Embed Size (px)
Citation preview

818 IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, VOL. 15, NO. 2, APRIL 2014
Continuous Head Movement Estimator forDriver Assistance: Issues, Algorithms,
and On-Road EvaluationsAshish Tawari, Student Member, IEEE, Sujitha Martin, Student Member, IEEE, and
Mohan Manubhai Trivedi, Fellow, IEEE
Abstract—Analysis of a driver’s head behavior is an integralpart of a driver monitoring system. In particular, the head poseand dynamics are strong indicators of a driver’s focus of attention.Many existing state-of-the-art head dynamic analyzers are, how-ever, limited to single-camera perspectives, which are susceptibleto occlusion of facial features from spatially large head move-ments away from the frontal pose. Nonfrontal glances away fromthe road ahead, however, are of special interest since interestingevents, which are critical to driver safety, occur during those times.In this paper, we present a distributed camera framework forhead movement analysis, with emphasis on the ability to robustlyand continuously operate even during large head movements.The proposed system tracks facial features and analyzes theirgeometric configuration to estimate the head pose using a 3-Dmodel. We present two such solutions that additionally exploit theconstraints that are present in a driving context and video data toimprove tracking accuracy and computation time. Furthermore,we conduct a thorough comparative study with different cameraconfigurations. For experimental evaluations, we collected a novelhead pose data set from naturalistic on-road driving in urbanstreets and freeways, with particular emphasis on events inducingspatially large head movements (e.g., merge and lane change). Ouranalyses show promising results.
Index Terms—Accident prevention, active safety, distraction,driver attention, driver behavior, driver gaze/glance, driver headdynamics, naturalistic driving, situational awareness.
I. INTRODUCTION
IN 2012 alone, there were 5.6 million police-reported motorvehicle crashes in the U.S., with over 33 000 fatalities,
which is a 3.3% increase from the previous year [1]. Driverdistraction (e.g., phone usage, talking, and eating) and inat-tention (drowsiness, fatigue, etc.) are some of the prominentcauses of the crashes. A comprehensive survey on automotivecollisions, however, demonstrated that a driver was 31% lesslikely to cause an injury-related collision when he had one ormore passengers who could alert him to unseen hazards [2].Consequently, there is great potential for intelligent driverassistance systems (IDASs) that are human centric [3]–[6] toalert the driver of potential dangers or even briefly guide them
Manuscript received July 30, 2013; accepted October 22, 2013. Date of pub-lication February 20, 2014; date of current version March 28, 2014. This workwas supported by the University of California Discovery Grant Program andindustry partners, particularly Audi AG and Volkswagen Electronics ResearchLaboratory. The Associate Editor for this paper was S. S. Nedevschi.
The authors are with the Laboratory for Intelligent and Safe Automobiles,University of California, San Diego, La Jolla, CA 92093 USA.
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TITS.2014.2300870
through a critical situation. Monitoring driver behavior is hencebecoming an increasingly important component of IDASs.
Driver head and eye dynamic behaviors are of particularinterest, as they have the potential to derive where or at whatthe driver is looking. Traditionally, the eye gaze and movementare considered good measures to identify an individual’s focusof attention. Vision-based systems are commonly used for gazetracking as they provide a noncontact and noninvasive solution.However, such systems are highly susceptible to illuminationchanges, particularly in real-world driving scenarios. Eye-gazetracking methods using corneal reflection with infrared illumi-nation have been primarily used indoors [7] but are vulnerableto sunlight. The robustness requirement of IDASs has suggestedthe use of head dynamics. Although a precise gaze direc-tion provides useful information, the head pose and dynamicsprovide a course gaze direction, which is often sufficient ina number of applications [8], [9]. Recent studies have usedhead motion, along with lane position and vehicle dynamics,to predict a driver’s intent to turn [10] and change lanes [11].In fact, head motion cues, when compared with eye-gaze cues,were shown to better predict lane change intent 3 s ahead ofthe intended event [12]. A significant amount of research hasgone toward fatigue and attention monitoring using driver headdynamics [13], [14]. In a more recent study, head dynamics hasbeen used to estimate a driver’s awareness of traffic objects bylearning which objects attract the driver’s gaze depending onthe situation [15].
Automatic head dynamics analysis remains a challengingvision problem. Not only should a head movement analyzerbe robust to ever-changing driving situations but it also needsto be continuously functional in a nonselective manner to gaina driver’s trust. Specifically, such a system should have thefollowing capabilities.
• Automatic: There should be no manual initialization, andthe system should operate without any human interven-tion. This criterion precludes the use of pure trackingapproaches that measure the head pose relative to someinitial configuration.
• Fast: The system must be able to estimate the head posewhile driving, with real-time operation.
• Wide operational range: The system should be able toaccurately and robustly handle spatially large and varyingspeeds of head movements.
• Lighting invariant: The system must work in varyinglighting conditions (e.g., sunny and cloudy).
1524-9050 © 2014 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.

TAWARI et al.: CoHMEt FOR DRIVER ASSISTANCE: ISSUES, ALGORITHMS, AND ON-ROAD EVALUATIONS 819
Fig. 1. Head movements during a merge event. The 3-D model of a headillustrates the observed facial feature from a fixed camera perspective and theself-occlusion that was induced by large head movements.
• Person invariant: The system must work across differentdrivers.
• Occlusion tolerant: The system should work in the pres-ence of typical partially occluding objects (e.g., eyewearand hats) or actions (e.g., hand movements).
Many state-of-the-art vision-based head pose algorithmshave taken the necessary steps to be automatic, fast, and personinvariant [16]. These systems have shown good performancewhen the head pose is near frontal. Martin et al. [24] showthat, during a typical ride, a driver spends 95% of the timefacing forward. Then, a system may be able to reliably perform95% of the time, but it is during those 5% nonfrontal glancesthat are of special interest when interesting events, which arecritical to driver safety, occur. Fig. 1 illustrates the typicaltemporal dynamics of the head pose seen from a fixed single-camera perspective during a merge maneuver. It is shown thatthe head pose quickly goes far from forward facing (about 0◦
in a yaw angle). It is during those times when the performanceof monocular-based systems significantly degrades due to thedecreased visibility of facial features and texture caused by self-occlusion.
Hence, we require a system with new sensing approachesto continuously estimate a driver’s head movement. A naturalchoice for the design of such a system is the use of multicam-eras [17], [18]. Multicamera systems exist in many other ap-plications, such as gesture recognition [19], [20], human bodypose and activity recognition [21], face detection, tracking andpose estimation in intelligent space, etc. A thorough study ofsuch systems in a vehicular setting utilizing naturalistic drivingdata, however, is lacking in literature. To this end, we proposea continuous head movement estimator (CoHMEt), which is akey component for an uninterrupted driver monitoring system.
Our contributions are threefold. First, we propose a dis-tributed camera solution and conduct a thorough study com-paring different configurations of multicameras. Second, wepropose two solutions for the head pose estimation based on ageometric method utilizing state-of-the-art techniques for facial
feature tracking. We introduce the spatiotemporal constraintsthat are available in a driving context to improve the headpose tracking accuracy and computation time. Furthermore,we compare the two solutions for different configurations andshow that the choice of algorithm determines the “best” cameraconfiguration. Finally, we quantitatively demonstrate the suc-cess of this system on the road. For this, we gather a data setthat targets spatially large head turns (away from the frontalpose) during different vehicle maneuvers. Although this makesthe data set challenging, it sets realistic requirements for thevision-based system to be a viable commercial solution. Weevaluate our proposed systems using two metrics, the error inan angular calculation in three degrees of freedom (pitch, yaw,and roll) and the failure rate, which is the percentage of thetime that the system’s output is unreliable. The part hardwareand part software solution of the multicamera perspectives willbe shown to improve the continuous head dynamics estimationduring critical events such as merges, lane changes, and turns.
II. RELATED RESEARCH
Naturalistic driving presents unique challenges for vision-based head dynamics estimation and tracking methods.Amongst research thrust and commercial offerings that canprovide an automatic head pose estimation, most of themlack rigorous and quantitative evaluation in an automobile. Ina car, ever-shifting lighting conditions cause heavy shadowsand illumination changes, and as a result, techniques thatdemonstrate high proficiency in stable lighting often will notwork in on-road driving situations. In this paper, our goal isto advance state-of-the-art technology for the head pose anddynamics estimation targeted for driver assistance systems. Inthis context, we review past works with a focus on systems thathave been evaluated in naturalistic driving or studies conductedin a laboratory/driving simulator setup that have potential buthave yet to be tested under naturalistic driving conditions. For agood overview of the head pose estimation in computer vision,see the survey by Murphy-Chutorian and Trivedi [16].
Head pose estimation algorithms can generally be clas-sified into the following main categories: geometric/shapefeature based, appearance/texture feature based, and hybrid(shape+texture) feature based methods. Methods based onshape features analyze geometric configuration of facial fea-tures along with face model (e.g. cylindrical [46], ellipsoidal[47] or mean 3D face [24]) to recover head pose. Smith etal. proposed several strategies using global motion and colorstatistics to detect and track both eyes, lip corners, and thebounding box of the face [48]. Based on these facial features,they estimated head orientation and gaze direction. However,the method cannot always find facial features when the driverwears eyeglasses, makes conversation or partial occlusion e.g.due to hands. Kaminski et al. analyzed the intensity, shape, andsize properties to detect the pupils, nose bottom, and pupil glints[49]. Using these detected points along with geometric model ofhuman face and eye, head orientation and gaze direction is esti-mated. However, the accuracy of the eye location significantlydrops in the presence of large head movements, causing degra-dation in the performance for deviation from the frontal pose.

820 IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, VOL. 15, NO. 2, APRIL 2014
To circumvent the precise localization of a detailed facialfeature, Ohue et al. proposed simple facial features, i.e., theleft and right borders, and the center of the face [22]. Alongwith these features, the authors used a cylindrical face modelto find the driver’s yaw direction. Lee et al. [8] used a similarshape feature with an ellipsoidal face model to improve theyaw estimate when the head significantly rotates away from thefrontal pose. The authors trained gaze classifiers in a supervisedframework to determine 18 gaze zones. Fu et al. designed asystem that categorizes the head pose into 12 different gazezones based on facial features [23]. The system automaticallylearns the zones based on different calibration points, such asside mirrors, rearview mirrors, etc. It takes, however, severalhours of driving before automatic calibration reaches similaraccuracy as that of the supervised training-based method. It isunclear whether the evaluations are performed in a stationaryor moving vehicle and if the drivers were asked to look towarddefined zones during data collection. A study that was con-ducted on naturalistic driving data by Martin et al. [24] trackedprominent facial features (e.g., eye corners, nose corners, andthe nose tip) and analyzed their geometric configurations toestimate the head pose. This is very similar to one of ourproposed approaches but is limited to a single perspective.
Appearance-based approaches attempt to use holistic facialappearance, where a face is treated as a 2-D pattern of intensityvariations. They assume that there exists a mapping relationshipbetween a 3-D face pose and certain properties of the facialimage, which is constructed based on a large number of trainingimages. Guo et al. [26] utilized the template face images thatwere distributed in the pose space to determine the head pose.The system operates by first finding the face using a cascadeof face detectors, and then, the best face exemplar in thetraining data set is found. The head pose of the exemplar isthe estimated head pose. The study provides little informationon the testing methodology and how the ground truth is ob-tained. Such methods, however, require the precise localizationof faces as matching is often sensitive to localization errors.Bär et al. [29] estimated a driver’s head pose using RGB-Dimages. Multiple templates are used to align 3-D point clouddata using the iterative closest point (ICP) algorithm to obtainthe head pose and, subsequently, a driver’s line of gaze byanalyzing the angles of the eyes in an RGB image. The tem-plate matching algorithm (the ICP algorithm) also suffers frominitialization errors.
Zhu and Ji [25] proposed a system to track the 2-D face loca-tion and the 3-D face pose simultaneously. The 3-D face poseis tracked using Kalman filtering, which, in turn, guides the2-D face localization. The system uses a planar face appearancetemplate to match with the current frame to obtain the bestpose parameters. It, however, requires initialization with thefrontal face, and tracking is performed from this initial position.Similar to other holistic approaches, the use of a full faceappearance template can be very limiting, particularly in a driv-ing scenario due to constant varying illumination conditions.The authors proposed to dynamically update the face model orwhen the track is lost, to use eye detection and fiducial facialfeatures to estimate the rough pose parameters. The evaluationis performed in a laboratory setting. With limited information
about the characteristics of the database, it is not clear how thesystem performs as a function of the out-of-plane rotation.
Wu and Trivedi detected discrete yaw and pitch by using acoarse-to-fine strategy using a quantized pose classifier [27].First, a coarse pose estimate is obtained by nearest prototypematching with Euclidean distance in the subspace of Gaborwavelets. Second, the pose estimate is refined by analyzingthe finer geometrical structure of facial features. This is ahybrid approach combining shape and texture features. Evalu-ations are performed in laboratory settings. More recent stud-ies have taken their research to naturalistic driving, where adriver is asked to drive on highways or urban roads as theywould do in their normal commute. One notable work byMurphy-Chutorian et al. estimated the initial head orientationusing a local gradient orientation feature and support vectorregression [30], which is called a static pose estimator. Finerhead orientations were computed by fitting and tracking a3-D face model. Although the tracking module showed goodperformance, the combined system suffered from inaccurateinitialization.
A summary of select studies, with emphasis on applicabilityto driver assistance systems, is provided in Table I. Apartfrom their original objective, the following important elementsthat are related to the employed methodology and evaluationstrategies are mentioned for comparison with the proposedCoHMEt framework.
• Objective: What is the purpose of the study (e.g., gazeestimation)?
• Methodology:
1) Feature: The type of features used (shape, texture, orhybrid).
2) Perspective: Whether the system utilizes a singlecamera or multicameras.
3) Resolution: Whether the system provides a discreteor continuous head pose estimate.
4) Degrees of freedom: The number of degrees of free-dom in the system output, e.g., rotation, i.e., pitch,yaw, and roll; and position, i.e., x, y, and z valuesfrom a reference frame.
• Evaluations:
1) Operation: Real time versus nonreal time.2) Dataset: In what environment the evaluation is
performed (naturalistic driving, a stationary vehicle,or a laboratory).
3) Metrics: The type of metrics used for the perfor-mance evaluation.
Our proposed approach falls in the category of shape-feature-based methods. Unlike appearance-based methods, they areintuitive and simple to implement (since the cause of failurecan be reasoned out well). The challenge, however, lies in therobust and accurate localization of facial features. With therecent advancements in facial feature tracking methods, werevisit them and perform a thorough evaluation in a naturalisticdriving scenario. Furthermore, with multicameras, we improvethe operational range while maintaining good accuracy. Unlikea stereo camera (an instance of multicameras) setup, we donot have any assumption of the visibility of the faces in both

TAWARI et al.: CoHMEt FOR DRIVER ASSISTANCE: ISSUES, ALGORITHMS, AND ON-ROAD EVALUATIONS 821
TABLE ISELECTED STUDIES ON THE VISION-BASED HEAD POSE AND DYNAMICS ESTIMATION SYSTEMS THAT ARE ALREADY TESTED OR
THAT HAVE POTENTIAL TO WORK IN AN AUTOMOBILE ENVIRONMENT
cameras nor do we require a lengthy calibration process. In fact,our cameras have a wide baseline and are uncalibrated. Theproposed framework independently utilizes them in a parallelfashion, and the results are further analyzed by later stages toprovide the final output.
III. ISSUES AND CHALLENGES IN CONTINUOUS AND
ROBUST HEAD MOVEMENT ANALYSIS
Researchers working on driver monitoring systems, par-ticularly for a driver’s head dynamics analysis, face uniquechallenges. As argued earlier, methods designed and tested incontrolled laboratory settings provide no guarantee of robustperformance in an automobile environment. Hence, a properevaluation on a naturalistic driving database is very muchrequired. The challenge lies in the design of a reliable, con-figurable, and yet affordable database collection module. It isnot just a matter of mounting cameras, but we also requireground truth for proper evaluation. An automobile settingduring driving, however, precludes the conventional methodsused in a laboratory environment, e.g., asking individuals tolook to a certain fixed direction. Care needs to be taken tonot distort the imagery input, e.g., by placing a marker on theface. Manually labeling either the direct head pose information
or, more objectively, the annotation of facial features can pro-vide head pose measurement. However, with the video data at30 frames/sec, it quickly becomes a daunting task and rendersitself practically infeasible. One good candidate could be mag-netic sensors. They are extensively used in laboratory settingswithout cluttering or obscuring visual data. However, they canbe unreliable in an automobile due to their high susceptibilityto noise and the presence of metal in the environment. Opticalmotion capture systems do provide a very reliable solution.However, they are often very expensive with bulky equipmentand require lengthy calibration. Inertial sensors utilizing ac-celerometers, gyroscopes, or other motion sensing devices canprovide a compact, inexpensive, and clean solution. However,they often suffer from drift associated with a gyroscope. Thiscan be solved, as proposed in this paper, by small amounts ofmanual annotation.
Another important aspect is the number of camera(s) andtheir placement. A camera should neither block a driver’sview for safe driving nor should its presence alter a driver’sbehavior. At the same time, the placement should not be proneto frequent occlusion. A choice of placement can very muchbe application dependent, although a desirable choice wouldbe one that covers as large a pose space, which is generallyexhibited by a driver during a typical ride, as possible. From a

822 IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, VOL. 15, NO. 2, APRIL 2014
computer vision perspective, however, the intrinsic propertiesof head dynamics present a challenge to the robustness of manyexisting algorithms. As described earlier, many existing state-of-the-art head pose estimation algorithms, either explicitly orimplicitly, rely on a portion of the face to be visible in theimage plane to estimate the head pose. This means that, evenduring large head movements, algorithms require the visibilityof facial features to continuously track the state of the head.With a single perspective of the driver’s head, however, largespatial head movements induce self-occlusion of facial features,as illustrated in the first two columns in Fig. 2. In Fig. 2, eachrow of images is taken from a different camera perspective,and each column of images is time synchronized. Clearly, theavailability of multiperspectives decreases the severity of self-occlusion at any instant in time, which translates to an increasein the robustness of the continuous head tracking.
Occlusion of facial features can also occur due to externalobjects (e.g., hand movements near the face region and sun-glasses). Depending on the camera perspective, the hand move-ments on a steering wheel during vehicle maneuvers, adjustingsunshade, pointing, etc., can cause occlusion. The two middlecolumns in Fig. 2 show examples of the latter two scenarioswith hand movements. The effects of lighting conditions arealso highly dependent on the camera location. In Fig. 2, thelast two columns illustrate the effects of lighting conditions.Therefore, a multiperspective approach with suitable cameraplacements can mitigate the adverse effect of any one cameraperspective being unreliable to track the head.
IV. CoHMEt: FRAMEWORK AND ALGORITHMS
Continuously and accurately monitoring a driver’s headmovement even during large deviations from the frontal poserequires an improved operating range of the head pose trackingsystem. For this, we propose a distributed camera framework in-side the vehicle cockpit. The framework treats each camera per-spective independently, and a perspective selection procedureprovides the final head pose estimation by analyzing temporaldynamics and the current quality of the estimated head posein each perspective. For the head pose estimation, we presenta geometric method where local features, such as eye corners,nose corners, and the nose tip, and their relative 3-D configura-tions, determine the pose. In the following sections, we presentautomatic facial feature detection and tracking methods, a poseestimation approach, and a perspective selection procedurein detail.
A. Facial Feature Detection and Tracking
In this paper, facial features refer to salient landmarks onthe face, such as eye corners, nose corners, the nose tip,the mouth contour, and the outer face contour, as shown inFig. 5. We present two formulations for automatic facial featuredetection and tracking based on two separate feature detectionmethods, i.e., the constrained local model (CLM) introduced byCristinacce and Cootes [31], [32] and the pictorial structurematching proposed by Felzenszwalb and Huttenlocher [33].Unlike images, video data provide temporal constraints; more-
over, a driving setting imposes spatial constraints on the de-tected facial features in the image plane. In our formulations,we introduce these spatiotemporal constraints to improve thetracking accuracy by reducing false detection and the computa-tion cost by reducing the search space.
1) CLM: The CLM represents objects, in our case, faces, us-ing local appearance descriptions centered around landmarks ofinterest and the parameterized shape model of those landmarks.A local representation of appearance circumvents many draw-backs of a holistic approach (e.g., the active appearance model),such as modeling complexity and sensitivity to illuminationchanges, and shows superior generalization performance tonovel unseen faces. The local descriptors are generally learnedfrom labeled training images for each landmark. These localrepresentations, however, are often ambiguous mainly due toa small support region with large appearance variation in thetraining data. The effect of the ambiguity is typically reducedby the shape model that constrains the joint positioning of thelandmarks.
A parameterized shape model to capture plausible deforma-tions of landmark locations is given in the following, which isalso known as a point distribution model (PDM), a term coinedby Cootes and Taylor [34]:
pi = sR2D(p̄i +Φiq) + t (1)
where pi = (xi, yi) is the 2-D location of the ith landmarkin image I. p̄i is the 2-D location of the ith landmark ofthe mean shape, and Φi encodes the shape variations. Rigidparameters θrg = {s, R2D, t}, with global scaling s, in-planerotation R2D, and translation t, along with nonrigid parameterq, represent the parameters of the PDM.
Let us define θ = {θrg, q}. The objective of the CLM, then,can be defined in a probabilistic framework as maximizingthe likelihood of the model parameters such that all of thefacial landmarks are aligned to their corresponding locations.With the assumption of conditional independence among thedetection of each landmark, the objective function becomes
L (θ|{li = 1}ni=1, I) = p ({li = 1}ni=1|θ, I)
=n∏
i=1
p(li = 1|θ, I) (2)
where li ∈ {+1, −1} is a discrete random variable denotingwhether the ith landmark is aligned or not.
To facilitate the optimization process so that it is efficientand numerically stable, the true response map p(li = 1|θ, I)of the local detectors are approximated by various models, suchas the parametric representation, i.e., the Gaussian density withdiagonal covariance [35], full covariance [36], and the Gaussianmixture model [37]; or the nonparametric representation, i.e.,the kernel density estimate (KDE) [38]. In our current imple-mentation, we chose the KDE for its fast convergence propertywith good tracking ability [38]. It has shown its efficacy inother applications as well, such as face expression recognition[39]. In the method, landmark locations are optimized viasubspace constrained mean shifts while enforcing their jointmotion via a shape model. The maximum likelihood estimate

TAWARI et al.: CoHMEt FOR DRIVER ASSISTANCE: ISSUES, ALGORITHMS, AND ON-ROAD EVALUATIONS 823
Fig. 2. Multiperspective data collected during naturalistic on-road driving. Each row of images shows that the images are from a particular camera location, andeach column of images is time synchronized. Locations of the camera: Camera 1 is near the left A pillar, Camera 2 is close to the dashboard, and Camera 3 is nearthe rearview mirror. Notice that challenges (e.g. external/self-occlusion, shadows, and illumination change) are present in real-world data.
of the parameters, however, does not exploit the constraintsetting present in the driving context. Since a driver’s seatlocation is fixed while driving, the body and head locationsare restricted, along with the head orientation observed fromthe fixed camera perspective. To incorporate these constraints,we learn the parameter space, particularly for rigid parametersθrg , online. We need to learn this online since each driver hasa different seat setting that is suitable for their driving.
To learn the probable face location and face size, face detec-tion is used to find bounding boxes Bi for the first NB facedetected frames as follows:
Bi = [ximin yimin xi
max yimax]
where i ∈ 1, . . . , NB . A restricted face region B∗ is obtained as
H(x, y) =∑Bi
U[x− xi
min
]U[y − yimin
]− U
[x− xi
max
]U[y − yimax
](3)
M(x, y) =U
[H(x, y)
γ− α
](4)
BR(P ) =
{(minx∈P
x, miny∈P
y, maxx∈P
x, maxy∈P
y
)}(5)
where U [·] is the unit step function, and normalization fac-tor γ = maxx, y H(x, y). α ∈ (0, 1) is a tuning parameter tocontrol the size of the expected face region M(x, y). A tightbounding rectangle BR(·), as defined in (5), is calculated usingthe set of points P = {p = (x, y) | M(x, y) > 0}. We callthis minimum bounding rectangle B∗ the restricted face region.Fig. 3 depicts the overall process. The estimated facial land-mark location pi within B∗ is considered admissible. Similarly,the probable size of the face is proportional to the size of B∗.Finally, the rotation parameter is inferred from the estimatedroll angle of the driver’s head. The estimated value within ±20◦
is considered admissible. When the estimated parameters do notsatisfy the given conditions, they are discarded, and the systemis reinitialized. This helps reduce false detection and improve
Fig. 3. Illustration of the online learning process of estimating the restrictedface region in the image plane.
the tracking quality (the accuracy and the failure rate). This isthe case since, during the optimization process, an initial guessof the parameters is based on the previous output. When there isno output from the previous frame, the face detection output inthe current frame is used to initialize the parameters. Discardingthe estimation, however, amounts to no system output, whichwe account for in one of the performance metrics, as explainedin Section V-B.
2) Mixture of Pictorial Structures (MPS): Using pictorialstructures, a face is modeled by a collection of parts arranged ina deformable configuration, where each part captures the localvisual descriptions of the face, and the spring-like connectionsbetween a certain pair of parts capture the deformable configu-ration [40]. This is naturally represented by an undirected graphG = (V, E), where vertices V = {v1, . . . , vn} correspond to nparts, and for each pair of connected parts, there exists an edge

824 IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, VOL. 15, NO. 2, APRIL 2014
Fig. 4. Process of reducing the search space for video analysis using the mixture of pictorial structures. The part space is reduced by constraining the regionaround the face location in the previous frame, as illustrated by the red box. Similarly, the mixture space is reduced by searching over the neighboring mixturecomponents around the estimated component from the previous frame, as illustrated by dotted blue box.
Fig. 5. Tracked facial feature/landmarks and their correspondences in a3-D face image. The solid red circles are the points utilized for the head posecalculation.
(vi, vj) ∈ E . A mixture of pictorial structures further capturesthe topological changes of the face due to varying head orien-tations. The best configuration of parts is found by maximizinga score function that measures both the appearance similaritySA(It, pi, m) of placing the ith part (i.e., node vi) at locationpi = (xi, yi) and the likely deformation SD(It, pi, pj , m)for each pair of connected parts. Optimization proceeds bymaximizing over all mixtures as follows:
S(It, P, m)=
nm−1∑i=0
SA(It, pi,m)+∑
(vi, vj)∈ESD(It, pi, pj , m)
S∗(It, P∗)= maxm∈{m̂t}
[max
p∈{P̂t}S(It, p, m)
]where m̂t ∈ M is a subset of all mixtures M defined by (6),and P̂ t is a rectangular region of interest defined by (8).
In literature, appearance similarity SA(It, pi, ·) is mod-eled in various ways, e.g., Gaussian derivative filter responsearound a point [33] and a feature-based description, such asthe histogram of gradient [41], the Haar-like feature [42], etc.SD(It, pi, pj , ·) is a distance function, e.g., a Mahalanobisdistance in some transformed space of pi and pj . In our imple-mentation, we use a discriminative and max-margin framework[41] to model the two scoring functions. Here, G for each mix-ture is a tree, and the optimization is efficiently performed withdynamic programming [33]. To improve the computation time,
Fig. 6. Perspective selection approach. The tracking phase utilizes the headpose and dynamics to switch between perspectives, whereas a scoring criterionduring a lost track reinitializes with the highest score camera.
we further incorporated spatiotemporal constraints to reducethe search space. First, the possible solutions for a configurationof parts are constrained to lie within a region where the headwas found in the previous frame. Second, the enumerations overall mixture components for the current frame can be reduced toneighboring mixture components around the estimate from theprevious frame as follows:
m̂t =m∗t−l + {−1, 0, 1} (6)
m∗t−1 = argmax
m∈{m̂t−1}
[max
p∈{P̂t−1}S(It, p, m)
](7)
P̂ t ={pi|pi ∈
(BR
(P ∗
t−1
)+ (−b, −b, +b, +b, )
)}(8)

TAWARI et al.: CoHMEt FOR DRIVER ASSISTANCE: ISSUES, ALGORITHMS, AND ON-ROAD EVALUATIONS 825
Fig. 7. Illustration of the multiperspective framework on a segment taken from a subject’s naturalistic on-road driving experiment. The horizontal axis representsthe frame number (w.r.t. the left camera), and the vertical axis represents the head rotations in the yaw rotation angle relative to the car reference frame. The blueasterisks represent the left camera, the red circles represent the center camera, and the magenta crosses represent the right camera. The plot shows the head scanby the driver from the left to the right mirror starting from the front pose. The evolution of the perspective selection is presented.
where m∗t−l is the mixture chosen for the previous frame It−1,
BR(·) is defined in (5), and b is the border width. Fig. 4depicts the overall process. These optimizations decreased theprocessing time by at least four folds.
B. Pose Estimation
Given a 3-D model of an object, the pose from orthographyand scaling (POS) [43] finds the position and orientation of thecamera coordinate with respect to the object reference frame.It minimizes the reprojection error using a weak perspectivetransform. Given a point on a 3-D model, e.g., Mi, and itsmeasured projection in the image plane, e.g., pi = (xi, yi),POS solves the following linear system of equations:
M0Mi · αi = x0xi, i = 1, . . . , Nc
M0Mi · αj = y0yi, i = 1, . . . , Nc
where M0Mi represents the vector from the reference pointon the 3-D model M0 to Mi, α is the scale factor associatedwith the weak perspective projection, and Nc is the numberof 3-D–2-D point correspondences. Vectors i and j form thefirst two rows of the rotation matrix, and the third row is givenby vector k = i× j, which is a cross product. Note, however,that, although k is perpendicular to i and j, vectors i and jare not necessarily perpendicular due to noisy 3-D–2-D point
correspondences. Therefore, the rotation matrix is projectedinto the SO(3) space by normalizing the magnitude of theeigenvalues.
To solve this system of equations, POS requires at least fourpoints of correspondences in general positions. The CLM andthe mixture of pictorial structures model, however, output morethan four fiducial points. In our current implementation, we usethe following fiducial points, i.e., four eye corners, two nosecorners, and a nose tip, as they are less deformable. Fig. 5shows these points (the red solid circle) on a test image andits corresponding points on the 3-D mean face model.
C. Perspective Selection Procedure
CoHMEt independently tracks the head in each camerastream, and their outputs are further analyzed to choose the bestperspective and corresponding head pose. The block diagram inFig. 6 illustrates this process for a general setup of N cameras,where the cameras are numbered in the increasing order fromthe leftmost position in the distributed camera array setup.In the proposed system, we utilize three cameras that werepositioned to the left, front, and right of the driver, respectively,as shown in Fig. 8. The system is initialized with the frontcamera, and during the tracking phase, transitions from oneperspective to another are allowed based on the operating range
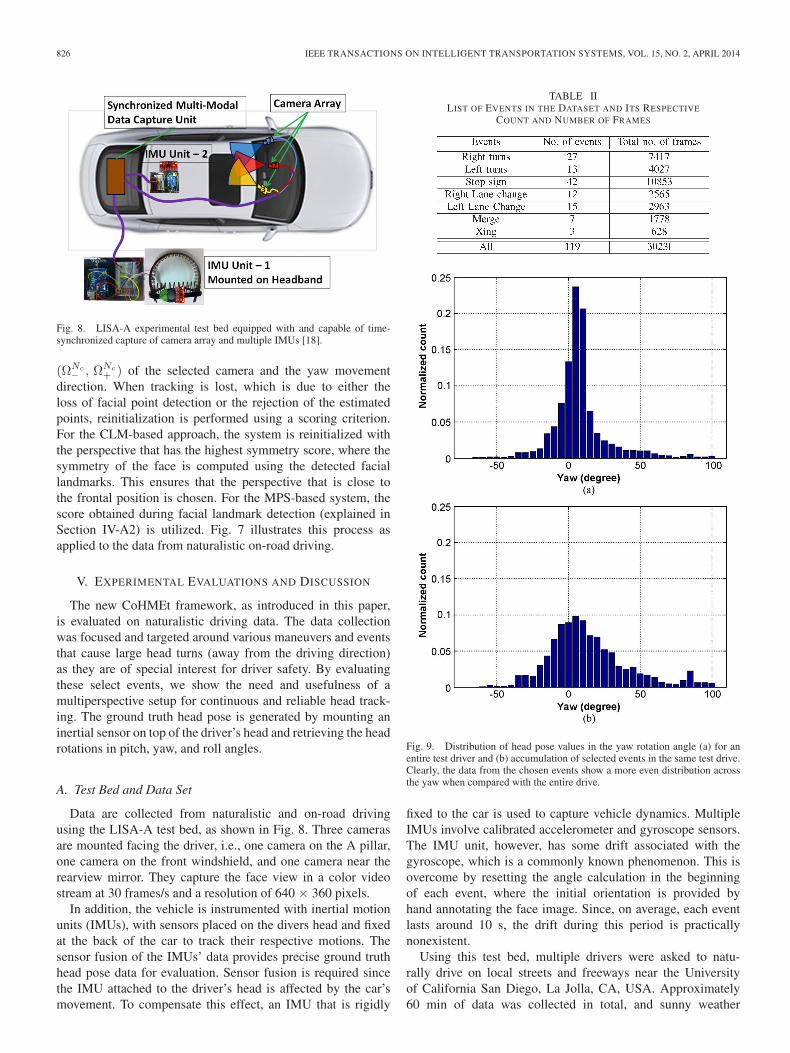
826 IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, VOL. 15, NO. 2, APRIL 2014
Fig. 8. LISA-A experimental test bed equipped with and capable of time-synchronized capture of camera array and multiple IMUs [18].
(ΩNc− , ΩNc
+ ) of the selected camera and the yaw movementdirection. When tracking is lost, which is due to either theloss of facial point detection or the rejection of the estimatedpoints, reinitialization is performed using a scoring criterion.For the CLM-based approach, the system is reinitialized withthe perspective that has the highest symmetry score, where thesymmetry of the face is computed using the detected faciallandmarks. This ensures that the perspective that is close tothe frontal position is chosen. For the MPS-based system, thescore obtained during facial landmark detection (explained inSection IV-A2) is utilized. Fig. 7 illustrates this process asapplied to the data from naturalistic on-road driving.
V. EXPERIMENTAL EVALUATIONS AND DISCUSSION
The new CoHMEt framework, as introduced in this paper,is evaluated on naturalistic driving data. The data collectionwas focused and targeted around various maneuvers and eventsthat cause large head turns (away from the driving direction)as they are of special interest for driver safety. By evaluatingthese select events, we show the need and usefulness of amultiperspective setup for continuous and reliable head track-ing. The ground truth head pose is generated by mounting aninertial sensor on top of the driver’s head and retrieving the headrotations in pitch, yaw, and roll angles.
A. Test Bed and Data Set
Data are collected from naturalistic and on-road drivingusing the LISA-A test bed, as shown in Fig. 8. Three camerasare mounted facing the driver, i.e., one camera on the A pillar,one camera on the front windshield, and one camera near therearview mirror. They capture the face view in a color videostream at 30 frames/s and a resolution of 640 × 360 pixels.
In addition, the vehicle is instrumented with inertial motionunits (IMUs), with sensors placed on the divers head and fixedat the back of the car to track their respective motions. Thesensor fusion of the IMUs’ data provides precise ground truthhead pose data for evaluation. Sensor fusion is required sincethe IMU attached to the driver’s head is affected by the car’smovement. To compensate this effect, an IMU that is rigidly
TABLE IILIST OF EVENTS IN THE DATASET AND ITS RESPECTIVE
COUNT AND NUMBER OF FRAMES
Fig. 9. Distribution of head pose values in the yaw rotation angle (a) for anentire test driver and (b) accumulation of selected events in the same test drive.Clearly, the data from the chosen events show a more even distribution acrossthe yaw when compared with the entire drive.
fixed to the car is used to capture vehicle dynamics. MultipleIMUs involve calibrated accelerometer and gyroscope sensors.The IMU unit, however, has some drift associated with thegyroscope, which is a commonly known phenomenon. This isovercome by resetting the angle calculation in the beginningof each event, where the initial orientation is provided byhand annotating the face image. Since, on average, each eventlasts around 10 s, the drift during this period is practicallynonexistent.
Using this test bed, multiple drivers were asked to natu-rally drive on local streets and freeways near the Universityof California San Diego, La Jolla, CA, USA. Approximately60 min of data was collected in total, and sunny weather

TAWARI et al.: CoHMEt FOR DRIVER ASSISTANCE: ISSUES, ALGORITHMS, AND ON-ROAD EVALUATIONS 827
Fig. 10. Setup of the one-camera view, the two-camera view, and the three-camera view, as discussed and compared for the performance evaluation of themultiview framework. The single-view setup is composed of the center camera only. The two-camera view setup is composed of the left and right cameras. Thethree-camera view setup is composed of the left, center, and right cameras.
TABLE IIION-ROAD PERFORMANCE EVALUATIONS OF THE PROPOSED CoHMEt
conditions allowed for varying lighting conditions. Addition-ally, driving in an urban setting, the drivers passed throughmany stop signs and made multiple turns, and driving on thefreeway allowed for multiple lane change occurrences, resultingin a data set with wide spatial changes in the head pose.
From the collected data, we select events when the driveris making right/left turns, right/left lane changes, stops at stopsigns, and freeway merges. Table II shows the events consid-ered, their respective counts during the total 60-min drive con-taining all drivers, and the total number of frames accumulatedfor each event. The evaluations reported in the following sectionwill be on these selected events. It is important to note thateach event can induce more than one sequence of spatiallywide head movements. Fig. 9 shows a typical histogram ofyaw angle distribution during a test drive. It is shown that,while considering the entire drive, the driver is near frontalfacing most of the time [see Fig. 9(a)]. However, the yawangle distribution is more spread out for the chosen events [seeFig. 9(b)].
B. On-Road Performance Evaluation
A series of experiments involving the naturalistic on-roaddata are conducted to characterize the performance of CoHMEt.The performance of CoHMEt, with three cameras and twocameras, are compared with the performance of a single-viewapproach. The spatial distribution of cameras for a three-, two-,and one-camera view from a top–down perspective is illustratedin Fig. 10. For a quantitative evaluation over the database,three metrics are used, i.e., the mean absolute error (MAE),the standard deviation error (STD), and the failure rate (thepercentage of the time when the system’s output is unreliable).Head tracking is considered lost if the estimated head poseis not available or is more than 20◦ from the ground truth ineither direction of the yaw rotation angle. The number of frames(where the head tracking is lost) normalized by the total numberof frames over all the events, gives failure rate.
As shown in Table III, the MPS+POS system shows ageneral trend of improvement in the failure rate from the one-
camera view to the two-camera view to the three-camera view.The best performance of 3.9% failure rate is achieved with thethree-camera view compared with that of over 15% for thesingle view, which is a significant improvement. However,for the CLM+POS system, the two-camera view performedthe worst. This is because the CLM+POS system requires anear frontal pose for initialization, and the front camera isabsent in the two-camera view configuration. The three-cameraview with the front camera again performed the best, with thefailure rate dropping by a half compared with the single frontcamera view. Hence, the choice of algorithms and the cameraconfigurations are tightly coupled. This is further discussed inthe following. In Table III, also notice that, irrespective of thenumber of cameras (observing each column), the MPS+POSalgorithm outperforms the CLM+POS approach. This can beattributed to the ability of the MPS formulation to incorporatethe global topological variation of the facial landmark due tothe different pose using different mixture components. Thedrawback of MPS, however, is computational complexity. Inour experiments, using an Intel 3.0-GHz central processingunit, the MPS+POS system without search space reduction, asexplained in Section IV-A., took ∼13 s to process one frameand that with search space reduction took ∼3 s for one frame,which is a fourfold improvement. The CLM+POS system, onthe other hand, runs in real time with ∼25 frames/s.
The MAE and STD for pitch, yaw, and roll are relativelysimilar across different configurations and the placements ofcameras. This is expected since a multicamera system indepen-dently combines each camera and is bounded by the single-viewaccuracy. Although a direct comparison with other reportederror rates in literature may not be appropriate, e.g., due todifferent databases, to put in perspective, we refer to the resultsof the study by Murphy-Chutorian and Trivedi [28], which areevaluated on on-road data. The authors reported that MAE is< 5◦ in the yaw angle when the system is initialized with theground truth. However, the fully automatic system had MAE> 10◦ in the yaw angle with a large STD of ≈ 17◦. Ourproposed framework, which is evaluated on the challengingnaturalistic on-road data set, has shown good results.

828 IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, VOL. 15, NO. 2, APRIL 2014
Fig. 11. Error distribution with respect to the true head pose in yaw. The graphs reflect the first three error quartiles respective of the true head pose in yaw forthe one-camera perspective (first column), the two-camera perspective (second column), and the three-camera perspective (third column) using the CLM+POSsystem (first row) and the MPS+POS system (second row).
Fig. 12. Quality of the head pose estimation from individual camera viewswith respect to the head orientations in the yaw angle, which is a useful meansof configuring the camera positions to maximize the operational range of theoverall system.
Next, we show in Fig. 11 the absolute yaw error statisticsas a function of the true yaw angle with respect to the frontcamera. The figure shows the first, second, and third quartileof the errors associated with the respective yaw bins. It canbe observed that the single-camera system quickly loses trackswith a high estimation error beyond 30◦ in either direction.However, the multicamera system is able to keep track over amuch wider span with better error statistics. Moreover, noticethat higher errors are associated at the two extremes, which isdue to the decreased visibility of facial landmarks caused byself-occlusion.
Finally, we conduct an experiment to study the operationalrange of the system and, for a given choice of an algorithm,how to obtain the “best” camera placement. We chose theMPS+POS system for this experiment since the MPS formu-lation provides a facial feature detection score (the higher thebetter), which we refer to here as quality. Fig. 12 shows the
quality of each of the three cameras as a function of the trueyaw angle. Given a desired level of quality, this can providethe operational range of a camera and how cameras should beplaced with respect to each other to maximize the operationalrange of the overall system.
VI. CONCLUDING REMARKS
Robust systems for observing the driver behavior will play akey role in the development of IDASs. Analyzing the driver’shead movement is becoming an increasingly important aspectof such systems, since it is a strong indicator of the driver’sfield of view, current focus of attention, and intent. In adriving environment, the driver is prone to make large spatialhead movements during maneuvers such as lane changes andright/left turns. During these crucial moments, it is importantto continuously and reliably track the head of the driver.Moreover, the system needs to perform uninterrupted with highaccuracy to be accepted and trusted by the driver.
In this paper, we have proposed CoHMEt to address thegiven design criteria. We have presented two approaches offacial feature tracking to compute the head pose, and wehave conducted systematic comparative studies with differ-ent configurations of multicamera systems. The best systemcould reliably track the head movement over 96% of the time.The evaluations are performed over the naturalistic real-worlddriving data set, which is a must as they present the actualscenario. To this end, we have collected a unique and noveldata set of naturalistic driving with distributed cameras. Thedata set targets spatially large head turns (away from the drivingdirection) during different maneuvers (e.g., merge and lanechange) on urban streets and freeways. Going forward, we willpursue a unified framework to combine the two approaches toimprove the computational cost without sacrificing the failurerate and the head pose error. Finally, the CoHMEt framework

TAWARI et al.: CoHMEt FOR DRIVER ASSISTANCE: ISSUES, ALGORITHMS, AND ON-ROAD EVALUATIONS 829
can be also adapted in other “intelligent environments” withmultiple participants [44] and multiple sensory cues [45].
ACKNOWLEDGMENT
The authors would like to thank the reviewers and theeditors for their constructive and encouraging feedback, theircolleagues, particularly N. Kumar and A. Corelli for their helpin the test bed configuration, and S. Sivaraman and E. Ohn-Barfor their comments and suggestions to improve this paper.
REFERENCES
[1] NHTSA, 2012 Motor Vehicle Crashes: Overview (dot-hs-811-856),www-nrd.nhtsa.dot.gov/Cats, 2013. [Online]. Available: http://www-nrd.nhtsa.dot.gov/Pubs/811856.pdf
[2] T. Rueda-Domingo, P. Lardelli-Claret, J. d. D. Luna-del Castillo,J. J. Jiménez-Moleón, M. Garcıa-Martın, and A. Bueno-Cavanillas, “Theinfluence of passengers on the risk of the driver causing a car collision inspain: Analysis of collisions from 1990 to 1999,” Accident Anal. Prev.,vol. 36, no. 3, pp. 481–489, May 2004.
[3] M. M. Trivedi, T. Gandhi, and J. McCall, “Looking-in and looking-out ofa vehicle: Computer-vision-based enhanced vehicle safety,” IEEE Trans.Intell. Transp. Syst., vol. 8, no. 1, pp. 108–120, Mar. 2007.
[4] M. M. Trivedi and S. Y. Cheng, “Holistic sensing and active displays forintelligent driver support systems,” Computer, vol. 40, no. 5, pp. 60–68,May 2007.
[5] K. S. Huang, M. M. Trivedi, and T. Gandhi, “Driver’s view and vehiclesurround estimation using omnidirectional video stream,” in Proc. IEEEIntell. Veh. Symp., 2003, pp. 444–449.
[6] A. Doshi, S. Y. Cheng, and M. M. Trivedi, “A novel active heads-up dis-play for driver assistance,” IEEE Trans. Syst., Man, Cybern., B, Cybern.,vol. 39, no. 1, pp. 85–93, Feb. 2009.
[7] E. D. Guestrin and M. Eizenman, “General theory of remote gaze estima-tion using the pupil center and corneal reflections,” IEEE Trans. Biomed.Eng., vol. 53, no. 6, pp. 1124–1133, Jun. 2006.
[8] S. J. Lee, J. Jo, H. G. Jung, K. R. Park, and J. Kim, “Real-time gazeestimator based on driver’s head orientation for forward collision warningsystem,” IEEE Trans. Intell. Transp. Syst., vol. 12, no. 1, pp. 254–267,Mar. 2011.
[9] A. Doshi and M. M. Trivedi, “Head and eye gaze dynamics during visualattention shifts in complex environments,” J. Vis., vol. 12, no. 2, pp. 1–15,Feb. 9, 2012.
[10] S. Y. Cheng and M. M. Trivedi, “Turn-intent analysis using body posefor intelligent driver assistance,” IEEE Pervasive Comput., vol. 5, no. 4,pp. 28–37, Oct.-Dec. 2006.
[11] J. C. McCall, D. P. Wipf, M. M. Trivedi, and B. D. Rao, “Lanechange intent analysis using robust operators and sparse bayesian learn-ing,” IEEE Trans. Intell. Transp. Syst., vol. 8, no. 3, pp. 431–440,Sep. 2007.
[12] A. Doshi and M. Trivedi, “On the roles of eye gaze and head dynamicsin predicting driver’s intent to change lanes,” IEEE Trans. Intell. Transp.Syst., vol. 10, no. 3, pp. 453–462, Sep. 2009.
[13] S. Baker, I. Matthews, J. Xiao, R. Gross, T. Kanade, and T. Ishikawa,“Real-time non-rigid driver head tracking for driver mental state esti-mation,” Carnegie Mellon Univ., Tech. Rep. CMU-RI-TR-04-10, Robot.Inst., Feb. 2004.
[14] J. P. Batista, “A real-time driver visual attention monitoring system,” inProceedings of the Second Iberian conference on Pattern Recognitionand Image Analysis—Volume Part I. Berlin, Germany: Springer-Verlag,2005, pp. 200–208.
[15] T. Bär, D. Linke, D. Nienhüser, and J. M. Zöllner, “Seen and missed trafficobjects: A traffic object-specific awareness estimation,” in Proc. IEEEIntell. Veh. Symp., Jun. 2013, pp. 31–36.
[16] E. Murphy-Chutorian and M. Trivedi, “Head pose estimation in computervision: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 4,pp. 607–626, Apr. 2009.
[17] S. Martin, A. Tawari, and M. M. Trivedi, “Monitoring head dynamics fordriver assistance systems: A multi-perspective approach,” in Proc. IEEEInt. Conf. Intell. Transp. Syst., 2013, pp. 2286–2291.
[18] A. Tawari and M. M. Trivedi, “Head dynamic analysis: A multi-viewframework,” in Proc. Workshop Soc. Behaviour Anal., Int. Conf. ImageAnal. Process., 2013, pp. 536–544.
[19] K. S. Huang and M. M. Trivedi, “Robust real-time detection, tracking, andpose estimation of faces in video streams,” in Proc. 17th Int. Conf. PatternRecog., 2004, vol. 3, pp. 965–968.
[20] C. Tran and M. Trivedi, “3-d posture and gesture recognition forinteractivity in smart spaces,” IEEE Trans. Ind. Informat., vol. 8, no. 1,pp. 178–187, Feb. 2012.
[21] M. Holte, C. Tran, M. Trivedi, and T. Moeslund, “Human pose esti-mation and activity recognition from multi-view videos: Comparativeexplorations of recent developments,” IEEE J. Sel. Topics Signal Process.,vol. 6, no. 5, pp. 538–552, Sep. 2012.
[22] K. Ohue, Y. Yamada, S. Uozumi, S. Tokoro, A. Hattori, and T. Hayashi,“Development of a new pre-crash safety system,” presented at the SAEWorld Congress Exhibition, Detroit, MI, USA, Apr. 3, 2006, ser. SAETechnical Paper 2006-01-1461.
[23] X. Fu, X. Guan, E. Peli, H. Liu, and G. Luo, “Automatic calibra-tion method for driver’s head orientation in natural driving environ-ment,” IEEE Trans. Intell. Transp. Syst., vol. 14, no. 1, pp. 303–312,Mar. 2013.
[24] S. Martin, A. Tawari, E.-M. Chutorian, S. Y. Cheng, and M. M. Trivedi,“On the design and evaluation of robust head pose for visual user in-terfaces: Algorithms, databases, and comparisons,” in Proc. 4th ACMSIGCHI Int. Conf. AUTO-UI, 2012, pp. 149–154.
[25] Z. Zhu and Q. Ji, “Real time 3d face pose tracking from an uncalibratedcamera,” in Proc. Conf. CVPRW, 2004, p. 73, IEEE.
[26] Z. Guo, H. Liu, Q. Wang, and J. Yang, “A fast algorithm face detectionand head pose estimation for driver assistant system,” in Proc. 8th Int.Conf. Signal Process., 2006, vol. 3.
[27] J. Wu and M. M. Trivedi, “A two-stage head pose estimation frame-work and evaluation,” Pattern Recog., vol. 41, no. 3, pp. 1138–1158,Mar. 2008.
[28] E. Murphy-Chutorian and M. Trivedi, “Head pose estimation and aug-mented reality tracking: An integrated system and evaluation for moni-toring driver awareness,” IEEE Trans. Intell. Transp. Syst., vol. 11, no. 2,pp. 300–311, Jun. 2010.
[29] T. Bär, J. F. Reuter, and J. M. Zöllner, “Driver head pose and gaze esti-mation based on multi-template icp 3-d point cloud alignment,” in Proc.IEEE ITSC, 2012, pp. 1797–1802.
[30] E. Murphy-Chutorian, A. Doshi, and M. M. Trivedi, “Head pose estima-tion for driver assistance systems: A robust algorithm and experimentalevaluation,” in Proc. IEEE Conf. Intell. Transp. Syst., 2007, pp. 709–714.
[31] D. Cristinacce and T. F. Cootes, “A comparison of shape constrained facialfeature detectors,” in Proc. 6th Int. Conf. Autom. Face Gesture Recog.,2004, pp. 375–380.
[32] D. Cristinacce and T. F. Cootes, “Feature detection and tracking withconstrained local models,” in Proc. British Mach. Vis. Conf., 2006,pp. 929–938.
[33] P. F. Felzenszwalb and D. P. Huttenlocher, “Pictorial structures for objectrecognition,” Int. J. Comput. Vis., vol. 61, no. 1, pp. 55–79, Jan. 2005.
[34] T. F. Cootes and C. J. Taylor, “Active shape models—“smart snakes”,” inBMVC92. New York, NY, USA: Springer-Verlag, 1992, pp. 266–275.
[35] T. Cootes and C. J. Taylor, “Active shape models - smart snakes,” in Proc.Brit. Mach. Vis. Conf., 1992, pp. 266–275.
[36] Y. Wang, S. Lucey, and J. Cohn, “Enforcing convexity for improvedalignment with constrained local models,” in Proc. IEEE CVPR,Jun. 2008, pp. 1–8.
[37] L. Gu and T. Kanade, “A generative shape regularization model for robustface alignment,” in Proc. 10th ECCV. Part I, 2008, pp. 413–426.
[38] J. Saragih, S. Lucey, and J. Cohn, “Face alignment through subspaceconstrained mean-shifts,” in Proc. IEEE 12th Int. Conf. Comput. Vis.,Oct. 2, 2009, pp. 1034–1041.
[39] A. Tawari and M. M. Trivedi, “Face expression recognition by cross modaldata association,” IEEE Trans. Multimedia, vol. 15, no. 7, pp. 1543–1552,Nov. 2013.
[40] M. A. Fischler and R. A. Elschlager, “The representation and matchingof pictorial structures,” IEEE Trans. Comput., vol. 100, no. 1, pp. 67–92,Jan. 1973.
[41] X. Zhu and D. Ramanan, “Face detection, pose estimation, and landmarklocalization in the wild,” in Proc. IEEE Conf. CVPR, 2012, pp. 2879–2886.
[42] M. Everingham, J. Sivic, and A. Zisserman, ““Hello! My name is . . .Buffy”—Automatic naming of characters in TV video,” in Proc. Brit.Mach. Vis. Conf., 2006, pp. 92.1–92.10.
[43] D. F. Dementhon and L. S. Davis, “Model-based object pose in 25 linesof code,” Int. J. Comput. Vis., vol. 15, no. 1/2, pp. 123–141, Jun. 1995.
[44] E. Murphy-Chutorian and M. M. Trivedi, “3d tracking and dynamic anal-ysis of human head movements and attentional targets,” in Proc. 2ndACM/IEEE ICDSC, 2008, pp. 1–8.

830 IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS, VOL. 15, NO. 2, APRIL 2014
[45] S. T. Shivappa, M. M. Trivedi, and B. D. Rao, “Audiovisual informa-tion fusion in human-computer interfaces and intelligent environments: Asurvey,” Proc. IEEE, vol. 98, no. 10, pp. 1692–1715, Oct. 2010.
[46] R. Valenti, T. Gevers, and T. Gevers, “Combining head pose and eyelocation information for gaze estimation,” IEEE Trans. Image Process.,vol. 21, no. 2, pp. 802–815, Feb. 2012.
[47] S. J. Lee, J. Jaeik, H. G. Jung, K. R. Park, and J. Kim, “Real-time gazeestimator based on driver’s head orientation for forward collision warningsystem,” IEEE Trans. Intell. Transp. Syst., vol. 12, no. 1, pp. 254–267,Mar. 2011.
[48] P. Smith, M. Shah, and N. da Vitoria Lobo, “Determining driver visualattention with one camera,” IEEE Trans. Intell. Transp. Syst., vol. 4, no. 4,pp. 205–218, Dec. 2003.
[49] J. Y. Kaminski, S.. Knaan, and A. Shavit, “Single image face orientationand gaze detection,” IEEE Trans. Intell. Transp. Syst., vol. 21, no. 1,pp. 85–98, Dec. 2003.
Ashish Tawari (S’13) received the B.Tech. degreein electrical engineering from the Indian Institute ofTechnology Bombay, Mumbai, India, in 2006 andthe M.S. degree from the University of CaliforniaSan Diego (UCSD), La Jolla, CA, USA, in 2010.He is currently working toward the Ph.D. degree atthe Laboratory for Intelligent and Safe Automobiles,UCSD.
From 2006 to 2008, he served as a Digital SignalProcessing Engineer with Qualcomm Inc. (India),and in the summer of 2010, he interned with the
Multimedia Research and Development Speech Team of Qualcomm Inc., SanDiego, CA, USA. His research interests lie in the the areas of multimodalsignal processing, speech and audio processing, computer vision and machinelearning.
Mr. Tawari was a recipient of the UCSD Powell Fellowship from 2008 to2011. His thesis proposal, which was advised by Mohan Trivedi, receivedhonorable mention at the Ph.D. Forum of the 2010 IEEE Intelligent VehiclesSymposium.
Sujitha Martin (S’07) received the B.S. degree inelectrical engineering from California Institute ofTechnology, Pasadena, CA, USA, in 2010 and theM.S. degree in electrical and computer engineer-ing from the University of California San Diego(UCSD), La Jolla, CA, USA, in 2012. She iscurrently working toward the Ph.D. degree at theLaboratory for Intelligent and Safe Automobiles,Computer Vision and Robotics Research Laboratory,UCSD.
Her research interests include computer vision,machine learning, human–computer interactivity, and gesture analysis.
Ms. Martin was a recipient of the UCSD Department of Electrical andComputer Engineering Fellowship from 2010 to 2011. Her poster presentation,which is titled “Optical Flow based Head Movement and Gesture Analyzer(OHMeGA),” received an honorable mention at the 32nd Annual ResearchExpo held by the Jacobs School of Engineering, UCSD.
Mohan Manubhai Trivedi (F’08) received the B.E.degree (with honors) from the Birla Institute ofTechnology and Science, Pilani, India, and the Ph.D.degree from Utah State University, Logan 1979.
He is currently a Professor of electrical and com-puter engineering, and he is the Founding Directorof the Computer Vision and Robotics Research Lab-oratory, University of California San Diego (UCSD),La Jolla, CA, USA. He has also established theLaboratory for Intelligent and Safe Automobiles,Computer Vision and Robotics Research Laboratory,
UCSD, where he and his team are currently pursuing research in distributedvideo arrays, active vision, human body modeling and activity analysis, intelli-gent driver assistance, and active safety systems for automobiles. His team hasplayed key roles in several major research initiatives. These include developingan autonomous robotic team for Shinkansen tracks, a human-centered vehiclecollision avoidance system, a vision-based passenger protection system for“smart” airbag deployment, and lane/turn/merge intent prediction modules foradvanced driver assistance. He regularly serves as a Consultant to industry andgovernment agencies in the U.S., Europe, and Asia.
Mr. Trivedi is a Fellow of the International Association of Pattern Recog-nition (for contributions to vision systems for situational awareness andhuman-centered vehicle safety) and the Society for Optical Engineering (forcontributions to the field of optical engineering). He was the recipient of theIEEE Intelligent Transportation Systems Society’s highest honor OutstandingResearch Award in 2013, the Pioneer Award (Technical Activities) and theMeritorious Service Award of the IEEE Computer Society, and the Distin-guished Alumni Award from Utah State University, Logan, UT, USA. A numberof his papers have won Best or Honorable Mention Awards at internationalconferences.