Embed Size (px)
Citation preview

225December 2016
第十八卷 第二期 2016 年 12 月(pp.225~248)
基於漸增式分群法之惡意程式自動分類研究陳嘉玫 a, * 賴谷鑫 b
a國立中山大學資訊管理系b中國文化大學資訊管理系
摘要
近年來網路犯罪份子為了有效地躲避安全機制的檢驗,而不斷地開發惡意程式或
是進行變種。現今分析方式大多數都只分析單一二進位檔案型態之惡意程式,無法適
合誘捕系統所捕獲到之原始碼與二進位檔混和型態的惡意程式。目前仍然缺少一個有
效且快速分析的工具針對誘捕系統所捕獲的惡意程式做分析。
本研究提出一個惡意程式分類系統,此系統擷取惡意程式原始碼、以及檔案結構
作為特徵值並且使用漸進式分群法分群。本研究利用漸增式的分群法改善階層式分群
演算法效率並且藉由惡意程式分群可以知道新捕獲的惡意程式是否屬於已知的分類或
是屬於新的類型。本研究與網路上知名病毒偵測與分類平台 Virustotal比較以驗證分類準確度,實驗證明本研究所提出的分類優於 Virustotal。
關鍵詞:誘捕系統、惡意程式分類、靜態分析、漸增式分群
Automatic Malware Classification Based on Incremental Clustering Algorithm
Chia-Mei Chena Gu-Hsin Laib
a Department of Information Management, National Sun Yat-Sen Universityb Department of Information Management, Chinese Culture University
AbstractIn recent years, cybercriminals have developed new malware or variants in order
to effectively evade inspection from security mechanisms. Most prior works focused on analyzing malware which contain only single binary file. However, most honeypot captured malware contain several binary and source files. Therefore, existing malware analysis
* 通訊作者 電子郵件:[email protected] 本研究受科技部專題研究計畫 103-2221-E-110 -049 -MY3與 104-2218-E-001-002補助,特此感謝。 DOI: 10.6188/JEB.2016.18(2).03

基於漸增式分群法之惡意程式自動分類研究
226 December 2016
approaches do not suitable for honeypot captured malware.In this research, a novel malware classification approach which analyzes features
extracted from malware’s file structure, source code and binary files and file name is proposed. An incremental clustering algorithm is developed to replace traditional hierarchical clustering algorithm for improving efficiency. By means of proposed system, when a honeypot captures a new malware, IT security staff could know whether the new malware belongs to any existing clusters or not. To evaluate the performance of proposed system, the proposed approach is compared with Virustotal- a popular platform for malware detection and classification. The experiment result shows that the proposed approach outperforms Virustotal.
Keywords: Honeypot, classification of malware, static analysis, incremental clustering
1. 前言
惡意程式的大量變種除了造成惡意軟體的種類遽增讓安全機制在辨別上更加困難
之外,對於使用者的威脅程度也是大增。如 2007年以來從家庭使用者與企業用戶竊取百萬以上金額的 Zeus殭屍網路,之後陸續產生出了許多新的變種。其中最著名的變種為 SpyEye殭屍網路。SpyEye主要攻擊對象為一般電腦用戶和中小型企業,主要手法為竊取用戶網路銀行資料。在 2011年 4 月到 6月期間,俄國駭客就利用 SpyEye 殭屍網路成功入侵 25000多個系統而獲取高達 320萬美元的不法所得(Trend Micro, 2011)。根據賽門鐵克 2011年年度調查報告,惡意攻擊數量較 2010年持續攀升了81%,而且特定惡意變種程式數量更多達 4.03億,較 2010年上升了 41%,顯示惡意軟體的變種數量及規模是日以俱增(Symantac, 2011)。
偵測以及處理惡意程式的攻擊將造成企業很大的成本,根據 Ponemon Institute 報告指出,2012 美國企業平均每周遭受到網路攻擊成功次數高達 102 次,而平均每次解決一件網路攻擊必須花費 24天,甚至最長高可達到 50 天,在這 24天期間,企業所涉及的平均損失為 591,780 美金,較 2011年平均 18 天的解決時間所估計的 415,748 美金平均損失增加 42%(HP, 2012)。因此網管者所面臨到的問題除了是正確偵測惡意的攻擊來源外,面對日益增加的資安事件,如何加快分析速度成為網管者
面臨到的一大挑戰。
透過誘捕系統的建置,網管者或資安人員可以補獲攻擊者所使用的惡意軟體。了

電子商務學報 第十八卷 第二期
227December 2016
解惡意程式的行為對於資安人員與數位鑑識人員十分重要。對資安人員而言,惡意程
式的行為代表攻擊者的主要意圖,了解攻擊者的主要意圖可以作為後續處理之判斷與
預防措施之依據;對數位鑑識者而言,了解惡意程式的行為可以得到攻擊者使用手法
以及目標。而了解惡意程式行為最簡單有效的方式即是將惡意程式進行分析與分類。
過去針對惡意程式分析手法主要分為動態分析與靜態分析。動態分析在一個受控
制的環境下(通常為虛擬機器)執行惡意程式後觀察其所產生的行為做進一步分析。
靜態分析在不執行惡意程式的前提下直接拿惡意程式檔案分析。當前惡意程式分析研
究大多著重在單一二進位檔案的分析,而惡意程式開發者多利用反虛擬機器機制以及
混淆機制以規避現行的惡意程式分析。此外誘捕系統所捕獲到的惡意程式類型眾多,
除了單一二進位檔案之外,大部分的惡意程式都由數量不等的原始檔、二進位檔或是
其他文字檔所組合而成,惟有完整的分析整個惡意程式所有的檔案才可以全盤了解攻
擊者的意圖。
有鑑於此,本研究將結合惡意程式內二進位檔案和原始檔的分析,提出一個對惡
意程式進行分類的方法。本研究擷取惡意程式的原始檔內容、檔案名稱、二進位檔內
容以及惡意程式的檔案結構部分透過靜態分析技術算出惡意程式之間的相似度。最後
本研究提出一套漸增式分群法可以快速的將新捕獲惡意程式做分群歸類的動作。本研
究所提出的漸增式分群法主要是利用群首(Cluster Head)的概念,針對每一群惡意軟體算出一個群首。如此一來當新的惡意程式被捕獲時,新補獲的惡意程式僅需要與
群首做相似度的比較,當組織內所補獲的惡意軟體樣本增多時,本研究所提出的方法
可以大幅減少分群所需要運算資源。有別於機器學習的分類方式,本研究所提出的分
類方式不會預先設定惡意程式的類別數量。當分類器發現該惡意程式不屬於現有樣本
的任何一群(類)時,本研究所提出的方法會自動的將它設定為新的類別,因此本研
究所提出的分類方式除了可以將已知的變種攻擊程式正確分類外,也可以分辨出該攻
擊對於組織而言是否屬於新型的攻擊。如果惡意程式屬於已知的族群,資安相關人員
可以不必分析該惡意程式,並根據之前對該族群所做的分析結果判斷該攻擊的嚴重程
度以做後續處理;而如果惡意程式不屬於任何已知的族群時,則此為新攻擊,本研究
所開發的系統自動將該惡意程式指派為獨立新分類。資安相關人員必須對此新攻擊做
分析以得知攻擊者的手法,藉以了解新攻擊所帶來的威脅並且做為未來分群的基礎。
就資訊科學而言,分類(Classification)以及分群(Clustering)為不同概念,分類通常運用於已知類別的分類法則。而在惡意程式分析的領域中,由於不斷有新類型攻擊
或惡意程式變種出現,因此分類演算法不適用惡意軟體分析。分群式演算法為非監督
式演算法,系統根據惡意程式的特性將資料作分群。分群式演算法的缺點則是僅對資
料作分群,但無法說明該群組的特性。本研究所採取的分析方式為分群演算法,透過
漸增式分群演算法對惡意程式作分群。而透過本系統執行結果後將會根據分群產生少

基於漸增式分群法之惡意程式自動分類研究
228 December 2016
數群首,透過手動分析群首的行為,可以了解每一群惡意程式的行為以及特性,此時
新進惡意程式分析的問題即為分類問題。透過本研究所提出的方式可以自動判定該新
惡意程式屬於已知或是未知的惡意程式類別。如果屬於未知類別,則分析人員需要手
動分析作為後續分析基礎。
透過本研究提出的方法除了可以加強企業與組織對於資訊安全的防護外也可以整
合組織現有的防禦機制(如入侵偵測系統或是 Security Operation System)。企業除了可以利用 Security Operation System關聯攻擊者的來源端以及目的端外,本研究所提出的惡意程式分類(群)可以提供攻擊者的意圖目標還有是否為新攻擊等資訊,彌
補傳統誘捕系統資訊不足的缺點。
2. 文獻探討
過去已經有許多研究提出以各種不同方式分析惡意軟體,以分析的手法而言,惡
意程式分析方法有動態分析以及靜態分析。大部分的動態分析或是靜態分析主要著重
在二進位檔案的分析。而以分析的對象而言,可以歸納為惡意程式的二進位檔以及原
始碼。以下針對相關的研究做探討。
動態分析(Dynamic Analysis)是一種與原始碼無關,而是透過惡意軟體的程序、檔案、機碼與網路行為(Bailey et al., 2007; Zhang et al., 2009; Firdausi et al., 2010; Nataraj et al., 2011)以及Win32 API call 分析惡意軟體(Lee and Mody, 2006; Prechelt et al., 2002; Rieck et al., 2011; Zhao et al., 2010; Inoue et al., 2008; Tian et al., 2009; Shankarapani et al., 2011)。而軟體執行的行為如載入的動態連結程式庫(Dynamic Link Library)、檔案的寫入或刪除、網路連線情況及機碼的修改行為等皆是動態分析所監控的目標。動態分析的優點為不必費時處理模糊化問題,且所需的
技術門檻較低。以下將說明與惡意軟體行為以及分類相關之研究作探討。
Bailey et al.(2007)的研究重視的是執行樣本後,程序、檔案、網路與機碼行為在執行過程中的所有變化;Zhang et al.(2009)以及 Nataraj et al.(2011) 的研究重視的行著重於自動啟動行為(Autorun Entries)、連接埠(Connect Ports)、DNS查詢記錄(DNS Records)、刪除的檔案(Drop Files)、程序的變動(Process Changes)與機碼的修改(Registry Mods)行為;Lee 與 Mody 的研究(Lee and Mody, 2006)重視的行為除了 API之外,還包括 API被呼叫時的狀態,如記憶體位置、參數等資訊。從這些文獻中可以得知,大部份的研究使用的特徵數量皆相當龐
大,因為特徵數量越多對於系統的判斷正確率就會增加,但是過多的特徵值將對系統
效能造成負荷。舉例而言 Bailey等人的研究為例,分析 500隻惡意軟體的相似度卻

電子商務學報 第十八卷 第二期
229December 2016
需要 2.5G的記憶體空間(Bailey et al., 2007)。動態分析主要是使用惡意軟體的二進位檔來進行分析,所以在樣本取得上相對靜態分析還要來的容易,但是二進位檔由於
受限於跨平台無法執行的因素,所以為了偵測不同類型的惡意軟體可能需要建造許多
不同環境來分析,這在分析的前置動作上會先花費不少時間。此外,有些殭屍網路沒
有殭屍網路的控制者所下的指令是不會觸發其行為,因此造成動態分析的困難。以及
攻擊者為了規避使用 VM環境所建置的動態分析系統,而發展反 VM技術的惡意程式,使其在 VM環境下不會產生行為。因此在惡意軟體動態分析上會因為無法收集到完整的行為模式而在分類上有所誤差。此外動態分析處理一個樣本所需耗費時間也
較為龐大。為了能夠更快速地對惡意軟體進行分析,故本研究採用靜態分析的方式分
析惡意軟體的行為。
靜態分析是(Static Analysis)一種白箱(White Box)分析方式,不實際執行惡意軟體,而是透過分析原始碼中的二進位碼、函式、結構、流程圖、或是 API call等,以了解惡意軟體的行為(Inoue et al., 2008; Tian et al., 2010; Yu et al., 2010; Wang et al., 2009; Santos et al., 2010)。最典型的靜態分析工具為防毒軟體,防毒軟體直接根據特徵值(病毒碼)比對二進位檔案內容。Virustotal(http://www.virustotal.com)為一知名線上掃毒平台,該平台整合 56種防毒軟體。使用者可以上傳嫌疑檔案,Virustotal會將 56種防毒檢查結果整理為一張表格。Virustotal整合了多種防毒引擎,並且保持最新的病毒碼,其檢測結果客觀可靠,因此本研究以此平台作為比較基礎。
n-gram 為另一種常用來分析二進位檔案的方式。n-gram方法,指的是在一個二進位檔案中,從不同的位置開始,分別取連續的 n個位元組,作為特徵值。Kolter與Maloof的研究將所蒐集的惡意軟體二進位檔案取 n-gram作為特徵,搭配了 Naive Bayes、決策樹、SVM、以及 Boosting等機器學習(Machine Learning)與資料探勘(Data Mining)的方法,用來偵測二進位檔案是否為惡意或良性,並且評估這些方法分類的結果(Kolter and Maloof, 2006)。但是 n-gram方法的缺點在於如何決定 n的大小。n取太短,則無法有鑑別度,反之,則可能造成了計算效能上的負擔。
為了可以取得更進一步的資訊,不少學者透過反組譯工具將二進位檔反組譯
(Disassemble)方式取得原始檔案或是組合語言檔案。Tian et al.(2010)的研究以API call做為惡意軟體分類的依據。首先,他們先將所有樣本進行反組譯以取得 API call,並紀錄所有樣本之使用的 API以及使用頻率(Global List),隨後透過樣本的向量值進行分類。Wang et al.(2009)的研究首先找出哪些是病毒經常使用的 API call,以及研究非病毒經常使用的 API call中,哪些是可以產生惡意的行為,並將這些資訊與事前機率,分別儲存在二張不同的 Hash table。對於待分析的樣本,則是利用已定義好的事前機率與樣本的 API call,計算事後機率,判斷此樣本是否為病毒。Santos et al.(2010)的研究則是依指令(Opcode)的相似性做為判斷惡意軟體與正

基於漸增式分群法之惡意程式自動分類研究
230 December 2016
常軟體的依據。Conti et al.(2010)首先提出將二進位檔內的二進位碼轉換成灰階影像格式,藉此可看出每一個不同類型的二進位檔在影像圖形呈現上也不相似,而同一
個類型的影像圖形結構上極為類似。而 Nataraj et al.(2011)的研究將此應用於惡意軟體二進位檔案的分類上,將轉化後的二進位檔灰階圖形再以 GIST影像特徵方式擷取特徵向量,再以歐氏距離去計算兩個二進位檔間的距離來分類。雖然現今有許多研
究對惡意軟體二進位檔案的靜態分析取得不錯的成效,但是仍然會受到惡意軟體二進
位檔案使用模糊化的技術而限制。模糊化技術會造成 API Call、CFG或是 n-gram等方法在特徵擷取上會產生出無用的特徵值而導致判斷出現誤差,藉此躲避靜態分析偵
測。而二進位檔轉影像檔的分析方式,因為不需要對二進位檔進行反組譯等動作來還
原成組合語言等程式碼,因此不必要進行反模糊化的動作,這會比 API Call、CFG和n-gram方式還要快速、花費成本少且有延展性,因此本研究採用此方式來進行惡意軟體內二進位檔的分析。
原始碼相似度比對通常運用在軟體分析、維護和抄襲檢測。一般的作法是利用軟
體原始碼內部的字串、結構、流程等特性,與另一個軟體內的原始碼檔案所擁有的相
同特性使用相似度方式比較之後,來辦斷是否是同一種軟體或是衍生版本。Prechelt et al.(2002)所開發的 JPlag系統就是將程式碼轉為字串表示,然後去找尋兩個程式碼間的最大長度的字串集,最後再使用相似度分數公式將兩程式碼間相似的字串程
度轉為百分比表示。Gitchell et al.(1999)則是開發了一款稱為 SIM的程式碼比對程式碼內的運算元、標點符號、關鍵字等都會轉為特定的字串,比對特徵字串是使用
編輯距離的方式算出兩個程式碼的最佳比對分數來當作是否相似的判斷依據。Cosma et al.(2012) 的研究就是運用潛在語意分析來解決程式作業抄襲檢測的議題,藉由潛在語意分析取出原始碼內語意詞彙的特徵矩陣,然後運用奇異值分解計算方式
(Singular Value Decomposition, SVD)將影響力較小的詞彙予以過濾,最後再使用Cosine Similarity的方式計算出兩者間的相似度判定是否是抄襲的作業。以上相關研究都著重在正常程式的抄襲部分,但是抄襲本身的行為與惡意程式開發者開發變種的
行為不同。抄襲者本身怕被看出來因此會更改舊有程式的結構或是變數名稱;而變種
惡意程式開發者將會延用大部分舊有惡意程式的結構以及內容。而就另一方面而言,
這些研究只針對原始碼內容部分做比較,並沒有考慮到惡意程式內的檔案結構以及二
進位檔的部分,因此不適合用於惡意程式的分類應用。
而在惡意軟體原始檔分類研究上,陳嘉玫等人提出了一個以惡意程式原始檔案內
容以及檔案名稱為基礎的惡意程式分類方式(陳嘉玫等人,2013)。在該的研究中以惡意程式的原始碼內容相似度比較為主,但是該研究中並沒有考慮到二進位檔以及檔
案結構的重要性。如果僅僅考慮到 Shell Script檔案本身內容而未考慮到惡意程式內所包含的二進位檔或是其 Shell Script檔案所執行的重要指令將會造成分類器的分類

電子商務學報 第十八卷 第二期
231December 2016
錯誤。
常見的非監督式學習分群演算法以 k-means(MacQueen, 1967)與階層式演算法為主。利用 k-means演算法最大的限制是在執行前必須先決定群集數量,面對到日益演化以及增加的惡意程式,k-means演算法不適合用來解決惡意程式分群問題。階層式演算法又分為有聚合式與分裂式兩種,在實際應用上以聚合式較常見。因演算
法中對於兩群之間的距離判斷方式不同,早期較著名的聚合式階層分群演算法約有 Single-link、Complete-link、Ward以及 Average-link,而其時間複雜度分別為 O(n2),O(n3),O(n3),O(n2)(Day and Edelsbrunner, 1984)。根據時間複雜度分析可知,階層式演算法面對到大量的惡意程式運算效能不佳。除此之外每當一個新的惡意樣本被
捕獲時系統必須重新執行分群程式,因此階層式演算法不適合用來解決惡意程式分群
問題。
由文獻探討可以得知目前並無一個有效的惡意程式分類器針對惡意程式的特性做
有系統的分析。本研究提出的分類器將觀察惡意程式的特性根據其原始檔內容、檔案
結構、檔案名稱以及二進為檔內容作分析,並且提出一套有效以及快速的分類機協助
網管人員對所偵測到的惡意攻擊做分析。
3. 研究方法
3.1 誘捕系統捕獲之惡意程式特性
在研究惡意程式分類前,首先要對誘捕系統所捕捉到的惡意程式架構做一個深入
了解。誘捕系統所捕捉惡意程式通常會有三種不同的形式,分別為 (1)單一原始檔;(2)單一二進位檔以及 (3)混合型態。圖 1(a)、1(b)以及 1(c)分別為單一原始檔、單一二進位檔以及混合型態惡意程式範例。
(a) 單一原始檔 (b) 單一二進位檔 (c) 混合型
圖 1 惡意程式形式

基於漸增式分群法之惡意程式自動分類研究
232 December 2016
單一原始檔的惡意程式,這類型程式碼檔主要是為 Perl程式碼檔,攻擊只需要執行該 Perl檔案便可以產生惡意行為。而惡意程式檔案本身如果為單一二進位檔,攻擊者直接執行此二進位檔便可以進行惡意行為。如果是混合型態的惡意程式,惡
意程式以壓縮工具包成一個壓縮檔,解壓縮後會存在數個檔案,這些檔案包含 Shell Script檔、C語言碼檔、Perl程式碼檔、二進位檔、文字檔等,如圖 1(c)所示。
藉由了解惡意程式本身可以得知惡意程式之內部的原始碼和二進位檔都具有其特
殊惡意行為。為了能完整分析惡意程式之行為,需要萃取惡意程式內的原始碼特徵值
和二進位檔特徵值進行比對。此外,由於惡意程式與其變種大部分都會重複利用相同
的檔案和元件,因此若兩個惡意程式內的檔案名稱相似代表著它們為同類型惡意程式
的可能性很高,所以本研究選用惡意程式內部的檔案名稱來當作特徵值。以此類推,
同類型的惡意程式與其變種在檔案結構,也就是所含有的檔案類型以及數量也是相近
的。圖 2為兩個相似惡意程式檔案結構的範例,而圖 3為不相似惡意檔案之檔案結構範例。
圖 2為兩個相似的惡意程式 A與 B之檔案結構,以惡意程式 A為例,其第一層目錄共有 9個檔案,其中文字檔有 2個,二進位檔有 2個而 Shell Script檔案有 5個;惡意程式 B之其第一層目錄共有 8個檔案,其中文字檔有 2個,二進位檔有 2個而 Shell Script檔案有 4個。而在第二層目錄中,其檔案數量以及類別都同樣為9個文字檔案。而圖 3為兩個不相似的惡意程式檔案結構比較,其中惡意程式 C只有一層而惡意程式 D有兩層目錄,其中檔案數量,還有檔案的類型分布都大為不相同。因此本研究假設惡意程式的開發者會利用舊有的檔案結構在新增或式修改功能
以快速開發變種的惡意程式。因此惡意程式的檔案結構為惡意程式分類的一個重要依
據。本研究根據惡意程式的特色使用惡意程式原始碼內容、惡意程式二進位檔內容、
惡意程式檔案名稱和惡意程式檔案結構這四個特徵值來進行惡意程式的比對。
2(a):惡意程式 A之第一層目錄檔案
圖 2 相似惡意程式檔案結構範例

電子商務學報 第十八卷 第二期
233December 2016
2(b):惡意程式 B之第一層目錄檔案
2(c):惡意程式 A之第二層目錄檔案
2(d):惡意程式 B之第二層目錄檔案
圖 2 相似惡意程式檔案結構範例(續)

基於漸增式分群法之惡意程式自動分類研究
234 December 2016
3(a):惡意程式 C之第一層目錄檔案
3(b):惡意程式 D之第一層目錄檔案
圖 3 不相似惡意程式檔案結構範例

電子商務學報 第十八卷 第二期
235December 2016
3(c):惡意程式 D之第二層目錄檔案
圖 3 不相似惡意程式檔案結構範例(續)
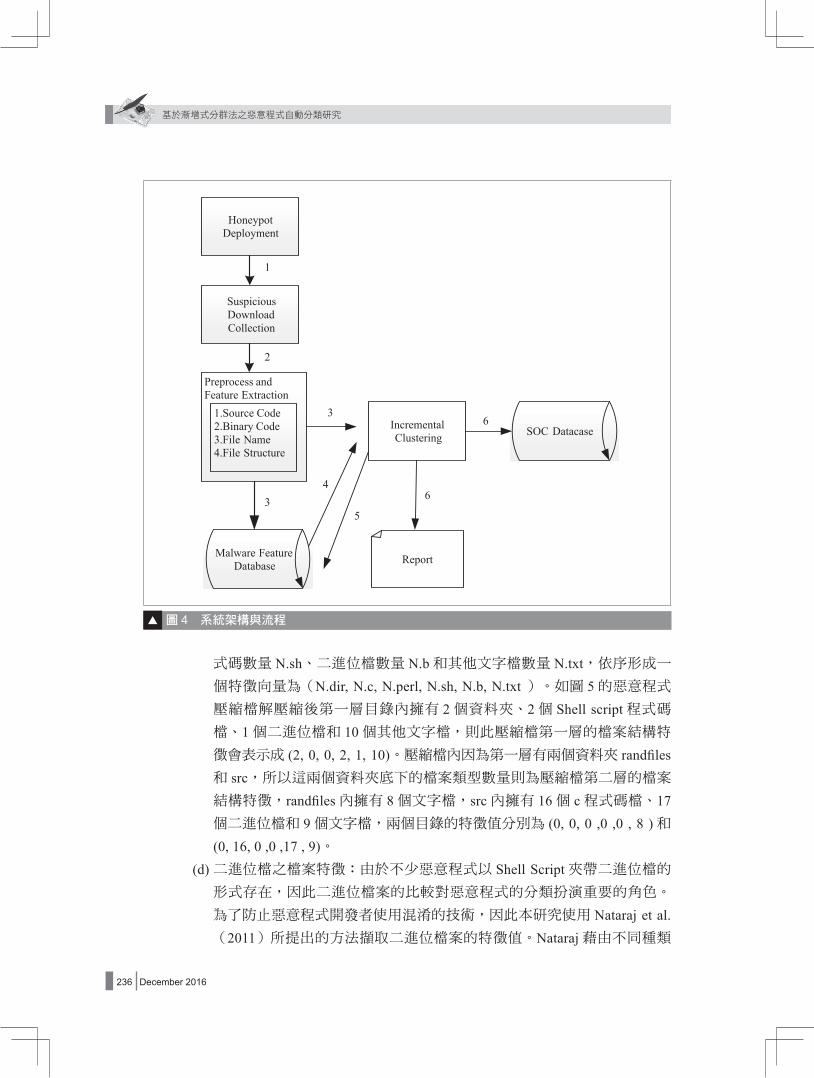
3.2 系統架構與流程
本節介紹本研究系統之架構與流程(如圖 4所示),以下對本研究所完成之功能詳述。
(1) Honeypot Deployment:為了捕捉到惡意程式之原始檔案,本研究必須架設誘捕系統,本研究架設中互動性的誘捕系統 Kippo。
(2) Suspicious Download Collection:由於本研究將在不同的地點以及不同網段架設誘捕系統,以收集更多不同種類的惡意程式,因此必須有一個中央集中的
機制將各地所捕獲到的惡意程式收集以利集中分析,本階段主要就是集中各
誘捕系統所捕獲到的惡意程式。
(3) Preprocess and Feature Extraction:在特徵萃取部分本研究將萃取惡意程式的(1)原始檔、(2)二進位執行檔、(3)檔案名稱以及 (4)檔案結構擷取特徵值。以下針對本研究所萃取的特徵值作介紹。
(a) 惡意程式之檔案名稱:本研究藉由擷取惡意程式每個目錄內之檔案名稱,依照順序組合成目錄內檔案名稱的字串
(b) 原始碼檔之檔案特徵:誘捕系統所收集到的惡意軟體原始碼主要有 C、Perl和 Shell Script三種程式語言所編寫,本系統針對以上這三種程式語言的特性分別選出所需的特徵值來作為比對的依據。
(c) 惡意程式之檔案結構:本研究選取惡意程式檔案結構特徵會計算惡意檔案樹狀結構內的檔案類型與數量,所計算的檔案類型的數量分別有資料夾數
量 N.dir、C程式碼檔數量 N.c、Perl程式碼檔數量 N.perl、Shell script程
基於漸增式分群法之惡意程式自動分類研究
236 December 2016
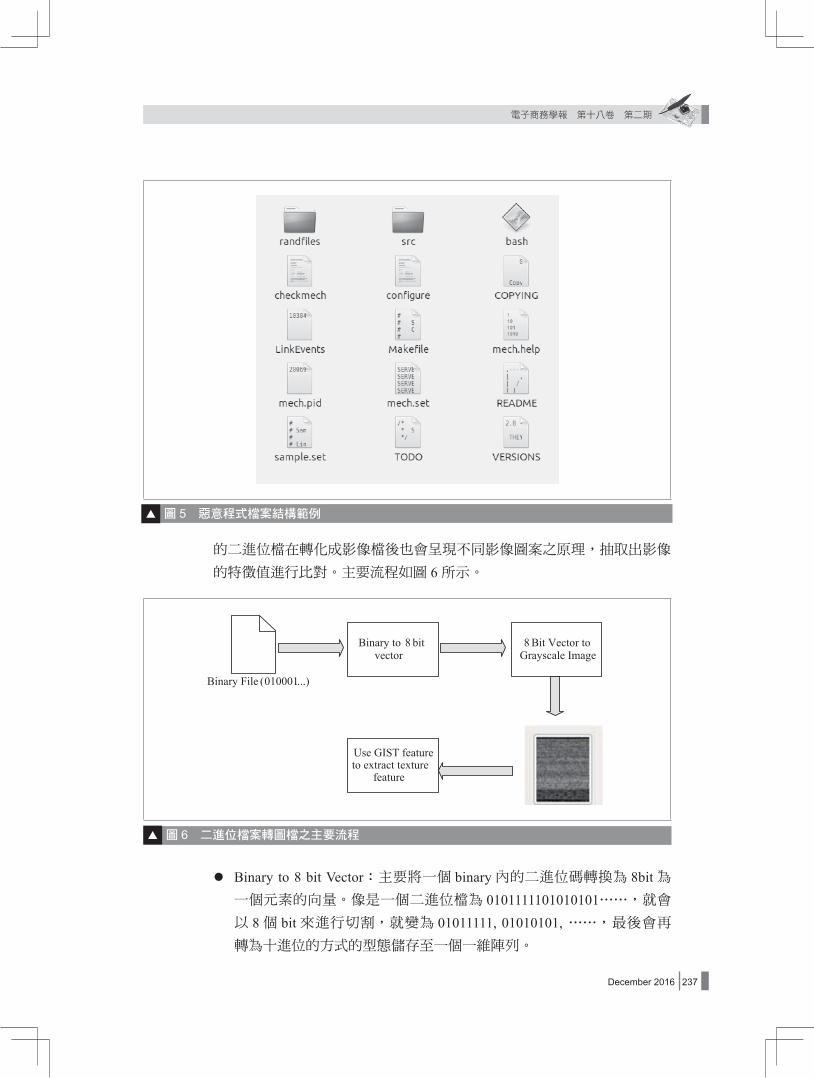
式碼數量 N.sh、二進位檔數量 N.b和其他文字檔數量 N.txt,依序形成一個特徵向量為(N.dir, N.c, N.perl, N.sh, N.b, N.txt )。如圖 5的惡意程式壓縮檔解壓縮後第一層目錄內擁有 2個資料夾、2個 Shell script程式碼檔、1個二進位檔和 10個其他文字檔,則此壓縮檔第一層的檔案結構特徵會表示成 (2, 0, 0, 2, 1, 10)。壓縮檔內因為第一層有兩個資料夾 randfiles和 src,所以這兩個資料夾底下的檔案類型數量則為壓縮檔第二層的檔案結構特徵,randfiles內擁有 8個文字檔,src內擁有 16個 c程式碼檔、17個二進位檔和 9個文字檔,兩個目錄的特徵值分別為 (0, 0, 0 ,0 ,0 , 8 )和(0, 16, 0 ,0 ,17 , 9)。
(d) 二進位檔之檔案特徵:由於不少惡意程式以 Shell Script夾帶二進位檔的形式存在,因此二進位檔案的比較對惡意程式的分類扮演重要的角色。
為了防止惡意程式開發者使用混淆的技術,因此本研究使用 Nataraj et al. (2011)所提出的方法擷取二進位檔案的特徵值。Nataraj藉由不同種類
Honeypot Deployment
Suspicious Download Collection
Preprocess and Feature Extraction
1.Source Code2.Binary Code3.File Name4.File Structure
Malware Feature Database
Incremental Clustering SOC Datacase
Report
2
1
3
3
4
5
6
6
圖 4 系統架構與流程
電子商務學報 第十八卷 第二期
237December 2016
的二進位檔在轉化成影像檔後也會呈現不同影像圖案之原理,抽取出影像
的特徵值進行比對。主要流程如圖 6所示。
Binary File (010001....)
Binary to 8 bit vector
8 Bit Vector to Grayscale Image
Use GIST feature to extract texture
feature
圖 6 二進位檔案轉圖檔之主要流程
l Binary to 8 bit Vector:主要將一個 binary內的二進位碼轉換為 8bit為一個元素的向量。像是一個二進位檔為 0101111101010101⋯⋯,就會以 8個 bit來進行切割,就變為 01011111, 01010101, ⋯⋯,最後會再轉為十進位的方式的型態儲存至一個一維陣列。
圖 5 惡意程式檔案結構範例

基於漸增式分群法之惡意程式自動分類研究
238 December 2016
l 8 Bit Vector to Grayscale Image:上述一維陣列所儲存的數字代表著灰階圖形的色彩,範圍是 0~255,0為黑色、255為白色。一維矩陣在此步驟會轉換成二維矩陣,以形成二進位檔的灰階影像檔。
l Use GIST Feature to Extract Texture Feature:經由上述步驟所轉化的灰階影像檔會在這個步驟去抽取出代表性的特徵值。本系統所使用的是
GIST圖形特徵擷取方式,GIST主要講求將一張圖片經由轉化成低維度的特徵向量去進行相似度比對。首先會將一張圖片先進行切割成 k個小區塊,然後每個小區塊進行傅立葉轉換,最後會再由 multiscale oriented filter將這些區塊轉化為 n*n*k的特徵矩陣,其中的 n是在filter中每個小區塊以 n*n的像素進行轉換。本系統會將產生的影像檔先統一重新調整為 64*64的大小,然後再進行特徵向量轉換的流程,圖形最後會產生 320個維度的特徵向量。
(e) SOC Database:本研究的樣本取自於多個來源之誘捕系統,因此惡意樣本經過本研究分群後,將細項資訊,如攻擊者 IP Address、攻擊時間、惡意檔案名稱、分群結果等資訊寫入 SOC以利網管者做深入分析。
4. 漸增式分群演算法
4.1 漸增式分群法介紹
漸增式分群法原理有別於傳統的聚合式分群法在每個未知新樣本進行分群時,
需要對整個樣本集重新再進行分群。漸增式分群法著重於當資料陸續新增時,盡可能
地不要重新對整個樣本進行計算,以達到快速分群的目的。漸增式分群開始於第一筆
資料會先當成是一個群集並且是該群集的群首,接下來的資料會跟群首進行相似度比
對,若新進資料與某一個群首的相似度為最高,且超過所定的門檻值,則合併成為
同一群集,並重新計算群首和檢查群集間是否相近而合併,否則就獨立為一群。這
個程序會一直進行到所有未分群的資料均分群為止。群首主要取得方式為計算每一
個群集內樣本特徵 值的平均數來當作群集代表點。本研究所取的四個特徵值中,原始碼檔特徵值是以字串形式所表示,無法直接以平均值的概念表達,所以本研究對
於字串型態的中心點表達方式則是利用 LCS(Longest Common Subsequence) 。LCS最主要是找尋兩字串間的共同子序列,其中取出最長的共同序列作為代表,計算最
長共同序列在兩字串長度裡所佔的比例當作兩字串的相似度。若某群集內有 p1、p2兩個樣本,內有 f1、f2是彼此間最相似的程式碼檔,特徵字串分別為 AABCBA和 AABCBDA,則代表此兩個檔案群首的特徵值為兩字串的 LCS,其中心點為AABCBA。

電子商務學報 第十八卷 第二期
239December 2016
二進位檔案特徵值的群首取法也是跟原始碼檔特徵值的方式類似,取出該群集內
每個樣本內的二進位檔與其他樣本內最相似的二進位檔來產生群首,與原始碼檔特徵
值的方式不同的是,二進位檔案特徵值是數值向量型態,因此群首算法如公式 (1)所示:
Center vv
ni
kik
n
( )= =∑
1 (1)
其中 Center(vi)代表群首特徵向量的第 i個維度,為 n個最相似的二進位檔特徵向量加總其在第 i個維度的特徵值 vi,最後除以 n個數取其平均值。檔案結構的特徵值則是同樣以上述二進位檔特徵值的方式來進行選擇。因此,一個群首會包含數個經由最
大共同子字串所選擇的原始碼檔特徵值、檔案名稱特徵值,以及數值向量型態的二進
位檔特徵值和檔案結構特徵值。
每當一個新的未知樣本加入一個群集之後,除了更新群首之外,群集間也會檢查
是否是相近的而合併成同一群集。在這裡會以每個群集的群首使用其特徵值進行相似
度計算,計算的方式等同於第三節的相似度計算公式,並會有一個門檻值決定是否合
併,若計算出的相似度超過其門檻值,則會對兩個群集進行合併的動作,新的群首也
將以上述的方式來進行選取。
由於漸增式分群法中每個新進的樣本只需跟群首進行比對,所以在比對的時間複
雜度上為 O(nm),在這裡 n代表著輸入進行分析的樣本總數,m代表著群集數,通常m會遠比 n還要來的小。一般傳統的分群法如階層式分群法,由於每個新進一個樣本需要重新與整個樣本進行比較,所以在比對的時間複雜度則會提升至 O(n2),當樣本數若逐漸增加時,傳統的分群法所花費的時間上會比漸增式分群法較多。
4.2 相似度計算公式
當誘捕系統捕獲樣本時,本研究會將新樣本與各群群首比較已決定該樣本屬於那
一群。本研究中樣本在與群首進行比較時,由於樣本與群首都擁有單一原始碼檔案、
單一二進位檔和原始碼檔、二進位檔、文字檔等多種檔案混合,壓縮檔的型態存在這
三種類型。以下將依樣本和群首各種不同情況分別說明相似度計算方式:
4.2.1 樣本為單一原始碼檔,群首也為單一原始碼所組成在此情況下樣本 f與群首 c依原始碼的相似度來進行比對,可以用以下公式 (2)
所表示。本研究公式 (2)之相似度公式參考陳嘉玫等人(2013)所提出的公式。
CodePatternSim f cEditDist Pattern Pattern
Max Lenf c
f( , )
( , )( ,= −1 LLenc )
(2)

基於漸增式分群法之惡意程式自動分類研究
240 December 2016
公式 (2) 為先計算出樣本和群首的原始碼特徵值 Patternf、Patternc 的 Edit Distance,然後再除以特徵值 Patternf、Patternc兩者的最大字串長度,最後再以 1減去獲得數值。本研究所使用的 Edit Distance為 Levenshtein Distance。Levenshtein Distance計算兩字串間所需要編輯變更的最少次數,編輯動作主要以字元的替換、插入和刪除作為計算。由於 Levenshtein Distance在進行串比對時不需要兩字串長度相同,並且所考慮的替換、插入和刪除動作也符合實際上原始碼更改的情形。
根據公式 (2) 若樣本與群首完全相同, EditDisc(Patternf,Patternc) 會為 0,因此CodePatternSim(f,c)為 1。若樣本與群首完全不相似,則 EditDisc(Patternf,Patternc)會為 Patternf、Patternc中的最大者。因此 CodePatternSim(f,c)為 0,表示為樣本與群首極不相似。公式 (2)結果會介於 0到 1之間的數字,相似度愈靠近 1表示樣本與群首間相似度愈大,反之若相似度愈靠近 0表示相似度愈小。
4.2.2 樣本為單一二進位檔,且群首也為單一二進位檔所組成在此情況下樣本 f與群首 c將會以公式 (3)表示。
BinaryPattenSim f c EuDist BinaryPatten BinaryPattenf c( , ) - ( ,1 ) (3)
公式 (3)樣本和群首的二進位檔特徵值 BinaryPatternf、BinaryPatternc以歐式距離
來計算,所得到的距離再用 1去減獲得相似度。
4.2.3 樣本與群首都為混和多種檔案之壓縮檔型態所組成針對此狀況,本研究在進行樣本 f與群首 c相似度計算時,會使用以下四種相似
度:
(1) CodeSim(f, c),為樣本與群首間總原始碼檔的相似度。其公式如公式 (4)。公式 (4)之相似度公式參考陳嘉玫等人(2013)所提出的公式。
CodeSim f c
Max CodePatternSim f c
Max n m
i jj
m
i
n
( , )( ( , ))
( , )= ==
∑∑11 (4)
由於群首以及樣本會有多個檔案且檔案數量可能不一樣,本研究所提出的
公式 (4)計算原始碼檔的相似度以樣本內的每一個原始碼檔特徵值去比較群首內的所有原始碼檔特徵值,使用公式 (2)的方式算出相似度,然後選出個別最大的相似度值加總,最後再除以樣本 f內的原始碼檔檔案數量得出。舉例而言,假設樣本有原始檔 f1,f2而群首有原始檔 c1,c2,c3。為
了算出總體相似度,首先分別 f1透過公式 (2)與 c1,c2,c3比較而取其最

電子商務學報 第十八卷 第二期
241December 2016
大 值 Max(CodePatternSim(f1, c1),CodePatternSim(f1, c2),CodePatternSim(f1, c3)) 而 之 後 f2 透 過 公 式 (2) 與 檔 案 c1,c2,c3 比 較 一 樣 取 其 最 大 值
Max(CodePatternSim(f2, c1),CodePatternSim(f2, c2),CodePatternSim(f2, c3))。兩個最大值數值加總在除以檔案數量即為總體原始碼相似度的數值。本研究將樣
本以及群首所有目錄的原始檔案納入計算。
(2) BinarySim(f, c),為樣本與群首間總二進位檔的相似度。其公式如公式 (5)。
BinarySim f c
Max BinaryPattenSim f c
Max n
i jj
m
i
n
( , )( ( , ))
( ,= ==
∑∑11
mm) (5)
公式 (5)計算二進位檔的總體相似度方式與上述公式 (4)類似,唯一不同之處在於公式 (5)主要是要算出二進位檔的相似度,因此將利用公式 (3)計算彼此之間的相似度值 BinaryPattenSim。最後將樣本 f內的每一個二進位檔所得出的相似度選出最大的相似度值加總,再除以樣本 f內的二進位檔檔案數量,便為樣本 f與群首 c間二進位檔的相似度。本研究將樣本以及群首所有目錄的二進位檔納入計算。
(3) FNameSim(f, c),為樣本與群首間檔名相似度。其公式如公式 (6)。
FNameSim f c
EditDist FNPattern FNPatternffirst c first( , ) (( ,
= −α 1))
( , ) )
( )((
Max FNLen FNLenEditDist FNPattern
ffirst cfirst+
− −1 1α ff ond c ond
f ond c ond
FNPatternMax FNLen FNLen
sec sec
sec sec
, )( , ) )
(6)
樣本 f與群首 c間檔案名稱的相似度主要跟總原始碼檔案間的相似度公式計算方式類似,若樣本 f與群首 c只有一層目錄,則分別取出樣本 f與群首 c的檔案目錄名稱特徵字串 FNPatternpfirst、FNPatterncfirst,計算出兩者間的Edit Distance,也是除以特徵值 FNPatternpfirst、FNPatterncfirst兩者的最大長度,最後再以 1去減獲得相似度 FNameSim(f, c)。若樣本 f與群首 c其中一個還有第二層目錄的特徵值,則會計算第二層目錄的檔案名稱相似度值,並與
前面的第一層目錄的檔案名稱相似度值利用 a權重值來進行加總。在觀察收集的樣本發現第一層目錄放置的大多為二進位檔案 而第二層目錄大多為原始檔案,而更深層的目錄較少包含重要檔案。考量到執行效能,本研究檔案結
構特徵值只考慮前兩層目錄。而考量到兩層目錄重要性相當,因此將 a定為0.5。
(4) StructSim(f,c),為樣本 f與群首 c間檔案結構的相似度。其公式如公式 (7)。

基於漸增式分群法之惡意程式自動分類研究
242 December 2016
StructSim f c
diff FSPattern FSPatternMax
cfirst ffirst( , ) (( , )(= β FFSNum FSNum
diff FSPattern FSPcfirst ffirst
c ond
, ) )
( )(( ,sec
+
−1 βaattern
Max FSNum FSNumf ond
c ond ff ond
sec
sec sec
)( , ) )
(7)
其中公式 (8)中 NumofDircfirst與 NumofDirffirst分別代表群首以及樣本第一層
目錄下目錄的數量;NumofSHcfirst與 NumofDirffirst分別代表群首以及樣本第
一層目錄下 Shell Script檔案的數量;NumofCcfirst與 NumofCffirst分別代表群
首以及樣本第一層目錄下 C語言檔案的數量;NumofPLcfirst與 NumofPLffirst分
別代表群首以及樣本第一層目錄下 Perl語言檔案的數量;最後 NumofBincfirst
與 NumofBinffirst分別代群首以及樣本第一層目錄下二進位檔案的數量。而
diff(FSPatterncsecond, FSPatternfsecond) 與上述概念類似,差別只在它是算出惡意程式第二層目錄之檔案結構。本研究中公式 (7)的β定為 0.5,其理由為惡意程式中,第一層以及的二層檔案結構同等重要。
diff FSPattern FSPattern NumofDir Numofcfirst ffirst cfirst( , )= − DDir
NumofSH NumofSH NumofC NumofCffirst
cfirst ffirst cfirst+ − + − fffirst
cfirst ffirst cfirstNumofPL NumofPL NumofBin NumofBi+ − + − nnffirst
(8)
最後兩個樣本的相似度將以公式 (9)來表達:
Similarity f c w CodeSim f c w BinarySim f cw FName
( , ) ( , ) ( , )= ⋅ + ⋅+ ⋅
1 23 SSim f c w StructSim f c( , ) ( , )+ ⋅4 (9)
其中 w1、w2、w3和 w4分別為以上四種相似度的權重值。本研究採用類神經
網路訓練出權重值。本研究採用倒傳遞類神經網路(Back Propagation Neural Network),其基本原理是利用最陡坡降法(The Gradient Steepest Descent Method)之觀念,在學習階段將誤差函數最小化,藉此獲得最適合的權重。類神經網路中的學習次數也會影響網路訓練的結果。本研究分別測試 100次、200次、500次和 1000次的學習次數實驗,結果顯示本研究的模型在100次以內便會收斂達到最適解,所以本研究的學習次數採用 100次。最後本研究利用 10 Cross-validation的方式來訓練類神經網路模型和驗證類神經網路所建構模型的結果。
5. 實驗環境與結果
本研究在進行實驗中的實驗樣本,主要是透過數個學術機構架設的誘捕系統,所
電子商務學報 第十八卷 第二期
243December 2016
收集到的樣本,這些誘捕系統主要都是運行在 Linux-base系統上。樣本的蒐集期間是從 2012年 3月份開始,一直到 2013年 12月為止,共 22個月份 317個壓縮檔樣本。本實驗結果在誘捕系統所收集到的壓縮檔樣本和惡意二進位檔會以 Virustotal中多數廠商所判定的分類結果來比較,並手動親自進行驗證。與一般的惡意程式偵測研究不
同,誘捕系統所捕獲的程式大多為已經確定的惡意程式,因此本研究所實驗目的並不
在於判定樣本為良性程式或是惡意程式與否。本研究實驗目的在於檢驗本研究所設計
的分群機制是否可以快速並且正確地對誘捕系統所捕獲的樣本做分群。而其分群結果
與專家手動分類做比較,驗證其分群演算法的優劣。
本實驗為進行誘捕系統收集樣本之分群將會與 SIM系統、陳嘉玫等人(2013)的系統和 Virustotal的分類結果做比較,以及將本系統的分群方式改為陳嘉玫等人研究中所使用的階層式分群以評估分群法影響分群的好壞。本研究挑取的比較對象為防
毒軟體,SIM以及陳嘉玫等人的研究。Virustotal為著名網路惡意程式掃描平台,利用 56種掃毒軟體的引擎直接分析二進位檔案,並將結果整理於一張表格。透過比較SIM、陳嘉玫以及 Virustotal,可以證明本研究所提出的方式優於目前原始檔分析方式以及二進位檔分析方式。本實驗將相似度的門檻值設為 0.8來當作分群歸類的依據,門檻值的取得為觀察數個變種所得到的值。最後會手動親自確認系統間分類差異的樣
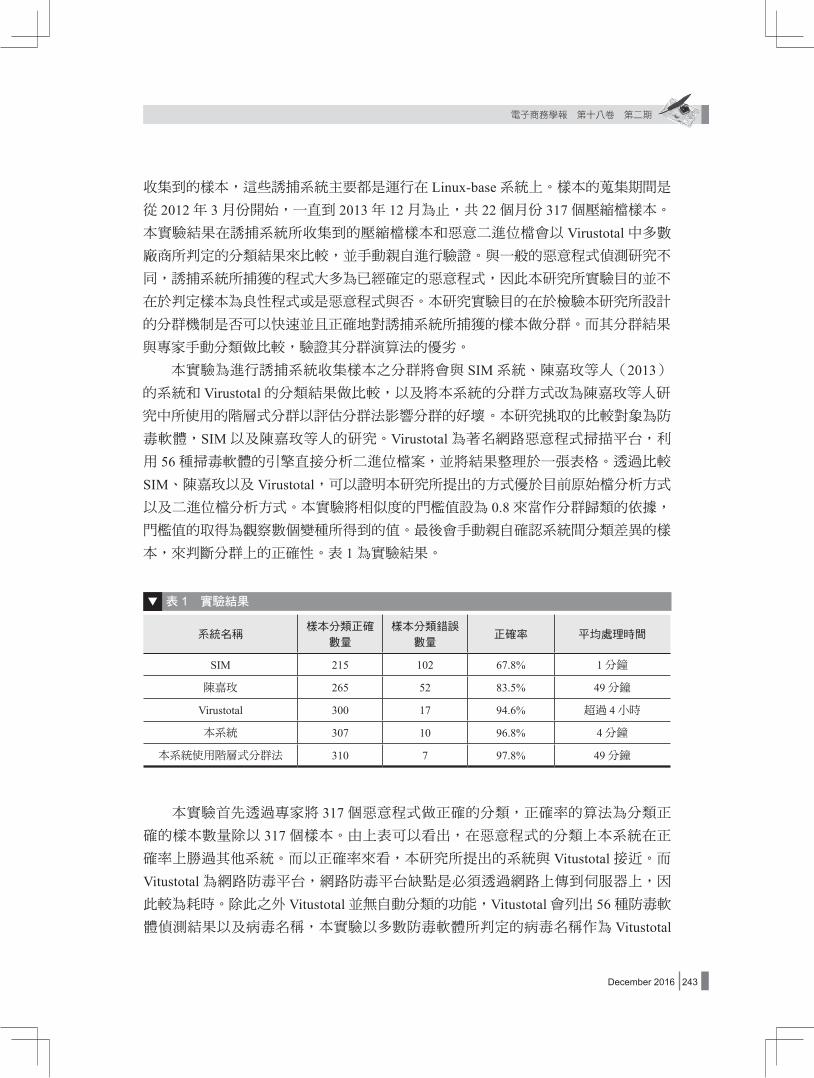
本,來判斷分群上的正確性。表 1為實驗結果。
表 1 實驗結果
系統名稱樣本分類正確
數量
樣本分類錯誤
數量正確率 平均處理時間
SIM 215 102 67.8% 1分鐘
陳嘉玫 265 52 83.5% 49分鐘
Virustotal 300 17 94.6% 超過 4小時
本系統 307 10 96.8% 4分鐘
本系統使用階層式分群法 310 7 97.8% 49分鐘
本實驗首先透過專家將 317個惡意程式做正確的分類,正確率的算法為分類正確的樣本數量除以 317個樣本。由上表可以看出,在惡意程式的分類上本系統在正確率上勝過其他系統。而以正確率來看,本研究所提出的系統與 Vitustotal接近。而Vitustotal為網路防毒平台,網路防毒平台缺點是必須透過網路上傳到伺服器上,因此較為耗時。除此之外 Vitustotal並無自動分類的功能,Vitustotal會列出 56種防毒軟體偵測結果以及病毒名稱,本實驗以多數防毒軟體所判定的病毒名稱作為 Vitustotal

基於漸增式分群法之惡意程式自動分類研究
244 December 2016
分類結果。由分類正確率、分類時間以及分類結果整理角度而言,本研究所提出的方
式皆優於 Vitustotal。而在陳嘉玫所提出的方法中,由於陳嘉玫等人(2013)的研究本身只針對惡意程式中的原始檔部分,而面對到部分惡意程式夾帶的二進位檔不同
時即會造成分類錯誤,因此分類正確率不如本系統。另外 SIM是分類速度最快的系統,SIM本身設計為針對軟體抄襲而設計,因此無法處理二進位檔。,由本研究所做的實驗可以得到抄襲偵測的系統不適用於惡意軟體分類的領域。
本系統在分群正確率達到 96.8%,其中分群錯誤的樣本主要原因是該惡意程式的壓縮檔內只有惡意二進位檔,以至於與其它群首的檔案名稱、結構等相似度比較數值
為 0,造成總相似度計算上無法超過門檻值判斷而分屬於不同群集。除此之外本研究也針對漸增式分群法效能做比較,由表 1的執行時間可以得到本研究所提出的演算法可以減少約 12倍的執行時間。兩種不同的演算法在執行效能上有極大的差距,其原因為若透過漸增式演算法,當有新的樣本進來時,系統只比較新樣本以及群集中心;
若利用傳統階層式演算法,每當有新樣本進來時,整個系統必須重新執行過一次,因
此效能上有極大的差異。而漸增式演算法所帶來的副作用為減少 1%的分類正確率,由於階層式演算法兩兩比對所有的惡意樣本,因此其精確度必然優於本研究所提出的
漸增式演算法。在大型的組織當中,由於所收集的樣本庫十分龐大,藉由漸增式演算
法的使用可以增加鑑識程序的效率,減少組織損失。但若組織十分重視分類正確率,
也可以採用本研究提出的架構輔以階層式分群法。
6. 結論
由於近年來組織紛紛建置誘捕系統收集惡意程式,因此含有原始碼檔的惡意程式
樣本愈來愈多。原始碼代表著一整個惡意程式運作的流程,因此對原始碼檔進行分析
便能直接取得程式最原始的行為與功能。惡意二進位檔則為惡意程式關鍵檔案,二進
位檔可提供惡意程式執行各種惡意行為,分析二進位檔也是了解攻擊者行為的重要工
作之一。本研究提出結合原始碼與二進位檔案的惡意程式分析,本研究使用惡意程式
的原始碼、二進位檔、目錄檔案名稱與目錄結構這四個特徵,透過類神經網路調整相
似度權重值,以及漸增式分群法的方式,得到快速且最佳的分群結果。根據實驗結果
顯示,本研究所提出的方式比其他的系統更能準確地對誘捕系統所捕獲的惡意程式進
行分群。本研究仍然在一些情境下有不足之處,本研究提出的演算法只能將新進的樣
本進行分群,不能提供惡意程式行為的詳細資訊。未來若搭配知識本體(Ontology)的形式,便可提供該群集內的知識概念給資安人員,讓資安人員對該群集有更進一步
的了解。

電子商務學報 第十八卷 第二期
245December 2016
參考文獻
陳嘉玫、楊佳蕙、賴谷鑫(2013)。基於結構相似度之惡意程式原始碼分類研究。電子商務學報,15(4),519-540。
Alazab, M., Layton, R., Venkatraman, S., & Watters, P. (2010). Malware detection based on structural and behavioral features of API calls. Proceedings of International Cyber Resilience Conference, Perth, Australia.
Bailey, M., Andersen, J., Morleyman, Z., & Jahanian, F. (2007). Automated classification and analysis of Internet malware. Proceedings of the 10th International Conference on Recent Advances in Intrusion Detection (RAID 2007), Gold Goast, Australia.
Conti, G., Bratus, S., & Shubinay, A. (2010). A visual study of primitive binary fragment types. Black Hat USA. Retireved July 4, 2010, from http://www.rumit.org/gregconti/publications/taxonomy-bh.pdf
Cosma, G., & Joy, M. (2012). An approach to source-code plagiarism detection and investigation using latent semantic analysis. IEEE Transactions on Computers, 61(3), 379-394.
Day, W. H., & Edelsbrunner, H. (1984). Efficient algorithms for agglomerative hierarchical clustering methods. Journal of Classification, 1(1), 7-24.
Firdausi, I., Lim, C., Erwin, A., & Nugroho, A. S. (2010). Analysis of machine learning techniques used in behavior-based malware detection. Proceedings of the Second International Conference on Advances in Computing, Control, and Telecommunica-tion Technologies (ACT), Jakarta, Indonesia.
Gitchell, D., & Tran, N. (1999). Sim: A utility for detecting similarity in computer programs. Proceedings of the 30th ACM Special Interest Group on Computer Science Education Technology Symposium, New Orleans, LA.
HP (2012). HP Research: Cybercrime Costs Rise Nearly 40 Percent, Attack Frequency Doubles. Retrieved October 08, 2012, from http://www.hp.com/hpinfo/newsroom/press/2012/121008a.html
Inoue, D., Yoshioka, K., Eto, M., Hoshizawa, Y., & Nakao, K. (2008). Malware behavior analysis in isolated miniature network for revealing malware’s network activity. Proceedings of the IEEE International Conference on Communications (ICC 2008), Beijing, China.
Kolter, J. Z., & Maloof, M. A. (2006). Learning to detect and classify malicious ex-ecutables in the wild. Journal of Machine Learning Research, 6, 2721-2744.

基於漸增式分群法之惡意程式自動分類研究
246 December 2016
Lee, T., & Mody, J. J. (2006). Behavioral classification. Proceedings of the 15th European Institute for Computer Antivirus Research Conference (EICAR 2006), Hamburg, Germany.
MacQueen, J. (1967). Some methods for classification and analysis of multivariate obser-vations. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, California, USA.
Nataraj, L., Karthikeyan, S., Jacob, G., & Manjunath, B. S. (2011). Malware images: Visu-alization and automatic classification. Proceedings of the 8th International Symposium on Visualization for Cyber Security, New York, USA.
Nataraj, L., Yegneswaran, V., Porras, P., & Zhang, J. (2011). A comparative assessment of malware classification using binary texture analysis and dynamic analysis. Proceed-ings of the 4th ACM Workshop on Security and Artificial Intelligence, Illinois, USA.
Prechelt, L., Malpohl, G., & Philippsen, M. (2002). Finding plagiarisms among a set of programs with jplag. Journal of Universal Computer Science, 8(11), 1016-1038.
Rieck, K., Holz, T., Willems, C., Duessel, P., & Laskov, P. (2008). Learning and clas-sification of malware behavior. Proceedings of the 5th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Paris, France.
Rieck, K., Trinius, P., Willems, C., & Holz, T. (2011). Automatic analysis of malware behavior using machine learning. Journal of Computer Security, 19(4), 639-668.
Santos, I., Brezo, F., Nieves, J., Penya, Y. K., Sanz, B., Laorden, C., & Bringsa, P. G. (2010). Idea: Opcode-sequence-based malware detection. Proceedings of the 2nd International Conference on Engineering Secure Software and Systems, Pisa, Italy.
Shankarapani, M. K., Ramamoorthy, S., Movva, R. S., & Mukkamala, S. (2011). Malware detection using assembly and API call sequences. Journal in Computer Virology, 7(2), 107-119.
Symantac (2011). Symantec Internet Security Threat Report (ISTR). Retrieved April 12, 2011, from https://www.symantec.com/content/dam/symantec/docs/reports/istr-21-2016-en.pdf
Tian, R., Islam, R., Batten, L., & Versteeg, S. (2010). Differentiating malware from cleanware using behavioral analysis. Proceedings of the 5th International Conference on Malicious and Unwanted Software, Nancy, France.
Tian, R., Batten, L., Islam, R., & Versteeg, S. (2009). An automated classification system based on the strings of trojan and virus families. Proceedings of the 4th International Conference on Malicious and Unwanted Software (MALWARE), Quebec, Canada.

電子商務學報 第十八卷 第二期
247December 2016
Trend Micro (2011). Soldier SpyEyes a Jackpot. Retrieved September 14, 2011, from http://blog.trendmicro.com/trendlabs-security-intelligence/soldier-spyeyes-a-jackpot
Wang, C., Pang, J., Zhao, R., & Liu, X. (2009). Using API sequence and bayes algorithm to detect suspicious behavior. Proceedings of International Conference on Communica-tion Software and Networks (ICCSN 2009), Sichuan, China.
Yu, S., Zhou, S., Liu, L., Yang, R., & Luo, J. (2010). Malware variants identification based on byte frequency. Proceedings of the 2nd International Conference on Network Secu-rity Wireless Communications and Trusted Computing (NSWCTC), Wuhan, China.
Zhang, J., Porras, P., & Yegneswaran, V. (2009). Host-rx:automated malware diagnosis based on probabilistic behavior models. California, USA: SRI International.
Zhao, H., Xu, M., Zheng, N., Yao, J., & Hou, Q. (2010). Malicious executables classifica-tion based on behavioral factor analysis. Proceedings of the International Conference on e-Education, e-Business, e-Management and e-Learning, Sanya, China.
.

基於漸增式分群法之惡意程式自動分類研究
248 December 2016





























