Embed Size (px)
Citation preview

© 2016 Imperva, Inc. All rights reserved.
Clustering of Web AttacksA Walk Outside the Lab
• Gilad Yehudai
@imperva

© 2016 Imperva, Inc. All rights reserved.
> gilad.history<· [“Math”,”Machine learning”] > gilad.employer<· “Imperva”> gilad.positonX<· “Security researcher”> gilad.social<· {“TWT”: “@Giladude”, “LNK”: “Gilad Yehudai”}> gilad.hobbies<· [“Cinema”, “Snooker”]

© 2017 Imperva, Inc. All rights reserved.
Agenda
• Why is it good?
• Our solution
• Results!
© 2017 Imperva, Inc. All rights reserved.
Web Application Firewall (WAF)
© 2017 Imperva, Inc. All rights reserved.
IP Attack Type Target URL Country
15.6.99.154 Remote Code execution /index.php Spain
212.5.224.98 Comment spam /news/culture/comments Russia
159.36.17.3 Remote Code execution /index.php Italy
83.31.15.251 Remote File Inclusion \phpmyadmin\scripts\setup.php China
178.130.2.14 Comment spam /news/health/comments Russia
165.32.9.17 Remote Code execution /index.php United States
5.101.255.255 Comment spam /news/technology/comments Russia
83.31.15.95 Remote Code execution /robots.txt China
91.149.64.56 Comment spam /news/politics/comments Russia
81.95.128.41 Comment spam /news/fnancial/comments Russia
129.12.63.25 Remote Code execution /index.php United kingdom
83.31.15.45 Cross-Site scripting /news/javascript:alert(0) China
83.31.15.26 SQL injection /wp-confgs China
Scanner from China. Single subnet
Comment spam from Russian
Remote code execution on /index.php

© 2017 Imperva, Inc. All rights reserved.

© 2017 Imperva, Inc. All rights reserved.

© 2017 Imperva, Inc. All rights reserved.
Clustering Points in the Plane

© 2017 Imperva, Inc. All rights reserved.
Clustering Algorithms – Basic Ingredients
• Input data
• Distance between two data points
• Choosing an algorithm

© 2017 Imperva, Inc. All rights reserved.
The Raw Data
• HTTP \ HTTPS request
POST /doc/test.html HTTP/1.1Host: www.test101.comAccept: text/htmlAccept-Language: en-usAccept-Encoding: gzip, deflateUser-Agent: Mozilla/4.0 DeepSecContent-Length: 35
bookId=1234&author=Tan+Ah+Teck
Method, URL, Protocol
Headers
Parameters

© 2017 Imperva, Inc. All rights reserved.
The Raw Data
• Additional Data:
– Source IP
– Attack type
– Time
– Attacked application

© 2017 Imperva, Inc. All rights reserved.
Data Enrichment

© 2017 Imperva, Inc. All rights reserved.
Data Enrichment - All About The IP
• What extra features can we extract from the source IP?

© 2017 Imperva, Inc. All rights reserved.
Data Enrichment - The URL is Greater Than the Sum of its Parts
• What extra features can we extract from the URL?

© 2017 Imperva, Inc. All rights reserved.
Distance Between Attacks
©bigstockphoto.com/First Bite

© 2017 Imperva, Inc. All rights reserved.
Distance between attacks
• Things to consider:
– Each feature gets its own distance measure
– Normalization
– Correlation (we’ll discuss it later)

© 2017 Imperva, Inc. All rights reserved.
Distance Between Strings
• Levenshtein distance
• Resource extension:
– Is “CSS” closer to “CSV” then to “HTML” ?
URL1 URL2 Distance/pictures/cat.jpg /pictures/dog.jpg 3

© 2017 Imperva, Inc. All rights reserved.
Discrete Distance
• Works well for certain strings
• Weighted discrete distance
•
© 2017 Imperva, Inc. All rights reserved.
Distance Between IPs
• IP as geo-location (coordinates)
Source: Google Maps

© 2017 Imperva, Inc. All rights reserved.
Distance Between IPs
• IP as a 32-dimensional data (IPV4)
– IP1 = 11001011100001000011111101110101– IP2 = 11001100101010101010110100101011
– Works better then the geo-location version!
•

© 2017 Imperva, Inc. All rights reserved.
Dealing With Correlation

© 2017 Imperva, Inc. All rights reserved.
Context Dimensions

© 2017 Imperva, Inc. All rights reserved.
Context Dimensions
• All the correlation is contained within each dimension
• No correlation between dimensions
• Total distance is a weighted sum of the distances

© 2017 Imperva, Inc. All rights reserved.
Clustering in Streaming Mode
© 2017 Imperva, Inc. All rights reserved.
Batch VS. Streaming
Clustering
Batch clustering Streaming clustering
© 2017 Imperva, Inc. All rights reserved.
Clustering in Streaming Mode
• Limited amount of memory
• Decisions in real time
• Ability to undo decisions

© 2017 Imperva, Inc. All rights reserved.
Clustering in Streaming Mode - Our Solution
• Store aggregated data (statistics)
• Undoing decisions based on aggregations
• Tradeoff between accuracy and performance

Results

Attacks on Apache Struts Vulnerabilities
Attacks on Apache Struts Vulnerabilities
Size IP User-Agent Country Region Attack
1 222.246.183.132 Auto Spider 1.0 China Hunan CVE-2017-5638Apache Struts Jakarta multiparcer RCE
5 219.132.74.62Auto Spider 1.0 China
Guangdong CVE-2016-3081: Apache Struts Code Execution
8 139.224.52.189Auto Spider 1.0 China
ZheijangCVE-2017-5638
Apache Struts Jakarta multiparcer RCE
1 223.74.235.37Auto Spider 1.0 China
Guangdong CVE-2013-2251:Apache Struts Code Execution
7 103.37.124.137Auto Spider 1.0 China
HebeiCVE-2017-5638
Apache Struts Jakarta multiparcer RCE
13 120.229.225.205Auto Spider 1.0 China
NoneCVE-2017-5638
Apache Struts Jakarta multiparcer RCE
8 27.151.13.198Auto Spider 1.0 China
Fujian CVE-2013-2251:Apache Struts Code Execution
5 183.18.125.40Auto Spider 1.0 China
GuangdongCVE-2017-5638
Apache Struts Jakarta multiparcer RCE

Size IP User-Agent URL Country
1 209.58.183.234 Microsoft WinRM Client OpenVAS /wsman Singapore
1 209.58.183.234 OPENVAS::SOAP / Singapore
1969 209.58.183.234 Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9)
Distributed Singapore

Distributed OpenVAS ScannerSize IP User-Agent URL Country
1 209.58.183.234 Microsoft WinRM Client OpenVAS /wsman Singapore
1 209.58.183.234OPENVAS::SOAP / Singapore
1969 209.58.183.234Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9) Distributed Singapore
1 196.52.38.4 Microsoft WinRM Client OpenVAS /wsman South Africa
1 196.52.38.4 OPENVAS::SOAP / South Africa
1796 196.52.38.4 Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9) Distributed South Africa
1 192.255.80.5 Microsoft WinRM Client OpenVAS /wsman US
1 192.255.80.5 OPENVAS::SOAP / US
1997 192.255.80.5 Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9) Distributed US
1 185.8.107.162 Microsoft WinRM Client OpenVAS /wsman Italy
1 185.8.107.162 OPENVAS::SOAP / Italy
2252 185.8.107.162 Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9) Distributed Italy

Additional topics
• Automatic creation / suggestion of blocking rules
• Clusters over time
• Analysis of timelines in streaming

To wrap it up…

© 2017 Imperva, Inc. All rights reserved.
@Giladude, @imperva
Thank You!
Danke schön!linkedin.com/in/gilad.yehudai

© 2016 Imperva, Inc. All rights reserved.
Clustering of Web AttacksA Walk Outside the Lab
• Gilad Yehudai
@imperva
- I will talk about using machine learning in order to cluster attacks on web applications
- Here we will discuss how we did the clustering, while having constraints related to using real data, and doing so in a real time environment where performance really mattered

© 2016 Imperva, Inc. All rights reserved.
> gilad.history<· [“Math”,”Machine learning”] > gilad.employer<· “Imperva”> gilad.positonX<· “Security researcher”> gilad.social<· {“TWT”: “@Giladude”, “LNK”: “Gilad Yehudai”}> gilad.hobbies<· [“Cinema”, “Snooker”]
- My background is mostly analytical, with experience in statistics and developing machine learning algorithms.
- I have a bachelor and master degree in mathematics.
- I work at Imperva which is a security company that have a spectrum of security products, protecting web applications and databases
- I am a researcher working on developing new products, I work on the border between web application security and machine learning
- I work as a security researcher in Imperva, what I do is mostly develop machine learning algorithms where the data is related to security – mainly web application security.

© 2017 Imperva, Inc. All rights reserved.
Agenda
• Why is it good?
• Our solution
• Results!
- I will try to convince you that clustering attacks on web application is an important task
- We’ll discuss our solution, how we did the clustering. Some of the decisions and dilemmas we had on the way
- Finally – we will see some results of the clustering

© 2017 Imperva, Inc. All rights reserved.
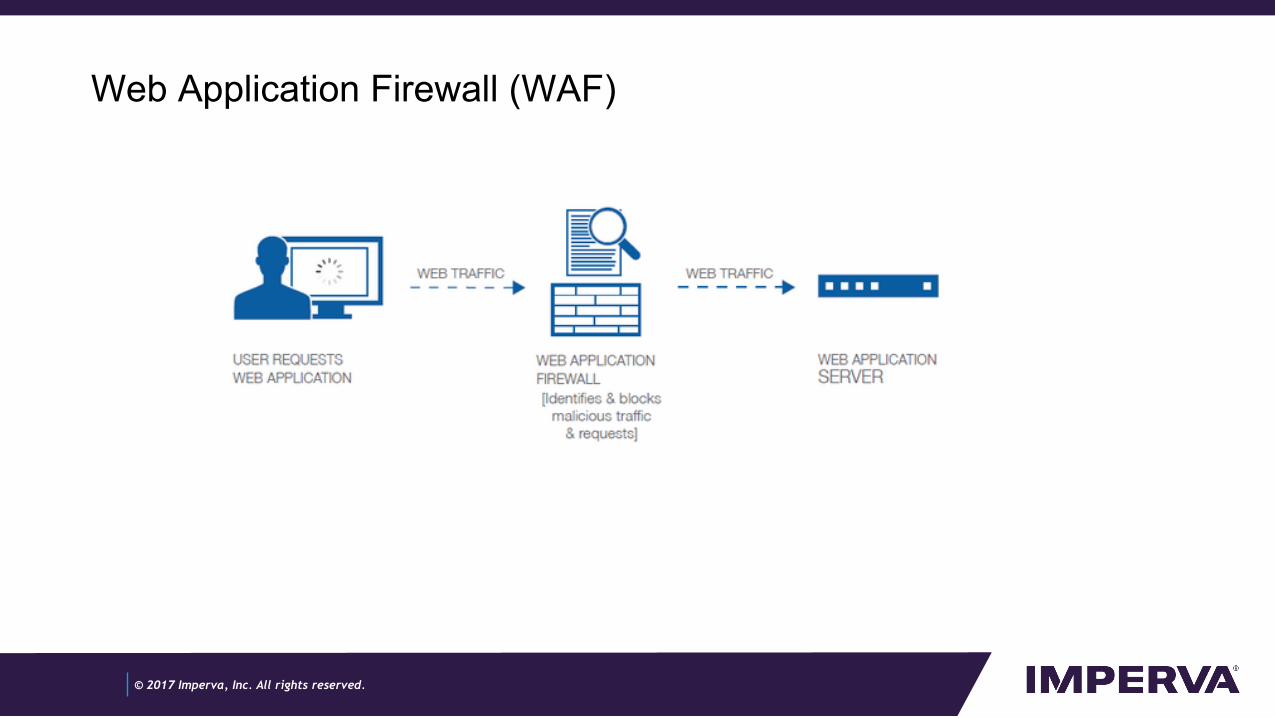
Web Application Firewall (WAF)
- Let’s talk a little bit about web application attacks and how we find them
- Web application firewall is a network component
- Each request sent by the user to the application is filtered by the firewall
- It then decides which is an attack, and stops it, and which is a legitimate request and let it through
- It also reports to the user on every attack that was found

© 2017 Imperva, Inc. All rights reserved.
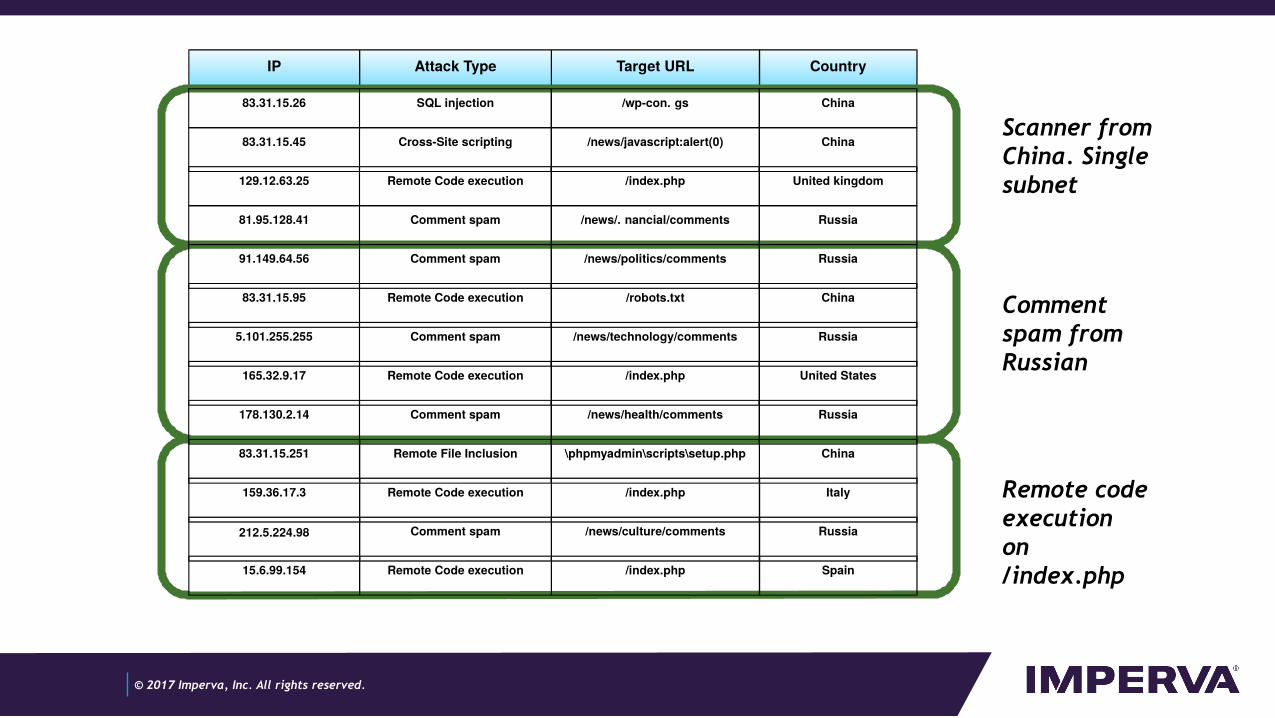
IP Attack Type Target URL Country
15.6.99.154 Remote Code execution /index.php Spain
212.5.224.98 Comment spam /news/culture/comments Russia
159.36.17.3 Remote Code execution /index.php Italy
83.31.15.251 Remote File Inclusion \phpmyadmin\scripts\setup.php China
178.130.2.14 Comment spam /news/health/comments Russia
165.32.9.17 Remote Code execution /index.php United States
5.101.255.255 Comment spam /news/technology/comments Russia
83.31.15.95 Remote Code execution /robots.txt China
91.149.64.56 Comment spam /news/politics/comments Russia
81.95.128.41 Comment spam /news/fnancial/comments Russia
129.12.63.25 Remote Code execution /index.php United kingdom
83.31.15.45 Cross-Site scripting /news/javascript:alert(0) China
83.31.15.26 SQL injection /wp-confgs China
Scanner from China. Single subnet
Comment spam from Russian
Remote code execution on /index.php
- You might find some patterns in the log- Rearranging the attacks helps find the
stories in them- 1) scanner from china doing many kinds
of attacks from the same subnet- 2) comment spammer from Russia
targeting the same URL pattern- 3) Remote code execution attack
targeting the /index.php page from a distributed origin

© 2017 Imperva, Inc. All rights reserved.
- But what if we have tens or hundreds of thousands of requests to cluster
- Each customer usually protects more than a single web application
- Each web application gets attacked for tens or hundreds of thousand times a day
- Finding the stories manually is impossible

© 2017 Imperva, Inc. All rights reserved.
- What is clustering in general?- Clustering is an area in machine
learning- The goal of clustering is to group the
data in such a way that objects in the same group are more similar to one another then to objects in other groups

© 2017 Imperva, Inc. All rights reserved.
Clustering Points in the Plane
- Clustering done for points in a 2-dimensional plane
- It is used for better analysis of the data, and finding patterns which are harder to find using manual analysis
- Clustering is a not a specific algorithm, but a general task to be solved. There are many different algorithms that do clustering.

© 2017 Imperva, Inc. All rights reserved.
Clustering Algorithms – Basic Ingredients
• Input data
• Distance between two data points
• Choosing an algorithm
- Every clustering algorithm has three basic ingredients
- First we need to decide what is the input data, it needs to be structured in order for an algorithm to process it. Our data is attacks on web applications
- Second we need to find a way to calculate distance between two data points, in our case the distance between two web application attacks
- Third, we need to decide on a clustering algorithm to use which uses the input data and the distance function and outputs clusters.

© 2017 Imperva, Inc. All rights reserved.
The Raw Data
• HTTP \ HTTPS request
POST /doc/test.html HTTP/1.1Host: www.test101.comAccept: text/htmlAccept-Language: en-usAccept-Encoding: gzip, deflateUser-Agent: Mozilla/4.0 DeepSecContent-Length: 35
bookId=1234&author=Tan+Ah+Teck
Method, URL, Protocol
Headers
Parameters
- Each HTTP request contains tons of information about the attack
- Not only what the attack is, but also about the tool, target and many hints that can be useful later on
- The data is not structured! We need to structure it in order to use it in an algorithm
- The structure is our choice, we decide what information will be useful and what is the best way to store it (for example, are all the headers important? If not which ones are?)
- Should we separate the query string and post body or treat them the same

© 2017 Imperva, Inc. All rights reserved.
The Raw Data
• Additional Data:
– Source IP
– Attack type
– Time
– Attacked application
- Since we get logs from a WAF we see additional meta data on each attack which may be very useful.
- The source IP may be a good indication on the origin of the attacker
- Every attack triggers some rule or sensor, so we usually know the kind of attack
- The time of the attack can be used to do timeline analysis of the attacks
- Sometimes we have extra information about the attacked application which may be useful. For example, which systems\servers they use, in what field that customer is (banking or financial\ healthcare \ online store etc.)
© 2017 Imperva, Inc. All rights reserved.
Data Enrichment
- The enrichment process is the part where we take the raw data, structure it in the form that fits the algorithm, and also add features to it based on our domain knowledge of the data
- In classic machine learning (before deep learning) finding the right features out of the data is one of the most important aspects of an algorithm
- Using domain knowledge we can take a single feature, like IP or URL and extract from it many other features that may be useful later

© 2017 Imperva, Inc. All rights reserved.
Data Enrichment - All About The IP
• What extra features can we extract from the source IP?
- The IP may indicate on the source of the attack
- Class C works best in our experiments, Class B+A are too general, and the ASN covers them better
- Geo location can be extracted from outside sources (we use maxmind). Note that it is not always accurate, and may change over time. Also different providers sometimes say different things
- City and coordinates was to low resolution on our experiments, it was better to use a combination of country and region (region being state in the US for example, or county in other places. China is huge where different counties may be far apart)
- Sometimes (well many times) attackers hide their actual IP, so all the other features in this case won’t matter. But what we saw, is that when attackers use some kind of anonymity framework (like TOR, proxy, anonymous proxies) they keep attacking using that same network. So the kind of anonimyty framework matters a lot in that case, although it is a weaker feature than geo-location for example

© 2017 Imperva, Inc. All rights reserved.
Data Enrichment - The URL is Greater Than the Sum of its Parts
• What extra features can we extract from the URL?
- The URL may indicate the target of the attack
- Sometimes attackers try to target a specific resource (whether it’s a php, html or jpg pages)
- Many web application have patterns in URL (/news/politics/article-name) attackers who scan the web site target different URLs that have the same pattern
- Attackers try to inject different code snippets into the URLs. By cleaning the injected code we can find a pattern in the URL. Here by deleting everything after the colon we get the same URL.
- The URL may indicate on the target system. URL for wordpress application for example wp-config. Internal apache URLs

© 2017 Imperva, Inc. All rights reserved.
Distance Between Attacks
©bigstockphoto.com/First Bite
- It is very easy to calculate distances between two points in a plane. It is also possible to do it in an n-dimensional space
- Our data is much more complex – not obvious how to calculate distance between two web application attacks
- In many algorithms, the goal of the feature selection is to embed the features in a Euclidean plane, and then use regular methods to calculate distance. In our case it is not clear how to embed features like URL or header signature to a plane.

© 2017 Imperva, Inc. All rights reserved.
Distance between attacks
• Things to consider:
– Each feature gets its own distance measure
– Normalization
– Correlation (we’ll discuss it later)
- We need to consider a couple of things when deciding on the distance measure
- Each feature needs to get its own distance function. The same function may work well on one feature and badly on another
- We need to normalize all the distances to be on the same scale. Example: one feature distance 0-1 and another 0-100. It is usually a good practice to choose distance measures that are easy to normalize.
- Some of our feature are correlated (same IP indicates same city, region, ASN etc.) this in general is bad in machine learning algorithms and we want to avoid it. We will discuss how to deal with the correlation later

© 2017 Imperva, Inc. All rights reserved.
Distance Between Strings
• Levenshtein distance
• Resource extension:– Is “CSS” closer to “CSV” then to “HTML” ?
URL1 URL2 Distance/pictures/cat.jpg /pictures/dog.jpg 3
- We have many strings in our data – URL being one of the most notable.
- Levenshtein distance is a good method for calculating distance between URLs.
- Explain how it works – number of single character edits: deletion, insertion, substitution
- Hamming also works for strings and is a very popular and known distance measure – in our experiments Levenshtein was better

© 2017 Imperva, Inc. All rights reserved.
Discrete Distance
• Works well for certain strings
• Weighted discrete distance
•
- Discrete distance works for all kinds of data
- Very easy, already normalized and works extremely well for several features.
- We may lose some info (or accuracy) using this distance measure, but sometimes it is OK to do so
- Every string or edit related distance will work not that well on the resource extension – for css-csv reason
- Weighted distance works well for related features – country + region + city each gets a different weight

© 2017 Imperva, Inc. All rights reserved.
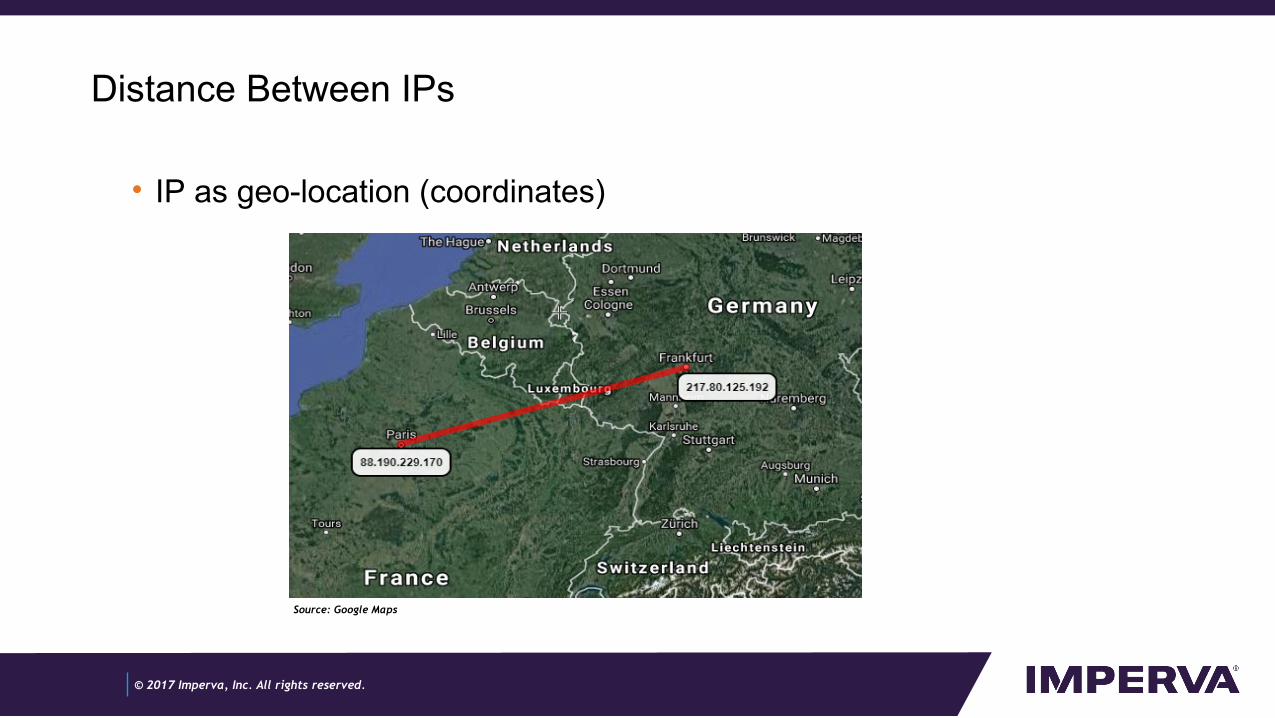
Distance Between IPs
• IP as geo-location (coordinates)
Source: Google Maps
- We know the exact coordinates of an IP using geo-location, so we can calculate the real distance from the two Ips.
- This doesn’t work that well – problems are IPs close to the border, big countries (China, Russia). Geo-location not always accurate – different providers may give different location

© 2017 Imperva, Inc. All rights reserved.
Distance Between IPs
• IP as a 32-dimensional data (IPV4)
– IP1 = 11001011100001000011111101110101– IP2 = 11001100101010101010110100101011
– Works better then the geo-location version!
•
- Each IP is represented in 32-bits (each number between 0-255 is 8 bits and there are four numbers)
- The distance is to look at the mutual prefix from the left, normalize by 1 over 32 and do 1 minus the result to get a distance function.
- This works much better than the 4-dimensional version. Easy to normalize and interpret!
© 2017 Imperva, Inc. All rights reserved.
Dealing With Correlation
- Correlation is a big problem in machine learning algorithms. Having a single mutual feature might mean having many mutual features (which are extracted from that single feature)
- By correlation I mean correlation of the features – where two features are correlated
- For example – The IP is correlated to the country or region. The URL is correlated to the URL extension
- Methods to deal with it – feature selection (throwing away some of the correlated features) won’t work for us. We use all the features.

© 2017 Imperva, Inc. All rights reserved.
Context Dimensions
- Our method to deal with correlation – separate all the feature into what we called “context dimension”
- Each dimension represent a single context of the attack.
- For example, the origin dimension includes all the features that may indicate on the origin.
- Each features is inside exactly one dimension

© 2017 Imperva, Inc. All rights reserved.
Context Dimensions
• All the correlation is contained within each dimension
• No correlation between dimensions
• Total distance is a weighted sum of the distances
- There are a couple of advantages using this method
- There is still correlation, but all of it is inside the dimensions.
- Between the dimensions there is no correlation.
- We calculate the distance inside each dimension, and the total distance is a weighted sum of those distances, we can control better which aspects of the attacks have a heavier weight in the distance.
- For example we saw in our experiments that the target dimension have less impact than the attack type and origin dimensions.

© 2017 Imperva, Inc. All rights reserved.
Clustering in Streaming Mode
- Now we will discuss the final part that glue it all together - choosing the right clustering algorithm.
- We got a restriction from our engineering department - the clustering must be done in streaming mode.
- There is too much data to be stored into datasets (at least when dealing with data from all the customers)
- Every time an attack happens, it must be clustered and then thrown away.
- As opposed to batch where we get all the data in the beginning

© 2017 Imperva, Inc. All rights reserved.
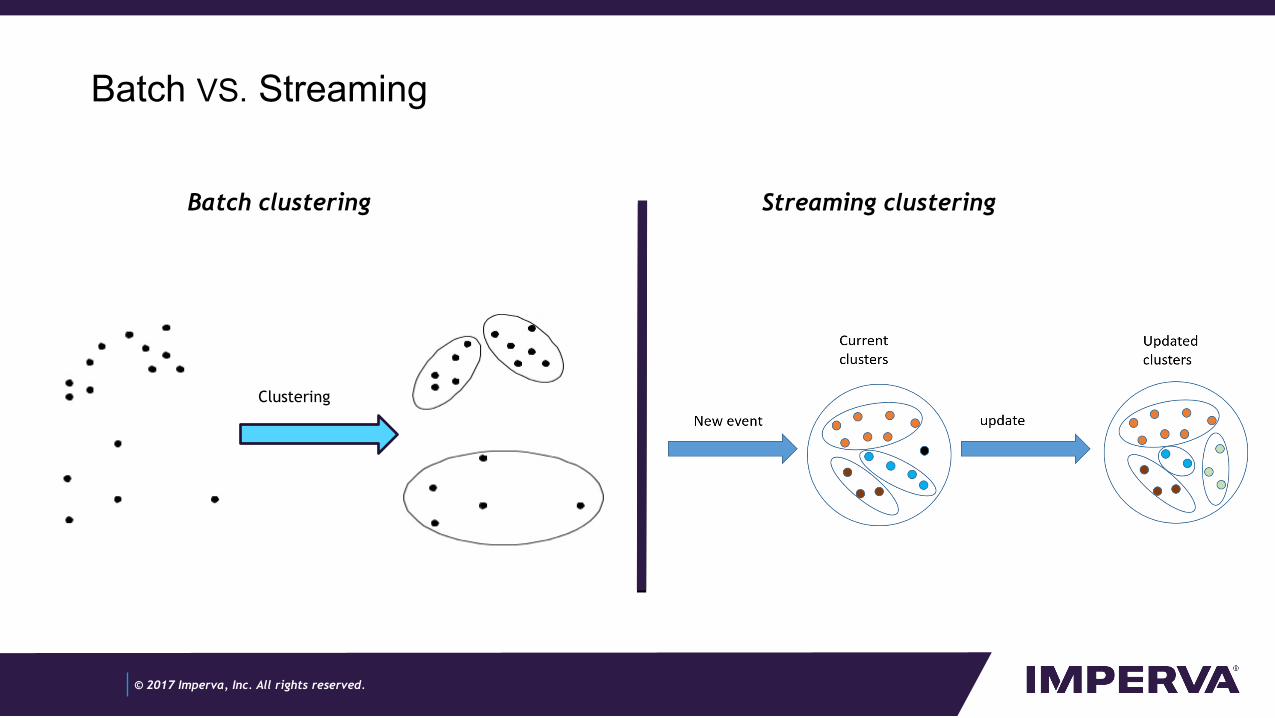
Batch VS. Streaming
Clustering
Batch clustering Streaming clustering
- In batch clustering (to your left) we get all the data in the beginning, and output the clusters.
- In streaming, we have a clustering state based on the data we have until now. A new attack enters the system, and we update the cluster state based on this attack
- Cluster may split, attacks may move from one cluster to another and clusters may merge.

© 2017 Imperva, Inc. All rights reserved.
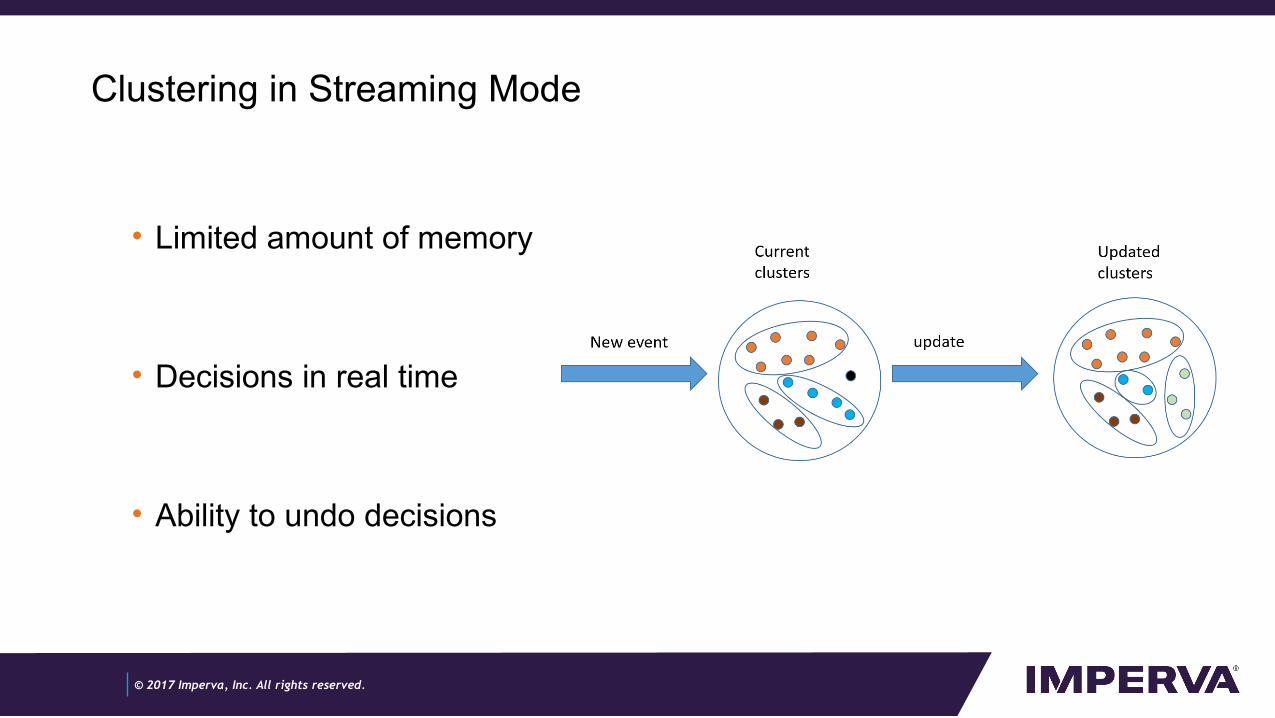
Clustering in Streaming Mode
• Limited amount of memory
• Decisions in real time
• Ability to undo decisions
- Picture demonstrating clustering in streaming - an event enter the system and may change the current state of the clustering
- In streaming there is a very limited amount of memory - we can’t store all the events
- The decisions that the algorithm makes must be in real time, an event that enters the system must be clustered somehow (or create a new cluster), an event can’t be kept hanging in the air.
- In streaming we only see the past events, as opposed to batch where we see all the events. Hence our decision is made based only on partial data. We need to have the ability to undo these decisions, meaning that an event need to be able to exit a narrative it was in.

© 2017 Imperva, Inc. All rights reserved.
Clustering in Streaming Mode - Our Solution
• Store aggregated data (statistics)
• Undoing decisions based on aggregations
• Tradeoff between accuracy and performance
- Picture demonstrating clustering in streaming - an event enter the system and may change the current state of the clustering
- In streaming there is a very limited amount of memory - we can’t store all the events
- The decisions that the algorithm makes must be in real time, an event that enters the system must be clustered somehow (or create a new cluster), an event can’t be kept hanging in the air.
- In streaming we only see the past events, as opposed to batch where we see all the events. Hence our decision is made based only on partial data. We need to have the ability to undo these decisions, meaning that an event need to be able to exit a narrative it was in.

Results
- We tested the algorithm on real data of web application attacks.
- Each dataset contained attacks on a single customer from a timeframe of around two days.

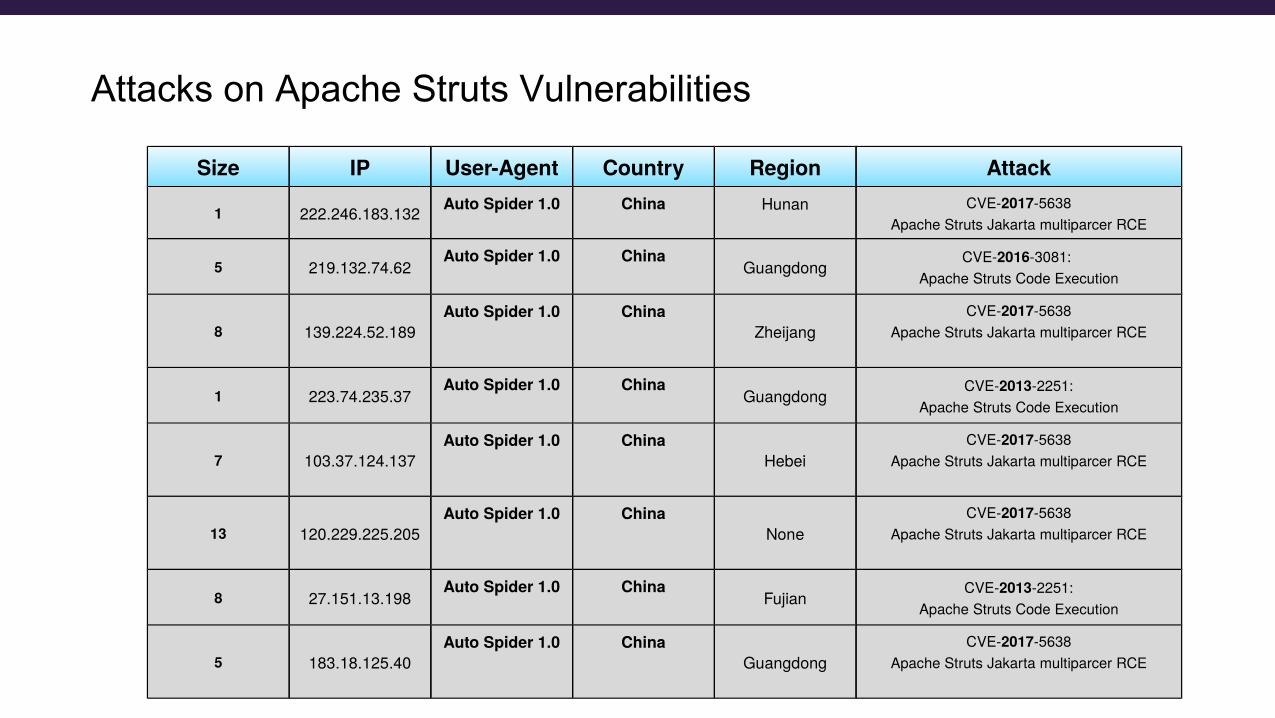
Attacks on Apache Struts Vulnerabilities
- Apache Struts is a popular framework for developing web applications
- Over the years many vulnerabilities of apache struts were released, mostly related to remote code execution attacks

Attacks on Apache Struts Vulnerabilities
Size IP User-Agent Country Region Attack
1 222.246.183.132 Auto Spider 1.0 China Hunan CVE-2017-5638Apache Struts Jakarta multiparcer RCE
5 219.132.74.62Auto Spider 1.0 China
Guangdong CVE-2016-3081: Apache Struts Code Execution
8 139.224.52.189Auto Spider 1.0 China
ZheijangCVE-2017-5638
Apache Struts Jakarta multiparcer RCE
1 223.74.235.37Auto Spider 1.0 China
Guangdong CVE-2013-2251:Apache Struts Code Execution
7 103.37.124.137Auto Spider 1.0 China
HebeiCVE-2017-5638
Apache Struts Jakarta multiparcer RCE
13 120.229.225.205Auto Spider 1.0 China
NoneCVE-2017-5638
Apache Struts Jakarta multiparcer RCE
8 27.151.13.198Auto Spider 1.0 China
Fujian CVE-2013-2251:Apache Struts Code Execution
5 183.18.125.40Auto Spider 1.0 China
GuangdongCVE-2017-5638
Apache Struts Jakarta multiparcer RCE
- The attacks here came from the same tool, auto spider 1.0 and all came from China
- Although the Ips are quite different and these are different regions in China which are far away from one another
- The attacks are all trying to use vulnerabilities of Apache struts, although the attack vectors themselves are different
- There are CVEs from 2017, 2016, 2013, different vectors of the same targeted system

Size IP User-Agent URL Country
1 209.58.183.234 Microsoft WinRM Client OpenVAS /wsman Singapore
1 209.58.183.234 OPENVAS::SOAP / Singapore
1969 209.58.183.234 Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9)
Distributed Singapore
- OpenVAS is a vulnerability scanner.- The way it works is by trying to open a
session by sending couple of single requests from the first two user agents, and after that launching the real attack with around 2K attacks from the third user agent
- A story can capture the way method that an attack is launched

Distributed OpenVAS ScannerSize IP User-Agent URL Country
1 209.58.183.234 Microsoft WinRM Client OpenVAS /wsman Singapore
1 209.58.183.234OPENVAS::SOAP / Singapore
1969 209.58.183.234Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9) Distributed Singapore
1 196.52.38.4 Microsoft WinRM Client OpenVAS /wsman South Africa
1 196.52.38.4 OPENVAS::SOAP / South Africa
1796 196.52.38.4 Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9) Distributed South Africa
1 192.255.80.5 Microsoft WinRM Client OpenVAS /wsman US
1 192.255.80.5 OPENVAS::SOAP /US
1997 192.255.80.5 Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9) DistributedUS
1 185.8.107.162 Microsoft WinRM Client OpenVAS /wsmanItaly
1 185.8.107.162 OPENVAS::SOAP/ Italy
2252 185.8.107.162 Mozilla/5.0 [en] (X11, U; OpenVAS 8.0.9) DistributedItaly
- This attack is actually much larger- This story captured 45K attacks from
around 15 different countries- All the attacks are launched in the same
method- This is a very targeted attack, doing that
for a single customer over a period of less than two days

Additional topics
• Automatic creation / suggestion of blocking rules
• Clusters over time
• Analysis of timelines in streaming
- Some additional topics that we haven’t talked about here but are worth to mention
- 1) Maybe if there is an interesting narrative we can use in order to create a new blocking rule
- For example, block based on the tool and the target
- 2) Maybe we can see a pattern by looking at clusters over a longer period of time
- For example, same cluster over a couple of days
- 3) How to do analysis of timelines in streaming

To wrap it up…
- We talked about why clustering attack makes analysis better and much easier
- It also helps finding pattern and stories in the data that may be hard to find using manual analysis
- We showed in general lines our solution, and some of the decisions we have to make on the way (choosing the right way to enrich the data, choosing a distance function for each feature etc.)
- This field of research (of clustering attacks) is broad and there are many new things to try and discover.

© 2017 Imperva, Inc. All rights reserved.
@Giladude, @imperva
Thank You!
Danke schön!linkedin.com/in/gilad.yehudai
Fēicháng g nxiè nǎ ǐFey Chong Gun Shee Neen





























