Embed Size (px)
Citation preview

Confirmatory Statistics:Identifying, Framing and Testing Hypotheses
Andrew Mead (School of Life Sciences)

Contents
Philosophy and Language Why test hypotheses? Underlying method Terminology and Language
Statistical tests for particular hypotheses Tests for means – t-tests and non-parametric
alternatives Tests for variances – F-tests Tests for frequencies – chi-squared test More tests for means – analysis of variance Issues with multiple testing
2

Comparative Studies
3
Much research is concerned with comparing two or more treatments/conditions/systems/… Interest is often in identifying which is “best”
Or, more likely, whether the best is better than some other
Statistical hypothesis testing provides a way of assessing this
In other areas of research we want to know the size or shape of some response Estimation, including a measure of uncertainty Modelling, including estimation of model
parameters And testing of whether parameters could take particular
values

Hypothesis testing
Scientific method: Formulate hypothesis Collect data to test hypothesis Decide whether or not to accept hypothesis Repeat
Scientific statements are falsifiable Hypothesis testing is about falsifying them.
4

Example
Hypothesis: Men have big feet What does this
mean? What kind of data do
we need to test it? What data would
cause us to believe it?
What would cause us not to believe it?
5

What does it mean?
Men have big feet On an absolute scale? Relative to what – women (or children or elephants)? For all men?
Need to add some precision to the statement
The average shoe size taken by adult males in the UK is larger than the average shoe size taken by adult females in the UK Perhaps after adjusting for general size Should think about what the alternative is (if our
hypothesis is not true)
6

What kind of data are useful?
Shoe sizes of adult men And of adult women? Or of children?
Additional data To adjust for other sources of variation Ages, heights, weights
Paired data from brothers and sisters? To control for other sources of variation Fraternal twins?
How much data?7

Assessing the hypothesis
What would cause us to believe it? If in our samples, the feet sizes of men were consistently
larger than those of women And perhaps that we couldn’t explain this by height/weight
Do we care how much bigger?
What would cause us not to believe it? If in our sample men’s shoe sizes were not on average
bigger Or maybe that some were bigger and some smaller
If the average was bigger, but (perhaps after adjusting for height/weight) it was not so much bigger that it might not have plausibly resulted from sampling variability How can we assess this?
8

Conclusions
Need to carefully define your hypothesis Think carefully about what you really mean Be precise
Make sure you measured everything relevant Or choose your samples to exclude other sources of
variability Need to have a way of assessing the evidence
Does the evidence support our hypothesis, or could it have occurred by chance?
We usually compare the hypothesis of interest with a (default) hypothesis that nothing interesting is happening i.e. that the apparent effect is just due to sampling variability
9

Assessing Evidence
Statistical significance testing is the classical statistical way to do this Standard way used in science
Typically this involves: Comparing two or more hypotheses
Often a default belief (null hypothesis) and what we are actually interested in (alternative hypothesis)
Considering how likely the evidence would be if each of the hypotheses were true
Deciding if there is enough evidence to choose the non-default (alternative) hypothesis over the default (null) hypothesis
10

Hypothesis testing in Science
In science, we take the default to be that nothing interesting is happening cf Occam’s razor ‘Do not multiply entities beyond
need’ ‘the simplest explanation is usually the correct
one’ Call this the null hypothesis Compare with the alternative hypothesis
that something interesting is happening E.g. Men have big feet
We generally deal with quantitative data, and so can set quantitative criteria for rejecting the null hypothesis11

Outcomes
12
Three possible outcomes from a significance test
1. We reach the correctconclusion
2. We incorrectly reject the nullhypothesis type 1 error most serious mistake
equivalent to a false conviction
as in a criminal trial, we strive to avoid this
3. We incorrectly accept the null hypothesis type 2 error

Type 1 error
Incorrectly reject the null hypothesis
Probability of making a Type 1 error is called the size of the test
This is the quantity (usually denoted a) usually associated with significance tests if a result is described as being significant at 5%, then this
means: “given a test of size 5% the result led to the rejection of the
null hypothesis” so, the probability of rejecting the null hypothesis when it is
true is 5%
Usually we want to control the size of the test, and choose for this to be small We want to be fairly certain before we change our view from
the default (null) hypothesis
13

Type 2 error
Incorrectly accept the null hypothesis
Probability of not making a Type 2 error is called the power of the test the probability of (correctly) rejecting the null hypothesis
when it is false power commonly written as (1 - b) so probability of making a type 2 error is b
Alternative hypotheses are usually not exact e.g. men’s feet are bigger than women’s are
not men’s feet are 10% bigger than women’s are power of a test will vary according to which exact
statement is true about the alternative hypothesis a test may have small power to detect a small difference but
will have higher power to detect a large difference so usually talk about the power of a test to detect some
specified degree of difference from the null hypothesis can calculate power for a range of differences and
construct a power curve
14

Formal language
Term Symbol Description
Null hypothesis H0 The default hypothesis, which we will believe until compelled to accept another
Alternative hypothesis
H1 The hypothesis which may prove to be true
Type 1 error Rejecting the null hypothesis when it is true
Type 2 error Accepting the null hypothesis when it is false
Size The probability of rejecting the null hypothesis when it is true
Power 1-
The probability of rejecting the null hypothesis when it is false
15

Conventional levels
Significance tests conventionally performed at certain ‘round’ sizes 5% (lowest level normally quoted in journals), 1%
and 0.1% may sometimes be reasonable to quote 10% values available in books of tables
Computer packages generally give exact levels (to some limit) traditionally round up to nearest conventional level editors becoming more accepting of quoting the exact level
but shouldn’t quote really small values
in tables significance sometimes shown using asterisks usually * = 5%, ** = 1%, *** = 0.1%
16

Confusing scientific and statistical significance Statistical significance indicates whether evidence
suggests that null hypothesis is false does not mean that differences have biological
importance If our experiment/sample is too big
treatment differences of no importance can show up as significant
consider size of treatment differences as well as statistical significance to decide whether treatment effects matter
If our experiment/sample is too small real and important differences between treatments may
escape detection if a treatment difference is not significant we cannot
assume that treatments are equal was power of test sufficient to detect important
differences? if a test is not significant this does not mean strong
evidence for null hypothesis, but lack of strong evidence for alternative hypothesis
17

Other potential problems
Significance testing deliberately makes it difficult to reject the null hypothesis Sometimes this is not what we are interested in doing May want to estimate some characteristic from the data May want to fit some sort of model to describe the data
Hypotheses tested here in terms of the parameter values
Possible to test inappropriate hypotheses Standard tests tend to have the null hypothesis that two
(or more) treatments are equal, or that a parameter equals zero.
If the question of interest is whether a parameter equals one, testing whether it’s different from zero doesn’t help
Could also be interested in determining that two treatments are similar (equivalence testing), so don’t want to test whether they are different
18

Summary of hypothesis testing theory (1)
Compare alternative hypothesis of interest to null hypothesis Null hypothesis (default) says nothing interesting
happening Do we really believe it?
Believe null hypothesis unless compelled to reject it Need strong evidence in favour of the alternative
hypothesis to reject the null hypothesis
Size of test () gives the probability of rejecting the null hypothesis when it is true Usually referred to as the significance level for the
test
19

Summary of hypothesis testing theory (2)
Pick a test statistic with good power for the alternative hypothesis of interest Power of a test (1 - ) gives the probability of
rejecting the null hypothesis when it is false Power changes with the particular statement
that is true for the alternative hypothesis
Size of test is used to determine the critical value of test statistic at which the null hypothesis is rejected
Statistical and scientific significance are different!
20

21

Applying statistical tests
22
Almost always using the collected data to test hypotheses about some larger population Using statistical methods to make inferences from the
collected data about a broader scenario What is the larger population? How broadly can the inferences be applied?
Most tests have associated assumptions that need to be met for the test to be valid If assumptions fail then conclusions from test are likely
to be flawed Need to assess the assumptions
Often related to the form of data – the way the data were collected

Selecting an appropriate test
23
‘100 Statistical Tests’ (G.K. Kanji, 1999, SAGE Publications) General introduction Example applications Classification of tests
By number of samples 1 sample, 2 samples, K samples
By type of data Linear, Circular
By type of test Parametric classical, Parametric, Distribution-free (non-
parametric), sequential By aim of test
Central tendency, proportion, variability, distribution functions, association, probability, randomness, ratio

Student’s t-test – for means
Three types of test :
One-sample To test whether the sample could have come
from a population with a specified mean value
Two-sample To test whether the two samples are from
populations with the same means
Paired-sample To test whether the difference between pairs
of observations from different samples is zero
24

One-sample t-test H0 : μ = μ0
H1 : μ ≠ μ0
Given a sample x1, x2,…, xn the test statistic, t, is the absolute difference between the sample mean and μ0, divided by the standard error of the mean
Compare the test statistic with the critical value from a t-distribution with (n - 1) degrees of freedom
For a test of size 5%, we will reject H0 if t is greater than the critical value such that 2.5% of the distribution is in each tail
Student’s t-test
0xt
sn
25
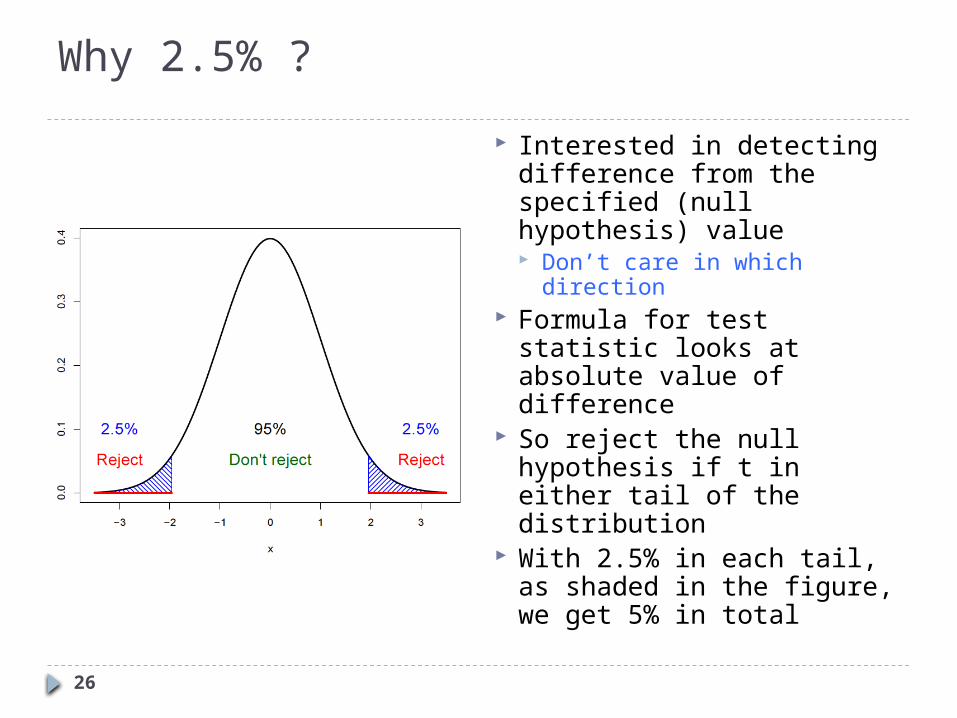
Why 2.5% ?
Interested in detecting difference from the specified (null hypothesis) value Don’t care in which
direction Formula for test statistic
looks at absolute value of difference
So reject the null hypothesis if t in either tail of the distribution
With 2.5% in each tail, as shaded in the figure, we get 5% in total
26

Example
Yields of carrots per hectare from 14 farmers:97.1 99.2 95.6 97.6 99.7 94.2 95.3 74.6 112.8 110.0 91.5 96.3 85.7 112.4
“standard” yield per hectare is 93, is this an abnormal year?
Test H0 : μ = 93 against H1 : μ ≠ 93
27

Calculations
Mean yield = 97.29 Standard deviation = 10.15 Standard error of mean = 10.15 / √14 =
2.71
Test statistic: t = |97.29 – 93| / 2.71 t = 4.29/2.71 t = 1.58
Critical value is t13; 0.025 = 2.160 Test statistic is smaller than this
So fail to reject (accept) H0 at the 5% significance level – not an abnormal year28

Power analysis
Alternative hypotheses were not exact, so we cannot calculate an exact power for this test
But we can calculate the power of the test to detect various specified degrees of difference from the null hypothesis
Reminder: Power is the probability of rejecting the null hypothesis when it is false
For the example, we would have accepted the null hypothesis if the absolute difference in means was less than the least significant difference 86.5
14
15.10160.2
025.0);1(
n
st n
29

Calculations
30
For the test, the power for any given “alternative” mean value, μ1, is the probability of getting a
value greater than 98.86 (mean + LSD = 93 + 5.86)
PLUS the probability of getting a
value less than 87.14 (mean – LSD = 93 - 5.86)
for a t-distribution with 13 degrees of freedom with mean μ1 and standard error as calculated from the observed standard deviation
μ1
p(<87.14)
p(>98.86) Power
77 0.999 0.000 0.99979 0.995 0.000 0.99581 0.979 0.000 0.97983 0.924 0.000 0.92485 0.778 0.000 0.77887 0.520 0.000 0.52089 0.252 0.002 0.25491 0.089 0.006 0.09593 0.025 0.025 0.05095 0.006 0.089 0.09597 0.002 0.252 0.25499 0.000 0.520 0.520
101 0.000 0.778 0.778103 0.000 0.924 0.924105 0.000 0.979 0.979107 0.000 0.995 0.995109 0.000 0.999 0.999

Power Curve
31

Two-sample test H0 : μ1 = μ2 H1 : μ1 ≠ μ2
The usual assumption for a two-sample t-test is that the distributions from which the two samples are taken have the same variances An alternative test allows the variances to be different
Given two samples x1, x2,…, xm and y1, y2,…, yn the test statistic t is calculated as the absolute value of the difference between the sample means, divided by the standard error of that difference (sed)
Compare the test statistic with the critical value from a t-distribution with (n +m - 2) degrees of freedom
For a test of size 5%, we will reject H0 if t is greater than the critical value such that 2.5% of the distribution is in each tail
Two sample test
x yt
sed
32

Paired sample t-test
Here we have paired observations, one from each sample, and are interested in differences between the samples, when we also believe there are differences between pairs H0 : μ1 = μ2 H1 : μ1 ≠ μ2
Because of the differences between pairs, it’s more powerful to test differences of the pairs
Given two paired samples x1, x2,…, xn and y1, y2,…, yn, we calculate the differences between each pair, d1, d2,…, dn, and calculate the mean, μd
Then we do a one-sample test to compare μd to zero
33

Assumptions
General assumption for all three types of test is that the values from each sample are independent and come from Normal distributions Assumption is for differences for the paired sample t-test
For the two-sample t-test we have the additional assumption that the distributions have the same variance (though there is a variant that allows different variances) Homoscedasticity
For the paired t-test we have the additional assumption that each observation in one sample can be ‘paired’ with a value from the other sample
34

One- and two-sided tests
All the t-tests described so far have been what is called two-sided
That is they have alternative hypotheses of the form ‘two things are different’
There are very similar tests available when the alternative hypothesis is that one mean is greater (or, alternatively, less) than the other
These are called one-sided tests Now calculate a signed test statistic For a test of size 5%, compare with critical value
such that 5% of distribution is in the tail
35

Power
A one-sided test is more powerful than a two-sided one to test a one-sided hypothesis
It can never reject the null hypothesis if the means differ in the direction not predicted by the alternative hypothesis
So when calculating the rejection region, we can use the entire size in the direction of interest36

Alternative (distribution-free) tests
37
Appropriate when data cannot be assumed to be from a Normal distribution Generally still for continuous data
Wilcoxon-Mann-Whitney rank sum test For two populations with the same mean
Sign tests for medians One-sample and two-sample tests
Signed rank tests for means One-sample and paired sample tests

Comparison of variances for two populations Obvious application to test whether two
samples for a two-sample t-test do come from populations with the same variance Rarely actually used for that Actually used in Analysis of Variance and
Linear Regression
F-test
2
1212 22
1
1
1
m
i
n
j
x x
msF
sy y
n
38
H0 : σ12 = σ2
2
H1 : σ12 ≠ σ2
2
Given two samples x1, x2,…, xm and y1, y2,…, yn, the test statistic F is given by the ratio of the sample variances, with the larger variance always in the numerator

Type of test and rejection regions
When comparing two samples we are usually interested in a two-sided test (no prior expectation about which will be larger)
Compare the test statistic with the critical value of an F-distribution with (m – 1) and (n – 1) degrees of freedom
For a test of size 5% we will reject H0 if F is greater than the critical value such that 2.5% is in the upper tail
For a one-sided test, with H1: σ12 > σ2
2 we calculate the test statistic with the variance for the first sample in the numerator, and reject H0 if F is greater than the critical value such that 5% is in the upper tail
Assumptions That the data are independent and normally distributed
for each sample
39

Alternative Tests
40
Bartlett’s Test, Hartley’s Test Extensions to cope with more than 2 samples
Siegel-Tukey rank sum dispersion test Non-parametric alternative for comparing two
samples

Chi-Squared Test
41
Two main applications Testing goodness-of-fit
e.g. for observed data to a distribution, or some hypothesised modekl
Testing association e.g. between two classifications of observations
Both applications essentially the same The test compares observed counts to those
expected under the null hypothesis Where these differ we would anticipate that the
test statistic will cause us to reject the null hypothesis

Testing Association
Test for association between (independence of) two classifications of observations
The Chi squared test involves comparing the observed counts with the expected counts under the null hypothesis
Under the null hypothesis of the independence of the two classifications, the counts in each row (column) of the table will be in the same proportions as the sums across all rows (columns)
Expected frequencies, eij, for each cell of the table are given by
Ri = row totals, Cj = column totals, N = overall total
N
CRN
N
C
N
Re jijiij
42

Test statistic
The test statistic is calculated from the squared difference between the observed and expected frequencies divided by the expected frequency for each cell, by taking their sum
exp
expobs 22
43
Compare the test statistic, χ2, with the critical values of a χ2-distribution with degrees of freedom equal to the number of rows minus one, times the number of columns minus one
For a test of size 5% we then reject the null hypothesis of independence if χ2 is greater than the critical value such that 5% of the distribution is in the upper tail

Pooling
The Chi-square test is an asymptotic test This means that the distribution of the test statistic under
the null hypothesis only approximately follows the stated distribution
The approximation is good if the expected number in each cell is more than about 5
Therefore, if some cells have an expected count of fewer than five, we must pool rows or columns until this constraint is satisfied
In pooling we should aim to avoid removing any interesting associations if possible
44

Goodness of Fit
The Chi-squared test can also be used to test goodness of fit of some observed counts to those predicted by a statistical distribution or model Examples include statistical distributions, Mendel’s laws of
genetic inheritance, … Expected values are calculated based on the predicted
probabilities If any expected values are fewer than five then an appropriate
pooling of categories must be made The test statistic is calculated as the same sum as for
the test of association It is compared to a Chi-squared distribution with degrees
of freedom equal to one fewer than the number of elements in the sum, less one for each parameter estimated from the data45

Summary of Chi-squared test
Allows testing ‘goodness of fit’ of observations to expected values under the model specified as the null hypothesis
Expected values can be from a probability distribution, or what is expected under some postulated relationship between variables Most commonly independence in contingency tables There are better tests for goodness of fit to a distribution
Test statistic is sum of contributions of the form (observed - expected)2 / expected
Compare with critical values from a Chi-squared distribution, with degrees of freedom depending on the number of contributions and the number of model parameters Asymptotic test: critical values only approximate Approximation is bad if too few expected in any ‘cell’ –
hence need all expected values to be at least 5.46

Analysis of Variance (ANOVA)
47
Initially a simple extension of the two-sample t-test to compare more than two samples Null hypothesis: all samples are from populations with the same
mean Alternative hypothesis: some samples are from populations with
different means Test statistic compares variance between sample means with
(pooled) variance within samples Reject null hypothesis if between-sample variance is
sufficiently larger than within-sample variance Use a one-sided F-test – between-sample variance will be larger if
the sample means are not all the same Still need to identify those samples that are from populations
with different means Use two-sample t-tests based on pooled within-sample variance
Same assumptions as for a two-sample t-test

Extensions
48
Can be applied to a wide range of designs Identify different sources of variability within an
experiment Blocks – sources of background (nuisance) variation Treatments – what we usually care about
Construct comparisons (contrasts) to address more specific questions
Also used to summarise the fitting of regression models Assess whether the variation explained by the
model is large compared with the background variation
Can also be used to compare two alternative (nested) models\ Does a more complex model provide an improved fit to
the data? Other approaches also available to address this
question

Multiple testing
49
Remember what specifying a test of size 5% means This is the probability of rejecting the null hypothesis when it is true
With a large number of related tests, will incorrectly reject some null hypotheses that are true
Multiple testing corrections modify the size of each individual test so that the size of the combined tests is 5% i.e. the overall probability of incorrectly rejecting any of the null
hypotheses is 5% Many different approaches with different assumptions
Tukey test (HSD), Dunnett’s test, Link-Wallace test, … Generally concerned with making all pairwise comparisons A well-designed experiment/study will have identified a
number of specific questions to be addressed Often these comparisons will be independent, so less need to
adjust the sizes of individual tests

Confirmatory Statistics
50
Hypothesis Testing – a five-step method (Neary, 1976) Formulate the problem in terms of hypotheses Calculate an appropriate test statistic from the data Choose the critical (rejection) region Decide on the size of the critical region Draw a conclusion/inference from the test
Large number of tests developed for particular problems Many readily implemented in statistical packages
Approaches can be extended for more complicated problems
Identification of appropriate test depends on the type of data, the type of problem, and the assumptions that we are willing to make





























