Embed Size (px)
Citation preview

IBM® DB2® for Linux®, UNIX®, and Windows®
Combining DB2 HADR with Q
Replication
Rich Briddell
Replication Center of Competency November 2011
IBM

Combining HADR with Q Replication Page 2
Table of contents
Combining DB2 HADR with Q Replication ................................................................ 1
Executive summary ......................................................................................................... 3
Introduction ...................................................................................................................... 4
Topologies ......................................................................................................................... 5
Queue Manager Configurations .................................................................................... 6
Multi Instance Queue Manager ................................................................... 7
Remote Queue Manager ............................................................................... 9
Remote Operation of Q Capture and / or Q Apply................................................... 10
Related Topics ................................................................................................................ 12
Establishing a Multi-Instance Queue Manager ....................................... 12
Establishing Remote Replication ............................................................... 12
Cataloging HADR Databases for Q Replication...................................... 13
Configuring MQ Channel Reconnect........................................................ 14
DB2 Automatic Client Reroute .................................................................. 15
HADR Database Issued for Q Replication ............................................... 15
Conclusion ...................................................................................................................... 16
Contributors.................................................................................................. 16
Notices ............................................................................................................................. 17
Trademarks ................................................................................................... 18

Combining HADR with Q Replication Page 3
Executive summary DB2 HADR provides an excellent whole database replication solution for high
availability. Q Replication provides a high-volume, low-latency replication solution that
uses WebSphere(R) MQ message queues to transmit transactions between source and
target databases. This paper examines combining the two types of replication.

Combining HADR with Q Replication Page 4
Introduction High Availability Disaster Recovery (HADR) is a replication feature of the IBM DB2 Data
Server that provides a solution for site outages by maintaining a full copy of a database
on a secondary server. The primary and secondary databases form a pair that is kept in
sync through log shipping. Only the primary database is capable of read/write access.
One limitation of HADR is that only two servers can participate and they must be nearly
identical in platform and version.
Both HADR and Q Replication are included as part of the DB2 LUW base installation,
making Q Replication a natural extension for HADR. To add Q Replication to an existing
HADR pair simply install a Q Replication license, such as the DB2 Homogeneous
Replication ESE Feature.
Q Replication doesn’t really know about HADR. Q Replication merely sees a source
database where it captures change data or a target database where it applies those
changes. Since the HADR primary is the only database in the pair that meets the criteria
for reading and writing, Q Replication always interfaces with the HADR pair through the
primary database. During a fail-over the replication programs must be started on
whichever server hosts the primary HADR server.
Since V9.7 FP1 the secondary HADR server can be used to provide data access to read-
only users. Since Q Replication doesn’t know that an HADR secondary exists, its usage
or failure has no affect on Q Replication.
HADR databases don’t fail-over by themselves. Commands can be issued manually or
some form of managing software can be used to control the fail-over. Custer
management software such as IBM® Tivoli® System Automation for Multi-platforms
(Tivoli SA MP) is generally used to detect and control the HADR fail-over. This same
software then controls the location and operation of the replication programs and MQ.
Since each server in the HADR pair has its own IP address, a fail-over from primary to
secondary can make finding the primary database an issue with HADR. Either
virtualized IP addresses or DNS re-routing are common methods used to provide a
consistent path for access to the primary database. If the one of these solutions is not
employed users must detect that the primary database is not available and find the
secondary themselves. Features such as DB2 Automatic Client Reroute can assist in this
discovery process.
Regardless of where Q Replication runs it requires access to three things:
� The replication executables
� The DB2 database(s)
� An MQ Queue Manager

Combining HADR with Q Replication Page 5
As previously mentioned Q Capture and Q Apply executables are available as part of the
DB2 software installation so will be available on both HADR servers. All of the
configuration information used by Q Replication is stored in control tables in the DB2
database and is replicated by HADR to the secondary server. The one part of the
replication environment not yet discussed is the MQ Queue Manager.
The Queue Manager persists all of its configuration information, logs and messages to
files on the server where it operates. There is no HADR-like feature of MQ to replicate its
data to another server, so we have to manage the availability of the Queue Manager and
its messages differently than we do DB2.
Below are two recommended options for establishing a Q Replication environment with
HADR:
� Multi-instance Queue Manager using shared disks
� Remote Queue Manager
Topologies Using a DB2 HADR pair as a Q Replication participant is becoming a common
configuration to extend the limitation on two servers and to connect the HADR pair to
other systems. HADR pairs can participate in all common Q Replication topologies to:
Act as a source of replication
Act as a target of replication

Combining HADR with Q Replication Page 6
As source and target, providing for expansion of HADR to more than a single pair
Queue Manager Configurations When evaluating these alternative topologies keep the following factors in mind:
� Is shared disk available to the HADR pair
� Will a virtualized IP address be used for primary server access
� Will WebSphere MQ Version 7.0.1 or above be used
Also remember the following to get the best Q Replication environment local is better.
Attempt to keep the Queue Manager on the same server as the Replication programs and
the replication programs on the same server as the database.
NOTE: MQ Clusters provide reduced administration and workload balancing (or
greater availability through multiple instances of a queue). It does not provide high

Combining HADR with Q Replication Page 7
availability of queues needed for an HADR configuration. Q Replication does not
support:
� configurations where Send or Receive queue names are not unique (multiple
instances of a queue)
� cluster distribution lists
Multi Instance Queue Manager
How does it work?
A new feature of WebSphere MQ Version 7, Multi-Instance Queue Manager provides an
active and a standby Queue Manager on separate servers. These Queue Managers rely
on shared disk to store definitions, log information and messages.
MQ software is installed on both servers and then a Queue Manager is created on the
primary server. When creating this Queue Manager you specify the alternate location for
the shared data. On a second server a command is issued to define up a Standby
instance based on the same shared information. Both Queue Mangers are created using
the same Queue Manager name.
Once defined, the two Queue Managers can be started in any sequence. Since both
Queue Managers have access to the same shared disk, the first one to start up places a
lock on the shared files and is considered the Active Queue Manager. When the second
Queue Manager starts up it finds the files locked and remains in a Standby mode,
awaiting release of the file locks when the Active Queue Manager fails.
The standby Queue Manager must detect failure of the primary and go through a
recovery/startup procedure before it is available for use.

Combining HADR with Q Replication Page 8
In this configuration each Queue Manager operates on a separate IP address and this
address does not change during fail-over. Virtual IP addresses and DNS rerouting are
not applicable to MQ in this configuration.
Multi-Instance Queue Manager solves the problem of access to MQ by the replication
programs, but how do other Queue Managers find the HADR based Queue Manager
after it fails over to a different IP address in order to transfer messages? Beginning in
MQ Version 7.0.1 the channels between Queue Managers can be configured to
automatically reconnect to the Standby Queue Manager using MQ Channel Reconnect
(below).
If MQ Version 7.0.1 is not available some complex solution must be implemented to
accomplish the same rerouting of messages. These could include:
� Manual channel reconfiguration
� Implementing MQ Aliases and reconfiguration during fail-over
� Reconfiguring Replication Control information during fail-over
None of these solutions is recommended.
How does it fit with HADR?
Q Replication always communicates with the Primary HADR database and must also
communicate with the Active Queue Manager, co-located on the primary HADR server.
The second Queue Manager runs in Standby mode on the Secondary HADR server.
During an HADR fail-over event The Queue Manager on the primary must be stopped (if
it has not failed) so that the Standby Queue Manager can take over.
Challenges:
Synchronizing the Active Queue Manager with the Primary HADR Server/Q Replication.
Since MQ and HADR will each determine the need to fail-over based on different criteria,
extra care must be taken to be sure both operate together properly
Configuring a Queue Manager that communicates with a MIQM so that the channels
reconnect to the active Queue Manager (Channel Reconnect)
References:
Details can be found at the MQ Information Center.
http://www-01.ibm.com/support/docview.wss?uid=swg27018127
Benefits:
The Queue Manager is always operating locally to the Q Replication programs, offering
the best performance.

Combining HADR with Q Replication Page 9
The Queue Manager on the secondary server will be available as soon as it detects a
Primary failure and runs through startup/recovery procedures.
Drawbacks:
� Requires shared disk.
� HADR and MQ have differing fail-over criteria. The status of the Queue
Manager is under MQ control, not control of cluster managing software. Since
the standby Queue Manager could take over based on transitory conditions that
do not also trigger the failover of the DB2 database (such as momentary
connectivity interruptions between the active Queue Manager and the shared file
system or unresponsiveness of queue manager processes) additional
administrative procedures may be required to return the active Queue Manager
to the server running the Q Replication processes.
Remote Queue Manager
How does it work?
Although a local MQ Server provides the best performance, Q Replication also supports
the use of MQ Client software on LUW platforms, allowing the Queue Manager to reside
anywhere on the network. In this configuration MQ client software is installed on each
of the HADR servers and configuration is limited to setting a few environment variables.
All MQ definitions, logs and processes reside on a separate server beyond the concern of
the HADR pair.
How does it fit with HADR?
Q Replication programs have access to the Queue Manager through MQ Client software
installed on both HADR servers. Availability of the Queue Manager is outside the scope
of the HADR pair and requires only proper environment configuration and network
access.
Combining HADR with Q Replication Page 10
Benefits:
� No shared disks
� Simple configuration with no MQ processes necessary on the HADR pair
Drawbacks:
� DB2 LUW solution only
� An additional piece of software, the MQ Client
� Sub-optimal performance is experienced by the Q Replication programs as they
communicate remotely to the Queue Manager get messages
� Introduces a third server to the overall environment.
� The server hosting the Queue Manager will require its own high availability
configuration, such as HACMP.
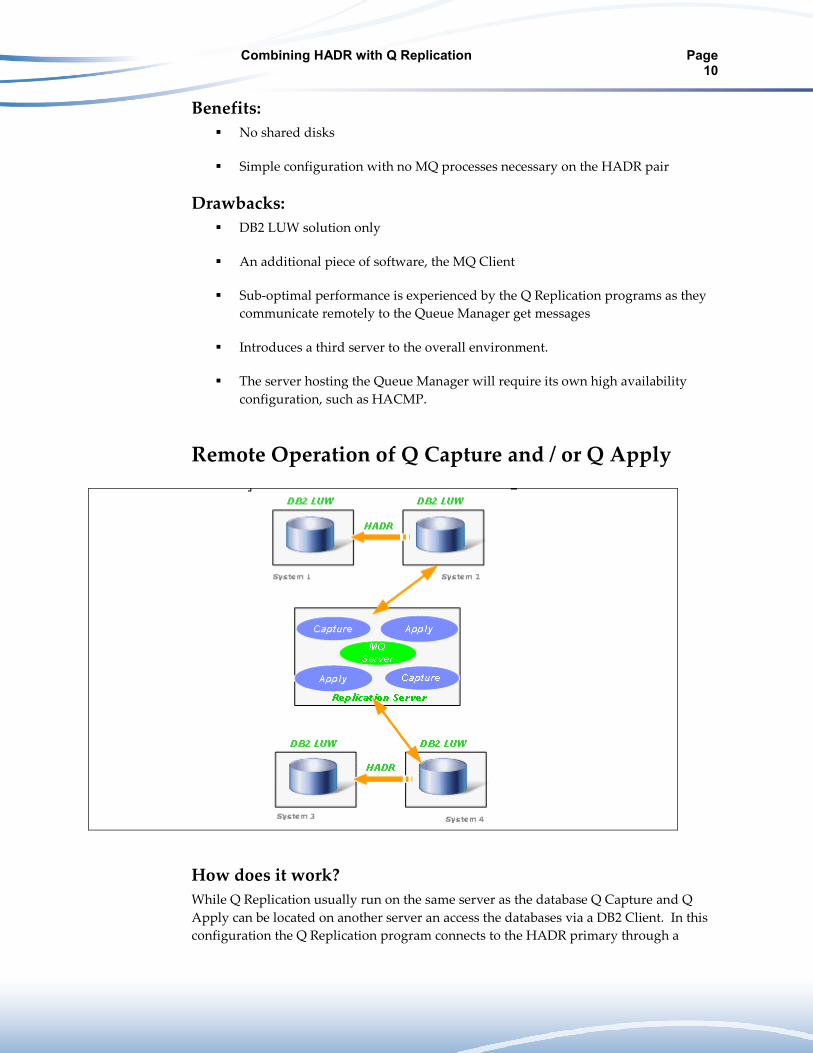
Remote Operation of Q Capture and / or Q Apply
How does it work?
While Q Replication usually run on the same server as the database Q Capture and Q
Apply can be located on another server an access the databases via a DB2 Client. In this
configuration the Q Replication program connects to the HADR primary through a

Combining HADR with Q Replication Page 11
virtual IP address maintained by cluster managing software or using DB2 Automatic
Client Reroute.
DB2 Client and possibly MQ Client software is installed on an additional server.
Replication programs and MQ are removed from the HADR server pair entirely.
How does it fit with HADR?
Q Replication uses remote access to contact the DB2 database. This decreases replication
performance but allows for centralization of all replication processes on a server external
to the HADR pair.
Several configurations are possible, implementing some combination of remote Q
Capture, remote Q Apply and even remote MQ. Each additional remote connection that
must be made in the data flow from source to target decreases performance and increases
latency.
Benefits:
• No shared disks.
• Simple configuration with replication programs removed from the HADR pair.
Drawbacks:
� An additional DB2 instance is required on the replication server, increasing
licensing costs.
� Sub-optimal performance is experienced by the Q Replication programs as they
communicate remotely with the databases instead of locally.
� Sub-optimal performance is experienced by the Q Replication programs as they
communicate remotely with the Queue Manager instead of locally.
� Capture must be at the same Version/Release or higher than the source
� Capture control tables must be at the same level as Capture
� Use the sample create control table DDL
� Replication Center and asnclp only create control tables based on DB2 level
� Introduces a third server to the overall HA environment.
� The server hosting the Queue Manager will require its own high availability
capability, such as HACMP.
� No code page or big/little endian translation possible between source & Q
Capture
� Not provide by DB2 log read API

Combining HADR with Q Replication Page 12
� Q Capture system must be same type of hardware and code page as source
Related Topics
Establishing a Multi-Instance Queue Manager � Create a shared disk that is accessible from both servers
� Install WebSphere MQ software on both servers
� Create a Queue Manager on the first server using the crtmqmq –md command,
placing its queue manager data and logs in shared network storage.
� Create the Standby Queue Manager on the other server using the addmqinf
command
� Configure channels on other Queue Managers that send data to the Multi-
Instance Queue Manager to reroute communications to the active Queue
Manager
� Use a listener service (as opposed to the command line runmqlsr command) so
that the listener will start automatically as part of queue manager startup:
DEFINE LISTENER(NAME) TRPTYPE(TCP) CONTROL(QMGR) PORT(PORT
NUMBER)
� Create a cluster managing script that stops the Queue Manager during a fail-over
and restarts it on the surviving server. The Queue Manager will operate on
different IP addresses and ports dependent on configuration.
Establishing Remote Replication � Configure the HADR pair with Virtual IP, DNS rerouting or DB2 Automatic
Client Reroute. All access o the databases will use normal client connections.
� Install DB2 on a separate server, following the restrictions outlined above for
code page, endian, etc.
� Install WebSphere MQ software, either Server or Client as appropriate.
� Catalog the source and/or target databases.
� Create password files using the asnpwd utility.

Combining HADR with Q Replication Page 13
Cataloging HADR Databases for Q Replication Q Capture and Q Apply typically run locally on the server hosting the active (primary)
HADR database. Q Apply will also need to connect to a source server to perform an
automatic load. To ensure that the replication programs operate properly be sure to
catalog the HADR databases consistently across all servers, including a configuration
workstation or a remote Q Replication server.
Since all databases will have the same name it is not possible to use the database name to
access all databases.
Assume a configuration where Q Replication is connecting two HADR pairs. The
database name is PRODDB. One site has servers EAST1.YOURCORP.COM and
EAST2.YOURCORP.COM, the other site has servers WEST1.YOURCORP.COM and
WEST2.YOURCORP.COM. The instance name is db2inst1 at all locations and the
database uses port 50000.
� Catalog the local database with an alias that indicates its site.
� Catalog the remote node (primary server).
� Catalog the remote database at the remote node using an alias that indicates its
site.
� Update the remote alias with alternate server (secondary) information.
catalog db PRODDB as PRODDBE ;
catalog tcpip node WESTNODE remote WEST1.CORP.COM server 50000;
catalog db PRODDB as PRODDBW at node WESTNODE;
update alternate server for db PRODDBW using hostname WEST2.CORP.COM port 50000;
catalog db PRODDB as PRODDBE ;
catalog tcpip node WESTNODE remote WEST1.CORP.COM server 50000;
catalog db PRODDB as PRODDBW at node WESTNODE;
update alternate server for db PRODDBW using hostname WEST2.CORP.COM port 50000;
catalog db PRODDB as PRODDBW ;
catalog tcpip node EASTNODE remote EAST1.CORP.COM server 50000;

Combining HADR with Q Replication Page 14
catalog db PRODDB as PRODDBE at node EASTNODE;
update alternate server for db PRODDBE using hostname EAST2.CORP.COM port 50000;
catalog db PRODDB as PRODDBW ;
catalog tcpip node EASTNODE remote EAST1.YOURCORP.COM server 50000;
catalog db PRODDB as PRODDBE at node EASTNODE;
update alternate server for db PRODDBE using hostname EAST2.CORP.COM port 50000;
Configuring MQ Channel Reconnect In configurations where the location of a Queue Manager changes, such as Multi-Instance
Queue Manager where each Queue Manager has it’s own IP address that does not
change during fail-over, all Queue Managers that participate with the pair must
The CONNAME attribute of channels is a comma-separated list of connection names; for
example, CONNAME('92.46.1.1(1415), 85.42.3.8(2423)'). The connections are tried in the
order specified in the connection list until a connection is successfully established. If no
connection is successful, the channel attempts to reconnect.
define channel(TO.HADR_SERVER)
chltype(SDR)
conname(‘HADR_PRIMARY(port),HADR_SECONDARY(port)’)
CONNAMES with multiple IP Addresses are supported on z/OS as well as on LUW, but
the total length is limited to 48 characters, (264 characters on LUW) so define system
short names in DNS or use IP addresses instead of long fully qualified domain names. A
sample channel definition including thw IP addresses of the Primary and Standby
Miltiple-Instance Queue Manager:
DEFINE CHANNEL(QM_SRC_TO_QM_HADR) +
CHLTYPE(SDR) +
CONNAME('9.30.11.16(28169),9.30.11.102(28169)') +
XMITQ(QM_HADR) +
REPLACE +

Combining HADR with Q Replication Page 15
TRPTYPE(TCP) +
DESCR('SENDER CHANNEL TO QM_HADR') +
DISCINT(0) +
HBINT(300) +
MAXMSGL(8388608)
DB2 Automatic Client Reroute Automatic client reroute is an IBM® Data Server feature that redirects client applications
from a failed server to an alternate server so the applications can continue their work
with minimal interruption when the primary server is unreachable. Automatic client
reroute can be accomplished only if an alternate server has been specified prior to the
failure.
In order for the DB2 database system to have the ability to recover from a loss of
communications, an alternative server location must be specified before the loss of
communication occurs. The UPDATE ALTERNATE SERVER FOR DATABASE command is
used to define the alternate server location on a particular database.
After you have specified the alternate server location on a particular database at the
server instance, the alternate server location information is returned to the IBM Data
Server Client as part of the connection process.
HADR Database Issued for Q Replication Another aspect of HADR that requires shared disk is the use of the DB2 LOAD utility.
When performing automatic loads of target tables Q Apply performs either an INSERT,
IMPORT (which uses INSERT) or LOAD operation. The load types that use a LOAD
statement will not work in an HADR environment without special configuration of Q
Apply.
NOTE: DB2 provides a registry variable DB2_LOAD_COPY_NO_OVERRIDE. This
variable does not perform the necessary changes to the LOAD operations performed by
Q Apply. Q Apply requires setting of the LOADCOPY_PATH Q Apply parameter
instead of the DB2_LOAD_COPY_NO_OVERRIDE registry variable. Setting
LOADCOPY_PATH to an NFS directory that is accessible from both the primary and
secondary servers prompts Q Apply to start the LOAD utility with the option to create a
copy of the loaded data in the specified path. The secondary server in the HADR
configuration then looks for the copied data in this path.
Since executing a load operation with the COPY NO option is not supported with HADR,
the command is automatically converted to a load operation with the
NONRECOVERABLE option. If a load operation is executed on the primary database

Combining HADR with Q Replication Page 16
with the NONRECOVERABLE option, the command will execute on the primary
database and the table on the standby database will be marked invalid.
Conclusion Combining these two DB2 replication technologies can help provide local and
geographically dispersed high availability solutions for DB2. Considering the topics
discussed can help you prepare your environment for a successful deployment.
Contributors
Contributor
Organization

Combining HADR with Q Replication Page 17
Notices This information was developed for products and services offered in the U.S.A.
IBM may not offer the products, services, or features discussed in this document in other
countries. Consult your local IBM representative for information on the products and services
currently available in your area. Any reference to an IBM product, program, or service is not
intended to state or imply that only that IBM product, program, or service may be used. Any
functionally equivalent product, program, or service that does not infringe any IBM
intellectual property right may be used instead. However, it is the user's responsibility to
evaluate and verify the operation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matter described in
this document. The furnishing of this document does not grant you any license to these
patents. You can send license inquiries, in writing, to:
IBM Director of Licensing
IBM Corporation
North Castle Drive
Armonk, NY 10504-1785
U.S.A.
The following paragraph does not apply to the United Kingdom or any other country where
such provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES
CORPORATION PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER
EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF NON-
INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do
not allow disclaimer of express or implied warranties in certain transactions, therefore, this
statement may not apply to you.
This information could include technical inaccuracies or typographical errors. Changes are
periodically made to the information herein; these changes will be incorporated in new
editions of the publication. IBM may make improvements and/or changes in the product(s)
and/or the program(s) described in this publication at any time without notice.
Any references in this information to non-IBM Web sites are provided for convenience only
and do not in any manner serve as an endorsement of those Web sites. The materials at
those Web sites are not part of the materials for this IBM product and use of those Web sites is
at your own risk.
IBM may use or distribute any of the information you supply in any way it believes
appropriate without incurring any obligation to you.
Any performance data contained herein was determined in a controlled environment.
Therefore, the results obtained in other operating environments may vary significantly. Some
measurements may have been made on development-level systems and there is no
guarantee that these measurements will be the same on generally available systems.
Furthermore, some measurements may have been estimated through extrapolation. Actual
results may vary. Users of this document should verify the applicable data for their specific
environment.
Information concerning non-IBM products was obtained from the suppliers of those products,
their published announcements or other publicly available sources. IBM has not tested those
products and cannot confirm the accuracy of performance, compatibility or any other
claims related to non-IBM products. Questions on the capabilities of non-IBM products should
be addressed to the suppliers of those products.
All statements regarding IBM's future direction or intent are subject to change or withdrawal
without notice, and represent goals and objectives only.
This information contains examples of data and reports used in daily business operations. To
illustrate them as completely as possible, the examples include the names of individuals,
companies, brands, and products. All of these names are fictitious and any similarity to the
names and addresses used by an actual business enterprise is entirely coincidental.

Combining HADR with Q Replication Page 18
COPYRIGHT LICENSE:
This information contains sample application programs in source language, which illustrate
programming techniques on various operating platforms. You may copy, modify, and
distribute these sample programs in any form without payment to IBM, for the purposes of
developing, using, marketing or distributing application programs conforming to the
application programming interface for the operating platform for which the sample
programs are written. These examples have not been thoroughly tested under all conditions.
IBM, therefore, cannot guarantee or imply reliability, serviceability, or function of these
programs. The sample programs are provided "AS IS", without warranty of any kind. IBM shall
not be liable for any damages arising out of your use of the sample programs.
Trademarks
IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International
Business Machines Corporation in the United States, other countries, or both. If these and
other IBM trademarked terms are marked on their first occurrence in this information with a
trademark symbol (® or ™), these symbols indicate U.S. registered or common law
trademarks owned by IBM at the time this information was published. Such trademarks may
also be registered or common law trademarks in other countries. A current list of IBM
trademarks is available on the Web at “Copyright and trademark information” at
www.ibm.com/legal/copytrade.shtml
Windows is a trademark of Microsoft Corporation in the United States, other countries, or
both.
UNIX is a registered trademark of The Open Group in the United States and other countries.
Linux is a registered trademark of Linus Torvalds in the United States, other countries, or both.
Other company, product, or service names may be trademarks or service marks of others.





























