Embed Size (px)
Citation preview

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 1/100
COMMUNICATIONSOF THE
ACMCACM.ACM.ORG 08/2015 VOL.58 NO.08
Association for
Computing Machinery
Network Science,Web Science,
and Internet Science
The Moral Challengesof Driverless Cars
Permissionless Innovation
Programming theQuantumFuture

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 2/100

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 3/100
ACM’s Career& Job Center
Are you looking for
your next IT job? Do you need Career Advice?
Visit ACM’s Career & Job Center at: http://jobs.acm.org
The ACM Career & Job Center is the perfect place to
begin searching for your next employment opportunity!
Visit today at http://jobs.acm.org
The ACM Career & Job Center offers ACM members a host ofcareer-enhancing benefits:
• A highly targeted focus on job
opportunities in the computing industry
• Access to hundreds of industry job postings
• Resume posting keeping you connected
to the employment market while letting you
maintain full control over your confidential
information
• Job Alert system that notifies you of
new opportunities matching your criteria
• Career coaching and guidance available
from trained experts dedicated to your
success
• Free access to a content library of the best
career articles compiled from hundreds of
sources, and much more!

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 4/100
2 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
COMMUNICATIONS OF THE ACM
Viewpoints
21 Privacy and Security
Security for Mobile and
Cloud Frontiers in Healthcare
Designers and developers of
healthcare information technologies
must address preexisting security
vulnerabilities and undiagnosed
future threats.
By David Kotz, Kevin Fu,
Carl Gunter, and Avi Rubin
24 Economic and Business Dimensions
Permissionless Innovation
Seeking a better approach
to pharmaceutical research
and development.
By Henry Chesbrough
and Marshall Van Alstyne
27 Kode Vicious
Hickory Dickory Doc
On null encryption and
automated documentation.
By George V. Neville-Neil
29 Education
Understanding the U.S. Domestic
Computer Science Ph.D. Pipeline
Two studies provide insights into
how to increase the number of
domestic doctoral students in
U.S. computer science programs.
By Susanne Hambrusch,
Ran Libeskind-Hadas, and Eric Aaron
33 Viewpoint
Learning Through
Computational Creativity Improving learning and achievement
in introductory computer science
by incorporating creative thinking
into the curriculum.
By Leen-Kiat Soh, Duane F. Shell,
Elizabeth Ingraham, Stephen Ramsay,
and Brian Moore
Departments
5 Editor’s Letter
Why Doesn’t ACM Have a SIG for
Theoretical Computer Science?
By Moshe Y. Vardi
7 Cerf’s Up
Invention
By Vinton G. Cerf
8 Letters to the Editor
Not So Easy to Forget
10 BLOG@CACM
Plain Talk on Computing Education
Mark Guzdial considers how
the variety of learning outcomes
and definitions impacts
the teaching of computer science.
25 Calendar
95 Careers
Last Byte
96 Upstart Puzzles
Brighten Up
By Dennis Shasha
News
13 Teaching Computers with Illusions
Exploring the ways human vision
can be fooled is helping developers
of machine vision.
By Esther Shein
16 Touching the Virtual
Feeling the way across
new frontiers at the interfaceof people and machines.
By Logan Kugler
19 The Moral Challenges
of Driverless Cars
Autonomous vehicles will need
to decide on a course of action
when presented with multiple less-
than-ideal outcomes.
By Keith Kirkpatrick
I M
A G E
B Y
A K I Y
O S H I
K I T
A O K A
13
Association for Computing Machinery
Advancing Computing as a Science & Profession

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 5/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 3
08/2015VOL. 58 NO. 08
Practice
36 Testing Web Applications
with State Objects
Use states to drive your tests.
By Arie van Deursen
44 From the EDVAC to WEBVACs
Cloud computing
for computer scientists.
By Daniel C. Wang
Articles’ development led byqueue.acm.org
Contributed Articles
52 Programming the Quantum Future
The Quipper language offers
a unified general-purpose
programming framework
for quantum computation.
By Benoît Valiron, Neil J. Ross,
Peter Selinger, D. Scott Alexander,
and Jonathan M. Smith
62 Surveillance and Falsification
Implications for Open Source
Intelligence Investigations
Legitimacy of surveillance is
crucial to safeguarding validity
of OSINT data as a tool forlaw-enforcement agencies.
By Petra Saskia Bayerl
and Babak Akhgar
70 Challenges Deploying
Complex Technologies in
a Traditional Organization
The National Palace Museum
in Taiwan had to partner with
experienced cloud providers
to deliver television-quality exhibits.
By Rua-Huan Tsaih, David C. Yen,
and Yu-Chien Chang
Review Articles
76 Network Science, Web Science,
and Internet Science
Exploring three interdisciplinary
areas and the extent to which they
overlap. Are they all part of the same
larger domain?
By Thanassis Tiropanis, Wendy Hall,
Jon Crowcroft, Noshir Contractor,
and Leandros Tassiulas
Research Highlights
84 Technical Perspective
Corralling Crowd Power
By Aniket (Niki) Kittur
85 Soylent: A Word Processor
with a Crowd Inside
By Michael S. Bernstein, Greg Little,
Robert C. Miller, Björn Hartmann,
Mark S. Ackerman, David R. Karger, David Crowell, and Katrina Panovich
I M
A G E
S B Y
G U
O Z H
O N G H U
A ; T H E
N A T I
O N A L P
A L A C E M U
S E U M ; I W
O N A U
S A K I E W I
C Z / A N D
R I J
B O R Y
S A S S O C I
A T E
S
70 76
About the Cover: Schrödinger’s cat, an iconicimage used for decades toillustrate the differencesin emerging theories inquantum mechanics,takes a 21st-century spinin this month’s cover story(p. 52), where quantumprogramming languagesare explored and a modelof quantum computation
is presented. Coverillustration by FutureDeluxe.
Watch the authors discusstheir work in this exclusiveCommunications video.http://cacm.acm.org/videos/programming- the-quantum-future
Watch the authors discusstheir work in this exclusiveCommunications video.http://cacm.acm.org/videos/soylent-a-word-processor-with-a-crowd-inside
44

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 6/100
COMMUNICATIONS OF THE ACMTrusted insights for computing’s leading professionals.
Communications of the ACM is the leading monthly print and online magazine for the computing and information technology fields.Communications is recognized as the most trusted and knowledgeable source of industry information for today’s computing professional.Communications brings its readership in-depth coverage of emerging areas of computer science, new trends in information technology,and practical applications. Industry leaders use Communications as a platform to present and debate various technology implications,public policies, engineering challenges, and market trends. The prestige and unmatched reputation that Communications of the ACM enjoys today is built upon a 50-year commitment to high-quality editorial content and a steadfast dedication to advancing the arts,sciences, and applications of information technology.
P L E
A S E
R E C Y
C L
E
T
H I
S M A G A
Z I
N E
ACM, the world’s largest educationaland scientific computing society, deliversresources that advance computing as ascience and profession. ACM provides thecomputing field’s premier Digital Libraryand serves its members and the computingprofession with leading-edge publications,conferences, and career resources.
Executive Director and CEOJohn WhiteDeputy Executive Director and COOPatricia RyanDirector, Office of Information SystemsWayne GravesDirector, Office of Financial ServicesDarren RamdinDirector, Office of SIG Services
Donna CappoDirector, Office of PublicationsBernard RousDirector, Office of Group PublishingScott E. Delman
ACM COUNCILPresidentAlexander L. WolfVice-PresidentVicki L. HansonSecretary/TreasurerErik AltmanPast PresidentVinton G. CerfChair, SGB BoardPatrick MaddenCo-Chairs, Publications BoardJack Davidson and Joseph Konstan
Members-at-LargeEric Allman; Ricardo Baeza-Yates;Cherri Pancake; Radia Perlman;Mary Lou Soffa; Eugene Spafford;Per StenströmSGB Council RepresentativesPaul Beame; Barbara Boucher Owens
BOARD CHAIRS
Education BoardMehran Sahami and Jane Chu PreyPractitioners BoardGeorge Neville-Neil
REGIONAL COUNCIL CHAIRSACM Europe CouncilFabrizio GagliardiACM India CouncilSrinivas PadmanabhuniACM China CouncilJiaguang Sun
PUBLICATIONS BOARDCo-ChairsJack Davidson; Joseph KonstanBoard MembersRonald F. Boisvert; Nikil Dutt; Roch Guerrin;Carol Hutchins; Yannis Ioannidis;Catherine McGeoch; M. Tamer Ozsu;Mary Lou Soffa
ACM U.S. Public Policy OfficeRenee Dopplick, Director1828 L Street, N.W., Suite 800Washington, DC 20036 USAT (202) 659-9711; F (202) 667-1066
Computer Science Teachers AssociationLissa Clayborn, Acting Executive Director
STAFF
DIRECTOR OF GROUP PUBLISHING Scott E. [email protected]
Executive EditorDiane CrawfordManaging EditorThomas E. LambertSenior EditorAndrew RosenbloomSenior Editor/NewsLarry FisherWeb EditorDavid RomanRights and PermissionsDeborah Cotton
Art DirectorAndrij BorysAssociate Art DirectorMargaret GrayAssistant Art DirectorMia Angelica BalaquiotDesignerIwona UsakiewiczProduction ManagerLynn D’AddesioDirector of Media SalesJennifer RuzickaPublic Relations CoordinatorVirginia GoldPublications AssistantJuliet Chance
ColumnistsDavid Anderson; Phillip G. Armour;Michael Cusumano; Peter J. Denning;Mark Guzdial; Thomas Haigh;Leah Hoffmann; Mari Sako;Pamela Samuelson; Marshall Van Alstyne
CONTACT POINTSCopyright [email protected] [email protected] of [email protected] to the [email protected]
WEBSITEhttp://cacm.acm.org
AUTHOR GUIDELINEShttp://cacm.acm.org/
ACM ADVERTISING DEPARTMENT
2 Penn Plaza, Suite 701, New York, NY10121-0701T (212) 626-0686F (212) 869-0481
Director of Media SalesJennifer Ruzicka [email protected]
Media Kit [email protected]
Association for Computing Machinery(ACM)2 Penn Plaza, Suite 701
New York, NY 10121-0701 USAT (212) 869-7440; F (212) 869-0481
EDITORIAL BOARD
EDITOR-IN-CHIEF Moshe Y. [email protected]
NEWS
Co-ChairsWilliam Pulleyblank and Marc SnirBoard MembersMei Kobayashi; Kurt Mehlhorn;Michael Mitzenmacher; Rajeev Rastogi
VIEWPOINTS
Co-ChairsTim Finin; Susanne E. Hambrusch;John Leslie KingBoard MembersWilliam Aspray; Stefan Bechtold;
Michael L. Best; Judith Bishop;Stuart I. Feldman; Peter Freeman;Mark Guzdial; Rachelle Hollander;Richard Ladner; Carl Landwehr;Carlos Jose Pereira de Lucena;Beng Chin Ooi; Loren Terveen;Marshall Van Alstyne; Jeannette Wing
PRACTICE
Co-ChairsStephen BourneBoard MembersEric Allman; Charles Beeler; Terry Coatta;Stuart Feldman; Benjamin Fried; PatHanrahan; Tom Limoncelli;Kate Matsudaira; Marshall Kirk McKusick;George Neville-Neil; Theo Schlossnagle;Jim Waldo
The Practice section of the CACMEditorial Board also serves asthe Editorial Board of .
CONTRIBUTED ARTICLESCo-ChairsAl Aho and Andrew ChienBoard MembersWilliam Aiello; Robert Austin; Elisa Bertino;Gilles Brassard; Kim Bruce; Alan Bundy;Peter Buneman; Peter Druschel;Carlo Ghezzi; Carl Gutwin; Gal A. Kaminka;James Larus; Igor Markov; Gail C. Murphy;Bernhard Nebel; Lionel M. Ni; Kenton O’Hara;Sriram Rajamani; Marie-Christine Rousset;Avi Rubin; Krishan Sabnani;Ron Shamir; Yoav Sh oham; Larry Snyder;Michael Vitale; Wolfgang Wahlster;Hannes Werthner; Reinhard Wilhelm
RESEARCH HIGHLIGHTS
Co-ChairsAzer Bestovros and Gregory MorrisettBoard MembersMartin Abadi; Amr El Abbadi; Sanjeev Arora;Dan Boneh; Andrei Broder; Doug Burger;Stuart K. Card; Jeff Chase; Jon Crowcroft;Sandhya Dwaekadas; Matt Dwyer;Alon Halevy; Maurice Herlihy; Norm Jouppi;Andrew B. Kahng; Henry Kautz; Xavier Leroy;Kobbi Nissim; Mendel Rosenblum;David Salesin; Steve Seitz; Guy Steele, Jr.;David Wagner; Margaret H. Wright
WE B
ChairJames LandayBoard Members
Marti Hearst; Jason I. Hong;Jeff Johnson; Wendy E. MacKay
ACM Copyright NoticeCopyright © 2015 by Association forComputing Machinery, Inc. (ACM).Permission to make digital or hard copiesof part or all of this work for personalor classroom use is granted withoutfee provided that copies are not madeor distributed for profit or commercialadvantage and that copies bear thisnotice and full citation on the firstpage. Copyright for components of thiswork owned by others than ACM mustbe honored. Abstracting with credit ispermitted. To copy otherwise, to republish,to post on servers, or to redistribute tolists, requires prior specific permissionand/or fee. Request permission to publishfrom [email protected] or fax
(212) 869-0481.For other copying of articles that carry acode at the bottom of the first or last pageor screen display, copying is permittedprovided that the per-copy fee indicatedin the code is paid through the CopyrightClearance Center; www.copyright.com.
SubscriptionsAn annual subscription cost is includedin ACM member dues of $99 ($40 ofwhich is allocated to a subscription toCommunications); for students, costis included in $42 dues ($20 of whichis allocated to a Communications subscription). A nonmember annualsubscription is $100.
ACM Media Advertising Policy
Communications of the ACM and otherACM Media publications accept advertisingin both print and electronic formats. Alladvertising in ACM Media publications isat the discretion of ACM and is intendedto provide financial support for the variousactivities and services for ACM members.Current Advertising Rates can be foundby visiting http://www.acm-media.org orby contacting ACM Media Sales at(212) 626-0686.
Single CopiesSingle copies of Communications of theACM are available for purchase. Pleasecontact [email protected].
COMMUNICATIONS OF THE ACM(ISSN 0001-0782) is published monthly
by ACM Media, 2 Penn Plaza, Suite 701,New York, NY 10121-0701. Periodicalspostage paid at New York, NY 10001,and other mailing offices.
POSTMASTERPlease send address changes toCommunications of the ACM 2 Penn Plaza, Suite 701New York, NY 10121-0701 USA
Printed in the U.S.A.
4 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 7/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 5
editor’s letter
Wikipedia defines Theoretical ComputerScience (TCS) as the “division or subset ofgeneral computer science and mathematicsthat focuses on more abstract or mathematical
aspects of computing.” This descrip-tion of TCS seems to be rather straight-forward, and it is not clear why thereshould be geographical variations in itsinterpretation. Yet in 1992, when YuriGurevich had the opportunity to spenda few months visiting a number of Eu-ropean centers, he wrote in his report,titled “Logic Activities in Europe,” that“It is amazing, however, how differentcomputer science is, especially theoret-ical computer science, in Europe and
the U.S.” (Gurevich was preceded byE.W. Dijkstra, who wrote an EWD Note 611 “On the fact that the Atlantic Oceanhas two sides.”)
This difference between TCS in theU.S. (more generally, North America)and Europe is often described by in-siders as “Volume A” vs. “Volume B,”referring to the Handbook of Theo-retical Computer Science, published in1990, with Jan van Leeuwen as editor.The handbook consisted of Volume A,focusing on algorithms and complex-
ity, and Volume B, focusing on formalmodels and semantics. In other words,
Volume A is the theory of algorithms, while Volume B is the theory of soft- ware. North American TCS tends tobe quite heavily Volume A, while Eu-ropean TCS tends to encompass both
Volume A and Volume B. Gurevich’sreport was focused on activities of the
Volume-B type, which is sometimes re-ferred to as “Eurotheory.”
Gurevich expressed his astonish-ment to discover the stark differencebetween TCS across the two sides of the
Atlantic, writing “The modern world isquickly growing into a global village.”
And yet the TCS gap between the U.S.and Europe is quite sharp. To see it,one only has to compare the programsof the two North American premierTCS conferences—IEEE Symposiumon Foundations of Computer Science(FOCS) and ACM Symposium on Theo-ry of Computing (STOC)—with that ofEurope’s premier TCS conference, Au-tomata, Languages, and Programming
(ICALP). In spite of its somewhat anach-ronistic name, ICALP today has threetracks with quite a broad coverage.
How did such a sharp division arisebetween TCS in North America and Eu-rope? This division did not exist prior tothe 1980s. In fact, the tables of contentsof the proceedings of FOCS and STOCfrom the 1970s reveal a surprisingly(from today’s perspective) high levelof Volume-B content. In the 1980s, thelevel of TCS activities in North Americagrew beyond the capacity of two annual
single-track three-day conferences, which led to the launching of what wasknown then as “satellite conferences.”Shedding the “satellite” topics allowedFOCS and STOC to specialize and devel-op a narrower focus on TCS. But this nar-rower focus in turn has influenced whatis considered TCS in North America.
It is astonishing to realize the term“Eurotheory” is used somewhat de-rogatorily, implying a narrow and eso-teric focus for European TCS. From myperch as Editor-in-Chief for Commu-nications, today’s spectrum of TCS is
vastly broader than what is revealed inthe programs of FOCS and STOC. Theissue is no longer Volume A vs. VolumeB or Northern America vs. Europe (orother emerging centers of TCS aroundthe world), but rather the broadening
gap between the narrow focus of FOCSand STOC and the broadening scopeof TCS. It is symptomatic indeed thatunlike the European Association forTheoretical Computer Science, ACMhas no Special Interest Group (SIG) forTCS. ACM does have SIGACT, a Spe-cial Interest Group for Algorithms andComputation Theory, but its narrowfocus is already revealed in its name. In2014 ACM established SIGLOG, “dedi-cated to the advancement of logic andcomputation, and formal methods in
computer science, broadly defined,”effectively formalizing the division ofTCS inside ACM.
This discussion is not of sociologicalinterest only. The North American TCScommunity has been discussing overthe past few years possible changes tothe current way of running its two con-ferences, considering folding FOCSand STOC into a single annual confer-ence of longer duration. A May 2015blog entry by Boaz Barak is titled “Turn-ing STOC 2017 into a ‘Theory Festival.’”
I like very much the proposed direc-tions for FOCS/STOC, but I would alsolike to see the North American TCScommunity show a deeper level of re-flectiveness on the narrowing of theirresearch agenda, starting with thequestion posed in the title of this edi-torial: Why doesn’t ACM have a SIG forTheoretical Computer Science?
Follow me on Facebook, Google+,and Twitter.
Moshe Y. Vardi, EDITOR-IN-CHIEF
Copyright held by author.
Why Doesn’t ACM Have a SIG forTheoretical Computer Science?
DOI:10.1145/2791388 Moshe Y. Vardi

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 8/100

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 9/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 7
cerf’s up
I am on a brief holiday in the U.K. visitingstately homes and manor houses in Cotswolds.If you have never had an opportunity to visitsome these incredibly large and elaborate
dwellings, you might give it some con-
sideration. What I have found most in-teresting is the mechanical ingenuityof our 16th- and 17th-century ancestors.
At one such mansion, I encountereda clever spit-turner before a huge fire-place driven by gravity. One pulled a
weight on a rope up to the ceiling andas the weight dropped, it turned a spit.The tricky bit was to control the rateof descent as to turn the spit slowly.
A rather clever gearing arrangementused a small gear to turn a larger one toachieve the desired effect.a Gears were
well known by then and used with wa-ter wheels and, of course, with clocks.
At the Folger Shakespeare Library in Washington, D.C., there is an exhibitof clocks made by John Harrisonb as
well as by others. Harrison is the fa-mous hero of Dava Sobel’s Longitude,c the story of the invention and refine-ment of the ship’s chronometer. Har-rison was in competition with theso-called Lunar Distance method ofestimating longitude. Edmund Hal-ley was the Astronomer Royal at that
time and strongly encouraged Harri-son’s work. After completing three seaclocks (H1–H3), Harrison concludedthat a compact watch could perform as
well or better. He designed his first sea
a I appreciated this design especially because asa young boy in the 1950s, I was designated toturn such a spit by hand in a large brick barbe-cue behind my home.
b https://en.wikipedia.org/?wiki/John_Harrisonc Sobel, D. Longitude: The True Story of a Lone Ge-
nius Who Solved the Greatest Scientific Problem
of His Time. Penguin, New York, 1995; ISBN0-14-025879-5.
watch (designated H4 now) and a voy-
age was undertaken in 1761 aboard theHMS Deptford from Portsmouth to Ja-maica and back. The watch performed
well but the Board of Longitude com-plained this might have been sheerluck and refused Harrison the £20,000prize that had been offered in the 1714Longitude Act. A second voyage wasundertaken to Bridgeport, Barbados
with Harrison’s son, William, onboard with H4. Also along on this voyage was the astronomer Reverend NevilMaskelyne, who carried out the calcu-
lations needed for the Lunar Distancemethod. Both methods worked fairly
well but Maskelyne became the Royal Astronomer on return from Barbadosand sat on the Longitude Board wherehe made a very negative report on theperformance of the watch. Maskelyne
was plainly biased and eventually Har-rison turned to King George III for as-sistance. You must read Sobel’s bookor watch the Granada dramatization tolearn the rest of the story!
There is so much history and drama
hidden in some of the mechanical de-signs in these ancient buildings. TheProtestant Reformation began in 1517
with the publication by Martin Lutherof his 95 theses. By the time of Henry
VIII, England was still Catholic but ow-ing to the refusal of the Pope to annulhis marriage to Catherine of Aragon,Henry persuaded the Parliament topass the Act of Supremacy in late 1534declaring Henry the supreme head ofthe Anglican Church. In 1540, the Cath-olic Church created the Jesuit Order tobattle the protestant movement. Jesuit
priests would be spirited across theEnglish Channel to be housed in statelyhomes of rich Catholic families. By thetime of Elizabeth I, it was illegal to prac-tice Catholicism in England and searchparties looking for Catholic priests werea regular feature of the time.
Many of the Catholic families hadhides built into their homes, spaces tohide priests and others simply to hide
valuables. At Harvington Hall, the man-
or house had many such hiding places.
d
Some were floorboards that could betilted to reveal spaces, sometimes stairsteps would lift up and in some cases,
wall timbers were actually mountedon axles to rotate if you knew where topush. The mechanical inventiveness ofthese hiding places was notable.
From the Harvington Hall article: In the late 16 th century, when the home
became part of a loose network of housesdedicated to hiding Catholic priests, Je-suit builder Nicholas Owen was sent to the
building to install a number of secret spotswhere they could be concealed, should theQueen’s men come calling.
Owen built little cubbies hidden be-hind false attic walls that could be ac-cessed through a fake chimney; a beamthat could flip up on an access pointrevealing a chamb er in the walls (whichwas only discovered 300 years later bysome children who were playing in thehouse); and, most elaborately, a secretroom hidden behind another hiddencompartment under a false stair. Smaller
compartments to hide the priests’ toolswere also built into the floors.
One could go on for many volumesabout the rich state of invention in thepast. In our computing world, inven-tion is still the coin of the realm, madeall the easier by evolving computing andnetworking platforms of the present.
d http://slate.me/1Jk1ISL
Vinton G. Cerf is vice president and Chief Internet Evangelistat Google. He served as ACM president from 2012–2014.
Copyright held by author.
InventionDOI:10.1145/2798333 Vinton G. Cerf

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 10/100
8 COMMUNICATIONS OF T HE ACM | AUGUST 2015 | VOL. 58 | NO. 8
etters to the editor
well-known questions about who ownsthe data, particularly when it is shared
in the interactions that characterize themodern Internet. Sales data and com-ments posted to friends’ social mediasites constitute examples of such data
where ownership is unclear, and evena photograph one takes can be consid-ered personal data of the people in thephoto. Moreover, while Abiteboul et al.mentioned the benefits of combiningand running analyses on data in one’spersonal repository, they did not ad-dress the more common task of how
to combine and analyze data from mil-lions of users of a service. Segregateddata in repositories maintained by itsindividual owners would protect thoseowners from the privacy violations ofbulk analyses but also introduce seri-ous hurdles for researchers looking toperform them.
Andy Oram, Arlington, MA
Help Kill a DangerousGlobal Technology Ban
Earlier this year, the Electronic FrontierFoundation launched “Apollo 1201,” aproject to reform Section 1201 of the1998 Digital Millennium Copyright Act,
which threatens researchers and de- velopers with titanic fines (even prisonsentences) for “circumventing” accessrestrictions (even when the access it-self is completely lawful) that stifle re-search, innovation, and repair. Worse,digital rights management, or DRM,
vendors claim publishing bug reportsfor their products breaks the law.
EFF has vowed to fix this.Law must not stand in the way of
adding legitimate functionality to com-puters. No technologist should facelegal jeopardy for warning users about
vulnerabilities, especially with tech-nology omnipresent and so intimatelybound up in our lives. People who un-derstand should demand an Internetof trustworthy things, not an Internetof vuln-riddled things pre-pwned forcriminals and spies.
Though the DMCA has been on thebooks since 1998, 1201 has hardly been
MEG LETA JONES’S Viewpoint“Forgetting Made (Too)
Easy” (June 2015) raisedan important concernabout whether the Court
of Justice of the European Union’sGoogle Spain judgment created anextra burden for data controllers likeGoogle and other search engines,though not clear is whether it is be-ing borne out or outweighs the privacygains for hundreds of millions of us-ers. She wrote Google “…is without anyguidance as to which interests should
trump others, when, and why.” Thisis not quite true. A number of guid-ing principles have been published,including from the Article 29 WorkingParty (the independent advisory bodyof representatives of the EuropeanData Protection Authorities that wouldarbitrate disputes under data-protec-tion law) and from Google’s own Ad-
visory Council. The European Union’sData Protection Directive also includesa number of defenses against and ex-emptions from data-protection com-
plaints. There is no reason to believe aclear set of principles will not emerge,especially as Google remains in closetouch with Data Protection Authorities,even if more complex cases demandclose and exhaustive inspection.
Google is meanwhile developing itsown jurisprudence; for example, along
with 79 other Internet scholars, I helped write an open letter to Google in May2015 (http://www.theguardian.com/technology/2015/may/14/dear-google-open-letter-from-80-academics-on-right-
to-be-forgotten) asking for more trans-parency, precisely to increase the public’sunderstanding of how the process is admin-istered, so researchers and other data con-trollers can learn from Google’s experience.
Moreover, there is no evidence ofa flood of frivolous “de-indexing” re-quests. Individuals do not “enforce”their right directly with the data con-troller; rather, they submit requeststhat can be turned down, and are.Google has fairly consistently rejectedabout 60% of such requests, with fewtaken further; for example, in the U.K.,
out of some 21,000 rejected requestsfor de-indexing as of June 2015, only
about 250 have been taken to the nextstep and referred to the U.K. Informa-tion Commissioner’s Office.
Also note the right to be de-indexedis not new but a right E.U. citizens havehad since the Data Protection Directive
was adopted by the European Unionin 1995. Surely the pursuit of this rightshould not have to wait for jurispru-dence to develop, especially as the ju-risprudence will emerge only if peoplepursue the right.
Kieron O’Hara, Southampton, U.K.
Author’s Response:The guidelines Article 29 Working Party
produced six months after the Court of
Justice of the European Union decision
(while welcome) are still incredibly vague,
point out how varied are the numerous
criteria EU member states must follow,
and raise additional sources of conflict
that deserve more debate and public
participation. As for terms like “Google
jurisprudence,” Google should have no jurisprudence. New rights in light of new
technology must be shaped carefully in an
international context, evolving through an
open, democratic process instead of the dark
corners of a detached intermediary.
Meg Leta Jones, Washington, D.C.
Who’s Digital Life Is It Anyway?Serge Abiteboul et al.’s Viewpoint“Managing Your Digital Life” (May2015) proposed an architecture for
preserving privacy while consolidatingthe data social media users and onlineshoppers scatter across multiple sites.However appealing one finds this vi-sion, which is similar to one I airedin an O’Reilly Radar article Dec. 20,2010 (http://oreil.ly/eX2ztY), a deeperlook at the ideal of personal data own-ership turns up complications thatmust be addressed before softwareengineers and users alike can hope toenjoy implementation of such a per-sonal information management sys-tem. These complications involve fairly
Not So Easy to ForgetDOI:10.1145/2797288

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 11/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 9
letters to the editor
rors and aborts. The purveyor of any ofthese programs cannot guarantee theprogress and safety properties of thesubsequent user-formed system willbe valid. Software developers and usersalike need the equivalent of the GoodHousekeeping Seal of Approval foreach vendor program, as well as a way
for users to assess the risks they createfor themselves when choosing to makeprograms interoperate. Moreover, us-ers must be able to do this each andevery time thereafter when anyone per-forms “maintenance” on a program ordataset in the user-specific ensemble.
Jack Ring, Gilbert, AZ
Communicationswelcomes your opinion. To submit aLetter to the Editor, please limit yourself to 500 words orless, and send to [email protected].
© 2015 ACM 0001-0782/15/08 $15.00
litigated, giving courts few opportuni-ties to establish precedents and pro-
vide clarity to computer scientists, en-gineers, and security researchers.
1201 advocates—mainly giant enter-tainment companies—pursue claimsonly against weak defendants. Whenstrong defendants push back, the other
side runs, as when a team led by Ed Felten(then of Princeton, now Deputy U.S.Chief Technology Officer) wrote a paperon a music-industry DRM called the Se-cure Digital Music Initiative (SDMI). TheRIAA threatened Felten and USENIX, at
whose August 2001 Security Symposiumthe paper was to be presented.
The Electronic Frontier Foundationtook Felten’s case, and the RIAA droppedthe threat and disavowed any intentionto pursue Felten over SDMI. It knew the
courts would reject the idea that recordexecutives get a veto over which techni-cal articles journals are able to publishand conferences can feature.
It is time to bring 1201’s flaws tocourt. EFF is good at it. One of its semi-nal cases, Bernstein v. United States,struck down the NSA’s ban on civilianaccess to crypto, arguing the code is aform of expressive speech entitled toFirst Amendment protection. EFF looksforward to proving that banning codestill violates the First Amendment.
That is where ACM members comein. EFF is seeking academic researchersand professors whose work is likely toattract threats due to 1201. If someonein your lab or department is working onsuch a project (or gave it up over fear oflitigation) EFF is interested in hearingabout it.
The legitimacy and perceived effi-cacy of 1201 is an attractive nuisance,inviting others to call for 1201-like pro-tections for their pet projects.
FBI Director James Comey has
called for backdoors on devices withencrypted file systems and communi-cations. As ACM members doubtlessunderstand, there is no way to sustaina backdoor without some legal prohi-bition on helping people install back-door-resistant code.
EFF is not just litigating against1201; working with a global networkof organizations, EFF is able to lobbythe world’s governments to rescindtheir own versions of 1201, lawspassed at the insistence of, say, theU.S. Trade Representative.
Time is running out. Please get intouch and help us help you kill 1201.
Cory Doctorow, London, U.K.
What Grounds forJahromi Release?
Jack Minker’s letter to the editor “Bah-
rain Revokes Masaud Jahromi’s Citi-zenship” (Apr. 2015) cited “attending arally on behalf of freedom” as an illegit-imate reason for the imprisonment ofsomeone he supports. All are in favor of“freedom,” of course, and would happi-ly attend rallies seeking such a univer-sal goal. But not all those seeking free-dom are laudable. Most prisoners andlawbreakers would like to have free-dom. Many terrorists call themselves“freedom fighters.” It is not enough to
proclaim innocence by saying a personis seeking freedom. It is necessary to bemore specific and comprehensive. Per-haps the person on whose behalf Mink-er advocates does indeed deserve to befree. But Minker’s description of theproblem was insufficient to convinceone that is the case.
Robert L. Glass, Brisbane, Australia
Author’s ResponseGlass assumes peaceful protesters (and
Jahromi perhaps imprisoned following a trialwith due process), as might be expected in
Australia. This is not the situation in Bahrain.
For a description of the repressive and
atrocious human rights situation in Bahrain,
see U.S. Department of State Universal
Periodic Reviews 2011–2015 (http://www.
state.gove/j/drl/upr/2015) and the report
of the Bahrain Independent Commission of
Inquiry (http://www.bici.org.bh).
Jack Minker, College Park, MD
Validity Seal of Approval forEvery ProgramLawrence C. Paulson’s letter to theeditor “Abolish Software Warranty Dis-claimers” (May 2015) on Carl Land-
wehr’s Viewpoint “We Need a BuildingCode for Building Code” (Feb. 2015)addressed only a minor factor in user-experienced angst. Any individual pro-gram includes few bugs on its own.But when a user invokes a suite of pro-grams, it is the logic, arithmetic, andsemantic incompatibilities among theprograms that result in system-level er-
Commonsense Reasoning
and Commonsense
Knowledge in Artificial
Intelligence
Bitcoin:
Under the Hood
Experiments as
Research Validation:
Have We Gone Too Far?
Theory Without
Experiments
Trustworthy Hardware from
Untrusted Components
Language Translation
at the Intersection
of AI and HCI
Plus the latest news aboutsensing emotions, the leapsecond, and new aggregators
for mobile users.
C o m i n g N e x t M o n t h i n C O M M U
N I C A T I O N S

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 12/100
10 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
Follow us on Twitter at http://twitter.com/blogCACM
The Communications Web site, http://cacm.acm.org,
features more than a dozen bloggers in the BLOG@CACM
community. In each issue of Communications, we’ll publishselected posts or excerpts.
Part of the problem is that generalCS faculty do not understand educa-tion research. In social sciences, de-
veloping an insight, a hypothesis, or a
“pre-theoretical” exploration is oftena lot of work, and it is a contributioneven before it is a theory, a model, oran intervention to improve some de-sired educational outcome.
A bigger problem is that we havemany different learning outcomes anddefinitions in computing education.I recently told a colleague at anotherinstitution about our BS in Computa-tional Media at the Georgia Instituteof Technology, which may be the mostgender-balanced ABET-accredited
computing program in the U.S. (seediscussion of enrollment at http://bit.ly/1IdgDR2, and of graduation rates athttp://bit.ly/1eNHsyE). The response
was, “That’s great that you have more women in computational media, but I want them in CS.”
The U.S. National Science Founda-tion (NSF) has been promoting twocomputer science courses in highschools across the country: ExploringCS (ECS, see http://www.exploringcs.org/) and the new Advanced Placementin Computer Science Principles (AP
CSP, see http://apcsprinciples.org/) .ECS and AP CSP are getting significantadoption across the U.S. Because highschool education is controlled by the
individual states (which may delegatecontrol down to the individual dis-tricts), not the federal government, itis difficult to make sure it is the samecourse in all those states. I am part ofan NSF Alliance that works with statesto improve their computing education(Expanding Computing EducationPathways Alliance, ECEP, http://ece-palliance.org/), and I am seeing statesstruggling with wanting to adopt ECSand AP CSP, but also wanting to fit thecourses to their values and needs.
In one state we work with in ECEP,the state decided to create its own ver-sion of Exploring CS. They kept allthe same technical material, but theyde-emphasized inquiry learning andequitable access to computing, in or-der to increase the technical content.They also wanted to ensure that allhigh school students learn about da-tabase systems, because that was im-portant for IT jobs in the state (theyare now reconsidering this decision).
In a couple of states, there will beCS Principles and AP CS Principles as
Mark Guzdial“The Babble ofComputing Education:Diverse Perspectives,
Confusing Definitions”http://bit.ly/1LFwTbTMay 22, 2015
Recruiting season for new faculty isdrawing to a close, and I felt a twingeof jealousy for non-education fields.
A robotics researcher can claim, “Myrobot is able to do this task fasterand more reliable than any other,”and a general computer science (CS)faculty audience can agree that taskis worth doing and doing better. AnHCI researcher can say, “People can
achieve this goal better and faster with my system,” and the general CSfaculty audience can see why that isimportant. When a computing educa-tion researcher says, “I now have newinsights into how people understandX,” the general CS faculty audienceoften does not know how to measurethe value of that insight. “But can thestudents program using X?” and “Canthey design systems using X?” and “Xis only important in domain Y, not inthe domain Z. How do you know if theycan work in domain Y?”
Plain Talk onComputing Education Mark Guzdial considers how the variety of learning outcomesand definitions impacts the teaching of computer science.
DOI:10.1145/2788449 http://cacm.acm.org/blogs/blog-cacm

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 13/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 11
blog@cacm
two different courses. One reason forthe difference will be the performancetasks in the AP CSP. The definition forthe new Advanced Placement exam inCS Principles will include evaluationof activities in the classroom, wherestudents describe code, create prod-ucts, and demonstrate that CS is a
creative and collaborative activity. Itis a great idea, but implementing ittakes time. The performance taskstake about 23 hours of classroomtime to complete. With practice forthe tasks (you would not want yourstudents to be evaluated on the firsttime they tried something), AP CSPmay cost a class 50 hours or more oftime, which might be spent on moreinstructional time.
Exploring CS was developed in high
school, but in some states is being ad-opted into middle schools. Middleschools differ even more dramaticallythan high schools. Some of the effortsto adopt ECS involve integrating it intomultidisciplinary science and math-ematics courses or units, which iscommon in the new Next GenerationScience Standards implementations(see California examples at http://bit.ly/1GjdgI1). A focus on equity incomputing is difficult to sustain whencomputing is just one of the several
disciplines integrated in the course. Isthe course still ECS then?
We have a babble of conflictinggoals, definitions, and learning out-comes around computing education.I regularly hear confusion among thestate education policymakers with
whom we work in ECEP: ˲ “Some people tell me that there’s
computer science without program-ming, and other people say program-ming is key to computer science.
Which is it?” ˲ “We go beyond programming in
our CS classes. In our first class, weteach students how companies man-age their IT customer service. Isn’tthat computer science? Why not?”
˲ “I want every student in my stateto know how to write SQL for Oracledatabase because that’s an important
job skill. Should I build that into ourstate’s version of ECS or our versionof CSP?”
˲ “The workers in our state needto learn applications and tools. I seethat in the job ads. I don’t see any-
body advertising for ‘computationalthinking.’”
˲ “Can you teach computer science
to our special needs students? To ourEnglish-Language Learner students?If you want to teach computer scienceto everyone, you have to cover every-one.”
˲ “Here’s our curriculum. What hasto go to make room for computer sci-ence?”
Just recently, the organization thatowns Advanced Placement, the Col-lege Board, struck partnerships withCode.org (http://usat.ly/1Q4is7b) and
with Project Lead the Way (PLTW,
http://bit.ly/1M265SG) to endorsetheir curricula for AP CS Principles.This is a major move to consolidate APCSP curricula. The whole purpose fordoing a new AP CS exam is to make itmore accessible, to get more schoolsto offer it, and to reach schools andstudents that did not previously haveaccess to CS education. If you werea principal of a school that never of-fered AP CS before and you have topick a curriculum, wouldn’t you picka College Board-endorsed curriculum
first? PLTW is expensive for schoolsto offer, unlike Code.org’s curricu-lum, which is free. Both offer teacherprofessional development (PD), butCode.org pays for part of their teacherPD. It is likely Code.org’s curriculum
will become the de facto standard forCS Principles.
That may be the right thing to growcomputing education. Diverse per-spectives are really valuable, but theyare also confusing. Most school ad-ministrators do not know what CS is.The College Board is not preventing
other CSP curricula. By backing a cou-ple of approaches, it becomes easierto figure out, “What is CS Principles?Ohhh—that’s CS Principles.” A littleless babble may go a long way towardincreasing access.
As a computing education re-searcher, I like the babble. I like many
different possibilities being exploredat once. I like a diversity of curricula,and schools with different values im-plementing the curricula in different
ways. As a computing education advo-cate, I understand the education sys-tem can only withstand so much bab-ble—especially at these early stages,
when computing is still misunder-stood. The teachers, principals, ad-ministrators, and policymakers whorun these systems need definitions to
help them understand computing. Itis difficult for computer scientists toagree on these definitions. Maybe theCollege Board and Code.org will do itfor us.
Many thanks to Barbara Ericson,Renee Fall, and Rick Adrion for com-ments and additions on this blog post.
While our work in ECEP is funded bythe U.S. NSF, the opinions expressedhere are my own and may not repre-sent NSF’s or the rest of ECEP’s.
CommentsIs there a de facto standard curriculum for
AP CSA? There does not seem to be one,
and that is probably good. AP CSA evolved
a lot over the years while AP CSP is brand
new. With code.org investing big in the
largest districts, I can see the temptation
to assume it will become the standard.
I suspect though that schools that already
have CS, especially CS without AP CSA,
may want to create their own to fit their
specific school environment. I
think (maybe hope is more accurate) that
some schools will want to experiment withdifferent tools, languages, and curriculum in
their version of AP CSP.
—Alfred Thompson
Mark Guzdial is a professor at the Georgia Institute ofTechnology.
© 2015 ACM 0001-0782/15/06 $15.00
“As a computingeducation researcher,I like the babble.I like many
different possibilitiesbeing exploredat once.”

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 14/100
SHAPE THE FUTURE OF COMPUTING.
JOIN ACM TODAY.
ACM is the world’s largest computing society, offering benefits and resources that can advance your career andenrich your knowledge. We dare to be the best we can be, believing what we do is a force for good, and in joiningtogether to shape the future of computing.
ACM PROFESSIONAL MEMBERSHIP:
q Professional Membership: $99 USD
q Professional Membership plus
ACM Digital Library: $198 USD ($99 dues + $99 DL)
q ACM Digital Library: $99 USD
(must be an ACM member)
ACM STUDENT MEMBERSHIP:
q Student Membership: $19 USD
q Student Membership plus ACM Digital Library: $42 USD
q Student Membership plus Print CACM Magazine: $42 USD
q Student Membership with ACM Digital Library plus
Print CACM Magazine: $62 USD
SELECT ONE MEMBERSHIP OPTION
q Join ACM-W: ACM-W supports, celebrates, and advocates internationally for the full engagement of women inall aspects of the computing field. Available at no additional cost.
Priority Code: CAPP
Name
ACM Member #
Mailing Address
City/State/Province
ZIP/Postal Code/Country
Purposes of ACM
ACM is dedicated to:
1) Advancing the art, science, engineering, and
application of information technology
2) Fostering the open interchange of information
to serve both professionals and the public
3) Promoting the highest professional and
ethics standards
Payment must accompany application. If paying by checkor money order, make payable to ACM, Inc., in U.S. dollarsor equivalent in foreign currency.
q AMEX q VISA/MasterCard q Check/money order
Total Amount Due
Credit Card #
Exp. Date
Signature
Return completed application to:ACM General Post OfficeP.O. Box 30777New York, NY 10087-0777
Prices include surface delivery charge. Expedited AirService, which is a partial air freight delivery service, isavailable outside North America. Contact ACM for moreinformation.
Payment Information
Satisfaction Guaranteed!
BE CREATIVE. STAY CONNECTED. KEEP INVENTING.
1-800-342-6626 (US & Canada)1-212-626-0500 (Global)
Hours: 8:30AM - 4:30PM (US EST)Fax: 212-944-1318
[email protected]/join/CAPP

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 15/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 13
Nnews
I M
A G E
C O U
R T E
S Y
O F
G O O G L E
R E
S E
A R C H
B L O G
Teaching Computerswith Illusions Exploring the ways human vision can be fooledis helping developers of machine vision.
Computers have already gottenpretty good at facial recognition, forexample, but they “will never under-stand the nuances we grasp right away
when we see a face and access all theinformation related to that face,’’ saysDale Purves, a neurobiology profes-sor at Duke University. People, on the
E
AR LI ER TH IS YE AR , debate overthe color of a dress set the In-ternet ablaze with discussionover why people were viewingthe same exact image, yet see-
ing it differently. Now throw comput-ers in the mix; unlike humans, who seecertain images differently, machinesregister and recognize visual images onanother level altogether. What humanssee is determined by biology, vision ex-perts say, while computers determine
vision from physical measurements. While the two fields can inform one
another, researchers say more workneeds to be done to teach computershow to improve their image recognition.
Those efforts are important be-
cause we want machines such as ro-bots to see the world the way we see it.“It’s practically beneficial,’’ says JeffClune, assistant professor and com-puter science director of the Evolving
Artificial Intelligence Lab at the Uni- versity of Wyoming. “We want robotsto help us. We want to be able to tellit to ‘go into the kitchen and grab myscissors and bring them back to me,’”so a robot has to be taught what akitchen looks like, what scissors are,and how to get there,” he says. “It hasto be able to see the world and the ob-
jects in it. There are enormous ben-efits once computers are really goodat this.”
Yet no matter how good machinesmight get at recognizing images, ex-perts say there are two things they arelacking that could trip them up: experi-ence and evolution.
Google’s winning entry in the 2014 ImageNet competition helps computers distinguishbetween individual objects.
Science | DOI:10.1145/2788451 Esther Shein

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 16/100
14 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
news
I M
A G E
B Y
A K I Y
O S H I
K I T
A O K A
ited information from the reality outthere and fill in the rest and take short-cuts and arrive at a picture that may notbe the perfect match with what’s outthere, but it’s good enough.”
One well-known example of an illu-sion humans and machines register dif-ferently is that of rotating snakes (http://
bit.ly/1IRuVDb). Martinez-Conde saysthe image is actually stationary, but ap-pears to move when viewed on paper,“because [of] the way our motion sen-sitivity circuits in the brain are put to-gether or work in such a way that when
you have a certain sequence [it] is inter-preted as motion, even though there’sno actual motion in the image.”
The human brain has vision neu-rons that specialize in detecting mo-tion, and that is what the majority of
people will see when they view the im-age, she says. However, age plays a rolein what people see as well.
Because the snake illusion is rela-tively new, what is still not well under-stood is why people who are about 40
years old or younger are more likely tosee motion, but those who are 50 yearsand older tend not to see it, Martinez-Conde notes. No one knows yet why themotor system experience changes aspeople age, she says. “The interestingthing is, the motor visual system dete-
riorates with age, and [yet] you tend tosee more reality than illusion. Seeing
motion in the [snake] illusion is a sign your visual system is healthy.”
Machine vision, on the other hand,is based on algorithms that can mea-sure items in the environment anduse them in driverless cars and else-
where, says Purves. Humans do nothave access to the same information
that machine algorithms dependupon for vision.
“We human beings … have a verydeep problem, being that we can’tget at the physical world because wedon’t have ways of measuring it withapparatus like laser scanners or radaror spectrophotometers, or other waysto make measurements of what’sphysically out there,’’ he says. Yet,“everyone admits we do better in facerecognition and making decisions
than machines do, using millions of years of evolutionary information” ona trial-and-error basis.
That does not stop people fromtrying to get humans and machinescloser to seeing the same illusions.Kokichi Sugihara, a mathematicianat Meiji University in Tokyo, has been
working on a program that will enablecomputers to perceive depth in 2Ddrawings. His interest is to “allow acomputer, by processing informationinput, to understand a 3D shape based
on a projection drawn with lines, he writes on the university’s website(http://bit.ly/1CAwz7F) .
“A computer often fails to recon-struct a 3D shape from a projectiondrawing and delivers error messages,
while humans can do this task veryeasily,’’ Sugihara writes. “We visualizea 3D object from a 2D drawing basedon the preconceived assumption thatis obtained through common senseand visual experience … however, thecomputer is not influenced by any as-
sumption. The computer examines ev-ery possibility in order to reconstructa 3D object and concludes that it is‘able to do it.’”
There are different methods thatcan be used to “fool” computer algo-rithms so what systems and humanssee is more closely aligned. One way toenhance artificial vision is to furtherstudy what our brains see, says Marti-nez-Conde. “We know, after all, they
work well enough and our visual sys-tem is pretty sophisticated, so having adeeper understanding of our visual sys-
other hand, “have a ton of informationbased on what that face means to us …and we immediately understand thebehavioral implications of a frown or asmile.” Getting to all that, he says, willbe a long struggle for machine vision“because machines so far don’t know
what’s important for behavioral suc-
cess in the world and what’s not.”In contrast, humans have grasped
those nuances based on millions of years of evolution, as well as individualexperience, Purves notes. “Many peo-ple have said in many elegant ways thatnothing in biology makes sense, exceptin the light of evolution. I think that’sexactly right. Machine vision fails torecognize that dictum.”
People are trying to get artificial sys-tems to see the world as it is, “whereas
for our brain, the way our nervous sys-tem evolved through the ages is notnecessarily to see the world as it is—it’sto see the world in a way that has madeour survival and our reproduction morelikely,’’ adds Susana Martinez-Conde,a professor and director of the Labora-tory of Integrative Neuroscience at theState University of New York (SUNY)Downstate Medical Center.
The human brain makes “a lot ofguesstimates,’’ explains Martinez-Conde, whose work focuses on visual
perception, illusions, and the neuro-logical basis for them. “We take lim-
The rotating snakes illusion, as presented by Ritsumeikan University professorAkiyoshi Kitaoka.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 17/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 15
news
plastic film that has static printed onit that is not visible to humans, butcould trick a facial recognition systeminto seeing an authorized securityagent instead of recognizing a knownterrorist,” Clune says.
While some believe one systemcould be fooled by certain images
whereas another system trained torecognize them would not be, sur-prisingly, that is not always the case,he says. “I can produce images withone network and show them to acompletely different network, and asurprising number of times the othernetwork is fooled by the same im-ages. So there really are some deepsimilarities in how these computernetworks are seeing the world.”
There is no good way yet to prevent
networks from being fooled by nefari-ous means, Clune says, but when thetechnology improves, “security holes
will be closed and they’ll becomesmarter and more effective,’’ he says.“They’ll also do a better job when theyencounter substantially different situ-ations than they were trained on.”
Today robots can be trained on onetype of image from the natural world,but if they encounter images that aretoo different, they break down andbehave in strange and bizarre ways,
Clune says. “They need to be able tosee the world and know what they’relooking at.”
Further Reading
Purves, D. and Lotto, R. B.Why We See What We Do: An Empirical
Theory of Vision. 2011 ISBN-10:0878935967
Macknik, S.L. and Martinez-Conde, S.Sleights of Mind: What the Neuroscienceof Magic Reveals About Our EverydayDeceptions. 2010 Henry Holt and Company,
LLC. ISBN: 978-0-8050-9281-3
Sugihara, K. (1986).
Interpretation of Line Drawing. MIT Press,Cambridge. http://www.evolvingai.org/publications
Nguyen, A., Yosinski, J., and Clune, J. (2015)Deep Neural Networks are EasilyFooled: High Confidence Predictions forUnrecognizable Images. In Computer
Vision and Pattern Recognition (CVPR ‘15),IEEE, 2015.
Esther Shein is a freelance technology and businesswriter based in the Boston area.
© 2015 ACM 0001-0782/15/08 $15.00
tem from a neuroscience perspectivecan be helpful to improving computer
vision.” She adds, however, that our visual system “is by no means perfect,so if we got to a point where computer
vision is almost as good, that wouldn’tmean the work is done.”
Humans have used natural selec-
tion to incorporate in the neural net- works in our brains every conceivablesituation in the world with visual input,says Purves. “Once computers do thatand evolve, in principal they should beas good as us, but it won’t be in visualmeasurements; they’re coming at [vi-sion] from a very different way. There’sgoing to be a limit that will never getthem to the level at which human be-ings operate.”
Yet machines can continue to be
improved. “If you want to make a re-ally good machine, evolve it’’ throughtrial-and-error experiences and bycompiling those experiences in theirartificial neural circuitry, says Purves.“There’s no reason that can’t be done;
you just have to feed them the infor-mation that we used to evolve a visualsystem.” He estimates that in 20 years’time, machine vision could be as goodas human vision, once vision scientistsare able to figure out how to evolve anartificial neural network to “survive” in
environments “that are as complicatedas the world we live in.”
“Humans and computers see things very differently, and there is a lot morefor us to do to figure out how these net-
works work,’’ agrees Clune. One trou-bling issue he addressed in a paper isthat if a computer identifies a random,static image as, say, a motorcycle, with100% certainty, it creates a securityloophole, he says. “Any time I could geta computer to believe an image is onething and it’s something else, there are
opportunities to exploit that to some-one’s own gain.”
For example, a pornography com-pany may produce images that appearto Google’s image filters like rabbits,but which contain advertisements
with nudity; or, a terrorist group couldget past artificial intelligence filterssearching for text embedded in im-ages by making those images appearto the AI as pictures of flowers, he ex-plains. Biometric security features arealso potentially vulnerable; “a terror-ist could wear a mask of transparent,
ACMMemberNewsTHE EXCITEMENT OFDATABASE SYSTEMS
Timos Sellis, aprofessor in theSchool ofComputerScience andInformationTechnology at
RMIT University in Melbourne, Australia, finds databasesystems exciting. “What attractsme most is the constantevolution to provide solutions topeople’s needs to manage dataof varying complexity, volume,and relationships.”
Sellis’ research focuses ondatabases, data management,and big data analytics. Hesays databases in the 1980sdealt mostly with financialdata, before coming to includeimages, geospatial data, andcomplex data from mobiledevices and sensors, giving riseto new analytic requirementsbased on new data typesand the increasingly diverseenvironments in which data isproduced.
After receiving anundergraduate degree in
engineering from the NationalTechnical University of Athens,Sellis earned a master’s degreein computer science fromHarvard University, and a Ph.D.in computer science from theUniversity of California, Berkeley.
In 2014, Sellis spearheadedthe launch of RMIT’s Data Analytics Lab, aimed at traininga new generation of big dataanalytics researchers. “We’repromoting an environment ofnetworking with other researchcenters, labs, and industrypartners, at the national and
international level,” he says.The lab applies analyticsto data from a broad rangeof industries, to foster theemergence of data value chains.“We’re looking holisticallyat user and text analytics, which have a huge potential totransform the efficiency andproductivity in many areas of theeconomy,” he explains. “Useranalytics in Smart Cities caninfer a person’s activity based ontheir spatiotemporal footprintin the city or in common areassuch as shopping malls, to offerpersonalized services.”
— Laura DiDio

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 18/100
16 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
news
I M
A G E
C O U
R T E
S Y
O F
B R I
S T
O L I
N T E
R A C T I
O N
A N D
G R A P H I
C S G R O U P
, U N I V E
R S I T Y
O F
B R I
S T
O L
Technology | DOI:10.1145/2788496 Logan Kugler
Touching the Virtual Feeling the way across new frontiersat the interface of people and machines.
air (https://youtu.be/H6U7hI_zIyU) . Waves of ultrasound displace the air,causing a pressure difference. Whenmultiple waves arrive at the sameplace simultaneously, a noticeablepressure difference is created at thatpoint. According to Long, “Touchableholograms, immersive virtual reality
(VR) that you can feel, and complextouchable controls in free space areall possible ways of using this system.”
The addition of a Leap Motion(https://www.leapmotion.com/) controller—an infrared sensor thattracks the precise position of a user’sfingers in 3D space—enables ultra-sound to be directed accurately at auser’s hands to produce the sensa-tion of touch, creating the impres-sion of exploring the surface of an ob-
ject, which enhances VR. The groupis working on using more complex
RESEAR CHER S HAVE BEEN hard at work redefining thehuman-machine interface,in particular looking at new
ways we can interact withcomputers through touch, without ac-tually touching something.
Holograms are not new technol-ogy, but there is a futuristic frisson sur-rounding the topic. A computer-gener-ated hologram is created by a sequence
of three-dimensional (3D) images thatare processed into a virtual image, a visual illusion. If you try to touch one, your hand will go through it.
What is new is the concept of touch-able holograms: not just projected intothe air, and not just superimposedonto an actual object, but “haptic ho-lograms” that you can not only touch,but interact with and move. Computerhaptics are the systems required—bothhardware and software—to render thetouch and feel of virtual objects. Haptic
holograms take this one step further: you can now “touch” a 3D projection, a virtual object, and actually feel it.
Haptic holograms create virtual ob- jects that have a digital interface, aninterface that is feel-able as well as visi-ble, by sculpting sound to make visibledigital features feel like physical ones.The virtual 3D haptic shape becomes atactile holographic display.
A Touching StoryThe skin covering the hand is packed
with receptors that communicatetactile feedback for light touch,heavy touch, pressure, vibration, hotand cold, and pain. This helps thebrain understand subtle tactile de-tails: smoothness, hardness, density,
weight, and so on.Ultrasound creates vibrations in the
air, projected at a set distance to matchthe surface of the hologram. The skin“feels” these vibrations at different wave-lengths to simulate softness/hardnessand more. This information enables a
virtual, 3D image to be “touched.”
To assist in the design and develop-ment of tactile interface applications,Marianna Obrist, a visiting researcherat Newcastle University and Lecturerin Interaction Design at the Universityof Sussex, and her colleagues createda tactile vocabulary of 14 categories ofhaptic feedback, such as prickly/tin-
gling, coming/going, and pulsing/flow-ing. “Pulsing” is a 16Hz vibration thatstimulates the Meissner’s corpuscle re-ceptors in the skin that are responsiblefor sensitivity to light touch.
Sriram Subramanian, professorof Human-Computer Interaction inthe Computer Science Departmentat Bristol University, co-directs theInteraction and Graphics Group. Thegroup, led by research assistant BenLong, developed the UltraHaptics(http://ultrahaptics.com/) system,
which creates haptic feedback in mid-
Ultrasound is focused to create the shape of a virtual sphere that may be felt.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 19/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 17
news
munication, measurement, and hu-man-machine interfaces. Accordingto Monnai, they anticipate guiding
human motions using the virtual im-age and force. “In our current system,users touch the hologram, but in fu-ture, it is also possible that the holo-gram touches users. This will enable,for example, having a virtual sportcoach who tells you how to move yourbody by stimulating you with visualand haptic sensations at the correcttiming and position.”
The haptic feedback in theirsystem is currently quite weak instrength. To present greater tactile
sensation, the Tokyo team has mod-ulated the temporal sequence of theforce, as vibration is felt more vividlythan stationary force, temporal se-quence, or a waveform (burst, contin-uous wave, or other). Monnai stressesthe importance of matching the sen-sation to the visual image, which ishampered by the lack of well-estab-lished guidelines for such design.The team continues to seek a way togenerate a stronger force, and Mon-nai says they intend to extend both
visual and tactile images from 2D to3D, and then they hope to design a 3Dtouchable hologram that allows forboth active and passive interaction.
Michael Page, an assistant professorin Toronto’s OCAD University facultyof art, currently is working on portingmedical and scientific data to the newgeneration of holographic technol-ogy, with some of the data being mul-tiplexed so it is interactive (touchable).His team created simulation tools formedical students, providing an auto-stereoscopic visual technology that
shapes with greater detail, possiblyby having a greater number of smallerspeakers to improve the resolution.
A key challenge, Subramanian ex-plains, is in “understanding in great-er detail how users perceive hapticfeedback with a mid-air haptic systemlike ours, which is able to target mul-
tiple mechanoreceptors simultane-ously. This will play an important rolein improving the fidelity of the tactilefeedback perceived.”
Subramanian envisions a range ofapplications for touchless haptics.This includes applications in automo-tive dashboards in which the user caninteract with the dashboard withouttaking their eyes off the road (for ex-ample, the user can wave their handin front of the dashboard to sense feel-
able knobs and dials). Another key application is in VR indeveloping lightweight, high-resolu-tion head-mounted displays. The Bris-tol group believes 3D haptics can play a“huge role” in increasing user immer-sion in VR games and applications.Their spin-off company, Ultrahaptics,is focusing on embedding the technol-ogy in a number of different productsranging from alarm clocks to home ap-pliances to cars.
Researchers at the University of To-
kyo, led by Hiroyuki Shinoda, createdthe Airborne Ultrasound Tactile Dis-play which, for example, allows a userto feel hologram raindrops bouncingoff their hands. Later, Yasuaki Mon-nai, project assistant professor of theuniversity’s Department of CreativeInformatics, and his colleagues atthe Shinoda-Makino Lab created a2D touchscreen floating in 3D. Hap-to-Mime (http://youtu.be/uARGRlp-CWg8) uses both ultrasound wavesand infrared sensors to give hands-
free tactile feedback. The interface isa virtual, holographic display on anultra-thin, floating reflective surface.Ultrasound exerts a mechanical force
where the beam is focused, which al-lows a virtual object, such as a pianokeyboard or an ATM number pad,to be felt, as changes in ultrasonicpressure give the illusion of differenttouch sensations.
The Tokyo team is particularlyinterested in electromagnetic wavepropagation and transmission sys-tems, applying them to wireless com-
The Bristol groupbelieves 3D hapticscan play a “hugerole” in increasing
user immersionin VR games andapplications.
projects 3D images without requiringthe viewer to wear glasses.
“Holograms are at the very top ofauto-stereoscopic volumetric viewingsystems. No other medium providesa higher sense of realism,” says Page.One big challenge is creating the“self-contained viewing system for
the holograms.”Sean Gustafson, a Ph.D. researcher
(who has since graduated) at the HassoPlattner Institute in Germany, workedon novel spatial interactive technology,such as placing an imaginary iPhoneon the palm of your hand. PatrickBaudisch and colleagues at PotsdamUniversity have continued this work toexplore other “imaginary interfaces”(screenless ultra-mobile interfaces),notably looking at tactile, spatial, vi-
sual, and sensed cues.Rather than optical illusions, Bau-disch and his team are now “bettingon the real thing” by working towarddeveloping personal fabricationequipment that works at interactiverates, ultimately in close to real time.Their WirePrint device, a collabora-tion between Hasso Plattner Insti-tute and Cornell University, prints3D objects as wireframe previews forfast prototyping by extruding fila-ments directly into 3D space instead
of printing layer-wise. As Baudisch ex-plains, “users interact by interactivelymanipulating the 3D shape of thedevice, while most of the know-howcomes from the machine, supportingusers in the process.”
Another approach is that of “datagloves.” As Patrik Göthe at ChalmersUniversity in Sweden says, “The nextparadigm of consumer technology ismostly about seamlessly moving thescreen interface to our surroundingsas holograms and projections.” His
concept is for a partial glove, coveringthumb and index finger, attached to the
wrist. It can interact with a holographickeyboard via touch-sensitive fingertips.
Haptic feedback in general is likelyto become mainstream. Apple has an-nounced its Force Touch trackpad onthe early 2015 MacBook Pro, declaredto be “a tour de force of engineering”by AppleInsider magazine (http://bit.ly/1FKi2bg). You will feel clicks as smalltaps on your finger. Pressure-sensing
APIs can also enable you to write yoursignature on the trackpad, with great-

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 20/100
18 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
news
CRA HONORSJAHANIAN, GATESThe Computing Research Association (CRA) has named
Farnam Jahanian, vice presidentfor research at Carnegie MellonUniversity (CMU), recipient of the2015 CRA Distinguished Service Award, bestowed upon one “whohas made an outstanding servicecontribution to the computingresearch community” ingovernment affairs, professionalsocieties, publications, orconferences, and whoseleadership “that has a majorimpact on computing research.”
Farnam has served as U.S.National Science Foundationassistant director for Computer &
Information Science & Engineering.He also has served as co-chair of
the Networking and InformationTechnology Research andDevelopment subcommittee of theNational Science and Technology
Council Committee on Technology.CRA also named Ann Quiroz
Gates, chair of the departmentof computer science at theUniversity of Texas at El Paso,to receive the 2015 A. NicoHabermann Award, bestowedupon individuals who have made“outstanding contributionsaimed at increasing thenumbers and/or successes ofunderrepresented groups in thecomputing research community.”
For over two decades,Gates has been a leader ininitiatives supporting Hispanics
and members of otherunderrepresented groups in
the computing field, includingleading the Computing Alliance of Hispanic-ServingInstitutions, and participating
in organizations including theSociety for Advancement ofHispanics/Chicanos and Native Americans in Science, theCenter for Minorities and People with Disabilities in IT, and the AccessComputing Alliance.
PAPADIMITRIOU RECEIVES2015 EATCS AWARDThe European Association forTheoretical Computer Science(EATCS) selected ChristosPapadimitriou, C. LesterHogan Professor of ElectricalEngineering and Computer
Science in the Computer Sciencedivision of the University of
California at Berkeley, to receivethe EATCS Award.
The organization saidPapadimitriou’s body of work
has had a profound and lastinginfluence on many areas ofcomputer science, contributing“truly seminal work” to fieldsincluding algorithmics,complexity theory, computationalgame theory, database theory,Internet and sensor nets,optimization, and robotics.
Papadimitriou also has written textbooks on thetheory of computation,combinatorial optimization,database concurrency control,computational complexity,and algorithms, helping
to inspire generations ofcomputer scientists.
Milestones
Computer Science Awards, Appointments
er pressure creating broader strokes.Haptic feedback is already integratedinto iMovie’s 10.0.7 update, and moreapps for OS X and other iOS devices areundoubtedly in the pipeline.
Touching the FutureTouchable 3D holograms can extend
the use of touch interaction to uncon- ventional situations. Here are somehands-on applications:
Real estate—The latest developmentsin haptic feedback enable potentialpurchasers to actually touch the tex-tures in a home when viewing a digitaltour: rough stone walls, smooth mar-ble, and so on. At the moment, thesetextures are only available on a sample-size scale, rather than as part of a life-
size set, but the technology is still auseful sales tool.
Medical examinations— When hapticholograms are combined with comput-erized tomography (CT), magnetic reso-nance imaging (MRI), and ultrasoundscans of an area of the body, surgeons
will be able to “feel” a tumor, for exam-ple, in advance of a live operation. Thistechnology is already available commer-cially from companies such as RealViewImaging in Israel, which has developed
medical holography for interventionalcardiology and diagnostic imaging.
Other potential applications in-clude: museum visitors holding ir-replaceable artifacts; sticky-fingeredchefs checking recipes; users avoidingthe germs invariably found on ATMkeypads and other public touch elec-
tronic devices, and visually impairedusers feeling their virtual interface.There is enormous potential for exploi-tation of the technology in the military,security, and education sectors, as wellas in the arts.
Light Years Ahead According to the January 2015 Holo-graphic Display Market report by Mar-ketsandMarkets, the touchable displaymarket will experience a compoundannual growth rate of more than 30% to
reach $3.57 billion by 2020. Research-ers feeling their way toward previously
Touchable 3Dholograms canextend the use oftouch interaction
to unconventionalsituations.
undreamed-of haptic hologram solu-tions should feel encouraged.
Further Reading
Gustafson, S. (2013).Imaginary interfaces. Doctoraldissertation, Hasso Plattner Institute,University of Potsdam.
http://bit.ly/1IL02DG
Gustafson, S., Holz, C., and Baudisch, P. (2011).
Imaginary phone: Learning imaginaryinterfaces by transferring spatial memoryfrom a familiar device. In Proceedings of
UIST 2011, 283-292.
http://bit.ly/1yuQ8Tu
Hoshi, T., Takahashi, M., Nakatsuma, N.,
and Shinoda, H. (2009).Touchable holography. Proceedings of
SIGGRAPH 2009.
http://bit.ly/1JKl4ju
Long, B., Seah, S.A., Carter, T.,
and Subramanian, S. (2014).Rendering volumetric haptic shapesin mid-air using ultrasound. ACM Transactions on Graphics, vol. 33.http://bit.ly/1DHqlrl
Obrist, M., Seah, S.A.,and Subramanian, S. (2014).Talking about tactile experiences.Proceedings of ACM CHI 2013 Conference
on Human Factors in Computing Systems (pp. 1659-1668). Paris, France.http://bit.ly/1yrnCln
Logan Kugler is a freelance technology writer based inTampa, FL. He has written for over 60 major publications.
© 2015 ACM 0001-0782/15/08 $15.00

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 21/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 19
news
I M
A G E
C O U
R T E
S Y
O F M E
R C E D E
S -
B E
N Z C A R S
Society | DOI:10.1145/2788477 Keith Kirkpatrick
The Moral Challengesof Driverless Cars Autonomous vehicles will need to decide on a course of actionwhen presented with multiple less-than-ideal outcomes.
create a system that can recognize babystrollers, shopping carts, plastic bags,and actual boulders, though today’s vi-sion systems are only able to make very
basic distinctions, such as distinguish-ing pedestrians from bicyclists.
“Many of the challenging scenariosthat an autonomous car may confrontcould depend on these distinctions,but many others are problematic ex-actly because there’s uncertainty about
what an object is or how many peopleare involved in a possible crash sce-nario,” Lin says. “As sensors and com-puting technology improves, we can’tpoint to a lack of capability as a way toavoid the responsibility of making an
informed ethical decision.” Assuming eventually these tech-
nical challenges will be overcome, it will be possible to encode and executeinstructions to direct the car how torespond to a sudden or unexpectedevent. However, the most difficult partis deciding what that response shouldbe, given that in the event of an im-pending or unavoidable accident, driv-ers are usually faced with a choice of atleast two less-than-ideal outcomes.
For example, in the event of an un-avoidable crash, does the car’s pro-
E VE RY TI ME A car heads outonto the road, drivers areforced to make moral and eth-ical decisions that impact notonly their safety, but also the
safety of others. Does the driver go fasterthan the speed limit to stay with the flowof traffic? Will the driver take her eyes
off the road for a split second to adjustthe radio? Might the driver choose tospeed up as he approaches a yellow lightat an intersection, in order to avoid stop-ping short when the light turns red?
All of these decisions have botha practical and moral component tothem, which is why the issue of allow-ing driverless cars—which use a combi-nation of sensors and pre-programmedlogic to assess and react to various situ-ations—to share the road with other
vehicles, pedestrians, and cyclists, has
created considerable consternationamong technologists and ethicists.
The driverless cars of the future arelikely to be able to outperform mosthumans during routine driving tasks,since they will have greater perceptiveabilities, better reaction times, and willnot suffer from distractions (from eat-ing or texting, drowsiness, or physicalemergencies such as a driver having aheart attack or a stroke).
“So 90% of crashes are caused, atleast in part, by human error,” says Bry-
ant Walker Smith, assistant professorin the School of Law and chair of theEmerging Technology Law Committeeof the Transportation Research Boardof the National Academies. “As danger-ous as driving is, the trillions of vehiclemiles that we travel every year meansthat crashes are nonetheless a rare eventfor most drivers,” Smith notes, listingspeeding, driving drunk, driving aggres-sively for conditions, being drowsy, andbeing distracted as key contributors toaccidents. “The hope—though at thispoint it is a hope—is that automation
can significantly reduce these kinds ofcrashes without introducing significantnew sources of errors.”
However, should an unavoidable
crash situation arise, a driverless car’smethod of seeing and identifying po-tential objects or hazards is differentand less precise than the human eye-brain connection, which likely will in-troduce moral dilemmas with respectto how an autonomous vehicle shouldreact, according to Patrick Lin, direc-tor of the Ethics + Emerging SciencesGroup at California Polytechnic StateUniversity, San Luis Obispo. Lin saysthe vision technology used in driverlesscars still has a long way to go before it
will be morally acceptable for use.“We take our sight and ability to dis-
tinguish between objects for granted,but it’s still very difficult for a com-puter to recognize an object as that ob-
ject,” Lin says, noting that today’s light-detection and ranging (LIDAR)-basedmachine-vision systems used on au-tonomous cars simply “see” numerical
values related to the brightness of eachpixel of the image being scanned, andthen infer what the object might be.
Lin says with specific training, iteventually will be technically feasible to

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 22/100
20 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
news
potential situations that can result in anaccident, it would seem resolving theseissues before driverless cars hit the roaden masse would be the only ethical wayto proceed. Not so, say technologists,noting unresolved ethical issues havealways been in play with automobiles.
“In some ways, there are ethical is-
sues in today’s products,” Smith says.“If you choose [to drive] an SUV, you areputting pedestrians at greater risk [ofinjury], even though you would believe
yourself to be safer inside, whether ornot that’s actually true.”
Further, a high degree of automa-tion is already present in vehicles onthe road today. Adaptive cruise control,lane-keeping assist technology, andeven self-parking technology is featuredon many vehicles, with no specific regu-latory or ethical guidelines for use.
In all likelihood, Google, Volkswa-gen, Mercedes, and the handful ofother major auto manufacturers thatare pressing ahead with driverless carsare unlikely to wait for ethical issues tobe fully resolved. It is likely basic tenets
of safe vehicle operation will be pro-grammed, such as directing the car toslow down and take the energy out of apotential crash, avoiding “soft” targetssuch as pedestrians, cyclists, or othersmaller objects, and selecting appro-priate trade-offs (choosing the colli-sion path that might result in the leastsevere injury to all parties involved inan accident) to be employed.
Another option to potentially deal with moral issues would be to cede con-trol back to the driver during periods of
congestion or treacherous conditions,so the machine is not required to makemoral decisions. However, this ap-proach is flawed: emergency situationscan occur at any time; humans are usu-ally unable to respond to a situation fastenough after being disengaged and, inthe end, machines are likely able to re-spond faster and more accurately thanhumans to emergency situations.
“When a robot car needs its humandriver to quickly retake the wheel, we’regoing to see new problems in the timeit takes that driver to regain enough
situational awareness to operate thecar safely,” Lin explains. “Studies haveshown a lag-time anywhere from a cou-ple seconds to more than 30 seconds—for instance, if the driver was dozingoff—while emergency situations couldoccur in split-seconds.”
This is why Google and others have
been pressing ahead for a fully autono-mous vehicle, though it is likely sucha vehicle will not be street-ready for atleast five years, and probably more. Thenavigation and control technology has
yet to be perfected (today’s driverlesscars tooling around the roads of Califor-nia and other future-minded states stillare unable to perform well in inclement
weather, such as rain, snow, and sleet,and nearly every inch of the roads usedfor testing have been mapped.)
Says Lin, “legal and ethical challeng-es, as well as technology limitations,are all part of the reason why [driver-less cars] are not more numerous oradvanced yet,” adding that industrypredictions for seeing autonomous
vehicles on the road vary widely, fromthis year to 2020 and beyond.
As such, it appears there is time formanufacturers to work through theethical issues prior to driverless carshitting the road. Furthermore, assum-ing the technological solutions can
provide enhanced awareness and safe-ty, the number of situations that re-quire a moral decision to be made willbecome increasingly infrequent.
“If the safety issues are handledproperly, the ethics issues will hope-fully be rarer,” says Handel.
Further Reading
Thierer, A., and Hagemann, R.,Removing Roadblocks to IntelligentVehicles and Driverless Cars, MercatusWorking Paper, September 2014,
http://bit.ly/1CohoV8
Levinson, J., Askeland, J., Becker, J.,
and Dolson, J.Towards fully autonomous driving: Systemsand algorithms, Intelligent Vehicles
Symposium IV (2011),
http://bit.ly/1BKd5A4
Ensor, J.,
Roadtesting Google’s new driverless car,The Telegraph, http://bit.ly/1x8VgfB
Keith Kirkpatrick is principal of 4K Research &Consulting, LLC, based in Lynbrook, NY.
© 2015 ACM 0001-0782/15/08 $15.00
gramming simply choose the outcomethat likely will result in the greatestpotential for safety of the driver and itsoccupants, or does it choose an option
where the least amount of harm is doneto any of those involved in an accident,such as having the car hit a telephonepole with the potential to cause the
driver a relatively minor injury, insteadof striking a (relatively) defenseless pe-destrian, bicyclist, or motorcycle rider,if the driver is less likely to be injured?
The answer is not yet clear, thoughthe moral decisions are unlikely to re-side with users, given their natural pro-pensity to protect themselves againsteven minor injuries, often at the ex-pense of others, Lin says.
“This is a giant task in front of theindustry,” Lin says. “It’s not at all clear
who gets to decide these rules. In a de-mocracy, it’s not unreasonable to thinkthat society should have input into thisdesign decision, but good luck in ar-riving at any consensus or even an in-formed decision.”
One potential solution would be thecreation and use of institutional reviewboards, which would compel autono-mous vehicle manufacturers to providepotential crash scenarios, explain whatits vehicles’ capabilities or responsesto those scenarios would be, and docu-
ment and explain why programmersmade those choices.
Jonathan Handel, a computer scien-tist turned lawyer, explains that ratherthan try to come up with hard-and-fastrules now, when driverless cars have
yet to interact on public roads outsideof tightly controlled testing runs, thesereview boards would provide a processto allow manufacturers, lawyers, ethi-cists, and government entities to workthrough these nascent, yet important,ethical decisions.
“I propose ethics review boards, or in-stitutional review boards,” Handel says.“I don’t think that we’re at a place in thistechnology, nor do I think we will be inthe first few years of it [being used], thatthere would be an obvious, one good an-swer to all these questions. For the eth-ics issue, I think we need a proceduralanswer, not a substantive one.”
He adds, “Eventually, consensusmay emerge organically on various is-sues, which could then be reflected inregulations or legislation.”
Given the near-infinite number of

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 23/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 21
Vviewpoints
I M
A G E F
R O M
S H U T T E
R S T
O C K
. C O M
Privacy and SecuritySecurity for Mobileand Cloud Frontiersin Healthcare Designers and developers of healthcare information technologiesmust address preexisting security vulnerabilities and undiagnosed
future threats.
The benefits of healthcare IT will beelusive if its security challenges are notadequately addressed. Security remainsone of the most important concernsin a recent survey of the health andmHealth sectors,12 and research has il-lustrated the risks incurred by cyber-at-tacks on medical devices such as pace-makers.5 More than two-thirds (69%) ofrespondents say their organization’s ITsecurity does not meet expectations for
FDA-approved medical devices.6 Privacy protection is also critical for
healthcare IT; although this columnfocuses on security, it should be notedthat many security breaches lead to dis-closure of personal information andthus an impact on patient privacy.
Critical Research ChallengesThe accompanying figure shows thecomplex trust relationships involved.Those who use medical information arediverse: families, clinicians, research-ers, insurers, and employers are some
I FEAR THE day when your securi-ty requirement kills one of my
patients,” said a medical
practitioner to the securityprofessionals proposing im-
proved security for the clinical infor-mation system. Every security profes-
sional is familiar with the challenge
of deploying strong security practices
around enterprise information sys-
tems, and the skepticism of well-in-
tentioned yet uncooperative stake-holders. At the same time, security
solutions can be cumbersome and
may actually affect patient outcomes.Information technology (IT) has great
potential to improve healthcare, prom-ising increased access, increased qual-ity, and reduced expenses. In pursuingthese opportunities, many healthcareorganizations are increasing their use ofmobile devices, cloud services, and Elec-tronic Health Records (EHRs). Insuranceplans and accountable-care organiza-tions encourage regular or even continu-
“
ous patient monitoring. Yet The Wash-ington Post found healthcare IT to be
vulnerable and healthcare organizationslagging behind in addressing knownproblems.9 Recent breaches at two ma-
jor health insurance companies1,7 under-score this point: the healthcare industrymoves toward automation and online re-cords, yet falls behind when addressingsecurity and privacy, ranking below retailin terms of cybersecurity.3
DOI:10.1145/2790830 David Kotz, Kevin Fu, Carl Gunter, and Avi Rubin

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 24/100
22 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
iewpoints
and whom will have access. Research-ers should develop new methods forauthentication, identification, dataanonymization, software assurance,device and system management—and
human factors should play a criticalrole in all of these methods. Some ofthe most-critical research challengesare described here.
Usable authentication tools. HealthIT presents many demanding prob-lems for users in authenticating them-selves to systems. Traditional authenti-cation mechanisms like passwords candisrupt workflow and interfere withthe primary mission of patient care.New authentication mechanisms mustblend into the clinical workspace, rec-ognize that staff often wear gloves and
masks (obviating solutions based onface and fingerprint recognition), and
work with smartphones, tablets, desk-tops, and laptops.
EHR systems should not arbitrarilylimit clinical staff from viewing an en-tire record—denying access in an emer-gency situation may lead to delayed
care or even death. However, “break-the-glass” provisions of many EHRs toprovide emergency access to patient re-cords make more information availablethan necessary for care. Break-the-glassmechanisms should expose patient re-cords in stages to provide needed infor-mation without providing too much in-formation, and trigger automated andorganizational audit mechanisms.
Patients are increasingly asked touse (or wear) mHealth technology out-
side the clinical setting, but might not want mHealth data to reveal detailedactivities. They might want to suspendreporting for periods of time, or blocksystems from storing or sharing datathat is not directly relevant to treatingtheir condition. Mechanisms shouldseparate data collection, analysis, and
presentation to limit data that travelsoutside the patient’s trust circle. Thesemechanisms should be easy to under-stand and use, indicating how datamay be collected, stored, and shared.
Fine-grained consent descriptionsshould interoperate across mHealthsystems and EHRs, and travel with datathat flows from one system to another.The foundation of any privacy-support-ing solution is a secure system withstrong mechanisms for identifying andauthenticating users.
The declining cost of gene se-quencing enables a new generationof precision medicine.11 Althoughthis technology has great promise,basic issues have yet to be handled:
how patients should access their owngenomic information, how they con-trol sharing with health profession-als, and how best to provide “direct toconsumer” services like support forgenealogy explorations.8
Trustworthy control of medical de- vices. Today’s sophisticated medicaldevices like infusion pumps and vital-sign monitors are increasingly net-
worked (possibly via the Internet) andrun safety-critical software. Network-capable medical devices may havecyber-security vulnerabilities that can
examples. Those who provide infor-mation are also diverse: traditional pa-tients, healthy athletes, children, the el-derly, and so forth. The mobile devicesand cloud systems are also diverse and
are often managed by multiple organi-zations. The result is a complex mix oftrust relationships with implicationsboth for technology and the social, eco-nomic, and regulatory environment in
which the technology operates.Designers and developers of health-
care information technologies canhelp by designing security into all de-
vices, apps, and systems, and by devel-oping policies and practices that recog-nize the rights of individuals regardinginformation collected on them: whereit will be stored, how it will be used,
The complex trust relationships involved in healthcare information technologies.
diversity of health subjects
person
actuatorssensors
mobiledevice
data
instructions,suggestions,
configurations
family, others
EHR orcloud service
clinical staff mobiledevice
diversity of information users
homegateway
d i v e r s i t y o f o w n
e r s h i p a n d m a n a g e m e n t
d i v e r s i t y o f
d e v i c e s a n d l o c a t i o n s

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 25/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 23
viewpoints
References1. Eastwood, B. Premera says data breach may affect
11 million consumers. FierceMobileHealthcare (Mar.18, 2015); http://www.fiercehealthit.com/story/premera-says-data-breach-may-affect-11-million-consumers/2015-03-18.
2. Fu, K. Trustworthy medical device software. In PublicHealth Effectiveness of the FDA 510(k) ClearanceProcess: Measuring Postmarket Performance and OtherSelect Topics. IOM (Institute of Medicine) WorkshopReport, National Academies Press, Washington, D.C.,
July 2011; https://spqr.eecs.umich.edu/papers/fu-trustworthy-medical-device-software-IOM11.pdf.3. Gagliord, N. Healthcare cybersecurity worse than retail:
BitSight. (May 28, 2014); http://www.zdnet.com/article/healthcare-cybersecurity-worse-than-retail-bitsight/.
4. Gunter, C.A., Liebovitz, D.M., and Malin, B. Experience-based access management: A life-cycle frameworkfor identity and access management systems. IEEESecurity & Privacy 9, 5 (Sept./Oct. 2011); DOI 10.1109/MSP.2011.72.
5. Halperin, D. et al. Pacemakers and implantable cardiacdefibrillators: Software radio attacks and zero-powerdefenses. In Proceedings of the IEEE Symposium onSecurity and Privacy (S&P). IEEE Press (May 2008),129–142; DOI: 10.1109/SP.2008.31.
6. Ponemon Institute. Third annual benchmark study onpatient privacy and data security (Dec. 2012); http://www.ponemon.org/local/upload/file/Third_Annual_Study_Patient_Privacy_FINAL5.pdf.
7. Millions of Anthem customers targeted in cyberattack.New York Times (Feb. 5, 2015); http://www.nytimes.com/2015/02/05/business/hackers-breached-data-of-millions-insurer-says.html.
8. Naveed, M. et al. Privacy in the genomic era.ACM Comput. Surv. 48 , 1, Article 6 (July 2015);DOI: http://dx.doi.org/10.1145.2767007.
9. O’Harrow, Jr., R. Health-care sector vulnerable tohackers, researchers say. Washington Post (Dec.2012); http://articles.washingtonpost.com/2012-12-25/news/36015727_1_health-care-medical-devices-patient-care.
10. Sametinger, J., Rozenblit, J., Lysecky, R., and Ott, P.Security challenges for medical devices. Commun.ACM 58 , 4 (Apr. 2015), 74–82; DOI 10.1145/2667218.
11. White House. FACT SHEET: President Obama’s PrecisionMedicine Initiative (Jan. 30, 2015); https://www.whitehouse.gov/the-press-office/2015/01/30/fact-sheet-president-obama-s-precision-medicine-initiative.
12. Whittaker, R. Issues in mHealth: Findings from key
informant interviews. Journal of Medical InternetResearch 14, 5 (May 2012); DOI 10.2196/jmir.1989.
David Kotz ([email protected])is a professorof computer science at Dartmouth College, principalinvestigator of the NSF-funded Trustworthy Health andWellness (THaW.org) project, and former director of theInstitute for Security, Technology, and Society (ISTS).
Kevin Fu ([email protected])is an associate professorof electrical engineering and computer science at theUniversity of Michigan, a member of the NIST InformationSecurity and Privacy Advisory Board, a member of theACM Committee of Computers and Public Policy, formerORISE Fellow at the FDA, and director of the ArchimedesCenter for Medical Device Security.
Carl Gunter ([email protected])is a professor ofcomputer science, a professor in the College of Medicine,and the director of the Illinois Security Lab and the HealthInformation Technology Center at the University ofIllinois, Urbana.
Avi Rubin ([email protected]) is a professor of computerscience and technical director of the Information SecurityInstitute at Johns Hopkins University, and principalinvestigator of one of the first NSF CyberTrust centers(on e-voting).
This research program is supported by a collaborativeaward from the National Science Foundation (NSF awardnumbers CNS-1329686, 1329737, 1330142, and 1330491).The views and conclusions contained in this materialare those of the authors and should not be interpretedas necessarily representing the official policies, eitherexpressed or implied, of NSF. Any mention of specificcompanies or products does not imply any endorsementby the authors or by the NSF.
Copyright held by authors.
have implications for patient safety.Medical devices must contain defensesagainst today’s known vulnerabilitiesand tomorrow’s anticipated threats.2
Medical devices must defendagainst conventional malware thatattacks their outdated operating sys-tems. For example, Conficker and bot-
net malware can break into unmain-tained systems easily; old operatingsystems provide large reservoirs forthe Conficker worm, and medical de-
vices can have long product life cyclesthat persist with outdated operating-system software. MRI machines run-ning Windows 95, pacemaker pro-grammers recently upgraded fromOS/2 to Windows XP, and pharmaceu-tical compounders running WindowsXP Embedded have been noted.
Medical devices must also with-stand threats that match the futureproduct life cycle, but it is difficult tosecure a device for 20 years. The 1995desktop computer could not withstandtoday’s threats of spam, malware,drive-by-downloads, and phishing at-tacks. It is difficult to design medicaldevices for evolving threats. Accord-ing to the Veterans Administration,modern malware can enter via USBdrives used by contractors upgradingmedical-device software. Better meth-
ods are needed to engineer securesoftware and ensure the correct soft-
ware is running. Improvements areneeded for detecting attempted net-
work attacks (wired or wireless), andfor dealing with attacks in progress
without compromising patient safety.Solutions aimed at desktop computersand Internet servers might not workfor medical devices. For more on thistopic, see the recent Communications article by Sametinger et al.10
Trust through accountability.
Health IT provides a foundation fordiagnosis, treatment, and other medi-cal decision making. This foundationmust be both dependable and trust-worthy. Technical security is essen-tial, but trust also critically dependson social, organizational, and legalframeworks behind the technology.Health IT must be accountable, whichmeans people and organizationsmust be held responsible for the waysthe systems are used. Systems config-ured to provide access to many mustbe backed by responsible organiza-
tions that determine who has accessand when. “Break-glass” mechanismsmust be guided by protocols about
who can break the glass, and for whatpurpose.
Audit logs of all health IT systemsare needed to monitor for buggy or in-appropriate behavior, and to supportpost-event analysis as well as the de-
velopment of proper access controls.4 There has been considerable study ofaudit logs and accountability for hospi-tal patient records, but mobile systemsand devices also need rigorous audit-ing. Automated analysis of audit logsin medical systems would be useful, as
would be the ability to detect anomalies(such as staff members looking at rarely
examined records or device settingschanged by a person not normally givenaccess to the device). Access restrictionsshould be imposed according to work-flow data and/or models trained via ma-chine learning to diminish reliance onpost-hoc accountability. There are manyresearch opportunities in this space.
ConclusionThe research community must ad-dress many fundamental and practicalchallenges to enable healthcare IT to
achieve the level of security essentialfor widespread adoption and success-ful deployment. For doctors and othercaregivers to embrace more secure so-lutions, they need to be usable and fit
within their clinical workflow. For pa-tients and family members to acceptthese technologies, they need to becomfortable with the privacy of theirpersonal information and able to ef-fectively use the security solutions thatsupport those privacy mechanisms.
We call on the research community totackle these challenges with us.
The benefitsof healthcare ITwill be elusive if itssecurity challenges
are not adequatelyaddressed.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 26/100
24 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
I M
A G E
B Y
S Y D
A P
R O D U
C T I
O N S
Economic andBusiness DimensionsPermissionlessInnovation Seeking a better approach to pharmaceuticalresearch and development.
tem, which allows anyone to access the
code, he saw an opportunity. He gaveaway Goldcorp geological data going
back to 1948 and challenged the world
to find gold in his data. The world did.
New models for discerning ore, visual-
izing veins, and improving extraction
were submitted, along with 110 sitesto look for gold at Red Lake—half of
them unknown to Goldcorp. Stock pur-
chased a year before and sold a year af-ter McEwan’s decision tripled in value.
Goldcorp gave permission and in-centives. It paid out $565 million, itshighest payout to two collaborating
PERMISSIONLESS INNOVATION,” IS the freedom to explore newtechnologies or businesses
without seeking prior approv-al.14 It has already produced
an explosion of goods and services inthe IT industry.14 Vint Cerf, a father ofthe Internet, invokes it when he arguesthe Web must remain open.4 It is cousin
to the end-to-end principle of placingapplication-specific functions at endpoints, where others can build, ratherthan in the core.11 It improves efficiencyand moves innovation closer to people
with ideas.3 Hundreds of thousands ofiOS and Android apps were not createdby Apple or Google, but by permission-less innovation made possible by pub-lished APIs (application programminginterfaces) and resulting market evolu-tion. It facilitates experimentation inparallel: actors launch their own experi-
ments without depending on the resultsof others. Permissionless innovationgreatly increases the speed of inventionand allows the ecosystem to provideideas its system designers never had.1
The pharmaceutical industry couldbenefit from this approach. A success-ful new drug can cost upward of $800million.5,6 Uncertainty about winningpatent races means firms race to secureintellectual property rights. Competi-tors need patent shears to trim patentthickets.5,6 Yet the awful expense ofmaintaining IP creates abandonment
“
problems due to the lag between costs
and revenues. Innovation slows8 while,ironically, only 8% of pharma firms mea-sure the value of their orphan patents.2
Industries outside the IT sector haveshown the benefit permissionless in-
novation. One example is the Cana-
dian firm Goldcorp, written off by ana-lysts due to debt and high production
costs.12 After decades of use, Goldcorp’s
Red Lake mine was underperforming.In-house geologists could not locate
further gold deposits. When Goldcorp
CEO Rob McEwan heard an MIT pre-sentation on the Linux operating sys-
DOI:10.1145/2790832 Henry Chesbrough and Marshall Van Alstyne
Vviewpoints

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 27/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 25
viewpoints
Australian teams that had never visitedthe mines. But Goldcorp retained aneconomic complement, deeds to the 55acres of Red Lake mines. Any increasesin value applied directly to Goldcorp’sassets. Permissionless innovationopened new insights that comple-mented Goldcorp’s assets in the same
way that Apple and Google openingtheir APIs added value to their operat-ing systems. McEwan did not give awaythe business, he gave away permissionto help find gold on his property.
Pharmaceutical firms can do thesame with their tapped-out mines.FDA review effectively handles Type 1errors, or false positives, such that un-safe, ineffective drugs seldom reachmarket. However, Type 2 errors—falsenegatives with more promise than their
owners realize—can be the abandoned veins of hidden gold. Viagra could havebeen one of these. It showed limitedpromise as a hypertension drug, but themen in the treatment group refused toreturn their samples at the end of hu-man trials, and treatment for erectiledysfunction has never the same. Simi-larly, Eli Lilly discovered the antibioticCubicin in the 1980s but abandonedit because it was too toxic to patients.
After licensing, a small unrelated firmdeveloped effective methods to poison
bacteria without poisoning people,and Cubicin became a front-line treat-ment against antibiotic-resistant or“super bug” staphylococcus—the mostsuccessful intravenous antibiotic everlaunched in the U.S.7 The value of Vi-agra and Cubicin came from the will-ingness to be innovative in ways notoriginally foreseen, to open innovationto outsiders and get value from what
would otherwise be false-negatives.The explosion of innovation in the
IT industry comes from modulariza-
tion of complex technologies and APIsto enable outsiders to access technolo-gies without asking for permission.Modular technologies can allow firmsto benefit from innovations of others bycreating a platform that connects theseelements together in useful, distinctive
ways. They separate the core technol-ogy of a firm from extensions outsidea firm as a governance model for in-novation. They direct external partiesto make contributions that are invitedand welcomed. They help the platformowner benefit from third-party innova-
tion by clarifying rules without requir-ing face-to-face interaction in advance.
New emerging rules apply to plat-forms that promote innovation.9 Craft-
ing technology to protect closed parts
benefits from open access like APIs so
others can use the technology withoutknowing what is inside it. Donating
technological assets to a commons orproviding subsidy for open technology(APIs and SDKs or software develop-
ment kits) can retain ownership overcomplementary assets one wishes to
monetize.13 Encouraging entry into
the open part of the technology lets athousand flowers bloom and does not
prevent selectively pricing access to the
closed part of the platform. The open
source dictum “with many eyes, allbugs are shallow”10 has a counterpart in
open innovation: with open APIs moreingenuity is possible. The platform
owner can observe external contribu-
tions that become popular in the mar-ket, but they must not grab too much of
this new wealth for themselves. Third-
party extensions make the platformmore valuable for customers and more
attractive for future innovators to drive
even further innovation. This happensonly if one does not confiscate what
other people build. Successful plat-
forms partner with innovators to share
the wealth, buy them at a fair price, orgrant them a grace period to collect
their rewards. For example, enterprisesoftware firm SAP outlines its future
projects in a public two-year roadmap
to let external parties know where tobuild, and what to avoid, in order to
pursue opportunities in the platform’s
ecosystem.9
So how do we apply this to pharma-
ceuticals, which are complex and wherepartitioning is challenging? Separating
the process into open and closed do-
mains and stimulating permissionlessinnovation in the open arena is a start.
Like Goldcorp, a pharma company can
provide open access to preclinical and
clinical data on a particular compound,and award prizes for third parties who
determine the best diseases to target,
or which variations to pursue. Assaysto proxy therapeutic benefit might be
shared widely, and compounds with
“hits” (signs of positive activity) canbecome a part of negotiation for de-
velopment. Computational models ofparticular compounds can be shared.
Calendarof Events August 7–9HPG ‘15: High PerformanceGraphics,
Los Angeles, CAContact: Steven MolnarEmail: [email protected]
August 7–9SCA ‘15: The ACM SIGGRAPH/Eurographics Symposium onComputer Animation,Los Angeles, CA,Contact: Jernej Barbic,Email: [email protected]
August 8DigiPro ‘15: The DigitalProduction Symposium,Los Angeles, CA,
Sponsored: ACM/SIG,Contact: Eric EndertonEmail: [email protected]
August 8–9SUI ‘15: Symposium onSpatial User Interaction,Los Angeles, CA,Co-Sponsored: ACM/SIG,Contact: Amy C. BanicEmail: [email protected]
August 9–13ICER ‘15: InternationalComputing EducationResearch Conference,
Omaha, NE,Sponsored: ACM/SIG,Contact: Brian Dorn,Email: [email protected]
August 9–13SIGGRAPH ‘15: Special InterestGroup on Computer Graphicsand Interactive TechniquesConference,Los Angeles, CA,Sponsored: ACM/SIG,Contact: Marc BarrEmail: [email protected]
August 17–21
SIGCOMM ‘15: ACM SIGCOMM2015 Conference,London, UK,Sponsored: ACM/SIG,Contact: Steve Uhlig Email: [email protected]
August 25–28MobileHCI ‘15: 17th InternationalConference on Human-Computer Interaction withMobile Devices and Services,Copenhagen, Denmark,Sponsored: ACM/SIG,Contact: Enrico Rukzio,Email: [email protected]

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 28/100
26 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
iewpoints
bipolar disorder, depression, and neu-ropathic pain. Drugs developed for oneuse are used for different conditions,as with Viagra. Drug development costsand the narrowing market focus createareas where permissionless innovationmakes sense. Independent researchersare already looking for new diseases to
target, using data and compounds ofpharma companies.
Think of permissionless innova-tion as a complement to traditionalresearch and development. Everythingdone to discover new drugs can still bedone, but permissionless innovationadds access and incentive so third par-ties contribute to solving challengesthat lie beyond the capacity of tradi-tional pharma firms. Ecosystems canrejuvenate research and development.
Through better governance, open in-novation, and strategic platform man-agement, smart firms can have thou-sands of partners innovate on their IPbut on their terms and without priorpermission. The future is open.
References1. Andreesen, M. The three kinds of platform you meet
on the Internet (Sept. 16, 2007); http://pmarchive.com/three_kinds_of_platforms_you_meet_on_the_internet.html.
2. Arora, A., Fosfuri, A., and Gambardella, A. Marketsfor Technology: The Economics of Innovation andCorporate Strategy. MIT Press, 2001.
3. Baldwin, C. and Clark, K. Design Rules. MIT Press,Cambridge, MA, 2001.
4. Cerf, V. Keep the Internet open. New York Times(May 24, 2012); http://www.nytimes.com/2012/05/25/opinion/keep-the-internet-open.html.
5. Chesbrough, H. Open Innovation: The New Imperativefor Creating and Profiting from Technology. HBS Press,Boston, MA, 2003.
6. Chesbrough, H. Why companies should have openbusiness models. MIT Sloan Management Review 48 ,2 (2012).
7. Chesbrough, H.W. and Chen, E.L. Recovering abandonedcompounds through expanded external IP licensing.California Management Review 55 , 4 (Apr. 2013), 83–101.
8. Hargreaves, I. Digital opportunity: A review ofintellectual property and growth. An independentreport. 2001.
9. Parker, G. and Van Alstyne, M. Innovation, openness,and platform control. Mimeo: Boston University (2015).http://ssrn.com/abstract=1079712.
10. Raymond, E. The Cathedral and the Bazaar. O’Reilly, 1999.
11. Saltzer, J.H., Reed, D.P., and Clark, D.D. End-to-endarguments in system design. ACM Transactions onComputer Systems (TOCS) 2, 4 (1984), 277–288.
12. Tapscott, D. and Williams, D.A. Innovation in the ageof mass collaboration. Business Week (Feb. 1, 2007).
13. Teece, D. Profiting from innovation. Research Policy , 1986.14. Thierer, A. Permissionless Innovation: The Continuing
Case for Comprehensive Technological Freedom.Mercatus Center at George Mason University, 2014.
Henry Chesbrough ([email protected]) is a professor at UC Berkeley’s Haas Business School.He is the author of Open Innovation, and five otherinnovation books.
Marshall Van Alstyne ([email protected]) is a professor ofinformation economics at Boston University, a visitingprofessor at the MIT Initiative on the Digital Economy,and coauthor of Platform Revolution; Twitter: InfoEcon.
Copyright held by authors.
Companies still can retain the pat-
ents. Drug companies already partition
rights to IP for research, field of use,geographic region, or preset conditions
such as royalties. A “part open, part
closed” governance structure permitspharma companies to invite others to
examine compounds and data and run
experiments without prior permission.
We already see this in practice when cli-
nicians use “off label” drugs to treat un-
met medical needs. Drugs approved bythe FDA for one treatment sometimes
work for another.
If a pharma company controls theplatform, why would others play?Pharma companies might keep thebest drugs closed, opening only the
least attractive. They can use platformsthat are too closed and do not attractpermissionless innovative activity. Weargue that third parties are sophisti-cated enough to differentiate betweenopportunity and lip service. Why pre-sume that pharma companies have allthe ideas? They do not know everythingoutside their core technologies andmarkets. Third parties with special-ized knowledge can find opportunitiespharma companies miss, just like oth-ers found veins of gold missed by Gold-
corp. Specialty companies can seekniche markets unattractive to largecompanies. Mission-oriented nonprof-its with humanitarian motives can lifteconomic restrictions when lookingfor therapies. In permissionless inno-
vation, all have a role to play.Turning things around, why would
pharma companies willingly opentechnology, data, and IP? Pharma com-panies are increasingly specialized bydisease, but their compounds mighthave benefits in other areas. Epilepsydrugs, for example, are prescribed for
Think ofpermissionlessinnovation as acomplement to
traditional researchand development.
Call forNominationsfor ACMGeneral Election
The ACM NominatingCommittee is preparingto nominate candidatesfor the officers of ACM:President,Vice-President,Secretary/Treasurer;and fiveMembers at Large.
Suggestions for candidates
are solicited. Names should be
sent by November 5, 2015 to the Nominating Committee Chair,
c/o Pat Ryan,
Chief Operating Officer,
ACM, 2 Penn Plaza, Suite 701,New York, NY 10121-0701, USA.
With each recommendation,
please include backgroundinformation and names of individuals
the Nominating Committee
can contact for additional
information if necessary.
Vinton G. Cerf is the Chair
of the Nominating Committee,
and the members areMichel Beaudouin-Lafon,
Jennifer Chayes, P.J. Narayanan,
and Douglas Terry.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 29/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 27
Vviewpoints
Article development led byqueue.acm.org
I M
A G E
B Y
A -
I M
A G E
DOI:10.1145/2790834 George V. Neville-Neil
Kode ViciousHickory Dickory DocOn null encryption and automated documentation.
how much the company would save onmedical bills if everyone had a cush-ioned wall to bang their heads against,
instead of those cheap, pressboarddesks that crack so easily.
Having a set of null crypto methodsallows you and your team to test twoparts of your system in near isolation.Make a change to the framework and
you can determine if that has sped upor slowed down the framework overall.
Add in a real set of cryptographic op-erations, and you will then be able tomeasure the effect the change has onthe end user. You may be surprised tofind that your change to the frameworkdid not speed up the system overall, as
Dear KV,
While reviewing some encryption codein our product, I came across an optionthat allowed for null encryption. Thismeans the encryption could be turnedon, but the data would never be en-crypted or decrypted. It would alwaysbe stored “in the clear.” I removed theoption from our latest source tree be-cause I figured we did not want an un-suspecting user to turn on encryptionbut still have data stored in the clear.One of the other programmers on myteam reviewed the potential change
and blocked me from committing it,saying the null code could be used fortesting. I disagreed with her, since Ithink the risk of accidentally using thecode is more important than a simpletest. Which of us is right?
NULL for Naught
Dear NULL,I hope you are not surprised to hearme say that she who blocked yourcommit is right. I have written quite
a bit about the importance of testingand I believe that crypto systems arecritical enough to require extra atten-tion. In fact, there is an important rolethat a null encryption option can playin testing a crypto system.
Most systems that work with cryp-tography are not single programs, butare actually frameworks into whichdiffering cryptographic algorithmscan be placed, either at build or run-time. Cryptographic algorithms arealso well known for requiring a greatdeal of processor resources, so much
so that specialized chips and CPUinstructions have been produced toincrease the speed of cryptographic
operations. If you have a crypto frame- work and it does not have a null opera-tion, one that takes little or no timeto complete, how do you measure theoverhead introduced by the frame-
work itself? I understand that estab-lishing a baseline measurement isnot common practice in performanceanalysis, an understanding I havecome to while banging my fist on mydesk and screaming obscenities. I of-ten think that programmers shouldnot just be given offices instead ofcubicles, but padded cells. Think of

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 30/100
28 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
iewpoints
says it does X!,” is not what you wantto hear yourself screaming after hoursof staring at a piece of code and itsconcomitant comment.
Even with a semiautomatic docu-mentation extraction system, you stillneed to write documentation, as an
API guide is not a manual, even for the
lowest level of software. How the API’sdocumentation comes together toform a total system and how it shouldand should not be used are two impor-tant features in good documentationand are the things that are lacking inthe poorer kind. Once upon a time I
worked for a company whose product was relatively low level and technical. We had automatic documentationextraction, which is a wonderful firststep, but we also had an excellent doc-
umentation team. That team took theraw material extracted from the codeand then extracted, sometimes gentlyand sometimes not so gently, the req-uisite information from the company’sdevelopers so they could not only editthe API guide, but then write the rel-evant higher-level documentation thatmade the product actually usable tothose who had not written it.
Yes, automatic documentation ex-traction is a benefit, but it is not theentire solution to the problem. Good
documentation requires tools and pro-cesses that are followed rigorously inorder to produce something of valueboth to those who produced it and tothose who have to consume it.
KV
Related articles
on queue.acm.org
API: Design Matters
Michi Henninghttp://queue.acm.org/detail.cfm?id=1255422
Microsoft’s Protocol DocumentationProgram: Interoperability Testing at ScaleA Discussion with Nico Kicillof,Wolfgang Grieskamp, and Bob Binder
http://queue.acm.org/detail.cfm?id=1996412
Kode Vicious vs. Mothra!George Neville-Neil
http://queue.acm.org/detail.cfm?id=1066061
George V. Neville-Neil ([email protected]) is the proprietor ofNeville-Neil Consulting and co-chair of the ACM Queueeditorial board. He works on networking and operatingsystems code for fun and profit, teaches courses onvarious programming-related subjects, and encouragesyour comments, quips, and code snips pertaining to hisCommunications column.
Copyright held by author.
it may be the overhead induced by theframework is quite small. But you can-not find this out if you remove the nullcrypto algorithm.
More broadly, any frameworkneeds to be tested as much as it can bein the absence of the operations thatare embedded within it. Comparing
the performance of network socketson a dedicated loopback interface,
which removes all of the vagaries ofhardware, can help establish a base-line showing the overhead of the net-
work protocol code itself. A null diskcan show the overhead present in file-system code. Replacing database calls
with simple functions to throw awaydata and return static answers to que-ries will show you how much overheadthere is in your Web and database
framework.Far too often we try to optimize sys-tems without sufficiently breakingthem down or separating out the parts.Complex systems give rise to complexmeasurements, and if you cannot rea-son about the constituent parts, youdefinitely cannot reason about the
whole, and anyone who claims theycan, is lying to you.
KV
Dear KV, What do you think of systems such asDoxygen that generate documentationfrom code? Can they replace handwrit-ten documentation in a project?
Dickering with Docs
Dear Dickering,I am not quite sure what you mean by“handwritten” documentation. Un-less you have some sort of fancy men-tal interface to your computer that I
have not yet heard of, any documenta-tion, whether in code or elsewhere ishandwritten or at least typed by hand.I believe what you are actually askingis if systems that can parse code andextract documentation are helpful, to
which my answer is, “Yes, but ...” Any sort of documentation extrac-
tion system has to have something to work with to start. If you believe thatextracting all of the function calls andparameters from a piece of code is suf-ficient to be called documentation,then you are dead wrong, but, unfortu-
nately, you would not be alone in yourbeliefs. Alas, having beliefs in common
with others does not make those beliefsright. What you will get from Doxygenon the typically, uncommented, code
base is not even worth the term “APIguide,” it is actually the equivalent ofrunning a fancy grep over the code andpiping that to a text formatting systemsuch as TeX or troff.
For code to be considered docu-mented there must be some set ofexpository words associated with it.Function and variable names, de-scriptive as they might be, rarely ex-plain the important concepts hidingin the code, such as, “What does thisdamnable thing actually do?” Many
programmers claim their code is self-documenting, but, in point of fact,self-documented code is so rare that Iam more hopeful of seeing a unicorngiving a ride to a manticore on the wayto a bar. The claim of self-document-ing code is simply a cover up for lazi-ness. At this point, most programmershave nice keyboards and should beable to type at 40–60 words per min-ute, some of those words can easily bespared for actual documentation. It isnot like we are typing on ancient line-
printing terminals.The advantage you get from a sys-
tem like Doxygen is that it providesa consistent framework in which to
write the documentation. Setting offthe expository text from the code issimple and easy and this helps in en-couraging people to comment theircode. The next step is to convincepeople to ensure their code matchesthe comments. Stale comments aresometimes worse than none at all be-cause they can misdirect you whenlooking for a bug in the code. “But it
For code to beconsidereddocumented theremust be some set
of expository wordsassociated with it.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 31/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 29
Vviewpoints
C O L L A G E
B Y
A N D
R I J
B O R Y
S A S S O C I
A T E
S / S H U T T E
R S T
O C K
EducationUnderstandingthe U.S. DomesticComputer SciencePh.D. PipelineTwo studies provide insights into how to increase the number ofdomestic doctoral students in U.S. computer science programs.
RECRUITING DOMESTIC STU-
DENTS (U.S. citizens andpermanent residents) intocomputer science Ph.D.programs in the U.S. is a
challenge for most departments, and
the health of the “domestic Ph.D.pipeline” is of concern to universi-ties, companies, government agen-cies, and federal research labs. Inthis column, we present results fromtwo studies on the domestic researchpipeline carried out by CRA-E, theEducation Committee of the Com-puting Research Association. Thefirst study examined the baccalau-reate origins of domestic Ph.D. re-cipients; the second study analyzedapplications, acceptances, and ma-
triculation rates to 14 doctoral pro-grams. Informed by findings fromthese studies, we also present recom-mendations we believe can strength-en the domestic Ph.D. pipeline.
While international students are—and will remain—crucial to the vitalityof U.S. doctoral programs, an increas-ing number of these graduates returnto their countries of origin for compet-itive job opportunities. The demandfor new computer science Ph.D.’s ishigh. Currently, approximately 1,600computer science Ph.D.’s are awarded
DOI:10.1145/2790854 Susanne Hambrusch, Ran Libeskind-Hadas, and Eric Aaron

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 32/100
30 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
iewpoints
programs ranked) in the 2014 U.S. News and World Report (USNWR) rank-ing of graduate programs in computerscience6 and during the 2007–2013period they produced about 19% of allcomputer science Ph.D.’s in the U.S.For those 14 departments, approxi-mately 35% of the Ph.D.’s are awarded
to domestic students.
Methodology of Admissions StudyOur admissions study partitioned the14 departments providing admissionrecords into those ranked 5–10 andthose ranked 11+. We refer to these 14departments as the consumers sincethey take students into their graduateprograms. The institutions where the7,032 students completed their under-graduate studies are called the produc-
ers. Approximately half of the 7,032graduate records came from consumerdepartments ranked 5–10 and halffrom departments ranked 11+. We in-tentionally did not include admissionsdata to consumer departments ranked1–4 since their graduate admissionsprofiles are significantly different (theiracceptance rates are typically one-thirdof those for schools ranked 5–10).
Admission records are for domes-tic students having completed a bac-calaureate degree at a producer in-
stitution. Each record includes thefollowing information: the name ofthe producer school, year the studentapplied to graduate school, name ofthe consumer school the student ap-plied to, decision of whether or notthe student was accepted by the con-sumer school, and—if the student wasaccepted—whether or not the studentchose to matriculate. The data alsoincluded gender, underrepresentedminority status, GPA, and GRE scores.
The dataset has some inherent
limitations. Admission records hadno names and thus students who ap-plied to multiple graduate programsproduced repeated records. Recordsdo not include important informationused in the admission process, such asrecommendation letters, statementsof purpose, and research achieve-ments. Finally, there is no way of know-ing which applicants accepting admis-sion actually did/will receive a Ph.D.
The 7,032 records came from a widerange of producer schools. To betteridentify and understand trends, we
each year from U.S. institutions, with
approximately 55% of these Ph.D.’shired by companies and federal re-search labs. Of the 1,600 Ph.D.’s,approximately 47% go to domesticstudents.1 Lucrative salaries and com-pelling jobs for new college graduatesadd to the challenge of encouragingdomestic students to pursue a Ph.D.
A first step in understanding thepipeline of domestic students to Ph.D.programs is to examine baccalaure-ate origins of domestic doctoral stu-dents.4 This is the focus of the first of
our studies, which found a relativelysmall number of colleges and univer-sities are the undergraduate schoolsof origin for most domestic Ph.D.students. Specifically, for the years2000–2010, just 12 schools accountedfor 20% of the approximately 5,500
domestic bachelor’s graduates who
received a Ph.D. in computer scienceand 54 schools were the undergradu-ate origins for approximately 50% ofdomestic Ph.D.’s. Approximately 730other schools were the origins of theother 50%; on average, these schoolshad less than one graduate every three
years receive a computer science Ph.D.To better understand the domes-
tic student pipeline and ultimatelymake recommendations for how toimprove it, we worked with 14 U.S.computer science Ph.D. programs
that provided graduate admissionsrecords during the period 2007–2013.This data, a total of 7,032 graduateadmissions records from domesticapplicants, formed the basis of oursecond study. The 14 departmentsranked 5 to 70 (out of 177 graduate
The seven producer groups.
ProducerGroup
Numberof Schools Explanation
TOP4 4 Top 4 CS departments (CMU, MIT, Stanford, UC Berkeley)
TOP25-4 2121 CS departments ranked in the top 25 by USNWR and
excluding the Top 4 CS departments
RU/VH-25 83Universities with a Carnegie classification of “Very High” research
excluding the Top 25 CS departments in USNWR
RU/H 99 Universities whose Carnegie classification is “High” research
Master’s 724 Schools with a Carnegie classification of Master’s institution
TOP25LA+ 27Schools ranked in the Top 25 Liberal Arts Colleges by USNWR plus
Olin and Rose-Hulman
BAC-25LA 246Schools with a Carnegie classification of Baccalaureate Arts and Sciences
four-year college excluding the TOP 25 LA
Figure 1. Admission rates of applications from the seven producer groups to consumerdepartments ranked 5–10 and 11+.
to consumer departments 5–10 to consumer departments 11+
45%
33%
21%
9% 10%
30%
18%
59%
50% 50%
42%39%
62%
41%
70%
60%
50%
40%
30%
20%
10%
0%TOP4
A d m i s s i o n R a t e
TOP25-4 RU/VH-25 RU/H Master’s TOP25LA+ BAC-25LA
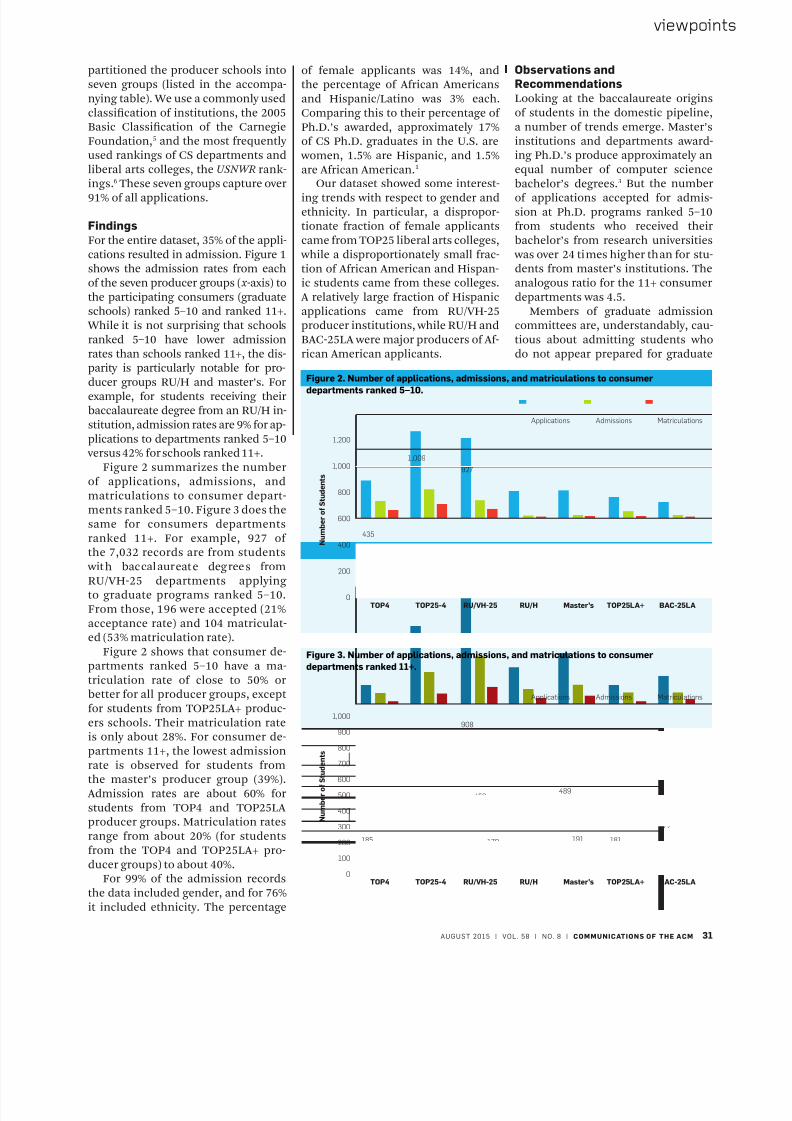
7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 33/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 31
viewpoints
Observations andRecommendationsLooking at the baccalaureate originsof students in the domestic pipeline,a number of trends emerge. Master’sinstitutions and departments award-ing Ph.D.’s produce approximately anequal number of computer science
bachelor’s degrees.3 But the numberof applications accepted for admis-sion at Ph.D. programs ranked 5–10from students who received theirbachelor’s from research universities
was over 24 times higher than for stu-dents from master’s institutions. Theanalogous ratio for the 11+ consumerdepartments was 4.5.
Members of graduate admissioncommittees are, understandably, cau-tious about admitting students who
do not appear prepared for graduate
partitioned the producer schools intoseven groups (listed in the accompa-nying table). We use a commonly usedclassification of institutions, the 2005Basic Classification of the CarnegieFoundation,5 and the most frequentlyused rankings of CS departments andliberal arts colleges, the USNWR rank-
ings.6 These seven groups capture over91% of all applications.
FindingsFor the entire dataset, 35% of the appli-cations resulted in admission. Figure 1shows the admission rates from eachof the seven producer groups (x-axis) tothe participating consumers (graduateschools) ranked 5–10 and ranked 11+.
While it is not surprising that schoolsranked 5–10 have lower admission
rates than schools ranked 11+, the dis-parity is particularly notable for pro-ducer groups RU/H and master’s. Forexample, for students receiving theirbaccalaureate degree from an RU/H in-stitution, admission rates are 9% for ap-plications to departments ranked 5–10
versus 42% for schools ranked 11+.Figure 2 summarizes the number
of applications, admissions, andmatriculations to consumer depart-ments ranked 5–10. Figure 3 does thesame for consumers departments
ranked 11+. For example, 927 ofthe 7,032 records are from students
with baccalaureate degrees fromRU/VH-25 departments applyingto graduate programs ranked 5–10.From those, 196 were accepted (21%acceptance rate) and 104 matriculat-ed (53% matriculation rate).
Figure 2 shows that consumer de-partments ranked 5–10 have a ma-triculation rate of close to 50% orbetter for all producer groups, exceptfor students from TOP25LA+ produc-
ers schools. Their matriculation rateis only about 28%. For consumer de-partments 11+, the lowest admissionrate is observed for students fromthe master’s producer group (39%).
Admission rates are about 60% forstudents from TOP4 and TOP25LAproducer groups. Matriculation ratesrange from about 20% (for studentsfrom the TOP4 and TOP25LA+ pro-ducer groups) to about 40%.
For 99% of the admission recordsthe data included gender, and for 76%it included ethnicity. The percentage
of female applicants was 14%, andthe percentage of African Americansand Hispanic/Latino was 3% each.Comparing this to their percentage ofPh.D.’s awarded, approximately 17%of CS Ph.D. graduates in the U.S. are
women, 1.5% are Hispanic, and 1.5%are African American.1
Our dataset showed some interest-ing trends with respect to gender andethnicity. In particular, a dispropor-tionate fraction of female applicantscame from TOP25 liberal arts colleges,
while a disproportionately small frac-tion of African American and Hispan-ic students came from these colleges.
A relatively large fraction of Hispanicapplications came from RU/VH-25producer institutions, while RU/H andBAC-25LA were major producers of Af-
rican American applicants.Figure 2. Number of applications, admissions, and matriculations to consumerdepartments ranked 5–10.
Applications Admissions Matriculations
435
1,009
927
315 317240
181194
331
196
29 3172
3297
156104
15 16 20 13
1,200
1,000
800
600
400
200
0TOP4
N u m b e r o f S t u d e n t s
TOP25-4 RU/VH-25 RU/H Master’s TOP25LA+ BAC-25LA
Figure 3. Number of applications, admissions, and matriculations to consumerdepartments ranked 11+.
Applications Admissions Matriculations
185
628
908
352
489
181
272
110
311
458
148191
113 112
26
103170
64 8024 47
1,000900
800
700
600
500
400
300
200
100
0TOP4
N u m b e r o f S t u d e n t s
TOP25-4 RU/VH-25 RU/H Master’s TOP25LA+ BAC-25LA

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 34/100
32 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
iewpoints
work, particularly if they have had nofirsthand research experience. Buttalented students with potential forresearch exist in all producer groups.Consumer departments interested inincreasing the number of domestic
Ph.D. students, and producer schools wanting to better advise their studentsto be competitive for graduate school,should consider the following inter-
ventions and strategies.Graduate admissions committees
need to be realistic about their appli-cant pools. Applicants from TOP25departments are highly desirable, andactive recruiting from TOP25 depart-ments may not be as effective as ex-pected. Even for highly ranked Ph.D.programs, matriculation rates for
these students are low.Graduate admissions committees
should also be aware of the breadthand differences of educational insti-tutions in the U.S. Our findings indi-cate some large graduate schools haveforged productive partnerships withcolleges and smaller universities intheir regions. These relationships canbegin with a faculty member from thePh.D. program giving a talk to under-graduates and faculty at prospectivepartner institutions, and it can evolve
into summer and academic-year re-search opportunities for undergradu-ate students from the partner collegesand universities.
Producer departments should sup-port and foster computer science stu-dent research communities and high-light student research achievements.One effective practice is to hold annu-al undergraduate research presenta-tions and poster sessions and provideincentives (such as food and bever-ages) to attract younger undergradu-ates to see what their peers have done.
Publicized recognition of undergrad-uate research achievements can alsobe effective.
Producer departments shouldhold periodic information sessionson careers in research, summer re-search experiences, and graduateschool, and should invite researchers
from industry and academia to speak with students about careers in re-search. Undergraduates—even thoseat research universities—often havemisconceptions about research andgraduate school.
Private and federal research labo-ratories can contribute to the healthof the domestic pipeline by expandingthe quantity and breadth of under-graduate research opportunities andencouraging summer interns to pur-
sue graduate studies.For all producer and consumerinstitutions, the Computer ScienceUndergraduate Research CONQUER
website2 has valuable informationand resources for supporting under-graduate involvement in research.This information can be useful in anystudent research environment, andin particular, it can be a resource tobring more students into the domes-tic Ph.D. pipeline.
References1. CRA Taulbee Survey; http://cra.org/resources/taulbee/.
2. CRA-E’s Undergraduate Research Conquer website(CONQUER); h ttp://cra.org/conquer.
3. Hambrusch, S. et al. Exploring the baccalaureateorigin of domestic Ph.D. students in computing fields.Computing Research News (Jan. 2013).
4. Hambrusch, S. et al. Findings from a pipelinestudy based on graduate admissions records. InProceedings of the CRA Snowbird Conference 2014 ;http://cra.org/crae/reports.
5. The Carnegie Classification of Institutions of HigherEducation; http://classifications.carnegiefoundation.org/.
6. U.S. News and World Report. Computer sciencerankings (2014); http://grad-schools.usnews.rankingsandreviews.com/best-graduate-schools/top-science-schools/computer-science-rankings.
Susanne Hambrusch ([email protected]) is aprofessor of computer sciences at Purdue University inWest Lafayette, IN.
Ran Libeskind-Hadas ([email protected]) is the R.Michael Shanahan Professor and Department Chair ofthe Department of Computer Science at Harvey MuddCollege in Claremont, CA.
Eric Aaron ([email protected]) is a visiting assistantprofessor of computer science at Vassar College inPoughkeepsie, NY.
The authors are members of the Computing ResearchAssociation Education Committee and gratefullyacknowledge valuable contributions by Charles Isbelland Elijah Cameron of the College of Computing at theGeorgia Institute of Technology.
Copyright held by authors.
Graduateadmissionscommittees needto be realistic
about theirapplicant pools.
C O M
M U N I
C A T I O
N S A P
P S
Available for iPad,
iPhone, and Android
Available for iOS,
Android, and Windows
Access the
latest issue,
past issues,
BLOG@CACM,
News, and
more.
i i l i

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 35/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF T HE ACM 33
Vviewpoints
C O L L A G E
S B Y
A N D
R I J
B O R Y
S A S S O C I
A T E
S / S H U T T E
R S T
O C K
ViewpointLearning ThroughComputational Creativity Improving learning and achievement in introductory computer scienceby incorporating creative thinking into the curriculum.
knowledge and skills, the more variedand interesting the possible novel pat-terns and combinations that mightemerge. To be creative one must broad-en one’s knowledge by acquiring infor-mation and skills outside one’s currentdomains of study and expertise.
˲ Challenging. Novelty emerges fromsituations where existing strategies andbehaviors are ineffective. The more dif-ficult the challenge, the more likely acreative, novel solution will emerge.
˲ Surrounding. Exposure to mul-tiple, ambiguous situations andstimuli create environments wherenovel strategies and behaviors mayemerge—for example, looking atthings in new ways, interacting withnew people, and considering multiplesensory representations.
˲ Capturing. Novelty is occurring allthe time, but most of it passes with-out recognition. Creativity requiresattention to and recording of noveltyas it occurs.
These core competencies have asolid anchoring in contemporary cog-nitive and neuroscience research.6
Just as Wing 10,11 makes a convinc-ing case for the universality of com-putational thinking, we argue thatEpstein’s core creative thinkingcompetencies are also a universallyapplicable skill set that provides afoundation not only for applyingone’s existing knowledge and skillsin creative ways, but also for engagingin lifelong learning to broaden one’scapabilities for work in interdisci-
THE NATIONAL SCIENCE Founda-tion’s “Rebuilding the Mosa-ic” reporta notes that address-ing emerging issues in allfields will require utilization
and management of large-scale data-bases, creativity in devising data-centricsolutions to problems, and applicationof computational and computer toolsthrough interdisciplinary efforts. Inresponse to these needs, introductorycomputer science (CS) courses are be-
coming more than just a course for CSmajors. They are becoming multipur-pose: designed not just to prepare futureCS scientists and practitioners, but alsoto inspire, motivate, and recruit newstudents to CS; provide computationalthinking tools and CS skills to studentsin other disciplines; and even train fu-ture CS K–12 teachers. This multifacetednature of introductory CS calls for new
ways of envisioning the CS curriculum. Along with computational thinking, cre-ativity has been singled out as critical to
addressing important societal problemsand central to 21st century skills (for ex-ample, the 2012 National Research Coun-cil report). Driven by these observations,
we see an opportunity to revise introduc-tory CS courses by explicitly integratingcreative thinking into the curriculum.
Creative ThinkingCreative thinking is not an innate tal-ent or the province of just a few individ-
a See http://www.nsf.gov/pubs/2011/nsf11086/nsf11086.pdf.
uals, and it is not confined to the arts.Rather, it is a process integral to hu-man intelligence that can be practiced,encouraged, and developed within anycontext.1,2,5,7–9 Epstein’s GenerativityTheory 2 breaks creative thinking downto four core competencies:
˲ Broadening.The more diverse one’s
DOI:10.1145/2699391 Leen-Kiat Soh, Duane F. Shell, Elizabeth Ingraham, Stephen Ramsay, and Brian Moore

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 36/100
34 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
iewpoints
As an example, in the Everyday Ob- ject CCE, students are asked to act likethe inventor of an ordinary object that
we might frequently use. The chal-lenge is to imagine this object doesnot exist and to describe in writtenlanguage: the mechanical function ofthe selected object; what need is ful-
filled by this object; and its physicalattributes and characteristics. The de-scription must be specific enough sothat someone who had never seen theobject could recognize it and under-stand how it works and understand
what benefits it provides. (Note: Stu-dents were given a list of objects—zip-per, mechanical pencil, binder clip,Ziploc bag, scissors, tape measure,stapler, nail clippers, umbrella, flash-light, can opener, clothespin, sticky
notes, toilet paper holder, revolvingdoor—from which to choose.) Stu-dents are then asked to consider and
write their responses to the followingquestions. Analysis: (1) Consider yourobject as a computer program. Draw adiagram that shows all its functions asboxes (name them), and for each func-tion, its inputs and outputs. Are thereshared inputs and outputs amongthe functions? (2) Consider the list ofphysical attributes and characteris-tics. Organize these such that each is
declared as a variable with its propertype. Can some of these attributes/characteristics be arranged into a hi-erarchy of related attributes/charac-teristics? Reflection: (1) Consider yourresponse to Analysis 1, are there func-tions that can be combined so that theobject can be represented with a moreconcise program? Are there new func-tions that should be introduced tobetter describe your object such thatthe functions are more modular? (2)Have you heard of abstraction? How
does abstraction in computer sciencerelate to the process of identifying thefunctions and characteristics as youhave done in this exercise?
Our CCEs are anchored in instruc-tional design principles shown to im-pact deep learning, transfer, and devel-opment of interpersonal skills. Theyare designed to provide instruction onCS concepts by combining hands-onproblem-based learning with writtenanalysis and reflection. They facilitatetransfer by using computational think-ing and CS content more abstractly and
plinary environments on increasinglycomplex problems.
Computational Creativity ExercisesIn our framework, both computation-al thinking and creative thinking are
viewed as cognitive tools that whenblended form computational creativ-ity. This blending is not conceived asa dichotomy, but rather as symbioticabilities and approaches. Computa-tional thinking and CS skills expand
the knowledge and tools that one hasavailable, thereby broadening the scopeof problem solutions. Challenging problems force computational tools tobe used in unanticipated and unusual
ways, leading to new computationalapproaches to both old and new prob-lems. Surrounding oneself with newenvironments and collaborators cre-ates novel ways of looking at problemsand attention to different stimuli andperspectives that may be relevant to ap-proaching a problem computationally.
Finally, capturing ideas for data repre-sentations and algorithms can lead tonew data structures and solution pro-cedures. By merging computationaland creative thinking, students can le-
verage their creative thinking skills to“unlock” their understanding of com-putational thinking.6
We have created a suite of Compu-tational Creativity Exercises (CCEs)designed to increase students’ compu-tational creativity. Each CCE has fourcommon components: Objectives,Tasks, CS Lightbulbs—explanations
connecting activities to CS concepts,ideas, and practices—and LearningObjects that relate the exercise tasksdirectly to CS topics. The principlesunderlying the design of our Computa-tional Creativity Exercises are balanc-ing of attributes between computation-al and creative thinking and mappingbetween computational and creativeconcepts and skills as they manifestin different disciplines. Each CCE re-quires approximately one to two hours
per student, but students are given two weeks to work on the exercises becauseof the collaboration required. TheCCEs are designed so that the studentshave hands-on and group tasks first, in
Week 1, and then reflect on their Week1 activities in Week 2 by answeringanalysis and reflection questions. Both
Week 1 and Week 2 are graded.
We see an
opportunity torevise introductoryCS courses byexplicitly integratingcreative thinkinginto the curriculum.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 37/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 35
viewpoints
ment of more CCEs. Furthermore, thebroader impacts of incorporating com-putational creativity into introductoryCS courses are wide-ranging includingreaching underrepresented groups inCS, outreach exposing young learnersto computational creativity, improvinglearning of CS, and preparing students
to be creative problem solvers in in-creasingly interdisciplinary domains.
We thus call to action CS (and otherSTEM) educators to investigate andadopt computational creativity in theircourses or curricula.
References1. Epstein, R. Cognition, Creativity, and Behavior:
Selected Essays. Praeger, 1996.2. Epstein, R. Generativity theory and creativity. Theories
of Creativity. Hampton Press, 2005.3. Miller, L.D. et al. Improving learning of computational
thinking using creative thinking exercises in CS-1computer science courses. FIE 43, (2013), 1426–1432.
4. Miller, L.D. et al. Integrating computational andcreative thinking to improve learning and performancein CS1. SIGCSE’2014 (2014), 475-480.
5. Robinson, K. Out of Our Minds: Learning to be Creative.Capstone, 2001.
6. Shell, D.F., Brooks, D.W., Trainin, G., Wilson,K., Kauffman, D.F., and Herr, L. The UnifiedLearning Model: How Motivational, Cognitive, andNeurobiological Sciences Inform Best TeachingPractices. Springer, 2010.
7. Shell, D.F. et al. Improving learning of computationalthinking using computational creativity exercises in acollege CS1 computer science course for engineers.FIE 44, to appear.
8. Shell, D.F. and Soh, L.-K. Profiles of motivatedself-regulation in college computer science courses:Differences in major versus required non-majorcourses. J. Sci. Edu. Tech. Technology (2013).
9. Tharp, T. The Creative Habit: Learn it and Use it forLife. Simon & Schuster, 2005.
10. Wing, J. Computational thinking. Commun. ACM 49, 3(Mar. 2006), 33–35.11. Wing, J. Computational thinking: What and why. Link
Magazine (2010).
Leen-Kiat Soh ([email protected]) is an associateprofessor in the Computer Science and EngineeringDepartment at the University of Nebraska.
Duane F. Shell ([email protected]) is a research professorat the University of Nebraska.
Elizabeth Ingraham ([email protected]) is anassociate professor of art at the University of Nebraska.
Stephen Ramsay ([email protected]) is theSusan J. Rosowski Associate Professor of English at theUniversity of Nebraska.
Brian Moore ([email protected]) is associateprofessor of music education and music technology at theUniversity of Nebraska.
This material is based upon work supported by theNational Science Foundation under grant no. 1122956.Additional support was provided by a Universityof Nebraska-Lincoln (UNL) Phase II Pathways toInterdisciplinary Research Centers grant. Any opinions,findings, conclusions, or recommendations expressedin our materials are solely those of the authors and donot necessarily reflect the views of the National ScienceFoundation or UNL.
Copyright held by authors.
without using programming code to ad-dress problems seemingly unrelated toCS. The CCEs foster development of cre-ative competencies by engaging multi-ple senses, requiring integrative, imagi-native thought, presenting challengingproblems and developing interpersonalskills using individual and collabora-
tive group efforts. The CCEs engagethe cognitive/neural learning processesof attention, repetition, and connection identified in the Unified Learning Mod-el6 on synthesis of research in cognitiveneuroscience, cognitive science, andpsychology. They enhance learning andretention of course material by focus-ing attention on computational think-ing principles, provide additional rep-etition of computational thinking andcomputing concepts from the class, and
provide connections of the material tomore diverse contexts and applicationsat a higher level of abstraction.
Some EvidenceFour CCEs were deployed in four dif-ferent introductory computer sciencecourses during the Fall 2012 semesterat the University of Nebraska, Lincoln.Each course was tailored to a differenttarget group (CS majors, engineeringmajors, combined CS/physical scienc-es majors, and humanities majors).
Findings from 150 students showedthat with cumulative GPA controlled,the number of CCEs completed wassignificantly associated with coursegrade ( F (3, 109) = 4.32, p = .006, partialEta2 = .106). There was a significantlinear trend ( p = .0001) from 2 to 4 exer-cises completed. The number of CCEscompleted also was significantly asso-ciated with a computational thinkingknowledge test score ( F (3, 98) = 4.76,
p = .004, partial Eta2 = .127), again witha significant linear trend ( p < .0001)
from 0–1 to 4 exercises completed with no differences for CS and non-CS majors.3,4 These findings indicateda “dosage” effect with course gradesand test scores increasing with eachadditional CCE completed. The in-creases were not trivial. Students in-creased by almost a letter grade andalmost one point on the knowledgetest per CCE completed.
In a second evaluation,7 we em-ployed a quasi-experimental designcomparing CCE implementation inthe introductory computer science
course tailored for engineers duringSpring 2013 ( N = 90, 96% completingthree or four exercises) to a control se-
mester ( N = 65) of no implementationin Fall 2013. Using Analysis of Cova-riance (ANCOVA), we found that stu-dents in the implementation semesterhad significantly higher computationalthinking knowledge test scores thanstudents in the control semester ( M =7.47 to M = 5.94) when controlling forstudents’ course grades, strategic self-regulation, engagement, motivation,and classroom perceptions. ( F (1, 106)= 12.78, p <.01, partial Eta2 = .108). CCEimplementation students also report-
ed significantly higher self-efficacyfor applying their computer scienceknowledge and skills in engineeringthan non-implementation students( M = 70.64 to M = 61.47; F (1, 153) =12.22, p <.01, partial Eta2 = .074).
Overall, in relation to traditionalfindings for classroom educationalinterventions, these are strong effectsthat demonstrate meaningful “real-
world” impact. The exercises appearto positively affect the learning of corecourse content and achievement for
both CS majors and non-majors. Thefindings support our contention thatthe Computational Creativity Exercisescan bring CS computational concepts toCS and non-CS disciplines alike and im-
prove students’ understanding of compu-tational thinking .
Call to ActionEncouraged by our evaluation findings,
we are currently working on adaptingthe CCEs to secondary schools, design-ing a course based on a suite of CCEs,as well as continuing with the develop-
These corecompetencies havea solid anchoringin contemporary
cognitive andneuroscienceresearch.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 38/100
36 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
practice
DOI:10.1145/2755501
Article development led by
queue.acm.org
Use states to drive your tests.
BY ARIE VAN DEURSEN
END-TO-END TESTING OF Web applications typicallyinvolves tricky interactions with Web pages by meansof a framework such as Selenium WebDriver.12 Therecommended method for hiding such Web-pageintricacies is to use page objects,10 but there arequestions to answer first: Which page objects should
you create when testing Web applications? Whatactions should you include in a page object? Which testscenarios should you specify, given your page objects?
While working with page objects during the pastfew months to test an AngularJS (https://angularjs.org)
Web application, I answered these questionsby moving page objects to the state level. Viewingthe Web application as a state chart made it mucheasier to design test scenarios and corresponding
page objects. This article describes the approach
that gradually emerged: essentially astate-based generalization of page ob-
jects, referred to here as state objects. WebDriver is a state-of-the-art tool
widely used for testing Web applica-tions. It provides an API to access ele-ments on a Web page as they are ren-dered in a browser. The elements canbe inspected, accessing text containedin tables or the element’s styling attri-butes, for example. Furthermore, the
API can be used to interact with thepage—for example, to click on links orbuttons or to enter text in input forms.
Thus, WebDriver can be used to scriptclick scenarios through a Web appli-cation, resulting in an end-to-end testsuite of an application.
WebDriver can be used to testagainst your browser of choice (Inter-net Explorer, Firefox, Chrome, amongothers). It comes with different lan-guage bindings, allowing you to pro-gram scenarios in C#, Java, JavaScript,or Python.
Page Objects. WebDriver providesan API to interact with elements on a
Web page as rendered in a browser.Meaningful end-user scenarios, how-ever, should not be expressed in termsof Web elements, but in terms of theapplication domain.
Therefore, a recommend patternfor writing WebDriver tests is to usepage objects. Such objects providean API over domain concepts imple-mented on top of Web-page elements,as illustrated in Figure 1, taken froman illustration by software designerMartin Fowler.4
These page objects hide the spe-cific element locators used (for exam-ple, to find buttons or links) and thedetails of the underlying “widgetry.”
As a result, the scenarios are morereadable and easier to maintain ifpage details change.
Page objects need not represent afull page; they can also cover part ofthe user interface such as a navigationpane or an upload button.
To represent navigation throughthe application, “methods on the Page-Object should return other PageOb-
Testing Web
Applicationswith StateObjects

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 39/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 37
I M
A G E
B Y
A L I
C I
A
K U
B I
S T
A / A N D
R I J
B O R Y
S A S S O C I
A T E
S
jects.”10 It is this idea that this articletakes a step further, leading to what we
will refer to as state objects.
Modeling Web Appswith State ChartsTo model Web application naviga-tion, let’s use statecharts from the
Unified Modeling Language (UML).Figure 2 shows a statechart used forlogging into an application. Usersare either authenticating or authen-ticated. They start not being authen-ticated, enter their credentials, andif they are OK, they reach the authen-ticated state. From there, they can logoff to return to the page where theycan authenticate.
This diagram traditionally leads totwo page objects:
˲ One for the login page, corre-sponding to the authenticating state.
˲ One for the logoff button, presenton any page shown in the authenticat-ed state.
To emphasize these page objectsrepresent states, they are given explicitresponsibilities for state navigationand state inspection, and they becomestate objects.
State Objects: Checksand Trigger MethodsTwo types of methods can be identifiedfor each state object:
˲ Inspection methods return the valueof key elements displayed in the brows-er when it is in the given state, such asa user name, the name of a document,or some metric value; They can be usedin test scenarios to verify the browserdisplays the expected values.
˲ Trigger methods correspond toan imitated user click and bring the
browser to a new state. In the authenti-cating state users can enter credentialsand click the submit button, which,assuming the credentials are correct,leads the browser to the next authen-ticated state. From there, the user canclick the logoff button to get back tothe authenticating state.
It is useful to combine the mostimportant inspection methods intoone self-check of properties that musthold whenever the application is inthat particular state. For example, onthe authenticating state, you would ex-pect fields for entering a user name ora password; there should be a submitbutton; and perhaps the URL should in-clude the login route. Such a self-checkmethod can then be used to verify thebrowser is indeed in a given state.
Scenarios: Triggering and check-ing events. Given a set of state objects,
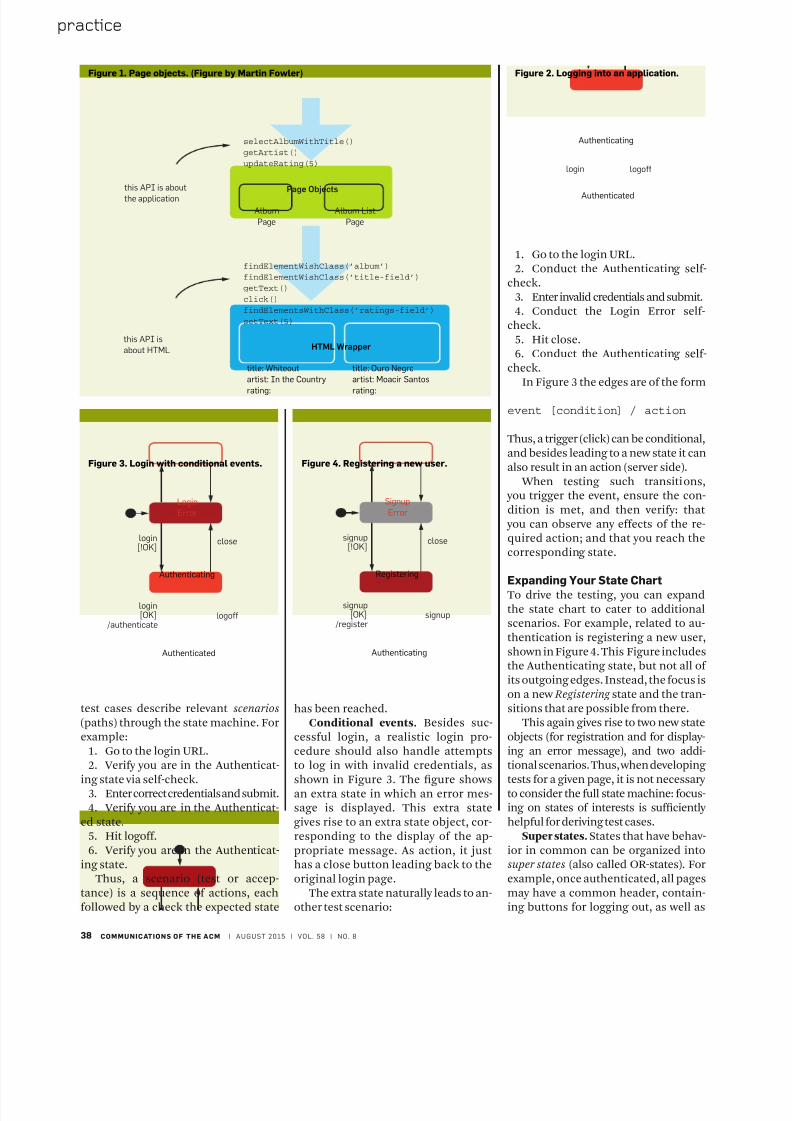
7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 40/100
38 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
practice
1. Go to the login URL.2. Conduct the Authenticating self-
check.3. Enter invalid credentials and submit.4. Conduct the Login Error self-
check.5. Hit close.
6. Conduct the Authenticating self-check.In Figure 3 the edges are of the form
event [condition] / action
Thus, a trigger (click) can be conditional,and besides leading to a new state it canalso result in an action (server side).
When testing such transitions, you trigger the event, ensure the con-dition is met, and then verify: that
you can observe any effects of the re-
quired action; and that you reach thecorresponding state.
Expanding Your State ChartTo drive the testing, you can expandthe state chart to cater to additionalscenarios. For example, related to au-thentication is registering a new user,shown in Figure 4. This Figure includesthe Authenticating state, but not all ofits outgoing edges. Instead, the focus ison a new Registering state and the tran-sitions that are possible from there.
This again gives rise to two new stateobjects (for registration and for display-ing an error message), and two addi-tional scenarios. Thus, when developingtests for a given page, it is not necessaryto consider the full state machine: focus-ing on states of interests is sufficientlyhelpful for deriving test cases.
Super states. States that have behav-ior in common can be organized intosuper states (also called OR-states). Forexample, once authenticated, all pagesmay have a common header, contain-ing buttons for logging out, as well as
test cases describe relevant scenarios
(paths) through the state machine. Forexample:
1. Go to the login URL.2. Verify you are in the Authenticat-
ing state via self-check.3. Enter correct credentials and submit.4. Verify you are in the Authenticat-
ed state.5. Hit logoff.6. Verify you are in the Authenticat-
ing state.Thus, a scenario (test or accep-
tance) is a sequence of actions, eachfollowed by a check the expected state
has been reached.
Conditional events. Besides suc-cessful login, a realistic login pro-cedure should also handle attemptsto log in with invalid credentials, asshown in Figure 3. The figure showsan extra state in which an error mes-sage is displayed. This extra stategives rise to an extra state object, cor-responding to the display of the ap-propriate message. As action, it justhas a close button leading back to theoriginal login page.
The extra state naturally leads to an-other test scenario:
Figure 1. Page objects. (Figure by Martin Fowler)
selectAlbumWithTitle()
getArtist()
updateRating(5)
findElementWishClass(’album’)
findElementWishClass(’title-field’)
getText()
click()
findElementsWithClass(’ratings-field’)
setText(5)
Page Objects
Album
Page
this API is about
the application
Album List
Page
HTML Wrapper
title: Whiteout
artist: In the Country
rating:
title: Ouro Negro
artist: Moacir Santos
rating:
this API is
about HTML
Figure 2. Logging into an application.
Authenticated
Authenticating
logofflogin
Figure 3. Login with conditional events.
Login
Error
Authenticated
closelogin[!OK]
logofflogin[OK]
/authenticate
Authenticating
Figure 4. Registering a new user.
Signup
Error
Authenticating
closesignup[!OK]
signupsignup[OK]
/register
Registering

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 41/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 39
practice
for navigating to key pages (for exam-ple, for managing your account or ob-taining help, shown in Figure 5).
Edges going out of the super state(such as logout) are shorthand for anoutgoing logout event for each of thefour internal states (the substates). Ex-panding the shorthand would lead to
the diagram in Figure 6 where the fiveoutgoing edges of the super state areexpanded for each of the four internalstates, leading to 4 * 5 = 20 (directed)edges (drawn as two-way edges to keepthe diagram manageable).
The typical way of implementingsuch super states is by having reusableHTML fragments, which in AngularJS,for example, are included via the ngIn-clude directive.1
In such cases, it is most natural to
create a state object corresponding tothe common include file. It containspresence checks for the required linksor buttons and event checks to see if,for example, clicking settings indeedleads to the Settings state.
A possible test scenario would then be:1. [Steps needed for login.]2. Conduct Portfolio self-check.3. Click settings link.4. Conduct Settings self-check.5. Click help link.6. Conduct Help self-check.
7. Click account link.8. Conduct Account self-check.9. Click portfolio link.10. Conduct Portfolio self-check.11. Click logout link.12. Conduct Authenticating self-check.
This corresponds to a single sce-nario testing the authenticated navi-gation pane. It tests that clickingthe account link from the Help page
works. It does not, however, checkthat clicking the account link fromthe Settings page works. In fact, this
test covers only four of the 20 edges inthe expanded graph.
Of course you can create tests for all20 edges. This may make sense if theapp-under-test has handcrafted thenavigation pane for every view insteadof using a single include file. In thatcase you may have reason to believethe different trails could reveal differ-ent bugs. Usually, however, testing allexpanded paths would be overkill forthe include file setting.
State traversals. The single test sce-nario for the navigation header visits
five different states, in one particularorder, shown in Figure 7. This is a rath-er long test and could be split into fourseparate test cases (Figure 8).
In unit testing, the latter would bethe preferred way. It has the advantageof the four tests being independent:failure in one of the steps does not af-
fect testing of the other steps. More-over, fault diagnosis is easier, since thefailed test case will be clearer.
The four independent tests, how-ever, are likely to take considerablylonger: every test requires explicit au-thentication, which will substantiallyslow down test execution. Therefore, inend-to-end testing it is more commonto see shared setup among test cases.
In terms of JUnit’s (http://junit.org) setup methods,9 a unit test suite would
typically make use of the @Before set-
up, which is executed again and again just before every @Test in the class.End-to-end tests, on the other hand,are more likely to use @BeforeClass inorder to be able to conduct expensivesetup methods only once.
Modal dialogs are typically used todisable any interaction until the user
has acknowledged an important mes-sage (“Are you sure you...”). Examplesare the login or sign-up error messagesshown earlier. Such modal dialogs callfor a separate state and, hence, for dis-tinct page objects, offering an acceptevent to close the dialog.
Modal dialogs can be implementedusing browser alerts (and WebDrivermust accept them before testing cancontinue) or JavaScript logic. In thelatter case, an extra check to be tested
could be the dialog is indeed modalFigure 5. Common behaviorin a super state.
Authenticated
Authenticating
loginlogout
Portfolio
Settings
Help
Account account
help
settings
portfolio
Figure 6. Expanding a super state.
Authenticating
Portfolio
Settings
Help
Account
Figure 7. Single testtraversing multiple states.
Authenticating
Portfolio
Settings
Help
Account
Figure 8. Separate testsfor different states.
Authenticating
Portfolio
Settings
Help
Account

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 42/100
40 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
practice
ing state machines in Testing Object-oriented Systems.3)
The tree in Figure 11 has been de-rived from the state machine showingsign-up and authentication as pre-sented earlier. Starting from the initialauthenticating state, let’s do a breadth-first traversal of the graph. Thus, perstate you first visit its direct successors.If you enter a state you visited already,
the visited state is drawn in gray as aleaf node. Then proceed to the next un-
visited state.The tree helps when designing tests
for an individual state: the path to thatstate in the tree is the shortest pathin the graph to that state. Besides, itclearly indicates which outgoing edgesthere are for a state.
The tree is also helpful for design-ing a test suite for the full state ma-chine: writing one test case for eachpath from the root to a leaf yields a test
suite that covers all transitions and,hence, covers all states in the machine.
Covering paths. While focusing onindividual states and their transitionsis a good way to spot and eliminate ba-sic faults, a trickier set of defects is vis-ible only when following a path alongmultiple states.
As an example, consider client-sidecaching. A framework such as Angu-larJS makes it easy to enable cachingfor (some) back-end HTTP calls. Doingthis right improves responsiveness andreduces network round-trips, since the
(that is, that any other interaction withthe page is disabled).
If the modal dialog is triggered bya state contained in a super state, thedialog state is not part of the super
state (since the super-state interac-tion is disabled in the dialog). Thus,the correct way to draw the login statemachine showing error handling andshared navigation would be as illus-trated in Figure 9. Here the error dia-log is not part of the navigation superstate, as it permits only the close eventand not clicking, for example, theabout link.
Some applications are fairly dialog-intensive—for example, when dealing
with registration, logging in, forget-ting passwords, among others. Many
of these dialogs serve only to notify theuser of a successful state change. Tosimplify the state diagrams the dialogscan then be drawn as annotations onthe edges, as in Figure 10.
The diagram at the top is the full ver-sion, and the one at the bottom is the ab-breviated version. Note the<<dialog>> annotation is important for implement-ing the test. The test cases must click theclose button of the dialog; otherwise,testing is blocked.
The transition tree. To supportreasoning about state reachability,as well as state and transition cover-age, it is helpful to turn a state dia-gram into a transition tree, as shownin Figure 11. (For more information,see Robert Binder’s chapter on test-
Figure 9. Login state machine with error handling and shared navigation.
Public Navigation
About
Registering
Authenticating login
signup
about
Authenticated
login[OK]logoff
login[!OK]
Login
Error
Figure 10. Using transitionannotations to simplify diagrams.
Registering
ShowingMessage
Registering
signup[OK]
close
signup[OK]«dialog»
Authenticating
Authenticating
Figure 11. Transition tree.
Signup
RegisteringLogin
Error AboutAuthenticated
login
about
close
signup[!OK]signup[OK]
signuplogin[!OK]
closelogoff
Authenticating
Authenticating Authenticating Authenticating AuthenticatingSignupError

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 43/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 41
practice
results of back-end calls are remem-bered instead of requested over andover again.
If, however, the results are subjectto change, this may lead to incorrectresults. For example, the client may re-quest an overview page with requiredinformation on one page, modify the
underlying data on the next page, andthen return to the original overviewpage. This corresponds to the red pathin Figure 12.
With caching enabled, the Portfoliostate will cache the back-end call results.The correct caching implementation ofthe Settings state would be to invalidatethe cache if changes were made. As a re-sult, when revisiting the Portfolio statethe call will be made again, and the up-dated results will be used.
A test case for this caching behaviormight look as follows:1. [Take shortest route to Portfolio.]2. Collect values of interest from
Portfolio.3. Click the settings link to navigate
to Settings.4. Modify settings that will affect
Portfolio values of interest.5. Click the portfolio link to navigate
back to Portfolio.6. Assert that modified values are
displayed.
In the AngularJS application men-tioned previously, this test case caughtan actual bug. Unfortunately, it is diffi-cult or expensive to come up with a teststrategy that covers all such paths pos-sibly containing bugs.
In the general case, in the presenceof loops there are infinitely many po-tential paths to follow. Thus, the tester
will need to rely on expertise to identifypaths of interest.
The transition tree-based approachdescribed previously provides so-
called round-trip coverage2—that is, itexercises each loop once until it getsback at a node already visited (oneround-trip). Assuming all super statesare expanded, this strategy would leadto a test case for the caching example.
Alternative criteria include alllength-N paths, in which every possiblepath of a given length must be exer-cised. The extra costs in terms of theincreased number of test cases to be
written can be substantial, however, soachieving such a criterion without au-tomated tools is typically hard.
In terms of state objects, testingpaths will not lead to new state ob-
jects—the states are already there. Theneed to assert properties along the path,however, may call for additional inspec-tion methods in the state objects.
Going BackwardThe browser’s back button providesstate navigation that requires specialattention. While this button makessense in traditional hypertext naviga-tion, in today’s Web applications itis not always clear what its behaviorshould be.
Web developers can alter the but-ton’s behavior by manipulating the his-tory stack. As such, you want to be ableto test a Web application’s back-buttonbehavior, and WebDriver provides an
API call for it.In terms of state machines, the backbutton is not a separate transition. In-stead, it is a reaction to an earlier (click)event. As such, back-button behavior isa property of an edge, indicating thetransition can be “undone” by follow-ing it in the reverse direction.
UML’s mechanism for giving specialmeaning to elements is to use annota-tions (profiles). In Figure 13 explicit<<back>> and <<noback>> annota-tions have been added to the edges to
indicate whether the back button canbe used after the click to return to theinitiating state. Thus, for simple navi-gation between the About, Registering,and Authenticating states, the backbutton can be used to navigate back.
Between the Authenticated and Au-thenticating state, however, the backbutton is effectively disabled: oncelogged off, clicking “Back” should notallow anyone to go to content requir-ing authentication. Knowing whichtransitions have special back behav-
ior will then guide the constructionof extra test scenarios verifying therequired behavior.
Super States with History As a slightly more sophisticated exam-ple of a super state, consider a table thatis sortable across different columns.Clicking on a column header causes thetable to be sorted, giving rise to a sub-state for every column (Figure 14).
The events come out of the superstate, indicating they can be triggeredfrom any substate and go into a par-
Figure 12. Faults on longer paths.
Authenticating
Portfolio
Help
Account
Settings
Figure 13. Back-button annotations.
Public Navigation
About
Registering
Authenticating login
«back>
signup
«back>
about
«back>
Authenticated
login[OK]
«noback»
logoff
«noback»
Figure 14. Super state with history.
Sorted Table
Sorted by A
Sorted by B
Sorted by Csort
on - C
sort
on - B
sorton - A
Details
portfoliodetails
H

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 44/100
42 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
practice
events (over Web sockets) such as pushnotifications for new email and stockprice adjustments, among others.
From a testing perspective, orthogo-nal regions are in principle indepen-dent and therefore can be tested inde-pendently.
Like OR-states, AND-states can be
expanded, in this case to make all pos-sible interleavings explicit. This blowsup the diagram considerably and,hence, the number of potential testcases. While testing a few of such in-terleavings explicitly makes sense andis doable, testing all of them calls forautomated test generation.
State-based stories. Last but notleast, states and state diagrams canalso be helpful when describing re-quirements with user stories and ac-
ceptance scenarios. For example, thereis a natural fit with the story formatproposed by technology consultantDan North.9 Such stories consist of ageneral narrative of the form “as a… I
want… so that…”, followed by a num-ber of acceptance scenarios of the form“given… when… then”.
In many cases, these acceptance sce-narios can be simply mapped to testinga single transition in the state diagram.The scenario then takes the form:
Given I have arrived in some state
When I trigger a particular eventThen the application conducts an ac-tion
And the application moves to someother state.
Thus, the state objects allow the API to interact with the state machineas suggested by these acceptance sce-narios. A single test case moves fromone state to another, and a full featureis described by a number of acceptancetest cases navigating through the statemachine, meanwhile checking how the
application behaves.
AngularJS PhoneCat Example As a complete example of testing with WebDriver and state objects, con-sider the AngularJS PhoneCat tutorial(https://docs.angularjs.org/tutorial). Ascreen shot of the PhoneCat applica-tion in action is shown in Figure 16.It comes with a test suite written inProtractor, which is the WebDriverJS11 extension tailored toward AngularJSapplications.
The application consists of a simple
ticular substate. When leaving thesortable table page—for example, byrequesting details for a given row—a design decision needs to be madeabout whether returning to that page(in this case by clicking the portfoliolink) should yield a table sorted bythe default column (A in this case) orshould restore the sorting according tothe last column clicked.
In UML statecharts, the first option
(returning to super state’s initial state)is the default. The second option (re-turning to the super state’s state as it
was before leaving) can be indicatedby marking the super state as a His-tory state, labeling it with a circled H.In both cases, if this behavior is im-portant and requires testing, an extrapath (scenario) is needed to verify thesuper state returns to the correct stateafter having been exited from a non-initial state.
And-states. Today’s Web applica-tions typically show a number of in-
dependent widgets, such as a contactlist in one and an array of pictures inanother. These widgets correspond tolittle independent state machines thatare placed on one page.
In UML statecharts, such statescan be described by orthogonal regions(also called AND-states), as shown inFigure 15. The Figure shows a Port-folio state, which consists of both asortable table and an Upload button
to add items. These can be used in-dependently, as indicated by the twohalves of the Portfolio state separatedby the dashed line. The upload dialogis modal, which is why it is outside thePortfolio class. After uploading, thetable remains sorted as it was, which is
why it is labeled with the H.Such orthogonal regions can be
used to represent multiple little statemachines present on one page. Statetransitions in these orthogonal regionsmay come from user interaction. Theycan also be triggered through server
Figure 15. Orthogonal regions.
cancelfile
selected/
analyze
Uploadable
upload
Sorted Table
Sorted by A
Sorted by B
Sorted by Csort
on - C
sort
on - B
sort
on - A
Portfolio
H
File
Selector
Figure 17. State diagram for phonecatalog.
select
image
sort
name
sort newest
search
Phone
Details
details
«back»
Phone
List
Figure 16. PhoneCat AngularJS Application.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 45/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 43
practice
list of phones that can be filtered byname and sorted alphabetically or byage. Clicking on one phone leads to fulldetails for the given phone type.
The WebdriverJS test suite provided with the tutorial consists of three testcases for each of the two views (phonelist and phone details), as well as one
test for the opening URL, for a total ofseven test cases.
The test suite in the original tutorialdoes not use page (or state) objects. Toillustrate the use of state objects, I’verewritten the PhoneCat test suite toa state object-based test suite, whichis available from my PhoneCat forkon GitHub (https://github.com/avan-deursen/angular-phonecat/pull/1).
The state diagram I used for thePhoneCat application is shown in Fig-
ure 17. It leads to two state objects (onefor each view). These state objects canbe used to express the original set ofscenarios. Furthermore, the state dia-gram calls for additional cases, for ex-ample for the ‘sort-newest’ transitionnot covered in the original test case.
The figure also makes clear there isno direct way to get from Phone Detailsto the Phone List. Here the browser’sback button is an explicit part of theinteraction design, which is why the<<back>> annotation was added to
the corresponding transition. (Notethis is the only edge with this property:clicking “Back” after any other transi-tion while in the Phone List state exitsthe application, as per AngularJS de-fault behavior).
Since the back button is essentialfor navigating between the two views,the state-based test suite also describesthis behavior through a scenario.
Lastly, as the Protractor and Web-DriverJS APIs are entirely based onasynchronous JavaScript promises,11
the state object implementations areasynchronous as well. For example, thePhone List state object offers a methodthat “schedules a command to sortthe list of phones” instead of block-ing until the phones are sorted. In this
way, the actual scenarios can chain thepromises together using, for example,the then promise operator.
AngularJS in production. Most ofthe figures presented in this article arebased on diagrams created for a Webapplication developed for a Delft Uni-
versity of Technology spinoff company.
The application lets users register, login, upload files, analyze and visualizethem, and inspect analysis results.
The application’s end-to-end testsuite uses state objects. It consists ofabout 25 state objects and 75 scenari-os. Like the PhoneCat test suite, it usesProtractor and consists of about 1,750
lines of JavaScript.The end-to-end test suite is run from
a TeamCity (https://www.jetbrains.com/teamcity/) continuous integrationserver, which invokes about 350 back-end unit tests, as well as all the end-to-end scenarios upon any change to theback end or front end.
The test suite has helped fix andfind a variety of bugs related to client-side caching, back-button behavior,table sorting, and image loading. Sev-
eral of these problems were a result ofincorrect data bindings caused by, forexample, typos in JavaScript variablenames or incomplete rename refac-torings. The tests also identified back-end API problems related to incorrectserver configurations and permissions(resulting in, for example, a 405 and anoccasional 500 HTTP status code), as
well as incorrect client / server assump-tions (the JavaScript Object Notationreturned by the server did not conformto the front end’s expectations).
Conclusion When doing end-to-end testing of a Web application, use states to drivethe tests:
˲ Model interactions of interest assmall state machines.
˲ Let each state correspond to a stateobject.
˲ For each state include a self-checkto verify the browser is indeed in thatstate.
˲ For each transition, write a scenar-
io conducting self-checks on the origi-nal and target states, and verify the ef-fects of the actions on the transition.
˲ Use the transition tree to reasonabout state reachability and transitioncoverage.
˲ Use advanced statechart conceptssuch as AND-states, OR-states, and an-notations to keep your diagrams con-cise and comprehensible.
˲ Consider specific paths through thestate machine that may be error prone;if you already have state objects for thestates on that path, testing the behavior
along that path should be simple. ˲ Exercise the end-to-end test suite in
a continuous integration server to spotintegration problems between HTML,
JavaScript, and back-end services. As with page objects, the details of
the browser interaction are encapsu-lated in the state objects and hidden
from the test scenarios. Most impor-tantly, the state diagrams and corre-sponding state objects directly guide
you through the overall process of test-suite design.
Related articleson queue.acm.org
Rules for Mobile Performance OptimizationTammy Everts
http://queue.acm.org/detail.cfm?id=2510122
Scripting Web Service Prototypes
Christopher Vincent http://queue.acm.org/detail.cfm?id=640158
Software Needs Seatbelts and AirbagsEmery D. Berger http://queue.acm.org/detail.cfm?id=2333133
References1. AngularJS. ngInclude directive; https://docs.angularjs.
org/api/ng/directive/ngInclude.2. Antoniol, G., Briand, L.C., Di Penta, M. and Labiche, Y.
A case study using the round-trip strategy for state-based class testing. In Proceedings 13th InternationalSymposium on Software Reliability Engineering. IEEE(2002), 269–279.
3. Binder, R.V. Testing Object-oriented Systems. Addison-Wesley, Reading, PA, 1999, Chapter 7.
4. Fowler, M. PageObject, 2013; http://martinfowler.com/
bliki/PageObject.html.5. Harel, D. 1987. Statecharts: a visual formalism for
complex systems. Science of Computer Programming8(3): 231–274.
6. Horrocks, I. Constructing the User Interface withStatecharts. Addison-Wesley, Reading, PA, 1999.
7. Leotta, M., Clerissi, D., Ricca, F., Spadaro, C. Improvingtest suites maintainability with the page object pattern:An industrial case study. In Proceedings of the Testing:Academic and Industrial Conference—Practice andResearch Techniques. IEEE (2013), 108–113.
8. Mesbah, A., van Deursen, A. and Roest, D. Invariant-based automatic testing of modern Web applications.IEEE Transactions on Software Engineering 38, 1(2012) 35–53.
9. North, D. What’s in a story?; http://dannorth.net/whats-in-a-story/.
10. Selenium. Page Objects, 2013; https://github.com/SeleniumHQ/selenium/wiki/PageObjects
11. Selenium. Promises. In WebDriverJS User’s Guide,2014; https://code.google.com/p/selenium/wiki/WebDriverJs#Promises.
12. SeleniumHQ. WebDriver; http://docs.seleniumhq.org/projects/webdriver/.
AcknowledgmentsThanks to Michael de Jong, Alex Nederlof, and Ali Mesbahfor many good discussions and for giving feedback on thispost. The UML diagrams for this post were made with thefree UML drawing tool UMLet (version 13.2).
Arie Van Deursen is a professor at Delft University ofTechnology where he leads the Software EngineeringResearch Group. To help bring his research into practice,he co-founded the Software Improvement Group in 2000and Infotron in 2010.
Copyright held by author.Publication rights licensed to ACM. $15.00.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 46/100
44 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
practice
I M
A G E
B Y
G U
O Z H
O N G H U
A
DOI:10.1145/2714079
Article development led by
queue.acm.org
Cloud computing for computer scientists.
BY DANIEL C. WANG
BY NOW EVERYONE has heard of cloud computing andrealized it is changing how traditional enterprise ITand emerging startups are building solutions for thefuture. Is this trend toward the cloud just a shift in thecomplicated economics of the hardware and softwareindustry, or is it a fundamentally different way ofthinking about computing? Having worked in theindustry, I can confidently say it is both.
Most articles on cloud computing focus too muchon the economic aspects of the shift and miss thefundamental changes in thinking. This article attemptsto fill the gap and help a wider audience betterappreciate some of the more fundamental issues relatedto cloud computing. Much of what is written hereshould not be earth shattering to those working with
these systems day to day, but the article may encourage
even expert practitioners to look attheir day-to-day issues in a more nu-
anced way.Here are the key points to be cov-
ered: ˲ A cloud computer is composed of
so many components that systemati-cally dealing with the failure of thosecomponents is an essential factor toconsider when thinking about the soft-
ware that runs on a cloud computer orinteracts with one.
˲ A common architectural patternused to deal with transient failures is
to divide the system into a pure compu-tational layer and a separate layer thanmaintains critical system state. Thisprovides reliability, scalability, andsimplicity.
˲ A well-established existing bestpractice is to have systems exposeidempotent interfaces so simple retrylogic can be used to mask most tran-sient failures.
˲ Simple analytic techniques canallow quantitative statements about
various retry policies and compare how
they impact reliability, worst-case la-tency, and average-case latency underan idealized failure model.
The first point about dealing withfailure may seem new to many who arenow hosting even small applicationson large multitenant cloud computersin order to benefit from economies ofscale. This is actually a very old issue,however, so the discussion shouldbegin not by talking about the latesttrends but by going back to the early
years of the electronic computer.
Lessons from EDVACand Von NeumannIn 1945 John von Neumann describedthe computational model of the firstfully electronic stored program com-puter. This was a side effect of himacting as a consultant with ENIACinventors John Mauchly and J. Pres-per Eckert. Although he was not theoriginator of many of the key ideas,his name is associated with the designapproach, and the von Neumann ar-chitecture was soon a standard design
From theEDVAC toWEBVACs

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 47/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 45

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 48/100
46 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
practice
between the processor and memory inthe EDVAC design. For lack of a bet-ter term let’s call these systems WEB-
VACs, for Worldwide Elastic Big Very Automated Clusters.
These WEBVACs are not conceptu-ally different from the farms of Webservers seen today in a traditional data
centers. WEBVACs use a proven archi-tecture that provides resiliency, scal-ability, and a very familiar program-ming model based on stateless HTTPrequests. The chief innovation is the de-gree and ease of configurability, as wellas elasticity and scale. One importantfeature of EDVAC that distinguished itfrom earlier computers such as ENIAC
was that EDVAC executed a programthat was stored in its memory as data,
while ENIAC was programmed by physi-
cally rewiring it for different problems.Figure 1 shows the conceptual similar-ity to both WEBVACs and the EDVAC.
Like EDVAC, modern cloud comput-ers allow for the automatic configura-tion of a complete server farm with afew simple artifacts. This eliminatesthe need for tedious and error-pronemanual configuration of servers, as isoften done in more traditional systems.
Building a reliable storage tier thatmeets the needs of the compute tier is achallenging task. Requests in the stor-
age tier need to be replicated acrossseveral servers using complex distrib-uted consensus protocols. There is a
wide range of approaches to buildingstorage tiers, as well as a great diversityin their APIs and consistency models.(It is difficult to do justice to this topicin the limited space here, so see the ad-ditional reading suggestions at the endof this article.) In the end, however, thestorage tier is just an abstraction thatis callable from the compute tier. Thecompute tier can rely on the guaran-
tees provided by the storage tier andtherefore uses a much simpler pro-gramming model.
This simpler programming model,in which all the important state of thesystem is stored in a generic storagetier, also simplifies disaster-recoveryscenarios since simple backup andrestore of the storage tier is often suf-ficient to restore an entire system intoa working state. Well-designed sys-tems have asynchronous continuousbackup of the storage tier to a replicain a physically different location. This
used for building electronic computers.The original EDVAC (electronic dis-crete variable automatic computer)draft report6 contains these interest-ing passages from von Neumann:
1.4 The remarks of 1.2 on the de-sired automatic functioning of the
device must, of course, assume itfunctions faultlessly. Malfunctioningof any device has, however, always afinite probability—and for a compli-cated device and a long sequence ofoperations it may not be possible tokeep this probability negligible. Anyerror may vitiate the entire output ofthe device. For the recognition andcorrection of such malfunctions in-telligent human intervention will ingeneral be necessary.
However, it may be possible to avoideven these phenomena to some extent.The device may recognize the mostfrequent malfunctions automatically,indicate their presence and location byexternally visible signs, and then stop.Under certain conditions it might evencarry out the necessary correction auto-matically and continue…
3.3 In the course of this discussionthe viewpoints of 1.4, concerned withthe detection, location, and under cer-tain conditions even correction, of mal-
functions must also receive some con-sideration. That is, attention must begiven to facilities for checking errors.
We will not be able to do anything likefull justice to this important subject,but we will try to consider it at least cur-sorily whenever this seems essential.5
The practical problems that concerned
von Neumann and the designers of theEDVAC in 1945 were the reliability of
vacuum tubes and the main memorystored with mercury delay lines. (A
modern hard drive is an amazing elec-tromechanical device as well, whichfinally is starting to be replaced withsolid-state memory.) The inventionof the transistor, integrated circuit,and error-correcting codes makes vonNeumann’s concerns seem quaint to-day. Single-bit errors and even multi-bit errors in computer systems, whilestill possible, are sufficiently rare thatthese problems are considered ines-sential. The ability to consider failureof system components, however, canno longer be ignored with the advent of
cloud computers that fill acres of space with commodity servers.
Murphy’s Law Triumphsover Moore’s Law
A cloud computer is composed of somany components, each with a finiteprobability of failure, that the probabil-
ity of all the components running with-out error at any point in time is close tozero. Failure and automated recoveryare hence essential areas of concern notonly at the hardware layer but also withthe software components. In short, weare at the point where Murphy’s Lawhas conquered Moore’s Law. Assum-ing all the components make a system
work flawlessly is a luxury that is no lon-ger possible. Fortunately, techniquesfor handling bit-level corruptions can
be adjusted and scaled to cloud com-puters, so most bit-level errors can bedetected, if not fixed. The types of fail-ures we are worried about, however,are those of a server or whole groups ofservers. We are also at a point where therates of certain failures are so high that
von Neumann’s suggestion that thesystem simply detect the error and waitfor a human operator to intervene is nolonger economically sensible.
You might ask if we can work hard-er to build more reliable systems, but
when the reliability of your main powersupply is inversely proportional to thedensity of wire-eating squirrels in yourregion or the probability that a worker
will drop an uninsulated wrench intoa power-distribution cabinet, it is dif-ficult to imagine a cost-effective andsystematic approach to address the re-liability of data centers that commonlyhouse as many as 100,000 servers.
From EDVAC to WEBVACOne very popular approach to dealing
with frequent server-level failures in adata center is to decompose the sys-tem into one or more tiers of serversthat process requests on a best-effortbasis and store any critical applica-tion state in a dedicated storage tier.Typically, there is a request load bal-ancer in front of each tier so that theindividual servers in the tier can failand have requests rerouted automati-cally. The key aspect of this design isa complete separation between long-term system state and computation.This is the same separation that exists

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 49/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 47
practice
location needs to be close enough thatdata can be efficiently and cost-effec-tively replicated, but distant enoughthat the probability of it encounteringthe same “act of God” is low. (Puttingboth your primary and backup datacenters near the same earthquakefault line is a bad idea.)
Since the backup is asynchronous,failover to the replica may incur somedata loss. That data loss, however, canbe bounded to acceptable and well-defined limits that come into play only
when an act of God may cause the com-plete destruction of the primary sys-tem. Carefully determining the physi-cal location of your data centers is thefirst case where there is a need to treatfailure in an end-to-end way. This sameend-to-end focus on failure is also im-
portant in the design and implementa-tion of software running on and inter-acting with the system.
How to Design Interfacesfor WEBVACs
WEBVACs ultimately provide APIsthat allow desktop computers, mobiledevices, or other WEBVACs to submitrequests and receive responses tothose requests. In any case, you endup with two agents that must com-municate with each other via some
interface over an unreliable channel.Reusing traditional designs from cli-ent-server systems or standard RPC
(remote procedure call) methods isnot the best approach. Andrew Tane-baum and Robbert van Resse4 de-scribe some common pitfalls whendoing naïve refactoring of code notdesigned for distributed scenarios,
which are generally applicable tothe APIs here as well. One particular
problem they call out is the 2AP (two-army problem), which demonstratesit is impossible to design a fully reli-able method for two agents to reachconsensus over an unreliable channelthat may silently drop messages.
This is a restricted version of themore general problem of dealing withByzantine failure, where the failuredoes not include data corruption. Asa consequence, there is simply no wayof building a system that can process
any request with 100% reliability if thechannel itself is unreliable. The 2AP
result, however, does not rule out pro-tocols that asymptotically approach100% reliability. A simple solution iscontinually transmitting a request upto some finite bound until some ac-knowledgment is received. If the errorrate of the channel is fixed and failuresare independent, then the likelihood
of success increases exponentially withthe number of transmissions.
In a large data center, not only isthe communication between serversunreliable, but also the servers them-selves are prone to failure. If a serverin the compute tier fails, then a re-quest that targeted it can be quicklyrerouted to an equivalent computeserver. The process of rerouting therequest is often not fully transparentand the request is lost during rerout-
ing, because the routing logic cannotimmediately detect the server failure
Figure 2. Simple interface used to enumerate files remotely.
enum Result {
Ok, /* Completed without errors. */
NoMore, /* No more names left to enumerate.*/
Fault /* Message lost in transit or unknown failure. */
};
/* Moves cursor before rst element in list of les. */
Result SetCursorToStart();
/* Get the current le name pointed to by the cursor.
* Returns NoMore if the cursor is moved past the last name.
*/
Result GetCurrentFileName(char leName[ MAXLENGTH]);
/* Move the cursor to the next le name.
* Returns NoMore if there is none.
*/
Result MoveToNextFileName();
Figure 3. A naïve function to enumerate files.
Result ListFilesStopAtAnyFault() { char leName[ MAXLENGTH];
Result res;
res = SetCursorToStart();
if (res != Ok) { return res; }
printf(“Start\n”);
for (;;) {
res = MoveToNextFileName();
if (res == NoMore) { break; }
if (res != Ok) { return res; }
res = GetCurrentFileName(leName);
printf(“File: %s”, leName);
}
printf(“End\n”);
return Ok;
}
Figure 1. EDVAC and WEBVAC.
Input/
Output
Electronic DiscreteVariable Automatic Computer
EDVAC
Processor
Memory
Worldwide Elastic Big
Very Automatic Cluster
WEBVAC
Input/
Output
Processor
Memory
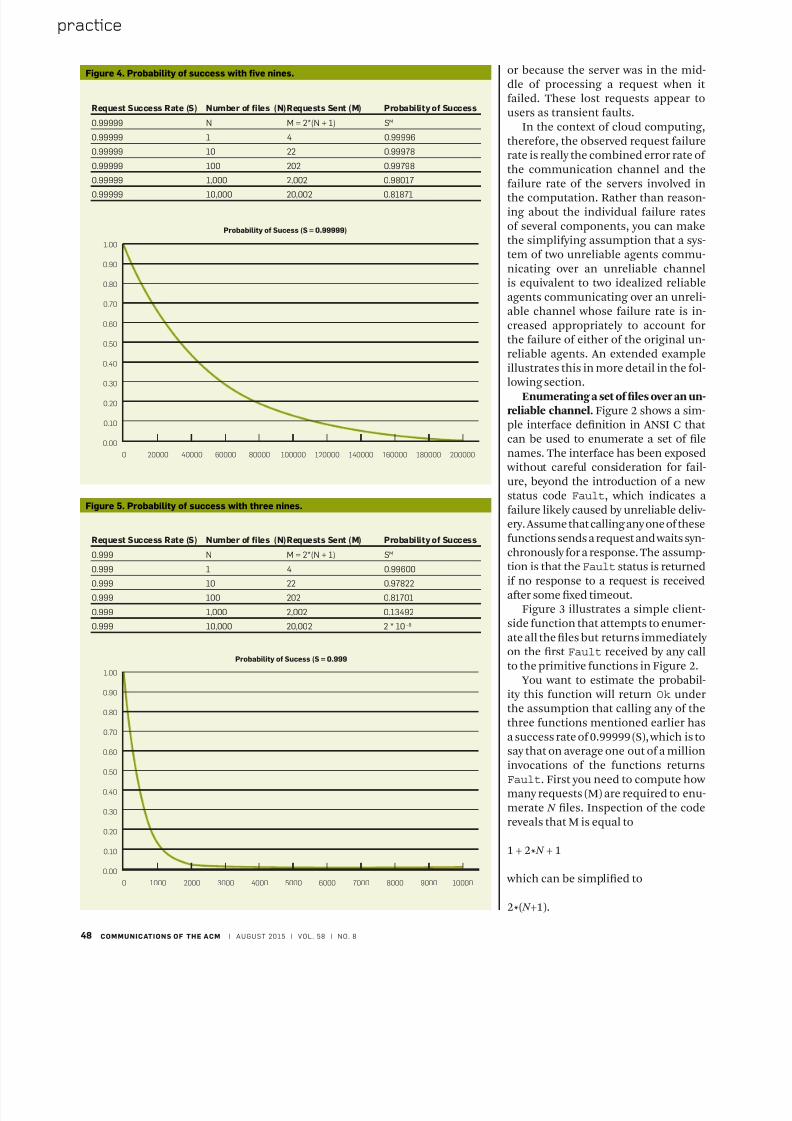
7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 50/100
48 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
practice
or because the server was in the mid-dle of processing a request when itfailed. These lost requests appear tousers as transient faults.
In the context of cloud computing,therefore, the observed request failurerate is really the combined error rate ofthe communication channel and the
failure rate of the servers involved inthe computation. Rather than reason-ing about the individual failure ratesof several components, you can makethe simplifying assumption that a sys-tem of two unreliable agents commu-nicating over an unreliable channelis equivalent to two idealized reliableagents communicating over an unreli-able channel whose failure rate is in-creased appropriately to account forthe failure of either of the original un-
reliable agents. An extended exampleillustrates this in more detail in the fol-lowing section.
Enumerating a set of files over an un-reliable channel. Figure 2 shows a sim-ple interface definition in ANSI C thatcan be used to enumerate a set of filenames. The interface has been exposed
without careful consideration for fail-ure, beyond the introduction of a newstatus code Fault, which indicates afailure likely caused by unreliable deliv-ery. Assume that calling any one of these
functions sends a request and waits syn-chronously for a response. The assump-tion is that the Fault status is returnedif no response to a request is receivedafter some fixed timeout.
Figure 3 illustrates a simple client-side function that attempts to enumer-ate all the files but returns immediatelyon the first Fault received by any callto the primitive functions in Figure 2.
You want to estimate the probabil-ity this function will return Ok underthe assumption that calling any of the
three functions mentioned earlier hasa success rate of 0.99999 (S), which is tosay that on average one out of a millioninvocations of the functions returnsFault. First you need to compute howmany requests (M) are required to enu-merate N files. Inspection of the codereveals that M is equal to
1 + 2* N + 1
which can be simplified to
2*( N +1).
Figure 4. Probability of success with five nines.
1.00
0.90
0.80
0.70
0.60
0.50
0.40
0.30
0.20
0.10
0.00
0 20000 40000 60000 80000 100000 120000 140000 160000 180000 200000
Probability of Sucess (S = 0.99999)
Request Success Rate (S) Number of files (N)Requests Sent (M) Probability of Success
0.99999 N M = 2*(N + 1) SM
0.99999 1 4 0.99996
0.99999 10 22 0.99978
0.99999 100 202 0.99798
0.99999 1,000 2,002 0.98017
0.99999 10,000 20,002 0.81871
Figure 5. Probability of success with three nines.
1.00
0.90
0.80
0.70
0.60
0.50
0.40
0.30
0.20
0.10
0.00
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000
Probability of Sucess (S = 0.999
Request Success Rate (S) Number of files (N)Requests Sent (M) Probability of Success0.999 N M = 2*(N + 1) SM
0.999 1 4 0.99600
0.999 10 22 0.97822
0.999 100 202 0.81701
0.999 1,000 2,002 0.13492
0.999 10,000 20,002 2 * 10–9

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 51/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 49
practice
Since the function fails immedi-ately on any fault, the probability of nofaults is simply the probability that allthe requests sent succeed, which is SM assuming failures are uniformly dis-tributed. For purposes of this analysis,let’s assume failure is independentand uniformly distributed. This simpli-
fying assumption allows a comparisonof the trade-offs of various approachesunder equivalent ideal failure models.In practice, however, the distributionof failures is typically neither uniformnor completely independent. The re-sults are summarized in Figure 4.
Depending on the workload char-acteristics, this success rate for thefirst attempt at listing files may be ac-ceptable. In this example, the successrate of 0.99999 (a five-nines success
rate results in fewer than 5.3 minutesof downtime a year for a continuouslyrunning system) is extremely high andtypically can be achieved only withsignificant investment in expensivehardware infrastructure. A more real-istic error rate would be 0.999 (a three-nines success rate results in fewerthan 8.8 hours of downtime a yearfor a continuously running system),
which is more typically seen with com-modity components. A three-ninessuccess rate produces the graph and
table of values in Figure 5.Clearly, a 3% failure rate for enumer-
ating 10 files is not a usable system. Youcan improve the probability of successby simply retrying the whole function,but this is not only inefficient, but also,for large N , the success rate is so low thatit would require an unreasonable num-ber of retries. If the probability of thefunction ListFilesStopAtAnyFault enumerating N files successfully is
LS( N )= S(2*( N +1) )
then the probability of failure is
LF ( N )= 1 – LS( N ).
The probability that after, at most, K re-tries the function succeeds is the sameas the probability
1 – LF ( N ) K
that is the complement of the probabil-ity that all invocations fail. For this dis-cussion, if the probability of success is
Figure 6. Simple retry wrappers over remote primitives.
#dene MAX_RETRIES 3
Result SetCursorToStartWithRetry() {
Result res;
for (int i = 0; i < MAX_RETRIES; i++) {
res = SetCursorToStart();
if (res != Fault) { return res; }
} return Fault;
}
Result GetCurrentFileNameWithRetry(
char leName[ MAXLENGTH]) {
...
}
Result MoveToNextFileNameWithRetry() {
…
}
Figure 7. Enumerating files using retry wrappers.
Result ListFilesWithRetry() {
char leName[ MAXLENGTH];
Result res;
res = SetCursorToStartWithRetry();
if (res != Ok) { return res; }
printf(“Start\n”);
for (;;) {
res = MoveToNextFileNameWithRetry();
if (res == NoMore) { break; }
if (res != Ok) { return res; }
res = GetCurrentFileNameWithRetry(leName);
printf(“File: %s”, leName);
}
printf(“End\n”);
return Ok;
}
Figure 8. An idempotent interface to enumerate files remotely.
typedef int tok_t;
/* Get start token with cursor before
rst element in list of les. */
Result GetStartToken(
tok_t *init);
/*
* Get the current le name pointed to * by the cursor relative to a state token.
* Returns NoMore if the cursor is moved past
* the last name.
*/
Result GetCurrentFileNameWithToken(
tok_t curent,
char leName[ MAXLENGTH]);
/* Move the given a token return the next state
* token with the cursor advanced. Returns NoMore
* if there is none.
*/
Result MoveToNextFileNameWithToken(
tok_t curent,
tok_t *next);
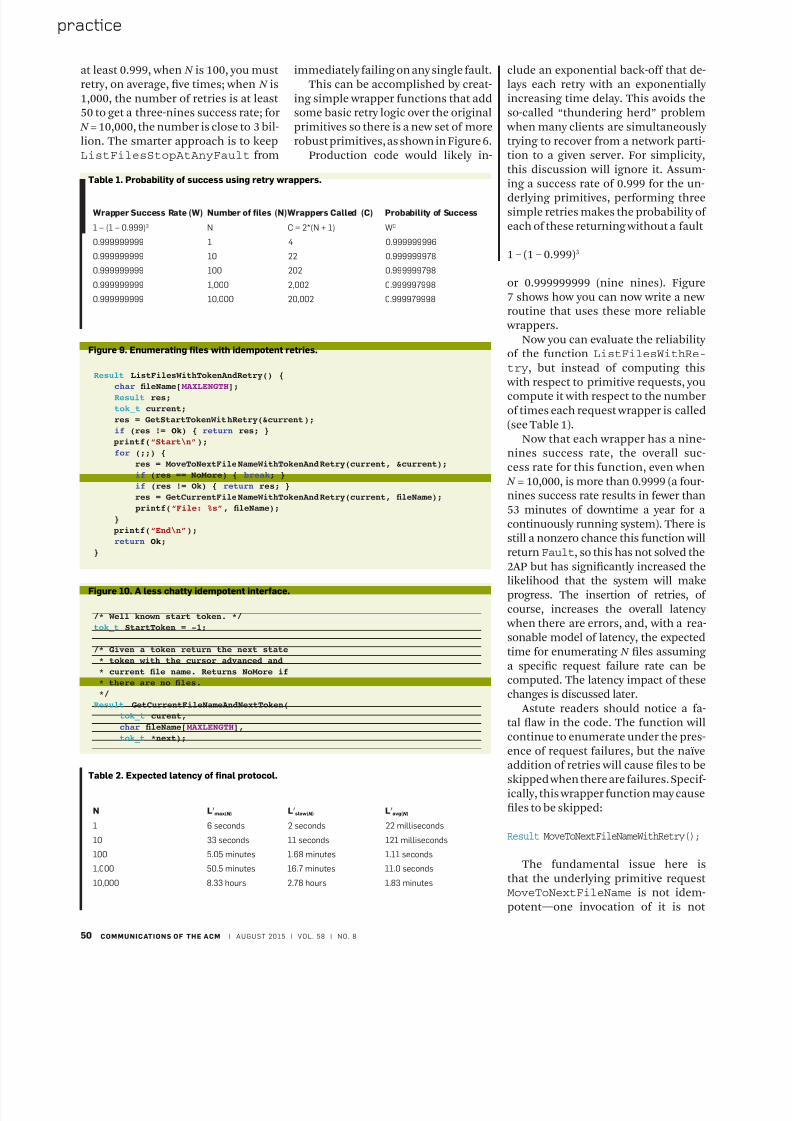
7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 52/100
50 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
practice
clude an exponential back-off that de-lays each retry with an exponentiallyincreasing time delay. This avoids theso-called “thundering herd” problem
when many clients are simultaneouslytrying to recover from a network parti-tion to a given server. For simplicity,this discussion will ignore it. Assum-
ing a success rate of 0.999 for the un-derlying primitives, performing threesimple retries makes the probability ofeach of these returning without a fault
1 – (1 – 0.999)3
or 0.999999999 (nine nines). Figure7 shows how you can now write a newroutine that uses these more reliable
wrappers.Now you can evaluate the reliability
of the function ListFilesWithRe-try, but instead of computing this with respect to primitive requests, youcompute it with respect to the numberof times each request wrapper is called(see Table 1).
Now that each wrapper has a nine-nines success rate, the overall suc-cess rate for this function, even when
N = 10,000, is more than 0.9999 (a four-nines success rate results in fewer than53 minutes of downtime a year for acontinuously running system). There is
still a nonzero chance this function willreturnFault, so this has not solved the2AP but has significantly increased thelikelihood that the system will makeprogress. The insertion of retries, ofcourse, increases the overall latency
when there are errors, and, with a rea-sonable model of latency, the expectedtime for enumerating N files assuminga specific request failure rate can becomputed. The latency impact of thesechanges is discussed later.
Astute readers should notice a fa-
tal flaw in the code. The function willcontinue to enumerate under the pres-ence of request failures, but the naïveaddition of retries will cause files to beskipped when there are failures. Specif-ically, this wrapper function may causefiles to be skipped:
Result MoveToNextFileNameWithRetry();
The fundamental issue here isthat the underlying primitive requestMoveToNextFileName is not idem-potent—one invocation of it is not
at least 0.999, when N is 100, you mustretry, on average, five times; when N is1,000, the number of retries is at least50 to get a three-nines success rate; for
N = 10,000, the number is close to 3 bil-lion. The smarter approach is to keepListFilesStopAtAnyFault from
immediately failing on any single fault.This can be accomplished by creat-
ing simple wrapper functions that addsome basic retry logic over the originalprimitives so there is a new set of morerobust primitives, as shown in Figure 6.
Production code would likely in-
Figure 9. Enumerating files with idempotent retries.
Result ListFilesWithTokenAndRetry() {
char leName[ MAXLENGTH];
Result res;
tok_t current;
res = GetStartTokenWithRetry(¤t);
if (res != Ok) { return res; }
printf(“Start\n”);
for (;;) {
res = MoveToNextFileNameWithTokenAndRetry(current, ¤t);
if (res == NoMore) { break; }
if (res != Ok) { return res; }
res = GetCurrentFileNameWithTokenAndRetry(current, leName);
printf(“File: %s”, leName);
}
printf(“End\n”);
return Ok;}
Figure 10. A less chatty idempotent interface.
/* Well known start token. */
tok_t StartToken = -1;
/* Given a token return the next state
* token with the cursor advanced and
* current le name. Returns NoMore if
* there are no les.
*/
Result GetCurrentFileNameAndNextToken(
tok_t curent,char leName[ MAXLENGTH],
tok_t *next);
Table 1. Probability of success using retry wrappers.
Wrapper Success Rate (W) Number of files (N)Wrappers Called (C) Probability of Success
1 – (1 – 0.999)3 N C = 2*(N + 1) WC
0.999999999 1 4 0.999999996
0.999999999 10 22 0.999999978
0.999999999 100 202 0.999999798
0.999999999 1,000 2,002 0.999997998
0.999999999 10,000 20,002 0.999979998
Table 2. Expected latency of final protocol.
N L′max(N ) L′slow(N ) L′avg(N )
1 6 seconds 2 seconds 22 milliseconds
10 33 seconds 11 seconds 121 milliseconds
100 5.05 minutes 1.68 minutes 1.11 seconds
1,000 50.5 minutes 16.7 minutes 11.0 seconds
10,000 8.33 hours 2.78 hours 1.83 minutes

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 53/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 51
practice
observationally equivalent to multipleinvocations of the function. Becauseof the 2AP, there is no way to have theserver or client agree if the cursor hasmoved forward or not on a fault. Theonly way to resolve this issue is to makeMoveToNextFileName idempotent.
There are a variety of techniques to
do this. One way is to include sequencenumbers to detect retries and havethe server track these numbers. Thesesequence numbers now become im-portant state that must be placed inthe storage tier for every client in thesystem, and this can result in scalabil-ity issues. A more scalable approach isto use an opaque state token similarto how cookies are used in HTTP tooffload state from the server to the cli-ent. The client can maintain the need-
ed state rather than have the servertrack. This leaves the API shown in Fig-ure 8, which includes only idempotentfunctions.
In this example the state token issimply an integer in a realistic sys-tem; it would more likely be a variable-length byte array that the system veri-fies is valid so that malicious clientscannot harm the system.
The retry wrappers GetStartTo-kenWithRetry, GetStartToken-
WithRetry, and MoveToNextFile-
NameWithTokenAndRetry can alsobe defined as earlier.
We can adjust our function to uses wrapped primitives over the idempo-tent API (see Figure 9).
The analysis performed earlier onthe slightly buggy version that lackedthe idempotent primitives is still valid,but now the function works correctlyand reliably. When N = 10,000, the suc-cess rate is 0.999979998 (four nines).
Analyzing and Improving Latency
Because the only practical way to de-tect message loss between sendersand receivers is via timeouts, it is im-portant to document a time bound onhow long either party should wait fora request to be processed. If a requestis processed after that time bound hasbeen exceeded, then consider the re-quest failed. Services typically definean upper bound for each API functionthey support (for example, 99.9% of allrequests will be successfully processed
within one second). If no upper timebound is specified, a guaranteed 99.9%
success rate is somewhat meaning-less; you may have to wait an infiniteamount of time for any single requestto complete successfully.
Determining a reasonable up-per bound for a system can be quitecomplex. It can be estimated obser-
vationally by looking at the distribu-
tion of latencies across a large sampleof requests and choosing the maxi-mum, or by simply having the serverinclude a watchdog timer with a clearupper bound that fails any requestthat exceeds the threshold. In eithercase, the worst-case bound is neededso that clients of the service can settimeouts appropriately, but these
worst-case bounds typically are veryconservative estimates of the actualaverage-case performance. An extend-
ed version of this article published in ACM Queue analyzes worst-case, av-erage-case, and slow-case latency forthe file-listing function.
Let’s assume that every primitiverequest to the server has a worst-casesuccessful latency of Rmax and averagetime of Ravg , with these parameters
we can analytically estimate how ourretry policy impacts latency. There
worst-case is based on a pathological worst-case scenario where the maxi-mum number of failures and retries
occur. This analysis is overly pessi-mistic, and we can instead use ouraverage-case analysis to derive a slow-case estimate where the distributionof retries is the same as our average-case analysis, but we assume every re-quest is as slow as possible.
Some readers may feel this finalimplementation is too “chatty” and amore efficient protocol could reduceserver round-trips. Indeed, three func-tions in the API can be replaced withone (see Figure 10).
This protocol has a fixed globallyknown start token and a single func-tion that returns both the current filename and next token in one request.There should be an expected improve-ment in latency, which can be seen byperforming a latency analysis of themodified protocol depicted in Table 2.
The details of this latency analysisare in the full article, and use very el-ementary techniques of probabilitytheory to analytically determine rea-sonable time out values for callers ofthe function to list files.
ConclusionThis article is a far from exhaustive sur-
vey about the many interesting issuessurrounding cloud computing. Thegoal is to demonstrate the breadth ofdeep problems still to be solved. Someof the trailblazers who developed theelectronic computer would be dumb-
founded by the computation we nowcarry in our pockets. They would beequally surprised at how robustlysome of their earliest ideas have stoodthe test of time. Taken in historicalcontext, the modern WEBVAC shouldnot be seen as the culmination of 70
years of human progress, but just thestart of a promising future that wecannot imagine.
Acknowledgments
Special thanks to Gang Tan for encour-aging me to write this article, and SteveZdancewic for providing feedback.
Related articleson queue.acm.org
Describing the Elephant: The DifferentFaces of IT as ServiceIan Foster and Steven Tuecke
http://queue.acm.org/detail.cfm?id=1080874
Lessons from the FloorDaniel Rogers
http://queue.acm.org/detail.cfm?id=1113334
From EDVAC to WEBVACsDaniel C. Wanghttp://queue.acm.org/detail.cfm?id=2756508
References1. Calder, B., Wang, J., Ogus, A. et al. Windows Azure
Storage: A highly available cloud storage service withstrong consistency. In Proceedings of the 23rd ACMSymposium on Operating Systems Principles (2011),143–157; DOI=10.1145/2043556.2043571.
2. DeCandia, G., Hastorun, D. et al. Dynamo: Amazon’shighly available key-value store. In Proceedings of21st ACM Symposium on Operating Systems Principles(2007), 205–220; DOI=10.1145/1294261.1294281
3. Ghemawat, S., Gobioff, H., Leung, S.-T. The Google filesystem. In Proceedings of the 19th ACM Symposiumon Operating Systems Principles, (2003), 29–43.DOI=10.1145/945445.945450; http://doi.acm.
org/10.1145/945445.945450.4. Tanenbaum, A.S., van Renesse, R. A critique of
the remote procedure call paradigm. In EuropeanTeleinformatics Conference Proceedings, ParticipantsEdition (1988), 775–783.
5. von Neumann, J. First Draft of a Report on theEDVAC. Technical Report, 1945. https://web.archive.org/web/20130314123032/http://qss.stanford.edu/~godfrey/vonNeumann/vnedvac.pdf.
6. Wikipedia. First draft of a report on the EDVAC; http://en.wikipedia.org/wiki/First_Draft_of_a_Report_on_the_EDVAC.
Daniel C. Wang has been working in the computingindustry for more than 15 years. He works on the AzureWeb Workload team. Any opinions in the article are his andnot of his employer.
Copyright held by author.Publication rights licensed to ACM. $15.00

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 54/100
52 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
I L L U
S T
R A T I
O N
B Y F U T U
R E D E
L U X E
DOI:10.1145/2699415
The Quipper language offers a unifiedgeneral-purpose programming frameworkfor quantum computation.
BY BENOÎT VALIRON, NEIL J. ROSS, PETER SELINGER,D. SCOTT ALEXANDER, AND JONATHAN M. SMITH
THE EARLIEST COMPUTERS, like the ENIAC, were rareand heroically difficult to program. That difficultystemmed from the requirement that algorithms beexpressed in a “vocabulary” suited to the particularhardware available, ranging from function tablesfor the ENIAC to more conventional arithmetic andmovement operations on later machines. Introductionof symbolic programming languages, exemplifiedby FORTRAN, solved a major difficulty for thenext generation of computing devices by enablingspecification of an algorithm in a form more suitablefor human understanding, then translating thisspecification to a form executable by the machine. The“programming language” used for such specificationbridged a semantic gap between the human and thecomputing device. It provided two important features:high-level abstractions, taking care of automatedbookkeeping, and modularity, making it easier to
reason about sub-parts of programs.
Quantum computation is a comput-ing paradigm where data is encoded
in the state of objects governed by thelaws of quantum physics. Using quan-tum techniques, it is possible to de-sign algorithms that outperform theirbest-known conventional, or classical,counterparts.
While quantum computers were en- visioned in the 20th century, it is likelythey will become real in the 21st cen-tury, moving from laboratories to com-mercial availability. This provides anopportunity to apply the many lessons
learned from programming classicalcomputing devices to emerging quan-tum computing capabilities.
Quantum Coprocessor ModelHow would programmers interact witha device capable of performing quan-tum operations? Our purpose here isnot to provide engineering blueprintsfor building an actual quantum com-puter; see Meter and Horsman13 for adiscussion of that agenda. What we de-scribe is a hypothetical quantum archi-
tecture in enough detail to cover howone would go about programming it.
Viewed from the outside, quantumcomputers perform a set of specializedoperations, somewhat analogous toa floating-point unit or a graphics co-processor. We therefore envision thequantum computer as a kind of copro-cessor that is controlled by a classicalcomputer, as shown schematically inFigure 1. The classical computer per-
Programmingthe QuantumFuture
key insights
˽ Quantum computer science is a newdiscipline dealing with the practicalintegration of all aspects of quantumcomputing, from an abstract algorithmin a research paper all the way tophysical operations.
˽ The programs written in a quantumprogramming language should be asclose as possible to informal high-leveldescriptions, with output suitable for thequantum coprocessor model.
˽ Other important aspects of the quantumprogramming environment includeautomated offline resource estimates
prior to deployment and facilities fortesting, specification, and verification.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 55/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 53

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 56/100
54 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
mately be the most likely realization ofquantum computers.13
Certain hardware-intensive low-lev-el control operations (such as quantumerror correction) may optionally be in-tegrated directly into the quantum unit.
We envision the quantum unit contain-ing a high-speed, specialized firmware
in charge of such a low-level “quantumruntime.” The quantum firmware isspecific to each physical realization ofa quantum coprocessor, programmedseparately off site. Although tightly de-pendent on the physical specificationsof the particular hardware, the quan-tum firmware is independent of the al-gorithms to be run.
The source code of any quantumprograms resides on the classicalunit. Through a conventional classi-
cal compilation, it produces execut-able code to be run on the conven-tional computer. We envision thequantum coprocessor will commu-nicate with its classical controllerthrough a message queue on whichthe classical computer is able to sendelementary instructions (such as “al-locate a new quantum bit,” “rotatequantum bit x,” and “measure quan-tum bit y”). After an operation is per-formed, the classical computer canread the results from the message
queue. In this model, the control flowof an algorithm is classical; tests andloops are performed on the classicaldevice. Both classical and quantumdata are first-class objects.
Via the message queue, the classi-cal runtime receives feedback (such asthe results of measurements) from thequantum unit. Depending on the algo-rithm, this feedback may occur only atthe end of the quantum computation(batch-mode operation) or interleaved
with the generation of elementary in-
structions (online operation). Thepossibility of online operation raisesadditional engineering challenges,as it requires the classical controllerto be fast enough to interact with thequantum runtime in real time. On theother hand, many common quantumalgorithms require only batch-modeoperation. We assume a quantum pro-gramming model flexible enough toaddress either type of operation.
As with a conventional program-ming environment, we separate the log-ical data structures from their physical
forms operations (such as compila-tion, conventional bookkeeping, cor-rectness checking, and preparation ofcode and data) for the quantum unit.The quantum coprocessor performs
only the quantum operations (such asinitializations, unitary operations, andmeasurements). This model of quan-tum computation is known as Knill’sQRAM model11 and is believed to ulti-
Figure 1. Mixed computation in the quantum coprocessor model.
Analysis
Quantum
Run Time
Classical
Compilation
Classical
Run Time Classical
Feedback
Program
Classical
Executable
Classical Analysis
Classical Unit
Logical Elementary
Instructions
Physical
Specifications
Quantum
Firmware
Physical
Computation
Quantum Unit
Figure 2. A quantum circuit.
A
B
C
Output WiresInput Wires
Figure 3. A quantum circuit fragment.
a 1
b1
W W
†
a 2
b2
W W†
•••
a 2n
b2n
W W†
r
e −iZt
•••
••
•
•••
|0〉
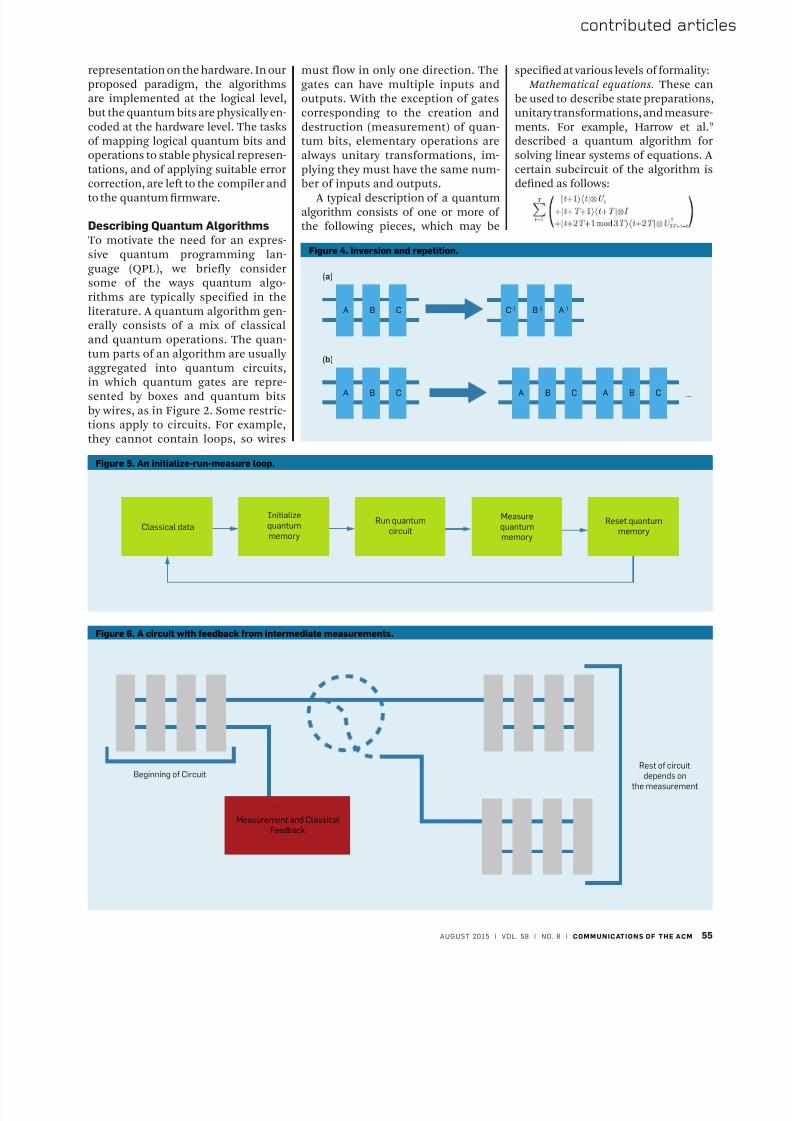
7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 57/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 55
contributed articles
representation on the hardware. In ourproposed paradigm, the algorithmsare implemented at the logical level,but the quantum bits are physically en-coded at the hardware level. The tasksof mapping logical quantum bits andoperations to stable physical represen-tations, and of applying suitable error
correction, are left to the compiler andto the quantum firmware.
Describing Quantum AlgorithmsTo motivate the need for an expres-sive quantum programming lan-guage (QPL), we briefly considersome of the ways quantum algo-rithms are typically specified in theliterature. A quantum algorithm gen-erally consists of a mix of classicaland quantum operations. The quan-
tum parts of an algorithm are usuallyaggregated into quantum circuits,in which quantum gates are repre-sented by boxes and quantum bitsby wires, as in Figure 2. Some restric-tions apply to circuits. For example,they cannot contain loops, so wires
must flow in only one direction. Thegates can have multiple inputs andoutputs. With the exception of gatescorresponding to the creation anddestruction (measurement) of quan-tum bits, elementary operations arealways unitary transformations, im-plying they must have the same num-
ber of inputs and outputs. A typical description of a quantum
algorithm consists of one or more ofthe following pieces, which may be
specified at various levels of formality: Mathematical equations. These can
be used to describe state preparations,unitary transformations, and measure-ments. For example, Harrow et al.9 described a quantum algorithm forsolving linear systems of equations. Acertain subcircuit of the algorithm is
defined as follows:
Figure 5. An initialize-run-measure loop.
Classical data
Initialize
quantum
memory
Run quantum
circuit
Measure
quantum
memory
Reset quantum
memory
Figure 4. Inversion and repetition.
A A-1B B-1C C-1
A B C A B C A B C ...
(a)
(b)
Figure 6. A circuit with feedback from intermediate measurements.
Measurement and Classical
Feedback
Beginning of CircuitRest of circuit
depends on
the measurement

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 58/100
56 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
ditioning a subroutine over the state ofa quantum register; and
Building quantum oracles. Enablethe programmer to build a quantumoracle from the description of a classi-cal function.
Our experience implementing a quantum algorithms suggests some
additional features that would be re-quirements for a quantum program-ming language:
Quantum data types. In classical lan-guages, data types are used to permitthe programmer to think abstractlyabout data instead of managing indi-
vidual bits or words. For example, inmost situations, a floating-point num-ber is best viewed as a primitive datatype supporting certain arithmetic op-erations, rather than an array of 64 bits
comprising an exponent, a mantissa,and a sign. Likewise, many quantumalgorithms specify richer data types,so the language should also providethese abstractions. For example, theQuantum Linear System Algorithm9 requires manipulation of quantumintegers and quantum real and com-plex numbers that can be representedthrough a floating-point or fixed-pre-cision encoding. Another example isHallgren’s algorithm8 for computingthe class number of a real quadratic
number field. One type of data that oc-curs in this algorithm, and that mustbe put into quantum superposition, isthe type of ideals in an algebraic num-ber field;
a By “implementing” an algorithm, we mean real-izing it as a computer program; we do not mean
we have actually run the programs on a quantumcomputer, although we have run parts of thealgorithms on quantum simulators.
Invocation of known quantum subrou-tines. Examples include the quantumFourier transform, phase estimation,amplitude amplification, and random
walks. For example, the algorithm inHarrrow et al.9 asks to “decompose |b⟩ in the eigenvector basis, using phaseestimation”;
Oracles. These are classical com-putable functions that must be made
reversible and encoded as quantumoperations. They are often described ata very high level; for example, Burhamet al.3 defined an oracle as “the truth
value of the statement f (x) ≤ f ( y)”;Circuit fragments. For example, the
circuit in Figure 3 is from Childs et al.4 Note, strictly speaking, the figure de-scribes a family of quantum circuits,parameterized by a rotation angle t anda size parameter n, as indicated by el-lipses “. . .” in the informal circuit. Ina formal implementation, this parame-
ter dependency must be made explicit; High-level operations on circuits.
Examples include “inversion,” wherea circuit is reversed, and “iteration,”
where a circuit is repeated, as in Figure4; and
Classical control. Many algorithmsinvolve interaction between the clas-sical unit and the quantum unit. Thisinteraction can take the form of simpleiteration, running the same quantum
circuit multiple times from scratch, asin Figure 5, or of feedback, where thequantum circuit is generated on the fly,possibly based on the outcome of pre-
vious measurements, as in Figure 6.
Requirements for QPLsIdeally, a quantum programming lan-guage should permit programmers toimplement quantum algorithms at a
level of abstraction that is close to howone naturally thinks about the algo-rithm. If the algorithm is most natu-rally described by a mathematical for-mula, then the programming languageshould support such a description
where possible. Similarly, if the algo-rithm is most naturally described bya sequence of low-level gates, the pro-gramming language should supportthis description as well.
The standard methods used to pres-ent many algorithms in the literature
can therefore be taken as guidelinesin the design of a language. Knill11 laidout requirements for quantum pro-gramming, including:
Allocation and measurement. Makeit possible to allocate and measurequantum registers and apply unitaryoperations;
Reasoning about subroutines. Permitreasoning about quantum subrou-tines, reversing a subroutine, and con-
Figure 7. A procedural example.
mycirc :: Qubit -> Qubit -> Circ (Qubit, Qubit)
mycirc a b = do
a <- hadamard a
b <- hadamard b
(a,b) <- controlled_not a b
return (a,b)H
H
Figure 8. A block structure example.
mycirc2 :: Qubit -> Qubit -> Qubit -> Circ (Qubit, Qubit, Qubit)
mycirc2 a b c = do
mycirc a b
with_controls c $ do
mycirc a b
mycirc b a
mycirc a c
return (a,b,c)
H H H
H H H H
H
1 2 3 41
2
3
4

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 59/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 57
contributed articles
Specification and verification. Inclassical programming, there is a vari-ety of techniques for ascertaining thecorrectness of programs, includingcompile-time type checking, runtimetype checking, formal verification, anddebugging. Among them, formal verifi-cation is arguably the most reliable but
also the most costly. The availabilityof strong compile-time guarantees re-quires very carefully designed program-ming languages. Debugging is cheapand useful and therefore ubiquitous inclassical-program development.
In quantum computation, the costof debugging is likely to be quite high.To begin with, observing a quantumsystem can change its state. A debuggerfor a quantum program would there-fore necessarily give incomplete in-
formation about its state when run onactual quantum hardware. The alterna-tive is to use a quantum simulator fordebugging. But this is not practical dueto the exponential cost of simulatingquantum systems. Moreover, it can beexpected that the initial quantum com-puters will be rare and expensive to runand therefore that the cost of runtimeerrors in quantum code will initially bemuch higher than in classical comput-ing. This shifts the cost-benefit analy-sis for quantum programming toward
strong compile-time correctness guar-antees, as well as formal specificationand verification.
A quantum programming languageshould have a sound, well-definedsemantics permitting mathematicalspecifications of program behaviorand program correctness proofs. Itis also beneficial for the language to
Figure 9. A circuit operator example.
timestep :: Qubit -> Qubit -> Qubit -> Circ (Qubit, Qubit, Qubit)
timestep a b c = do
mycirc a b
qnot c `controlled` (a,b)
reverse_simple mycirc (a,b)
return (a,b,c)
H H
H H
mycirc m y c i r c
Figure 10. A circuit transformer example.
timestep2 :: Qubit -> Qubit -> Qubit -> Circ (Qubit, Qubit, Qubit)
timestep2 = decompose_generic Binary timestep
H
H
H
H
V V* V
Binary decomposition
of the Toffoli gate
Figure 12. The circuit from Figure 11 made reversible.
classical_to_reversible :: (Datable a, QCData b) => (a -> Circ b) -> (a,b) -> Circ (a,b)classical_to_reversible (unpack template_f)
inputs still inputs
Computing f Copying result Uncomputing garbage
0
0
0
Wire for storing
output
Old value XOR
with result0
0
0
Figure 11. A functional-to-reversible translation example.
inputs still inputs
output
0
0
0
garbage
build_circuitf :: [Bool] -> Bool
f as = case as of
[] -> False
[h] -> h
h:t -> h ‘bool_xor‘ f t
unpack template_f :: [Qubit] -> Circ Qubit

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 60/100
58 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
have a strong static type system thatcan guarantee the absence of mostruntime errors (such as violations ofthe no-cloning property of quantuminformation);b and
Resource sensitivity and resource es-timation. At first, quantum computers
will probably not have many qubits.
The language should thus includetools to estimate the resources re-quired for running a particular piece ofcode (such as number of qubits, num-ber of elementary gates, or other rel-
b The absence of cloning is already guaranteedby the physics, regardless of what the pro-gramming language does. However, one couldsimilarly say the absence of an illegal memoryaccess is guaranteed by a classical processor’spage-fault mechanism. It is nevertheless desir-able to have a programming language that canguarantee prior to running the program that thecompiled program will never attempt to accessan illegal memory location or, in the case of aquantum programming language, will not at-tempt to apply a controlled-not gate to qubits n and m, where n = m.
Figure 13. A procedural example.
import Quipper
w :: (Qubit,Qubit) -> Circ (Qubit,Qubit)
w = named_gate “W”
toffoli :: Qubit -> (Qubit,Qubit) -> Circ Qubit
toffoli d (x,y) = qnot d ‘controlled‘ x .==. 1 .&&. y .==. 0
eiz_at :: Qubit -> Qubit -> Circ ()
eiz_at d r =
named_gate_at “eiZ” d ‘controlled‘ r .==. 0
circ :: [(Qubit,Qubit)] -> Qubit -> Circ ()
circ ws r = do
label (unzip ws,r) ((“a”,”b”),”r”)
with_ancilla $ \d -> do
mapM_ w ws
mapM_ (toffoli d) ws
eiz_at d r
mapM_ (toffoli d) (reverse ws)
mapM_ (reverse_generic w) (reverse ws)
return ()
main = print_generic EPS circ (replicate 3 (qubit,qubit)) qubit
Figure 15. The circuit generated by the code in Figure 13, with 30 qubit pairs.
a[0]
b[0]
a[1]
b[1]
a[2]
b[2]
a[3]
b[3]
a[4]
b[4]
a[5]
b[5]
a[6]
b[6]
a[7]
b[7]
a[8]
b[8]
a[9]
b[9]
a[10]
b[10]
a[11]
b[11]
a[12]
b[12]
a[13]
b[13]
a[14]
b[14]
a[15]
b[15]
a[16]
b[16]
a[17]
b[17]
a[18]
b[18]
a[19]
b[19]
a[20]
b[20]
a[21]
b[21]
a[22]
b[22]
a[23]
b[23]
a[24]
b[24]
a[25]
b[25]
a[26]
b[26]
a[27]
b[27]
a[28]
b[28]
a[29]
b[29]
r
0
W 1
W 2
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
W 1
W 2
eiZ
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
W 1*
W 2*
0
W 1
Figure 14. The circuit generated by the code in Figure 13, with three qubit pairs.
a[0]
b[0]
a[1]
b[1]
a[2]
b[2]
r
0 eiZ
W1*
W2*
0
W1
W2
W1
W2
W1
W2
W1*
W2*
W1*
W2
*

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 61/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 59
contributed articles
evant resources) prior to deployment.One particular issue for language de-signers is how to handle quantum er-ror correction. As the field advances, adecision must be made as to whethererror correction should be exposed tothe programmer (potentially allowingfor optimization by hand) or whether
it is more efficient to let the compileror some other tool apply error correc-tion automatically. Due to the potentialfor undesirable interactions betweenquantum error correction (which addsredundancy) and the optimization stepof a compiler (which removes redun-dancy), the design and implementa-tion of any quantum programminglanguage must be aware of the require-ments of quantum error correction.
Prior Work on QPLsSeveral quantum programming lan-guages have been developed by re-searchers around the world.5 Some, in-cluding van Tonder’s quantum lambdacalculus,18 are primarily intended astheoretical tools. The first quantumprogramming language intended forpractical use was arguably Ömer’sQCL,14 a C-style imperative languagesupporting “structured quantum pro-gramming.” QCL provides simple reg-isters but no high-level quantum data
types. It could also benefit from greatersupport for specification and verifica-
tion. Partly building on Ömer’s work,Bettelli et al.2 proposed a language thatis an extension of C++. The guardedcommand language qGCL of Sandersand Zuliani16 hints at a language forprogram specification.
The first quantum programminglanguage in the style of functional pro-gramming was the quantum lambdacalculus of Selinger and Valiron,17
providing a unified framework for ma-nipulating classical and quantum data.
The quantum lambda calculus has a well-defined mathematical semanticsthat guarantees the absence of runtimeerrors in a well-typed program. Thelanguage is easily extended with induc-tive data types (such as lists) and recur-sion. One shortcoming of the quantumlambda calculus, however, is that itdoes not separate circuit constructionfrom circuit evaluation. It thus lacks
the ability to manipulate quantum cir-cuits as data, as well as the ability to au-
Figure 16. The calcRweights function.
calcRweights y nx ny lx ly k theta phi =
let (xc’,yc’) = edgetoxy y nx ny in
let xc = (xc’-1.0)*lx - ((fromIntegral nx)-1.0)*lx/2.0 in
let yc = (yc’-1.0)*ly - ((fromIntegral ny)-1.0)*ly/2.0 in
let (xg,yg) = itoxy y nx ny in
if (xg == nx) then
let i = (mkPolar ly (k*xc*(cos phi)))*(mkPolar 1.0 (k*yc*(sin phi)))* ((sinc (k*ly*(sin phi)/2.0)) :+ 0.0) in
let r = ( cos(phi) :+ k*lx )*((cos (theta - phi))/lx :+ 0.0) in i * r
else if (xg==2*nx-1) then
let i = (mkPolar ly (k*xc*cos(phi)))*(mkPolar 1.0 (k*yc*sin(phi)))*
((sinc (k*ly*sin(phi)/2.0)) :+ 0.0) in
let r = ( cos(phi) :+ (- k*lx))*((cos (theta - phi))/lx :+ 0.0) in i * r
else if ( (yg==1) && (xg<nx) ) then
let i = (mkPolar lx (k*yc*sin(phi)))*(mkPolar 1.0 (k*xc*cos(phi)))*
((sinc (k*lx*(cos phi)/2.0)) :+ 0.0) in
let r = ( (- sin phi) :+ k*ly )*((cos(theta - phi))/ly :+ 0.0) in i * r
else if ( (yg==ny) && (xg<nx) ) then
let i = (mkPolar lx (k*yc*sin(phi)))*(mkPolar 1.0 (k*xc*cos(phi)))*
((sinc (k*lx*(cos phi)/2.0)) :+ 0.0) in
let r = ( (- sin phi) :+ (- k*ly) )*((cos(theta - phi)/ly) :+ 0.0) in i * r
else 0.0 :+ 0.0
Figure 17. The calcRweights circuit.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 62/100
60 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
erating a circuit; Block structure. Functions generat-
ing circuits can be reused as subrou-tines to generate larger circuits. Op-erators (such as with _ control) cantake an entire block of code as an argu-ment, as in Figure 8. Note “do” intro-duces an indented block of code, and
“$” is an idiosyncrasy of Haskell syntaxthat can be ignored by the reader here;
Circuit operators. Quipper can treatcircuits as data and provide high-leveloperators for manipulating whole cir-cuits. For example, the operator re-
verse _ simple reverses a circuit, asin Figure 9;
Circuit transformers. Quipper pro- vides user-programmable “circuittransformers” as a mechanism formodifying a circuit on a gate-by-gate
basis. For example, the timestep cir-cuit in Figure 9 can be decomposedinto binary gates using the Binary transformer, as in Figure 10; and
Automated functional-to-reversibletranslation. Quipper provides a specialkeyword build _ circuit for auto-matically synthesizing a circuit from anordinary functional program, as in Figure11. The resulting circuit can be made re-
versible with the operator classical _to _ reversible, as in Figure 12.
Experience with Quipper We have used Quipper to implementseven nontrivial quantum algorithmsfrom the literature, based on docu-ments provided by the QuantumComputer Science program of theU.S. Intelligence Advanced ResearchProjects Activity (IARPA).10 All of thesealgorithms can be run, in the sensethat we can print the correspondingcircuits for small parameters andperform automated gate counts forcircuits of less tractable sizes. Each
of these algorithms (see the tablehere) solves some problem believedto be classically hard, and each algo-rithm provides an asymptotic quan-tum speedup, though not necessar-ily an exponential one. These sevenalgorithms cover a broad spectrumof quantum techniques; for example,the table includes several algorithmsthat use the Quantum Fourier Trans-form, phase estimation, Trotteriza-tion, and amplitude amplification.IARPA selected the algorithms forbeing comparatively complex, which
tomatically construct unitary circuitsfrom a classical description. Theseproblems were partly addressed by theQuantum IO Monad of Green and Al-tenkirch,7 a functional language that isa direct predecessor of Quipper.
The Quipper LanguageBuilding on this previous work, weintroduce Quipper, a functional lan-guage for quantum computation.
We chose to implement Quipper as adeeply embedded domain-specific lan-guage (EDSL) inside the host languageHaskell; see Gill6 for an overview of ED-SLs and their embedding in Haskell.Quipper is intended to offer a unifiedgeneral-purpose programming frame-
work for quantum computation. Itsmain features are:
Hardware independence. Quipper’sparadigm is to view quantum compu-tation at the level of logical circuits.The addition of error-correcting codesand mapping to hardware are left toother components further down thechain of compilation;
Extended circuit model. The initial-ization and termination of qubits isexplicitly tracked for the purpose of an-cilla management;
Hierarchical circuits. Quipper fea-tures subroutines at the circuit level,
or “boxed subcircuits,” permitting acompact representation of circuits inmemory;
Versatile circuit description language.Quipper permits multiple program-ming styles and can handle both pro-cedural and functional paradigms ofcomputation. It also permits high-levelmanipulations of circuits with pro-grammable operators;
Two runtimes. A Quipper programtypically describes a family of circuits
that depends on some classical pa-rameters. The first runtime is “circuitgeneration,” and the second runtimeis “circuit execution.” In batch-modeoperation, as discussed earlier, thesetwo runtimes take place one after theother, whereas in online operation,they may be interleaved;
Parameter/input distinction. Quipperhas two notions of classical data: “pa-rameters,” which must be knownat circuit-generation time, and “in-puts,” which may be known only atcircuit-execution time. For example,the type Bool is used for Boolean pa-rameters, and the type Bit is used forBoolean inputs;
Extensible data types. Quipper offersan abstract, extensible view of quan-tum data using Haskell’s powerful
type-class mechanism; and Automatic generation of quantumoracles. Many quantum algorithms re-quire some nontrivial classical compu-tation to be made reversible and thenlifted to quantum operation. Quipperhas facilities for turning an ordinaryHaskell program into a reversible cir-cuit. This feature is implemented us-ing a self-referential Haskell featureknown as “Template Haskell” that en-ables a Haskell program to inspect andmanipulate its own source code.
Quipper Feature Highlights We briefly highlight some of Quipper’sfeatures with code examples:
Procedural paradigm. In Quipper,qubits are held in variables, and gatesare applied one at a time. The type ofa circuit-producing function is dis-tinguished by the keyword Circ afterthe arrow, as in Figure 7. The functionmycirc inputs a and b of type Qubit and outputs a pair of qubits while gen-
A selection of quantum algorithms.
Algorithm Description
Binary Welded Tree4 Finds a labeled node in a graph by performing a quantum walk
Boolean Formula1 Evaluates an exponentially large Boolean formula using
quantum simulation; QCS version computes a winning
strategy for the game of Hex
Class Number8 Approximates the class group of a real quadratic number field
Ground State Estimation19 Computes the ground state energy level of a molecule
Quantum Linear Systems9 Solves a very large but sparse system of linear equations
Unique Shortest Vector15 Finds the shortest vector in an n-dimensional lattice
Triangle Finding12 Finds the unique triangle inside a very large dense graph

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 63/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 61
contributed articles
is why some better-known but tech-nically simpler algorithms (such asShor’s factorization algorithm) werenot included.
Using Quipper, we are able to per-form semi- or completely automatedlogical-gate-count estimations for eachof the algorithms, even for very large
problem sizes. For example, in the caseof the triangle-finding algorithm, thecommand
./tf -f gatecount
-o orthodox
-n 15 -l 31 -r 6
produces the gate count for the com-plete algorithm on a graph of 215 verti-ces using an oracle with 31-bit integersand a Hamming graph of tuple size
2
6
. This command runs to completionin less than two minutes on a laptopcomputer and produces a count of30,189,977,982,990 gates and 4,676 qu-bits for this instance of the algorithm.
Examples. As a further illustration,here are two subroutines written inQuipper:
Procedural example. First, we formal-ize the circuit family in Figure 3. Thiscircuit implements the time step fora quantum walk in the Binary WeldedTree algorithm.4 It inputs a list of pairs of
qubits (ai, bi), and a single qubit r . It firstgenerates an ancilla, or scratch-space,qubit in state |0⟩. It then applies the two-qubit gate W to each of the pairs (ai, bi),followed by a series of doubly controlledNOT-gates acting on the ancilla. After amiddle gate eiZt , it applies all the gates inreverse order. The ancilla ends up in thestate |0⟩ and is no longer needed. TheQuipper code is in Figure 13, yieldingthe circuit in Figure 14. If one replacesthe “3” with a “30” in the main function,one obtains a larger instance of this cir-
cuit family, as in Figure 15; and A functional-to-reversible translation.
This example is from the QuantumLinear Systems algorithm.9 Amongother things, this algorithm containsan oracle calculating a vector r of com-plex numbers; Figure 16 shows thecore function of the oracle. Note it re-lies heavily on algebraic and transcen-dental operations on real and complexnumbers (such as sin, cos, sinc, andmkPolar), as well as on subroutines(such as edgetoxy and itoxy) notshown in Figure 16. This function is
readily processed using Quipper’s au-tomated circuit-generation facilities.
Algebraic and transcendental func-tions are mapped automatically toquantum versions provided by an exist-ing Quipper library for fixed-point realand complex arithmetic. The result isthe rather large circuit in Figure 17.
ConclusionPractical quantum computation re-quires a tool chain extending from ab-stract algorithm descriptions down tothe level of physical particles. Quan-tum programming languages are animportant aspect of this tool chain.Ideally, such a language enables aquantum algorithm to be expressedat a high level of abstraction, similarto what may be found in a research paper,
and translates it down to a logical circuit. We view this logical circuit as an inter-mediate representation that can then befurther processed by other tools, addingquantum control and error correction,and finally passed to a real-time sys-tem controlling physical operations.
Quipper is an example of a lan-guage suited to a quantum coproces-sor model. We demonstrated Quip-per’s feasibility by implementingseveral large-scale algorithms. Thedesign of Quipper solved some major
programming-language challengesassociated with quantum computa-tion, but there is still much to do, par-ticularly in the design of type systemsfor quantum computing. As an em-bedded language, Quipper is confinedto using Haskell’s type system, pro-
viding many important safety guaran-tees. However, due to Haskell’s lack ofsupport for linear types, some safetyproperties (such as the absence of at-tempts to clone quantum informa-tion) are not adequately supported.
The design of ever better type systemsfor quantum computing is the subjectof ongoing research.
References1. Ambainis, A., Childs, A.M., Reichardt, B.W., Špalek,
R., and Zhang, S. Any AND-OR formula of size N canbe evaluated in time N 1/2+o(1) on a quantum computer.SIAM Journal on Computing 39, 2 (2010), 2513–2530.
2. Bettelli , S., Calarco, T., and Serafini, L. Toward anarchitecture for quantum programming. The EuropeanPhysical Journal D 25 , 2 (2003), 181–200.
3. Burham, H., Durr, C., Heiligman, M., Hoyer, P., Magniez,F., Santha, M., and de Wolf, R. Quantum algorithmsfor element distinctness. In Proceedings of the16 th Annual IEEE Conference on Computational
Complexity (Chicago, June 18–21). IEEE ComputerSociety Press, 2001, 131–137.
4. Childs, A. M., Cleve, R., Deotto, E., Farhi, E., Gutmann,S., and Spielman, D.A. Exponential algorithmicspeedup by a quantum walk. In Proceedings of the35 th Annual ACM Symposium on Theory of Computing(San Diego, CA, June 9–11). ACM Press, New York,2003, 59–68.
5. Gay, S.J. Quantum programming languages: Surveyand bibliography. Mathematical Structures inComputer Science 16 , 4 (2006), 581–600.
6. Gill, A. Domain-specific languages and code synthesisusing Haskell. Commun. ACM 57 , 6 (June 2014), 42–49.
7. Green, A. and Altenkirch, T. The quantum IO monad.
In Semantic Techniques in Quantum Computation, S.Gay and I. Mackie, Eds. Cambridge University Press,Cambridge, U.K., 2009, 173–205.
8. Hallgren, S. Polynomial-time quantum algorithmsfor Pell’s equation and the principal ideal problem.Journal of the ACM 54, 1 (Mar. 2007), 4:1–4:19.
9. Harrow, A.W., Hassidim, A., and Lloyd, S. Quantumalgorithm for solving linear systems of equations.Physical Review Letters 103, 15 (Oct. 2009), 150502-1–150502-4.
10. IARPA Quantum Computer Science Program. BroadAgency Announcement IARPA-BAA-10-02, Apr. 2010;https://www.fbo.gov/notices/637e87ac1274d030ce2ab69339ccf93c
11. Knill, E.H. Conventions for Quantum Pseudocode.Technical Report LAUR-96-2724. Los Alamos NationalLaboratory, Los Alamos, NM, 1996.
12. Magniez, F., Santha, M., and Szegedy, M. Quantumalgorithms for the triangle problem. SIAM Journal on
Computing 37 , 2 (2007), 413–424.13. Meter, R.V. and Horsman, C. A blueprint for building aquantum computer. Commun. ACM 56 , 10 (Oct. 2013),84–93.
14. Ömer, B. Quantum Programming in QCL. Master’sThesis. Institute of Information Systems, TechnicalUniversity of Vienna, Vienna, Austria, 2000; tph.tuwien.ac.at/~oemer/qcl.html
15. Regev, O. Quantum computation and lattice problems.SIAM Journal on Computing 33, 3 (2004), 738–760.
16. Sanders, J.W. and Zuliani, P. Quantum programming.In Proceedings of the Fifth International Conferenceon Mathematics of Program Construction, Vol. 1837of Lecture Notes in Computer Science (Ponte deLima, Portugal, July 3–5). Springer-Verlag, BerlinHeidelberg, 2000, 80–99.
17. Selinger, P. and Valiron, B. A lambda calculusfor quantum computation with classical control.Mathematical Structures in Computer Science 16 , 3(2006), 527–552.
18. van Tonder, A. A lambda calculus for quantumcomputation.SIAM Journal of Computation 33, 5(2004), 1109–1135.
19. Whitfield, J.D., Biamonte, J., and Aspuru-Guzik, A.Simulation of electronic structure Hamiltonians usingquantum computers. Molecular Physics 109, 5 (Mar.2011), 735–750.
Benoît Valiron ([email protected]) isan assistant professor in the engineering schoolCentraleSupélec and a researcher in the Computer ScienceLaboratory of the Université Paris Sud, Paris, France.
Neil J. Ross ([email protected]) is a Ph.D. candidateat Dalhousie University, Halifax, Nova Scotia, Canada.
Peter Selinger ([email protected])is a professorof mathematics at Dalhousie University, Halifax, NovaScotia, Canada.
D. Scott Alexander ([email protected]) is achief scientist at Applied Communication Science, BaskingRidge, NJ.
Jonathan M. Smith ([email protected]) is the Olga andAlberico Pompa Professor of Engineering and AppliedScience and a professor of computer and informationscience at the University of Pennsylvania, Philadelphia, PA.
Copyright held by authors.Publication rights licensed to ACM. $15.00
Watch the authors discusstheir work in this exclusiveCommunications video.http://cacm.acm.org/
videos/programming-the-quantum-future

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 64/100
62 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
DOI:10.1145/2699410
Legitimacy of surveillance is crucial tosafeguarding validity of OSINT data as a toolfor law-enforcement agencies.
BY PETRA SASKIA BAYERL AND BABAK AKHGAR
OPEN SOURCE INTELLIGENCE, or OSINT, has become apermanent fixture in the private sector for assessingconsumers’ product perceptions, tracking publicopinions, and measuring customer loyalty.12 The publicsector, and, here, particularly law-enforcement agencies,including police, also increasingly acknowledge the valueof OSINT techniques for enhancing their investigativecapabilities and response to criminal threats.5
OSINT refers to the collection of intelligence from
information sources freely available in the public
domain, including offline sources(such as newspapers, magazines, ra-
dio, and television), along with infor-mation on the Internet.4,16,17 The spreadof social media has vastly increased thequantity and accessibility of OSINTsources.3,11 OSINT thus complementstraditional methods of intelligencegathering at very low to no cost.4,15
OSINT increasingly supports the work of law-enforcement agencies inidentifying criminals and their activi-ties (such as recruitment, transfer ofinformation and money, and coordina-
tion of illicit activities);
18
for instance,the capture of Vito Roberto Palazzolo,a treasurer for the Italian mafia on therun for 30 years was accomplished inpart by monitoring his Facebook ac-count.8 OSINT also demonstrated itspotential to help respond quickly tocriminal behavior outside the Internet,as during, for instance, public disorder(such as the 2011 U.K. riots).1 OSINThas therefore become an importanttool for law-enforcement agenciescombating crime and ultimately safe-
guarding our societies.14
To fulfill these functions, OSINT
depends on the integrity and accuracyof open data sources. This integrity is
jeopardized if Internet users choosenot to disclose personal informationor even provide false information on
Surveillance
andFalsificationImplications
for Open SourceIntelligenceInvestigations
key insights
˽ Falsification of personal informationonline is widespread, though users do notfalsify information in a uniform way; sometypes of information are more likely to be
falsified, leading to systematic differencesin the reliability of the information forOSINT applications.
˽ Acceptance of and propensity forfalsification is linked to attitudes towardonline surveillance; the more negativepeople’s attitudes toward governmentalonline surveillance, the more likely theyare to accept information falsificationand provide false information.
˽ The source of online surveillance—state agencies vs. private companiesvs. unnamed organizations—seems toaffect whether assumptions about
online surveillance are linked toinformation falsification.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 65/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 63
I M
A G E
B Y
A R T
S H
O C K
themselves.7,9 Such omissions and fal-sifications can have grave consequenc-es if decisions are being made fromdata assumed to be accurate but thatis not.19
This issue is especially relevantsince the revelations by former NSAcontractor Edward Snowden of large-scale monitoring of communicationsand online data by state agencies
worldwide. The revelations createdconsiderable mistrust by citizens ofInternet-based surveillance by theirown governments, bringing the ten-sion between the security of societyand the fundamental right to privacyinto sharp profile. These discussionsbegin to show concrete effects; forinstance, use of privacy-sensitive key-
words in Google searches changed
from the period before to the periodafter Snowden’s revelations, as usersproved less willing to use keywords“that might get them in trouble withthe [U.S.] government.”10 Despitemandatory national and internationaldata protection and privacy regula-tions, Internet users thus seem waryof online surveillance and in conse-quence modify their online behavior.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 66/100
64 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
picture of how far and in what waysconcerns about online surveillancechange informationbases relevantto law-enforcement agencies’ useof open source intelligence. In ourcurrent research, we aim to system-atically investigate whether shifts inonline behaviors are likely and, if so,
what form they might take. In thisarticle, we report on a study in which
we focused on the falsification ofpersonal information, investigatingthe link between falsification accep-tance and falsification propensity
with attitudes toward online surveil-lance, privacy concerns, and assump-tions about online surveillance bydifferent organizations.
Study Design and Sample
To understand Internet users’ atti-tudes toward falsification of personalinformation in connection with onlinesurveillance, we conducted an onlinesurvey between January and March2014 using the micro-work platform
Amazon Mechanical Turk to recruitparticipants.a A total of 304 users re-sponded to our request, of which 298provided usable answers. Our sampleconsisted largely of experienced In-ternet users (72.2% had more than 11
years of experience) and intensive us-
ers (41.3% using the Internet for atleast seven hours per day). The major-ity (83.9%) of participants lived in theU.S., 9.4% in India, and the others werefrom Canada, Croatia, Kenya, or Ro-mania (0.4% to 1.1% per country). Thegender distribution was nearly equal,
with 48.9% male vs. 50.4% female par-ticipants; 0.7% preferred not to answerthe question. Participants were rela-tively young, with a majority 40 years or
younger (67.3%), of which most (35.6%) were between 21 and 30 years of age.
Older participants were slightly under-represented, with 9.5% between 51 and60 and 3.9% over 60; 0.7% preferrednot to answer the question. The ques-tionnaire was administered online. Oncompletion of the survey participants
were paid $0.70 through the Mechani-cal Turk platform. The survey took anaverage four minutes to complete.
a Amazon Mechanical Turk is an online servicethat allows recruitment of participants world-
wide for jobs of short duration, often lasting onlyseveral minutes; see https://www.mturk.com
For organizations using OSINT intheir decision making, changes inusers’ online behaviors, specificallytheir willingness to provide accurateaccounts about themselves, are prob-lematic. Not only do they increase theincidence of false information, theyalso raise the complexity and costs for
information validation, or authentica-tion of individuals’ Web footprints,against additional and trusted sources.
A better understanding of thetendency of Internet users of whenand why to change their online be-havior in response to online surveil-lance can help pinpoint especiallyproblematic areas for the validityof OSINT methods. Such an under-standing can further guide efforts
for more targeted cross validations.So far, organizations, including law-enforcement agencies, lack a clear
Figure 1. Respondents’ attitudes toward the positive and negative sides of state onlinesurveillance.
G e n e r a l
a c c e p t an c e
B e n e fi t s
T h r e a t s
54321
1 = completely disagree, 3 = neutral, 5 = completely agree
Question: When you think about the possibility of state authoritiesmonitoring your online behaviors (online surveillance),how much do you agree with the following statements?
If monitoring online behaviors could prevent onlinecrime/terrorism, state authorities should collect such data.
If monitoring online behaviors could prevent offlinecrime/terrorism, state authorities should collect such data.
Monitoring online behaviors ensures that the Internet remains a safe place.
Online surveillance increases the safety of our society.
The surveillance of online behavioris necessary to forestall cyber-criminals.
The monitoring of online behaviors is necessaryto prevent terrorism in the real world.
The monitoring of online behaviorsundermines the trust in our government.
Online surveillance threatens our freedomof expression and speech.
Monitoring of the web can prevent offline crimes.
Monitoring of the web can prevent cyber-crime/terrorism.
Online surveillance undermines social relationships online.
Figure 2. Gender differences in perceived benefits and threats of state online surveillance.
Question: When you think about the possibility of state authoritiesmonitoring your online behaviors (online surveillance),how much do you agree with the following statements?
If monitoring online behaviors could prevent offlinecrime/terrorism, state authorities should collect such data.
If monitoring online behaviors could prevent onlinecrime/terrorism, state authorities should collect such data.
Monitoring online behaviors ensuresthat the Internet remains a safe place.
Online surveillance increases the safety of our society.
The surveillance of online behavioris necessary to forestall cyber-criminals.
The monitoring of online behaviors is necessaryto prevent terrorism in the real world.
The monitoring of online behaviorsundermines the trust in our government.
Online surveillance threatens our freedomof expression and speech.
Online surveillance undermines social relationships online.
Monitoring of the web can prevent offline crimes.
Monitoring of the web can prevent cyber-crime/terrorism.
womenmen
womenmen
women
menwomen
men
womenmen
womenmen
womenmen
womenmen
womenmen
womenmen
womenmen
G e n e r a l
a c c e p t an c e
B e n e fi t s
T h r e a t s
54321
1 = completely disagree, 3 = neutral, 5 = completely agree
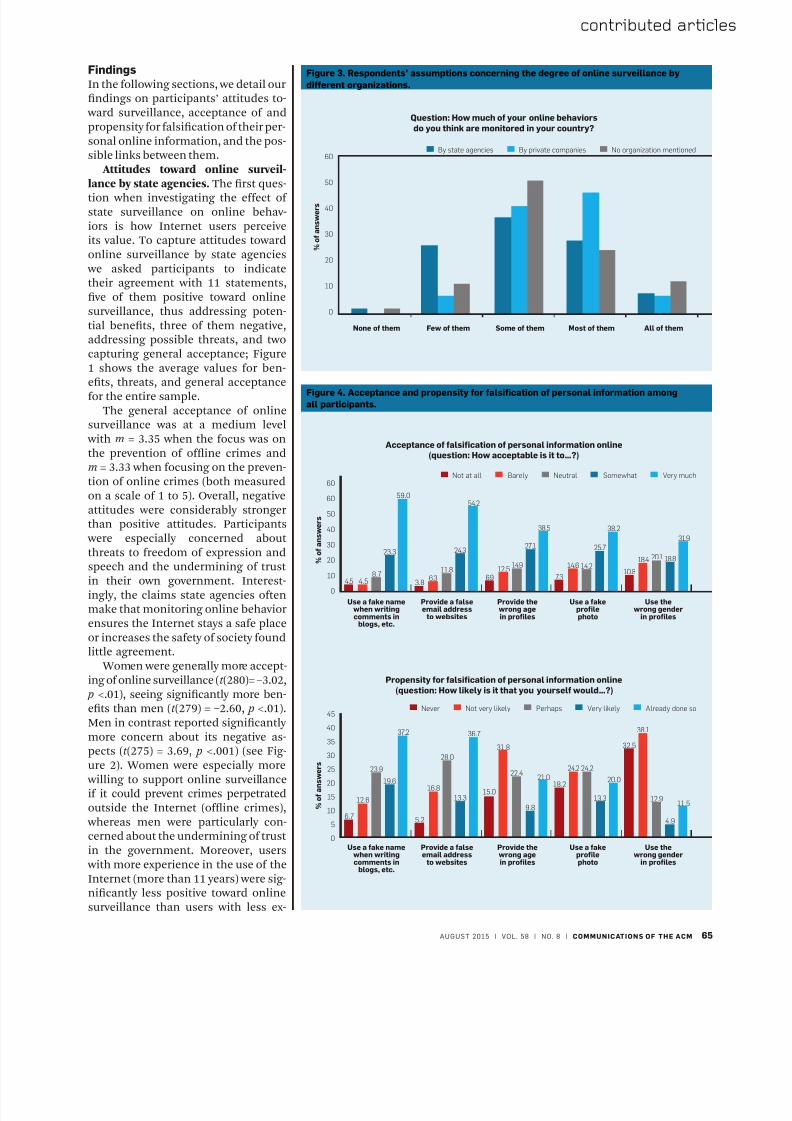
7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 67/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 65
contributed articles
FindingsIn the following sections, we detail ourfindings on participants’ attitudes to-
ward surveillance, acceptance of andpropensity for falsification of their per-sonal online information, and the pos-sible links between them.
Attitudes toward online surveil-
lance by state agencies. The first ques-tion when investigating the effect ofstate surveillance on online behav-iors is how Internet users perceiveits value. To capture attitudes towardonline surveillance by state agencies
we asked participants to indicatetheir agreement with 11 statements,five of them positive toward onlinesurveillance, thus addressing poten-tial benefits, three of them negative,addressing possible threats, and two
capturing general acceptance; Figure1 shows the average values for ben-efits, threats, and general acceptancefor the entire sample.
The general acceptance of onlinesurveillance was at a medium level
with m = 3.35 when the focus was onthe prevention of offline crimes andm = 3.33 when focusing on the preven-tion of online crimes (both measuredon a scale of 1 to 5). Overall, negativeattitudes were considerably strongerthan positive attitudes. Participants
were especially concerned aboutthreats to freedom of expression andspeech and the undermining of trustin their own government. Interest-ingly, the claims state agencies oftenmake that monitoring online behaviorensures the Internet stays a safe placeor increases the safety of society foundlittle agreement.
Women were generally more accept-ing of online surveillance (t (280)= –3.02,
p <.01), seeing significantly more ben-efits than men (t (279) = –2.60, p <.01).
Men in contrast reported significantlymore concern about its negative as-pects (t (275) = 3.69, p <.001) (see Fig-ure 2). Women were especially more
willing to support online surveillanceif it could prevent crimes perpetratedoutside the Internet (offline crimes),
whereas men were particularly con-cerned about the undermining of trustin the government. Moreover, users
with more experience in the use of theInternet (more than 11 years) were sig-nificantly less positive toward onlinesurveillance than users with less ex-
Figure 3. Respondents’ assumptions concerning the degree of online surveillance bydifferent organizations.
60
50
40
30
20
10
0
By state agencies By private companies No organization mentioned
None of them Few of them Some of them Most of them All of them
% o f a n s w e r s
Question: How much of your online behaviorsdo you think are monitored in your country?
Figure 4. Acceptance and propensity for falsification of personal information amongall participants.
4.5
6.7 5.2
15.018.2
32.5
3.86.9 7.3
10.84.5
12.6
16.8
31.8
24.2
38.1
6.312.5 14.6
18.4
8.7
23.9
28.0
22.424.2
12.9
11.814.9 14.2
20.123.3
19.6
13.39.8
13.3
4.9
24.327.1 25.7
18.8
59.0
37.2 36.7
21.0 20.0
11.5
54.2
38.5 38.2
31.9
60
60
50
40
30
20
10
0
45
40
35
30
25
20
15
10
5
0
Not at all Barely Neutral Somewhat Very much
Never Not very likely Perhaps Very likely Already done so
Use a fake namewhen writingcomments in
blogs, etc.
Use a fake namewhen writingcomments in
blogs, etc.
Provide a falseemail address
to websites
Provide a falseemail address
to websites
Provide thewrong agein profiles
Provide thewrong agein profiles
Use a fakeprofilephoto
Use a fakeprofilephoto
Use thewrong gender
in profiles
Use thewrong gender
in profiles
% o f a n
s w e r s
% o f a n s w e r s
Acceptance of falsification of personal information online(question: How acceptable is it to…?)
Propensity for falsification of personal information online(question: How likely is it that you yourself would…?)
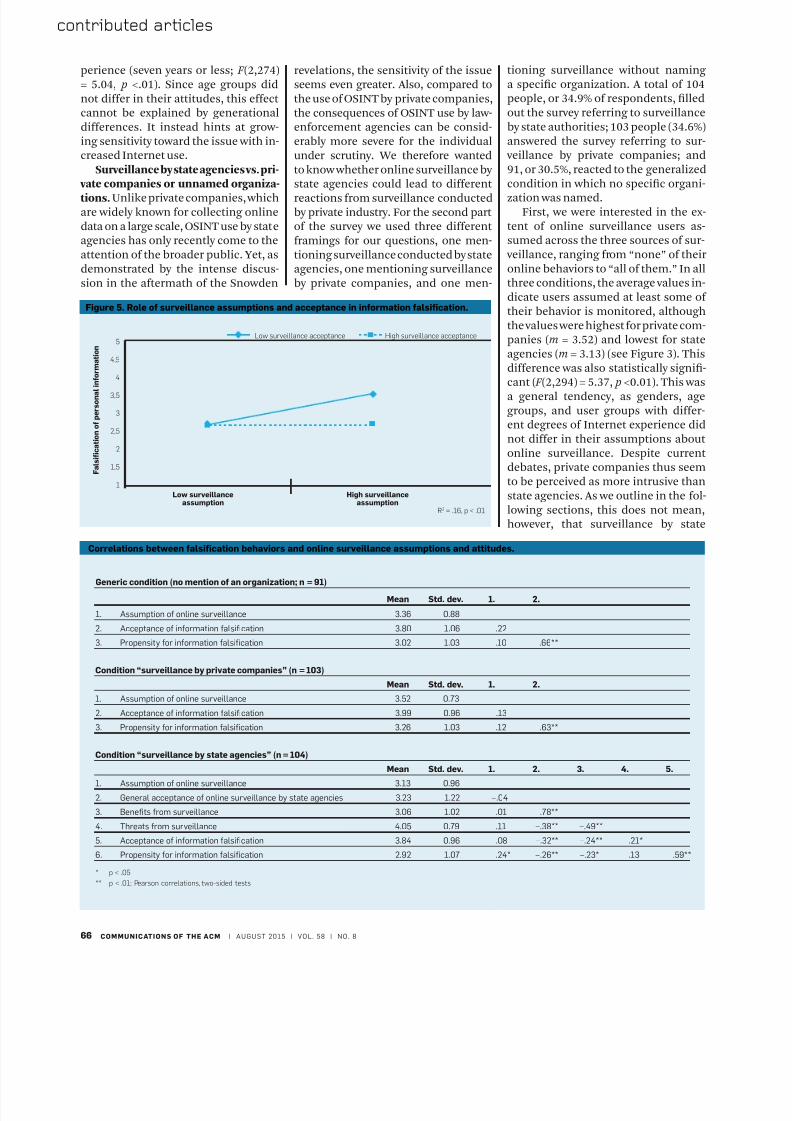
7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 68/100
66 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
tioning surveillance without naminga specific organization. A total of 104people, or 34.9% of respondents, filledout the survey referring to surveillanceby state authorities; 103 people (34.6%)answered the survey referring to sur-
veillance by private companies; and91, or 30.5%, reacted to the generalized
condition in which no specific organi-zation was named.
First, we were interested in the ex-tent of online surveillance users as-sumed across the three sources of sur-
veillance, ranging from “none” of theironline behaviors to “all of them.” In allthree conditions, the average values in-dicate users assumed at least some oftheir behavior is monitored, althoughthe values were highest for private com-panies (m = 3.52) and lowest for state
agencies (m = 3.13) (see Figure 3). Thisdifference was also statistically signifi-cant ( F (2,294) = 5.37, p <0.01). This wasa general tendency, as genders, agegroups, and user groups with differ-ent degrees of Internet experience didnot differ in their assumptions aboutonline surveillance. Despite currentdebates, private companies thus seemto be perceived as more intrusive thanstate agencies. As we outline in the fol-lowing sections, this does not mean,however, that surveillance by state
perience (seven years or less; F (2,274)= 5.04, p <.01). Since age groups didnot differ in their attitudes, this effectcannot be explained by generationaldifferences. It instead hints at grow-ing sensitivity toward the issue with in-creased Internet use.
Surveillance by state agencies vs. pri-
vate companies or unnamed organiza-tions. Unlike private companies, whichare widely known for collecting onlinedata on a large scale, OSINT use by stateagencies has only recently come to theattention of the broader public. Yet, asdemonstrated by the intense discus-sion in the aftermath of the Snowden
revelations, the sensitivity of the issueseems even greater. Also, compared tothe use of OSINT by private companies,the consequences of OSINT use by law-enforcement agencies can be consid-erably more severe for the individualunder scrutiny. We therefore wantedto know whether online surveillance by
state agencies could lead to differentreactions from surveillance conductedby private industry. For the second partof the survey we used three differentframings for our questions, one men-tioning surveillance conducted by stateagencies, one mentioning surveillanceby private companies, and one men-
Correlations between falsification behaviors and online surveillance assumptions and attitudes.
Generic condition (no mention of an organization; n = 91)
Mean Std. dev. 1. 2.
1. Assumption of online surveillance 3.36 0.88
2. Acceptance of information falsification 3.80 1.06 .22
3. Propensity for information falsification 3.02 1.03 .10 .66**
Condition “surveillance by private companies” (n = 103)
Mean Std. dev. 1. 2.
1. Assumption of online surveillance 3.52 0.73
2. Acceptance of information falsification 3.99 0.96 .13
3. Propensity for information falsification 3.26 1.03 .12 .63**
Condition “surveillance by state agencies” (n = 104)
Mean Std. dev. 1. 2. 3. 4. 5.
1. Assumption of online surveillance 3.13 0.96
2. General acceptance of online surveillance by state agencies 3.23 1.22 –.04
3. Benefits from surveillance 3.06 1.02 .01 .78**
4. Threats from surveillance 4.05 0.79 .11 –.38** –.49**
5. Acceptance of information falsification 3.84 0.96 .08 –.32** –.24** .21*
6. Propensity for information falsification 2.92 1.07 .24* –.26** –.23* .13 .59**
* p < .05** p < .01; Pearson correlations, two-sided tests
Figure 5. Role of surveillance assumptions and acceptance in information falsification.
5
4,5
4
3,5
3
2,5
2
1,5
1Low surveillance
assumptionHigh surveillance
assumption
F a l s i fi c a t i o n o f p e r s o n a l i n f o r m a t i o n
Low surveillance acceptance High surveillance acceptance
R2 = .16, p < .01

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 69/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 67
contributed articles
agencies is seen as less intrusive thanthat of private companies.
Degree of acceptance and propen-sity to falsify personal information on-line. To understand whether concernsabout online surveillance affect thetendency to falsify personal informa-tion online, we asked participants in
all three conditions the same two ques-tions: How acceptable is it to falsify per-sonal online information (acceptanceof falsification, from 1 = not at all to 5= very much)? And how likely are youto falsify your own personal informa-tion online (propensity for falsification,from 1 = never to 5 = already done so)?
We asked participants about thefalsification of five types of informa-tion that are fixtures in most onlineprofiles: providing a false name, pro-
viding a fake email address, providingthe wrong age, using a fake photo, andproviding the wrong gender.
Taking all five together, usersshowed a high level of acceptancefor falsification (m = 3.88, SD = 0.99),
while the propensity for falsifica-tion was somewhat less (m = 3.06, SD = 1.05). Still, only a very small group(3.4%) indicated they would never fal-sify any information, whereas 7.4% in-dicated having already done so for allfive categories.
Interestingly, falsification ac-ceptance and propensity were notuniform across all five. Using a falsename and false email address wasseen as acceptable, whereas a falseprofile photo and wrong gender wereconsidered much less acceptable (seetop part of Figure 4). Only 9.0% ofthe participants considered falsify-ing their own name as completely orhighly unacceptable; for the falsifica-tion of one’s gender, this was 29.2%.The same trend emerged for the pro-
pensity of falsifying information;37.0% of participants indicated theyhad already used a fake name andemail address, while 70.6% reportedthey would never use the wrong gen-der or were very unlikely to do so (seebottom part of Figure 4). Users thusseem nearly five times more likely toindicate the wrong name and morethan six times more likely to providea wrong email address than reportthe wrong gender. This suggests thefalsification of personal informationfollows specific patterns; that is, dif-
ferent pieces of information in a pro-file may have a disparate likelihood ofbeing valid or invalid, or “differential
validity of information types.”To compare the effect of the three
surveillance sources, we summarizedthe five types of information into onescore for acceptance and one score for
propensity, respectively. The three con-ditions did not differ in terms of falsi-fication acceptance ( F (2,285) = 0.92,nonsignificant) but resulted in at leasta marginal effect for falsification pro-pensity ( F (2,281) = 2.77, p = .06). This
was due to a slightly greater propen-sity for falsification when surveillance
was conducted by private companies(m = 3.26) compared to state agencies(m = 2.91; t = –2.29, p<.05). Gender,age groups, and length of Internet use
had no effect on either outcome.Linking information falsification with surveillance assumptions and at-titudes. We next considered influenceof surveillance awareness, attitudestoward surveillance, and privacy con-cerns on information falsification.Because we used three separate ver-sions of the survey to determine theinfluence of the organization con-ducting surveillance, the questionson degree of surveillance awarenessand falsification acceptance and pro-
pensity referred to different entities:state agencies, private organizations,or no organization in particular. Wetherefore calculated the correlationsbetween surveillance awareness andinformation falsification for each ofthe three groups separately. This alsogave us the opportunity to investigate
whether the context of surveillancehad an effect on falsification behav-iors. The table here reports the resultsfor each of the three conditions.
Interestingly, assumptions of on-
line surveillance had an effect on fal-sification acceptance and propensityonly when online surveillance wasframed in the context of state agen-cies or as generalized activity. In thesecases, assumptions about onlinesurveillance had a clear positive link
with either the propensity to falsifypersonal information or the accep-tance of this behavior, as in the table.For surveillance conducted by privatecompanies, no such significant linkemerged. Again, this suggests thequestion of who conducts the sur-
The moreparticipants
perceived onlinesurveillance bystate agencies asproblematic, themore willing theywere to acceptfalsification.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 70/100
68 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
in it, can pose concrete challenges forthe validity of online data—and con-sequently for the validity of decisionsbased on the data. While our study isonly a small window into this complexissue, it demonstrates that onlinesurveillance may have very concrete,practical implications for the use and
usefulness of OSINT, specifically forlaw-enforcement agencies. Surveil-lance is not neutral. On the contrary,our study attests that surveillancepractices could threaten the integrityof the very data they rely on.
Falsification tendencies as a re-action to online surveillance createchallenges for the usability of opensource data, especially increasinglyfor the effort required to validateinformation. OSINT has long been
hailed as a cheap or even “no cost”source of operational informationfor law-enforcement agencies.4,16 Our findings suggest that increas-ing awareness of online surveillance,including painful revelations ofproblematic surveillance practicesby states and law-enforcement agen-cies, may severely reduce this ben-efit, at least for those Internet users
with a more critical outlook towardstate authorities and/or greater needfor privacy.
Technical solutions to counter theincreased likelihood of falsificationare available; for instance, Dai et al.5 proposed a number of “trust score”computation models that try to deter-mine data trustworthiness in anony-mized social networks using a trustedstandard. Additional solutions arethinkable using validity pattern min-ing, reasoning-based semantic datamining, and open source analysistechniques. One important avenuefor identifying false information is to
identify possible links between pro-files of a single user and then minethe data between profiles for valida-tion. Users often explicitly link theirprofiles. For example, Twitter postsand Instagram photos can be orga-nized so they appear on a user’s Face-book timeline. This gives a direct and
verified link to further information.Users may also post under the samepseudonym on a number of profiles.Collecting the data associated witheach of these profiles provides fur-ther opportunity for corroboration.
veillance may play a role in influenc-ing concrete falsification behaviors.Surveillance by state agencies couldtrigger more concrete reactions thaneither generalized surveillance ormonitoring by private companies.
As in the third generalized condi-tion, all questions referred uniformly
to state agencies, this subgroup ofparticipants gave us the opportunityto further investigate the link betweenattitudes toward online surveillanceby state agencies and falsification. Inthis subgroup, we found a clear linkbetween attitudes toward online sur-
veillance, acceptance, and propensityfor falsification. The greater the gen-eral acceptance and perceived benefitsof surveillance, the less acceptingparticipants were of falsifying infor-
mation and the less likely they wereto do it themselves. Similarly, themore participants perceived onlinesurveillance by state agencies as prob-lematic, the more willing they were toaccept falsification.
In addition, acceptance of onlinesurveillance moderated the relation-ship between falsification and as-sumed degree of surveillance. Whilegreater assumptions of surveillancegenerally increased the propensity forfalsification, this reaction was espe-
cially strong for people with a low ac-ceptance of online surveillance by stateagencies (see Figure 5). This observa-tion suggests an important interac-tion between awareness and attitudes.
While surveillance awareness alonemay lead to information falsification,the main trigger to falsifying personalinformation seems to be the extentsurveillance is seen as (in)appropri-ate. This logic links tendencies forfalsification of one’s own informationto how much one considers state agen-
cies legitimate and trustworthy, thusemphasizing the potentially critical ef-fect of negative press on the viability ofOSINT-based decisions.
More than a Moral DilemmaOur study demonstrates that discus-sions about “privacy” vs. the “rightful-ness” of online surveillance is morethan a moral dilemma. Rather, the de-gree to which individuals are aware ofonline surveillance and the way they
view the acceptability of this act, in-cluding the organizations implicated
Law-enforcementagencies will have
to become moresensitive to thereactions theirown practicesmight create forthe viability of theirmethods and inconsequence the
decisions they takebased on thesemethods.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 71/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 69
contributed articles
As with Dai et al.,5 another tacticmight be to attempt to match the so-cial graph of users across networks.Inconsistencies in personal data maybe identified by verifying where thesenetworks overlap.
The most difficult part in infor-mation validations is determining
the technological solutions thatmust be employed to carry out the
validation. Two such techniques areclassification and association min-ing. Machine-learning-based clas-sification techniques can be usedto establish a ground-truth datasetcontaining information known tobe accurate. By training models onthis data, outliers in new data couldindicate the trustworthiness of theinformation may warrant further
investigation. Association mining(or association rule learning) canbe used to discover relationshipsbetween variables within datasets,including social media and otherOSINT sources.12 These associationrules can take data from the linksdiscovered between multiple socialnetworks and be used to validate theexisting i nformation.
Still, all these technical solutionsrely on the cross-validation of opensource information with other (open
or closed) sources. Growing falsifi-cation tendencies in the wake of in-creasing online surveillance aware-ness will make such cross-validationsnot only increasingly necessary butalso more complex and costly. Here,the notion of differential validity, asevidenced in our data, may provide a
valuable perspective toward a moresystematic and targeted approach toinformation validation by guiding
validation efforts toward more or lessproblematic data. This approach fol-
lows the observation that personalinformation seems to possess system-atic variations in its veracity, leadingto differential validity patterns. Whileour study focused on only a small setof static personal information, weassume similar patterns are also ob-servable for other areas, as well as formore dynamic data.
An interesting question in this re-gard is how “volatile” falsifications ofpersonal information tend to be. Dousers stick with one type of falsifica-tion (such as consistently modifying
name, relationship status, or age)across services, or do these piecesof information vary across services?
Also, do users always use the samecontent (such as the same false dateof birth or photo)? Extending ourknowledge of such falsification or
validity patterns can considerably
reduce the effort involved in validat-ing OSINT-based data. In our currentstudy, we did not investigate the rea-sons behind the differences in falsi-fication acceptance and propensityfor the various types of personal in-formation. Getting a clearer under-standing of these reasons could tellus much about the contexts in whichfalsification are more or less likely, as
well as the strategies Internet usersemploy to remain private.
Conclusion We clearly cannot return to the daysof the “uninformed” or “unaware”Internet user, and law-enforcementagencies therefore need to find waysto deal with the consequences of on-line surveillance awareness by thegeneral public and the possible rami-fications it may have for the trustwor-thiness of online information. While
we do not suggest OSINT will loseits value for investigation processes,
we certainly think law-enforcementagencies will have to become moresensitive to the reactions their ownpractices might create for the viabil-ity of their methods and in conse-quence the decisions they take basedon these methods.
Employing ever more advancedtechnical solutions is not the (sole)solution. Our findings make clearthat even more than the pure factof online surveillance, it is the per-ceived purpose and legitimacy of
the act that are the main driversbehind the extent to which users al-ter their behaviors online. This ex-plains the role of (largely negativelytinted) public discussions for thebehavioral changes in the wake ofSnowden’s revelations.10 They alsohighlight the criticality of properlylegitimizing online surveillance toreduce distrust in law-enforcementagencies and thus pressures towardinformation falsifications and prob-ably changes in online behaviorsmore generally.
References1. Barlett, J., Miller, C., Crump, J., and Middleton, L.
Policing in an Information Age. Demos, London, U.K.,Mar. 2013.
2. Bell, P. and Congram, M. Intelligence-led policing (ILP)as a strategic planning resource in the fight againsttransnational organized crime (TOC). InternationalJournal of Business and Commerce 2, 12 (2013), 15–28.
3. Best, C. Challenges in open source intelligence.In Proceedings of the Intelligence and SecurityInformatics Conference (Athens, Greece, Sept. 12–14,
2011), 58–62.4. Best Jr., R.A. and Cumming, A. Open Source Intelligence(OSINT): Issues for Congress. Congressional ResearchService, Washington, D.C., Dec. 2007; https://www.fas.org/sgp/crs/intel/RL34270.pdf
5. Dai, C, Rao, F.Y, Truta, T.M., and Bertino, E. Privacy-preserving assessment of social network datatrustworthiness. In Proceedings of the EighthInternational Conference on Collaborative Computing (Pittsburgh, PA, Oct. 14–17, 2012), 97–106.
6. Gibson, S. Open source intelligence: An intelligencelifeline. The RUSI Journal 149, 1 2004), 16–22.
7. Joinson, A.N., Reips, U.D., Buchanan, T., and Schofield,C.B.P. Privacy, trust, and self-disclosure online.Human-Computer Interaction 25 , 1 (2010), 1–24.
8. La Stampa. Mafia, fermato Vito Roberto Palazzoloscovato a Bangkok grazie a Facebook. La Stampa(Mar. 31, 2012); http://www.lastampa.it/2012/03/31/italia/cronache/mafia-fermato-vito-roberto-palazzoloscovato-a-bangkok-grazie-a-facebook-
vpnxhM5z5chH3iuIjttksJ/pagina.html 9. Lenhart, A., Madden, M., Cortesi, S., Duggan, M., Smith,
A., and Beaton, M. Teens, Social Media, and Privacy.Pew Internet and American Life Project Report,Washington, D.C., 2013; http://www.pewinternet.org/2013/05/21/teens-social-media-and-privacy/
10. Marthew, A. and Tucker, C. Government Surveillanceand Internet Search Behavior. Working Paper. SocialScience Research Network, Rochester, NY, Mar. 2014;https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2412564
11. Mercado, S.C. Sailing the sea of OSINT in the informationage. Studies in Intelligence 48 , 3 (2009), 45–55.
12. Nancy, P., Ramani, R.G., and Jacob, S.G. Mining ofassociation patterns in social network data (Facebook100 universities) through data mining techniques andmethods. In Proceedings of the Second InternationalConference on Advances in Computing and InformationTechnology . Springer, Berlin, 2013, 107–117.
13. Neri, F., Aliprandi, C., Capeci, F., Cuadros, M., and By,T. Sentiment analysis on social media. In Proceedingsof the 2012 International Conference on Advances inSocial Networks Analysis and Mining (Istanbul, Turkey,Aug. 26–29, 2012), 919–926.
14. Omand, D., Bartlett, J., and Miller, C. Introducingsocial media intelligence. Intelligence and NationalSecurity 27 , 6 (2012), 801–823.
15. Ratzel, M.P. Europol in the combat of internationalterrorism. NATO Security Through Science Series,Volume 19. IOS Press, Amsterdam, 2007, 11–16.
16. Steele, R.D. The importance of open source intelligenceto the military. International Journal of Intelligenceand Counter Intelligence 8 , 4 (1995), 457–470.
17. Steele, R.D. Open source intelligence. Chapter 10in Handbook of Intelligence Studies, J. Loch, Ed.Routledge, New York, 2007, 129–147.
18. Stohl, M. Cyberterrorism: A clear and present danger,the sum of all fears, breaking point, or patriot games?Crime, Law, and Social Change 46 , 4–5 (2006), 223–238.
19. The Telegraph. Connecticut school shooting: Policewarn of social media ‘misinformation.’ The Telegraph (Dec. 16, 2012); http://www.telegraph.co.uk/telegraphtv/9748745/Connecticut-school-shooting-police-warn-of-social-media-misinformation.html
Petra Saskia Bayerl ([email protected]) is an assistantprofessor for technology and organizational behavior andprogram director technology of the Center of Excellencein Public Safety Management at the Rotterdam Schoolof Management, Erasmus University Rotterdam, theNetherlands.
Babak Akhgar ([email protected]) is a professor ofinformatics and director of the Center of Excellence inTerrorism, Resilience, Intelligence, and Organized CrimeResearch at Sheffield Hallam University, U.K.
© 2015 ACM 0001-0782/15/08 $15.00

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 72/100
70 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
DOI:10.1145/2716309
The National Palace Museum in Taiwan hadto partner with experienced cloud providersto deliver television-quality exhibits.
BY RUA-HUAN TSAIH, DAVID C. YEN, AND YU-CHIEN CHANG
AS MU SEUMS FOCUS increasingly on the public, they mustdevelop new means of attracting and entertaining their
visitors. Information and communication technologies(ICT) have great potential in this area. But deployingcomplex ICT in a traditional organizational setting likea museum is likely to be challenging.
The word “museum” comes from the Greek word“mouseion,” signifying both the seat of the Musesand a building specifically used to store and exhibithistoric and natural objects. From a knowledge-management perspective, museums preserve, create,
and share knowledge. In a museum, ancient wisdom
is preserved in objects and rediscov-ered through research. In terms of
their intellectual contribution, muse-ums create knowledge by recruitingresearchers and giving them neces-sary incentives and resources. As a re-sult, museums offer abundant knowl-edge to all. In the past, professionalresearchers worked independently toenhance their own expertise in theirrespective academic fields rather thanfor the benefit of the general public.
Although museums stage exhibitions, visitors rarely have an intimate view of
the related objects, which must be pro-tected and preserved.In line with social development, the
function of museums has graduallychanged over the years—first object-oriented (before 1980), then educa-tion-focused (1980s to 2000s), and fi-nally public-centered (after 2000).4 TheInternational Council of Museums9 redefined the 21st-century museum asfollows: “A nonprofit institution in theservice of society and its development,open to the public, which acquires,
conserves, researches, communicates,and exhibits the tangible and intan-gible heritage of humanity and its en-
vironment for the purposes of educa-tion, study and enjoyment.”
Advanced information technologies(such as cloud computing) and com-munication technologies (such as glob-al telephone systems and third- andfourth-generation mobile telecommu-nications technologies) are converging.
Challenges
DeployingComplexTechnologiesin a TraditionalOrganization
key insights
˽ We developed a conceptual frameworkfor how an organization can providea new ICT-enabled service througha value-networkwide solution forestablishing a service ecosystem.
˽ Any traditional organization mustunderstand the needs of its businesspartners to be able to set up suchan ecosystem.
˽ To implement a new value networkfor providing an ICT-enabled service,museums must consider these non-technical but ICT-related issues
before and during development ofprojects related to a new service.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 73/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 71
I M
A G E
C O U
R T E
S Y
O F T H E
N A T I
O N A L P
A L A C E M U
S E U M
This convergence has created a consid-erably less expensive ICT infrastructurethat more effectively connects compo-nents, including information, knowl-edge, content, people, organizations,
information systems, and other hetero-geneous devices. As a result, new ICT-enabled services are available at lowercost to customers in general and mem-bers of the younger generation in par-ticular. ICT-enabled services provideonline, real-time interactive opportuni-ties through applications; for example,a number of ICT-enabled services areoffered through mobile applications.
Previous studies1,7,12 showed mu-seums use computing technologiesprimarily to increase interactivity and
enhance their visitors’ experience vis-iting a museum. Various ICT-enabledmuseum services have been designedto meet the needs of the public; forexample, the world’s top museums,including the Louvre Museum in Par-is, the Metropolitan Museum of Artin New York, and the National PalaceMuseum (NPM) in Taiwan, have estab-lished Facebook fan pages and otherinteractive, social, informative, enter-taining online elements to stimulateawareness of and interest in their col-lections and encourage users to visit
their physical sites. Another exampleis the British Museum Channel playing
video clips of exhibitions, collections,and behind-the-scenes experiences atthe museum. This content is available
on the museum’s website. These tech-nologies and platforms are expanding
ways visitors access and interpret theobjects displayed in museums.2
ICT-supported services enable mu-seums to expand their social role and
values by improving the timing and in-creasing the scope of their individualand collective engagement with visi-tors worldwide. Their services can beused to reach out to frequent museum
visitors and potential visitors and non- visitors alike. Their purpose is to en-
hance the interaction and visiting ex-perience of a broader range of visitors,on-site or online. Many such servicesare designed specifically to attract
young people, who are often interestedin experiencing new ICT and accus-tomed to using multimedia services intheir daily lives.
Digital Archives ProjectNPM was recognized in 2014 as oneof the most visited museums in the
world by The Art Newspaper and is dis-tinguished by its extensive collection
of high-quality artifacts from Chinesehistory, making it one of the most pop-ular destinations in Taiwan for inter-national tourists. NPM managementis supervised by the Executive Yuan,
the highest administrative organ in thegovernment of Taiwan.
NPM implemented the NationalDigital Archives Program (2002–2013)to digitize its collections on an ongo-ing basis, resulting in a large volumeof high-quality IT-generated contenton the museum’s cultural and histori-cal artifacts. In addition, NPM recog-nizes the novel opportunity providedby video and interactive objects to in-troduce historical treasures and reviveinterest in ancient artifacts. NPM also
uses corporate advertising to stimu-late the public’s imagination and helpthem more fully appreciate China’shistorical artifacts. It continues toproduce a number of videos related tocollections, IT-generated content, andbehind-the-scenes experience at themuseum.
The videos produced by the muse-um have been extremely successful atsharing NPM’s digital collection world-
wide. In 2007, NPM used cutting-edgetechniques to create a 3D animationcalled Adventures in the NPM that was
Adventures in the NPM: Poster for Formosa Odyssey.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 74/100
72 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
considered a milestone accomplish-ment, winning first prize in the publicsection of the 2008 Tokyo International
Anime Fair, in addition to the Prix Coupde Coeur award at the in 2008 FestivalInternational de l’Audiovisuel et duMultimédia sur le Patrimoine. At the2009 Muse Awards, organized by the
Media and Technology ProfessionalNetwork of the American Alliance ofMuseums, NPM received a Silver Awardfor marketing development for a docu-mentary called Inside: The Emperor’sTreasure and a multimedia installationcalled Passé-Future: The Future Museumof NPM . In 2013, at the 46th Houston In-ternational Film Festival, NPM gainedadditional recognition by winning sixmajor awards: two platinum, two gold,one bronze, and one special-jury. Its
lighthearted comedic entry Journeying from Past to Present—APP Minifilm re-ceived a Platinum Award, the festival’shighest accolade, in the network cat-egory. NPM plans to showcase its mostrepresentative collections on the globalstage by internationally releasing itsanimated video Adventures in the NPM .Released in 2011, Adventures in the NPM
2 featured treasures from the PalaceMuseum in Beijing to inspire and pro-mote collaboration.
In 2012, NPM partnered with
Google to display exquisite Chineseartifacts worldwide on Google’s ArtProject webpage. The Art Project ini-tiative allowed NPM to publicly displayits collections on an online platform,overcoming the temporal and spatialboundaries separating the museumfrom the rest of the world. NPM chose18 artifacts familiar to the Taiwanesepublic to reach audiences worldwideon the Art Project webpage.
The experience collaborating withGoogle and creating so many high-
quality videos inspired NPM to con-struct a video-streaming website toenable young people to access themuseum’s collections of inspiring Chi-nese artifacts. The iPalace initiative(http://npm.nchc.org.tw) was devel-oped, then revised in December 2014to address this goal.
iPalaceThe table here outlines NPM strategic
vision for the iPalace initiative. Thetarget audience includes mainly youngpeople who use Web browsers, are in-
Figure 3. Process of diffusing iPalace from its prototype.
Prototype
Facilityexpenditure
Major challenges Interorganizational Technical
ICT facilities Video production
Transformationexpenditure
Competency
Market-related expenditure
Major challenges Managerial Organizational
Major challenges Social Managerial Interorganizational
Servicesystem
Serviceperformance
Outsourcing
Deployment
Diffusion
Figure 1. Components of the iPalace service system (adapted from Huang et al. 8).
Strategic service vision for iPalace
Sustainability
iPalace Service System
Components of iPalace Service System
Video Production(outsourcing)
Video Management
Channel Curator
IP Counsel
Advertisement Business
Customer Service
Service PlatformManagement
Cloud-computing System(outsourcing)
Infrastructure ofCloud Computing
Platform ofCloud Computing
Software ofCloud Computing
Figure 2. NIST cloud computing reference architecture (source: Liu et al. 10).
Cloud Provider Cloud BrokerCloud
Consumer
Cloud Auditor
Service Orchestration
Security Audit
Resource Abstractionand Control Layer
Physical Resource Layer
Hardware
BusinessSupport
ServiceIntermediation
ServiceAggregation
ServiceArbitrage
Provisioning/Configuration
Portability/Interoperability
Facility
Privacy ImpactAudit
PerformanceAudit
Cloud Carrier
Service Layer
SaaS
PaaS
IaaS
Cloud ServiceManagement
S e c u
r i t y
P r i v a c y

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 75/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 73
contributed articles
terested in China’s heritage, and enjoy videos and animations. The serviceconcept emphasizes efficiently curat-ed, well-organized video exhibitionsthat deliver fresh, attractive video con-tent with smooth streaming in the formof a television program, giving viewersa high-quality online experience with
NPM artifacts. Achieving these goalsinvolves several operating strategies: a
video-production process to ensure vid-eos and animations are original and at-tractive; regular updating of the appear-ance of the interface to make it userfriendly; and load balancing with suchfeatures as a task-oriented process de-sign, an elastic Web service infrastruc-ture, and peer-to-peer networking ca-pability. As NPM’s online counterpart,iPalace must deliver services that com-
plement the museum’s brand reputa-tion while also coping with potentialhuge peaks in demand.
From the museum’s perspective,iPalace was a radical innovation in ICT-enabled service, or RIIS. In addition, itis primarily a video-streaming servicebased on Web technology that providesa wonderful online visiting experiencenot linked to an in-gallery experience.Technically, however, iPalace requiresexpertise in sophisticated cloud-com-puting technology NPM does not have.
From the public’s perspective, iPalaceis radically different from NPM’s tradi-tionally text-heavy webpages. Typicalmuseum video channels offer a varietyof video clips; for instance, the videocontent of the British Museum Chan-nel is accessed through individualclicks on video clips. In contrast, op-eration of the iPalace initiative wouldbe like a television program that broad-casts continuously until the viewerturns off the channel.
iPalace Value NetworkThe iPalace prototype was built in ac-cordance with the strategic service vi-sion within a reasonable timeframeand with limited effort. As the proto-type was positively evaluated,3 NPMsought to transform the pilot servicesystem into a real-world service sys-tem by implementing a full-scale valuenetwork. However, as outlined in Fig-ure 1, the full iPalace value networkincludes video-production and cloud-computing services—areas where NPMlacked expertise. As a result, time and
effort beyond the museum’s capabil-ity would have been necessary to verti-cally integrate the full value network.NPM thus chose a value-networkwidesolution involving outsourcing videoproduction and cloud computing. Asdiscussed earlier, though NPM previ-ously outsourced video production, it
lacked experience outsourcing cloud-computing systems.
After several rounds of negotia-tion with potential outsourcing part-ners regarding the cloud-computingsystem, NPM became more realisticabout how it could address the com-plexity of the iPalace value network;for instance, it recognized the useful-ness of the cloud-computing refer-ence architecture developed by theU.S. National Institute of Standards
and Technology involving cloud con-sumers, cloud providers, cloud carri-ers, cloud auditors, and cloud brokers,as outlined in Figure 2. In outsourcingthe cloud-computing system for iPal-ace, NPM functioned as a cloud cus-tomer aligned with other cloud actorsidentified as reliable strategic part-ners. Ultimately, it was necessary forNPM to collaborate with four catego-ries of business partners in the iPalace
value network:Content makers. Studios, channel
managers, and cloud operators;Connectivity makers. Cloud opera-
tors, Internet service providers, andtelephone operators;
Technology makers. Infrastructuremanufacturers and middleware manu-facturers; and
Sponsors. Agencies and advertisersproviding sponsorship.
Leading the Value NetworkFitzsimmons and Fitzsimmons5 saidone of the challenges facing all ser-
vice innovators is how to achieve therequired degree of integration; Figure
3 outlines the process of diffusing iPal-ace, beginning with its prototype. Relat-ed activities can be classified into threearchitectural categories—outsourcing,deployment, and diffusion—based onexpected outcomes and underlyingexpenditure. Outsourcing activities in-
volve expenditure on appropriate ICT-enabled facilities through interorga-nizational collaboration. Deploymentactivities require expenditure on trans-formation, as NPM and its partners
must ensure the museum’s existing ca-pabilities and ICT facilities are able tosupport iPalace. Moreover, the muse-um’s diffusion activities must be ableto translate the new service system intoconcrete service performance throughmarket-related expenditure on specificmeans of diffusing iPalace.
The challenges in the deploymentprocess, as in Figure 3, relate to intra-organizational integration (such as em-ployee acceptance involving employeeculture and incentives and other orga-
nizational matters); processes in orga-nizational management/reengineering(such as enforcement of interdepart-mental collaboration or establishmentof new departments and functions); andacceptance of a reference group. Addi-tional professionals (such as curators
Power consumption for typical components.Strategic service vision for iPalace (adapted from Huang et al.8).
Service-DeliverySystem
OperatingStrategy
ServiceConcept
Targeted MarketSegments
Fresh, attractive video
content
Well-defined NPM
experiences:˲ NPM images; ˲ Ease of use; and
˲ In-depth insight intoChinese culture and
aesthetics.
Smooth video delivery
Continual provision of
new video exhibitions
Periodically changing
interface appearance
Effective load balancing:˲ Task-oriented
process design; ˲ Elastic Web-service
infrastructure;˲ Peer-to-peer
networking; and˲ Distributed system
architecture capable
of multitasking.
Video service that
smoothly displays NPMrelics:˲ Well-arranged
exhibition;˲ Available anytime,
anywhere; and˲ Uninterrupted
multicasting.
Easy-to-use user
interface:˲ Updated for the
occasion; and˲ In-depth insight into
Chinese culture and
aesthetics.
Young people who ˲ Use Web browsers;
˲ Are interested inChina’s heritage; and
˲ Enjoy videos and
animations.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 76/100
74 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
contributed articles
Operation of theiPalace initiative
would be like atelevision programthat broadcastscontinuouslyuntil the viewerturns offthe channel.
and marketers) must also be recruitedto implement iPalace, as in Figure 1. Incontrast, the challenges in outsourcingand diffusion activities, as in Figure 3,relate to interorganizational integra-tion. NPM thus had to ensure video pro-duction and cloud computing could beoutsourced appropriately.
Theoretically, RIIS diffusion is an or-ganizational process involving partici-pants from different industries and sec-tors across the value network. Althoughthe aim of the service-science disciplineis facilitating and improving interactionand collaboration of multiple entities toachieve mutual benefits, service sciencestudies are generally summarized as“too much, too little, or too soon.”11
Reflecting the museum visitor’sperspective on iPalace, NPM seeks to
gain a comprehensive understandingof the role, responsibilities, and in- volvement of every stakeholder asso-ciated with the iPalace value network.Moreover, iPalace delivers a viewing ex-perience and post-viewing experiencethat must complement one another toensure success.
With regard to the viewing process,the museum’s online visitors desire anemotionally positive experience facili-tated by a personal computer or por-table computing device. As outlined
in NPM’s strategic vision for iPalace,fresh, attractive video content, well-defined NPM experiences, and smooth
video streaming are necessary for en-suring online visitors have a positiveexperience online. NPM recognizes thecontent maker is responsible for pro-ducing fresh, attractive video content,the channel manager curates the videocontent and defines the NPM experi-ence, and the connectivity maker en-sures smooth video streaming.
With regard to the post-viewing
experience, iPalace service qualitydirectly correlates with viewer sat-isfaction, as with any commercialmedia experience in the real world.Service provision and the fulfillmentof museum visitor needs are criticaldeterminants of a viewer’s use andenjoyment of iPalace. As a result,all parties in the iPalace value net-
work, including NPM, content mak-ers, connectivity makers, technologymakers, and sponsors, must ensureeffective viewer relationship man-agement (VRM) and viewer fulfill-
ment. Note the emotive force of tradi-tional television media leads viewersfrom brand awareness to brand con-sideration. This is where the processends, and no other means extendsinto the post-viewing period. In con-trast, agents (such as NPM, sponsors,and advertisers) are able to harness
the reach and emotional power ofiPalace and motivate viewers to com-plete the post-viewing process. Thisability makes iPalace attractive tosponsors and advertisers and in turnto other service partners and stake-holders. During the post-viewing pe-riod, connectivity makers, sponsors,and advertisers are likely to risk loss of
visitors’ attention or failure to attractnew visitors due to substandard VRMor insufficient viewer fulfillment.
Although iPalace theoretically con-sists of two processes, online visitorsparticipate in both, yet regard them asa single, seamless experience. Online
visitors expect a high-quality, consis-tently reliable service that safeguardsuser privacy. To ensure the success ofiPalace technology, all participants inthe iPalace value network must fulfillthis expectation. However, service qual-ity and reliability, as well as privacy, areparticularly important for the channelmanager and connectivity maker, who
are likely to be deemed iPalace “provid-ers” by museum visitors. The brands ofthe channel manager and connectiv-ity maker may also be subject to nega-tive evaluation if mistakes are made inservice delivery; that is, online visitorscontact the channel manager or theconnectivity maker if iPalace deliversa disappointing experience. Museum
visitors usually view brands that fail tofulfill VRM and viewer-fulfillment ex-pectations negatively. As iPalace’s VRMis Internet-based, it faces a particular
threat of negative evaluation, as thereare more than one billion Internet us-ers (and thus potential museum visi-tors) worldwide.
All parties are thus responsible fordetermining the most appropriate wayto carry iPalace through the value net-
work, addressing several significant is-sues along the way:
Carrier-rights agreements. Carrieragreements, including channel spon-sorship, are a key point of negotiation;in addition, connectivity makers mustexercise caution when creating (or

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 77/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 75
contributed articles
outsourcing) VRM and viewer-fulfill-ment solutions;
Creative-rights agreements. Creativerights are a significant issue of con-tention among the various contentmakers. NPM’s current distributionagreements do not include the rightto develop an overlay on top of existing
video content. Therefore, any futuredistribution agreements must includeincentives for studios to allow channelmanagers to build iPalace enhance-ments; and
Sharing income from sponsorships.Facility expenditure, transformationexpenditure, and market expenditurerepresent an ongoing burden for NPMand its service partners, requiring ad-ditional income from the service pro-
vided. NPM must address conflicts that
involve other partners, including own-ership of sponsorship income and howto share it fairly.
ConclusionGarrison et al.6 said trust “between cli-ent organization and cloud provider isa strong predictor of a successful clouddeployment.” It was therefore nec-essary for NPM to identify a suitablemethod of collaboration with othercloud actors, as well as with other busi-ness partners. NPM, a governmental
entity, determined its own process ofcollaboration, which is largely regulat-ed and conservative. NPM investigatedthe possibility of working with othercloud actors, including IBM, YouTube,Google, and domestic companies thathave not yet established themselvesas professional cloud actors. Thesealternatives presented strategic andmanagerial barriers, as well as differ-ent levels of technological readiness.Following several rounds of negotia-tion, the museum became more real-
istic about the future of iPalace anddeployment of relevant complex tech-nologies; for instance, due to the com-plicated political issues involved incollaborating with foreign actors, NPMidentified a domestic value networkas its first choice for helping developmuseum artifacts and exhibitions. AsTaiwan’s cloud actors are not yet fullyprofessional, NPM had to deal with alack of technological readiness. In ad-dition, NPM encountered conceptualdifferences relating to expenses, profitmaking, and trust when dealing with
certain domestic cloud actors; for in-stance, it did not wish to pursue com-mercialization due to the museum’snot-for-profit status and operation,
whereas most potential cloud actorsaim to profit substantially from iPal-ace. NPM’s current business modeldoes not involve generating and shar-
ing more than reasonable revenue.NPM has thus chosen to work with theNational Center for High-performanceComputing in Taiwan, as the Center’smain objective is national technologi-cal advancement rather than pure prof-it making.
This study has several potential im-plications for managers of any tradi-tional organization with less-advancedICT expertise. To deploy and launchan RIIS, managers must establish and
lead a radically innovative ICT-enabledservice system. They must have in-depth understanding of all businesspartners and stakeholders involvedin the embedded value network. Theymust negotiate carrier-rights agree-ments and creative-rights agreements.
And they must also develop an effec-tive business model (such as incomesharing) to ensure success. Moreover,as in the case of iPalace, trust mustalso be nurtured and sustained.
Traditional organizations could
also face other challenges, includingconflicting laws and regulations thatdiscourage development and imple-mentation of an RIIS strategy; ineffec-tive partners unable to provide expect-ed service; inferior ICT infrastructurethat makes new ICT-enabled serviceunattractive, thereby invalidating the
whole project; and inadequate custom-er (or social) acceptance.
Market-related expenditure is alsorequired to support social objectives(such as government support and so-
cial acceptance), interorganizationalgoals (such as satisfying key stakehold-ers, identifying trustworthy partners,maintaining good institutional gover-nance, and understanding competi-tors’ strategies), and managerial objec-tives (such as knowing the market andresponding proactively).
The NPM experience provides othertraditional organizations with lessonson how to deploy sophisticated tech-nology; for instance, when an organiza-tion comprehensively implements anRIIS strategy to gain competitive advan-
tage, unresolved challenges like thosedescribed here could inhibit the RIISand impede (and delay) the organiza-tion’s evolution. On the other hand, thechallenges associated with RIIS entail a
valuable business opportunity for orga-nizations able to implement an organi-zation-centered, ICT-enabled, radically
innovative value network.
Acknowledgments We gratefully acknowledge financialsupport from the Ministry of Scienceand Technology, Taiwan, project num-bers NSC 101-2420-H-004-005-MY3,NSC 102-2420-H-004-006-MY2, andMOST 103-2410-H-004-204.
References1. Bannon, L., Benford, S., Bowers, J., and Heath, C.
Hybrid design creates innovative museum experiences.Commun. ACM 48 , 3 (Mar. 2005), 62–65.
2. Bartak, A. The departing train: Online museummarketing in the age of engagement. In MuseumMarketing: Competing in the Global Marketplace ,R. Rentschler and A.-M. Hede, Eds. Butterworth-Heinemann, Oxford, U.K., 2007, 21–37.
3. Chang, W., Tsaih, R.H., Yen, D.C., and Han, T.S. TheICT Predicament of New ICT-enabled Service .Unpublished working paper, 2014; http://arxiv.org/abs/1506.02128
4. Chang, Y. The Constitution and Understanding ofMarketing Functions in the Museum Sector . UnpublishedPh.D. thesis. King’s College London. London, U.K.,2011; http://library.kcl.ac.uk:80/F/?func=direct&doc_number=001355984&local_base=KINGS.
5. Fitzsimmons, J.A. and Fitzsimmons, M.J. ServiceManagement: Operations, Strategy, InformationTechnology. McGraw-Hill/Irwin, New York, 2008.
6. Garrison, G., Kim, S., and Wakefield, R.L. Successfactors for deploying cloud computing. Commun. ACM
55 , 9 (Sept. 2012), 62–68.7. Hsi, S. and Fait, H. RFID enhances visitors’ museumexperience at the Exploratorium. Commun. ACM 48 , 9(Sept. 2005), 60–65.
8. Huang, S.Y., Chao, Y.T., and Tsaih, R.H. ICT-enabledservice design suitable for museum: The case of theiPalace channel of the National Palace Museum inTaipei. Journal of Library and Information Science 39,1 (Apr. 2013), 84–97.
9. International Council of Museums. ICOM Definition ofa Museum, 2007; http://icom.museum/definition.html
10. Liu, F., Tong, J., Mao, J., Bohn, R., Messina, J., Badger,L., and Leaf, D. NIST Cloud Computing ReferenceArchitecture. National Institute of Standardsand Technology Special Publication 500-292,Gaithersburg, MD, 2011; http://www.nist.gov/customcf/get_pdf.cfm?pub_id=909505
11. Spohrer, J. and Maglio, P.P. Service science: Toward asmarter planet. Chapter 1 in Introduction to ServiceEngineering, G. Salvendy and W. Karwowski, Eds. John
Wiley & Sons, Inc., New York, 2010, 3–30.12. vom Lehn, D. Generating aesthetic experiences from
ordinary activity: New technology and the museumexperience. Chapter 8 in Marketing the Arts: A FreshApproach, D. O’Reilly and F. Kerrigan, Eds. Routledge,London, U.K., 2010, 104–120.
Rua-Huan Tsaih ([email protected]) is the vicedean of the Office of Research and Development of anda professor of MIS in the College of Commerce at theNational Chengchi University in Taipei, Taiwan.
David C. Yen ([email protected]) is the dean of anda professor in the School of Economics and Business atthe State University of New York at Oneonta, Oneonta, NY.
Yu-Chien Chang ([email protected]) is an assistantprofessor in the College of Commerce at the NationalChengchi University in Taipei, Taiwan.
© 2015 ACM 00010782/15/08 $15.00

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 78/100
76 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
review articles
I M
A G E
B Y I W
O N A
U S A K I E W I
C Z / A N D
R I J
B O R Y
S A S S O C I
A T E
S
DOI:10.1145/2699416
Exploring three interdisciplinary areas and theextent to which they overlap. Are they all partof the same larger domain?
BY THANASSIS TIROPANIS, WENDY HALL, JON CROWCROFT,NOSHIR CONTRACTOR, AND LEANDROS TASSIULAS
THE OBSERVATION OF patterns that characterizenetworks, from biological to technological and social,and the impact of the Web and the Internet on societyand business have motivated interdisciplinary researchto advance our understanding of these systems. Theirstudy has been the subject of Network Science researchfor a number of years. However, more recently we have
witnessed the emergence of two new interdisciplinaryareas: Web Science and Internet Science.
Network Science can be traced to its mathematicalorigins dating back to Leonard Euler’s seminal workon graph theory 15 in the 18th century and to its social
scientific origins two centuries later by the psychiatrist
Jacob Moreno’s25 efforts to develop“sociometry.” Soon thereafter, the
mathematical framework offered bygraph theory was also picked up bypsychologists,2 anthropologists,23 andother social scientists to create an in-terdiscipline called Social Networks.The interdiscipline of Social Networksexpanded even further toward the endof the 20th century with an explosionof interest in exploring networks inbiological, physical, and technologi-cal systems. The term Network Sci-ence emerged as an interdisciplinary
area that draws on disciplines such asphysics, mathematics, computer sci-ence, biology, economics, and sociol-ogy to encompass networks that werenot necessarily social.1,26,35 The studyof networks involves developing ex-planatory models to understand theemergence of networks, buildingpredictive models to anticipate theevolution of networks, and construct-ing prescriptive models to optimizethe outcomes of networks. One of themain tenets of Network Science is
to identify common underpinningprinciples and laws that apply across
very different networks and explore why in some cases those patterns vary. The Internet and the Web, giventheir spectacular growth and impact,are networks that have captured theimagination of many network scien-tists.13 In addition, the emergence of
NetworkScience,Web Science,and Internet
Science key insights
˽ Web Science and Internet Science aimto understand the evolution of the Web
and the Internet respectively and toinform debates about their future. Thesegoals lead to different priorities in theirresearch agendas even though theircommunities overlap.
˽ Network Science aims to understandthe evolution of networks regardlessof where they emerge including: theInternet as a network transforming andforwarding information among peopleand things, and the Web as a network ofcreation and collaboration.
˽ Given their intellectual complementarities,we propose sharing and harmonizingthe data research infrastructures
being developed across these threeinterdisciplinary communities.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 79/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 77

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 80/100
78 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
review articles
the need for multidisciplinary re-search on Internet Science that seeksto understand the psychological, soci-ological, and economic implicationsof the Internet’s evolution along theseprincipled directions. Hence, InternetScience is an emerging interdisciplin-ary area that brings together scientists
in network engineering, computation,complexity, security, trust, mathemat-ics, physics, sociology, economics,political sciences, and law. This ap-proach is very well exemplified by theearly Internet topology study.16
Interdisciplinary relationships. Allthree areas draw on a number of dis-ciplines for the study, respectively, ofthe nature and impact of the Web, ofthe Internet, and of networks in gen-eral on government, business, peo-
ple, devices, and the environment.However, each of them examineshow those actors co-create and evolvein distinct, unique ways as shown onFigure 1. For Web Science it is theaspect of linking those actors andthe content with which they interactmaking associations between themand interpreting them. For InternetScience it is the aspect of communi-cation among actors and resourcesas processes that can shape informa-tion relay and transformation. For
Network Science, it is the aspect ofhow these entities, when consideredto be part of a network, exhibit cer-tain characteristics and might ad-here to underpinning laws that canhelp understand their evolution.
However, to understand better thesimilarities and differences betweenthese areas and to establish the po-
online social networks and the poten-tial to study online interactions on amassive, global scale hold the prom-ise of further, potentially invaluableinsights to network scientists on net-
work evolution.24
Web Science6 is an interdisciplinaryarea of much more recent vintage that
studies the Web not only at the level ofsmall technological innovations (mi-cro level) but also as a phenomenonthat affects societal and commercialactivities globally (macro level); to alarge extent, it can be considered thetheory and practice of social machineson the Web. Social machines wereconceptualized by Tim Berners-Lee in1999 as artifacts where people do thecreative work and machines interme-diate.3 Semantic Web and linked data
technologies can provide the meansfor knowledge representation and rea-soning and enable further support forsocial machines.20
Studying the Web and its impact re-quires an interdisciplinary approachthat focuses not only on the techno-logical level but also on the societal,political, and commercial levels. Es-tablishing the relationship betweenthese levels, understanding how theyinfluence each other, investigatingpotential underpinning laws, and ex-
ploring ways to leverage this relation-ship in different domains of humanactivity is a large part of the Web Sci-ence research agenda. Web Sciencedraws on disciplines that include thesocial sciences, such as anthropology,communication, economics, law, phi-losophy, political science, psychology,and sociology as well as computer sci-
ence and engineering. A major focusof the Web Science research agenda isto understand how the Web is evolv-ing as a socio-technical phenomenonand how we can ensure it will contin-ue to evolve and benefit society in the
years to come.Internet Science. The Internet has
provided the infrastructure on whichmuch of human activity has becomeheavily dependent. After only a fewdecades of Internet development itis self-evident that if the Internet be-came unavailable, the consequencesfor society, commerce, the economy,defense, and government would behighly disruptive. The success of theInternet has often been attributedto its distributed governance model,the principle of network neutrality,
and its openness.
14
At the same time,concerns related to privacy, secu-rity, openness, and sustainability areraised and researched as they are of-ten at the center of contestations onthe Internet.11 The Internet can beseen as an infrastructure, the social
value of which must be safeguarded.18 It is the infrastructure that enabledthe evolution of the Web along withP2P applications, more recently thecloud, and, in the near future, the In-ternet of Things. It has been argued
the infrastructural layer of the Inter-net and that of the Web must be keptseparately to foster innovation.4 Arecent study 7 identified a number ofprincipled directions along which theInternet needs to evolve; those includeavailability, inclusiveness, scalability,sustainability, openness, security, pri-
vacy, and resilience. This motivates
Figure 1. Web, Internet, and Network Science aspects.
Social Sciences
Engineering
Computer Science
Psychology
Law
Economics
Education
Mathematics
…
P e o p l e
G o v e r n
m e n t
Business
D e v i c e s
E n v i r o n m e n t
Web Science
The content (co)creation, linkage, and evolution aspect: Web protocols, code, and policies
Internet Science
The information relay and transformation aspect: Internet protocols, code, and policies
Network Science
Network properties and network evolution

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 81/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 79
review articles
All three areasdraw on a number
of disciplines forthe study,respectively, of thenature and impactof the Web, of theInternet, and ofnetworks in generalon government,
business, people,devices, andthe environment.
tential for synergies, a framework fora more detailed comparison is needed.
A Comparison ofInterdisciplinary AreasIt takes only a quick read througha short description of each of theseinterdisciplinary areas5,32,35 for one
to realize that, to a very large extent,they all draw from very similar sets ofdisciplines. Venn diagrams that havebeen used to illustrate the involve-ment of different disciplines in eacharea are indicative of this overlap. Forexample, psychology and economicsare considered relevant to NetworkScience,29 Internet Science,7 and WebScience.20 This can give rise to cer-tain questions such as: “If there is somuch overlap, aren’t these areas one
and the same?” or “Would they allmerge in the future?” Other questionsinclude: “Which community is morerelevant to my research?” or “Whatdevelopments could we expect fromeach area in the future?” To explorethose questions we propose a frame-
work of examining those interdisci-plinary areas, which includes lookingat the way these communities haveformed, and the different languagesof discourse these communities haveemployed in their research.
Community formation. Althoughnot all three interdisciplinary do-mains were established at the sametime, one can argue that research inthose areas dates back before their of-ficial starting date. At the same time,one can also argue there are differenc-es in how communities around thosedomains emerged.
The formation of the Social Net- works community can be traced backto a series of social network conferenc-es that started in the 1970s17 with an
important conference in Dartmouthin 1975 that brought together sociolo-gists, anthropologists, social psychol-ogists, and mathematicians from theU.S. and Europe. This was followedby Lin Freeman’s launch of Social
Networks in 1978, and Barry Wellmanfounding the International Networkfor Social Network Analysis (INSNA)in 1976 and its annual Sunbelt SocialNetworks conference in 1981. Begin-ning in the 1990s, the social scientists
were joined by a large and growinginflux of scholars from the physical
and life sciences who began explor-ing networks in social systems. Thiseffort was acknowledged and furthercatalyzed by the launch of the annualNetwork Science (NetSci) conferencein 2006, a major infusion of fund-ing in 2008 from the Army ResearchLaboratory for the development of
an interdisciplinary Network ScienceCollaborative Technology Alliance(NS-CTA), and the launch of the Net-work Science Journal in 2013.a Clearlythere was already a community inplace, which engaged in interdisci-plinary work long before those initia-tives; one can argue a hybrid bottom-up and top-down approach is thecommunity formation model that wasfollowed for Network Science.
For the Web Science community,
it was around 2006 when it was real-ized that understanding the impact ofthe Web was essential to safeguard itsdevelopment in the future. The WebScience Research Initiative (WSRI)
was established in 2006 and later de- veloped into the Web Science Trust(WST) as part of the top-down ap-proach to the formation of the WebScience community. The WSRI raiseda banner for those who were engagedin research on the Web as a socio-technical phenomenon, including the
social network research community. A similar community formation mod-el was followed for Internet Science,
where the European Network of Excel-lence in Network Science (EINS)b,32 isone of the most significant activitiesto bring together the research com-munity in this area. Areas such as pri-
vacy and network neutrality have beenhighlighted as priorities in the Inter-net Science agenda.
It can be argued the top-downmodel of community formation can
accelerate research in emergent in-terdisciplinary areas but, in order tobe successful, it requires a signifi-cant investment of resources fromindividuals, from research institu-tions, and from industry or govern-ment. Although the Web Scienceand the Internet Science commu-nities were formed mostly in a top-down fashion, the sustainability of
a http://journals.cambridge.org/
action/displayJournal?jid=NWSb http://www.internet-science.eu

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 82/100
80 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
review articles
in the future and the research meth-ods or data will continue to minglebetween these three areas. For ex-ample, data on the Internet of Thingsmight not remain exclusive to Inter-net Science since that data could becombined with data on human be-havior on the Web from the Web Sci-
ence perspective or to explore emer-gence and outcomes of the networksthey enable from the Network Sciencepoint of view. Similarly, data on thebehavior of users on the Web will beused to explore the use of bandwidthin the underlying Internet infrastruc-ture. The different types of measure-ment point to the fact that often, partof the research, especially in the top-down-formed areas of Internet Sci-ence and Web Science, is associated
to specific goals.Given this shared pool of methodsand data resources, each area em-ploys mixed methods to leverage thispool in different ways according totheir research agendas as illustratedin Figure 2. Those agendas are in-formed by different research goals.
Research goals. “Web Science isfocused on how we could do thingsbetter, while Network Science is morefocused on how things work;”36 the“doing things better” refers to lever-
aging the potential of the Web andensuring its continuing sustainability.Similar claims are made on behalf ofInternet Science and Network Science.
Although the use of the term ‘science’relates to the systematic organizationof knowledge and is not directly linkedto goals, we argue that goals do play arole in the formation of these interdis-ciplinary areas and in shaping theirresearch agendas, scientific contribu-tion, and impact. In Web Science, thestudy of the Web itself is crucial,21 as
is safeguarding the Web and its evolu-tion.19 In Internet Science, the evolu-tion and sustainability of the Internetand its services are central objectives;it is understood that tussles will al-
ways be the case on the Internet andthat accommodating them is neces-sary in order to ensure its evolution.11 It seems that in both Internet Scienceand Web Science applied researchcomes first but it should be informedby the development of a basic researchprogram. In addition, neither WebScience nor Internet Science is tech-
those communities was ensured byresearch funding from key researchinstitutions, national research coun-cils, the European Union, and signifi-cant effort by individuals.
Use of a lingua franca. Beyondcommunity formation, there are dif-ferences in the language of discourse
(the lingua franca) that is employed ineach area. Network scientists initiallyshared graph theory as their linguafranca but have more recently em-ployed models taken from physicalprocesses (percolation, diffusion) andgame theory 13 to describe processeson graphs. They have also movedfrom descriptive network metrics tothe development of novel inferentialtechniques to test hypotheses aboutthe evolution of a network based
on various self-organizing mecha-nisms.27,28 As a result, the use of graphtheory is not necessarily the founda-tion for contemporary Network Sci-ence research. Further, there is use ofcomplex systems analysis to deal withphase changes and discontinuitiesbetween different operating regimes;these are used to study why epidemicsand pandemics spread globally. As aresult, many Network Science publi-cations are featured in journals suchas Nature.
The Web Science community hasnot yet embraced a lingua francaper se but one can argue that an un-derstanding of Web standards, tech-nologies, and models (HTTP, XML,
JavaScript, REST, models of commu-nication, ontologies) and of frame-
works of social theory are compo-nents of what could develop into alingua franca. The W3C has been fos-tering a significant part of the discus-sion on Web protocols and their im-plications. A basic understanding of
the evolution of the Web on both themicro and macro levels is the founda-tion for Web Science research.
Similar means of discourse areemployed in the Internet Sciencecommunity. For Internet Science,the components of the lingua francainclude the set of Internet standards(RFCs) and associated commentaryand implementation (or even C code)as in Stevens’ books,30,31 as well asthe existence of de facto standardimplementations of systems in opensource. They also include a basic
understanding of the principles ofInternet protocols, infrastructure(routers, links, AS topology), socialscience (preferential attachmentmodels), law, and policy.
Research methodologies. In Net- work Science, research methodolo-gies involve network modeling and
network analysis9,10 on networks thatinclude, but are by no means restrict-ed to, the Web and the Internet. InInternet Science, methodologies thatemploy measurements of engage-ment of Internet users with onlineresources and the Internet of Thingsare prevalent. In Web Science, mixedresearch methods that combine inter-pretative and positivist approachesare employed widely to understandthe evolution of the Web based on
online social network datasets, click-stream behavior, and the use of the Web data.
Beyond methodologies, the WebScience community is working onproviding the Web Science Obser-
vatory,33,34 a global-distributed re-source with datasets and analytictools related to Web Science. Simi-larly, the EINS project is workingon providing an evidence base forInternet Science research. And theNetwork Science community has a
long tradition of making canonicalnetwork datasets available for use bythe community along with networkanalysis software such as UCINET8 and large-scale repositories of net-
work data such as SNAP.22
Clearly there is an overlap in theresearch methodologies of thesethree areas:
˲ They draw on data gathered fromsocial networks, infrastructures, sen-sors and the Internet of Things;
˲ They involve measurement, mod-
eling, simulation, visualization, hy-pothesis testing, interpretation andexploratory research; and
˲ They use analytical techniques toquantify properties of a network (ab-stract, virtual, or real) as well as morequalitative techniques.
So far, there has been significantemphasis on the social sciences in
Web Science, on both social sciencetheories and methodologies in Net-
work Science, and on protocols andcomputer science in Internet Sci-ence. However, these foci will change

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 83/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 81
review articles
nology neutral; each one relies on spe-cific protocols and standards. Further,one can argue that even the code thatimplements those standards embedspolicy on which each respective com-munity has reached some consensus.On the other hand, Network Scienceis technology agnostic and it overlaps
only in part with Internet Science and Web Science, since it explores emer-gent structural patterns and flowson network structures be they social,biological, the Web, or the Internet.Finally, Web Science and Internet Sci-ence are both also engineering disci-plines; they are about building better,stronger, more robust, efficient, andresilient systems. Network Sciencehas been predominantly focused onunderstanding and describing emer-
gent processes, although access tolarge datasets has increased interestin both predictive analytics to antici-pate network changes and prescrip-tive analytics to optimize networks toaccomplish certain desired goals. Inessence, Network Science is aspiringto take insights from basic research toengineer better networks.12
Comparisons. Despite the differ-ences between these areas in termsof the community formation mod-els, lingua francas, and goals, many
of the research methods they employare common. This points to potentialsynergies on topics in which these ar-eas overlap and the potential for mo-bilization within those communitieson topics in which there is little or nooverlap. Figure 3 shows such topicsfrom each of these areas:
1. Web Science: The area of Web-based social media is one exampleof primarily Web Science research.Network aspects are not the exclu-sive part of this since social media
research focuses on associations andinteraction among people and socialmedia resources.
2. Internet Science: Research on howthe Internet of Things affects informa-tion collection and transformation isprimarily Internet Science researchthat cannot rely exclusively on networkresearch either.
3. Network Science: Transport net- works provide an example of networkscience research that does not neces-sarily relate to Internet or Web science.
4. Web Science and Internet Science:
Network neutrality is an example thatrequires understanding of both Weband Internet technology and it doesnot necessarily draw primarily on net-
work science techniques.5. Internet Science and Network Sci-
ence: Content Delivery Networks can
require network techniques for distri-bution prediction and optimizationand, at the same time, understandingof how Internet protocols and peoplerelate to shaping that demand.
6. Network Science and Web Science: Diffusion on social media such as
Figure 2. Network, Internet, and Web Science methodologies.
Internet Science:Internet Engineering
Internet Evolution
QUALITATIVE QUANTITATIVE
MEASUREMENT, MODELING,SIMULATION, VISUALIZATION,
INTERPRETATION ,HYPOTHESIS TESTING
Web Science:Web Infrastructure
Social machinesWeb Evolution
DATAmedia
social networksnetwork usage
device dataopen dataarchives
environment data
Network Science:Underpinning network laws
Scale-free network evolution
Figure 3. Research topics differentiating areas and overlaps.
Network
Science
3
6
7
5
4
1
2
Web
Science
Internet
Science
for example, loT
for example, CDN
for example,SOPA trust
for example, diffusionon Twitter
for example,net neutrality
for example, social media
for example, transport networks

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 84/100
82 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
review articles
24. Monge, P.R. and Contractor, N.S. Theories ofCommunication Networks. Oxford University Press, 2003.
25. Moreno, J.L. Who Shall Survive? Foundations ofSociometry, Group Psychotherapy and Socio-Drama(2nd ed.). Beacon House, Oxford, England, 1953.
26. Newman, M.E.J. Networks: An Introduction. OxfordUniversity Press, 2010.
27. Robins, G., Snijders, T., Wang, P., Handcock, M., andPattison, P. Recent developments in exponentialrandom graph (p*) models for social networks.Social Networks 29, 2 (2007), 192–215; doi:10.1016/j.socnet.2006.08.003
28. Snijders, T.A.B., Van de Bunt, G.G., and Steglich, C.E.G.Introduction to stochastic actor-based models fornetwork dynamics. Social Networks 32, 1 (2010).44–60; doi:10.1016/j.socnet.2009.02.004
29. Steen, M.V. Computer science, informatics, and thenetworked world. Internet Computing, IEEE 15 , 3(2011), 4–6.
30. Stevens, W.R. TCP/IP Illustrated, Vol. 1: TheProtocols, (1993).
31. Stevens, W.R. and Wright, G.R. TCP/IP Illustrated, Vol.2: The Implementation, (1995).
32. The EINS Consortium. EINS Factsheet. The EINSNetwork of Excellence, EU-FP7 (2012); http://www.internet-science.eu/publication/231.
33. Tiropanis, T., Hall, W., Hendler, J. de Larrinaga,Christian. The Web Observatory: A middle layerfor broad data. Dx.Doi.org 2, 3 (2014), 129–133;doi:10.1089/big.2014.0035
34. Tiropanis, T., Hall, W., Shadbolt, N., de Roure, D.,
Contractor, N. and Hendler, J. The Web ScienceObservatory. Intelligent Systems, IEEE 28 , 2 (2013),100–104.
35. Watts, D. The ‘new’ science of networks. AnnualReview of Sociology , (2004).
36. Wright, A. Web science meets network science.Commun. ACM 54, 5 (May 2011).
Thanassis Tiropanis ([email protected]) isan associate professor with the Web and Internet ScienceGroup, Electronics and Computer Science, University ofSouthampton, U.K.
Wendy Hall ([email protected]) is a professor ofComputer Science at the University of Southampton, U.K.She is a former president of ACM.
Jon Crowcroft ([email protected]) is theMarconi Professor of Communications Systems in the
Computer Lab, at the University of Cambridge, U.K.Noshir Contractor ([email protected]) is the JaneS. & William J. White Professor of Behavioral Sciences inthe McCormick School of Engineering & Applied Science,the School of Communication, and the Kellogg School ofManagement at Northwestern University, Chicago, IL.
Leandros Tassiulas ([email protected]) is theJohn C. Malone Professor of Electrical Engineering at YaleUniversity, New Haven, CT.
© 2015 ACM 0001-0782/15/08 $15.00
Twitter is an example that relies on Web Science socio-technical researchmethods and, at the same time, onnetwork analytic methods.
7. Web Science, Internet Science, and Network Science: Research on trust on-line or on SOPA (Stop Online Piracy
Act) and its side effects draws on all
networks and on techniques that areaware of Web and Internet protocolsand code.
As the Web and the Internet con-tinue to evolve it could be that some ofthese topics will shift.
Conclusion We provide a comparison among Net- work, Web, and Internet Science. Wealso propose a framework for com-paring interdisciplinary areas based
on their community formation, lin-gua francas, research methods andresources, and research goals. Wecan gain additional insights of therelationship among these areas byconducting co-author and co-citationanalysis of publications within theseareas and explore the extent to whichthese are distinct or merging interdis-ciplinary intellectual communities.Such an analysis would be even moremeaningful as the related confer-ences and journals mature and as the
similarities and differences amongthese areas potentially crystallize.
Both Internet Science and Web Sci-ence are technology-aware and theirrespective lingua francas includeknowledge of the protocols and sys-tems supporting the Internet andthe Web, while Network Science istechnology-agnostic. There are argu-ments in keeping the two layers ofthe Internet and the Web separateto foster innovation;4 consequently,Internet Science and Web Science
remain two distinct interdisciplinaryareas given they have different goals,those of safeguarding the Internetand the Web, respectively. NetworkScience explores phenomena that in-clude, but are not limited to, the Webor the Internet.
However, given the shared pool ofmixed methods and datasets amongthese three interdisciplinary areas,there are compelling benefits for col-laboration to harmonize and share re-sources; this should be a high priorityfor researchers and funding agencies.
Acknowledgments. The prepara-tion of this manuscript was supportedby funding from the U.S. Army Re-search Laboratory (9500010212/0013//
W911NF-09-2-0053), the National Sci-ence Foundation (CNS-1010904) andthe European Union FP7 Network ofExcellence in Internet Science–EINS
(grant agreement No 288021). The views, opinions, and/or findings con-tained here are those of the authors,and should not be construed as an of-ficial Department of the Army, NSF orEuropean Commission position, poli-cy, or decision, unless so designated byother documents.
References1. Barabási, A.-L. and Albert, R. Emergence of scaling in
random networks. Science 286 , 5439 (1999), 509–512.2. Bavelas, A. Communication patterns in task-oriented
groups. J. Acoustical Society of America 22 , 6 (1950),
725–730.3. Berners-Lee, T. Weaving the Web. Texere Publishing,
1999.4. Berners-Lee, T. Long live the Web. Scientific American,
(2010).5. Berners-Lee, T., Hall, W., Hendler, J.A., O’Hara, K.
and Shadbolt, N. A framework for Web science.Foundations and Trends in Web Science 1. 1 (2006b),1–130.
6. Berners-Lee, T., Hall, W., Hendler, J., Shadbolt, N. andWeitzner, D. Computer science enhanced: Creating ascience of the Web. Science 313, 5788 (2006a), 769.
7. Blackman, C., Brown, I., Cave, J., Forge, S., Guevara,K., Srivastava, L. and Popper, M.T.W.R. Towards aFuture Internet , (2010). European Commission DGINFSO Project SMART 2008/0049.
8. Borgatti, S., Everett, M.G. and Freeman, L.C. ComputerSoftware: UCINET 6. Analytic Technologies, 2006.
9. Börner, K., Sanyal, S. and Vespignani, A. Network
science. B. Cronin, Ed. Annual Review of InformationScience & Technology, 41 (2007), 537–607.10. Carrington, P. J., Scott, J., and Wasserman, S., eds.
Models and Methods in Social Network Analysis.Cambridge University Press, 2005.
11. Clark, D.D., Wroclawski, J., Sollins, K.R., and Braden,R. Tussle in cyberspace: Defining tomorrow’s Internet.Aug. 2002. ACM.
12. Contractor, N.S. and DeChurch, L.A. (in press).Integrating social networks and human social motivesto achieve social influence at scale. In Proceedings ofthe National Academy of Sciences.
13. Easley, D. and Kleinberg, J. Networks Crowds andMarkets. Cambridge University Press, 2010.
14. Economides, N. Net neutrality, non-discrimination anddigital distribution of content through the Internet.ISJLP 4 (2008), 209.
15. Euler, L. Konigsberg Bridge problem Commentariiacademiae scientiarum Petropolitanae 8 (1741),128–140.
16. Faloutsos, F., Faloutsos, P. and Faloutsos, C. Onpower-law relationships of the Internet topology.ACM SIGCOMM CCR. Rev. 29, 4 (1999).
17. Freeman, L.C. The Development Of Social NetworkAnalysis. Booksurge LLC, 2004.
18. Frischmann, B.M. Infrastructure. OUP USA, 2012.19. Hall, W. and Tiropanis, T. Web evolution and
Web Science. Computer Networks 56 , 18 (2012),3859–3865.
20. Hendler, J. and Berners-Lee, T. From the semantic webto social machines: A research challenge for AI on theWorld Wide Web. Artificial Intelligence (2009), 1–10.
21. Hendler, J., Shadbolt, N., Hall, W., Berners-Lee, T.and Weitzner, D. Web Science: an interdisciplinaryapproach to understanding the Web. Commun. ACM51, 7 (July 2008).
22. Leskovec, J. Stanford large network dataset collection,2011; http://snap.stanford.edu/data/index.html
23. Mitchell, J.C. The Kalela Dance; Aspects of Social
Relationships among Urban Africans. ManchesterUniversity Press, 1956.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 85/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 83
research highlights
P. 85
Soylent: A Word Processor with a Crowd InsideBy Michael S. Bernstein, Greg Little, Robert C. Miller, Björn Hartmann,Mark S. Ackerman, David R. Karger, David Crowell, and Katrina Panovich
P. 84
TechnicalPerspectiveCorrallingCrowd PowerBy Aniket (Niki) Kittur

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 86/100
84 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
retainer, enabling time-sensitive ap-
plications such as helping blind us-ers navigate their surroundings. Thequality of crowd work has increased byorders of magnitude due to researchranging from improved task design(for example, using Bayesian Truth Se-rum where workers predict others’ an-swers), to leveraging workers’ behav-ioral traces (for example, looking atthe way workers do their work insteadof their output), to inferring workerquality across tasks and reweighting
their influence accordingly.Perhaps the most important ques-tion for the future of crowd work is
whether it is capable of scaling up tothe highly complex and creative tasksembodying the pinnacle of humancognition, such as science, art, and in-novation. As the authors, myself, andothers have argued (for example, inThe Future of Crowd Work), doing somay be critical to enabling crowd work-ers to engage in the kinds of fulfilling,impactful work we would desire for
our own children. Realizing this future will require highly interdisciplinaryresearch into fundamental challengesranging from incentive design to repu-tation systems to managing interde-pendent workflows. Such research willbe complicated by but ultimately moreimpactful for grappling with the shift-ing landscape and ethical issues sur-rounding global trends towards decen-tralized work. Promisingly, there havebeen a number of recent examples ofresearch using crowds to accomplish
complex creative work including jour-nalism, film animation, design cri-tique, and even inventing new prod-ucts. However, the best (or the worst)may be yet to come: we stand now atan inflection point where, with a con-certed effort, computing researchcould tip us toward a positive future ofcrowd-powered systems.
Aniket (Niki) Kittur is an associate professor and theCooper-Siegel chair in the Human-Computer InteractionInstitute at Carnegie Mellon University, Pittsburgh, PA.
Copyright held by author.
EARLY PIONEERS IN computing, such as
Herb Simon and Allen Newell, realizedthat human cognition could be framedin terms of information processing.Today, research like that described inthe following paper is demonstratingthe possibilities of seamlessly connect-ing human and machine informationprocessors to accomplish creative tasksin ways previously unimaginable. Thisresearch is made possible by the riseof online crowdsourcing, in which mil-lions of workers worldwide can be re-
cruited for nearly any imaginable task.For some kinds of work and some fieldsof computer science these conditionshave led to a renaissance in which largeamounts of information are parallel-ized and labeled by human workers,generating unprecedented training setsfor domains ranging from natural lan-guage processing to computer vision.
However, complex and creativetasks such as writing or design arenot so straightforward to decomposeand parallelize. Imagine, for example,
a crowd of 100 workers let loose on your next paper with instructions toimprove anything they find. You canquickly envision the challenges withcoordinating crowds, including avoid-ing duplication of effort, dealing withconflicting viewpoints, and creating asystem robust to any individual’s lackof global context or expertise. Thus,the parallelized independent taskstypical of crowdsourcing today seema poor match for the rich interactivityrequired for writing and editing tasks.
These coordination and interactiv-ity issues have been critical barriersto harnessing the power of crowds forcomplex and creative real-world tasks.
The authors introduce and realize anexciting vision of using crowd workersto power an interactive system—here,a word processor—in accomplishingcomplex cognitive tasks such as intelli-gently shortening text or acting as flex-ible “human macro.” This vision goesbeyond previous “Wizard of Oz”-styleapproaches (in which humans are usedto prototype functionality that is diffi-
cult to program) to permanently wiring
human cognition into interactive sys-tems. Such “crowd-powered systems”could enable the creation of entirelynew forms of computational supportnot yet possible, and to build up train-ing data that could help develop AI.
A central challenge in realizing this vision is coordinating crowds to ac-complish interdependent tasks thatcannot be easily decomposed; for ex-ample, a paragraph in which one sen-tence needs to flow into the next. The
authors introduce a crowd program-ming pattern called Find-Fix-Verify, which breaks down tasks such thatsome workers identify areas that needtransformation, others transform themost commonly identified areas, andothers select the best transforma-tions. Although no single individualneed work on (or even read) the entirearticle, effort is focused into key areas
while maintaining context within thoseareas. The authors show evidence thatusing this pattern crowds could col-
lectively accomplish tasks with high-quality output—including shorteningtext, proofreading, and following open-ended instructions—despite relativelyhigh individual error rates.
One might ask how such an ap-proach scales in terms of time or com-plexity. In terms of time, crowd mar-ketplaces can suffer from a latencyproblem in waiting for tasks to be ac-cepted by workers, and indeed this ac-counted for the bulk of time in eachcondition (~20 minutes). In terms of
complexity, the authors acknowledgean important limitation in the degreeof interdependence supported; forexample, changes requiring modifica-tion of large areas or related but sepa-rate areas can lead to quality issues.
However, the field (including theauthors) has since made tremendousprogress in scaling up the speed, qual-ity, and complexity of crowd work. Thetime needed to recruit a crowd workerhas dropped from minutes to secondsfollowing the development of meth-ods such as paying workers to be on
Technical PerspectiveCorralling Crowd PowerBy Aniket (Niki) Kittur
To view the accompanying paper,visit doi.acm.org/10.1145/2791285 rh
research highlights
DOI:10.1145/2791287

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 87/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 85
Soylent: A Word Processor with a Crowd Inside
By Michael S. Bernstein, Greg Little, Robert C. Miller, Björn Hartmann, Mark S. Ackerman, David R. Karger,
David Crowell, and Katrina Panovich
DOI:10.1145/2791285
AbstractThis paper introduces architectural and interaction patternsfor integrating crowdsourced human contributions directlyinto user interfaces. We focus on writing and editing, com-plex endeavors that span many levels of conceptual andpragmatic activity. Authoring tools offer help with pragmat-ics, but for higher-level help, writers commonly turn to otherpeople. We thus present Soylent, a word processing interfacethat enables writers to call on Mechanical Turk workers to
shorten, proofread, and otherwise edit parts of their docu-ments on demand. To improve worker quality, we introducethe Find-Fix-Verify crowd programming pattern, which splitstasks into a series of generation and review stages. Evaluationstudies demonstrate the feasibility of crowdsourced editingand investigate questions of reliability, cost, wait time, and
work time for edits.
1. INTRODUCTION Word processing is a complex task that touches on many goalsof human-computer interaction. It supports a deep cognitiveactivity—writing—and requires complicated manipulations.
Writing is difficult: even experts routinely make style, gram-mar, and spelling mistakes. Then, when a writer makes high-level decisions like changing a passage from past to presenttense or fleshing out citation sketches into a true referencessection, she is faced with executing daunting numbers ofnontrivial tasks across the entire document. Finally, when thedocument is a half-page over length, interactive software pro-
vides little support to help us trim those last few paragraphs.Good user interfaces aid these tasks; good artificial intelli-gence helps as well, but it is clear that we have far to go.
In our everyday life, when we need help with complex cog-nition and manipulation tasks, we often turn to other people.
Writing is no exception5: we commonly recruit friends and col-
leagues to help us shape and polish our writing. But we can-not always rely on them: colleagues do not want to proofreadevery sentence we write, cut a few lines from every paragraphin a 10-page paper, or help us format 30 ACM-style references.
Soylent is a word processing interface that utilizes crowdcontributions to aid complex writing tasks ranging fromerror prevention and paragraph shortening to automationof tasks such as citation searches and tense changes. UsingSoylent is like having an entire editorial staff available as
you write. We hypothesize that crowd workers with a basicknowledge of written English can support both novice andexpert writers. These workers perform tasks that the writermight not, such as scrupulously scanning for text to cut orupdating a list of addresses to include a zip code. They can
also solve problems that artificial intelligence cannot yet,for example flagging writing errors that the word processordoes not catch.
Soylent aids the writing process by integrating paidcrowd workers from Amazon’s Mechanical Turk platforminto Microsoft Word. Soylent is peoplea: its core algorithmsinvolve calls to Mechanical Turk workers (Turkers). Soylentis comprised of three main components:
1. Shortn, a text shortening service that cuts selected textdown to 85% of its original length on average withoutchanging the meaning of the text or introducing writ-ing errors.
2. Crowdproof , a human-powered spelling and grammarchecker that finds problems Word misses, explains theerror, and suggests fixes.
3. The Human Macro, an interface for offloading arbitrary word processing tasks such as formatting citations orfinding appropriate figures.
The main contribution of Soylent is the idea of embedding paid crowd workers in an interactive user interface to support
complex cognition and manipulation tasks on demand . Thispaper contributes the design of one such system, an imple-mentation embedded in Microsoft Word, and a program-ming pattern that increases the reliability of paid crowd
workers on complex tasks. It then expands these contribu-tions with feasibility studies of the performance, cost, andtime delay of our three main components and a discussionof the limitations of our approach with respect to privacy,delay, cost, and domain knowledge.
The fundamental technical contribution of this systemis a crowd programming pattern called Find-Fix-Verify.Mechanical Turk costs money and it can be error-prone; to be
worthwhile to the user, we must control costs and ensure cor-
rectness. Find-Fix-Verify splits complex crowd intelligencetasks into a series of generation and review stages that uti-lize independent agreement and voting to produce reliableresults. Rather than ask a single crowd worker to read andedit an entire paragraph, for example, Find-Fix-Verify recruitsone set of workers to find candidate areas for improvement,another set to suggest improvements to those candidates,
A full version of this paper was published in Proceedings
of ACM UIST 2010.
a With apologies to Charlton Heston (1973): Soylent is made out of people.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 88/100
research highlights
86 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
Proofreading is emerging as a common task on Mechan-ical Turk. Standard Mindsb offers a proofreading servicebacked by Mechanical Turk that accepts plain text via a webform and returns edits 1 day later. By contrast, Soylent isembedded in a word processor, has much lower latency, andpresents the edits in Microsoft Word’s user interface. Our
work also contributes the Find-Fix-Verify pattern to improve
the quality of such proofreading services. Automatic proofreading has a long history of research9
and has seen successful deployment in word processors.However, Microsoft Word’s spell checker frequently suf-fers from false positives, particularly with proper nounsand unusual names. Its grammar checker suffers from theopposite problem: it misses blatant errors.c Human check-ers are currently more reliable, and can also offer sugges-tions on how to fix the errors they find, which is not alwayspossible for Word—for example, consider the common (butmostly useless) Microsoft Word feedback, “Fragment; con-sider revising.”
Soylent’s text shortening component is related to docu-ment summarization, which has also received substantialresearch attention.12 Microsoft Word has a summarizationfeature that uses sentence extraction, which identifies wholesentences to preserve in a passage and deletes the rest, pro-ducing substantial shortening but at a great cost in con-tent. Shortn’s approach, which can rewrite or cut parts ofsentences, is an example of sentence compression, an areaof active research that suffers from a lack of training data.3 Soylent’s results produce training data to help push thisresearch area forward.
The Human Macro is related to AI techniques for end-userprogramming. Several systems allow users to demonstrate
repetitive editing tasks for automatic execution; examplesinclude Eager, TELS, and Cima.4
3. SOYLENTSoylent is a prototype crowdsourced word processing inter-face. It is currently built into Microsoft Word (Figure 1),a popular word processor and productivity application.
and a final set to filter incorrect candidates. This pro-cess prevents errant crowd workers from contributingtoo much or too little, or introducing errors into thedocument.
In the rest of this paper, we introduce Soylent and itsmain components: Shortn, Crowdproof, and The HumanMacro. We detail the Find-Fix-Verify pattern that enables
Soylent, then evaluate the feasibility of Find-Fix-Verify andour three components.
2. RELATED WORKSoylent is related to work in two areas: crowdsourcing sys-tems and artificial intelligence for word processing.
2.1. CrowdsourcingGathering data to train algorithms is a common use of crowd-sourcing. For example, the ESP Game19 collects descriptionsof objects in images for use in object recognition. MechanicalTurk is already used to collect labeled data for machine
vision
18
and natural language processing.
17
Soylent tacklesproblems that are currently infeasible for AI algorithms, even with abundant data. However, Soylent’s output may be usedto train future AIs.
Soylent builds on work embedding on-demand work-forces inside applications and services. For example,
Amazon Remembers uses Mechanical Turk to find prod-ucts that match a photo taken by the user on a phone, andPEST16 uses Mechanical Turk to vet advertisement recom-mendations. These systems consist of a single user opera-tion and little or no interaction. Soylent extends this workto more creative, complex tasks where the user can makepersonalized requests and interact with the returned data
by direct manipulation.Soylent’s usage of human computation means that
its behavior depends in large part on qualities of crowd-sourcing systems and Mechanical Turk in particular. Rosset al. found that Mechanical Turk had two major popu-lations: well-educated, moderate-income Americans,and young, well-educated but less wealthy workers fromIndia.15 Kittur and Chi8 considered how to run user stud-ies on Mechanical Turk, proposing the use of quantitative
verifiable questions as a verification mechanism. Find-Fix-Verify builds on this notion of requiring verification tocontrol quality. Heer and Bostock6 explored MechanicalTurk as a testbed for graphical perception experiments,
finding reliable results when they implemented basicmeasures like qualification tests. Little et al.11 advocatethe use of human computation algorithms on MechanicalTurk. Find-Fix-Verify may be viewed as a new design pat-tern for human computation algorithms. It is specificallyintended to control lazy and overeager Turkers, identify
which edits are tied to the same problem, and visualizethem in an interface. Quinn and Bederson14 have authoreda survey of human computation systems that expands onthis brief review.
2.2. Artificial intelligence for word processingSoylent is inspired by writers’ reliance on friends and colleaguesto help shape and polish their writing.5
Figure 1. Soylent adds a set of crowd-powered commands to theword processor.
b
http://standardminds.com/.c http://faculty.washington.edu/sandeep/check.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 89/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 87
It demonstrates that computing systems can reach out tocrowds to: (1) create new kinds of interactive support fortext editing, (2) extend artificial intelligence systems suchas style checking, and (3) support natural language com-mands. These three goals are embedded in Soylent’s threemain features: text shortening, proofreading, and arbitrarymacro tasks.
3.1. Shortn: Text shorteningShortn aims to demonstrate that crowds can support newkinds of interactions and interactive systems that were verydifficult to create before. Some authors struggle to remain
within length limits on papers and spend the last hours ofthe writing process tweaking paragraphs to shave a few lines.This is painful work and a questionable use of the authors’time. Other writers write overly wordy prose and need helpediting. Automatic summarization algorithms can identifyrelevant subsets of text to cut.12 However, these techniquesare less well-suited to small, local language tweaks like
those in Shortn, and they cannot guarantee that the result-ing text flows well.Soylent’s Shortn interface allows authors to condense
sections of text. The user selects the area of text that is toolong—for example, a paragraph or section—then pressesthe Shortn button in Word’s Soylent command tab (Figure 1).In response, Soylent launches a series of Mechanical Turktasks in the background and notifies the user when the textis ready. The user can then launch the Shortn dialog box(Figure 2). On the left is the original paragraph; on the rightis the proposed revision. Shortn provides a single slider toallow the user to continuously adjust the length of the para-graph. As the user does so, Shortn computes the combina-
tion of crowd trimmings that most closely match the desiredlength and presents that text to the user on the right. Fromthe user’s point of view, as she moves the slider to make theparagraph shorter, sentences are slightly edited, combined
and cut completely to match the length requirement. Areasof text that have been edited or removed are highlighted inred in the visualization. These areas may differ from oneslider position to the next.
Shortn typically can remove up to 15%–30% of a para-graph in a single pass, and up to 50% with multiple itera-tions. It preserves meaning when possible by encouraging
crowd workers to focus on wordiness and separately veri-fying that the rewrite does not change the user’s intendedmeaning. Removing whole arguments or sections is left tothe user.
3.2. Crowdproof: Crowdsourced copyeditingShortn demonstrates that crowds can power new kinds ofinteractions. We can also involve crowds to augment theartificial intelligence built into applications, for exampleproofreading. Crowdproof instantiates this idea.
Soylent provides a human-aided spelling, grammar, andstyle checking interface called Crowdproof (Figure 3). The
process finds errors, explains the problem, and offers one tofive alternative rewrites. Crowdproof is essentially a distrib-uted proofreader or copyeditor.
To use Crowdproof, the user highlights a section of textand presses the proofreading button in the Soylent ribbontab. The task is queued to the Soylent status pane and theuser is free to keep working. Because Crowdproof costsmoney, it does not issue requests unless commanded.
When the crowd is finished, Soylent calls out the erro-neous sections with a purple dashed underline. If theuser clicks on the error, a drop-down menu explains theproblem and offers a list of alternatives. By clicking onthe desired alternative, the user replaces the incorrect
text with an option of his or her choice. If the user hoversover the Error Descriptions menu item, the popout menusuggests additional second-opinions of why the error wascalled out.
Figure 2. Shortn allows users to adjust the length of a paragraph via a slider. Red text indicates locations where the crowd has provided arewrite or cut. Tick marks on the slider represent possible lengths.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 90/100
research highlights
88 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
3.3. The human macro: Natural language crowdscripting
Embedding crowd workers in an interface allows us toreconsider designs for short end-user programming tasks.Typically, users need to translate their intentions intoalgorithmic thinking explicitly via a scripting language orimplicitly through learned activity.4 But tasks conveyed tohumans can be written in a much more natural way. Whilenatural language command interfaces continue to struggle
with unconstrained input over a large search space, humansare good at understanding written instructions.
The Human Macro is Soylent’s natural language com-mand interface. Soylent users can use it to request arbitrary
work quickly in human language. Launching the HumanMacro opens a request form (Figure 4). The design challenge
here is to ensure that the user creates tasks that are scopedcorrectly for a Mechanical Turk worker. We wish to preventthe user from spending money on a buggy command.
The form dialog is split in two mirrored pieces: a task entryform on the left, and a preview of what the crowd worker willsee on the right. The preview contextualizes the user’s request,reminding the user that they are writing something akin to aHelp Wanted or Craigslist advertisement. The form suggeststhat the user provide an example input and output, which isan effective way to clarify the task requirements to workers. Ifthe user selected text before opening the dialog, they have theoption to split the task by each sentence or paragraph, so (forexample) the task might be parallelized across all entries on
a list. The user then chooses how many separate workers he would like to complete the task. The Human Macro helps debugthe task by allowing a test run on one sentence or paragraph.
The user chooses whether the crowd workers’ sugges-tions should replace the existing text or just annotate it. Ifthe user chooses to replace, the Human Macro underlinesthe text in purple and enables drop-down substitution like theCrowdproof interface. If the user chooses to annotate, the feed-back populates comment bubbles anchored on the selectedtext by utilizing Word’s reviewing comments interface.
4. PROGRAMMING WITH CROWDSThis section characterizes the challenges of leveraging crowdlabor for open-ended document editing tasks. We introduce
the Find-Fix-Verify pattern to improve output quality inthe face of uncertain crowd worker quality. As we preparedSoylent and explored the Mechanical Turk platform, we per-formed and documented dozens of experiments.d For thisproject alone, we have interacted with over 10,000 workersacross over 2,500 different tasks. We draw on this experiencein the sections to follow.
4.1. Challenges We are primarily concerned with tasks where crowd work-ers directly edit a user’s data in an open-ended manner.These tasks include shortening, proofreading, and user-requested changes such as address formatting. In ourexperiments, it is evident that many of the raw results that
workers produce on such tasks are unsatisfactory. As arule-of-thumb, roughly 30% of the results from open-endedtasks are poor. This “30% rule” is supported by the experi-mental section of this paper as well. Clearly, a 30% errorrate is unacceptable to the end user. To address the prob-lem, it is important to understand the nature of unsatisfac-
tory responses.High variance of effort. Crowd workers exhibit high vari-
ance in the amount of effort they invest in a task. We mightcharacterize two useful personas at the ends of the effortspectrum, the Lazy Turker and the Eager Beaver . The LazyTurker does as little work as necessary to get paid. For ex-ample, we asked workers to proofread the following error-filled paragraph from a high school essay site.e Ground-trutherrors are colored below, highlighting some of the low qual-ity elements of the writing:
While GUIs made computers more intuitive and easier to learn,
they didn't let people be able to control computers efficiently.
a
While GUIs made computers more intuitive and easier to learn,
they didn't allow people to control computers efficiently.
While GUIs made computers more intuitive and easier to learn,they didn't let people be able to control computers efficiently.
ad t ople be able to contr l computer
Figure 3. Crowdproof is a human-augmented proofreader. The drop-down explains the problem (blue title) and suggests fixes (goldselection).
Figure 4. The Human Macro allows users to request arbitrary tasksover their document. Left: user’s request pane. Right: crowd workertask preview, which updates as the user edits the request pane.
d
http://groups.csail.mit.edu/uid/deneme/.e http://www.essay.org/school/english/ofmiceandmen.txt.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 91/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 89
Both the Lazy Turker and the Eager Beaver are looking fora way to clearly signal to the requester that they have com-pleted the work. Without clear guidelines, the Lazy Turker
will choose the path that produces any signal and the EagerBeaver will produce too many signals.
Crowd workers introduce errors. Crowd workers attempt-ing complex tasks can accidentally introduce substantial
new errors. For example, when proofreading paragraphsabout the novel Of Mice and Men, workers variously changedthe title to just Of Mice, replaced existing grammar errors
with new errors of their own, and changed the text to statethat Of Mice and Men is a movie rather than a novel. Sucherrors are compounded if the output of one worker is usedas input for other workers.
The result: Low-quality work. These issues compoundinto what we earlier termed the 30% rule: that roughly one-third of the suggestions we get from workers on MechanicalTurk are not high-enough quality to show an end user. Wecannot simply ask workers to help shorten or proofread a
paragraph: we need to guide and coordinate their activities.These two personas are not particular to MechanicalTurk. Whether we are using intrinsic or extrinsic motiva-tors—money, love, fame, or others—there is almost alwaysan un-even distribution of participation. For example, in
Wikipedia, there are many Eager Beaver editors who try hardto make edits, but they introduce errors along the way andoften have their work reverted.
4.2. The Find-Fix-Verify patternCrowd-powered systems must control the efforts of both theEager Beaver and Lazy Turker and limit the introduction oferrors. Absent suitable control techniques for open-ended
tasks, the rate of problematic edits is too high to be useful. We feel that the state of programming crowds is analogousto that of UI technology before the introduction of designpatterns like Model-View-Controller, which codified bestpractices. In this section, we propose the Find-Fix-Verify pat-tern as one method of programming crowds to reliably com-plete open-ended tasks that directly edit the user’s data. f
We describe the pattern and then explain its use in Soylentacross tasks like proofreading and text shortening.
Find-Fix-Verify description. The Find-Fix-Verify patternseparates open-ended tasks into three stages where workerscan make clear contributions. The workflow is visualized inFigure 5.
Both Shortn and Crowdproof use the Find-Fix-Verify pat-tern. We will use Shortn as an illustrative example in thissection. To provide the user with near-continuous control ofparagraph length, Shortn should produce many alternativerewrites without changing the meaning of the original textor introduceg grammatical errors. We begin by splitting theinput region into paragraphs.
The theme of loneliness features through-
out many scenes in Of Mice and Men and
is often the dominant theme of sections
during this story. This theme occurs dur-
ing many circumstances but is not pres-
ent from start to finish. In my mind for
a theme to be pervasive is must be pres-
ent during every element of the story.There are many themes that are present
most of the way through such as sacri-
fice, friendship and comradeship. But in
my opinion there is only one theme that
is present from beginning to end, this
theme is pursuit of dreams.
However, a Lazy Turker inserted only a single character tocorrect a spelling mistake. The single change is highlightedbelow:
The theme of loneliness featuresthroughout many scenes in Of Mice and
Men and is often the dominant theme of
sections during this story. This theme
occurs during many circumstances but is
not present from start to finish. In my
mind for a theme to be pervasive is must
be present during every element of the
story. There are many themes that are
present most of the way through such
as sacrifice, friendship and comrade-
ship. But in my opinion there is only
one theme that is present from beginning
to end, this theme is pursuit of dreams.
This worker fixed the spelling of the word comradeship,leaving many obvious errors in the text. In fact, it is not sur-prising that the worker chose to make this edit, since it wasthe only word in the paragraph that would have been under-lined in their browser because it was misspelled. A first chal-lenge is thus to discourage workers from exhibiting suchbehavior.
Equally problematic as Lazy Turkers are Eager Beavers.Eager Beavers go beyond the task requirements in order tobe helpful, but create further work for the user in the pro-cess. For example, when asked to reword a phrase, one Eager
Beaver provided a litany of options:
The theme of loneliness features through-
out many scenes in Of Mice and Men and is
often the principal, significant, pri-
mary, preeminent, prevailing, foremost,
essential, crucial, vital, critical theme
of sections during this story.
In their zeal, this worker rendered the resulting sen-tence ungrammatical. Eager Beavers may also leave extracomments in the document or reformat paragraphs. It
would be problematic to funnel such work back to theuser.
f Closed-ended tasks like voting can test against labeled examples for qualitycontrol.10 Open-ended tasks have many possible correct answers, so goldstandard voting is less useful.g Word’s grammar checker, eight authors and six reviewers on the original
Soylent paper did not catch the error in this sentence. Crowdproof later did,and correctly suggested that “introduce” should be “introducing.”

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 92/100
research highlights
90 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
highlight its differences from the original. We use majority voting to remove problematic rewrites and to decide if thepatch can be removed. At the end of the Verify stage, we havea set of candidate patches and a list of verified rewrites foreach patch.
To keep the algorithm responsive, we use a 15-minutetimeout at each stage. If a stage times out, we still wait for
at least six workers in Find, three workers in Fix, and three workers in Verify.
Pattern discussion. Why should tasks be split into indepen-dent Find-Fix-Verify stages? Why not let crowd workers findan error and fix it, for increased efficiency and economy? LazyTurkers will always choose the easiest error to fix, so combin-ing Find and Fix will result in poor coverage. By splitting Findfrom Fix, we can direct Lazy Turkers to propose a fix to patchesthat they might otherwise ignore. Additionally, splitting Findand Fix enables us to merge work completed in parallel. Hadeach worker edited the entire paragraph, we would not know
which edits were trying to fix the same problem. By splitting
Find and Fix, we can map edits to patches and produce amuch richer user interface—for example, the multiple optionsin Crowdproof’s replacement dropdown.
The Verify stage reduces noise in the returned result. Thehigh-level idea here is that we are placing the workers inproductive tension with one another: one set of workers isproposing solutions, and another set is tasked with lookingcritically at those suggestions. Anecdotally, workers are bet-ter at vetting suggestions than they are at producing original
work. Independent agreement among Verify workers canhelp certify an edit as good or bad. Verification trades offtime lag with quality: a user who can tolerate more error butneeds less time lag might opt not to verify work or use fewer
verification workers.Find-Fix-Verify has downsides. One challenge that the Find-
Fix-Verify pattern shares with other Mechanical Turk algo-rithms is that it can stall when workers are slow to accept thetask. Rather than wait for ten workers to complete the Find taskbefore moving on to Fix, a timeout parameter can force ouralgorithm to advance if a minimum threshold of workers havecompleted the work. Find-Fix-Verify also makes it difficult for aparticularly skilled worker to make large changes: decompos-ing the task makes it easier to complete for the average worker,but may be more frustrating for experts in the crowd.
5. IMPLEMENTATION
Soylent consists of a front-end application-level add-in toMicrosoft Word and a back-end service to run MechanicalTurk tasks (Figure 5). The Microsoft Word plug-in is writtenusing Microsoft Visual Studio Tools for Office (VSTO) andthe Windows Presentation Foundation (WPF). Back-endscripts use the TurKit Mechanical Turk toolkit.11
Shortn in particular must choose a set of rewrites whengiven a candidate slider length. When the user specifies adesired maximum length, Shortn searches for the longestcombination of rewrites subject to the length constraint.
A simple implementation would exhaustively list all combi-nations and then cache them, but this approach scales poorly
with many patches. If runtime becomes an issue, we can view the search as a multiple-choice knapsack problem. In a
The first stage, Find, asks several crowd workers to iden-tify patches of the user’s work that need more attention. Forexample, when shortening, the Find stage asks ten workersfor at least one phrase or sentence that needs to be short-ened. Any single worker may produce a noisy result (e.g.,Lazy Turkers might prefer errors near the beginning of a
paragraph). The Find stage aggregates independent opin-ions to find the most consistently cited problems: multipleindependent agreement is typically a strong signal that acrowd is correct. Soylent keeps patches where at least 20%of the workers agree. These are then fed in parallel into theFix stage.
The Fix stage recruits workers to revise each agreed-uponpatch. Each task now consists of a constrained edit to an areaof interest. Workers see the patch highlighted in the para-graph and are asked to fix the problem (e.g., shorten the text).The worker can see the entire paragraph but only edit the sen-tences containing the patch. A small number (3–5) of workerspropose revisions. Even if 30% of work is bad, 3–5 submis-
sions are sufficient to produce viable alternatives. In Shortn, workers also vote on whether the patch can be cut completely.If so, we introduce the empty string as a revision.
The Verify stage performs quality control on revisions. We randomize the order of the unique alternatives gener-ated in the Fix stage and ask 3–5 new workers to vote onthem (Figure 5). We either ask workers to vote on the bestoption (when the interface needs a default choice, likeCrowdproof) or to flag poor suggestions (when the inter-face requires as many options as possible, like Shortn). Toensure that workers cannot vote for their own work, we banall Fix workers from participating in the Verify stage for thatparagraph. To aid comparison, the Mechanical Turk taskannotates each rewrite using color and strikethroughs to
Find“Identify at least one area that can be shortened
without changing the meaning of the paragraph.”
Fix“Edit the highlighted section to shorten its length
without changing the meaning of the paragraph.”
Verify“Choose at least one rewrite that has significant
style errors in it. Choose at least one rewrite that significantly changes the meaning of the sentence.”
Soylent, a prototype...
shorten(text)
return(patches)Soylent is, a prototype...
Soylent is a prototypes...
Soylent is a prototypetest...
is a
prototype
s,
...
est.
Find overlapping areas (patches)
Randomize order of suggestions
Soylent is a prototypecrowdsourced wordprocessing interface. Itfocuses on three maintasks: shortening theuser’s writing,proofreading [...]
Soylent, a prototypecrowdsourced word
processing interface,focuses on threetasks: shorteningthe user’s writing,proofreading [...]
Mechanical TurkMicrosoft WordC# and Visual Studio Tools for Office Javascript, Java and TurKit
Figure 5. Find-Fix-Verify identifies patches in need of editing, recruitscrowd workers to fix the patches, and votes to approve work.
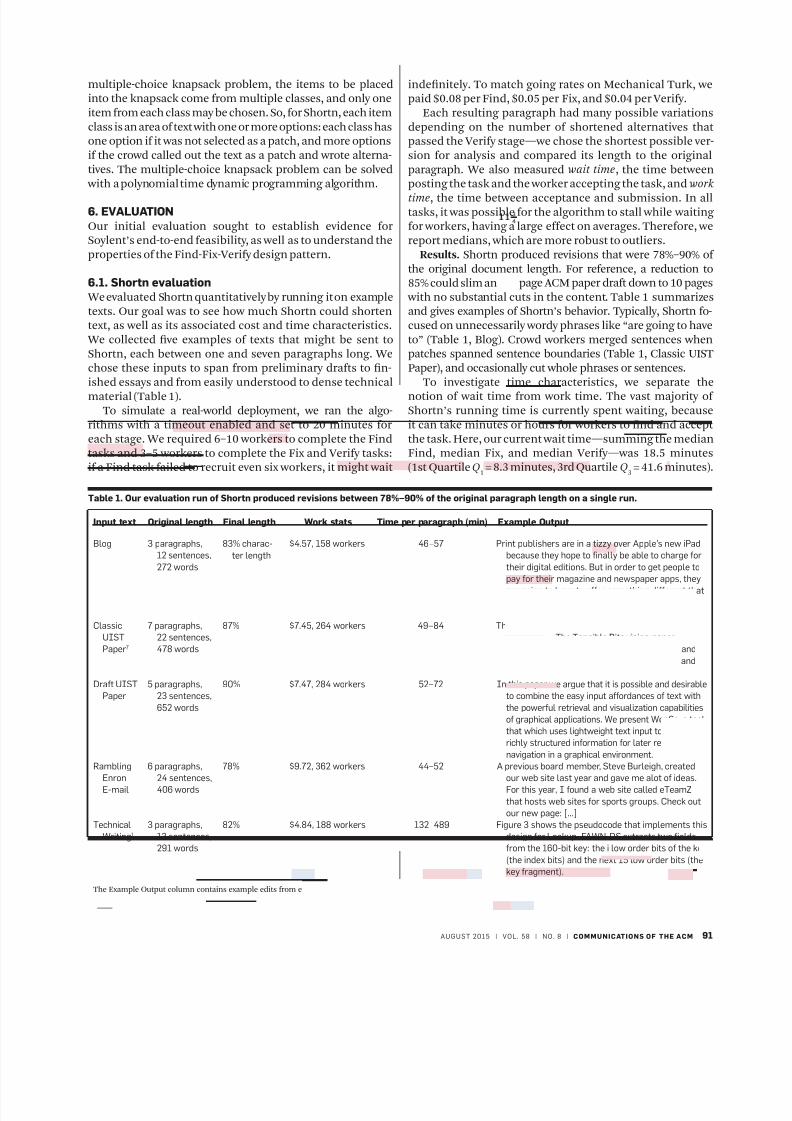
7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 93/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 91
multiple-choice knapsack problem, the items to be placedinto the knapsack come from multiple classes, and only oneitem from each class may be chosen. So, for Shortn, each itemclass is an area of text with one or more options: each class hasone option if it was not selected as a patch, and more optionsif the crowd called out the text as a patch and wrote alterna-tives. The multiple-choice knapsack problem can be solved
with a polynomial time dynamic programming algorithm.
6. EVALUATIONOur initial evaluation sought to establish evidence forSoylent’s end-to-end feasibility, as well as to understand theproperties of the Find-Fix-Verify design pattern.
6.1. Shortn evaluation We evaluated Shortn quantitatively by running it on exampletexts. Our goal was to see how much Shortn could shortentext, as well as its associated cost and time characteristics.
We collected five examples of texts that might be sent to
Shortn, each between one and seven paragraphs long. Wechose these inputs to span from preliminary drafts to fin-ished essays and from easily understood to dense technicalmaterial (Table 1).
To simulate a real-world deployment, we ran the algo-rithms with a timeout enabled and set to 20 minutes foreach stage. We required 6–10 workers to complete the Findtasks and 3–5 workers to complete the Fix and Verify tasks:if a Find task failed to recruit even six workers, it might wait
indefinitely. To match going rates on Mechanical Turk, wepaid $0.08 per Find, $0.05 per Fix, and $0.04 per Verify.
Each resulting paragraph had many possible variationsdepending on the number of shortened alternatives thatpassed the Verify stage—we chose the shortest possible ver-sion for analysis and compared its length to the originalparagraph. We also measured wait time, the time between
posting the task and the worker accepting the task, and worktime, the time between acceptance and submission. In alltasks, it was possible for the algorithm to stall while waitingfor workers, having a large effect on averages. Therefore, wereport medians, which are more robust to outliers.
Results. Shortn produced revisions that were 78%–90% ofthe original document length. For reference, a reduction to85% could slim an page ACM paper draft down to 10 pages
with no substantial cuts in the content. Table 1 summarizesand gives examples of Shortn’s behavior. Typically, Shortn fo-cused on unnecessarily wordy phrases like “are going to haveto” (Table 1, Blog). Crowd workers merged sentences when
patches spanned sentence boundaries (Table 1, Classic UISTPaper), and occasionally cut whole phrases or sentences.To investigate time characteristics, we separate the
notion of wait time from work time. The vast majority ofShortn’s running time is currently spent waiting, becauseit can take minutes or hours for workers to find and acceptthe task. Here, our current wait time—summing the medianFind, median Fix, and median Verify—was 18.5 minutes(1st Quartile Q
1 = 8.3 minutes, 3rd Quartile Q
3 = 41.6 minutes).
Table 1. Our evaluation run of Shortn produced revisions between 78%–90% of the original paragraph length on a single run.
Input text Original length Final length Work stats Time per paragraph (min) Example Output
Blog 3 paragraphs,12 sentences,
272 words
83% charac-ter length
$4.57, 158 workers 46–57 Print publishers are in a tizzy over Apple’s new iPadbecause they hope to finally be able to charge for
their digital editions. But in order to get people to
pay for their magazine and newspaper apps, they
are going to have to offer something different that
readers cannot get at the newsstand or on the
open Web.
Classic
UIST
Paper7
7 paragraphs,
22 sentences,
478 words
87% $7.45, 264 workers 49–84 The metaDESK effort is part of the larger Tangible
Bits project. The Tangible Bits vision paper,
which introduced the metaDESK along with and
two companion platforms, the transBOARD and
ambient ROOM.
Draft UIST
Paper
5 paragraphs,
23 sentences,
652 words
90% $7.47, 284 workers 52–72 In this paper we argue that it is possible and desirable
to combine the easy input affordances of text with
the powerful retrieval and visualization capabilities
of graphical applications. We present WenSo, a toolthat which uses lightweight text input to capture
richly structured information for later retrieval and
navigation in a graphical environment.
Rambling
Enron
6 paragraphs,
24 sentences,
406 words
78% $9.72, 362 workers 44–52 A previous board member, Steve Burleigh, created
our web site last year and gave me alot of ideas.
For this year, I found a web site called eTeamZ
that hosts web sites for sports groups. Check out
our new page: […]
Technical
Writing1
3 paragraphs,
13 sentences,
291 words
82% $4.84, 188 workers 132–489 Figure 3 shows the pseudocode that implements this
design for Lookup. FAWN-DS extracts two fields
from the 160-bit key: the i low order bits of the key
(the index bits) and the next 15 low order bits (the
key fragment).
The Example Output column contains example edits from each input.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 94/100
research highlights
92 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
70%–80% with each iteration. We ceased after 3 iterations,having shortened the text to less than 50% length withoutsacrificing much by way of readability or major content.
6.2. Crowdproof evaluationTo evaluate Crowdproof, we obtained a set of five input textsin need of proofreading. These inputs were error-ridden
text that passes Word’s grammar checker, text written byan ESL student, quick notes from a presentation, a poorly
written Wikipedia article (Dandu Monara), and a draft UISTpaper. We manually labeled all spelling, grammatical andstyle errors in each of the five inputs, identifying a total of49 errors. We then ran Crowdproof on the inputs using a20-minute stage timeout, with prices $0.06 for Find, $0.08for Fix, and $0.04 for Verify. We measured the errors thatCrowdproof caught, that Crowdproof fixed, and that Wordcaught. We ruled that Crowdproof had caught an error if oneof the identified patches contained the error.
Results. Soylent’s proofreading algorithm caught 33 of the
49 errors (67%). For comparison, Microsoft Word’s grammarchecker found 15 errors (30%). Combined, Word and Soylentflagged 40 errors (82%). Word and Soylent tended to identifydifferent errors, rather than both focusing on the easy andobvious mistakes. This result lends more support to Crowd-proof’s approach: it can focus on errors that automaticproofreaders have not already identified.
Crowdproof was effective at fixing errors that it found.Using the Verify stage to choose the best textual replace-ment, Soylent fixed 29 of the 33 errors it flagged (88%). Toinvestigate the impact of the Verify stage, we labeled eachunique correction that workers suggested as grammatical ornot. Fully 28 of 62 suggestions, or 45%, were ungrammati-
cal. The fact that such noisy suggestions produced correctreplacements again suggests that workers are much betterat verification than they are at authoring.
Crowdproof’s most common problem was missing aminor error that was in the same patch as a more egregiouserror. The four errors that Crowdproof failed to fix were allcontained in patches with at least one other error; LazyTurkers fixed only the most noticeable problem. A secondproblem was a lack of domain knowledge: in the ESL input,
workers did not know what a GUI was, so they could not knowthat the author intended “GUIs” instead of “GUI.” There werealso stylistic opinions that the original author might not haveagreed with: in the Draft UIST input, the author had a pen-
chant for triple dashes that the workers did not appreciate.Crowdproof shared many running time characteristics
with Shortn. Its median work time was 2.8 minutes (Q1 = 1.7 min-
utes, Q3 = 4.7 minutes), so it completes in very little work time.
Similarly to Shortn, its wait time was 18 minutes (Median = 17.6,Q
1 = 9.8, Q
3 = 30.8). It cost more money to run per paragraph
(m = $3.40, s = $2.13) because it identified far more patches perparagraph: we chose paragraphs in dire need of proofreading.
6.3. Human macro evaluation We were interested in understanding whether end userscould instruct Mechanical Turk workers to perform open-ended tasks. Can users communicate their intention clearly?Can workers execute the amateur-authored tasks correctly?
This wait time can be much longer because tasks can stall waiting for workers, as Table 1 shows.
Considering only work time and assuming negligible waittime, Shortn produced cuts within minutes. We again esti-mate overall work time by examining the median amount oftime a worker spent in each stage of the Find-Fix-Verify pro-cess. This process reveals that the median shortening took
118 seconds of work time, or just under 2 minutes, whensummed across all three stages (Q
1 = 60 seconds, Q
3 = 3.6
minutes). Using recruitment techniques developed sincethis research was published, users may see shortening tasksapproaching a limit of 2 minutes.
The average paragraph cost $1.41 to shorten under ourpay model. This cost split into $0.55 to identify an average oftwo patches, then $0.48 to generate alternatives and $0.38 tofilter results for each of those patches. Our experience is thatpaying less slows down the later parts of the process, but itdoes not impact quality 13—it would be viable for shorteningparagraphs under a loose deadline.
Qualitatively, Shortn was most successful when the inputhad unnecessary text. For example, with the Blog input, Shortn was able to remove several words and phrases without chang-ing the meaning of the sentence. Workers were able to blendthese cuts into the sentence easily. Even the most technicalinput texts had extraneous phrases, so Shortn was usually ableto make at least one small edit of this nature in each paragraph.
As Soylent runs, it can collect a large database of these straight-forward rewrites, then use them to train a machine learningalgorithm to suggest some shortenings automatically.
Shortn occasionally introduced errors into the paragraph. While workers tended to stay away from cutting material theydid not understand, they still occasionally flagged such patches.
As a result, workers sometimes made edits that were grammati-cally appropriate but stylistically incorrect. For example, it maybe inappropriate to remove the academic signaling phrase “Inthis paper we argue that. . .” from an introduction. Cuts werea second source of error: workers in the Fix stage would votethat a patch could be removed entirely from the sentence, but
were not given the chance to massage the effect of the cut intothe sentence. So, cuts often led to capitalization and punctua-tion problems at sentence boundaries. Modern auto-correctiontechniques could catch many of these errors. Parallelism wasanother source of error: for example, in Technical Writing(Table 1), the two cuts were from two different patches, andthus handled by separate workers. These workers could not
predict that their cuts would not match, one cutting the par-enthetical and the other cutting the main phrase.
To investigate the extent of these issues, we coded all 126shortening suggestions as to whether they led to a grammaticalerror. Of these suggestions, 37 suggestions were ungrammatical,again supporting our rule of thumb that 30% of raw worker edits
will be noisy. The Verify step caught 19 of the errors (50% of 37) while also removing 15 grammatical sentences. Its error rate wasthus (18 false negatives + 15 false positives)/137 = 26.1%, againnear 30%. Microsoft Word’s grammar checker caught 13 of theerrors. Combining Word and Shortn caught 24 of the 37 errors.
We experimented with feeding the shortest output fromthe Blog text back into the algorithm to see if it could con-tinue shortening. It continued to produce cuts between

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 95/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 93
Method. We generated five feasible Human Macro scenar-ios. These scenarios included changing the tense of a storyfrom past tense to present tense, finding a Creative Commons-licensed image to illustrate a paragraph, giving feedback ona draft blog post, gathering BibTeX for some citations, andfilling out mailing addresses in a list. We recruited two sets ofusers: five undergraduate and graduate students in our com-
puter science department (4 males) and five administrativeassociates in our department (all females). We showed eachuser one of the five prompts, consisting of an example inputand output pair. We purposefully did not describe the taskto the participants so that we would not influence how they
wrote their task descriptions. We then introduced partici-pants to The Human Macro and described what it would do.
We asked them to write a task description for their promptusing The Human Macro. We then sent the description toMechanical Turk and requested that five workers completeeach request. In addition to the ten requests generated byour participants, one author generated five requests himself
to simulate a user who is familiar with Mechanical Turk. We coded results using two quality metrics: intention(did the worker understand the prompt and make a goodfaith effort?) and accuracy (was the result flawless?). If the
worker completed the task but made a small error, the result was coded as good intention and poor accuracy.
Results. Users were generally successful at communicatingtheir intention. The average command saw an 88% intentionsuccess rate (max = 100%, min = 60%). Typical intention errorsoccurred when the prompt contained two requirements: forexample, the Figure task asked both for an image and proofthat the image is Creative Commons-licensed. Workers readfar enough to understand that they needed to find a picture,
found one, and left. Successful users clearly signaled Cre-ative Commons status in the title field of their request.
With accuracy, we again see that roughly 30% of workcontained an error. (The average accuracy was 70.8%.)
Workers commonly got the task mostly correct, but failedon some detail. For example, in the Tense task, some work-ers changed all but one of the verbs to present tense, andin the List Processing task, sometimes a field would not becorrectly capitalized or an Eager Beaver would add too muchextra information. These kinds of errors would be danger-ous to expose to the user, because the user might likewisenot realize that there is a small error in the work.
7. DISCUSSIONThis section reviews some fundamental questions about thenature of paid, crowd-powered interfaces as embodied in Soylent.Our work suggests that it may be possible to transition froman era where Wizard of Oz techniques were used only as prototyp-ing tools to an era where a “Wizard of Turk” can be permanently
wired into a system. We touch on resulting issues of waittime, cost, legal ownership, privacy, and domain knowledge.
In our vision of interface outsourcing, authors haveimmediate access to a pool of human expertise. Lag times inour current implementation are still on the order of minutesto hours, due to worker demographics, worker availability,the relative attractiveness of our tasks, and so on. Whilefuture growth in crowdsourced work will likely shorten lag
times, this is an important avenue of future work. It may bepossible to explicitly engineer for responsiveness in returnfor higher monetary investment, or to keep workers around
with other tasks until needed.2
With respect to cost, Soylent requires that authors pay all workers for document editing—even if many changes never findtheir way into the final work product. One might therefore argue
that interface outsourcing is too expensive to be practical. Wecounter that in fact all current document processing tasks alsoincur significant cost (in terms of computing infrastructure,time, software and salaries); the only difference is that interfaceoutsourcing precisely quantifies the price of each small unit of
work. While payment-per-edit may restrict deployment to com-mercial contexts, it remains an open question whether the gainsin productivity for the author are justified by the expense.
Regarding privacy, Soylent exposes the author’s docu-ment to third party workers without knowing the workers’identities. Authors and their employers may not want suchexposure if the document’s content is confidential or other-
wise sensitive. One solution is to restrict the set of workersthat can perform tasks: for example, large companies couldmaintain internal worker pools. Rather than a binary oppo-sition, a continuum of privacy and exposure options exists.
Soylent also raises questions over legal ownership of the result-ing text, which is part-user and part-Turker generated. Do theTurkers who participate in Find-Fix-Verify gain any legal rightsto the document? We believe not: the Mechanical Turk workercontract explicitly states that it is work-for-hire, so results belongto the requester. Likewise with historical precedent: traditionalcopyeditors do not own their edits to an article. However, crowd-sourced interfaces will need to consider legal questions carefully.
It is important that the research community ask how
crowd-sourcing can be a social good, rather than a tool thatreinforces inequality. Crowdsourcing is a sort of renewal ofscientific management. Taylorism had positive impacts onoptimizing workflows, but it was also associated with thedehumanizing elements of factory work and the industrialrevolution. Similarly, naive crowdsourcing might treat peo-ple as a new kind of abstracted API call, ignoring the essen-tial humanness of these sociotechnical systems. Instead, weneed to evolve our design process for crowdsourcing systemsto involve the crowds workers’ perspective directly.
8. CONCLUSIONThe following conclusion was Shortn’ed to 85% length: This
chapter presents Soylent, a word processing interface that usescrowd workers to help with proofreading, document shorten-ing, editing and commenting tasks. Soylent is an exampleof a new kind of interactive user interface in which the enduser has direct access to a crowd of workers for assistance
with tasks that require human attention and common sense.Implementing these kinds of interfaces requires new softwareprogramming patterns for interface software, since crowdsbehave differently than computer systems. We have introducedone important pattern, Find-Fix-Verify, which splits complexediting tasks into a series of identification, generation, and
verification stages that use independent agreement and voting produce reliable results. We evaluated Soylent with arange of editing tasks, finding and correcting 82% of grammar

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 96/100
research highlights
94 COMMUNICATIONS OF THE ACM | AUGUST 2015 | VOL. 58 | NO. 8
Michael S. Bernstein ([email protected]) Stanford University, Stanford, CA.
Björn Hartmann ([email protected]) Computer Science Division Universityof California, Berkeley, CA.
Greg Little ([email protected])
Mark S. Ackerman ([email protected]) Computer Science & EngineeringUniversity of Michigan, Ann Arbor, MI.
Robert C. Miller ([email protected]) MITCSAIL, Cambridge, MA.
David R. Karger ([email protected]) MITCSAIL, Cambridge, MA.
David Crowell ([email protected])
Katrina Panovich ([email protected]), Google, Inc., Mountain View, CA.
errors when combined with automatic checking, shorteningtext to approximately 85% of original length per iteration, andexecuting a variety of human macros successfully.
Future work falls in three categories. First are new crowd-driven features for word processing, such as readability analy-sis, smart find-and-replace (so that renaming “Michael” to“Michelle” also changes “he” to “she”) and figure or citation
number checking. Second are new techniques for optimizingcrowd-programmed algorithms to reduce wait time and cost.Finally, we believe that our research points the way towardintegrating on-demand crowd work into other authoringinterfaces, particularly in creative domains like image editingand programming.
References 1. Andersen, D.G., Franklin, J., Kaminsky, M.,
Phanishayee, A., Tan, L., Vasudevan, V.FAWN: A fast array of wimpy nodes. InProc. SOSP ‘09 (2009).
2. Bigham, J.P., Jayant, C., Ji, H.,Little, G., Miller, A., Miller, R.C., Miller,R., Tatrowicz, A., White, B., White, S.,Yeh, T. VizWiz: Nearly real-timeanswers to visual questions. InProc. UIST ‘10 (2010).
3. Clarke, J., Lapata, M. Modelsfor sentence compression:A comparison across domains,training requirements and evaluationmeasures. In Proc. ACL ‘06 (2006).
4. Cypher, A. Watch What I Do. MITPress, Cambridge, MA, 1993.
5. Dourish, P., Bellotti, V. Awareness andcoordination in shared workspaces.In Proc. CSCW ‘92 (1992).
6. Heer, J., Bostock, M. Crowdsourcinggraphical perception: Using Mechanical
Turk to assess visualization design.In Proc. CHI ‘10 (2010).
7. Ishii, H., Ullmer, B. Tangible bits:Towards seamless interfaces betweenpeople, bits and atoms. In Proc. UIST‘97 (1997).
8. Kittur, A., Chi, E.H., Suh, B. Crowd-sourcing user studies with MechanicalTurk. In Proc. CHI ‘08 (2008).
9. Kukich, K. Techniques for automaticallycorrecting words in text. ACM Comput.Surv. (CSUR) 24, 4 (1992), 377–439.
10. Le, J., Edmonds, A., Hester, V.,Biewald, L. Ensuring quality incrowdsourced search relevanceevaluation: The effects oftraining question distribution.In Proc. SIGIR 2010 Workshopon Crowdsourcing for SearchEvaluation (2010), 21–26.
11. Little, G., Chilton, L., Goldman, M.,Miller, R.C. TurKit: Humancomputation algorithms on
Mechanical Turk. In Proc. UIST ‘10 (2010) ACM Press.
12. Marcu, D. The Theory andPractice of Discourse Parsingand Summarization. MIT Press,Cambridge, MA, 2000.
13. Mason, W., Watts, D.J. Financialincentives and the performance ofcrowds. In Proc. HCOMP ‘09 (2009)ACM Press.
14. Quinn, A.J., Bederson, B.B. Humancomputation: A survey and taxonomyof a growing field. In Proc. CHI ‘11 (2011) ACM.
15. Ross, J., Irani, L., Silberman, M.S.,Zaldivar, A., Tomlinson, B. Whoare the crowdworkers? Shiftingdemographics in Amazon MechanicalTurk. In alt.chi ‘10 (2010) ACM Press.
16. Sala, M., Partridge, K., Jacobson, L.,Begole, J. An exploration intoactivity-informed physicaladvertising using PEST. In Pervasive‘07 , volume 4480 of Lecture Notesin Computer Science (Berlin,Heidelberg, 2007), Springer, Berlin,Heidelberg.
17. Snow, R., O’Connor, B., Jurafsky, D.,Ng, A.Y. Cheap and fast—But is
it good? Evaluating non-expertannotations for natural languagetasks. In Proc. ACL ‘08 (2008).
18. Sorokin, A., Forsyth, D. Utility dataannotation with Amazon MechanicalTurk. Proc. CVPR ‘08 (2008).
19. von Ahn, L., Dabbish, L. Labelingimages with a computer game.In CHI ‘04 (2004).
© 2015 ACM 0001-0782/15/08 $15.00
Watch the authors discusstheir work in this exclusiveCommunications video.http://cacm.acm.org/videos/soylent-a-word-processor-with-a-crowd-inside
ACM Transactionson Interactive
Intelligent Systems
ACM Transactions on InteractiveIntelligent Systems (TIIS). Thisquarterly journal publishes paperson research encompassing thedesign, realization, or evaluation ofinteractive systems incorporatingsome form of machine intelligence.
World-Renowned Journals from ACM ACM publishes over 50 magazines and journals that cover an array of established as well as emerging areas of the computing field.
IT professionals worldwide depend on ACM's publications to keep them abreast of the latest technological developments and industry
news in a timely, comprehensive manner of the highest quality and integrity. For a complete listing of ACM's leading magazines & journals,
including our renowned Transaction Series, please visit the ACM publications homepage: www.acm.org/pubs.
PLEASE CONTACT ACM MEMBER
SERVICES TO PLACE AN ORDER
Phone: 1.800.342.6626 (U.S. and Canada)
+1.212.626.0500 (Global)
Fax: +1.212.944.1318
(Hours: 8:30am–4:30pm, Eastern Time)Email: [email protected]
Mail: ACM Member Services
General Post Offi ce
PO Box 30777
New York, NY 10087-0777 USA
ACM Transactions on ComputationTheory (ToCT). This quarterly peer-reviewed journal has an emphasison computational complexity, foun-dations of cryptography and othercomputation-based topics in theo-retical computer science.
ACM Transactionson Computation
Theory
www.acm.org/pubs

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 97/100
AUGUST 2015 | VOL. 58 | NO. 8 | COMMUNICATIONS OF THE ACM 95
CAREERS
Boise State UniversityDepartment of Computer Science
Eight Open Rank, Tenured/Tenure-Track
Faculty Positions
The Department of Computer Science at Boise
State University invites applications for eight
open rank, tenured/tenure-track faculty posi-
tions. Seeking applicants in the areas of big data
(including distributed systems, HPC, machine
learning, visualization), cybersecurity, human
computer interaction and computer science edu-
cation research. Strong applicants from other ar-
eas of computer science will also be considered.
Applicants should have a commitment to
excellence in teaching, a desire to make signifi-
cant contributions in research, and experience
in collaborating with faculty and local industry to
develop and sustain funded research programs. A PhD in Computer Science or a closely related
field is required by the date of hire. For additional
information, please visit http://coen.boisestate.
edu/cs/jobs.
California State University, East Bay(Hayward, CA)Department of Computer Science
Faculty Position in Computer Science
2 POSITIONS (OAA Position No 15-16 CS-DATA/
CLOUD/CORE-TT ) The Department invites appli-
cations for 2 tenure-track appointments as Assis-
tant Professor in Computer Science (considering
all areas of computer science, capable of teaching
in emerging areas) starting Fall 2016. For details
see http://www20.csueastbay.edu/about/career-
opportunities/. For questions, email: cssearch@
mcs.csueastbay.edu.
ENDOWED CHAIR IN
COMPUTER SYSTEMS
The Department of Computer Science at the University of British Columbia (UBC) Vancouver Campus, is seeking candidateswith exceptional scientific records in the area of Computer Systems, broadly defined, for a fully endowed chair at the rankof tenured Professor, made possible by a generous donation to the department by David Cheriton, a distinguished StanfordProfessor and UBC alumnus. UBC Computer Science (www.cs.ubc.ca ) ranks among the top departments in North America,with 54 tenure-track faculty, 200 graduate students, and 1500 undergraduates.
The successful candidate must demonstrate sustained research and teaching excellence judged by the followingkey factors: i) publication record in the highest caliber international computer science systems, networking, operatingsystems, distributed systems, and security conferences and journals; ii) impact on the field and/or industry resulting fromhis or her publications, or resulting from other research artifacts such as software; iii) successful mentorship of graduatestudents, and collaboration with other researchers in the field; iv) teaching of both undergraduate and graduate courses anddepartment service; and v) external funding and leadership within his or her research community. Preference will be given tocandidates that have built or contributed to the building of real software systems of note. Outstanding industrial researchersare also encouraged to apply—all evidence of a candidate’s public speaking, teaching and mentoring effectiveness, suchas in seminars, tutorials, or student project supervision, will be considered. The potential of an applicant’s research programto complement and extend existing research strengths of the department and the University will be an important factor inselection. The anticipated start date is July 1, 2016.
Applicants must submit a CV, a research statement, a teaching statement, and the names of at least four references.
The teaching statement should include a record of teaching interests and experience. Applications may be submitted onlineat https://apps.cs.ubc.ca/fac-recruit/systems/apply/form.jsp.The website will remain open for submissions through the end of the day on September 1st, 2015. The website may
remain open past that date at the discretion of the recruiting committee. All applications submitted while the websiteremains open will be considered.
UBC hires on the basis of merit and is strongly committed to equity and diversity within its community. We especiallywelcome applications from members of visible minority groups, women, Aboriginal persons, persons with disabilities,persons of minority sexual orientations and gender identities, and others with the skills and knowledge to engageproductively with diverse communities. All qualified candidates are encouraged to apply; however, Canadian citizens andpermanent residents will be given priority.
If you have questions about the application process, please contact the Chair of the Systems Recruiting Subcommitteeby email at [email protected]
Norm HutchinsonChair, Systems Recruiting Subcommittee
Department of Computer ScienceUniversity of British Columbia
Vancouver BC V6T 1Z4Canada
Please do not email applications. Apply online via: https://apps.cs.ubc.ca/fac-recruit/systems/apply/form.jsp
TENURE-TRACK AND TENURED FACULTY POSITIONS IN
INFORMATION SCIENCE AND TECHNOLOGY
The newly launched ShanghaiTech University invites talented faculty candidatesto fill multiple tenure-track/tenured positions as its core founding team in the Schoolof Information Science and Technology (SIST). Candidates should have outstandingacademic records or demonstrate strong potential in cutting-edge research areas
of information science and technology. They must be fluent in English. Overseasacademic training is highly desired. Besides establishing and maintaining aworld-class research profile, faculty candidates are also expected to contributesubstantially to graduate and undergraduate education within the school.
ShanghaiTech is matching towards a world-class research university as a hub fortraining future generations of scientists, entrepreneurs, and technological leaders.Located in a brand new campus in Zhangjiang High-Tech Park of the cosmopolitanShanghai, ShanghaiTech is at the forefront of modern education reform in China.
Academic Disciplines: We seek candidates in all cutting edge areas ofinformation science and technology that include, but not limited to: computerarchitecture and technologies, micro-electronics, high speed and RF circuits,intelligent and integrated information processing systems, computations,foundation and applications of big data, visualization, computer vision, bio-computing, smart energy/power devices and systems, next-generation networking,statistical analysis as well as inter-disciplinary areas involving information scienceand technology.
Compensation and Benefits: Salary and startup funds are internationallycompetitive, commensurate with experience and academic accomplishment. Wealso offer a comprehensive benefit package to employees and eligible dependents,including housing benefits. All regular faculty members will be within tenure-tracksystem commensurate with international practice for performance evaluation andpromotion.
Qualifications:
• Ph.D. (Electrical Engineering, Computer Engineering, Computer Science, orrelated field)
• A minimum relevant research experience of 4 years.
Applications: Submit (in English, PDF version) a cover letter, a 2-3 page detailedresearch plan, a CV with demonstrated strong record/potentials; plus copies of 3most significant publications, and names of three referees to: [email protected]. For more information, visit http://www.shanghaitech.edu.cn .
Deadline: August 31, 2015 (or unt il positions are filled).
ADVERTISING INCAREER OPPORTUNITIES
How to Submit a Classified Line Ad: Send an e-mailto [email protected]. Please include text,and indicate the issue/or issues where the ad willappear, and a contact name and number.
Estimates: An insertion order will then bee-mailed back to you. The ad will by typesetaccording to CACM guidelines. NO PROOFS can besent. Classified line ads are NOT commissionable.
Rates: $325.00 for six lines of text, 40 charactersper line. $32.50 for each additional line after thefirst six. The MINIMUM is six lines.
Deadlines: 20th of the month/2 months priorto issue date. For latest deadline info, pleasecontact: [email protected]
Career Opportunities Online: Classified andrecruitment display ads receive a free duplicatelisting on our website at: http://jobs.acm.org
Ads are listed for a period of 30 days.
For More Information Contact:ACM Media Sales
at 212-626-0686 or

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 98/100
96 COMMUNICATIONS OF T HE ACM | AUGUST 2015 | VOL. 58 | NO. 8
ast byte
C O L L A G E
B Y
A N D
R I J
B O R Y
S A S S O C I
A T E
S / S H U T T E
R S T
O C K
DOI:10.1145/2791401 Dennis Shasha
Upstart PuzzlesBrighten Up
2. Now imagine you want to take NumBad flares (not just NumBad -1)on your trip with the guarantee all aregood. Which strategy would give youthe best chance of achieving this? Forthis challenge, the number of flares
you use up in testing is unimportant.Upstart 2. Given NumPerBag and
NumBad , suppose you want to take d more than NumBad with the guaranteeall are good. What is the best strategy
to use (it may be a hybrid), and whatprobability of success as a function ofd can you achieve?
Solution to 1, or taking NumBad – 1good flares on the trip. Unbalanced,because it will use up 1 + NumPerBag –
NumBad flares in the worst case, where-as balanced may use up 1 + 2*( NumPer-
Bag – NumBad ) in the worst case.Solution to 2, or taking NumBad good
flares on the trip. With the unbalancedstrategy, if you are lucky enough to starttesting flares with the bad bag, you will
be able to take NumBad good flares forsure. If you start testing flares with thegood bag, then you will test 1 + NumPer-
Bag – NumBad flares from that good bag,leaving you NumBad – 1 good flares. But
you can get one more good flare fromthe bad bag by testing flares from thatbag until you discover all NumBad flaresand seeing whether you have any moreflares left in that bag. With the balancedstrategy, if you discover no bad flare bythe time both bags have NumBad flaresleft and the next flare tested is also good,
then the strategy fails to deliver NumBad flares that are all good. However, thatis the only case in which the balancedstrategy loses. Balanced is thus better.
All are invited to submit their solutions [email protected];solutions to upstartsand discussion will be posted at http://cs.nyu.edu/cs/faculty/shasha/papers/cacmpuzzles.html
Dennis Shasha ([email protected]) is aprofessor of computer science in the Computer ScienceDepartment of the Courant Institute at New YorkUniversity, New York, as well as the chronicler of his goodfriend the omniheurist Dr. Ecco.
Copyright held by author.Publication rights licensed to ACM $15.00
Balanced. Take a flare from the firstbag and test it, then one from the otherbag and test it, and continue alternat-ing until you find a bad one or youreach NumBad -1 in one of the bags, in
which case you know the remainingones in that bag are good; andUnbalanced. Keep taking one flare
from a single bag and testing it until you find a bad one or reach NumBad -1in that bag.
Which strategy uses up fewer flaresin the worst case?
The average case is worthy of an up-start challenge:
Upstart 1. Assuming NumBad = 3, arethere values of NumPerBag for whichthe balanced strategy uses up fewer
flares than the unbalanced strategy onaverage, assuming no particular order-ing of the flares in either bag? And vice
versa. Is there some mixed strategy thatis better than either one alone?
YO U AR E GI V EN two bags, each contain-ing some number NumPerBag of flares.You know there are NumBad flares inone of the bags but not which bag. Theother bag has all good flares. Each time
you test a flare, you use it up.Here is the first challenge: You wantto take NumBad -1 flares with you and
want to know all are good. Further, you want to use up as few flares as possiblein the process. It is fine that when youare done, you may not know which of theunused flares you leave behind are good.
Warm-up. If all the flares in the badbag are indeed bad, then how manyflares would you need to test?
Solution to this warm-up. Test justone flare in one bag. After that you
would have at least NumPerBag -1 = NumBad -1 good flares to take from thebag you know has only good flares.
For general values of NumPerBag and NumBad , consider two strategies:
Contemplating two bagscontaining flares, only one ofwhich with bad flares; the goalis to take only good flares,which could come from one orfrom both bags, on a trip.

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 99/100

7/23/2019 Communications of the ACM - August 2015
http://slidepdf.com/reader/full/communications-of-the-acm-august-2015 100/100
Where every discipline in the computer graphics and interactive techniques
community weaves together a story of personal growth and powerful creation. Discover unique
SIGGRAPH stories using the Aurasma app, then come to SIGGRAPH and build your own.
Discover Your Story
[ DOWNLOAD AURASMA FROM YOUR APP STORE AND SCAN IMAGE ABOVE ]