Embed Size (px)
Citation preview


Connecting Michigan for Health Patient Matching on FHIR
June 10, 2016
Adam W. Culbertson, M.S. HHS, Innovator-In-
Residence
Contact: [email protected]

•Background on Patient Matching •Challenges to Matching •Metrics For Algorithm Performance •Previous Algorithm Evaluation Work •Current Work with FHIR and Matching
Overview

Background on Matching
HIMSS © 2016

Patient Matching Definition
Patient matching: Comparing data from multiple sources to identify records that represent the same patient. Typically involves comparing varied demographic fields from different health data stores to create a unified view of a patient.
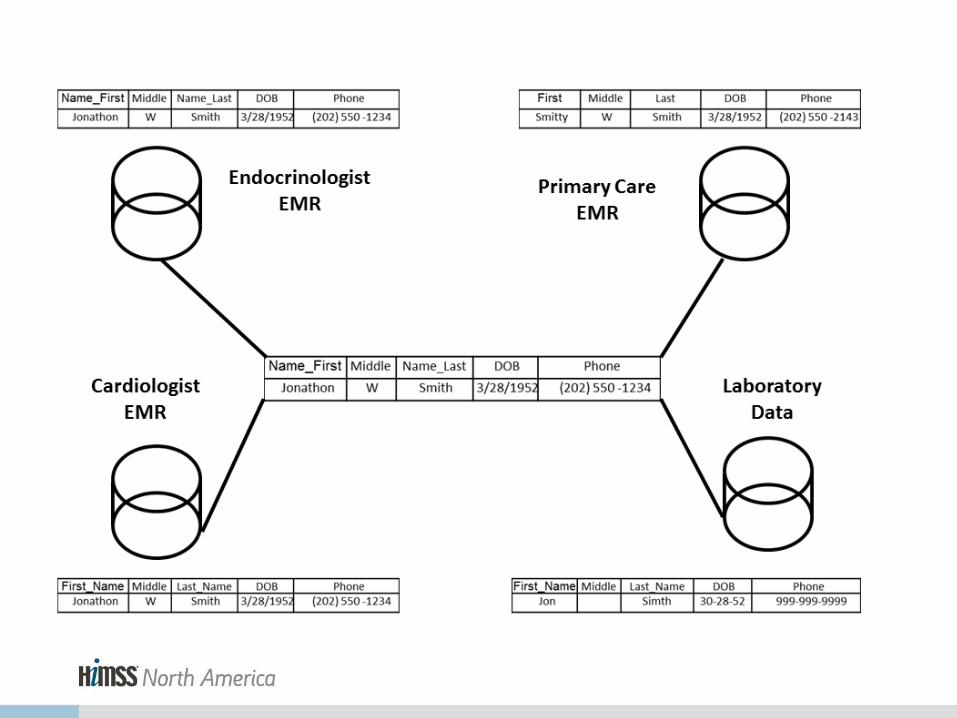
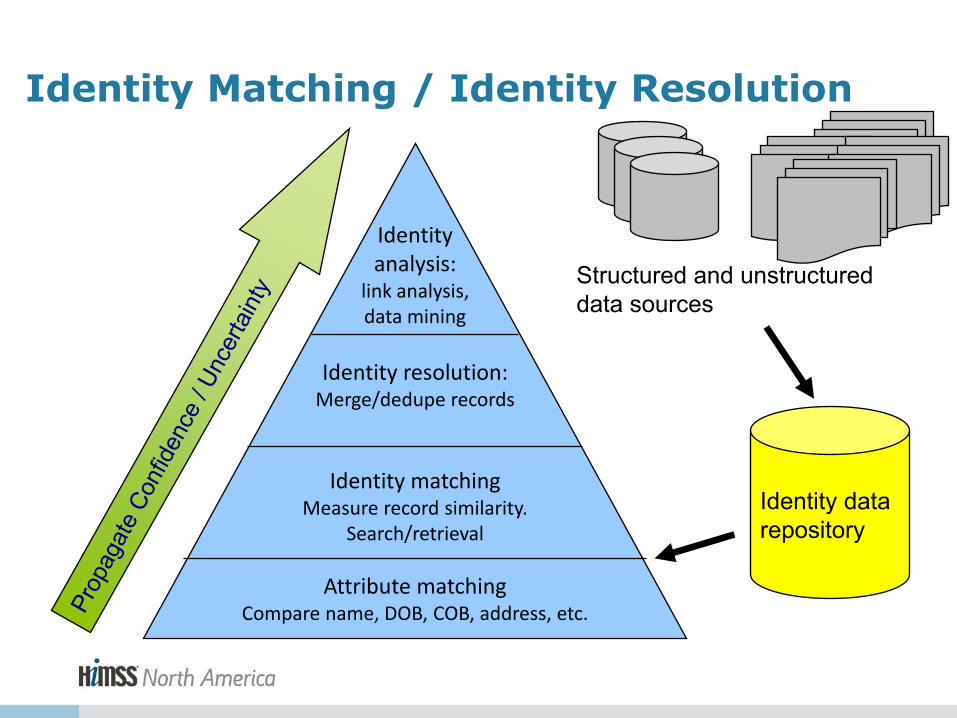
Identity Matching / Identity Resolution
Identity analysis:
link analysis, data mining
Identity resolution:
Merge/dedupe records
Identity matching Measure record similarity.
Search/retrieval
Attribute matching Compare name, DOB, COB, address, etc.
Identity data repository
Structured and unstructured data sources
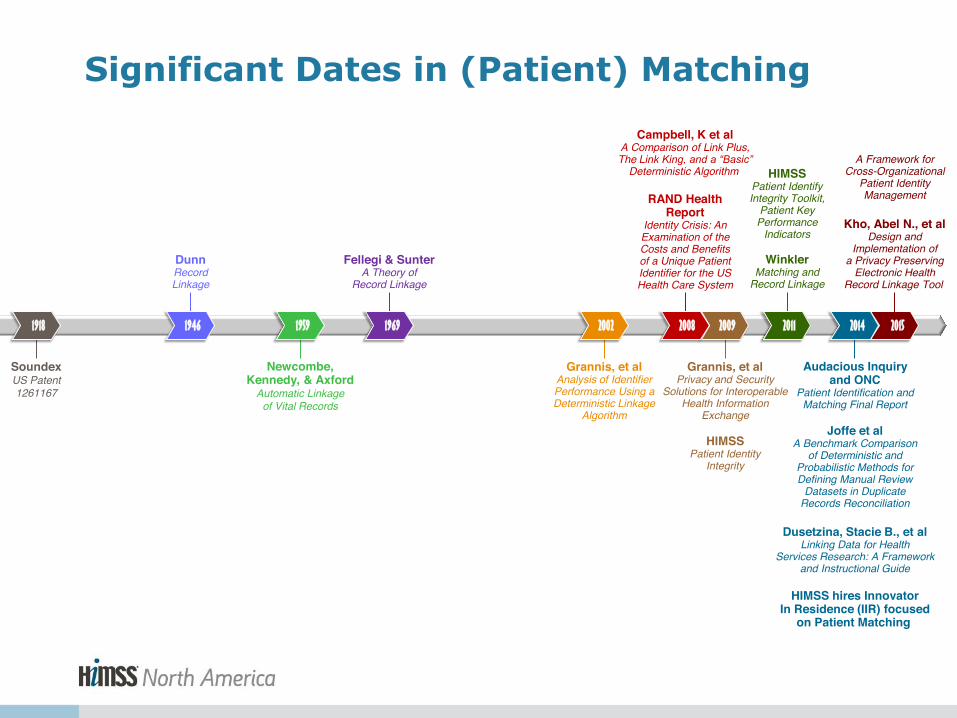
Significant Dates in (Patient) Matching
A Framework for Cross-Organizational
Patient Identity Management
2015
Kho, Abel N., et al Design and
Implementation of a Privacy Preserving
Electronic Health Record Linkage Tool
HIMSS Patient Identity
Integrity
Grannis, et al Privacy and Security
Solutions for Interoperable Health Information
Exchange
2009
Joffe et al A Benchmark Comparison
of Deterministic and Probabilistic Methods for Defining Manual Review
Datasets in Duplicate Records Reconciliation
Dusetzina, Stacie B., et al Linking Data for Health
Services Research: A Framework and Instructional Guide
HIMSS hires Innovator In Residence (IIR) focused
on Patient Matching
Audacious Inquiry and ONC
Patient Identification and Matching Final Report
2014
HIMSS Patient Identify Integrity Toolkit,
Patient Key Performance
Indicators
Winkler Matching and
Record Linkage
2011
Newcombe, Kennedy, & Axford
Automatic Linkage of Vital Records
1959
Dunn Record Linkage
1946
Soundex US Patent 1261167
1918
Fellegi & Sunter A Theory of
Record Linkage
1969
Grannis, et al Analysis of Identifier Performance Using a Deterministic Linkage
Algorithm
2002
Campbell, K et al A Comparison of Link Plus, The Link King, and a “Basic”
Deterministic Algorithm
RAND Health Report
Identity Crisis: An Examination of the Costs and Benefits of a Unique Patient Identifier for the US Health Care System
2008

Challenges to Matching

Availability of Data Attributes
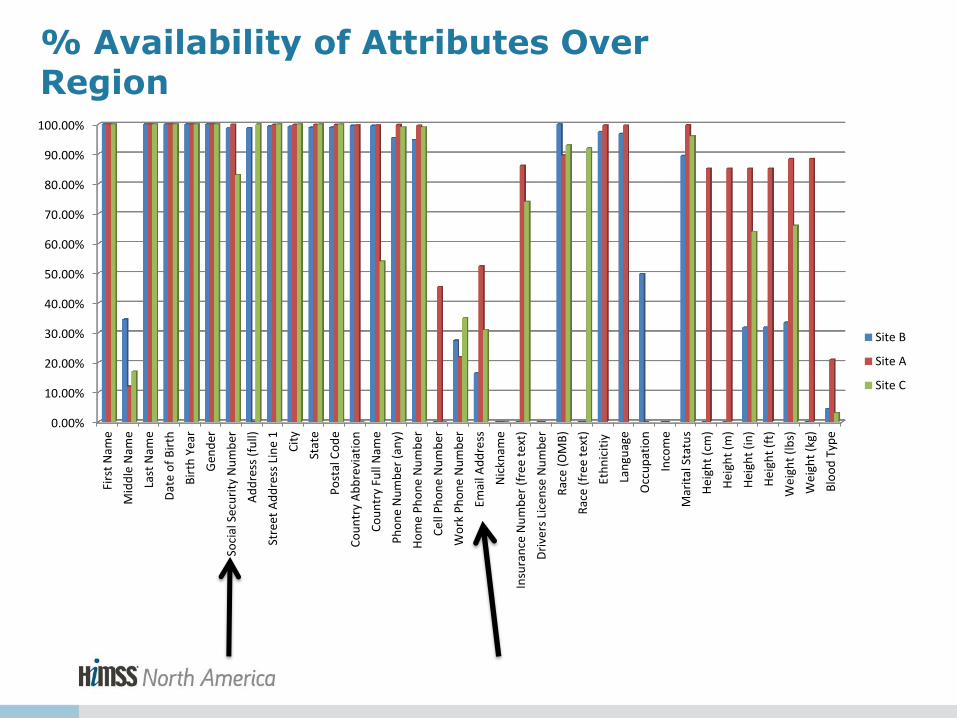
% Availability of Attributes Over Region
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%Fi
rst N
ame
Mid
dle
Nam
eLa
st N
ame
Date
of B
irth
Birt
h Ye
arG
ende
rSo
cial
Sec
urity
Num
ber
Addr
ess (
full)
Stre
et A
ddre
ss L
ine
1Ci
tySt
ate
Post
al C
ode
Coun
try
Abbr
evia
tion
Coun
try
Full
Nam
ePh
one
Num
ber (
any)
Hom
e Ph
one
Num
ber
Cell
Phon
e N
umbe
rW
ork
Phon
e N
umbe
rEm
ail A
ddre
ssN
ickn
ame
Insu
ranc
e N
umbe
r (fr
ee te
xt)
Driv
ers L
icen
se N
umbe
rRa
ce (O
MB)
Race
(fre
e te
xt)
Ethn
iciti
yLa
ngua
geO
ccup
atio
nIn
com
eM
arita
l Sta
tus
Heig
ht (c
m)
Heig
ht (m
)He
ight
(in)
Heig
ht (f
t)W
eigh
t (lb
s)W
eigh
t (kg
)Bl
ood
Type
Site B
Site A
Site C
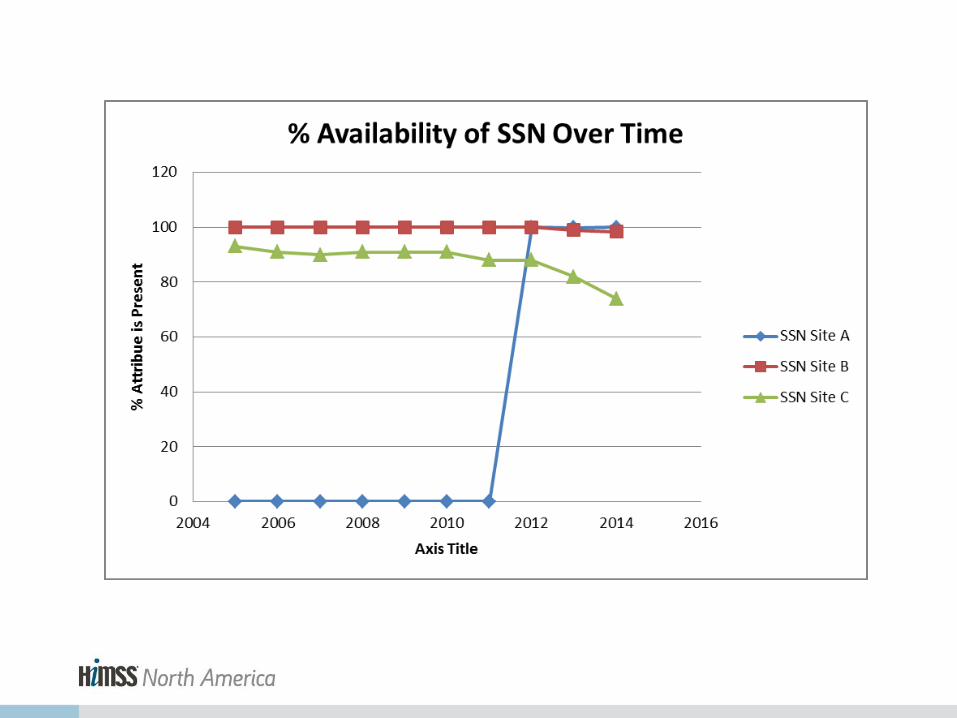
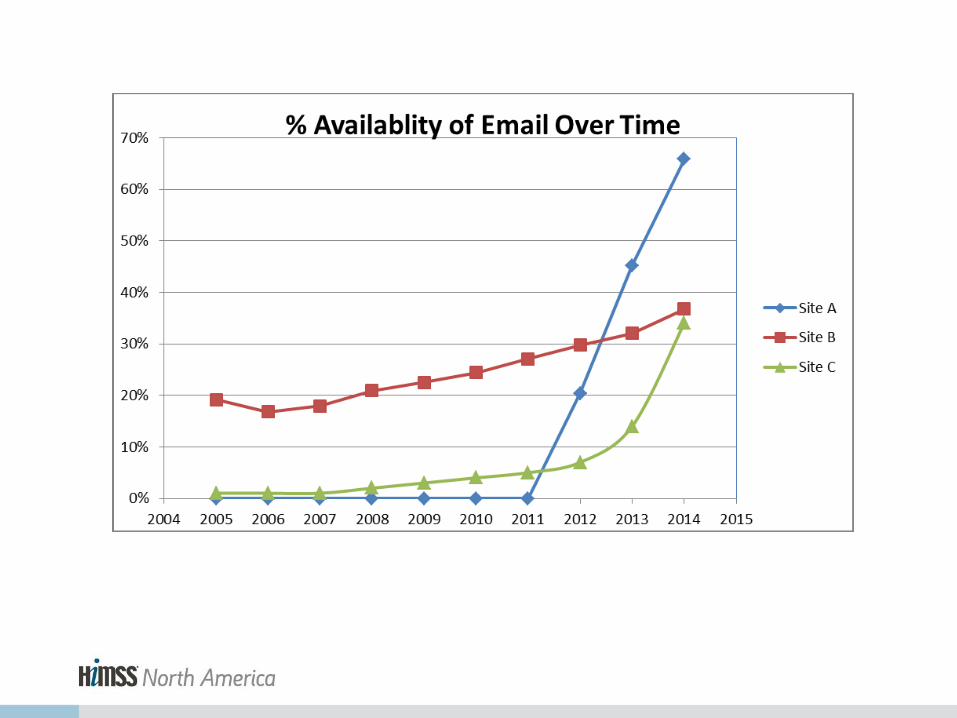

Data Quality
HIMSS © 2016

• Data Quality is a Key – Garbage in and Garbage out
• Data entry errors increase data matching complexity – Various algorithmic solutions to address these, not perfect
• Types of errors: – Missing or Incomplete Values – Inaccurate data – Fat finger errors – Information is out of date – Transposed names – Misspelled names
Data Quality

• Transposition errors
• Mary Sue vs Sue Marie
• Smitty, John vs John, Smitty
• Names change over time
• Marriage, Divorce
• More than one way to spell name
• Jon, John
• Data entry
– Fat-finger = typo, transposition, etc.
• Phonetic variation
– Double names may not be given in full
Data Quality

• Lack of transparency in how patient matching algorithms perform
• Varied claims in algorithm performance • Need greater transparency in system performance • Need reporting on match rates in terms of precision and
recall • Good news! There are well established metrics for
algorithm performance
Metrics for Algorithm Performance

Metrics for Algorithm Performance

• Ideal outcome of any matching exercise is correctly answering this one question hundreds or thousands of times, Are these two things the same thing?
– Correctly identifying all the true positives and true negatives while minimizing the number of errors, false positives and false negatives
Patient Matching Goal

• True Positive- The two records represent the same patient
• True Negative- The two records don't represent the same patient
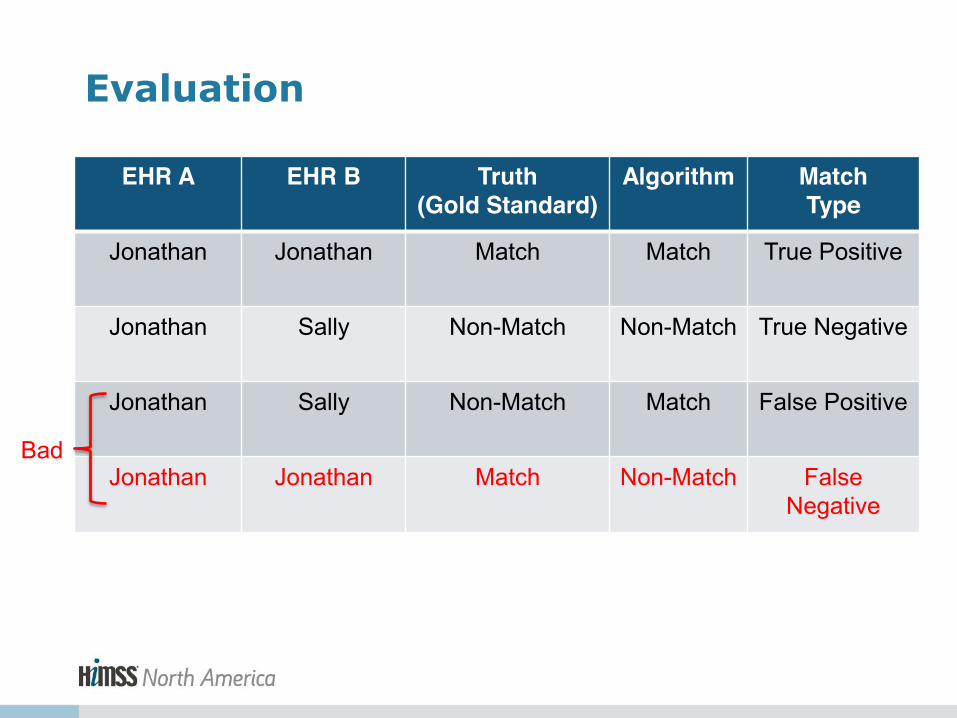
Patient Matching Terminology

• False Negative: The algorithm misses a record that should be matched
• False Positive: The algorithm creates a link to two records that don’t actually match
Patient Matching Terminology
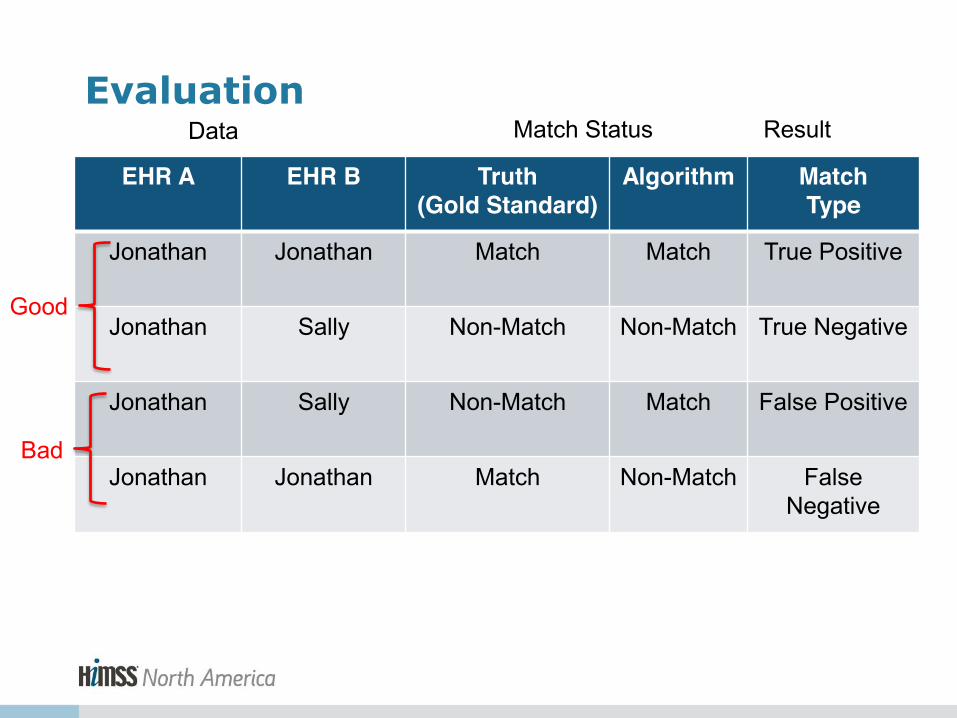
EHR A EHR B Truth (Gold Standard)
Algorithm Match Type
Jonathan Jonathan Match Match True Positive
Jonathan Sally Non-Match Non-Match True Negative
Jonathan Sally Non-Match Match False Positive
Jonathan Jonathan Match Non-Match False Negative
Evaluation
Good
Bad
Data Match Status Result
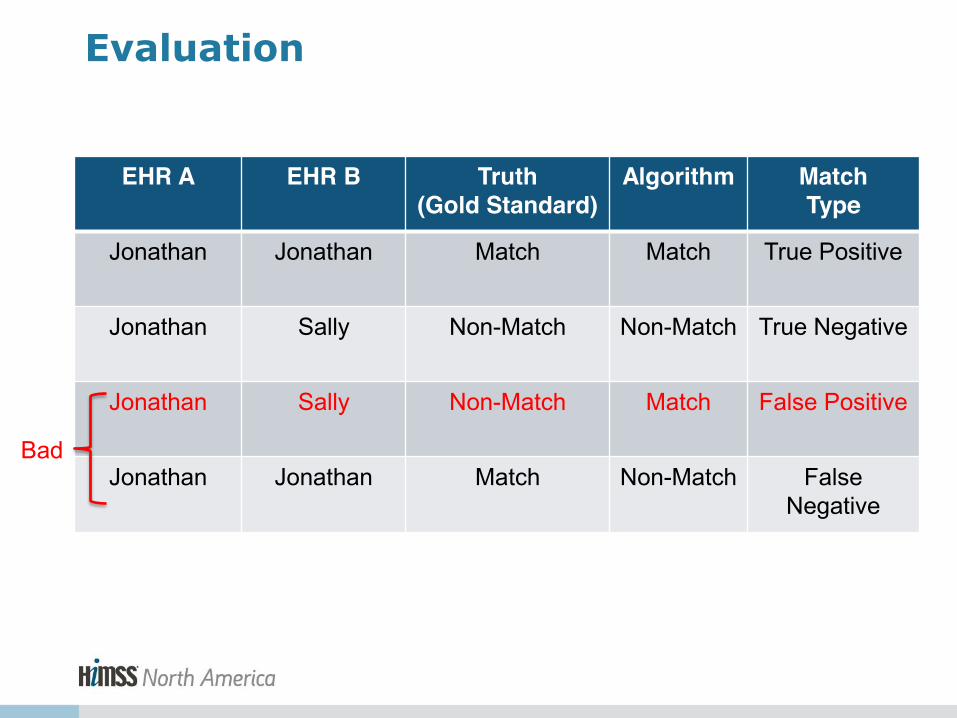
EHR A EHR B Truth (Gold Standard)
Algorithm Match Type
Jonathan Jonathan Match Match True Positive
Jonathan Sally Non-Match Non-Match True Negative
Jonathan Sally Non-Match Match False Positive
Jonathan Jonathan Match Non-Match False Negative
Evaluation
Bad
EHR A EHR B Truth (Gold Standard)
Algorithm Match Type
Jonathan Jonathan Match Match True Positive
Jonathan Sally Non-Match Non-Match True Negative
Jonathan Sally Non-Match Match False Positive
Jonathan Jonathan Match Non-Match False Negative
Evaluation
Bad

Truth
Algorithm
Positive Negative
Positive True Positive False Positive
Negative False Negative True Negative
Evaluation
Recall
Precision
Precision = True Positives / (True Positives + False Positives)
Recall = True Positives / (True Positives + False Negatives)

• Calculation – Precision = True Positives / (True Positives + False
Positives)
– Recall = True Positives / (True Positives + False Negatives)
• Tradeoffs between Precision and Recall – F-Measure
Evaluation

Evaluation of Algorithms

• Dataset University of Texas
• ~2.6 Million Records
• Randomly Select 20K records for Manual Review
– Records reviewed by two reviewers for match status
• Data split into
– 10,000 Training & 10,000 Test
Evaluation of Algorithms

• Then Run Three Open Source Algorithms
– FEBRL
– FRIL
– CHOICE MAKER
• Run for Baseline and Optimized
Run Algorithms

• Freely Extensible Biomedical Record Linkage system (FEBRL) developed since 2002 between Australian National University in Canberra and New South Whales Department of Health in Sydney, Australia.
• Has Data Cleaning Module • Hybrid Model
– Probabilistic – Fuzzy string matching – Rules
FEBRL

• Fine-Grained Records Integration and Linkage Tool (FRIL) developed between the CDC and EMORY University 2008
• Used to link birth defects monitoring program with data and birth certificate data
• Hybrid – Machine Learning – Probabilistic Matching
FRIL

• Developed by the New York Department of Public Health, used to link records for immunization and lead registries
• Hybrid System
– Machine Learning
– Probabilistic Matching
– Rules
Choice Maker
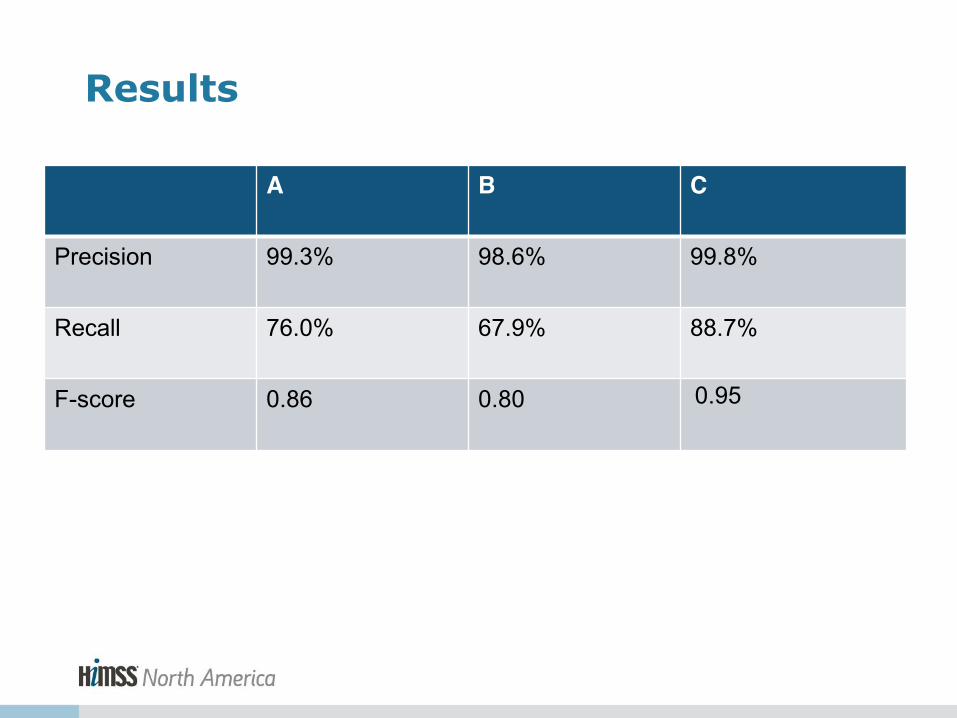
A B C
Precision 99.3% 98.6% 99.8%
Recall 76.0% 67.9% 88.7%
F-score 0.86 0.80 0.95
Results
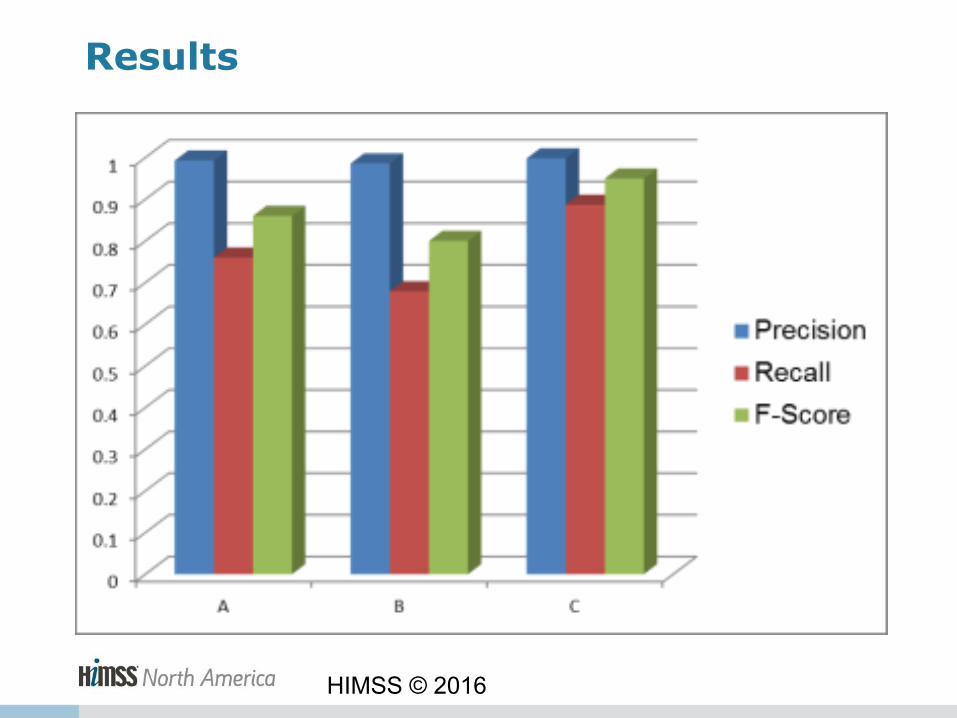
Results
HIMSS © 2016

• Only one data set
– Algorithms will perform differently on different data sets
• Short period of time to tune the algorithms
• Used simple models
• Simplest use case for matching
Limitations to Algorithm Evaluation

Limitations to Algorithm Evaluation
• Differences in data input format
• Differences in output formant
• Needed to write code to compare the output
• FEBRL only outputs matches so difficult to calculate false positives

Patient Matching on FHIR
Simplest Model
Client Server
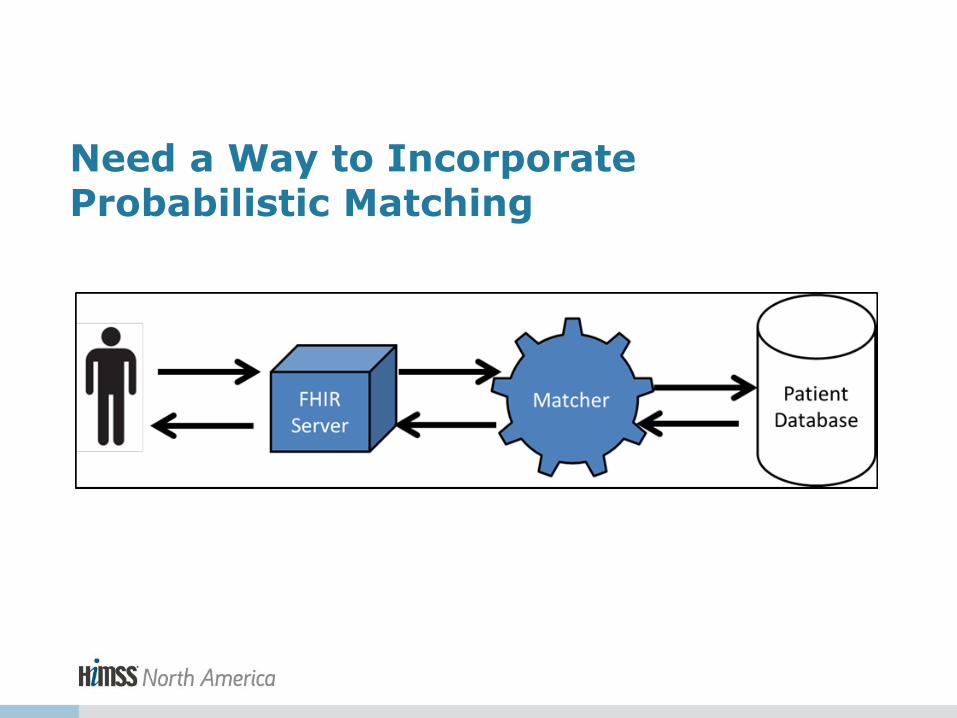
Need a Way to Incorporate Probabilistic Matching

FHIR
• FHIR Necessary But not Sufficient for Interoperability • No Magic Bullet for Matching
– Currently many different matching solutions work well – No standardized solution to allow uniform integration into Health
IT enterprises. • Challenge
– FHIR great solution for connection, structure • Provides more than one way to do things
– Need ability to do complex matching and entity Resolution • Matching Complex Challenge
– Dirty Data – Blocking – Schema Matching – Computational Complexity – Lack of Unique Identifiers or Identifiers
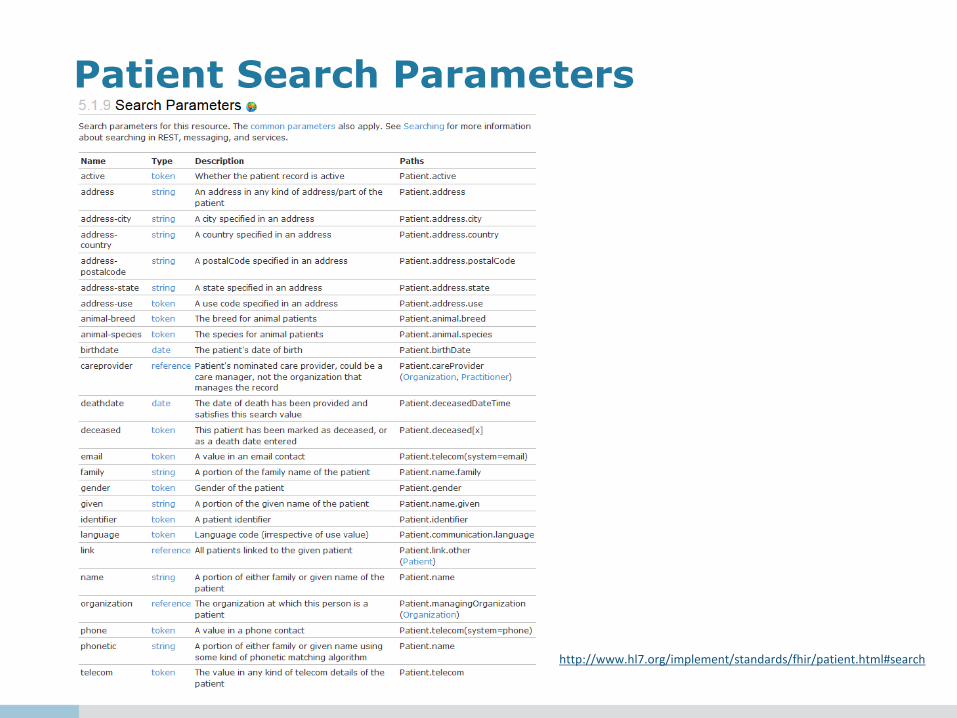
Patient Search Parameters
http://www.hl7.org/implement/standards/fhir/patient.html#search

How FHIR Can Help
• FHIR Enabled Patient Matching – Current matching system have different scoring scales which
makes interpretation of meaning difficult when using different systems.
• 0-1, 0-100%, -4000-40000 – Standardize patient matching score
• -1 – 1, 0-100%, 0-1, (Probable, Possible, Certainly Not), Others • Testing of Patient Matching Systems
– Fit for Use • Algorithms tested on data that is representative of its use case.
– Add validation stamp to returned FHIR profiles • Move towards a specification for patient matchers that allows them to be
interchanged like SMART on FHIR applications

Use Case
• A patient arrives at a provider
• The provider wants to query an eMPI to see if there are existing records for this person

What’s missing to satisfy the use case?
• The user can’t specify min/max matching scores on the returned results
• There is a desire for uniformity on the search score that is returned
– Additionally, information on system validation and training would be helpful in interpreting the results.

Sample Query
• SearchPerson: POST https://pme.mybluemix.net/mdmcloud/pme/search/person
– {
"person": { "legalName": [ { "lastName":"Smith", "givenNameOne":"Tiger" } ], "businessAddress": { "addressLineOne": "12 Main street", "residenceNumber": "22", "city":"Toronto", "provinceState": "Ontario", "zipPostalCode": "M5V 6D8", "country": "Canada“ } } }
https://www.ng.bluemix.net/docs/#services/probabilisticmatch/index.html accessed Feb. 18th 2016

Sample Response
• { "searchPersonResult": [ { "matchType": “CERTAIN", "score": "95", "sourceId": { "primaryKey": "101", "source": "MDMSP" } }, {
• "matchType": "POSSIBLE_MATCH", "score": "94", "sourceId": { "primaryKey": "102", "source": "MDMSP" } },
https://www.ng.bluemix.net/docs/#services/probabilisticmatch/index.ht
ml accessed Feb. 18th 2016

Search Using FHIR
• Advanced Search Abstraction – GET
[base]/Patient?query=name¶meters... • Example
– GET [base]/Patient?given=Robert& \ family=Smith&birthdate=1990-01-01
• This can be leveraged to create a patient matching system interface

Potential Extensions to Search • Single Threshold
• GET [BASE]/Patien?given=Robert&Family=1990-01-01&/score?minscore>=90
• Dual Threshold • GET [BASE]/Patien?given=Robert&Family=1990-01-
01&/score?minscore>=90&maxscore>=95 • Could then cut off matches automatically as non-
match, match, or needs further review

• ONC and MITRE are working on a test harness for patient matching systems
• This test harness specifies a FHIR based interface for patient matching systems
• The interface we specified could be used more broadly than the test harness. It could be a way to provide a FHIR based way to integrate patient matching systems into healthcare enterprises.
A Segway to FHIR Enabled Matching

Test Harness Integration with Record Matching Systems • Desired End State
– FHIR–based interaction between test harness and record matching systems
– Test Harness can facilitate the comparison of match results for the same data set from multiple record matching systems
• Challenge
– Diversity of Record Matching Systems • Variety of mechanisms to ingest data • Variety of mechanisms to select, and sometimes adjust,
matching criteria • Variety of ways to express matching results
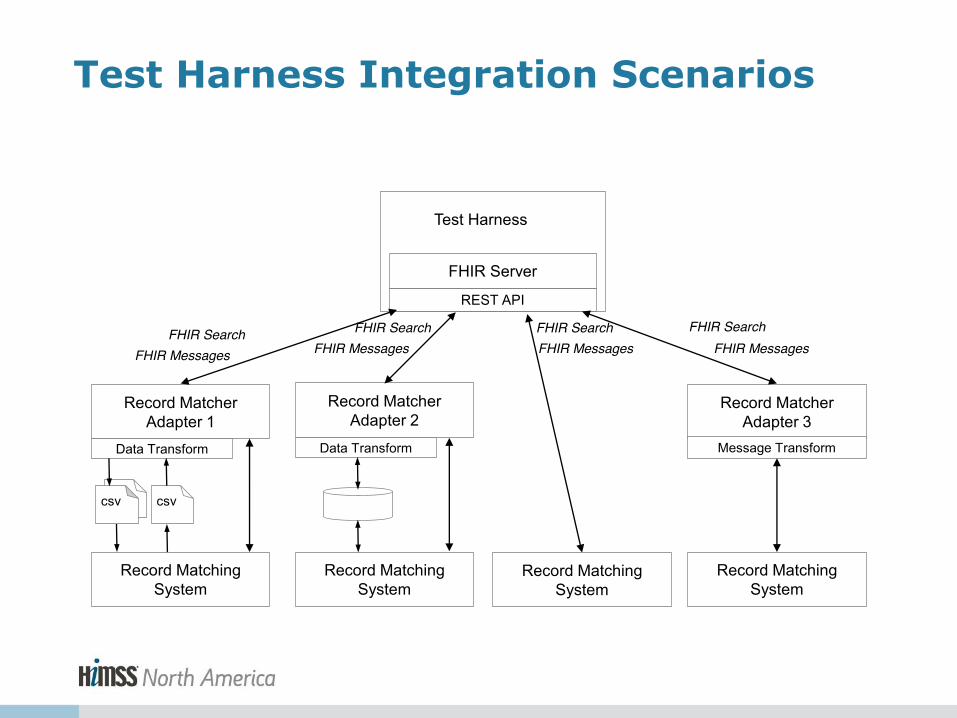
Test Harness Integration Scenarios
csv
Record Matcher Adapter 3
Test Harness
FHIR Server
REST API
FHIR Messages
Record Matching System
Message Transform
Record Matcher Adapter 1
Record Matching System
Data Transform
Record Matcher Adapter 2
Record Matching System
csv csv
Data Transform
Record Matching System
FHIR Messages FHIR Messages FHIR Messages FHIR Search FHIR Search FHIR Search FHIR Search

Test Harness Online Resources
• Interface Specification: http://mitre.github.io/test-harness-interface/
• Implementation (pre-alpha): – Test Harness: https://github.com/mitre/ptmatch
• FHIR Server it depends on: https://github.com/intervention-engine/fhir
– Record Matcher Adapter: https://github.com/mitre/ptmatchadapter

Questions?





























