Embed Size (px)
Citation preview

Competitive learningCollege voor cursus Connectionistische modellen
M Meeter

2
Unsupervised learning
To-be-learned patterns not wholly provided by modeller
Hebbian unsupervised learning
Competitive learning

3
The basic idea
© Rumelhart & Zipser, 1986

4
What’s it good for?
discovering structure in the input
discovering categories in the input Classification networks:
ART (Grossberg & Carpenter)
CALM (Murre & Phaf)
mapping inputs onto a topographic map Kohonen maps (Kohonen) CALM - Maps (Murre & Phaf)

5
Features of Competitive learning Two or more layers (no auto-association)
Competition between output nodes
Two phases: determining a winner learning
Weight normalisation

6
Two or more layers
Input must come from outside the inhibitory clusters
© Rumelhart & Zipser, 1986
7
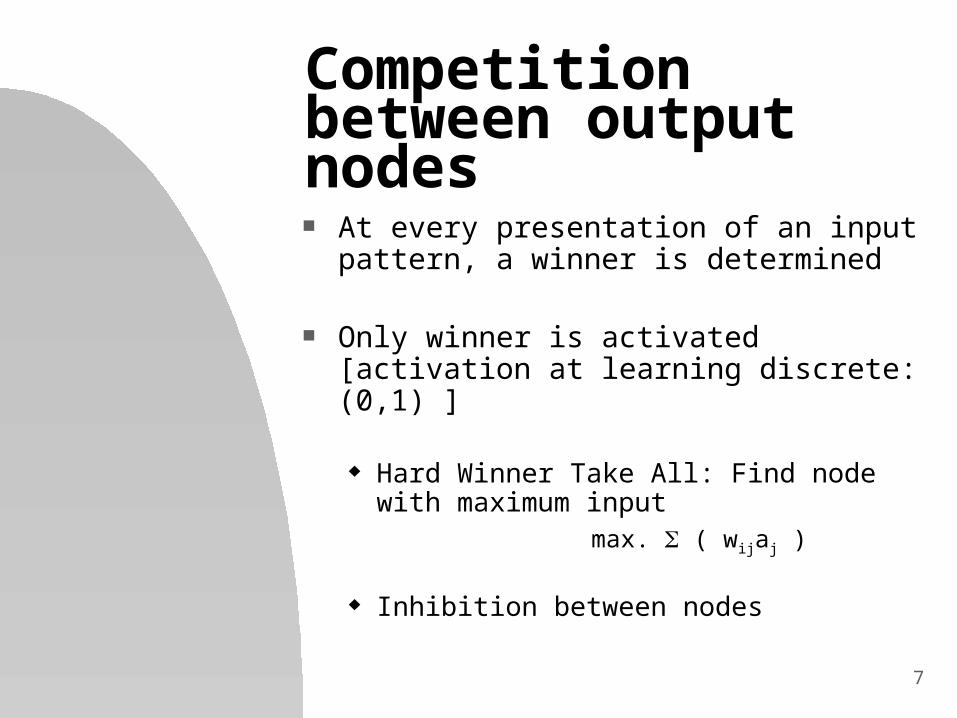
Competition between output nodes At every presentation of an input pattern,
a winner is determined
Only winner is activated [activation at learning discrete: (0,1) ]
Hard Winner Take All: Find node with maximum input
max. ( wijaj )
Inhibition between nodes

8
Inhibition between nodes
Example: inhibition in CALM
V V
R
V
RR
A
E
Low
HighFlat
Strange
AE
Up Gaussian
Learning intermodular connections

9
Two phases
1. One node wins the competition
2. That node learns, others not
Nodes start off with random weights
No ‘correct’ output connected with inputs: unsupervised learning

10
Weight normalisation
Weights of winner node i changed wij = * aj
Weights add up to constant sum... wij = 1
rule of Rumelhart & Zipser:wij = g * ai / nk - g * wij
…or constant distance: (wij)
2 = 1

11
Geometric interpretation
Both weights & input patterns can be seen as vectors in a hyper space
Euclidian normalisation [ (wij)2 = 1]
all vectors on a sphere in space of n dimensions (n = number of inputs)
node with weight vector closest to input vector is winner
Linear normalisation [ wij = 1] all weights on a plane

12
Geometric interpretation II
Weight vectors move towards input in the hyper space
wij= g * ai/nk - g * wij
Output nodes move towards clusters in inputs
© Rumelhart & Zipser, 1986

13
Stable / unstable
Output nodes move towards clusters in inputs
If input not clustered...
...output nodes will continue moving through input space! © Rumelhart & Zipser, 1986

14
Statistical equivalents
Sarle (1994):Classification = k-means clustering
Kohonen = mapping continuous dimensions onto discrete ones
Statistical techniques usually more efficient...
...because statistical techniques use whole data set

15
Importance of competitive learning Supervised - unsupervised learning
Structure input sets not always given
Natural categories

16
Competitive learning in the brain Lateral inhibition feature of most parts of
the brain
… Implements winner-take-all ?

17
Part II

18
Map formation in the brain
Topographic maps omnipresent in the sensory regions of the brain
retinotopic maps: neurons ordered as the locations of their visual field on the retina
tonotopic maps: neurons ordered according to tone for which they are sensitive
maps in somatosensory cortex: neurons ordered according to body part for which they are sensitive
maps in motor cortex: neurons ordered according to muscles they control

19
Somatosensory maps
© Kandel, Schwartz & Jessell, 1991

20
Somatosensory maps II
© Kandel, Schwartz & Jessell, 1991
21
Speculations
Map formation ubiquitous (also semantic maps?)
How do maps form? gradients in neurotransmitters pruning
22
Kohonen maps
Teuvo Kohonen first to show how maps can develop
Self Organising Maps (S.O.M.)
Demonstration: the ordering of colours (colours are vectors in a 3-dimensional space of brightness, hue, saturation).

23
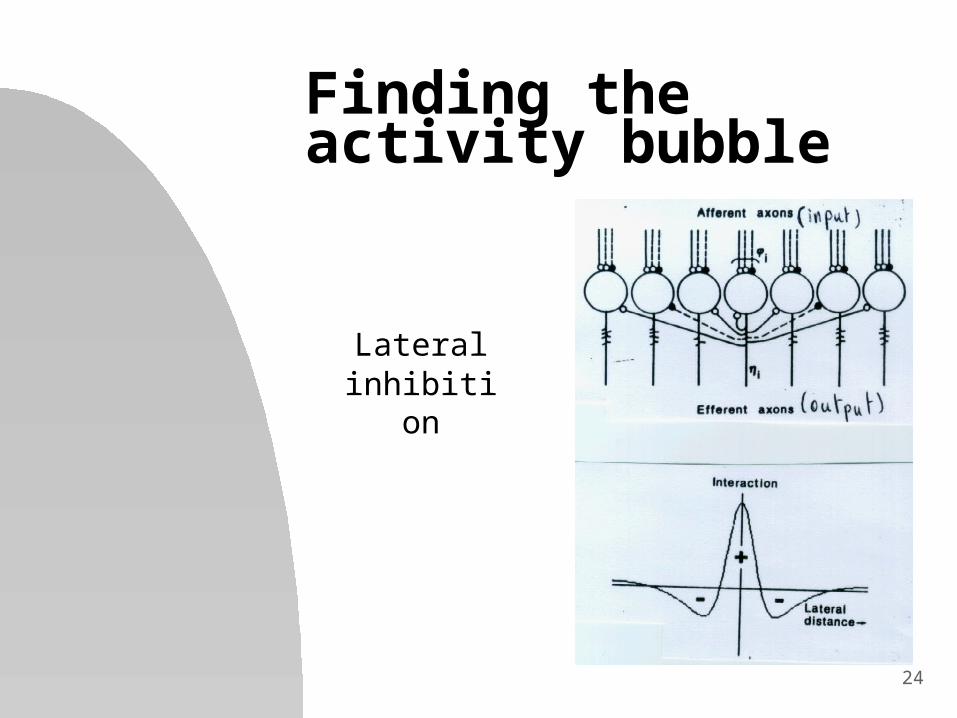
Kohonen algorithm
Finding the activity bubble
Updating the weights for the nodes in the active bubble
24
Finding the activity bubble
Lateral inhibition

25
Finding activity bubble II
Find the winner
Activate all nodes in the neighbourhood of the winner

26
Updating the weights
Move weight vector of winner towards the input vector
Do the same for the active neighbourhood nodes
weight vectors of neigbouring nodes will start resembling each other

27
Simplest implementation
Weight vectors & input patterns all have length 1 (e.i., (wij)
2 = 1 ) Find node whose weight vector has mimimal
distance to the input vector:min. (aj - wij)2
Activate all nodes in neighbourhood radius Nt
Update weights of active nodes by moving weights towards the input vector:
wij = t * ( aj - wij)
wij(t+1) = wij(t) + t * ( aj - wij(t) )

28
Results of Kohonen
© Kohonen, 1982

29
Influence of neighbourhood radius
© Kohonen, 1982
Larger neighbourhood size leads to faster learning

30
Results II: the phonological typewriter
© Kohonen, 1988

31
Phonological typewriter II
© Kohonen, 1988
32
Kohonen conclusions
Darn elegant
Pruning?
Speech recognition uses Hidden Markov Models
33
Summary
Prime example of unsupervised learning Two phases:
winner node is determined weights are updated of the winner only
Very good at discovering structure: discovering categories mapping the input onto a topographic
map Competitive learning important paradigm
in connectionism