Embed Size (px)
Citation preview

Clustering on Intel MIC with Huge Datasets
Andreas BauerGregor DaißMax Franke
June 26, 2015
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 1 / 18
Einleitung
Clustering: Gruppierung zusammengehoriger Datenpunkte
Implementierung des Clustering-Algorithmus von Pehersdorfer et al.
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 2 / 18
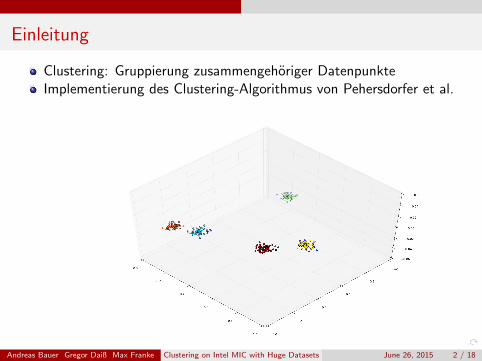
Einleitung
Clustering: Gruppierung zusammengehoriger DatenpunkteImplementierung des Clustering-Algorithmus von Pehersdorfer et al.
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 2 / 18

Die Daten
Wetter- und Solardaten
Stuttgart, Nikosia, Kairo
Dezember 2006 – November 2014, jede Sekunde
241 Sensoren, 30 Solarmodule, 2.5TB
Nur Stuttgart
Nur 111 Sensoren uber 13 Module, 1TB
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 3 / 18

Die Daten
Wetter- und Solardaten
Stuttgart, Nikosia, Kairo
Dezember 2006 – November 2014, jede Sekunde
241 Sensoren, 30 Solarmodule, 2.5TB
Nur Stuttgart
Nur 111 Sensoren uber 13 Module, 1TB
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 3 / 18
Resultate
1TB⇒ 100GB∼90% Einsparung
Abfragen: 4–12h ⇒ 10ms–50min
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 4 / 18
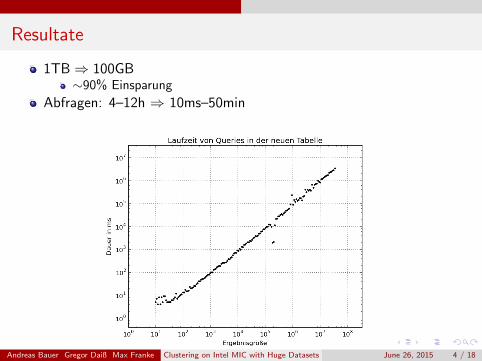
Resultate
1TB⇒ 100GB∼90% Einsparung
Abfragen: 4–12h ⇒ 10ms–50min
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 4 / 18
Datensatzgenerierung
Wahl der Sensoren
Wahl der Jahreszeit
Wahl der Uhrzeit
Datensatzgroße
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 5 / 18

Datensatzgenerierung
Wahl der Sensoren
Wahl der Jahreszeit
Wahl der Uhrzeit
Datensatzgroße
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 5 / 18
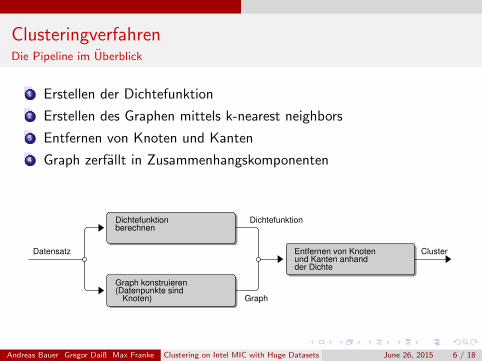
ClusteringverfahrenDie Pipeline im Uberblick
1 Erstellen der Dichtefunktion
2 Erstellen des Graphen mittels k-nearest neighbors
3 Entfernen von Knoten und Kanten
4 Graph zerfallt in Zusammenhangskomponenten
Dichtefunktionberechnen
Dichtefunktion
Datensatz Entfernen von Knotenund Kanten anhandder Dichte
Cluster
Graph konstruieren(Datenpunkte sind
Knoten) Graph
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 6 / 18
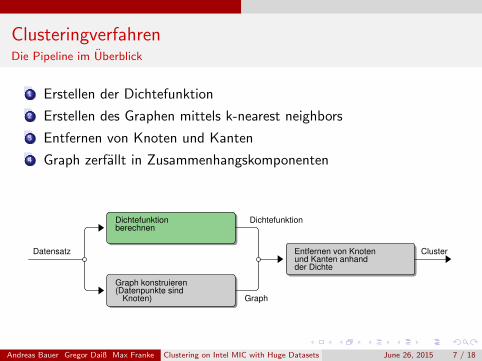
ClusteringverfahrenDie Pipeline im Uberblick
1 Erstellen der Dichtefunktion
2 Erstellen des Graphen mittels k-nearest neighbors
3 Entfernen von Knoten und Kanten
4 Graph zerfallt in Zusammenhangskomponenten
Dichtefunktionberechnen
Dichtefunktion
Datensatz Entfernen von Knotenund Kanten anhandder Dichte
Cluster
Graph konstruieren(Datenpunkte sind
Knoten) Graph
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 7 / 18

ClusteringverfahrenSchatzung der Dichte
Die Dichteschatzung u wird mittels eines dunnen Gitters erstellt:
Gitter
X1,1
X2,1 X2,3
Basisfunktionen
f (~x) ≈ u(~x) =∑i
αiϕi
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 8 / 18

ClusteringverfahrenSchatzung der Dichte
Ansatz zur Bestimmung von α nach Hegland:
R(u) =
∫Ω
(u(x)− fε)2 + λ
∫Ω
(Su(x))2
R(u) −−−−→u in V
min!
Man erhalt nun ein LGS, das nach α aufzulosen ist (zum Beispiel perCG-Verfahren).Mit diesem α erzeugen wir auf dem dunnen Gitter direkt dieDichtefunktion.
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 9 / 18

ClusteringverfahrenSchatzung der Dichte
Ansatz zur Bestimmung von α nach Hegland:
R(u) =
∫Ω
(u(x)− fε)2 + λ
∫Ω
(Su(x))2
R(u) −−−−→u in V
min!
Man erhalt nun ein LGS, das nach α aufzulosen ist (zum Beispiel perCG-Verfahren).Mit diesem α erzeugen wir auf dem dunnen Gitter direkt dieDichtefunktion.
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 9 / 18

ClusteringverfahrenSchatzung der Dichte - Speicherproblem
Probleme beim Losen des LGS:
(A+ λI )α =1
NBT~1
Ai ,k = (ϕi , ϕk)L2
Große O(N2), zu groß um explizit abgespeichert zu werden
⇒ Matrixeintrage mussen in jedem Matrix-Vektor Produkt neu berechnetwerden.
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 10 / 18

ClusteringverfahrenSchatzung der Dichte - Speicherproblem
Probleme beim Losen des LGS:
(A+ λI )α =1
NBT~1
Ai ,k = (ϕi , ϕk)L2
Große O(N2), zu groß um explizit abgespeichert zu werden
⇒ Matrixeintrage mussen in jedem Matrix-Vektor Produkt neu berechnetwerden.
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 10 / 18

ClusteringverfahrenSchatzung der Dichte - Speicherproblem
Probleme beim Losen des LGS:
(A+ λI )α =1
NBT~1
Ai ,k = (ϕi , ϕk)L2
Große O(N2), zu groß um explizit abgespeichert zu werden
⇒ Matrixeintrage mussen in jedem Matrix-Vektor Produkt neu berechnetwerden.
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 10 / 18
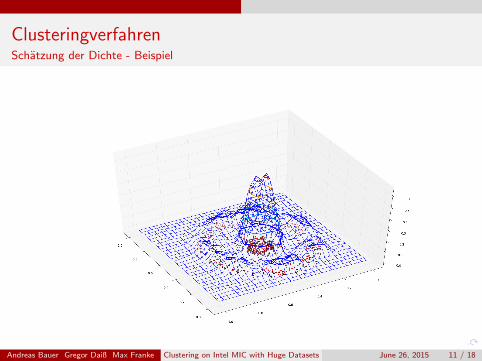
ClusteringverfahrenSchatzung der Dichte - Beispiel
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 11 / 18
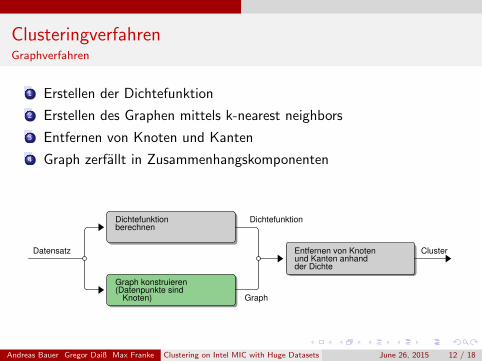
ClusteringverfahrenGraphverfahren
1 Erstellen der Dichtefunktion
2 Erstellen des Graphen mittels k-nearest neighbors
3 Entfernen von Knoten und Kanten
4 Graph zerfallt in Zusammenhangskomponenten
Dichtefunktionberechnen
Dichtefunktion
Datensatz Entfernen von Knotenund Kanten anhandder Dichte
Cluster
Graph konstruieren(Datenpunkte sind
Knoten) Graph
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 12 / 18

Aufbau des Nachbarschaftsgraphen
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 13 / 18

Aufbau des Nachbarschaftsgraphen
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 13 / 18
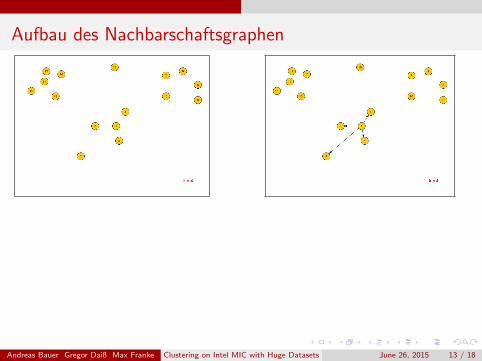
Aufbau des Nachbarschaftsgraphen
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 13 / 18

Aufbau des Nachbarschaftsgraphen
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 13 / 18
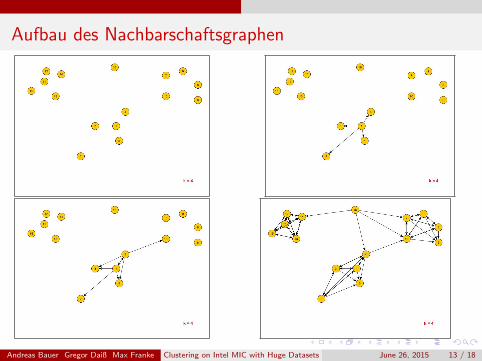
Aufbau des Nachbarschaftsgraphen
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 13 / 18
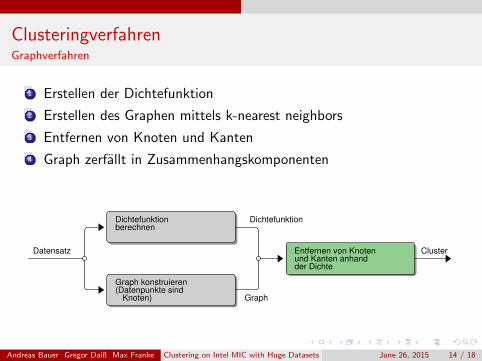
ClusteringverfahrenGraphverfahren
1 Erstellen der Dichtefunktion
2 Erstellen des Graphen mittels k-nearest neighbors
3 Entfernen von Knoten und Kanten
4 Graph zerfallt in Zusammenhangskomponenten
Dichtefunktionberechnen
Dichtefunktion
Datensatz Entfernen von Knotenund Kanten anhandder Dichte
Cluster
Graph konstruieren(Datenpunkte sind
Knoten) Graph
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 14 / 18

Loschen von Knoten und Kanten
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 15 / 18

Loschen von Knoten und Kanten
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 15 / 18
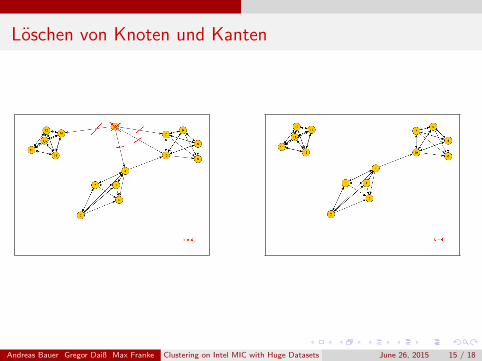
Loschen von Knoten und Kanten
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 15 / 18
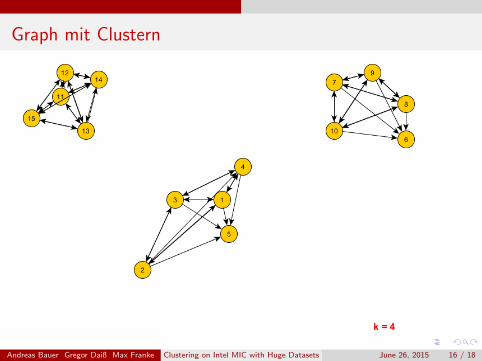
Graph mit Clustern
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 16 / 18

BeispieleLaufzeiten
Generierter Datensatz mit 105 Punkten, 10 Dimensionen
k = 6 ⇒ 731 Cluster
37% der Punkte im gleichen Cluster61% der Punkte in keinem ClusterRestliche Cluster Große ≤ 30
1.138s 0.046s
Rechte Seiteder Gleichungberechnen
LGS berechnen(CG Vefahren)
6.9s [1]
Kanten Entfernen + Cluster suchen
21.53s
Graph erstellen(k nearest neighbors)
1Aktualisierte Ergebnisse
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 17 / 18

BeispieleLaufzeiten
Generierter Datensatz mit 105 Punkten, 10 Dimensionen
k = 6 ⇒ 731 Cluster
37% der Punkte im gleichen Cluster61% der Punkte in keinem ClusterRestliche Cluster Große ≤ 30
1.138s 0.046s
Rechte Seiteder Gleichungberechnen
LGS berechnen(CG Vefahren)
6.9s [1]
Kanten Entfernen + Cluster suchen
21.53s
Graph erstellen(k nearest neighbors)
1Aktualisierte Ergebnisse
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 17 / 18
LIVEDEMO
Andreas Bauer Gregor Daiß Max Franke Clustering on Intel MIC with Huge Datasets June 26, 2015 18 / 18





























