Embed Size (px)
Citation preview

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 1/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1166
Conversational Interfaces: Advances and ChallengesVictor W. Zue and James R. Glass
Abstract The last decade has witnessed the emergenceof a new breed of human computer interfaces that com-
bines several human language technologies to enable humansto converse with computers using spoken dialogue for in-formation access, creation, and processing. In this paper,we introduce the nature of these conversational interfaces,and describe the underlying human language technologieson which they are based. After summarizing some of therecent progress in this area around the world, we discuss de-velopment issues faced by researchers creating these kindsof systems, and present some of the ongoing and unmet re-search challenges in this eld.
Keywords Conversational interfaces, spoken dialogue sys-tems, speech understanding systems.
I. Introduction
COMPUTERS are fast becoming a ubiquitous part of our lives, brought on by their rapid increase in per-formance and decrease in cost. With their increased avail-ability comes the corresponding increase in our appetite forinformation. Today, for example, nearly half the popula-tion of North America are users of the World Wide Web,and the growth is continuing at an astronomical rate. Vastamounts of useful information are being made widely avail-able, and people are utilizing it routinely for education,decision-making, nance, and entertainment. Increasingly,people are interested in being able to access the informa-tion when they are on the move – anytime, anywhere, andin their native language. A promising solution to this prob-
lem, especially for small, hand-held devices where conven-tional keyboard and mice can be impractical, is to imparthuman-like capabilities onto machines, so that they canspeak and hear, just like the users with whom they needto interact. Spoken language is attractive because it is themost natural, efficient, exible, and inexpensive means of communication among humans.
When one thinks about a speech-based interface, twotechnologies immediately come to mind: speech recogni-tion and speech synthesis. There is no doubt that theseare important and as yet unsolved problems in their ownright, with a clear set of applications that include documentpreparation and audio indexing. However, these technolo-
gies by themselves are often only a part of the interface so-lution. Many applications that lend themselves to spokeninput/output – inquiring about weather or making travelarrangements – are in fact exercises in information accessand/or interactive problem solving. The solution is oftenbuilt up incrementally, with both the user and the com-puter playing active roles in the “conversation.” Therefore,several language-based input and output technologies mustbe developed and integrated to reach this goal. The result-
The authors are with the Spoken Language Systems Group, MITLaboratory for Computer Science, Cambridge, MA 02139 USA (URL:www.sls.lcs.mit.edu).
ing conversational interface 1 is the subject of this paper.Many speech-based interfaces can be considered conver-
sational, and they may be differentiated by the degree withwhich the system maintains an active role in the conver-sation. At one extreme are system-initiative , or directed-dialogue transactions where the computer takes completecontrol of the interaction by requiring that the user answera set of prescribed questions, much like the touch-tone im-plementation of interactive voice response (IVR) systems.In the case of air travel planning, for example, a directed-dialogue system could ask the user to “Please say just thedeparture city.” Since the user’s options are severely re-stricted, successful completion of such transactions is easierto attain, and indeed some successful demonstrations anddeployment of such systems have been made [5,64]. At theother extreme are user-initiative systems in which the userhas complete freedom in what they say to the system, (e.g.,“I want to visit my grandmother”) while the system re-mains relatively passive, asking only for clarication whennecessary. In this case, the user may feel uncertain as towhat capabilities exist, and may, as a consequence, strayquite far from the domain of competence of the system,leading to great frustration because nothing is understood.Lying between these two extremes are systems that incor-porate a mixed-initiative , goal-oriented dialogue, in whichboth the user and the computer participate actively to solvea problem interactively using a conversational paradigm. It
is this latter mode of interaction that is the primary focusof this paper.What is the nature of such mixed initiative interaction?
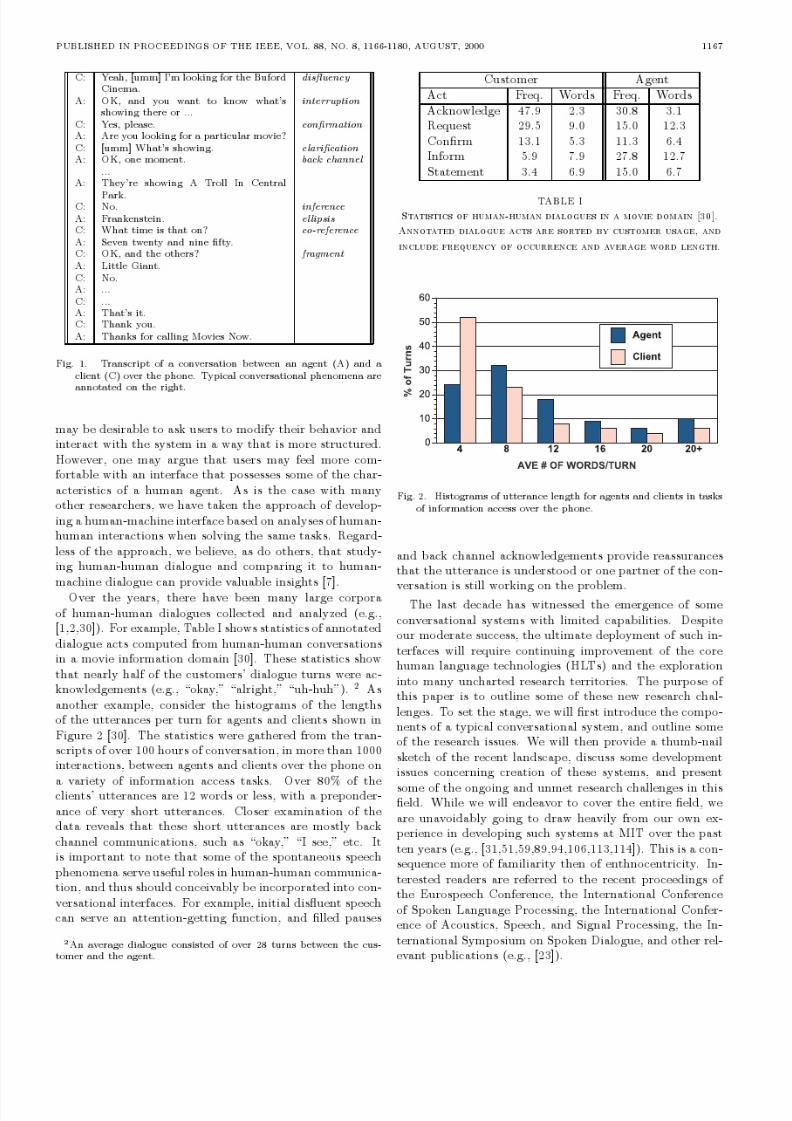
One way to answer the question is to examine human-human interactions during joint problem solving [30]. Fig-ure 1 shows the transcript of a conversation between anagent (A) and a client (C) over the phone. As illustrated bythis example, spontaneous dialogue is replete with disu-encies, interruption, conrmation, clarication, ellipsis, co-reference, and sentence fragments. Some of the utterancescannot be understood properly without knowing the con-text in which they appear. As we shall see, while presentsystems cannot handle all these phenomena satisfactorily,
some of them are being dealt with in a limited fashion.Should one build conversational interfaces by mimick-ing human-human interactions? Opinion in this regard issomewhat divided. Some researchers argue that human-human dialogues can be quite variable, containing frequentinterruptions, speech overlaps, incomplete or unclear sen-tences, incoherent segments, and topic switches. Someof these variabilities may not contribute directly to goal-directed problem solving [102]. For practical reasons, it
1 Throughout this paper, we will use the terms conversational in-terfaces , conversational systems , and spoken dialogue systems inter-changeably.
8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 2/15

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 3/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1168
SPEECHSYNTHESIS
LANGUAGEUNDERSTANDING
LANGUAGEGENERATION
SPEECHRECOGNITION
DIALOGUEMANAGER
DATABASE
DISCOURSE
CONTEXTSEMANTIC
FRAME
Graphs & Tables
Fig. 3. A generic block diagram for a typical conversational interface.
II. Underlying Technologies and Research Issues
A. System Architecture
Figure 3 shows the major components of a typical con-versational interface. The spoken input is rst processedthrough the speech recognition component. The naturallanguage component, working in concert with the recog-nizer, produces a meaning representation for the utterance.For information retrieval applications illustrated in this g-ure, the meaning representation can be used to retrieve theappropriate information in the form of text, tables andgraphics. If the information in the utterance is insuffi-cient or ambiguous, the system may choose to query theuser for clarication. If verbal conveyance of the infor-mation is desired, then natural language generation andtext-to-speech synthesis are utilized to produce the spo-
ken responses. Throughout the process, discourse informa-tion is maintained and fed back to the speech recognitionand language understanding components, so that sentencescan be properly understood in context. Finally, a dialoguecomponent manages the interaction between the user andthe computer. The nature of the dialogue can vary signi-cantly depending on whether the system is creating or clar-ifying a query prior to accessing an information database,or perhaps negotiating with the user in a post information-retrieval phase to relax or somehow modify some aspectsof the initial query.
Figure 3 does not adequately convey the notion thata conversational interface may include input and outputmodalities other than speech. While speech may be theinterface of choice, as is the case with phone-based interac-tions and hands-busy/eyes-busy settings, there are clearlycases where speech is not a good modality, especially, forexample, on the output side when the information con-tains maps, images, or large tables of information whichcannot be easily explained verbally. Human communica-tion is inherently multimodal, employing facial, gestural,and other cues to communicate the underlying linguisticmessage. Thus, speech interfaces should be complementedby visual and sensory motor channels. The user should beable to choose among many modalities, including gestur-
ing, pointing, writing, and typing on the input side [21,90],and graphics and a talking head on the output side [56], toachieve the task in hand in the most natural and efficientmanner.
The development of conversational interfaces offers a setof signicant challenges to speech and natural languageresearchers, and raises several important research issues,some of which will be discussed in the remainder of thissection.
B. Spoken Input: From Signal to Meaning
Spoken language understanding involves the transforma-tion of the speech signal into a meaning representation thatcan be used to interact with the specic application back-end. This is typically accomplished in two steps, the con-version of the signal to a set of words (i.e., speech recogni-tion), and the derivation of the meaning from the word hy-potheses (i.e., language understanding). A discourse com-ponent is often used to properly interpret the meaning of an utterance in the larger context of the interaction.
B.1 Automatic Speech Recognition
Input to conversational interfaces is often generated ex-temporaneously - especially from novice users of these sys-tems. Such spontaneous speech typically contains disu-encies (i.e., unlled and lled pauses such as “umm” and“aah,” as well as word fragments). In addition, the in-put utterances are likely to contain words outside the sys-tem’s working vocabulary – a consequence of the fact thatpresent-day technology can only support the developmentof systems within constrained domains. Thus far, someattempts have been made to deal with the problem of disuency. For example, researchers have improved their
system’s recognition performance by introducing explicitacoustic models for the lled pauses [9,108]. Similarly,“trash” models have been used to detect the presence of word fragments or unknown words [38], and procedureshave been devised to learn the new words once they havebeen detected [3]. Suffice it to say, however, that the de-tection and learning of unknown words continues to be aproblem that needs our collective attention. A related topicis utterance- and word-level rejection, in the presence of ei-ther out-of-domain queries or unknown words [69].
An issue that is receiving increasing attention by the re-search community is the recognition of telephone qualityspeech. It is not surprising that some of the rst conver-sational systems available to the general public were ac-cessible via telephone (e.g., [5,10,64,98]), in many cases re-placing presently existing IVR systems. Telephone qualityspeech is signicantly more difficult to recognize than highquality recordings, both because of the limited bandwidthand the noise and distortions introduced in the channel[53]. The acoustic condition deteriorates further for cellu-lar telephones, either analog or digital.
B.2 Natural Language Understanding
Speech recognition systems typically implement linguis-tic constraints as a statistical language model (i.e., n -gram)

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 4/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1169
that species the probability of a word given its predeces-sors. While these language models have been effective inreducing the search space and improving performance, theydo not begin to address the issue of speech understand-ing. On the other hand, most natural language systems aredeveloped with text input in mind; it is usually assumedthat the entire word string is known with certainty. Thisassumption is clearly false for speech input, where manyalternative words hypotheses are competing for the sametime span in any sentence hypothesis produced by the rec-ognizer (e.g., “euthanasia” and “youth in Asia,”) and somewords may be more reliable than others because of varyingsignal robustness. Furthermore, spoken language is oftenagrammatical, containing fragments, disuencies and par-tial words. Language understanding systems designed fortext input may have to be modied in fundamental waysto accommodate spoken input.
Natural language analysis has traditionally been pre-dominantly syntax-driven – a complete syntactic analysisis performed which attempts to account for all words in an
utterance. However, when working with spoken material,researchers quickly came to realize that such an approach[12,28,87] can break down dramatically in the presence of unknown words, novel linguistic constructs, recognition er-rors, and spontaneous speech events such as false starts.
Due to these problems, many researchers have tended tofavor more semantic-driven approaches, at least for spo-ken language tasks in constrained domains. In such ap-proaches, a meaning representation is derived by “spot-ting” key words and phrases in the utterance [109]. Whilethis approach loses the constraint provided by syntax, andmay not be able to adequately interpret complex linguisticconstructs, the need to accommodate spontaneous speech
input has outweighed these potential shortcomings. At thepresent time, many systems have abandoned the notionof achieving a complete syntactic analysis of every inputsentence, favoring a more robust strategy that can stillbe used to produce an answer when a full parse is notachieved [43,88,97]. This can be accomplished by identify-ing parsable phrases and clauses, and providing a separatemechanism for gluing them together to form a completemeaning analysis [88]. Ideally, the parser includes a proba-bilistic framework with a smooth transition to parsing frag-ments when full linguistic analysis is not achievable. Exam-ples of systems that incorporate such stochastic modellingtechniques can be found in [36,60].
How should the speech recognition component interactwith the natural language component in order to obtain thecorrect meaning representation? One of the most popularstrategies is the so-called N -best interface [19], in whichthe recognizer proposes its best N complete sentence hy-potheses one by one, stopping with the rst sentence that issuccessfully analyzed by the natural language component.In this case, the natural language component acts as a l-ter on whole sentence hypotheses. Alternatively, competingrecognition hypotheses can be represented in the form of a word graph [39], which is more compact than an N -bestlist, thus permitting a deeper search if desired.
In an N -best list, many of the candidate sentences maydiffer minimally in regions where the acoustic informationis not very robust. While confusions such as “an” and“and” are acoustically reasonable, one of them can often beeliminated on linguistic grounds. In fact, many of the topN sentence hypotheses might be eliminated before reachingthe end if syntactic and semantic analyses take place earlyon in the search. One possible solution, therefore, is forthe speech recognition and natural language componentsto be tightly coupled, so that only the acoustically promis-ing hypotheses that are linguistically meaningful are ad-vanced. For example, partial theories can be arranged on astack, prioritized by score. The most promising partial the-ories are extended using the natural language componentas a predictor of all possible next-word candidates; none of the other word hypotheses are allowed to proceed. There-fore, any theory that completes is guaranteed to parse. Re-searchers are beginning to nd that such a tightly coupledintegration strategy can achieve higher performance thanan N -best interface, often with a considerably smaller stack
size [33,35,61,110]. The future is likely to see increasinguse of linguistic analysis at earlier stages in the recognitionprocess.
B.3 Discourse
Human verbal communication is a two-way process in-volving multiple, active participants. Mutual understand-ing is achieved through direct and indirect speech acts,turn taking, clarication, and pragmatic considerations. Adiscourse ability allows a conversational system to under-stand an utterance in the context of the previous interac-tion. As such, discourse can be considered to be part of the input processing stage. To communicate effectively, a
system must be able to handle phenomena such as deic-tic (e.g., verbal pointing as in “I’ll take the second one”)and anaphoric reference (e.g., using pronouns as in “what’stheir phone number”) to allow users to efficiently refer toitems currently in focus. An effective system should alsobe able to handle ellipsis and fragments so that a user doesnot have to fully specify each query. For instance, if a usersays, “I want to go from Boston to Denver,” followed with,“show me only United ights,” he/she clearly does not wantto see all United ights, but rather just the ones that yfrom Boston to Denver. The ability to inherit informationfrom preceding utterances is particularly helpful in the faceof recognition errors. The user may have asked a complex
question involving several restrictions, and the recognizermay have misunderstood a single word, such as a ightnumber or an arrival time. If a good context model exists,the user can then utter a very short correction phrase, andthe system will be able to replace just the misunderstoodword, preventing the user from having to repeat the entireutterance, running the risk of further recognition errors.
C. Output Processing: From Information to Signal
On the output side, a conversational interface must beable to convey the information to the user in natural sound-ing sentences. This is typically accomplished in two steps:

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 5/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1170
the information is converted into well-formed sentences,which are then fed through a text-to-speech (TTS) systemto generate the verbal responses.
C.1 Natural Language Generation
Spoken language generation serves two important roles.First and foremost, it provides a verbal response to the
user’s queries, which is essential in applications where vi-sual displays are unavailable. In addition, it can providefeedback to the user in the form of a paraphrase, conrmingthe system’s proper understanding of the input query. Al-though there has been much research on natural languagegeneration (NLG), dealing with the creation of coherentparagraphs (e.g., [57,77]), the language generation com-ponent of a conversational system typically produces theresponse one sentence at a time, without paragraph levelplanning. Research in language generation for conversa-tional systems has not received nearly as much attentionas has language understanding, especially in the U.S., per-haps due to the funding priorities set forth by the major
government sponsors. In many cases, output sentences aresimply word strings, in text or pre-recorded acoustic for-mat, that are invoked when appropriate. In some cases,sentences are generated by concatenating templates afterlling slots by applying recursive rules along with appropri-ate constraints (person, gender, number, etc.) [32]. Therehas also been some recent work using more corpus-basedmethods for language generation in order to provide morevariation in the surface realization of the utterance [65].
C.2 Speech Synthesis
The conversion of text to speech is the nal stage of output generation. TTS systems in the past were primar-ily rule driven, requiring the system developers to possessextensive acoustic-phonetic and other linguistic knowledge[47]. These systems are typically very intelligible, but suffergreatly in naturalness. In recent years, we have seen theemergence of a new, concatenative approach, brought onby inexpensive computation/storage, and the availability of large corpora [8,83]. In this corpus-based approach, unitsexcised from recorded speech are concatenated to form anutterance. The selection of the units is based on a searchprocedure subject to a predened distortion measure. Theoutput of these TTS systems is often judged to be morenatural than that of the rule-based systems [65].
Currently in most conversational systems, the languagegeneration and text-to-speech components are not closelycoupled; the same text is generated whether it is to be reador spoken. Furthermore, systems typically expect the lan-guage generation component to produce a textual surfaceform of a sentence (throwing away valuable linguistic andprosodic knowledge) and then require the text-to-speechcomponent to produce linguistic analysis anew. Recently,there has been some work in concept-to-speech generation[58]. Such a close coupling can potentially produce higherquality output speech than could be achieved with a de-coupled system, since it permits ner control of prosody.Whether language generation and speech synthesis compo-
nents should be tightly integrated, or can remain modularbut effectively coupled by augmenting text output with amarkup language (e.g., SABLE [96]) remains to be seen.Clearly however, these two components would benet froma shared knowledge base.
D. Dialogue Management
The dialogue modelling component of a conversationalsystem manages the interaction between the user and thecomputer. The technology for building this component isone of the least developed in the HLT repertoire, especiallyfor mixed-initiative dialogue systems considered in this pa-per. Although there has been some theoretical work on thestructure of human-human dialogue [37], this has not ledto effective insights for building human-machine interactivesystems. As mentioned previously, there is also consider-able debate in the speech and language research communi-ties about whether modelling human-machine interactionsafter human-human dialogues is necessary or appropriate(e.g., [13,82,102]).
Dialogue modelling means different things to differentpeople. For some, it includes the planning and problem solving aspects of human computer interactions [1]. Inthe context of this paper, we dene dialogue modellingas the preparation, for each turn, of the system’s side of the conversation, including verbal, tabular, and graphicalresponse, as well as any clarication requests.
Dialogue modelling and management serves many roles.In the early stages of the conversation the role of the di-alogue manager might be to gather information from theuser, possibly clarifying ambiguous input along the way, sothat, for example, a complete query can be produced forthe application database. The dialogue manager must be
able to resolve ambiguities that arise due to recognition er-ror (e.g., “Did you say Boston or Austin”) or incompletespecication (e.g., “On what day would you like to travel”).
In later stages of the conversation, after information hasbeen accessed from the database, the dialogue managermight be involved in some negotiation with the user. Forexample, if there were too many items returned from thedatabase, the system might suggest additional constraintsto help narrow down the number of choices. Pragmati-cally, the system must be able to initiate requests so thatthe information can be reduced to digestible chunks (e.g.,“I found ten ights, do you have a preferred airline or con-necting city”).
In addition to these two fundamental operations, the dia-logue manager must also inform and guide the user by sug-gesting subsequent sub-goals (e.g., “Would you like me toprice your itinerary?”), offer assistance upon request, helprelax constraints or provide plausible alternatives when therequested information is not available (e.g., “I don’t havesunrise information for Oakland, but in San Francisco ...”),and initiate clarication sub-dialogues for conrmation. Ingeneral the overall goal of the dialogue manager is to takean active role in directing the conversation towards a suc-cessful conclusion for the user.
The dialogue manager can inuence other system com-

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 6/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1171
ponents by, for example, dynamically making dialoguecontext-dependent adjustments to language models or dis-course history. At the highest level, it can help detect theappropriate broad subdomain (e.g., weather, air travel, orurban navigation). Within a particular domain, certainqueries could introduce a focus of attention on a subset of the lexicon. For instance, in a dialogue about a trip toFrance, the initial user utterance, “I’m planning a trip toFrance ,” would allow the system to greatly enhance theprobabilities on all the French destinations. Finally, when-ever the system asks a directed question, the languagemodel probabilities can be altered so as to favor appro-priate responses to the question. For example, when thesystem asks the user to provide a date of travel, the sys-tem could temporarily enhance the probabilities of dateexpressions in the response.
There are many ways dialogue management has beenimplemented. Many systems use a type of scripting lan-guage as a general mechanism to describe dialogue ow(e.g., [15,92,98]). Other systems represent dialogue ow by
a graph of dialogue objects or modules (e.g., [5,101]). An-other aspect of system implementation is whether or notthe active vocabulary or understanding capabilities changedepending on the state of the dialogue. Some systems arestructured to allow a user to ask any question at any pointin the dialogue, so that the entire vocabulary is active atall times. Other systems restrict the vocabulary and/orlanguage which can be accepted at particular points in thedialogue. The trade-off is generally one of increased userexibility (in reacting to a system response or query), andone of increased system understanding accuracy, due to theconstraints on the user input.
III. Recent ProgressIn the past decade there has been increasing activity in
the area of conversational systems, largely due to govern-ment funding in the U.S. and Europe. By the late 1980’sthe DARPA spoken language systems (SLS) program wasinitiated in the U.S., while the Esprit SUNDIAL (SpeechUnderstanding and DIALog) program was underway in Eu-rope [71]. The task domains for these two programs wereremarkably similar in that both involved database accessfor travel planning, with the European one including bothight and train schedules, and the American one being re-stricted to air travel. The European program was a mul-tilingual effort involving four languages (English, French,German, and Italian), whereas the American effort was,understandably, restricted to English. All of the systemsfocused within a narrowly dened area of expertise, andvocabulary sizes were generally limited to several thousandwords. Nowadays, these types of systems can typically runin real-time on standard workstations and PCs with no ad-ditional hardware.
Strictly speaking, the DARPA SLS program cannot beconsidered conversational in that its attention focused en-tirely on the input side. However, since the technologydeveloped during the program had a signicant impact onthe speech understanding methods used by conversational
systems, it is worth describing in more detail. The programadopted the approach of developing the underlying inputtechnologies within a common domain called Air Travel In-formation Service, or atis [76]. Atis permits users to queryfor air travel information, such as ight schedules from onecity to another, obtained from a small, static relationaldatabase excised from the Official Airline Guide. By re-quiring that all system developers use the same database,it was possible to compare the performance of various spo-ken language systems based on their ability to extract thecorrect information from the database, using a set of pre-scribed training and test data, and a set of interpretationguidelines. Indeed, common evaluations occurred at regu-lar intervals, and steady performance improvements wereobserved for all systems. At the end of the program, thebest system achieved a word error rate of 2.3% and a sen-tence error rate of 15.2% [68]. Additionally, the best systemachieved an understanding error rate of 5.9% and 8.9% fortext and speech input, respectively. 3
The European SUNDIAL project differed in several ways
from the DARPA SLS program. Whereas the SLS programhad regular common evaluations, the SUNDIAL projecthad none. Unlike the SLS program however, the SUNDIALproject aimed at building systems that could be publiclydeployed. For this reason, the SUNDIAL project desig-nated dialogue modelling and spoken language generationas integral parts of the research program. As a result, thishas led to some interesting advances in Europe in dialoguecontrol mechanisms.
Since the end of the SLS and SUNDIAL programs in1995, and 1993 respectively, there have been other spon-sored programs in spoken dialogue systems. In the recentlycompleted ARISE (Automatic Railway Information Sys-
tems for Europe) project, which was a part of the LE3program, participants developed train timetable informa-tion systems covering three different languages (Dutch,French, and Italian) [24]. Groups explored alternative di-alogue strategies, and investigated different technology is-sues. Four prototypes underwent substantial testing andevaluation (e.g., [17,50,84]). In the U.S., a new DARPAfunded project called Communicator has begun, whichemphasizes dialogue-based interactions incorporating bothspeech input and output technologies. One of the proper-ties of this program is that participants are using a commonsystem architecture to encourage component sharing acrosssites [91]. Participants in this program are developing both
their own dialogue domains, and a common complex traveltask (e.g., [29]).In addition to the research sponsored by these larger pro-
grams, there have been many other independent initiativesas well. Although there are far too many to list here, someexamples include the Berkeley Restaurant Project (BeRP),which provided restaurant information in the Berkeley, Cal-ifornia area [44]. The AT&T AutoRes system allowed usersto make rental car reservations over the phone via a toll-
3 All the performance results quoted here are for the so-called“evaluable” queries, i.e., those queries that are within domain andfor which an appropriate answer is available from the database.

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 7/15

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 8/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1173
Fig. 4. Averaged number of dialogue turns for several applicationdomains.
has the potential benet of shortening the interval betweentechnology demonstration and its deployment. Above all,real applications that can help people solve problems willbe used by real users, thus providing us with a rich andcontinuing source of useful data. These data are far moreuseful than anything we could collect in a laboratory envi-
ronment.What constitutes real domains and real users? One mayrightfully argue that only commercially deployed systemscapable of providing robust and scalable solutions can trulybe considered real. A laboratory prototype that is onlyavailable to the public via perhaps a single phone line isquite different from a commercially deployed system. Nev-ertheless, we believe a research strategy that incorporatesas much realism as possible early into the system’s researchand development life cycle is far more preferable to onethat attempts to develop the underlying technologies ina concocted scenario. At the very least, a research pro-totype capable of providing real and useful information,
made available to a wide range of users, offers a valuablemechanism for collecting data that will benet the devel-opment of both types of systems. We will illustrate thispoint in the next section with one of the systems we havedeveloped at MIT.
How do we select the applications that are well matchedto our present capabilities? The answer may lie in exam-ining human-human data. Figure 4 displays the averagenumber of dialogue turns per transaction for several ap-plication domains. The data are obtained from the sametranscription of the 100 hours of real human-human inter-actions described earlier. As the data clearly show, helpinga user select a movie or a restaurant is considerably less
complex than helping a user to look for employment.
B. Data Collection
Developing conversational interfaces is a classic chickenand egg problem. In order to develop the system capabil-ities, one needs to have a large corpus of data for systemdevelopment, training and evaluation. In order to collectdata that reect actual usage, one needs to have a systemthat users can speak to. Figure 5 illustrates a typical cycleof system development. For a new domain or language,one must rst develop some limited natural language ca-pabilities, thus enabling an “experimenter-in-the-loop,” or
wizard-of-oz , data collection paradigm, in which an exper-imenter types the spoken sentences to the system, afterremoving spontaneous speech artifacts. This process hasthe advantage of eliminating potential recognition errors.The resulting data are then used for the development andtraining of the speech recognition and natural languagecomponents. As these components begin to mature, itbecomes feasible to collect more data using the “system-in-the-loop,” or wizardless , paradigm, which is both morerealistic and more cost effective. Performance evaluationusing newly collected data will facilitate system renement.
System Refinement
LimitedNL
Capabilities
DataCollection(Wizard)
PerformanceEvaluation
Expanded
NLCapabilities
SpeechRecognition
DataCollection
(Wizardless )
Fig. 5. Illustration of data collection procedures.
The means and scale of data collection for system devel-opment and evaluation has evolved considerably over thelast decade. This is true for both the speech recognitionand speech understanding communities, and can be seenin many of the systems in the recent ARISE project [24],and elsewhere. At MIT, for example, the voyager ur-ban navigation system was developed in 1989 by recruiting100 subjects to come to our laboratory and ask a series of questions to an initial wizard-based system [31]. In con-trast, the data collection procedure for the more recentjupiter weather information system consists of deployinga publicly available system, and recording the interactions[114]. There are large differences in the number of queries,the number of users, and the range of issues which the dataprovide. By using a system-in-the-loop form of data collec-tion, system development and evaluation become iterativeprocedures. If unsupervised methods were used to augmentthe system ASR and NLU capabilities, system developmentcould become continuous (e.g., [46]).
Figure 6 shows, over a two-year period, the cumulativeamount of data collected from real users using the MITjupiter system and the corresponding word error rates(WER) of our recognizer. Before we made the system ac-cessible through a toll-free number, the WER was about10% for laboratory collected data. The WER more thantripled during the rst week of data collection. As moredata were collected, we were able to build better lexical,language, and acoustic models. As a result, the WER con-
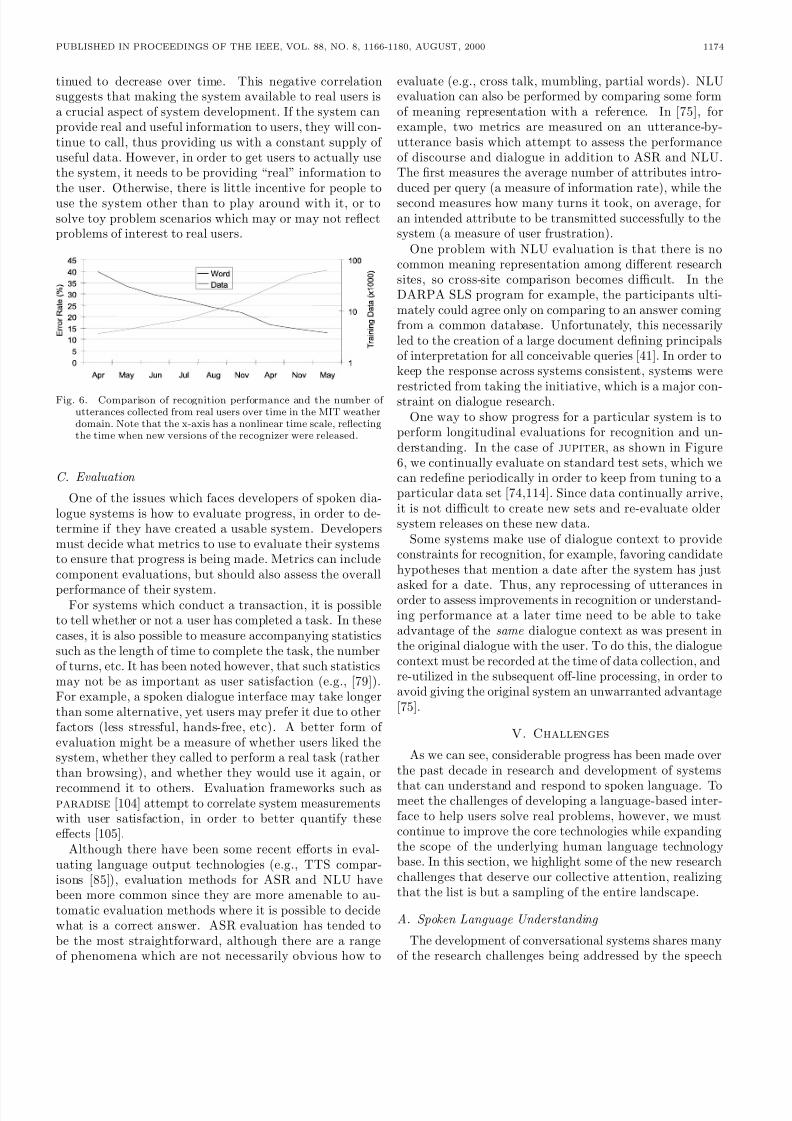
8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 9/15

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 10/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1175
recognition community for other applications such asspeech dictation and spoken document retrieval, althoughthe recognizer is often exercised in different ways. For ex-ample, in contrast to desktop dictation systems, the speechrecognition component in a conversational system is oftenrequired to handle a wide range of channel variations. In-creasingly, landline and cellular phones are the transducerof choice, thus requiring the system to deal with narrowchannel bandwidths, low signal-to-noise ratios, diversity inhandset characteristics, drop-out, and other artifacts. Inmany situations where speech input is especially appropri-ate (e.g., hands-busy/eyes-busy) there can be signicantbackground noise (e.g., cars), and possibly stress on thepart of the speaker. Robust conversational systems will berequired to handle these types of phenomena.
Another problem that is particularly acute for conversa-tional systems is the recognition of speech from a diversespeaker population. In the data we collected for jupiter ,for example, we observed a signicant number of children,as well as users with strong dialects and non-native accents.
The challenge posed by these data to speaker-independentrecognition technology must be met [54], since conversa-tional interfaces are intended to serve people from all walksof life.
A solution to these channel and speaker variability prob-lems may be adaptation. For applications in which the en-tire interaction consists of only a few queries, short-termadaptation using only a small amount of data would be nec-essary. For applications where the user identity is known,the system can make use of user proles to adapt notonly acoustic-phonetic characteristics, but also pronunci-ation, vocabulary, language, and possibly domain prefer-ences (e.g., user lives in Boston, prefers aisle seat when
ying).An important problem for conversational systems is the
detection and learning of new words. In a domain such asjupiter or electronic Yellow Pages, a signicant fractionof the words uttered by users may not be in the system’sworking vocabulary. This is unavoidable partly because itis not possible to anticipate all the words that all users arelikely to use, and partly because the database is usuallychanging with time (e.g., new restaurants opening up). Insystems such as jupiter , users will sometimes try to helpthe system with unknown city names by spelling the word(e.g., “I said B A N G O R, Bangor”), or emphasizingthe syllables in the word (which usually leads to worse re-sults!). In the past, we have not paid much attention to theunknown word problem because the tasks the speech recog-nition community has chosen often assume a closed vocab-ulary. In the limited cases where the vocabulary has beenopen, unknown words have accounted for a small fraction of the word tokens in the test corpus. Thus researchers couldeither construct generic “trash word” models and hope forthe best, or ignore the unknown word problem altogetherand accept a small penalty on word error rate. In real ap-plications, however, the system must be able to cope withunknown words simply because they will always be present,and ignoring them will not satisfy the user’s needs – if a
person wants to know how to go from the train station toa restaurant whose name is unknown to the system, theywill not settle for a response such as, “I am sorry I don’tunderstand you. Please rephrase the question.” The sys-tem must be able not only to detect new words, taking intoaccount acoustic, phonological, and linguistic evidence, butalso to adaptively acquire them, both in terms of their or-thography and linguistic properties. In some cases, fun-damental changes in the problem formulation and searchstrategy may be necessary. While some research is beingconducted in this area [3,38], much more work remains tobe done.
For simple applications such as auto-attendant, it is pos-sible for a conversational system to achieve “understand-ing” without utilizing sophisticated natural language pro-cessing techniques. For example, one could perform key-word or phrase spotting on the recognizer’s output to ob-tain a meaning representation. As the interactions becomemore complex, involving multiple turns, the system mayneed more advanced natural language analysis in order to
achieve understanding in context.Although there are many examples in the literature of both partial and fully unsupervised learning methods ap-plied to natural language processing, NLU in the contextof conversational systems remains mainly a knowledge in-tensive process. Even stochastic approaches that can learnthe linguistic regularities automatically require that a largecorpus be properly annotated with syntactic and semantictags [36,60,70]. One of the continuing challenges facing re-searchers is the discovery of processes that can automatethe discovery of linguistic facts.
Competing strategies to achieve robust understandinghave been explored in the research community. For exam-
ple, the system could adopt the strategy of rst performingword- and phrase-spotting, and rely on full linguistic anal-ysis only when necessary. Alternatively, the system couldrst perform full linguistic analysis in order to uncover thelinguistic structure of the utterance, and relax the con-straints through robust parsing and word/phrase-spottingonly when full linguistic analysis fails. At this point, itis not clear which of these strategies would yield the bestperformance. Continued investigation is clearly necessary.
B. Spoken Language Generation
With few exceptions, current research in spoken languagesystems has focused on the input side, i.e., the understand-ing of the input queries, rather than the conveyance of theinformation. It is interesting to observe, however, that thespeech synthesis component is the one that often leaves themost lasting impression on users - especially when it doesnot sound especially natural. As such, more natural sound-ing speech synthesis will be an important research topic forspoken dialogue systems in the future.
Spoken language generation is an extremely importantaspect of the human-computer interface problem, espe-cially if the transactions are to be conducted over a tele-phone. Models and methods must be developed that willgenerate natural sentences appropriate for spoken output,

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 11/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1176
across many domains and languages. For applicationswhere all information must be conveyed aurally, particu-lar attention must be paid to the interaction between lan-guage generation and dialogue management – the systemmay have to initiate a clarication sub-dialogue to reducethe amount of information returned from the back-end, inorder not to generate unwieldy verbal responses.
As mentioned earlier, recent work in speech synthesisbased on non-uniform units has resulted in much improvedsynthetic speech quality [42,83]. However, we must con-tinue to improve speech synthesis capabilities, particularlywith regard to the encoding of prosodic and possibly par-alinguistic information such as emotion. As is the caseon the input side, we must also explore integration strate-gies for language generation and speech synthesis. Finally,evaluation methodologies for spoken language generationtechnology must be continued to be developed, and morecomparative evaluations performed [85].
Many researchers have observed that the precise wordingof the system response can have a large impact on the user
response. In general, the more vaguely worded responsewill result in the larger variation of inputs [5,78]. Whichtype of response is more desirable will perhaps depend onwhether the system is used for research or commercial pur-poses. If the nal objective is to improve understanding of awider variety of input, then a more general response mightbe more appropriate. A more directed response, however,would most likely improve performance in the short-term.
The language generation used by most spoken dialoguesystems tends to be static, using the identical response pat-tern in its interaction with users. While it is quite possiblethat users will prefer consistent feedback from a system,we have observed that introducing variation in the way we
prompt users for additional queries (e.g., “Is there anythingelse you’d like to know?” “Can I help you with anythingelse?”, “What else?”) is quite effective in making the sys-tem appear less robotic and more natural to users. It wouldbe interesting to see if a more stochastic language genera-tion capability would be well received by users. In addition,the ability to vary the prosody of the output (e.g., applycontrastive stress to certain words) also becomes importantin reducing the monotony and unnaturalness of speech re-sponses.
A more philosophical question for language generation iswhether or not to personify the system in its responses tousers. Naturally, there are varied opinions on this matter.In many situations we have found that an effective responseis one commonly used in human-human interaction (e.g.,“I’m sorry”). Users do not seem to be bothered by thepersonication evident in our deployed systems.
Although prosody impacts both speech understandingand speech generation, prosodic features have been mostwidely incorporated into text-to-speech systems. However,there have been attempts to make use of prosodic infor-mation for both recognition and understanding [40,66,86],and it is hopeful that more research will appear in this areain the future. In the Verbmobil project, researchers havebeen able to show considerable improvement in process-
ing speed when integrating prosodic information into thesearch component during recognition [63].
C. Dialogue Management
In most current dialogue systems, the design of the di-alogue strategy is typically hand-crafted by the systemdevelopers, and as such is largely based on their intu-
ition about the proper dialogue ow. This can be atime-consuming process, especially for mixed-initiative di-alogues, whose result may not generalize to different do-mains. There has been some recent research exploring theuse of machine learning techniques to automatically deter-mine dialogue strategy [52]. Regardless of the approach,however, there is the need to develop the necessary infras-tructure for dialogue research. This includes the collectionof dialogue data, both human-human and human-machine.These data will need to be annotated, after developing an-notation tools and establishing proper annotation conven-tions. In the last decade, speech recognition and languageunderstanding communities have benetted from the avail-
ability of large, annotated corpora. Similar efforts are des-perately needed for dialogue modelling. Organizationssuchas the Special Interest Group on Dialogue (SIGdial) of theAssociation for Computational Linguistics aim to advancedialogue research in areas such as portability, evaluation,resource sharing, and standards, among others [95].
Since we are far from being able to develop omnipotentsystems capable of unrestricted dialogue, it is necessary forcurrent systems to accurately convey their limited capabil-ities to the user, including both the domain of knowledgeof the system itself, and the kind of speech queries that thesystem can understand. While expert users can eventuallybecome familiar with at least a subset of the system ca-
pabilities, novices can have considerable difficulty if theirexpectations are not well-matched with the system capabil-ities. This issue is particularly relevant for mixed-initiativedialogue systems; by providing more exibility and freedomto users to interact with the system, one could potentiallyincrease the danger of them straying out of the system’sdomain of expertise. For example, our jupiter systemknows only short-term weather forecasts, yet users ask awide-variety of legitimate weather questions (e.g., “What’sthe average rainfall in Guatemala in January?” or, “Whenis high tide tomorrow?”) which are outside the system’s ca-pabilities, along with a wide variety of non-weather queries.Even if users are aware of the system’s domain of knowl-edge, they may not know the range of knowledge within thedomain. For example, jupiter does not know all 23,000cities in the United States, so it is necessary to be ableto detect when a user is asking for an out-of-vocabularycity, and then help inform the user what cities the systemknows without listing all possibilities. Finally, even if theuser knows the full range of capabilities of the system, theymay not know what type of questions the system is able tounderstand.
In order to assist users to stay within the capabilitiesof the system, some form of “help” capability is required.However, it is difficult to provide help capabilities since

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 12/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1177
users may not know when to ask for it, and when they do,the help request may not be explicit, especially if they donot understand why the system was misbehaving in therst place. Regardless, the help messages will clearly needto be context dependent, with the system offering the ap-propriate suggestions depending on the dialogue states.
Another challenging area of research is the recovery from
the inevitable misunderstandings that a system will make.Errors could be due to many different phenomena (e.g.,acoustics, speaking style, disuencies, out-of-vocabularywords, parse coverage, or understanding gaps), and it canbe difficult to detect that there is a problem, determinewhat the problem is caused by, and convey to the user anappropriate response that will x the problem.
Many systems incorporate some form of condence scor-ing to try to identify problematic inputs (e.g., [5,45]). Thesystem can then either try an alternative strategy to helpthe user, or back off to a more directed dialogue and/or onethat requires explicit conrmation [78,81,99]. Based on ourstatistics with jupiter , however, we have found that, when
an utterance is rejected, it is highly likely that the next ut-terance will be rejected as well [69]. Thus, it appears thatcertain users have an unfortunate tendency to go into a re-jection death spiral which can be hard to get out of! Usingcondence scoring to perform partial understanding mightallow for more rened corrective dialogue, (e.g., requestinginput of only the uncertain regions). Partial understandingmay also help in identifying out-of-vocabulary words, andenable more constructive feedback from the system aboutthe possible courses of action (e.g., “I heard you ask forthe weather in a city in New Jersey. Can you spell it forme?”).
Spoken dialogue systems can behave quite differently de-
pending on what input and output modalities are availableto the user. In displayless environments such as the tele-phone, it might be necessary to tailor the dialogue so asnot to overwhelm the user with information. When dis-plays are available, however, it may be more desirable tosimply summarize the information to the user, and to showthem a table or image, etc. Similarly, the nature of the in-teraction will change if alternative input modalities, suchas pen or gesture, are available to the user. Which modalityis most effective will depend, among other things, on en-vironment (e.g., classroom), user preference, and perhapsdialogue state [67].
Researchers are also beginning to study the additionof back-channel communication in spoken dialogue re-sponses, in order to make the interaction more natural.Prosodic information from fundamental frequency and du-ration appear to provide important clues as to when back-channelling might occur [62,111]. Intermediate feedbackfrom the system can also be more informative to the userthan silence or idle music when inevitable delays occur inthe dialogue (e.g., “Hold on while I look for the cheapestprice for your ight to London...”).
Finally, many systems are able to handle interruptionsby allowing the user to “barge in” over the system response(e.g., [5,64,81]). To date, barge-in has been treated primar-
ily as an acoustic problem, with perhaps some interactionwith a speech recognizer. However, it clearly should alsobe viewed as an understanding problem, so that the sys-tem can differentiate among different types of input suchas noise, back-channel, or a signicant question or state-ment, and take appropriate actions. In addition, it will benecessary to properly update the dialogue status to reectthe fact that barge-in occurred. For example, if the systemwas reading a list of ights, the system might need to re-member where the interruption occurred - especially if theinterruption was under-specied (e.g., “I’ll take the Unitedight,” or “Tell me about that one”).
D. Portability
Creating a robust, mixed-initiative dialogue system canrequire a tremendous amount of effort on the part of re-searchers. In order for this technology to ultimately besuccessful, the process of porting existing technology tonew domains and languages must be made easier. Overtime, researchers have made the technology more modular.
Over the past few years, different research groups havebeen attempting to make it easier for non-experts to cre-ate new domains. Systems which modularize their dialoguemanager try to take advantage of the fact that a dialoguecan often be broken down into a set of smaller sub-dialogues(e.g., dates, addresses), in order to make it easier to con-struct dialogue for a new domain (e.g., [5,101]). For exam-ple, researchers at OGI have developed rapid developmentkits for creating spoken dialogue systems, which are freelyavailable [101], and which have been used by students tocreate their own systems [100]. On the commercial sidethere has been a signicant effort to develop the Voice eX-tensible Markup Language (VoiceXML) as a standard to
enable internet content and information access via voiceand phone [103]. To date these approaches have been ap-plied only to directed dialogue strategies. Much more re-search is needed in this area if we are to try to allow systemswith complex dialogue strategies to generalize to differentdomains.
Currently, the development of speech recognition andlanguage understanding technologies has been domain andlanguage specic, requiring a large amount of annotatedtraining data. However, it may be costly, or even impos-sible, to collect a large amount of training data for cer-tain applications or languages. Therefore, we must addressthe problems of producing a conversational system in anew domain and language given at most a small amountof domain-specic training data. To achieve this goal, wemust strive to cleanly separate the algorithmic aspects of the system from the application-specic aspects. We mustalso develop automatic or semi-automatic methods for ac-quiring the acoustic models, language models, grammars,semantic structures for language understanding, and di-alogue models required by a new application. The issueof portability spans across different acoustic environments,databases, knowledge domains, and languages. Real de-ployment of multilingual spoken language technology can-not take place without adequately addressing this issue.

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 13/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1178
VI. Concluding Remarks
In this paper, we have attempted to outline some of theimportant research challenges that must be addressed be-fore spoken language technologies can be put to pervasiveuse. The timing for the development of human languagetechnology is particularly opportune, since the world is mo-bilizing to develop the information highway that will be
the backbone of future economic growth. Human languagetechnology will play a central role in providing an interfacethat will dramatically change the human-machine commu-nication paradigm from programming to conversation . Itwill enable users to efficiently access, process, manipulate,and absorb a vast amount of information. While muchwork needs to be done, the progress made collectively bythe community thus far gives us every reason to be op-timistic about elding such systems, albeit with limitedcapabilities, in the near future.
VII. Acknowledgements
The authors would like to thank Paulo Baggia, An-drew Halberstadt, Lori Lamel, Guiseppe Riccardi, AlexRudnicky, and Bernd Souvignier for providing the statis-tics about their spoken dialogue systems used in this pa-per. The authors would also like to thank Joseph Po-lifroni, Stephanie Seneff, and the two anonymous review-ers who made many helpful suggestions to improve theoverall quality of the paper. This research was supportedby DARPA under contract N66001-99-1-8904, monitoredthrough Naval Command, Control and Ocean SurveillanceCenter.
References[1] J. Allen, et al., “The TRAINS project: A Case Study in Dening
a Conversational Planning Agent,” J. Experimental and Theo-retical AI, 7, 7–48, 1995.
[2] A. Anderson et al., “The HCRC Map Task Corpus,” Languageand Speech, 34(4), 351–366, 1992.
[3] A. Asadi, R. Schwartz, and J. Makhoul, “Automatic Mod-elling for Adding New Words to a Large Vocabulary ContinuousSpeech Recognition System,” Proc. ICASSP , 305–308, 1991.
[4] H. Aust, M. Oerder, F. Seide, and V. Steinbiss, “The PhilipsAutomatic Train Timetable Information System,” Speech Com-munication, 17, 249–262, 1995.
[5] E. Barnard, A. Halberstadt, C. Kotelly, and M. Phillips, “A Con-sistent Approach to Designing Spoken-Dialog Systems,” Proc.ASRU Workshop , Keystone, CO, 1999.
[6] M. Bates, R. Bobrow, P. Fung, R. Ingria, F. Kubala, J. Makhoul,L. Nguyen, R. Schwartz, and D. Stallard, “The BBN/HARCSpoken Language Understanding System,” Proc. ICASSP, 111–114, 1993.
[7] N. Bernsen, L. Dybkjaer, and H. Dybkjaer, “Cooperativity inHuman-Machine and Human-Human Spoken Dialogue,” Dis-course Processes , 21(2), 213–236, 1996.
[8] M. Beutnagel, A. Conkie, J. Schroeter, Y. Stylianou, and A.Syrdal, “The AT&T Next-Gen TTS System,” Proc. ASA , Berlin,1999.
[9] J. Butzberger, H. Murveit, and M. Weintraub, “SpontaneousSpeech Effects in Large Vocabulary Speech Recognition Applica-tions,” Proc. ARPA Workshop on Speech and Natural Language ,339–344, 1992.
[10] R. Billi, R. Canavesio, and C. Rullent, “Automation of TelecomItalia Directory Assistance Service: Field Trial Results,” Proc.IVTTA, 11–16, 1998.
[11] M. Blomberg, R. Carlson, K. Elenius, B. Granstrom, J.Gustafson, S. Hunnicutt, R. Lindell, and L. Neovius, “An Exper-
imental Dialogue System: Waxholm,” Proc. Eurospeech , 1867-1870, 1993.
[12] R. Bobrow, R. Ingria, and D. Stallard, “Syntactic and Seman-tic Knowledge in the DELPHI Unication Grammar,” Proc.DARPA Speech and Natural Language Workshop , 230–236,1990.
[13] L. Boves and E. den Os, “Applications of Speech Technology:Designing for Usability,” Proc. IEEE Worshop on ASR and Un-derstanding, 353–362, 1999.
[14] B. Buntschuh et al., “VPQ: A Spoken Language Interface toLarge Scale Directory Information,” Proc. ICSLP, 2863–2866,1998.
[15] R. Carlson and S. Hunnicutt, “Generic and Domain- SpecicAspects of the Waxholm NLP and Dialogue Modules,” Proc.ICSLP , 677-680, 1996.
[16] J. Cassell, “Embodied Conversation: Integrating Face and Ges-ture into Automatic Spoken Dialogue Systems,” to appear, Spo-ken Dialogue Systems, Luperfoy (ed.), MIT Press.
[17] G. Castagnieri, P. Baggia, and M. Danieli, “Field Trials of theItalian ARISE Train Timetable System,” Proc. IVTTA, 97–102,1998.
[18] CMU Movieline, http://www.speech.cs.cmu.edu/Movieline[19] Y. Chow and R. Schwartz, “The N-Best Algorithm: An Effi-
cient Procedure for Finding Top N Sentence Hypotheses,” Proc.ARPA Workshop on Speech and Natural Language , 199–202,1989.
[20] M. Cohen, Z. Rivlin, and H. Bratt, “Speech Recognition inthe ATIS Domain using Multiple Knowledge Sources,” Proc.DARPA Spoken Language Systems Technology Workshop, 257–260, 1995.
[21] P. Cohen, M. Johnson, D. McGee, S. Oviatt, J. Clow, andI. Smith, “The Efficiency of Multimodal Interaction: A CaseStudy,” Proc. ICSLP, 249–252, 1998.
[22] P. Constantinides, S. Hansma, and A. Rudnicky, “A Schema-based Approach to Dialog Control,” Proc. ICSLP, 409–412,1998.
[23] P. Dalsgaard, L. Larsen, and I. Thomsen, ( Eds .) Proc. ESCATutorial and Research Workshop on Spoken Dialogue Systems:Theory and Application , Vigsø, Denmark, 1995
[24] E. den Os, L. Boves, L. Lamel, and P. Baggia, “Overview of theARISE project,” Proc. Eurospeech, 1527–1530, 1999.
[25] M. Denecke, and A. Waibel, “Dialogue Strategies Guiding Usersto Their Communicative Goals,” Proc. Eurospeech, 2227–2230,1997.
[26] L. Devillers, and H. Bonneau-Maynard, “Evaluation of DialogStrategies for a Tourist Information Retrieval System,” Proc.ICSLP, 1187–1190, 1998.
[27] V. Digilakis et al., “Rapid Speech Recognizer Adaptation to NewSpeakers,” Proc. ICASSP, 765–768, 1999.
[28] J. Dowding, J. Gawron, D. Appelt, J. Bear, L. Cherny, R. Moore,and D. Moran, “Gemini: A Natural Language System for SpokenLanguage Understanding,” Proc. ARPA Workshop on Human Language Technology, 21–24, 1993.
[29] M. Eskenazi, A. Rudnicky, K. Gregory, P. Constantinides,R. Brennan, C. Bennett, and J. Allen, “Data Collection andProcessing in the Carnegie Mellon Communicator,” Proc. Eu-rospeech, 2695–2698, 1999.
[30] G. Flammia, “Discourse Segmentation of Spoken Dialogue: AnEmpirical Approach,” Ph.D. Thesis, MIT, 1998.
[31] J. Glass, G. Flammia, D. Goodine, M. Phillips, J. Polifroni, S.Sakai, S. Seneff, and V. Zue, “Multilingual Spoken-LanguageUnderstanding in the MIT Voyager System,” Speech Communi-cation , 17, 1–18, 1995.
[32] J. Glass, J. Polifroni, and S. Seneff, “Multilingual Language Gen-eration across Multiple Domains,” Proc. ICSLP , 983–976, 1994.
[33] D. Goddeau, “Using Probabilistic Shift-Reduce Parsing inSpeech Recognition Systems,” Proc. ICSLP , 321–324, 1992.
[34] D. Goddeau, H. Meng, J. Polifroni, S. Seneff, and S.Busayapongchai, “A Form-Based Dialogue Manager for SpokenLanguage Applications,” Proc. ICSLP, 701–704, 1996.
[35] D. Goodine, S. Seneff, L. Hirschman, and M. Phillips, “Full In-tegration of Speech and Language Understanding in the MITSpoken Language System,” Proc. Eurospeech , 845–848, 1991.
[36] A. Gorin, G. Riccardi, and J. Wright, “How may I help you?,”Speech Communication, 23, 113–127, 1997.

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 14/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1179
[37] B. Grosz and C. Sidner, “Plans for Discourse,” in Intentions in Communication . MIT Press, 1990.
[38] L. Hetherington and V. Zue, “New words: Implications for Con-tinuous Speech Recognition,” Proc. Eurospeech , 475-931, 1991.
[39] L. Hetherington, M. Phillips, J. Glass, and V. Zue, “ A ∗ WordNetwork Search for Continuous Speech Recognition,” Proc. Eu-rospeech, 1533–1536, 1993.
[40] J. Hirschberg, “Communication and Prosody: Functional As-pects of Prosody,” Proc. ESCA Workshop on Dialogue and Prosody, 7–15, 1999.
[41] L. Hirschman et al., “Multi-site Data Collection for a SpokenLanguage Corpus,” Proc. DARPA Workshop on Speech and Natural Language, 7–14, 1992.
[42] X. Huang, A. Acero, J. Adcock, H.W. Hon, J. Goldsmith, J.Liu, and M. Plumpe, “WHISTLER: A Trainable Text-to-SpeechSystem,” Proc. ICSLP , 2387–2390, 1996.
[43] E. Jackson, D. Appelt, J. Bear, R. Moore, and A. Podlozny, “ATemplate Matcher for Robust NL Interpretation,” Proc. DARPASpeech and Natural Language Workshop , 190–194, 1991.
[44] D. Jurafsky, C. Wooters, G. Tajchman, J. Segal, A. Stolcke,E. Fosler, and N. Morgan, “The Berkeley Restaurant Project,”Proc. ICSLP, 2139-2142, 1994.
[45] A. Kellner, B. Rueber, and H. Schramm, “Using Combined De-cisions and Condence Measures for Name Recognition in Auto-matic Directory Assistance Systems,” Proc. ICSLP, 2859–2862,1998.
[46] T. Kemp, and A. Waibel, “Unsupervised Training of a SpeechRecognizer: Recent Experiments,” Proc. Eurospeech, 2725–2728, 1999.
[47] D. Klatt, “Review of text-to-speech conversion for English,” J.Acoust. Soc. Am., 82(3), 737–793, 1987.
[48] J. Kowtko and P. Price, “Data Collection and Analysis in the AirTravel Planning Domain,” Proc. DARPA Speech and Natural Language Workshop, October 1989.
[49] L. Lamel, S. Bennacef, J.L. Gauvain, H. Dartigues, and J.Temem, “User Evaluation of the Mask Kiosk,” Proc. ICSLP,2875–2878, 1998.
[50] L. Lamel, S. Rosset, J.L. Gauvain, S. Bennacef, M. Garnier-Rizet, and B. Prouts, “The LIMSI ARISE System,” Proc.IVTTA , 209–214, 1998.
[51] R. Lau, G. Flammia, C. Pao, and V. Zue, “WebGalaxy - In-tegrating Spoken Language and Hypertext Navigation,” Proc.Eurospeech , 883–886, 1997.
[52] E. Levin, R. Pieraccini, and W. Eckert, “Using Markov DecisionProcess for Learning Dialogue Strategies,” Proc. ICASSP , 201–204, 1998.
[53] “Speech Perception by Humans and Machines,” Speech Commu-nication, 22(1), 1–15, 1997.
[54] K. Livescu, “Analysis and Modelling of Non-Native Speech forAutomatic Speech Recognition,” S.M. Thesis, MIT, 1999.
[55] S. Marcus, et al., “Prompt Constrained Natural Language –Evolving the Next Generation of Telephony Services,” Proc. IC-SLP, 857–860, 1996.
[56] D. Massaro, Perceiving Talking Faces: From Speech Perception to a Behavioral Principle , MIT Press.
[57] D. McDonald and L. Bolc (Eds.), Natural Language Gener-ation Systems (Symbolic Computation Articial Intelligence) ,Springer Verlag, Berlin, 1998.
[58] K. McKeown, S. Pan, J. Shaw, D. Jordan, and B. Allen, “Lan-guage Generation for Multimedia Healthcare Briengs, Proc.Applied Natural Language Proc., 1997.
[59] H. Meng, S. Busayapongchai, J. Glass, D. Goddeau, L. Hether-ington, E. Hurley, C. Pao, J. Polifroni, S. Seneff, and V. Zue, “AConversational System in the Automobile Classieds Domain,”Proc. ICSLP , 542–545, 1996.
[60] S. Miller, R. Schwartz, R. Bobrow, and R. Ingria, “Statisti-cal Language Processing Using Hidden Understanding Models,”Proc. ARPA Speech and Natural Language Workshop , 278–282,1994.
[61] R. Moore, D. Appelt, J. Dowding, J. Gawron, and D. Moran,“Combining Linguistic and Statistical Knowledge Sources inNatural-Language Processing for ATIS,” Proc. ARPA Spoken Language Systems Workshop , 261–264, 1995.
[62] H. Noguchi and Y. Den, “Prosody-Based Detection of the Con-text of Backchannel Responses,” Proc. ICSLP , 487–490, 1998.
[63] E. Noth, “On the Use of Prosody in Automatic Dialogue Un-derstanding,” Proc. ESCA Workshop on Dialogue and Prosody,25–34, 1999.
[64] Nuance Communications, http://www.nuance.com[65] A. Oh, “Stochastic Natural Language Generation for Spoken
Dialog Systems,” M.S. Thesis, CMU, May 2000.[66] M. Ostendorf, C. Wightman, and N. Veilleux, “Parse Scoring
with Prosodic Information: An Analysis/Synthesis Approach,”Computer Speech & Language, 7(3), 193–210, 1993.
[67] S. Oviatt, “Multimodal Interfaces for Dynamic InteractiveMaps”, Proc. Conference on Human Factors in Computing Sys-tems: CHI ’96 , 95–102, 1996.
[68] D. Pallett, J. Fiscus, W. Fisher, J. Garafolo, B. Lund, A. Mar-tin, and M. Pryzbocki, “Benchmark Tests for the ARPA Spo-ken Language Program,” Proc. ARPA Spoken Language SystemsTechnology Workshop , 5-36, 1995.
[69] C. Pao, P. Schmid, and J. Glass, “Condence Scoring for SpeechUnderstanding Systems,” Proc. ICSLP, 815–818, 1998.
[70] K. Papineni, S. Roukos, and R. Ward, “Maximum Likelihoodand Discriminative Training of Direct Translation Models,”Proc. ICASSP, 189–192, 1998.
[71] J. Peckham, “A New Generation of Spoken Dialogue Systems:Results and Lessons from the SUNDIAL Project,” Proc. Eu-rospeech , 33-40, 1993.
[72] R. Pieraccini, and E. Levin, “Stochastic Representation of Se-mantic Structure for Speech Understanding,” Speech Communi-
cation, 11, 283–288, 1992.[73] R. Pieraccini, E. Levin, and W. Eckert, “AMICA: The AT&Tmixed initiative conversational architecture,” Proc. Eurospeech,1875–1879, 1997.
[74] J. Polifroni, S. Seneff, J. Glass, and T. Hazen, “EvaluationMethodology for a Telephone-based Conversational System,”Proc. Int. Conf. on Lang. Resources and Evaluation, 42–50,1998.
[75] J. Polifroni, and S. Seneff, “Galaxy-II as an Architecture for Spo-ken Dialogue Evaluation,” to appear Proc. Int. Conf. on Lang.Resources and Evaluation , 2000.
[76] P. Price, “Evaluation of Spoken Language Systems: the Atis Do-main,” Proc. DARPA Speech and Natural Language Workshop ,91-95, 1990.
[77] E. Reiter and R. Dale, Building Natural Language Generation Systems, Cambridge University Press, Cambridge, 2000.
[78] S. Rosset, S. Bennacef, and L. Lamel, “Design Strategies for Spo-ken Language Dialog Systems,” Proc. Eurospeech, 1535–1538,1999.
[79] A. Rudnicky, M. Sakamoto, and J. Polifroni, “Evaluating Spo-ken Language Interaction,” Proc. DARPA Speech and Natural Language Workshop, 150–159, October, 1989.
[80] A. Rudnicky, J.M. Lunati, and A. Franz, “Spoken LanguageRecognition in an Office Management Domain,” Proc. ICASSP ,829–832, 1991.
[81] A. Rudnicky, E. Thayer, P. Constantinides, C. Tchou, R. Shern,K. Lenzo, W. Xu, and A. Oh, “Creating Natural Dialogs inthe Carnegie Mellon Communicator System,” Proc. Eurospeech,1531–1534, 1999.
[82] D. Sadek, “Design Considerations on Dialogue Systems: FromTheory to Technology - The Case of Artimis,” Proc. ESCAWorkshop on Interactive Dialogue in Multi-Modal Systems, 173–188, Kloster Irsee, 1999.
[83] Y. Sagisaka, N. Kaiki, N. Iwahashi, and K. Mimura, “ATR ν -Talk Speech Synthesis System,” Proc. ICSLP , 483-486, 1992.
[84] A. Sanderman, J. Sturm, E. den Os, L. Boves, and A. Cremers,“Evaluation of the Dutch Train Timetable Information Systemdeveloped in the ARISE Project,” Proc. IVTTA, 91–96, 1998.
[85] J. van Santen, L. Pols, M. Abe, D. Kahn, E. Keller, and J.Vonwiller, “Report on the 3rd ESCA TTS Workshop EvaluationProcedure,” Proc. 3rd ESCA Workshop on Speech Synthesis ,329–332, Jenolan Caves, Australia, 1998.
[86] E. Shriberg et al., “Can Prosody Aid the Automatic Classica-tion of Dialog Acts in Conversational Speech?,” Language and Speech, 41, 439–447, 1998.
[87] S. Seneff, “ Tina : A natural language system for spoken languageapplications,” Computational Linguistics , 18(1), 61–86, 1992.
[88] S. Seneff, “Robust Parsing for Spoken Language Systems,” Proc.ICASSP , 189–192, 1992.

8/7/2019 CI advantages & disadvatages
http://slidepdf.com/reader/full/ci-advantages-disadvatages 15/15
PUBLISHED IN PROCEEDINGS OF THE IEEE, VOL. 88, NO. 8, 1166-1180, AUGUST, 2000 1180
[89] S. Seneff, V. Zue, J. Polifroni, C. Pao, L. Hetherington, D. God-deau, and J. Glass, “The Preliminary Development of a Display-less Pegasus System,” Proc. ARPA Spoken Language Technol-ogy Workshop , 212–217, 1995.
[90] S. Seneff, D. Goddeau, C. Pao, and J. Polifroni, “Multimodaldiscourse modelling in a multi-user multi-domain environment,”Proc. ICSLP , 188–191, 1996.
[91] S. Seneff, E. Hurley, R. Lau, C. Pao, P. Schmid, and V. Zue,“Galaxy-ii : A Reference Architecture for Conversational Sys-tem Development,” Proc. ICSLP, 931–934, 1998.
[92] S. Seneff, R. Lau, and J. Polifroni, “Organization, Communi-cation, and Control in the galaxy-ii Conversational System,”,Proc. Eurospeech, 1271–1274, 1999.
[93] S. Seneff, R. Lau, J. Glass, and J. Polifroni, “The Mercury Sys-tem for Flight Browsing and Pricing,” MIT Spoken LanguageSystem Group Annual Progress Report, 23–28, 1999.
[94] S. Seneff and J. Polifroni, “A New Restaurant Guide Conver-sational System: Issues in Rapid Prototyping for SpecializedDomain,” Proc. ICSLP , 665–668, 1996.
[95] SIGdial URL: http://www.sigdial.org/[96] R. Sproat, A. Hunt, M. Ostendorf, P. Taylor, A. Black, K. Lenzo,
and M. Edgington, “SABLE: A Standard for TTS Markup,”Proc. ICSLP , 1719–1722, 1998.
[97] D. Stallard and R. Bobrow, “Fragment Processing in the DEL-PHI System,” Proc. DARPA Speech and Natural LanguageWorkshop, 305–310, 1992.
[98] V. Souvignier, A. Kellner, B. Rueber, H. Schramm, and F. Seide,“The Thoughtful Elephant: Strategies for Spoken Dialogue Sys-tems,” IEEE Trans. SAP , 8(1), 51–62, 2000.
[99] J. Sturm, E. den Os, and L. Boves, “Dialogue Management inthe Dutch ARISE Train Timetable Information System,” Proc.Eurospeech, 1419–1422, 1999.
[100] S. Sutton, E. Kaiser, A. Cronk, and R. Cole, “Bringing SpokenLanguage Systems to the Classroom,” Proc Eurospeech , 709–712,1997.
[101] S. Sutton, et al., “Universal Speech Tools: The CSLU Toolkit,”Proc. ICSLP , 3221–3224, 1998.
[102] D. Thomson and J. Wisowaty, “User Confusion in Natural Lan-guage Services,” Proc. ESCA Workshop on Interactive Dialoguein Multi-Modal Systems, 189–196, Kloster Irsee, 1999.
[103] VoiceXML URL: http://www.voicexml.org/[104] M. Walker, D. Litman, C. Kamm, and A. Abella, “PARADISE:
A General Framework for Evaluating Spoken Dialogue Agents,”Proc. ACL/EACL , 271–280, 1997.
[105] M. Walker, J. Boland, and C. Kamm, “The Utility of ElapsedTime as a Usability Metric for Spoken Dialogue Systems,” Proc.ASRU Workshop, 1167–1170, Keystone, CO, 1999.
[106] W. Wang, J. Glass, H. Meng, J. Polifroni, S. Seneff, and V. Zue,“Yinhe: A Mandarin Chinese Version of the Galaxy System’”Proc. Eurospeech , 351–354, 1997.
[107] N. Ward, “Using Prosodic Cues to Decide when to ProduceBack-Channel Utterances,” Proc. ICSLP , 1728–1731, 1996.
[108] W. Ward, “Modelling Non-Verbal Sounds for Speech Recog-nition,” Proc. DARPA Workshop on Speech and Natural Lan-guage , 47–50, 1989.
[109] W. Ward, “The CMU Air Travel Information Service: Un-derstanding Spontaneous Speech,” Proc. ARPA Workshop on Speech and Natural Language , 127–129, 1990.
[110] W. Ward, “Integrating Semantic Constraints into the SPHINX-II Recognition Search,” Proc. ICASSP , II-17-20, 1994.
[111] W. Ward, and S. Issar, “Recent Improvements in the CMUSpoken Language Understanding System,” Proc. ARPA Human Language Technology Workshop , 213–216, 1996.
[112] J. Yi and J. Glass, “Natural-Sounding Speech Synthesis UsingVariable Length Units,” Proc. ICSLP, 1167–1170, 1998.
[113] V. Zue, S. Seneff, J. Polifroni, M. Phillips, C. Pao, D. Goddeau,J. Glass, and E. Brill, “ Pegasus : A Spoken Language Interfacefor On-Line Air Travel Planning,” Speech Communication , 15,331-340, 1994.
[114] V. Zue, S. Seneff, J. Glass, J. Polifroni, C. Pao, T. Hazen, andL. Hetherington, “ Jupiter : A Telephone-Based ConversationalInterface for Weather Information,” IEEE Trans. SAP , 8(1), 85–96, 2000.
Victor W. Zue received the Doctor of Sci-ence degree in Electrical Engineering from theMassachusetts Institute of Technology in 1976.He is currently a Senior Research Scientist atMIT, Associate Director of the Institute’s Lab-oratory for Computer Science, and head of itsSpoken Language Systems Group. Dr. Zue’smain research interest is in the development of conversational interfaces to facilitate gracefulhuman/computer interactions. He has taught
many courses at MIT and around the world,and he has also written extensively on this subject. He is a Fellowof the Acoustical Society of America. In 1994, he was elected Distin-guished Lecturer by the IEEE Signal Processing Society.
James R. Glass received the B.Eng. degreefrom Carleton University, Ottawa, Canada, in1982, the M.S. and Ph.D. degrees in ElectricalEngineering and Computer Science from theMassachusetts Institute of Technology, Cam-bridge, in 1984, and 1988, respectively. Sincethen he has worked in MIT’s Laboratory forComputer Science where he is currently a Prin-cipal Research Scientist and Associate Head of
the Spoken Language Systems Group. His re-search interests include acoustic-phonetic mod-eling, speech recognition and understanding, and corpus-based speechsynthesis. He served as a member of the IEEE Acoustics, Speech,and Signal Processing, Speech Technical Committee from 1992-1995.From 1997-1999 he served as an associate editor for the IEEE Trans-actions on Speech and Audio Processing.





























