Embed Size (px)
Citation preview

Computer Vision GroupUniversity of California Berkeley
1
Cue Integration in
Figure/Ground Labeling
Xiaofeng Ren, Charless Fowlkes and Jitendra Malik

Computer Vision GroupUniversity of California Berkeley
2
Abstract
We present a model of edge and region grouping using a conditional random field built over a scale-invariant representation of images to integrate multiple cues. Our model includes potentials that capture low-level similarity, mid-level curvilinear continuity and high-level object shape. Maximum likelihood parameters for the model are learned from human labeled groundtruth on a large collection of horse images using belief propagation. Using held out test data, we quantify the information gained by incorporating generic mid-level cues and high-level shape.

Computer Vision GroupUniversity of California Berkeley
3
Introduction
CRF
Conditional Random Fields on triangulated images, trained to integrate low/mid/high-level grouping cues

Computer Vision GroupUniversity of California Berkeley
4
Inference on the CDT Graph
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
XeXeXe
Xe
Xe
Xe
Xe
Xe
Xe
Yt
Yt
Yt
Yt
Yt
Yt
Yt
Yt
YtYt
Z
Contour variables {Xe}
Region variables {Yt}
Object variable {Z}
Integrating {Xe},{Yt} and{Z}: low/mid/high-level cues
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
Xe
XeXeXe
Xe
Xe
Xe
Xe
Xe
Xe
Yt
Yt
Yt
Yt
Yt
Yt
Yt
Yt
YtYt
Z

Computer Vision GroupUniversity of California Berkeley
5
Grouping Cues• Low-level Cues
– Edge energy along edge e
– Brightness/texture similarity between two regions s and t
• Mid-level Cues– Edge collinearity and junction frequency at
vertex V
– Consistency between edge e and two adjoining regions s and t
• High-level Cues– Texture similarity of region t to exemplars
– Compatibility of region shape with pose
– Compatibility of local edge shape with pose
• Low-level Cues– Edge energy along edge e
– Brightness/texture similarity between two regions s and t
• Mid-level Cues– Edge collinearity and junction frequency at
vertex V
– Consistency between edge e and two adjoining regions s and t
• High-level Cues– Texture similarity of region t to exemplars
– Compatibility of region shape with pose
– Compatibility of local edge shape with pose
L1(Xe|I)L2(Ys,Yt|I)
M1(XV|I)
M2(Xe,Ys,Yt)
H1(Yt|I)H2(Yt,Z|I)H3(Xe,Z|I)

Computer Vision GroupUniversity of California Berkeley
6
Conditional Random Fields for Cue Integration
,,|,exp),(
1,,, IZYXE
IZIZYXP
ts
tse
e IYYLIXLE,
21 |,|
ts
etsV
V XYYMIXM,
21 ,,|
e
et
tt
t IZXHIZYHIYH |,|,| 321
Estimate the marginal posteriors of X, Y and Z
Computer Vision GroupUniversity of California Berkeley
7
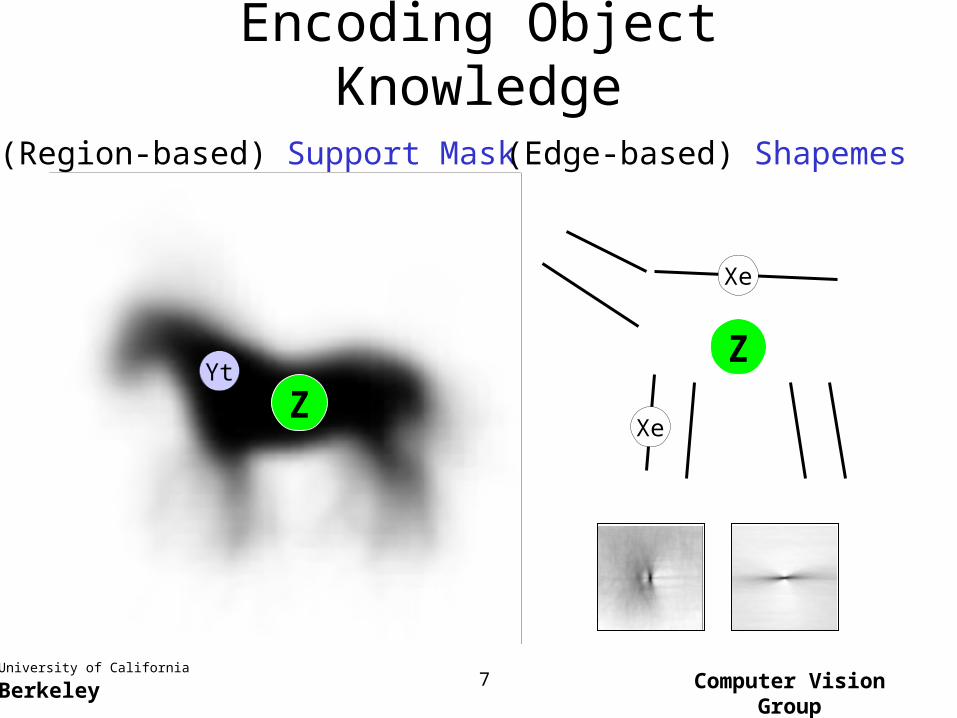
Encoding Object Knowledge
(Region-based) Support Mask
Yt
Z
(Edge-based) Shapemes
Xe
Z
Xe

Computer Vision GroupUniversity of California Berkeley
8
H3(Xe,Z|I): local shape and pose
distribution ON(x,y,i)
shapeme j(vertical pairs) distribution ON(x,y,j)
Let S(x,y) be the shapeme at image location (x,y); (xo,yo) be the object location in Z. Compute average log likelihood SON(e,Z) as:
eyx
oo yxSyyxxONe ,
),(,,log1
eOFFOFF
eONONe
XZeS
XZeSIZXH
),(
),(|,3
Then we have:
SOFF(e,Z) is defined similarly.
shapeme i(horizontal line)

Computer Vision GroupUniversity of California Berkeley
9
Training and Testing
• Trained on half (172) of the grayscale horse images from the [Borenstein & Ullman 02] Horse Dataset.
• Use human-marked segmentations to construct groundtruth labels on both CDT edges and triangles.
• Uses loopy belief propagation for approximate inference; takes < 1 second to converge for a typical image.
• Parameter estimation with gradient descent for maximum likelihood; converges in 1000 iterations.
• Tested on the other half of the horse images in grayscale.
• Quantitative evaluation against groundtruth: precision-recall curves for both contours and regions.
• Trained on half (172) of the grayscale horse images from the [Borenstein & Ullman 02] Horse Dataset.
• Use human-marked segmentations to construct groundtruth labels on both CDT edges and triangles.
• Uses loopy belief propagation for approximate inference; takes < 1 second to converge for a typical image.
• Parameter estimation with gradient descent for maximum likelihood; converges in 1000 iterations.
• Tested on the other half of the horse images in grayscale.
• Quantitative evaluation against groundtruth: precision-recall curves for both contours and regions.

Computer Vision GroupUniversity of California Berkeley
10

Computer Vision GroupUniversity of California Berkeley
11

Computer Vision GroupUniversity of California Berkeley
12
Results
Input Input Pb Output Contour Output Figure

Computer Vision GroupUniversity of California Berkeley
13
Input Input Pb Output Contour Output Figure

Computer Vision GroupUniversity of California Berkeley
14
Input Input Pb Output Contour Output Figure

Computer Vision GroupUniversity of California Berkeley
15
Conclusion• Constrained Delaunay Triangulation provides a scale-
invariant discrete structure which enables efficient probabilistic inference.
• Conditional random fields combine joint contour and region grouping and can be efficiently trained.
• Mid-level cues are useful for figure/ground labeling, even when powerful object-specific cues are present.
• Constrained Delaunay Triangulation provides a scale-invariant discrete structure which enables efficient probabilistic inference.
• Conditional random fields combine joint contour and region grouping and can be efficiently trained.
• Mid-level cues are useful for figure/ground labeling, even when powerful object-specific cues are present.

Computer Vision GroupUniversity of California Berkeley
16
Thank You

Computer Vision GroupUniversity of California Berkeley
17




























