliziuni apar.
Pentru fiecare coliziune, emiţătorii afectaţi trebuie să retransmită pachetele, ceea ce cauzează alte coliziuni. Cu cât sunt mai multe pachete retransmise, se generează mai mult trafic în reţea şi deci numărul de coliziuni apărute poate creşte. Acest fenomen se numeşte coliziune în lanţ şi afectează sever performanţa segmentului respectiv de reţea. Despre coliziuni mai mult în capitolele 2 şi 4.
Scurgerea de pachete poate avea drept rezultat pierderea de pachete. Toate dispozitivele de reţea au memorii-tampon pentru pachete. Când pachetele de date sunt primite de la reţea ele sunt plasate în aceste memorii aşteptând să le vină rândul să fie transmise. Pierderea pachetelor poate fi cauzată şi de un spaţiu de memorie-tampon insuficient sau încărcarea UCP-urilor.
Fiecare port al dispozitivului de rutare sau comutare conţine o zonă de memorii-tampon individuale care acceptă pachete destinate să părăsească interfaţa. Dacă apare trafic excesiv de reţea sosind mai multe pachete decât poate transmite portul, memoria se va umple.
Dacă memoria-tampon a dispozitivului de reţea s-a umplut, pachetele care vor veni se vor pierde. Acest fenomen se întâmplă frecvent pentru dispozitivele de reţea care conectează reţelele rulând la viteze diferite (de exemplu comutator sau rutor 10/100). Dacă traficul soseşte printr-o conexiune de 100 MB şi este destinat unor legături de viteză scăzută (10 MB), pachetele vor fi salvate în memorii şi curând se vor satura, cauzând pierderea de pachete şi retransmiterea lor de către dispozitivul emiţător.
Pentru a micşora acest efect, dispozitivele de reţea sunt configurate pentru a aloca spaţii

152
de memorare mai ample pentru manipularea pachetelor. Nu putem prevedea toate condiţiile reţelei pentru o bună funcţionare şi pierderea de pachete încă va apare. 3.17.2.4. Monitorizarea lăţimii de bandă disponibile
Lăţimea de bandă maxim disponibilă cap-la-cap ne dă încărcarea de trafic care traversează calea respectivă. Măsurarea lăţimii de bandă disponibile a reţelei prin comanda ttcp
Oferă o măsură realistică a performanţei de reţea între 2 sisteme, deoarece permite ca măsurătorile să fie luate atât de la punctul local cât şi de la punctul îndepărtat al transmisiei.
Utilizatorii care rulează aplicaţii ce transmit structuri mari de date vor avea o lăţime de bandă disponibilă mai mică decât utilizatorii care vor rula aplicaţii ce vor transmite structuri de date mai mici.
Opţiunea -l setează lungimea paginii scrise/citite (puteţi încerca cu 32 kocteţi=32768 biţi, 64k, 128k) pentru a stabili care este cea mai bună valoare pentru performanţă. ttcp transferă date prin TCP de la memorie la memorie între sistemele finale şi măsoară lăţimea de bandă disponibilă TCP cap-la-cap.
De exemplu pe o reţea 100BaseT obţineţi peste 8500 kBps pentru semi-duplex şi peste 11500 kBps pentru full duplex.
Exemplul următor ilustrează statistica pe care o observaţi dacă aţi rulat un simplu test ttcp între două staţii de lucru pe o reţea ,,curată”. Pe prima staţie de lucru introduceţi comanda:
ttcp - r - s şi veţi obţine:
ttcp-r: buflen=8192, nbuf=2048, align=16384/0, port=5001 tcp ttcp-r: socket ttcp-r: accept from 193.226.34.186 ttcp-r: 16777216 bytes in 19.99 real seconds = 819.60 KB/sec +++ ttcp-r: 10288 I/O calls, msec/call = 1.99, calls/sec = 514.67
ttcp-r: 0.1user 3.4sys 0:19real 17%
La a 2-a staţie de lucru introduceţi comanda: ttcp - t - s nume_prima_staţie şi obţineţi:
ttcp-t: buflen=8192, nbuf=2048, align=16384/0, port=5001 tcp -> venus ttcp-t: socket ttcp-t: connect ttcp-t: 16777216 bytes in 19.98 real seconds = 820.02 KB/sec +++ ttcp-t: 2048 I/O calls, msec/call = 9.99, calls/sec = 102.50
ttcp-t: 0.0user 2.3sys 0:19real 12%
Statisticile lăţimii de bandă disponibile sunt scrise îngroşat şi sunt exprimate în kBps. Valorile obţinute pe cele 2 staţii de lucru sunt apropiate şi indică o performanţă bună de reţea între sisteme. Pentru măsurarea lăţimii de bandă a reţelei pentru reţelele locale se poate folosi şi netperf.

153
Atenţie! Pentru reţele răspândite pe arii întinse (care comunică între ele prin Internet lăţimea de bandă nu poate fi măsurată precis). 3.17.2.5. Monitorizarea interfeţelor
Comanda ifconfig setează sau verifică interfeţele de reţea TCP/IP. Atribuie adresele IP, masca subreţelei şi adresele de difuzare (broadcast) pentru fiecare interfaţă. ifconfig este realizată în timpul butării prin scriptul principal de configurare a reţelei (/etc/init.d/network).
Comanda ifconfig setează valorile specifice pentru interfeţe temporar şi le niţializează, doar pentru teste, în schimb comanda chdev păstrează setările după rebutare. 3.17.2.6. Identificarea şi setarea interfeţelor de reţea
Placa de reţea se poate identifica la iniţializarea sistemului de operare şi din lista componentelor hardware de pe calculator.
Folosind utilitarul ifconfig cu opţiunea -a puteţi identifica din informaţiile afişate care sunt interfeţele de reţea. Următorul pas este setarea porţi implicite. Comanda ifconfig verifică dacă interfaţa a fost setată corect.
Parametrii de reţea care se pot modifica de către administrator prin comanda ifconfig sunt: • dimensiunea cozii de transmisie a adaptorului (valori 16, 32, 64, 128 şi implicit 256); • driverul nu suportă coadă software; • dimensiunea cozii de recepţie (16, 32, … 256); • viteza mediului de transmisie; • spaţiul inter-pachete (gap) (valori valide în intervalul 96 ÷ 252, incrementate cu 4); Pentru viteze de transmisie a mediului de comunicaţie de 100 MB, (valoarea implicită)
este 0,96 microsecunde. • dimensiunea bufferului de recepţie. Dimensiunea minimă este dimensiunea cozii de recepţie şi maximă este 2 kB (valoarea
implicită 384). Înainte de a rula comanda ifconfig interfaţa trebuie dezataşată şi la final din nou ataşată,
aşa cum se vede mai jos:
# ifconfig en0 detach # chdev -l ent0 -a tx_que_size=128 # ifconfig en0 hostname up
Comanda netstat afişează informaţii cu privire la trafic pe interfeţele de reţea configurate, respectiv:
• rutele şi starea lor; • statistici cumulative pentru interfaţă; • numărul de pachete recepţionate, transmise şi pierdute în subsistemele care comunică; • adresa oricărui protocol de control al blocurilor, asociat cu socketurile şi starea tuturor
socketurilor. Comanda netstat: afişează care interfeţe de reţea sunt configurate şi care sunt disponibile.
Tot comanda netstat arată starea reţelei prin identificarea socketurilor active, a rutării şi al traficului. Puteţi observa adresele de reţea pentru interfeţe şi unitatea maximă de transmisie MTU (Maximum Transmission Unit), depinzând de opţiunea selectată.

154
Socket poate fi tradus prin racord, mufă, soclu. Socket, din punct de vedere hardware, reprezintă un punct final al unei legături de comunicaţie în ambele sensuri dintr-o reţea. Socket, din punct de vedere software, reprezintă un punct final între 2 programe care comunică în reţea. Altfel spus, este o abstracţiune software folosită pentru a reprezenta fiecare capăt al unei conexiuni între 2 procese care rulează în reţea. Fiecare socket (TCP şi UDP) este ataşat unui port astfel încât să identifice unic programul căruia îi sunt destinate datele. Dacă aplicaţia de reţea foloseşte socketuri se încadrează în modelul de operare client-server.
Comanda netstat cu opţiunea -I este folosită pentru a determina numărul de pachete
trimise şi recepţionate şi pentru a afişa statistici pentru interfaţa specificată pe care le raportează la intervalul de timp dat. În schimb netstat -i arată starea tuturor interfeţelor configurate.
# netstat -I en0 5 input (en0) output input (Total) output packets errs packets errs colls packets errs packets errs colls 8305067 0 7784711 0 0 20731867 0 20211853 0 0 3 0 1 0 0 7 0 5 0 0 24 0 127 0 0 28 0 131 0 0 CTRL C
Cu opţiunea –v, comanda netstat afişează statistici pentru fiecare interfaţă la nivelul
legăturii de date (Token Ring, Ethernet, FDDI sau ATM). Aceste statistici prezintă erorile de transmisie/recepţie datorate erorilor hardware sau de reţea, pachete difuzate, încărcarea DMA, erori datorate coliziunilor sau coliziunilor întârziate. Câmpurile cele mai importante din ieşirea comenzii sunt subliniate.
# netstat -v ------------------------------------------------------------- ETHERNET STATISTICS (ent0) : Device Type: IBM 10/100 Mbps Ethernet PCI Adapter (23100020) Hardware Address: 00:60:94:e9:29:18 Elapsed Time: 9 days 19 hours 5 minutes 51 seconds Transmit Statistics: Receive Statistics: -------------------- ------------------- Packets: 0 Packets: 0 Bytes: 0 Bytes: 0 Interrupts: 0 Interrupts: 0 Transmit Errors: 0 Receive Errors: 0 Packets Dropped: 0 Packets Dropped: 0 Bad Packets: 0 Max Packets on S/W Transmit Queue: 0 S/W Transmit Queue Overflow: 0 Current S/W+H/W Transmit Queue Length: 0 Broadcast Packets: 0 Broadcast Packets: 0 Multicast Packets: 0 Multicast Packets: 0 No Carrier Sense: 0 CRC Errors: 0 DMA Underrun: 0 DMA Overrun: 0 Lost CTS Errors: 0 Alignment Errors: 0 Max Collision Errors: 0 No Resource Errors: 0 Late Collision Errors: 0 Receive Collision Errors: 0 Deferred: 0 Packet Too Short Errors: 0 SQE Test: 0 Packet Too Long Errors: 0 Timeout Errors: 0 Packets Discarded by Adapter: 0 Single Collision Count: 0 Receiver Start Count: 0 Multiple Collision Count: 0 Current HW Transmit Queue Length: 0 General Statistics: ------------------- No mbuf Errors: 0 Adapter Reset Count: 0 Driver Flags: Up Broadcast Running Simplex 64BitSupport PrivateSegment IBM 10/100 Mbps Ethernet PCI Adapter Specific Statistics: ------------------------------------------------ Chip Version: 25 RJ45 Port Link Status : down

155
Media Speed Selected: 10 Mbps Half Duplex Media Speed Running: Unknown Receive Pool Buffer Size: 384 Free Receive Pool Buffers: 128 No Receive Pool Buffer Errors: 0 Inter Packet Gap: 96 Adapter Restarts due to IOCTL commands: 0 Packets with Transmit collisions: 1 collisions: 0 6 collisions: 0 11 collisions: 0 2 collisions: 0 7 collisions: 0 12 collisions: 0 3 collisions: 0 8 collisions: 0 13 collisions: 0 4 collisions: 0 9 collisions: 0 14 collisions: 0 5 collisions: 0 10 collisions: 0 15 collisions: 0 Excessive deferral errors: 0x0 ------------------------------------------------------------- TOKEN-RING STATISTICS (tok0) : Device Type: IBM PCI Tokenring Adapter (14103e00) Hardware Address: 00:20:35:7a:12:8a Elapsed Time: 29 days 18 hours 3 minutes 47 seconds Transmit Statistics: Receive Statistics: -------------------- ------------------- Packets: 1355364 Packets: 55782254 Bytes: 791555422 Bytes: 6679991641 Interrupts: 902315 Interrupts: 55782192 Transmit Errors: 0 Receive Errors: 1 Packets Dropped: 0 Packets Dropped: 0 Bad Packets: 0 Max Packets on S/W Transmit Queue: 182 S/W Transmit Queue Overflow: 42 Current S/W+H/W Transmit Queue Length: 0 Broadcast Packets: 18878 Broadcast Packets: 54615793 Multicast Packets: 0 Multicast Packets: 569 Timeout Errors: 0 Receive Congestion Errors: 0 Current SW Transmit Queue Length: 0 Current HW Transmit Queue Length: 0 General Statistics: ------------------- No mbuf Errors: 0 Lobe Wire Faults: 0 Abort Errors: 12 AC Errors: 0 Burst Errors: 1 Frame Copy Errors: 0 Frequency Errors: 0 Hard Errors: 0 Internal Errors: 0 Line Errors: 0 Lost Frame Errors: 0 Only Station: 1 Token Errors: 0 Remove Received: 0 Ring Recovered: 17 Signal Loss Errors: 0 Soft Errors: 35 Transmit Beacon Errors: 0 Driver Flags: Up Broadcast Running AlternateAddress 64BitSupport ReceiveFunctionalAddr 16 Mbps IBM PCI Tokenring Adapter (14103e00) Specific Statistics: --------------------------------------------------------- Media Speed Running: 16 Mbps Half Duplex Media Speed Selected: 16 Mbps Full Duplex Receive Overruns : 0 Transmit Underruns : 0 ARI/FCI errors : 0 Microcode level on the adapter :001PX11B2 Num pkts in priority sw tx queue : 0 Num pkts in priority hw tx queue : 0 Open Firmware Level : 001PXRS02
Dacă pachetele difuzate sunt peste 20% din totalul pachetelor recepţionate, reţeaua este
încărcată şi folosiţi multidifuzarea care permite ca mesajul să fie trimis unui grup de calculatoare gazdă. Dacă magistrala MCA (Micro Channel Architecture) pe 32 de biţi este prea încărcată
pentru adaptor, DMA (Direct Memory Access) nu mai poate fi operaţională pentru pachete.
3.17.2.7. Încărcarea reţelei
Pentru a verifica supraîncărcarea reţelei Ethernet calculaţi (din comanda netstat -v) raportul:
n1+ n2

156
supraîncărcarea = --------------------------------------------------- , numărul total de pachete transmise
unde n1 = numărul transmisiilor fără succes datorate coliziunilor, iar n2 = numărul transmisiilor fără succes datorate erorilor de expirare de timp pe care le raportează adaptorul.
Dacă acest rezultat este mai mare decât 5% reorganizaţi reţeaua pentru a balansa încărcarea.
O altă indicaţie pentru reţea prea încărcată (din comanda netstat -v) este dacă numărul total de coliziuni de la ieşirea comenzii (pentru Ethernet) este mai mare de 10% din numărul total de pachete transmise, conform formulei:
numărul de coliziuni încărcareaEthernet = -------------------------------------------- > 0,1
numărul de pachete transmise
Comanda netstat -i monotorizează starea interfeţelor de reţea în timpul experimentului pentru a vedea dacă sistemul pierde pachete şi prezintă coliziunile. netstat -i -Z şterge toate contoarele statistice pentru comanda netstat -i.
Exemplul următor arată rezultatul comenzii netstat -i, care afişează starea interfeţelor care sunt folosite pentru trafic TCP/IP.
$ netstat -i Name Mtu Net/Dest Address Ipkts Ierrs Opkts Oerrs Collis Queue lo0 8232 software localhost 1280 0 1280 0 0 0 le0 1500 loopback venus 1628480 0 347070 16 39354 0
Rezultatul comenzii prezintă: numelui interfeţei folosite în transmisie (Name), numărului
total de pachete recepţionate (Ipkts), numărului total de pachete trimise (Opkts), dimensiunii maxime în octeţi a pachetelor transmise folosind interfaţa (Mtu), numărului total de erori de intrare (Ierrs) şi ieşire (Oerrs), numărului de coliziuni detectate (Coll).
Ieşirea comenzii arată câte pachete transmite şi recepţionează o maşină prin fiecare interfaţă. O maşină cu trafic de reţea activ (adică puternic) va arăta ambele valori pentru Ipkts şi Opkts în continuă creştere.
Calculaţi rata de eroare a pachetelor care sosesc prin împărţirea numărului de erori de intrare (Ierrs) la numărul total de pachete sosite (Ipkts). Rata de eroare a pachetelor care pleacă este numărul de pachete eronate de plecare (Oerrs) împărţit la numărul total de pachete expediate (Opkts). Dacă rata de eroare de recepţie este mare (peste 0,25%), calculatorul gazdă poate pierde pachete.
Calculaţi rata de apariţie a coliziunilor în reţea prin împărţirea numărului de coliziuni numărate (Collis) prin numărul de pachete plecate (Opkts), total înmulţit cu 100. În acest exemplu rata de producere a coliziunilor este 11%. O rată a coliziunilor mai mare decât 5 până la 10 % poate indica o problemă.
Pe un sistem dat, dacă viteza de apariţie a coliziunilor la ieşire este în mod constant mai mare decât 5% faţa de aceea a altui sistem, aceasta indică probleme fizice precum : ramificaţie cu pierderi, transiver, terminator pierdut. Dacă coliziunile sunt frecvente reţeaua trebuie subdivizată sau memoria este insuficientă pe staţiile de lucru fără discuri, pentru a nu mai pierde date.
În exemplul de mai jos, viteza de apariţie a coliziunilor este de aproximativ 0,45%, care

157
este în limite acceptabile. Opţiunea netstat -v determină rata de apariţie a coliziunii. netstat -i Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll qfa0 65280 central thumper 498690 937 1066135 3 4858
lo0 65535 loopback localhost 1678915 0 1678915 0 0
Dacă numărul de erori apărute (Ierrs) în timpul recepţionării pachetelor de intrare este mai
mare decât 1 procent (1%) din numărul total de pachete de intrare din comanda netstst –i, adică Ierrs > 0,01 * Ipkts, atunci rulaţi netstat -m pentru a verifica o lipsă de memorie a reţelei. 3.17.2.8. Comenzi pentru mediul Ethernet
Ethernet detectează coliziunea prin CSMA/CD (Carrier Sense Multiple Access Collision Detect).
Atât reţelele Ethernet cât şi reţelele locale IEEE 802.3 sunt reţele cu difuzare (în bandă largă). Cu alte cuvinte toate staţiile văd toate cadrele. Fiecare staţie trebuie să examineze cadrele recepţionate pentru a determina dacă staţia respectivă este destinaţia. Dacă aceasta este o destinaţie, cadrul este trimis pentru procesare spre un protocol de la un nivel mai sus.
Când există probleme legate de mediul Ethernet, folosiţi comenzile show interfaces ethernet şi show interfaces fastethernet care vă oferă informaţii ce vă ajută să izolaţi problemele cu privire la interfaţă. Putem indica opţional pe linia de comandă slotul unui card de reţea, interfaţa, numărul de pachete al fiecărui tip de protocol care sunt trimise prin interfaţă. Dacă nu daţi argumente referitor la slot, interfaţa şi numărul de pachete, comanda va afişa statistici pentru toate interfeţele Ethernet din reţea. Aceste statistici se referă la:
a) starea reţelei: dacă interfaţa este activă sau a fost dezactivată de administrator; b) dimensiunea maximă a pachetului MTU (Maximum Transmission Unit): pe care
interfaţa îl poate manevra (în octeţi); c) lăţimea de bandă a intereţei: în kilobiţi per secundă; d) întârzierea interfeţei: în microsecunde; e) disponibilitatea interfeţei: ca procent din 255 (255/255 reprezintă 100%), calculată ca
o medie exponenţială timp de 5 minute; f) încărcarea interfeţei: ca procent din 255 (idem disponibilitate); g) ultima intrare şi ultima ieşire: numărul de ore, minute şi secunde de când ultimul
pachet a fost recepţionat cu succes (intrare) şi transmis (ieşire); h) ultima resetare: numărul de ore, minute şi secunde sau nimic de când interfaţa a fost
ultima dată resetată datorită unei transmisii care a durat prea mult; i) coada de aşteptare de ieşire, coada de aşteptare pentru intrare, scurgerile:
numărul pachetelor scăpate din cauza umplerii cozii. j) erorile. Acestea vor fi prezentate separat în capitolul 4. 3.17.3. Monitorizarea datelor care circulă prin reţea şi interpretarea statisticilor obţinute Utilizarea pachetelor de dimensiune mare pentru comanda ping
O altă problemă pentru măsurarea disponibilităţii este mărimea pachetelor folosite în cererile ping.

158
Multe dispozitive de reţea manipulează pachete cu ajutorul mai multor memorii-tampon, bazate pe mărimea medie a pachetului. Diferite memorii-tampon manevrează diferite pachete. Astfel, prea multe pachete dintr-o mărime particulară pot cauza pierderea pachetelor pentru categoria respectivă de mărime, în timp ce pachetele de alte dimensiuni trec fără probleme.
De exemplu, comutatoarele au de obicei 3 clase de memorii-tampon: una pentru pachete mici, una pentru pachete de mărime medie şi ultima pentru pachete mari. Pentru a avea acurateţe asupra testării dispozitivului de reţea trebuie să trimiteţi pachete de mărime diferită pentru a verifica diferite memorii-tampon.
Anumite aplicaţii care testează performanţa reţelei vă permit să selectaţi mărimea pachetelor folosite pentru testare. Atenţie! Din motive de securitate, marea majoritate a sistemelor de operare UNIX, permit doar superuser-ului să trimită prin ping pachete de dimensiune mare.
Aveţi grijă cînd trimiteţi pachete de dimensiunea mare către serverele de la distanţă să nu afectaţi funcţionarea acestora.
Mărimea implicita a pachetului folosită de ping este de 64 octeţi (56 octeţi de date şi 8 octeţi antetul ICMP).
Dacă folosiţi opţiunea -s (dimensiune pachet) puteţi modifica mărimea pachetului până la dimensiunea maximă permisă pe un segment de reţea (de exemplu pentru reţele Ethernet este de 1500 octeţi).
După ce alternaţi mărimi diferite ale pachetelor în comanda ping pe ecran va apare o statistică în care sunt informaţii legate de pierderea de pachete şi timpii parcurşi de pachete între sursă şi destinaţie.
Exemplu de comandă ping care foloseşte pachete de dimensiune mare.
# ping -s 1000 193.226.34.186 PING 193.226.34.186 (193.226.34.186):1000 data bytes 1008 bytes from 193.226.34.186:icmp_seq=0 ttl=127 time=2.947 ms 1008 bytes from 193.226.34.186:icmp_seq=1 ttl=127 time=2.972 ms 1008 bytes from 193.226.34.186:icmp_seq=2 ttl=127 time=2.964 ms 1008 bytes from 193.226.34.186:icmp_seq=3 ttl=127 time=2.955 ms 1008 bytes from 193.226.34.186:icmp_seq=4 ttl=127 time=3.089 ms 1008 bytes from 193.226.34.186:icmp_seq=5 ttl=127 time=2.991 ms 1008 bytes from 193.226.34.186:icmp_seq=6 ttl=127 time=2.983 ms ^C ---193.226.34.186 ping statistics --- 7 packets transmitted,7 packets received,0%packet loss round-trip min/avg/max/stddev =2.947/2.985/3.089/0.058 ms
#
În acest exemplu toate pachetele de dimensiune mare au fost recepţionate cu succes, adică toate segmentele de reţea între calculatorul sursă şi calculatorul destinaţie transportă fără probleme pachete largi de date.
Dacă există pachete pierdute de dimensiune mare şi nu există pierderi pentru pachetele de dimensiune mică, înseamnă că problema este la memoria-tampon a unui rutor sau comutator undeva în reţea. Marea majoritate a rutoarelor şi comutatoarelor permit administratorilor să schimbe dimensiunea alocată memoriei-tampon pentru a seta marea majoritatea acestora la o dimensiune particulară a pachetului. 3.17.4. Monitorizarea rutării şi a tabelelor de rutare şi interpretarea statisticilor obţinute
Comanda traceroute se foloseşte în testarea reţelei, măsurarea şi administrarea ei. Comanda traceroute este foarte folosită pentru reţele izolate şi probleme ale rutoarelor în

159
reţelele mari eterogene. Afişează numele şi adresele tuturor rutoarelor intermediare care suportă câmpul timp-de-viaţă TTL (time-to-live) în IP. Afişează şi cantitatea de timp pe care pachetul îl petrece călătorind către rutor, în rutor şi părăsind rutorul. Atenţie! Comanda traceroute creşte încărcarea reţelei şi trebuie luat în considerare acest aspect când testăm reţeaua cu această comandă. Deoarece aduce încărcare pe reţea nu folosiţi comanda traceroute în timpul operaţiilor obişnuite sau din scripturi automate. 3.17.4.1. Testarea rutării cu comanda traceroute
Comanda ping confirmă disponibilitatea reţelei IP, dar nu poate puncta probleme izolate. De exemplu, când există multe salturi (porţi şi rutoare) între sistemul dvs. şi destinaţie
poate apare o problemă undeva de-a lungul căii. Ping nu informează motivele pierderii pachetului. Sistemul destinaţie poate avea o problemă, dar este necesar să cunoaşteţi unde a fost pachetul pierdut. De aceea, comanda traceroute poate să vă informeze unde este localizat pachetul şi pentru ce ruta a fost pierdută. Dacă pachetele dvs. trebuie să treacă prin rutoare şi legături care aparţin şi sunt administrate de alte companii este dificil să verificăm legătura între rutoare prin comanda telnet. De asemenea, rutoarele pot fi verificate şi cu cu netstat.
Reţineţi că primul pachet spre fiecare poartă sau destinaţie are nevoie de un timp dus-întors mai lung, datorită încărcării cauzate de ARP. În reţelele larg răspândite geografic, primul pachet consumă mai multă memorie datorită stabilirii conexiunii şi poate cauza o depăşire a acestui timp.
Timpul implicit pentru fiecare pachet este de 3 secunde. Îl puteţi modifica cu opţiunea -w. În cazul în care folosiţi DNS de fiecare dată înainte ca traceroute să trimită un pachet,
serverul DNS este căutat. Comanda traceroute poate avea probleme pentru o cale lungă până la destinaţie, sau
rute de reţea complexe. Dacă problema este de la legătura de comunicaţie, folosiţi un timp de expirare mai lung cu opţiunea -w.
3.17.4.2. Folosirea traceroute pentru căi redundante
Într-o reţea care are căi redundante, este de dorit să determinăm pe care cale o iau pachetele la un moment dat. Dacă determinaţi că pachetele nu urmează o cale eficientă, puteţi face modificări simple de configuraţie ale rutoarelor pentru a modifica valoarea timpului de răspuns.
Programul UNIX traceroute permite ca administratorul de reţea să determine exact pe ce rută merg pachetele între două puncte ale reţelei. Traceroute foloseşte valorile timpului de viaţă IP TTL (Time To Live).
Valoarea TTL specifică câte hopuri (escale, salturi) face un pachet individual înainte de a expira. Dacă rutorul primeşte un pachet cu o valoare TTL expirată, raportează dispozitivului de reţea care a trimis pachetul că a apărut o problemă.
Rutorul însuşi trebuie să returneze pachetul, iar fiecare rutor traversat de-a lungul căii reţelei este identificat.
Pornind de la valoare 1 pentru TTL şi incremetând-o la fiecare încercare ping, utilizatorul traceroute forţează rutoarele îndepărtate de-a lungul căii reţelei să expire pachetul ping şi să întoarcă către client pachetul ICMP neajuns la destinaţie.
Formatul comenzii traceroute este:

160
traceroute [-dFinrvx][-f primul timp de viaţă][-g poarta][-i interfaţa][-m timpul de viaţă maxim][-p portul][-q numărul de cereri][-s adresa sursă][-t tos][-w timp de aşteptare] host [lungime pachet]
Valorile implicite pentru toate opţiunile se folosesc pentru a trimite probe simple
traceroute la calculatorul gazdă îndepărtat. Exemple de locaţii spre care puteţi proba comanda traceroute prin Internet găsiţi la
adresa http://www.tracert.com/cgi-bin/trace.pl. Rezultatele afişate de programul traceroute arată fiecare rutor care răspunde la pachetul
de test expirat de-a lungul căii către calculatorul gazdă destinaţie. Timpii de răspuns dus-întors pot varia pentru diferite încărcări pe rutoarele individuale.
Cel mai bun lucru este să alegeţi teste de bază sub diferite încărcări ale reţelei pentru a
vedea cum şi când fiecare cale a reţelei este utilizată. 3.17.4.3. Încărcare echilibrată (load balancing)
Comanda route poate fi folosită pentru a crea, adăuga, menţine şi şterge intrări în tabelele de rutare statice ale reţelei, pentru a umple tabelele de rutare şi pentru a afişa informaţii (metrici) despre rute. În mod normal, tabelele de rutare sunt manevrate automat de demonii (comenzile de pe server) routed şi gated.
Comanda route este folosită pentru a ruta trafic înapoi de la calculatorul gazdă. Este cel mai bine să folosim rutarea prin calculatorul gazdă.
Folosind această rutare specială prin calculatorul gazdă între porţi şi reţea poate fi o metodă efectivă de echilibrare a încărcării reţelei prin sistemele front-end.
Echilibrarea este limitată de către lăţimea de bandă a reţelei destinaţie. Când reţeaua destinaţie are lăţime de bandă mai multă relativ la sistemele front-end, această formă de echilibrare poate fi foarte utilă.
Deciziile de rutare sunt făcute pe baza adresei Internet. Dacă aveţi probleme de rutare, folosiţi opţiunea -n pentru comanda route, care va afişa
adresele IP mai degrabă decât a face un DNS şi să afişaţi numele calculatoarelor gazdă (comanda netstat -rn afişează tabelele de rutare). 3.17.5. Monitorizarea protocoalelor, a performanţelor acestora şi interpretarea statisticilor obţinute
Comanda ttcp este folosită pentru a testa performanţe TCP şi UDP. Aceasta oferă o măsură mai realistică a performanţei decât testele standard (ping, rup, spray). Permite ca măsurătorile să fie făcute atât la capătul local cât şi cel îndepărtat al transmisiei.
Comanda netstat -p protocol, prezintă statistici despre protocolul dat ca variabilă (ip, tcp, udp, icmp) cu privire la numărul total de pachete recepţionate, numărul total de fragmente recepţionate, fragmente pierdute după expirarea timpului, sumă de control greşită a antetelor, pachete trimise de la calculatorul gazdă (nu cuprinde datagramele transmise, depăşirea memoriilor-tampon ale socketului). Exemple ale comenzii netstat pentru protocoalele IP, UDP şi TCP:

161
# netstat -p ip ip: : 491351 total packets received 0 bad header checksums 0 with size smaller than minimum 0 with data size < data length 0 with header length < data size 0 with data length < header length 0 with bad options 0 with incorrect version number 25930 fragments received 0 fragments dropped (dup or out of space) 0 fragments dropped after timeout 12965 packets reassembled ok 475054 packets for this host 0 packets for unknown/unsupported protocol 0 packets forwarded 3332 packets not forwardable 0 redirects sent 405650 packets sent from this host 0 packets sent with fabricated ip header 0 output packets dropped due to no bufs, etc. 0 output packets discarded due to no route 5498 output datagrams fragmented 10996 fragments created 0 datagrams that can't be fragmented 0 IP Multicast packets dropped due to no receiver 0 ipintrq overflows
# netstat -p udp udp: 11521194 datagrams received 0 incomplete headers 0 bad data length fields 0 bad checksums 16532 dropped due to no socket 232850 broadcast/multicast datagrams dropped due to no socket 77 socket buffer overflows 11271735 delivered 796547 datagrams output
# netstat -p tcp tcp: 63726 packets sent 34309 data packets (6482122 bytes) 198 data packets (161034 bytes) retransmitted 17437 ack-only packets (7882 delayed) 0 URG only packets 0 window probe packets 3562 window update packets 8220 control packets 71033 packets received 35989 acks (for 6444054 bytes) 2769 duplicate acks 0 acks for unsent data 47319 packets (19650209 bytes) received in-sequence 182 completely duplicate packets (29772 bytes) 4 packets with some dup. data (1404 bytes duped) 2475 out-of-order packets (49826 bytes) 0 packets (0 bytes) of data after window 0 window probes 800 window update packets 77 packets received after close 0 packets with bad hardware assisted checksum 0 discarded for bad checksums 0 discarded for bad header offset fields 0 connection request 3125 connection requests 1626 connection accepts 4731 connections established (including accepts) 5543 connections closed (including 31 drops) 62 embryonic connections dropped 38552 segments updated rtt (of 38862 attempts) 0 resends due to path MTU discovery 3 path MTU discovery terminations due to retransmits 553 retransmit timeouts 28 connections dropped by rexmit timeout 0 persist timeouts 464 keepalive timeouts 26 keepalive probes sent 1 connection dropped by keepalive

162
0 connections in timewait reused 0 delayed ACKs for SYN 0 delayed ACKs for FIN 0 send_and_disconnects
3.17.5.1. Probleme de performanţă pentru FTP
Pentru a investiga problemele de performanţă pentru trimitere (upload) folosiţi netstat pentru a înregistra valorile pentru pachete trimise şi pachete retransmise, trimiteţi cantităţi mari de date (de exemplu cu FTP la câteva servere FTP îndepărtate) şi folosiţi din nou netstat pentru a înregistra noile valori pentru pachetele trimise şi pachetele retransmise.
Scădeţi cele 2 valori corspunzătoare celor 2 situaţii de test. Dacă valoarea pachetelor retransmise creşte mai mult (cu câteva procente) decât
creşterea pachetelor trimise, în această situaţie apare o problemă de pierdere de pachete asociată cu expediere de date.
Alte sisteme de operare decât Windows (de exemplu MacOSX, Linux), raportează pentru comanda netstat -s- p tcp rezultate care includ şi pachetele duplicate recepţionate precum şi segmentele recepţionate. Un pachet duplicat poate fi recepţionat dacă un pachet de confirmare pe care calculatorul îl trimite (răspuns pentru pachetele de date recepţionate de la sistemul final îndepărtat) a fost pierdut şi nu a ajuns la calculatorul îndepărtat, astfel încât calculatorul îndepărtat retransmite pachetul de date.
Pentru a investiga problemele de performanţă pentru recepţie (download) folosiţi netstat pentru a înregistra valorile pentru pachete recepţionate şi pachete duplicate, descărcaţi date multe prin FTP (evitând web proxy caches) şi folosiţi din nou netstat pentru a înregistra noile valori pentru pachetele recepţionate şi pachetele duplicate. Scădeţi cele 2 valori corespunzătoare celor 2 situaţii de test. Dacă valoarea pachetelor duplicate creşte peste câteva procente din valoarea pachetelor recepţionate, în această situaţie apare o problemă de pierdere de pachete asociată cu descărcare de date. 3.17.6. Monitorizarea performanţelor de reţea
O parte din comenzile ce vor fi analizate în acest subcapitol cu privire la performanţă, au mai fost descrise în subcapitolele anteroare, deoarece aveau legătură cu alte aspecte ale reţelei.
În tabelul de mai jos sunt prezentate comenzile disponibile pentru monitorizarea performanţelor de reţea.
Comanda Descrierea ping indică confirmarea răspunsurilor hosturilor din reţea spray testează siguranţa dimensiunii pachetelor. Această comandă poate spune când pachetele
pot fi întârziate sau pierdute. snoop capturează pachete de la reţea şi trasează apelurile de la fiecare client spre fiecare server. netstat afişează starea reţelei, incluzând starea interfeţelor care sunt folosite pentru trafic TCP/IP,
tabele de rutare IP şi statistici pentru protocoalele UDP, TCP, ICMP şi IGMP. nfsstat afişează statistici despre server şi client care pot fi folosite în identificarea problemelor NFS. 3.17.6.1. Confirmarea răspunsurilor calculatoarelor gazdă din reţea
$ ping hostname Dacă suspectaţi probleme de natură fizică folosiţi comanda ping pentru a obţine timpul de

163
răspuns de la calculatoarele gazdă din reţea. Dacă timpul de răspuns de la un calculator gazdă nu este în valorile normale pentru distanţa la care se găseşte calculatorul gazdă respectiv, trebuie să investigăm problemele fizice ale calculatorului gazdă respectiv. Problemele fizice por fi cauzate de:
• împământare improprie; • lipsa terminalelor; • reflexia semnalului • lipsa cablurilor sau a conectorilor.
Ping fără opţiuni trimite un singur pachet către un calculator gazdă din reţea. Dacă ping
are opţiunea -s se trimite câte o datagramă pe secundă către un calculator gazdă. Se indică timpul de răspuns dus-întors (RTT) pentru fiecare datagramă şi o statistică (RTT). $ ping -s pluto 64 bytes from pluto (193.226.34.186): icmp_seq=0. time=10. ms 64 bytes from pluto (193.226.34.186): icmp_seq=5. time=0. ms 64 bytes from pluto (193.226.34.186): icmp_seq=6. time=0. ms ^C ----pluto PING Statistics---- 8 packets transmitted, 8 packets received, 0% packet loss round-trip (ms) min/avg/max = 0/3.33/10
3.17.6.2. Trimiterea de pachete de o anumită dimensiune către calculatoare gazdă din reţea
Testarea siguranţei dimensiunii pachetelor se face folosind comanda spray. $ spray [-c count -d interval -l packet_size] host name -c count este numărul de pachete care se trimit -d delay interval este numărul de microsecunde de pauză între expedierea pachetelor.
Dacă nu folosiţi întârziere (delay) trebuie să rulaţi fără memorie tampon. -l packet_size este dimensiunea pachetului; host name este calculatorul gazdă către care se trimit pachete.
Exemplu Se trimit 100 pachete (-c 100) către un calculator gazdă şi fiecare pachet are o
dimensiune de 2048 octeţi (-l 2048). Pachetele sunt trimise cu o întârziere de 20 microsecunde între fiecare rafală (-d 20).
Prin comanda $ spray -c 100 -d 20 -l 2048 pluto, se trimit 100 pachete de lungime 2048 octeţi către pluto, iar rezultatul comenzii este :
$ spray -c 100 -d 20 -l 2048 pluto sending 100 packets of length 2048 to pluto ... no packets dropped by pluto
279 packets/sec, 571392 bytes/sec
3.17.6.3. Capturarea pachetelor de la reţea
Pentru a captura pachete de la reţea şi urmării apelurile de la fiecare client către fiecare server folosim snoop. Această comandă amprente de timp precise, care permit ca numeroase probleme de performanţă de reţea să fie cu rapiditate izolate.

164
# snoop 3.17.6.4. Verificarea stării reţelei
Prezentarea informaţiilor de stare ale reţelei, precum statistici despre starea interfeţelor de reţea, tabelele de rutare şi diferite protocoale le obţinem folosind comanda netstat.
Comanda netstat poate fi folosită şi pentru a determina cantitatea de trafic de pe reţea şi problemele de performanţă datorate congestiei reţelei.
Comenzile nettest (de partea clientului) şi nettestd (de partea serverului) oferă teste de performanţă ale clientului şi serverului pentru diferite tipuri de conexiuni de reţea care suportă cod TCP/IP. Aceasta include domeniu UNIX, comunicaţii prin socket TCP şi UDP.
Vor fi discutate în continuare doar opţiunile relevante pentru determinarea performanţei de reţea. Pentru comanda netstat, opţiunea:
-i afişează starea interfeţelor TCP/IP; -r afişează tabela de rutare IP; -s afişează statistici pentru protocoalele UDP, TCP, ICMP şi IGMP. Opţiunea –i a fost prezentată deja la monitorizarea interfeţelor. În exemplul următor se prezintă ieşirea comenzii netstat -s care afişează statistici despre
protocoalele UDP, TCP, ICMP şi IGMP.
UDP udpInDatagrams =196543 udpInErrors = 0 udpOutDatagrams =187820 TCP tcpRtoAlgorithm = 4 tcpRtoMin = 200 tcpRtoMax = 60000 tcpMaxConn = -1 tcpActiveOpens = 26952 tcpPassiveOpens = 420 tcpAttemptFails = 1133 tcpEstabResets = 9 tcpCurrEstab = 31 tcpOutSegs =3957636 tcpOutDataSegs =2731494 tcpOutDataBytes =1865269594 tcpRetransSegs = 36186 tcpRetransBytes =3762520 tcpOutAck =1225849 tcpOutAckDelayed =165044 tcpOutUrg = 7 tcpOutWinUpdate = 315 tcpOutWinProbe = 0 tcpOutControl = 56588 tcpOutRsts = 803 tcpOutFastRetrans = 741 tcpInSegs =4587678 tcpInAckSegs =2087448 tcpInAckBytes =1865292802 tcpInDupAck =109461 tcpInAckUnsent = 0 tcpInInorderSegs =3877639 tcpInInorderBytes =-598404107 tcpInUnorderSegs = 14756 tcpInUnorderBytes =17985602 tcpInDupSegs = 34 tcpInDupBytes = 32759 tcpInPartDupSegs = 212 tcpInPartDupBytes =134800 tcpInPastWinSegs = 0 tcpInPastWinBytes = 0 tcpInWinProbe = 456 tcpInWinUpdate = 0 tcpInClosed = 99 tcpRttNoUpdate = 6862 tcpRttUpdate =435097 tcpTimRetrans = 15065 tcpTimRetransDrop = 67 tcpTimKeepalive = 763 tcpTimKeepaliveProbe= 1 tcpTimKeepaliveDrop = 0 IP ipForwarding = 2 ipDefaultTTL = 255 ipInReceives =11757234 ipInHdrErrors = 0 ipInAddrErrors = 0 ipInCksumErrs = 0 ipForwDatagrams = 0 ipForwProhibits = 0 ipInUnknownProtos = 0 ipInDiscards = 0 ipInDelivers =4784901 ipOutRequests =4195180 ipOutDiscards = 0 ipOutNoRoutes = 0 ipReasmTimeout = 60 ipReasmReqds = 8723 ipReasmOKs = 7565 ipReasmFails = 1158 ipReasmDuplicates = 7 ipReasmPartDups = 0 ipFragOKs = 19938 ipFragFails = 0 ipFragCreates =116953 ipRoutingDiscards = 0 tcpInErrs = 0 udpNoPorts =6426577 udpInCksumErrs = 0 udpInOverflows = 473 rawipInOverflows = 0 ICMP icmpInMsgs =490338 icmpInErrors = 0

165
icmpInCksumErrs = 0 icmpInUnknowns = 0 icmpInDestUnreachs = 618 icmpInTimeExcds = 314 icmpInParmProbs = 0 icmpInSrcQuenchs = 0 icmpInRedirects = 313 icmpInBadRedirects = 5 icmpInEchos = 477 icmpInEchoReps = 20 icmpInTimestamps = 0 icmpInTimestampReps = 0 icmpInAddrMasks = 0 icmpInAddrMaskReps = 0 icmpInFragNeeded = 0 icmpOutMsgs = 827 icmpOutDrops = 103 icmpOutErrors = 0 icmpOutDestUnreachs = 94 icmpOutTimeExcds = 256 icmpOutParmProbs = 0 icmpOutSrcQuenchs = 0 icmpOutRedirects = 0 icmpOutEchos = 0 icmpOutEchoReps = 477 icmpOutTimestamps = 0 icmpOutTimestampReps= 0 icmpOutAddrMasks = 0 icmpOutAddrMaskReps = 0 icmpOutFragNeeded = 0 icmpInOverflows = 0 IGMP: 0 messages received 0 messages received with too few bytes 0 messages received with bad checksum 0 membership queries received 0 membership queries received with invalid field(s) 0 membership reports received 0 membership reports received with invalid field(s) 0 membership reports received for groups to which we belong 0 membership reports sent
Comanda netstat cu opţiunea -r arătă dacă o rută validă spre destinaţia dorită este
disponibilă În exemplul următor ieşirea comenzii netstat -r afişează tabela de rutate IP:
Routing Table: Destination Gateway Flags Ref Use Interface ------------------ -------------------- ----- ----- ------ --------- localhost localhost UH 0 2817 lo0 earth-bb pluto U 3 14293 le0 224.0.0.0 pluto U 3 0 le0 default mars-gate UG 0 14142
Câmpurile de raportul netstat -r (ieşirile comenzii) sunt descrise în tabelul următor.
Nume câmp Tip Descriere U Calea este activă. G Calea este printr-o poartă. H Calea este spre un host.
Flags
D Calea a fost creată dinamic (s-a folosit redirectare). Ref Arată numărul curent de rute care împart acelaşi nivel legătură de date. Use Indică numărul de pachete care au fost expediate. Interface Listează interfaţa de reţea care este folosită pentru rută.
3.17.6.5. Afişarea statisticilor despre NFS Server şi Client.
Un calculator poate fi simultan atât server NFS (Network File System) cât şi client NFS Unul din factorii importanţi care afectează performanţa NFS este viteza de retransmisie. Dacă serverul de fişiere nu poate răspunde la cererea clientului, clientul retransmite
cererea de un număr de ori specificat înainte de a termina (închide conexiunea). Fiecare retransmisie implică încărcarea sistemului şi creşterea traficului prin reţea. Retransmiterile în număr mare cauzează probleme de performanţă.
În cazul în care retransmisiile sunt frecvente, trebuie să verificăm: • încărcarea serverelor care consumă mult timp pentru a răspunde la cereri; • o reţea Ethernet care pierde pachete; • congestia reţelei, care încetineşte transmiterea pachetelor.

166
Comanda: nfsstat - c afişează statistici ale clientului nfsstat -s afişează statistici ale serverului nfsstat -m afişează statistici de reţea pentru fiecare sistem de fişiere.
$ nfsstat –c Client rpc: Connection oriented: calls badcalls badxids timeouts newcreds badverfs timers 1595799 1511 59 297 0 0 0 cantconn nomem interrupts 1198 0 7 Connectionless: calls badcalls retrans badxids timeouts newcreds badverfs 80785 3135 25029 193 9543 0 0 timers nomem cantsend 17399 0 0 Client nfs: calls badcalls clgets cltoomany 1640097 3112 1640097 0 Version 2: (46366 calls) null getattr setattr root lookup readlink read 0 0% 6589 14% 2202 4% 0 0% 11506 24% 0 0% 7654 16% wrcache write create remove rename link symlink 0 0% 13297 28% 1081 2% 0 0% 0 0% 0 0% 0 0% mkdir rmdir readdir statfs 24 0% 0 0% 906 1% 3107 6% Version 3: (1585571 calls) null getattr setattr lookup access readlink read 0 0% 508406 32% 10209 0% 263441 16% 400845 25% 3065 0% 117959 7% write create mkdir symlink mknod remove rmdir 69201 4% 7615 0% 42 0% 16 0% 0 0% 7875 0% 51 0% rename link readdir readdir+ fsstat fsinfo pathconf 929 0% 597 0% 3986 0% 185145 11% 942 0% 300 0% 583 0% commit 4364 0% Client nfs_acl: Version 2: (3105 calls) null getacl setacl getattr access 0 0% 0 0% 0 0% 3105 100% 0 0% Version 3: (5055 calls) null getacl setacl 0 0% 5055 100% 0 0%
3.18. Măsurarea performanţelor reţelei IP
O definiţie funcţională a performanţei de reţea: Performanţa reţelei ar reprezenta abilitatea (în sens de viteză) de a transporta cantităţi
mari de date, dar nu este suficientă, deoarece pentru anumite aplicaţii este importantă şi întârzierea totală între punctele finale ale comunicaţiei, precum şi rata de pierdere a pachetelor (adică câte pachete ajung la destinaţie din toalul de pachete trimise). Deci, performanţa reţelei nu înseamnă numai viteză de transport.
De asemenea, există diferenţă între descrierea performanţei unei părţi particulare a reţelei şi performanţa reţelei ca entitate. Căile cu trafic scăzut au mai puţin impact asupra metricilor de performanţă ale reţelei în ansamblu, faţă de căile cu trafic încărcat.
Parametrii de performanţă au fost deja analizaţi. După ce am stabilit care sunt indicatorii de performanţă determinăm cum aceştia pot fi măsuraţi şi cum pot fi interpretate rezultatele măsurătorilor.
Există 2 abordări cu privire la colectarea informaţiilor. a) abordarea activă: să injectăm trafic pentru testare în reţea şi să măsurăm performanţa
acesteia în aceste condiţii; b) abordare pasivă: colectăm informaţii de administrare de la elementele active din reţea,

167
folosind un protocol dedicat pentru administrare fără a perturba traficul.
a) În această categorie se găsesc comenzile sistemului de operare cu privire la administrarea reţelei şi care au fost prezentate anterior. Exemplificăm în continuare comanda ping şi traceroute. 3.18.1. Măsurarea performanţei cu ping
Un emiţător generază o cerere de pachet ecou ICMP (Internet Control Message Protocol) şi îl direcţionează spre sistemul ţintă dorit. La trimiterea pachetului, emiţătorul porneşte cronometrul. Sistemul destinaţie ia antetul ICMP şi trimite înapoi pachetul la emiţător ca un răspuns ecou ICMP. Când pachetul soseşte la sistemul emiţător (de origine), cronometrul se opreşte şi raportează timpul scurs.
Răspunsul ping indică că sistemul ţintă este conectat la reţea şi este în stare funcţională să răspundă la pachetul ping.
Dacă trimiteţi ping la o adresă IP îndepărată, atunci puteţi obţine numeroase metrici de performanţă: timpul scurs până la răspuns pentru fiecare pachet recepţionat, numărul pachetelor pierdute, numărul pachetelor duplicate şi pachetele care au fost reordonate de către reţea.
Când memoria-tampon a rutorului este supraîncărcată, rutorul este forţat să descarce pachete şi se observă prin ping creşterea numărului de pachete pierdute.
Folosiţi regulat testul cu ping pentru mai multe căi din reţea pentru a stabili metrica liniei de bază a căii respective. Comparând aceste valori veţi vedea care căi sunt mai solicitate.
Multe rutoare folosesc căi rapide de comutare a pachetelor de date, pe când, unitatea centrală de prelucrare a rutorului poate fi folosită să proceseze cererile ping. Procesul de răspuns ping poate primi o prioritate planificată mai scăzută, deoarece operaţiile rutorului reprezintă funcţii mult mai critice ale aceastuia. De aceea, poate creşte întârzierea şi pierderea pachetelor raportate de ping, ca urmare a algoritmului de planificare şi încărcare a procesului din rutor.
Pachetele ping nu pot fi adunate (stivuite). Variând lungimea pachetului şi comparând timpii ping ai unui rutor către rutorul următor
din cale, lăţimea de bandă a legăturii poate fi stabilită cu câteva grade de aproximare cerute, deoarece coada de aşteptare din fundal induce nivelul jitterului din reţea. 3.18.2. Descoperirea căii folosind traceroute
Traceroute este utilitar de administrare a reţelei bazat pe timpul depăşit al mesajului ICMP. O secvenţă de pachete UDP este generatăe la calculatorul gazdă ales ca destinaţie (ţintă), cu o valoare cerută în câmpul timp de viaţă TTL (time to live) din antetul IP. Aceasta generează o secvenţă de mesaje ICMP cu timp depăşit care provin de la rutorul pentru care a expirat TTL.
Ca şi ping, traceroute măsoară timpul scurs între transmisia şi recepţia pachetului ICMP corespunzător. În acest caz, rezultatele complete prezentate la execuţia traceroute expun nu doar elemente de pe calea spre destinaţie, dar şi întârzierea şi pierderea de pachete caracteristice fiecărui element de pe căile parţiale. Traceroute poate fi folosită de asemenea cu opţiuni de a pierde ruta sursă pentru a descoperi calea între 2 calculatoare gazdă îndepărtate.
Traceroute este o comandă bună pentru raportarea stării sistemului de rutare.

168
3.18.3. Măsurători într-un singur sens
Ping şi traceroute măsoară timpul dus-întors (RTT) între 2 puncte de pe aceeaşi cale a reţelei. Reţelele IP au trafic în rafală şi sunt dominate de trafic TCP, iar traficul TCP foloseşte un
mecanism de control al transportului unde întoarcerea şirul de pachete de recunoaştere ACK (acknowledgement) guvernează acţiunile emiţătorului.
Dacă datele nu semnalează la emiţător distorsiunile datorate reţelei pentru un interval complet de RTT, atunci pentru adaptarea consecventă la condiţiile de reţea ale expeditorului vom lua un timp RTT mai mare. Pentru a avea performanţă, timpul de bază de 1-2 secunde este adecvat. Pentru reţelele mari, timpul de bază de măsurare este între 60 şi 300 secunde.
Măsurarea întârzierii şi a pachetelor pierdute prin ping şi traceroute este o valoare cumulativă de pe ambele căi (de trimitere şi de întoarcere) (se măsoară întârzierea şi pierderea pachetelor cumulată de pe cele 2 căi).
Formula următoare calculează pachetele ajunse cu succes la destinaţie:
numărul de pachete pierdute pachete ajunse cu succes = 1 - ------------------------------------------
numărul total de pachete
Pentru pachete de 100 octeţi, ping a raportat un timp de răspuns de la 50 ms la 180 ms, iar pierderea pachetelor a mers de la 2% la 8%. 3.18.4. Măsurarea performanţei cu SNMP
Măsurarea performanţei cu SNMP face parte din abordarea pasivă (b) de colectare a informaţiilor pentru măsurarea performanţelor reţelelor
SNMP este o aplicaţie de administrare a reţelelor IP. SNMP poate informa total despre performanţa reţelei în ansamblu (performanţa totală a reţelei). Operarea cu SNMP este o operaţie înlănţuită, unde o staţie de administrare direcţionează periodic liste de diferite elemente de administrare şi colectează răspunsuri. Aceste răspunsuri sunt folosite pentru a actualiza imaginea asupra stării de operare a reţelei.
Reordonarea pachetelor apare când se folosesc comutatoare paralele pe un singur element de reţea şi se utilizează legături paralele între rutoare.
Există un număr mare de obiecte în MIB incluzând General Objects, Session Statistics Table, Session Sender Table, Reservation Requests Received Table, Reservation Requests Forwarded Table, RSVP (Resource Reservation Protocol) Interface Attributes, Table şi RSVP Neighbor Table. 3.19. Indicaţii pentru protocoale în urma executării comenzilor de mai sus 3.19.1. Indicaţii pentru protocolul IP

169
Pentru reţele cu MTU mic, dacă 10% sau mai mult din pachete sunt fragmentate trebuie să investigaţi pentru a determina cauza. Un număr mare de fragmente indică faptul că protocoalele de deasupra nivelului IP de pe calculatoarele gazdă de la distanţă conduc date către IP cu dimensiuni ale datelor mai mari decât MTU a interfeţei.
Porţile sau rutoarele de pe calea reţelei pot avea de asemenea un MTU de dimensiune mult mai mică decât alte noduri din reţea.
Fragmentarea determină încărcarea suplimentară a UCP astfel încât este important să determinăm cauza. Multe aplicaţii pot cauza fragmentarea.
Pentru protocolul UDP suma de control eronată se poate datora problemelor la cablu sau la cardul de reţea.
Dacă datagramele UDP recepţionate sunt datagrame de difuzare, nu sunt generate erori ICMP. Dacă această valoare este mare investigaţi cum manevrează aplicaţiile socketutile.
Supraîncărcarea memoriei-tampon a socketului se poate datora insuficientelor socketuri UDP pentru transmisie şi recepţie.
3.19.2. Indicaţii pentru protocolul TCP
Pentru protocolul TCP statisticile prezintă: • pachete expediate; • pachete de date; • pachete de date retransmise; • pachete recepţionate; • pachete duplicate; • retransmiteri datorate expirării timpului. Pentru statisticile TCP, comparaţi numărul pachetelor trimise cu numărul pachetelor de
date retransmise. Dacă numărul pachetelor retransmise este peste 10 - 15% din totalul pachetelor expediate, TCP indică expirarea timpului astfel încât traficul reţelei poate fi prea încărcat pentru a întoarce confirmarea ACK înainte de consumarea timpului. O gâtuire la nodul receptor sau probleme generale ale reţelei pot de asemenea cauza retransmisia TCP, care va creşte traficul prin reţea, lucru care va contribui la problemele de performanţă ale reţelei.
Comparaţi şi numărul de pachete recepţionate cu numărul de pachete duplicate. Dacă pentru TCP la nodul de transmisie îi expiră timpul înainte ca să fie recepţionat un ACK de la nodul receptor, acesta va retransmite pachetul. Pachetele duplicate apar când nodul receptor primeşte toate pachetele retransmise. Dacă numărul pachetelor duplicate depăşeşte 10 - 15 %, problema se poate datora traficului de reţea sau gâtuirii la nodul receptor. Pachetele duplicate sporesc traficul prin reţea.
Valoarea pentru timpul care expiră în cazul transmisiei apare când TCP trimite un pachet, dar nu recepţionează în timp un ACK. Apoi retrimite pachetul. Această valoare este incrementată şi dacă nodul receptor nu primeşte pachetul eventual îl va pierde.
Comanda netstat -s prezintă statistici pentru fiecare protocol (comparativ cu netstat -p care prezintă statistici pentru protocolul specificat).
netstat -r opţiune relevantă pentru performanţă care afişează valoarea PMTU (Path Maximmum Transmission Unit = MTU a căii).
Pentru 2 calculatoare gazdă care comunică de-a lungul unei căi a unei reţele complexe,

170
un pachet transmis va fi fragmentat dacă dimensiunea acestuia este mai mare decât cel mai mic MTU al oricărei reţele pe calea respectivă. Deoarece fragmentarea pachetului poate conduce la reducerea performanţei reţelei, este de preferat să se evite fragmentarea prin transmiterea de pachete cu o dimensiune care să nu depăşească cel mai mic MTU al căii din reţea. Această dimensiune se numeşte PMTU (MTU a căii). Comanda netstat -r afişează această valoare.
Comanda netstat -r -f inet afişează doar tabelele de rutare. Comanda netstat -D afişează pachetele sosite şi plecate pentru fiecare nivel de-a lungul
subsistemului de comunicaţie şi pachetele pierdute la fiecare nivel. Comanda netstat -s afişează detalii pentru nivelul protocoale. Dacă reţeaua este gata congestionată, modificarea MTU sau a cozii de aşteptare nu
ajută. 3.19.3. Dimensiunea maximă a segmentului pentru TCP
Dimensiunea maximă a pachetelor pe care TCP le trimite poate avea impact major asupra lăţimii de bandă, deoarece este mult mai eficient să expediezi prin reţea pachetele de dimensiunea cea mai mare. TCP controlează această dimensiune maximă, cunoscută drept dimensiunea maximă a segmentului MSS (Maximum Segment Size) pentru fiecare conexiune TCP. Pentru reţele direct ataşate, TCP calculează MSS folosind dimensiunea MTU a interfeţei de reţea şi apoi scade antetul protocolului care vine cu datele în pachetul TCP (de exemplu pentru MTU de 1500 octeţi, va rezulta MSS de 1460 octeţi după scăderea a 20 de octeţi pentru antetul IP v4 şi 20 de octeţi pentru antetul TCP (pentru IP v6 antetul are 40 octeţi).
Protocolul TCP include un mecanism pentru fiecare capăt al conexiunii să anunţe MSS să fie folosit prin conexiune, când conexiunea este creată (câmpul OPTIONS în antetul TCP anunţă un MSS propus). MSS ales este cea mai mică valoare oferită de cele 2 puncte finale care comunică. Dacă un punct final nu oferă propriul MSS, atunci sunt alocaţi 536 octeţi, care reprezintă o performanţă scăzută. Fiecare punct final cunoaşte doar MTU-ul reţelei la care este ataşat şi nu cunoaşte ce dimensiune are MTU al altei reţele care poate fi între cele 2 puncte finale. TCP ştie corect MSS doar dacă ambele puncte finale sunt pe aceeaşi reţea. Valoarea MSS anunţată de protocolul TCP în timpul setării conexiunii depinde dacă alt punct final este un sistem local pe aceeaşi reţea fizică (sistemele au acelaşi număr de reţea) ori dacă acesta este pe o reţea diferită (la distanţă).
Deoarece valoarea 1460 octeţi este cea mai mare posibilă pentru MSS care poate fi găzduită fără fragmentare IP, această alocare este optimă (pentru calculatoarele gazdă, din aceeaşi reţea).
Comanda netstat -ao afişează toate conexiunile TCP şi câmpul MSS pentru fiecare socket, iar netstat -r afişează tabelele de rutare şi arată dacă dimensiunea MTU a căii este de 1500 octeţi. Valoarea implicită pentru MSS de 512 octeţi poate fi depăşită prin specificarea unei rute statice către o anumită reţea îndepărtată. Comanda nestat - s s-au netstat - p ip indică contorul care numără depăşirile de flux.
Un exemplu de comandă netstat –r:
Routing tables Destination Gateway Flags Refs Use If PMTU Exp Groups Route tree for Protocol Family 2 (Internet): default res101141 UGc 0 0 en1 - -
171
ausdns01.srv.ibm res101141 UGHW 1 225 en1 1500 - 10.1.14.0 server1 UHSb 0 0 en1 - - => 10.1.14/24 server1 U 6 2228 en1 - - server1 loopback UGHS 6 111 lo0 - - 10.1.14.255 server1 UHSb 0 0 en1 - - 127/8 loopback U 7 17 lo0 - - 192.1.0/24 en1host2 UGc 0 0 en0 - - en0host1 en1host2 UGHW 2 109 en0 1500 - 192.1.1.0 en1host1 UHSb 0 0 en0 - - => 192.1.1/24 en1host1 U 2 2 en0 - - en1host1 loopback UGHS 0 2 lo0 - - 192.1.1.255 en1host1 UHSb 0 0 en0 - -

172
3.20 Sumar capitol
Pe parcursul acestui capitol au fost prezentate probleme legate de administrarea componentelor logice ale reţelelor. În prima parte a capitolului s-a analizat sistemul de operare referitor la administrarea proceselor, administrarea unităţii centrale de prelucrare, administrarea memoriei interne, administrarea sistemului de fişiere, administrarea dispozitivelor periferice, încheiând cu probleme de performanţă a acestor resurse. În continuare, s-au prezentat aplicaţiile pentru comunicaţie şi măsurătorile asupra câtorva dintre aceste. Protocoalele de comunicaţie şi protocoalele de rutare sunt amintite pe scurt în cuprinsul acestui capitol. Ultima parte a prezentului capitol este alocată comenzilor de sistem folosite în monitorizarea, administrarea şi creşterea performanţelor reţelelor de calculatoare. Capitolul se încheie cu indicaţii pentru protocoalele IP şi TCP cu privire la rezultatele obţinute în urma executării comenzilor de sistem prezentate.
3.21. Concluzii Avantajele unei monitorizări continue a performanţei sistemului
Monitorizarea continuă poate face: • detectarea uneori a problemelor de bază înainte de a avea efect advers; • detectarea problemelor care afectează productivitatea utilizatorului; • colectează date atunci când problema apare pentru prima dată; • permite să stabilim linia de bază pentru comparare. Pentru o monitorizare cu succes, periodic trebuie să obţinem informaţii legate de
performanţă de la sistemul de operare, să stocăm aceste informaţii pentru utilizări viitoare în probleme de diagnoză, în beneficiul administratorului de sistem, să detectăm situaţiile care cer colectarea de date suplimentare. concluzii
Monitorizarea continuă a performanţelor sistemului se poate realiza prin comenzile sistemului de operare prezentate în acest capitol.
Puteţi folosi şi utilitare de monitorizare sau puteţi scrie dvs. shell scripturi care să înregistreze datele despre starea sistemului când apar probleme şi să avertizeze asupra problemelor de performanţă.

173










