Embed Size (px)
Citation preview

Combining Lexical Semantic Resources with Question & Answer Archives for Translation-Based Answer Finding
Delphine Bernhard and Iryna GurevvchUbiquitous Knowledge Processing (UKP) Lab
Computer Science DepartmentTechnische Universit¨at Darmstadt, Hochschulstraße 10
D-64289 Darmstadt, Germany
ACL 2009
Reporter: Kan-Wen TienDate: 2009.10.22

Outlines
• Introduction• Related Work• Parallel Datasets• Semantic Relatedness Experiments• Answer Finding Experiments• Conclusion

• Introduction• Related Work• Parallel Datasets• Semantic Relatedness Experiments• Answer Finding Experiments• Conclusion

Introduction
• Lexical gap between queries and documents or questions and answers
• Several solutions:– Query reformulation, query paraphrasing– Query expansion – Semantic information retrieval

Introduction
• Several solutions:– Integrate monolingual statistical translation
models in the retrieval process (1999)• Drawback: limited availability of truly parallel
monolingual corpora
• Training data often consist in question-answer pairs and usually extracted from the evaluation corpus itself

• Introduction
• Related Work• Parallel Datasets• Semantic Relatedness Experiments• Answer Finding Experiments• Conclusion

Related Work
• Statistical translation models for retrieval• Built synthetic training data • Train translation models on Q&A pairs – Answers -> source language– Questions -> target language
• Select the most important terms to build compact translation models

• Introduction• Related Work
• Parallel Datasets• Semantic Relatedness Experiments• Answer Finding Experiments• Conclusion

Parallel Datasets
• Different data resources:(1)Manually-tagged question reformulations
and question-answer pairs from the WikiAnswers social Q&A site
(2) Glosses from WordNet, Wiktionary, Wikipedia and Simple Wikipedia


Parallel Datasets
(1) Manually-tagged question reformulations and question-answer pairs
• From social Q&A sites: WikiAnswers (WA)– Question-Answer Pairs (WAQA)
– Question Reformulations (WAQ)
[URL]

Parallel Datasets
(2) Glosses from WordNet, Wiktionary, Wikipedia and Simple Wikipedia
• Lexical Semantic Resources (LSR)– Word sense alignment
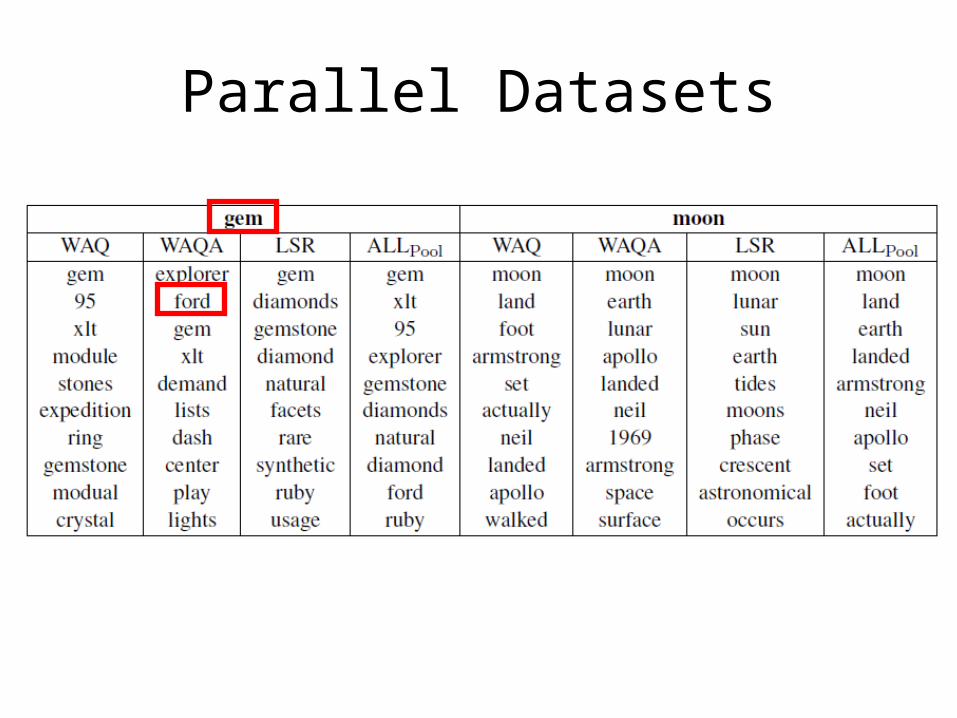
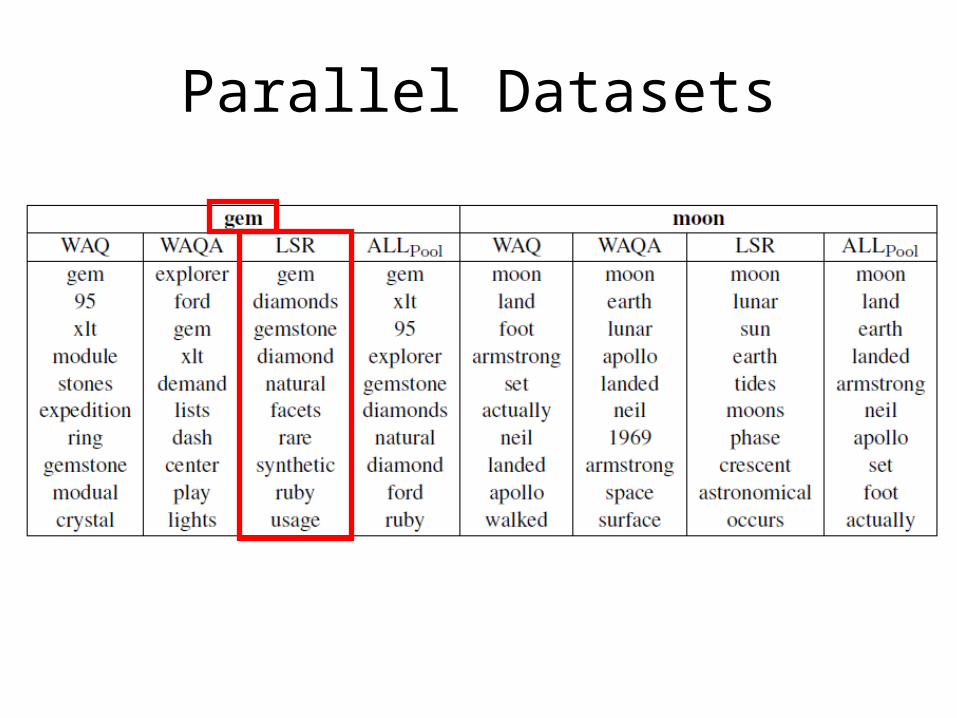
• Example !

Parallel Datasets
• Example: “moon”– Wordnet (sense 1): The natural satellite of the
Earth.– English Wiktionary: The Moon, the satellite of
planet Earth.– English Wikipedia: The Moon (Latin: Luna) is
Earth’s only natural satellite and the fifth largest natural satellite in the Solar System.

Parallel Datasets
Three datasets: • Question-Answer Pairs (WAQA)
1,227,362 parallel pairs
• Question Reformulations (WAQ)4,379,620 parallel pairs
• Lexical Semantic Resources (LSR)397,136 pairs

Parallel Datasets
• Translation Model Training– Pre-processing steps
– GIZA++ SMT Toolkit -> word-to-word translation probabilities
– IBM translation model 1

Parallel Datasets
• Combination of the datasets– Lin (combination of models after training)
– Pool (concatenating the corpora before training)

Parallel Datasets
Parallel Datasets
Parallel Datasets

• Introduction• Related Work• Parallel Datasets
• Semantic Relatedness Experiments• Answer Finding Experiments• Conclusion

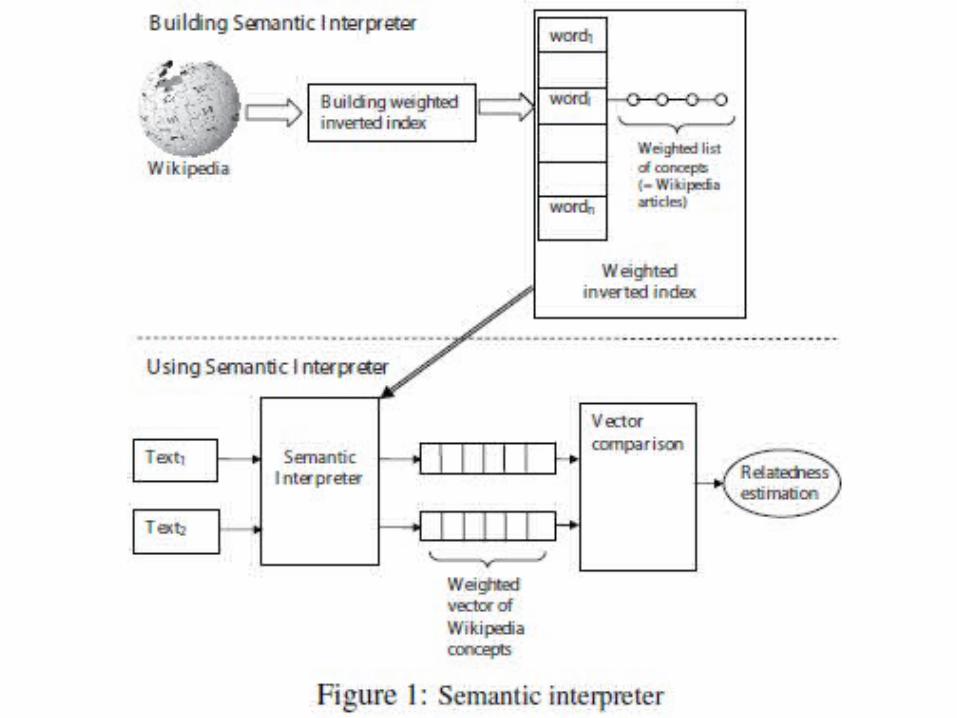
Semantic Relatedness Experiments• Goal: Word translation probabilities vs.
Concept vector based measure
• Concept vector based measure relying on Explicit Semantic Analysis(Gabrilovich and Markovitch, 2007)
• Compare with traditional semantic relatedness measures

Semantic Relatedness Experiments

Semantic Relatedness Experiments
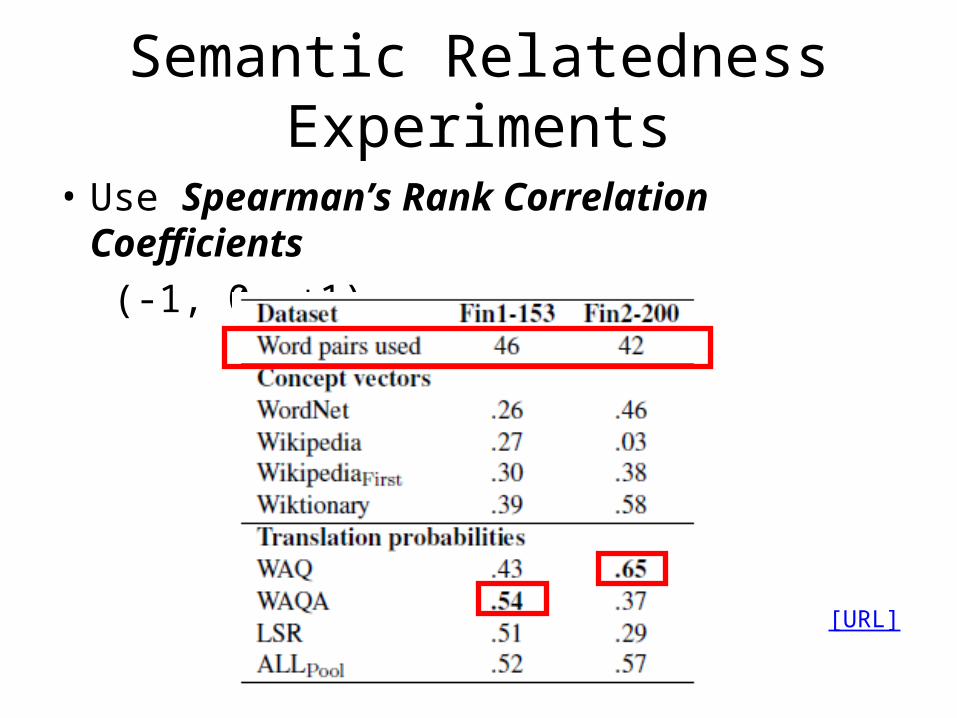
• Testing data set: 353 word-to-word pairs– Created by Finkelstein et al. (2002)– Fin1-153: 153 pairs– Fin2-200: 200 pairs

Semantic Relatedness Experiments
• Testing data set: 353 word-to-word pairs– Created by Finkelstein et al. (2002)– Fin1-153: 153 pairs– Fin2-200: 200 pairs

Semantic Relatedness Experiments
• Use Spearman’s Rank Correlation Coefficients (-1, 0, +1)
[URL]
Semantic Relatedness Experiments
• Use Spearman’s Rank Correlation Coefficients (-1, 0, +1)
[URL]

• Introduction• Related Work• Parallel Datasets• Semantic Relatedness Experiments
• Answer Finding Experiments• Conclusion

Answer Finding Experiments
• Goal: provide an extrinsic evaluation of the translation probabilities by employing them in an answer finding task.
• Using a ranking function to perform retrieval

Answer Finding Experiments
• Ranking function (β = 0.8, λ = 0.5)

Answer Finding Experiments
• Ranking function (β = 0.8, λ = 0.5)

Answer Finding Experiments
• Ranking function (β = 0.8, λ = 0.5)
Query likelihood modelTranslation model

Answer Finding Experiments
• Testing data: Microsoft Research QA Corpus• 1,364 questions, 9,780 answers• 5 levels of relevance judgements:
0: No Judgement Made1: Extract Answers3: Off Topic4: On Topic, Off Target5: Partial Answer

Answer Finding Experiments
• Testing data: Microsoft Research QA Corpus• 1,364 questions, 9,780 answers• 5 levels of relevance judgements:
0: No Judgement Made1: Extract Answers3: Off Topic4: On Topic, Off Target5: Partial Answer

Answer Finding Experiments

Answer Finding Experiments
• Mean Average Precision (MAP)• Mean R-Precision (R-prec)• Baselines: – Query likelihood model (QLM) ---> β = 0
– LuceneQuery likelihood model Translation model
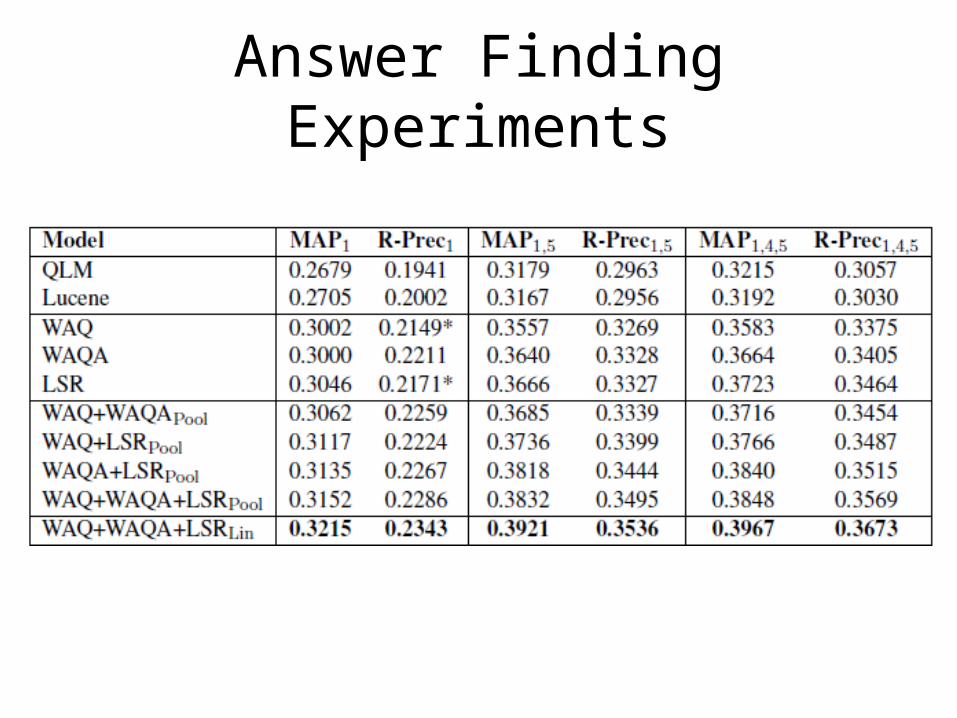
Answer Finding Experiments

Answer Finding Experiments
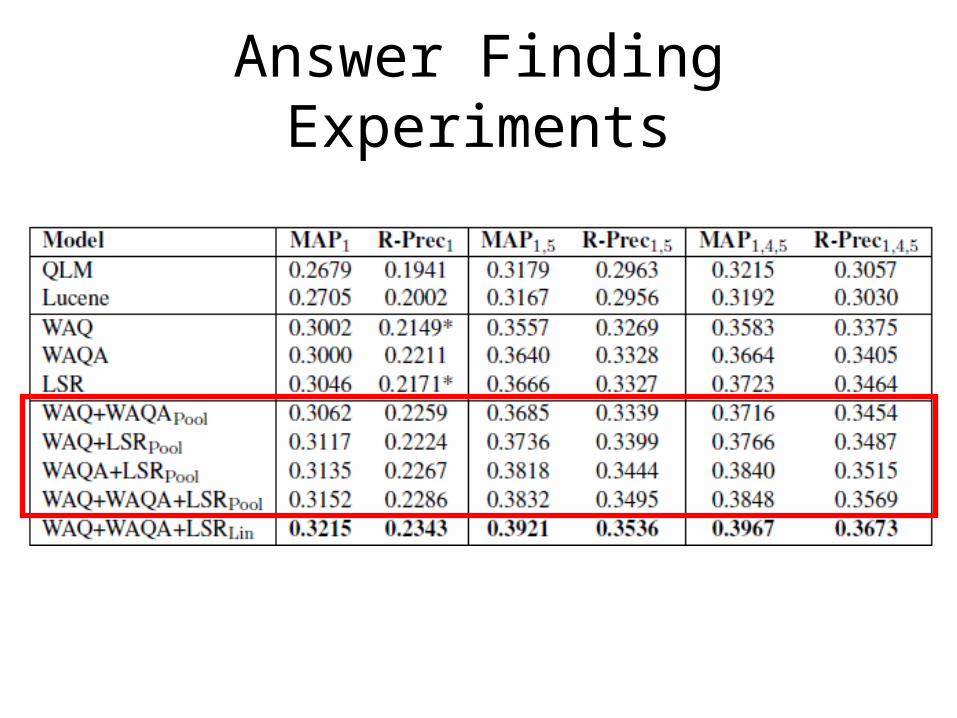
Answer Finding Experiments

Answer Finding Experiments

Answer Finding Experiments




• Introduction• Related Work• Parallel Datasets• Semantic Relatedness Experiments• Answer Finding Experiments
• Conclusion

Conclusion
• Propose new kinds of datasets for training• Provide the first intrinsic evaluation of word
translation probabilities with respect to human relatedness rankings for reference word pairs
• Models based on translation probabilities for answer finding
Thank you !





























