Embed Size (px)
Citation preview

Cluster Hardware Overview(IA-32 Pentium)
Kent Milfeld
10/31/2002
The University of Texas at AustinTexas Advanced Computing Center

2Cluster Hardware Overview (IA-32 Pentium 4)
Outline: Cluster Systems
• Cluster Architecture– Nodes -- 2-way SMP (Dell Xeon Pentium 4)– Motherboard -- 2-way SMP (ServerWorks)– Interconnect -- Switch (Myrinet)
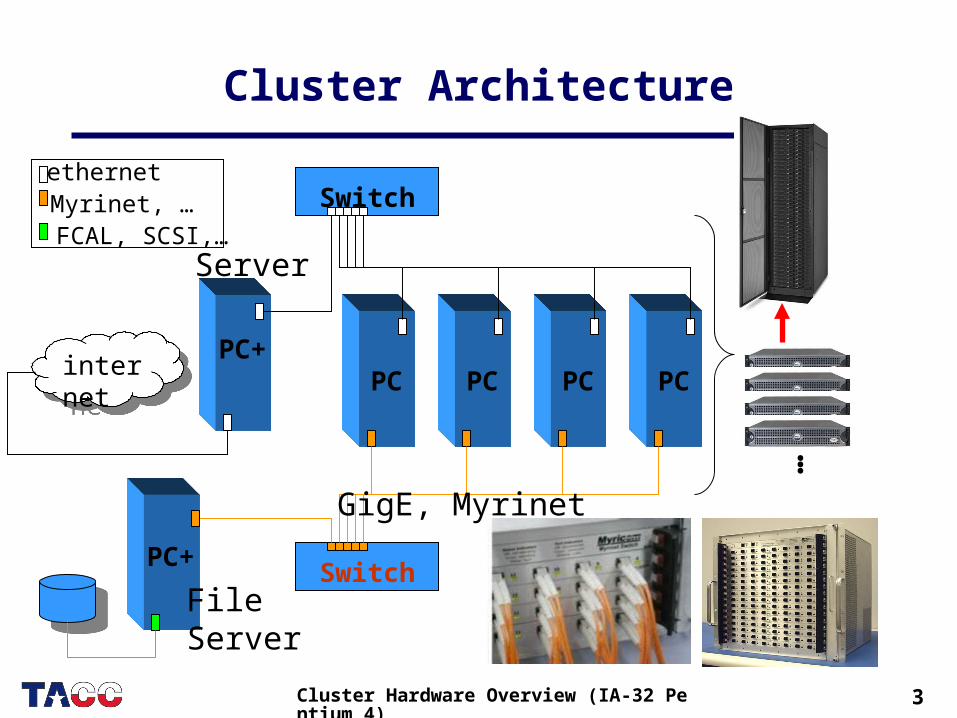
3Cluster Hardware Overview (IA-32 Pentium 4)
Cluster Architecture
internet
internet
Switch
Server
PC PC PC PCPC+
GigE, Myrinet
Switch
FileServer
PC+
ethernetMyrinet, …FCAL, SCSI,…
…

4Cluster Hardware Overview (IA-32 Pentium 4)
Node
Processors: Two 2.4GHz Intel® Xeon Processors (2U ) Chipset: ServerWorks Grand Champ LE chipset Memory: 2GB 2:1 memory interleave (200MHz DDR SDRAM)
FSB: 400MHz (Front Side Bus) Cache: 512KB L2 Advanced Transfer Cache Disk: Dual-channel integrated Ultra3 (Ultra160)
SCSI Adaptec® AIC-7899 (160Mb/s) controller
Dell PowerEdge 2650
2U
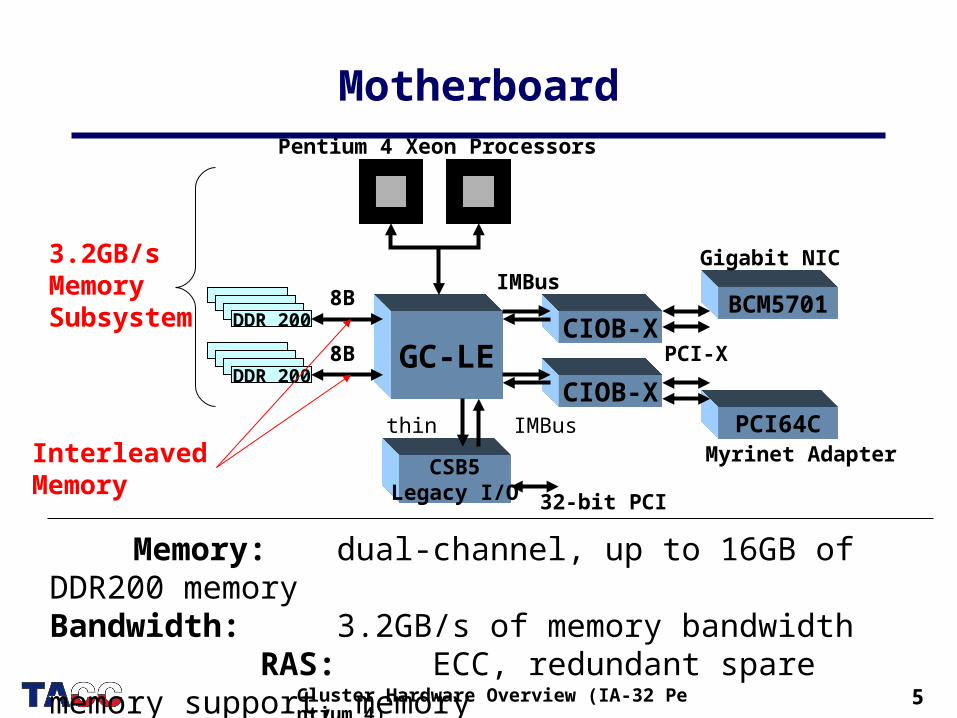
5Cluster Hardware Overview (IA-32 Pentium 4)
Motherboard
GC-LE
BCM5701
CIOB-X
CIOB-X
PCI64C
CSB5Legacy I/O
DDR 200
DDR 200
32-bit PCI
thin IMBus
IMBus8B
8B
Pentium 4 Xeon Processors
PCI-X
3.2GB/sMemorySubsystem
InterleavedMemory
Memory: dual-channel, up to 16GB of DDR200 memoryBandwidth: 3.2GB/s of memory bandwidth RAS: ECC, redundant spare memory support, memory
scrubbing & chipkill
Gigabit NIC
Myrinet Adapter
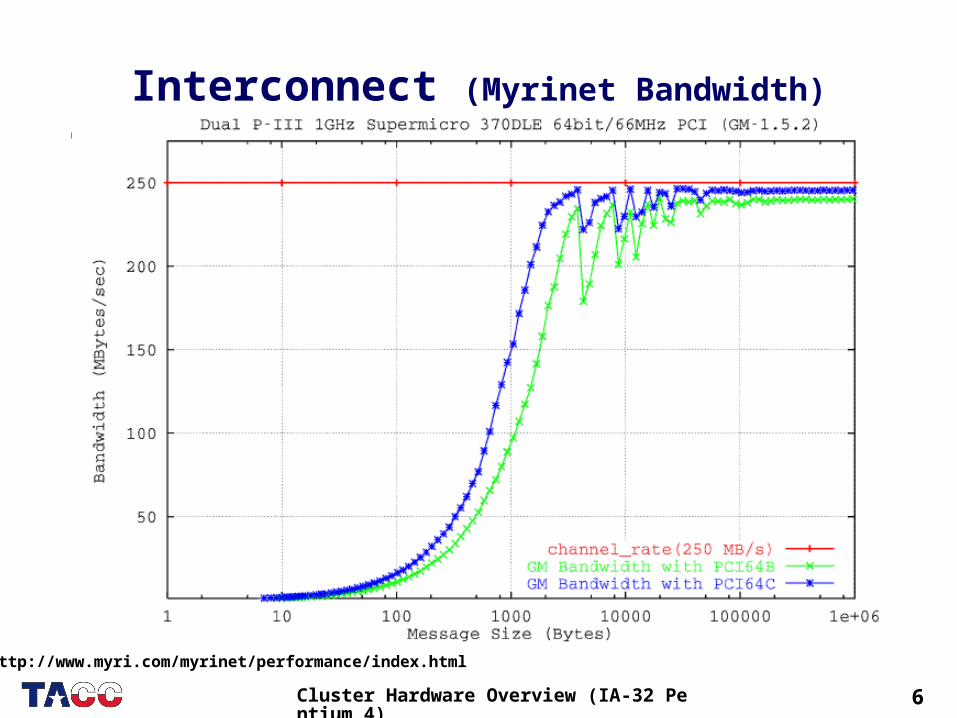
6Cluster Hardware Overview (IA-32 Pentium 4)
Interconnect (Myrinet Bandwidth)
http://www.myri.com/myrinet/performance/index.html
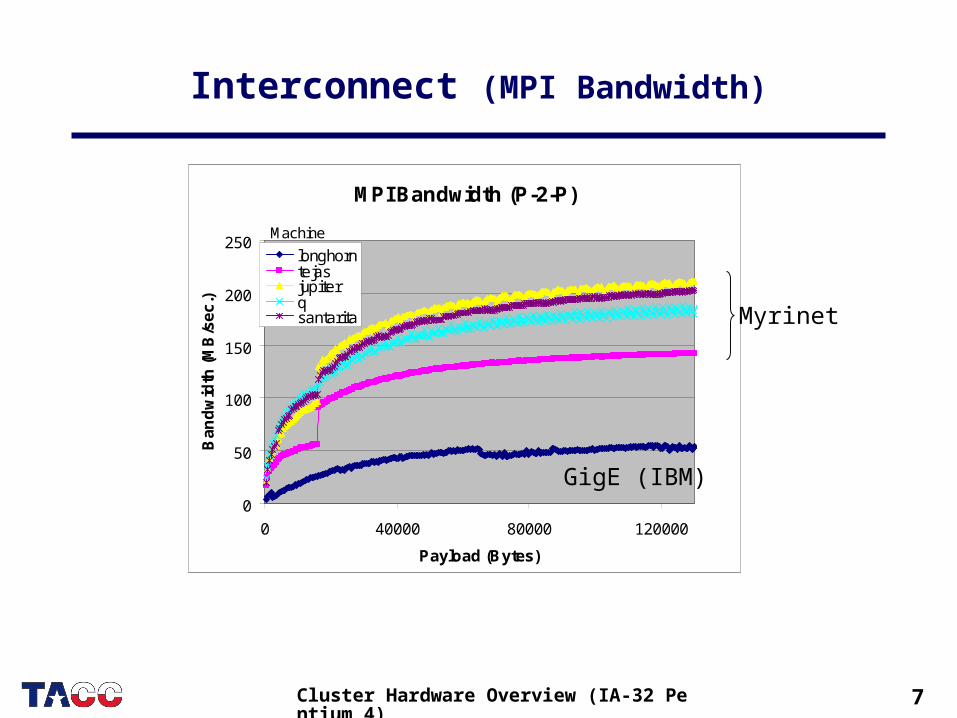
7Cluster Hardware Overview (IA-32 Pentium 4)
Interconnect (MPI Bandwidth)
MPI Bandwidth (P-2-P)
0
50
100
150
200
250
0 40000 80000 120000
Payload (Bytes)
Ba
nd
wid
th (
MB
/se
c.)
longhorntejasjupiterqsantarita
Machine
GigE (IBM)
Myrinet

8Cluster Hardware Overview (IA-32 Pentium 4)
Outline: Pentium 4 Microarchitecture
• Features
• Block Diagrams (data flow / hardware)
• Out-of-Order (OO) execution
• Speeds & Feeds
• Floating Point & Memory Performance
• Registers / Caches
• SIMD
• Compiler Design
• Optimizations

9Cluster Hardware Overview (IA-32 Pentium 4)
Architecture Features
• NetBurst Microarchitecture
• Instruction Cache (Execution Trace Cache)
• Out-of-Order (OO) execution engine
• Double-pumped Arithmetic Logic Unit
• Memory Subsystem (L1 access in 2 CP)
• Floating Point/Multi-Media performance

10Cluster Hardware Overview (IA-32 Pentium 4)
Basic Features
• 42 million transistors (0.18u), 217 mm**2, 55watts @1.5GHz, 6 levels of aluminum interconnect)
• Up to 3.0GHz
• 400/533 MHz FSB
• 144 128/64-bit SIMD instructions– SSE2 (Streaming Extension 2)
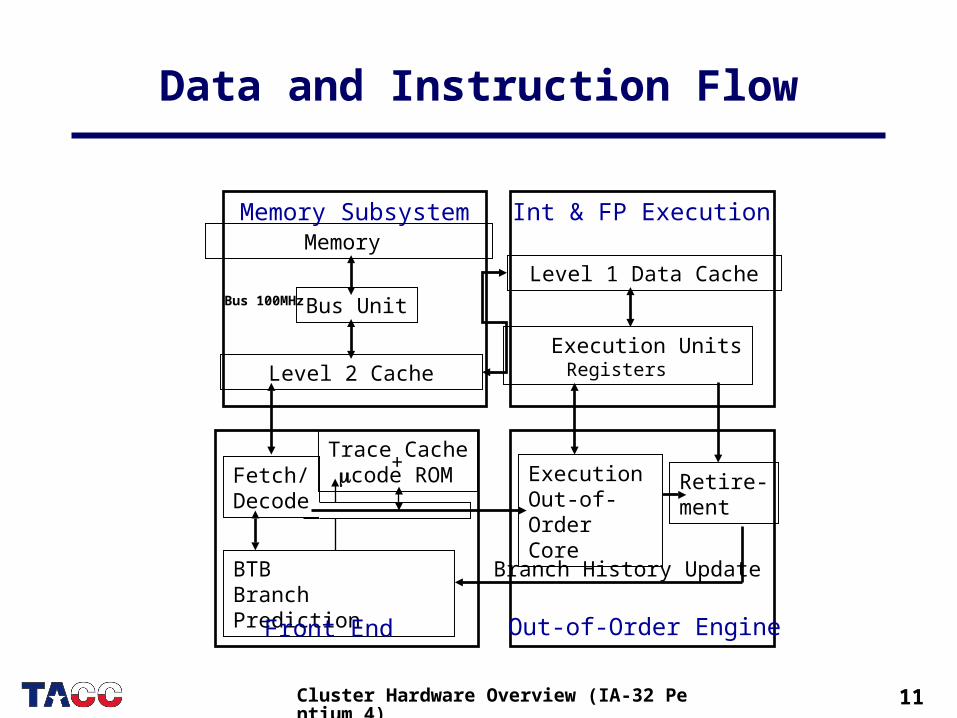
11Cluster Hardware Overview (IA-32 Pentium 4)
Data and Instruction Flow
Level 1 Data Cache
Execution UnitsRegisters Level 2 Cache
Execution Out-of-OrderCore
Retire-ment
Trace Cachecode ROMFetch/
Decode
BTBBranch Prediction
Branch History Update
Memory Int & FP ExecutionMemory Subsystem
Out-of-Order EngineFront End
Bus 100MHz Bus Unit
+
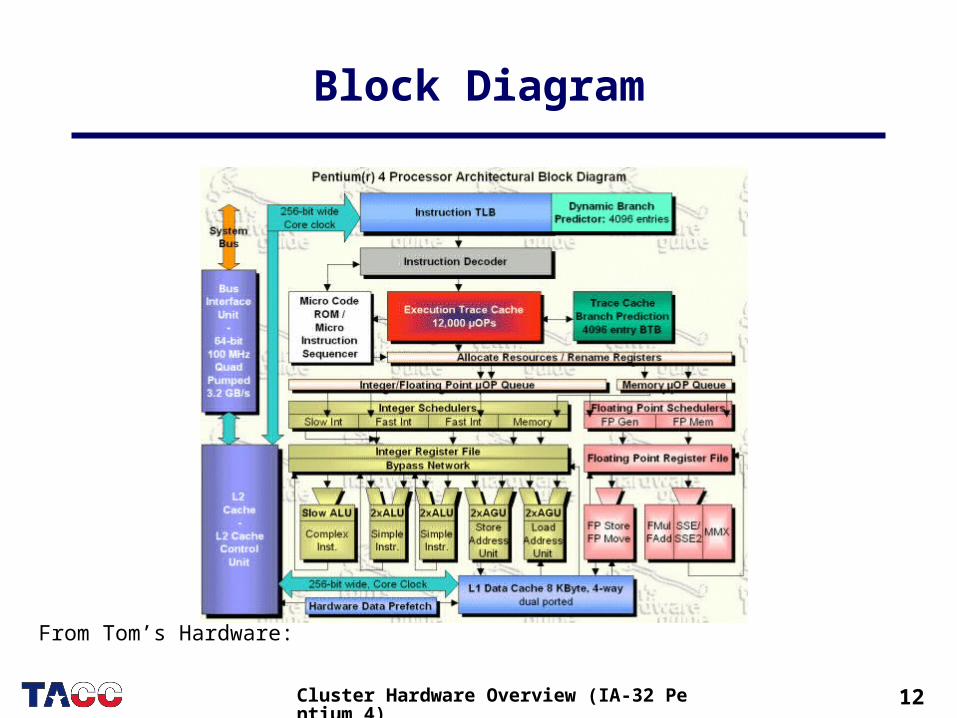
12Cluster Hardware Overview (IA-32 Pentium 4)
Block Diagram
From Tom’s Hardware:

13Cluster Hardware Overview (IA-32 Pentium 4)
Out-of-Order Execution
• Non deterministic because Out-of-Order Execution
• Stalls overcome by parallel execution, buffering, and speculation.
In Order Issue
Out of Order Execution
In Order Retirement

14Cluster Hardware Overview (IA-32 Pentium 4)
Out-of-Order Execution -- Pipeline
Fetch1
Fetch2
Decode3
Decode4
Decode5
Rename6
ROB Rd7
Rdy/Sch8
Dispatch9
Exec10
TC Fetch1
Drive Rename Que Sch Disp FR Flgs Drive2
TC Fetch3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Alloc Sch Sch Disp FR BrCkEx
Pentium III processor misprediction pipeline
Pentium 4 processor misprediction pipeline

15Cluster Hardware Overview (IA-32 Pentium 4)
Pentium 4 Speeds & Feeds
L1 DataRegs.
W PF Word (64 bit) Int Integer (64 bit)CP Clock Period
Memory
4 W CP
8KBL2
1 W (load) CP
1 W 6 CP
@400MHz FSB 2.4GHz CPU PC800 RDRAM
2 CP
~4 CP(3uops/CP stream)
Latencies
TraceCache
Exec
1 W (store) CP
2-7 CP ~90 CP
Line size L1/L2 =8/16/ W
256/512KB
32B wide
on die
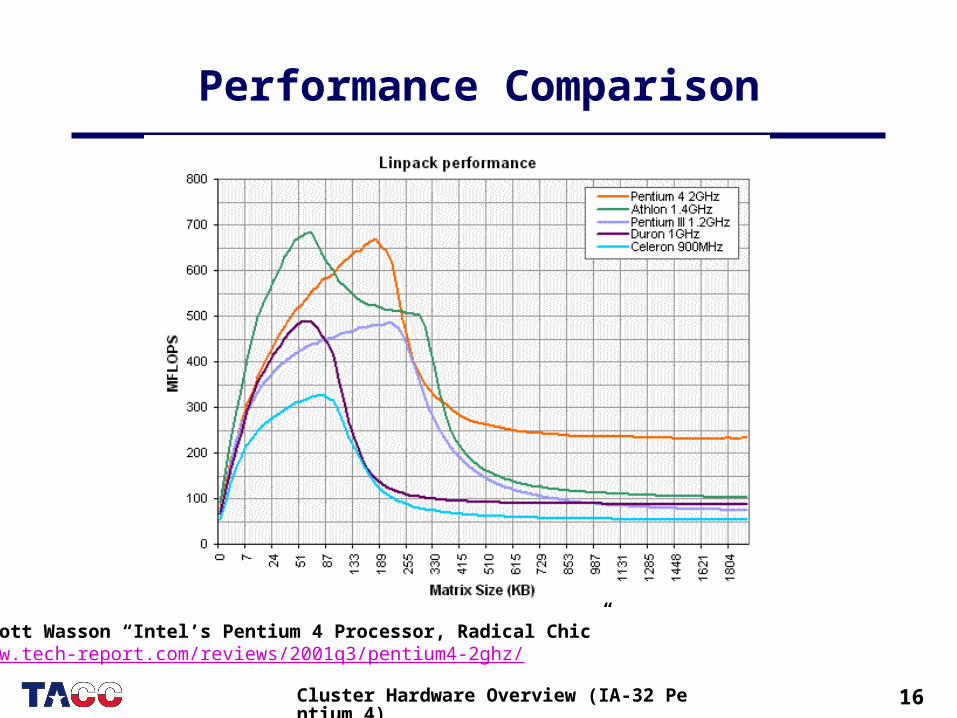
16Cluster Hardware Overview (IA-32 Pentium 4)
Performance Comparison
Scott Wasson “Intel’s Pentium 4 Processor, Radical Chic”www.tech-report.com/reviews/2001q3/pentium4-2ghz/
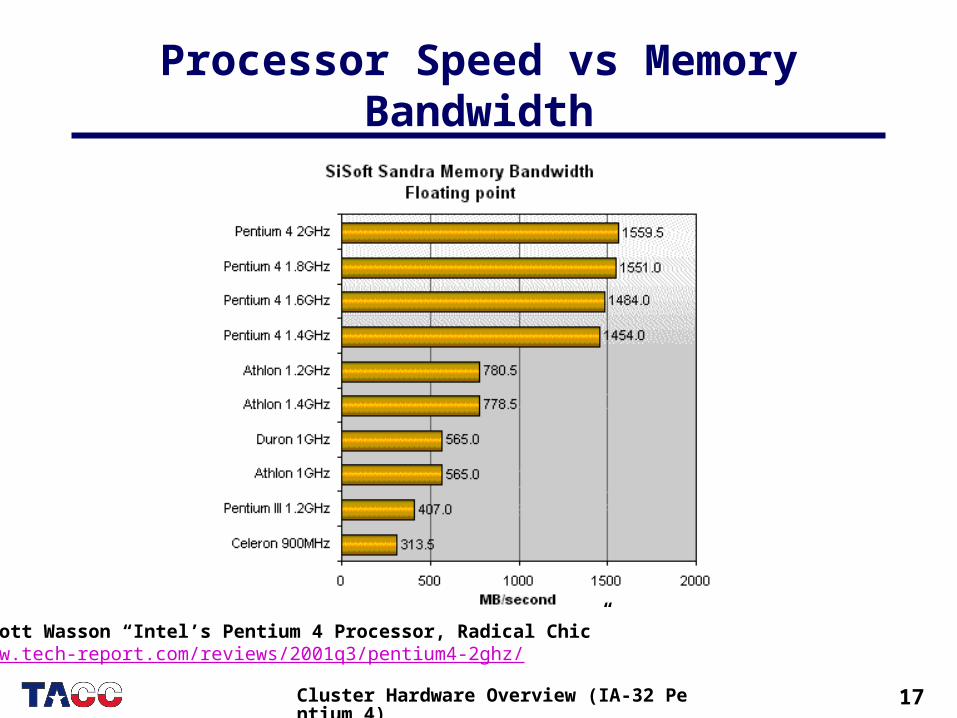
17Cluster Hardware Overview (IA-32 Pentium 4)
Processor Speed vs Memory Bandwidth
Scott Wasson “Intel’s Pentium 4 Processor, Radical Chic”www.tech-report.com/reviews/2001q3/pentium4-2ghz/
18Cluster Hardware Overview (IA-32 Pentium 4)
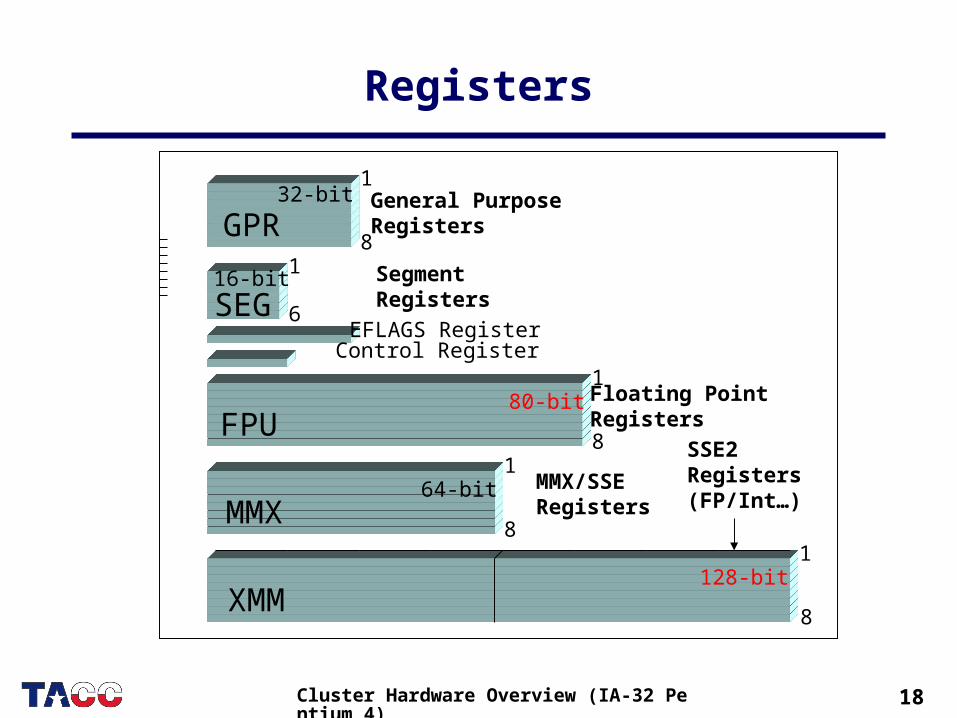
Registers
1
GPR
SEG
MMX
8
64-bit
32-bit
16-bit
XMM
FPU80-bit
128-bit1
1
1
1
6
8
8
8
General Purpose Registers
Segment Registers
Floating PointRegisters
MMX/SSERegisters
SSE2Registers(FP/Int…)
EFLAGS RegisterControl Register
19Cluster Hardware Overview (IA-32 Pentium 4)
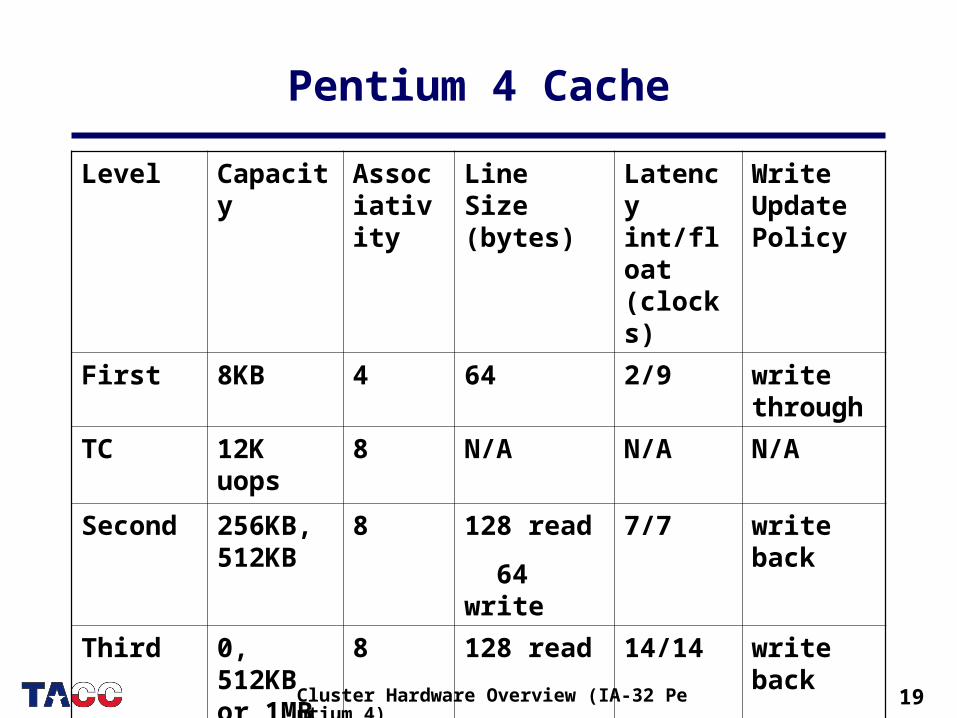
Pentium 4 Cache
Level Capacity Associativity
Line Size (bytes)
Latency int/float (clocks)
Write Update Policy
First 8KB 4 64 2/9 write through
TC 12K uops
8 N/A N/A N/A
Second 256KB, 512KB
8 128 read
64 write
7/7 write back
Third 0, 512KB or 1MB
8 128 read
64 write
14/14 write back

20Cluster Hardware Overview (IA-32 Pentium 4)
SIMD
• Beginning with Pentium II SIMD Technology was integrated into the Hardware & Instruction Set. SSE2was implemented in Pentium 4.
Instructions PackedData
RegistersMXM 64-bit
RegistersXMM 128bit
APPS
MMX INTB,W,Q
Yes --- Imaging, MM, comm.
SSE SP Float Yes --- 3-D geo/renderingvideo en/decode
SSE2 INT, SP/DPFloat
Yes Yes 4-D graphicsScientific Comp
• Intel Hyper-Threading TechnologyUse OpenMP pragmas & Directives with Intel Compiler.Higher Performance realized with Multi-Entry Threading (MET)

21Cluster Hardware Overview (IA-32 Pentium 4)
Compiler Design “all for one” with SIMD
C++/C Front End Fortran 95 Front End
Code Restructuring & IPO
OpenMP/AutomaticParallelization & Vectorization
HLO & Scalar Opt.
Lower Level Code Gen. & Optimization
IA-32 IA-64
outlining
Multi-EntryThreading
Uses guide-based multi-threaded run-time libraryfrom Intel KAI Software Laboratory (KSL)
22Cluster Hardware Overview (IA-32 Pentium 4)
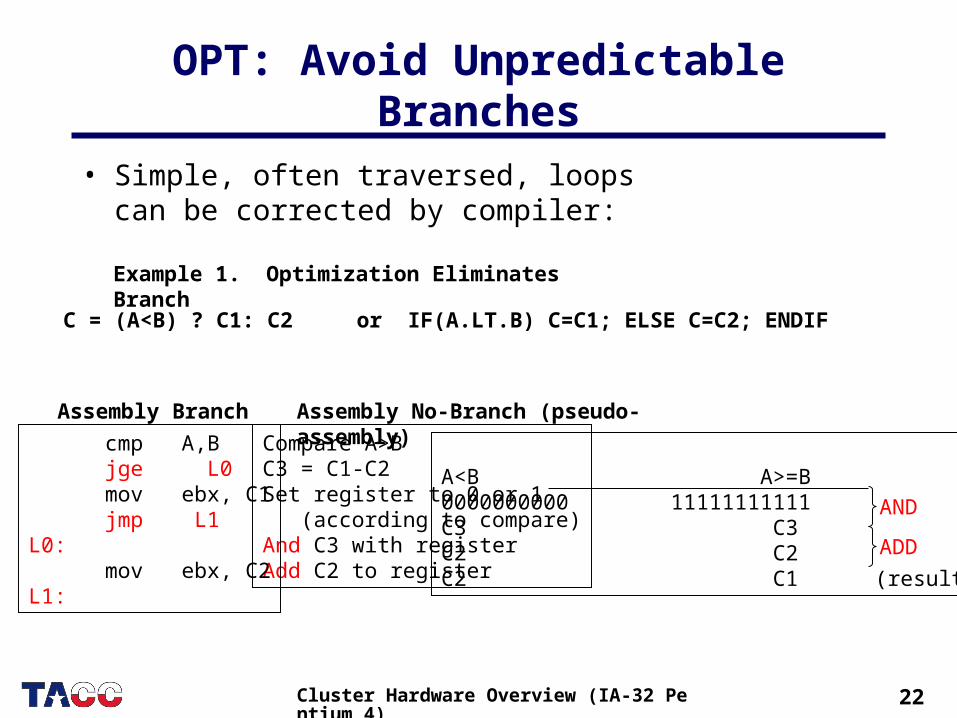
OPT: Avoid Unpredictable Branches
• Simple, often traversed, loops can be corrected by compiler:
C = (A<B) ? C1: C2 or IF(A.LT.B) C=C1; ELSE C=C2; ENDIF
Compare A>BC3 = C1-C2Set register to 0 or 1 (according to compare)And C3 with registerAdd C2 to register
A<B A>=B0000000000 11111111111C3 C3C2 C2C2 C1 (result)
AND
ADD
Example 1. Optimization Eliminates Branch
cmp A,B jge L0 mov ebx, C1 jmp L1L0: mov ebx, C2L1:
Assembly Branch Assembly No-Branch (pseudo-assembly)

23Cluster Hardware Overview (IA-32 Pentium 4)
OPT: Make code consistent with static prediction algorithm
• Predict backward conditional branches to be taken (loops).
• Predict forward conditional branches to be NOT taken.
• Predict indirect branches to be NOT taken.
If <condition>{…}for <condition>{…}
loop{…}<condition>
Forward Conditional branches not taken (fall through)
Backward Conditional branches taken

24Cluster Hardware Overview (IA-32 Pentium 4)
OPT: Make code consistent with static prediction algorithm
• Inline functions with branch structure: A mispredicted branch can lead to larger performance penalties inside a small function than if that function is inlined
• Be careful not to increase “working set” beyond what will fit in the trace cache.
• Indirect branches degrade performance if they are non-predictable. (switches, computed GOTOs, call through pointers)

25Cluster Hardware Overview (IA-32 Pentium 4)
OPT: Unrolling
• If loop count is small, unroll Pentium 4 code so that only up to 16 iterations are performed. They will all be predicted. (Only 4 suggested for PII and PIII.)
• Other concerns: registers, working set size in trace cache, and prefetching may be more important.
OPT: Memory
• Inappropriate Alignment and Forwarding are the sources of large delays.

26Cluster Hardware Overview (IA-32 Pentium 4)
OPT: General Optimization Concerns
• Instruction Decoding is less important(than with Pentium III)
• Some Latencies of simple arithmetic ops have decreased (2x faster local clock)
• Memory latency hiding is better. (Hardware Prefetching)
• New Cacheability Instructions (streamline stores and manage cache usage)
• Fewer prefetches required. (64-byte cache lines compared to 32-bytes (PII, PIII); but false sharing more important.
• L2 code misses should be less. (Trace Cache is used in lieu of L1 code cache.

27Cluster Hardware Overview (IA-32 Pentium 4)
OPT: X87/SSE2 Instructions
• Avoid changing between 3 (or more) floating-point modes. [FLDCW (mode change= precision & rounding control, etc. e.g. converting to int.] Must flush instruction pipe.
• Masked floating-point exceptions require “assistance” from slower microcode operations to handle masked exception. Avoid propagation of overflow, underflow and denormalized operands.

28Cluster Hardware Overview (IA-32 Pentium 4)
OPT: X87/SSE2 Instructions
• Set mode to convert underflows to zero (FTZ mode).
• Set mode to convert denormalized floats to zero (DAZ mode).
-- Use FTZ and DAX when speed is important and a slight loss in precision is acceptable.

29Cluster Hardware Overview (IA-32 Pentium 4)
References
• http://www.tomshardware.com/
• http://www.myri.com
• http://www.serverworks.com
• http://developer.intel.com/design/pentium4/manuals/index2.htm
• http://www3.sk.sympatico.ca/jbayko/cpu.html


























