Embed Size (px)
Citation preview

2017年5月16日@統計モデリング
担当:田中冬彦
統計モデリング 第五回 配布資料
文献: a) J. アルバート (石田基広, 石田和枝訳): Rで学ぶベイズ統計学入門, 丸善出版, 2012年
配布資料の一部は以下からもDLできます. 短縮URL http://tinyurl.com/lxb7kb8
b) H. Jeffreys: Theory of Probability. 3rd ed. Oxford University Press, UK, 1961.
c) R.E. Kass and A.E. Raftery: Bayes factor and model uncertainty. J. Amer. Statist. Assoc. vol. 90 (1995) , 773—795.

第八回 線形モデルのベイズ解析
今後の予定 第五回 ベイズファクター
第七回 グループ発表1 -3 -2 -1 0 1 2
0.0
0.1
0.2
0.3
0.4
posterior distribution
theta
dist
ribut
ion
sample histogram
x
Freq
uenc
y
-2 -1 0 1 2
05
1015
∞→M
)()2()1( ,,, Mθθθ のヒストグラム )|( xθπ の関数形
第六回 数値技法
第九回 一般化線形モデルのベイズ解析

理解度チェック:ベイズ統計の基本 前回の講義内容に沿って〇か×をつけてください
ベイズ統計での分析では統計モデルを設定した後、パラメータの事後分布を分析者が設定する必要がある.
数百人の村での寄生虫の感染率調査を考えている. 検査用の資材
が10人分しかない場合、老人や子供など感染しやすい人を優先して検査すべきである.
ベイズ統計の根本は、結局のところ、条件付き確率(条件付き分布)に基いた推論・推測である
前回は二項モデルの共役事前分布を用いて積分で事後分布を計算した.
ベイズ統計, 特に条件付き確率の計算は迷惑メールフィルタだけでなく, 機械学習や人工知能などの基礎にもなっている.

今日の内容
1.事前分布の設定の指針 2.事後分布の計算練習 3.事後分布に基いた統計解析 4.問題編 (ガンバ大阪の戦績データを題材) 5.解決編1~統計モデル構築 6.解決編2~ベイズファクター 7.第一回グループ発表の説明

本日の主役
独立2集団の二項モデル+事前分布
( ) ),(~, 2121 θθπθθ
),(~ 111 θnBinX),(~ 222 θnBinX

1. 事前分布の設定の指針

実際の分析 → 事前分布は分析者が設定
理論的には未解決問題(万能な方法はない!)だが応用上は以下の方針
事前分布の設定の指針
a) 一様分布; 十分, 分散が大きい分布; 無情報事前分布
b) 統計モデルと相性の良い(計算しやすい)確率分布
c) 事前の情報を反映した分布
今回は a, b について軽く説明 (前回は c) のタイプ)

各統計モデル (確率密度関数) に対して、 条件付き分布が計算しやすい
事前分布のクラスがあり, 共役事前分布 という(多くのテキストで紹介)
理解を深めるため, 後で簡単な例で手を動かしてみる
1. 二項分布 + ベータ分布
2. ポアソン分布 + ガンマ分布
3. 正規分布 + 正規分布
ここで紹介する組合わせ
共役事前分布
共役事前分布
注意点 各分布の確率関数・密度関数の具体的な形を使った計算になる

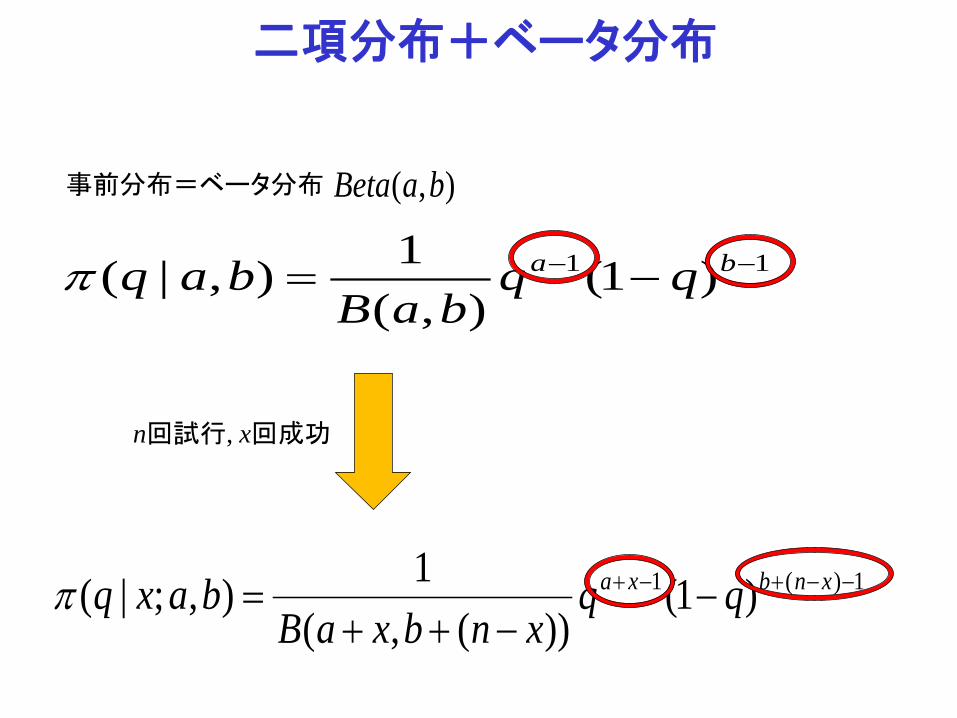
二項分布+ベータ分布
nx ,,2,1,0 =xnx qq
xn
qxp −−
= )1()|(
統計モデル=二項分布(n回の試行)
事前分布=ベータ分布
11 )1(),(
1),|( −− −= ba qqbaB
baqπ
n回試行, x回成功した場合の事後分布もベータ分布
1)(1 )1())(,(
1),;|( −−+−+ −−++
= xnbxa qqxnbxaB
baxqπ
ハイパーパラメータ(超母数) 0, >ba
),( baBeta
二項分布+ベータ分布
事前分布=ベータ分布
11 )1(),(
1),|( −− −= ba qqbaB
baqπ
n回試行, x回成功
1)(1 )1())(,(
1),;|( −−+−+ −−++
= xnbxa qqxnbxaB
baxqπ
),( baBeta
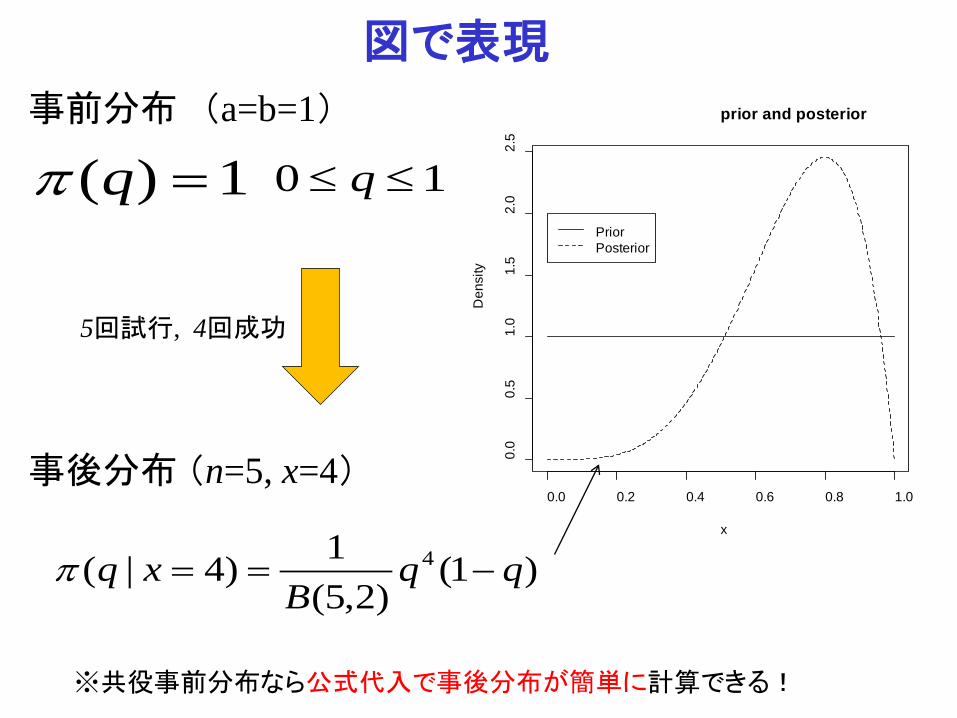
図で表現 事前分布 (a=b=1)
1)( =qπ
)1()2,5(
1)4|( 4 qqB
xq −==π
事後分布 (n=5, x=4) 0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
2.0
2.5
prior and posterior
x
Den
sity
PriorPosterior
10 ≤≤ q
5回試行, 4回成功
※共役事前分布なら公式代入で事後分布が簡単に計算できる!

( ) λλλ −= ex
xpx
!)|( ,2,1,0=x
統計モデル=ポアソン分布
事前分布=ガンマ分布
be
baba b
a 1)(
1),|( /1
λλλπ −−
Γ=
xが観測された場合の事後分布もガンマ分布
*1
*)(1),;|( */
1
be
bxabax b
xaλλλπ −
−+
+Γ=
ハイパーパラメータ(超母数) 0, >ba
1*
+=
bbb
ポアソン分布+ガンマ分布
),( baGa

ツールなどを利用する場合, 分布記号を用いて記載できるとよい
この時, 事後分布(ガンマ分布)を分布記号で書くと
1*
+=
nbbb
),(~ baGaλ
~,,, 21 nXXX i.i.d. )(λPo
*),(~ bxaGa tot+λ
,21 ntot xxxx +++=
ポアソン分布+ガンマ分布
0 20 40 60 80 1000.
000.
020.
040.
060.
080.
10
Prior and Posterior
theta
Den
sity
PriorPosterior
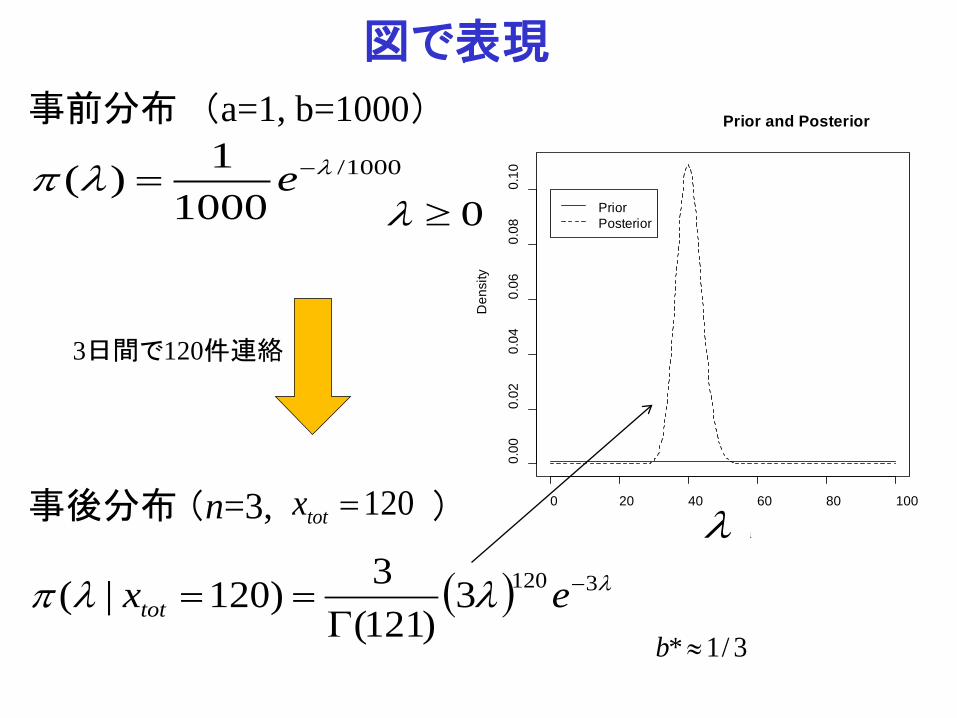
図で表現 事前分布 (a=1, b=1000)
1000/
10001)( λλπ −= e
事後分布 (n=3, )
0≥λ
3日間で120件連絡
120=totx
( ) λλλπ 31203)121(
3)120|( −
Γ== extot
3/1* ≈b
λ

統計モデル=正規分布(分散既知)
事前分布=正規分布
sx
es
2)( 2
21 θ
π
−−),(N~,,1 sxx n θ
i.i.d.
vev
v 2)( 2
21),|(
ξθ
πξθπ
−−
=
ハイパーパラメータ(超母数) 0,R >∈ vξ
xが観測された場合の事後分布も正規分布
wew
vy 2)( 2
21),;|(
ςθ
πξθπ
−−
=n
nxy
sn
v
xsn
vsn
vw=
+
+=+= ,1
1
,11 ξς
正規分布+正規分布

無情報事前分布
無情報事前分布 (Noninformative prior) 統計モデルのパラメータについて特に情報はないが、ベイズ分析を行いたい場合に用いる事前分布の慣習的な呼び名
参考 理論的には古くから未解決の問題(研究としては面白い!)
事前の情報がない場合に使う「デフォルトの事前分布」程度の意味
客観ベイズ解析(Objective Bayesian Analysis)などともいう
例外的なケース: コンパクト群が作用する統計モデル → 群上の不変測度(Haar measure) を使えばOK
用語 objective prior, vague prior.
⇔ subjective prior, informative prior

無情報事前分布の設定方法
1.有限の範囲 → (とりあえず)一様分布
2.無限の範囲で共役事前分布あり → 分散を大きくなるように設定
実用的な設定
3.無限の範囲だが共役事前分布なし → 分散大の正規分布など
理論からのSuggest (Noninformative prior の理論研究の結果)
1.いくつか事前分布を試してみて, 結果があまり変わらないことが重要
2.普通はデータ数が増えるほど, 事前分布の影響は小さくなる
⇔ データ数があるのに、事前分布と事後分布がほとんど変化しない場合は、かなり問題 【注意】

参考:無情報事前分布の理論研究
1.パラメータの非線形変換で不変な事前分布 (ex: Jeffreys prior)
2.統計モデルを多様体とみて幾何学的な定義 (ex: alpha-parallel prior)
理論的な提案
3.非ベイズで求めた結果と整合性があえばよい(ex: Matching prior )
(prior , posterior がほとんど同じということは, 事前の「信念」が強すぎてデータを無視するようなモデルを作っていることになる)
4.prior, posterior の変化が最大となる事前分布
cf) Reference prior (*1) ))|(||)((maxarg xD θπθππ
5.Reference prior (4)にConditional Principleを導入 (Latent information prior *2)
*1) Bernardo, JRSS, 1979, 2) Komaki, JSPI 2011

理解度チェック:事前分布の設定
各統計モデルについて情報量をゼロにする事前分布が一意的に定まり、無情報事前分布という
統計モデルのパラメータについてなんらかの情報がある場合、積極的に無情報事前分布を用いる必要はない
統計モデルのパラメータに関する情報が特にない場合, 無情報事前分布を1つ定めて分析すれば十分である
サンプルサイズ(データ数)が大きいほど、事前分布の影響が大きくなるため, その設定には慎重になるべきである.
共役事前分布が存在する統計モデルの場合でも, パラメータに関する情報がない場合は, 共役事前分布を使わない方がよい.

2. 事後分布の計算練習

例題:シナリオ大賞 (以下は架空のものです)
・村上冬樹さんは「泣けるシナリオ大賞」を目指して, 「冬のカナタ」というシナリオを書き上げました.
・目標としては国民の8割以上が泣くシナリオを目指しています.
・ 周囲の友人に「冬のカナタ」を読んでもらい, 泣いたかどうかを聞きました.
事後分布の計算
カナタが!
カナタが!!
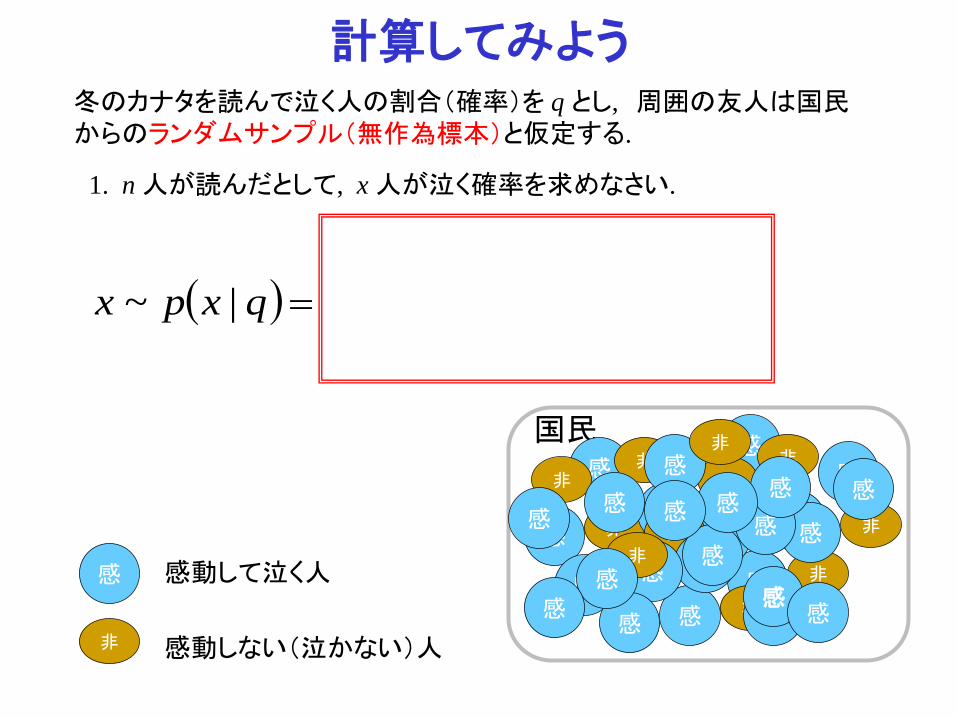
1. n 人が読んだとして, x 人が泣く確率を求めなさい.
計算してみよう
( ) =qxpx |~
国民 感
非
非
非
感 感
感
感
感
非
感 感
感
非 感
非
感 感
非 感
非 感
感 非
感
非 感
感 感 感
非
感 感
感 感
感 感
感
感 感
感 感動して泣く人
非 感動しない(泣かない)人
冬のカナタを読んで泣く人の割合(確率)を q とし, 周囲の友人は国民からのランダムサンプル(無作為標本)と仮定する.

計算してみよう
( ) ),1(2~ qqq −=π
2. 泣けるシナリオを描いたつもりでもなかなか泣くところまではいかない. 冬樹さんは q に関する事前分布を次のように表現した.
10 ≤≤ q
今回, 3人の友人中3人とも泣いたという.
次のステップに沿って, q の事後分布を求めなさい.
( ) =qp |3
(a) 1. で求めた確率関数に, n=x=3 を代入した式 (尤度)を書きなさい.
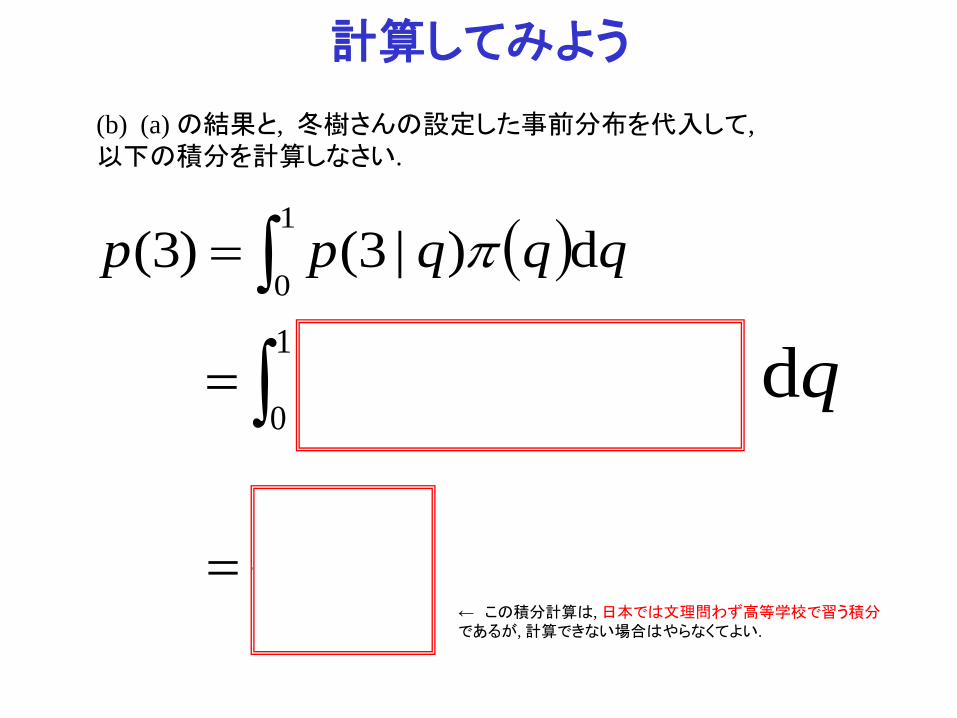
計算してみよう (b) (a) の結果と, 冬樹さんの設定した事前分布を代入して, 以下の積分を計算しなさい.
( )∫=1
0d)|3()3( qqqpp π
∫=1
0
3 )d-2(1 qqq qd
101
=← この積分計算は, 日本では文理問わず高等学校で習う積分であるが, 計算できない場合はやらなくてよい.
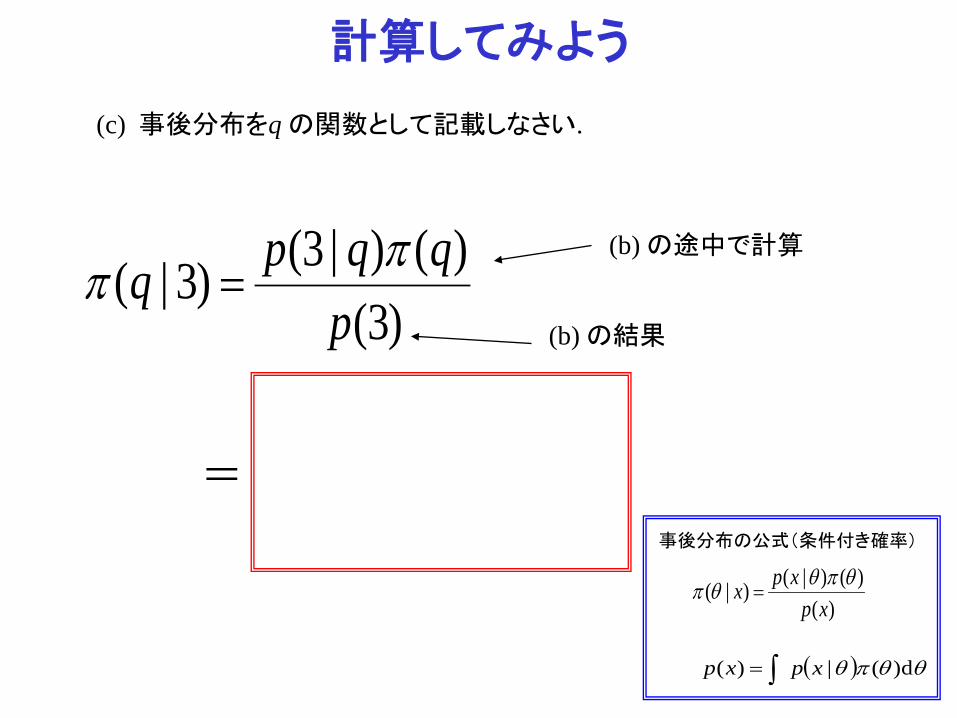
計算してみよう (c) 事後分布をq の関数として記載しなさい.
)3()()|3()3|(
pqqpq ππ =
)()()|()|(
xpxpx θπθθπ =
事後分布の公式(条件付き確率)
( )∫= θθπθ d)(|)( xpxp
(b) の結果
(b) の途中で計算
( )qq −= 120 3

挑戦してみよう (Extra Exe)
( ) ,)1(),(
1~ 11 −− −= ba qqbaB
qq π
冬樹さんの事前分布を共役事前分布で表現してみよう
EX-1: q, 1-q の指数から, a, b はいくらになるか. (B(a,b) はqを含まない定数)
,1=a ,2=bEX-2: EX-1 の解答と, n=x=3 を、前節で紹介した共役事後分布の公式に代入せよ. 直接, 積分計算で求めた結果と, q, (1-q)の指数が一致しているか?
( ) )1()2,4(
13|~ 3 qqB
qq −=π ),1(20 3 qq −=

3. 事後分布に基いた統計解析

ベイズ統計での分析 1.点推定は従来の統計(最尤推定)も含む 2.区間推定・仮説検定に相当するものは、より柔軟でわかりやすく
ここでのポイント

事後分布が計算できたとして、具体的には?
・点推定 ・区間推定 (信頼区間) ・仮説検定
)|(~,,...
1 θxpXXdii
n
統計モデルに基いた分析【第二回】 データの統計分析
1.データに応じた統計モデルの設定 (母集団分布のモデル化)
2.パラメータ の推測 θ

事後分布に基づいたパラメータ推定(1/2)
あくまで、データを得た後での「我々の知識の不確かさ」の表現
1. 事後分布の期待値: (ベイズ推定量と呼ぶことが多い)
→ 事後分布を用いたパラメータの推定値の与え方は色々
∫= θθπθδπ d)|()( xx
2. 事後分布のメジアン(中央値)
3. 事後分布のモード(最頻値):MAP推定量
事後分布の意味
点推定量
*最尤推定量(MLE) = 一様分布の時のMAP推定量
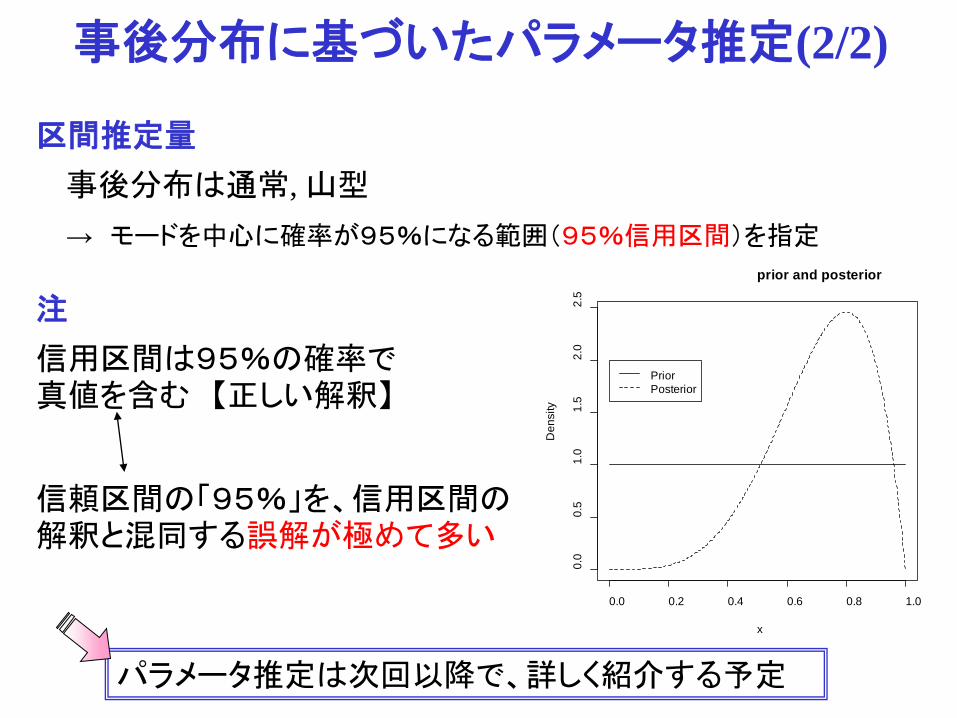
事後分布は通常, 山型 → モードを中心に確率が95%になる範囲(95%信用区間)を指定
信頼区間の「95%」を、信用区間の解釈と混同する誤解が極めて多い
信用区間は95%の確率で真値を含む 【正しい解釈】
区間推定量
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.5
1.0
1.5
2.0
2.5
prior and posterior
x
Den
sity
PriorPosterior
注
事後分布に基づいたパラメータ推定(2/2)
パラメータ推定は次回以降で、詳しく紹介する予定

4. 問題編

実はすごい発見をしてしまったYO!
ある上司の主張

実はすごい発見をしてしまったYO!
というわけで、しばし、彼の大発見(?)の説明をお聞きください
ある上司の主張

2014年8月~2015年5月までの試合結果
2014年 8/2(土) 18:00 ガンバ大阪 2 -0 横浜F・マリノス 万博記念競技場 8/9(土) 19:00 大宮アルディージャ 0- 2 ガンバ大阪 NACK5スタジアム大宮 ・・・・・
2015年 ・・・・・ 5/2(土) 14:00 浦和レッズ 1-0 ガンバ大阪 埼玉スタジアム2002
戦績は以下のサイトで公開: http://labola.jp/club/%E3%82%AC%E3%83%B3%E3%83%90%E5%A4%A7%E9%98%AA/match/month/3
ガンバ大阪の戦績
調べたらビックリだYO!
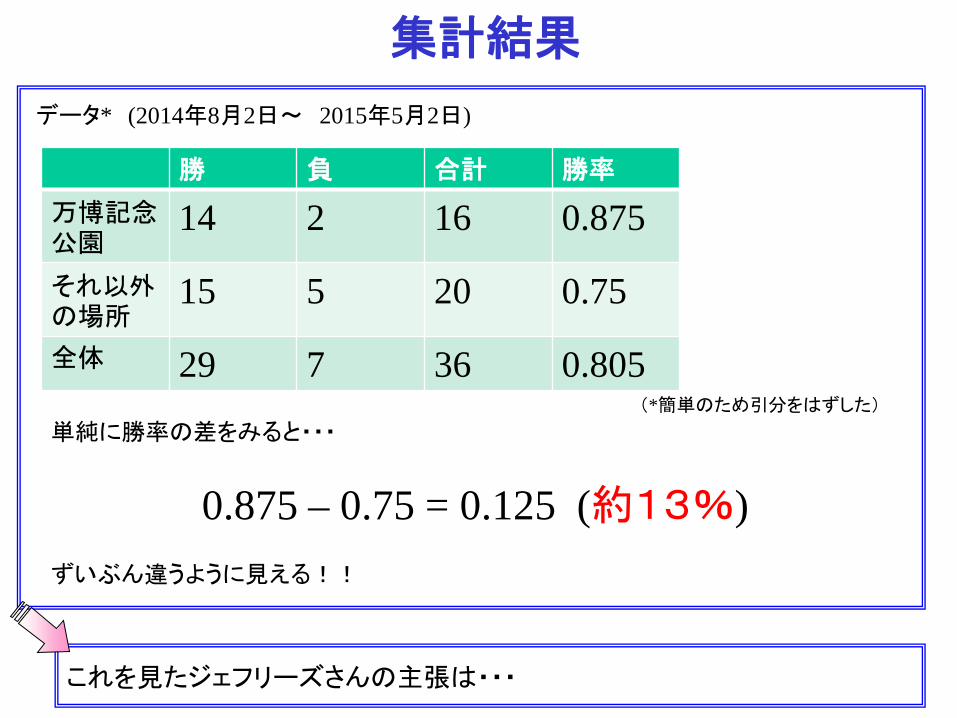
集計結果
万博記念公園での試合 試合数(引き分けは外す) 16 14勝 2敗 勝率 0.875
データ* (2014年8月2日~ 2015年5月2日)
万博記念公園以外での試合 試合数(引き分けは外す) 20 15勝 5敗 勝率 0.75
単純に勝率の差をみると・・・
ずいぶん違うように見える!!
勝 負 合計 勝率 万博記念公園
14 2 16 0.875
それ以外の場所
15 5 20 0.75
全体 29 7 36 0.805 (*簡単のため引分をはずした)
これを見たジェフリーズさんの主張は・・・
0.875 – 0.75 = 0.125 (約13%)

つまり, スタジアム
には勝利の女神がいるんだYO!

はたしてジェフリーズさんの主張は正しいのだろうか. 適当な統計モデルを構築, 彼の提示したデータを用いて検証しなさい
統計モデリングの課題
検証頼むYO!

5.解決編1 ~統計モデルの構築

データはたくさんあるけれど・・・
4月5日の試合は開始直後に
先制ゴールで試合の流れが決まった気がする. どうやってモデル化?
天候や気温もあるし 出場選手の情報もあるし・・・

統計モデルの構成
以上の仮定をするとシンプルなモデルができる
ランダムさの仮定 試合の勝ち負けに寄与する要素: 出場選手, 天候, 気温, 相手チームとメンバー, etc. → +, -がうまく打ち消し合い変動は小さい
独立同一性の仮定
毎回, 一定の確率 (ホーム), (アウェイ) で勝ち, 各試合の結果は独立
→ 各試合の順序や日付も無視
Hθ Aθ

モデル1(ホームとアウェイで勝率が同じモデル)
2つの統計モデル 試合の勝敗のモデル構築*
*ガンバ大阪の選手・サポーターの皆さま、ごめんなさい
モデル2 (ホームの方が勝率が高いモデル)
HHHAAA xnH
xH
H
HxnA
xA
A
AHAHA x
nxn
xxp −− −
−
= )1()1(),|,(2 θθθθθθ
HA θθ <
HHAAHA xnxnxx
H
H
A
AHA x
nxn
xxp −+−+ −
= )1()|,(1 θθθ

6. 解決編2 ~ベイズファクター

尤度関数・尤度比【統計の復習】
パラメータ の各値に対する(相対的な)もっともらしさ(likelihood)を表現(確率解釈できるとは限らない)
解釈
尤度(ゆうど)関数 確率関数・確率密度関数の x 部分に実際のデータを代入し, パラメータ の関数とみなしたもの.
パラメータに関係ない項を無視することもある.
)|(~ θxpx
θ
例 612=x
)|612()( θθ pL =
θ

尤度関数・尤度比【統計の復習】
1より十分大きいか小さい場合, 片方のパラメータ(モデル)の方がもう片方よりも、もっともらしい
解釈
尤度(ゆうど)比
異なるパラメータや異なるモデルでの尤度関数の値の比(異なるモデルの場合、定数項を捨ててはいけない)
)|(~ θxpx 700,600=θ例 612=x
)700|612()600|612(
)700()600(
pp
LL
=

計算してみよう! 統計モデルの例
公式
分散 s は既知の定数とする
sx
es
xp 2)( 2
21)|(
θ
πθ
−−
=),(N~ sx θ
( )ss
xxp πθθ 2log21
2)()|(log
2
−−
−=
1. x = 62 として対数をとった尤度関数を書きなさい. (s はそのままでよい.) 問題
=)(log θL ( )ss
πθ 2log21
2)62( 2
−−
−
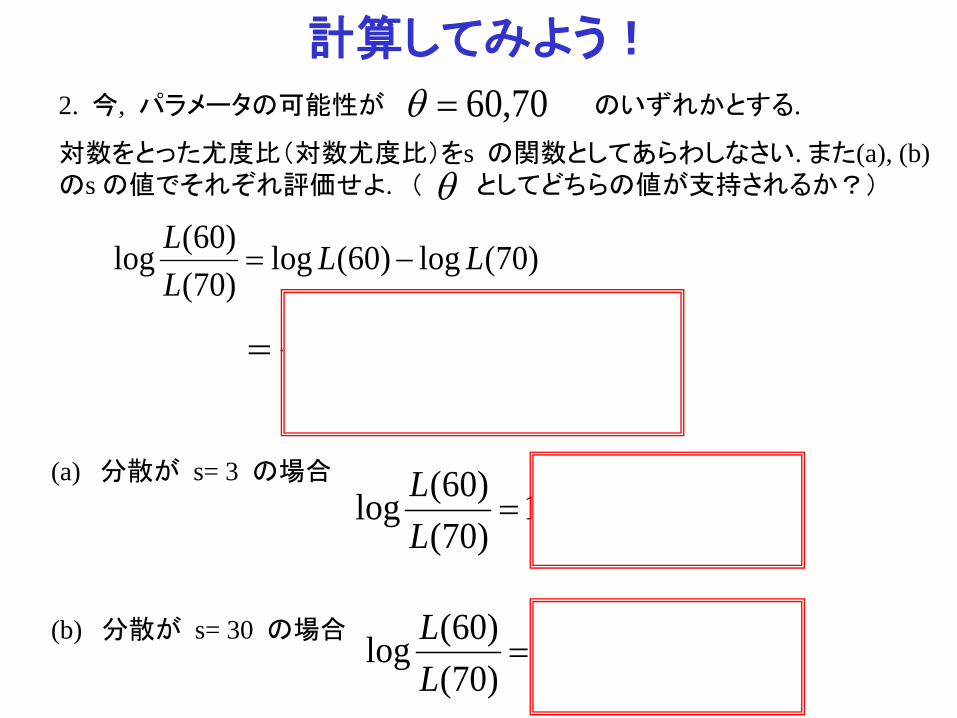
計算してみよう!
(a) 分散が s= 3 の場合
)70(log)60(log)70()60(log LL
LL
−=
2. 今, パラメータの可能性が のいずれかとする.
対数をとった尤度比(対数尤度比)をs の関数としてあらわしなさい. また(a), (b) のs の値でそれぞれ評価せよ. ( としてどちらの値が支持されるか?)
s30
=
70,60=θ
(b) 分散が s= 30 の場合
10)70()60(log =
LL
1)70()60(log =
LL
θ

周辺尤度とベイズファクター
モデル1:
∫= )()()( d)()|(:)( jjj
jjj xpxm θθξθ
ベイズファクター (Jeffreys, 1961; Kass and Raftery 1995)
)()(:)(
2
112 xm
xmxB =
2つのモデルの比較 手元のデータ x をよりよく説明する統計モデル(仮説)を選ぶ
各モデルの周辺尤度
)|(~ )1(1 θxpx
モデル2: )|(~ )2(2 θxpx
各モデルごとのパラメータは未知!
各モデルのパラメータに事前分布 を設定して「平均化」 )( )( jj θξ

ベイズファクターによる判断の目安
Jeffreys (1961, Appendix B)
1 to 3.2 Not worth more than a bare mention
3.2 to 10 Substantial 10 to 100 Strong
> 100 Decisive
← 2.310 2/1 ≈
データはモデル2よりモデル1を支持
支持の強さ (正確な値でなくオーダーで判断)
1)()()(
2
112 >=
xmxmxB

モデル1
各統計モデルと事前分布 勝率の事前分布
モデル2 10 ≤≤≤ HA θθ
),(~ baBetaθ
10~),( ≤≤≤ HAUHA θθθθ 計算の簡単のため一様分布で表現
a=b=1 (一様分布)とa=b=1/2(Jeffreys )でやってみる
10 ≤≤θ
HHHAAA xnH
xH
H
HxnA
xA
A
AHAHA x
nxn
xxp −− −
−
= )1()1(),|,(2 θθθθθθ
HA θθ <
HHAAHA xnxnxx
H
H
A
AHA x
nxn
xxp −+−+ −
= )1()|,(1 θθθ

モデル1
モデル1の周辺尤度
a=b=1 (一様分布)とa=b=1/2(Jeffreys )でやってみる
),())()(,(
baBbxxnnaxxB
xn
xn HAHAHA
H
H
A
A ++−+++
=
> A <- 1; > B <- 1; > N_home <- 16; N_away <- 20; > N_win_home <- 14; N_win_away <- 15; > M1 <- choose(N_away, N_win_away)* choose(N_home, N_win_home)*beta(N_win_home + N_win_away + A, (N_home - N_win_home ) + (N_away - N_win_away) +B )/beta(A,B);
ガンバ大阪のデータでは
====
=)2/1(,00487.0
)1(,00602.0),(1 ba
baxxm HA
∫ −+−+ −
=
1
01 )()1(),( θθξθθ dxn
xn
xxm HHAAHA xnxnxx
H
H
A
AHA

モデル2
BF.calc <- function(N1, N2, y1, y2){ bf <- 0; for( k in 0:y2){ bf <- bf + choose(y2, k)* beta(k+1, N2 - y2 +1)*beta(N1 + N2 - y1 -y2+k +2 , y1 + y2 -k+1); } bf <- 2*bf * choose(N1, y1)* choose(N2, y2); return(bf); } M2 <- BF.calc(N_away, N_home, N_win_away, N_win_home);
ガンバ大阪のデータでは
∑=
+−+++−−++−+
=
Hx
kHAHAHAHH
H
H
H
A
A kxxkxxnnBxnkBkx
xn
xn
0)1,2()1,1(2
00451.0),(2 =HA xxm
モデル2の周辺尤度
1
12
1 θθθ
−−
=z
∫ ∫ −− −−
=
1
0
1
2 )1()1(2),(A
HHHAAAAH
xnH
xH
xnA
xA
H
H
A
AHA dd
xn
xn
xxmθ
θθθθθθ

ここまでの結論
(*通常の仮説検定でも10%の勝率の差は有意とはいえない)
2種類のモデルを用いた仮説の比較
ベイズファクター(周辺尤度の比)は1程度
33.1),(),(
2
112 ==
HA
HA
xxmxxmB
スタジアムの女神は幻だったYO

補足
さらなる検討のためには【グループタスクのヒント】
・データ数を増やす ・統計モデルの精緻化 (単純な二項分布はひどい・・・さすがに選手に失礼)
・共変量を加える (試合メンバーや天候, 勝率に影響を与える要素を増やす)
注意点
1. ホーム・アウェイで勝率が変わらないモデルでも、同じくらい説明できることが示されただけ(片方を否定する結果ではない!)
2. 統計モデルに改良の余地もある!
第8・9回

まとめ:ベイズファクター ベイズでは複数のモデル・仮説で周辺尤度比を比較して検討
一般の場合 先の例では2つのモデルで比較したが、 3つ以上でも同様にできる
∫= )d()|(:)( )()( jj
jjj xpxm θξθ
ベイズファクター = 2つのモデルの周辺尤度の比
)()(
:)(xmxm
xBk
jjk =
仮説 = 統計モデル JjjM ,,1}{ =
各モデルで余計なパラメータは積分で消して周辺尤度を求める

7. グループタスク第一回

第一回グループ発表(6/6 開催)
・40点満点
・グループごとに点数をつける
・グループ内で貢献度が著しく低い・高い個人は補正
・他グループが提出する評価点・コメントも参考【追加】
採点方法
第一回の要件
・ベイズファクターを利用した分析が入っていること!
・事前分布、事後分布は発表の際, 数式と視覚的な表示をいれる
・事前分布はいろいろ試してみる
・実データを利用し, 複数の観点から分析

評価方法
暫定評価点 20点未満 → 不合格とし別の機会に再度発表
審査の流れ 1.全発表終了後、各グループごとに審査、まずは、コメントを発表してもらう
2.不十分な点に関して、発表グループは弁解、反論も可
3.1,2の討議をもとに、各グループ 最大10点で点数評価
(発表グループは自分たちの評価はしない)
暫定評価点
(各グループの評点 × 7)/ 2 + 教員補正(+-)
暫定評価点と他グループからの最大点、最小点は公表
注.グループ内で貢献度が著しく低い・高い個人は補正

発表直前チェックシート
□収集したデータの説明と統計分析の目的
□実装(R言語)の概要
□モデリング手法の検討
□グループ内の作業分担
□分析結果の解釈と検討
□グループでの作業分担は適切か、分析結果を全員が理解しているか
□設定した課題の難易度(うまくいかなくてもよいが試行錯誤は必要)
□発表スライドの内容やその他のルール・要件をきちんと満たしているか
評価の観点
発表スライドに含めるべき内容

その他
・履修者人数分配布資料を用意してもよい (義務ではない)
発表に関するルール ・各グループ 一回発表 (発表順も決めておき, 13時~発表開始できるように)
・発表&質疑応答で20分程度×2~3 + 審査(グループディスカッション)
・グループ発表の回は、グループごとに固まって座る
・収集データ, 分析に用いたソースコードはzip ファイルでまとめて,
教員(田中(冬))に事前送付
6/6 第一回テーマ: ベイズモデリング
6/27(予定) 第二回テーマ: 一般化線形モデリング
7/25(予定) 第三回テーマ: スパースモデリング
日程 (予定)






![[XLS] · Web view統計表9 統計表8 統計表7 統計表6 統計表5 統計表4 統計表3 統計表2 統計表1-3 統計表1-2 統計表1-1 総 数 (単位:千人) 傷 病](https://img.pdfslide.net/doc/110x75/5b0d33387f8b9af65e8d497a/xls-view9-8-7-6-5-4-3.jpg)