Embed Size (px)
DESCRIPTION
This is a sample of a manual I developed while at Wideband for a software math and science digital signal processing library for the Analog Devices ADSP-21K. It contains the detailed descriptions of the routines and shows the programmers had a complete and useful solution.
Citation preview

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-55
CHAPTER 5 Function Descriptions For The ADSP-21K Optimized DSP Library
Each function described in the following pages includes the following topics in order to better understand its use:
• Name
• Description of the function's operation
• The algorithm as applicable
• Synopsis of function prototype
• Domain valid for arguments
• Accuracy of the returned value(s)
• Execution time in machine cycles
• Notes applicable to this function

ADSP-21K Optimized DSP Library User’s Manual
5-56 Wideband Computers, Inc.
acort ( a, c, m, n )
NAME Auto-correlation (Time Domain)
DESCRIPTION Computes the time domain auto-correlation of the real elements stored in input vectora[ ]. Values m and n define the number of auto-correlation values to compute. Theresulting auto-correlation values are stored in output vector c[ ].
ALGORITHM
SYNOPSIS void acort ( a, c, m, n )
float *a ; /* Pointer to input vector a[ ] */
float *c ; /* Pointer to output vector c[ ] */
int m ; /* Lag count m */
int n ; /* Number of elements in vector a[ ] */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + 9*M + (M+1) (2*N-M)
NOTES The file tacort.c included in the distribution tape provides an example of this func-tion’s use.
Note that the lag count m must be less than or equal to the number of floating-point elements (i.e. ).
Ci Ai j+ Aj• i 0 1 2 …m 1–, , ,{ }=j 0=
n i– 1–
∑=
m n≤

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-57
acos_wci ( x )
NAME Arc Cosine
DESCRIPTION This function computes the arc cosine of a floating-point number, x. The computed value returned from this function is in the range [0 to π ] radians. A domain error is returned if x is not in the range [-1 to +1].
ALGORITHM
SYNOPSIS float acos_wci ( float x )
DOMAIN -1.0 < x < +1.0
ACCURACY 7.75 decimal digits
EXECUTION TIME If A <= 0.5 then 55 cycles, Else if A >0.5 then 75 cycles
NOTES The file tacos.c included in the distribution tape provides an example of this function's use.
acosh_wci ( x )
NAME Inverse Hyperbolic Cosine
DESCRIPTION This function computes the inverse hyperbolic cosine of a floating-point number, x.
ALGORITHM
SYNOPSIS float acosh_wci ( float x )
DOMAIN 1.0 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 72 cycles
NOTES The file tacosh.c included in the distribution tape provides an example of this func-tion's use.
return x( )1–cos=
return x( )1–cosh=

ADSP-21K Optimized DSP Library User’s Manual
5-58 Wideband Computers, Inc.
alawc ( a, i, c, k, n )
NAME a-Law Compression
DESCRIPTION This routine performs an a-law compression on the elements in input vector a and out-puts the compressed results to output vector c.
ALGORITHM
SYNOPSIS void alawc ( a, i, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector i */
int *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Number of floating-point elements */
DOMAIN 0 to 255
ACCURACY 7.75 decimal digits
EXECUTION TIME 49 + 12 * ( N-1 )
NOTES The file talawc.c included in the distribution tape provides an example of this func-tion’s use.
The alawc() routine takes a linear 13-bit signed speech sample and compresses it according to CCITT (now ITU) recommendation G.711. The 8-bit compressed sample is output to vector c.
This function is found on the serial port hardware for the ADSP-2106x DSP proces-sors.
Cmk alaw compression of Ami=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-59
alawe ( a, i, c, k, n )
NAME a-Law Expansion
DESCRIPTION This routine performs an a-law expansion on the elements in input vector a and out-puts the expanded results to output vector c.
ALGORITHM
SYNOPSIS void alawe ( a, i, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector i */
int *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Number of floating-point elements */
DOMAIN 0 to 255
ACCURACY 7.75 decimal digits
EXECUTION TIME 46 + 17 * ( N-1 )
NOTES The file talawe.c included in the distribution tape provides an example of this func-tion’s use.
The alawe() routine takes an 8-bit compressed speech sample and expands it accord-ing to CCITT (now ITU) recommendation G.711. The 13-bit signed sample is output to vector c.
This function is found on the serial port hardware for the ADSP-2106x DSP proces-sors.
Cmk alaw expansion of Ami=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-60 Wideband Computers, Inc.
alpha ( df, a, &al, &n )
NAME Kaiser-Bessel Window Shape Parameter
DESCRIPTION Computes a Kaiser-Bessel window shape parameter for later use by the kaiser( ) win-dow mutiply library function. The computation is based on the input attenutation specified in input scalar a and the transition width specified in real input scalar df. From this, a count of floating-point elements (output scalar n) and an output window shape parameter (output scalar al) is computed.
ALGORITHM
SYNOPSIS void alpha ( df, a, &al, &n )
float dm *df ; /* Input transition width in fs units */
float dm a ; /* Input ripple attenutation in dB */
float dm &al ; /* Output alpha window shape parameter */
int &n ; /* Output floating-point element count */
-3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
If A 21 then al 0=≤Else If
A 50 then al 0.5842 A 21–( )0.40.07886 A 21–( )•+•=<
Else Ifal 0.1102 A 8.7–( )•=
Number of Elements n is computed as follows:
If A 21 then d A 7.95–( )
14.36------------------------- else d 0.922==>
n 1 ceiling d df⁄( )+=
n n 1 remainder n 2⁄( )–+=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-61
EXECUTION TIME If a >= 50 then 143 Cycles
If 21 < a < 50 then 221 Cycles
If A <= 21 then 124 Cycles
NOTES The file talpha.c included in the distribution tape provides an example of this func-tion’s use.
asin_wci ( x )
NAME Arc Sine
DESCRIPTION This function computes the arc sine of a floating-point number, x. The computed value returned from this function is in the range [-π/2 to π/2] radians. A domain error is returned if x is not in the range [-1 to +1].
ALGORITHM
alpha ( df, a, &al, &n )
df ∆f fs⁄ A ripple attentuation in dB, δ=,= 10 A 20⁄–=
return x( )1–sin=

ADSP-21K Optimized DSP Library User’s Manual
5-62 Wideband Computers, Inc.
SYNOPSIS float asin_wci ( float x )
DOMAIN - 1.0 < x < +1.0
ACCURACY 7.75 decimal digits
EXECUTION TIME If A <= 0.5 then 55 cycles, Else if A >0.5 then 73 cycles
NOTES The file tasin.c included in the distribution tape provides an example of this function's use.
asinh_wci ( x )
NAME Inverse Hyperbolic Sine
DESCRIPTION This function computes the inverse hyperbolic sine of a floating-point number, x.
ALGORITHM
SYNOPSIS float asinh_wci ( float x )
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 57 cycles
NOTES The file tasinh.c included in the distribution tape provides an example of this func-tion's use.
asin_wci ( x )
return x( )1–sinh=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-63
aspec ( a, c, n )
NAME Accumulating Auto-spectrum
DESCRIPTION Computes the auto-spectrum of complex input vector a by multiplying vector a by its complex conjugate and adding the resulting real number to the current value of vector c. Vector c must be initialized prior to invoking a series of accumulating auto-spec-trum calls.
ALGORITHM
SYNOPSIS void aspec ( a, c, n )
complex *a ; /* Pointer to input vector a */
float *c ; /* Pointer to output vector c */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 28 + 6*N cycles
NOTES The file taspec.c included in the distribution tape provides an example of this func-tion’s use.
The stride of vectors a and c must always be 1.
If you wish to clear the auto-spectrum results before they are added to output vector cuse the vclr( ) function. If the results are not cleared using vclr( ), autospectrum resultsare added to output vector c, thus computing an accumulating autospectrum.
Note that input vector a is of type complex, and data arguments supplied to this routinewill be treated as interleaved real and imaginary data.
Cm Cm Re2Am Im2Am+ +⇐
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-64 Wideband Computers, Inc.
atan_wci ( x )
NAME Arc Tangent
DESCRIPTION This function computes the arc tangent of a floating-point number x. The computed value returned from this function is in the range [-π/2 to +π/2] radians.
ALGORITHM
SYNOPSIS float atan_wci ( float x )
DOMAIN - 4.2E+37 < x < +4.2E+37
ACCURACY 7.75 decimal digits
EXECUTION TIME 59 cycles
NOTES The file tatan.c included in the distribution tape provides an example of this function's use.
return x( )1–tan=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-65
atan2_wci ( y, x )
NAME Arc Tangent 2 Arguments
DESCRIPTION This function computes the arc tangent of a floating-point number x. The computed
value returned from this function is in the range [-π to +π] radians.
ALGORITHM
SYNOPSIS float atan2_wci ( y, x )
float dm y ; /* Input value y */
float dm x ; /* Input value x */
DOMAIN - 4.2E+37 < y/x < +4.2E+37, except x = 0.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 76 cycles
NOTES The file tatan2.c included in the distribution tape provides an example of this func-tion's use.
returnyx---
1–
tan=

ADSP-21K Optimized DSP Library User’s Manual
5-66 Wideband Computers, Inc.
atanh_wci ( x )
NAME Inverse Hyperbolic Tangent
DESCRIPTION This function computes the inverse hyperbolic tangent of a floating-point number, x.
ALGORITHM
SYNOPSIS float atanh_wci ( float x )
DOMAIN -1.0 to +1.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 59 cycles
NOTES The file tatanh.c included in the distribution tape provides an example of this func-tion's use.
return x( )1–tanh=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-67
bartlett ( a, i, c, k, n )
NAME Bartlett Window
DESCRIPTION This function generates a Bartlett window multiply on the elements of input vector a and places the results in output vector c.
ALGORITHM
SYNOPSIS void bartlett ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 + 17 * ( N-1 ) cycles
NOTES The file tbartlett.c included in the distribution diskette provides an example of this function’s use.
The Bartlett window is also known as a triangular window.
Cmk Ami 1m
12---n–
12---n
----------------–
•=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-68 Wideband Computers, Inc.
biquad ( x, d, c, y, n )
NAME Bi-Quad IIR Filter
DESCRIPTION Using a bi-quad implementation, this function computes an IIR ( Infinite Impulse Response ) filter using coefficients stored in input vector c, delay node points stored in input buffer d, and applied to the elements of input vector x. The results are stored in output vector y.
ALGORITHM
where
SYNOPSIS void biquad ( x, d, c, y, n )
float *x ; /* Pointer to input buffer vector x of length n */
float *d ; /* Pointer to input delay node buff vector d of length 2 */
float *c ; /* Pointer to input coeff buffer vector c of length 5 */
float *y ; /* Pointer to output buffer vector y of length n */
int n ; /* Number of input/output samples to compute */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
H z( )B0 B1z
1–B2z
2–+ +
1 A1z1–
– A2z2–
–------------------------------------------------=
Dm A2 Dm 2– A1 Dm 1– xm+•+•=
Ym B2 Dm 2– B1 Dm 1– Dm+•+•=
m 0 1 2 … n 1–, , , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-69
EXECUTION TIME 65 + 13*N
NOTES This is a single bi-quad form of an infinite impulse response filter (IIR), defined by the first equation shown above. It is implemented using a delay node buffer d shown in the second and third equation shown above. The coefficients a[ ] and b[ ] are passed in a single array c[ ] given by the following:
Prior to executing the filter loop, the two “oldest” delay node values are loaded from buffer d[ ]. When the filter loop has completed (n samples have been processed) the two “newest” delay node values are written to d[ ]. In this way the filter delay node states are retained between calls, allowing filtering on blocks of contiguous samples. The user is responsible for allocating the delay node array and for initializing its ele-ments to zero prior to the first call to biquad( ).
Defining
Then
The coefficient buffer length is defined symbolically in the file dsppac.h as DSP_BIQUAD_NCOEFF. The delay node buffer length is defined symbolically in the file dsppac.h as DSP_BIQUAD_NDELAY.
The number of input samples n must be greater than or equal to 5.
The file tbiquad.c included in the distribution tape provides an example of this func-tion’s use.
biquad ( x, d, c, y, n )
c 0[ ] A2 c 1[ ] B2 c 2[ ] A1 c 3[ ] B1 c 4[ ] B0 =====
d0 Dm d1 Dm 1 – d2 Dm 2 –===
d0 c0 d2 c2 d1 xm+•+•=
ym c1 d2 c3 d1 c4 d0•+•+•=
d2 d1=
d1 d0=
m 0 1 2 … n 1–, , , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-70 Wideband Computers, Inc.
blkman ( a, i, c, k, w, h, n )
NAME Blackman Window Multiply
DESCRIPTION Multiplies the input vector a[ ] by a Blackman window and stores the result to vector c[ ].
ALGORITHM
SYNOPSIS void blkman ( a, i, c, k, w, h, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
float pm *w ; /* Pointer to cosine weights array */
int h ; /* Element stride for weights array */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Cmk Ami 0.42 0.50 2πmiN
------------- 0.08 4πmiN
-------------cos•+cos•–•=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-71
EXECUTION TIME 41 + 4*(N-1) cycles
NOTES The file tblkman.c included in the distribution tape provides an example of this func-tion’s use.
For real-time applications, the Blackman window can be computed once, and a simplemultiply used to window data as shown in the variable . The Blackman Win-dow is computed using the winwts( ) function found in the DSP Pac library. The win-wts( ) function computes the weights array using the sin and cosine functions. Thisarray is pointed to by variable w listed in the synopsis section above.
The blkman( ) function is a vector function. You may therefore use the stride argu-ments i, k and h to decimate both the input and output for data congruence. For exam-ple, suppose you use winwts( ) to compute the FFT weights for a 16K FFT. This wouldresult in an fftwts array whose length would be 16,384 points. If you were to laterdecide to compute an FFT of length 1,024 and run a Blackman Window on the results,you would not need to rerun the winwts( ) function to generate new weights. Simplyuse the old weights and stride by 16 (16,384/1024 = 16) on stride element h to obtainthe correct Blackman window FFT weights . In this manner you need only computewinwts( ) once and later us them for varying length FFTs and windowing functions.
The cosine arguments are held in input vector w[ ] and can be computed from the win-wts( ) function. Note that larger vector sizes of w[ ] can be used by changing the stridefor w[ ]. For example, if w[ ] were computed for a window of size 2,048, but a Black-man Window of 1,024 was needed, use a stride of 2,048/1,024 = 2.
Note that the Blackman window has a passband ripple of 0.0017 dB, a maximum stop-band attenuation of 74 dB, and a 57 dB main lobe relative to side lobe.
blkman ( a, i, c, k, w, h, n )
Wml

ADSP-21K Optimized DSP Library User’s Manual
5-72 Wideband Computers, Inc.
blkmanh ( a, i, c, k, w, h, n )
NAME Blackman-Harris Window Multiply
DESCRIPTION Multiplies the input vector a[ ] by a Blackman-Harris window and stores the result to output vector c[ ].
ALGORITHM
SYNOPSIS void blkmanh ( a, i, c, k, w, h, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
float pm *w ; /* Pointer to cosine weights array */
int h ; /* Element stride for weights array */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Cmk Ami 0.35875 0.48829 2πmiN
------------- 0.14128 4πmiN
-------------cos•+cos•– 0.01168 6πmiN
-------------cos•–•=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-73
EXECUTION TIME 54 + 6*(N-1) cycles
NOTES The file tblkmanh.c included in the distribution tape provides an example of thisfunction’s use.
For real time applications, the Blackman-Harris window can be computed once, and asimple multiply used to window data, as shown in the variable . The Blackman-Harris Window is computed using the winwts( ) function found in the DSP Pac library.The winwts( ) function computes the weights array using the sin and cosine functions.This array is pointed to by variable w listed in the synopisis section above.
The blkmanh function is a vector function. You may therefore use the stride argu-ments i, k and h to decimate both the input and output for data congruence. For exam-ple, suppose you use winwts( ) to compute the FFT weights for a 16K point FFT. Thiswould result in an fftwts array whose length would be 16,384 points. If you were tolater decide to compute an FFT of length 1,024 and run a Blackman-Harris Window onthe results, you would not need to rerun the winwts( ) function to generate newweights. Simply use the old weights and stride by 16 (16,384/1024 = 16) on stride ele-ment h to obtain the correct window FFT weights . In this manner you need only com-pute winwts( ) once and later us them for varying length FFTs and windowingfunctions.
The cosine arguments are held in input vector w[ ] and can be computed from the win-wts( ) function. Note that larger vector sizes of w[ ] can be used by changing the stridefor w[ ]. For example, if w[ ] were computed for a window of size 2,048, but a Black-man Window of 1,024 was needed, use a stride of 2,048/1,024 = 2.
Note that the Blackman-Harris window has a passband ripple of 0.0017 dB, a maxi-mum stopband attenuation of 74 dB, and a 57 dB main lobe relative to side lobe.
blkmanh ( a, i, c, k, w, h, n )
Wml

ADSP-21K Optimized DSP Library User’s Manual
5-74 Wideband Computers, Inc.
cacort ( a, c, m, n )
NAME Complex Auto-Correlation (Time Domain)
DESCRIPTION Computes the time domain auto-correlation of the complex elements stored in inputvector a[ ]. Values m and n define the number of auto-correlation values to compute.The resulting auto-correlation values are stored in output complex vector c[ ].
ALGORITHM
SYNOPSIS void cacort ( a, c, m, n )
complex dm *a ; /* Pointer to input vector a[ ] */
complex dm *c ; /* Pointer to output vector c[ ] */
int m ; /* Lag count m */
int n ; /* Number of elements in vector a[ ] */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 39 + ( 9 + 5 * n ) * n
NOTES The file tacort.c included in the distribution tape provides an example of this func-tion’s use.
Note that the lag count m must be less than or equal to the number of floating-point elements (i.e. ).
The strides of vectors a[ ] and c [ ] must be 1.
Ci Ai j+ Aj• i 0 1 2 …m 1–, , ,{ }=
j 0=
n i– 1–
∑=
m n≤

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-75
ccdotpr ( a, i, b, j, c, k, n )
NAME Complex Dot Product Multiply by Conjugate
DESCRIPTION This function computes the complex dot product of complex input vector a by the complex conjugate of input vector b and stores the results in complex output vector c. This can be alternatively expressed as C=AB*.
ALGORITHM
SYNOPSIS void ccdotpr ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 64 + 4*(N-1) cycles
NOTES The file tccdotpr.c included in the distribution diskette provides an example of this function’s use.
Re C{ } Re Ami{ } Re Bmj{ } Im Ami{ } Im Bmj{ }•+•
m 0=
n 1–
∑=
Im C{ } R– e Ami{ } Im Bmj{ } Im Ami{ } Re Bmj{ }•+•
m 0=
n 1–
∑=
m 0 1 2…n 1–, ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-76 Wideband Computers, Inc.
ccmmul ( a, b, x, y, b, z, c )
NAME Complex Matrix Multiply By Congugate of Complex Matrix
DESCRIPTION This function computes the multiplication of the conjugate of complex input matrix a [ ] [ ] times the elements of complex input matrix b[ ] [ ]. The dimensions of com-plex input matrix a[ ] [ ] are x and y, while the dimensions of complex input matrix b[ ] [ ] are defined by input scalars y and z. The results are stored in complex output matrix c[ ] [ ], which is of dimensions x and z.
ALGORITHM
SYNOPSIS void ccmmul( a, x, y, b, z, c )
complex dm *a ; /* Pointer to complex input matrix a[ ][ ] */
int x ; /* Number of rows in complex matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] And */
/* Number of rows in complex matrix b[ ][ ] */
complex dm *b ; /* Pointer to complex input matrix b[ ][ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
complex dm *c ; /* Pointer to complex output matrix c[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Re Cij( ) Re( )Aik Re( )Bkj Im( )Aik Im( )Bkj•+•[ ]
k 1=
y
∑=
Im Cij( ) Re( )Cik Im( )Bkj Re( )Bkj Im( )Aik•–•[ ]
k 1=
y
∑=
for i 0 1 …x, ,{ }=for j 0 1 …z, ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-77
EXECUTION TIME 62 + ( 6 + ( 12 + 7 * Y ) * Z ) * X cycles
NOTES The file tccmmul.c included in the distribution diskette provides an example of this function’s use.
a[x][y] =
b[y][z] =
x = 3, y = 4, z = 3 ;
ccmmul ( a, x, y, b, z, c ) ;
The resulting values in output matrix c [ ] [ ] would be as follows:
c[x][y] =
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
ccmmul ( a, b, x, y, b, z, c )
1 1, 2 2, 3 3, 4 4,5 5, 6 6, 7 7, 8 8,9 9, 10 10, 11 11, 12 12,
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,
270 10, 310 10, 350 10,606 26, 610 26, 814 26,942 42, 1110 42, 1278 42,

ADSP-21K Optimized DSP Library User’s Manual
5-78 Wideband Computers, Inc.
ccmsmul ( a, x, y, b, c )
NAME Complex Scalar-Complex Congugate Matrix Multiplication
DESCRIPTION This function computes the multiplication of the conjugate of the complex input matrix a[ ] [ ] times complex input scalar b. The dimensions of complex input matrix a[ ] [ ] are x and y. The results are stored in complex output matrix c[ ] [ ], which is of dimensions x and y.
ALGORITHM
SYNOPSIS void ccmsmul( a, x, y, b, c )
complex dm *a ; /* Pointer to complex input matrix a[ ][ ] */
int x ; /* Number of rows in complex matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
complex dm *b ; /* Pointer to complex input scalar b */
complex dm *c ; /* Pointer to complex output matrix c[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cxy B Axy•=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-79
EXECUTION TIME 46 + 2 * X * Y cycles
NOTES The file tccmsmul.c included in the distribution diskette provides an example of this function’s use.
a[x][y] =
b = {8,2}
x = 8, y = 7 ;
ccmsmul ( a, x, y, b, c ) ;
The resulting values in output matrix c [ ] [ ] would be as follows:
c[x][y] =
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
ccmsmul ( a, x, y, b, c )
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,25 26, 27 28, 29 30,
12 14–, 32 26–, 52 38–,72 50–, 92 62–, 112 74–,
132 86–, 152 98–, 172 110–,192 122–, 212 134–, 232 146–,252 158–, 272 170–, 292 182–,

ADSP-21K Optimized DSP Library User’s Manual
5-80 Wideband Computers, Inc.
cccort ( a, b, c, m, n )
NAME Complex Cross-Correlation (Time Domain)
DESCRIPTION Computes the time domain (real) cross-correlation of the time domain (real) elements stored in complex input vectors a[ ] and b[ ]. The result is stored in complex output vector c [ ]. Values m and n define the number of cross-correlation values to compute. The implementation uses a time domain technique.
ALGORITHM
SYNOPSIS void cccort ( a, b, c, m, n )
complex dm *a ; /* Pointer to input vector a[ ] */
complex dm *b ; /* Pointer to input vector b[ ] */
complex dm *c ; /* Pointer to output vector c[ ] */
int m ; /* Lag count m */
int n ; /* Number of elements in vector c[ ] */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 41 + ( 9 + 5 * n ) * m
NOTES The file tcccort.c included in the distribution tape provides an example of this func-tion’s use.
Note that the lag count must be less than or equal to the number of floating-point ele-ments (i.e. ).
The strides of vectors a[ ], b[ ], and c[ ] must always be 1.
Ci Ai j+ Bj i 0 1 2 … m, 1–, , ,{ }=•
j 0=
n i– 1–
∑=
m n≤

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-81
ccort ( a, b, c, m, n )
NAME Cross-Correlation (Time Domain)
DESCRIPTION Computes the time domain (real) cross-correlation of the time domain (real) elements stored in input vectors a[ ] and b[ ]. The result is stored in output real vector c [ ]. Val-ues m and n define the number of cross-correlation values to compute. The implemen-tation uses a time domain technique.
ALGORITHM
SYNOPSIS void ccort ( a, b, c, m, n )
float *a ; /* Pointer to input vector a[ ] */
float *b ; /* Pointer to input vector b[ ] */
float *c ; /* Pointer to output vector c[ ] */
int m ; /* Lag count m */
int n ; /* Number of elements in vector c[ ] */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + 9 * M + (M+1)(2*N-M)
NOTES The file tccort.c included in the distribution tape provides an example of this func-tion’s use.
Note that the lag count must be less than or equal to the number of floating-point ele-ments (i.e. ).
The strides of vectors a, b, and c must always be 1.
Cm Ai j+ Bj i 0 1 2 … m, 1–, , ,{ }=•
j 0=
n i– 1–
∑=
m n≤

ADSP-21K Optimized DSP Library User’s Manual
5-82 Wideband Computers, Inc.
cdesamp ( data, coeff, output, d, n, p )
NAME Complex Decimating Finite Impulse Response (FIR) Filter
DESCRIPTION The function computes the convolution of complex vectors data [ ] and coeff [ ] plac-ing the results in complex vector output [ ]. The number of output samples n and the number of coefficients p may be dissimilar. n elements will be written to output [ ].
Complex vector data [ ] represents the real and imaginary (I and Q) components of the input data respectively. Likewise, complex vector coeff [ ] represents the real and imaginary ( I and Q) components of the coefficient data. A complex multiply and add is performed to compute the convolutional output. The decimation factor d is used to stride the next starting point in data [ ].
ALGORITHM
SYNOPSIS void cdesamp ( data, coeff, output, d, n, p )
complex dm *data ; /* Complex input data ( len n+p-1 ) */
complex pm *coeff ; /* Complex coefficients ( len p ) */
complex dm *output ; /* Complex output data ( len n ) */
int d ; /* Decimation factor */
int n ; /* Number of output samples */
int p ; /* Number of coefficients */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Output i[ ] data i d j+•[ ] coeff p j– 1–[ ]•
j 0=
p 1–
∑=
i 0 1 2…n 1–, ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-83
EXECUTION TIME 36 + ( 7 + 5 * p ) * n cycles
NOTES The file tcdesamp.c included in the distribution tape provides an example of this func-tion’s use.
The number of filter output samples to generate can be obtained as follows:
where ndata is the number of elements in data[ ].
A complex correlation can be performed by reversing the order of the coefficients vec-tor.
cdesamp ( data, coeff, output, d, n, p )
n ndata p–( ) d⁄ 1+=

ADSP-21K Optimized DSP Library User’s Manual
5-84 Wideband Computers, Inc.
cdotpr ( a, i, b, j, c, k, n )
NAME Complex Dot Product
DESCRIPTION This function computes the complex dot product of complex input vector a and com-plex input vector b and stores the results in complex output vector c. This can altena-tively thought of as .
ALGORITHM
SYNOPSIS void cdotpr ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 64 + 4*(N-1) cycles
NOTES The file tcdotpr.c included in the distribution diskette provides an example of this function’s use.
C A B•=
Re C{ } Re Ami{ } Re Bmj{ } Im Ami{ } Im Bmj{ }•–•
m 0=
n 1–
∑=
Im C{ } Re Ami{ } Im Bmj{ } Im Ami{ } Re Bmj{ }•+•
m 0=
n 1–
∑=
m 0 1 2…n 1–, ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-85
ceil_wci ( x )
NAME Round Up to Nearest Integer
DESCRIPTION This function computes the smallest integral value greater than or equal to the float-ing-point number x. A floating-point representation of this integer value is returned.
ALGORITHM
SYNOPSIS float ceil_wci ( float x )
DOMAIN -3.4E+38 to 3.40E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 cycles
NOTES The file tceil.c included in the distribution tape provides an example of this function's use.
return smallest int x≥=

ADSP-21K Optimized DSP Library User’s Manual
5-86 Wideband Computers, Inc.
cfft ( xr, xi, wr, wi, wstr, yr, yi, n )
NAME Fast Fourier Transform Of Complex Input Data
DESCRIPTION Computes the Fast Fourier Transform of the complex input elements stored in com-plex input vector a. The results are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cfft ( xr, xi, wr, wi, wstr, yr, yi, n )
float dm *xr ; /* Pointer to real input data */
float dm *xi ; /* Pointer to imaginary input data */
float pm *wr ; /* Pointer to cosine table */
float dm *wi ; /* Pointer to sine table */
int wstr ; /* Cosine/sine table stride */
float dm *yr ; /* Pointer to real output data */
float pm *yi ; /* Pointer to imaginary output data */
int n ; /* FFT Size (In Complex Elements) */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME See Attached Table Below
Cm Akei2πmk– n⁄
m 0 1 2 … n, 1–, , ,{ }=
k 0=
n 1–
∑=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-87
NOTES This is a radix-2 Fast Fourier Transform using parallel data memory/program memorydata accesses to maximize the throughput on the 21020/60/62 processor. The complexinput data is separated into real and imaginary parts, xr and xi. These vectors must bealigned on an address which is an integer multiple of the FFT size, as required for21K bit-reverse addressing. The input vectors are both in data memory; the imagi-nary data is bit-reversed into program memory at the beginning of the routine. Thenumber of elements n supplied to the algorithm must be an integral power of two anda minimum of 32.
The complex output is separated into real and imaginary parts, yr and yi. These vec-tors may have arbitrary address alignment; however yr is in the data memory and yi isin the program memory. Vectors xr and xi must be in data memory and each must bealigned to an integral multiple of n.
Vectors wr and wi are in program memory and data memory respectively and aregiven the values:
The weight stride wst allows cfft() to be called with varying sizes n from a single setof weights.These weights are generated using the fftwts() function.
This precomputed FFT weight approach was implemented in order to ensure accurateresults and boost the available cfft() dynamic range to approximately 130 dB forlonger length (>16K) FFTs. This is accomplished by using an implementation thatdoes not rely on a recursive call to a sin/cosine approximation routine, as found inother implementations. Rather, the FFT weights are precomputed accurately using thefftwts() function. This is sufficient for A/D converters with bit lengths up to 22 bits.
The number of elements n must be an integral power of two and a minimum of 32.Vector yr is in data memory and has a minimum size of n. Vector yi is in programmemory and has a minimum size of n.
The file tcfft.c included in the distribution tape provides an example of this function’suse.
cfft ( xr, xi, wr, wi, wstr, yr, yi, n )
wr k[ ] 2πk wst*n⁄[ ] k 0 1 … wstn 2 1–⁄, , ,( )program memory=cos=
wi k[ ] 2πk wst*n⁄[ ]sin k 0 1 … wstn 2 1–⁄, , ,( )data memory==

ADSP-21K Optimized DSP Library User’s Manual
5-88 Wideband Computers, Inc.
SPECIAL NOTES Previous users have sometimes reported problems associated with implementing inter-rupt service routines (ISRs), when used in conjunction with the FFT routines ( cfft( ),cffti( ), rfft( ), rffti( ) ). Observations related to the Wideband technical staff typicallyinclude a description of the Wideband routine executing perfectly, but unable to returnto an exact state after being interrupted by the ISR ( what is described as a “tumbleinto the weeds.” )
The Wideband Fast Fourier transforms, both complex and real, forward and inverse,use the built-in bit reversing and circular addressing capabilites of the SHARC archi-tecture. Also, other routines such as some of the FIR filters use the SHARC’s internalcircular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the mode 1 regiser, which is associated withbir reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In such circumstances where they are not saved and restored by the ISRthey are unable to return the proper length parameter ( L Register ) used for circularaddressing or the proper mode ( Mode 1 Register ) used in Bit Reversing. This resultsin the strange manefestations users sometimes report.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.
For a detailed review of the relationships between the various FFT functions and how to use them with one another, see the final section of Chapter 4.
cfft ( xr, xi, wr, wi, wstr, yr, yi, n )
ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-89
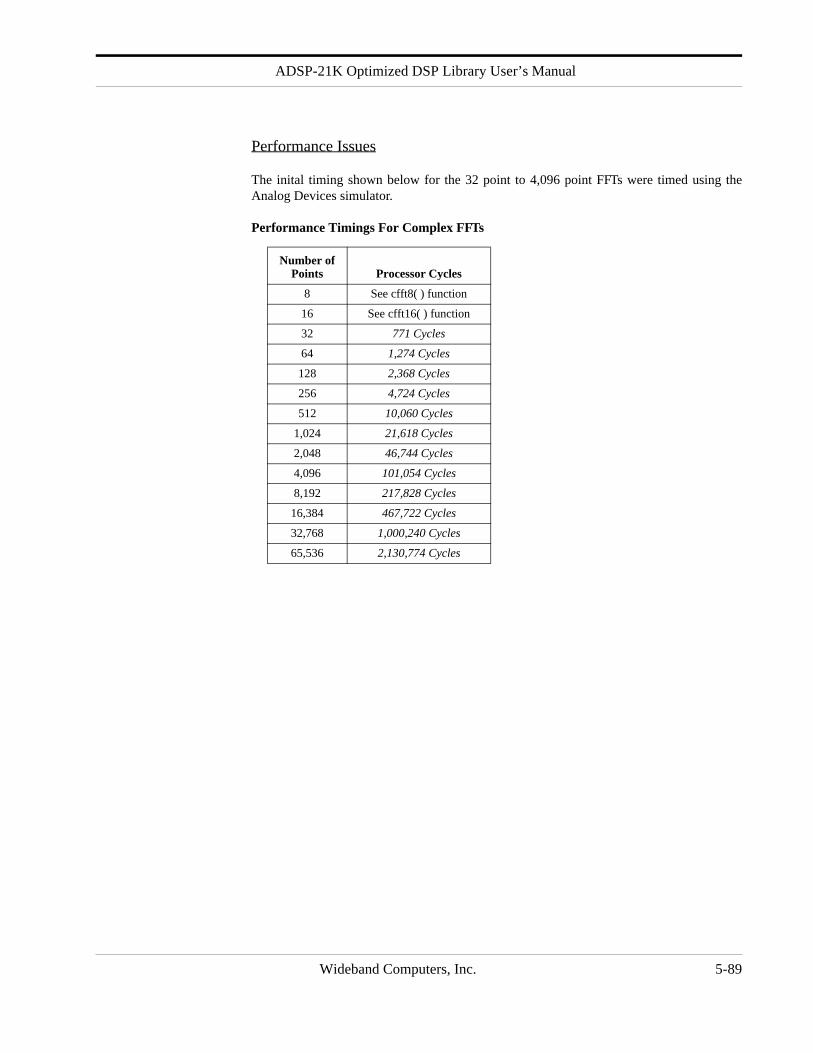
Performance Issues
The inital timing shown below for the 32 point to 4,096 point FFTs were timed using theAnalog Devices simulator.
Performance Timings For Complex FFTs
Number of Points Processor Cycles
8 See cfft8( ) function
16 See cfft16( ) function
32 771 Cycles
64 1,274 Cycles
128 2,368 Cycles
256 4,724 Cycles
512 10,060 Cycles
1,024 21,618 Cycles
2,048 46,744 Cycles
4,096 101,054 Cycles
8,192 217,828 Cycles
16,384 467,722 Cycles
32,768 1,000,240 Cycles
65,536 2,130,774 Cycles

ADSP-21K Optimized DSP Library User’s Manual
5-90 Wideband Computers, Inc.
cfft2d ( xr, xi, wr, wi, wstr, tmpdm, tmppm, n )
NAME Complex 2-Dimensional Fast Fourier Transform
DESCRIPTION Computes a 2-Dimensional Fast Fourier Transform of the complex input elements stored in vector a[ ]. The results are stored in complex output vector c[ ].
ALGORITHM
SYNOPSIS void cfft2d ( xr, xi, wr, wi, wstr, tmpdm, tmppm, n )
float dm *xr ; /* Pointer to real input/output data */
float dm *xi ; /* Pointer to imaginary input/output data */
float pm *wr ; /* Pointer to cosine table */
float dm *wi ; /* Pointer to sine table */
int wstr ; /* Consine/sine Table table */
float dm *tmpdm ; /* Pointer to real output data */
float pm *tmppm ; /* Pointer to imag output data */
int n ; /* CFFT2D Size (Complex Elements n x n) */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Cr c, Ak
c 0=
n 1–
∑ e2– πj r R c C⋅+⋅( ) n⁄( )
r 0=
n 1–
∑=
R 0 1 …n 1–, ,{ }=
C 0 1 …n 1–, ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-91
EXECUTION TIME 32 x 32 Pts. 44,532 cycles
64 x 64 Pts. 165,364 cycles
128 x 128 Pts. 659,572 cycles
cfft2d ( xr, xi, wr, wi, wstr, tmpdm, tmppm, n )

ADSP-21K Optimized DSP Library User’s Manual
5-92 Wideband Computers, Inc.
NOTES The input data is an nxn complex matric x separated into real and imaginary parts xrand xi stored as follows:
Variables r and c are the row and column numbers.
The DFT output replaces the input, and is stored as follows:
A radix-2 Fast Fourier Transform (FFT) algorithm is used to compute the individualrow and column DFTs.
The number of elements n must be an integral power of two and a minimum of 32.
Vectors xr and xi must be in data memory and are adress-aligned to an integral multi-ple of n.
Vectors wr and wi must be in program memory and data memory respectively and arepre-computed to be:
Vector tmpdm must be in data memory, having a minimum size of n, and be address-aligned to an integral multiple of n.
Vector tmppm must be in program memory and have a minimum size of n,and beaddress-aligned to an integral multiple of n.
The file tcfft2d.c included in the distribution tape provides an example of this func-tion’s use.
cfft2d ( xr, xi, wr, wi, wstr, tmpdm, tmppm, n )
Re xr c,( ) xr r n c+•[ ]=
r 0 1 … n 1–, , ,{ } c 0 1 … n 1–, , ,{ }==
Im xr c,( ) xi r n c+•[ ]=
r 0 1 … n 1–, , ,{ } c 0 1 … n 1–, , ,{ }==
Re FR C,( ) xr R n C+•[ ]=
R 0 1 … n 1–, , ,{ } C 0 1 … n 1–, , ,{ }==
Im FR C,( ) xi R n C+•[ ]=
R 0 1 … n 1–, , ,{ } C 0 1 … n 1–, , ,{ }==
wr k[ ] 2πk wst*n⁄[ ] k 0 1 … wstn 2 1–⁄, , ,( )=cos=
wi k[ ] 2πk wst*n⁄[ ]sin k 0 1 … wstn 2 1–⁄, , ,( )==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-93
cfft8 ( xr, xi, yr, yi )
NAME 8-Point Complex Fast Fourier Transform (Inline)
DESCRIPTION Computes the Fast Fourier Transform of the complex input elements stored in input vector xr and xi. The results are stored in output vector yr and yi.
ALGORITHM
SYNOPSIS void cfft8 ( xr, xi, yr, yi )
float dm *xr ; /* Pointer to real input data */
float dm *xi ; /* Pointer to imaginary input data */
float dm *yr ; /* Pointer to real output data */
float pm *yi ; /* Pointer to imaginary output data */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Ym Xke2πj m k 8⁄•( )–
m 0 1 2 … 7,, , ,{ }=
k 0=
7
∑=

ADSP-21K Optimized DSP Library User’s Manual
5-94 Wideband Computers, Inc.
EXECUTION TIME 184 Cycles
NOTES This is an 8-point radix-2 Fast Fourier Transform using parallel data memory/programmemory data accesses to maximize the throughput on the 21020/60/62 processor.
The complex input data is separated into real and imaginary parts, xr and xi. Thesevectors must be aligned on an address which is an integer multiple of the FFTsize, as required for 21K bit-reverse addressing. The input vectors are both in datamemory; the imaginary data is bit-reversed into program memory at the beginning ofthe routine.
This algorithm utilizies a decimation in time approach. As the cffti( ) function requiresa minimum of 32-points as input, there is no corresponding inverse algorithm for thisroutine. The complex output is separated into real and imaginary parts, yr and yi.These vectors may have arbitrary address alignment; however yr is in the data mem-ory and yi is in the program memory.
•Vectors xr and xi are defined in cfft8dta.asm using the dm_align segment to ensure address alignment.
For a detailed review of the relationships between the various FFT functions and how to use them with one another, see the final section of Chapter 4.
The file tcfft8.c included in the distribution tape provides an example of this func-tion’s use.
cfft8 ( xr, xi, yr, yi )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-95
cfft16 ( xr, xi, yr, yi )
NAME 16-Point Complex Fast Fourier Transform (Inline)
DESCRIPTION Computes the Fast Fourier Transform of the complex input elements stored in input vector xr and xi. The results are stored in output vector yr and yi.
ALGORITHM
SYNOPSIS void cfft16 ( xr, xi, yr, yi )
float dm *xr ; /* Pointer to real input data */
float dm *xi ; /* Pointer to imaginary input data */
float dm *yr ; /* Pointer to real output data */
float pm *yi ; /* Pointer to imaginary output data */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Ym Xke2πj16–
m 0 1 2 … 15,, , ,{ }=
k 0=
15
∑=

ADSP-21K Optimized DSP Library User’s Manual
5-96 Wideband Computers, Inc.
EXECUTION TIME 388 Cycles
NOTES This is an 16-point radix-2 Fast Fourier Transform using parallel data memory/pro-gram memory data accesses to maximize the throughput on the 21020/60/62 proces-sor.
The complex input data is separated into real and imaginary parts, xr and xi. Thesevectors must be aligned on an address which is an integer multiple of the FFTsize, as required for 21K bit-reverse addressing. The input vectors are both in datamemory; the imaginary data is bit-reversed into program memory at the beginning ofthe routine.
This algorithm utilizies a decimation in time approach. As the cffti( ) function requiresa minimum of 32-points as input, there is no corresponding inverse algorithm for thisroutine. The complex output is separated into real and imaginary parts, yr and yi.These vectors may have arbitrary address alignment; however yr is in the data mem-ory and yi is in the program memory.
•Vectors xr and xi are defined in cfft16dt.asm using the dm_align segment to ensure address alignment.
For a detailed review of the relationships between the various FFT functions and how to use them with one another, see the final section of Chapter 4.
The file tcfft16.c included in the distribution tape provides an example of this func-tion’s use.
cfft16 ( xr, xi, yr, yi )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-97
cffti ( xr, xi, wr, wi, wstr, yr, yi, n )
NAME Inverse Complex FFT
DESCRIPTION Computes the Inverse Fast Fourier Transform of the input elements stored in vectors xr and xi. The results are stored in complex output vector c. Note the Inverse FFT is the same as the Forward FFT except that the sign of the imaginary components of the twiddle factors is negated. The Inverse FFT swaps the real and imaginary input data, perform the Forward FFT with the same weights table, and swaps the real and imagi-nary ouptut data. Scaling by 1/N is then performed.
ALGORITHM
SYNOPSIS void cffti ( xr, xi, wr, wi, wstr, yr, yi, n )
float dm *xr ; /* Pointer to real input data */
float dm *xi ; /* Pointer to imaginary input data */
float pm *wr ; /* Pointer to cosine table */
float dm *wi ; /* Pointer to sine table */
int wstr ; /* Cosine/sine table stride */
float dm *yr ; /* Pointer to real output data */
float pm *yi ; /* Pointer to imaginary output data */
int n ; /* FFT Size (In Complex Elements) */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 22,650 Cycles @ 1,024 Points - Data and Program In On-Board Cache
Cm1n--- Ake
i2πmk n⁄ m 0 1 2 … n, 1–, , ,{ }=
k 0=
n 1–
∑=

ADSP-21K Optimized DSP Library User’s Manual
5-98 Wideband Computers, Inc.
NOTES This is a radix-2 inverse Fast Fourier Transform using parallel DM/PM data accessesto maximize the throughput on the 21020 processor.The complex input data is sepa-rated into real and imaginary parts, xr and xi. These vectors must be aligned on anaddress which is an integer multiple of the FFT size, as required for 21K bit-reverse addressing. The input vectors are both in DM; the imaginary data is bit-reversed into PM at the beginning of the routine.The number of elements n must be anintegral power of two and a minimum of 32.
The complex output is separated into real and imaginary parts, yr and yi. These vec-tors may have arbitrary address alignment; however yr is in the DM and yi is in thePM. Vectors xr and xi mus be in data memory and each must be aligned to an integralmultiple of n.
Vectors wr and wi are in program memory and data memory respectively and aregiven the values:
The weight stride, wst, allows for calling cfft() with varying sizes n from a single setof weights. These weights are generated using the fftwts( ) function.
Vector yr is in data memory and has a minimum size of n.Vector yi is in programmemory and has a minimum size of n.
The file tcfft.c included in the distribution tape provides an example of this function’suse.
cffti ( xr, xi, wr, wi, wstr, yr, yi, n )
wr k[ ] 2πk wst*n⁄[ ] k 0 1 … wstn 2 1–⁄, , ,( )=cos=
wi k[ ] 2πk wst*n⁄[ ]sin k 0 1 … wstn 2 1–⁄, , ,( )==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-99
SPECIAL NOTES Previous users have sometimes reported problems associated with implementing inter-rupt service routines (ISRs), when used in conjunction with the FFT routines (cfft ( ),cffti ( ), rfft ( ), rffti ( ) ). Observations related to the Wideband technical staff typi-cally include a description of the Wideband routine executing perfectly, but unable toreturn to an exact state after being interrupted by the ISR ( a “tumble into the weeds.” )
The Wideband Fast Fourier transforms, both complex and real, forward and inverse,use the built-in bit reversing and circular addressing capabilites of the SHARC archi-tecture. Also, other routines such as some of the FIR filters use the SHARC’s internalcircular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the mode 1 regiser, which is associated withbir reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In such circumstances where they are not saved and restored by the ISRthey are unable to return the proper length parameter ( L Register ) used for circularaddressing or the proper mode ( Mode 1 Register ) used in Bit Reversing. This resultsin the strange manefestations users sometimes report.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.
For a detailed review of the relationships between the various FFT functions and howto use them with one another, see the final section of Chapter 4.
cffti ( xr, xi, wr, wi, wstr, yr, yi, n )
ADSP-21K Optimized DSP Library User’s Manual
5-100 Wideband Computers, Inc.
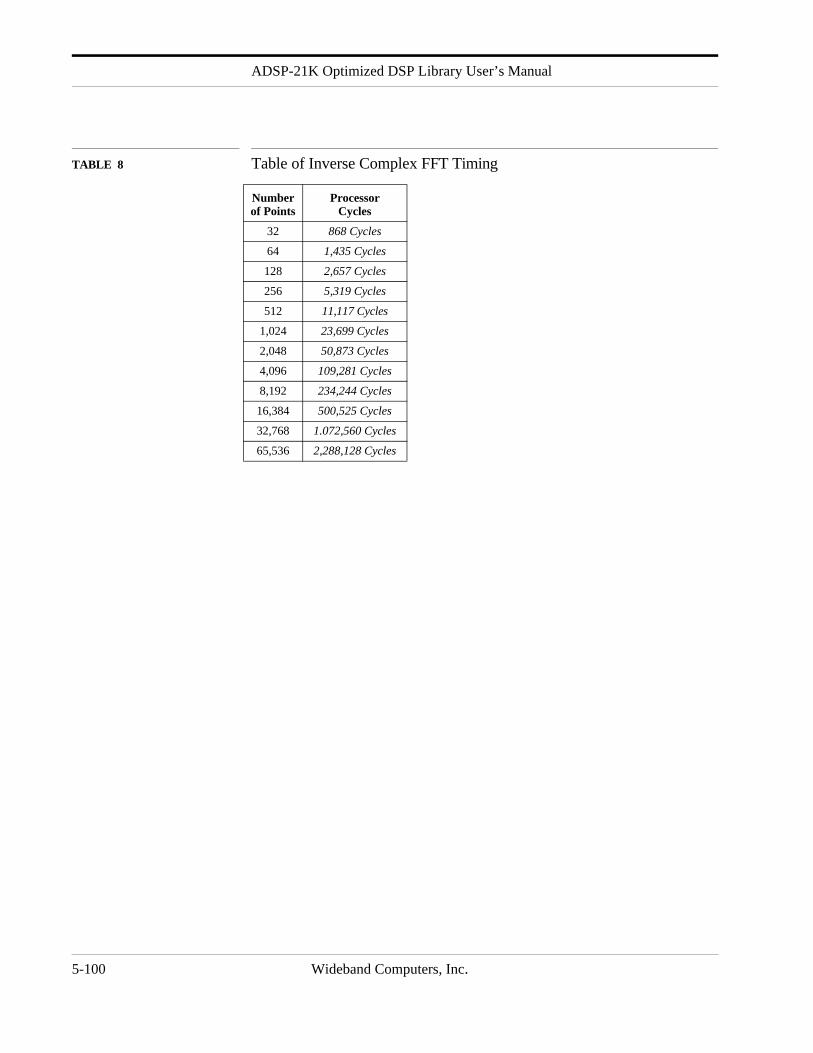
TABLE 8 Table of Inverse Complex FFT Timing
Number of Points
Processor Cycles
32 868 Cycles
64 1,435 Cycles
128 2,657 Cycles
256 5,319 Cycles
512 11,117 Cycles
1,024 23,699 Cycles
2,048 50,873 Cycles
4,096 109,281 Cycles
8,192 234,244 Cycles
16,384 500,525 Cycles
32,768 1.072,560 Cycles
65,536 2,288,128 Cycles

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-101
cfir ( ii, qq, ci, cq, oi, oq, d, n, p )
NAME Complex Finite Impulse Response Filter
DESCRIPTION The function cfir( ) computes the convolution of vectors ii[ ], iq[ ], ci[ ], and cq[ ] placing the results in oi[ ] and oq[ ] respectively. The number of output samples n and the number of coefficients p may be dissimilar. n elements will be writtento oi[ ] and oq[].
The vectors ii[ ] and iq[ ] represent the real and imaginary (I and Q) components of the input data respectively. Likewise,the vectors ci[ ] and cq[ ] represent the real and imaginary (I and Q) components of the coefficient data. A complex multiply and add is performed to compute the convolutional output. The decimation factor d is used to stride the next starting ii[ ] and iq[ ] data.
ALGORITHM
SYNOPSIS void cfir ( ii, qq, ci, cq, oi, oq, d, n, p )
*/ float dm *ii ; Input samples for I data ( len n+p-1 ) */
*/ float dm *iq ; Input samples for Q data ( len n+p-1 ) */
*/ float pm *ci ; Coefficients for I data ( len p ) */
*/ float pm *cq ; Coefficients for Q data ( len p ) */
*/ float dm *oi ; Output samples for I data ( len n ) */
*/ float dm *oq ; Output samples for Q data ( len n ) */
*/ int d ; Decimation factor */
*/ int n ; Number of output samples */
*/ int p ; Number of coefficients */
C i[ ] a a d j+•[ ] b p j– 1–[ ]•
j 0=
p 1=
∑=
m 0 1 2 … n 1–,, , ,{ }=
where
a [ ] compromises complex components ii [ ] and iq [ ]
b [ ] compromises complex components ci [ ] and cq [ ]
c [ ] compromises complex components oi [ ] and oq [ ]

ADSP-21K Optimized DSP Library User’s Manual
5-102 Wideband Computers, Inc.
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 59 + ( 9 + 5 * p ) * n cycles
NOTES The file tfir.c included in the distribution tape provides an example of this function’s use.
The number of filter output samples to generate can be obtainted as follows:
where ndata is the number of elements in ii[ ] and iq[ ].
A correlation can be performed by reversing the order of the coefficients vector.
cfir ( ii, qq, ci, cq, oi, oq, d, n, p )
n ndata p–( )d 1+
----------------------------=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-103
chksum ( a, i, type, n )
NAME Perform Checksum
DESCRIPTION This function performs a checksum on a memory block. The memory block is defined by the start address a offset by n. The type flag determines whether dm or pm memory is tested ( 1 = dm, 0 = pm).
ALGORITHM
SYNOPSIS void chksum ( a, i, type, n )
int a ; /* Start address of memory */
int i ; /* Memory Stride */
int type ; /* Type of memory to test ( dm or pm ) */
int n ; /* Length of block to be checked */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 17 + 2 * N cycles
NOTES The file tchksum.c included in the distribution diskette provides an example of this function’s use.
chksum( ) performs a two’s complement on the sum of the elements within the mem-ory block. The check sum value is returned.
Return Checksum⇐

ADSP-21K Optimized DSP Library User’s Manual
5-104 Wideband Computers, Inc.
cmadd ( a, b, x, y, c )
NAME Complex Matrix Addition
DESCRIPTION This function computes the addition of complex input matrix a with complex input matrix b and stores the results to complex output matrix c.
ALGORITHM
SYNOPSIS void cmadd ( a, b, x, y, c )
complex dm *a ; /* Pointer to input matrix a [ ][ ] */
complex dm *b ; /* Pointer to input matrix b [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] & b[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ]& b[ ][ ]*/
complex dm *c ; /* Pointer to output matrix c [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cri11 Cri12 Cri13Cri21 Cri22 Cri23
Ari11 Ari12 Ari13Ari21 Ari22 Ari23
Bri11 Bri12 Bri13Bri21 Bri22 Bri23
+=
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-105
EXECUTION TIME 32 + 3*X*Y cycles
NOTES The file tcmadd.c included in the distribution diskette provides an example of this function’s use.
The addition of a complex matrix is mathematically expressed as follows:
An example of the additon of one complex matrix to another is as follows:
cmadd ( a, b, x, y, c )
Real C x[ ] y[ ] A x[ ] y[ ]Real B x[ ] y[ ]Real+=
Imaginary C x[ ] y[ ] A x[ ] y[ ]Imaginary B x[ ] y[ ]Imaginary+=
A x[ ] y[ ]
1 2, 3.8 1.7, 8.8 5.5, 9.9 14,7.1 5, 9.3 1.6, 0.4 1, 51 3.3,0.9 1, 8 5, 2.1 6, 3.1 1–,–9.3 1, 2.5 1.5, 6.9 9, 10 22.1,
1.3 1.4, 0.2 4.5, 0.9 51.4, 1.5 4.4,9.2 4, 7.8 1.7, 61 3.4, 14.3 1.4,
=
B [x] [y]
3.2 1, 8.8 2, 9.9 3, 44.3 13.3,8.1 4, 6.5 5, 3.2 6, 2.3 9.9–,–8.9 7, 2.8 8, 1.7 9, 8.1 2.2–,–
6.4 10, 11 1.3, 12 4.5, 22.9 5.4–,6.5 7, 2.1 8, 2.2 9, 32 9.8,1.1 4, 7.7 5, 4.4 6, 2.1 0.3–,–
=
x=6, y=4
C [x] [y]
4.2 3, 12.6 3.7, 18.7 8.5, 54.2 27.3,15.2 9, 15.8 6.6, 3.6 7, 48.7 6.6–,9.8 8, 10.8 13, 3.8 15, 11.2 3.2–,–
15.7 11, 13.5 2.8, 18.9 13.5, 32.9 16.7,7.8 8.4, 2.3 12.5, 3.1 60.4, 33.5 14.2,10.3 8, 15.5 6.7, 65.4 9.4, 12.2 1.1,
=

ADSP-21K Optimized DSP Library User’s Manual
5-106 Wideband Computers, Inc.
cmmov ( a, x, y, b )
NAME Complex Matrix Move
DESCRIPTION This function moves a source complex input matrix a to a destination complex output matrix b.
ALGORITHM
SYNOPSIS void cmmov ( a, x, y, b )
complex dm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
complex dm *b ; /* Pointer to output matrix b [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 13 + ( 2 * X * Y ) cycles
NOTES The file tcmmov.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matricies can be thought of as one long array (vector) where the beginning of each row is offset by the length of the col-umn.
Cri11 Cri12 Cri13Cri21 Cri22 Cri23
Ari11 Ari12 Ari13Ari21 Ari22 Ari23
⇐
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-107
cmmul ( a, x, y, b, z, c )
NAME Complex Matrix Multiplication
DESCRIPTION This function computes the multiplication of complex input matrix a times complex input matrix b and stores the results to complex output matrix c. The dimension of complex matrix a [ ] [ ] is x and y and the dimension of complex input matrix b [ ] [ ] is y and z. The resulting complex output matrix c [ ] [ ] is of dimension x and z.
ALGORITHM
SYNOPSIS void cmmul ( a, x, y, b, z, c )
complex dm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
/* Number of rows in matrix b[ ][ ] */
complex dm *b ; /* Pointer to input matrix b [ ][ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
complex dm *c ; /* Pointer to output matrix c [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cri11 Cri12
Cri21 Cri22
Ari11 Ari12 Ari13
Ari21 Ari22 Ari23
Bri11 Bri12
Bri21 Bri22
Bri31 Bri32
•=
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
5-108 Wideband Computers, Inc.
EXECUTION TIME 45 + (4 + ( 10 + 5 * Y) * Z) * X cycles
NOTES The file tcmmul.c included in the distribution diskette provides an example of this function’s use.
The multiplication of a complex matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the length of the col-umn.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element of c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
ri indicates that each component of the matrix is composed of a complex number which has both a real and imaginary component.
An example of the multipication of one complex matrices by another is as follows:
cmmul ( a, x, y, b, z, c )
C x[ ] y[ ] Real Sum + Imaginary Sum( ) where
k 1=
y
∑=
Real Sum AReal BReal• AImaginary BImagainary•–=
Imaginary Sum AReal BImaginary• BReal AImaginary•+=
A x[ ] y[ ]1 1, 2 2, 3 3, 4 4,5 5, 6 6, 7 7, 8 8,9 9, 10 10, 11 11, 12 12,
B [y] [z]
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,
==
x=3, y=4, z=3
C [ ] 10 270,– 10 310,– 10– 350,26 606,– 26 710,– 26 814,–42 942,– 42 1110,– 42 1278,–
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-109
cmmul_dpd ( a, x, y, b, z, c )
NAME Complex Matrix Multiplication (Data Memory x Program Memory to Data Memory)
DESCRIPTION This function computes the multiplication of complex input matrix a[ ] (in data mem-ory) times complex input matrix b[ ] (in program memory) and stores the results to complex output matrix c[ ] (in data memory). The dimension of complex matrix a [ ] [ ] is x and y and the dimension of complex input matrix b [ ] [ ] is y and z. The resulting complex output matrix c [ ] [ ] is of dimension x and z.
ALGORITHM
SYNOPSIS void cmmul_dpd ( a, x, y, b, z, c )
complex dm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
/* Number of rows in matrix b[ ][ ] */
complex pm *b ; /* Pointer to input matrix b [ ][ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
complex dm *c ; /* Pointer to output matrix c [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cri11 Cri12
Cri21 Cri22
Ari11 Ari12 Ari13
Ari21 Ari22 Ari23
Bri11 Bri12
Bri21 Bri22
Bri31 Bri32
•=
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
5-110 Wideband Computers, Inc.
EXECUTION TIME 49 + (4 + ( 6 + 4 * Y) * Z) * X cycles
NOTES The file tcmmuldpd.c included in the distribution diskette provides an example of this function’s use.
The multiplication of a complex matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the length of the col-umn.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element of c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
ri indicates that each component of the matrix is composed of a complex number which has both a real and imaginary component.
An example of the multipication of one complex matrices by another is as follows:
cmmul_dpd ( a, x, y, b, z, c )
C x[ ] y[ ] Real Sum + Imaginary Sum( ) where
k 1=
y
∑=
Real Sum AReal BReal• AImaginary BImagainary•–=
Imaginary Sum AReal BImaginary• BReal AImaginary•+=
A x[ ] y[ ]1 1, 2 2, 3 3, 4 4,5 5, 6 6, 7 7, 8 8,9 9, 10 10, 11 11, 12 12,
B [y] [z]
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,
==
x=3, y=4, z=3
C [ ] 10 270,– 10 310,– 10– 350,26 606,– 26 710,– 26 814,–42 942,– 42 1110,– 42 1278,–
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-111
cmmul_dpp ( a, x, y, b, z, c )
NAME Complex Matrix Multiplication (Data Memory x Program Memory to Program Mem-ory)
DESCRIPTION This function computes the multiplication of complex input matrix a[ ] (in data mem-ory) times complex input matrix b[ ] (in program memory) and stores the results to complex output matrix c[ ] (in program memory). The dimension of complex matrix a [ ] [ ] is x and y and the dimension of complex input matrix b [ ] [ ] is y and z. The resulting complex output matrix c [ ] [ ] is of dimension x and z.
ALGORITHM
SYNOPSIS void cmmul_dpp ( a, x, y, b, z, c )
complex dm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
/* Number of rows in matrix b[ ][ ] */
complex pm *b ; /* Pointer to input matrix b [ ][ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
complex pm *c ; /* Pointer to output matrix c [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cri11 Cri12
Cri21 Cri22
Ari11 Ari12 Ari13
Ari21 Ari22 Ari23
Bri11 Bri12
Bri21 Bri22
Bri31 Bri32
•=
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
5-112 Wideband Computers, Inc.
EXECUTION TIME 49 + (4 + ( 6 + 4 * Y) * Z) * X cycles
NOTES The file tcmmuldpp.c included in the distribution diskette provides an example of this function’s use.
The multiplication of a complex matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the length of the col-umn.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element of c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
ri indicates that each component of the matrix is composed of a complex number which has both a real and imaginary component.
An example of the multipication of one complex matrices by another is as follows:
cmmul_dpp ( a, x, y, b, z, c )
C x[ ] y[ ] Real Sum + Imaginary Sum( ) where
k 1=
y
∑=
Real Sum AReal BReal• AImaginary BImagainary•–=
Imaginary Sum AReal BImaginary• BReal AImaginary•+=
A x[ ] y[ ]1 1, 2 2, 3 3, 4 4,5 5, 6 6, 7 7, 8 8,9 9, 10 10, 11 11, 12 12,
B [y] [z]
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,
==
x=3, y=4, z=3
C [ ] 10 270,– 10 310,– 10– 350,26 606,– 26 710,– 26 814,–42 942,– 42 1110,– 42 1278,–
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-113
cmmul_pdd ( a, x, y, b, z, c )
NAME Complex Matrix Multiplication (Program Memory x Data Memory to Data Memory)
DESCRIPTION This function computes the multiplication of complex input matrix a[ ] (in program memory) times complex input matrix b[ ] (in data memory) and stores the results to complex output matrix c[ ] (in data memory). The dimension of complex matrix a [ ] [ ] is x and y and the dimension of complex input matrix b [ ] [ ] is y and z. The resulting complex output matrix c [ ] [ ] is of dimension x and z.
ALGORITHM
SYNOPSIS void cmmul_pdd ( a, x, y, b, z, c )
complex pm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
/* Number of rows in matrix b[ ][ ] */
complex dm *b ; /* Pointer to input matrix b [ ][ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
complex dm *c ; /* Pointer to output matrix c [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cri11 Cri12
Cri21 Cri22
Ari11 Ari12 Ari13
Ari21 Ari22 Ari23
Bri11 Bri12
Bri21 Bri22
Bri31 Bri32
•=
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
5-114 Wideband Computers, Inc.
EXECUTION TIME 49 + (4 + ( 6 + 4 * Y) * Z) * X cycles
NOTES The file tcmmulpdd.c included in the distribution diskette provides an example of this function’s use.
The multiplication of a complex matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the length of the col-umn.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element of c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
ri indicates that each component of the matrix is composed of a complex number which has both a real and imaginary component.
An example of the multipication of one complex matrices by another is as follows:
cmmul_pdd ( a, x, y, b, z, c )
C x[ ] y[ ] Real Sum + Imaginary Sum( ) where
k 1=
y
∑=
Real Sum AReal BReal• AImaginary BImagainary•–=
Imaginary Sum AReal BImaginary• BReal AImaginary•+=
A x[ ] y[ ]1 1, 2 2, 3 3, 4 4,5 5, 6 6, 7 7, 8 8,9 9, 10 10, 11 11, 12 12,
B [y] [z]
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,
==
x=3, y=4, z=3
C [ ] 10 270,– 10 310,– 10– 350,26 606,– 26 710,– 26 814,–42 942,– 42 1110,– 42 1278,–
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-115
cmmul_pdp ( a, x, y, b, z, c )
NAME Complex Matrix Multiplication (Program Memory x Data Memory to Program Mem-ory)
DESCRIPTION This function computes the multiplication of complex input matrix a[ ] (in program memory) times complex input matrix b[ ] (in data memory) and stores the results to complex output matrix c[ ] (in program memory). The dimension of complex matrix a [ ] [ ] is x and y and the dimension of complex input matrix b [ ] [ ] is y and z. The resulting complex output matrix c [ ] [ ] is of dimension x and z.
ALGORITHM
SYNOPSIS void cmmul_pdp ( a, x, y, b, z, c )
complex pm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
/* Number of rows in matrix b[ ][ ] */
complex dm *b ; /* Pointer to input matrix b [ ][ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
complex pm *c ; /* Pointer to output matrix c [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cri11 Cri12
Cri21 Cri22
Ari11 Ari12 Ari13
Ari21 Ari22 Ari23
Bri11 Bri12
Bri21 Bri22
Bri31 Bri32
•=
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
5-116 Wideband Computers, Inc.
EXECUTION TIME 49 + (4 + ( 6 + 4 * Y) * Z) * X cycles
NOTES The file tcmmulpdp.c included in the distribution diskette provides an example of this function’s use.
The multiplication of a complex matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the length of the col-umn.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element of c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
ri indicates that each component of the matrix is composed of a complex number which has both a real and imaginary component.
An example of the multipication of one complex matrices by another is as follows:
cmmul_pdp ( a, x, y, b, z, c )
C x[ ] y[ ] Real Sum + Imaginary Sum( ) where
k 1=
y
∑=
Real Sum AReal BReal• AImaginary BImagainary•–=
Imaginary Sum AReal BImaginary• BReal AImaginary•+=
A x[ ] y[ ]1 1, 2 2, 3 3, 4 4,5 5, 6 6, 7 7, 8 8,9 9, 10 10, 11 11, 12 12,
B [y] [z]
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,
==
x=3, y=4, z=3
C [ ] 10 270,– 10 310,– 10– 350,26 606,– 26 710,– 26 814,–42 942,– 42 1110,– 42 1278,–
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-117
cmsmul ( a, x, y, b, c )
NAME Complex Scalar-Matrix Multiplication
DESCRIPTION This function computes the multiplication of complex input matrix a[ ] [ ] times com-plex input scalar b and stores the results to complex output matrix c. The dimensionsof complex input matrix a[ ] [ ] and complex output matrix c[ ] [ ] are of dimensions xand y.
ALGORITHM
SYNOPSIS void cmsmul ( a, x, y, b, c )
complex dm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
/* Number of rows in matrix b[ ][ ] */
complex dm *b ; /* Pointer to input scalar b [ ][ ] */
complex dm *c ; /* Pointer to output matrix c [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cri11 Cri12 Cri13
Cri21 Cri22 Cri23
Ari11 Ari12 Cri13
Ari21 Ari22 Ari23
Bri•=
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
5-118 Wideband Computers, Inc.
EXECUTION TIME 46 + 2*X*Y cycles
NOTES The file tcmsmul.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
An example of a complex scalar-matrix multiplication is as follows:
cmsmul ( a, x, y, b, c )
C x[ ] y[ ]
4.00 18.0, 16.0 38.0, 28.0 58.0,40.0 78.0, 52.0 98.0, 64.0 118,76.0 138, 88.0 158, 100 178,112 198, 124 218, 136 238,148 258, 160 287, 172 298,
=
A x[ ] y[ ]
1.0 2.0, 3.0 4.0, 5.0 6.0,7.0 8.0, 9.0 10, 11 12,13 14, 15 16, 17 18,19 20, 21 22, 23 24,25 26, 27 28, 29 30,
B 8 2,[ ] x=8, y=7 ==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-119
cmsub ( a, b, x, y, c )
NAME Complex Matrix Subtraction
DESCRIPTION This function computes the subtraction of complex input matrix b[ ] [ ] from complex input matrix a[ ] [ ] and stores the results to complex output matrix c[ ] [ ].
ALGORITHM
SYNOPSIS void cmsub ( a, b, x, y, c )
complex dm *a ; /* Pointer to input matrix a [ ][ ] */
complex dm *b ; /* Pointer to input matrix b [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] & b[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ]& b[ ][ ]*/
complex dm *c ; /* Pointer to output matrix c [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cri11 Cri12 Cri13Cri21 Cri22 Cri23
Ari11 Ari12 Ari13Ari21 Ari22 Ari23
Bri11 Bri12 Bri13Bri21 Bri22 Bri23
–=
where ri indicates a real and imaginary component

ADSP-21K Optimized DSP Library User’s Manual
5-120 Wideband Computers, Inc.
EXECUTION TIME 32 + ( 3 * X * Y ) cycles
NOTES The file tcmsub.c included in the distribution diskette provides an example of this function’s use.
The subtraction of a complex matrices is mathematically expressed as follows:
An example of the subtraction of one complex matrix from another is as follows:
cmsub ( a, b, x, y, c )
Real C x[ ] y[ ] A x[ ] y[ ]Real B x[ ] y[ ]Real–=
Imaginary C x[ ] y[ ] A x[ ] y[ ]Imaginary B– x[ ] y[ ]Imaginary=
A x[ ] y[ ]1.0 2.0, 3.8 1.7, 8.8 5.5,7.1 5.0, 9.3 1.6, 0.4 1.0,0.9 1.0, 8.0 5.0, 2.1 6.0,
=
B [x] [y] 3.2 1.0, 8.8 2.0, 9.9 3.0,8.1 4.0, 6.5 5.0, 3.2 6.0,
8.9 7.0·, 2.8 8.0, 1.7 9.0,
·
=
x=3, y=3
C [x] [y] 2.2 1.0,– 5.0 0.3–,– 1.1 2.5,–1.0 1.0,– 2.8 3.4–, 2.8 5.0–,–
8.0 6.0–,– 5.2 3.0–, 0.4 3.0–,
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-121
cmtrans ( a, b, x, y )
NAME Complex Matrix Transpose
DESCRIPTION This function transposes the contents of complex input matrix a[ ] [ ] and places the results in complex output matrix b[ ] [ ]. The dimensions of matrix a [ ] [ ] are x and y and the dimensions of output matrix b [ ] [ ] are y and x.
ALGORITHM
SYNOPSIS void cmtrans ( a, b, x, y )
complex dm *a ; /* Pointer to complex input matrix a [ ][ ] */
complex dm *b ; /* Pointer to complex output matrix b [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
/* Number of columns in matrix b[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
/* Number of rows in matrix b[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
If A
Ari11 Ari12
Ari21 A22
Ari31 Ari32
then AT Ari11 Ari21 Ari31
Ari12 Ari22 Ari32
==
Where ri indicates a real and imaginary pair of numbers

ADSP-21K Optimized DSP Library User’s Manual
5-122 Wideband Computers, Inc.
EXECUTION TIME 34 + ( 3+4*Y ) * X cycles
NOTES The file tcmtrans.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
Transposing a matrix is performed as follows:
An example of a complex matrix transpose is as follows:
cmtrans ( a, b, x, y )
B Realnm A Realmn=
B Imaginarynm A Imaginarymn=
for m=0, x and n=0, y
x 4 y=3,=
B y[ ] x[ ]1 2, 7 8, 13 14, 19 20,3 4, 9 10, 15 16, 21 22,5 6, 11 12, 17 18, 23 24,
=
A x[ ] y[ ]
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-123
cmvmul ( a, x, y, b, c )
NAME Complex Matrix-Vector Multiply
DESCRIPTION This function multiplies the elements of complex input matrix a[ ] [ ] times the ele-ments of complex input vector b. The length of complex input vector b is defined by input scalar y, while the dimensions of complex input matrix a is defined by input sca-lars x and y. The results are stored in complex output vector c, which is of length x.
ALGORITHM
SYNOPSIS void cmvmul( a, x, y, b, c )
complex dm *a ; /* Pointer to complex input matrix a [ ][ ] */
int x ; /* Number of rows in complex matrix a[ ][ ] */
int y ; /* Number of columns in matrix vector a[ ][ ] */
/* Number of elements in vector b[ ] */
complex dm *b ; /* Pointer to complex input vector b [ ] */
complex dm *c ; /* Pointer to complex output vector c */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cx Axk Bk•
k 1=
y
∑=

ADSP-21K Optimized DSP Library User’s Manual
5-124 Wideband Computers, Inc.
EXECUTION TIME 41 + ( 14 + 7 * Y ) * X cycles
NOTES The file tcmvmul.c included in the distribution diskette provides an example of this function’s use.
a[x] [y]=
b[x] = { 1, 1, 2, 2 3, 3 };
x = 4, y = 3 ;
cmvmul ( a, 4, 3, b, c ) ;
The resulting values in output vector [c] would be as follows:
c[3] = { -6, 50, -6, 122, -6, 194, -6, 266 }
The storage methodology for matricies is by rows. Matricies can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
The first row of matrix a [ ] [ ] times vector b is the first element of vector c. The sec-ond row of matrix a [ ] [ ] times vector b is the second element of vector c, etc.
cmvmul ( a, x, y, b, c )
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-125
coher ( a, b, c, d, n )
NAME Coherence Function
DESCRIPTION Computes the coherence function of two signals. The real input vectors a and b are the signal’s auto-spectra. Their cross-spectrum is in complex input vector c. The results are stored in real output vector d.
ALGORITHM
SYNOPSIS void coher ( a, b, c, d, n )
float *a ; /* Pointer to input vector a */
int *b ; /* Pointer to input vector b */
float *c ; /* Pointer to complex input vector c */
int *d ; /* Pointer to output vector d */
int n ; /* Number of elements in vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + 11*N Cycles
NOTES The file tcoher.c included in the distribution tape provides an example of this func-tion’s use.
The strides of vectors a, b, c, and d must always be 1.
Should real input vectors a or b should equal zero, this would result in an attempt to divide by zero, which is an illegal operation.
Dml
Re Cm{ }2Im Cm{ }2
+
Am Bm•------------------------------------------------------- m 0 1 2 … m, 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-126 Wideband Computers, Inc.
comb ( a, b )
NAME Combination
DESCRIPTION This function computes the combination of input scalar a by input scalar b, and returns the result in comb. The number of combinations refers to the different ways of choos-ing b objects from a total of a, without regard for their order.
ALGORITHM
SYNOPSIS void comb ( a, b )
int dm a ; /* Input value a */
int dm b ; /* Input value b */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 33 + ( A - B ) * 4 cycles
NOTES The file tcomb.c included in the distribution diskette provides an example of this func-tion’s use.
The value of input scalar a must be greater than or equal to 0. If not, a value of -99 is returned.
The value of input scalar b must be less then the value of input scalar a. If not, a value of -99 is returned.
comb a!b! a b–( )• !-----------------------------=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-127
conv ( a, i, b, j, c, k, na, nb )
NAME Convolution Function
DESCRIPTION Computes the convolution of input vectors a with vector b, placing the results in out-put vector c. na + nb-1 elements will be written to output vector c as a result of this operation. na and nb may be dissimilar.
ALGORITHM
SYNOPSIS void conv ( a, i, b, j, c, k, na, nb )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for vector a */
float pm *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for vector c */
int na ; /* Number of element to compute */
int nb ; /* Element count in vector b */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 42 + (7+NC)*N cycles
NOTES The file tconv.c included in the distribution tape provides an example of this func-tion’s use.
na elements will be written to output vector c as a result of this operation, where:
Cm Am q+ Bnb q 1 ––•q 0=
nb 1–
∑=
m 0 1 2 … na 1–,, , ,{ }=
na sizeof a( ) nb– 1+≤

ADSP-21K Optimized DSP Library User’s Manual
5-128 Wideband Computers, Inc.
conv2d ( a, nr, nc, b, c, k )
NAME 2-Dimensional Convolution, KxK Kernel
DESCRIPTION Computes the 2-dimensional convolution of input matrix a[ ] [ ] with input kernel matrix b[ ] [ ] , placing the results in output matrix c[ ] [ ].
ALGORITHM
SYNOPSIS void conv2d ( a, nr, nc, b, c, k )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
int nr ; /* Number of rows in matrix a[ ][ ] to convolve */
int nc ; /* Number of columns in matrix a to convolve */
float dm *b ; /* Pointer to input kernel matrix b [ ] [ ] */
float dm *c ; /* Pointer to output matrix c */
int k ; /* Kernel size; */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 45 + ( 3 + ( 6 + ( 6 + 2k ) k ) (nc - k + 1 )) (nr - k + 1) cycles
NOTES The file tconv2d.c included in the distribution tape provides an example of this func-tion’s use.
C r c,( ) b k 1– i–[ ] k 1– j–[ ] a r i+[ ] c j+[ ]•
j 0=
k 1–
∑i 0=
k 1–
∑=
r 0 1 2 … nr k– 1+,, , ,{ }=
c 0 1 2 … nc k– 1+,, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-129
conv3x3 ( a, x, y, b, c )
NAME 2-Dimensional Convolution of a Matrix and a 3x3 Kernel
DESCRIPTION Computes the 2-D convolution of input matrices a and b, and places the results in out-put matrix c. The image in matrix a is filtered with a 3-by-3 kernel in matrix b.
ALGORITHM
SYNOPSIS void conv3x3 ( a, x, y, b, c )
float *a ; /* Pointer to input matrix a */
int x ; /* Number of rows in matrix a */
int y ; /* Number of columns in matrix a */
float *b ; /* Pointer to coeff matrix b */
float *c ; /* Pointer to output matrix c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 54 + (30*(C-2)(R-2) cycles where C = # of columns and r = # of rows
NOTES The file tconv3x3.c included in the distribution tape provides an example of this func-tion’s use.
Matrix b must be 3x3.
The strides of matrices a, b, and c must be 1.
Cmn Am p n q+,+ Bpq•q 0=
2
∑p 0=
2
∑=
m 0 1 2 … x, 2–, , ,{ }=
n 0 1 2 … y, 2–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-130 Wideband Computers, Inc.
conv3x3p ( a, x, y, b, c )
NAME 2-Dimensional Convolution of a Matrix and a 3x3 Program Memory Kernel
DESCRIPTION Computes the 2-D convolution of input matrices a[ ] [ ] and b[ ] [ ], and places the results in output matrix c[ ] [ ]. The image in matrix a[ ] [ ] is filtered with a 3-by-3 kernel in matrix b[ ] [ ]. Note that the 3x3 kernel is in pm (program memory).
ALGORITHM
SYNOPSIS void conv3x3p ( a, x, y, b, c )
float *a ; /* Pointer to input vector a */
int x ; /* Number of rows in vector a */
int y ; /* Number of columns in vector a */
float pm *b ; /* Pointer to coeff vector b */
float dm *c ; /* Pointer to output vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 54 + ( 30 + 27 (Y-2))(X-2)/2 cycles
NOTES The file tconv3x3p.c included in the distribution tape provides an example of this function’s use.
Matrix b must be 3x3.
The strides of matrices a, b, and c must be 1.
Cmn Am p n q+,+ Bpq•q 0=
2
∑p 0=
2
∑=
m 0 1 2 … x, 2–, , ,{ }=
n 0 1 2 … y, 2–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-131
conv5x5 ( a, x, y, b, c )
NAME 2-Dimensional Convolution of a Matrix and a 5x5 Kernel
DESCRIPTION Computes the 2-Dimensional convolution of input matrices a[ ] [ ] and b[ ] [ ], and places the results in output matrix c[ ] [ ]. The image in matrix a[ ] [ ] is filtered with a 2-Dimensional Convolution with a 5-by-5 kernel in matrix b[ ] [ ].
ALGORITHM
SYNOPSIS void conv5x5 ( a, x, y, b, c )
float *a ; /* Pointer to input matrix a */
int x ; /* Number of rows in matrix a */
int y ; /* Number of columns in matrix a */
float *b ; /* Pointer to coeff matrix b */
float *c ; /* Pointer to output matrix c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 58 + 76*(X-4)(Y-4)cycles
NOTES The file tconv5x5.c included in the distribution tape provides an example of this func-tion’s use
Matrix b must be 5x5.
The strides of matrices a, b, and c must be 1.
Cmn Am p n q+,+ Bpq•
q 0=
4
∑p 0=
4
∑=
m 0 1 2 … x, 4–, , ,{ }=
n 0 1 2 … y, 4–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-132 Wideband Computers, Inc.
conv5x5p ( a, x, y, b, c )
NAME 2-Dimensional Convolution of a Matrix and a 5x5 Kernel in Program Memory
DESCRIPTION Computes the 2-D convolution of input matrices a[ ] [ ] and b[ ] [ ], and places the results in output matrix c[ ] [ ]. The image in matrix a[ ] [ ] is filtered with a 5-by-5 kernel in matrix b[ ] [ ]. Note that the 5 x 5 kernel is in pm (program memory).
ALGORITHM
SYNOPSIS void conv5x5p ( a, x, y, b, c )
float *a ; /* Pointer to input vector a */
int x ; /* Number of rows in vector a */
int y ; /* Number of columns in vector a */
float pm *b ; /* Pointer to coeff vector b */
float dm *c ; /* Pointer to output vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 95 + (74+75(Y-4))(X-4)/2cycles
NOTES The file tconv5x5p.c included in the distribution tape provides an example of this function’s use
Matrix b must be 5x5.
The strides of matrices a, b, and c must be 1.
Cmn Am p n q+,+ Bpq•
q 0=
4
∑p 0=
4
∑=
m 0 1 2 … x, 4–, , ,{ }=
n 0 1 2 … y, 4–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-133
conv7x7 ( a, x, y, b, c )
NAME 2-Dimensional Convolution of a Matrix and a 7x7 Kernel
DESCRIPTION Computes the 2-Dimensional convolution of input matrices a[ ] [ ] and b[ ] [ ], and places the results in output matrix c[ ] [ ]. The image in matrix a[ ] [ ] is filtered with a 2-Dimensional Convolution with a 7-by-7 kernel in matrix b[ ] [ ].
ALGORITHM
SYNOPSIS void conv5x5 ( a, x, y, b, c )
float *a ; /* Pointer to input matrix a */
int x ; /* Number of rows in matrix a */
int y ; /* Number of columns in matrix a */
float *b ; /* Pointer to coeff matrix b */
float *c ; /* Pointer to output matrix c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 33 + (3+235(Y-6))(X-6) cycles
NOTES The file tconv7x7.c included in the distribution tape provides an example of this func-tion’s use
Matrix b must be 7x7.
The strides of matrices a, b, and c must be 1.
Cm Am p+ n q+, Bpq•q 0=
6
∑p 0=
6
∑=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-134 Wideband Computers, Inc.
coord2 ( a, b, c, d, n )
NAME 2-Dimensional Coordinate Transformation
DESCRIPTION Translates and rotates input matrix b[ ] [ ] according to the rotation matrix a[ ] [ ] and translation vector c. The results are stored in matrix d[ ] [ ].
ALGORITHM
SYNOPSIS void coord2 ( a, b, c, d, n )
float *a ; /* Pointer to rotation matrix a */
float *b ; /* Pointer to input vector b */
float *c ; /* Pointer to translation vector */
float *d ; /* Pointer to output vector c */
int n ; /* Number coordinate pairs */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 56 + 9*(N-1) cycles
NOTES The file tcoord2.c included in the distribution tape provides an example of this func-tion’s use
Dm 0, Bm 0, A0 0,• Bm 1, A1 0,• C0+ +=
Dm 1, Bm 0, A0 1,• Bm 1, A1 1,• C1+ +=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-135
coord3 ( a, b, c, d, n )
NAME 3-Dimensional Coordinate Transformation
DESCRIPTION Translates and rotates input matrix b[ ] [ ] according to the rotation matrix a[ ] [ ] and translation vector c[ ] [ ]. The results are stored in matrix d[ ] [ ].
ALGORITHM
SYNOPSIS void coord3 ( a, b, c, d, n )
float *a ; /* Pointer to rotation matrix a */
float *b ; /* Pointer to input vector b */
float *c ; /* Pointer to translation vector */
float *d ; /* Pointer to output vector c */
int n ; /* Number coordinate pairs */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 79 + 16*(N-1) cycles
NOTES The file tcoord3.c included in the distribution tape provides an example of this func-tion’s use.
Dm 0, Bm 0, A0 0,• Bm 1, A1 0,• Bm 2, A2 0,• C0+ + +=
Dm 1, Bm 0, A0 1,• Bm 1, A1 1,• Bm 2, A2 1,• C1+ + +=
Dm 2, Bm 0, A0 2,• Bm 1, A1 2,• Bm 2, A2 2,• C2+ + +=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-136 Wideband Computers, Inc.
corr ( a, i, b, j, c, k, n, nb )
NAME Correlation Function
DESCRIPTION Computes the correlation of input vectors a with vector b, placing the results in output vector c.
ALGORITHM
SYNOPSIS void corr ( a, i, b, j, c, k, n, nb )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for vector a */
float pm *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for vector c */
int n ; /* Number of elements to compute */
int nb ; /* Element count in vector b */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 52 + N*(11+(NB-1)*2) cycles
NOTES The file tcorr.c included in the distribution tape provides an example of this function’s use.
Note that the elements of input vector b must be placed in program memory (pm).
Cm Am p+ Bp•p 0=
nb 1–
∑=
m 0 1 2 … n 1–,, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-137
corr2d ( a, nr, nc, b, c, k )
NAME 2-Dimensional Correlation, K x K Kernel
DESCRIPTION Computes the 2-dimensional correlation of input matrix a[ ] [ ] with input kernel matrix b[ ] [ ], placing the results in output matrix c[ ] [ ].
ALGORITHM
SYNOPSIS void corr2d ( a, nr, nc, b, c, k )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
int nr ; /* Number of rows in matrix a[ ][ ] */
int nc ; /* Number of columns in matrix a[ ][ ] */
float dm *b ; /* Pointer to input kernel matrix b[ ][ ] */
float dm *c ; /* Pointer to output matrix c[ ][ ] */
int k ; /* Kernel Size ( k x k ) of input matrix b */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 35 + ( 4 + ( 5 + ( 5 + 4k ) k )(nc - k + 1))(nr - k + 1) cycles
NOTES The file tcorr2d.c included in the distribution tape provides an example of this func-tion’s use.
C r c,( ) A r u c v+,+( ) B u v,( )•
v 0=
k 1–
∑u 0=
k 1–
∑=
r 0 1 2 … nr 1– 1+,, , ,{ }=
c 0 1 2 … nc k– 1+,, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-138 Wideband Computers, Inc.
cos_wci ( x )
NAME Cosine
DESCRIPTION This function computes the cosine of a floating-point number, x ( x is measured in radians ). The computed value is returned from this function.
ALGORITHM
SYNOPSIS float cos_wci ( float x )
DOMAIN - 205,884 < x < 205,884 radians
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 cycles
NOTES The file tcos.c included in the distribution tape provides an example of this function's use.
cosh_wci ( x )
NAME Hyperbolic Cosine
DESCRIPTION This function computes the hyperbolic cosine of a floating-point number, x ( x is mea-sured in radians ). The computed value is returned from this function.
ALGORITHM
SYNOPSIS float cosh_wci ( float x )
DOMAIN -88 to +88
ACCURACY 7.75 decimal digits
EXECUTION TIME 58 cycles
NOTES The file tcosh.c included in the distribution tape provides an example of this function's use.
return x( )cos=
return x( )cosh=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-139
cspec ( a, b, c, n)
NAME Accumulating Cross-Spectrum
DESCRIPTION Computes the cross-spectrum of complex input vectors a and b by multiplying the conjugate of vector a by vector b and adding the result to the current value of vector c. Input/Output vector c must be initialized prior to invoking a series of accumulating cross-spectrum calls.
ALGORITHM
SYNOPSIS void cspec ( a, b, c, n )
complex *a ; /* Pointer to complex input vector a */
complex *b ; /* Pointer to complex input vector b */
complex *c ; /* Pointer to complex input/output vector c */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 37 + 8*N Cycles
NOTES The file tcspec.c included in the distribution tape provides an example of this func-tion’s use.
Cm Cm Am* Bm• m 0 1 2 … n, 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-140 Wideband Computers, Inc.
cvabs ( a, i, c, k, n )
NAME Complex Vector Absolute Value
DESCRIPTION This function computes the complex absolute value of complex input vector a and stores the results in real output vector c.
ALGORITHM
SYNOPSIS void cvabs ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.7 x 1019 < abs (a.im) +1.7 x 1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 49 + 17*(N-1) cycles
NOTES The file tcvabs.c included in the distribution diskette provides an example of this function’s use.
Cmk Re2
Ami{ } Im2
Ami{ }+ m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-141
cvadd ( a, i, b, j, c, k, n )
NAME Complex Vector Add
DESCRIPTION This function adds the elements of complex input vector a to the elements of complex input vector b. The results in are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvadd ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 52 + 6*(N-1) cycles
NOTES The file tcvadd.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami Bmj m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-142 Wideband Computers, Inc.
cvadd_pd ( a, i, b, j, c, k, n )
NAME Complex Vector Add
DESCRIPTION This function adds the elements of complex input vector a to the elements of complex input vector b. The results in are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvadd_pd ( a, i, b, j, c, k, n )
complex dm *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex pm *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex dm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 33 + 4*(N-1) cycles
NOTES The file tcvaddpd.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami Bmj m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-143
cvadd_pp ( a, i, b, j, c, k, n )
NAME Complex Vector Add
DESCRIPTION This function adds the elements of complex input vector a to the elements of complex input vector b. The results in are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvadd_pp ( a, i, b, j, c, k, n )
complex dm *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex pm *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex pm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 33 + 4 * (N-1) cycles
NOTES The file tcvaddpp.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami Bmj m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-144 Wideband Computers, Inc.
cvcma ( a, i, b, j, c, k, d, l, n )
NAME Complex Vector Conjugate, Multiply and Add
DESCRIPTION This function multiplies the elements of complex input vector a by the congugate ele-ments of complex input vector b, and then adds complex input vector c to the product. The results in are stored in complex output vector d.
ALGORITHM
SYNOPSIS void cvcma ( a, i, b, j, c, k, d, l, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex input vector c */
int k ; /* Address stride in words for input vector c */
complex *d ; /* Pointer to complex output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 68 +8*(N-1) cycles
NOTES The file tcvcma.c included in the distribution diskette provides an example of this function’s use.
The * sign signifies the computation of the complex conjugate.
Dml Ami B*mj•( ) Cmk m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-145
cvcmpx ( a, i, b, j, c, k, n )
NAME Complex Vector Create From Reals
DESCRIPTION This function creates a complex output vector c by combining the elements of real input vector a and real input vector b.
ALGORITHM
SYNOPSIS void cvcmpx ( a, i, b, j, c, k, n )
float *a ; /* Pointer to real input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + 4*N cycles
NOTES The file tcvmpx.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Ami m 0 1 2 …n 1–, , ,{ }==
Im Cmk{ } Bmj=

ADSP-21K Optimized DSP Library User’s Manual
5-146 Wideband Computers, Inc.
cvcmpx_dpp ( a, i, b, j, c, k, n )
NAME Complex Vector Create From Reals, Data Memory and Program Memory to Program Memory
DESCRIPTION This function creates a complex output vector c by combining the elements of real input vector a[ ] and real input vector b[ ] and the results are placed in complex output vector c[ ]. Vector a[ ] is in data memory, while vectors b[ ] and c[ ] are in program memory.
ALGORITHM
SYNOPSIS void cvcmpx ( a, i, b, j, c, k, n )
float dm *a ; /* Pointer to real input vector a */
int i ; /* Address stride in words for input vector a */
float pm *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex pm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 24 + 3*N cycles
NOTES The file tcvmpx.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Ami m 0 1 2 …n 1–, , ,{ }==
Im Cmk{ } Bmj=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-147
cvcmpxi ( a, i, b, j, c, k, n )
NAME Complex Vector Create From Integers
DESCRIPTION This function creates a complex output vector c by combining the elements of integer input vector a and integer input vector b.
ALGORITHM
SYNOPSIS void cvcmpxi ( a, i, b, j, c, k, n )
int *a ; /* Pointer to integer input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to integer input vector b */
int j ; /* Address stride in words for input vector b */
complexi*c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 30 + 4*N cycles
NOTES The file tcvmpxi.c included in the distribution diskette provides an example of this function’s use.
complexi is a new type known as complex integer.
Re Cmk{ } Ami m 0 1 2 …n 1–, , ,{ }==
Im Cmk{ } Bmj=

ADSP-21K Optimized DSP Library User’s Manual
5-148 Wideband Computers, Inc.
cvcmul ( a, i, b, j, c, k, n )
NAME Complex Vector Conjugate and Multiply
DESCRIPTION This function multiplies the conjugate of the elements of complex input vector a times the elements of complex input vector b. The results are stored in complex output vec-tor c.
ALGORITHM
SYNOPSIS void cvcmul( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 58 + 6*(N-1) cycles
NOTES The file tcvcmul.c included in the distribution diskette provides an example of this function’s use.
Cmk A*mi Bmj• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-149
cvconj ( a, i, c, k, n )
NAME Complex Vector Conjugate
DESCRIPTION This function conjugates the elements of complex input vector a and stores the results in complex output vector c.
ALGORITHM
SYNOPSIS void cvconj ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 4*N cycles
NOTES The file tcvconj.c included in the distribution diskette provides an example of this function’s use.
Cmk A*mi m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-150 Wideband Computers, Inc.
cvdiv ( a, i, b, j, c, k, n )
NAME Complex Vector Division
DESCRIPTION This function divides the elements of complex input vector a bythe elements of com-plex input vector b. The results are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvdiv ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 85 + 26*(N-1) cycles
NOTES The file tcvdiv.c included in the distribution diskette provides an example of this func-tion’s use.
CmkAmi
Bmi------------ m 0 1 2 …n 1–, , ,{ } ==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-151
cvexp ( a, i, c, k, n )
NAME Complex Vector Exponential
DESCRIPTION This function computes the complex exponential of real input vector a and stores the result in complex output vector c.
ALGORITHM
SYNOPSIS void cvexp ( a, i, c, k, n )
float dm *a ; /* Pointer to real input vector a */
int i ; /* Address stride in words for input vector a */
complex dm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -109 < a[i] < +109
ACCURACY 7.75 decimal digits
EXECUTION TIME 39 + 47 * N cycles
NOTES The file tcvexp.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Ami mcos= 0 1 2 …n 1–, , ,{ }=
Im Cmk{ } Ami sin =

ADSP-21K Optimized DSP Library User’s Manual
5-152 Wideband Computers, Inc.
cvexpm ( a, i, b, j, c, k, n )
NAME Complex Vector Exponential and Multiply
DESCRIPTION This function computes the complex exponential of real input vector a, multiplies it by a complex vector b, and stores the result in complex output vector c.
ALGORITHM
SYNOPSIS void cvexpm ( a, i, b, j, c, k, n )
float dm *a ; /* Pointer to real input vector a */
int i ; /* Address stride in words for input vector a */
complex dm *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex dm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -109 < a[i] < +109
ACCURACY 7.75 decimal digits
EXECUTION TIME 54 + 51*N cycles
NOTES The file tcvexpm.c included in the distribution diskette provides an example of this function’s use.
Re Cmk( ) ami( ) Re bmj( )• ami( )sin Im bmj( )•–cos=
Im Cmk( ) ami( ) Re bmj( )• ami( )cos Im bmj( )•+sin=
m= 0 1 2 …n 1–, , ,{ }

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-153
cvfill ( a, c, k, n )
NAME Complex Vector Fill
DESCRIPTION This function copies the complex input scalar a to the complex output vector c.
ALGORITHM
SYNOPSIS void cvfill ( a, c, k, n )
complex *a ; /* Pointer to complex input scalar a */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 + 2*N cycles
NOTES The file tcvfill.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk A m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-154 Wideband Computers, Inc.
cvma ( a, i, b, j, c, k, d, l, n )
NAME Complex Vector Multiply and Add
DESCRIPTION This function multiplies complex input vector a times complex input vector b, and then adds complex input vector c to the product. The results are stored in complex out-put vector d.
ALGORITHM
SYNOPSIS void cvma ( a, i, b, j, c, k, d, l, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex intput vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex intput vector c */
int k ; /* Address stride in words for input vector c */
complex *d ; /* Pointer to complex outtput vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 68 + 8*(N-1) cycles
NOTES The file tcvma.c included in the distribution diskette provides an example of this func-tion’s use.
Dml Ami Bmj• Cmk m 0 1 2…n 1–, ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-155
cvmags ( a, i, c, k, n )
NAME Complex Vector Magnitude Squared
DESCRIPTION This function computes the complex magnitude squared of complex input vector a and stores the result in real output vector c.
ALGORITHM
SYNOPSIS void cvmags ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1018 < abs(a[i]) < +1018
ACCURACY 7.75 decimal digits
EXECUTION TIME 25 + 3*(N-1) cycles
NOTES The file tcvmags.c included in the distribution diskette provides an example of this function’s use.
Cmk Re2 Ami{ } Im2 Ami{ } m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-156 Wideband Computers, Inc.
cvmagsa ( a, i, b, j, c, k, n )
NAME Complex Vector Magnitude Squared and Add
DESCRIPTION This function computes the complex magnitude squared of complex input vector a, adds real input vector b to the sum, and stores the result in real output vector c.
ALGORITHM
SYNOPSIS void cvmagsa ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -10 x 1018 < a[i] < +10 x 1018
ACCURACY 7.75 decimal digits
EXECUTION TIME 34 + 4*(N-1) cycles
NOTES The file tcvmagsa.c included in the distribution diskette provides an example of this function’s use.
Cmk Re2 Ami{ } Im2 Ami{ }+[ ] Bmj+=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-157
cvmmul ( a, b, x, y, c )
NAME Complex Vector-Matrix Multiply
DESCRIPTION This function multiplies the elements of complex input vector a times the elements of complex input matrix b[ ] [ ]. The length of complex input vector a is defined by input scalar x, while the dimensions of complex input matrix b[ ] [ ] is defined by input sca-lars x and y. The results are stored in complex output vector c, which is of length y.
ALGORITHM
SYNOPSIS void cvmmul( a, b, x, y, c )
complex *a ; /* Pointer to complex input vector a [ ] */
complex *b ; /* Pointer to complex input matrix b [ ][ ] */
int x ; /* Number of rows in cmplx matrix vector b[ ][ ] */
/* Number of elements in vector a[ ] */
int y ; /* Number of columns in matrix vector b[ ][ ] */
complex *c ; /* Pointer to complex output vector c */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cj Ak Bk j,•
k 0=
x 1–
∑=
j 0 1 2…y, ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-158 Wideband Computers, Inc.
EXECUTION TIME 44 + ( 12 + 7 * (X-1) ) * Y cycles
NOTES The file tcvmmul.c included in the distribution diskette provides an example of this function’s use.
a[x] = { 1, 1, 2, 2 3, 3 4, 4 };
b[x][y] =
x = 4, y = 3 ;
cmmul ( a, 4, 3, b, c ) ;
The resulting values in output vector c would be as follows:
c[3] = { -10, 270, -10, 310, -10, 350 }
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
Vector a time the first row of matrix b[ ] [ ] is the second element of vector c, etc.
cvmmul ( a, b, x, y, c )
1 2, 3 4, 5 6,7 8, 9 10, 11 12,
13 14, 15 16, 17 18,19 20, 21 22, 23 24,

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-159
cvmov ( a, i, c, k, n )
NAME Complex Vector Move
DESCRIPTION This function moves the complex input vector a to complex output vector c.
ALGORITHM
SYNOPSIS void cvmov ( a, i, c, k, n )
complex dm *a ; /* Pointer to input vector a */
int i ; /* Address stride for input vector a */
complex pm *c ; /* Pointer to output vector c */
int k ; /* Address stride for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 4*N cycles
NOTES The file tcvmov.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-160 Wideband Computers, Inc.
cvmov_dp ( a, i, c, k, n )
NAME Complex Vector Move From Data Memory to Program Memory
DESCRIPTION This function moves the complex input vector a to complex output vector c. Complex vector a is in data memory while complex vector c is in program memory.
ALGORITHM
SYNOPSIS void cvmov_dp ( a, i, c, k, n )
complex dm *a ; /* Pointer to input vector a */
int i ; /* Address stride for input vector a */
complex pm *c ; /* Pointer to output vector c */
int k ; /* Address stride for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 25 + 2*(N-1) cycles
NOTES The file tcvmovdp.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-161
cvmov_pd ( a, i, c, k, n )
NAME Complex Vector Move From Program Memory to Data Memory
DESCRIPTION This function moves the complex input vector a to complex output vector c. Complex vector a is in program memory while complex vector c is in data memory.
ALGORITHM
SYNOPSIS void cvmov_pd ( a, i, c, k, n )
complex pm *a ; /* Pointer to input vector a */
int i ; /* Address stride for input vector a */
complex dm *c ; /* Pointer to output vector c */
int k ; /* Address stride for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 2*(N-1) cycles
NOTES The file tcvmovpd.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-162 Wideband Computers, Inc.
cvmul ( a, i, b, j, c, k, n )
NAME Complex Vector Multiply
DESCRIPTION This function multiplies complex input vector a times complex input vector b, and stores the result in complex output vector c.
ALGORITHM
SYNOPSIS void cvmul ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 58 + 6*(N-1) cycles
NOTES The file tcvmul.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami Bmj• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-163
cvneg ( a, i, c, k, n )
NAME Complex Vector Negate
DESCRIPTION This function negates the elements of complex input vector a and stores them in com-plex output vector c.
ALGORITHM
SYNOPSIS void cvneg ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 4*N cycles
NOTES The file tcvneg.c included in the distribution diskette provides an example of this function’s use.
Cmk A– mj m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-164 Wideband Computers, Inc.
cvphase ( a, i, c, k, n )
NAME Complex Vector Phase
DESCRIPTION This function computes the phase of the elements of complex input vector a, and stores the result in real output vector c.
ALGORITHM
SYNOPSIS void cvphase ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, Re{Amj} cannot equal zero or a divide by zero error will occur.
ACCURACY 7.75 decimal digits
EXECUTION TIME 68 + 76 * N cycles
NOTES The file tcvphase.c included in the distribution diskette provides an example of this function’s use.
Cmk
Im Ami{ }
Re Ami{ }-------------------------atan m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-165
cvradd ( a, i, b, j, c, k, n )
NAME Complex Vector And Real Vector Add
DESCRIPTION This function adds real input vector b to the elements of complex input vector a and stores the results in complex output vector c.
ALGORITHM
SYNOPSIS void cvradd ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 5*(N-1) cycles
NOTES The file tcvradd.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Bmj+=
Im Cmk{ } Im Ami{ }=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-166 Wideband Computers, Inc.
cvrdiv ( a, i, b, j, c, k, n )
NAME Complex Vector And Real Vector Divide
DESCRIPTION This function divides the elements of complex input vector a by the elements of real input vector b. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvrdiv ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, [b] cannot be zero or a divide by zero error will occur.
ACCURACY 7.75 decimal digits
EXECUTION TIME 40 + 12*N cycles
NOTES The file tcvrdiv.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ }Re Ami{ }
Bmj-------------------------=
Im Cmk{ }Im Ami{ }
Bmj-------------------------=
m 0 1 2…n 1–, ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-167
cvrecp ( a, i, c, k, n )
NAME Complex Vector Reciprocal
DESCRIPTION This function computes the complex reciprocal of the elements of complex input vec-tor a. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvrecp ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, the absolute value of a[real] must not equal the absolute value of a[imaginary] or a division by zero error will occur.
ACCURACY 7.75 decimal digits
EXECUTION TIME 70 + 21*(N-1) cycles
NOTES The file tcvrecp.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ }Re Ami{ }
Re2 Ami{ } Im2 Ami{ }+--------------------------------------------------------------- =
Im Cmk{ }Im– Ami{ }
Re2 Ami{ } Im2 Ami{ }+--------------------------------------------------------------- =
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-168 Wideband Computers, Inc.
cvrmul ( a, i, b, j, c, k, n )
NAME Complex Vector Multiply By Real Vector
DESCRIPTION This function multiplies the elements of complex input vector a times the elements of real input vector b. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvrmul ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 5*(N-1) cycles
NOTES The file tcvrmul.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Bmj{ }•=
Im Cmk{ } Im Ami{ } Bmj{ }•=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-169
cvrmul_dpd ( a, i, b, j, c, k, n )
NAME Complex Vector Multiply By Real Vector
DESCRIPTION This function multiplies the elements of complex input vector a times the elements of real input vector b. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvrmul_dpd ( a, i, b, j, c, k, n )
complex dm *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float pm *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex dm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 32+4*(N-1) cycles
NOTES The file tcvrmdpd.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Bmj{ }•=
Im Cmk{ } Im Ami{ } Bmj{ }•=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-170 Wideband Computers, Inc.
cvrmul_dpp ( a, i, b, j, c, k, n )
NAME Complex Vector Multiply By Real Vector
DESCRIPTION This function multiplies the elements of complex input vector a times the elements of real input vector b. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvrmul_dpp ( a, i, b, j, c, k, n )
complex dm *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float pm *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex pm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 32+4*(N-1) cycles
NOTES The file tcvrmdpp.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Bmj{ }•=
Im Cmk{ } Im Ami{ } Bmj{ }•=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-171
cvrmul_pdd ( a, i, b, j, c, k, n )
NAME Complex Vector Multiply By Real Vector
DESCRIPTION This function multiplies the elements of complex input vector a times the elements of real input vector b. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvrmul_pdd ( a, i, b, j, c, k, n )
complex pm *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float dm *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex dm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 36 + 3 * (N-1) cycles
NOTES The file tcvrmpdd.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Bmj{ }•=
Im Cmk{ } Im Ami{ } Bmj{ }•=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-172 Wideband Computers, Inc.
cvrmul_pdp ( a, i, b, j, c, k, n )
NAME Complex Vector Multiply By Real Vector
DESCRIPTION This function multiplies the elements of complex input vector a times the elements of real input vector b. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvrmul_pdp ( a, i, b, j, c, k, n )
complex pm *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float dm *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex pm *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 33 + 4 * (N-1) cycles
NOTES The file tcvrmpdp.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Bmj{ }•=
Im Cmk{ } Im Ami{ } Bmj{ }•=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-173
cvrsub ( a, i, b, j, c, k, n )
NAME Complex Vector Subtract Real Vector
DESCRIPTION This function subtracts the elements of real input vector b from the elements of com-plex input vector a. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvrsub ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 5*(N-1) cycles
NOTES The file tcvrsub.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Bmj–=
Im Cmk{ } Im Ami{ }=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-174 Wideband Computers, Inc.
cvsadd ( a, i, b, c, k, n )
NAME Complex Vector Add Complex Scalar
DESCRIPTION This function adds a complex input scalar b to the elements of complex input vector a. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvsadd ( a, i, b, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input scalar b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 37 + 4*(N-1) cycles
NOTES The file tcvsadd.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Re B{ } +=
Im Cmk{ } Im Ami{ } Im B{ }+=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-175
cvsdiv ( a, i, b, c, k, n )
NAME Complex Vector Divide By Complex Scalar
DESCRIPTION This function divides the elements of complex input vector a by complex input scalar b. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvsdiv ( a, i, b, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input scalar b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, Re{Bmj} and Im{Bmj} must not both equal zero or a divide by zero error will occur.
ACCURACY 7.75 decimal digits
EXECUTION TIME 51 + 6*(N-1) cycles
NOTES The file tcvsdiv.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ }Re Ami{ } Re B{ } Im Ami{ } Im B{ }•+•
Re2
B{ } Im2
B{ }+---------------------------------------------------------------------------------------------------- =
Im Cmk{ }Im Ami{ } Re B{ } Re Ami{ } Im B{ }•–•
Re2
B{ } Im2
B{ }+---------------------------------------------------------------------------------------------------- =
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-176 Wideband Computers, Inc.
cvsma ( a, i, b, c, k, d, l, n )
NAME Complex Vector Multiply By Complex Scalar & Add Complex Vector
DESCRIPTION This function multiplies the elements of complex input vector a by a complex input scalar b time, then the elements of complex input vector c to the product. The result is stored in complex output vector d.
ALGORITHM
SYNOPSIS void cvsma ( a, i, b, c, k, d, l, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input scalar b */
complex *c ; /* Pointer to complex input vector c */
int k ; /* Address stride in words for input vector c */
complex *d ; /* Pointer to complex output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 65 + 6*(N-1) cycles
NOTES The file tcvsma.c included in the distribution diskette provides an example of this function’s use.
An alternative way of expressing the algorithm is as follows:
Re Dml{ } Re Ami{ } Re B{ } I– m Ami{ } Im B{ }••[ ] Re Cmk{ }+=
Im Dml{ } Re Ami{ } Im B{ } Im Ami{ } Re B{ }•+•[ ] Im Cmk{ }+=
m 0 1 2 …n 1–, , ,{ }=
D Ab C+( )=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-177
cvsmul ( a, i, b, c, k, n )
NAME Complex Vector Multiply By Complex Scalar
DESCRIPTION This function multiplies the elements of complex input vector a by a complex input scalar b time. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvsmul ( a, i, b, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input scalar b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 37 + 4*(N-1) cycles
NOTES The file tcvsmul.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } Re B{ } I– m Ami{ } Im B{ }••[ ]=
Im Cmk{ } Re Ami{ } Im B{ } Im Ami{ } Re B{ }•+•[ ]=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-178 Wideband Computers, Inc.
cvsqrt ( a, i, c, k, n )
NAME Complex Vector Square Root
DESCRIPTION This function computes the square root of the elements of complex input vector a and stores the results in complex output vector c.
ALGORITHM
SYNOPSIS void cvsqrt ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 67 + 171 * N cycles
NOTES The file tcvsqrt.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } α θ cos=
Im Cmk{ } α θ where: sin=
α Re2
Ami{ } Im2
Ami{ }+
12---
=
θ
Im Ami{ }
Re Ami{ }-----------------------atan
2---------------------------------------=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-179
cvssub ( a, i, b, c, k, n )
NAME Complex Vector Subtract Complex Scalar
DESCRIPTION This function subtracts a complex input scalar b from the elements of complex input vector a. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvssub ( a, i, b, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input scalar b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 37 + 4*(N-1) cycles
NOTES The file tcvssub.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } R– e B{ }=
Im Cmk{ } Im Ami{ } I– m B{ }=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-180 Wideband Computers, Inc.
cvsub ( a, i, b, j, c, k, n )
NAME Complex Vector Subtract
DESCRIPTION This function subtracts the elements of complex input vector b from the elements of complex input vector a. The result are stored in complex output vector c.
ALGORITHM
SYNOPSIS void cvsub ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
complex *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
complex *c ; /* Pointer to complex output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 52 + 6*(N-1) cycles
NOTES The file tcvsub.c included in the distribution diskette provides an example of this function’s use.
Re Cmk{ } Re Ami{ } R– e Bmj{ }=
Im Cmk{ } Im Ami{ } I– m Bmj{ }=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-181
dct8x8 ( im, dir )
NAME 8 x 8 Two-Dimensional Discrete Cosine Transform
DESCRIPTION This function calculates an 8x8 two dimensional discrete cosine transform (DCT) of the elements in input matrix im[ ] [ ]. The dir direction flag determines if a forward or inverse 2 dimensional discrete cosine transform is performed ( 1 = forward, 0 = inverse). The transform is returned in matrix im[ ] [ ].
ALGORITHM
SYNOPSIS void dct8x8 ( im, dir )
int *im ; /* Pointer to input/output matrix im [ ] [ ] */
int dir ; /* Decision flag ( forward = 1 , inverse = 0 ) */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
imkl2n---akal immn
πk 2m 1+( )2n
---------------------------- πl 2n 1+( )2n
--------------------------coscos
n 0=
N 1–
∑m 0=
N 1–
∑=
k 0 to N-1, l 0 to N-1==
a 0[ ]1
2------- a j[ ], 1 for j 0 n,≠ 8= = =

ADSP-21K Optimized DSP Library User’s Manual
5-182 Wideband Computers, Inc.
EXECUTION TIME 2,464 cycles forward
2,578 cycles inverse
NOTES The file t8x8dct.c included in the distribution diskette provides an example of this function’s use. The forward 8x8 2D-DCT is performed in two summation steps.
For the first summation step, the input matrix im[ ] [ ] is scaled by 2/N. The resulting matrix im[ ] [ ] is multiplied times the cosine matrix cm[ ] [ ] by rows. In otherwords, row 0 of im[ ] [ ] times row 0 of cm[ ] [ ] is row 0, col 0 of the result matrix[ ] [ ], row 0 of im[ ] [ ] times row 1 of cm[ ] [ ] is row 0, col 1 of the result matrix[ ] [ ], etc.
im * cm = Result matrix
| m1 m2 m3 |------->| c1 c2 c3 | | mr0*cr0 mr0*cr1 mr0*cr2 |
| m4 m5 m6 | \----->| c4 c5 c6 | = | mr1*cr0 mr1*cr1 mr1*cr2 |
| m7 m8 m9 | \--->| c7 c8 c9 | | mr2*cr0 mr2*cr1 mr2*cr2 |
where: mr0 = row 0 of im
mr1 = row 1 of im
mr2 = row 2 of im
cr0 = row 0 of cm
cr1 = row 1 of cm
cr2 = row 2 of cm
For the second summation step, the cosine matrix cm[ ] [ ] is multiplied by the result matrix[ ] [ ] using normal matrix multiplication (ie. row times column).
cm[ ][ ] * Result matrix = DCT matrix
| c1 c2 c3 | | mr0*cr0 mr0*cr1 mr0*cr2 |
| c4 c5 c6 | * | mr1*cr0 mr1*cr1 mr1*cr2 | = DCT matrix
| c7 c8 c9 | | mr2*cr0 mr2*cr1 mr2*cr2 |
As a final step, the first row and first column (row 0 and col 0) of the DCT matrix is scaled by the A0 constant ( 1/sqrt(2) ).
The inverse 8x8 2D-DCT is also performed in two summation steps. Before the first step, input matrix im[ ][ ] is scaled by the A0 constant ( 1/sqrt(2) ) for the first row and first column (row0 and col 0). Then the resulting matrix im[ ][ ] is scaled by2/N.
dct8x8( ) is an in-place computation (ie. the original data of matrix im[ ][ ] is destroyed).
dct8x8 ( im, dir )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-183
desamp ( a, b, c, nc, p, d )
NAME Direct Form Decimating Finite Impulse Response (FIR) Filter
DESCRIPTION The function computes a FIR ( Finite Impulse Response) filter using coefficients stored in vector b applied to the elements of input vector a. The results are stored in vector c and computed according to a decimation index d. The number of desired out-put filter samples to generate is specified by the parameter nc, while the size of vector b (taps) is specified by p.
ALGORITHM
SYNOPSIS void desamp ( a, b, c, nc, p, d )
float *a ; /* Pointer to input vector a */
float *b ; /* Pointer to coefficients vector b */
float *c ; /* Pointer to output vector c */
int nc ; /* Number of samples to generate */
int p ; /* Number of coefficients (taps)in vector b */
int d ; /* Decimation index */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Cm Am d• j+ Bp j– 1– m 0 1 2 … nc, 1–, , ,{ }=•j 0=
p 1–
∑=

ADSP-21K Optimized DSP Library User’s Manual
5-184 Wideband Computers, Inc.
EXECUTION TIME 25 + ( 7 + P-1 ) * NC cycles
NOTES The file tdesamp.c included in the distribution tape provides an example of this func-tion’s use.
The argument nc is the number of filter output samples to generate. It is obtained as follows:
where na is the number of elements in a.
The number of a samples consumed is
This function differs from the fir_wci( ) function in that it performs a direct convolu-tion of the input data. Since there is no delay memory, the convolution value for the first sample uses the first nc number of points (number of taps) of the input data.
desamp ( a, b, c, nc, p, d )
nc na p–( ) d⁄=
nc d•

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-185
desampd ( a, b, p, m, c, n, nc, d, fill )
NAME Compute Finite Impulse Response (FIR) Filter of Two Vectors with Decimation and Delay Memory
DESCRIPTION This function computes a FIR ( Finite Impulse Response) filter with decimation using input samples in vector a[ ] and coefficients in vector b[ ]. The results are returned in output vector pointed to by the double pointer c.
The double pointers m and c and the pointer to fill are defined such that they are updated by desampd( ). This allows processing of a continious sample stream across multiple function calls.
The address pointed to by m contains the current position within the delay line p. The address pointed to by c contains the current position within the output vector. The pointer fill contains the contents of the fill value.
ALGORITHM
For Example, Set the Decimation Factor d = 3, and fill = 1
First Set Second Set
a[ ] = 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0
p [ ] = 0 0 0 0 1b [ ] = 5 4 3 2 1=1
0 1 2 3 45 4 3 2 1=2
3 4 5 6 75 4 3 2 1=65
6 7 8 9 05 4 3 2 1=100
9 0 1 2 35 4 3 2 1=55
2 3 4 5 65 4 3 2 1=50
5 6 7 8 95 4 3 2 1=95

ADSP-21K Optimized DSP Library User’s Manual
5-186 Wideband Computers, Inc.
SYNOPSIS void desampd ( a, b, p, m, c, n, nc, d, fill )
float dm *a ; /* Pointer to input sample vector a (length n) */
float dm *b ; /* Pointer to input coefficient vector b
(length nc) */
float pm *p ; /* Base address of delay line vector (length nc)*/
float dm **m ; /* Current Pointer in delay */
float dm **c ; /* Current Pointer in output vector c */
int n ; /* Count of floating-point elements in a [ ] */
int nc ; /* Count of floating-point elements in b [ ] */
int d ; /* Decimation factor */
int *fill ; /* Pointer to fill value for delay line */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 86 + fill + ( 6 + nc + d ) * w cycles
where: w = ( int ) ( ( n - fill ) / d ) + 1 Note: fill can vary call to call
NOTES The file tdesamp.c included in the distribution tape provides an example of this func-tion’s use.
Reverse the order of the coefficients (taps) to compute the convolution. Example- Compute the convolution for:
data = { x1, x2, x3, x4, ....} taps = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
To compute the convolution order the taps as follows:
taps = { 10, 9, 8, 7, 6, 5, 4, 3, 2, 1 } and call the desampd( ) function.
Pipelining of the sample loop requires that there be at least two data samples (n>=2) when calling this function.
The decimation algorithm requires that the number of samples is greater than the deci-mation factor and that the decimation factor is greater than or equal to two.
desampd ( a, b, p, m, c, n, nc, d, fill )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-187
doppler ( a, i, c, k, n )
NAME Generate Doppler Signal
DESCRIPTION The function generates a doppler signal using the input data signal contained within input real vector a and places the doppler signal in output real vector c.
ALGORITHM
SYNOPSIS void doppler ( a, i, c, k, n )
float dm *a ; /* Pointer to real input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 56 + 50 * N cycles
NOTES The file tdoppler.c included in the distribution tape provides an example of this func-tion’s use.
Cmk Ami 1 Ami–( )2π
Ami 0.05+--------------------------
sin•=
0 Ami 1≤ ≤
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-188 Wideband Computers, Inc.
dotpr ( a, i, b, j, c, n )
NAME Dot Product
DESCRIPTION This function computes the dot product of vector a and vector b. The scalar result is stored in c.
ALGORITHM
SYNOPSIS void dotpr ( a, i, b, j, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + 2*(N-1) cycles
NOTES The file tdotpr.c included in the distribution diskette provides an example of this func-tion’s use.
C Ami Bmj•
m 0=
n 1–
∑=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-189
dotpr_dp ( a, i, b, j, c, n )
NAME Dot Product
DESCRIPTION This function computes the dot product of vector a and vector b. The scalar result is stored in c.
ALGORITHM
SYNOPSIS void dotpr_dp ( a, i, b, j, c, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float pm *b ; /* Pointer to complex input vector b */
int j ; /* Address stride in words for input vector b */
float dm *c ; /* Pointer to output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + N cycles
NOTES The file tdotprdp.c included in the distribution diskette provides an example of this function’s use.
C Ami Bmj•
m 0=
n 1–
∑=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-190 Wideband Computers, Inc.
endian ( a, i, c, k, n )
NAME Endian Order
DESCRIPTION This function computes reverses the byte order for input vector a and places the result in output vector c.
ALGORITHM
SYNOPSIS void endian ( a, i, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 + 6*(N-1) cycles
NOTES The file tendian.c included in the distribution diskette provides an example of this function’s use.
The endian ( ) function reverses the byte order for input vector a [ ] and places the result in output vector c [ ].
For example:
int a [3] = { 0x04030201, 0x08070605, 0x12111009 } ;
endian ( a, 1, c, 1, 3 ) ;
int c [3] = { 0x01020304, 0x05060708, 0x09101112 } ;
Ck Ai in reverse byte order=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-191
exp_wci ( x )
NAME Exponential Base e
DESCRIPTION This function computes the exponential of floating-point number, x
ALGORITHM
SYNOPSIS float exp_wci ( float x )
DOMAIN -88.0 to 88.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 cycles
NOTES The file texp.c included in the distribution tape provides an example of this function's use.
exp10_wci ( x )
NAME Exponential Base 10
DESCRIPTION This function computes the exponential base 10 of floating-point number, x.
ALGORITHM
SYNOPSIS float exp10_wci ( float x )
DOMAIN -38 to +38
ACCURACY 7.75 decimal digits
EXECUTION TIME 46 cycles
NOTES The file texp10.c included in the distribution tape provides an example of this func-tion's use.
return ex=
return 10x=

ADSP-21K Optimized DSP Library User’s Manual
5-192 Wideband Computers, Inc.
fabs_wci ( x )
NAME Absolute Value
DESCRIPTION This function computes the absolute values of a floating-point number, x. The com-puted value is returned from this function.
ALGORITHM
SYNOPSIS float fabs_wci ( float x )
DOMAIN -3.40E38 to 3.40E38
ACCURACY 7.75 decimal digits
EXECUTION TIME 4 cycles
NOTES The file tfabs.c included in the distribution tape provides an example of this function's use.
return x=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-193
fact ( a )
NAME Factorial
DESCRIPTION This function computes the factorial based on the element contained within input sca-lar a.
ALGORITHM
SYNOPSIS float fact ( a )
int *a ; /* Input value */
DOMAIN 0 to 34
ACCURACY 7.75 decimal digits
EXECUTION TIME 13 cycles
NOTES The file tfact.c included in the distribution diskette provides an example of this func-tion’s use.
The factorial is computed as follows:
c = 1 * 2 * 3 * 4 * 5 * ... a
Input scalar a must be >= 0. If not, a value of -99 is returned.
return a!=

ADSP-21K Optimized DSP Library User’s Manual
5-194 Wideband Computers, Inc.
fct ( x, y, wr, wi, tmpdm, tmppm, n )
NAME Fast Cosine Transform
DESCRIPTION Computes the Fast CosineTransform of complex input vectors x and y. The imaginary and real weights array are stored in complex output vectors wr and wi. Tempory stor-age space used to compute the Fast CosineTransform are designated by tmpdm for temporary data memory and tmppm for temporary program memory.
ALGORITHM
SYNOPSIS void fct ( x, y, wr, wi, tmpdm, tmppm, n )
float *x ; /* Pointer to real input vector x */
float *y ; /* Pointer to real output vector y */
float *wr ; /* Pointer to real (cosine) weights array wr */
float *wi ; /* Pointer to imaginary (sin) weights array wi */
float *tmpdm ; /* Pointer to temporary dm storage space */
float *tmppm ; /* Pointer to temporary pm storage space */
int n ; /* Element count for floating point input */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Fπ k i 1 2⁄+( )••
2----------------------------------------cos
k i, 0=
n 1–
∑=
m 0 1 2 … n 1–,, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-195
EXECUTION TIME 16,465 cycles ( 128 Pts ) - Currently C Code Only
NOTES The file tfct.c included in the distribution tape provides an example of this function’s use.
Vectors wr and wi are in program memory and data memory respectively and aregiven the values:
Note that these are identical to the cosine/sin vectors used for a Complex Fast Fourier Transform (cfft( )) of size 4*n.
Vector x has a minimum size of n
Vectors tmppm and tmpdm are in program and data memory respectively and have mimimum sizes of .
n must be an integer power of 2 and greater than 32 points.
fct ( x, y, wr, wi, tmpdm, tmppm, n )
wr k[ ] 2πk wst*n⁄[ ] k 0 1 … wstn 2 1–⁄, , ,( )program memory=cos=
wi k[ ] 2πk wst*n⁄[ ]sin k 0 1 … wstn 2 1–⁄, , ,( )data memory==
n 2⁄

ADSP-21K Optimized DSP Library User’s Manual
5-196 Wideband Computers, Inc.
fftwts ( wr, wi, n )
NAME FFT Weights Array
DESCRIPTION The fftwts( ) function computers the weights (or twiddles) array for an FFT Computa-tion. Only a single weights array for the maximum length FFT is required. Typically a weights array is computed for half the FFT size.
ALGORITHM
SYNOPSIS void fftwts ( wr, wi, n )
float pm *wr ; /* Pointer to output real weight table */
float dm *wi ; /* Pointer to output imaginary weight table */
int n ; /* Number of weights to generate */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 37 + 45 * ( N-1 ) cycles
NOTES The file tfftwts.c included in the distribution tape provides an example of this func-tion’s use.
Note that a new function called winwts( ) was introduced to correct a discrepancy with the hamm( ) window function, whose weights were originally calculated using the formula . This was incorrect as this required the FFT function to allo-cate twice the amount of memory to contain the weights. To correct the problem, a new function was introduced called the winwts( ) which uses the formula
to perform the weights calculation while the fftwts( ) function was mod-ified to use the formula for the fft weights calculation.
wrm πmn---- m 0 1 2 … n, 1–, , ,{ }=cos=
wim πmn---- m 0 1 2 … n, 1–, , ,{ }=sin=
2 π m•• n⁄
2 π m•• n⁄π m• n⁄

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-197
fht ( x, wr, wi, tmpdm, n )
NAME Fast Hartley Transform
DESCRIPTION Computes the Fast Hartley Transform of complex input/output vector x. The real and imaginary weights array are stored in wr and wi. Temporary storage space used to compute the fast cosine transform is designated by tmpdm for temporary dm memory.
ALGORITHM
SYNOPSIS void fht ( x, wr, wi, tmpdm, n )
float *x ; /* Pointer to real input/output vector x */
float *wr ; /* Pointer to real cosine weights array wr */
float *wi ; /* Pointer to imaginary weights array wi */
float *tmpdm ; /* Pointer to temporary dm storage space */
int n ; /* Element count for floating point input */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
H k( ) He k( ) Ho k( ) 2πk N⁄( ) Ho N 2⁄( ) k–( ) 2πk N⁄( )sin+cos[ ]+=
H k N 2⁄+( ) He k( ) Ho k( ) 2πk N⁄( ) Ho N 2⁄( ) k–( ) 2πk N⁄( )sin+cos[ ]–=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-198 Wideband Computers, Inc.
EXECUTION TIME 82,173 cycles ( 128 Pts ) - ( Currently Only C Code Version Available )
NOTES The file tfht.c included in the distribution tape provides an example of this function’suse.
This implementation is a recursive algorithm that does not employ explicit bit-reversed addressing. Therefore, no address alignment restrictions are imposed.
Vectors wr and wi are in program memory and data memory respectively and aregiven the values:
Note that these are twice the length of the cosine/sin vectors used for a Complex FastFourier Transform of the same size.
Vector tmpdm, which is in data memory, and has a mimimum sizes of .
n must be an integer power of 2.
fht ( x, wr, wi, tmpdm, n )
wr k[ ] 2πk n⁄[ ] k 0 1 … n 1–, , ,( )program memory=cos=
wr k[ ] 2πk n⁄[ ]sin k 0 1 … n 1–, , ,( ) data memory==
4 n•

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-199
fir_wci ( x, h, y, b, d, n, p )
NAME Direct Form FIR Filter
DESCRIPTION Computes a FIR ( Finite Impulse Response Filter) using the coefficients stored in vec-tor h applied to the elements of vector x. The results are stored in vector y.
ALGORITHM
SYNOPSIS void fir_wci ( x, h, y, b, d, n, p )
float *x ; /* Pointer to input samples x */
float pm *h ; /* Pointer to coefficient in vector h */
float *y ; /* Pointer to output vector y */
float *b ; /* Pointer to start of delay memory */
float **d ; /* Double Pointer to delay memory d */
int n ; /* Number of input samples n */
int p ; /* Number of coefficients p */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Yk Hp 1 i–– Xk i– k 0 1 2 … n 1–,, , ,{ }=•
i 0=
p 1–
∑=

ADSP-21K Optimized DSP Library User’s Manual
5-200 Wideband Computers, Inc.
EXECUTION TIME 50 + P + (N-1) * (4+P) cycles
NOTES The file tfir.c included in the distribution tape provides an example of this function’s use.
Negative indices of x in the above equation are handled using a delay memory buffer d. ‘d’ represents the initial filter state, and should be set to zero prior to the first calling of fir_wci( ). On subsequent calls d is updated by fir_wci( ), allowing processing of a continuous input sample stream across multiple function calls.
This routine uses pipelined coding techniques to execute in an optimal manner. There-fore, the number of data points (n) supplied to the routine must also be greater than or equal to 2.
float *x, the pointer to input samples x, is of size n
float pm *h, the pointer to coefficient in vector h, is of size p
float *y, the pointer to output vector y, is of size n
Reverse the order of the coefficients (taps) to compute the convolution. Example- To compute the convolution for:
data = { x1, x2, x3, x4, ....} taps = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
To compute the convolution order the taps as follows:
taps = { 10, 9, 8, 7, 6, 5, 4, 3, 2, 1 } and call the fir_wci function.
fir_wci ( x, h, y, b, d, n, p )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-201
fir5 ( x, h, y, d, n )
NAME 5-Tap Finite Impulse Response (FIR) Filter
DESCRIPTION Computes a 5-Tap FIR ( Finite Impulse Response Filter) using the coefficients stored in vector h applied to the elements of vector x. The results are stored in vector y.
ALGORITHM
SYNOPSIS void fir5 ( x, h, y, d, n )
float *x ; /* Pointer to input samples x */
float pm *h ; /* Pointer to coefficient in vector h */
float *y ; /* Pointer to output vector y */
float **d ; /* Double Pointer to delay memory d */
int n ; /* Number of input samples n */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Yk H4 i– Xk i– k 0 1 2 … n 1–,, , ,{ }=•
i 0=
4
∑=

ADSP-21K Optimized DSP Library User’s Manual
5-202 Wideband Computers, Inc.
EXECUTION TIME 55 + (N-1)*7 cycles
NOTES The file tfir5.c included in the distribution tape provides an example of this function’s use.
Negative indices of x in the above equation are handled using a delay memory buffer d. ‘d’ represents the initial filter state, and should be set to zero prior to the first calling of fir5( ). On subsequent calls d is updated by fir5( ), allowing processing of a contin-uous input sample stream across multiple function calls.
Reverse the order of the coefficients (taps) to compute the convolution. Example - Compute the convolution for:
data = { x1, x2, x3, x4, ....} taps = { 1, 2, 3, 4, 5 }
To compute the convolution order the taps as follows:
taps = { 5, 4, 3, 2, 1 } and call the fir5 function.
fir5 ( x, h, y, d, n )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-203
firlms ( x, h, y, d, n, p, b )
NAME Adaptive FIR Filter
DESCRIPTION Computes an adaptive FIR (Finite Impulse Response) filter using coefficients stored in vector h applied to the elements of vector x. The results are stored in vector y.
ALGORITHM
SYNOPSIS Void firlms ( x, h, y, d, n, p, b)
float *x; /* Pointer to input samples vector xof length n */
float *h ; /* Pointer to coefficients vector h of length p */
float *y ; /* Pointer to output sampoles vector y of length n/p */
float *d ; /* Pointer to delay memory of length p */
int n ; /* Number of input samples */
int p ; /* Number of coefficients */
float b ; /* Adaption coefficient */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME TBS cycles
NOTES The file tfirlms.c included in the distribution tape provides an example of this func-tion’s use.
Negative indicies of x in the above equation are handled using a delay memory buffer d. d represents the initial filter state, and should be set to zero prior to firlms calling firlms( ). On subsequent calls d is updated by firlms( ), allowing processing of contin-ious input sample stream across multiple function calls.
The number of input samples n must be greater than or equal to the number of coeffi-cients p.
yk hk i, xk i– k 0 1 2 … n 1–,, , ,{ }=
i 0=
p 1–
∑=
hk h b+ k 1– xk 1–=

ADSP-21K Optimized DSP Library User’s Manual
5-204 Wideband Computers, Inc.
floor_wci ( x )
NAME Round Down to Nearest Integer
DESCRIPTION This function computes the largest integral value less than or equal to the floating-point number x. A floating-point representation of this integral value is returned.
ALGORITHM
SYNOPSIS float floor_wci ( float x )
DOMAIN -3.4E+38 to 3.40E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 cycles
NOTES The file tfloor.c included in the distribution tape provides an example of this function's use.
fmod_wci ( x, y )
NAME Floating-Point Remainder
DESCRIPTION This function computes the floating-point remainder of x/y. The computed value is returned from this function.
ALGORITHM
SYNOPSIS float fmod_wci ( float x, float y )
DOMAIN -2.14E9 to 2.14E9
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 cycles
NOTES The file tfmod.c included in the distribution tape provides an example of this func-tion's use.
return largest int x≤=
return xy--- fix x
y---– sign x( )•=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-205
frexp_wci ( x, n )
NAME Get Mantissa and Exponent
DESCRIPTION This function computes the fractional portion and the exponent of a floating-point number, x. The fractional value is returned from this function and the integer value is stored at the pointer, n.
ALGORITHM ,
SYNOPSIS float frexp_wci ( float x, int *n )
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 14 cycles
NOTES The file tfrexp.c included in the distribution tape provides an example of this func-tion's use.
x f 2N• return f=,= n N=

ADSP-21K Optimized DSP Library User’s Manual
5-206 Wideband Computers, Inc.
hamm ( a, i, c, k, w, h, n )
NAME Hamming Window Multiply
DESCRIPTION Computes a Hamming window on the values held in real input vector a using the cosine weights array values held in real input vector w. The results are stored in real output vector c.
ALGORITHM
SYNOPSIS void hamm ( a, i, c, k, w, h, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
float pm *w ; /* Pointer to cosine weights array */
int h ; /* Element stride for weights array */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Cmk Ami 0.54 0.46Arg
n---------
cos•– •=
Arg 2 π i••=
i 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-207
EXECUTION TIME 35 + 3*N
NOTES The file thamm.c included in the distribution tape provides an example of this func-tion’s use.
The Hamming Window is computed using the winwts( ) function. The winwts( ) func-tion computes the weights array using the cosine function. This array is pointed to byvector w listed in the synopsis section shown above.
The input vector w contains the pre-computed cosine value cos ( Arg / n ) which maybe computed from the winwts( ) function.
hamm( ) is a vector function. You may therefore use the stride arguments i, k and h todecimate both input and output for data congruence. For instance, suppose you use thewinwts( ) function to compute the FFT weights for a 16K point FFT. This would resultin an array whose length would be 16,384 points. If you were to later decide to com-pute an FFT of length 1,024 and run a Hamming Window on the results, you would notneed to rerun the winwts( ) function to generate new weights. Simply use the oldweights previously calculated and then stride by 16 (16,384/1024 = 16) on stride ele-ment h to obtain the correct window FFT weights. In this manner you may computewinwts( ) once, and later us them for varying length FFTs and windowing functions.
The Hamming window has a passband ripple of 0.0194 dB, a maximum stopbandattenuation of 53 dB, and a 41 dB main lobe relative to side lobe.
hamm ( a, i, c, k, w, h, n )

ADSP-21K Optimized DSP Library User’s Manual
5-208 Wideband Computers, Inc.
hann ( a, i, c, k, n, f, w, h )
NAME Hanning Window Multiply
DESCRIPTION Computes a Hanning window on the values held in real input vector a using the cosine weights array values held in real input vector w. The results are stored in real output vector c.
ALGORITHM
SYNOPSIS void hann ( a, i, c, k, n, f, w, h )
float dm *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float dm *c ; /* Pointer to resultant output vector c */
int k ; /* Element stride for output vector c */
int n ; /* Element count for ooutput vector c */
int f ; /* Normalization flag */
float pm *w ; /* Pointer to weights array */
int h ; /* Element stride for weights array */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Cm Ami α• 1Arg
n---------
cos–• =
if F 0 then α 0.5 (Un-normalized)==
Arg 2 π i••=
i 0 1 2 … n, 1–, , ,{ }=
if F 1 then α 0.8165 (Normalized)==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-209
EXECUTION TIME 36 + 2*N
NOTES The file thann.c included in the distribution tape provides an example of this func-tion’s use.
This routine utilizes a normalization flag specified by the variable F. If the flag is setto 0, the routine internally loads 0.5 to F and therefore becomes non-normalized. If theflag is set to 1, the routine internally loads 0.8165 to F and is thereforenormalized.
The Hanning Window is computed using the winwts( ) function. The winwts( ) func-tion computes the weights array using the cosine function. This array is pointed to byvector w listed in the synopsis section shown above.
The input vector w contains the pre-computed cosine value cos ( Arg / n ) which maybe computed from the winwts( ) function.
hann( ) is a vector function. You may therefore use the stride arguments i, k and h todecimate both input and output for data congruence. For instance, suppose you use thewinwts( ) function to compute the FFT weights for a 16K point FFT. This would resultin an array whose length would be 16,384 points. If you were to later decide to com-pute an FFT of length 1,024 and run a Hanning Window on the results, you would notneed to rerun the winwts( ) function to generate new weights. Simply use the oldweights previously calculated and then stride by 16 (16,384/1024 = 16) on stride ele-ment h to obtain the correct window FFT weights. In this manner you may computewinwts( ) once, and later us them for varying length FFTs and windowing functions.
The Hanning window has a passband ripple of 0.0546 dB, a maximum stopband atten-uation of 44 dB, and a 31 dB main lobe relative to side lobe.
hann ( a, i, c, k, n, f, w, h )
2 3⁄( )

ADSP-21K Optimized DSP Library User’s Manual
5-210 Wideband Computers, Inc.
inl ( dataloc, fltmax, inlloc, min, max, n )
NAME Integral Non-linearity
DESCRIPTION The inl( ) function calculates the integral non-linearity based on the values supplied in input vector dataloc, input scalar fltmax, and the number of points supplied in input scalar n. The results are placed in output scalar min and max, while the results of the integral non-linearity calculation are output to vector inlloc.
ALGORITHM
pts = ( int ) ( n + 0.5 ) ;
devicelsb = ( dataloc[pts-1] - dataloc [0] ) / (pts - 1) ;
min = fltmax ;max = - fltmax ;
for ( i = 0; i < pts ; i++ ){ inlloc[i] = ( dataloc[i] - ( devicelsb * i + dataloc ) ) / devicelsb ; min = ( min < inlloc[i] ) ? min : inlloc[i] ; max = ( max > inlloc[i] ) ? max : inlloc[i] ;}
SYNOPSIS void inl ( dataloc, fltmax, inlloc, min, max, n )
float dm *dataloc ; /* Pointer to real input vector a */
float dm fltmax ; /* Maximum Boundaries a */
float dm *inlloc ; /* Pointer to output vector inlloc */
float dm *min ; /* Output scalar minimum */
float dm *max ; /* Output scalar maximum */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 48 + 5 * (INT) (N+0.5) cycles
NOTES The file tinl.c included in the distribution tape provides an example of this function’s use. The integral non-lineariry function is often used by designers of automated test equipment (ATE) to test the performance of A/D semiconductor devices.

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-211
iqunpk ( srcptr, dstptri, dstptrq, m, n, trans, isize, justify )
NAME Unpack an IQ Integer Packed Matrix
DESCRIPTION This function unpacks integer packed matrix srcptr[ ] [ ] into its I and Q component matricies. The routine unpacks an arbitrary number of data bits (up to 16 bits maxi-mum), and masks the remaining bits, thus allowing the use of upto a 16-bit A/D. The integer packed format is described below.
The I component is stored in output matrix dstptri[ ] [ ], while the Q component is stored in output matrix dstptrq[ ] [ ]. The number of rows in input matrix srcptr[ ] [ ] is defined by input scalar m, while the number of columns in input matrix srcptr[ ] [ ] is defined by input scalar n. Additionally, a transpose flag argument trans determines the strorage method, where trans = 0 is normal while trans = 1 is transposed.
ALGORITHM
SYNOPSIS Void iqunpk ( srcptr, dstptri, dstptrq, m, n, trans, isize,
justify )
int *srcptr ; /* Pointer to input matrix srcptr [ ] [ ] */
float *dstptri ; /* Pointer to output matrix dstptri [ ] */
float *dstptrq ; /* Pointer to output matrix dstptrq [ ] */
int m ; /* Number of rows in matrix srcptr [ ] [ ] */
int n ; /* Number of columns in matrix srcptr [ ] [ ] */
int trans ; /* Transpose Flag ( 0 = normal, 1 = transpose)*/
int isize ; /* Size of Integer to Unpack ( 16 bits max ) */
int justify ; /* Justify Flag ( 0 = left, 1 = right ) */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Source Matrix Destination Matrix I, Destination Matrix Q⇒

ADSP-21K Optimized DSP Library User’s Manual
5-212 Wideband Computers, Inc.
EXECUTION TIME 49 + ( 3 + 6*N )*M cycles
NOTES The file tiqunpk.c included in the distribution tape provides an example of this func-tion’s use.
This function unpacks integer packed matrix srcptr[ ] [ ] into its I and Q component matricies. The integer packed format is described below:
X Bits I A/D 16-X Bits X Bits Q A/D 16-X Bits
31 0
Or
16-X Bits X Bits I A/D 16-X Bits X Bits Q A/D
31 0
where: X is the size if the integer to unpack (isize) and justify determines whether the data is left or right justified.
For example, for isize = 12 and justify = 0, the input data is expected to look like:
12 Bits I A/D 4 Bits 12 Bits Q A/D 4 Bits
31 20 19 16 15 4 3 0
Bits 0-3 and bits 16-19 are assumed to be zero.
The integer element is read and masked for both the I and Q data. Each data is then separated and converted to a floating-point format. The data is then stored in their respective destination matrices (dstptri and dstptrq).
Additionally, the transpose flag (trans) determines the storage method. If trans is set to zero, the element is stored in its respective position (ie, the destination matrix is the same as the source matrix, m by n). If trans is 1, the element is stored in its transposed position (the destination matrix is a transpose of the source matrix n by m). The justify falg determines the justification of the data. If justify is 0, the elements are left justi-fied. If justify is 1, the elements are right justified.
iqunpk ( srcptr, dstptri, dstptrq, m, n, trans, isize, justify )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-213
kaiser ( a, i, c, alpha, n )
NAME Kaiser-Bessel Window Multiply
DESCRIPTION Computes a Kaiser-Bessel window on the values held in real input vector a . The results are stored in real output vector c.
ALGORITHM
SYNOPSIS void kaiser ( a, i, c, alpha, n)
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *c ; /* Pointer to resultant output vector c */
float alpha ; /* Kaiser window shape parameter */
int n ; /* Element count for output vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Ci Ai
I0 α i 2M i–( )( )
M-----------------------------------------
I0 α( )----------------------------------------------• =
i 0 1 2 … n, 1–, , ,{ }=
where
I0 x( )
x2---
k
k!----------
2
k 0=
∞
∑=
α scalar derived from alpha() function=

ADSP-21K Optimized DSP Library User’s Manual
5-214 Wideband Computers, Inc.
EXECUTION TIME 68 + 18*B + (41+18*B) * (N-1)
NOTES The file tkaiser.c included in the distribution tape provides an example of this func-tion’s use.
Note that B described in the execution time shown above is the number of iternationsneeded to complete the 0th order Bessel function and is indeterminate.
is a modified Bessel function of the 1st kind and oth order give by theform
and M, the midpoint is defined as
Alpha is the Kaiser window shape parameter as described by the library func-tion alpha( ).
The Kaiser-Bessel is often used in situations where great control is desired over the shape of the filter. In many situtations, use of the Hamming or Hanning windows result in implementations where the stopband and passband are considered unobtain-able due to the ripple factor .This shape value is adjustable and allows the window to obtain any desired ripple value or attenutation value. It has a stopband attenuation of
, and a passband of .
kaiser ( a, i, c, alpha, n )
I0
I0
x2---
2
k!----------
k 0=
∞
∑=
M N 1–( )2
-----------------=
α( )
δ
20 δ10log– 17.372δ

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-215
ldexp_wci ( x, n )
NAME Multiply by Power of 2
DESCRIPTION This function computes x multiplied by 2N. A range error may occur when x times is greater then 3.40E+38.
ALGORITHM
SYNOPSIS float ldexp_wci ( float x, int n )
DOMAIN -3.4E+38 to 3.40E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 4 cycles
NOTES The file tldexp.c included in the distribution tape provides an example of this func-tion's use.
2n
return x 2n•=

ADSP-21K Optimized DSP Library User’s Manual
5-216 Wideband Computers, Inc.
linint ( xr, yr, xp, yp, slope, sflag, m, n )
NAME Linear Interpolation
DESCRIPTION This function calculates the linear interpolation using a reference grid formed by vec-tors xr [ ] and yr [ ]. The slope is computed from these vectors and placed in vector slope [ ]. A linear interpolation is computed for vector yp[ ] using the vectors slope [ ], xr [ ], yr [ ] and xp [ ]. This is illustrated below for a single xp point.
yp yr
yr2
yp1
yr1 xr
xr1 xr2
xp
xp1
ALGORITHM
See Pseudo Algorithm in Notes Section Below For A Better Description
SYNOPSIS void linint ( xr, yr, xp, yp, slope, sflag, m, n, )
float dm *xr ; /* Pointer to input vector xr [ ] */
float pm *yr ; /* Pointer to input vector yr [ ] */
float pm *xp ; /* Pointer to input vector xp [ ] */
float dm *yp ; /* Pointer to output vector yp [ ] */
float dm *slope ; /* Pointer to temp vector slope [ ] */
int sflag ; /* Slope Flag ( 1 = do slope, 0 = skip slope )*/
int n ; /* Number of elements in xr [ ] and yr [ ] */
int m ; /* Number of output elments in yp [ ] */
DOMAIN -3.4E+38 to 3.4E+38
slope xr2 xr1–yr2 yr1–-----------------------=
yp1 yr1 slope xp1 xr1–( )•+=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-217
ACCURACY 7.75 decimal digits
EXECUTION TIME for sflag = 1, 57 + 14 * ( n -1 ) + (14 + w) * m where w = 5 for xp [i] < xr [0] = 7 for xp [i] > = xr[n-1] = indeterminant, but < 4 *n
for sflag = 0, 57 + ( 14 + w) * m where w = 5 for xp [i] < xr [0] = 7 for xp [i] > = xr[n-1] = indeterminant, but < 4 *n
NOTES The file tlinint.c included in the distribution tape provides an example of this func-tion’s use.
The sflag determines if the slope needs to be computed. If sflag is 1 the slope is com-puted. If sflag is 0 the slope in not computed and the current values in slope [ ] are used. This provides for an initial call that computes slope [ ]. Subsequent calls skip slope [ ] computations saving overhead.
Values for vector xr [ ] are assumed to be in ascending order. The number of elements computed for slope [ ] is 1 less than the number of reference points in xr [ ] and yr [ ] (n - 1).
If xp1 should be bound beyond the bounds between xr[0] and xr[n-1] (the lowest and highest points respectively), then yp1 will be set to either yr[0] or yr[n-1].
if ( xp[i] < xr[0] ) yp[i] = yr [0]else if ( xp[i] >= xr[n-1] ) yp[i] = yr[n-1]else compute linear interpolation . .end if
linint ( xr, yr, xp, yp, slope, sflag, m, n )

ADSP-21K Optimized DSP Library User’s Manual
5-218 Wideband Computers, Inc.
linmag ( yr, i, yi, j, linmag, k, n )
NAME Vector Linear Magnitude
DESCRIPTION This function computes the linear magnitude from input complex vectors yr and yi. The results are stored to output vector linmag.
ALGORITHM
SYNOPSIS void linmag ( yr, i, yi, j, linmag, k, n )
float dm *yr ; /* Pointer to input vector yr (real) */
int i ; /* Element stride for input vector yr */
float pm *yi ; /* Pointer to input vector yi (imaginary) */
int j ; /* Element stride for input vector yi */
int dm *linmag ; /* Pointer to output vector linmag */
int k ; /* Element stride for output vector linmag */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 49 + 19*(N-1)
NOTES The file tlinmag.c included in the distribution tape provides an example of this func-tion’s use.
Note that vector yi is in pm memory. This function is tailored to use the output prod-ucts from the cfft () function call.
linmag m[ ]k yri m[ ]2 yij m[ ]2
+[ ]
12---
=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-219
log_wci ( x )
NAME Natural Logarithm
DESCRIPTION This function computes the natural logarithm of a floating-point number x. A domain error occurs if the argument is negative. A range error occurs if the argument is zero.
ALGORITHM
SYNOPSIS float log_wci ( float x )
DOMAIN 0.0 to 3.4 E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 43 cycles
NOTES The file tlog.c included in the distribution tape provides an example of this function's use.
log10_wci ( x )
NAME Base 10 Logarithm
DESCRIPTION This function computes the base 10 logarithm of a floating-point number x. A domain error occurs if the argument is negative. A range error occurs if the argument is zero.
ALGORITHM
SYNOPSIS float log10_wci ( float x )
DOMAIN 0.0 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 42 cycles
NOTES The file tlog10.c included in the distribution tape provides an example of this func-tion's use.
return loge x( )=
return log10 x( )=

ADSP-21K Optimized DSP Library User’s Manual
5-220 Wideband Computers, Inc.
logmag ( yr, i, yi, j, logmag, k, n )
NAME Vector Log Based Magnitude
DESCRIPTION This function computes the log based magnitude from input complex vectors yr and yi. The results are stored to output vector logmag.
ALGORITHM
SYNOPSIS void logmag ( yr, i, yi, j, logmag, k, n )
float dm *yr ; /* Pointer to input vector yr (real) */
int i ; /* Element stride for input vector yr */
float pm *yi ; /* Pointer to input vector yi (imaginary) */
int j ; /* Element stride for input vector yi */
int dm *logmag ; /* Pointer to output vector logmag */
int k ; /* Element stride for output vector logmag */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 63 + 35*N
NOTES The file tlogmag.c included in the distribution tape provides an example of this func-tion’s use.
If the sum of the squares of input vectors yr[ ] and yi [ ] is 0.0, then the input value used is .
mlog ag m[ ]k 10 yri m[ ]2 yij m[ ]2
+[ ]log=
m 0 1 2 … n, 1–, , ,{ }=
3.4 38–×10

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-221
lsqreg ( a, b, &c, &d, n )
NAME Least-Squares Regression Fit
DESCRIPTION This routine calculates the linear least-squares regression fit of the elements within input vector a (the dependent x-coordinate values) with the corresponding elements within input vector b (the independent y-coordinate values), and places the resulting output slope in scalar c and the resulting output y-intecept in scalar d.
ALGORITHM
SYNOPSIS void lsqreg ( a, b, &c, &d, n)
float *a ; /* Pointer to x-coordinate input vector x */
float *b ; /* Pointer to y-coordinate input vector y */
float *c ; /* Pointer to resultant output slope c */
float *d ; /* Pointer to resultant output y-intercept */
int n ; /* Element Count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
C slope
n AmBm Xm Ym
i 0=
n 1–
∑i 0=
n 1–
∑–
i 0=
n 1–
∑
n Am2
Am
i 0=
n 1–
∑
2
–
i 0=
n 1–
∑
-------------------------------------------------------------------------==
D y-intercept= y C x•( )–=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-222 Wideband Computers, Inc.
EXECUTION TIME 99 + 5 * ( N - 1 )
NOTES The file tlsqreg.c included in the distribution tape provides an example of this func-tion’s use.
This routine calculates a linear regression line (a best-fit of the data) using the inputvariables contained within input vector a[ ] and input vector b[ ].
This routine does not support striding as statistically, the answers presented in outputscalars c and d will hold more significance as more data points are passed through thealgorithm. We wanted to discourage results which may not be statistically sound.
Recall from elementary algebra the traditional y-intecept, slope linear equation for-mula: where is the slope of the line and is the y-intercept. This formulacan be re-written as where is now the y-intercept and is now the slope.We can now derive the y-intercept (which we implement in this routine) using the cal-culated slope and the arithmetic mean of the y values ( input vector b[ ] values ) bysimply solving for as follows: where and are the arithmetic mean of they and x ( input vectors y[ ] and x[ ] ) input values respectively.
Note that this implementation is computationally faster than the traditional regressionformula usually found in statistical textbooks:
where the y-intercept is found to be a function of the
slope:
Note that in both methods the y-intercept calculation is the same, with being equal tothe arithmetic mean of all the x-values (input vector a[ ] ), while is equal to the arith-metic mean of all the y-values ( input vector b[ ] ).
In order for the least squares regression model to hold statistically true, a number ofassumptions regarding the input data in vectors [x] and [y] must also hold true:
1. For each value of input vector a, each corresponding value of vector y[ ] must be an independent value sampled at random.
2. The variances of the vector b values must be homoscedatic, i.e. have distribu-tions equal to one another.
To measure the accuracy of the predicted linear least sqaures regression use the see( )function to predict the standard error of estimate which will measure the variance ofthe y values ( input vector b[ ] ) around the true regression line.
lsqreg ( a, b, &c, &d, n )
y mx b+= mx by' a bx+= a b
a a y bx–= y x
slopexi x–( ) yi y–( )∑
xi x–( )2∑-------------------------------------------=
y-intercept y slope x•( )–=
xy

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-223
madd ( a, b, x, y, c )
NAME Matrix Add
DESCRIPTION This function computes the addition of input matrix a[ ] [ ] with input matrix b[ ] [ ] and stores the results to output matrix c[ ] [ ].
ALGORITHM
SYNOPSIS void madd ( a, b, x, y, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
float dm *b ; /* Pointer to input matrix b [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] and b[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] & b[ ][ ] */
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 26 + 3*(N-1) cycles
NOTES The file tmadd.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matricies can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
This algorithm computes the sum of two matrices of the same order: i.e., the number of rows and columns of input matrix a[ ] [ ] must equal the number of rows and col-umns of input matrix b[ ] [ ].
C11 C12 C13
C21 C22 C23
A11 A12 C13
A21 A22 A23
B11 B12 B13
B21 B22 B23
+=

ADSP-21K Optimized DSP Library User’s Manual
5-224 Wideband Computers, Inc.
mand ( a, b, x, y, c )
NAME AND Two Matrices
DESCRIPTION This function mand( ) logically ANDs elements of matrices a [ ] [ ] and b [ ] [ ], plac-ing the results in ouput matrix c [ ] [ ]. Matices a [ ] [ ] and b [ ] [ ] are of the same demension. Matrix c [ ] [ ] is a 0-1 matrix.
ALGORITHM
SYNOPSIS void mand ( a, b, x, y, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
float dm *b ; /* Pointer to input matrix b [ ] [ ] */
int x ; /* Number of rows in vector a[ ][ ] & b [ ] [ ] */
int y ; /* Number of columns in vector a[ ][ ] & b [ ] [ ]*/
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
C11 C12
C21 C22
A11 A12
A21 A22
ANDB11 B12
B21 B22
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-225
EXECUTION TIME 33 + 4 * ( N -1 ) cycles
NOTES The file tmand.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
An example of a matrix AND is provided below.
a[ ][ ] = ;
b[ ][ ] =
x = 3, y = 3 ;
mand ( a, b, x, y, c ) ;
The resulting values in output vector c would be as follows:
c[ ][ ] =
mand ( a, b, x, y, c )
1.0 1.7 5.55.0 1.6 1.01.0 5.0 6.0
0 1.7 5.55.0 1.6 1.01.0 0.0 6.0
0 1 11 1 11 0 1

ADSP-21K Optimized DSP Library User’s Manual
5-226 Wideband Computers, Inc.
maxm ( a, x, y )
NAME Maximum Value of a Matrix
DESCRIPTION This function finds the element in input matrix a[ ] [ ] with the maximum value and returns it from the function. The number of rows contained within input matrix a[ ] [ ] is defined by input integer x while the number of columns is defined by input scalar y.
ALGORITHM
SYNOPSIS float maxm ( a, x, y )
float *a ; /* Pointer to input/output matrix a[ ][ ] */
int x ; /* Number of rows in input/output vector a[ ][ ] */
int y ; /* Number of columns in input/output vector a[ ][ ]*/
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 10 + X * Y cycles
NOTES The file tmaxm.c included in the distribution diskette provides an example of this function’s use.
Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of columns.
return maximum element in matrix A⇐

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-227
maxmc ( a, x, y, mx, my )
NAME Maximum Element of Matrix With Coordinates
DESCRIPTION This function finds the element in input matrix a[ ] [ ] with the maximum value along with its coordinates. The maximum value is returned from the function call, the maxi-mum x-coordinate is output in scalar mx, and the maximum y-coordinate in output scalar my. The number of rows contained within input matrix a[ ] [ ] is defined by input scalar x while the number of columns is defined by input scalar y.
ALGORITHM
SYNOPSIS float maxmc ( a, x, y, mx, my )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
int x ; /* Number of rows in input vector a[ ][ ] */
int y ; /* Number of columns in input vector a[ ][ ] */
int mx ; /* X-coordinate of the maximum value */
int my ; /* Y-coordinate of the maximum value */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 8 * X * Y cycles
NOTES The file tmaxmc.c included in the distribution diskette provides an example of this function’s use.
Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of columns.
The coordinates reflects the largest elements. In other words, if the two largest ele-ments are equal, the coordinates are those of the second element.
The coordinate system begins with zero. If there are 7 elements in a column and 8 ele-ments in a row, then the column range is 0 to 6 and the row range is 0 to 7.
return maximum element of matrix A[ ][ ] with coordinates⇐

ADSP-21K Optimized DSP Library User’s Manual
5-228 Wideband Computers, Inc.
maxmgv ( a, i, c, n )
NAME Maximum Magnitude of Vector
DESCRIPTION This function finds the element in input vector a with the maximum magnitude and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void maxmgv ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output maximum value scalar c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 + 2*(N-1) cycles
NOTES The file tmaxmgv.c included in the distribution diskette provides an example of this function’s use.
if C Ami then m 0 1 2 …n 1–, , ,{ }=<
C Ami=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-229
maxmgvi ( a, i, c, d, f, n )
NAME Vector Maximum Magnitude with Index
DESCRIPTION This function finds the element in input vector a with the maximum magnitude and stores the result in output scalar c. The index of the maximum value of a is returned in output scalar d. A flag f controls the return of either the first or last maximum index is encountered.
ALGORITHM
D= Index of Maximum Magnitude Value of A
If f = 0 then the First Maximum Magnitude Returned
If f > 0 then the Last Maximum Magnitude Returned
SYNOPSIS void maxmgvi ( a, i, c, d, f, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to output maximum value scalar c */
int dm d ; /* Pointer to index of maximum value d */
int f ; /* Flag to indicate first or last mag returned */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
if C Ami then m 0 1 2 …n 1–, , ,{ }=<
C Ami=

ADSP-21K Optimized DSP Library User’s Manual
5-230 Wideband Computers, Inc.
EXECUTION TIME 31 + 4*N cycles
NOTES The file tmaxmgvi.c included in the distribution diskette provides an example of this function’s use.
The flag f indicates wether the index of the first or last magnitude is returned. If f is set to 0 then the index of the first maximum magnitude encountered in the input array is returned in d. If f is set to > 0 then the index of the last maximum magnitude encoun-tered in the input array is returned in d.
The search for the first or last magnitude is accomplished by searching backwards and forwards respectively.
The index is referenced to zero at the beginning of the array.
maxmgvi ( a, i, c, d, f, n )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-231
maxv ( a, i, c, n )
NAME Vector Maximum Value
DESCRIPTION This function finds the element in input vector a with the maximum value and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void maxv ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 + 1*(N-1) cycles
NOTES The file tmaxv.c included in the distribution diskette provides an example of this func-tion’s use.
if C Ami then m 0 1 2 …n 1–, , ,{ }=<
C Ami=

ADSP-21K Optimized DSP Library User’s Manual
5-232 Wideband Computers, Inc.
maxvi ( a, i, c, d, n )
NAME Vector Maximum Value With Index
DESCRIPTION This function finds the element in input vector a with the maximum value and stores the result in output scalar c. It also locates the index of the maximum values and stores it in output scalar d.
ALGORITHM
SYNOPSIS void maxvi ( a, i, c, d, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output maximum value scalar c */
int *d ; /* Pointer to output maximum index scalar d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 + 3*N cycles
NOTES The file tmaxvi.c included in the distribution diskette provides an example of this function’s use.
This routine is slower than the maxv routine as the index of the largest element is returned along with the maximum value. If the input array a has two values that are computed to be the maximum, and both are equal, then the routine returns the index of the last largest element encountered during the search, as the maximum element.
if C Ami then m 0 1 2 …n 1–, , ,{ }=<
C Ami=
D index of max element=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-233
mchol ( a, b, c, n )
NAME Choleski Decomposition
DESCRIPTION This function computes a Choleski decomposition of input matrix a[ ] [ ]. The lower triangular matrix is stored to output matrix b[ ] [ ] while the upper triangular matrix is stored to output matrix c[ ] [ ].
ALGORITHM
SYNOPSIS void mchol ( a, b, c, n )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
float dm *b ; /* Pointer to lower output matrix b[ ][ ] */
float dm *c ; /* Pointer to upper output matrix c[ ][ ] */
int n ; /* Number of rows and column */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
A [ ] [ ] Blower triangular [ ] [ ],Cupper triangular [ ] [ ]⇒

ADSP-21K Optimized DSP Library User’s Manual
5-234 Wideband Computers, Inc.
EXECUTION TIME 116+(3(N-1)+(3+2N)N+(42+3(N-1)+(9+4(N-1))(N-2))(N-2) cycles
NOTES The file tmchol.c included in the distribution diskette provides an example of this function’s use.
The Choleski Decomposition is computed as follows:
where C [ ] [ ] is the transpose of B [ ] [ ].
An example of a Choleski Decomposition is provided as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
It is assumed that the input matrix is positive definite. No error checking is provided for this.
mchol ( a, b, c, n )
A [ ] [ ] = B[ ] [ ] C [ ] [ ] •
A
4 2– 4 22– 10 2– 7–
4 2– 8 42 7– 4 7
n=4,=
B
2 0 0 01– 3 0 0
2 0 2 01 2– 1 1
=
C
2 1– 2 10 3 0 2–0 0 2 10 0 0 1
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-235
mconst ( a, b, x, y )
NAME Constant Matrix
DESCRIPTION This function creates a constant output matrix a whose elements are all equal to the assigned constant supplied in input scalar constant b. The input integer scalar x con-tains the number of rows in input matrix a[ ] [ ]. The input integer scalar y contains the number of columns in input matrix a[ ] [ ].
ALGORITHM
SYNOPSIS void mconst ( a, b, x, y )
float dm *a ; /* Pointer to output matrix a [ ][ ] */
float dm b ; /* Input scalar b constant */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 9 + ( X * Y ) cycles
NOTES The file tmconst.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
Ax y, B=

ADSP-21K Optimized DSP Library User’s Manual
5-236 Wideband Computers, Inc.
mcpivot ( a, b, c, x )
NAME Complete Pivoting For a Matrix
DESCRIPTION This function performs a complete pivoting of input matrix a[ ] [ ]. The results are returned in output matrix a[ ] [ ]. Vector b[ ] is used to return the row interchanges. Vector c[ ] is used to return the column interchanges. The row and column dimensions of matrix a[ ] [ ] are x. The vector dimension of b[ ] and c[ ] are also are also defined by input scalar x.
ALGORITHM Complete pivoting attempts to arrange matrix a[ ] [ ] in an optimal order by swapping rows and columns. This optimal order arranges elements of a[ ] [ ] so that round off errors are reduced when using the mlu( ) and mfbsub( ) functions. When swapping rows and columns, the largest elements ( in magnitude) are placed along the diagonal.
SYNOPSIS void mcpivot ( a, b, c, x )
float dm *a ; /* Pointer to input/output matrix a[ ][ ] */
int dm *b ; /* Pointer to output vector b[ ] */
int dm *c ; /* Pointer to output vector c[ ] */
int x ; /* Number of rows and columns in matrix a[ ][ ]*/
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-237
EXECUTION TIME 82 + 2X + (43+8X+(2+11X)X)X cycles
NOTES The file tmcpivot.c included in the distribution diskette provides an example of this function’s use.
Complete pivoting attempts to find the largest elements for the diagonal. First, the entire matrix is searched for the element with the largest magnitude. Its’ row and column is swapped with the 0th row and column. The 0th row and column are excluded and the minor sub-matrix is searched for the largest magnitude. Its row and column are swapped with the 1st row and column. This process is performed until the last row and column are left.
Given:
The element with the largest magnitude is -16.
The element with the largest magnitude in the minor sub-matrix (excluding row 0 and column 0) is 12.
The element with the largest magnitude in the minor sub-matrix (excluding rows 0 and 1 and columns 0 and 1) is 9.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of columns. Vector b [ ] and c [ ] need not be initialized. They are assigned within the function. For the example above, the vector for interchanges is interpreted as follows:
b[0] - Row 0 was swapped with row 3b[1] - Row 1 was swapped with row 2b[2] - Row 2 was swapped with row 3
The row vector interchange b[ ] is used by the function mfbsub() in solving for the unknowns in a set of simultaneous linear equations.
mcpivot ( a, b, c, x )
B 0 0 0 0 C,= 0 0 0 0 A
4 2 9 18 3 0 57 6 10 1216– 14 13 15
=,=
B 3 0 0 0 C,= 0 0 0 0 A
16– 14 13 158 3 0 57 6 10 124 2 9 1
=,=
B 3 2 0 0 C,= 0 3 0 0 A
16– 15 13 147 12 10 68 5 0 34 1 9 2
=,=
B 3 2 3 0 C,= 0 3 2 0 A
16– 15 13 147 12 10 64 1 9 28 5 0 3
=,=

ADSP-21K Optimized DSP Library User’s Manual
5-238 Wideband Computers, Inc.
mdeterm ( a, x )
NAME Determinant of a Matrix
DESCRIPTION This function computes the determinant of input matrix a [ ] [ ] and returns the result. The row and column dimension of matrix a [ ] [ ] is x.
ALGORITHM
SYNOPSIS void mdeterm ( a, x )
float dm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows and columns in matrix a[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Return Determinant mdeterm matrix A( )=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-239
EXECUTION TIME 51 + (12 + (16 + 4 * X) * ( X-1 )) * ( X-1 ) + ( X-1) cycles
NOTES The file tmdeterm.c included in the distribution diskette provides an example of this function’s use.
This algorithm performs elementary row operations to reduce the matrix to upper tri-angular form. The determinant is the product of the diagonal elements.
An example of computing a matrix determinant is provided below.
determ = 2.0 * 4.0 * 6.0 = 48.0
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
Note that the diagonal elements must be non-zero. Use the library function mcpivot( ) to rearrange the matrix to get the diagonal elements to non-zero.
For small matrices (2x2 or 3x3) use mdetrm2( ) or mdetrm3( ).
The source matrix a [ ] [ ] is destroyed by the process. ( It is in upper-triangular form ).
The source matrix a [ ] [ ] has to be sqaure.
If at any time row reduction causes a diagonal elements to be zero, the determinant is zero.
mdeterm ( a, x )
If A2.0 1.0– 3.04.0 2.0 1.06.0– 1.0– 2.0
and x = 3=
A2 1– 30 4 5–6– 1– 2
from 2nd row subtract 2 * the first row (the reference row)=
A2 1– 30 4 5–6– 1– 2
from 3rd row subtract 3 * the first row (the reference row)=
A2 1– 30 4 5–6– 1– 2
from 3rd row subtract 1 * the second row (the reference row)=

ADSP-21K Optimized DSP Library User’s Manual
5-240 Wideband Computers, Inc.
mdetrm2 ( a )
NAME Determinant of a 2x2 Matrix
DESCRIPTION This function computes the determinant of a 2x2 input matrix a [ ] [ ] and returns the result.
ALGORITHM
SYNOPSIS void mdetrm2 ( a )
float dm *a ; /* Pointer to 2x2 input matrix a [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 12 cycles
NOTES The file tmdetrm2.c included in the distribution diskette provides an example of this function’s use.
The determinant of a 2x2 matrix is computed as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
Return Determinant mdetrm2 A( )=
If A a bc d
then determ a d b c•–•==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-241
mdetrm3 ( a )
NAME Determinant of a 3x3 Matrix
DESCRIPTION This function computes the determinant of a 3x3 input matrix a [ ] [ ] and returns the result.
ALGORITHM
SYNOPSIS void mdetrm3 ( a )
float dm *a ; /* Pointer to 3x3 input matrix a [ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 25 cycles
NOTES The file tmdetrm3.c included in the distribution diskette provides an example of this function’s use.
The determinant of a 3x3 matrix is computed as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
Return Determinant mdetrm3 A( )=
If A
x11 x12 x13x21 x22 x23x31 x32 x33
then determ =
A x11 x22 x33••( ) x12 x23 x31••( ) x13 x21 x32••( ) x11 x23 x32••( )– x12 x21 x33••( )– x13 x22 x31••( )–+ +=

ADSP-21K Optimized DSP Library User’s Manual
5-242 Wideband Computers, Inc.
meandev ( a, i, b, c, n )
NAME Mean Deviation
DESCRIPTION This routine calculates the mean deviation of the elements within input vector a from the mean input scalar b, and places the results in output scalar c.
ALGORITHM
SYNOPSIS void meandev ( a, i, b, c, n)
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *b ; /* Pointer to input mean scalar b */
float *c ; /* Pointer to resultant output scalar c */
int n ; /* Element Count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 50 + 3 * ( N - 1 )
NOTES The file meandev.c included in the distribution tape provides an example of this func-tion’s use.
C 1 n------ Ami b–
i 0=
n 1–
∑• m 0 1 2 … n, 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-243
memtest ( a, i, type, pattern, n )
NAME Memory Test
DESCRIPTION This function performs a sanity check on the memory location specified by the start address a for a block of memory defined by n. The type flag determines whether dm or pm memory is tested. ( 1 = dm, 0 = pm ).
memtest( ) writes a test pattern to memory and reads it back. If the written pattern is the same as the pattern read, a 1 is returned to indicate a passed test. If the written pat-tern does not match the read pattern, a 0 is returned to indicate a failed test.
ALGORITHM
SYNOPSIS void memtest ( a, i, type, pattern, n )
int a ; /* Start address of memory */
int i ; /* Memory stride */
int type ; /* Type of memory to test ( 1=dm or 0=pm ) */
int pattern ; /* Test pattern to read/write */
int n ; /* Length of block to be checked */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 16 + 4 * N cycles
NOTES The file tmemtest.c included in the distribution diskette provides an example of this function’s use.
Return 1 or 0⇐

ADSP-21K Optimized DSP Library User’s Manual
5-244 Wideband Computers, Inc.
mextr ( a, ax, ay, b, bx, by, ix, iy )
NAME Extract A Sub-Matrix From A Source Matrix
DESCRIPTION This function extracts an output sub-matrix a[ ] [ ] from an input source matrix b[ ] [ ] starting at a point described by input row integer ix and input column integer iy. The results are stored to output matrix a[ ] [ ].
ALGORITHM
SYNOPSIS void mextr ( a, ax, ay, b, bx, by, ix, iy )
float dm *a ; /* Pointer to output sub-matrix a[ ][ ] */
int ax ; /* Number of rows in sub-matrix a[ ][ ] */
int ay ; /* Number of columns in sub-matrix a[ ][ ] */
float dm *b ; /* Pointer to input source matrix b[ ][ ] */
int bx ; /* Number of rows in source matrix b[ ][ ] */
int by ; /* Number of columns in source matrix b[ ][ ] */
int ix ; /* Extract position for row start */
int iy ; /* Extract position for column start */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
A 0 00 0
ax 2 , ay=2, =,=
Bstart
0 0 00 1 40 7 9
bx 3 , by=3, =,=
ix 1 , iy=1, =
Afinish1 47 9
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-245
EXECUTION TIME 48 + ( 3 + 2 * Y ) * X cycles
NOTES The file tmextr.c included in the distribution diskette provides an example of this function’s use.
This function extract a sub-matrix a[ ] [ ] from a source matrix b[ ] [ ]. Matrix a[ ] [ ] row and column must be less than the row and column of matrix b[ ] [ ]. Example as follows:
The coordinate system begins with zero. If there are 7 elements in a column and 8 ele-ments in a row, then the column is 0 to 6 and the row is 0 to 7.
The extract position must be a valid position (i.e., non-negative). However, it is allowed to have an extract position such that only a part of the sub-matrix is extracted (i.e. if ix > bx - ax).
Example as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
mextr ( a, ax, ay, b, bx, by, ix, iy )
A0 0 00 0 00 0 0
B,
0 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 1 2 3 0 0 00 0 4 5 6 0 0 00 0 7 8 9 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 0
Extract Position 2 2,( ) Afinal
1 2 34 5 67 8 9
=,=,= =
A0 0 00 0 00 0 0
B,
0 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 1 20 0 0 0 0 0 4 50 0 0 0 0 0 7 8
Extract Position 4 6,( ) Afinal
1 2 04 5 07 8 0
=,=,= =

ADSP-21K Optimized DSP Library User’s Manual
5-246 Wideband Computers, Inc.
mfbsub ( a, b, c, d, x )
NAME Matrix Forward-Back Substitution
DESCRIPTION This routine performs a forward and back substitution using matrices a[ ][ ], b[ ][ ] and vector c[ ]. The results are placed in input/output vector c[ ]. Vector d[ ] is used to order the input solution vector c[ ] to match the swapping that may have been done in mppivot ( ) or mcpivot ( ). The row and column dimensions of the matrices and the vector dimensions are x.
ALGORITHM This function uses matrices from the LU decomposition function mlu( ) to solve a set of simul-taneous linear equations for a set of unknowns. The L and U decomposed matrices are repre-sented by a[ ][ ] and b[ ][ ] respectively. A system of simultaneous linear equations can be written as: Ax = b, where A represents the coefficients of the equations in matrix form, x repre-sents a vector of unknowns and b represents a vector of the solutions.
Decomposing A = LU the above equation can be rewritten as: LUx = b. Setting y = Ux, the equation becomes Ly = b. Use forward substitution to solve for y. Once y is found, use back substitution to solve for x.
Forward Substitution - This solves for the temporary solution used in back substitution. Forward substitution uses the L component of the LU decompositon and solves for a temporary set of unknowns. These unknowns are then used by back substitution.
Back Substitution - Back substitution uses the U component of the LU Decomposition and solves for the system of unknowns.
SYNOPSIS void mfbsub ( a, b, c, d, x )
float dm *a ; /* Pointer to input matrix a */
float dm *b ; /* Pointer to input matrix b */
float dm *c ; /* Pointer to input matrix c */
float dm *d ; /* Pointer to input matrix d */
int x ; /* Number of rows,columns & vector length*/
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-247
EXECUTION TIME 72 + ( 8 + 4 * X - 1) ( X - 1) + ( 28 + 4 * X -1) ( X - 1)
NOTES
The file tmfbsub.c included in the distribution tape provides an example of this function’s use.
Prior to Forward-Back substitution, the intial input solution vector c[] is ordered by the order vector d[].
For the example above, the input solution vector c[] was originally = { 1, 2, 3, 4 }.
0w + 1x - 3y - 4z = 11w - 1x + 0y + 4z = 22w + 1x + 2y + 3z = 36w + 2x + 4y + 8z = 4
The order vector d[ ] (from mppivot( )) = { 3, 2, 3, 3 }. The operation of vector d[ ] on c[ ] yields: C D
1 2 3 4 3 2 3 34 2 3 1 ^ Swap position 0 with 34 3 2 1 ^ Swap position 1 with 24 3 1 2 ^ Swap position 2 with 34 3 1 2 ^ Swap position 3 with 3
The full process for solving a system of simultaneous linear equations is to call mppivot( ) or mcpivot( ) to order the equation matrix, followed by mlu( ) to perform LU decomposition fol-lowed by mfbsub( ) to perform forward-back substitution
The reason this was broken up in this way is that pivoting and LU Decomposition need only be performed once. The Forward-Back substitution can be called for multiple input solution vec-tors c[ ]. This way a system of linear equations can be solved for many solutions without the expense of pivoting or decomposing every time.
If pivoting was not performed (via mcpivot( ) or mppivot( )), then set the order vector d[ ] = 0, 1, 2, 3, ... N. This ensures that no swapping will be performed.
mfbsub ( a, b, c, d, x )
6 2 4 8+ + +2 1 2 3+ + +0 1 3– 4–+1 1– 0 4+ +
wxyz
L⇒=
1 0 0 00.333 1 0 0
0 3 1 00.166 4– 0.4– 1
U
6 2 4 80 0.333 0.666 0.3330 0 5.00– 5.00–0 0 0 2
=,=
Back Substitution
6 2 4 80 0.333 0.666 0.3330 0 5– 5–0 0 0 2
=
wxyz
•
4.0001.6664.000–
6.400
w 4.2–=x 6.6=y 2.4–=z 3.2=
⇒=
Forward Substitution
1 0 0 00.333 1 0 0
0 3 1 00.166 4– 0.4– 1
y1y2y3y4
•
4312
y1 4=y2 1.666=y3 4–=y4 6.4=
⇒==

ADSP-21K Optimized DSP Library User’s Manual
5-248 Wideband Computers, Inc.
mident ( a, x )
NAME Martix Identity
DESCRIPTION This function creates an output identity matrix a [ ] [ ] whose diagonal elements are all 1s and all the other elements are 0s. The matrix created is square, with the size of the rows and columns being supplied by input scalar x.
ALGORITHM for i=0 to number of rows
for j=0 to number of columns
if (i=j)
a[i][j]=1
else
a[i][j]=0
SYNOPSIS void mident ( a, x )
float dm *a ; /* Pointer to output matrix a [ ][ ] */
int x ; /* Number of rows and columns in matrix a[ ][ ] */
DOMAIN 0 to 362
ACCURACY 7.75 decimal digits
EXECUTION TIME 11 + ( 2 + X ) * X cycles
NOTES The file tmident.c included in the distribution diskette provides an example of this function’s use.
An example of an identity matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
If x=4 then a[ ][ ]
1 0 0 00 1 0 00 0 1 00 0 0 1
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-249
minm ( a, x, y )
NAME Minimum Value of a Matrix
DESCRIPTION This function finds the element in input matrix a[ ] [ ] with the minimum value and returns it from the function . The number of rows contained within input matrix a[ ] [ ] is defined by input integer x while the number of columns is defined by input scalar y.
ALGORITHM
SYNOPSIS float minm ( a, x, y )
float *a ; /* Pointer to input/output matrix a[ ][ ] */
int x ; /* Number of rows in input/output vector a[ ][ ] */
int y ; /* Number of columns in input/output vector a[ ][ ]*/
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 10 + X * Y cycles
NOTES The file tminm.c included in the distribution diskette provides an example of this function’s use.
Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of columns.
return minimum element in matrix A⇐

ADSP-21K Optimized DSP Library User’s Manual
5-250 Wideband Computers, Inc.
minmc ( a, x, y, mx, my )
NAME Minimum Element of Matrix With Coordinates
DESCRIPTION This function finds the element in input matrix a[ ] [ ] with the minimum value along with its coordinates. The minimum value is returned from the function call, the mini-mum x-coordinate is output in scalar mx, and the minimum y-coordinate in output sca-lar my. The number of rows contained within input matrix a[ ] [ ] is defined by input scalar x while the number of columns is defined by input scalar y.
ALGORITHM
SYNOPSIS float minmc ( a, x, y, mx, my )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
int x ; /* Number of rows in input vector a[ ][ ] */
int y ; /* Number of columns in input vector a[ ][ ] */
int mx ; /* X-coordinate of the minimum value */
int my ; /* Y-coordinate of the minimum value */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 8 * X * Y cycles
NOTES The file tminmc.c included in the distribution diskette provides an example of this function’s use.
Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of columns.
The coordinates reflects the last smallest element. In other words, if the two smallest elements are equal, the coordinates are those of the second element.
The coordinate system begins with zero. If there are 7 elements in a column and 8 ele-ments in a row, then the column range is 0 to 6 and the row range is 0 to 7.
return minimum element of matrix A[ ][ ] with coordinates⇐

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-251
minmgv ( a, i, c, n )
NAME Minimum Magnitude of Vector
DESCRIPTION This function finds the element in input vector a with the minimum magnitude and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void minmgv ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output maximum value scalar c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 + 2*(N-1) cycles
NOTES The file tminmgv.c included in the distribution diskette provides an example of this function’s use.
if C Ami then m 0 1 2 …n 1–, , ,{ }=>
C Ami=

ADSP-21K Optimized DSP Library User’s Manual
5-252 Wideband Computers, Inc.
minmgvi ( a, i, c, d, f, n )
NAME Vector Minimum Magnitude with Index
DESCRIPTION This function finds the element in input vector a with the minimum magnitude and stores the result in output scalar c. The index of the minimum value of a is returned in output scalar d. A flag f controls the return of either the first or last minimum index encountered.
ALGORITHM
D= Index of Minimum Magnitude Value of A
If f = 0 then the First Minimum Magnitude Returned
If f > 0 then the Last Minimum Magnitude Returned
SYNOPSIS void minmgvi ( a, i, c, d, f, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to output minimum value scalar c */
int dm d ; /* Pointer to index of minimum value d */
int f ; /* Flag to indicate first or last mag returned */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
if C Ami then m 0 1 2 …n 1–, , ,{ }=>
C Ami=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-253
EXECUTION TIME 31 + 4*N cycles
NOTES The file tminmgvi.c included in the distribution diskette provides an example of this function’s use.
The flag f indicates wether the first or last magnitude is returned if multiple minimum values are encountered. If f is set to 0 then the index of the first minimum magnitude encountered in the input array is returned in d. If f is set to > 0 then the index of the last minimum magnitude encountered in the input array is returned in d.
The search for the first or last magnitude is accomplished by searching backwards and forwards respectively.
The index is referenced to zero at the beginning of the array.
minmgvi ( a, i, c, d, f, n )

ADSP-21K Optimized DSP Library User’s Manual
5-254 Wideband Computers, Inc.
minsrt ( a, ax, ay, b, bx, by, ix, iy )
NAME Insert Sub-Matrix Into Source Matrix
DESCRIPTION This function inserts an input sub-matrix a[ ] [ ] into an input/output source matrix b[ ] [ ] at a point described by input row integer ix and input column integer iy. The results are stored to output matrix b[ ] [ ].
ALGORITHM
SYNOPSIS void minsrt ( a, ax, ay, b, bx, by, ix, iy )
float dm *a ; /* Pointer to input sub-matrix a[ ][ ] */
int ax ; /* Number of rows in sub-matrix a[ ][ ] */
int ay ; /* Number of columns in sub-matrix a[ ][ ] */
float dm *b ; /* Pointer to input source matrix b[ ][ ] */
int bx ; /* Number of rows in source matrix b[ ][ ] */
int by ; /* Number of columns in source matrix b[ ][ ] */
int ix ; /* Insert position for row start */
int iy ; /* Insert position for column start */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
A 1 47 9
ax 2 , ay=2, =,=
Bstart
0 0 00 0 00 0 0
bx 3 , by=3, =,=
ix 1 , iy=1, =
Bfinish
0 0 00 1 40 7 9
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-255
EXECUTION TIME 48 + ( 3 + 2 * Y ) * X cycles
NOTES The file tminsrt.c included in the distribution diskette provides an example of this function’s use.
This function inserts submatrix a[ ] [ ] into source matrix b[ ] [ ]. Matrix a[ ] [ ] row and column must be less than the row and column of matrix b[ ] [ ]. Example as fol-lows:
The coordinate system begins with zero. If there are 7 elements in a column and 8 ele-ments in a row, then the column is 0 to 6 and the row is 0 to 7.
The insert position must be a valid position (i.e., non-negative). However, it is allowed to have an insert position such that only a part of the sub-matrix is inserted (i.e. if ix > bx - ax).
Example as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
minsrt ( a, ax, ay, b, bx, by, ix, iy )
A1 2 34 5 67 8 9
B,
0 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 0
Insert Position 3 3,( ) Bfinal
0 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 1 2 3 0 00 0 0 4 5 6 0 00 0 0 7 8 9 0 00 0 0 0 0 0 0 0
=,=,= =
A1 2 34 5 67 8 9
B,
0 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 0
Insert Position 3 6,( ) Bfinal
0 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 0 00 0 0 0 0 0 1 20 0 0 0 0 0 4 50 0 0 0 0 0 7 80 0 0 0 0 0 0 0
=,=,= =

ADSP-21K Optimized DSP Library User’s Manual
5-256 Wideband Computers, Inc.
minv ( a, i, c, n )
NAME Vector Minimum Value
DESCRIPTION This function finds the element in input vector a with the minimum value and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void minv ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 + 1*(N-1) cycles
NOTES The file tminv.c included in the distribution diskette provides an example of this func-tion’s use.
if C Ami then m 0 1 2 …n 1–, , ,{ }=>
C Ami=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-257
minvi ( a, i, c, d, n )
NAME Vector Minimum Value With Index
DESCRIPTION This function finds the element in input vector a with the minimum value and stores the result in output scalar c. It also locates the index of the minimum value and stores it in output scalar d.
ALGORITHM
SYNOPSIS void minvi ( a, i, c, d, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output maximum value scalar c */
int *d ; /* Pointer to output maximum index scalar d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 + 3*N cycles
NOTES The file tminvi.c included in the distribution diskette provides an example of this function’s use.
This routine is slower than the minv routine as the index of the smallest element is returned along with the maximum value. If input array a has two values that are com-puted to be the minimum, and both are equal, then the routine returns the index of the last smallest element encountered during the search, as the minimum element.
if C Ami then m 0 1 2 …n 1–, , ,{ }=>
C Ami=
D index of minimum value=

ADSP-21K Optimized DSP Library User’s Manual
5-258 Wideband Computers, Inc.
minvrt ( a, b, x )
NAME Matrix Invert
DESCRIPTION This function inverts input matrix a[ ] [ ] and places the results in output matrix b[ ] [ ]. The dimensions of input matrix a[ ] [ ] and output matrix b[ ] [ ] are x.
This algorithm uses the Gaussian elimination with partial pivoting technique. Gauss-ian elimination is performed using LU decomposition.
ALGORITHM
SYNOPSIS void minvrt ( a, b, x )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
float dm *b ; /* Pointer to input matrix b[ ][ ] */
int x ; /* Number of rows and columns in matricies */
a[ ][ ] and b[ ][ ]
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME See Execution Timing Listed at End of Discussion Section
NOTES The file tminvrt.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matricies can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
This algorithm is broken into four section. The four sections are as follows:
1. Partial Pivoting - finding the largest elements along the diagonal by row.
2. LU Decompostion - partitioning the source matrix into its L and U compo-nents.
3. Forward Substitution - solving for temporary unknowns.
4. Back Substitution - solving for the inverse.
If A 5.0 8.0 1.00.0 2.0 1.04.0 3.0 1.0–
then A1–
5.0 11.0– 6.0–4.0– 9.0 5.0
8.0 17.0– 10.0–
==
where B[ ] A1–[ ]=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-259
minvrt() computes the inverse of matrix a[][] and places the result in b[][]. The row and column dimensions of matri-ces a[][] and b[][] are x.
This algorithm uses the Gaussian Elimination with partial pivoting technique. Gaussian Elimination is performed using LU decomposition.
The inverse is performed as follows:-1b[n][n] = a[n][n] for n = 0 to x
An example of a matrix inversion is provided below.
float dm a[][] = 5.0 8.0 1.0 0.0 2.0 1.0
4.0 3.0 -1.0 int x = 3 ;int errror ;
error = minvrt ( a, b, x ) ;
The resulting values in matrix b[] is as follows:
b[] = 5.0 -11.0 -6.0 -4.0 9.0 5.0 8.0 -17.0 -10.0
If matrix a[][] is singular (ie. there is no inverse) then minvrt() returns a non-zero value. Otherwise minvrt() returns zero with the inverse matrix in b[][].
NOTES on Matrix Invert Routine for ADSP-210xx SHARC Family of Processors
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the begin-ning of each row is offset by the number of columns.
The algorithm is broken into four sections. These are:
1. Partial Pivoting - finding the largest elements along the diagonal by row.2. LU Decomposition - partitioning the source matrix into its L and U components3. Forward Substitution - solving for temporary unknowns4. Back Substitution - solving for the inverse
Partial Pivoting - This entails finding the largest element in the matrix or sub-matrix along the diagonal. The first pivot is found by searching the entire matrix for the largest element in the first column of each row (ignoring sign). Swapping the row with the largest element with the first row puts the element in the upper left corner. Now exclude the first row, the sub-matrix is searched for the next largest element in the second column. Perform swapping again positions the element in the next pivot (the next position along the diagonal). Repeat for the remaining elements along the diagonal.

ADSP-21K Optimized DSP Library User’s Manual
5-260 Wideband Computers, Inc.
Given:
a[][] = 5 8 1 0 2 1 4 3 -1
The element with the largest magnitude in col 0 is 5.
a[][] = 5 8 1 --> Swapped 1st row and 1st row 0 2 1 4 3 -1
The element with the largest magnitude in the minor sub-matrix (excluding row 0 and col 0) is 4.a[][] = 5 8 1 4 3 -1 --> Swapped 2nd row and 3rd row 0 2 1
LU Decomposition - This finds the L and U component of the source matrix after complete pivoting is done. The L component represents the lower triangular form and the U component the upper triangular form. The lower triangular form contains elements below the diagonal and the upper triangular form contains elements along the diagonal and above. The elements in L are the scalars (factors) used to reduce (by column) the non-pivot rows to zero. The elements in U are the results after row reduction has been performed using the scalars in L.
Since LU decomposition uses a pivot element (an element along the diagonal) as a divisor to compute a scalar, a check for a zero pivot is performed prior decomposition. If a zero pivot is found, then the function is aborted and a status flag of non-zero is returned.
An example of LU Decomposition is provided below: diagonal and above. The elements in L are the scalars (factors)used to reduce (by column) the non-pivot rows to zero. The elements in U are the results after row reduction has been per-formed using the scalars in L.
Given a[][] = 5 8 1 4 3 -1 --> Reduce these rows so that 0 2 1 --> col 0 is 0
Decompose a[][] = l[][] * u[][]
Scalar of -4/5 (-0.8) times the first row plus the second row.Scalar of -0/5 (0) times the first row plus the third row.
u[][] = 5.000 8.000 1.000 -0.800 -3.400 -1.800 --> Reduce these rows so that 0.000 2.000 1.000 --> col 1 is 0
1[][] = 1.000 0.000 0.000 -0.800 1.000 0.000 0.000 0.000 1.000
Scalar of 2/3.4 (0.58823529) times the second row plus the third row.

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-261
u[][] = 5.000000000 8.000000000 1.000000000 0.000000000 -3.400000000 -1.800000000 0.000000000 0.000000000 -0.058823529
1[][] = 1.000000000 0.000000000 0.000000000 -0.800000000 1.000000000 0.000000000 0.000000000 0.588235294 1.000000000
Normally LU decomposition would consist of two matrices (an L matrix and a U matrix). The L matrix has the form1 0 0 a 1 0 for a 3x3 matrix b c 1 where a, b, c are the scalars used in row operations to reduce the matrix to upper triangu-lar form.
The U matrix has the form
d e f0 g h for a 3x3 matrix0 0 iwhere d, e, f, g, h, i are the elements after row operations have reduce the matrix to upper triangular form.
See Richard Bronson Linear Algebra An Introduction., Academic Press, Inc. 1995 pp. 65-66.
For efficiency, the LU decomposition is placed together in a[][] in partioned form. That is, the original matrix a[][] is replaced with
d e f
__a| g h|__b c| i
So for the above example, the LU decomposition would look like the following in matrix a[][].
a[][] = 5.000000000 8.000000000 1.000000000 -0.800000000 -3.400000000 -1.800000000 0.000000000 0.588235294 -0.058823529
Forward Substitution - This solves for the solution used in back substitution. Forward substitution uses the L component found above and a corresponding column in the identity matrix to solve for a set of temporary unknowns. The process is completed for all remaining columns. These unknowns are then used by backsubstitution.
Back Substitution - This solves for the inverse solution in the identity matrix. Back substitution uses the U component found above and a corresponding column in the identity matrix containing the solution from forward substitution to solve for theinverse. The process is completed for all remaining columns.
Forward and back substitution uses the matrix from the LU decomposition to solve a set of simultaneous linear equations for a set of unknowns.

ADSP-21K Optimized DSP Library User’s Manual
5-262 Wideband Computers, Inc.
A system of simultaneous linear equations can be written as:
Ax = b
where: A - represents the coefficients of the equations in matrix form x - represents a vector of unknowns b - represents a vector of the solutions
Decomposing A = LU the above equation can be rewritten as: LUx = b Setting y = Ux, the equation becomes Ly = b
Use forward substitution to solve for y. Once y is found, use back substitution to solve for x.
Using the property that A*A-1 = I (that is matrix a[][] times its inverse equals the identity matrix), the LU decomposition with forward-back substitution can be used to solve for the inverse.
In this case the vector b represents a column in the identity matrix. Looping for each column solves for the inverse of matrix a[][].
Example: Given the set of simultaneous linear equations forthree unknowns (x, y, z).
5x + 8y + 1z = 14x + 3y - 1z = 00x + 2y + 1z = 0
This system has the matrix form:
| 5 8 1 | | x | | 1 || 4 3 -1 | * | y | = | 0 || 0 2 1 | | z | | 0 |
LU decomposition of the coefficient matrix yields
u[][] = 5.000000000 8.000000000 1.000000000 0.000000000 -3.400000000 -1.800000000 0.000000000 0.000000000 -0.058823529
l[][] = 1.000000000 0.000000000 0.000000000 -0.800000000 1.000000000 0.000000000
0.000000000 0.588235294 1.000000000
Using forward substitution, solve for a temporary set of unknowns (Ly = b)
| 1.000000000 0.000000000 0.000000000 | | y1 | | 1 || -0.800000000 1.000000000 0.000000000 | * | y2 | = | 0 || 0.000000000 0.588235294 1.000000000 | | y3 | | 0 |
y1 = 10.80000y1 + y2 = 00.588235294y2 + y3 = 0

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-263
y1 = 1y2 = -0.800000000y3 = 0.470588232
Using back substitution, solve for the set of unknowns (Ux = y)
| 5.000000000 8.000000000 1.000000000 | | x | | 1 || 0.000000000 -3.400000000 -1.800000000 | * | y | + | -0.80000000 || 0.000000000 0.000000000 -0.058823529 | | z | | 0.47058823 |
5.000000000x + 8.000y + 1.000000000z = 1- 3.400y - 1.800000000z = -0.80000000- 0.058823529z = 0.47058823
x = 5y = -4z = 8
Cycle Time = n =
3 - 481 27 - 94,6214 - 804 28 - 104,8565 - 1,264 29 - 115,8046 - 1,885 30 - 127,4897 - 2,691 31 - 139,9358 - 3,706 32 - 153,1669 - 4,954 33 - 167,20610 - 6,459 34 - 182,07911 - 8,245 35 - 197,80912 - 10,336 36 - 214,42013 - 12,756 37 - 231,93614 - 15,529 38 - 250,38115 - 18679 39 - 269,77916 - 22,230 40 - 290,15417 - 26,206 41 - 311,53018 - 30,631 42 - 333,93119 - 35,529 43 - 357,38120 - 40,924 44 - 381,90421 - 46,840 45 - 407,52422 - 53,301 46 - 434,26523 - 60,331 47 - 462,15124 - 67,954 48 - 491,20625 - 76,194 49 - 521,45426 - 85,075 50 - 552,919

ADSP-21K Optimized DSP Library User’s Manual
5-264 Wideband Computers, Inc.
mkron ( a, x, y, b, m, n, c )
NAME Computes the Kronecker Product of Two Matrices
DESCRIPTION This function computes the Kronecker Product of two input matrices a[ ] [ ] and b[ ] [ ], placing the results in output matrix c[ ] [ ]. The dimensions of input matrix a[ ] [ ] are defined by scalar inputs x and y, while the dimensions of input matrix b[ ] [ ] are defined by scalar inputs m and n. The resulting output matrix c[ ] [ ] is defined of dimensions x*m and y*n.
ALGORITHM
SYNOPSIS void mkron ( a, x, y, b, m, n, c )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
float dm *b ; /* Pointer to input matrix b[ ][ ] */
int m ; /* Number of rows in matrix b[ ][ ] */
int n ; /* Number of columns in matrix b[ ][ ] */
float dm *c ; /* Pointer to output matrix c[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Kronecker A [ ] [ ] x B [ ] [ ]( ) C [ ] [ ]=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-265
EXECUTION TIME 48 + ( 4 + ( 4 + ( 4 + 3 * N ) * Y ) * M ) * X cycles
NOTES The file tmkron.c included in the distribution diskette provides an example of this function’s use.
The Kronecker Product is computed as follows:
for i=0 to number of rows in a[ ][ ]
for j=0 to number of columns in a[ ][ ]
for k=0 to number of rows in b[ ][ ]
for l=0 to number of columns in b[ ][ ]
c[i+k] [j+1] = a[i][j] * b[k][i]
An example of a Kronecker Product is provided as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
mkron ( a, x, y, b, m, n, c )
A
1 1 1 1 21 1 1 1 21 1 1 1 21 1 9 10 20
B, 1 23 4
x, 4 y, 5 m, 2 n, 2= = = = = =
C
1 2 1 2 1 2 1 2 2 43 4 3 4 3 4 3 4 6 81 2 1 2 1 2 1 2 2 43 4 3 4 3 4 3 4 6 81 2 1 2 1 2 1 2 2 43 4 3 4 3 4 3 4 6 81 2 1 2 9 18 10 20 20 403 4 3 4 27 36 30 40 60 80
=

ADSP-21K Optimized DSP Library User’s Manual
5-266 Wideband Computers, Inc.
mlu ( a, b, c, x )
NAME Matrix LU Decomposition
DESCRIPTION This function computes the LU decomposition of input matrix a[ ] [ ]. The results are output to matrix b[ ] [ ] and matrix c[ ] [ ]. Output matrix b[ ] [ ] contains the lower tri-angular form (L) of the decomposition and output matrix c[ ] [ ] contains the upper tri-angular form (U) of the decomposition.
LU decomposition factorizes the source matrix a[ ] [ ] into L and U matrices such that a=LU. The lower triangular form (L) contains elements below a diagonal of ones and the upper triangular form (U) contains elements along the diagonal and above. The elements in L are the scalars (factors) used to reduce (by column) the non-pivot rows to zero. The elements in U are the results after row reduction has been performed using scalars in L.
LU decomposition is used primarily to slove for a system of simultaneous linear equa-tions. After decomposition, the L and U matrices are used by mfbsub( ) (forward and back substitution) to solve for the unknowns.
ALGORITHM
If A=
6 2 4 82 1 2 30 1 3– 4–1 1– 0 4
then
B=
6 2 4 80 0.333 0.6662 0.3330 0 5– 5–0 0 0 2
C=
1 0 0 00.333 1 0 0
0 3 1 00.166 4– 0.– 400 1
,

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-267
SYNOPSIS int mlu ( a, b, c, x )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
float dm *b ; /* Pointer to output lower matrix b [ ] [ ] */
float dm *c ; /* Pointer to output upper matrix c [ ] [ ] */
int x ; /* Number of rows and columns in
matrices a [ ], b [ ] and c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME TBS cycles
NOTES The file tmlu.c included in the distribution diskette provides an example of this func-tion’s use.
LU decomposition does not perform pivoting. There are two pivoting functions avail-able (mcpivot( ) for complete pivoting and mppivot( ) for partial pivoting). It is rec-ommended that the library functions mcpivot( ) or mppivot ( ) be used prior to mlu( ) being called to reduce roundoff error.
Since mlu( ) uses a pivot element (an element along the diagonal) as a divisor to com-pute a scalar, a check for a zero is performed during decomposition. If a zero pivot is found, then the function is aborted and a status flag of 0 is returned. Otherwise, a value of 1 is returned to indicate a successful LU decomposition.
Matricies b[ ] [ ] and c[ ] [ ] are distinct and are initialzed prior to LU decomposition. Output matrix b[ ] [ ] is filled with input matrix a[ ] [ ] values and output matrix c[ ] [ ] is zeroed out.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
mlu ( a, b, c, x )

ADSP-21K Optimized DSP Library User’s Manual
5-268 Wideband Computers, Inc.
mmax ( a, b, x, y, c )
NAME Maximum Value of Pair of Matrices
DESCRIPTION This function finds the element in input matrix a[ ] [ ] or input matrix b[ ] [ ] with the maximum value and returns it in output matrix c[ ] [ ] . The number of rows contained within input matrices a[ ] [ ] and b[ ] [ ] are defined by input scalar x while the number of columns is defined by input scalar y.
ALGORITHM
SYNOPSIS void mmax ( a, b, x, y, c )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
float dm *b ; /* Pointer to input matrix b[ ][ ] */
int x ; /* Number of rows in input vector a[ ][ ] */
int y ; /* Number of columns in input vector a[ ][ ] */
float dm *c ; /* Pointer to output matrix c[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 + 3 * ( X * Y - 1 ) cycles
NOTES The file tmmax.c included in the distribution diskette provides an example of this function’s use.
Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of columns.
C11 C12
C21 C22
maxA11 A12
A21 A22
B11 B12
B21 B22
,
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-269
mmin ( a, b, x, y, c )
NAME Minimum Value of Pair of Matrices
DESCRIPTION This function finds the element in input matrix a[ ] [ ] or input matrix b[ ] [ ] with the minimum value and returns it in output matrix c[ ] [ ] . The number of rows contained within input matrices a[ ] [ ] and b[ ] [ ] are defined by input scalar x while the number of columns is defined by input scalar y.
ALGORITHM
SYNOPSIS void mmin ( a, b, x, y, c )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
float dm *b ; /* Pointer to input matrix b[ ][ ] */
int x ; /* Number of rows in input vector a[ ][ ] */
int y ; /* Number of columns in input vector a[ ][ ] */
float dm *c ; /* Pointer to output matrix c[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 + 3 * ( X * Y - 1 ) cycles
NOTES The file tmmin.c included in the distribution diskette provides an example of this function’s use.
Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of columns.
C11 C12
C21 C22
minA11 A12
A21 A22
B11 B12
B21 B22
,
=

ADSP-21K Optimized DSP Library User’s Manual
5-270 Wideband Computers, Inc.
mmov ( a, x, y, b )
NAME Move a Source Matrix to a Destination Matrix
DESCRIPTION This function copies the contents of input matrix a[ ] [ ] to output matrix b[ ] [ ]. The number of rows in input matrices a[ ] [ ] and b[ ] [ ] is represented by scalar input x. The number of columns in input matrices a[ ] [ ] and b[ ] [ ] is represented by scalar input y.
ALGORITHM
SYNOPSIS void mmov ( a, x, y, b )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
int x ; /* Number of rows in input matrices a[ ][ ] & b */
int y ; /* Number of columns in input matrix a[ ][ ]& b */
float dm *b ; /* Pointer to output matrix b[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 12 + 2 * X * Y cycles
NOTES The file tmmov.c included in the distribution diskette provides an example of this function’s use.
The matrices are assumbed to be identical.
Bx y, Ax y,=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-271
mmov_dp ( a, x, y, b )
NAME Move a Source DM Matrix to a Destination PM Matrix
DESCRIPTION This function copies the contents of input matrix a[ ] [ ] to output matrix b[ ] [ ]. The number of rows in input matrices a[ ] [ ] and b[ ] [ ] is represented by scalar input x. The number of columns in input matrices a[ ] [ ] and b[ ] [ ] is represented by scalar input y. Input matrix a[ ] [ ] is in data memory while output matrix b[ ] [ ] is in pro-gram memory.
ALGORITHM
SYNOPSIS void mmov_dp ( a, x, y, b )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
int x ; /* Number of rows in input matrices a[ ][ ] & b */
int y ; /* Number of columns in input matrix a[ ][ ]& b */
float pm *b ; /* Pointer to output matrix b[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 10 + X * Y cycles
NOTES The file tmmovpd.c included in the distribution diskette provides an example of this function’s use.
The matrices are assumed to be identical.
Bx y, Ax y,=

ADSP-21K Optimized DSP Library User’s Manual
5-272 Wideband Computers, Inc.
mmov_pd ( a, x, y, b )
NAME Move a Source PM Matrix to a Destination DM Matrix
DESCRIPTION This function copies the contents of input matrix a[ ] [ ] to output matrix b[ ] [ ]. The number of rows in input matrices a[ ] [ ] and b[ ] [ ] is represented by scalar input x. The number of columns in input matrices a[ ] [ ] and b[ ] [ ] is represented by scalar input y. Input matrix a[ ] [ ] is in program memory while output matrix b[ ] [ ] is in data memory.
ALGORITHM
SYNOPSIS void mmov_pd ( a, x, y, b )
float pm *a ; /* Pointer to input matrix a[ ][ ] */
int x ; /* Number of rows in input matrices a[ ][ ] & b */
int y ; /* Number of columns in input matrix a[ ][ ]& b */
float dm *b ; /* Pointer to output matrix b[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 10 + X * Y cycles
NOTES The file tmmovpd.c included in the distribution diskette provides an example of this function’s use.
The matrices are assumed to be identical.
Bx y, Ax y,=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-273
mmul ( a, x, y, b, z, c )
NAME Matrix Multiply
DESCRIPTION This function computes the multiplication of input matrix a times input matrix b and stores the results to output matrix c. The dimensions of matrix a [ ] [ ] are x and y and the dimensions of input matrix b [ ] [ ] are y and z. The resulting ouput matrix c [ ] [ ] is of dimensions x and z.
ALGORITHM
SYNOPSIS void mmul ( a, x, y, b, z, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
float dm *b ; /* Pointer to input matrix b [ ] [ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 48 + (5+(9+2*Y)*Z)*X cycles
NOTES The file tmmul.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element pf c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
C11 C12
C21 C22
A11 A12 A13
A21 A22 A23
B11 B12
B21 B22
B31 B32
•=

ADSP-21K Optimized DSP Library User’s Manual
5-274 Wideband Computers, Inc.
mmul_dpd ( a, x, y, b, z, c )
NAME Matrix Multiply
DESCRIPTION This function computes the multiplication of input matrix a times input matrix b and stores the results to output matrix c. The dimensions of matrix a [ ] [ ] are x and y and the dimensions of input matrix b [ ] [ ] are y and z. The resulting ouput matrix c [ ] [ ] is of dimensions x and z.
ALGORITHM
SYNOPSIS void mmul_dpd ( a, x, y, b, z, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
float pm *b ; /* Pointer to input matrix b [ ] [ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34+(4+(6+Y)*Z)*X cycles
NOTES The file tmmuldpd.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element pf c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
C11 C12
C21 C22
A11 A12 A13
A21 A22 A23
B11 B12
B21 B22
B31 B32
•=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-275
mmul_dpp ( a, x, y, b, z, c )
NAME Matrix Multiply
DESCRIPTION This function computes the multiplication of input matrix a times input matrix b and stores the results to output matrix c. The dimensions of matrix a [ ] [ ] are x and y and the dimensions of input matrix b [ ] [ ] are y and z. The resulting ouput matrix c [ ] [ ] is of dimensions x and z.
ALGORITHM
SYNOPSIS void mmul_dpp ( a, x, y, b, z, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
float pm *b ; /* Pointer to input matrix b [ ] [ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
float pm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34+(4+(6+Y)*Z)*X cycles
NOTES The file tmmuldpp.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element pf c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
C11 C12
C21 C22
A11 A12 A13
A21 A22 A23
B11 B12
B21 B22
B31 B32
•=

ADSP-21K Optimized DSP Library User’s Manual
5-276 Wideband Computers, Inc.
mmul_pdd ( a, x, y, b, z, c )
NAME Matrix Multiply
DESCRIPTION This function computes the multiplication of input matrix a times input matrix b and stores the results to output matrix c. The dimensions of matrix a [ ] [ ] are x and y and the dimensions of input matrix b [ ] [ ] are y and z. The resulting ouput matrix c [ ] [ ] is of dimensions x and z.
ALGORITHM
SYNOPSIS void mmul_pdd ( a, x, y, b, z, c )
float pm *a ; /* Pointer to input matrix a [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
float dm *b ; /* Pointer to input matrix b [ ] [ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34+(4+(6+Y)*Z)*X cycles
NOTES The file tmmulpdd.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element pf c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
C11 C12
C21 C22
A11 A12 A13
A21 A22 A23
B11 B12
B21 B22
B31 B32
•=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-277
mmul_pdp ( a, x, y, b, z, c )
NAME Matrix Multiply
DESCRIPTION This function computes the multiplication of input matrix a times input matrix b and stores the results to output matrix c. The dimensions of matrix a [ ] [ ] are x and y and the dimensions of input matrix b [ ] [ ] are y and z. The resulting ouput matrix c [ ] [ ] is of dimensions x and z.
ALGORITHM
SYNOPSIS void mmul_pdp ( a, x, y, b, z, c )
float pm *a ; /* Pointer to input matrix a [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
float dm *b ; /* Pointer to input matrix b [ ] [ ] */
int z ; /* Number of columns in matrix b[ ][ ] */
float pm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34+(4+(6+Y)*Z)*X cycles
NOTES The file tmmulpdp.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
The first row of a [ ] [ ] times the first column of b [ ] [ ] is the first element pf c [ ] [ ] (row 1, column 1). The first row of a [ ] [ ] times the second row of b [ ] [ ] is the sec-ond element of c [ ] [ ] (row 1, column 2 ) ... etc.
This algorithm follows the general law of matrix multiplication whereby the number of columns of input matrix a must equal the number of rows of input matrix b.
C11 C12
C21 C22
A11 A12 A13
A21 A22 A23
B11 B12
B21 B22
B31 B32
•=

ADSP-21K Optimized DSP Library User’s Manual
5-278 Wideband Computers, Inc.
mnot ( a, x, y, c )
NAME Complement Matrix
DESCRIPTION This function mnot( ) logically complements the elements of matrix a [ ] [ ], placing the complemented elements in ouput matrix c [ ] [ ]. Matices a [ ] [ ] and c [ ] [ ] are of the same dimension. Matrix c [ ] [ ] is a 0-1 matrix.
ALGORITHM
SYNOPSIS void mnot ( a, x, y, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
int x ; /* Number of rows in vector a[ ][ ] */
int y ; /* Number of columns in vector a[ ][ ] */
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
ComplementC11 C12
C21 C22
A11 A12
A21 A22
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-279
EXECUTION TIME 33 + 4 * ( N -1 ) cycles
NOTES The file tmnot.c included in the distribution diskette provides an example of this func-tion’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
An example of a matrix compliment is provided below.
a[ ][ ] = ;
x = 3, y = 3 ;
mnot ( a, x, y, c ) ;
The resulting values in output vector c would be as follows:
c[ ][ ] =
mnot ( a, x, y, c )
1.0 1.7 5.55.0 1.6 1.00.0 5.0 6.0
1 1 11 1 10 1 1

ADSP-21K Optimized DSP Library User’s Manual
5-280 Wideband Computers, Inc.
mnull ( a, x, y )
NAME Create Null Matrix
DESCRIPTION This function creates an output null matrix a [ ] [ ] whose elements are all 0s. The number of rows is defined by input scalar x, while the number of columns is defined by input scalar y.
ALGORITHM
SYNOPSIS void mnull ( a, x, y )
float dm *a ; /* Pointer to output matrix a [ ][ ] */
int x ; /* Number of rows in output matrix a[ ][ ] */
int y ; /* Number of columns in output matrix a[ ][ ] */
DOMAIN 0 to 131,000
ACCURACY 7.75 decimal digits
EXECUTION TIME 9 + ( X * Y ) cycles
NOTES The file tmnull.c included in the distribution diskette provides an example of this function’s use.
An example of a null matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
Axy 0=
If x = 4 and y = 5 then a[][]
0 0 0 0 00 0 0 0 00 0 0 0 00 0 0 0 0
=
x 0 y 0>,>

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-281
modf_wci ( x, *n )
NAME Get Fraction and Integer
DESCRIPTION This function computes the integer and fractional parts of a floating-point number, x. The fractional value is returned from this function. The integer part is stored in the object pointed to by n.
ALGORITHM
SYNOPSIS float modf_wci ( float x )
DOMAIN -2.14E9 to 2.14E9
ACCURACY 7.75 decimal digits
EXECUTION TIME 13 cycles
NOTES The file tmodf.c included in the distribution tape provides an example of this func-tion's use.
return x fix x–( ) sign x( )•=

ADSP-21K Optimized DSP Library User’s Manual
5-282 Wideband Computers, Inc.
mor ( a, b, x, y, c )
NAME OR Two Matrices
DESCRIPTION This function mor( ) logically ORs elements of matrices a [ ] [ ] and b [ ] [ ], placing the results in ouput matrix c [ ] [ ]. Matrices a [ ] [ ] and b [ ] [ ] are of the same demension. Matrix c [ ] [ ] is a 0-1 matrix.
ALGORITHM
SYNOPSIS void mor ( a, b, x, y, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
float dm *b ; /* Pointer to input matrix b [ ] [ ] */
int x ; /* Number of rows in vector a[ ][ ] & b [ ] [ ] */
int y ; /* Number of columns in vector a[ ][ ] & b [ ] [ ]*/
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
C11 C12
C21 C22
A11 A12
A21 A22
ORB11 B12
B21 B22
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-283
EXECUTION TIME 33 + 4 * ( N -1 ) cycles
NOTES The file tmor.c included in the distribution diskette provides an example of this func-tion’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
An example of a matrix OR is provided below.
a[ ][ ] = ;
b[ ][ ] =
x = 3, y = 3 ;
mor ( a, b, x, y, c ) ;
The resulting values in output vector c would be as follows:
c[ ][ ] =
mor ( a, b, x, y, c )
0.0 1.7 5.55.0 1.6 1.01.0 0.0 6.0
0.0 1.7 5.55.0 1.6 0.01.0 0.0 6.0
0 1 11 1 11 0 1

ADSP-21K Optimized DSP Library User’s Manual
5-284 Wideband Computers, Inc.
morth ( a, x )
NAME Orthogonal Matrix Check
DESCRIPTION This function transposes input matrix a[ ] [ ] and determines if the matrix is orthogo-nal. If it is orthogonal, a value of 1 is returned. Otherwise a value of 0 is returned.
An orthgonal matrix is one whose transposed matrix times the original matrix equals the identity matrix. The matrix must be square.
ALGORITHM
SYNOPSIS void morth ( a, x )
float dm *a ; /* Pointer to input matrix a[ ][ ] */
int x ; /* Number of rows and columns in matrix a[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
If A
0.5 0.5 0.5 0.50.5– 0.5– 0.5 0.50.5– 0.5 0.5– 0.50.5– 0.5 0.5 0.5–
then=
0.5 0.5 0.5 0.50.5– 0.5– 0.5 0.50.5– 0.5 0.5– 0.50.5– 0.5 0.5 0.5–
0.5 0.5– 0.5– 0.5–0.5 0.5– 0.5 0.50.5 0.5 0.5– 0.50.5 0.5 0.5 0.5–
•
1 0 0 00 1 0 00 0 1 00 0 0 1
=
Morth returns 0

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-285
EXECUTION TIME 30 + ( 8 + ( 12 + 2 * X ) * X ) * X cycles
NOTES The file tmorth.c included in the distribution diskette provides an example of this function’s use.
Transposing a matrix is computed as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
morth ( a, x )
B n[ ] m[ ] A m[ ] n[ ] for m=0 to x-1 and n=0 to x-1=

ADSP-21K Optimized DSP Library User’s Manual
5-286 Wideband Computers, Inc.
movavg ( a, i, w, c, k, n )
NAME Moving Average
DESCRIPTION This function computes a moving average on the input vector a, using input scalar w as the width of the sliding window. The sucessive moving average are placed in output vector c.
ALGORITHM
SYNOPSIS void movavg ( a, i, w, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int w ; /* Pointer to the length of sliding window w */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cmk1
w 1–------------- Ami
0
w
∑• m 0 1 2 …n, 1 }–, ,{==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-287
EXECUTION TIME 52 + 3N-2W
NOTES The file tmovavg.c included in the distribution tape provides an example of this func-tion's use.
movavg() computes the mean of a moving window using vector [a] as an input. The result is stored in output vector [c]. Elements in a vector [a] are successively summed. The number of elements summed is defined by the window length. This sum is then divided by the window length.
Example:
[a] = { 2, 4, 0, 1, 3, 5, 3, 1, 4, 7, 1, };
Window size w = 9
c[0] = ( 2 + 4 + 0 + 1 + 3 + 5 + 3 + 1 + 4 ) / 9 = 2.55555
c[1] = ( 4 + 0 + 1 + 3 + 5 + 3 + 1 + 4 + 7 ) / 9 = 3.11111
c[2] = ( 0 + 1 + 3 + 5 + 3 + 1 + 4 + 7 + 1 ) / 9 = 2.77777
Given a population n and a window size w, there are answers stored to output vector [c].
The length of the window cannot exceed the population size divided by the striding. (i.e., w < = n / i).
The number of moving averages computed is determined by the total number of ele-ments minus the window size.
movavg ( a, i, w, c, k, n )
n w–( ) 1+

ADSP-21K Optimized DSP Library User’s Manual
5-288 Wideband Computers, Inc.
mppivot ( a, b, x )
NAME Partial Pivoting For a Matrix
DESCRIPTION This function performs partial pivoting of input matrix a[ ] [ ]. The results are returned in output matrix a[ ] [ ]. Vector b [ ] is used to return the row interchanges. The row and column dimensions of matrix a[ ] [ ] is x. The vector dimension of b[ ] is also x.
ALGORITHM Parital pivoting attempts to arrange matrix a[ ][ ] in an optimal order by swapping rows. This optimal order aranges elements of a[ ] [ ] so that round off erros are reduced when using the mlu( ) and mfbsub( ) functions. When swappping rows, the largest elements (magnitude) are placed along the diagonal.
SYNOPSIS void mppivot ( a, b, x )
float dm *a ; /* Pointer to input/output matrix a[ ][ ] */
int dm *b ; /* Pointer to output vector b[ ] */
int x ; /* Number of rows and columns in matrix a[ ][ ]*/
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-289
EXECUTION TIME 62 + X + (24 + 11*X ) * X cycles
NOTES The file tmppivot.c included in the distribution diskette provides an example of this function’s use.
Partial pivoting attempts to find the largest elements for the diagonal among the rows. First, the elements in the first column are searched for the largest magnitude. Its’ row is swapped with the 0th row. The 0th row is excluded and the minor sub-matrix is searched for the largest magnitude in the 1st column. Its row is swapped with the 1st row. This process is performed until the last row is left.
Given:
The element with the largest magnitude is -16.
The element with the largest magnitude in the minor sub-matrix (excluding row 0 and column 0) is 6.
The element with the largest magnitude in the minor sub-matrix (excluding rows 0 and columns 0 and 1) is 9.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns. Vector b[ ] need not be initialized. It is assigned within the function. For the example above, the vector is interpreted as follows:
b[0] - Row 0 was swapped with row 3b[1] - Row 1 was swapped with row 2b[2] - Row 2 was swapped with row 3
The row vector interchange b[ ] is used by the function mfbsub() in solving for the unknowns in a set of simultaneous linear equations.
mppivot ( a, b, x )
B 0 0 0 0 A
4 2 9 18 3 0 57 6 10 1216– 14 13 15
=,=
B 3 0 0 0 A
16– 14 13 158 3 0 57 6 10 124 2 9 1
=,=
B 3 2 0 0 A
16– 14 13 157 6 10 128 3 0 54 2 9 1
=,=
B 3 2 3 0 A
16– 14 13 157 6 10 124 2 9 18 3 0 5
=,=

ADSP-21K Optimized DSP Library User’s Manual
5-290 Wideband Computers, Inc.
mpulse ( delta, i, sigma, j, factor, a, k, n )
NAME Monopulse Function
DESCRIPTION This function performs a monpulse computation on vectors delta and sigma using the scaling factor. The results are stored to output vector a.
ALGORITHM
SYNOPSIS void mpulse ( delta, i, sigma, j, factor, a, k, n )
complex pm *delta ; /* Pointer to input vector delta */
int i ; /* Vector delta element stride */
complex pm *sigma ; /* Pointer to input vector sigma */
int j ; /* Vector sigma element stride */
complex dm factor ; /* Complex input scalar factor */
float dm *a ; /* Pointer to Output Vector a[ ] */
int k ; /* Vector a element stride */
int n ; /* Element Count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 7 + 19*N cycles
NOTES The file tmpulse.c included in the distribution diskette provides an example of this function’s use.
Amk 0.5Re deltami s̃igmamj•[ ]
sigmamj2
factor•----------------------------------------------------------•=
where s̃igmamj Complex Conjugate of sigmamj=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-291
mpulsep ( delta_r, delta_i, i, sigma_r, sigma_i, j, factor, a, k, n )
NAME Monopulse Function (Program Memory)
DESCRIPTION This function performs a monpulse computation on vectors delta and sigma using the scaling factor. The results are stored to output vector a.
ALGORITHM
SYNOPSIS void mpulsep ( delta_r, delta_i, i, sigma_r, sigma_i, j, factor,
a, k, n )
float pm *delta_r ; /* Pointer to input vector delta real */
float dm *delta_i ; /* Pointer to input vector delta imag */
int i ; /* Vector delta element stride */
float pm *sigma_r ; /* Pointer to input vector sigma real */
float dm *sigma_i ; /* Pointer to input vector sigma imag */
int j ; /* Vector sigma element stride */
complex dm factor ; /* Complex Input Scalar Factor */
float dm *a ; /* Pointer to Output Vector a[ ] */
int k ; /* Vector a element stride */
int n ; /* Element Count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 75 + 19*N cycles
NOTES The file tmpulsep.c included in the distribution diskette provides an example of this function’s use.
Amk 0.5Re deltami s̃igmamj•[ ]
sigmamj2
factor•----------------------------------------------------------•=
where s̃igmamj Complex Conjugate of sigmamj=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-292 Wideband Computers, Inc.
mskew ( a, x )
NAME Matrix Skew-Symmetric Check
DESCRIPTION This function performs a transpose of input matrix a and determines if the matrix is skew-symmetric. The input integer scalar x contains the number of rows and columns in sqaure input matrix a[ ] [ ].
If it is skew-symmetric a value of 1 is returned. Otherwise a value of zero is returned.
ALGORITHM
SYNOPSIS void mskew ( a, x )
float dm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
/* Number of columns in matrix a[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
return (1 or 0) Is
A11 A12 A13 …
A21 A22 A23 …
… … … …
Skew-Symmetric?=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-293
EXECUTION TIME 10 + ( 3 + 5 * X ) * X cycles
NOTES The file tmskew.c included in the distribution diskette provides an example of this function’s use.
A skew-symmetric matrix is one whose transposed elements are equal to the negative of its corresponding elements (i.e. ). For the diagonal elements, the only value that satisfies this condition is zero. The matrix must be square.
Transposing is peformed as follows:
An example of a skew-symmetric matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
mskew ( a, x )
Amn A– nm=
Bnm Amn for m=0, x and n=0, x=
Amn
0 1 1– 0 0 0 01– 0 0 0 0 0 0
1 0 0 0 0 0 00 0 0 0 0 0 00 0 0 0 0 0 10 0 0 0 0 0 1–0 0 0 0 1– 1 0
=

ADSP-21K Optimized DSP Library User’s Manual
5-294 Wideband Computers, Inc.
msmul ( a, x, y, b, c )
NAME Matrix Scalar Multiply
DESCRIPTION This function computes the multiplication of input matrix a times input scalar b and stores the results to output matrix c [ ] [ ]. The dimensions of input matrix a[ ] [ ] and output matrix c[ ] [ ] are x and y.
ALGORITHM
SYNOPSIS void msmul ( a, x, y, b, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
float dm *b ; /* Pointer to input scalar b [ ] [ ] */
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 2*X*Y cycles
NOTES The file tmsmul.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matricies can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
C11 C12 C13
C21 C22 C23
A11 A12 A13
A21 A22 A23
B•=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-295
msqe ( a, i, b, j, c, n )
NAME Mean Squared Error
DESCRIPTION This routine calculates the mean squared error of the elements within input vector a from the mean input vector b, and places the results in output scalar c.
ALGORITHM
SYNOPSIS void msqe ( a, i, b, j, c, n)
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Element stride for vector b */
float *c ; /* Pointer to resultant output scalar */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 53 +3*(N-1)
NOTES The file tmsqe.c included in the distribution tape provides an example of this func-tion’s use.
C 1 n
------- Ami Bmj–[ ]2
i 0=
n 1–
∑• m 0 1 2 … n, 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-296 Wideband Computers, Inc.
msub ( a, b, x, y, c )
NAME Matrix Subtract
DESCRIPTION This function computes the subtraction of input matrix b[ ] [ ] from input matrix a[ ] [ ] and stores the results to output matrix c[ ] [ ] .
ALGORITHM
SYNOPSIS void msub ( a, b, x, y, c )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
float dm *b ; /* Pointer to input matrix b [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] and b[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] & b[ ][ ] */
float dm *c ; /* Pointer to output matrix c [ ] [ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 3*X*Y cycles
NOTES The file tmsub.c included in the distribution diskette provides an example of this func-tion’s use.
The storage methodology for matrices is by rows. Matricies can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
This algorithm computes the difference of two matrices of the same order: i.e, the number of rows and columns of input matrix a[ ] [ ] must equal the number of rows and columns of input matrix b[ ] [ ] .
C11 C12 C13
C21 C22 C23
A11 A12 A13
A21 A22 A23
B11 B12 B13
B21 B22 B23
–=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-297
msym ( a, x )
NAME Matrix Symmetric Check
DESCRIPTION This function performs a transpose of input matrix a[ ] [ ] and determines if the matrix is symmetric.
If it is symmetric a value of 1 is returned. Otherwise a value of zero is returned.
The number of rows and columns in input matrix a[ ] [ ] is supplied in input scalar arguments x.
ALGORITHM
SYNOPSIS void msym ( a, x )
float dm *a ; /* Pointer to input matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
/* Number of columns in matrix a[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
return (1 or 0) Is
A11 A12 A13 …
A21 A22 A23 …
… … … …
Symmetrical?=

ADSP-21K Optimized DSP Library User’s Manual
5-298 Wideband Computers, Inc.
EXECUTION TIME 18 + ( 3 + 4X)*X cycles
NOTES The file tmsym.c included in the distribution diskette provides an example of this function’s use.
A symmetric matrix is one whose transposed elements are equal to its corresponding elements (i.e. ). The matrix must be square.
Transposing is peformed as follows:
An example of a symmetric matrix is as follows:
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
msym ( a, x )
Amn Anm=
Bnm Amn for m=0, x and n=0, x=
Amn
1 1 1 0 0 0 01 1 0 0 0 0 01 0 1 0 0 0 00 0 0 0 0 0 00 0 0 0 1 0 10 0 0 0 0 1 10 0 0 0 1 1 1
=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-299
mtrace ( a, x )
NAME Matrix Trace
DESCRIPTION This function computes the trace of input matrix a[ ] [ ] and returns the resulting sum. The input integer scalar x contains the number of rows and columns in input matrix a[ ] [ ].
ALGORITHM
SYNOPSIS float mtrace ( a, x )
float dm *a ; /* Pointer to output matrix a [ ][ ] */
int x ; /* Number of rows and columns in matrix a[ ][ ] */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 8 + X cycles
NOTES The file tmtrace.c included in the distribution diskette provides an example of this function’s use.
The trace is the sum of the diagonal elements of a square matrix
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
return trace a i[ ] i[ ]
i 0=
x
∑=
If a[][]
1 1.7 5.5 145 1.6 1 511 5 6 11 1.5 9 10
and x 4 then trace = 18.6==

ADSP-21K Optimized DSP Library User’s Manual
5-300 Wideband Computers, Inc.
mtrans ( a, b, x, y )
NAME Matrix Transpose
DESCRIPTION This function transposes the contents of input matrix a and places the results in output matrix b. The dimensions of matrix a[ ] [ ] are x and y and the dimensions of output matrix b[ ] [ ] are y and x.
ALGORITHM
SYNOPSIS void mtrans ( a, b, x, y )
float dm *a ; /* Pointer to input matrix a [ ] [ ] */
float dm *b ; /* Pointer to input matrix b [ ] [ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
Number of columns in matrix b[ ][ ]
int y ; /* Number of columns in matrix a[ ][ ] */
Number of rows in matrix b[ ][ ]
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + (3 + 2*Y) * X cycles
NOTES The file tmtrans.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
If A
A11 A12
A21 A22
A31 A32
then AT A11 A21 A31
A12 A22 A32
==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-301
mulawc ( a, i, c, k, n )
NAME u-Law Compression
DESCRIPTION This routine performs an u-law compression on the elements in input vector a and out-puts the compressed results to output vector c.
ALGORITHM
SYNOPSIS void mulawc ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector i */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Number of floating-point elements */
DOMAIN 0 to 255
ACCURACY 7.75 decimal digits
EXECUTION TIME 49 + 16 * ( N-1 )
NOTES The file tmulawc.c included in the distribution tape provides an example of this func-tion’s use.
The mulawc() routine takes a linear 14-bit signed speech sample and compresses it according to CCITT (now ITU) recommendation G.711. The 8-bit compressed sample is output to vector c.
Cmk ulaw compression of Ami=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-302 Wideband Computers, Inc.
mulawe ( a, i, c, k, n )
NAME u-Law Expansion
DESCRIPTION This routine performs an u-law expansion on the elements in input vector a and out-puts the expanded results to output vector c.
ALGORITHM
SYNOPSIS void mulawe ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector i */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Number of floating-point elements */
DOMAIN 0 to 255
ACCURACY 7.75 decimal digits
EXECUTION TIME 48 + 14 * ( N-1 )
NOTES The file tmulawe.c included in the distribution tape provides an example of this func-tion’s use.
The mulawe() routine takes an 8-bit compressed speech sample and expands it according to CCITT (now ITU) recommendation G.711. The 14-bit signed sample is output to vector c.
Cmk ulaw expansion of Ami=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-303
munity ( a, x, y )
NAME Unity Matrix
DESCRIPTION This function creates a constant output matrix a whose elements are all equal 1. The input integer scalar x contains the number of rows in input matrix a[ ] [ ]. The input integer scalar y contains the number of columns in input matrix a[ ] [ ].
ALGORITHM
SYNOPSIS void munity ( a, x, y )
float dm *a ; /* Pointer to output matrix a [ ][ ] */
int x ; /* Number of rows in matrix a[ ][ ] */
int y ; /* Number of columns in matrix a[ ][ ] */
DOMAIN 0 to 131,000
ACCURACY 7.75 decimal digits
EXECUTION TIME 9 + ( X * Y ) cycles
NOTES The file tmunity.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the number of col-umns.
Axy 1=
x 0 y 0>,>

ADSP-21K Optimized DSP Library User’s Manual
5-304 Wideband Computers, Inc.
mve ( a, i, c, n )
NAME Vector Mean
DESCRIPTION This function computes the mean of the elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void mve ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 1*(N-1) cycles
NOTES The file tmve.c included in the distribution diskette provides an example of this func-tion’s use.
C 1n--- Ami
m 0=
n 1–
∑= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-305
mvemg ( a, i, c, n )
NAME Vector Mean of Magnitudes
DESCRIPTION This function computes the mean of the magnitudes of the elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void mvemg ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 30 + 1*(N-1) cycles
NOTES The file tmvemg.c included in the distribution diskette provides an example of this function’s use.
C 1n--- Ami
m 0=
n 1–
∑= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-306 Wideband Computers, Inc.
mvesq ( a, i, c, n )
NAME Vector Mean of Squares
DESCRIPTION This function computes the mean of the squares of all elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void mvesq ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -1.8 x1019 to +1.8 x1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 30 + 2*(N-1) cycles
NOTES The file tmvesq.c included in the distribution diskette provides an example of this function’s use.
The function can be used to compute Parseval’s theorem. Parseval’s theorem is often used as a way to compute the total signal power of a signal after being transformed by an FFT. This allows signal power to easily be calculated in the frequency domain.
C 1n--- A2
mim 0=
n 1–
∑= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-307
mvessq ( a, i, c, n )
NAME Vector Mean of Signed Squares
DESCRIPTION This function computes the mean of the signed squares of all elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void mvessq ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + 3*(N-1) cycles
NOTES The file tmvessq.c included in the distribution diskette provides an example of this function’s use.
C 1n--- Ami Ami•
m 0=
n 1–
∑= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-308 Wideband Computers, Inc.
mvmul ( a, x, y, b, c )
NAME Matrix-Vector Multiply
DESCRIPTION This function multiplies input matrix a[ ] [ ] by input vector b, and stores the result in output vector c. The dimensions of input matrix a[ ] [ ] are supplied in input integer scalar arguments x and y while the length of input vector b is supplied in input integer scalar y. The resulting output vector c is of length x.
ALGORITHM
SYNOPSIS void mvmul ( a, x, y, b, c )
float *a ; /* Pointer to input matrix a */
int x ; /* Number of rows in matrix a */
/* Number of columns in matrix a */
int y ; /* Number of elements in vector b */
float *b ; /* Pointer to input vector b */
float *c ; /* Pointer to output vector c */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 33 + ( 7 + 2 * Y ) * X cycles
NOTES The file tmvmul.c included in the distribution diskette provides an example of this function’s use.
The storage methodology for matrices is by rows. Matrices can be thought of as one long array (vector) where the beginning of each row is offset by the length of the col-umn.
The first row of a[ ] [ ] times vector b is the first element of vector c. The first row of a[ ] [ ] times vector b is the second elements of vector c, etc.
Cm Am k, Bk•
k 0=
y 1–
∑=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-309
perm ( a, b )
NAME Permutation
DESCRIPTION This function computes the permutation of input scalar a and input scalar b. The result is returned in perm.
ALGORITHM
SYNOPSIS void perm ( a, b )
int dm a ; /* Input value a */
int dm b ; /* Input value b */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 + B*2 cycles
NOTES The file tperm.c included in the distribution diskette provides an example of this func-tion’s use.
The of input scalar a must be positive. If not, a value of -99 is returned.
The value of input scalar b must be positive and less then the value of input scalar a. If not, a value of -99 is returned.
return a!a b–( )!
------------------=

ADSP-21K Optimized DSP Library User’s Manual
5-310 Wideband Computers, Inc.
polar ( a, i, c, k, n )
NAME Vector Cartesian To Polar Coordinates Conversion
DESCRIPTION This function converts Cartesian (rectangular) coordinates in real input vector a to polar coordinates and stores the results in real output vector c. All input coordinates are considered to be in radians.
ALGORITHM
SYNOPSIS void polar ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Re Cmk{ } Re2
Ami{ } Im2
Ami{ }+=
Im Cmk{ }Im Ami{ }
Re Ami{ }------------------------atan= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-311
EXECUTION TIME 63 + 91*N cycles
NOTES The file tpolar.c included in the distribution diskette provides an example of this func-tion’s use.
Cartesian coordinates are sometimes refered to as rectangular or x,y coordinates. Polar coordinates are sometimes refered to as magnitude, phase or radius, angle coordinates.
Note that the synposis section does not list either the Cartesian coordinates in input vector a or the Polar coordinates in output vector c as type complex. However, for computational purposes you may consider these as complex types, each having a real and imaginary portion consisting of either an x,y or a magnitude, phase component. The algorithm expects the Cartesian and Polar coordinates to be supplied in pairs, analagous to the manner in which we treat complex pairs. They are dyads which are considered to be atomic.
Note that this algorithm is the opposite of rect, which converts Polar coordinates to rectangular coordinates.
polar ( a, i, c, k, n )

ADSP-21K Optimized DSP Library User’s Manual
5-312 Wideband Computers, Inc.
pow_wci ( x, y )
NAME Power
DESCRIPTION This function computes x raised to the power y. A domain error is returned if x is neg-ative and y is not an integral value.
ALGORITHM
SYNOPSIS float pow_wci ( float x, float y )
DOMAIN -3.4E+38 to 3.4E+38 ( range of y depends on x )
ACCURACY 7.75 decimal digits
EXECUTION TIME 83 cycles
NOTES The file tpow.c included in the distribution tape provides an example of this function's use.
return xy=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-313
rangev ( a, i, &c, n )
NAME Range of Vector
DESCRIPTION This routine computes the range between the maximum value and minimum value of the elements in input vector a and places the results in output scalar c.
ALGORITHM
SYNOPSIS void range ( a, i, &c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 24 + 2 * ( N-1 )
NOTES The file trangev.c included in the distribution tape provides an example of this func-tion’s use.
rangev() sucessively searches all elements within input vector [a] and computes the range between the maximum and minimum values.
C Max a[ ] Min a[ ]– from 0 to n-1=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-314 Wideband Computers, Inc.
rect ( a, i, c, k, n )
NAME Vector Polar To Cartesian Coordinates Conversion
DESCRIPTION This function converts polar coordinates (magnitude, phase) in input vector a to Car-tesian (real, imaginary) coordinates and stores the results in output vector c. All input coordinates are considered to be in radians.
ALGORITHM
SYNOPSIS void rect ( a, i, c, k, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Re Cmk{ } R= e Ami{ } Im Ami{ }cos•
Im Cmk{ } Re Ami{ } Im Ami{ }sin•=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-315
EXECUTION TIME 41 + 49 * N cycles
NOTES The file trect.c included in the distribution diskette provides an example of this func-tion’s use.
Polar coordinates are sometimes refered to as magnitude, phase or radius, angle coor-dinates. Cartesian coordinates are sometimes refered to as rectangular or x,y coordi-nates.
Note that the synposis section does not list either the Polar coordinates in input vector a or the Cartesian coordinates in output vector c as type complex. However, for com-putational purposes you may consider these as complex types, each having a real and imaginary portion consisting of either an x,y or a magnitude, phase component. The algorithm expects the Polar and Polar coordinates to be supplied in pairs, analagous to the manner in which we treat complex pairs. They are dyads which are considered to be atomic.
Note that this algorithm is the opposite of polar, which converts Rectangular coordi-nates to Polar coordinates.
rect ( a, i, c, k, n )

ADSP-21K Optimized DSP Library User’s Manual
5-316 Wideband Computers, Inc.
rfft ( x, real, imag, sintab, costab, wstr, n )
NAME Fast Fourier Transform of Real Input/Output Data
DESCRIPTION The routines computes an out-of-place, Radix-2 decimation in frequency FFT of length 64 or greater on input data x. Input data is no destroyed during the course of the execution of this routines.
ALGORITHM
SYNOPSIS void rfft ( x, real, imag, sintab, costab, wstr, n )
float dm *x ; /* Pointer to real input data */
float dm *real ; /* Pointer to output real data */
float pm *imag ; /* Pointer to output imaginary data */
float dm *sintab ; /* Pointer to sine table */
float pm *costab ; /* Pointer to cosine table */
int wstr ; /* Cosine/sine table stride */
int n ; /* FFT Size (In Real Elements) */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME See Attached Table Below
Cm e2πjmk– n⁄
m 0 1 2 … n, 1–, , ,{ }=
m 0=
h 1–
∑=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-317
NOTES The file trfft.c included in the distribution tape provides an example of this function’suse.
This algorithm is the fastest performing routine amongst the rfft( ), rffts( ) andrfftip() routines. This algorithm operates using an out-of-place methodology. Notethat versions 2.5 and lower of the Wideband Optimized DSP Library containedan rfft( ) routine which has been renamed rfftip( ). The current routine rfft( ) dif-fers significantly from the previous rfft( ) routine found in earlier versions of thelibrary. See the final section of Chapter 4 for more details.
The real FFT is accomplished by doing an N/2 complex FFT of y(i), whereRE[y(i)]=x(2i) and Im[y(i)] = x(2i+1) for i=0,1,...,n-1. This is followed by some calcu-lation to derive X(k) from Y(k). This method has been refered to as “packing”. Inputdata is NOT destroyed during the course of this routine. Note that only N/2+1 FFTpoints are needed to deine the real FFT spectra because of the Hermitian symmetry(complex conjugate) of the real FFT.
x [n] is the real normal-ordered input in DMreal [n/2+1] are the real parts of fft stored in DMimag [n/2+1] are the imaginary parts of fft stored in PMsintab [n/2] are the imaginary parts of weight/twiddle data in DMcostab [n/2] are the real parts of weight/twiddle data in PM
The weight/twiddle tables are in sintab[ ] and costab[ ] respectively and are given thevalues:
for i = { 0, 1, ..., wstr*n/2-1 }
The last 3 timings on timing chart were extrapolated from the based cycle count of1,024 points using the following formula:
Cycle count for
This cycle count will probably be on the low side as there may not be enough on-chipmemory to accomodate the accurate measument of large FFTs.
Restrictions:
• The number of elements n must be an integral power of 2 and a minimum of 64.• The input vector x[ ] must be in dm memory and must be aligned to an address which is
an integral multiple of n.• The input vector x[ ] is strided by one.• The output vectors are real[ ] and imag[ ] are in dm and pm memory respectively.• The real and imaginary weights/twiddles (cosine and sine data) are defined in pm and
dm memory respectively.
rfft ( x, real, imag, sintab, costab, wstr, n )
sintab[i] π i wstrn2---•
⁄• and tab[i]cos π i wstrn2---•
ڥcos=sin=
nn
2nlog•
10242
of1024log•---------------------------------------------- 1 024 cycle,•= n=
n2
nlog•10240
----------------------- 11 990,•=

ADSP-21K Optimized DSP Library User’s Manual
5-318 Wideband Computers, Inc.
SPECIAL NOTES Previous users have sometimes reported problems associated with implementing inter-rupt service routines (ISRs), when used in conjunction with the FFT routines (cfft ( ),cffti( ), rfft( ), rffti( ), etc. ). Observations related to the Wideband technical staff typ-ically include a description of the Wideband routine executing perfectly, but unable toreturn to an exact state after being interrupted by the ISR ( a “tumble into the weeds” ).
The Wideband Fast Fourier transforms, both complex and real, forward and inverse,use the built-in bit reversing and circular addressing capabilites of the SHARC archi-tecture. Also, other routines such as some of the FIR filters use the SHARC’s internalcircular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the mode 1 regiser, which is associated withbit reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In such circumstances where they are not saved and restored by the ISRthey are unable to return the proper length parameter ( L Register ) used for circularaddressing or the proper mode ( Mode 1 Register ) used in Bit Reversing. This resultsin the strange manefestations users sometimes report.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.
For a detailed review of the relationships between the various FFT functions and howto use them with one another, see the final section of Chapter 4.
rfft ( x, real, imag, sintab, costab, wstr, n )
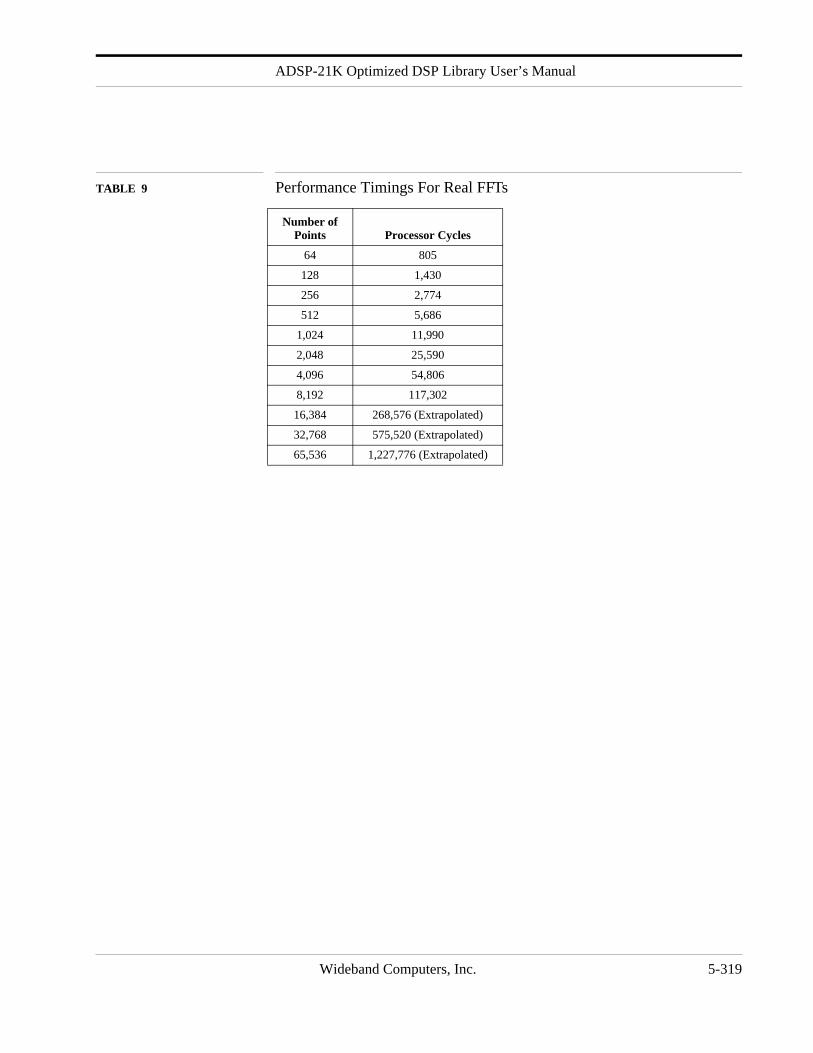
ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-319
TABLE 9 Performance Timings For Real FFTs
Number of Points Processor Cycles
64 805
128 1,430
256 2,774
512 5,686
1,024 11,990
2,048 25,590
4,096 54,806
8,192 117,302
16,384 268,576 (Extrapolated)
32,768 575,520 (Extrapolated)
65,536 1,227,776 (Extrapolated)

ADSP-21K Optimized DSP Library User’s Manual
5-320 Wideband Computers, Inc.
rfft8 ( xr, yr, yi )
NAME 8-Point Real Fast Fourier Transform (Inline)
DESCRIPTION Computes the Fast Fourier Transform of the real elements stored in input vector xr. The results are stored to output vector yr and yi. This routine is coded fully inline for minimum execution time but is structured as an out-of-place routine.
ALGORITHM
SYNOPSIS void rfft8 ( xr, yr, yi )
float dm *xr ; /* Pointer to real input data */
float dm *yr ; /* Pointer to real output data */
float pm *yi ; /* Pointer to imaginary output data */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 136 Cycles
NOTES This is an 8-point radix-2 Fast Fourier Transform using parallel data memory/programmemory data accesses to maximize the throughput on the 21020/60/62 processor.
The real input data is in vector xr. This vector must be aligned on an address whichis an integer multiple of the FFT size, as required for 21K bit-reverse addressing.The input vector is in data memory.
The complex output is separated into real and imaginary parts, yr and yi. These vec-tors may have arbitrary address alignment; however yr is in the data memory and yi isin the program memory.
The file trfft8.c included in the distribution tape provides an example of this func-tion’s use.
The entire algorithm is coded inline for optimal execution speed.
For a detailed review of the relationships between the various FFT functions and howto use them with one another, see the final section of Chapter 4.
Ym Xke2πj m k 8⁄•( )–
m 0 1 2 … 7,, , ,{ }=
k 0=
7
∑=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-321
SPECIAL NOTES Some end users have reported reported problems associated with implementing inter-rupt service routines (ISRs) used in conjunction with the rfft8( ) routine. Recordedobservations forwarded to the Wideband technical staff usually include a descriptionof the Wideband routine somehow “tumbling into the weeds” after being interupted byan ISR. This is because the exact state of the fft routine is not saved and restored wheninterupted by the ISR.
All Wideband Fast Fourier transform routines, both complex and real, forward andinverse, use the built-in bit reversing and circular addressing capabilites of theSHARC architecture. This is also true of other routines such as some of the FIR filters,which use the SHARC’s internal circular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the Mode1 register, which is associatedwith bit reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In circumstances where they are not saved and restored by the callingISR, the length parameter ( L Register ) used for circular addressing or the propermode ( Mode1 Register ) used in bit reversing are not properly restored. This resultsin the strange manefestations users sometimes report, as the fft routine, upon restora-tion continues to execute code but the Mode 1 Register or L Register are not restored,thus indicating a false count or mode.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.

ADSP-21K Optimized DSP Library User’s Manual
5-322 Wideband Computers, Inc.
rfft16 ( xr, yr, yi )
NAME 16-Point Real Fast Fourier Transform (Inline)
DESCRIPTION Computes the Fast Fourier Transform of the real elements stored in input vector xr. The results are stored to output vector yr and yi. This routine is coded fully inline for minimum execution time but is structured as an out-of-place routine.
ALGORITHM
SYNOPSIS void rfft16 ( xr, yr, yi )
float dm *xr ; /* Pointer to real input data */
float dm *yr ; /* Pointer to real output data */
float pm *yi ; /* Pointer to imaginary output data */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 337 Cycles
NOTES This is an 16-point radix-2 Fast Fourier Transform using parallel data memory/pro-gram memory data accesses to maximize the throughput on the 21020/60/62 proces-sor.
The real input data is in vector xr. This vector must be aligned on an address whichis an integer multiple of the FFT size, as required for 21K bit-reverse addressing.The input vector is in data memory.
The complex output is separated into real and imaginary parts, yr and yi. These vec-tors may have arbitrary address alignment; however yr is in the data memory and yi isin the program memory.
The file trfft16.c included in the distribution tape provides an example of this func-tion’s use.
The entire algorithm is coded inline for optimal execution speed.
For a detailed review of the relationships between the various FFT functions and howto use them with one another, see the final section of Chapter 4.
Ym Xke2πj m k 16⁄•( )–
m 0 1 2 … 15,, , ,{ }=
k 0=
15
∑=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-323
SPECIAL NOTES Some end users have reported reported problems associated with implementing inter-rupt service routines (ISRs) used in conjunction with the rfft16( ) routine. Recordedobservations forwarded to the Wideband technical staff usually include a descriptionof the Wideband routine somehow “tumbling into the weeds” after being interupted byan ISR. This is because the exact state of the fft routine is not saved and restored wheninterupted by the ISR.
All Wideband Fast Fourier transform routines, both complex and real, forward andinverse, use the built-in bit reversing and circular addressing capabilites of theSHARC architecture. This is also true of other routines such as some of the FIR filters,which use the SHARC’s internal circular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the Mode1 register, which is associatedwith bit reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In circumstances where they are not saved and restored by the callingISR, the length parameter ( L Register ) used for circular addressing or the propermode ( Mode1 Register ) used in bit reversing are not properly restored. This resultsin the strange manefestations users sometimes report, as the fft routine, upon restora-tion continues to execute code but the Mode 1 Register or L Register are not restored,thus indicating a false count or mode.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.

ADSP-21K Optimized DSP Library User’s Manual
5-324 Wideband Computers, Inc.
rfft32 ( xr, yr, yi )
NAME 32-Point Real Fast Fourier Transform (Inline)
DESCRIPTION Computes the Fast Fourier Transform of the real elements stored in input vector xr. The results are stored to output vector yr and yi. This routine is coded fully inline for minimum execution time but is structured as an out-of-place routine.
ALGORITHM
SYNOPSIS void rfft32 ( xr, yr, yi )
float dm *xr ; /* Pointer to real input data */
float dm *yr ; /* Pointer to real output data */
float pm *yi ; /* Pointer to imaginary output data */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 689 Cycles
NOTES This is an 32-point radix-2 Fast Fourier Transform using parallel data memory/pro-gram memory data accesses to maximize the throughput on the 21020/60/62 proces-sor.
The real input data is in vector xr. This vector must be aligned on an address whichis an integer multiple of the FFT size, as required for 21K bit-reverse addressing.The input vector is in data memory.
The complex output is separated into real and imaginary parts, yr and yi. These vec-tors may have arbitrary address alignment; however yr is in the data memory and yi isin the program memory.
The file trfft32.c included in the distribution tape provides an example of this func-tion’s use.
The entire algorithm is coded inline for optimal execution speed.
For a detailed review of the relationships between the various FFT functions and howto use them with one another, see the final section of Chapter 4.
Ym Xke2πj m k 32⁄•( )–
m 0 1 2 … 31,, , ,{ }=
k 0=
31
∑=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-325
SPECIAL NOTES Some end users have reported reported problems associated with implementing inter-rupt service routines (ISRs) used in conjunction with the rfft32( ) routine. Recordedobservations forwarded to the Wideband technical staff usually include a descriptionof the Wideband routine somehow “tumbling into the weeds” after being interupted byan ISR. This is because the exact state of the fft routine is not saved and restored wheninterupted by the ISR.
All Wideband Fast Fourier transform routines, both complex and real, forward andinverse, use the built-in bit reversing and circular addressing capabilites of theSHARC architecture. This is also true of other routines such as some of the FIR filters,which use the SHARC’s internal circular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the Mode1 register, which is associatedwith bit reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In circumstances where they are not saved and restored by the callingISR, the length parameter ( L Register ) used for circular addressing or the propermode ( Mode1 Register ) used in bit reversing are not properly restored. This resultsin the strange manefestations users sometimes report, as the fft routine, upon restora-tion continues to execute code but the Mode 1 Register or L Register are not restored,thus indicating a false count or mode.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.

ADSP-21K Optimized DSP Library User’s Manual
5-326 Wideband Computers, Inc.
rffti ( real, imag, x, sintab, costab, wstr, n )
NAME Inverse Fast Fourier Transform of Real Input/Output Data
DESCRIPTION Computes the inverse real FFT ( Fast Fourier Transform ) of length 64 or greater on input data X(n). X(n) is converted into U(n) + jV(n), where U(n) and V(n) are the real and imaginary parts of the FFT transform of x(2n) + jx(2n+1). An inverse FFT is then performed on U(n) + jV(n) to yield x(n).
ALGORITHM
SYNOPSIS void rffti ( real, imag, x, sintab, costab, wstr, n )
float dm *real ; /* Pointer to real input data */
float pm *imag ; /* Pointer to input imaginary data */
float dm *x ; /* Pointer to output data */
float dm *sintab ; /* Pointer to sine weight table */
float pm *costab ; /* Pointer to cosine weight table */
int wstr ; /* Weight stride */
int n ; /* Number of Elements */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME See Attached Table Below
Xm Um Vj m 0 1 2 … n, 1–, , ,{ }=⋅
j 0=
h 1–
∑=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-327
NOTES The file trffti.c included in the distribution tape provides an example of this function’suse.
The inverse FFT is accomplished by switching the real and imaginary parts, taking the forward FFT, then then switching the real and imaginary again. Note that for an N point IFFT, only N/2+1 FFT points are needed because of the Hermitian symmetry of the real FFT. Input data is destroyed during the course of the routine.
real [n/2+1] are real frequency domain data in DMimag [n/2+1] are imaginary frequency domain data in PMx [n] is the real normal-ordered output in DMsintab [n/2] are the imaginary part of weight/twiddle data in DMcostab [n/2] are the real part of weight/twiddle data in PM
The weight/twiddle tables are in sintab[ ] and costab[ ] respectively and are given thevalues:
for i = { 0, 1, ..., wstr*n/2-1 }
The last 3 timings on timing chart were extrapolated from the based cycle count of1,024 points using the following formula:
Cycle count for
This cycle count will probably be on the low side as there may be enough on-chipmemory to accomodate large FFTs.
Restrictions
• The number of elements n must be an integral power of 2 and a minimum of 64.
• The output vector x[ ] and input vector real[ ] must be in dm memory and must be aligned to an address which is an integral multiple of n.
• The output vector x[ ] is strided by one.
• The input vectors are real[ ] and imag[ ] are in dm and pm memory respectively.
• The real and imaginary weights/twiddles (cosine and sine data) are defined in pm and dm memory respectively
rffti ( real, imag, x, sintab, costab, wstr, n )
sintab[i] π i wstrn2---•
ڥsin=
tab[i]cos π i wstrn2---•
ڥcos=
nn
2nlog•
10242
of1024log•---------------------------------------------- 1 024 cycle,•= n=
n2
nlog•10240
----------------------- 13 794,•=

ADSP-21K Optimized DSP Library User’s Manual
5-328 Wideband Computers, Inc.
Previous users have sometimes reported problems associated with implementing inter-rupt service routines (ISRs) when used in conjunction with the FFT routines ( cfft( ),cffti( ), rfft( ), rffti( ) ). Observations related to the Wideband technical staff typicallyinclude a description of the Wideband routine executing perfectly, but unable to returnto an exact state after being interrupted by the ISR ( a veritable “tumble into theweeds.” )
The Wideband Fast Fourier transforms, both complex and real, forward and inverse,use the built-in bit reversing and circular addressing capabiliites of the SHARC archi-tecture. Also, other routines such as some of the FIR filters use the SHARC’s internalcircular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the mode 1 regiser, which is associated withbir reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In such circumstances where they are not saved and restored by the ISRthey are unable to return the proper length parameter ( L Register ) used for circularaddressing or the proper mode ( Mode 1 Register ) used in Bit Reversing. This resultsin the strange manefestations users sometimes report.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.
For a detailed review of the relationships between the various FFT functions and howto use them with one another, see the final section of Chapter 4.
rffti ( real, imag, x, sintab, costab, wstr, n )
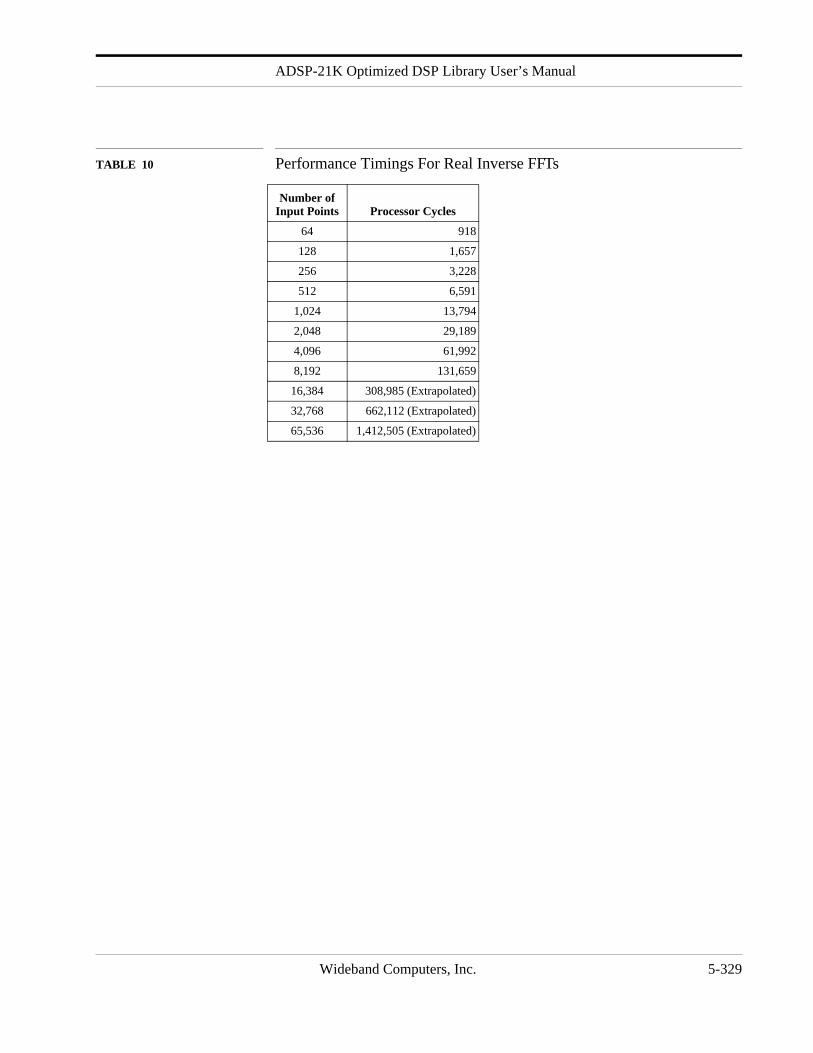
ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-329
TABLE 10 Performance Timings For Real Inverse FFTs
Number of Input Points Processor Cycles
64 918
128 1,657
256 3,228
512 6,591
1,024 13,794
2,048 29,189
4,096 61,992
8,192 131,659
16,384 308,985 (Extrapolated)
32,768 662,112 (Extrapolated)
65,536 1,412,505 (Extrapolated)

ADSP-21K Optimized DSP Library User’s Manual
5-330 Wideband Computers, Inc.
rfftip ( data, wr, wi, wstr, tmp_dm, tmp_pm, n )
NAME Fast Fourier Transform of Real Input/Output Data In Place
DESCRIPTION This routine computes a Radix-2, in-place, decimation-in-time, Discrete Fourier Transform of real-valued input data using a Fast Fourier Transform (FFT) algorithm. The input vector data[ ] is a real-valued vector of n elements. On return from the rfftip ( ) call, data[ ] contains n/2 complex values representing the DFT of the input function. In previous versions of theWideband library ( 2.5 and below) this function was known as the rfft ( ) function. See the final section of Chapter 4 for more details.
To compute the inverse of the the rfftip ( ) function, reorder the output data from rfftip( ) using the vrfftip ( ) function, and then call the rffti ( ) function, supplying the results from the vrfftip ( ) function.
Restrictions
The number of elements n must be an integral power of 2 and a minimum of 64.
Vectors tmp_pm and tmp_dm are work buffers of minimum lenght n/2 and must be in program memory and data memory respectively.
Vectors wr and wi are in program memory and data memory respectively, and are given the values
wr[k] = cos [2 pi k / (wstr*n)], k = 0, 1, ..., wstr*n/2-1wr[k] = sin [2 pi k / (wstr*n)], k = 0, 1, ..., wstr*n/2-1
Vector data must be in data memory and must be aligned to an address which isan integral multiple of n.
ALGORITHM
SYNOPSIS void rfftip ( data, wr, wi, wstr, tmp_dm, tmp_pm, n )
float dm *data ; /* Pointer to real input/output data */
float pm *wr ; /* Pointer to cosine table */
float dm *wi ; /* Pointer to sine table */
int dm wstr ; /* Weight stride */
float dm *tmp_dm ; /* Pointer to DM work buffer */
float dm *tmp_pm ; /* Pointer to PM work buffer */
int n ; /* FFT Size (In Real Elements) */
Fk Fie2πij ik n⁄( )–
k 0 1 2 … n, 1–, , ,{ }=
i 0=
n 1–
∑=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-331
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME See Attached Table Below
NOTES This function computes a Discrete Fourier Transform of real-valued input data using aFast Fourier Transform (FFT) algorithm. The input vector data is a real-valued func-tion on n elements. On return from the rfftip( ) call, data[] contains n/2 complex val-ues representing the DFT of the input function.
The general expression for the DFT is as follows:
F[ ] and f[ ] are complex-valued vectors. rffts( ) assumes that f[ ] is a real-valued vec-tor, i.e., Im(f) = 0. The DFT of a real-valued function has the following properties:
and
rfftip( ) makes use of these properties to “stuff” the complex-valued output functioninto the n-element real input vector. The DFT values are stored such that
To compute the inverse of the the rfftip( ) function, reorder the output data fromrfftip( ) using the vrfftip( ) function, and then call the rffti( ) function, supplying theresults from the vrfftip( ) function.
The rfft( ) algorithm executes faster than the rffts( ) algorithm, which in turn executesfaster than the rfftip( ) algorithm.
The file trfftip.c included in the distribution tape provides an example of this func-tion’s use.
rfftip ( data, wr, wi, wstr, tmp_dm, tmp_pm, n )
Fk fie2πj i k n⁄( )– k 0 1 2 … n, 1–, , ,{ }=
i 0=
n 1–
∑=
Fn k– Fk∗ k 0 1 … n 1–, , ,{ }== m Fn 2⁄( ) Im F0( ) 0==
Re F0( ) data 0[ ]=
Re Fk( ) data 2 k•[ ] k 1 2 … n 2 1–⁄, , ,{ }==
Im Fk( ) data 2 k 1+•[ ] k 1 2 … n 2 1–⁄, , ,{ }==
Re Fn 2⁄( ) data 1[ ]=
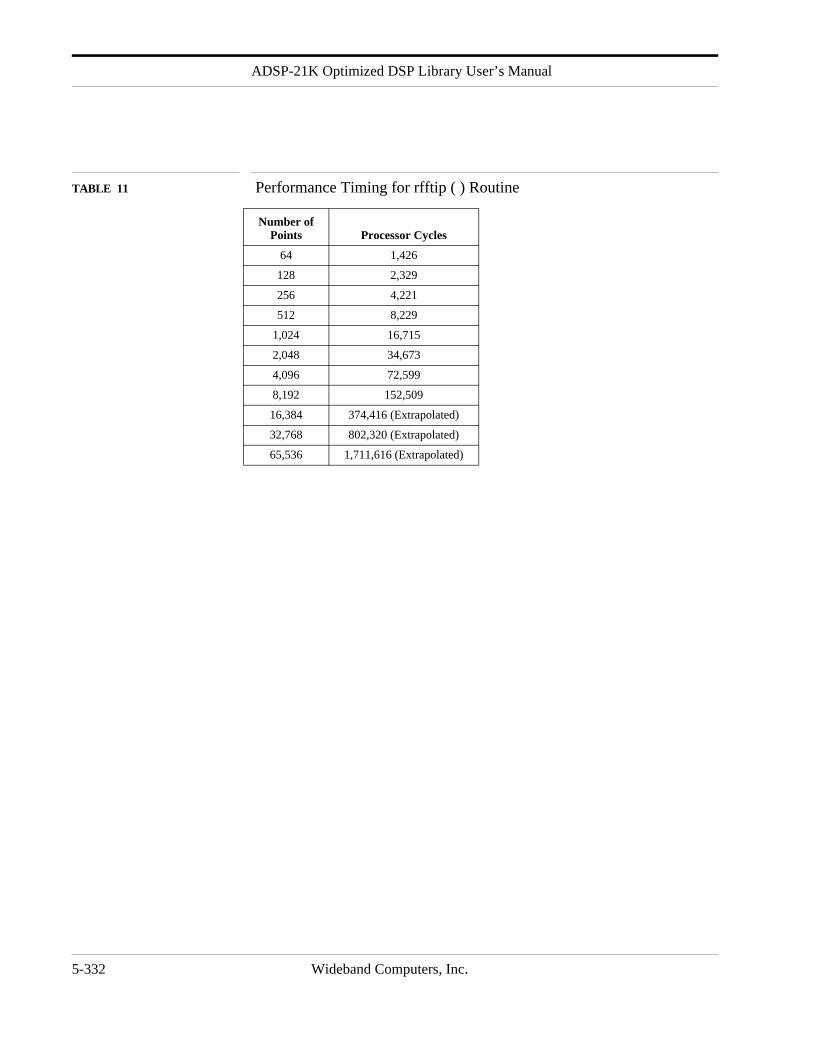
ADSP-21K Optimized DSP Library User’s Manual
5-332 Wideband Computers, Inc.
TABLE 11 Performance Timing for rfftip ( ) Routine
Number of Points Processor Cycles
64 1,426
128 2,329
256 4,221
512 8,229
1,024 16,715
2,048 34,673
4,096 72,599
8,192 152,509
16,384 374,416 (Extrapolated)
32,768 802,320 (Extrapolated)
65,536 1,711,616 (Extrapolated)

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-333
SPECIAL NOTES Some end users have reported reported problems associated with implementing inter-rupt service routines (ISRs) used in conjunction with the fft routines. Recorded obser-vations forwarded to the Wideband technical staff usually include a description of theWideband routine somehow “tumbling into the weeds” after being interupted by anISR. This is because the exact state of the fft routine is not saved and restored wheninterupted by the ISR.
All Wideband Fast Fourier transform routines, both complex and real, forward andinverse, use the built-in bit reversing and circular addressing capabilites of theSHARC architecture. This is also true of other routines such as some of the FIR filters,which use the SHARC’s internal circular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the Mode1 register, which is associatedwith bit reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In circumstances where they are not saved and restored by the callingISR, the length parameter ( L Register ) used for circular addressing or the propermode ( Mode1 Register ) used in bit reversing are not properly restored. This resultsin the strange manefestations users sometimes report, as the fft routine, upon restora-tion continues to execute code but the Mode 1 Register or L Register are not restored,thus indicating a false count or mode.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.

ADSP-21K Optimized DSP Library User’s Manual
5-334 Wideband Computers, Inc.
rffts ( x, tmppm, sintab, costab, wtstr, n )
NAME Fast Fourier Transform of Real Input/Output Data Using Sorenson Method
DESCRIPTION This routine computes a Radix-2 in-place, decimation-in-time, Discrete Fourier Transform of real-valued input data using a Fast Fourier Transform (FFT) algorithm. The input vector x [ ] is a real-valued vector of n elements. On return from the rffts ( ) call, x[ ] contains n/2 complex values representing the DFT of the input function. To compute the inverse of the the rffts ( ) function, reorder the output data from the rffts( ) function using the vrffts ( ) function, and then call the rffti ( ) function, supplying the results from the vrffts ( ) function.
Restrictions
The number of elements n must be an integral power of 2 and a minimum of 64.
Vector x must be in data memory and must be aligned to an address which is anintegral multiple of n.
ALGORITHM
SYNOPSIS void rffts ( x, tmppm, sintab, costab, wtstr, n )
float dm *x ; /* Pointer to real input/output data */
float pm *tmppm ; /* Pointer to scratch pm data */
float dm *sintab ; /* Pointer to sine weight table */
float pm *costab ; /* Pointer to Cosine weight table */
int dm *wtstr ; /* Weight stride */
int n ; /* FFT Size (In Real Elements) */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Fk Fie2πij ik n⁄( )–
k 0 1 2 … n, 1–, , ,{ }=
i 0=
n 1–
∑=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-335
EXECUTION TIME See Attached Table Below
NOTES This function computes a Discrete Fourier Transform of real-valued input data using aFast Fourier Transform (FFT) algorithm. The input vector data is a real-valued func-tion on n elements. On return from the rfft( ) call, x contains n/2 complex values rep-resenting the DFT of the input function.
The general expression for the DFT is as follows:
F[] and f[] are complex-valued vectors. rffts( ) assumes that f[] is a real-valued vector,i.e., Im(f) = 0. The DFT of a real-valued function has the following properties:
and
rffts( ) makes use of these properties to “stuff” the complex-valued output functioninto the n-element real input vector. The DFT values are stored such that
Re ( F[0] ) = x[0]Re ( F[1] ) = x[1] . .Re ( F[n/2] ) = x[n/2]Im ( F[n/2-1] ) = x[n/2+1]Im ( F[n/2-2] ) = x[n/2+2] . .
Im ( F[1] ) = x[n-1]
This algorithm was adapted from the FORTRAN program developed by HenrikSorenson et al., in the IEEE Transaction on ASSP, June 1987.
To compute the inverse of the the rffts( ) function, reorder the output data from therffts( ) function using the vrffts( ) function, and then call the rffti( ) function, supply-ing the results from the vrffts( ) function.
The rfft( ) algorithm executes faster than the rffts( ) algorithm, which in turn executesfaster than the rfftip( ) algorithm.
The file trffts.c included in the distribution tape provides an example of this function’suse.
rffts ( x, tmppm, sintab, costab, wtstr, n )
Fk fie2πj i k n⁄( )– k 0 1 2 … n, 1–, , ,{ }=
i 0=
n 1–
∑=
Fn k– Fk∗ k 0 1 … n 1–, , ,{ }== Im Fn 2⁄( ) Im F0( ) 0==
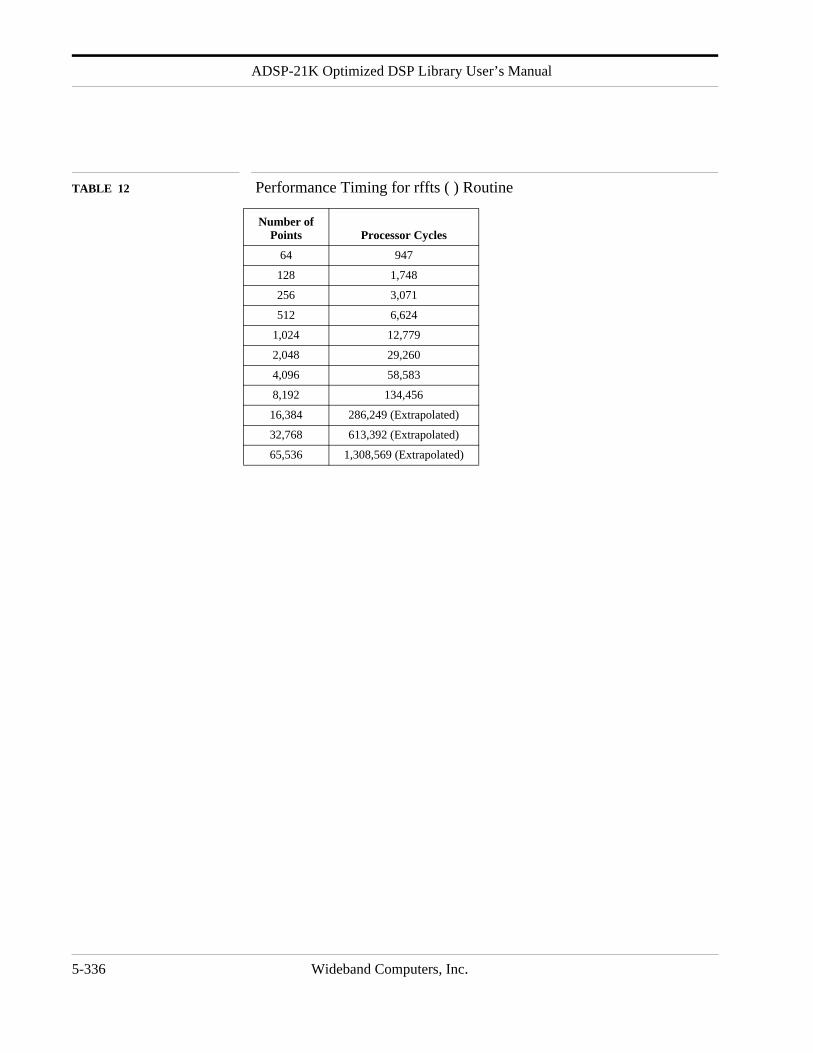
ADSP-21K Optimized DSP Library User’s Manual
5-336 Wideband Computers, Inc.
TABLE 12 Performance Timing for rffts ( ) Routine
Number of Points Processor Cycles
64 947
128 1,748
256 3,071
512 6,624
1,024 12,779
2,048 29,260
4,096 58,583
8,192 134,456
16,384 286,249 (Extrapolated)
32,768 613,392 (Extrapolated)
65,536 1,308,569 (Extrapolated)

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-337
SPECIAL NOTES Some end users have reported reported problems associated with implementing inter-rupt service routines (ISRs) used in conjunction with the fft routines. Recorded obser-vations forwarded to the Wideband technical staff usually include a description of theWideband routine somehow “tumbling into the weeds” after being interupted by anISR. This is because the exact state of the fft routine is not saved and restored wheninterupted by the ISR.
All Wideband Fast Fourier transform routines, both complex and real, forward andinverse, use the built-in bit reversing and circular addressing capabilites of theSHARC architecture. This is also true of other routines such as some of the FIR filters,which use the SHARC’s internal circular addressing capabilities.
End users are usually cognizant that their ISR calling routine is responsible for savingand restoring the registers of the Wideband routines. However, end users sometimesforget to save and restore ( push and pop ) the Mode1 register, which is associatedwith bit reversing and the B ( base ) and L ( length ) registers associated with circularaddressing. In circumstances where they are not saved and restored by the callingISR, the length parameter ( L Register ) used for circular addressing or the propermode ( Mode1 Register ) used in bit reversing are not properly restored. This resultsin the strange manefestations users sometimes report, as the fft routine, upon restora-tion continues to execute code but the Mode 1 Register or L Register are not restored,thus indicating a false count or mode.
To properly save and restore the above mentioned registers in an ISR, refer to page 4-21, section 4.3 of the Analog Devices ADSP-21000 Family C Tools Manual (#31-000005-08, dated August 95) which references examples of in line assembly codewithin C code to save and restore registers.

ADSP-21K Optimized DSP Library User’s Manual
5-338 Wideband Computers, Inc.
rmvesq ( a, i, c, n )
NAME Vector Root Mean Square
DESCRIPTION This function computes the root mean square of all elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void rmvesq ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 46 + 2*(N-1) cycles
NOTES The file trmvesq.c included in the distribution diskette provides an example of this function’s use.
If all elements in input vector a are zero, a zero value is returned.
C 1n--- A2
mi
m 0=
n 1–
∑= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-339
rsqrt_wci ( x )
NAME Reciprocal Square Root
DESCRIPTION This function computes the reciprocal square root a floating-point number, x. The computed value is returned from this function. A domain error occurs if x < 0.0.
ALGORITHM
SYNOPSIS float rsqrt_wci ( float x )
DOMAIN 0.0 to 3.40E38
ACCURACY 7.75 decimal digits
EXECUTION TIME 19 cycles
NOTES The file trsqrt.c included in the distribution tape provides an example of this func-tion's use.
return 1.0
x-------=

ADSP-21K Optimized DSP Library User’s Manual
5-340 Wideband Computers, Inc.
scvdiv ( a, i, b, c, k, n )
NAME Scalar Divide By Vector
DESCRIPTION This function divides input scalar b by input vector a and stores the result in output vector c.
ALGORITHM
SYNOPSIS void scvdiv ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Count of floating-point elements */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 37 + 10*(N-1) cycles
NOTES The file tscvdiv.c included in the distribution diskette provides an example of this function’s use.
This routine does not contain logic to check for an attempted divide by zero. If an ele-ment of vector a [ ] is set to zero an attempt to divide by zero error will occur.
CmkB
Ami---------- m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-341
scvpow ( a, i, b, c, k, n )
NAME Compute the Powers of a Scalar to a Vector
DESCRIPTION This function computes the results of scalar b raised to an element in input vector a [ ]. The results are stored in output vector c.
ALGORITHM
SYNOPSIS void scvpow ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of the base b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 50 + 61*N cycles for a < > 0 and b > 0
50 + 6*N cycles for a = 0 and b > 0
25 + 7*N cycles for b <= 0
NOTES The file tscvpow.c included in the distribution diskette provides an example of this function’s use.
1. For input scalar b equal to zero, elements in input vector a[ ] must be greater than zero.
2. For input scalar b less then zero, elements in input vector a[ ] must be equal to zero.
3. -99 is returned for conditions 1 or 2 not satisfied.
Cmk BAmi
m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-342 Wideband Computers, Inc.
scvsub ( a, i, b, c, k, n )
NAME Subtract Vector from Scalar
DESCRIPTION This function subtracts input vector a from input scalar b by and stores the result in output vector c.
ALGORITHM
SYNOPSIS void scvsub ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Count of floating-point elements */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 39 + 2*(N-1) cycles
NOTES The file tscvsub.c included in the distribution diskette provides an example of this function’s use.
Cmk B Ami – m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-343
see ( yi, sl, a, b, s, c, n )
NAME Standard Error of Estimate
DESCRIPTION This function computes the standard error of estimate of predicted y values of the lin-ear least-squares regression fit (see lsqreg( )) from the actual y values. Input vector c contains the actual measured input y values while input vector b contains the values predicted by the linear least-squares regression fit formula. The ideal y values are cal-culated from the scalar input y-intercept yi, the scalar input slope sl, and the x-coordi-nates values found within input vector a. The routine then calculates the standard error of estimate and places the results in output scalar d.
ALGORITHM
SYNOPSIS void see ( yi, sl, a, b, s, c, n )
float *yi ; /* Pointer to input scalar y-intercept yi */
int *sl ; /* Pointer to input scalar slope sl */
float *a ; /* Pointer to intput measured x values vector a */
float *b ; /* Pointer to intput measured x values vector b */
int s ; /* Element stride for input vectors [a] and [b] */
float *d ; /* Pointer to resultant output scalar error c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Bms yi sl Ams•( )+=
where yi= calculated y-intercept from the lsqreg() function
where sl= calculated slope from the lsqreg() function
D
n Cms Bms–( )2
i 0=
n 1–
∑n 2–
--------------------------------------------------=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-344 Wideband Computers, Inc.
EXECUTION TIME 82 + 5*(N-1) cycles
NOTES The file tsee.c included in the distribution tape provides an example of this function's use.
This routine implements a mathematical technique to estimate the variance of the mea-sured data in input vector c from the ideal predicted data calculated from the lsqreg( ) regression equation routine. It can be thought of as a measure of the standard deviation of the measured population (input vector c) from the ideal population (input vector b) predicted by the linear regression line equation. As such, it can be used as an accurate predictor of the variation of the measured y data values (input vector c) about the pre-dicted ideal regression line, and hence shed light into the error contained within the sampled data.
Note that in order to execute this operation, you must first execute the lsqreq( ) routine to compute a y-intercept and x-coordinate vector. The resulting regression equation will yield two values, a, the y-intercept and b, the slope. When both values are used with the input value x, which represents the actual (observe value) x-coordinate, an ideal resulting y, which we represented as can be calculated. The formula is as fol-lows: .
We have renamed the variables a and b to yi and sl for clairity. This calculation is per-formed on each input x-coordinate value to an ideal array, which we call vector b, which contains the resulting idealized y values predicted by the regression equation. Each of these values, in turn, is compared to the actual measured y values to yield the final standard error fo the estimate.
Also note that the input scalar s contains the stride values for vectors a, and b, which should remain equal throughout the calculation.
An ideal value is calculated for each observed x value. The resulting values are placed in input array b.
see ( yi, sl, a, b, s, c, n )
y'y a bx+=
y'

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-345
sin_wci ( x )
NAME Sine
DESCRIPTION This function computes the sine of a floating-point number x where x is measured in radians. The computed value is returned from this function.
ALGORITHM
SYNOPSIS float sin_wci ( float x )
DOMAIN - 205,884 < x < 205,884 radians
ACCURACY 7.75 decimal digits
EXECUTION TIME 28 cycles
NOTES The file tsin.c included in the distribution tape provides an example of this function's use.
return x( )sin=

ADSP-21K Optimized DSP Library User’s Manual
5-346 Wideband Computers, Inc.
sinc ( a, i, c, k, n )
NAME Sinc Function
DESCRIPTION This function computes the sinc function of the input elements contained within input vector a and stores the result to output vector c.
ALGORITHM
SYNOPSIS void sinc ( a, i, c, k, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for input vector a */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 49 + 35*N cycles
NOTES The file tsinc.c included in the distribution diskette provides an example of this func-tion’s use.
Note that A cannot be equal to zero or a divide by zero error will occur.
Cmk
Amisin
Ami----------------- m 0 1 2 …n, 1 }–, ,{==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-347
sinh_wci
NAME Hyperbolic Sine
DESCRIPTION This function computes the hyperbolic sine of a floating-point number, x ( x is mea-sured in radians ). The computed value is returned from this function.
ALGORITHM
SYNOPSIS float sinh_wci ( float x )
DOMAIN -88 to +88
ACCURACY 7.75 decimal digits
EXECUTION TIME 56 cycles
NOTES The file tsinh.c included in the distribution tape provides an example of this function's use.
return x( )sinh=

ADSP-21K Optimized DSP Library User’s Manual
5-348 Wideband Computers, Inc.
slidwin ( a, i, w, c, k, n )
NAME Sliding Window
DESCRIPTION This function computes a sliding window summation of the values contained within input vector a, defined using input scalar w as the width of the sliding window. The sliding window summations are placed in output vector c.
ALGORITHM
SYNOPSIS void slidwin ( a, i, w, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int w ; /* Pointer to the length of sliding window w */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
Cmk Ami
0
w
∑ m 0 1 2 …n, 1 }–, ,{==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-349
EXECUTION TIME 38 + ( W - 1 ) + 3 * ( N - W )
NOTES The file tslidwin.c included in the distribution tape provides an example of this func-tion's use.
slidwin() computes the sum of a moving window using vector a as an input vector. The results are stored to output vector c. Elements in a vector a are successively summed. The number of elements summed is defined by the window length. This sum is then stored.
Example:
[a] = { 2, 4, 0, 1, 3, 5, 3, 1, 4, 7, 1, };
Window size w = 9
c[0] = ( 2 + 4 + 0 + 1 + 3 + 5 + 3 + 1 + 4 ) = 23
c[1] = ( 4 + 0 + 1 + 3 + 5 + 3 + 1 + 4 + 7 ) = 28
c[2] = ( 0 + 1 + 3 + 5 + 3 + 1 + 4 + 7 + 1 ) = 25
The length of the window cannot exceed the population size divided by the striding. (i.e., w < = n / i).
The number of elements computed is determined by the total number of elements minus the window size.
slidwin ( a, i, w, c, k, n )

ADSP-21K Optimized DSP Library User’s Manual
5-350 Wideband Computers, Inc.
snd ( a, i, b, c, n )
NAME Signal Noise Distortion
DESCRIPTION This function computes the signal to noise density of the input elements contained within input vector a with respect to the input signal scalar b and stores the result to output scalar c.
ALGORITHM
SYNOPSIS void snd ( a, i, b, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input signal b */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 130 + 2 * (N-1) cycles
NOTES The file tsnd.c included in the distribution diskette provides an example of this func-tion’s use.
C 2010
B( ) 2010
Ami∑ log•–log•=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-351
sqrt_wci ( x )
NAME Square Root
DESCRIPTION This function computes the square root a floating-point number, x. The computed value is returned from this function. A domain error occurs if x < 0.
ALGORITHM
SYNOPSIS float sqrt_wci ( float x )
DOMAIN 0.0 to 3.40E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 cycles
NOTES The file tsqrt.c included in the distribution tape provides an example of this function's use.
return x=

ADSP-21K Optimized DSP Library User’s Manual
5-352 Wideband Computers, Inc.
std ( a, i, c, n )
NAME Standard Deviation
DESCRIPTION This function computes the standard deviation of the input elements contained within input vector a and stores the result to output scalar c.
ALGORITHM
SYNOPSIS void std ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 57 + 4 * (N-1) cycles
NOTES The file tstd.c included in the distribution diskette provides an example of this func-tion’s use.
Cn ami
2ami∑
2
–∑n n 1–( )
--------------------------------------------------=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-353
sve ( a, i, c, n )
NAME Vector Sum
DESCRIPTION This function computes the sum of the elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void sve ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 14 + 1*(N-1) cycles
NOTES The file tsve.c included in the distribution diskette provides an example of this func-tion’s use.
C Ami
m 0=
n 1–
∑= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-354 Wideband Computers, Inc.
svemg ( a, i, c, n )
NAME Vector Sum Magnitudes
DESCRIPTION This function computes the sum of the magnitudes of the elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void svemg ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 19 + 2*(N-1) cycles
NOTES The file tsvemg.c included in the distribution diskette provides an example of this function’s use.
C Ami
m 0=
n 1–
∑=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-355
svesq ( a, i, c, n )
NAME Vector Sum of the Squares
DESCRIPTION This function computes the sum of the squares of the elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void svesq ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x 1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 19 + 2*(N-1) cycles
NOTES The file tsvesq.c included in the distribution diskette provides an example of this func-tion’s use.
C A2mi
m 0=
n 1–
∑=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-356 Wideband Computers, Inc.
svessq ( a, i, c, n )
NAME Vector Sum of the Signed Squares
DESCRIPTION This function computes the sum of the signed squares of the elements in input vector a and stores the result in output scalar c.
ALGORITHM
SYNOPSIS void svessq ( a, i, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x 1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 + 3*(N-1) cycles
NOTES The file tsvessq.c included in the distribution diskette provides an example of this function’s use.
C Ami Ami•
m 0=
n 1–
∑= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-357
tan_wci ( x )
NAME Tangent
DESCRIPTION This function computes the tangent of a floating-point number, x ( x is measured in radians ). The computed value is returned from this function.
ALGORITHM
SYNOPSIS float tan_wci ( float x )
DOMAIN - 205,884 < x < 205,884 radians
ACCURACY 7.75 decimal digits
EXECUTION TIME 49 cycles
NOTES The file ttan.c included in the distribution tape provides an example of this function's use.
tanh_wci ( x )
NAME Hyperbolic Tangent
DESCRIPTION This function computes the hyperbolic tangent of a floating-point number, x ( x is measured in radians ). The computed value is returned from this function.
ALGORITHM
SYNOPSIS float tanh_wci ( float x )
DOMAIN -88 to +88
ACCURACY 7.75 decimal digits
EXECUTION TIME 66 cycles
NOTES The file ttanh.c included in the distribution tape provides an example of this function's use.
return x( )tan=
return x( )tanh=

ADSP-21K Optimized DSP Library User’s Manual
5-358 Wideband Computers, Inc.
vaam ( a, i, b, j, c, k, d, l, e, h, n )
NAME Vector Add, Add, and Multiply
DESCRIPTION This function adds two input vectors a and b, adds two other input vectors c and d, then multiplies the two intermediate results, and stores the result in output vector e.
ALGORITHM
SYNOPSIS void vaam ( a, i, b, j, c, k, d, l, e, h, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to input vector d */
int l ; /* Address stride in words for input vector d */
float *e ; /* Pointer to output vector e */
int h ; /* Address stride in words for output vector e */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 59 + 5*(N-1) cycles
NOTES The file tvaam.c included in the distribution diskette provides an example of this func-tion’s use.
Emh Ami Bmj+( ) Cmk Dml+( )•=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-359
vabs ( a, i, c, k, n )
NAME Vector Absolute Value
DESCRIPTION This function computes the absolute value of all elements of vector a and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vabs ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4E+38 to +3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 22 + 2*(N-1) cycles
NOTES The file tvabs.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-360 Wideband Computers, Inc.
vacos ( a, i, c, k, n )
NAME Vector Arccosine
DESCRIPTION This function computes the arc cosine ( inverse cosine ) for each element in input vec-tor a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vacos ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 to +1.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 66 + (35 to 56)*N cycles
NOTES The file tvacos.c included in the distribution diskette provides an example of this func-tion’s use.
If the input argument supplied from in input vector a is less than 0.5 then the inner loop of this routine will execute in 36 cycles. If the input argument supplied in input vector a is greater than 0.5 then the inner-loop of this routine will execute in 56 cycles.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=acos=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-361
vacosh ( a, i, c, k, n )
NAME Vector Inverse Hyperbolic Cosine
DESCRIPTION This function computes the inverse hyperbolic cosine for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vacosh ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 to +1.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 42 + 57*N cycles
NOTES The file tvacosh.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=acosh=

ADSP-21K Optimized DSP Library User’s Manual
5-362 Wideband Computers, Inc.
vacot ( a, i, c, k, n )
NAME Vector Arc Cotangent
DESCRIPTION This function computes the arc cotangent ( inverse cotangent ) for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vacot ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 48 + (60 to 77 to 63 to 53)*N cycles
NOTES The file tvacot.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amiacot m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-363
vacoth ( a, i, c, k, n )
NAME Vector Arc Hyperbolic Cotangent
DESCRIPTION This function computes the arc hyperbolic cotangent ( inverse hyperbolic tangent ) for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vacoth ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 39 + 59*N cycles
NOTES The file tvacoth.c included in the distribution diskette provides an example of this function’s use.
Cmk Amiacoth m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-364 Wideband Computers, Inc.
vacsc ( a, i, c, k, n )
NAME Vector Arc Cosecant
DESCRIPTION This function computes the arc cosecant ( inverse cosecant ) for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vacsc ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 54 + (43 to 62)*N cycles
NOTES The file tvacsc.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amiacsc m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-365
vacsch ( a, i, c, k, n )
NAME Vector Arc Hyperbolic Cosecant
DESCRIPTION This function computes the arc hyperbolic cosecant ( inversehyperbolic cosecant ) for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vacsch ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 + 65*N cycles
NOTES The file tvacsch.c included in the distribution diskette provides an example of this function’s use.
Cmk Amiacsch m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-366 Wideband Computers, Inc.
vadd ( a, i, b, j, c, k, n )
NAME Vector Add
DESCRIPTION This function adds two input vectors a and b, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vadd ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 3*(N-1) cycles
NOTES The file tvadd.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami Bmj+ m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-367
vam ( a, i, b, j, c, k, d, l, n )
NAME Vector Add and Multiply
DESCRIPTION This function adds two input vectors a and b, then multiplies the sum by input vector c and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vam ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 + 4*(N-1) cycles
NOTES The file tvam.c included in the distribution diskette provides an example of this func-tion’s use.
Dml Ami Bmj+( ) Cmk• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-368 Wideband Computers, Inc.
vand ( a, i, b, j, c, k, n )
NAME Vector And
DESCRIPTION This function performs a 32-bit logical AND of each element in input vector a with each element in input vector b and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vand ( a, i, b, j, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 33 + 3*(N-1) cycles
NOTES The file tvand.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami AND Bmj( )= m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-369
var_wci ( a, i, c, n )
NAME Variance
DESCRIPTION This function computes the variance of the input elements contained within input vec-tor a and stores the result to output scalar c.
ALGORITHM
SYNOPSIS void var_wci ( a, i, &c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output scalar c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 40 + 3 * (N-1) cycles
NOTES The file tvarwci.c included in the distribution diskette provides an example of this function’s use.
Cn ami
2ami∑
2
–∑n n 1–( )
--------------------------------------------------=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-370 Wideband Computers, Inc.
vascm ( a, i, b, j, c, d, l, n )
NAME Vector Add and Scalar Multiply
DESCRIPTION This function adds two input vectors, a and b, then multiplies the sum by an input sca-lar c and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vascm ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 3*(N-1) cycles
NOTES The file tvascm.c included in the distribution diskette provides an example of this function’s use.
Dml Ami Bmj+( ) C• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-371
vascs ( a, i, b, j, c, d, l, n )
NAME Vector Add and Scalar Subtract
DESCRIPTION This function adds two input vectors a and b, then subtracts input scalar c from the sum, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vascs ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 3*(N-1) cycles
NOTES The file tvascs.c included in the distribution diskette provides an example of this func-tion’s use.
Dml Ami Bmj+( ) C– m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-372 Wideband Computers, Inc.
vasec ( a, i, c, k, n )
NAME Vector Arcsecant
DESCRIPTION This function computes the arcsecant ( inverse secant ) for each element in input vec-tor a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vasec ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 63 + (46 to 65)*N cycles
NOTES The file tvasec.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amiasec m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-373
vasech ( a, i, c, k, n )
NAME Vector Arc Hyperbolic Secant
DESCRIPTION This function computes the arc hyperbolic secant ( inverse hyperbolic secant ) for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vasech ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 37 + ( 7 to 9 to 60)*N cycles
NOTES The file tvasech.c included in the distribution diskette provides an example of this function’s use.
Cmk Amiasech m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-374 Wideband Computers, Inc.
vashift ( a, i, c, k, n, h )
NAME Vector Arithmetic Shift
DESCRIPTION This function performs an arithmetic shift of h bits on each 32-bit element in input vector a and stores the results in output vector c. If h is negative the bits are right-shifted with a sign fill into the most significant bit (MSB). If h is positive the bits are left-shifted with a zero fill into the least significant bit (LSB).
ALGORITHM if then
Sign Fill MSB
else
Zero Fill LSB
SYNOPSIS void vashift ( a, i, c, k, n, h )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
int h ; /* Length of arithmetic shift */
DOMAIN H must be between -32 to +32.
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 2*(N-1) cycles
NOTES The file tvashift.c included in the distribution diskette provides an example of this function’s use. Note that each right-shift or left-shift is shifted through the carry bit.
H 0< m 0 1 2 …n, 1 }–, ,{=
Cmk Ami H»=
Cmk Ami H«=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-375
vasin ( a, i, c, k, n )
NAME Vector Arcsine
DESCRIPTION This function computes the arcsine ( inverse sine ) for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vasin ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 to +1.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 71 + (36 to 56)*N cycles
NOTES The file tvasin.c included in the distribution diskette provides an example of this func-tion’s use.
If the input argument supplied in input vector a is less than 0.5 then the inner-loop of this routine will execute in 36 cycles. If the input argument supplied in input vector a is greater than 0.5 then the inner-loop of this routine will execute in 56 cycles.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=asin=

ADSP-21K Optimized DSP Library User’s Manual
5-376 Wideband Computers, Inc.
vasinh ( a, i, c, k, n )
NAME Vector Inverse Hyperbolic Sine
DESCRIPTION This function computes the inverse hyperbolic sine for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vasinh ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 to +1.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 53*N cycles
NOTES The file tvasinh.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=asinh=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-377
vasm ( a, i, b, j, c, k, d, l, e, h, n )
NAME Vector Add, Subtract and Multiply
DESCRIPTION This function adds two input vectors, a and b, adds two other input vectors, c and d, then multiplies the two intermediate results, and stores the result in output vector e.
ALGORITHM
SYNOPSIS void vasm ( a, i, b, j, c, k, d, l, e, h, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to input vector d */
int l ; /* Address stride in words for input vector d */
float *e ; /* Pointer to output vector e */
int h ; /* Address stride in words for output vector e */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 59 + 5*(N-1) cycles
NOTES The file tvasm.c included in the distribution diskette provides an example of this func-tion’s use.
Emh Ami Bmj+( ) Cmk Dml–( )• =
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-378 Wideband Computers, Inc.
vaspec ( a, i, b, j, c, k, n )
NAME Vector Accumulating Auto-spectrum
DESCRIPTION Computes an accumulating autospectrum of vector elements found within input vec-tor a[ ] and vector b[ ]. The accumulated result is stored in output vector c.
ALGORITHM
SYNOPSIS void vaspec ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Stride of a [ ] */
float *b ; /* Pointer to input vector b */
int j ; /* Stride of b [ ] */
float *c ; /* Pointer to output vector c */
int k ; /* Stride of c [ ] */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 4*N cycles
NOTES The file tvaspec.c included in the distribution tape provides an example of this func-tion’s use.
The stride of vectors a and c must always be 1.
If you wish to clear the auto-spectrum results before they are added to output vector cuse the vclr( ) function. If the results are not cleared using vclr( ), autospectrum resultsare added to output vector c, thus computing an accumulating autospectrum.
The vaspec( ) function is intended to compliment the outputs from the cfft( ) and rfft( )functions.
Cmk Cmk Ami– Bmj+⇐
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-379
vatan ( a, i, c, k, n )
NAME Vector Arctangent
DESCRIPTION This function computes the arctangent ( inverse tangent ) for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vatan ( a, i, c, k, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34 + 57*N cycles
NOTES The file tvatan.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=atan=

ADSP-21K Optimized DSP Library User’s Manual
5-380 Wideband Computers, Inc.
vatan2 ( y, i, x, j, c, k, n )
NAME Vector Arctangent, 2 Arguments
DESCRIPTION This function computes the arctangent ( inverse tangent ) for each element in input vectors y and x, and stores the result in output vector c. All angles in vector c are returned in radians. Vector y is divided by vector x to obtain the tangent for the argu-ment to the inverse tangent computation.
ALGORITHM
SYNOPSIS void vatan2 ( y, i, x, j, c, k, n )
float dm *y ; /* Pointer to input vector y */
int i ; /* Address stride in words for input vector a */
float dm *x ; /* Pointer to input vector x */
int j ; /* Address stride in words for input vector b */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109 , Bmj should not equal zero.
ACCURACY 7.75 decimal digits
EXECUTION TIME 50 + 70 (max) *N cycles
NOTES The file tvatan2.c included in the distribution diskette provides an example of this function’s use.
Cmk 2YmiXmj---------
m 0 1 2 …n 1–, , ,{ }=atan=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-381
vatanh ( a, i, c, k, n )
NAME Vector Inverse Hyperbolic Tangent
DESCRIPTION This function computes the inverse hyperbolic tangent for each element in vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vatanh ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 51*N cycles
NOTES The file tvatanh.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=atanh=

ADSP-21K Optimized DSP Library User’s Manual
5-382 Wideband Computers, Inc.
vavexp ( a, i, b, c, k, n )
NAME Vector Exponential Average
DESCRIPTION This function computes the exponential average of input vector a weighted by input scalar b. The results are stored to output vector c.
ALGORITHM
SYNOPSIS void vavexp ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for inoput vector a */
float *b ; /* Scalar Weighting Factor */
float *c ; /* Pointer to input/output vector c */
int k ; /* Element stride for input/output vector c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 39 + 3*N
NOTES The file tvavexp.c included in the distribution tape provides an example of this func-tion’s use.
Note that vector c is both an input and output vector. If you wish to clear this vector before use, use the vclr( ) function which will initialize the contents of input vector c with zeroes.
Input scalar b, the scalar weighting factor, should not equal zero to avoid a divide by zero error.
Cmk
Cmk B 1–( ) Ai+•
B------------------------------------------------ m 0 1 2 … n, 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-383
vavlin ( a, i, b, c, k, n )
NAME Vector Linear Average
DESCRIPTION This function computes the linear average of input vector a weighted by input scalar b. The results are stored to output vector c.
ALGORITHM
SYNOPSIS void vavlin ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for inoput vector a */
float *b ; /* Scalar Weighting Factor */
float *c ; /* Pointer to input/output vector c */
int k ; /* Element stride for input/output vector c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 39 + 3*N
NOTES The file tvavlin.c included in the distribution tape provides an example of this func-tion’s use.
Note that vector c is both an input and output vector. If you wish to clear this vector before use, use the vclr( ) function which will initialize the contents of input vector c with zeroes.
Input scalar b, the scalar weighting factor, should not equal zero to avoid a divide by zero error.
Cmk
Cmk B Ai+•
B 1.0+---------------------------------- m 0 1 2 … n, 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-384 Wideband Computers, Inc.
vbsort ( a, b, n )
NAME Vector Perform Bubble Sort
DESCRIPTION This function performs a bubble sort on input/ouput vector a. The sort order is deter-mined by the sort flag b. For b=1, input/output vector a is sorted in ascending order, smallest to largest. For b=0, input/ouput vector a is sorted in descending order, largest to smallest. The output is stored in vector a.
ALGORITHM
SYNOPSIS void vbsort ( a, b, n )
float dm *a ; /* Pointer to input\output vector a */
float b ; /* Sort flag */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 45 + N*(6 + 7*N) cycles
NOTES The file tvbsort.c included in the distribution diskette provides an example of this function’s use.
If B 1 then A is sorted smallest to largest=
If B 0 then A is sorted largest to smallest=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-385
vcbrt ( a, i, c, k, n )
NAME Vector Cube Root
DESCRIPTION This function computes the cube root of each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vcbrt ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 50 + 75*N cycles
NOTES The file tvcbrt.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami3 m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-386 Wideband Computers, Inc.
vceil ( a, i, c, k, n )
NAME Vector Ceiling (Round Up To Nearest Integral Value)
DESCRIPTION This function computes the smallest integral value greater than or equal to the float-ing-point number in input vector a and stores a floating-point representation of this integral result in output vector c.
ALGORITHM
SYNOPSIS void vceil ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 24 + 7*N cycles
NOTES The file tvceil.c included in the distribution diskette provides an example of this func-tion’s use. This function is the opposite of vfloor( ).
Cmk smallest integer Ami≥= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-387
vclip ( a, i, b, c, d, l, n )
NAME Vector Clip
DESCRIPTION This function uses a lower-threshold scalar b and an upper-threshold scalar c to clip each element in input vector a and stores the results in output vector d.
ALGORITHM
SYNOPSIS void vclip ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input lower-threshold scalar b */
float c ; /* Value of input upper-threshold scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 19 + 3*(N-1) cycles
NOTES The file tvclip.c included in the distribution diskette provides an example of this func-tion’s use.
if Ami B then Dml B m 0 1 2 … n, 1–, , ,{ }==<
if Ami C then Dml C=>
else Dml Ami=

ADSP-21K Optimized DSP Library User’s Manual
5-388 Wideband Computers, Inc.
vclr ( c, k, n )
NAME Vector Clear
DESCRIPTION This function sets all elements of input-output vector c to 0.0.
ALGORITHM
SYNOPSIS void vclr ( c, k, n )
float *c ; /* Pointer to input-output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN 0 to 131,000
ACCURACY 7.75 decimal digits
EXECUTION TIME 8 + 1*N cycles
NOTES The file tvclr.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk 0.0= m 0 1 2 …n 1–, , ,{ }=
0 k 0 n<,<

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-389
vcmerg ( a, i, b, j, c, k, d, l, n )
NAME Vector Compressed Merge
DESCRIPTION This function merges two input vectors a and b based on the values contained within gating vector c. The results are stored in output vector d. Either vector a or vector b’s element is stored into output vector d based on the value of the corresponding element in vector c.
ALGORITHM if then
else
SYNOPSIS void vcmerg ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 45 + 6*N cycles
NOTES The file tvcmerg.c included in the distribution diskette provides an example of this function’s use.
Cmk 0.0≠
Dml Bmj=
Dml Amj=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-390 Wideband Computers, Inc.
vcmprs ( a, i, b, j, c, k, n )
NAME Vector Compress
DESCRIPTION This function compresses the elements of input vector a based upon the values con-tained within input vector b. The results are stored in vector c.
ALGORITHM if then
SYNOPSIS void vcmprs ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 28 + 4*N cycles
NOTES The file tvcmprs.c included in the distribution diskette provides an example of this function’s use.
Bmj 0.0≠
Cmk Ami=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-391
vcos ( a, i, c, k, n )
NAME Vector Cosine
DESCRIPTION This function computes the cosine for each element in input vector a, and stores the result in output vector c. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vcos ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 39 + 23 * N cycles
NOTES The file tvcos.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=cos=

ADSP-21K Optimized DSP Library User’s Manual
5-392 Wideband Computers, Inc.
vcos_dp ( a, i, c, k, n )
NAME Vector Cosine_dp
DESCRIPTION This function computes the cosine for each element in input vector a, and stores the result in output vector c. Vector a is in program memory while vector c is in data memory. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vcos_dp ( a, i, c, k, n )
float pm *a ; /* Pointer to input vector a */
int i ; /* Address stride for input vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 22 * N cycles
NOTES The file tvcos.c included in the distribution diskette provides an example of this func-tion’s use.
A separate example routine was not constructed to show the use of the program mem-ory to data memory data flow.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=cos=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-393
vcosh ( a, i, c, k, n )
NAME Vector Hyperbolic Cosine
DESCRIPTION This function computes the hyperbolic cosine for each element in input vector a, and stores the result in output vector c.All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vcosh ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 36 + 44*N cycles
NOTES The file tvcosh.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=cosh=

ADSP-21K Optimized DSP Library User’s Manual
5-394 Wideband Computers, Inc.
vcot ( a, i, c, k, n )
NAME Vector Cotangent
DESCRIPTION This function computes the cotangent for each element in input vector a, and stores the result in output vector c. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vcot ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 39 + 32*N cycles
NOTES The file tvcot.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=cot=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-395
vcoth ( a, i, c, k, n )
NAME Vector Hyperbolic Cotangent
DESCRIPTION This function computes the hyperbolic cotangent for each element in input vector a, and stores the result in output vector c. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vcoth ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 52*N cycles
NOTES The file tvcoht.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amicoth m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-396 Wideband Computers, Inc.
vcsc ( a, i, c, k, n )
NAME Vector Cosecant
DESCRIPTION This function computes the cosecant for each element in input vector a, and stores the result in output vector c. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vcsc ( a, i, c, k, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 51 + 34*N cycles
NOTES The file tvcsc.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=csc=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-397
vcsch ( a, i, c, k, n )
NAME Vector Hyperbolic Cosecant
DESCRIPTION This function computes the hyperbolic cosecant for each element in input vector a, and stores the result in output vector c. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vcsch ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 36 + 52*N cycles
NOTES The file tvcsch.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amicsch m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-398 Wideband Computers, Inc.
vcube ( a, i, c, k, n )
NAME Vector Cube
DESCRIPTION This function computes the cube of input vector a and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vcube ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1012 to +3.4 x 1012
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 3*(N-1) cycles
NOTES The file tvcube.c included in the distribution diskette provides an example of this function’s use.
Cmk A3mi m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-399
vdblina ( a, i, c, k, n )
NAME Vector Convert Decibels To Linear Volt Units
DESCRIPTION This function converts each input element in vector a, assumed to be in Decibels units to linear volt units and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vdblina ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN Arguments greater than 770 will result in an overflow condition as 1038.5 is approxi-mately 3.4 x 1038, the positive upper-limit of the processor.
ACCURACY 7.75 decimal digits
EXECUTION TIME 40 + 36*N cycles
NOTES The file tvdblina.c included in the distribution diskette provides an example of this function’s use.
Input units to this routine are considered to be in Decibels while output units are con-sidered to be in linear volts.
Cmk 10Ami 0.05•[ ]
m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-400 Wideband Computers, Inc.
vdblinp ( a, i, c, k, n )
NAME Vector Convert Decibels To Linear Power Units
DESCRIPTION This function converts each input element in vector a, assumed to be in Decibels units to linear power units and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vdblinp ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN Arguments greater than 385 will result in an overflow condition as 1038.5 is approxi-mately 3.4 x 1038, the positive upper-limit of the processor.
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 + 30*N cycles
NOTES The file tvdblinp.c included in the distribution diskette provides an example of this function’s use. Input units to this routine are considered to be in decibels while output units are considered to be in linear power units.
Cmk 10Ami 0.10•[ ]
m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-401
vdeg ( a, i, c, k, n )
NAME Vector Degrees to Radians
DESCRIPTION This function converts each element in input vector a, assumed to be in degrees, to radians, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vdeg ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 + 2*(N-1) cycles
NOTES The file tvdeg.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk 0.01745329 Ami• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-402 Wideband Computers, Inc.
vdist ( a, i, b, j, c, k, n )
NAME Vector Distance
DESCRIPTION This function computes the square root of the sum of squares of input vectors a and b and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vdist ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN (a2 + b2) should not exceed the domain of [0.0 to +3.4 x 1038]
ACCURACY 7.75 decimal digits
EXECUTION TIME 54 + 20*N cycles
NOTES The file tvdist.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami2 Bmj
2+ m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-403
vdiv ( a, i, b, j, c, k, n )
NAME Vector Divide
DESCRIPTION This function divides input vector a by input vector b, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vdiv ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, Bmj cannot = 0.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 11*(N-1) cycles
NOTES The file tvdiv.c included in the distribution diskette provides an example of this func-tion’s use.
This routine does not contain any code to detect an attempt to divide by zero, as opti-mum performance is the objective.
Use the routine vdivz( ) should you wish to check for the presence of zero in the denominator.
Cmk
Ami
Bmj---------- m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-404 Wideband Computers, Inc.
vdivz ( a, i, b, j, c, d, l, n )
NAME Vector Divide with Zero Check
DESCRIPTION This function divides input vector a by input vector b, and stores the result in output vector d. If input b is zero then scalar c is stored into output vector d.
ALGORITHM
SYNOPSIS void vdivz ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 14*N cycles
NOTES The file tvdivz.c included in the distribution diskette provides an example of this func-tion’s use.This routine is slightly slower than vdiv( ) as extra logic is included to check for an attempt to divide by zero.
if Bmj 0.0 then m 0 1 2 …n 1–, , ,{ }=≠
Dml
Ami
Bmj---------- else=
Dml C=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-405
venvlp ( a, i, b, j, c, k, d, l, n )
NAME Vector Envelope
DESCRIPTION This function computes an envelope around input vector c. If an input vector c element either exceeds the upper-limit specified in vector a or falls below the lower-limit spec-ified in vector b, it is copied to output vector d. Otherwise a zero is stored into output vector d.
ALGORITHM if then
else
SYNOPSIS void venvlp ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to upper-limit threshold input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to lower-limit threshold input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 35 + 8*N cycles
NOTES The file tvenvlp.c included in the distribution diskette provides an example of this function’s use.
The lower-limit threshold b should not exceed the upper-limit threshold a.
Bmj Cmk Ami> >
Dml Cmk=
Dml 0.0=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-406 Wideband Computers, Inc.
veq ( a, i, b, j, c, k, n )
NAME Vector Equal
DESCRIPTION This function compares each element in input vectors a and b for equality. Either 1.0 or 0.0 is stored in output vector c depending on the results of the comparison.
ALGORITHM if then
else
SYNOPSIS void veq ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 41 + 5*N cycles
NOTES The file tveq.c included in the distribution diskette provides an example of this func-tion’s use.
Ami Bmj=
Cmk 0.0=
Cmk 1.0=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-407
vexp ( a, i, c, k, n )
NAME Vector Natural Exponential
DESCRIPTION This function computes the natural exponential for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vexp ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -88.0 to +88.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 47 + 29*N cycles
NOTES The file tvexp.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk eAmi
m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-408 Wideband Computers, Inc.
vexp10 ( a, i, c, k, n )
NAME Vector Base 10 Exponential
DESCRIPTION This function computes the base 10 exponential for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vexp10 ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -38.0 to +38.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 47 + 29*N cycles
NOTES The file tvexp10.c included in the distribution diskette provides an example of this function’s use.
Cmk 10Ami
m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-409
vexp2 ( a, i, c, k, n )
NAME Vector Base 2 Exponential
DESCRIPTION This function computes the base 2 exponential for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vexp2 ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -127.0 to +127.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 47 + 29*N cycles
NOTES The file tvexp2.c included in the distribution diskette provides an example of this function’s use.
Cmk 2Ami
m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-410 Wideband Computers, Inc.
vfill ( a, c, k, n )
NAME Vector Fill
DESCRIPTION This function sets all elements of output vector c to a value specified by input scalar a.
ALGORITHM
SYNOPSIS void vfill ( a, c, k, n )
float a ; /* Value of specified scalar fill a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 8 + 1*N cycles
NOTES The file tvfill.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk A= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-411
vfix ( a, i, c, k, n )
NAME Vector Floating-Point To Integer Conversion
DESCRIPTION This function truncates each real element in input vector a to a 32-bit integer and stores the results in integer output vector c. Positive values of a are truncated to the next smallest integer value. Negative values of a are truncated to the next larger inte-ger.
ALGORITHM
SYNOPSIS void vfix ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN Floating-Point value of Ami must be within -2,147,483,648 to +2,147,483,647
ACCURACY 7.75 decimal digits
EXECUTION TIME 37 + 5*(N-1) cycles
NOTES The file tvfix.c included in the distribution diskette provides an example of this func-tion’s use. The routine is the opposite of vfloat( ). All conversions using vfix( ) trun-cate the fractional portion of the number.
There is no error checking in this routine. For negative values of a outside the domain, a +1 is returned. For positive values of a outside the domain, a -1 is returned.
For faster functions which are related but may have special application rules, see vnfix( ), vpfix( ) and virnd( ).
Cmk fix Ami( )= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-412 Wideband Computers, Inc.
vfloat ( a, i, c, k, n )
NAME Vector Integer To Floating-Point Conversion
DESCRIPTION This function converts each integer element in integer input vector a to a 32-bit real and stores the results in floating-point output vector c.
ALGORITHM
SYNOPSIS void vfloat ( a, i, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34 + 2*(N-1) cycles
NOTES The file tvfloat.c included in the distribution diskette provides an example of this function’s use.
This routine is the opposite of vfix( ).
Cmk float Ami( )= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-413
vfloor ( a, i, c, k, n )
NAME Vector Floor (Round Down To Nearest Integral Value)
DESCRIPTION This function computes the largest integral value less than or equal to the floating-point number in input vector a and stores a floating-point representation of this integer result in output vector c.
ALGORITHM
SYNOPSIS void vfloor ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + 2*(N-1) cycles
NOTES The file tvfloor.c included in the distribution diskette provides an example of this function’s use.
This function is the opposite of vceil( ).
There is no error checking in this routine.
Cmk l earg st integer Ami≤= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-414 Wideband Computers, Inc.
vfrac ( a, i, c, k, n )
NAME Vector Truncate To Fraction
DESCRIPTION This function computes the fractional portion of each element in input vector a and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vfrac ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN Floating-Point value of Ami must be within -2,147,483,648 to +2,147,483,647
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + 5*(N-1) cycles
NOTES The file tvfrac.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami – float fix Ami( )( )= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-415
vgathr ( a, b, j, c, k, n )
NAME Vector Gather
DESCRIPTION This function copies selected elements of input vector a to output vector c using the integer elements in input vector b to determine which elements are to be copied to out-put vector c.
ALGORITHM
SYNOPSIS void vgathr ( a, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, Bmj must be within the valid range of integers.
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 5*N cycles
NOTES The file tvgathr.c included in the distribution diskette provides an example of this function’s use.
This function is the opposite of the scatter function, vscatr( ).
This function performs the same operation as vindex( ) execpt that vgathr( ) expects input vector b to be type integer. Note that only vectors band c may stride.
Cmk ABmj= m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-416 Wideband Computers, Inc.
vge ( a, i, b, j, c, k, n )
NAME Vector Greater Than Or Equal
DESCRIPTION This function compares each element in input vectors a and b for a greater than or equal condition. Either 1.0 or 0.0 is stored in output vector c depending on the results of the comparison.
ALGORITHM if then
else
SYNOPSIS void vge ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 41 + 5*N cycles
NOTES The file tvge.c included in the distribution diskette provides an example of this func-tion’s use.
Ami Bmj≥
Cmk 0.0=
Cmk 1.0=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-417
vgenp ( a, i, b, j, c, k, n, m )
NAME Vector Generation by Linear Interpolation and Extrapolation
DESCRIPTION This function generates a output vector c for the control points specified in input vec-tor b and the data values specified in input vector a.
ALGORITHM for i = 0 to n - 1 if i <= ( int ) ( b[0] ) c[i] = a[0]
else if i > ( int ) ( b[i-1} )
c[i] = a[i-1]
else
for k = 0 to m - 2
if [ ( int ) ( b[k] ) < i <= ( int ) ( b[k+1] ) ]
c[i] = a[k] +
( i - b[i] ) *
( a[i+1] - a[i] ) /
( b[i+1] - b[i] )
where: n = Number of points to interpolate
m = Number of elements in vectors a[ ] and b [ ]
SYNOPSIS void vgenp ( a, i, b, j, c, k, n, m )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for inoput vector a */
float *b ; /* Pointer to input vector */
int j ; /* Element stride for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for output vector c */
int n ; /* Number of points to interpolate */
int m; /* Element count in vectors a and b */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits

ADSP-21K Optimized DSP Library User’s Manual
5-418 Wideband Computers, Inc.
EXECUTION TIME 42 + 3*(N-1)
NOTES The file tvgenp.c included in the distribution tape provides an example of this func-tion’s use.
vgenp ( a, i, b, j, c, k, n, m )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-419
vgt ( a, i, b, j, c, k, n )
NAME Vector Greater Than
DESCRIPTION This function compares each element in input vectors a and b for a greater than condi-tion. Either 1.0 or 0.0 is stored in output vector c depending on the results of the com-parison..
ALGORITHM if then
else
SYNOPSIS void vgt ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 41 + 5*N cycles
NOTES The file tvgt.c included in the distribution diskette provides an example of this func-tion’s use.
Ami Bmj>
Cmk 0.0=
Cmk 1.0=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-420 Wideband Computers, Inc.
vhist ( a, i, c, n, vmin, vmax, nbin, oor )
NAME Vector Histogram
DESCRIPTION This function computes an accumulating histogram of vector elements found in inputreal vector a. The output of the histogram is placed in output integer vector c. The out-of-range count is output into integer oor.
ALGORITHM
SYNOPSIS void vhist ( a, i, c, n, vmin, vmax, nbin, oor)
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
int *c ; /* Pointer to output vector c */
int n ; /* Count of floating-point elements */
float vmin ; /* Minimum range of histogram */
float vmax ; /* Maximum range of histogram */
int nbin ; /* Number of desired bins in histogram */
int *oor ; /* Pointer to out-of-range count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
oor 0=
delta vmax vmin–( ) nbin⁄ 1–=
bin int a k[ ] vmin–( ) delta⁄( )=
if bin 0≥( )and bin nbin-1<( )then
++c k[ ]
else
++ *oor( )
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-421
EXECUTION TIME 47 + 15*N (Maximum)
47 + 8*N (Minimum)
NOTES The file tvhist.c included in the distribution tape provides an example of this func-tion’s use.
"Bins" numbered 0 through nbin-1 are defined by dividing the interval from vmin tovmax into nbin equal segments. The bins are arranged so that the minimum value of 0corresponds to vmin and the maximum value of bin nbin-1 corresponds to vmax.
For each element in input vector a, the bin whose boundaries contain the element'svalue is determined, and that bin's histogram counter is incremented. An out-of-rangecounter (oor) is maintained to indicate the number of elements which were not con-tained within any bin boundaries.
vhist( ) does not clear the histogram results in output vector c. Instead the histogramresults are added to output vector c, enabling repeated calls to vhist( ) to perform anaccumulating histogram. Function vclr( ) may be used to initially clear the histogramresults vector.
Also note the following special considerations:
Arguments nbin, n, and vmax should not vary between accumulating histogram calls.
The size of the bin specified by the operator cannot be less than 1. There is no errorchecking for this type of error within the code.
The stride of output vector c is always one.
The sum of the elements within the bin plus the number of out-of-range (oor) elementsshould always equal the number of elements supplied in nbin by the operator.
Typical main loop execution time is between 8 and 15 cycles.
Since output vector c is an integer, then the number of floating-point elements pro-cessed must be less then 232.
vhist ( a, i, c, n, vmin, vmax, nbin, oor )

ADSP-21K Optimized DSP Library User’s Manual
5-422 Wideband Computers, Inc.
vhisti ( a, i, c, n, vmin, vmax, nbin, oor )
NAME Vector Integer Histogram
DESCRIPTION This function computes an accumulating integer histogram on the vector elementsfound in input integer vector a. The output of the histogram is placed in output integervector c. The out-of-range count is output into integer oor.
ALGORITHM
SYNOPSIS void vhisti ( a, i, c, n, vmin, vmax, nbin, oor )
int *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
int *c ; /* Pointer to output vector c */
int n ; /* Count of integer elements */
int vmin ; /* Minimum range of histogram */
int vmax ; /* Maximum range of histogram */
int nbin ; /* Number of desired bins in histogram */
int *oor ; /* Pointer to out-of-range count */
DOMAIN -2,147,483,648 to 2,147,483,647
ACCURACY 7.75 decimal digits
oor 0=
delta vmax vmin–( ) nbin⁄ 1–=
bin int a k[ ] vmin–( ) delta⁄( )=
if bin 0≥( )and bin nbin-1<( )then
++c k[ ]
else
++ *oor( )
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-423
EXECUTION TIME 49 + 16*N
NOTES The file tvhisti.c included in the distribution tape provides an example of this func-tion’s use.
"Bins" numbered 0 through nbin-1 are defined by dividing the interval from vmin tovmax into nbin equal segments. The bins are arranged so that the minimum value of 0corresponds to vmin and the maximum value of bin nbin-1 corresponds to vmax.
For each element in input vector a, the bin whose boundaries contain the element'svalue is determined, and that bin's histogram counter is incremented. An out-of-rangecounter (oor) is maintained to indicate the number of elements which were not con-tained within any bin boundaries.
vhisti( ) does not clear the histogram results in output vector c. Instead the histogramresults are added to output vector c, enabling repeated calls to vhist( ) to perform anaccumulating histogram. Function vclr( ) may be used to initially clear the histogramresults vector.
Also note the following special considerations:
Arguments nbin, n, vmin and vmax should not vary between accumulating histogramcalls.
The size of the bin specified by the operator cannot be less than 1. There is no errorchecking for this type of error within the code.
The stride of output vector c is always one.
The sum of the elements within the bin plus the number of out-of-range (oor) elementsshould always equal the number of elements supplied in nbin by the operator.
Typical main loop execution time is between 9 and 16 cycles.
vhisti ( a, i, c, n, vmin, vmax, nbin, oor )

ADSP-21K Optimized DSP Library User’s Manual
5-424 Wideband Computers, Inc.
viclip ( a, i, b, c, d, l, n )
NAME Vector Inverted Clip
DESCRIPTION This function computes an inverted clip using a lower-threshold scalar b and an upper-threshold scalar c to clip each element in input vector a and stores the results in output vector d.
ALGORITHM
SYNOPSIS void viclip ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input lower-threshold scalar b */
float c ; /* Value of input upper-threshold scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 25 + 10*N cycles
NOTES The file tviclip.c included in the distribution diskette provides an example of this func-tion’s use.
if B Ami C then m 0 1 2 …n 1–, , ,{ }=< <
if Ami 0 then >
Dml C=
else
Dml B=
else
Dml Ami=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-425
vimag ( a, i, c, k, n )
NAME Vector Copy Imaginary Parts
DESCRIPTION This function creates a real output vector c based on the imaginary portion of complex input vector a.
ALGORITHM
SYNOPSIS void vimag ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 + 2*(N-1) cycles
NOTES The file tvimag.c included in the distribution diskette provides an example of this function’s use.
Cmk Im Ami{ } m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-426 Wideband Computers, Inc.
vindex ( a, b, j, c, k, n )
NAME Vector Index
DESCRIPTION This function copies selected elements of input vector a to output vector c using the integer elements in input vector b to determine which elements are to be copied to out-put vector c. The values within vector b are assumed to be type real and are converted to type integer.
ALGORITHM
SYNOPSIS void vindex ( a, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN 0 to +3.4 x 1038, Bmj must be within the valid range of integers before conversion.
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 6*N cycles
NOTES The file tvindex.c included in the distribution diskette provides an example of this function’s use.
This function is the opposite of the scatter function, vscatr( ). This function performs the same operation as vgathr( ) execpt that vgathr( ) expects input vector b to be type integer. Note that only vectors b and c may stride.
Cmk Aint Bmj ][= m 0 1 2 … n 1–, , , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-427
vintb ( a, i, b, j, c, d, l, n )
NAME Vector Linear Interpolate
DESCRIPTION Linearly interpolates between elements of two input vectors a and b according to a floating-point input scalar c and stores the result to output vector d.
ALGORITHM
SYNOPSIS void vintb ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Element stride for vector b */
float *c ; /* Pointer to input scalar c */
float *d; /* Pointer to input vector d */
int l ; /* Element stride for vector d */
int n ; /* Element count
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 42 + 3*(N-1)
NOTES The file tvintb.c included in the distribution tape provides an example of this func-tion’s use.
Dml Ami C Bmj Ami–( ) • m 0 1 2 … n, 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-428 Wideband Computers, Inc.
vipimul ( a, i, c, k, n )
NAME Vector Multiply By
DESCRIPTION This function multiplies the contents of input vector a by the constant . The results are placed in output vector c.
ALGORITHM
SYNOPSIS void vipmul ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 30 + 2*(N-1)
NOTES The file tvipimul.c included in the distribution tape provides an example of this func-tion’s use.
This routine computes as the sum of two number toachieve 40-bit precision. To use this routine as a scalar multiplier where the number of points to be computed is one (n = 1), set the stride of the input vector a to 0.
1 π⁄
1 π⁄
Cmk Ami1π---•=
1 π⁄

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-429
virnd ( a, i, c, k, n )
NAME Vector Round Floating Point to Integer
DESCRIPTION This function rounds the floating point value of each element in input vector a and stores the results in output vector c. The floating point value is converted to integer form and stored in output vector c.
ALGORITHM
SYNOPSIS void virnd ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34 + 2*(N-1) cycles
NOTES The file tvirnd.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk round Ami( )= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-430 Wideband Computers, Inc.
vle ( a, i, b, j, c, k, n )
NAME Vector Less Than Or Equal
DESCRIPTION This function compares each element in input vectors a and b for a less than or equal-condition. Either 1.0 or 0.0 is stored in output vector c depending on the results of the comparison.
ALGORITHM if then
else
SYNOPSIS void vle ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 41 + 5*N cycles
NOTES The file tvle.c included in the distribution diskette provides an example of this func-tion’s use.
Ami Bmj≤
Cmk 0.0=
Cmk 1.0=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-431
vlim ( a, i, b, c, d, l, n )
NAME Vector Limit
DESCRIPTION This function compares each element of input vector a to input scalar b. For elements of vector a less than or equal to scalar b the negated value of input scalar c is stored in the corresponding element of output vector d. Otherwise, the value of input scalar c is stored into the corresponding element of d.
ALGORITHM
SYNOPSIS void vlim ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input lower-threshold scalar b */
float c ; /* Value of input upper-threshold scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 22 + 4*N cycles
NOTES The file tvlim.c included in the distribution diskette provides an example of this func-tion’s use.
if Ami B then Dml C– m 0 1 2 …n 1–, , ,{ }==<
else Dml C=

ADSP-21K Optimized DSP Library User’s Manual
5-432 Wideband Computers, Inc.
vlindba ( a, i, c, k, n )
NAME Vector Convert Linear Volt Units To Decibels
DESCRIPTION This function converts each input element invector a, assumed to be in linear volt units to Decibels and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vlindba ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN a > 0 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 65 + 33*N cycles
NOTES The file tvlindba.c included in the distribution diskette provides an example of this function’s use.
Input units to this routine are considered to be in linear volt units while output units are considered to be in decibels.
Cmk 20 10 Ami( )log• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-433
vlindbp ( a, i, c, k, n )
NAME Vector Convert Linear Power Units To Decibels
DESCRIPTION This function converts each input element in vector a, assumed to be in linear power units to Decibels and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vlindbp ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN a > 0 to + 3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 65 + 33*N cycles
NOTES The file tvlindbp.c included in the distribution diskette provides an example of this function’s use.
Input units to this routine are considered to be in linear power units while output units are considered to be in decibels.
Cmk 10 10 Ami( )log• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-434 Wideband Computers, Inc.
vlmerg ( a, i, b, j, c, k, d, l, n )
NAME Vector Logical Merge
DESCRIPTION This function logically merges two input vectors a and b based on the values con-tained within gating vector c. The results are stored in output vector d. Either vector a or vector b’s element is stored into output vector d based on the value of the corre-sponding element in vector c.
ALGORITHM if then
else
SYNOPSIS void vlmerg ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 45 + 6*N cycles
NOTES The file tvlmerg.c included in the distribution diskette provides an example of this function’s use.
C 0.0≠
Dml Ami=
Dml Bmj=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-435
vlog ( a, i, c, k, n )
NAME Vector Natural Logarithm
DESCRIPTION This function computes the natural logarithm for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vlog ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN A > 0.0 to +3.4 x1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 58 + 30*N cycles
NOTES The file tvlog.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amilog m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-436 Wideband Computers, Inc.
vlog10 ( a, i, c, k, n )
NAME Vector Base 10 Logarithm
DESCRIPTION This function computes the base 10 logarithm for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vlog10 ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN A > 0.0 to +3.4 x1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 58 + 30*N cycles
NOTES The file tvlog10.c included in the distribution diskette provides an example of this function’s use.
Cmk 10Amilog m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-437
vlog2 ( a, i, c, k, n )
NAME Vector Base 2 Logarithm
DESCRIPTION This function computes the base 2 logarithm for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vlog2 ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN A > 0.0 to +3.4 x1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 58 + 30*N cycles
NOTES The file tvlog2.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk 2Amilog m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-438 Wideband Computers, Inc.
vlshift ( a, i, c, k, n, h )
NAME Vector Logical Shift
DESCRIPTION This function performs a logical shift of h bits on each 32-bit element in input vector a and stores the results in output vector c. If h is negative the bits are right-shifted with a zero fill into the most significant bit (MSB). If h is positive the bits are left-shifted with a sign fill into the least significant bit (LSB).
ALGORITHM if then
Zero Fill MSB
else
Sign Fill LSB
SYNOPSIS void vlshift ( a, i, c, k, n, h )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
int h ; /* Length of logical shift */
DOMAIN H must be between -32 to +32.
ACCURACY 32-bits
EXECUTION TIME 23 + 2*(N-1) cycles
NOTES The file tvlshift.c included in the distribution diskette provides an example of this function’s use.
H 0<
Cmk Ami H»=
Cmk Ami H«=
m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-439
vlt ( a, i, b, j, c, k, n )
NAME Vector Less Than
DESCRIPTION This function compares each element in input vectors a and b for a less than condition. Either 1.0 or 0.0 is stored in output vector c depending on the results of the compari-son.
ALGORITHM if then
else
SYNOPSIS void vlt ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 41 + 5*N cycles
NOTES The file tvlt.c included in the distribution diskette provides an example of this func-tion’s use.
Ami Bmj<
Cmk 0.0=
Cmk 1.0=
m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-440 Wideband Computers, Inc.
vlthr ( a, i, b, c, k, n )
NAME Vector Lower Threshold
DESCRIPTION This function computes an output vector c based on a comparison of input vector a and threshold scalar b.
ALGORITHM if then
else
SYNOPSIS void vlthr ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input threshold scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 2 * ( N-1 ) cycles
NOTES The file tvlthr.c included in the distribution diskette provides an example of this func-tion’s use.
Ami Bmj>
Cmk Ami=
Cmk B=
m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-441
vma ( a, i, b, j, c, k, d, l, n )
NAME Vector Multiply and Add
DESCRIPTION This function multiplies two input vectors a and b, then adds the product to input vec-tor c and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vma ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 + 4*(N-1) cycles
NOTES The file tvma.c included in the distribution diskette provides an example of this func-tion’s use.
Dml Ami Bmj•( ) Cmk m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-442 Wideband Computers, Inc.
vmags ( a, i, b, j, c, k, n )
NAME Vector Magnitude Squared
DESCRIPTION This function computes the magnitude squared of real input vectors a and b and stores the result in real output vector c.
ALGORITHM
SYNOPSIS void vmags ( a, i, b, j, c, k, n )
float dm *a ; /* Pointer to real input vector a */
int i ; /* Address stride in words for input vector a */
float pm *b ; /* Pointer to real input vector b */
int j ; /* Address stride in words for input vector b */
float dm *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + 3*N cycles
NOTES The file tvmags.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami( )2Bmj( )2
m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-443
vmax ( a, i, b, j, c, k, n )
NAME Vector Maximum
DESCRIPTION This function computes the maximum of each element of input vectors a and b and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vmax ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 3*(N-1) cycles
NOTES The file tvmax.c included in the distribution diskette provides an example of this func-tion’s use.
if Ami Bmj then m 0 1 2 …n 1–, , ,{ }=≥
Cmk Ami else=
Cmk Bmj=

ADSP-21K Optimized DSP Library User’s Manual
5-444 Wideband Computers, Inc.
vmax3 ( a, i, b, j, c, k, d, l, n )
NAME Vector Maximum of 3 Vectors
DESCRIPTION This function performs a vector maximum operation on input vectors a, b, and c. The results are stored in output vector d. An element from vector a is compared to corre-sponding element in vectors b and c. The maximum element is stored to output vector d.
ALGORITHM
SYNOPSIS void vmax3 ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector c */
int l ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 57 + 4*(N-1) cycles
NOTES The file tvmax3.c included in the distribution diskette provides an example of this function’s use.
Dml Ami=
if Dml Bmj then <
Dml Bmj =
if Dml Cmk then<
Dml Cmk =
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-445
vmaxmg ( a, i, b, j, c, k, n )
NAME Vector Maximum Magnitude
DESCRIPTION This function computes the magnitude of each element of input vectors a and b and stores the maximum magnitude in output vector c.
ALGORITHM
SYNOPSIS void vmaxmg ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + 3*(N-1) cycles
NOTES The file tvmaxmg.c included in the distribution diskette provides an example of this function’s use.
if Ami Bmj then m 0 1 2 …n 1–, , ,{ }=≥
Cmk Ami else=
Cmk Bmj=

ADSP-21K Optimized DSP Library User’s Manual
5-446 Wideband Computers, Inc.
vmin ( a, i, b, j, c, k, n )
NAME Vector Minimum
DESCRIPTION This function computes the minima of each element of input vectors a and b and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vmin ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 3*(N-1) cycles
NOTES The file tvmin.c included in the distribution diskette provides an example of this func-tion’s use.
if Ami Bmj then m 0 1 2 …n 1–, , ,{ }=<
Cmk Ami else=
Cmk Bmj=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-447
vmin3 ( a, i, b, j, c, k, d, l, n )
NAME Vector Minimum of 3 Vectors
DESCRIPTION This function performs a vector minimum operation on input vectors a, b, and c. The results are stored in output vector d. An element from vector a is compared to corre-sponding element in vectors b and c. The minimum element is stored to output vector d.
ALGORITHM
SYNOPSIS void vmin3 ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector c */
int l ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 57 + 4*(N-1) cycles
NOTES The file tvmin3.c included in the distribution diskette provides an example of this function’s use.
Dml Ami=
if Dml Bmj then >
Dml Bmj =
if Dml Cmk then>
Dml Cmk =
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-448 Wideband Computers, Inc.
vminmg ( a, i, b, j, c, k, n )
NAME Vector Minimum Magnitude
DESCRIPTION This function computes the magnitude of each element of input vectors a and b and stores the minimum magnitude in output vector c.
ALGORITHM
SYNOPSIS void vminmg ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + 3*(N-1) cycles
NOTES The file tvminmg.c included in the distribution diskette provides an example of this function’s use.
if Ami Bmj then m 0 1 2 …n 1–, , ,{ }=≤
Cmk Ami else=
Cmk Bmj=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-449
vmma ( a, i, b, j, c, k, d, l, e, h, n )
NAME Vector Multiply, Multiply, and Add
DESCRIPTION This function multiplies two input vectors a and b, then multiplies another two input vectors c and d, then adds the products and stores the result in output vector e.
ALGORITHM
SYNOPSIS void vmma ( a, i, b, j, c, k, d, l, e, h, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to input vector d */
int l ; /* Address stride in words for input vector d */
float *e ; /* Pointer to output vector e */
int h ; /* Address stride in words for output vector e */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 59 + 5*(N-1) cycles
NOTES The file tvmma.c included in the distribution diskette provides an example of this function’s use.
Emh Ami Bmj•( ) Cmk Dml•( )+=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-450 Wideband Computers, Inc.
vmms ( a, i, b, j, c, k, d, l, e, h, n )
NAME Vector Multiply, Multiply, and Subtract
DESCRIPTION This function multiplies two input vectors a and b, then multiplies another two input vectors c and d, then subtracts the products and stores the result in output vector e.
ALGORITHM
SYNOPSIS void vmms ( a, i, b, j, c, k, d, l, e, h, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to input vector d */
int l ; /* Address stride in words for input vector d */
float *e ; /* Pointer to output vector e */
int h ; /* Address stride in words for output vector e */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 59 + 5*(N-1) cycles
NOTES The file tvmms.c included in the distribution diskette provides an example of this function’s use.
Emh Ami Bmj•( ) Cmk Dml•( )–=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-451
vmmul ( a, b, x, y, c )
NAME Vector Matrix Multiply
DESCRIPTION This function multiplies input vector a by input matrix b, and stores the result in out-put vector c. The length of vector a is supplied in input integer scalar x and the dimen-sions of matrix b is supplied in input integer scalars x and y. The resulting output vector c is of length y.
ALGORITHM
SYNOPSIS void vmmul ( a, b, x, y, c )
float *a ; /* Pointer to input vector a */
float *b ; /* Pointer to input matrix b */
int x ; /* Number of rows in matrix b */
/* Number of elements in vector a */
int y ; /* Number of columns in matrix b */
float *c ; /* Pointer to output vector c */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + ( 6 + 2 ( X-1 ) ) * Y cycles
NOTES The file tvmmul.c included in the distribution diskette provides an example of this function’s use.
Vector a times the first column of matrix b[ ] [ ] is the first element of vector c. Vector a times the second column of matrix b[ ] [ ] is the second elements of vector c, etc.
Cm Ak Bk m,•
k 0=
x 1–
∑=
m 0 1 2 …y 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-452 Wideband Computers, Inc.
vmov ( a, i, c, k, n )
NAME Vector Move
DESCRIPTION This function copies all elements of input vector a to output vector c.
ALGORITHM
SYNOPSIS void vmov ( a, i, c, k, n )
float a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 18 + 2*N cycles
NOTES The file tvmov.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-453
vmov_dp ( a, i, c, k, n )
NAME Vector Move Data Memory to Program Memory
DESCRIPTION This function copies all elements of input vector a to output vector c. Vector a is in data memory while vector c is in program memory.
ALGORITHM
SYNOPSIS void vmov_dp ( a, i, c, k, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride for input vector a */
float pm *c ; /* Pointer to output vector c */
int k ; /* Address stride for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 15 + N cycles
NOTES The file tvmovdp.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-454 Wideband Computers, Inc.
vmov_pd ( a, i, c, k, n )
NAME Vector Move Program Memory to Data Memory
DESCRIPTION This function copies all elements of input vector a to output vector c. Vector a is in program memory while vector c is in data memory.
ALGORITHM
SYNOPSIS void vmov_pd ( a, i, c, k, n )
float pm *a ; /* Pointer to input vector a */
int i ; /* Address stride for input vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 15 + N cycles
NOTES The file tvmov.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-455
vmov_pp ( a, i, c, k, n )
NAME Vector Move Program Memory to Program Memory
DESCRIPTION This function copies all elements of input vector a to output vector c. Vector a is in program memory while vector c is in program memory.
ALGORITHM
SYNOPSIS void vmov_pd ( a, i, c, k, n )
float pm *a ; /* Pointer to input vector a */
int i ; /* Address stride for input vector a */
float pm *c ; /* Pointer to output vector c */
int k ; /* Address stride for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 18 + 2*N cycles
NOTES The file tvmov.c included in the distribution diskette provides an example of this func-tion’s use.
A separate example routine was not constructed to show the use of program memory to program memory data flow.
Cmk Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-456 Wideband Computers, Inc.
vms ( a, i, b, j, c, k, d, l, n )
NAME Vector Multiply and Subtract
DESCRIPTION This function multiplies two input vectors a and b, then subtracts input vector c from the product and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vms ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 + 4*(N-1) cycles
NOTES The file tvms.c included in the distribution diskette provides an example of this func-tion’s use.
Dml Ami Bmj•( ) Cmk m 0 1 2 …n 1–, , ,{ }=–=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-457
vmsca ( a, i, b, j, c, d, l, n )
NAME Vector Multiply and Scalar Add
DESCRIPTION This function multiplies two input vectors a and b, then adds input scalar c to the prod-uct and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vmsca ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 3*(N-1) cycles
NOTES The file tvmsca.c included in the distribution diskette provides an example of this function’s use.
Dml Ami Bmj•( ) C m 0 1 2 …n, 1–, ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-458 Wideband Computers, Inc.
vmscs ( a, i, b, j, c, d, l, n )
NAME Vector Multiply and Scalar Subtract
DESCRIPTION This function multiplies two input vectors a and b, then subtracts input scalar c from the product and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vmscs ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 3*(N-1) cycles
NOTES The file tvmscs.c included in the distribution diskette provides an example of this function’s use.
Dml Ami Bmj•( ) C– m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-459
vmul ( a, i, b, j, c, k, n )
NAME Vector Multiply
DESCRIPTION This function multiplies two input vectors a and b, and stores the result in output vec-tor c.
ALGORITHM
SYNOPSIS void vmul ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 3*(N-1) cycles
NOTES The file tvmul.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami Bmj• m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-460 Wideband Computers, Inc.
vnabs ( a, i, c, k, n )
NAME Vector Negative Absolute Value
DESCRIPTION This function computes the negated absolute values of all elements in input vector a and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vnabs ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 2*(N-1) cycles
NOTES The file tvnabs.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami–= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-461
vnand ( a, i, b, j, c, k, n )
NAME Vector Not And
DESCRIPTION This function performs a 32-bit logical AND of each element in input vector a with each element in input vector b. Next, the logical complement (NOT) of the AND is performed. The results are then stored in output vector c.
ALGORITHM
SYNOPSIS void vnand ( a, i, b, j, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 33 + 3*(N-1) cycles
NOTES The file tvnand.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami NAND Bmj( )= m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-462 Wideband Computers, Inc.
vnco ( f, amp, c, k, n )
NAME Vector Compute NCO Values
DESCRIPTION This function computes the nco ( numerically controlled oscillator ) values for a given bin, amplitude, and number of stages. The values are stored in output vector c[ ]. The nco values are computed for points. The cosine function is used to compute each nco function.
ALGORITHM Loop j = 0 to 2^n-1 nco = f * j nco = nco masked with 2^n-1 nco = nco * 2 * Pi / 2^n nco = amp * cos ( nco ) / 2^nEnd Loop
SYNOPSIS void vnco ( f, amp, c, k, n )
int f ; /* Input Bin Selection */
float dm amp ; /* Input Amplitude */
float dm *c ; /* Pointer to output vector C[ ] */
int k ; /* Vecotr C[ ] element stride */
int n ; /* Number of Stages (ie. 2^n) */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 49 + 29 * 2^N cycles
NOTES The file tvnco.c included in the distribution diskette provides an example of this func-tion’s use.
2n 1–

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-463
vncoarb ( table, tabsize, phase, acc, output, n )
NAME Vector Compute NCO Values
DESCRIPTION This function computes a series of output NCO (numerically controlled oscillator) values in output vector output based on a scalar input value tabsize, an input vector table, and a input scalar phase argument. The number of points to compute is based on the input parameter supplied in scalar n.
ALGORITHM
SYNOPSIS void vncoarb ( table, tabsize, phase, acc, output, n )
float dm *table ; /* Pointer to input nco vector table */
int tabsize ; /* Input Table Size */
int phase ; /* Input Phase Step */
int acc ; /* Input/Output Accumulator Index */
float dm *output ; /* Pointer to output vector */
int n ; /* Number of points to compute */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
output tabletabsize phase•=

ADSP-21K Optimized DSP Library User’s Manual
5-464 Wideband Computers, Inc.
EXECUTION TIME 22 + 6 * N cycles
NOTES The file tvncoarb.c included in the distribution diskette provides an example of this function’s use.
It is assumed that the input accumulator is initialized prior to this function being called. Otherwise, successive calls allows this function to generate a continuous nco table.
vncoarb( ) extracts the nco values for a given input table, phase, accumulator index
The accumulator index acc is a starting offset into the input nco vector table[ ]. The phase step phase is the added offset to the accumulator index up to n points. The table size tabsize is the size of the input nco vector table[ ]. It is used to wrap the accumula-tor index acc to the beginning of the input nco vector table[ ] if the accumulator index acc is greater than tabsize.
for i = 0 to n
if acc >= tabsize then
acc = acc - tabsize
end if
output[i] = table[acc]
acc = acc + phase
end loop
vncoarb ( table, tabsize, phase, acc, output, n )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-465
vne ( a, i, b, j, c, k, n )
NAME Vector Not Equal
DESCRIPTION This function compares each element in input vectors a and b for non-equality. Either 1.0 or 0.0 is stored in output vector c depending on the results of the comparison.
ALGORITHM if then
else
SYNOPSIS void vne ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 41 + 5*N cycles
NOTES The file tvne.c included in the distribution diskette provides an example of this func-tion’s use.
Ami Bmj≠
Cmk 0.0=
Cmk 1.0=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-466 Wideband Computers, Inc.
vneg ( a, i, c, k, n )
NAME Vector Negate
DESCRIPTION This function computes the negated values all elements in input vector a and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vneg ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 + 2*(N-1) cycles
NOTES The file tvneg.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk A– mi= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-467
vnfix ( a, i, c, k, n )
NAME Vector Floating-Point To Integer Conversion for Negative Arguments
DESCRIPTION This function converts each real element in input vector a to the next smallest 32-bit integer and stores the results in integer output vector c. The algorithm assumes that only negative numbers are supplied in input vector a, and performs no error checking for positive numbers.
ALGORITHM
SYNOPSIS void vnfix ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN Floating-Point value of Ami must be within 0 to +2,147,483,648
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 5*(N-1) cycles
NOTES The file tnfix.c included in the distribution diskette provides an example of this func-tion’s use. The routine is the opposite of vfloat( ). All conversions using vnfix( ) trun-cate the fractional portion of the negative number.
Cmk fix negative Ami( )= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-468 Wideband Computers, Inc.
vnmerg ( a, i, b, j, c, k, d, l, n )
NAME Vector Negative Merge
DESCRIPTION This function merges two input vectors a and b based on the values contained within gating vector c. The results are stored in output vector d. Either vector a or vector b’s element is stored into output vector d based on the value of the corresponding element in vector c.
ALGORITHM if then
else
SYNOPSIS void vnmerg ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 45 + 6*N cycles
NOTES The file tvnmerg.c included in the distribution diskette provides an example of this function’s use.
Cmk 0.0<
Dml Bmj=
Dml Ami=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-469
vnor ( a, i, b, j, c, k, n )
NAME Vector Not Or
DESCRIPTION This function performs a 32-bit logical OR of each element in input vector a with each element in input vector b. Next the logical complement (NOT) of the OR is per-formed. The results are then stored in output vector c.
ALGORITHM
SYNOPSIS void vnor ( a, i, b, j, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 33 + 3*(N-1) cycles
NOTES The file tvnor.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk NOT Ami OR Bmj( )= m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-470 Wideband Computers, Inc.
vnot ( a, i, c, k, n )
NAME Vector Not (Complement)
DESCRIPTION This function performs a bitwise logical complement (NOT) on the elements of input vector a. The complemented results are then stored in output vector c.
ALGORITHM
SYNOPSIS void vnot ( a, i, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 27 + 2*(N-1) cycles
NOTES The file tvnot.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk NOT A= mi m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-471
vnxor ( a, i, b, j, c, k, n )
NAME Vector Not Exclusive Bitwise Or
DESCRIPTION This function performs a bitwise exclusive OR of each element in input vector a with each element in input vector b. Next, the logical complement (NOT) of the bitwise OR is performed. The results are then stored in output vector c.
ALGORITHM
SYNOPSIS void vnxor ( a, i, b, j, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 33 + 3*(N-1) cycles
NOTES The file tvnxor.c included in the distribution diskette provides an example of this function’s use.
Cmk NOT Ami XOR Bmj( ) m 0 1 2…n 1 }–, ,{==

ADSP-21K Optimized DSP Library User’s Manual
5-472 Wideband Computers, Inc.
vor ( a, i, b, j, c, k, n )
NAME Vector Or
DESCRIPTION This function performs a 32-bit logical OR of each element in input vector a with each element in input vector b and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vor ( a, i, b, j, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 33 + 3*(N-1) cycles
NOTES The file tvor.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami OR Bmj( )= m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-473
vpack ( a, i, b, j, fill, n )
NAME Pack a Floating-Point Vector of Ones and Zeros Into 32-Bit Words Arguments
DESCRIPTION This function reads an input vector a, which is assumed to contains either floating-point 1s or 0s. If a 1 is read, a bit is set in output vector b. Likewise, if a 0 is read a bit is cleared in output vector b. The next value is read and the next corresponding bit is set/cleared.
The order in which the bits are set/cleared is determined by the fill flag.
ALGORITHM
SYNOPSIS void vpack ( a, i, b, j, fill, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to output vector c */
int j ; /* Address stride in words for output vector c */
int fill ; /* Fill direction flag ( Either 1 or -1 ) */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 43 +65*(Integer) (N/32) + 2*(M Mod 32) cycles
NOTES The file tvpack.c included in the distribution diskette provides an example of this function’s use.
32 elements are packed into a 32-bit word. For non-multiples of 32, the remaining ele-ments are packed into a 32-bit work and is zero filled.
The vector size of b should be at least (N/32). If N is not a multiple of 32 then the vec-tor size of b should be (N/32 + 1).
The order in which the bits are set/cleared is determined by the fill flag. If the fill flag is set = 1, the bits are packed from LSB to MSB. If the fill flag is set = -1, the bits are packed from MSB to LSB.
Bmj Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-474 Wideband Computers, Inc.
vpcki ( a, i, b, j, fill, n )
NAME Pack an Integer Vector of Ones and Zeros Into 32-Bit Words Arguments
DESCRIPTION This function reads an input vector a, which is assumed to contains either integer 1s or 0s. If a 1 is read, a bit is set in output vector b. Likewise, if a 0 is read a bit is cleared in output vector b. The next value is read and the next corresponding bit is set/cleared.
The order in which the bits are set/cleared is determined by the fill flag.
ALGORITHM
SYNOPSIS void vpcki ( a, i, b, j, fill, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to output vector c */
int j ; /* Address stride in words for output vector c */
int fill ; /* Fill direction flag ( Either 1 or -1 ) */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 40 +65*(Integer) (N/32) + 2*(M Mod 32) cycles
NOTES The file tvpack.c included in the distribution diskette provides an example of this function’s use.
32 elements are packed into a 32-bit word. For non-multiples of 32, the remaining ele-ments are packed into a 32-bit work and is zero filled.
The vector size of b should be at least (N/32). If N is not a multiple of 32 then the vec-tor size of b should be (N/32 + 1).
The order in which the bits are set/cleared is determined by the fill flag. If the fill flag is set = 1, the bits are packed from LSB to MSB. If the fill flag is set = -1, the bits are packed from MSB to LSB.
Bmj Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-475
vpfix ( a, i, c, k, n )
NAME Vector Floating-Point To Integer Conversion for Positive Arguments
DESCRIPTION This function converts each real element in input vector a to the next smallest 32-bit integer and stores the results in integer output vector c.
The algorithm assumes that only positive numbers are supplied in input vector a, and performs no error checking for negative numbers.
ALGORITHM
SYNOPSIS void vpfix ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN Floating-Point value of Ami must be within 0 to +2,147,483,647
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + 2*(N-1) cycles
NOTES The file tvpfix.c included in the distribution diskette provides an example of this func-tion’s use. The routine is the opposite of vfloat( ). All conversions using vpfix( ) trun-cate the fractional portion of the positive number.
Cmk fix positive Ami( )= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-476 Wideband Computers, Inc.
vphase ( re, i, im, j, ph, k, n )
NAME Vector Phase
DESCRIPTION This function computes the phase of the elements of real input vector re and imagi-nary input vector im, and stores the result in real output vector ph.
ALGORITHM Real Imaginary Ph [ ] Quadrant
>0 >0 Phi 1
<0 >0 PI - Phi 2
<0 <0 PI + Phi 3
>0 <0 2*PI - Phi 4
where: if ( |real| > |imaginary| )
Phi = atan ( |real| / |imaginary| )
else
Phi = PI/2 - atan ( |imaginary| / |real| )
SYNOPSIS void vphase ( re, i, im, j, ph, k, n )
float *re ; /* Pointer to complex input vector re */
int i ; /* Address stride in words for input vector re */
float *im ; /* Pointer to real input vector im */
int j ; /* Address stride in words for input vector im */
float *ph ; /* Pointer to real output vector ph */
int k ; /* Address stride in words for output vector ph */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, the real or imaginary component cannot equal zero or a divide by zero error will occur.
ACCURACY 7.75 decimal digits
EXECUTION TIME 68 + 47 * N cycles
NOTES The file tvphase.c included in the distribution diskette provides an example of this function’s use.

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-477
vpimul ( a, i, c, k, n )
NAME Vector Multiply By
DESCRIPTION This function multiplies the contents of input vector a by the constant . The results are placed in output vector c.
ALGORITHM
SYNOPSIS void vpimul ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 30 + 2*(N-1)
NOTES The file tvpimul.c included in the distribution tape provides an example of this func-tion’s use.
This routine computes as the sum of two number toachieve 40-bit precision. To use this routine as a scalar multiplier where the number of points computed is one (n = 1), set the stride of the input vector a to 0.
π
π
Cmk Ami π • m 0 1 2 …n 1–, , ,{ }==
π

ADSP-21K Optimized DSP Library User’s Manual
5-478 Wideband Computers, Inc.
vpmerg ( a, i, b, j, c, k, d, l, n )
NAME Vector Positive Merge
DESCRIPTION This function merges two input vectors a and b based on the values contained within gating vector c. The results are stored in output vector d. Either vector a or vector b’s element is stored into output vector d based on the value of the corresponding element in vector c.
ALGORITHM if then
else
SYNOPSIS void vpmerg ( a, i, b, j, c, k, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 45 + 6*N cycles
NOTES The file tvpmerg.c included in the distribution diskette provides an example of this function’s use.
Cmk 0.0≥
Dml Bmj=
Dml Ami=
m 0 1 2 …n, 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-479
vpoly ( a, as, b, bs, c, cs, n, p )
NAME Vector Polynomial Evaluation
DESCRIPTION Evaluates values of a p-order polynomial for vector b using coefficients in vector a. The number of coefficients in vector a must be p+1 since p+1 coefficients are required for a p-order polynomial.
ALGORITHM
SYNOPSIS void vpoly ( a, as, b, bs, c, cs, n, p )
float *a ; /* Pointer to coefficient vector a */
int as ; /* Element stride for vector a */
float *b ; /* Pointer to input vector b */
int bs ; /* Element stride for vector b */
float *c ; /* Pointer to output vector c */
int cs ; /* Element stride for vector c */
int n ; /* Element count for vector c */
int p ; /* Polynomial order (degree) */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 46 + (5+2*(P-1))*N
NOTES The file tvpoly.c included in the distribution tape provides an example of this func-tion’s use.
Input vector a must have a minimum length of .Note that this is an index from zero to p.
Input vector b must have a minimum length of
Output vector c must have a minimum length of .
n must be a minimum of 1.
Ccs m• Aai m• Bbs m•p i– •
i 0=
p
∑=
m 0 1 2 … n, 1–, , ,{ }=
as p 1+( )•
bs n•
cs n•

ADSP-21K Optimized DSP Library User’s Manual
5-480 Wideband Computers, Inc.
vpow ( a, i, b, c, k, n )
NAME Vector Power
DESCRIPTION This function computes the base b exponential for each element in vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vpow ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of the base b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 52 + 69*N cycles
NOTES The file tpow.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk BAmi
m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-481
vprn ( a, b, c, d, l, n )
NAME Vector PRN Generator
DESCRIPTION Generates a series of binary values representing the Pseudo-Random Number sequence for the polynomial specified. The sequence is stored in output vector d.
ALGORITHM
SYNOPSIS void vprn ( a, b, c, d, l, n )
int *a ; /* Pointer to input seed a */
int b ; /* Pointer to register length b */
int c ; /* Pointer to polynomial value */
int *d ; /* Pointer to output vector d */
int l ; /* Element stride for vector d */
int n ; /* Element count */
DOMAIN 0 to 232 - 1 Unsigned (= 4,294,967,295)
ACCURACY 7.75 decimal digits
EXECUTION TIME TBS
NOTES The file tvprn.c included in the distribution tape provides an example of this func-tion’s use.
Note the domain range on the input.
Bitm 1– of Ami Bitm n– Bit0⊕=
Ami Ami>>1=
Cmk LSB of Ami=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-482 Wideband Computers, Inc.
vpspec ( data, pspec, j, n )
NAME Vector Power Spectra
DESCRIPTION This function computes the power spectra from the input vector data [ ] and places the results in output vector pspec [ ]. The number of elements processed is n.
ALGORITHM
SYNOPSIS void vpspec ( data, pspec, j, n )
float dm *data ; /* Pointer to input vector data [ ] */
float dm *pspec ; /* Pointer to output vector pspec */
int j ; /* Element stride for vector pspec [ ] */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 103
ACCURACY 7.75 decimal digits
pspec 0[ ] data 0[ ]2=
pspec m[ ] data 2 m•[ ]2
data 2 m 1+•[ ] d– ata 2 m 1+•[ ]( )•–=
m 1 2 …n 2–, ,{ }=
pspec n 1–[ ] data 1[ ]2=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-483
EXECUTION TIME 21 + 4*(N-1)
NOTES The file tpspec.c included in the distribution tape provides an example of this func-tion’s use.
The number of elements processed is n. This number represents 1/2 the rfft size (ie. for an rfft size of N=128, there are N/2 = 64 complex values).
This function assumes the input vector data is derived from the output of the rfftip( ) function call. This data is formatted as follows (F[ ] represents a complex values vec-tor):
Note: n = N/2 where N represents the rfft size
Re (F[0]) = data [0]
Re (F[k]) = data [2*k] for k = { 1,2, ... n-2}
Im (F[k]) = data [2*k+1] for k = { 1,2, ... n-2}
Re (F[n-1]) = data [1]
The power spectra is computed as follows:
pspec[0] = data [0]^2
pspec = data[2*m]^2 - data[2*m+1] * (-data[2*m+1] ) for m=1 to n-2
pspec [n-1] = data[1]^2
Note that vector yi is in pm memory. This function is tailored to use the output prod-ucts from a rfftip( ) function call.
vpspec ( data, pspec, j, n )

ADSP-21K Optimized DSP Library User’s Manual
5-484 Wideband Computers, Inc.
vpythag ( a, i, b, j, c, k, d, l, e, h, n )
NAME Vector Pythagoras
DESCRIPTION This function calculates the the Pythagorean formula for four input input vectors a, b, c, and d. The results are stored in output vector e.
ALGORITHM
SYNOPSIS void vpythag ( a, i, b, j, c, k, d, l, e, h, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to input vector d */
int l ; /* Address stride in words for input vector d */
float *e ; /* Pointer to output vector e */
int h ; /* Address stride in words for output vector h */
int n ; /* Element count */
DOMAIN (a2-c2) +(b2-d2) should not exceed the domain of 0.0 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 81 + 23*(N-1) cycles
NOTES The file tvpythag.c included in the distribution diskette provides an example of this function’s use.
Emh A( mi Cmk– )2 B( mj Dml– )
2+=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-485
vqint ( a, i, b, j, c, k, n )
NAME Vector Quadratic Interpolation
DESCRIPTION Performs a quadratic interpolation on the elements of input vector a using values spec-ified in input vector b. The results are stored in output vector c.
ALGORITHM
SYNOPSIS void vqint ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *b ; /* Pointer to coefficient vector b */
int j ; /* Element stride for vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 53 + 20*N
NOTES The file tvqint.c included in the distribution tape provides an example of this func-tion’s use.
The values of input interpolation vector b must be greater than or equal to 0 after con-version to a truncated integer. Input interpolation vector b must also be less than orequal to m-2 after conversion to a truncated integer.
Cmk 0.5 Ax 1– y2
y–( )• 2.0 Ax•+• 1 y2
–( )• Ax 1+ y2
y+( )•+=
x max 1 int Bj,( )=
y Bj x–=
y2
y y•=
1 int Bj( ) m 2–≤≤
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-486 Wideband Computers, Inc.
vqsort ( a, b, n )
NAME Vector Quick Sort
DESCRIPTION This function performs a quick sort on all elements within input vector a, and stores the result in output vector a. The input sort flag b determines if the results are returned in ascending or decending order.
ALGORITHM
SYNOPSIS void vqsort( a, b, n )
float dm *a ; /* Pointer to input/output vector a */
int *b ; /* Input sort flag b */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
If b = 0 then Output Am Input Am sorted largest to smallest (descending) =
If b = 1 then Output Am Input Am sorted smallest to largest (ascending) =
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-487
EXECUTION TIME 47 cycles overhead
While loop 43 cycles
Partition scans (left to right) 3
N * log N comparisons (Average Case)
N2 comparisons (Worst Case)
NOTES The file tvqsort.c included in the distribution diskette provides an example of this function’s use.
The sort flag b determines the sort order of the algorithm, as described in the equation system above. Note that vector a is both an input and an output vector.
This algorithm uses a non-recursive implementation. The crux of the algorithm is the partitioning scheme. Partitioning arranges the elements such that (for some random reference elements in the array):
• Elements less that the reference element a[i] are positioned before the ref-erence element (a[0] ... a[i-1].
• Elements greater that the reference element a[i] are positioned after the ref-erence element (a[i+1] ... a[n].
The reference element is choosen randomly, in this case the right most element of the array.
Partitioning returns the index of the left most element. This is then used to determine the left and right indices for the next round of partitioning until the array is sorted.
vqsort ( a, b, n )

ADSP-21K Optimized DSP Library User’s Manual
5-488 Wideband Computers, Inc.
vrad ( a, i, c, k, n )
NAME Vector Convert Radian to Degrees
DESCRIPTION This function converts each element in input vector a, assumed to be in radians to degrees, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vrad ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -5.9 x 1036 to +5.9 x 1036
ACCURACY 7.75 decimal digits
EXECUTION TIME 21 +2*(N-1) cycles
NOTES The file tvrad.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk 57.2957795 Ami• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-489
vramp ( a, b, c, k, n )
NAME Vector Build Ramp
DESCRIPTION Creates a ramp of ascending or descending elements and stores the result to output vector c. Input scalar value a is the offset of the ramp to be created. Input scalar value b is the slope of the ramp to be created.
ALGORITHM
SYNOPSIS void vramp ( a, b, c, k, n )
float a ; /* Value of ramp offset */
float b ; /* Value of ramp slope */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 10 + N
NOTES The file tvramp.c included in the distribution tape provides an example of this func-tion’s use.
Cmk A m B• m 0 1 2 … n, 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-490 Wideband Computers, Inc.
vrandn ( a, c, k, n )
NAME Vector Build Normal Distribution
DESCRIPTION Creates a Normally distributed group of elements and stores the result to vector c.
ALGORITHM
SYNOPSIS void vrandn ( a, c, k, n )
unsigned int *a ; /* Pointer to input/output seed a */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Element count for vector c */
DOMAIN Seed (*a) is valid unsigned integer from 1 to 232 - 1 (= 4,294,967,295). Returns uni-form point [0 to 1].
ACCURACY 7.75 decimal digits
Ck U3 2⁄3±
i 0=
9
∑=
U x± is uniform distribution in x, x–( )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-491
EXECUTION TIME 26 + 87*N
NOTES The file tvrandn.c included in the distribution tape provides an example of this func-tion’s use.
vrandn( ) generates a vector of pseudo-random numbers (PRNs) having a normal dis-tribution.The distribution is said to be normal if the mean of the distribution is equal to 0 and the variance is equal to 1.
Uniformly-distributed PRNs are used to generate the normal PRNs. From calculus, recall that the Central Limit Theorem states that when samples are generated by sum-ming “large” numbers of uniform random numbers, the resulting distribution is nor-mal. In this case, ten uniform PRNs are summed to produce each normal point.
The uniform PRNs are generated using a linear-congruent method. This method multi-plies a “seed” by a large fixed number, resulting in overflow; the least-significant bits of the product are retained, and the integer value they represent is uniformly random in nature. This integer PRN forms the mantissa of a uniform floating-point PRN in the range [0,1]. The sum is shifted and scaled to produce a normal PRN.
The final seed is returned through argument a and can be used as the initial seed on subsequent calls to randn( ). For additional information, see the discussion of linear congruent generators in the vrandu( ) notes section.
vrandn ( a, c, k, n )

ADSP-21K Optimized DSP Library User’s Manual
5-492 Wideband Computers, Inc.
vrandu ( a, c, k, n )
NAME Vector Build Uniform Distribution
DESCRIPTION Creates a group of elements uniformly distributed in [0,1] and stores the result in out-put vector c.
ALGORITHM
SYNOPSIS void vrandu ( a, c, k, n )
unsigned int *a ; /* Pointer to input/output seed a */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Element count for vector c */
DOMAIN Seed (*a) is valid unsigned integer from 1 to 232 - 1. Returns normal point [0 to 1].
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 7*N
NOTES The file tvrandu.c included in the distribution tape provides an example of this func-tion’s use.
This algorithm generates uniform pseudo-random numbers (PRNs) in [0,1] using a lin-ear-congruent method. The method used multiplies a “seed” value supplied by the user by a large fixed number, resulting in overflow. The least-significant bits of the product are retained, and the integer value they represent is uniformly random in nature. This integer PRN forms the mantissa of a uniform floating-point PRN in the range [0,1].
The linear congruent method is pseudo-random: the sequence of pseudo-random num-bers will repeat itself within 232 iterations. For an excellent discussion of the methods used see pages 275-277 in Numerical Recipes in C by Press, Teukolsky, Vetterling & Flannery, Second Edition, Cambridge University Press, New York, New York, 1992.
The final seed is returned through argument a and can be used as the initial seed on subsequent calls to vrandu( ).
Ck float Ik( ) 232⁄( )=
where I0 *a=
Ik 110351524 Ik 1– 12345+•[ ]% 232
=
k 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-493
vreal ( a, i, c, k, n )
NAME Vector Copy Real Parts
DESCRIPTION This function creates a real output vector c based on the real portion of complex input vector a.
ALGORITHM
SYNOPSIS void vreal ( a, i, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 19 + 2*(N-1) cycles
NOTES The file tvreal.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Re Ami{ } m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-494 Wideband Computers, Inc.
vrecip ( a, i, c, k, n )
NAME Vector Reciprocal
DESCRIPTION This function computes the reciprocal values all elements of input vector a and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vrecip ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, except 0.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 20 + 10*N cycles
NOTES The file tvrecip.c included in the distribution diskette provides an example of this function’s use.
Should one of the elements of input vector a be set to zero, this routine does not con-tain any logic to check for any attempted divide by zero. If this is a concern, use the vrecipz( ) routine, which executes slower but checks for attempted divides by zero.
Cmk1
A----
mi=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-495
vrecipz ( a, i, b, c, k, n )
NAME Vector Reciprocal with Zero Domain Check
DESCRIPTION This function computes the reciprocal values all elements of input vector a and stores the results in output vector c. If element a is found to be zero, scalar b is stored to out-put vector c.
ALGORITHM
SYNOPSIS void vrecipz ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, except 0.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 25 + 13*N cycles
NOTES The file tvrecipz.c included in the distribution diskette provides an example of this function’s use.
if Ami 0.0 then C= mk B m 0 1 2 …n 1–, , ,{ }==
else Cmk1
Amk-----------=

ADSP-21K Optimized DSP Library User’s Manual
5-496 Wideband Computers, Inc.
vreim ( a, i, b, j, c, k, n )
NAME Vector Copy Real and Imaginary Parts
DESCRIPTION This function extracts the real and imaginary components from a complex input vector a and saves the results into a real output vector b and a real ouput vector c respectively.
ALGORITHM
SYNOPSIS void vreim ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to real output vector b */
int j ; /* Address stride in words for output vector b */
float *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 22 + 4*N cycles
NOTES The file tvreims.c included in the distribution diskette provides an example of this function’s use.
Bmj Re Ami{ } m 0 1 2 …n 1–, , ,{ }==
Cmk Im Ami{ } m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-497
vreim_pdp ( a, i, b, j, c, k, n )
NAME Vector Copy Real and Imaginary Parts, Vector B[ ] in Data Memory
DESCRIPTION This function extracts the real and imaginary components from a complex input vector a[ ] and saves the results into a real output vector b[ ] and a real ouput vector c[ ] respectively. Vectors a[ ] and c[ ] are in pm memory while vector b[ ] is in dm mem-ory.
ALGORITHM
SYNOPSIS void vreim_pdp ( a, i, b, j, c, k, n )
complex pm *a ; /* Pointer to complex input vector a */
int i ; /* Address stride in words for input vector a */
float dm *b ; /* Pointer to real output vector b */
int j ; /* Address stride in words for output vector b */
float pm *c ; /* Pointer to real output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 22 + 4*N cycles
NOTES The file tvreims_pdp.c included in the distribution diskette provides an example of this function’s use.
Bmj Re Ami{ } m 0 1 2 …n 1–, , ,{ }==
Cmk Im Ami{ } m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-498 Wideband Computers, Inc.
vrfftip ( x, real, imag, n )
NAME Sort Ouptut Data from rfftip( ) Real, In-Place FFT Function
DESCRIPTION This function sorts the output data in x[ ] that was generated by the rfftip( ) function into its real and imaginary components. The components outputted are placed in vec-tors real[ ] and imag[ ] respectively. This function is intended to condition the output from rfftip( ) for use in computing the inverse real FFT with the rffti( ) function.
ALGORITHM
SYNOPSIS void vrfftip ( x, real, imag, n )
float dm *x ; /* Pointer to output data from rfftip() */
float dm *real ; /* Pointer to Real output vector */
float pm *imag ; /* Pointer to imaginary output vector */
int n ; /* Element count */
DOMAIN No Restrictions
ACCURACY 7.75 decimal digits
EXECUTION TIME 26 + 3*N cycles
NOTES The file tvrfftip.c included in the distribution diskette provides an example of this function’s use.
The value of n should be 1/2 the size of the original FFT.
The vector sizes for real[ ] and imag[ ] are n/2+1; where real[0] = real[n/2] and imag[0] = imag[n/2].
For a detailed review of the interelationships between the various FFT functions and how to use them with one another, see the final section of Chapter 4.
Re F 0[ ] ( ) data 0[ ]=
Re F 1[ ] ( ) data 2 k•[ ] k= 0 1 2 … n 2⁄, 1–, , ,{ }=
Im F k[ ] ( ) data 2 k 1+•[ ]k= 0 1 2 … n 2⁄, 1–, , ,{ }=
Re F n 2⁄[ ] ( ) data 1[ ]=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-499
vrffts ( x, real, imag, n )
NAME Sort Ouptut Data from rffts( ) Real, In-Place FFT Function
DESCRIPTION This function sorts the output data in x[ ] that was generated by the rffts( ) function into its real and imaginary components. The components outputted are placed in vec-tors real[ ] and imag[ ] respectively. This function is intended to condition the output from rffts( ) for use in computing the inverse real FFT with the rffti( ) function.
ALGORITHM
SYNOPSIS void vrffts ( x, real, imag, n )
float dm *x ; /* Pointer to output data from rfftip() */
float dm *real ; /* Pointer to Real output vector */
float pm *imag ; /* Pointer to imaginary output vector */
int n ; /* Element count */
DOMAIN No Restrictions
ACCURACY 7.75 decimal digits
Re F 0[ ] ( ) x 0[ ]=
Re F 1[ ] ( ) x 1[ ]=
. .
Re F n 2⁄[ ] ( ) x n 2⁄[ ]=
Im F n 2 1–⁄[ ] ( ) x n 2 1+⁄[ ]=
Im F n 2 2–⁄[ ] ( ) x n 2 2+⁄[ ]=
. .
Im F 1[ ] ( ) x n 1–[ ]=

ADSP-21K Optimized DSP Library User’s Manual
5-500 Wideband Computers, Inc.
EXECUTION TIME 35 + 3*N cycles
NOTES The file tvrffts.c included in the distribution diskette provides an example of this func-tion’s use.
The value of n should be 1/2 the size of the original FFT.
The vector sizes for real[ ] and imag[ ] are n/2+1; where real[0] = real[n/2] and imag[0] = imag[n/2].
For a detailed review of the interelationships between the various FFT functions and how to use them with one another, see the final section of Chapter 4.
vrffts ( x, real, imag, n )

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-501
vrol ( a, i, c, k, n )
NAME Vector Rotate Left
DESCRIPTION This function performs a 1-bit left-rotation on each element in input vector a. The results are stored in output vector c.
ALGORITHM
SYNOPSIS void vrol ( a, i, c, k, n )
unsigned int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
unsigned int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 23 + 2*(N-1) cycles
NOTES The file tvrol.c included in the distribution diskette provides an example of this func-tion’s use.
The carry bit is not rotated in this routine. For left-rotations greater then 5 use the vrot( ) routine.
Cmk bit0[ ] Ami bit31[ ]=
Cmk bitn[ ] Ami bitn 1–[ ]=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-502 Wideband Computers, Inc.
vror ( a, i, c, k, n )
NAME Vector Rotate Right
DESCRIPTION This function performs a 1-bit right-rotation on each element in input vector a. The results are stored in output vector c.
ALGORITHM
SYNOPSIS void vror ( a, i, c, k, n )
unsigned int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
unsigned int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 23 + 2*(N-1) cycles
NOTES The file tvror.c included in the distribution diskette provides an example of this func-tion’s use. The carry bit is not rotated in this routine. For right-rotations greater then 5 use the vrot( ) routine.
Cmk bit31[ ] Ami bit0[ ]= Cmk bitn[ ] Ami bitn 1+[ ]=
m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-503
vrot ( a, i, c, k, n, h )
NAME Vector Rotate N Bits
DESCRIPTION This function performs multiple h-bit right or left-rotations on each 32-bit element in input vector a. The results are then stored in output vector c. If h is negative the bits are rotated-right with the least significant bit (LSB) being rotated into the most signif-icant bit (MSB). If h is positive the bits are rotated-left with the MSB being rotated into the LSB.
ALGORITHM
SYNOPSISvoid vrot ( a, i, c, k, n, h )
unsigned int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
unsigned int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
int h ; /* Length And direction of rotation */
DOMAIN h must be an unsigned integer between -65,536 and +65,536. The argument is later range reduced within the routine to an argument between 0 to -31.
ACCURACY 32-bits
EXECUTION TIME 23 + 2*(N-1) cycles
NOTES The file tvrot.c included in the distribution diskette provides an example of this func-tion’s use.
The carry-bit is not rotated in this routine. For bit-rotation less then 5 use the vror( ) or vrol( ) routines. For bit-rotations greater then 5 use this routine.
if h 0<( )then (rotate right h-bits)
c bit31[ ] a bit0[ ] a bitn[ ] a bitn 1+[ ]=,=
else h 0>( )then (rotate left h-bits)
c bit0[ ] a bit31[ ] a bitn 1+[ ] a bitn[ ]=,=
m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
5-504 Wideband Computers, Inc.
vround ( a, i, c, k, n )
NAME Vector Round
DESCRIPTION This function computes the nearest whole number of each element in input vector a and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vround ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 28 + 2*(N-1) cycles
NOTES The file tvround.c included in the distribution diskette provides an example of this function’s use.
This function is the opposite of the vfloor( ) function, described in the preceding page.
Cmk floor Ami 0.5+( )= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-505
vrsqrt ( a, i, c, k, n )
NAME Vector Reciprocal Square Root
DESCRIPTION This function computes the reciprocal square root for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vrsqrt ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN 0.0 to +3.4 x 1038,
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + (17 to 5)*N cycles
NOTES The file tvrsqrt.c included in the distribution diskette provides an example of this function’s use.
Since division by zero is an illegal operation which will result in an error, input vector a must be greater then zero. This routine will execute faster than vsqrtz( ), as it does not contain logic to check for domain entires less than or equal to zero.
Cmk1.0
Ami
-------------- m 0 1 2 …n, 1–, ,{ }==
Amj 0>

ADSP-21K Optimized DSP Library User’s Manual
5-506 Wideband Computers, Inc.
vrsqrtz ( a, i, b, c, k, n )
NAME Vector Reciprocal Square Root with Domain Check
DESCRIPTION This function computes the reciprocal square root for each element in vector a, and stores the result in output vector c.
If input vector a is less or equal to zero, the value of scalar b is stored to output vector c.
ALGORITHM
SYNOPSIS void vrsqrtz ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 33 + 18*N cycles
NOTES The file tvrsqrtz.c included in the distribution diskette provides an example of this function’s use.
This routine is slower than vrsqrt( ), but checks for the presence of the less than or equal to 0.0 condition in the denominator.
if Ami 0.0 then m 0 1 2 …n 1–, , ,{ }=>
Cmk1.0Ami
-------------- else=
Cmk B=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-507
vrsum ( a, i, b, c, k, n )
NAME Vector Running Sum
DESCRIPTION Computes a running sum integration on the elements in input vector a scaled by input scalar b. The results are placed in input/output vector c.
ALGORITHM
SYNOPSIS void vrsum ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float b ; /* Weighting Factor */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 26 + 2*N
NOTES The file tvrsum.c included in the distribution tape provides an example of this func-tion’s use.
Vector c is both an input and output vector. If you desire to clear the vector, use the vclr( ) function to initialize the value of vector c to zero.
is not used in the sum to provide an output format consistent with vtrap( ) and vsimp( ).
Cmk C m 1–( )k Ami B•+=
C0 0.0=
m 0 1 2 … n, 1–, , ,{ }=
Ami

ADSP-21K Optimized DSP Library User’s Manual
5-508 Wideband Computers, Inc.
vrvrs ( c, k, n )
NAME Vector Reverse Order
DESCRIPTION This function reverse orders the elements of real input/output vector c. This operation is performed in-place with the output saved in input/output vector c.
ALGORITHM
SYNOPSIS void vrvrs ( c, k, n )
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 4*N cycles
NOTES The file tvrvrs.c included in the distribution diskette provides an example of this func-tion’s use.
Note that this process is performed in-place, and is therefore destructive to the original elements in vector c.
Temp Cmk=
Cmk C n 1– m–[ ]k=
C n 1– m–[ ]k Temp=
m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-509
vsasm ( a, i, b, c, d, l, n )
NAME Vector Scalar Add and Scalar Multiply
DESCRIPTION This function adds input vector a with input scalar b, multiplies the sum by input sca-lar c, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vsasm ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + 2*(N-1) cycles
NOTES The file tvsasm.c included in the distribution diskette provides an example of this function’s use.
Dml Ami B+( ) C• m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-510 Wideband Computers, Inc.
vsassb ( a, i, b, c, d, l, n )
NAME Vector Scalar Add and Scalar Subtract
DESCRIPTION This function adds input vector a with input scalar b, subtracts input scalar c from the sum, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vsassb ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 2*(N-1) cycles
NOTES The file tvsassb.c included in the distribution diskette provides an example of this function’s use.
Dml Ami B+( ) C– m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-511
vscadd ( a, i, b, c, k, n )
NAME Vector Scalar Add
DESCRIPTION This function adds input scalar b to each element of input vector a. The results are stored in output vector c.
ALGORITHM
SYNOPSIS void vscadd ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34 + 2*(N-1) cycles
NOTES The file tvscadd.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami B+ m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-512 Wideband Computers, Inc.
vscatr ( a, b, j, c, n )
NAME Vector Scatter
DESCRIPTION This function copies the elements of input vector a to output vector c using integer input vector b as the indices to be copied into vector c.
ALGORITHM
SYNOPSIS void vscatr ( a, b, j, c, n )
float *a ; /* Pointer to input vector a */
int *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038, Bmj must be within the valid range of integers.
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 5*N cycles
NOTES The file tvscatr.c included in the distribution diskette provides an example of this function’s use.
This function is the opposite of the vgathr( ) and vindex( ) functions, vgathr( ). This function performs the same operation as vgathr( ) execpt that vgathr( ) expects input vector b to be type real. Note that only vectors a and b may stride.
CBmj
Am= m 0 1 2 … n 1–, , , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-513
vscdiv ( a, i, b, c, k, n )
NAME Vector Scalar Divide
DESCRIPTION This function divides input vector a by input scalar b, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vscdiv ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + 2*(N-1) cycles
NOTES The file tvscdiv.c included in the distribution diskette provides an example of this function’s use.
This routine does not contain logic to check for an attempted divide by zero. If scalar b is set to zero an attempt to divide by zero will occur.
Cmk
Ami
B---------- m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-514 Wideband Computers, Inc.
vscma ( a, i, b, j, c, d, l, n )
NAME Vector Scalar Multiply and Vector Add
DESCRIPTION This function multiplies input vector a times input scalar c, then adds input vector b to the product, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vscma ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector b */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 3*(N-1) cycles
NOTES The file tvscma.c included in the distribution diskette provides an example of this function’s use.
Dml Ami C•( ) Bmj+ m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-515
vscmsb ( a, i, b, j, c, d, l, n )
NAME Vector Scalar Multiply and Vector Subtract
DESCRIPTION This function multiplies input vector a by scalar c, subtracts input vector b from the product, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vscmsb ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector b */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 3*(N-1) cycles
NOTES The file tvscmsb.c included in the distribution diskette provides an example of this function’s use.
Dml Ami C•( ) Bmj– m 0 1 2 …n, 1–, ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-516 Wideband Computers, Inc.
vscmul ( a, i, b, c, k, n )
NAME Vector Scalar Multiply
DESCRIPTION This function multiplies input vector a by input scalar b and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vscmul ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34 + 2*(N-1) cycles
NOTES The file tvscmul.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami B• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-517
vscsub ( a, i, b, c, k, n )
NAME Vector Scalar Subtract
DESCRIPTION This function subtracts input scalar b from input vector a, and stores the result in out-put vector c.
ALGORITHM
SYNOPSIS void vscsub ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 34 + 2*(N-1) cycles
NOTES The file tvscsub.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami B– m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-518 Wideband Computers, Inc.
vsec ( a, i, c, k, n )
NAME Vector Secant
DESCRIPTION This function computes the secant for each element in input vector a, and stores the result in output vector c. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vsec ( a, i, c, k, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 51 + 34*N cycles
NOTES The file tvsec.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amisec m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-519
vsech ( a, i, c, k, n )
NAME Vector Hyperbolic Secant
DESCRIPTION This function computes the hyperbolic secant for each element in input vector a, and stores the result in output vector c. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vsech ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 36 + 52*N cycles
NOTES The file tvsech.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amisech m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-520 Wideband Computers, Inc.
vsfloat ( a, c, sign, n )
NAME Vector Integer To Floating-Point Conversion of Short Word
DESCRIPTION This function successively applies the float instruction to the short word in integer vector a and stores the results into output vector c. The lower 16-bit word or LSW of the element in vector a is extracted and then converted. The same is done for the upper 16-bit word or MSW.
The number of elements in n is defined by the size of vector a. The sign extension flag determines whether the 16-bit word is sign extended or not before conversion ( 0 = unsigned, 1 = signed ).
ALGORITHM
SYNOPSIS void vsfloat ( a, c, sign, n )
int dm *a ; /* Pointer to input vector a */
float dm *c ; /* Pointer to output vector c */
int sign ; /* Sign Extension Flag */
int n ; /* Element count ( size of a ) */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 30 + 6 * ( N-1 ) cycles
NOTES The file tsvfloat.c included in the distribution diskette provides an example of this function’s use.
Cmk float Ami( )= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-521
vsimps ( a, i, b, c, n )
NAME Vector Simpson’s Rule Integration
DESCRIPTION Integrates input vector a scaled by input scalar b according to Simpson’s rule, and stores the result to output vector c.
ALGORITHM
SYNOPSIS void vsimps ( a, i, b, c, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float b ; /* Value of input scalar b */
float *c ; /* Pointer to accumulator output vector c */
int n ; /* Element count for vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 46 + 7*N
NOTES The file tvsimp.c included in the distribution tape provides an example of this func-tion’s use.
The number of points n must be an odd number great than or equal to 3.
C0 0.0=
C1 0.5 B A0 B1+( )••=
Ci Ci 2– 0.333333 B Ai 2– 4 Ai 1– Ai+•+( )••+=

ADSP-21K Optimized DSP Library User’s Manual
5-522 Wideband Computers, Inc.
vsin ( a, i, c, k, n )
NAME Vector Sine
DESCRIPTION This function computes the sine for each element in input vector a, and stores the result in output vector c. All angles in input vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vsin ( a, i, c, k, n )
float dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float dm *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 23*N cycles
NOTES The file tvsin.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=sin=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-523
vsinh ( a, i, c, k, n )
NAME Vector Hyperbolic Sine
DESCRIPTION This function computes the hyperbolic sine for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vsinh ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 36 + 44*N cycles
NOTES The file tvsinh.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Amisinh m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-524 Wideband Computers, Inc.
vsm ( a, i, b, j, c, k, d, l, n )
NAME Vector Subtract and Multiply
DESCRIPTION This function subtracts input vector b from input vector a, multiplies the difference by input vector c, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vsm ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input scalar b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input scalar c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 + 4*(N-1) cycles
NOTES The file tvsm.c included in the distribution diskette provides an example of this func-tion’s use.
Dml Ami Bmj–( ) Cmk• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-525
vsmsad ( a, i, b, c, d, l, n )
NAME Vector Scalar Multiply and Scalar Add
DESCRIPTION This function multiplies input vector a by input scalar b, adds input scalar c to the product, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vsmsad ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 31 + 2*(N-1) cycles
NOTES The file tvsmsad.c included in the distribution diskette provides an example of this function’s use.
Dml Ami B•( ) C m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-526 Wideband Computers, Inc.
vsmssb ( a, i, b, c, d, l, n )
NAME Vector Scalar Multiply and Scalar Subtract
DESCRIPTION This function multiplies input vector a by input scalar b, and then subtracts input sca-lar c from the product. The result are stored in output vector d.
ALGORITHM
SYNOPSIS void vsmssb ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector b */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 2*(N-1) cycles
NOTES The file tvsmssb.c included in the distribution diskette provides an example of this function’s use.
Dml Ami B•( ) C – m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-527
vsmvsma ( a, i, b, j, c, k, d, e, n )
NAME Vector Muliply By Scalar, Add to Vector Multiplied By Scalar
DESCRIPTION This function multiplies input vector a by input scalar d and adds the results to the multiplication of input vector b times scalar e, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vsmvsma ( a, i, b, j, c, k, d, e, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input scalar b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
float *d ; /* Pointer to input scalar d */
float *e ; /* Pointer to input scalar e */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 52 + 3 * ( N-1 ) cycles
NOTES The file tvsmvsma.c included in the distribution diskette provides an example of this function’s use.
Cml Ami D•( ) Bmj E•( ) m 0 1 2 …n 1–, , ,{ }=+=

ADSP-21K Optimized DSP Library User’s Manual
5-528 Wideband Computers, Inc.
vsq ( a, i, c, k, n )
NAME Vector Square
DESCRIPTION This function computes the square for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vsq ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x 1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 22 + 2*(N-1) cycles
NOTES The file tvsq.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami2
m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-529
vsqrt ( a, i, c, k, n )
NAME Vector Square Root
DESCRIPTION This function computes the square root for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vsqrt( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN 0.0 to +3.4 x 1038, Ami must be > 0.0
ACCURACY 7.75 decimal digits
EXECUTION TIME 19 + 14*N cycles
NOTES The file tvsqrt.c included in the distribution diskette provides an example of this func-tion’s use.
This routine does not check for the presence of a number less than zero in Ami.
Cmk Ami m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-530 Wideband Computers, Inc.
vsqrtz ( a, i, b, c, k, n )
NAME Vector Square Root With Zero Domain Check
DESCRIPTION This function computes the square root for each element in input vector a, and stores the result in output vector c. If input vector a is found to be less than zero, the value of input scalar b is stored to output vector c.
ALGORITHM
SYNOPSIS void vsqrtz( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Value of input scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 19 + 17*N cycles
NOTES The file tvsqrtz.c included in the distribution diskette provides an example of this function’s use.
if Ami 0.0 then m 0 1 2 …n 1–, , ,{ }=<
Cmk B else=
Cmk Ami=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-531
vssbsa ( a, i, b, c, d, l, n )
NAME Vector Scalar Subtract and Scalar Add
DESCRIPTION This function subtracts input scalar b from input vector a, adds the difference to input scalar c, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vssbsa ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 2*(N-1) cycles
NOTES The file tvssbsa.c included in the distribution diskette provides an example of this function’s use.
Dml Ami B–( ) C+ m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-532 Wideband Computers, Inc.
vssbsm ( a, i, b, c, d, l, n )
NAME Vector Scalar Subtract and Scalar Multiply
DESCRIPTION This function subtracts input scalar b from input vector a, multiplies the difference by input scalar c, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vssbsm ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input scalar b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 2*(N-1) cycles
NOTES The file tvssbsm.c included in the distribution diskette provides an example of this function’s use.
Dml Ami B–( ) C• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-533
vssca ( a, i, b, j, c, d, l, n )
NAME Vector Subtract and Scalar Add
DESCRIPTION This function subtracts input vector b from input vector a, adds input scalar c to the difference, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vssca ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 3*(N-1) cycles
NOTES The file tvssca.c included in the distribution diskette provides an example of this func-tion’s use.
Dml Ami Bmj–( ) C+ m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-534 Wideband Computers, Inc.
vsscm ( a, i, b, j, c, d, l, n )
NAME Vector Subtract and Scalar Multiply
DESCRIPTION This function subtracts input vector b from input vector a, multiplies the difference by input scalar c, and stores the result in output vector d.
ALGORITHM
SYNOPSIS void vsscm ( a, i, b, j, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input scalar b */
int j ; /* Address stride in words for input vector b */
float c ; /* Value of input scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 3*(N-1) cycles
NOTES The file tvsscm.c included in the distribution diskette provides an example of this function’s use.
Dml Ami Bmj–( ) C• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-535
vssm ( a, i, b, j, c, k, d, l, e, h, n )
NAME Vector Subtract, Subtract & Multiply
DESCRIPTION This function subtracts two input vectors, a minus b, subtracts two other input vectors c minus d, then multiplies the two intermediate results, and stores the result in output vector e.
ALGORITHM
SYNOPSIS void vssm ( a, i, b, j, c, k, d, l, e, h, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
float *d ; /* Pointer to input vector d */
int l ; /* Address stride in words for input vector d */
float *e ; /* Pointer to output vector e */
int h ; /* Address stride in words for output vector e */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 59 + 5*(N-1) cycles
NOTES The file tvssm.c included in the distribution diskette provides an example of this func-tion’s use.
Emh Ami Bmj–( ) Cmk Dml–( )•=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-536 Wideband Computers, Inc.
vssort ( a, b, c, n )
NAME Selection Sort
DESCRIPTION This function performs a selection sort on input/output vector a according to the num-ber of elements defined in input scalar c. The sort order (ascending or descending) is defined by input scalar b, while the number of elements in input/output vector a is defined in input scalar n.
ALGORITHM for i = 0 to c
min = 1
for j = i+1 to n
if a[j] < a[min] then
min = j
end if
swap a[min] and a[i]
end loop
end loop
SYNOPSIS void vssort ( a, b, c, n )
float dm *a ; /* Pointer to input/output vector a */
int b ; /* Input sort flag */
int c ; /* Number of elements to sort */
int n ; /* Count of floating point elements */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-537
EXECUTION TIME 22 + (10 + 5*N) cycles
NOTES The file tvssort.c included in the distribution diskette provides an example of this function’s use.
vssort ( ) performs a selection sort on input vector a. A selection sort searches the vec-tor for a value (largest or smallest) and swaps it with a vector position (either from the left or the right). This process is repeated for the next value and position until the sort is finished. The type of sorting is determined by flags explained as follows:
The sort order is determined by the sort flag b.
For b =1, the sort order is ascending order (smallest to largest).
For b =0, the sort order is descending order (largest to smallest to largest).
The number of elements that are sorted is determined by input scalar c. The size of the input/output vector is defined by input scalar a.
The remaining non-sorted elements in the vector are left in the respective swapped positions.
Example:
float a[8] = { 1.2, 10.5, 3.0, 4.0, 12.2, 7.8, 9.0, 0.5 };
vssort ( a, 0, 3, 8 ) ;
a = { 12.2, 10.5, 9.0, 4.0, 1.2, 7.8, 3.0, 0.5 } ;
vssort ( a, 1, 3, 8 ) ;
a = { 0.5, 1.2, 3.0, 4.0, 10.5, 7.8, 9.0, 12.2 } ;
The number of elements to sort must be less than or equal to the number of elements in a. ( c <= n ).
If the order of the sorted elements is out of order (i.e., want the lowest values in descending order) use the function vrvrs( ) to reverse the order . Likewise, if the desired sorted elements are out of position in the vector ( i.e., want lowest three ele-ments in the middle of the vector ) use the function vswap( ) to switch the order.
vssort ( a, b, c, n )

ADSP-21K Optimized DSP Library User’s Manual
5-538 Wideband Computers, Inc.
vssq ( a, i, c, k, n )
NAME Vector Signed Square
DESCRIPTION This function computes the signed square for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vssq ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.8 x 1019 to +1.8 x 1019
ACCURACY 7.75 decimal digits
EXECUTION TIME 23 + 3*(N-1) cycles
NOTES The file tvssq.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami Ami• m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-539
vsub ( a, i, b, j, c, k, n )
NAME Vector Subtract
DESCRIPTION This function subtracts input vector b from input vector a, and stores the result in out-put vector c.
ALGORITHM
SYNOPSIS void vsub ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 3*(N-1) cycles
NOTES The file tvsub.c included in the distribution diskette provides an example of this func-tion’s use.
Cm Ami Bmj– m 0 1 2 …n 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-540 Wideband Computers, Inc.
vswap ( a, i, c, k, n )
NAME Vector Swap
DESCRIPTION This function swaps each element of input vector a with each element of output vector c.
ALGORITHM
SYNOPSIS void vswap ( a, i, c, k, n )
float a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input/output vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for input/output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 18 + 1*N cycles
NOTES The file tvswap.c included in the distribution diskette provides an example of this function’s use.
Temp Bmj C= mk m 0 1 2 …n 1–, , ,{ }=
Cmk Ami=
Ami Temp Bmj=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-541
vtan ( a, i, c, k, n )
NAME Vector Tangent
DESCRIPTION This function computes the tangent for each element in vector a, and stores the result in output vector c. All angles in vector a are assumed to be in radians.
ALGORITHM
SYNOPSIS void vtan ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 47 + 32*N cycles
NOTES The file tvtan.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=tan=

ADSP-21K Optimized DSP Library User’s Manual
5-542 Wideband Computers, Inc.
vtanh ( a, i, c, k, n )
NAME Vector Hyperbolic Tangent
DESCRIPTION This function computes the hyperbolic tangent for each element in input vector a, and stores the result in output vector c.
ALGORITHM
SYNOPSIS void vtanh ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -1.0 x 109 to +1.0 x 109
ACCURACY 7.75 decimal digits
EXECUTION TIME 38 + 52*N cycles
NOTES The file tvtanh.c included in the distribution diskette provides an example of this function’s use.
Cmk Ami m 0 1 2 …n 1–, , ,{ }=tanh=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-543
vthr ( a, i, b, c, k, n )
NAME Vector Threshold
DESCRIPTION This function computes an output vector c based on a comparison of input vector a and threshold scalar b.
ALGORITHM
SYNOPSIS void vthr ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input threshold scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 17 + 2*N cycles
NOTES The file tvthr.c included in the distribution diskette provides an example of this func-tion’s use.
This routine is also an alias for the vlthr( ) routine.
if Ami B then Cmk B m 0 1 2 …n 1–, , ,{ }==<
else Cmk Ami=

ADSP-21K Optimized DSP Library User’s Manual
5-544 Wideband Computers, Inc.
vthres ( a, i, b, c, k, n )
NAME Vector Threshold With Zero Fill
DESCRIPTION This function compares input vector a to input scalar b. For each element in input vec-tor a greater than or equal to the threshold input scalar b, the value of the element in vector a is stored in the corresponding element of output vector c. Otherwise, the ele-ment in output vector c is set equal to 0.0.
ALGORITHM
SYNOPSIS void vthres ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input threshold scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 29 + 4*N cycles
NOTES The file tvthres.c included in the distribution diskette provides an example of this function’s use.
if Ami B then Cmk Ami m 0 1 2 …n 1–, , ,{ }==≥
else Cmk 0.0=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-545
vthrsc ( a, i, b, c, d, l, n )
NAME Vector Threshold With Signed Constant
DESCRIPTION This function compares input vector a to input scalar b. For each element in input vec-tor a greater than or equal to the threshold input scalar b, the value of input scalar c is stored in the corresponding element of output vector d. Otherwise, the output element in vector d is set equal to negative input scalar c.
ALGORITHM
SYNOPSIS void vthrsc ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input threshold scalar b */
float c ; /* Value of fill scalar c */
float *d ; /* Pointer to output vector d */
int l ; /* Address stride in words for output vector d */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 22 + 4*N cycles
NOTES The file tvthrsc.c included in the distribution diskette provides an example of this function’s use.
if Ami B then Dml C m 0 1 2 …n 1–, , ,{ }==≥
else Dml C–=

ADSP-21K Optimized DSP Library User’s Manual
5-546 Wideband Computers, Inc.
vtmerg ( a, i, b, j, c, k, n )
NAME Vector Tapered Merge
DESCRIPTION This function performs a tapered merge. A comparison of two input vectors a and b determines whether vectors a or b are copied into output vector c.
ALGORITHM if then
else
SYNOPSIS void vtmerg ( a, i, b, j, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
float *c ; /* Pointer to input vector c */
int k ; /* Address stride in words for input vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 51 + 7*N cycles
NOTES The file tvtmerg.c included in the distribution diskette provides an example of this function’s use.
Ami Bmj<
Cmk Bmj=
Cmk Amj=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-547
vtrans ( a, i, b, j, c, k, n )
NAME Transfer Function
DESCRIPTION Computes the transfer function for the auto-spectrum provided by complex input vec-tor a and the cross-spectrum provided by input vector b. The result is stored in com-plex output vector c.
ALGORITHM
SYNOPSIS void vtrans ( a, i, b, j, c, k, n )
complex *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Element stride for vector b */
complex *c ; /* Pointer to accum output scalar c */
int k ; /* Element stride for vector c */
int n ; /* Element count to compute */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 27 + 3*N
NOTES The file tvtrans.c included in the distribution tape provides an example of this func-tion’s use.
Vector a is assumed to be a cross-spectrum.
Vector b is assumed to be an autospectrum.
Re Cmk{ }Re Bmj{ }
Ami------------------------= Im Cmk{ }
Im Bmj{ }
Ami------------------------=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-548 Wideband Computers, Inc.
vtrapz ( a, i, b, c, k, n )
NAME Vector Trapezoidal Integration
DESCRIPTION Performs a trapezoid-rule integration on input vector a placing the results in outputvector c. B is a scalar value which typically represents the abcissa increment betweenelements of vector a (the step size), hence allowing scaling.
ALGORITHM
SYNOPSIS void vtrapz ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float b ; /* Scaling/Factor (Step Size) */
float *c ; /* Pointer to output vector c */
int k ; /* Element stride for vector c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 30 + 3*(N-1)
NOTES The file tvtrapz.c included in the distribution tape provides an example of this func-tion’s use.
C0 0.0=
Cmk C m 1–( )kB Ami A m 1–( )i+[ ]•
2------------------------------------------------------+=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-549
vunpack ( a, i, b, j, fill, n )
NAME Unpack a Input Vector of 32-Bit Words Into a Floating Point Vector of Ones and Zeros
DESCRIPTION This function reads an input vector a, bit by bit. If a 1 is read, a bit is set in output vec-tor b corresponding to floating-point 1. Likewise, if a 0 is read a bit is set in output vector b to floating-point 0. The next value is read and the next corresponding bit is set.
The order in which the bits are set/cleared is determined by the fill flag. If the fill=1, the bits are read from LSB to MSB. If fill=-1, the bits are read from MSB to LSB.
ALGORITHM
SYNOPSIS void vunpack ( a, i, b, j, fill, n )
int dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int dm *b ; /* Pointer to output vector b */
int j ; /* Address stride in words for output vector b */
int fill ; /* Fill direction flag ( Either 1 or -1 ) */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 44 +97*(Integer) (N/32) + 3*(M Mod 32) cycles
NOTES The file tvunpack.c included in the distribution diskette provides an example of this function’s use.
32 elements are packed into a 32-bit word. For non-multiples of 32, the remaining ele-ments are packed into a 32-bit work and is zero filled.
The vector size of b should be at least (N/32). If N is not a multiple of 32 then the vec-tor size of b should be (N/32 + 1).
Bmj Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-550 Wideband Computers, Inc.
vunpcki ( a, i, b, j, fill, n )
NAME Unpack an Input Vector of Ones and Zeros Into Integer 32-Bit Words Arguments
DESCRIPTION This function reads an input vector a bit by bit. . If a 1 is read, a bit is set in output vec-tor b to integer 1. Likewise, if a 0 is read a bit is in output vector b is set to integer 0. The next value is read and the next corresponding bit is set.
The order in which the bits are set is determined by the fill flag. If fill =1, then the bits are read from LSB to MSB. If fill = -1, the bits are read from MSB to LSB.
ALGORITHM
SYNOPSIS void vunpcki ( a, i, b, j, fill, n )
int dm *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int dm *b ; /* Pointer to output vector b */
int j ; /* Address stride in words for output vector b */
int fill ; /* Fill direction flag ( Either 1 or -1 ) */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 41 +65*(Integer) (N/32) + 2*(M Mod 32) cycles
NOTES The file tvunpack.c included in the distribution diskette provides an example of this function’s use.
32 elements are packed into a 32-bit word. For non-multiples of 32, the remaining ele-ments are packed into a 32-bit work and is zero filled.
The vector size of b should be at least (N/32). If N is not a multiple of 32 then the vec-tor size of b should be (N/32 + 1).
Bmj Ami= m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-551
vuthr ( a, i, b, c, k, n )
NAME Vector Upper Threshold
DESCRIPTION This function computes an output vector c based on a comparison of input vector a and threshold scalar b.
ALGORITHM
SYNOPSIS void vuthr ( a, i, b, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
float b ; /* Value of input threshold scalar b */
float *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN -3.4 x 1038 to +3.4 x 1038
ACCURACY 7.75 decimal digits
EXECUTION TIME 32 + 2*N cycles
NOTES The file tvuthr.c included in the distribution diskette provides an example of this func-tion’s use.
if Ami B then Cmk Ami =<
else Cmk B=
m 0 1 2 …n 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-552 Wideband Computers, Inc.
vxcs ( a, i, b, c, d, l, n )
NAME Vector Multiply by Sine and Cosine
DESCRIPTION The function vxcs( ) computes the real and imaginary components from the values held within vector a [ ] by multiplying by the sine and cosine of the input frequency b and phase (in radians) c. The results are stored in output vector d.
ALGORITHM
SYNOPSIS void vxcs ( a, i, b, c, d, l, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for input vector a */
float *b ; /* Pointer to Freq in radians per element*/
float *c ; /* Pointer to input/output phase in radians*/
complex *d ; /* Pointer to output vector d */
int l ; /* Element stride for output vector d */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
Re Dml{ } Ami B m•( ) C+( )cos•=
Im Dml{ } Ami B m•( ) C+( )sin•=
C n B C+•=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-553
EXECUTION TIME 66 + 48 * N
NOTES The file tvxcs.c included in the distribution tape provides an example of this function’s use.
vxcs ( ) computes the real and imaginary components from the values held within vec-tor a by multiplying by the sine and cosine of the input frequency b and phase c. The return value is stored in output vector d.
This routine reduces the argument to a modulo fraction before using a polynomial approximation from Cody and Waite to estimate the sine value. The polynomial used is appropriate for 32-bit computations. In addition, the innner loop of coefficient is unrolled to eliminate setting up a loop each time.
All arguments are assumed to be in radians.
The phase c is also computed for the next frame such that succesive calls to vxcs ( ) will produce a continuous signal.
should be normalized such that .
vxcs ( a, i, b, c, d, l, n )
Re Dmk{ } Ami Bm C+( )cos•=
Im Dmk{ } Ami Bm C+( )sin•=
m 0 1 2 … n, 1–, , ,{ }=
π
C n B C+•= π– c π< <

ADSP-21K Optimized DSP Library User’s Manual
5-554 Wideband Computers, Inc.
vxor ( a, i, b, j, c, k, n )
NAME Vector Exclusive Or
DESCRIPTION This function performs a bitwise exclusive OR of each element in input vector a with each element in input vector b and stores the results in output vector c.
ALGORITHM
SYNOPSIS void vxor ( a, i, b, j, c, k, n )
int *a ; /* Pointer to input vector a */
int i ; /* Address stride in words for input vector a */
int *b ; /* Pointer to input vector b */
int j ; /* Address stride in words for input vector b */
int *c ; /* Pointer to output vector c */
int k ; /* Address stride in words for output vector c */
int n ; /* Element count */
DOMAIN No restrictions
ACCURACY 32-bits
EXECUTION TIME 33 + 3*(N-1) cycles
NOTES The file txor.c included in the distribution diskette provides an example of this func-tion’s use.
Cmk Ami XOR Bmj( )=
m 0 1 2…n 1 }–, ,{=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-555
welch ( a, i, c, k, n )
NAME Welch Window Multiply
DESCRIPTION Computes a Welch window on the values held in real input vector a. The results are stored in real output vector c.
ALGORITHM
SYNOPSIS void welch ( a, i, c, k, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *c ; /* Pointer to resultant output vector c */
int k ; /* Element stride for output vector c */
int n ; /* Element count for ooutput vector c */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 67 + 15 * ( N-1 )
NOTES The file twelch.c included in the distribution tape provides an example of this func-tion’s use.
welch( ) is a vector function. You may therefore use the stride arguments i and k todecimate both input and output for data congruence with other routines.
Cm Ami 1m 0.5 n 1–( )–[ ]
0.5 n 1+( )---------------------------------------
2–• =
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
5-556 Wideband Computers, Inc.
winwts ( wr, i, n )
NAME Window Cosine Weights Array
DESCRIPTION The routine computes the cosine weights array for a windowing computation such as the hamm( ) and hann( ) functions.
ALGORITHM
SYNOPSIS void winwts ( wr, i, n )
float pm *wr ; /* Pointer to output weights table wr[ ] */
int i ; /* Vector wr[ ] element stride */
int n ; /* Count of floating point elements */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 30 + 23*(N-1) cycles
NOTES The file twinwts.c included in the distribution tape provides an example of this func-tion’s use.
This function is introduced to correct a discrepancy with the hamm( ) and hann( ) window function, whose weights were originally calculated using the formula
. This was incorrect as this required the fft function to allocate twice the amount of memory to contain the weights. To correct the problem, a new function was introduced called the winwts( ) (shown above) which uses the formula to perform the weights calculation while the fftwts( ) function was modified to use the formula for the fft weights calculation.
wrm 2 πmn----••
for m 0 1 2 … n, 1–, , ,{ }=cos=
2 π m•• n⁄
2 π m•• n⁄
π m• n⁄

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-557
wtmean ( a, i, b, j, &c, n )
NAME Weighted Mean
DESCRIPTION This routine calculates the mean of the elements within input vector a weighted by the elements within input vector b, and places the results in scalar c.
ALGORITHM
SYNOPSIS void wtmean ( a, i, b, j, &c, n)
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
float *b ; /* Pointer to input vector b */
int j ; /* Element stride for vector b */
float *c ; /* Pointer to resultant scalar c */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 53 + 3 * ( N - 1 )
NOTES The file twtmean.c included in the distribution tape provides an example of this func-tion’s use.
C
Ai Bj•
i 0 j 0=,=
n 1–
∑
Bj
j 0=
n 1–
∑
----------------------------------------- m 0 1 2 … n, 1–, , ,{ }==

ADSP-21K Optimized DSP Library User’s Manual
5-558 Wideband Computers, Inc.
zeroxng ( a, i, n )
NAME Zero Crossing Detector
DESCRIPTION This routine detects the number of times the elements within input vector a cross the zero axis (ie. in connecting the points, how many times the connection crosses the zero axis). The result is returned from the function.
ALGORITHM
SYNOPSIS void zeroxng ( a, i, n )
float *a ; /* Pointer to input vector a */
int i ; /* Element stride for vector a */
int n ; /* Element count */
DOMAIN -3.4E+38 to 3.4E+38
ACCURACY 7.75 decimal digits
EXECUTION TIME 45 + N * ( 7+H-1 )
NOTES The file tzeroxng.c included in the distribution tape provides an example of this func-tion’s use.
if Ami A m 1+( )i•( ) 0<( )
count count 1+=
m 0 1 2 … n, 1–, , ,{ }=

ADSP-21K Optimized DSP Library User’s Manual
Wideband Computers, Inc. 5-559

ADSP-21K Optimized DSP Library User’s Manual
5-560 Wideband Computers, Inc.





























