Embed Size (px)
Citation preview

Compiler and Runtime Support for EnablingGeneralized Reduction Computations
on Heterogeneous Parallel Configurations
Vignesh Ravi, Wenjing Ma, David Chiu and Gagan AgrawalDepartment of Computer Science and Engineering
The Ohio State UniversityColumbus, Ohio - 43210
1

Outline
• Motivation• Challenges Involved• Generalized Reductions• Overall System Design• Code Generation Module• Dynamic Work Distribution• Experimental Results• Conclusions
2

Motivation
• Heterogeneous architectures are common– Eg., Today’s desktops & notebooks
– Multi-core CPU + Graphics card on PCI-E
• 3 of the top 7 in latest top 500 list– Nebulae, No. 1 in peak performance and No. 2 in linpack
performance
– Use Multi-core CPUs and GPU (C 2050) on each node
• Multi-core CPU and GPU usage still independent– Resources may be under-utilized
• Can Multi-core CPU and GPU be used simultaneously for a single computation
3

Challenges Involved
• Programmability– Manually orchestrate separate code for multi-core CPU and
GPU
– Eg., Pthread/OpenMP + CUDA
• Work Distribution– CPU and GPUs have different charateristics
– Vary in compute power, memory sizes, and latencies
– Distributed non-coherent memories
• Performance– Is there a benefit? (against CPU-only & GPU-only)
– Not much prior work available, need deeper study
4

Contributions
• We target generalized reduction computations for heterogeneous architectures – Ongoing work considers other dwarfs
• We focus on a combination of multi-core CPU & a GPU
• Compiler system automatically generates middleware/ CUDA code from high-level (sequential) C code
• Efficient dynamic work distribution at runtime
• We show significant performance gain from the use of heterogeneous configurations– K-Means (60% improvement)
– PCA (63% improvement)
5

Generalized Reduction Computations
6
{* Outer sequential loop*}
While(unfinished) {
{*Reduction loop*}
Foreach( element e) {
(i, val) = compute(e)
RObj(i) = Reduc(Robj(i), val)
}
}
Reduction ObjectShared Memory
Comm./Assoc. operation
• Similar to Map-Reduce model• But only one stage, Reduction• Reduction Object, Robj, exposed to programmer• Large intermediate results avoided• Reduction Object is a shared memory [Race conditions]• Reduction operation, Reduc, is associative or commutative• Order of processing can be arbitrary
We target a particular class of applications in this work

Overall System Design
7
User Input:Simple C code with
annotations
Application Developer
Multi-core Middleware
API
GPU Code for CUDA
Compilation Phase
Code Generator
Run-time System
Worker Thread Creation and Management
Map Computation to CPU and GPU
Dynamic Work Distribution
Key Components

User Input: Format & Example
8
• Simple Sequential C code with annotations– Variable Information
– Sequential Reduction functions
• Variable Information Examples– K int [K is an integer variable of size, sizeof(int)]
– Centers float* 5 K [Centers is a pointer to float of size 5*K*sizeof(float)]
• Sequential Reduction Functions– Identify reduction structure
– Represent them as one or more reduction functions [unique labels]
– Only use variables declared in ‘Variable Information’

Program Analysis & Code Generation
9
VariableInformation
Sequential ReductionFunctions
User Input
Variable Analyzer
Code Analyzer
Program Analyzer
Code Generator
Host Program Kernel Function(s)
Executable CUDA Program

Dynamic Work Distribution
10
• Key component of runtime system
• Relative performance of CPU & GPU varies for every application
Two General Approaches:
1. Work Sharing– Centralized, Shared Work queue
– Worker threads consume from shared queue when idle
2. Work Stealing– Private work queue for each worker process
– Idle process steals work from a busy process

Dynamic Work Distribution
11
Our Approach:
• Centralized Work Sharing, reasons as follows:– Limitation in GPU memory size
– High latency memory transfer between CPU and GPU
– In case of Work Stealing: If GPU is much faster than CPU, then GPU have to poll CPU frequently for data.
– Leads to high data transfer overhead
Based on Centralized Work Sharing, we propose two work distribution schemes:
• Uniform Chunk Size scheme (UCS)
• Non-Uniform Chunk Size scheme (NUCS)

Uniform Chunk Size Scheme
12
• Global Work Queue
• Idle processor consumes work from the queue
• FCFS policy
• Fast worker ends up processing more than slow worker
• Slow worker still processes reasonable portion of data
Master/Job Scheduler
Worker 1
Worker n
Worker 1
Worker n
Fast Workers
Slow Workers

Key Observations
13
Important observations based on architecture
• Each CPU core is slower than a GPU
• CPU memory latency is relatively much small
• GPU memory latency is very high
Optimization
• Minimize GPU memory transfer overheads
• Take advantage of small memory latency of CPU
• Thus, CPU benefits from small chunks, while, GPU benefits from larger chunks
• Leads to Non-Uniform Chunk size distribution
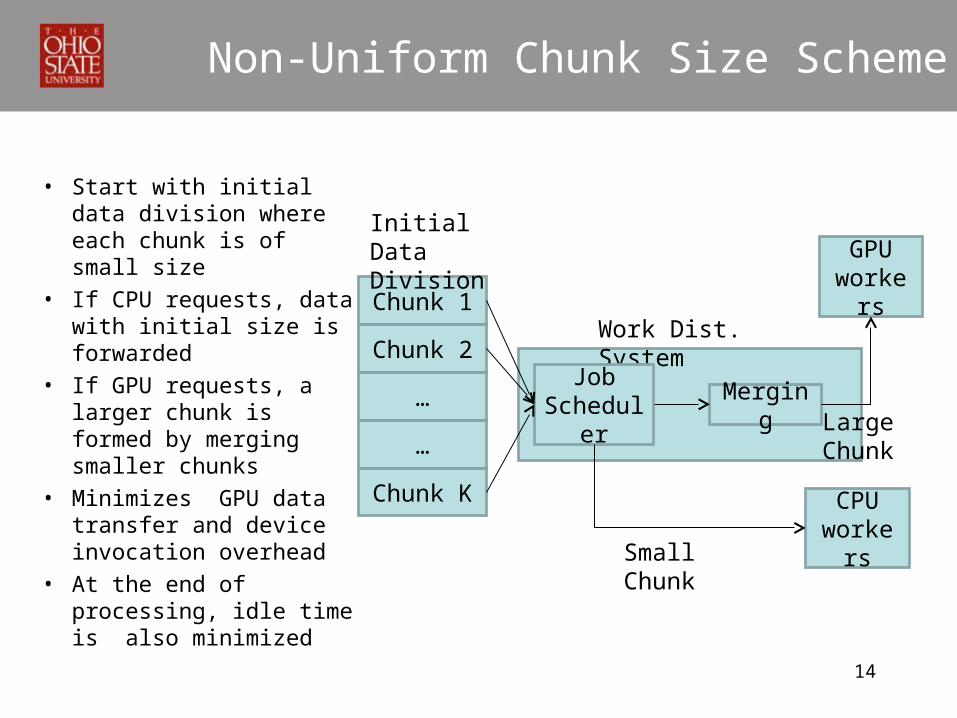
Non-Uniform Chunk Size Scheme
14
• Start with initial data division where each chunk is of small size
• If CPU requests, data with initial size is forwarded
• If GPU requests, a larger chunk is formed by merging smaller chunks
• Minimizes GPU data transfer and device invocation overhead
• At the end of processing, idle time is also minimized
Chunk 1
Chunk 2
…
…
Chunk K
Initial Data Division
Work Dist. System
Job Scheduler
Merging
GPU workers
CPU workersSmall Chunk
Large Chunk

April 18, 2023 15
Experimental Setup
Setup• AMD Opteron 8350 processors• 8 CPU cores• 16 GB Main Memory• Nvidia GeForce 9800 GTX• 512 MB Device Memory
Applications• K-Means Clustering [6.4 GB]• Principal Component Analysis (PCA) [8.5 GB]• Both follow generalized reduction structure
15

April 18, 2023 16
Experimental Goals
• Evaluate the performance from a multi-core CPU and the GPU independently
• Study how the chunk-size impacts the individual performance.
• Study performance gain from simultaneously exploiting both multi-core CPU and GPU
• Evaluation of two dynamic distribution schemes for heterogeneous setting
16

Performance of K-Means CPU-only & GPU-only
17
X-axis 1
X-axis 2
8.8 x
20 x

Performance of PCA CPU-only & GPU-only
186.35 x
~ 4x
Contrary to K-MeansCPU is faster than GPU
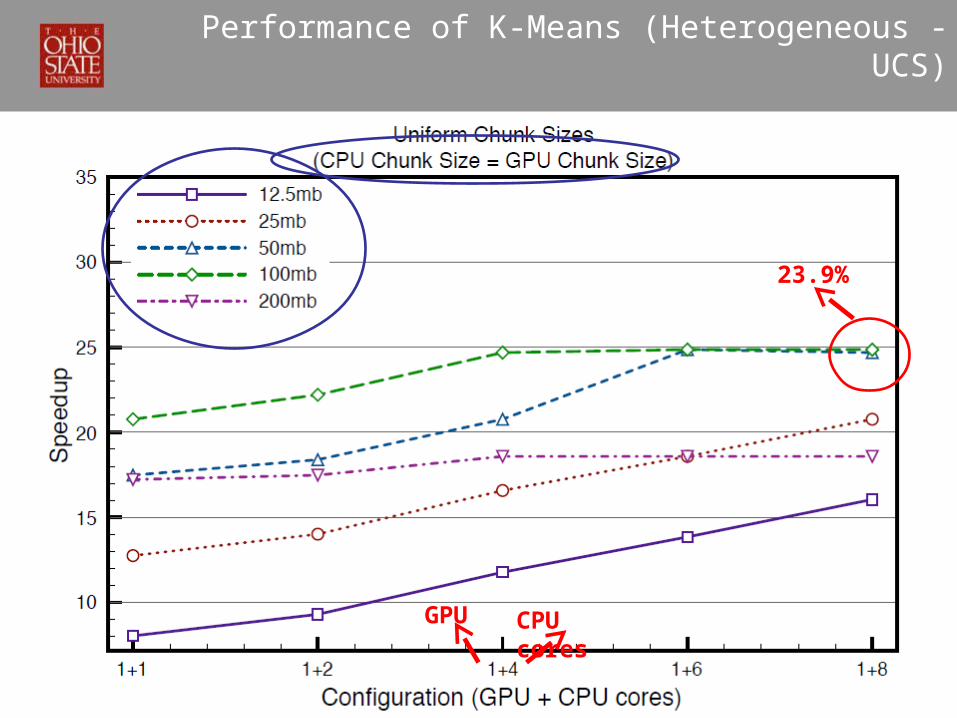
Performance of K-Means (Heterogeneous - UCS)
19
GPU CPU cores
23.9%

Performance of K-Means (Heterogeneous - NUCS)
20
60%

Performance of PCA (Heterogeneous - UCS)
21
45.2%

Performance of PCA (Heterogeneous - NUCS)
22
63.8%

Work Distribution in K-Means
23

Work Distribution in PCA
24

Conclusions
• Compiler and Run-time support for Generalized reduction computations on heterogeneous architectures
• Compiler system automatically generates middleware/ CUDA code from high-level sequential C code
• Run-time system supports efficient work distribution scheme
• Work distribution scheme minimizes the overheads with GPU data transfer
• We achieve 60% performance benefit from K-Means and 63% from PCA on heterogeneous configurations
25

Ongoing Work
• Other dwarfs – Stencil computations– Indirection array based reductions
• Cluster of Heterogeneous Nodes
• Support for fault-tolerance
• Exploiting advanced GPU features
26

27
Thank You!
Questions?
Contacts:Vignesh Ravi - [email protected]
Wenjing Ma - [email protected]
David Chiu - [email protected]
Gagan Agrawal - [email protected]





























