Embed Size (px)
Citation preview

199
Capítulo 6
Experiências com reconhecimento de dígitos
6.1 Introdução
Neste capítulo descreve-se um conjunto de experiências relacionadas com reconhecimento
de dígitos isolados, de forma a avaliar e validar os vários esquemas de pré-processamento
espectral com base auditiva enunciados nos capítulos anteriores. Embora se trate de uma
tarefa de reconhecimento específica, os resultados obtidos permitem evidenciar as
vantagens em utilizar uma representação espectral com base auditória.
Inicialmente será feita uma descrição da base de dados e dos métodos utilizados, seguindo-
se uma descrição dos resultados de reconhecimento e a sua interpretação.
6.2 Caracterização da base de dados
No presente trabalho foi utilizada uma base de dados de fala em Português, recolhida
através da linha telefónica, denominada TELEFALA [Neves et al, 95]. A escolha de uma
base de dados de fala telefónica reflecte o interesse em obter sistemas de reconhecimento a
funcionar de forma robusta sobre a linha telefónica. Além disso, as aplicações telefónicas

200 Capítulo 6 -Experiências com Rec. de dígitos
são um dos campos de aplicação mais importantes da tecnologia do reconhecimento
automático de fala.
A base de dados TELEFALA é constituída por locuções de dígitos isolados, cadeias de
dígitos, nomes e apelidos e algumas palavras de controlo1. O número de locutores é cerca
de 1000. A recolha da base de dados foi efectuada de Junho a Setembro de 1994. Os sinais
correspondentes às locuções foram gravados utilizando uma frequência de amostragem de
8kHz com uma resolução de 8 bits por amostra e formato PCM-lei µ. Na figura 6.1
mostram-se alguns quadros que caracterizam esta base de dados quanto à distribuição
geográfica e etária dos locutores participantes.
Age class
0
50
1 0 0
150
200
1 0 -1 9 2 0 -2 9 3 0 -3 9 4 0 -4 9 5 0 -5 9 > 6 0
N o t Invited
Invited
< 1 0
2 5 0
3 0 0
a)
Classe etária Femininos Masculinos<10 60% 40%
10 - 20 63% 37%20 - 30 59% 41%30 - 40 47% 53%40 - 50 40% 60%50 - 60 40% 60%
>60 65% 35%
b)
c)Figura 6.1 - Alguns valores relativos à base de dados TELEFALA [Neves et al, 95]. a) Distribuição delocutores participantes na recolha por classe etária. b) Distribuição dos locutores por género. c) Distribuiçãono território nacional da origem das ligações telefónicas para o sistema de recolha.
Do subconjunto da base de dados referente às locuções de dígitos isolados foi tomado um
conjunto de cerca de 4200 locuções dígitos, depois partido (aleatoriamente) em duas partes
de tamanho idêntico, uma para treino dos modelos de reconhecimento e outra para o teste
1 As palavras de controlo são: “não”, “sim”, “repetir”, “cancelar” e “acabar”.

6.2 Caracterização da base de dados 201
do desempenho de reconhecimento. Iremos referenciar estas duas partições como conjunto
de treino e de teste.
Na tabela 6.1 caracterizam-se os conjuntos de treino e teste. A base de dados TELEFALA
está organizada por sessões que correspondem à gravação das locuções referentes a um
dado locutor. Assim, na tabela 6.1 o número de sessões indica o número de locutores
incluídos no conjunto2. Os dois conjuntos foram etiquetados manualmente, indicando-se
também na tabela 6.1 as etiquetas atribuídas. Apesar de praticamente todas as locuções
conterem um segmento inicial e final sem fala, nem todos os segmentos do sinal foram
etiquetados; certos segmentos com ruído devido à linha telefónica ou ruído ambiente, foram
deixados sem etiquetas. Daí que o número de etiquetas /sil/ seja inferior a duas vezes o
número de locuções. Os dígitos, obviamente, foram etiquetados em todos os casos.
Tabela 6.1 - Caracterização das bases de dados de dígitos de treino e de teste.As palavras entre barras indicam etiquetas atribuídas nas locuções. A etiqueta/sil/ refere-se a um segmento de silêncio na locução.
Conjunto de treino Conjunto de teste
Nº de Sessões 791 795Locutores masculinos 391 404Locutores femininos 400 391Nº total de locuções 2140 2117
/zero/ 200 197/um/ 209 207/dois/ 281 278/três/ 228 226
/quatro/ 217 214/cinco/ 190 188/seis/ 199 197/sete/ 192 190/oito/ 207 205/nove/ 217 215/sil/ 3547 3531
Duração média por locução
883ms 877ms
O conjunto de treino pode considerar-se pequeno tendo em conta que vão ser estimados
modelos estatísticos e tendo também em conta a dimensão das bases de dados actualmente
2 O número real de locutores é ligeiramente inferior ao número de sessões. Isto acontece devido ao facto deterem sido consideradas sessões de gravação que não foram concluídas ou que não foi possível caracterizar olocutor mas que, mesmo assim, ainda continham geralmente muitas locuções de dígitos isolados. Nestescasos é impossível saber exactamente se esses locutores fazem parte de outras sessões (a não sersubjectivamente por audição das locuções).

202 Capítulo 6 -Experiências com Rec. de dígitos
existentes. A baixa dimensão deste conjunto de treino torna-se evidente quando se tenta
estimar modelos para reconhecimento com um número elevado de parâmetros. Mesmo
assim, é perfeitamente possível fazer comparações e retirar conclusões dos resultados
obtidos.
Outro aspecto que deve ser focado em relação aos dois conjuntos de locuções é a
variabilidade em termos acústicos e linguísticos. Tem interesse caracterizar a amplitude
máxima dos sinais uma vez que, tal como foi visto no capítulo anterior, existem
representações dos sinais com base auditiva que são bastante dependentes deste factor. Na
figura 6.2 a) e b) mostram-se histogramas da amplitude máxima nas locuções dos conjuntos
de treino e teste. Existe uma variação deste parâmetro de cerca de 20 vezes, embora os
histogramas sejam idênticos nos dois conjuntos. A barra elevada na amplitude 8000 indica
que uma percentagem significativa das locuções apresenta amplitude máxima ou que
ocorreu “clipping” no processo de gravação dos sinais3. Quanto ao ruído existente nas
locuções, pode considerar-se que o conjunto tomado é “limpo”, isto é, existe uma clara
distinção entre as energias do sinal referente aos dígitos e aos segmentos etiquetados como
silêncio. Tal é mostrado na figura 6.2 c) e d). Fazendo uma estimativa das médias dos
histogramas referentes a silêncio e fala poderemos dizer que a relação sinal-ruído média, em
ambos os conjuntos, é de cerca de 40dB.
Existe muita variabilidade inter locutor uma vez que existem muitos locutores em relação ao
número de locuções por locutor (em média, cerca de 2,5 e nunca superior a 4). Também
evidente nas locuções é a variabilidade linguística decorrente da origem geográfica dos
locutores. Além disso, existem variações acentuadas quanto ao ritmo e estilo de produção
das locuções, existindo locuções muito bem articuladas mas também muitas em que
dificilmente se percebe qual foi o dígito proferido. Por exemplo algumas locuções do dígito
/zero/ não se distinguem bem do dígito /sete/. Existem igualmente ruídos de respiração e
labiais no início e fim das locuções.
Apesar de estes factores de variabilidade terem sido identificados através audição das
locuções, não foi feita uma caracterização quantitativa destes factores.
3 O “clipping” que ocorre nas locuções não é grave: ao reproduzir estas locuções não se percebe que existedistorção.

6.3 Método de reconhecimento 203
0 2000 4000 6000 8000 100000
50
100
150
200
250
300
350
400
450
500Distrib. Amplitude Máxima (treino)
0 2000 4000 6000 8000 100000
50
100
150
200
250
300
350
400
450
500Distrib. Amplitude Máxima (teste)
a) b)
-10 0 10 20 30 40 50 60 700
50
100
150
200
250
300
dB
Distrib. Energia (treino)
/sil/
dígitos
-10 0 10 20 30 40 50 60 700
50
100
150
200
250
300
dB
Distrib. Energia (teste)
dígitos
/sil/
c) d)Figura 6.2 - a), b) Histogramas das distribuições de amplitude máxima referentes às locuções de dígitos dosconjuntos de treino e de teste. c), d) Histogramas de energia para os segmentos das locuções etiquetadoscomo silêncio (símbolo /sil/) e dígitos.
6.3 Método de reconhecimento
A técnica de reconhecimento automático de fala considerada neste trabalho baseia-se em
modelos de Markov não observáveis (HMM -“Hidden Markov Models”) usando
distribuições de probabilidade contínuas (CDHMMs). A modelação com HMMs é uma das
técnicas mais poderosas que existe actualmente para o reconhecimento de fala. Existem
excelentes textos que descrevem a teoria da modelação com HMMs (por exemplo, [Jelinek,
76], [Rabiner et al, 85], [Rabiner & Juang, 86, 93], [Juang & Rabiner, 85], [Deller et al,
93], [Young, 96], [HTK, 95]), estando esta modelação muito bem estabelecida. Na
descrição sumária que se segue o objectivo é apenas introduzir a notação utilizada neste
capítulo.

204 Capítulo 6 -Experiências com Rec. de dígitos
Um modelo de Markov não observável é um modelo estocástico definido à custa de dois
processos embebidos. Um desses processos estocásticos é um processo de Markov discreto
(cadeia de Markov com N estados), cujas transições entre estados sinalizam uma mudança
das propriedades estatísticas do sinal que modelam (ou que geram). Associado a cada
estado da cadeia existe outro processo (contínuo ou discreto) que descreve a estatística do
sinal associado a esse estado. Esta modelação aplica-se a sinais de fala uma vez que, de uma
maneira geral, a fala caracteriza-se por uma sequência de segmentos quase estacionários
mas com propriedades diferentes, correspondentes a diferentes configurações do tracto
vocal e da fonte de excitação. Esta caracterização é especialmente evidente no caso de
transições entre sons fricativos e vogais. Usualmente os HMMs modelam uma sequência de
vectores que constituem a representação compacta do sinal, designada neste âmbito por
sequência de observações. O termo “não observável” associado a estes modelos deriva do
facto de em cada instante apenas se conhecer a observação modelada (ou gerada) e não o
estado da cadeia visitado nesse instante.
A cadeia de Markov nos HMMs não é usualmente definida com todas as transições
possíveis entre estados. Consideram-se apenas transições que implicam uma sequência
temporal bem determinada referindo-se a cadeia de Markov como cadeia “esquerda-direita”
(figura 6.3c). Neste caso os estados são percorridos em sequência, da esquerda para a
direita, e sem a possibilidade de haver transições no sentido inverso.
Um modelo HMM é caracterizado parametricamente através da matriz de probabilidades de
transição entre estados, aij bem como das funções densidade de distribuição associadas a
cada estado. A forma mais corrente de HMMs utiliza funções densidade de distribuição
contínuas definidas como uma soma de M funções gaussianas a Q dimensões (mistura de M
componentes), onde Q representa a dimensão do vector de observação, X. Estas funções
são assim caracterizadas, para um estado j da cadeia, por vectores de médias (µjm), matrizes
de covariância, Σjm e pelo vector de pesos da mistura, cj. A função densidade associada ao
estado j, bj(X), caracteriza-se portanto através da seguinte expressão:
b c cj jm jm jm
m
M
jm
m=
M
( ) ( , , )X X= ==
∑ ∑N µ Σ1 1
1 , , (6.1)
onde ( )N X, ,µ Σjm jm corresponde à função densidade gaussina a Q dimensões:

6.3 Método de reconhecimento 205
( )( )
( ) ( )N X X X, , expµ ΣΣ
µ Σ µ−1jm jm
Q
jm
jm
T
jm jm= − − −
1
2
1
2π. (6.2)
Nesta expressão T indica transposição, Σ jm−1 representa a matriz de covariância inversa e
|Σjm| o seu determinante.
Associados aos HMMs podem identificar-se 3 problemas fundamentais que são resolvidos
por 3 importantes algoritmos:
• Avaliação: problema do cálculo da probabilidade de um modelo λk gerar uma sequência
de observações, X1,T = {X1, X2,…, XT}, Pr{X1,T|λk.}. Resolução com algoritmo
“forward-backward”.
• Aprendizagem: problema da estimação dos parâmetros do modelo. Resolução com
algoritmo de Baum-Welch.
• Descodificação: problema do cálculo de uma sequência óptima de estados dado X1,T e o
modelo λk. Resolução com algoritmo de Viterbi.
O algoritmo de Viterbi é usado preferencialmente no processo de reconhecimento embora,
no caso de palavras isoladas, pudesse ser também usado o passo “forward” do algoritmo
“forward-backward”.
No reconhecimento de fala contínua uma locução pode conter várias palavras4: W1,n =
{w1,…,wn}. Neste caso, o problema consiste em determinar a sequência de palavras mais
provável, w*, dada a sequência de observações X1,T . De acordo com o teorema de Bayes, é
necessário neste caso calcular:
{ } { } { }{ }w W
W W
wn T
w
n T n
T
* arg max Pr | arg maxPr Pr |
Pr, ,
, , ,
,
= =1 1
1 1 1
1
XX
X. (6.3)
Nesta expressão, a probabilidade de X1,T pode considerar-se constante. Assim, o problema
do reconhecimento consiste no cálculo das duas probabilidades definidas no numerador da
expressão anterior. A primeira delas conduz à definição de um modelo de linguagem que
especifica a probabilidade de ocorrência da sequência de palavras e é independente da
sequência de observações. A segunda probabilidade é determinada por um modelo acústico
4 O conceito de “palavra” pode não ter uma correspondência directa com o conceito linguístico. Poderepresentar uma palavra, uma sílaba, um fonema ou outra unidade acústico-fonética.

206 Capítulo 6 -Experiências com Rec. de dígitos
que é, neste caso, constituído pela aglomeração de HMMs referentes às palavras do
dicionário.
No presente trabalho a tarefa de reconhecimento de dígitos pode ser vista como um
problema de reconhecimento de palavras ligadas, uma vez que pode ou não existir um
segmento de silêncio antes e depois de um dígito. Neste caso, o vocabulário do
reconhecedor é composto por 11 palavras e portanto 11 modelos HMM: 10 para os dígitos
e um modelo para silêncio (símbolo /sil/). A gramática (rede de palavras) definida para a
tarefa de reconhecimento de dígitos é caracterizada pelo diagrama da figura 6.3a). Os 10
modelos HMM referentes aos dígitos são todos idênticos, definidos com 7 estados e mistura
gaussiana com M componentes. O valor de M varia de 1 a 6. O diagrama da figura 6.3c)
indica a cadeia esquerda-direita referente a estes modelos5. O modelo de silêncio tem apenas
3 estados e não é um modelo esquerda-direita (figura 6.3b)). Existe uma transição do último
estado para o inicial para melhor modelar sequências de silêncio em que possa existir,
ocasionalmente, algum ruído impulsivo. Esta transição permite evitar que se transite para
uma próxima palavra sempre que ocorra um pico breve de energia do sinal durante um
período de silêncio.
/nove/
/sil/
/um/
/zero/
/sil/ s1 s2 s3
a11 a22 a33
a13
a12
a31
s1 s2 s3
a11 a22 a33
a13
a12 s5 s6 s7
a55 a66 a77
s4
a44
a) b)
c)
a23…
Figura 6.3 - a) Rede utilizada no reconhecimento de dígitos isolados. b) Cadeia de Markovpara o modelo HMM referente os segmentos etiquetados com /sil/. c) Cadeia de Markov“esquerda-direita” referente aos modelos de dígitos.
Para fazer o treino dos modelos bem como o reconhecimento foi utilizado o software HTK
[HTK, 95]. Trata-se de um conjunto de rotinas (“toolbox”) para gerar vários tipos de
5 Os 7 estados referidos corresponde a estados ditos “emissores”, isto é, em que existem funções densidadeassociadas. Além destes estados existe um estado inicial e final, “não-emissores”, que servem paraconcatenar modelos entre si.

6.4 Métodos 207
representações acústicas dos sinais; para definir e estimar modelos HMM e também para
fazer testes de reconhecimento. É uma ferramenta “standard”, de uso generalizado pela
comunidade científica ligada ao reconhecimento automático de fala.
6.4 Métodos
Nesta secção descrevem-se sumariamente os métodos utilizados na geração dos vários tipos
de representação acústica dos sinais e no treino dos HMMs. As várias representações dos
sinais foram geradas utilizando a ferramenta MatLab. Esta ferramenta apresenta a vantagem
de facilmente se visualizar os resultados obtidos e de rapidamente se poder implementar
novos algoritmos. Porém, a implementação obtida não é tão eficiente em termos
computacionais como a que se consegue com uma programação em linguagem C.
6.4.1 Representação acústica
No caso do cálculo dos parâmetros das representações mais convencionais, baseadas em
bancos de filtros (MFCC, RASTA, etc.), o processamento convencional consiste no
seguinte. É feita uma pré-ênfase aos sinais com um filtro FIR de ordem 1 e com factor de
pré-ênfase 0,95. Seguidamente o sinal é dividido em frames de 256 amostras com avanço de
80 amostras às quais à aplicada uma janela de Hamming. É depois calculada a FFT de cada
frame, tomado o seu módulo quadrado e guardados os coeficientes correspondentes à
frequência normalizada no intervalo [0,…,π], ou seja 129 coeficientes. Esta representação
corresponde ao espectro de potência de termo curto dos sinais. Sendo x[n] uma frame de
sinal a analisar e N o tamanho da janela de Hamming, w[n], o espectro de potência da frame
m tem a seguinte expressão:
( )P k x n w n k Nm N( ) FFT ,...,= =[ ] [ ] , 2
0 2 (6.4)
Finalmente, este espectro de termo curto é multiplicado pelo quadrado da resposta em
frequência dos filtros dos canais do banco de filtros, constituindo a respectiva soma a
energia de termo curto à saída do banco. Mais precisamente, para um banco de filtros

208 Capítulo 6 -Experiências com Rec. de dígitos
definido com Nbank canais e respostas em frequência definidas pelas DFTs Hi(k), a energia de
termo curto referente ao canal i é calculada através da seguinte expressão6:
E i P k H k i Nm m
k
N
i bank( ) ( ) ( ) ,...,/
= ==
∑0
22
1 , (6.5)
Esta operação equivale ao cálculo da energia de termo curto associada à convolução
circular do sinal pela resposta a impulso dos filtros. A representação baseada em banco de
filtros corresponde assim a uma sequência de Nframe vectores com Nbank componentes, onde
Nframe é o número de frames do sinal tomadas de 80 em 80 amostras (resolução temporal de
10ms).
No caso da análise com bancos de filtros derivados da modelação coclear é utilizada uma
abordagem diferente: os sinais são filtrados por cada filtro do banco, sendo as respostas
temporais obtidas aplicadas a modelos de CCIs/sinapses. Para obter a representação final
em termos de taxa média de disparos, é utilizado um procedimento idêntico à divisão em
blocos e aplicação de janelas de Hamming, da mesma forma que na análise descrita atrás.
Esta operação consiste numa filtragem passa-baixo da taxa média de disparos com um filtro
FIR de tamanho 256 e frequência de corte 50 Hz7, de forma a poder-se decimar a taxa
instantânea de disparos a um ritmo de 100Hz, ou seja, de 80 em 80 amostras.
Na modelação LPC o espectro é caracterizado pelos coeficientes LPC associados a cada
frame, utilizando-se para o seu cálculo o método da autocorrelação [Rabiner & Schafer,
78]. A ordem do modelo LPC considerada é p=12 (excepto na modelação PLP e RASTA-
PLP onde se toma p=8). A técnica PLP consiste em calcular o espectro de potência dos
sinais com o banco de filtros PLP (secção 3.3.5) ao qual é aplicado uma raiz cúbica. A
partir deste espectro de potência “perceptual” aplica-se uma IDFT para obter p+1 valores
de autocorrelação com os quais se determinam os p coeficientes LPC. No caso da
representação RASTA, é utilizada uma implementação também em ambiente MatLab, mas
que respeita na íntegra uma implementação em “C”, de domínio público, desenvolvida no
6 No caso de filtros triangulares e na modelação PLP não é aplicado o quadrado às respostas Hi(k). Tambéma implementação MFCC considerada usa “amplitudes” em vez de potência.
7 Um filtro FIR de tamanho 256 e frequência de corte 50Hz, projectado com diferentes métodos, apresentacoeficientes muito semelhantes a uma janela de Hanning ou de Hamming. Embora a janela de Hanningapresente neste caso características um pouco superiores à janela de Hamming, esta última foi escolhidapara uniformizar esta operação com a divisão do sinal em frames.

6.4 Métodos 209
ICSI8. Na técnica RASTA o espectro de potência PLP (antes da aplicação da raiz cúbica) é
passado a um domínio logarítmico (ou “quase logarítmico” na técnica Lin-Log RASTA),
aplicando-se neste domínio a filtragem RASTA referida no capítulo 5. Depois desta
filtragem aplica-se a operação inversa (exponencial) seguindo-se as operações normais na
técnica PLP.
6.4.2 Transformação com DCT
Qualquer que seja a representação espectral considerada, as observações a fornecer aos
modelos HMM correspondem a uma sequência de vectores, cada um deles contendo
informação espectral de termo curto relativa a frames do sinal. Por razões de eficiência,
existe toda a vantagem em utilizar matrizes de covariância diagonais na caracterização dos
HMMs (para terem matrizes inversas e determinantes imediatos; ver expressão (6.2)). Isto
implica que a representação espectral em consideração deverá apresentar parâmetros com
baixa correlação entre eles. Desta forma, considera-se usualmente uma transformação linear
da representação espectral, que torne, tanto quanto possível, os coeficientes
descorrelacionados. A transformada de cosseno discreta (DCT) é invariavelmente utilizada
uma vez que corresponde a uma alternativa, eficiente embora sub-óptima, da KLT -
transformada de Karhunen-Loève [Therrien, 92], [Deller et al, 93].
A representação MFCC (e a representação cepstral, de um modo geral) corresponde
igualmente à DCT do logaritmo do espectro. No caso de cepstrum LPC, isto é, cepstrum
derivado da modelação LPC, é utilizada uma recursão directa dos parâmetros LPC [Markel
& Gray, 82, pp. 230], embora a analogia com a DCT seja evidente dadas as propriedades de
simetria do cepstrum [Oppenheim & Schafer, 75]. De facto, a DFT inversa de uma
sequência par equivale a uma DCT. Porém, a expressão da DCT considerada usualmente
não corresponde exactamente à DFT de uma sequência par mas sim à seguinte expressão
[Davis & Mermelstein, 80], [Deller et al, 93], [HTK, 95]:
8 Versão RASTA_2_2 implementada por Nelson Morgan e colaboradores, no ICSI (“InternationalComputer Science Institute”, Universidade de Berkeley; http://www.icsi.berkeley.edu/). Este código em “C”pode ser obtido por ftp no seguinte URL: www.icsi.berkley.edu/ftp/global/pub/speech/rasta/. Foram apenasconsideradas as implementações L-RASTA (RASTA com expansão logarítmica) e J-RASTA (Lin-LogRASTA) com J constante.

210 Capítulo 6 -Experiências com Rec. de dígitos
( )cN
X n kn k
k
N
N= −=
∑22 12
1
cos ( )π , n = 0,…,N−1. (6.6)
Neste caso tomou-se N=Nbank para simplificar a notação. Xk corresponde à representação
baseada em banco de filtros (logaritmo do espectro ou algo equivalente) e cn representa os
coeficientes da DCT. O índice k corresponde ao índice do canal do banco de filtros. Assim,
o canal k=0 correspondente a uma CF nula que não é utilizada, pelo que X0=0. O mesmo se
passa relativamente ao canal N+1 que corresponde à frequência normalizada π9.
Por vezes o parâmetro c0 não é incluído na representação a fornecer aos modelos de
reconhecimento, outras vezes, em seu lugar é incluída a energia relativa a cada frame de
sinal. Na secção seguinte a inclusão do parâmetro c0 será sempre explicitamente indicada.
Os testes de reconhecimento considerados neste trabalho utilizam sempre matrizes de
covariância diagonais, pelo que a transformação com DCT ou parâmetros cepstrais LPC
são sempre usados.
Uma outra propriedade da DCT (ou melhor, da KLT) é que a energia dos coeficientes da
transformação é ordenada estando concentrada nos primeiros coeficientes. Devido a este
facto, não é necessário utilizar todos os N coeficientes da DCT. A prática usual consiste em
truncar os coeficientes a partir de uma dada ordem usando-se apenas Q coeficientes (Q<N).
Tendo em conta a expressão (6.6) facilmente se pode mostrar que neste caso a DCT inversa
é definida através da seguinte expressão:
( )XN
cc n k k = , ,N Xk n N
n
N
= + −
=
=
−
∑2
22 1 1 00
2
1
1
0cos ( ) ... ;π , . (6.7)
Esta expressão permite verificar o que acontece à representação X quando os coeficientes cn
são truncados. Na figura 6.4 mostra-se o sonograma de um dígito com uma representação
de taxa média de disparos e o efeito da truncagem dos coeficientes cn. Como se pode
observar, os primeiros 16 dos 35 coeficientes preservam praticamente toda a informação
espectral uma vez que não existe uma distinção significativa nos sonogramas. Quando um
menor número de coeficientes é utilizado, existe, obviamente, um efeito de suavização
espectral, que pode inclusivamente ser importante na redução da variabilidade inter locutor.
9 No caso de um banco de filtros em cascata baseado em modelos cocleares, os índices dos canais devem sertomados por ordem inversa, uma vez que os índices baixos dizem respeito a CFs elevadas e vice-versa.

6.4 Métodos 211
10 20 30 40 50 60 70 80 90
5
10
15
20
25
30
35
Q=35
10 20 30 40 50 60 70 80 90
5
10
15
20
25
30
35
Q=15
10 20 30 40 50 60 70 80 90
5
10
15
20
25
30
35
Q=8
a) b) c)Figura 6.4 - Efeito na representação espectral da truncagem dos coeficientes da DCT. a) Representaçãode taxa média de disparos original (dígito /oito/) com 35 canais. b) Mesma representação, de acordo coma expressão (6.7) quando são anulados os coeficientes c16 - c34. c) Mesmo caso, com coeficientes c9 - c34
anulados.
Uma operação habitual de uniformização associada a parâmetros cepstrais, consiste no
“liftering” (filtragem no domínio cepstral) e que deriva do facto dos coeficientes cepstrais
decaírem rapidamente segundo o seu índice (“quefrency”). Com esta operação pretende-se
uniformizar a variância dos parâmetros, aumentando os parâmetros de ordem mais elevada
[Juang et al, 87]. Para tal é utilizada parte de um ciclo sinusoidal ou uma curva de potência,
de acordo com as seguintes expressões:
( )� sin ,...,cL
n L c n Qn n= +
=1
21π , , (6.8a)
� ,...,c n c n Qnl
n= = , 1 . (6.8b)
No presente trabalho utilizou-se a primeira expressão, apenas em algumas situações, com os
seguintes valores: L=16 para Q=12; L=20 para Q=15 e L=25 para Q=18. A segunda
expressão é utilizada no processamento RASTA com l=0,6. Esta normalização não é
contudo muito importante no reconhecimento baseado em HMMs.
Outra transformação da representação cepstral que é usual considerar na modelação HMM
corresponde aos parâmetros delta, já anteriormente referidos. Estes parâmetros fornecem
informação da dinâmica espectral e são caracterizados pela inclinação da recta de regressão
linear dos coeficientes ao longo do tempo (neste caso 5 frames). Correspondem assim a
uma “derivada” em ordem ao tempo (em tempo discreto) dos parâmetros originais. O seu
cálculo é tomado de acordo com a seguinte expressão:

212 Capítulo 6 -Experiências com Rec. de dígitos
∆c t
k c k t
k
k c k tn
nk
k
nk
( )
( )
( )=⋅ +
= ⋅ +=−
=−
=−
∑
∑∑2
2
2
2
22
21
10 , t = 3,…,Nframe−2 . (6.9)
Para as duas primeiras e as duas últimas frames são tomadas cópias do 1º e último vector
delta calculado.
Outro aspecto que importa referir é o método utilizado para determinar a relação sinal-
ruído (SNR) dos sinais. Nas experiências com ruído é adicionado ruído branco aos sinais
com distribuição gaussiana de média nula e variância σ2, em função da SNR considerada:
SNR log(dB) =
10 10 2
Ps
σ, (6.10)
onde Ps é a potência média do sinal. Para o cálculo de σ é usual considerar-se a potência
média do sinal ao longo de toda a locução. Porém, quando existem longos períodos de
silêncio nas locuções esta média vem artificialmente baixa. Faz mais sentido considerar a
potência média referente apenas aos segmentos onde existe fala. Desta forma, neste trabalho
a potência média dos sinais é calculada com base nas frames de sinal que apresentam
energia superior a 30 dB. De acordo com os histogramas da figura 6.2, este limiar
corresponde a rejeitar a grande maioria dos segmentos de silêncio no cálculo da potência
média dos sinais.
6.4.3 Estimação dos parâmetros dos modelos HMM
Refere-se nesta secção a metodologia usada na estimação dos parâmetros dos modelos
HMM. Os parâmetros da representação espectral em questão são guardados em ficheiros
com o formato HTK [HTK, 95], utilizando-se apenas a partir desta fase as ferramentas da
“toolbox” HTK. Os modelos são inicialmente definidos com uma única componente
gaussiana (com matrizes diagonais) e os parâmetros estimados com base em iterações
sucessivas do algoritmo de Viterbi. Em cada iteração a sequência de estados mais provável
é calculada e actualizadas as médias e variâncias dos parâmetros associados a esse estado.
Considera-se um máximo de 35 iterações, embora geralmente o processo de estimação
convirja ao fim de cerca de uma ou duas dezenas de iterações10. Com os modelos assim
10 A ferramenta HTK utilizada é o HInit.

6.4 Métodos 213
gerados, considera-se seguidamente outra fase idêntica, agora utilizando a reestimação de
Baum-Welch11. Nestas duas fases os modelos são treinados de forma isolada e é utilizada a
informação relativa à segmentação das locuções. Isto é, a estimação de cada modelo tem
por base as correspondentes etiquetas bem como as marcas temporais de início e fim na
sequência de observações associada a cada locução.
Segue-se uma fase de reestimação embebida em que todos os modelos são estimados em
simultâneo utilizando todo o conjunto de treino12. Apenas as etiquetas são utilizadas mas
não as marcas. Com esta reestimação embebida seria possível utilizar um conjunto de treino
maior, apenas com uma transcrição em termos das unidades a reconhecer. Tal não
corresponde ao presente caso pois todo o conjunto de treino foi etiquetado e segmentado.
Esta fase permite aliviar o problema de eventuais incorrecções na segmentação das
locuções. São consideradas 6 iterações sucessivas de reestimação embebida guardando-se
os modelos em cada iteração. Posteriormente os testes de reconhecimento utilizam os
modelos gerados nas várias iterações no sentido de averiguar em qual se obteve a maior
generalização. Muitos passos de reestimação podem conduzir a uma “especialização” dos
modelos no conjunto de treino (“super aprendizagem”) e assim perder a capacidade de
generalização face a dados novos. Verificou-se que a partir da 5ª ou 6ª iteração as
percentagens de reconhecimento relativas ao conjunto de teste baixam. Desta forma, foram
consideradas apenas 6 iterações de reestimação embebida.
O processo descrito diz respeito a modelos com uma única componente gaussiana. Para
considerar uma mistura guassiana, o número de componentes é sucessivamente
incrementado entre reestimações embebidas. O processo de incrementar as componentes da
mistura consiste em duplicar a componente com maior peso (ver expressão (6.1)), dividir os
pesos das duas cópias por 2 e perturbar o vector de médias ligeiramente13. O processo
global é repetido até se obterem funções densidade com uma mistura de 6 componentes
gaussianas. Concluindo, para cada representação espectral considerada são gerados 36
conjuntos de modelos, referentes aos 6 passos de reestimação (R=1,…,6) e às 6
componentes da mistura (M=1,...,6). Os testes de reconhecimento são efectuados apenas
nalgumas configurações (valores de R e M iguais a 4, 5 e 6, ou seja, 9 testes), uma vez que
11 Ferramenta HRest.12 Ferramenta HERest.13 Ferramenta HHEd, comando MU.

214 Capítulo 6 -Experiências com Rec. de dígitos
para menos reestimações ou menos componentes as taxas de reconhecimento foram,
geralmente, sempre inferiores à dos casos considerados.
As taxas de reconhecimento que se irão apresentar são calculadas com base nos dígitos
correctamente identificados, sem tomar em consideração as identificações com o modelo de
silêncio. Por exemplo, caso seja identificada a sequência { /sil/, /zero/, /sil/ }, {/zero/, /sil/},
{/sil/, /zero/} ou simplesmente {/zero/}, considera-se uma correcta identificação se o dígito
em questão é o zero, ignorando-se os “apagamentos” ou “inserções” do símbolo /sil/. A
taxa de reconhecimento para cada dígito é calculada tomando os valores da tabela de
confusão referentes às correctas identificações dos dígitos e dividindo pelo número total de
locuções desse dígito no conjunto de teste. A taxa média de reconhecimento indicada é a
média das taxas de reconhecimento dos dígitos. De notar que a taxa de reconhecimento dos
símbolos /sil/ indica até que ponto a reestimação embebida “respeitou” a segmentação
manual da base de dados. Existem muitos “apagamentos” do símbolo /sil/ devido ao facto
de se terem tomado, no processo de segmentação e etiquetagem, segmentos de silêncio com
duração muito baixa (poucas frames). Estes segmentos são em geral absorvidos pelos
modelos dos dígitos, embora isso dependa muito do tipo de representação considerada.
6.5 Testes de Reconhecimento
A comparação de diversas representações espectrais em reconhecimento de fala constitui
um assunto algumas vezes abordado na literatura. No presente caso tem interesse
considerar os trabalhos onde uma representação auditiva entra no conjunto a comparar. Um
destes trabalhos mais recentes é o estudo apresentado em [Jankowski et al, 95] onde é
comparada a representação MFCC com os modelo auditivos de Seneff e de Ghitza (EIH,
secção 5.2.2.4). É utilizada a base de dados TI-105 que compreende um vocabulário de 105
palavras de comando mas onde entram apenas 8 locutores com 5 locuções de cada palavra
para o conjunto de teste e 3 locuções para o conjunto de treino. Trata-se portanto de uma
base de dados ainda mais reduzida do que a do presente trabalho, obrigando a que os
modelos HMM das palavras partilhem muitos parâmetros entre si devido à reduzida
quantidade de dados de treino. Os testes de robustez das representações incluem a adição
de ruído e a filtragem dos sinais. A conclusão principal é que não existe uma clara vantagem

6.5 Testes de Reconhecimento 215
na utilização da representação auditiva em relação à representação MFCC, embora a
representação auditiva apresente resultados ligeiramente superiores para SNRs abaixo dos
30dB ou para o caso da filtragem dos sinais. Também nesse trabalho se confirma a
conhecida degradação da representação LPC em condições de ruído.
Num outro trabalho [Leung et al, 93] são comparadas representações espectrais bem como
técnicas de classificação numa tarefa de reconhecimento de fonemas utilizando a base de
dados TIMIT e NTINIT [Jankowski et al, 90]. A representação correspondente ao modelo
de Seneff é também incluída. No entanto a melhor percentagem de reconhecimento obtida
com esta representação é inferior às percentagens obtidas com as representações MFCC ou
PLP.
Outros trabalhos apresentam conclusões muito mais optimistas relativamente à
representação auditiva. Por exemplo em [Stern et al, 96], utilizando também o modelo de
Seneff, mostra-se que quando diferentes microfones são usados nos conjuntos de treino e de
teste, tanto a representação de taxa média de disparos como a representação GSD
apresentam uma substancial melhoria no desempenho do reconhecimento (>20%) em
relação à representação de base (cepstrum LPC). Hunt e Lefèbvre, [Hunt & Lefèbvre, 88],
comparando um modelo auditivo (algo parecido com o GSD) com a representação MFCC,
indicam igualmente uma melhoria substancial da representação auditiva numa tarefa de
reconhecimento de dígitos isolados. Em [Cohen, 89] é utilizado um modelo idêntico aos
primeiros estágios da técnica PLP mas que inclui um modelo de CCIs/sinapses (modelo de
Schroeder e Hall, [Schroeder & Hall, 74]). É indicada uma redução de 40% na taxa de
erros com a utilização do modelo auditivo em comparação com uma representação de
banco de filtros numa tarefa de reconhecimento, dependente do locutor, de frases
compostas de palavras isoladas. De forma análoga, Ghitza [Ghitza, 88], apresenta as
vantagens da utilização do EIH em relação ao cepstrum LPC na presença de ruído.
Nas secções seguintes são apresentados resultados de reconhecimento utilizando várias das
representações focadas no capítulo 5. Resultados preliminares do presente estudo foram
apresentados em [Perdigão e Sá, 97], embora neste caso se tenham considerado modelos de
dígitos inteiros, incluindo os períodos de silêncio. O número de locuções considerado nos
conjuntos de treino e teste era também ligeiramente inferior ao actual.

216 Capítulo 6 -Experiências com Rec. de dígitos
6.5.1 Bancos de filtros, LPC e RASTA
Em primeiro lugar interessa considerar os resultados de reconhecimento utilizando
representações acústicas convencionais. Assim, as primeiras experiências foram efectuadas
utilizando parâmetros MFCC e LPC, sem e com parâmetros delta. Os resultados
apresentam-se na tabela 6.2. A taxa média de reconhecimento que se consegue obter com
estas representações é baixa, entre 89% e 91%. A variação do número de parâmetros
cepstrais não influencia significativamente este resultado, no entanto, tomando um banco de
filtros com menor número de canais conduz a uma melhoria dos resultados (20 canais e 12
coeficientes - 4ª linha da tabela 6.2). Esta generalização é conseguida à custa de uma
redução da resolução espectral que, para o caso de reconhecimento de dígitos, se mostra
adequada. Note-se que a taxa média de reconhecimento obtida com Q=18 não baixou
relativamente aos casos com menor número de coeficientes, o que leva a admitir que o
conjunto de treino é suficiente, pelo menos para este número de parâmetros14.
Tabela 6.2 - Taxas de reconhecimento, em percentagem, relativas à modelação MFCC, LPC e RASTA.O par M/R indica o número de componentes da mistura gaussiana e o número de reestimaçõesembebidas para os quais se obteve a melhor taxa média de reconhecimento. A letra “E” indica que àrepresentação se juntou a energia de termo curto do sinal; “∆” significa que se adicionaram parâmetrosdelta e “0” indica adição do parâmetro c0. A coluna “Rec(%)” corresponde à taxa média dereconhecimento relativa apenas aos dígitos (colunas “0” a “9”). Na modelação J-RASTA o valor de J éfixo e igual a 10-6.
sigla Nbank Q Rec(%) M/R 0 1 2 3 4 5 6 7 8 9 /sil/
MFCC 35 12 89,0 4/6 87,8 76,3 95,7 75,2 96,3 94,7 82,7 93,7 93,2 94,4 93,6
MFCC_Q15 35 15 89,25 6/6 90,4 75,8 93,9 74,3 97,7 95,2 83,2 90,5 96,1 95,3 94
MFCC_Q18 35 18 89,59 6/4 89,8 80,2 95 73,9 96,7 95,2 86,3 91,1 95,6 92,1 94,8
MFCC_20_12 20 12 89,78 6/4 89,8 80,7 94,2 75,7 97,2 94,1 84,8 93,2 93,7 94,4 95,3
MFCC0 35 12+c0 90,27 5/4 90,9 81,2 94,2 77,9 96,7 95,2 84,8 93,7 95,6 92,6 92,3
MFCC_E_D 3512+E+
12∆+∆E 97,69 6/4 96,4 96,6 97,1 96,5 100 97,3 96,4 97,9 98,5 100 95
LPC p=12 12 89,91 4/3 91,9 82,1 95 74,8 93,5 95,7 83,8 91,1 94,6 96,7 95,9
LPC0 p=12 12+c0 90,82 5/4 90,4 83,6 94,2 77,9 93,5 97,3 84,8 94,2 95,6 96,7 93,5
LPC_E_D p=1212+E+
12∆+∆E 97,95 6/4 98,5 97,1 98,2 96,5 100 98,4 95,9 97,4 97,6 100 94,1
PLP 15 9 (8+c0) 90,58 5/5 92,9 81,6 94,6 77,0 93,5 95,2 86,3 94,2 94,6 95,8 90,5
L-RASTA 15 9 (8+c0) 97,61 6/4 98 96,6 97,8 93,8 99,5 98,9 95,4 97,9 99 99,1 68,6
J-RASTA 15 9 (8+c0) 96,27 4/6 95,4 93,7 95 92,9 99,5 96,8 94,9 96,3 98,5 99,5 63,6
14 O número de parâmetros a estimar em cada modelo corresponde a: N(estados)xM(misturas)x[Q(médias)+Q(variâncias)+1(pesos)], neste caso 1554 parâmetros. Como o tamanho médio dos dígitos, emframes, é cerca de 60 e o número de locuções de treino por dígito é cerca de 200, significa que existem, emmédia, apenas 8 frames de sinal por parâmetro a estimar.

6.5 Testes de Reconhecimento 217
Taxas de Erro (%)
0
5
10
15
20
25
30
35
40
Méd
ia
/zer
o/
/um
/
/doi
s/
/três
/
/qua
tro/
/cin
co/
/sei
s/
/set
e/
/oito
/
/nov
e/
/sil/
MFCCMFCC_Q15MFCC_Q18MFCC_20_12MFCC0MFCC_E_DLPCLPC0LPC_E_DL-RASTAJ-RASTA
Figura 6.5 - Taxas de erro de reconhecimento (%) relativas às representações indicadas na tabela 6.2
Quando se junta informação de energia (energia relativa às frames ou o parâmetro c0) bem
como informação dinâmica (através da adição de parâmetros delta), obtêm-se resultados
muito superiores. De facto, a taxa de reconhecimento obtida com parâmetros LPC com
energia e deltas (98%) corresponde ao melhor resultado obtido em todos os testes
efectuados. A figura 6.5 mostra de forma gráfica os resultados da tabela 6.2, onde se pode
observar que os maiores erros de reconhecimento acontecem para os dígitos um, três e seis.
Outro teste de interesse tem a ver com a modelação PLP e RASTA, cujos resultados se
indicam igualmente na tabela 6.2. A designação L-RASTA diz respeito à utilização do
logaritmo do espectro de potência e a designação J-RASTA à modelação anteriormente
referida como Lin-Log RASTA. Nestes casos a energia do sinal é representada através do
logaritmo do erro médio quadrático de predição linear (coeficiente c0). É impressionante o
resultado obtido com a modelação RASTA com um número tão reduzido de parâmetros,
quase idêntico ao resultado com a representação MFCC com energia e parâmetros delta (9
contra 26 parâmetros por vector de características). A explicação para este bom resultado
pode ser interpretada de vários pontos de vista. Em primeiro lugar, pela normalização
cepstral face a diferentes condições da linha telefónicas e telefones usados na gravação das
locuções. Depois pela suavização espectral derivada da modelação LPC implícita neste
método. Finalmente, devido à reduzida dimensão do conjunto de treino. Apesar de todas
estas hipóteses serem razoáveis, a segunda hipótese deverá ter um peso significativo. A
partir dos coeficientes LPC obtidos na representação RASTA é possível construir
sonogramas relativos aos espectro de potência, antes da conversão em cepstrum LPC. A
observação destes sonogramas mostra que, de facto, a representação é muito suavizada
tanto temporalmente como na frequência. É também interessante verificar que a taxa de
reconhecimento relativa aos segmentos de silêncio é muito mais baixa que nos outros casos

218 Capítulo 6 -Experiências com Rec. de dígitos
e resulta de “apagamentos” do símbolo /sil/. Isto acontece porque os parâmetros da
representação relativos ao segmento de silêncio final apresentam médias muito diferentes
das do segmento de silêncio inicial, devido à filtragem RASTA que tende a anular a
componente média das trajectórias temporais do espectro logarítmico (ver figura 5.10 ou
5.13). Devido à suavização espectral, os 7 estados dos modelos são suficientes para
caracterizar os dígitos bem como este segmento final de silêncio.
Outro teste considerado consistiu em comparar o desempenho de reconhecimento quando
se utiliza um banco de filtros baseado em modelos cocleares em vez dos filtros triangulares
da análise MFCC. A análise é em tudo idêntica à análise MFCC com a excepção das
respostas dos filtros. Na tabela 6.3 indicam-se os resultados obtidos. Verifica-se uma ligeira
melhoria dos resultados apenas nos modelos da cóclea humana, CocH, e “gamma-tone” em
especial no primeiro. Este resultado confirma o que se disse na secção 5.3.2 a respeito da
similaridade da representação com base em bancos de filtros, mas também indica que não é
de todo indiferente a escolha das respostas dos filtros.
Tabela 6.3 - Resultados de reconhecimento paradiferentes bancos de filtros. PLPfb: banco de filtrosusado na modelação PLP; CocH: modelo da cócleahumana; Gamma: filtros “gamma-tone”; Seneff:estágio I do modelo de Seneff; CocF: modelo funcional.Energia não incluída.
M/R Taxa Média de Rec. (%)MFCC 4/6 89,00PLPfb 5/4 89,00CocH 4/6 90,34Gamma 4/6 90,12Seneff 3/6 89,53CocF 6/4 88,74
6.5.2 Modelos das CCIs/sinapses
Testes semelhantes aos anteriores, mas agora com a inclusão dos modelos das
CCIs/sinapses, foram feitos apresentando-se os resultados na tabela 6.4. Estes resultados
indicam uma melhoria significativa da capacidade de descriminação desta representação.
Sem utilizar qualquer tipo de normalização ou compensação, o melhor resultado consegue-
se com a utilização do banco de filtros “gamma-tone” e o modelo de CCIs/sinapses de

6.5 Testes de Reconhecimento 219
Martens-Immerseel (95,65%, sigla “GMarH2”15). O modelo de Seneff apresenta os piores
resultados embora isso se deva não tanto ao modelo de CCIs/sinapses mas mais ao banco de
filtros. De facto, utilizando o modelo de CCIs/sinapses de Seneff com o banco de filtros
“gamma-tone” (sigla “GSenM10”), a taxa de reconhecimento sobe, o que mostra que o
problema reside (também) no banco de filtros e não apenas no modelo de CCIs/sinapses.
Além disso, confirmam-se resultados anteriores, [Jankowski et al, 95], [Leung et al, 93],
que indicam que a representação de sincronia (GSD) é superior (neste caso apenas
ligeiramente) à de taxa média de disparos.
Tabela 6.4 - Taxas médias de reconhecimento para várias configurações de bancos defiltros e modelos de CCIs/sinapses. As letras das siglas indicam a composição do testecomo se explica parcialmente na coluna “Notas”. O número de parâmetros é Q=12excepto quando é indicado outro valor.
Sigla M/R rec.% Banco CCI fspo fsat lifter Notas
HMarH2l 5/5 92,45 CocH Mar2 50 150 16 Mar2: Martens-Immerseel, n=2
HMarH2c 6/5 92,12 CocH Mar2 50 150 - H: HSR-LT; c: “center clipper”
HMarH20 6/6 92,79 CocH Mar2 50 150 - 0: c/ coef. c0
HMarH2c0 6/6 92,84 CocH Mar2 50 150 - c/ “center clipper” e coef. c0
HMarH2nc0 5/6 96,95 CocH Mar2 50 150 - n: normalização de amplitude
HMarH2lQ18 6/6 92,56 CocH Mar2 50 150 25 Q=18: c1 - c18
HMarH2acl 5/4 94,66 CocH Mar2 50 150 16 Limiar: A=max(x)/1000; clipper
GMedH1 6/6 93,31 gamma Med 50 100 - G: “gamma-tone”; Med: Meddis
GMedH3 6,4 94,00 gamma Med 20 200 16 L=16
GMedH20 6/6 93,02 gamma Med 50 150 - c/ coef. c0
GMarH1 6/6 92,76 gamma Mar 50 100 - Mar: Martens-Immerseel, n=1
GMarH1Q18 6/6 92,02 gamma Mar 50 100 - Q=18: c1 - c18
GMarH2 6/6 95,65 gamma Mar2 50 150 -
GMarH20 6/5 95,76 gamma Mar2 50 150 -
GMarH2c0 6/6 96,24 gamma Mar2 50 150 -
GMarH2nc0 5/5 97,85 gamma Mar2 50 150 - norm.+clipper+c0
SSenM1 6/4 84,92 Sen Sen 17 116 - Sen: modelo de Seneff
SSenM10 6/4 86,67 Sen Sen 17 116 - M1: MSR-MT;
SSenM1n0 5/5 88,01 Sen Sen 17 116 - c/ normalização de amplitude
SSenGSD 6/4 86,89 Sen Sen 17 116 - GSD
GSenM10 6/5 91,12 gamma Sen 17 116 - c/ coef. c0
FMarH20 6/6 94,32 CocF Mar2 50 150 - c/ coef. c0
GMFA0 6/6 96,74 gamma - 10 150 - Modelo simplificado c/ coef. c0
15 A primeira letra das siglas indica o banco de filtros (H: CocH; G: “gamma-tone”; F: CocF e S: Seneff(estágio I). As 5 letras seguintes indicam o modelo de CCIs/sinapses e o tipo de fibra (Mar: Martens-Immerseel; Med: Meddis; Sen: Seneff (estágio II); H: HSR; M: MSR). O dígito seguinte ao tipo de fibradiferencia a taxa espontânea de disparos e de saturação. As outras letras indicam pós-processamento e/ouos parâmetros utilizados: “c” indica “clipping” e “0” indica a adição do coeficiente c0. A sigla “GMFA”indica o modelo funcional de adaptação, apresentado na secção 5.5, com banco de filtros “gamma-tone”.

220 Capítulo 6 -Experiências com Rec. de dígitos
A inclusão do coeficiente c0 conduz sempre a resultados superiores, como seria de esperar.
O uso do “center clipper” e principalmente da normalização de amplitude também conduz a
resultados substancialmente melhores. A normalização consistiu em tomar a amplitude
máxima de todas as locuções constante. Tal como foi discutido no capítulo 5, as variações
de amplitude dos sinais constitui um aspecto crítico na representação de taxa média de
disparos dada a reduzida gama dinâmica dos modelos. Daí o ganho substancial verificado
com a normalização de amplitude.
Consegue-se com a utilização de normalização e “clipping” (siglas “HMarH2nc0” e
“GMarH2nc0”) um resultado substancialmente superior ao obtido com a representação
LPC ou MFCC e aproximadamente igual ao obtido com a utilização de parâmetros delta. O
modelo funcional de adaptação (secção 5.5, sigla “GMFA0”) apresenta também um bom
resultado tendo em conta que a complexidade computacional exigida para o cálculo desta
representação é equivalente ao caso da representação MFCC.
A figura 6.6 mostra os mesmos resultados da tabela 6.4 mas em termos de erros de
reconhecimento e por ordem de desempenho.
Erros (%)
0
2
4
6
8
10
12
14
16
GM
arH
2nc0
HM
arH
2nc0
GM
FA
0
GM
arH
2c0
GM
arH
20
GM
arH
2
HM
arH
2acl
FM
arH
20
GM
edH
3
GM
edH
1
GM
edH
20
HM
arH
2c0
HM
arH
20
GM
arH
1
HM
arH
2lQ
18
HM
arH
2l
HM
arH
2c
GM
arH
1Q18
GS
enM
10
MF
CC
0
SS
enM
1n0
SS
enG
SD
SS
enM
10
SS
enM
1
Figura 6.6 - Taxas de erros de reconhecimento relativas aos valores da tabela 6.4. A representaçãoMFCC é incluída para comparação.

6.5 Testes de Reconhecimento 221
6.5.3 Ruído aditivo e convolucional
Apesar da representação de taxa média de disparos apresentar melhores resultados que a
representação baseada em bancos de filtros ou LPC, importa saber como se degrada o
reconhecimento com a adição de ruído ou com a filtragem dos sinais. No caso da adição de
ruído, será de esperar uma degradação acentuada no desempenho do reconhecimento
devido principalmente à subida das médias dos parâmetros nos segmentos do sinal onde
antes existia silêncio, o que se verifica de facto. Na tabela 6.5 e figura 6.7 comparam-se as
taxas de erro de reconhecimento sem e com ruído bem como com filtragem dos sinais, para
vários tipos de representação. A relação sinal-ruído considerada foi de 20dB. O filtro usado
para distorcer os sinais tem a resposta em frequência que se apresenta na figura 6.8, com a
qual se tenta aproximar a resposta de um microtelefone. As taxas de erro são bastante
elevadas para esta SNR e devido a este facto não se fizeram testes para SNRs mais baixas.
A análise destes resultados permite tirar as seguintes conclusões:
Tabela 6.5 - Taxas de desempenho de reconhecimento, empercentagem, para várias representações dos sinais e nassituações sem ruído, com filtragem linear e com ruído aditivocom uma relação sinal-ruído de 20dB. As representações estãoordenadas pelas taxas de reconhecimento na situação de ruídoaditivo.
Sigla s/ Ruído Filtragem SNR=20dB JRasta 96,27 93,71 91,38 GMarH2nc0 97,85 96,79 90,76 LRasta 97,61 97,55 90,68 GMarH2c0 96,24 93,19 88,34 HMarH2nc0 96,95 94,22 86,93 LPC_E_D 97,95 94,96 85,90 HMarH2c0 92,84 88,88 84,43 MFCC_E_D 97,69 94,81 81,28 MFCC0 90,27 78,98 75,50 SSenM10 86,67 84,93 70,29 GMFA0 96,74 92,62 67,11 GMarH20 95,76 92,73 65,39 FMarH20 94,32 92,34 62,92 LPC0 90,82 82,27 62,38 HMarH20 92,79 89,27 56,55

222 Capítulo 6 -Experiências com Rec. de dígitos
Erros (%)
0
5
10
15
20
25
30
35
40
45JR
asta
GM
arH
2nc0
LRas
ta
GM
arH
2c0
HM
arH
2nc0
LPC
_E_D
HM
arH
2c0
MF
CC
_E_D
MF
CC
0
SS
enM
10
GM
FA
0
GM
arH
20
FM
arH
20
LPC
0
HM
arH
20
s/ Ruído
Filtragem
SNR=20dB
Figura 6.7 - Taxas de erro de reconhecimento para as situações sem ruído, com distorção porfiltragem linear e com adição de ruído branco com relação sinal-ruído de 20dB. Os números, emtermos de percentagem de reconhecimento, indicam-se na tabela 6.5.
• A representação de taxa média de disparos é altamente sensível à adição de ruído, ainda
mais que a representação LPC ou MFCC. Este resultado verifica-se em todos os
modelos de CCIs/sinapses (incluindo o modelo funcional de adaptação) e contrasta com
os resultados apresentados em [Jankowski et al, 95] onde o modelo de Seneff apresenta
um desempenho semelhante ou superior à representação MFCC (com energia e
parâmetros delta). No presente caso, apesar do modelo de Seneff conduzir a uma taxa de
erros, na situação de ruído, inferior à dos outros modelos de CCIs/sinapses, esta taxa de
erros é superior à obtida com a representação MFCC, mesmo sem parâmetros delta.
Uma possível explicação para esta diferença pode consistir no tipo de HMMs usados
naquele trabalho com partilha de parâmetros.
• Para o caso da distorção dos sinais por filtragem linear, a representação de taxa média de
disparos conduz, de uma maneira geral, a taxas de reconhecimento superiores aos casos
das representações tradicionais, mesmo as que incluem parâmetros delta. A
representação L-RASTA apresenta para esta situação a taxa de erros mais baixa,
praticamente sem alteração relativamente à situação sem ruído.
• A utilização de “center clipping” (associado apenas ao modelo de Martens-Immerseel)
apresenta vantagens indiscutíveis, baixando a taxa de erros de 20 a 30%. Este resultado
esperado está de acordo com a melhoria de desempenho de reconhecimento reportada
em [Vereecken & Martens, 95].

6.5 Testes de Reconhecimento 223
102
103
-15
-10
-5
0
5
f [Hz]
dB
|H(f )|
102
103
-0.05
0
0.05
0.1
0.15
0.2
x πarg{H(f )}
f [Hz]
Figura 6.8 - Resposta em frequência do filtro utilizado na distorção em frequência dos sinais.Corresponde a uma função racional com 3 pares de pólos complexos conjugados equivalentes àsfrequências de 400, 2000 e 3900 Hz e um zero simples em z=0,9.
• A utilização de normalização de amplitude dos sinais apresenta também vantagens tanto
no caso de ruído aditivo como no caso da distorção em frequência. A conjugação de
“center clipping” e normalização conduz às taxas de reconhecimento mais baixas,
praticamente semelhantes à dos casos L-RASTA e J-RASTA.
• A representação J-RASTA apresenta a mais baixa taxa de erros na situação de ruído
aditivo enquanto a representação L-RASTA se mostra insensível à distorção em
frequência dos sinais. Testes de reconhecimento com uma SNR de 10dB apresentam,
para estas representações, taxas de erro ainda abaixo dos 30% (L-RASTA: 28,8%; J-
RASTA: 25,1%).
• A representação LPC com energia e deltas (LPC_E_D) mostrou nestes testes ser
superior à equivalente representação MFCC (MFCC_E_D) embora, sem parâmetros
delta, a representação MFCC seja superior.
A conjugação da adição de ruído com a filtragem linear agrava substancialmente as taxas de
erro nas representações LPC e MFCC, mas tal não acontece, de uma maneira geral, nas
representações de taxa média de disparos. A figura 6.9 mostra esta situação relativamente a
algumas representações. Os efeitos da adição de ruído e da filtragem linear combinam-se de
forma não linear no domínio cepstral o que faz com que as médias e as variâncias dos
parâmetros cepstrais derivados venham afectados [Moreno et al, 95]. Por outro lado,
conforme foi discutido no capítulo 5, a taxa média de disparos nas partes vozeadas não vem
significativamente alterada. Nesta representação o efeito mais prejudicial é a adição de ruído

224 Capítulo 6 -Experiências com Rec. de dígitos
uma vez que faz subir a taxa média de disparos nos segmentos não vozeados ou de baixa
energia. Isto justifica o abaixamento da taxa de erros, no caso de ruído e filtragem
relativamente à situação de apenas ruído, nas representações auditivas consideradas na
figura 6.9. Este facto terá a ver com a atenuação do ruído proporcionada pelo filtro de
distorção abaixo de 2kHz, que conduz a uma redução do patamar da taxa média de disparos
nos canais com CFs baixas.
Erros (%)
0
10
20
30
40
50
60
MFCC_E_D LPC_E_D LRasta JRasta GMarH2nc0 HMarH2nc0
Limpo
SNR=20dB
Filtragem
Ruído+filt.
Figura 6.9 - Taxas de erro de reconhecimento para os casos de distorção por ruído aditivo,convolucional e a conjugação dos dois tipos de distorção (adição de ruído seguida de filtragemlinear).
Foram também feitos testes com as representações derivadas de redes de inibição lateral e
representações de sincronia. Foram consideradas redes LIN lineares e a rede não linear
definida pela expressão (5.3) (referenciada com “L2”). As outras redes consideradas variam
de acordo com os pesos de inibição tomados, a operação final de rectificação (função abs(x)
ou max(x,0)) e as variáveis de entrada (taxa média ou taxa instantânea de disparos). As
redes LIN são referenciadas nas siglas das representações com “L1” a “L6”. Além das redes
LIN considerou-se igualmente o esquema GSD (secção 5.2.2.2) e a autocorrelação em
atrasos inversamente proporcionais às CFs (expressão 5.2), referenciado com “A” nas
siglas.
A utilização destes esquemas de processamento nem sempre proporciona uma redução das
taxas de erro em relação às representações sem a sua aplicação. Na presença de ruído,
existe de facto uma melhoria substancial nas taxas de reconhecimento relativamente às taxas
obtidas sem a utilização das redes LIN, entre 15 a 20% (não mostrado). Na figura 6.10
apresentam-se os resultados para vários tipos de representações sem ruído.

6.5 Testes de Reconhecimento 225
Erros (%)
0
2
4
6
8
10
12
14
HM
arH
2ncL
2
HM
arH
1L2
FM
arH
2cL2
FM
arH
2cL3
GM
arH
2ncL
3
GM
arH
2ncL
5
GM
arH
2ncL
2
GM
arH
2cL3
GM
arH
2cL2
GM
arH
2A
GM
arH
1L2
GM
arH
2cA
GM
arH
2ncL
4
GM
arH
2cL6
GM
arH
2ncL
1
GM
edH
1L2
SS
enM
1L3
Figura 6.10 - Taxas de erro de reconhecimento em percentagem relativas a representações queutilizam redes LIN. Na designação das representações, “L1” a “L6” indica diferentes tipos de redeLIN. “A” indica a representação correspondente à expressão (5.2).
Testes relativos aos melhores modelos, na situação de ruído, indicam-se na figura 6.11.
Como se pode observar, a representação GSD é inferior à representação de taxa média de
disparos para os dois casos considerados, embora seja superior no caso do modelo de
Seneff. A rede não linear (“L2”) também não apresenta vantagens em relação a redes
lineares. Esta conclusão é também evidente por observação da figura 6.10. De uma maneira
geral, pode dizer-se que este pós-processamento da taxa média de disparos, ou não conduz
a melhores resultados, ou não é compensatório face ao incremento computacional exigido16.
Convém notar, contudo, que esta conclusão é apenas válida no caso da utilização da
normalização de nível e compensação de ruído (“clipping”) associada aos modelos. Sem a
sua utilização existe uma clara vantagem em utilizar redes LIN devido às propriedades de
supressão de ruído e normalização da representação. Os resultados das figuras 6.10 e 6.11
sugerem que é preferível fazer uma pré-normalização dos sinais em cada canal do banco de
filtros antes de os aplicar aos modelos de CCIs/sinapses que um pós processamento da taxa
média de disparos.
16 De facto, a utilização de uma rede LIN requer uma grande utilização de memoria uma vez que operasimultaneamente sobre a taxa instantânea de disparos relativa a vários canais.

226 Capítulo 6 -Experiências com Rec. de dígitos
Erros (%)
0
5
10
15
20
25
HM
arH
2nc0
HM
arH
2nc0
GS
D
HM
arH
2nc0
L2
GM
arH
2nc0
GM
arH
2nc0
GS
D
GM
arH
2nc0
A
GM
arH
2nc0
L1
GM
arH
2nc0
L2
s/ Ruído
SNR=20dB
Ruído+Filt.
Figura 6.11 - Taxas de erro relativas aos dois melhores modelos auditivos sem e com pós-processamento da taxa média de disparos. Compara-se o desempenho de reconhecimento com asrepresentações LIN (“L1” e “L2”) e de sincronia: GSD (“GSD”) e autocorrelação (“A”) (expressão5.2). Estas representações indicam-se como sufixos nas siglas. A linha a tracejado divide osresultados relativos ao modelo “HMarH2” dos do modelo “GMarH2”.
6.5.4 Testes com o modelo funcional de adaptação
Os resultados apresentados mostram que existem particularidades da representação auditiva
que apresentam claras vantagens em relação às representações convencionais. Dada a maior
complexidade computacional exigida pelos modelos de CCIs/sinapses, tem interesse
verificar se o modelo simplificado de adaptação, apresentado no capítulo 5, apresenta as
mesmas vantagens. Nas experiências com este modelo foi utilizado o banco de filtros
“gamma-tone” e é sempre utilizado o coeficiente c0 da DCT. As experiências diferenciam-se
na parte correspondente à rectificação de meia onda. Na tabela 6.6 indicam-se as diferentes
configurações do modelo funcional de adaptação bem como as taxas de reconhecimento
obtidas.
Na primeira situação (banco de filtros “gamma-tone”, Modelo Funcional de Adaptação” -
sigla “GMFA01”), os resultados estão já apresentados nas figuras 6.6 e 6.7 com a sigla
“GMFA0”. Apesar de se conseguir um bom resultado na situação dos sinais limpos, a
degradação com ruído é muito acentuada. É de salientar que em relação à representação

6.5 Testes de Reconhecimento 227
MFCC equivalente (“MFCC0”) se obtém um desempenho cerca de 6% superior, para o
mesmo número de parâmetros e essencialmente a mesma complexidade computacional. A
degradação com o ruído deve-se principalmente ao módulo de adaptação, pelo que se
deverá fazer alguma compensação face ao ruído. Na segunda situação (sigla “GMFA02”)
foi utilizada uma subtracção espectral simples que consistiu em subtrair à energia à saída de
cada canal o valor mínimo da energia ao longo de toda a locução. Houve uma melhoria da
taxa de reconhecimento nas situações de ruído, no entanto ainda não muito significativa. Na
terceira situação (“GMFA03”) tomou-se o dobro da energia mínima, que baixou as taxas de
erro uma vez que este valor está mais próximo da potência média de ruído nos canais. Na
situação seguinte (“GMFA04”) tomou-se o mesmo procedimento mas agora com base no
valor RMS em vez da energia. Uma vez que a variância dos valores RMS é menor que a
variância da energia, verifica-se um melhor desempenho na situação de ruído. No entanto o
resultado obtido na situação de ruído mais filtragem é inferior.
A utilização da rede LIN não linear aplicada à taxa média de disparos mostra que alguma
normalização é feita face a distorções convolucionais. No entanto o desempenho do
reconhecedor baixa na presença de ruído. Um resultado essencialmente idêntico a este
obtém-se fazendo uma filtragem RASTA das trajectórias temporais da taxa média de
disparos. Na situação sem ruído obtém-se um taxa de reconhecimento praticamente igual à
obtida com a parametrização LPC com deltas.
Estas experiências indicam que o uso da subtracção espectral com base na energia à saída
dos canais apresenta vantagens significativas neste modelo. Contudo, os resultados
analisados até agora são sempre inferiores ao do melhor dos modelos auditivos (sigla
“GMarH2nc0”). O problema reside essencialmente no facto da potência média do ruído ser
mal estimada uma que se toma a mínima energia de termo curto dos sinais ao longo de toda
a locução. Este procedimento é seguido para garantir que o valor a subtrair diz respeito a
segmentos onde existe apenas ruído. No entanto, como a variância da energia de termo
curto (relativa ao ruído) é elevada e a distribuição desta energia é assimétrica (secção
5.5.1), o valor mínimo que se toma corresponde a um valor muito subestimado da potência
média do ruído. Um método mais eficaz consiste em filtrar passa-baixo os valores da
energia de forma a reduzir a sua variância e assim estimar melhor a potência média do
ruído. Esta filtragem pode ser feita sem processamento extra uma vez que o modelo de
adaptação usa uma filtragem passa-baixo do valor RMS dos sinais à saída de cada canal do
banco de filtros. Um procedimento essencialmente idêntico, onde é utilizado um filtro IIR
228 Capítulo 6 -Experiências com Rec. de dígitos
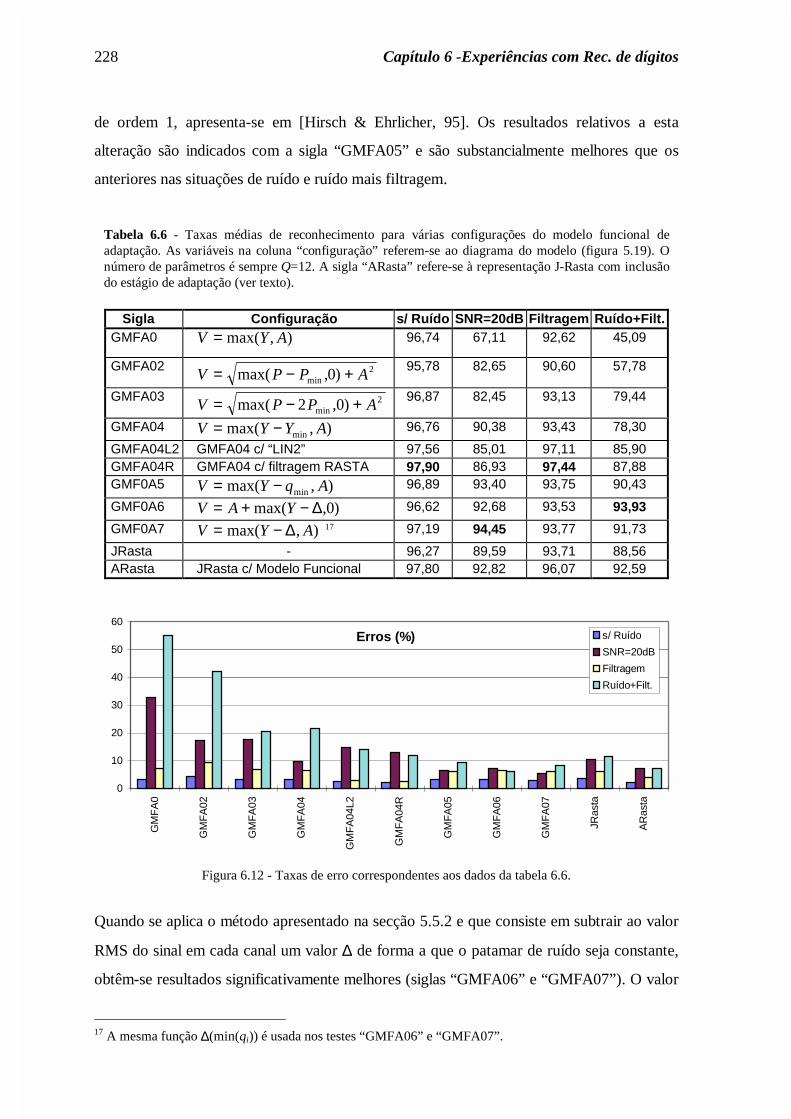
de ordem 1, apresenta-se em [Hirsch & Ehrlicher, 95]. Os resultados relativos a esta
alteração são indicados com a sigla “GMFA05” e são substancialmente melhores que os
anteriores nas situações de ruído e ruído mais filtragem.
Tabela 6.6 - Taxas médias de reconhecimento para várias configurações do modelo funcional deadaptação. As variáveis na coluna “configuração” referem-se ao diagrama do modelo (figura 5.19). Onúmero de parâmetros é sempre Q=12. A sigla “ARasta” refere-se à representação J-Rasta com inclusãodo estágio de adaptação (ver texto).
Sigla Configuração s/ Ruído SNR=20dB Filtragem Ruído+Filt. GMFA0 V Y A= max( , ) 96,74 67,11 92,62 45,09
GMFA02V P P A= − +max( , )min 0 2 95,78 82,65 90,60 57,78
GMFA03V P P A= − +max( , )min2 0 2 96,87 82,45 93,13 79,44
GMFA04 V Y Y A= −max( , )min96,76 90,38 93,43 78,30
GMFA04L2 GMFA04 c/ “LIN2” 97,56 85,01 97,11 85,90 GMFA04R GMFA04 c/ filtragem RASTA 97,90 86,93 97,44 87,88 GMF0A5 V Y q A= −max( , )min
96,89 93,40 93,75 90,43
GMF0A6 V A Y= + −max( , )∆ 0 96,62 92,68 93,53 93,93
GMF0A7 V Y A= −max( , )∆ 17 97,19 94,45 93,77 91,73
JRasta - 96,27 89,59 93,71 88,56 ARasta JRasta c/ Modelo Funcional 97,80 92,82 96,07 92,59
Erros (%)
0
10
20
30
40
50
60
GM
FA
0
GM
FA
02
GM
FA
03
GM
FA
04
GM
FA
04L2
GM
FA
04R
GM
FA
05
GM
FA
06
GM
FA
07
JRas
ta
AR
asta
s/ Ruído
SNR=20dB
Filtragem
Ruído+Filt.
Figura 6.12 - Taxas de erro correspondentes aos dados da tabela 6.6.
Quando se aplica o método apresentado na secção 5.5.2 e que consiste em subtrair ao valor
RMS do sinal em cada canal um valor ∆ de forma a que o patamar de ruído seja constante,
obtêm-se resultados significativamente melhores (siglas “GMFA06” e “GMFA07”). O valor
17 A mesma função ∆(min(qi)) é usada nos testes “GMFA06” e “GMFA07”.

6.5 Testes de Reconhecimento 229
de ∆ resulta da modelação da distribuição dos valores RMS como uma função de
distribuição gama, o que é correcto para ruído gaussiano. Este bom resultado resulta do
facto de se subtrair um valor superior quando o ruído é mais intenso mas também do facto
do patamar de ruído ser constante, contrariamente ao que é usualmente feito na técnica
usual de subtracção espectral não linear. Desta forma existe menor variabilidade na
representação obtida para níveis de ruído bastante díspares.
6.5.5 J-Rasta e adaptação
Muitos dos resultados apresentados não são directamente comparáveis devido aos
diferentes bancos de filtros e diferentes tipos de representação utilizados. Para mostrar as
vantagens da caracterização espectral com base auditiva foi feita uma experiência que se
pode considerar conclusiva. A ideia consistiu em utilizar a representação J-RASTA mas
onde a compressão logarítmica foi substituída pelo estágio de adaptação do modelo
funcional proposto. Portanto, em vez de se considerar o logaritmo do espectro de potência,
toma-se o modelo de adaptação a operar com a raiz quadrada da potência em cada canal. O
limiar do modelo (constante A) e o valor de saturação foram ajustados de forma a que a
curva estática de taxa de disparos-intensidade coincida aproximadamente com a curva
log(1+JPi), onde J=10-6 e Pi corresponde à potência à saída do canal i18. Como se pode
observar pela figura 6.13a), para o caso de sinais estacionários, as curvas de compressão
nos dois casos são praticamente coincidentes. Vai existir uma diferença entre as duas
situações devido à adaptação, tal como se mostra através de um exemplo na figura 6.13b).
As taxas de reconhecimento obtidas para esta nova representação indicam-se na tabela 6.6
(sigla “ARasta”) e mostram que houve de facto um aumento da capacidade de
discriminação com esta representação. Além disso, em todas as situações de distorção dos
sinais (ruído, filtragem e ruído mais filtragem) as taxas de reconhecimento aumentaram em
relação aos resultados com a modelação J-RASTA. Esta experiência comprova que a
adaptação constitui claramente um factor de robustez na representação dos sinais.
18 O limiar do modelo é neste caso muito mais elevado (A=500) que nos casos precedentes devido apenas aofacto de não se ter considerado o factor de normalização 1/N no cálculo do espectro de potência (onde Ncorresponde ao tamanho da janela de análise).

230 Capítulo 6 -Experiências com Rec. de dígitos
20 40 60 80 100 1200
2
4
6
8
10
12
14
Y [dB]
log(1+JP)
( )110 2
f V
B Vfsat
spo+
−
V P A
J
A
B
= +
===
−
2
610
500
64 24,
0 20 40 60 80 100
-6
-4
-2
0
2
4
6
8
10
12
14
frames
i=4
log(1+JPi)
(fi −10)/10
log(JPi)
a) b)Figura 6.13 - a) Comparação da curvas de compressão usada na modelação J-RASTA com a curva deestática do modelo de adaptação simplificado. P representa a potência num dado canal. A constantefspo não é efectivamente subtraída uma vez que é eliminada pela filtragem RASTA; na expansãoexponencial que se segue à filtragem RASTA a taxa média de disparos é dividida por 10. b) Exemploda diferença entre as representações com logaritmo e com taxa média de disparos para o caso de umalocução do dígito /nove/ e canal 4 do banco de filtros.
6.6 Discussão e conclusões
Os resultados de reconhecimento apresentados neste capítulo mostram que existem de facto
vantagens em utilizar uma representação com base auditiva. Porém, este estudo permite
igualmente concluir que estas vantagens não se verificam sem a utilização de alguma
compensação face a ruído ou variações de amplitude dos sinais. Esta conclusão contrasta
com outras apresentadas, tal como foi referido no início desta secção, e é devida às
diferentes condições da tarefa de reconhecimento considerada. Muitas das comparações
apresentadas na literatura dizem respeito a reconhecimento dependente do locutor [Ghitza,
88], [Jankowski et al, 90], enquanto neste trabalho se considera reconhecimento
independente do locutor. Noutros casos consideram-se modelos baseados em “fones”
[Leung et al, 93] enquanto neste caso se consideram palavras inteiras. Em grande parte
destas comparações o modelo de Seneff é utilizado chegando-se a conclusões diferentes nos
vários trabalhos. No presente caso o modelo de Seneff conduziu a piores resultados
relativamente aos outros modelos de CCIs/sinapses considerados. Este resultado não era de
prever tendo em conta a comparação dos modelos feita no capítulo 4 onde se conclui que
os modelos são genericamente equivalentes. Uma explicação para a diferença verificada
reside, com grande certeza, nas diferentes características da taxa máxima de disparos no

6.6 Discussão e conclusões 231
“onset” dos sinais, onde o modelo de Seneff apresenta os valores mais baixos (cf. figura
4.18b)). Esta característica é importante para acentuar o início das vogais e transições entre
segmentos com energias bem diferenciadas e será utilizada na segmentação dos sinais em
termos de estados nos modelos HMM. Uma vez que a taxa média de disparos é tomada
num período longo, os picos da taxa instantânea de disparos vão ficar pouco salientes na
representação final, a não ser que estes picos sejam muito elevados, como acontece nos
modelos de Martens-Immerseel e de Meddis. O banco de filtros considerado contribui
adicionalmente para a diferença dos resultados entre os modelos auditivos, tal como foi
referido anteriormente.
Ao comparar os resultados obtidos com os modelos auditivos relativamente às
representações convencionais com o mesmo número de parâmetros, verifica-se uma
distinção clara a favor dos modelos auditivos (com a excepção do modelo de Seneff),
existindo uma diferença de cerca de 2% a 6% na taxas de reconhecimento. Quando a taxa
de erros de base é mais elevada, como por exemplo em [Stern et al, 96], a distinção entre
modelos auditivos e representações convencionais será mais notória, tal como é salientado
em [Jankowski et al, 90].
A representação RASTA inclui implicitamente uma modelação em termos de parâmetros
delta pelo que os resultados obtidos são idênticos aos que se obtêm com as representações
MFCC ou LPC com a adição de parâmetros delta. Esta representação é portanto bastante
“compacta” e é especialmente indicada para o reconhecimento de palavras inteiras. O
modelo funcional de adaptação proposto, apesar de incluir algumas simplificações em
relação aos modelos de CCIs/sinapses, é igualmente adequado para a tarefa de
reconhecimento considerada, conseguindo-se resultados idênticos ou mesmo superiores aos
que se conseguem com a modelação RASTA. Uma vez que a representação auditiva
apresenta uma resolução temporal mais fina que a representação RASTA, deverá apresentar
vantagens mais evidentes no reconhecimento baseado em sub-palavras, embora não tenham
sido feitas experiências que confirmem esta superioridade.
As experiências feitas com ruído mostram que a representação auditiva se degrada de uma
forma muito mais acentuada que as representações convencionais. Esta degradação é
principalmente evidente nos segmentos dos sinais com baixa energia. Isto faz com que nesta
tarefa de reconhecimento o símbolo /sil/ seja quase sempre eliminado na sequência
reconhecida, sendo os dígitos reconhecidos na grande maioria dos casos como /seis/, /sete/
ou /três/. As vantagens da representação auditiva podem, no entanto, ser mantidas se for

232 Capítulo 6 -Experiências com Rec. de dígitos
feita uma compensação face ao ruído. Portanto, a ideia mais ou menos bem estabelecida de
que os modelos auditivos são superiores em situações de degradação dos sinais não é
genericamente correcta.
Como conclusões deste estudo podem salientar-se as seguintes aspectos:
• A utilização de um banco de filtros “gamma-tone” ou de um banco baseado no modelo
da cóclea humana é preferível à utilização de filtros triangulares.
• A adaptação contribui para salientar os picos espectrais e os extremos de segmentos dos
sinais com energias bem diferenciadas, o que constitui um factor de robustez da
representação obtida. Além disso, a adaptação contribui para uma normalização da
representação face a distorções convolucionais.
• A compensação face a ruído nos modelos auditivos é preferível a um pós-processamento
com base em modelos de inibição lateral ou de sincronia.
• O modelo funcional de adaptação proposto conduz a um desempenho de reconhecimento
muito superior ao que se consegue com a representação baseada em banco de filtros. A
diferença essencial entre a modelação com banco de filtros e o modelo proposto reside
essencialmente na inclusão da adaptação, sendo a complexidade computacional nos dois
casos comparável.
• A inclusão do estágio da adaptação do modelo funcional na modelação RASTA conduz
a um modelo ainda melhor, o que comprova a importância da adaptação na
representação robusta dos sinais.

6.6 Discussão e conclusões 233
6.1 Introdução ........................................................................................................... 1996.2 Caracterização da base de dados .......................................................................... 1996.3 Método de reconhecimento .................................................................................. 2036.4 Métodos .............................................................................................................. 207
6.4.1 Representação acústica.................................................................................. 2076.4.2 Transformação com DCT.............................................................................. 2096.4.3 Estimação dos parâmetros dos modelos HMM .............................................. 212
6.5 Testes de Reconhecimento ................................................................................... 2146.5.1 Bancos de filtros, LPC e RASTA .................................................................. 2166.5.2 Modelos das CCIs/sinapses ........................................................................... 2186.5.3 Ruído aditivo e convolucional........................................................................ 2216.5.4 Testes com o modelo funcional de adaptação ................................................ 2266.5.5 J-Rasta e adaptação....................................................................................... 229
6.6 Discussão e conclusões ........................................................................................ 230
A determinação da potência média devida ao ruído pode ser alcançada de uma maneira
bastante mais eficaz. O problema reside na variância da energia de termo curto, na situação
de ruído branco. De facto, construindo histogramas da distribuição desta energia com
excitação de ruído branco, verifica-se que segue aproximadamente uma distribuição gama,
embora para valores superiores ao pico da distribuição esta seja claramente exponencial. Tal
é indicado na figura 6.13 relativamente a dois canais do banco de filtros “gamma-tone”.
dependendo de muitos factores, como a tarefa de reconhecimento em causa, a
representação de referência considerada para comparação ou os factores de normalização e
compensação que são ou não tomados. Isto explica as diferentes conclusões As conclusões
de outros trabalhos onde comparações idênticas entre representações auditivas
Nas condições do presente trabalho em que o reconhecimento é independente do locutor,
com muitos locutores incluídos na base de dados de treino e baseado em modelos de
palavras inteiras (e não sub-palavras)
- reconhecimento de dígitos inteiros
O presente estudo não confirma os resultados optimistas apresentados na literatura. Uma

234 Capítulo 6 -Experiências com Rec. de dígitos
os resultados optimistas apresentados na literatura devem ser vistos de um ponto de vista
crítico.
Isto pode ser interpretado da seguinte forma: o ruído tem um efeito na taxa média de
disparos apenas quando a energia do sinal é baixa e afecta pouco as respostas nas partes
vozeadas. Nesta situação as médias e variâncias dos HMMs referentes a estados que
caracterizam estes segmentos são desajustadas afectando a correcta segmentação de Viterbi
em termos da sequência de estados.
A taxa de erros sobe substancialmente devido ao facto de as médias dos parâmetros
Convém notar, contudo, que este abaixamento da taxa de erros se deve principalmente à
utilização do “center clipper” que tenta em cada canal atenuar é Como neste caso a
filtragem é seguida da adição de ruído, equivale à adição de ruído colorido (ruído branco
filtrado pelo filtro com resposta em frequência da figura 6.8), o que aumenta a SNR em
vários canais. A sequência inversa, isto é, filtragem seguida de adição de ruído, deverá
produzir taxas de erro mais elevadas. De facto, tal é verificado.
Vejamos agora … Na modelação com HMMs, o cálculo do logaritmo da probabilidade de
ocorrência de uma observação C={c1…Q} num estado s e modelo λ, para o caso de matrizes
de covariância diagonais, é dado por:
( )ln ,P C s Cc
te n c
cn
Q
n
n
λµ
σ= −
−
=∑1
2
0
2
Nesta expressão Q representa o número de coeficientes da DCT utilizados; µcn e σcn
representam, respectivamente, a média e o desvio padrão dos coeficientes cn associados ao
modelo λ e estado s. Conforme é salientado em [Nadeu et al, 95, a correspondência entre a
representação cn e Xk pode ser explorada no sentido de clarificar a robustez da
representação. A expressão anterior pode ser vista como uma convolução circular. De
facto, através da relação de Parseval podem obter-se as seguintes relações:
cc Xn
n
N
kk
N
02
2
1
1
2
12
+ ==
−
=∑ ∑

6.6 Discussão e conclusões 235
As médias ucn e uXk respeitam a mesma relação de transformação por DCT. Assim, vem
que:
( ) ( ) ( )cc X
c
n c
n
N
k X
k
N
n k
0
2
2
1
12
1
0
2
−+ − = −
=
−
=∑ ∑
µµ µ
Adianta-se que os resultados obtidos não confirmam a vantagem da utilização do modelo de
Seneff, embora outros modelos de CCIs/sinapses apresentem uma ligeira melhoria. No
entanto, representações mais elaboradas, baseadas em LINs ou sincronia mostram uma clara
vantagem. Outro aspecto que merece referência, não focado nos trabalhos referidos acima,
é a robustez da representação RASTA quando comparada com representações mais
tradicionais.
De uma forma geral, parece-nos perfeitamente razoáveis as observações feitas em [ quanto
às diferentes conclusões entre esse trabalho e outros. De facto, em muitos trabalhos (como
em [Stern et al, 96 e [Ghitza, 88) a comparação é feita com cepstrum LPC que, como se
sabe, não apresenta robustez a ruído. Por outro lado, as taxas de erro
Se por um lado se confirmam as conclusões apresentadas em [Jankowski et al, 95 quanto àbaixa robustez da representação de taxa média de disparos na presença de ruído, por outrolado mostra-se que certas representações utilizando inibição lateral conduzem a um bomdesempenho de reconhecimento. Outro aspecto interessante, não focado nos trabalhosreferidos acima, é a robustez da representação RASTA quando comparada comrepresentações mais tradicionais.
Notar que a repetição dos testes não conduz sempre aos mesmos resultados podendo existir
uma diferença de 0.5% nas percentagens de reconhecimento.
Uma vez que as locuções não têm segmentos de silêncio iniciais suficientemente longos paraobter uma estimativa da energia, considerou-se um método não causal: em cada canal osinal é filtrado obtendo-se o valor mínimo que é depois usado no modelo.





























