Embed Size (px)
Citation preview

Chapter 3.2: ProcessesChapter 3.2: Processesmodified by your instructormodified by your instructor

3.2 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Chapter 3: ProcessesChapter 3: Processes
Process Concept
Process Scheduling
Operations on Processes
Cooperating Processes
Interprocess Communication
Communication in Client-Server Systems
This is a very important chapter now that we have completed the introductory materials.
This will require two to three lectures.

3.3 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Operations on ProcessesOperations on Processes

3.4 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Process ManagementProcess Management
A UNIX process is a unique instance of a running or runnable program.
Every process in a UNIX system has the following attributes:
Some code (text)
Some data
A stack
A unique process ID (PID) number (usually an integer)
Processes may be created / terminated dynamically and run concurrently. (dynamically means? Concurrently means?)
Creating parent is called parent; new processes: children.
Hence, a tree of processes can be created.

3.5 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Process Creation (Process Creation (different sourcedifferent source)) In Solaris, the top process pid = 0 and is Sched (the Scheduler process). Sched ‘creates’ several processes including
init – serves as root process for all user processes Init is also the only visible process in the system at startup.
pageout and Fsflush (stands for file system flush)
Last two responsible for managing memory and file system. Only way to create a new process is to duplicate an existing process. When a process duplicates, the parent and child processes are virtually
identical except for PIDs, PPIDs, and run times. The child’s code and stack are a copy of the parent’s and it even continues
to execute the same code. A child process may, however, in certain instances replace its code with
that of another executable file. This makes it somewhat different than its parent, but its dependency still holds.
For example, when ‘init’ starts executing, it quickly duplicates several times. Hierarchy looks like:
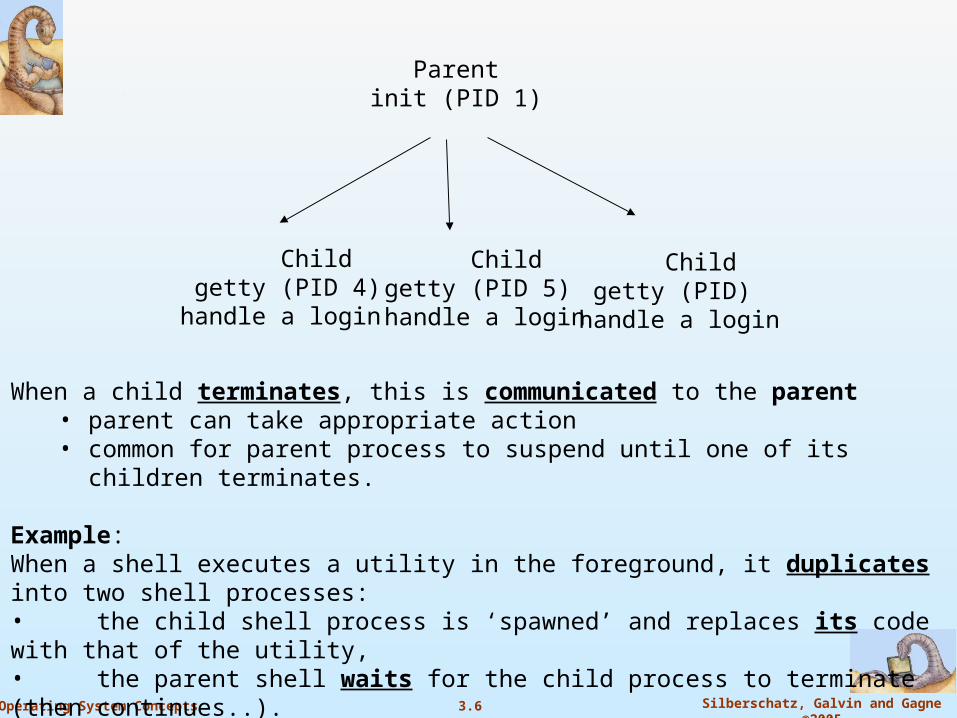
3.6 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Parent init (PID 1)
Child getty (PID 4)handle a login
Child getty (PID 5) handle a login
Child getty (PID)handle a login
When a child terminates, this is communicated to the parent• parent can take appropriate action • common for parent process to suspend until one of its children terminates.
Example: When a shell executes a utility in the foreground, it duplicates into two shell processes: • the child shell process is ‘spawned’ and replaces its code with that of the utility,• the parent shell waits for the child process to terminate (then continues..).
When the child process terminates, the original parent process is awakened.See next slide. This also includes the required system calls as well.
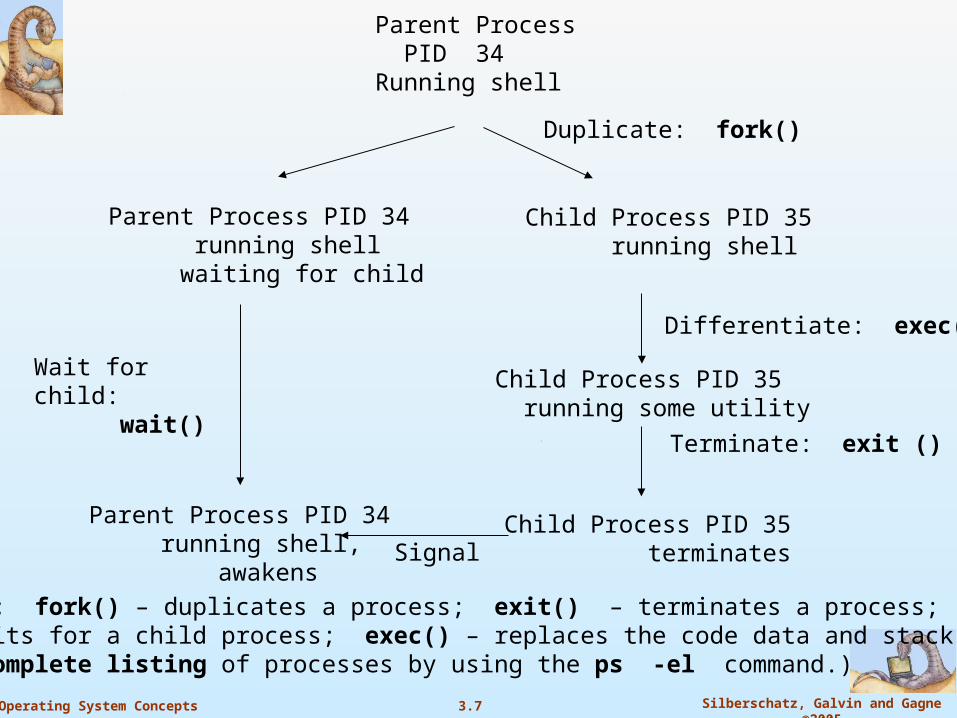
3.7 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Parent Process PID 34Running shell
Parent Process PID 34 running shell waiting for child
Child Process PID 35 running shell
Duplicate: fork()
Differentiate: exec()
Child Process PID 35 running some utility
Child Process PID 35 terminates
Terminate: exit ()
Wait for child: wait()
Parent Process PID 34 running shell, awakens
Signal
System calls: fork() – duplicates a process; exit() – terminates a process; wait() – waits for a child process; exec() – replaces the code data and stack of a process(Can get a complete listing of processes by using the ps -el command.)

3.8 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Process Creation (text)Process Creation (text) Thus, parent processes create children processes, which, in turn
create other processes. A large tree of processes can result. All processes need resources (CPU, memory, files, I/O devices…)
This implies need for resource sharing Child processes may get resources from the operating system, May share some resources (e.g. memory, files) or Parent may need to ‘partition’ its resources among its children.
Sharing / partitioning resources prevents overloading the system by creating many processes.
Needed parameters may also be passed from parent to child Example in book: process to display a file: img.jpg on a screen
Parent needs to pass name of the file (needed to open / write file) and name of the output device.
OS might pass the resources (alternatively) to the child process directly.
Here, the child just transfers the data between the two open files.

3.9 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Process Creation (Cont.)Process Creation (Cont.)
Execution – two possibilities. Parent and children execute concurrently, or Parent waits until some / all children terminate
Address space – two possibilities here too. Child is duplicate of parent (has same program and data as parent)
or Child has a new program loaded into it
To illustrate: consider a UNIX example fork() system call creates new process exec() system call used after a fork() to replace the process’
memory space with a new program Let’s consider code for forking a separate process………
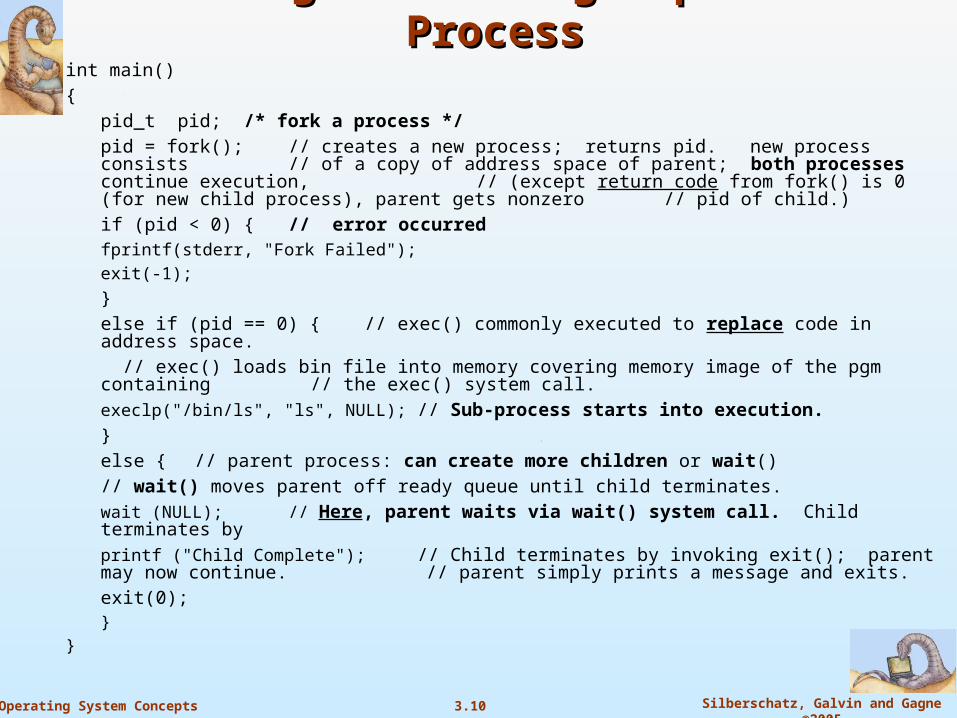
3.10 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
C Program Forking Separate ProcessC Program Forking Separate Processint main(){
pid_t pid; /* fork a process */pid = fork(); // creates a new process; returns pid. new process consists // of a copy of address space of parent; both processes continue execution,
// (except return code from fork() is 0 (for new child process), parent gets nonzero // pid of child.) if (pid < 0) { // error occurred
fprintf(stderr, "Fork Failed");exit(-1);
}else if (pid == 0) { // exec() commonly executed to replace code in address space.
// exec() loads bin file into memory covering memory image of the pgm containing // the exec() system call.
execlp("/bin/ls", "ls", NULL); // Sub-process starts into execution. }else { // parent process: can create more children or wait()
// wait() moves parent off ready queue until child terminates.
wait (NULL); // Here, parent waits via wait() system call. Child terminates by
printf ("Child Complete"); // Child terminates by invoking exit(); parent may now continue. // parent simply prints a message and exits.
exit(0); }
}
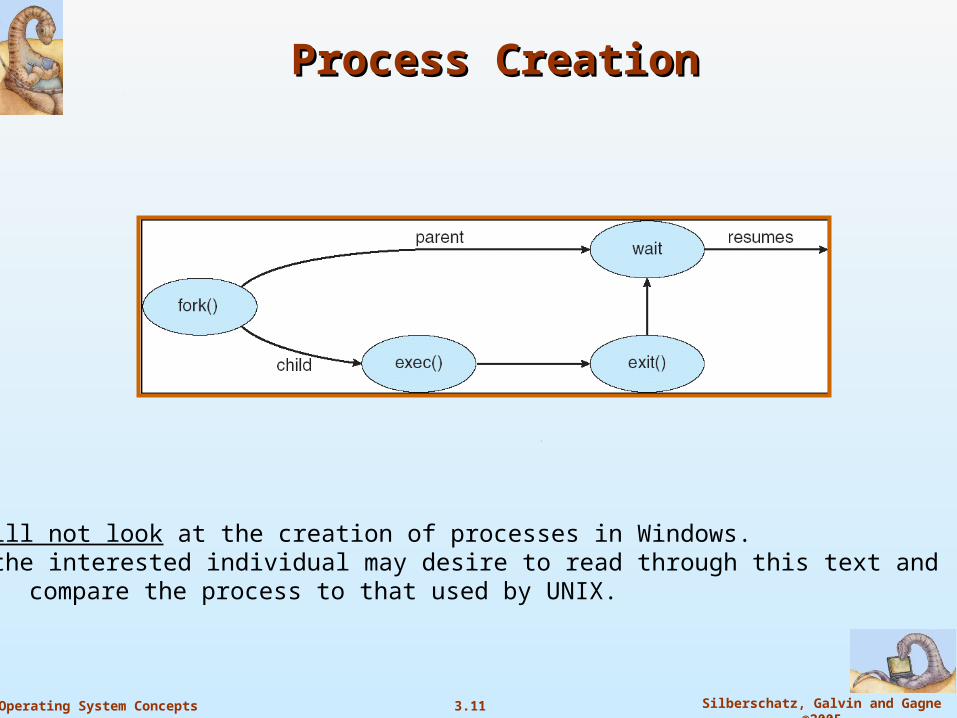
3.11 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Process CreationProcess Creation
We will not look at the creation of processes in Windows. But the interested individual may desire to read through this text and
compare the process to that used by UNIX.

3.12 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Process TerminationProcess Termination exit() Process executes last statement and asks the operating system to
delete it by issuing the exit system call. Output data (pid) from child is returned to parent (via wait) Process’ resources are de-allocated by operating system
Parent may also terminate execution of children processes (abort()) Parent may do so in cases where
Child has exceeded allocated resources (but parent must have some mechanism to know the state of its children)
Child task no longer required (but parent must be able to monitor) If parent is exiting
Some operating system do not allow child to continue if its parent terminates If so, OS may terminate all children – cascading termination
If OS does allow parent to terminate without terminating child processes, child processes are assigned init() as their new parent process. Init() then monitors child processes and their execution behaviors.

3.13 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Cooperating ProcessesCooperating Processes
All operating systems have provisions for cooperating processes. Processes may be
independent - process cannot affect / be affected by the execution of another process, or cooperating - process can affect / be affected by the execution of another process
Advantages of process cooperation Information sharing – allows concurrent access for files Computation speed-up – can break execution units into subtasks that can run in
parallel (if computing system is a multiprocessor…) Modularity – good design strategy – break system into separate processes or
threads Convenience – can be working on different tasks at the same time – in parallel. These are major pluses for cooperating processes……
Notion of sharing data may be implemented using: Shared memory, or Message passing.

3.14 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Shared Memory; Message PassingShared Memory; Message Passing
Shared Memory Region of memory established; Processes communicate via common area by reading / writing. Very efficient mechanism to facilitate sharing.
Simple memory accesses. Sharing memory provides very fast speed / convenience to communicate Need system call only to establish common area.
Message Passing Useful for exchanging smaller amounts of data. Little possibility of conflict Easier to implement Typically implemented via system calls and thus requires more time
consuming intervention by the kernel.
Never any free lunches, of course. There are issues!

3.15 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Cooperating Processes – Shared MemoryCooperating Processes – Shared Memory
Can be complicated. The shared memory usually is found in the address space of the process
creating the shared memory segment. Other processes must ‘attach’ to this area. Processes must allow other processes access into their address space! Format and location of data are determined by the processes. Issues centering around simultaneous access must be addressed.
This ‘smacks’ of the popular producer-consumer process. To allow concurrent access, there is usually a buffer that can be written to
by one process and read by another. But access must be synchronized! (Chapter 6)
To facilitate proper buffering and synchronization, one might consider two approaches: unbounded buffers and bounded buffers.

3.16 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Shared Memory – buffering options…Shared Memory – buffering options…
unbounded-buffer places no practical limit on the size of the buffer
Buffer is in ‘producer’s area, so producer may always add new items since size is unbounded
Consumer may have to wait for items to be posted.
bounded-buffer assumes that there is a fixed buffer size.
Consumer may have to wait if buffer is empty to read something
Producer may have to wait to post something if buffer is full.
Let’s look at some implementing code from the textbook.
3.17 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
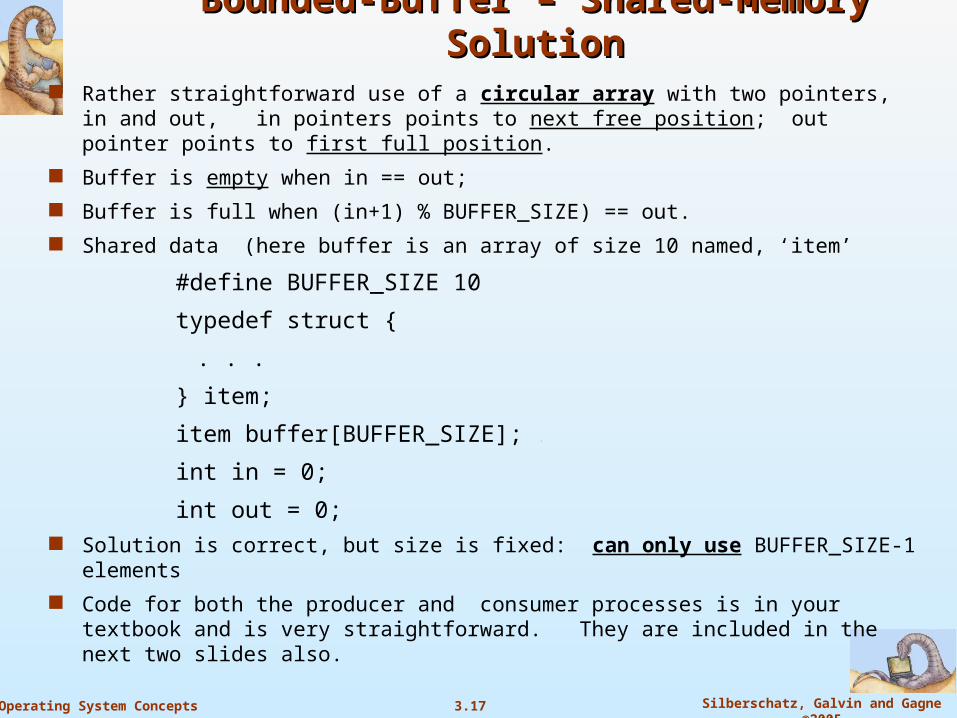
Bounded-Buffer – Shared-Memory SolutionBounded-Buffer – Shared-Memory Solution Rather straightforward use of a circular array with two pointers, in and out,
in pointers points to next free position; out pointer points to first full position.
Buffer is empty when in == out;
Buffer is full when (in+1) % BUFFER_SIZE) == out.
Shared data (here buffer is an array of size 10 named, ‘item’
#define BUFFER_SIZE 10
typedef struct {
. . .
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0; Solution is correct, but size is fixed: can only use BUFFER_SIZE-1 elements
Code for both the producer and consumer processes is in your textbook and is very straightforward. They are included in the next two slides also.

3.18 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Bounded-Buffer – Insert() MethodBounded-Buffer – Insert() Method
while (true) { // looks at ‘in’ pointer…. /* Produce an item */
while (((in = (in + 1) % BUFFER SIZE count) == out) ; /* do nothing -- no free buffers */ buffer[in] = item; // insert element into buffer in = (in + 1) % BUFFER SIZE;
{
Standard circular queue implemented in an array data structure

3.19 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Bounded Buffer – Remove() MethodBounded Buffer – Remove() Method
while (true) {
while (in == out)
; // do nothing – buffer is empty
// remove an item from the buffer
item = buffer[out]; // read item from queue.
out = (out + 1) % BUFFER SIZE;
// adjust out pointer; allows for circularity
return item;
{Please note that the implemented code is accommodated by the affected processes themselves, once a common area is established.

3.20 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Interprocess Communication (IPC)Interprocess Communication (IPC)Message-Passing SystemsMessage-Passing Systems
IPC is a mechanism for processes to communicate and to synchronize their actions without sharing an address space. This is very important – to not ‘share’ in one process’ address space!
Particularly useful in a distributed computing environment
Message system – processes communicate with each other without resorting to shared variables, but require two basic IPC operations: send / receive.
send(message) – message size fixed or variable Fixed size: System-level implementation is straightforward but makes
the programming task somewhat difficult. Variable size: requires more complex system-level implementation,
but programming task is actually easier. receive(message)

3.21 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Interprocess Communication (IPC)Interprocess Communication (IPC)Message-Passing SystemsMessage-Passing Systems
Example: So we have two processes that need to commuinicate… If P and Q wish to communicate, they need to:
establish a communication link between them exchange messages via send/receive
Question is exactly how to establish the link…… Sounds simple. But there are many ways to do this, and they are not
equivalent.
Implementation of communication link physical (e.g., shared memory, hardware bus) – not our concern in this chapter. logical (e.g., logical properties) – our concern…
Logically implementing a link can be done in a few interesting, essential ways using the send() and receive() functions.

3.22 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Implementation QuestionsImplementation Questions
We have some key question: First: How are links established?
Can a link be associated with more than just two processes?
How many links can there be between every pair of communicating processes?
What is the capacity of a link?
Is the size of a message that the link can accommodate fixed or variable?
Is a link unidirectional or bi-directional?
Big, important issues.

3.23 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Direct CommunicationDirect Communication
In the direct communications scenario, each process must reference (name) the other explicitly – by name. send (P, message) – send a message to process P receive(Q, message) – receive a message from process Q
Answering the questions on previous slide: Properties of links using the send() and receive() messages: Links are established automatically between every pair of processes that
desire to communicate But they need to know the other’s identity.
Links are established with exactly one pair of communicating processes Thus, equivalently, there’s only one link Links may be unidirectional but are usually bi-directional

3.24 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Direct Communication Direct Communication Symmetric / Asymmetric addressingSymmetric / Asymmetric addressing
Here we have symmetry in addressing – both sender and receiver processes must name the other to communicate.
Asymmetric addressing requires only sending process name the recipient. Formats for the send() and receive() are a bit different, but straightforward.
One (of several) major disadvantages is that hard coding is required. We use hard coding to identify the specific process. This can be a major disadvantage!!! It is often not necessarily know who will receive a message!
Any changes in identifiers can cause rippling effect and, in general, is a less desirable technique.
Consider a different scheme – indirect communications.

3.25 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Indirect CommunicationIndirect Communication Messages are directed and received from mailboxes (also referred to
as ports) Each mailbox has a unique id. In some implementations, this is an
integer, like port 80 or port 22. Processes can communicate only if they share a mailbox
Properties of this kind of communication link Link established only if processes share a common mailbox A link can be associated with many processes Each pair of processes may share several communication links
That is, there may be a number of mailboxes…
Link may be unidirectional or bi-directional Clearly, there is a number of ways for processes to communicate.
But, as is always the case, where there is ‘power’ there is complexity. We do this all the time, as we shall see…

3.26 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Indirect CommunicationIndirect Communication((rightright from the Textbook here) from the Textbook here)
Suppose processes P1, P2, and P3 share mailbox A
Process P1 sends a message to the mailbox A.
P2 and P3 both execute a receive() from A.
Who gains access to the mailbox?
There are lots of issues here, like who owns the mailbox for starters.
But essentially access may controlled in a number of ways: Allow connection to be associated with two processes at most
Allow only one process at a time issue a receive() operation
Let the system select – likely via an algorithm – who will receive the message
Could be a round robin or perhaps some kind of priority scheme for alternating or establishing the receive().

3.27 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Indirect Communications - Mailboxes
Does the process or the operating system really own the mailbox? Options: Mailbox owned by Process: (part of its address space)
Only owner can receive and the user only sends. At process termination, mailbox goes away. Sending() processes are notified that mailbox doesn’t exist.
Mailbox owned by Operating System Has its own existence; not part of or attached to a process. OS must provide control of course (later in chapter 6) allowing a process to:
Create a new mailbox Send and receive messages using this mailbox, and Deleting a mailbox.
Such a creating process is the owner by default and is, thus, the only process that can receive messages via the mailbox.
Interestingly, ownership can be passed to other processes via system calls, but this is beyond where we are at this time.

3.28 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
SynchronizationSynchronization
OK. Processes can communicate via messages.
But there are number of issues here that address blocking and
non-blocking phenomena.
Are processes allowed to continue when sending or receiving or must they ‘wait’ until a message is sent or received in order to continue processing?
This is referred to as Synchronization.
In operating systems programming, there is a good deal of synchronization required for many operations! (Chapter 6 is devoted to this phenomenon.)
So, what do processes do when ‘sending’ or ‘receiving’ messages?
What are the options?

3.29 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Synchronization – Blocking and UnblockingSynchronization – Blocking and Unblocking Blocking is considered synchronous; that is, processes must
‘coordinate’ their actions with each other; there is a dependency.
In a Blocking Send, the sender is blocked until the message is received.
Sending process cannot continue processing.
In a Blocking Receive, the receiving process is blocked until a message is available for it.
Non-blocking is considered asynchronous (no real dependencies!)
Non-blocking send has the sender send the message and continue. It is not blocked.
Non-blocking receive has the receiver receive a valid message or null. It is not blocked.
These are very important issues and impact overall performance. (Later!)

3.30 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
BufferingBuffering What about the messages themselves? What happens to them?? Messages are inserted into or removed from a queue for processes
attempting to communicate. Of course, the size of the queue and the insert() and remove() algorithms
come to bear. Clearly when there is ‘queueing’ there are a variety of algorithms on the size
of queue, priority of queue elements, and how to process the queue… Queue of messages may be implemented in one of three ways
1. Zero capacity – 0 messages. Called a message system with no buffering. Sender must wait for receiver to get the message. (rendezvous)
2. Bounded capacity – finite length of n messagesHere, insert() is simple.
Message inserted directly into queue or a pointer to the message is maintained.
Sender can continue (not blocked) But if queue is full, sender must wait (block) until room in the queue becomes available. (referred to as automatic buffering)
3. Unbounded capacity – infinite length (also referred to as automatic buffering). Sender never waits. Clearly this requies some system overhead…

3.31 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Client-Server CommunicationClient-Server Communication
We’ve discussed how processes might communicate using shared memory and how they might communicate using message passing.
We’ve looked at a number of considerations.
Can use the same strategies for Client-Server Communication itself...
In this architecture, let’s consider: Sockets
Remote Procedure Calls
Remote Method Invocation (Java)

3.32 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
SocketsSockets
A socket is defined as an endpoint for communication
Processes communicate using pairs of sockets.
Sockets - created to facilitate communications between distributed processes.
Sockets are defined by an IP address concatenated with a port number.
In a client-server architecture, a server simply waits for a client request by listening to a specific port.
Server: Upon arrival, the server accepts the connection from the client socket to complete the connection. Port numbers below 1024 (1K) are considered ‘well known’ and are used to implement specific
standard services.
Client: Here, a connection and is assigned a port by the host computer. Port number is > 1024 and somewhat arbitrarily assigned.
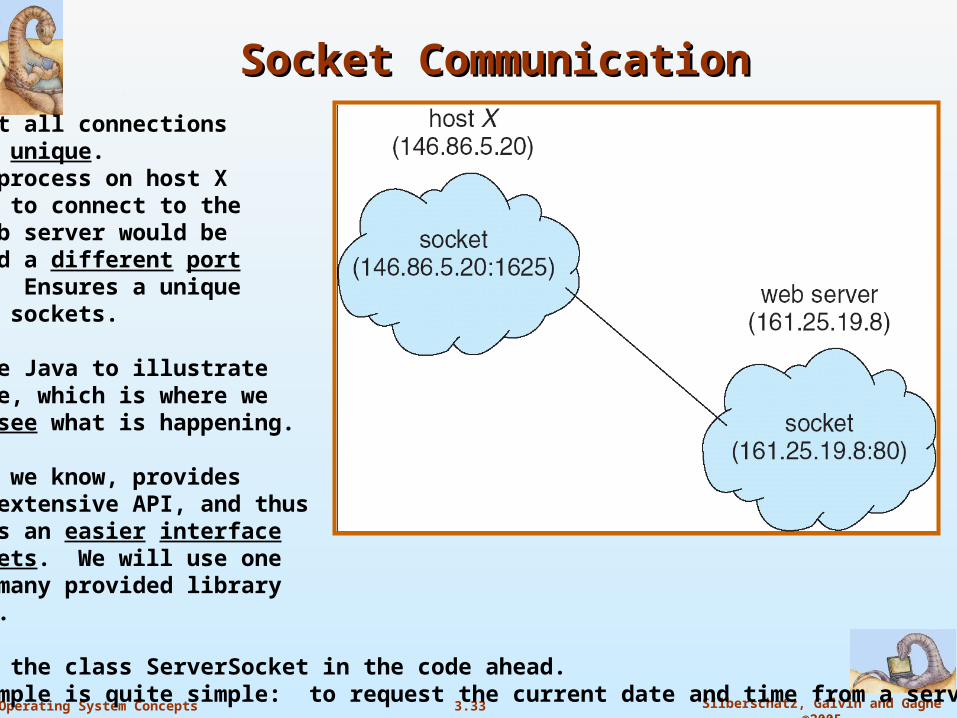
Example: we’ve got a client on host X with IP address 146.86.5.20 wishes to connect to a web server (which listens on port 80) at actual address 161.25.19.8, host X may be assigned port 1625.
Connection now consists of a pair of sockets: 146.86.5.20:1625 on client and 161.25.19.8:80 on the web server.
3.33 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Socket CommunicationSocket CommunicationNote that all connections must be unique.Another process on host X wishing to connect to the same web server would be assigned a different port number. Ensures a unique pair of sockets.
Let’s use Java to illustrate the code, which is where we really see what is happening.
Java, as we know, provides a very extensive API, and thus provides an easier interface to sockets. We will use one of the many provided library classes.
Will use the class ServerSocket in the code ahead. This example is quite simple: to request the current date and time from a server.
3.34 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
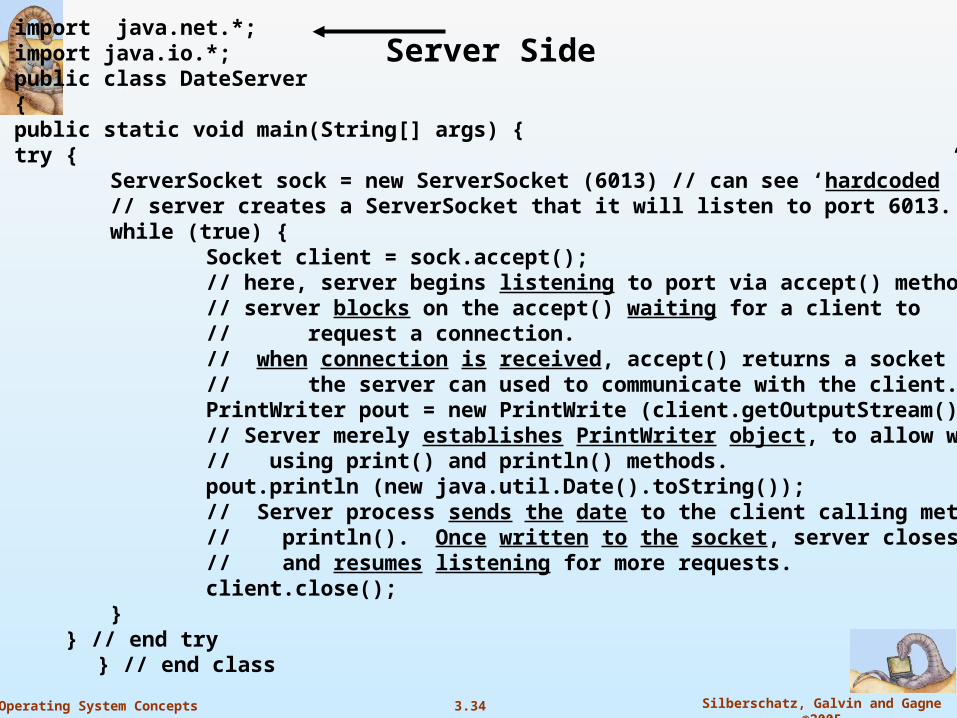
import java.net.*;import java.io.*;public class DateServer{public static void main(String[] args) {try {
ServerSocket sock = new ServerSocket (6013) // can see ‘hardcoded”// server creates a ServerSocket that it will listen to port 6013.while (true) {
Socket client = sock.accept();// here, server begins listening to port via accept() method.// server blocks on the accept() waiting for a client to // request a connection.// when connection is received, accept() returns a socket that// the server can used to communicate with the client.PrintWriter pout = new PrintWrite (client.getOutputStream(), true);// Server merely establishes PrintWriter object, to allow writing// using print() and println() methods.pout.println (new java.util.Date().toString());// Server process sends the date to the client calling method// println(). Once written to the socket, server closes socket// and resumes listening for more requests.client.close();
} } // end try
} // end class
Server Side

3.35 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
import java.net.*;import java.io.*;public class DateClient{public static void main(String[] args) {try {
// client creates a socket and requests connection at IP and port belowSocket sock = new Socket (“127.0.0.1”, 6013)
// once a connection is established, client can read from the socket using// normal stream I/O statementsInputStream in = sock.getInputStream();BufferedReader bin = new BufferedReader (new InputStreamReader(in));
// read date data from the socket:String line;while ( (line = bin.readLine()) != null)
System.outl.println (line); // client reads and prints msg out.
// once data is received from server, client closes socket and exits.sock.close();} // end try
catch (IOException ioe {System.err.println (ioe);
} // end catch} // end main
} // end DateClient
Client Side

3.36 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Lastly on Sockets
IP address 127.0.0.1 is a special IP address known as the loopback.
When a computer refers to 127.0.0.1, it is referring to itself.
This tradition allows a client and server on same host to communicate using TCP/IP protocol.
IP address could be replaced with web address as well.
Socket communications is low level and allows only unstructured stream of bytes.
This means the client or server must impose a structure on the data.
RPC and RMI are more powerful – coming up.

3.37 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Remote Procedure CallsRemote Procedure Calls Remote procedure call (RPC) abstracts procedure calls between processes on networked
systems.
Since we are dealing with processes on different, separate systems, we do not use a shared memory approach (of course); rather, we must use a message-based system.
Recall that communications using sockets provides unstructured data such that the recipients must provide a structure to the data. Remember also that is is considered low-level communications.
More: it is considered somewhat primitive and requires work on part of clients…
RPC supports procedural programming wherein procedures and functions are called – not objects. (done a lot in C programming)
In RPC, messages are addressed to an RPC daemon, (background process who listens to a port on a remote system.
Each message contains an identifier of the function to be executed and parameters to be passed to that function.
Results are executed by the remote system; output received by client in a separate message.

3.38 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
RPC – more
A system usually has a single network address but can have many ports used to differentiate types of network services the system might provide.
Messages sent must have a port number in the beginning of the message, and the message is actually addressed to a specific port. (think SSH or newer process like this…)
Example: on the remote system, if there is a background process (daemon) whose job it is to provide a list of the system’s current users, the daemon must be assigned (attached) to a specific port.
Any remote system could then obtain the list of current users by sending an RPC message to this port number on the server.

3.39 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
RPC – Semantics – Issue 1
Other interesting issues:
Some machines (known as big-endian) use high memory addresses for significant byte for integer representation; others use low end (little-endian).
Some RPC systems define a machine-independent representation of this data and that converts data into this form. We say that the server ‘unmarshals’ the data and converts it to
its machine-dependent format.
The representation is referred to as ‘external data representation (XDR).

3.40 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
RPC – Semantics – Issue 2
Another issue: RPCs can fail or be duplicated and executed a number of
times due to common network problems. Many times we simply continue to send a message….
So, we’ve got to prevent messages repeatedly acted upon. Must ensure messages are acted upon either
Exactly once, (more difficult to implement – done on most systems)or Acted upon at most once. These seem to be the same, but they are not.
For ‘at most once,’ a timestamp is attached to each message, which the server must manage. This comes directly from the machine hardware itself. If repeat messages are encountered, they are ignored. Good for client, who can repeatedly send message and know that the
message will only be handled at most one time.

3.41 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
RPC – Semantics – Issue 2 continued
‘Exactly once’ is different, and we simply need to ensure server does receive the request.
Here, the server needs to implement an ‘exactly once’ protocol (as above) but it also sends an ACK to the client citing that the RPC was received and executed.
In practice, then, a client must resend an RPC until it received an ACK.
Beyond this course at this time: Other issues involve binding that takes place during
link, load, or execution time so that a procedure call’s name is replaced by the memory address of the procedure call.
These and other issues are best left to a course in networking and data communications…

3.42 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
RPC – lastly
RPC approach is convenient in implementing a distributed file system (much more discussed in a grad course in distributed operating systems…)
This approach may be readily implemented using a set of RPC daemons and clients.
Messages - attached to the distributed file system port on a server where the file operation is to take place, such as a read, write, etc.
The return message contains response from the call which is executed by the distributed file system daemon on behalf of the client.
Example: message might request a transfer of a complete file or simply a block of data. Large transfers might necessitate a number of requests…
3.43 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
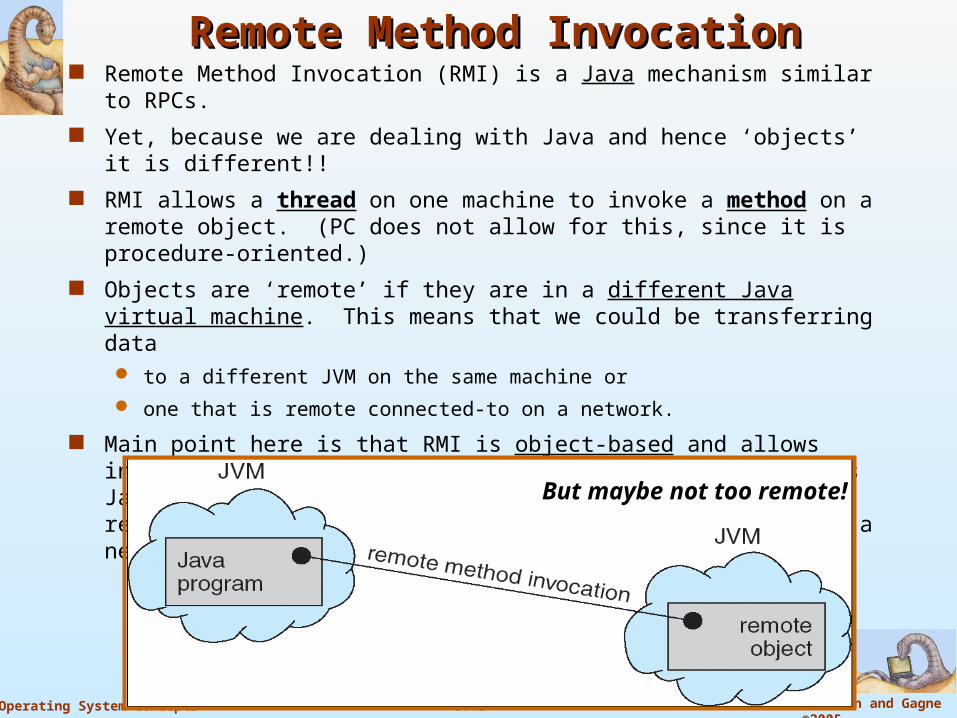
Remote Method InvocationRemote Method Invocation Remote Method Invocation (RMI) is a Java mechanism similar to RPCs.
Yet, because we are dealing with Java and hence ‘objects’ it is different!!
RMI allows a thread on one machine to invoke a method on a remote object. (PC does not allow for this, since it is procedure-oriented.)
Objects are ‘remote’ if they are in a different Java virtual machine. This means that we could be transferring data to a different JVM on the same machine or
one that is remote connected-to on a network.
Main point here is that RMI is object-based and allows invocation of methods on remote objects; Because this is Java, parameters may be objects and thus further lets us readily develop applications that are distributed across a network.
But maybe not too remote!

3.44 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Remote Method InvocationRemote Method Invocation Of course, as in RPCs, we want all this to be transparent to the programmer.
RMI therefore uses a series of stubs and skeletons.
A stub is a proxy for the remote object that resides on the client.
When client invokes a remote service, a stub for the remote object is created.
The client-side stub then creates a parcel consisting of the name of the remote method and the marshaled parameters.
Stub then sends this ‘parcel’ to the server, where a ‘skeleton’ for the remote object un-marshals the parameters and invokes the desired remote method on the server.
Then, the skeleton (on the server) marshals any return values (or exceptions) into a parcel and returns the parcel to the client.
Client-side stub un-marshals returned values, as you would expect, and passes them to the client.
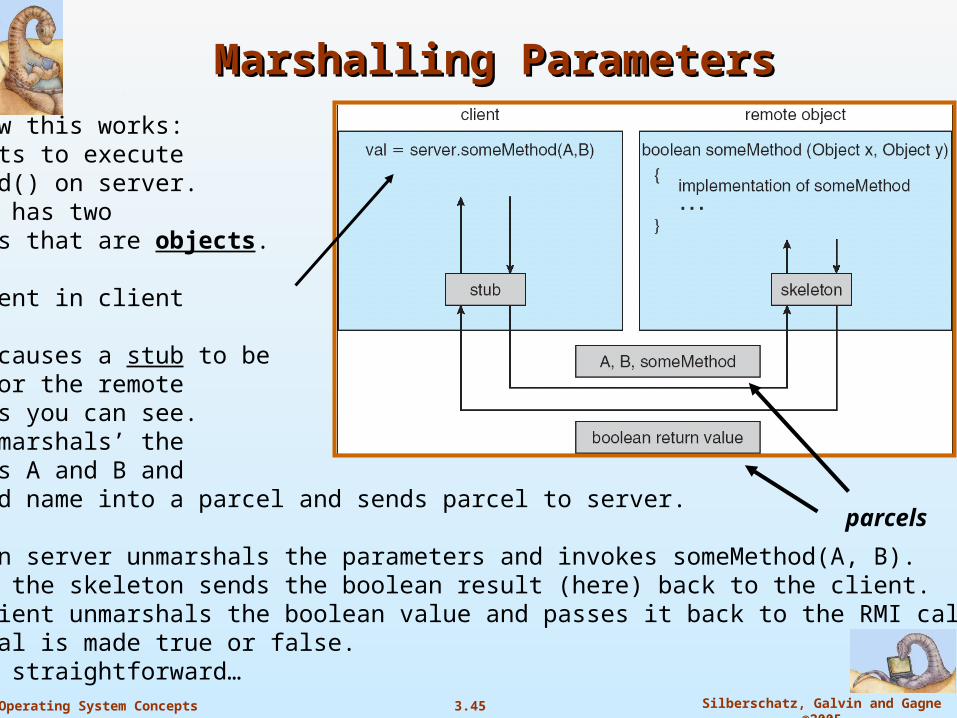
3.45 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
Marshalling ParametersMarshalling Parameters
Can see how this works:Client wants to execute someMethod() on server.someMethod has two parameters that are objects.
See statement in client
This call causes a stub to be created for the remote object, as you can see.The stub ‘marshals’ the parameters A and B and the method name into a parcel and sends parcel to server.
Skeleton on server unmarshals the parameters and invokes someMethod(A, B). When done, the skeleton sends the boolean result (here) back to the client. Stub in client unmarshals the boolean value and passes it back to the RMI call, and (above) val is made true or false. Reasonably straightforward…
parcels

3.46 Silberschatz, Galvin and Gagne ©2005Operating System Concepts
RMI – last So all of this is made transparent to Java programmers. But one should
understand the underlying features… If parameters are local, then Call by Value (copied) is used and the
object is serialized (flattened; converted into a byte stream). If parameters are also remote objects, then they are passed by
reference (Call by Reference), where an address is passed. In our example, if A is a local object and B is a remote object, A is
serialized and passed by copy (Call by Value) whereas B is passed by reference.
This procedure allows the server to invoke methods on B remotely. IF local objects are to be passed as parameters to remote objects, then
these objects must implement the interface java.io.Serializable. Many objects in the core Java API implement Serializable, which allows
them to be used with RMI. Simply stated, when we serialize an object, the state of the object is
converted to a byte stream. Used a lot in storing objects in a relational database system, which stores
byte streams and not ‘objects’

End of Chapter 3End of Chapter 3





























