Embed Size (px)
Citation preview

WHITE PAPER
Choosing between Windows and Linux for High Performance Computing A Crimson Perspective April 2010 A CRIMSON CONSULTING GROUP BUSINESS WHITE PAPER

WHITE PAPER
www.crimson-consulting.com ii
Introduction ........................................................................................................... 1
Lower Total Cost of Ownership ............................................................................ 2
Performance of Windows HPC Server vs. Linux Alternatives ............................... 3 The LINPACK benchmark and the Top 500 List......................................................................3
HPC System Efficiency ..........................................................................................................5
Real-World Application Benchmarks ......................................................................................6
Microkernel Benchmarks .......................................................................................................7
SOA-Based HPC application benchmarks ..............................................................................8
What Are Customers Saying? ...........................................................................................9
Integration Within the Stack and with Corporate Infrastructures ......................... 10 The HPC Stack in Windows HPC Server and Linux Alternatives ................................. 10
Fragmentation vs. Integration.......................................................................................... 12
Developing HPC Applications ......................................................................................... 13
Tuning HPC Applications ................................................................................................. 13
Integration with Corporate Infrastructures ............................................................................. 14
Speeding up Excel calculations with HPC clusters ................................................................ 14
Vision: Planning for Change ............................................................................... 15 Cloud Computing.............................................................................................................. 15
Large Scale Data Analytics ............................................................................................. 17
Workflow ........................................................................................................................... 17
Virtualization ..................................................................................................................... 18
Exploiting Multicore Processors ...................................................................................... 19
Summary ............................................................................................................ 20
Appendix A ......................................................................................................... 21
Appendix B ......................................................................................................... 24
Appendix C ......................................................................................................... 26
About Crimson Consulting .................................................................................. 26

WHITE PAPER
www.crimson-consulting.com 1
Introduction High Performance Computing (HPC), or supercomputing, is no longer the exclusive domain of scientific research and advanced engineering. Networked clusters of relatively inexpensive “commodity” computers can deliver parallel processing power that exceeds that of the dedicated supercomputers of the past. Cluster-based HPC is opening the door to innovation in areas such as financial modeling, computer animation rendering, product safety simulations, product design, medical research, and many other fields at a price that even mid-sized organizations can afford. In addition, many businesses are finding the scalability of cluster computing ideal for accelerating general business applications. Today, the Linux operating system dominates the cluster High Performance Computing (HPC) market. There is now a well-developed ecosystem of Linux-based HPC applications, middleware and tools (both commercial and open source). Linux is often the default operating system choice for HPC clusters because choosing Linux is widely considered a “safe choice.” However, that dominance is increasingly threatened by a credible challenger: Microsoft. With the recent introduction of Microsoft Windows HPC Server 2008 R21
, the company has given further evidence of its commitment to high performance computing. Evidence strongly suggests that Windows HPC Server should be seriously considered by any organization adopting an HPC platform, or extending an existing implementation.
In this paper, which was commissioned by Microsoft, we review this evidence, organized around four factors that are foundational to evaluating an HPC platform: Total Cost of Ownership, Integration, Performance, and Execution and Vision. Compared to Linux alternatives, Windows HPC Server
■ Can deliver a lower TCO than Linux alternatives,
■ Can deliver performance equal or superior to Linux alternatives
■ Offers more extensive integration, both within the “stack” and with the dominant corporate infrastructure
■ Represents the latest step in execution of a credible, long-term vision
The paper assumes some technical depth in the reader, especially in the sections related to performance and integration, where the discussion is necessarily somewhat technical in nature. At the end, we supply appendices tabulating and summarizing Microsoft claims about Windows HPC Server 2008 R2, with links to additional Microsoft information, as a convenience to readers interested in pursuing further research. 1 Referred to for the remainder of this paper as “Windows HPC Server.”

WHITE PAPER
www.crimson-consulting.com 2
Lower Total Cost of Ownership This topic is exhaustively reviewed in a companion quantitative white paper2
, so we will merely summarize the conclusions of that paper here.
There are 3 major elements to the total cost of ownership.
■ Initial acquisition of the software
■ Support
■ Administration and management
When all these three components are considered, the TCO for Windows HPC Server can be substantially lower than that of two different Linux-based HPC solutions comprising a combination of the Red Hat Enterprise Linux (RHEL) operating system and a popular HPC middleware stack (Figure 1). The analysis was based on a typical HPC scenario running in hardware and software environments specified to be as similar as possible.
Five Year Total Cost of Ownership for 250 Compute Nodes and 1000
Figure 1: Window HPC Server vs. Linux TCO Comparison
Based on an HPC deployment scenario of 250 compute nodes and 1,000 desktop nodes, Windows HPC Server 2008 R2 proves to be significantly less expensive than popular Linux-based HPC stacks running on Red Hat Enterprise Linux: 32% less than Platform LSF and 51% less than DataSynapse GridServer. 2 Crimson White Paper: Evaluating the Lifecycle Costs of High Performance Computing Solutions:
Windows® HPC Server and Linux-based Solutions. This paper is a quantitative TCO analysis against two popular Linux-based HPC platforms.
$0
$200,000
$400,000
$600,000
$800,000
$1,000,000
$1,200,000
$1,400,000
Windows HPC Server 2008 RHEL and Platform LSF RHEL and Data Synapse
Acquisition &Implementation
VendorSupport
Administration

WHITE PAPER
www.crimson-consulting.com 3
There are three primary reasons why the TCO for Windows HPC Server is lower:
■ HPC middleware that is included in Windows HPC Server must be purchased and maintained separately for Linux-based platforms
■ While commercial Linux may be available at little or no cost, vendors such as RedHat charge a substantial amount for support and maintenance.
■ Windows expertise (both for development and administration) is more readily available and is less costly than Linux expertise. Existing Windows experts can be easily trained to work with Windows HPC Server
Performance of Windows HPC Server vs. Linux Alternatives Of course, TCO must be considered in the context of performance. Due to its head start and dominant presence in high performance computing, Linux is often perceived as far superior to Windows HPC Server in sheer performance. As we shall see, this perception falls well short of the truth. An analysis of benchmark data demonstrates that Windows performance can match that of Linux on similar systems in HPC scenarios likely to be of interest to a wide range of users. Before proceeding, we must be note that benchmarks are an attempt to radically simplify performance evaluation by reducing it to a set of numbers that are easy to compare. As such, they are just a starting point for performance analysis. Any given result is merely a snapshot of a point in time for a specific set of computing operations, and rarely will benchmark numbers precisely measure the aspects of HPC most critical to a user’s needs. It is important to ascertain how relevant the benchmarked operations are to the real-world scenario for which the HPC platform will be deployed. Using them uncritically will inevitably mislead or even hide more than is actually revealed. In the following section, we compare Windows HPC Server and Linux-based supercomputer performance in the light of the four primary questions any HPC evaluator should keep in mind when considering benchmark results:
■ How much, if at all, does each software component (OS plus middleware) contribute to the benchmark results? Does the benchmark reveal real differences?
■ How efficiently do the software components exploit the capabilities of the hardware? This has particular bearing on TCO comparisons.
■ How do the alternatives compare using “real-world” benchmarks (i.e., those based on ISV and open-source application performance) or other performance comparisons or measurements that may be more relevant?
■ What is the experience of actual users?
The LINPACK Benchmark and the Top 500 List In the HPC space, the High-Performance LINPACK (HPL) benchmark is the one most often cited. LINPACK is a software library for performing numerical linear algebra on digital computers. As such, its operations are a measure of a system's floating point computing power. Introduced by Jack Dongarra, it measures how fast a computer solves a dense N by N system of linear equations Ax = b, which is a common task in engineering. The result is reported in millions of

WHITE PAPER
www.crimson-consulting.com 4
floating point operations per second (MFLOP/s, sometimes simply called FLOPS). For large-scale distributed-memory systems this benchmark as the basis of rank in the TOP500 list of the world's fastest supercomputers. Before we analyze HPL, we should address the most obvious question that arises from even the most casual perusal of the TOP500 list: why are over 80% of the computers on the list running some distribution of Linux? Why is Windows so sparsely represented? There are three reasons of particular salience for the comparison undertaken in this white paper:
■ Most of the largest systems in the Top 500 are either in national laboratories or academia, which have traditionally favored open-source software for a variety of non-technical reasons.
■ Windows has only recently become a serious contender in the HPC space while Linux has been the incumbent for a long time.
■ Financial firms that have very large clusters, and are known to favor Windows HPC Server, typically do not participate in the Top 500 rankings, for obvious competitive reasons.
As this white paper will demonstrate, there are many reasons to expect that the composition of the TOP500 list will change to become less lop-sided as Microsoft continues developing Windows HPC. Software Component Contributions to HPL Results All HPC systems are a complex assemblage of numerous hardware and software components including:
■ Processors (CPUs) and Graphics Processors (GPGPUs)
■ Memory
■ Interconnects (Infiniband, GigE, 10GigE, etc.)
■ Software:
■ Operating System
■ Job Schedulers
■ MPI stack (MPI libraries and executables) HPL is a CPU-intensive benchmark which measure how efficiently a system can run DGEMM math libraries. Its results say less about how much the operating system contributes to the performance, than about how good a job the operating system does in getting out of the way of other components. That is, the role of operating system is to cause as little "jitter" as possible. Certainly, the operating system and other parts of the HPC stack such as MPI and networking libraries have a role to play, but they are not major factors in the results of a HPL benchmark.

WHITE PAPER
www.crimson-consulting.com 5
For HPL benchmarks, it is largely the first three components that determine performance:
■ The number of nodes, processors, GPGPUs and cores
■ The amount of memory per node and total amount of memory
■ The performance of the interconnects The HPL benchmark results are thus more or less a proxy for the size of the system. It is the quintessential "throw hardware at the problem" situation. The larger the system you can assemble, greater the HPL results. It has little to do with the operating system―be it Linux, UNIX or Windows.
HPC System Efficiency Although HPL benchmark results are largely hardware-determined, that doesn’t mean that the TOP500 list is useless as a comparison of Windows HPC Server and Linux-based alternatives. The TOP500 allows us to calculate the efficiency of a given supercomputing cluster as the ratio of the theoretical maximum performance (Rpeak) of the HPC system to the actual observed maximum performance (Rmax). This is very much a function of the operating system and middleware components. As noted above, since it indicates how effectively the software components make use of hardware, it is part of the context necessary to make a TCO comparison fully meaningful. In the November 2009 TOP500, the average efficiency of the listed systems is approximately 73.5%. As shown in the table below, each of the Windows HPC-based supercomputers that are or have appeared in the TOP500 exhibited an efficiency in excess of this average. At the very least, we must judge Windows HPC Server to offer efficiencies on par with that of Linux or UNIX-based systems, which makes its TCO advantage even more compelling.
Table 1: Windows-Based TOP500 Systems
Rank Site Year Cores RMax RPeak Efficiency
19 Shanghai Supercomputer Center 2008 30720 180600 233472 77.4%
73 NCSA 2007 9600 68480 89587.2 76.4%
74 University of Southampton 2009 8000 66680 72320 92.2%
94 HWW/Universitaet Stuttgart 2009 5376 50790 60211.2 84.4%
106 HPC2N - Umea University 2008 5376 46040 53760 85.6%
Why is Windows Efficient? Microsoft attributes the high efficiency of Windows in part to the MS-MPI stack based on the Argonne National Laboratory MPICH2, tuned specifically to leverage Windows NetworkDirect. It should be noted, however, that MS-MPI is only one of several high-performance stacks, both commercial and open-source (such as the Intel MPI Library), that are available for Windows HPC Server.

WHITE PAPER
www.crimson-consulting.com 6
Microsoft NetworkDirect may be thought of as Remote Direct Memory Access (RDMA) networking for Windows, offering the same benefits: CPU bypass, OS bypass, and memory bypass. The more direct path it makes available to networking hardware delivers wire-speed communications with latency below 5 µs, to support two goals:
■ Match the performance of custom, hardware-specific, high-speed MPI drivers without the expense of specialized hardware.
■ Improve shared memory performance for higher speed on multi-core nodes.
Real-World Application Benchmarks For organizations planning to run an off-the-shelf ISV application, the benchmarks published by the ISV will be more relevant than synthetic ones such as HPL. In this section we analyze two ISV performance benchmarks to compare, as much as possible, the performance of Windows HPC Server and Linux alternatives on actual commercial software. ANSYS FLUENT v12 (Truck Model) This benchmark is based on ANSYS FLUENT modeling software from ANSYS, Inc. running the Truck model3 Figure 2. illustrates the results comparing Windows HPC Server and Linux performance on IBM idataplex nodes with same processor, memory, and InfiniBand interconnect. The results indicate Windows HPC Server matches Linux performance from a single node with 8 cores to 32 nodes with 256 cores.
Figure 2: ANSYS FLUENT v12 benchmark (Truck Model)
3 As yet unpublished benchmark: 14M cells, IBM System x iDataPlex platform with 2.66Ghz Intel Xeon Processor 5500, 24GB DDR3 memory/node, Mellanox Connect-X InfiniBand)
0
200
400
600
800
1000
1200
1400
1600
1800
8 16 32 64 128 256
Flue
nt R
atin
g (H
ighe
r is
bette
r)
Number of CPU Cores
Windows Linux

WHITE PAPER
www.crimson-consulting.com 7
LS-DYNA (Car2Car Simulation) This benchmark is based on LS-DYNA simulation software from Livermore Software Technology Corporation, running Car2Car, a simulation of two cars crashing into each other.4
Figure 3: LS-DYNA Car2Car simulation
We could not find two hardware configurations that were identical so we picked two that were as close as possible. Both are running on very similar Intel Xeon processors: the Linux benchmark is running at a higher clock speed but slightly smaller memory/node. Since we do not know how much clock speed or memory size contribute to this benchmark, we can say no more than that the two platforms deliver similar results across a range of nodes and core numbers. Given that such close results would have been impossible only a couple of years ago, the benchmark at the very least shows Microsoft’s commitment to and momentum in high performance computing.
Microkernel Benchmarks STREAM is a public benchmark that measures the sustainable memory bandwidth of a system. This is important for many types of HPC applications, whose operations often exceed processor cache capacity, thus making system memory performance a limiting factor. STREAM measures memory throughput on a single node as an indication of the potential performance of a given OS/processor combination on very large vector-style applications, and many public examples are available. For instance, Figure 4 illustrates nearly identical memory throughput for Linux and Windows HPC Server on Intel’s Xeon X5550 processor.5
4 As yet unpublished benchmark: Windows: 2.66GHz Intel Xeon Processor X5550, 24GB DDR3 memory/node, QDR InfiniBand
Linux: 2.8GHz Intel Xeon Processor X5560, 18GB DDR3 memory/node, QDR InfiniBand 5 Windows benchmark source: http://blogs.technet/com/eec/archive/2009/07/15/3264921.aspx Linux benchmark source: http://www.advancedclustering.com/company-blog/stream-benchmarking.html
0
20000
40000
60000
80000
100000
120000
140000
8 16 32 64 128 256 512
Wal
l tim
e (L
ower
is b
ette
r)
Number of CPU Cores
Windows Linux

WHITE PAPER
www.crimson-consulting.com 8
Figure 4: STREAM benchmark on Intel Xeon X5550 processor
SOA-Based HPC application benchmarks There is a class of HPC applications―often called “Embarrassingly Parallel”―that are easily divided into very large numbers of parallel tasks, with no dependency or communication between them. Because they are not dependent on inter-process communication, these applications typically do not use MPI and so a well-tuned MPI stack does not contribute to their performance6
.
These applications are interactive, rather than batch-oriented. They are most easily programmed using a Service Oriented Architecture (SOA) programming model that encapsulates the core calculations as software modules to eliminate the need to write low-level code. SOA-based HPC applications are used for tasks such as gene matching, computational physics, rendering, and quite extensively in the financial industry in support of the Monte Carlo methods used by analysts to construct stochastic or probabilistic financial models. We are aware of several large financial firms running applications of this nature on Windows HPC Server. Because of the competitive nature of that industry, these firms are unwilling to disclose any benchmarks that would enable us to compare Windows HPC Server and Linux for this class of applications. However, a recent Crimson survey undertaken for Microsoft indicated that the performance of Windows HPC Server exceeded the expectations of these customers. 6 More details on the characteristics, attributes and requirements for this new class of applications can be garnered from this Microsoft paper: Overview of SOA Programming Model and Runtime System for Windows HPC Server 2008
35000
35500
36000
36500
37000
37500
Microsoft HPC Server Linux
Triad Function (GB/s)

WHITE PAPER
www.crimson-consulting.com 9
Despite this paucity of public information, we can reach a conclusion about one aspect of Windows HPC Server performance for such applications, based on benchmark results from Milliman MG-ALFA (Asset Liability Financial Analysis), a modeling application for the insurance industry that employs a SOA-based architecture. As shown in Figure 5, for this application, Windows HPC Server demonstrates near-linear speedup: 172x on 200 cores, which bodes well for its scalability and performance for similar computing loads. Of course, since this application is available only on Windows HPC Server, this benchmark offers no comparison with the performance and scalability of Linux.
Figure 5: Milliman MG-ALFA scalability benchmark
What Are Customers Saying? “Tests of Windows HPC Server 2008 have shown that it delivers accurate results with no compromise on speed compared with the previous Linux implementation used by the centre.”
“Our performance tests were so conclusive that we’re now converting our Linux server to run on Windows HPC Server 2008. We’re never going back to Linux.”
“We've done benchmarks with up to 256 cores that showed performance that meets, and in some cases exceeds, the Linux tests done on the same hardware.
Prof. Andy Keene Head, Rolls-Royce University Technology
Centre (UTC) for Computational Engineering Southampton University
Dr. Marco Derksen Manager of R&D
Stork Thermeq
Greg Keller Technical Principal
R System

WHITE PAPER
www.crimson-consulting.com 10
Integration within the Stack and with Corporate Infrastructures Not surprisingly, given Microsoft’s overall vision, their high performance computing effort stresses integration, both within the HPC stack, and with Windows-based corporate infrastructures, now the dominant paradigm. Here we review the implications of Microsoft HPC Server integration for organizations considering implementing or upgrading an HPC platform.
The HPC Stack in Windows HPC Server and Linux Alternatives A complete HPC system is a complex hardware and software system that must be assembled from components supplied by multiple vendors, as illustrated by Table 2.
Table 2: HPC System Components
Category Representative Vendors/Products
Servers IBM, Dell, HP, Silicon Graphics, Cray, Sun/Oracle. HP, Fujitsu
Storage EMC, Hitachi, Network Appliance, Sun/Oracle, HP
Networking / Interconnects Cisco, IBM, Myricom, Mellanox, Voltaire
Softw
are
Operating System Linux, Unix, Windows HPC Server
HPC Middleware
Windows HPC Server (included), DataSynapse, Platform Computing, PBS Works, Torque, Ganglia, ClusterCorp, Bright Computing, Altair, Hadoop, Moab
Development Tools
Microsoft Visual Studio, Eclipse, MPI, Intel Parallel Studio, NVidia Parallel NSight, Vampir, Allinea, numerical libraries, compilers, etc.
HPC Middleware can include components such as:
■ Job schedulers
■ Job submission and monitoring
■ Reporting, billing and analytics
■ Resource provisioning, scheduling and management
■ Network management
■ Cluster management and monitoring tools
■ Application management and monitoring tools
■ Application provisioning and deployment
■ Distributed data caching The software in an HPC system is referred to as the “HPC stack,” which is simply all of the software deemed necessary to develop, deploy, and manage a high performance computing cluster—a definition that varies according to a user’s needs. Assembling even a fairly simple HPC stack from open-source software can be a daunting task, but this was the norm for a long time in academic and research settings. Indeed, many current
WHITE PAPER
www.crimson-consulting.com 11
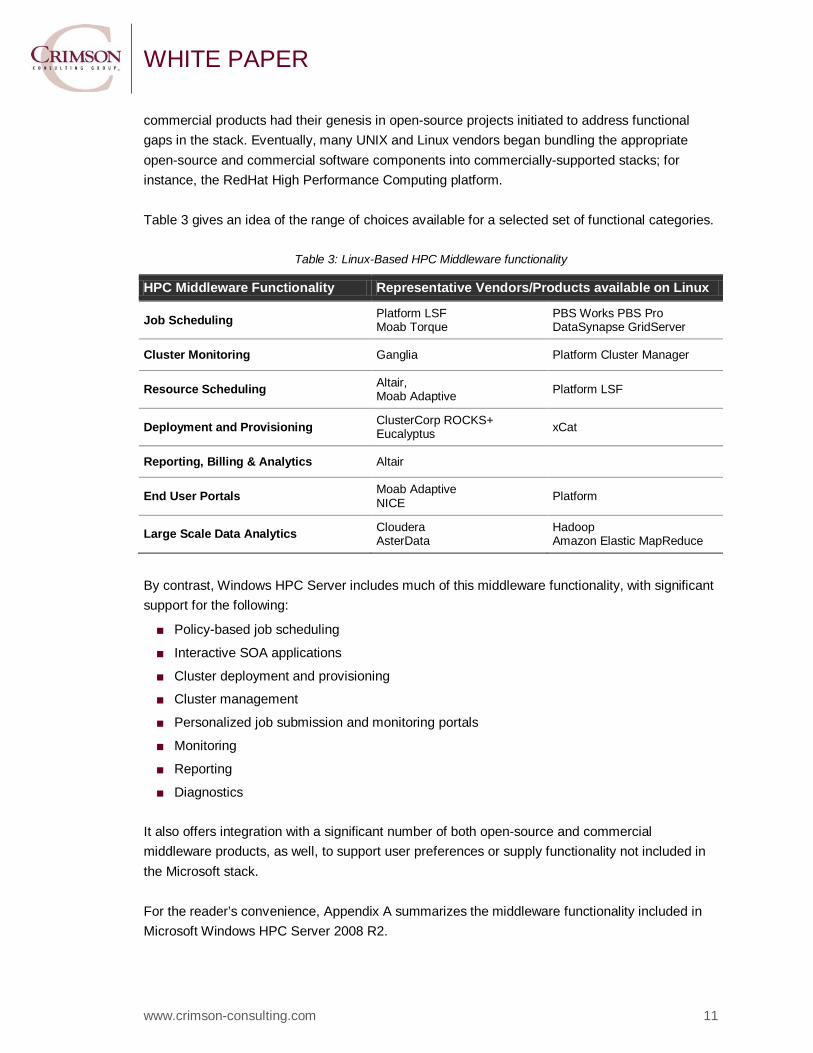
commercial products had their genesis in open-source projects initiated to address functional gaps in the stack. Eventually, many UNIX and Linux vendors began bundling the appropriate open-source and commercial software components into commercially-supported stacks; for instance, the RedHat High Performance Computing platform. Table 3 gives an idea of the range of choices available for a selected set of functional categories.
Table 3: Linux-Based HPC Middleware functionality
HPC Middleware Functionality Representative Vendors/Products available on Linux
Job Scheduling Platform LSF Moab Torque
PBS Works PBS Pro DataSynapse GridServer
Cluster Monitoring Ganglia Platform Cluster Manager
Resource Scheduling Altair, Moab Adaptive Platform LSF
Deployment and Provisioning ClusterCorp ROCKS+ Eucalyptus xCat
Reporting, Billing & Analytics Altair
End User Portals Moab Adaptive NICE Platform
Large Scale Data Analytics Cloudera AsterData
Hadoop Amazon Elastic MapReduce
By contrast, Windows HPC Server includes much of this middleware functionality, with significant support for the following:
■ Policy-based job scheduling
■ Interactive SOA applications
■ Cluster deployment and provisioning
■ Cluster management
■ Personalized job submission and monitoring portals
■ Monitoring
■ Reporting
■ Diagnostics It also offers integration with a significant number of both open-source and commercial middleware products, as well, to support user preferences or supply functionality not included in the Microsoft stack. For the reader’s convenience, Appendix A summarizes the middleware functionality included in Microsoft Windows HPC Server 2008 R2.

WHITE PAPER
www.crimson-consulting.com 12
Fragmentation vs. Integration There is no doubt that commercially-supported Linux HPC platforms are capable of excellent performance. However, we believe that there are some potential downsides to such bundled solutions compared to an integrated, single-vendor product. Higher administration and management costs Depending on user needs and application type, a bundled solution may require more time and effort for administration and management. For instance, the Red Hat HPC Platform includes only a very simple workload scheduler (Platform Lava) that lacks the full functionality needed to balance a computational workload across a cluster, as is included in the Microsoft offering. Separate commercial products, such as Moab Adaptive or Platform LSF must be purchased, or open-source software obtained (e.g., Torque, Lava, and Maui). These require additional expertise and are not integrated with the management interface. In addition, the fact that Red Hat does not control updates and revisions to the various pieces of their solution obtained from other sources, puts increasing responsibility on system administrators to determine which tools work with which application versions even though the distribution and installation of such updates is automated. In a mission-critical environment, this additional risk may not be acceptable. In addition, HPC compute efficiency is dependent on very fine performance tuning, which may be harder to accomplish in an environment that has been assembled from disparate parts. Delayed problem resolution resulting from lack of accountability In a complex system with many interdependent parts, it is hard to isolate problems. Resolving an issue may require coordination among two or more vendors, which often leads to finger pointing and delay in resolution. Some Windows HPC Server customers interviewed by Crimson have noted the desirability of having “a single throat to choke” for complex HPC deployments. Reduced agility imposed by more difficult upgrades It is fairly common for each of the individual components in a bundled stack to be at different version levels, ship at different times and have different dependencies or prerequisites. In such a scenario, upgrading a single component is often very hard to do since it is not clear whether the new version of a component is compatible with all the other components it connects to. Consequently users tend to defer such changes as far as possible, even if it means that they are unable to take advantage of the latest advancements. Less effective troubleshooting caused be limited end-to-end visibility Effective troubleshooting, debugging and performance tuning requires that users have the ability to seamlessly trace calls across process and component boundaries. As well, users should be able to correlate profiling data, error logs, event logs, error messages and other data easily to get

WHITE PAPER
www.crimson-consulting.com 13
a high-level view of what is happening across the entire stack. This is naturally harder to achieve with a heterogeneous set of components.
Developing HPC Applications Integration of an HPC platform’s application development tools with the rest of the stack is an important consideration, as is the availability of the expertise required to make most effective use of the platform. Overall, the range of tools available to Linux or Windows HPC developers is comparable. However, we believe that here Microsoft possesses an potential advantage that has been a major driver for its success in corporate computing, and promises the same for high-performance computing: the Visual Studio integrated development environment (IDE). This IDE is used by an enormous developer community, and Microsoft’s vision for HPC includes tools to harness this expertise to make HPC applications more widely available and less costly. The latest iteration of this IDE, Visual Studio 2010, includes an extensive set of integrated tools, compilers, libraries and third-party party plug-in to help developers develop parallel applications for Windows HPC Server. These include:
■ Support for developing MPI-based applications, including a MPI cluster debugger.
■ Support for developing Service Oriented Applications (SOA)–based applications, including a cluster SOA debugger and profiler.
■ Parallel LINQ and Task Parallel Library (TPL), included in .NET 4.0
■ Parallel pattern library
■ Support for GPU computing (partnered with NVidia) The IDE, like the platform it serves, also offers integration with a significant number of both open-source and commercial tools to support user preferences or supply functionality not included in Visual Studio. These include tools for integrating or porting Linux and UNIX-based applications to make interoperation with or transition to Windows HPC Server easier. Several of the customers interviewed by Crimson for the companion TCO white paper noted the ease with which such a transition could be made as a major consideration in their decision process. For the reader’s convenience, Appendix B summarizes the application development functionality included in Microsoft Visual Studio 2010.
Tuning HPC Applications It is also important to consider what tools are available to tune applications for optimal efficiency on a given HPC platform. Microsoft HPC Server and Linux alternatives are comparable in this respect, in part because many popular open-source performance analysis and monitoring tools such as Jumpshot, Vampir and Ganglia are available for Windows as well. For the reader’s convenience, Appendix C summarizes the performance analysis capabilities included with Microsoft Windows HPC Server 2008 R2.

WHITE PAPER
www.crimson-consulting.com 14
Integration with Corporate Infrastructures For an increasing number of customers, the ability of Windows HPC Server to leverage other Windows infrastructure components is a major consideration. Within the compass of this white paper there is insufficient scope to review all of the possible integration points and benefits. Here we note some of the more salient, focusing on Excel integration in particular as an example par excellence of how integration with the dominant Windows platform can be attractive to a wide range of users.
■ Microsoft Office SharePoint Server (MOSS) can provide a workflow foundation for high performance computing. Instead of patching a workflow together from various vendors, MOSS can be used with the Windows Workflow Foundation to control and tie together various features of computational scenarios (Access, Request, and Analyze).
■ System Center Operations Manager can provide end-to-end service management for HPC deployments. It enables systems administrators to perform HPC management tasks using a familiar user interface and manage very large collections of compute nodes as a single system.
■ SQL Server Reporting Services can be leveraged for custom reporting of HPC cluster performance and operation.
■ Active Directory can simplify cluster deployment and expansion, as well as job submission. For the reader’s convenience, Appendix D supplies some links to further reading on infrastructure integration in Windows HPC Server.
Speeding up Excel calculations with HPC clusters Microsoft Office Excel is a critical business tool for a wide range of industries. It offers a great deal of power for statistical analysis and modeling; in fact, it should properly be considered a numerical programming tool for non-programmers. As such, it can be extended almost without limit. Unfortunately, as the calculations and modeling performed in Excel become more and more complex, workbooks consume more and more computing power and take longer and longer to calculate, shackling their business value. This makes HPC clusters an attractive proposition for customers pushing the envelope with Excel. The market has responded with a number of middleware products to support Excel calculations (e.g., DataSynapse GridServer). It is inarguable that Microsoft has the home field advantage here. After all, the cluster support built into Excel, while exposed for use by other vendors, originates with Microsoft. At the very least, Windows HPC Server will always be first to market with any related innovation. Beyond that, Microsoft has expended considerable effort in understanding the ways in which customers might use an HPC cluster to accelerate Excel calculations, and so there are three technical options for doing so. These are using Excel as a cluster SOA client, running Excel user defined functions (UDFs) on a cluster, and running Excel workbooks on a cluster. As a result, Windows HPC Server 2008 R2 can reduce calculation times for Excel workbooks by one or more orders of magnitude, scaling nearly linearly as nodes or cores are added.

WHITE PAPER
www.crimson-consulting.com 15
Vision: Planning for Change High performance computing is evolving rapidly, building on innovations in all its foundational technologies: hardware, networking, storage, processors, memory, clustering, middleware, development tools and applications. The rate of change is increasing, and its impact is increasingly disruptive, especially as regards HPC middleware. What customers will expect from HPC middleware in a few years will be very different from what it offers today. The focus of today’s HPC middleware tends to be functionality such job scheduling, cluster management, resource management, deployment, provisioning, and so forth. But these concern functionality gaps that are closing, and although they will continue to be important, a new wave of innovation is sweeping through HPC. Some of the most salient technologies, which we review in more detail further on, are:
■ Cloud Computing
■ Large-scale data analytics
■ Workflow
■ Virtualization
■ Multicore processors The potential impact and benefits of these technologies make choosing the right middleware vendor increasingly important. Not all of today’s vendors will survive the creative destruction ongoing in HPC, and the cost of switching vendors can only get higher as a company invests more resources in a particular vendor’s vision. The purpose of this section is to review some of the evidence that leads us to conclude that Microsoft is well-positioned to deliver on its HPC vision, which encompasses all of these technologies. Its portfolio includes products such as Azure, Hyper-V, Visual Studio, Dryad and SharePoint that may put Microsoft in a better position exploit these technologies that any of its Linux-based competitors, who lack similar resources and scale. All indications are that Microsoft will be an increasingly important part of high performance computing for the foreseeable future.
Cloud Computing Cloud computing revolution is poised to transform every aspect of computing from personal computing to enterprise IT, but its biggest impact will be in High Performance Computing. Cloud computing will address many of the challenges and limitations of on-premise clusters that have frustrated HPC users and administrators, providing ability to run HPC applications at a scale and speed not possible today. This in turn will spur the creation of new types of HPC applications. Scale As cloud computing matures the power of the larger public clouds will vastly exceed that of today’s largest HPC computers, making possible solutions for previously intractable problems or enabling applications that take days to complete today to run in hours or minutes.

WHITE PAPER
www.crimson-consulting.com 16
Collaboration Most current collaboration models require moving large amounts of data across wide area networks, which can be very expensive and time consuming. With the ability to store data in public clouds and process it using highly-distributed HPC clusters, it will be easier to share data within and between companies, universities, research labs and governments. Utilization Efficiency and Cost The peak-to-average computation utilization for HPC applications can vary significantly. The challenge is to strike a balance between peak provisioning and consequent under-utilization during average demand, and average provisioning at the cost of sub-optimal performance under peak loads. Public clouds charge only for the computing capacity used. Given the right infrastructure, this can eliminate much of the up-front investment required for peak loads. Users can either run their HPC applications entirely in the Cloud or use Clouds as overflow for peak loads (“Cloud Burst” scenarios). To realize these benefits, HPC middleware software must (among other things) support:
■ Administrators: Creating mixed-mode clusters that extend seamlessly from on-premise to the cloud.
■ Administrators: Ensuring that security and identity are enforced at all times as computation crosses desktop, cluster and cloud boundaries.
■ Users: Submitting jobs for execution on the desktop, the on-premise cluster or one or more public clouds.
■ Developer: Profiling and debugging applications no matter where they are executing.
■ Business decision-makers: Monitoring in real time the amount of cloud resources being consumed and imposing quotas if necessary.
In addition to the new capabilities this will require of HPC middleware, cloud providers will need to cooperate with HPC platform vendors to provide the needed hooks, functionality and customizations to run HPC applications at speeds that users expect. Examples include:
■ Deployment options that do not use virtual machines for extremely high-speed applications,
■ A lean operating system with fast startup times,
■ Dedicated high-speed interconnects for MPI style applications
■ Integrated services such as distributed caching for applications that need fast access to data.
Microsoft is well placed to deliver on the promise of cloud computing and HPC. The company has already made a huge investment in Azure that includes over a billion dollars in multiple data centers7
7
. This is a level of investment that few other companies have made or can match.
Microsoft invests $500m in Illinois data center and Inside Microsoft's $550 Million Mega Data Centers

WHITE PAPER
www.crimson-consulting.com 17
Microsoft has also recognized HPC as one the most important workloads on Azure, as repeatedly stated by Microsoft “Server and Tools Business” President Bob Muglia―who owns both cloud and HPC products8
.
There is no technical obstacle to Linux-based HPC middleware vendors partnering with general- purpose public cloud providers such as Amazon EC2 or Google App Services. However, to provide the features, functionality and customizations necessary to realize the full potential of HPC in the cloud will present tremendous business challenges, not least of which will be integration with the Windows platform that dominates business computing.
Large Scale Data Analytics Data volumes measured in hundreds of terabytes or even petabytes are becoming quite common. Online applications with millions of users as well as the proliferation of digital cameras and camcorders, video surveillance, and various sensors (e.g. RFID, GPS, industrial monitoring, etc.) are adding to the data overload. With storage capacity increasing and storage prices decreasing in accordance with Moore’s law, all this data tends to be retained indefinitely. However, HPC applications today tend to be computationally-intensive: their primary focus is on peak processing power. The world’s largest supercomputer has peak performance over 2 petaFLOPs, but such power by itself is inadequate to handle data-intensive analytic applications. Traditional tools for data analysis such as distributed relational databases are either technically incapable of handling such large data volumes or are prohibitively expensive. New approaches are being tried to handle the problem of “Large Scale Data Analytics”. The solution involves executing data processing logic in parallel on very large clusters of commodity servers. Although this appears to be a clear example of an application ideal for HPC, it should be noted that the current most-popular product in this space, Hadoop, is not based on any HPC product. Nonetheless, high performance computing is clearly one path to large scale data analytics. Microsoft has acknowledged this with its push to integrate Dryad9 (a solution for running data–parallel programs on a cluster) with Microsoft Windows HPC Server10
Workflow
. To date, Linux-based HPC vendors do not appear to have addressed this problem space.
Most organizations cannot afford to run HPC applications in silos. HPC applications are increasingly part of a bigger workflow that involves coordination and collaboration between team members as well as between teams, within an organization and frequently between organizations. An HPC job may consist of several sub-jobs (tasks) that may display fairly 8 Microsoft's server chief talks cloud (Q&A) 9 http://research.microsoft.com/en-us/projects/dryad/ 10 Data-Intensive Computing on Windows HPC Server with the DryadLINQ Framework

WHITE PAPER
www.crimson-consulting.com 18
complex dependencies. A HPC application may consist of several jobs that are likewise interdependent. This requires attention to a number of factors, including:
■ Ensuring that jobs are executed in a specific sequence.
■ Executing a particular job only if a previous set of jobs completes successfully; otherwise executing a different job.
■ Routing new jobs to the right team member after a job has been completed.
■ Cleaning up after a job has been successfully completed to prepare the stage for the next jobs (e.g., extracting the necessary data from a central store or pre-populating a cache).
In more complex, but not atypical, scenarios, an entire HPC application could be a mere step in a long-running project lasting several months that could involve a large number of HPC applications. Clearly this calls for a deep integration of HPC middleware technology and workflow. The current set of HPC middleware products on the market is primarily focused on executing individual jobs on a cluster. Integrating these products with a workflow product is a do-it-yourself project. Microsoft appears well-positioned to deliver a workflow-enabled HPC product by integrating Microsoft Windows HPC Server 2008 with its widely used SharePoint server product, specifically its powerful workflow capabilities11. As noted previously, Microsoft has taken a step towards this by enabling end users to interact with a Windows HPC Server through a SharePoint Web portal12
Virtualization
.
Virtualization is an emerging technology that is fundamentally reshaping how enterprises deploy
and manage applications. Enterprises are using virtualization to get the following benefits:
■ Reduced cost resulting from increased server utilization and fewer servers deployed: lower capital, system administration, and power and cooling expenses.
■ Increased operational flexibility resulting from dynamic resource management, faster server provisioning and improved desktop and application deployment.
■ Increased availability for improved business continuity by securely backing up and migrating entire virtual environments with no interruption in service. This can eliminate planned downtime and enable immediate recovery from unexpected issues.
■ Improved desktop manageability and security through centralized deployment and management of secure desktop environments. Users can access these locally or remotely, with or without a network connection, on almost any standard desktop, laptop or tablet.
11 http://msdn.microsoft.com/library/aa830816.aspx#office2007ssintrotoworkflows__introduction 12 Windows HPC Pack 2008 Integration with SharePoint

WHITE PAPER
www.crimson-consulting.com 19
Virtualization and HPC Deeply integrating HPC with virtualization technology can potentially offer the following benefits:
Sharing. It will possible to run multiple heterogeneous applications, possibly requiring different
operating systems, on the same cluster at the same time. A single node in the cluster could safely
and securely be running jobs from different applications at the same time.
Simplified Application Management. Virtualization, by packaging all the required software into
a single deployable unit, can help ensure that all the right software—correct versions, patches,
and all the prerequisites needed to execute a job―is available on a particular node in the cluster,
both before and after a job.
Seamless integration with public clouds. Many public clouds accept virtual machines as
deployment and execution units. By integrating virtualization with HPC, it will be possible to
create virtual clusters so that applications can seamless extend from desktops to on-premise
clusters to public clouds,
Server Harvesting. It is common for HPC applications to run on file, print and other types of
servers when they are idle. The process of configuring these servers and deploying the
necessary software in order to be able run HPC applications can be simplified using virtualization.
Microsoft appears very well positioned to deliver on the benefits of integrating virtualization with
HPC due to its portfolio of virtualization products that include Windows Server 2008 R2 Hyper-V,
Systems Center Virtual Machine Manager 2008 R2 for management and Microsoft Forefront for
end-to-end security
Exploiting Multicore Processors Over the past few years the doubling in computing speed described by Moore’s Law is coming, not from increased clock speeds, but by from the addition of “cores” to microprocessors. This multicore architecture impacts all software application developers. With increasing clock speeds, software products become proportionately faster without developer effort. Multicore processors require parallelism to deliver their speed boost. Parallel programs are hard to develop, test and troubleshoot and require new tools to deal with the added complexity involved. Similar tools are required for developing parallelism across clusters, the next logical step. However, most of the tools available today require extensive expertise in parallel computing concepts, limiting the pool of available developers and increasing the cost of developing HPC applications.

WHITE PAPER
www.crimson-consulting.com 20
To properly exploit multicore and multicluster architectures, developers require, at a minimum:
■ Parallelism extensions to current popular programming languages
■ Possibly, a new language specifically aimed at simplifying parallel application
■ A collection of general-purpose and domain-specific parallel libraries.
■ A set of parallel performance analyzers, debugger and, profilers.
■ An Integrated Development Environment (IDE) that integrates all of the above As described in a previous section of this document, Microsoft already offers a set of tools to assist in parallel application development integrated into Visual Studio. This foundation puts the company in a position to deliver a comprehensive, fully integrated, toolset for developing multicore and multicluster HPC applications, and presents a difficult challenge to Linux-based HPC middleware vendors. Summary Based on evidence from publicly-available sources as well as interviews and surveys of Microsoft customers, Crimson concludes that Windows HPC Server (whose latest instantiation is Microsoft Windows HPC Server 2008 R2) belongs on the short list of any organization considering implementing or upgrading an HPC platform. Compared to Linux alternatives, Windows HPC Server 2008 R2
■ Can deliver a lower TCO than Linux alternatives,
■ Can deliver performance equal or superior to Linux alternatives
■ Offers more extensive integration, both within the “stack” and with the dominant corporate infrastructure
■ Represents the latest step in execution of a credible, long-term vision

WHITE PAPER
www.crimson-consulting.com 21
Appendix A The following table of middleware functionality is based on the Microsoft document, Technical Overview of Windows HPC Server 2008 R2 Beta.
HPC Middleware functionality included in Windows HPC Server 2008 R2
Job Scheduling Policies Scheduling policies determine how resources are allocated to jobs. Windows HPC Server 2008 R2 provides the ability to switch between traditional first-come, first-serve scheduling and a new service-balanced scheduling policy designed for SOA/dynamic (grid) workloads, with support for preemption, heterogeneous matchmaking (targeting of jobs to specific types of nodes), growing and shrinking of jobs, backfill, exclusive scheduling, and task dependencies for creating workflows. Job Workflows The job Scheduler supports basic tasks, such as those that are executed from the command line, as well as parametric sweeps. Just-in-time parametric sweep expansion improves performance for creating large parametric task sweeps by creating individual parameter sweep steps as needed rather than at submission time. The job Scheduler is Non-Uniform Memory Architecture (NUMA)-aware and multicore-aware, allowing for the intelligent scheduling of jobs on large clusters of multicore nodes at the processor core, processor socket, and compute node levels
Interactive jobs With Windows HPC Server 2008 R2, tasks can run interactively as SOA applications. Windows HPC Server 2008 R2 provides enhanced support for SOA workloads, helping organizations more easily build interactive HPC applications, make them more resilient to failure, and more easily manage those applications. Key features include:
■ A fire-and-recollect programming model—sometimes called fire-and-forget—enabling developers to implement re-attachable sessions by decoupling requests and responses.
■ Durable Sessions where the SOA runtime persists requests and their corresponding responses on behalf of the client.
■ Message Resilience where in the case of a temporary broker node failure or a catastrophic failure of the cluster, the SOA broker nodes will persist calculation requests and results. The session can continue without lost requests or results after the cluster recovers and the broker nodes are restarted.
■ High-Availability Broker Nodes (Broker Restart/Failover): Automated broker failover, enables organizations to preserve computation results in the event of a failure. The cluster will migrate active sessions on failed broker nodes to healthy ones, thereby enabling nonstop processing.

WHITE PAPER
www.crimson-consulting.com 22
Cluster Management Windows HPC Server 2008 R2 is designed to facilitate ease-of-management. It provides a graphical Administration Console that puts all the tools required for system management at an administrator’s fingertips, including the ability to easily drill down on node details such as metrics, logs, and configuration status. Support for the Windows PowerShell scripting language facilitates the automation of system administration tasks. An enhanced “heat map” view provides system administrators with an “at a glance” view of cluster status, including the ability to define tabs with different views of system health and resource usage. Other new management-related features in Windows HPC Server 2008 R2 include additional criteria for filtering views, support for location-based node grouping, a richer reporting database for building custom reports, and an extensible diagnostic framework. Graphical Administration Console Based on the Microsoft System Center 2007 user interface, the Administration Console in Windows HPC Server 2008 R2 integrates every aspect of cluster management. The Administration Console has five navigation panes:
■ Configuration, which includes the To Do List, Network Configuration Wizard, and Node Template Generation Wizard.
■ Node Management, which is used to monitor node status and initiate node-specific actions such as deployment, bringing nodes offline or online, and adding or removing nodes.
■ Job Management, which provides control of job scheduling and status.
■ Diagnostics, which allows administrators to select a node or group of nodes and run diagnostic tests to validate network connectivity, job execution, configurations, performance, and so on—including the ability to view the progress of tests and view past test results.
■ Charts and Reports, which displays standard reports in support of both scheduled and on-demand reporting.
The Administration Console also provides support for pivoting between these navigation panes for effective contextual monitoring. For example, when using the job Management pane to view a job that has failed, an administrator can easily pivot to the Node Management Pane to view the status of the nodes upon which that job ran. Similarly, from the Node Management pane, the administrator can select a set of nodes and pivot to the Diagnostics pane to view the diagnostics that have run on the nodes. Furthermore, operations that are performed using the graphical Administration Console also can also be performed from the command line using Windows PowerShell.
Monitoring With the included Graphical Administration console and heat map systems administrators get an at-a-glance view of the system health and performance for clusters upwards of 1000 nodes. System administrators can define and prioritize up to three metrics (as well as minimum and maximum thresholds for each metric) to build customized views of cluster health and status. Customizable Tabs enable administrators to configure, for example, one tab to provide a heat map view of networking parameters, a second tab to provide a heat map view of job usage, and a third tab to provide a list view of failed operations.
Deployment Windows HPC Server 2008 R2 builds on the capabilities provided by the Windows Deployment Services transport to simplify and streamline the deployment and updating of cluster nodes. Graphical Deployment Tools are integrated into the graphical Administration Console, allowing system administrators to quickly select nodes for deployment and easily monitor deployment progress. The Administration Console includes diagnostic tests that can be used post-deployment to detect common problems, monitor node loading, and view job status across the cluster. Diskless booting of compute nodes is provided through support for iSCSI boot from a storage array.

WHITE PAPER
www.crimson-consulting.com 23
Reporting Windows HPC Server 2008 R2 provides both built-in reports and an extensible reporting framework, which allows for the development of custom reports using tools such as SQL Server Reporting Services. Windows HPC Server 2008 R2 provides a set of prebuilt reports and charts to help system administrators understand system status, usage, and performance. Accessed through the Reports and Charts tab on the Administrator Console, these prebuilt reports span four main categories: node availability, job resource usage, job throughput, and job turnaround. Windows HPC Server 2008 R2 collects far more data than its predecessor, including node attributes, node event history, job configurations, job task summaries, job state and statistics, and job allocation history. The data is stored in the head node database and can be exported to a separate reporting database or data warehouse for reporting. Tools such as SQL Server Reporting Services or Microsoft Office Excel can be used to create custom reports and graphs for scenarios such as daily operational analysis, charge-back reporting, cluster utilization and analysis, and capacity planning. The data is made available through predefined database views so that administrators can easily build their own reports. Node performance metric history can also be retrieved using PowerShell commands
Diagnostics Windows HPC Server 2008 R2 provides a set of prebuilt diagnostic reports to help system administrators verify that their clusters are working properly, along with a systematic way of running the tests and storing and viewing results. This significantly improves an administrator’s experience in verifying deployment, troubleshooting failures, and detecting performance degradation. Cluster administrators can view a list of these diagnostic tests, run them, change diagnostic parameters at runtime, and view the results using the Diagnostics tab in the Administration Console or by using Windows PowerShell™ commands. Extensible Diagnostic Framework New in Windows HPC Server 2008 R2, an extensible diagnostic framework enables cluster administrators, developers, and HPC industry partners to easily create custom diagnostic tests—as may be required to verify that custom and/or third-party hardware or software is working correctly. Independent hardware and software vendors can use this capability to create their own diagnostic tests, which cluster administrators can add to the list of out-of-the-box diagnostic tests in Windows HPC Server 2008 R2 and run in the same way as the built-in diagnostic tests—thereby helping to reduce support calls and increase customer satisfaction.

WHITE PAPER
www.crimson-consulting.com 24
Appendix B The following table of Microsoft tools for HPC application development has been assembled from a variety of Microsoft sources referenced in the footnotes.
HPC Application Development functionality included in Visual Studio 2010
Developing MPI based applications
MS-MPI is a high performance solution based on the MPICH2 reference implementation, developed in collaboration with Indiana University. Microsoft offers MPI.NET13
MPI Cluster Debugger
a new managed MPI library API. MS-MPI is integrated with Event Tracing for Windows (ETW) enabling MPI message monitoring and profiling. A Visual Studio 2010 integrated 14
new add-in for Visual Studio 2008
helps in debugging MPI applications running on Windows HPC Server 2008 R2. The MPI Cluster Debugger extends the Microsoft remote debugger functionality, simplifying the process of debugging multiple cooperating processes that are running on a remote cluster. The
, which is also integrated into Visual Studio 2010, allows programmers to select a cluster head node, the number of cores, and hit F5 to debug the MPI program.
Developing SOA based applications
Visual Studio helps in developing an emerging class of interactive SOA-based HPC applications that typically do not use MPI. The architecture involves clients communicating, in a request/response mode, with “services” running on the cluster.
■ The communication layer is built using Window Communication Foundation (WCF), which is included as part of the Microsoft .NET framework. One of the key new programming models introduced in Windows HPC Server 2008 was Cluster SOA, built on WCF with advanced scheduling and load balancing provided by Windows HPC Server’s scheduler/broker.
■ Previously, debugging Cluster SOA was limited to basic WCF/.Net style debugging with no cluster integration. In Visual Studio 2010, an add-in for Cluster SOA allows developers to choose a head node, debug nodes and services, deploy runtime libraries and clean up automatically.
Parallel LINQ and Parallel Task Libraries (TPL)
Parallel LINQ (PLINQ)15
is a parallel implementation of LINQ to Objects. PLINQ implements the full set of LINQ standard query operators as extension methods for the T:System.Linq namespace and has additional operators for parallel operations. PLINQ combines the simplicity and readability of LINQ syntax with the power of parallel programming. Just like code that targets the Task Parallel Library, PLINQ queries scale in the degree of concurrency based on the capabilities of the host computer.
The purpose of the Task Parallel Libraries (TPL)16
ThreadPool
is to make developers more productive by simplifying the process of adding parallelism and concurrency to applications. The TPL scales the degree of concurrency dynamically to most efficiently use all the processors that are available. In addition, the TPL handles the partitioning of the work, the scheduling of threads on the , cancellation support, state management, and other low-level details.
13 http://www.osl.iu.edu/research/mpi.net 14 For more details see http://msdn.microsoft.com/en-us/library/dd560808(VS.100).aspx, http://blogs.technet.com/windowshpc/archive/2009/06/02/mpi-cluster-debugger-in-visual-studio2010-beta1.aspx or http://channel9.msdn.com/shows/The+HPC+Show/MPI-Cluster-Debugger-Visual-Studio-2010-Launch-Integration/ 15 http://msdn.microsoft.com/en-us/library/dd460688.aspx 16 http://msdn.microsoft.com/en-us/library/dd460717.aspx

WHITE PAPER
www.crimson-consulting.com 25
GPU programming with NVIDIA Parallel Nsight
GPUs are becoming popular in HPC systems as a way to boost performance beyond what the CPUs alone can provide. Parallel Nsight17
Third party support
is a plug-in to Visual Studio that accelerates CPU and GPU application development. NVIDIA’s Parallel Nsight allows developers to leverage the CPU for course grained parallelism and the GPU for massively parallel computing. It includes Parallel Nsight Debugger to debug CUDA C/C++ and DirectCompute source code directly on the GPU hardware. Currently the industry’s only GPU hardware debugging solution, it can greatly increase debugging speed and accuracy. Programmers can use familiar Visual Studio Locals, Watches, Memory and Breakpoints windows. Parallel Nsight Analyzer for GPU Computing isolates performance bottlenecks by viewing system-wide CPU+GPU events. Support is included for all major GPU Computing APIs, including CUDA C/C++, OpenCL, and Microsoft DirectCompute.
Microsoft has partnered with leading parallel computing development tool vendors to ensure that their products are available to Windows and Visual Studio developers. These include Numerical libraries such as Intel Math Kernel Library (MKL), AMD Core Math Library (ACML), Rogue Wave / Visual Numerics IMSL libraries, Numerical Algorithms Group (NAG) C library as well as commercial and open source libraries such as LAPACK, ATLAS, GotoBlas, GSL and NMath. Intel Parallel Studio Development Toolkit18
■ Parallel Compose to write code using Intel Threading Building Blocks and OpenMP, as well as Microsoft Concurrency Runtime
is a set of plug-ins for Visual Studio 2010 aimed at C/C++ developers targeting single multicore desktops with shared memory programming. It includes:
■ Parallel Inspector to debug code, detect deadlocks and race conditions.
■ Parallel Amplifier to find bottlenecks in code and tune it for multicore performance.
Programmers can also use Vampir for profiling and Allinea’s Visual studio debugger plug-in for debugging.
17 http://developer.nvidia.com/object/nsight.html 18 http://software.intel.com/en-us/intel-parallel-studio-home/

WHITE PAPER
www.crimson-consulting.com 26
Appendix C The administration console for Windows HPC Server 2008 R2 now includes diagnostics that record latency and throughput for a set of nodes or the whole cluster and allow easy comparison using SQL Server Reporting Services. Table 4 lists the performance analysis tools included.
Table 4: Windows HPC Server performance analysis tools
Tool Name File Name Function
Trace Capture, Processing, and Command-Line Analysis tool
Xperf.exe Captures traces, post-processes them for use on any machine, and supports command-line (action-based) trace analysis.
Visual Trace Analysis tool Xperfview.exe Presents trace content in the form of interactive graphs and summary tables.
On/Off Transition Trace Capture tool
Xbootmgr.exe Automates on/off state transitions and captures traces during these transitions.
Further information is available from Microsoft at: http://msdn.microsoft.com/en-us/performance/cc825801.aspx About Crimson Consulting We help executives achieve market leadership. Crimson is a management consulting firm focused on marketing. Our clients include Adobe, Cisco, eBay, Hitachi, HP, IBM, Intel, Microsoft, Oracle, SAP, Seagate, Symantec and Verizon. We are experts in the marketing of technology solutions For more information, contact: Crimson Consulting Group (650) 960-3600 x335 [email protected]





























