Embed Size (px)
Citation preview

Controlling Overlap in
Content-Oriented XML Retrieval
Charles L. A. Clarke
School of Computer Science
University of Waterloo
Waterloo, Canada

Content-Oriented XML Retrieval
Documents not Data
Natural Language Queries “text index compression”
Ranked Results

Goal
In response to a user query, select and return an appropriately ranked mix of document components… paragraphs, sections, subsections, bibliographic entries, articles, etc.
In response to a user query, select and return an appropriately ranked

IEEE Journal Article in XML
<article> <fm> <atl>Text Compression for Dynamic Document Databases</atl> <au>Alistair Moffat</au> <au>Justin Zobel</au> <au>Neil Sharman</au> <abs> <p> <b>Abstract</b> For compression of text...</p> </abs> </fm> <bdy> <sec> <st>INTRODUCTION</st> <ip1>Modern document databases contain vast quantities of text...</ip1> <p>There are good reasons to compress the text stored in a...</p> </sec> <sec> <st>REDUCING MEMORY REQUIREMENTS</st>... <ss1><st>2.1 Method A</st> <ip1>The first method... </sec> ... </bdy></article>
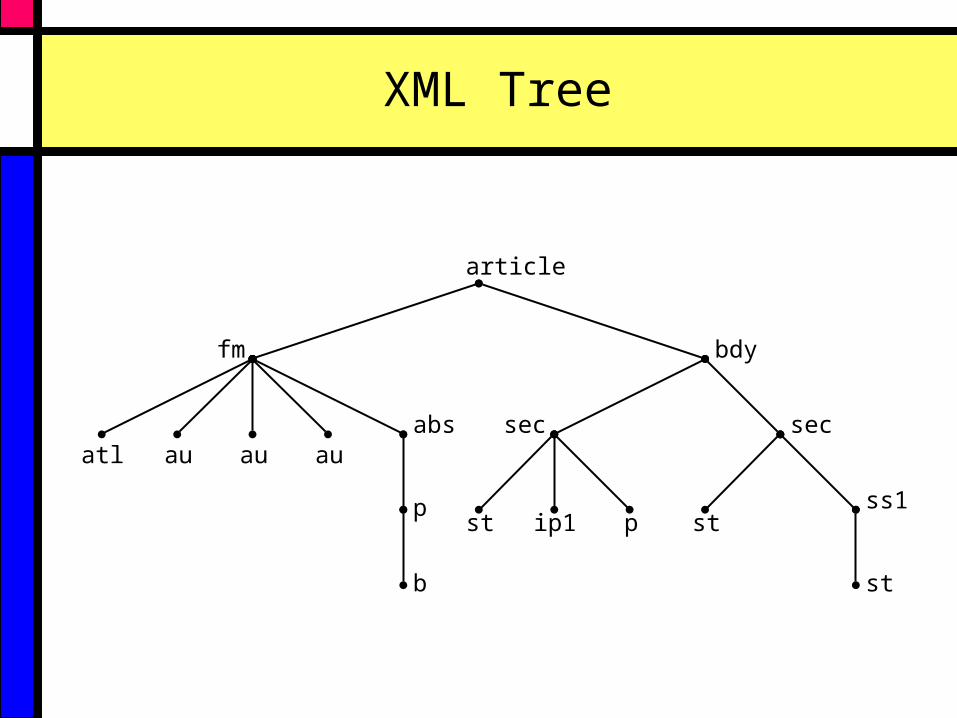
XML Tree
article
fm bdy
atl au au auabs
p
b
sec
st ip1 p
sec
stss1
st
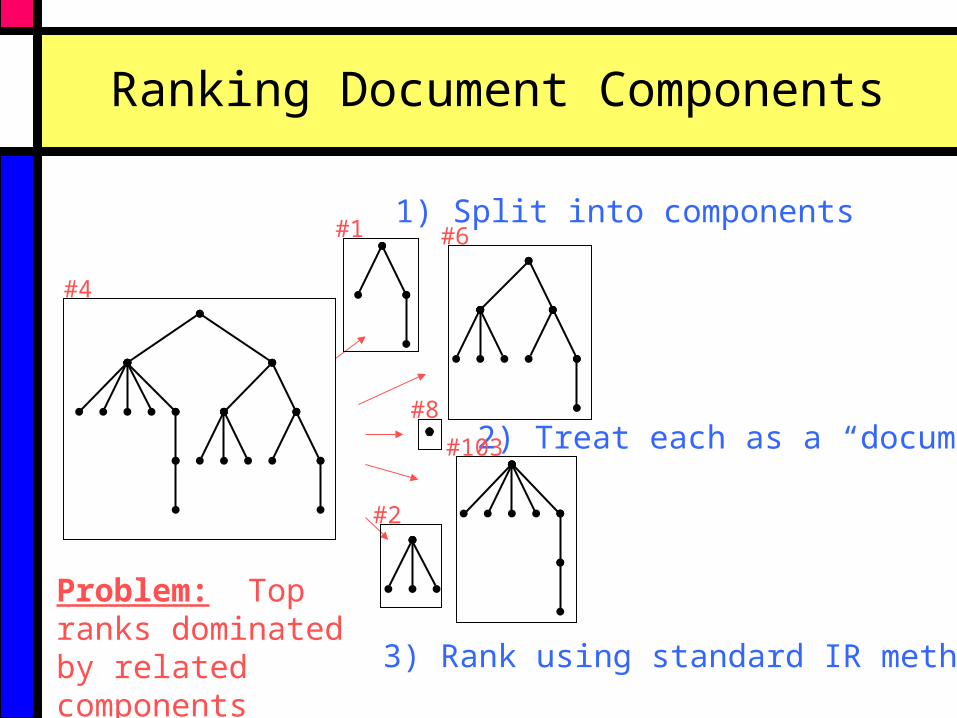
Ranking Document Components
1) Split into components
2) Treat each as a “document”
3) Rank using standard IR methods
#1 #6
#2
#103
#8
#4
Problem: Top ranks dominated by related components
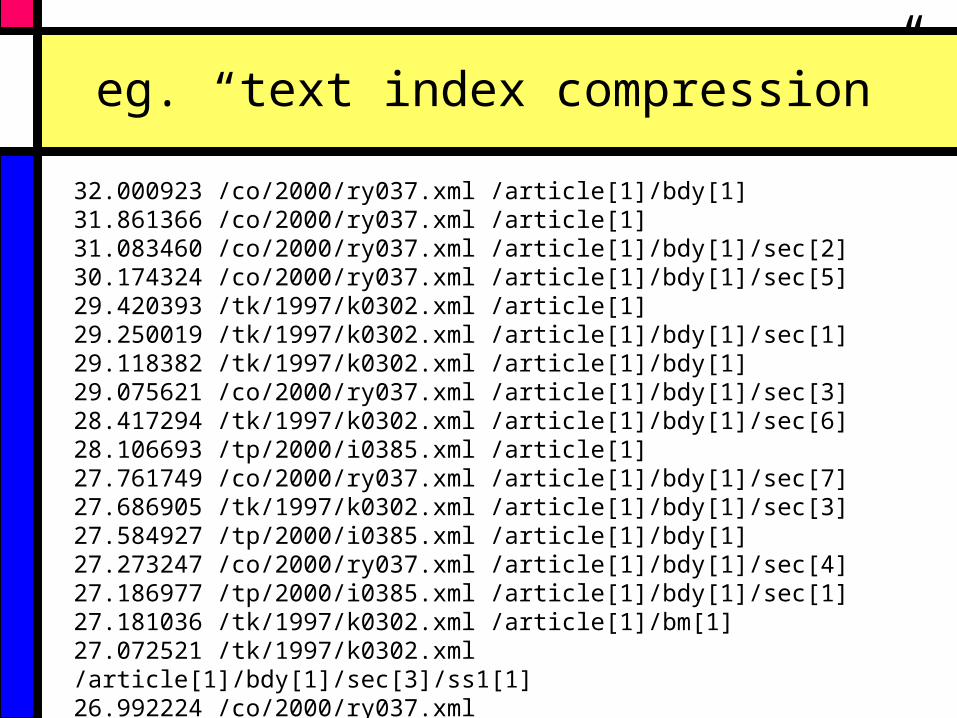
eg. “text index compression”
32.000923 /co/2000/ry037.xml /article[1]/bdy[1]31.861366 /co/2000/ry037.xml /article[1]31.083460 /co/2000/ry037.xml /article[1]/bdy[1]/sec[2]30.174324 /co/2000/ry037.xml /article[1]/bdy[1]/sec[5]29.420393 /tk/1997/k0302.xml /article[1]29.250019 /tk/1997/k0302.xml /article[1]/bdy[1]/sec[1]29.118382 /tk/1997/k0302.xml /article[1]/bdy[1]29.075621 /co/2000/ry037.xml /article[1]/bdy[1]/sec[3]28.417294 /tk/1997/k0302.xml /article[1]/bdy[1]/sec[6]28.106693 /tp/2000/i0385.xml /article[1]27.761749 /co/2000/ry037.xml /article[1]/bdy[1]/sec[7]27.686905 /tk/1997/k0302.xml /article[1]/bdy[1]/sec[3]27.584927 /tp/2000/i0385.xml /article[1]/bdy[1]27.273247 /co/2000/ry037.xml /article[1]/bdy[1]/sec[4]27.186977 /tp/2000/i0385.xml /article[1]/bdy[1]/sec[1]27.181036 /tk/1997/k0302.xml /article[1]/bm[1]27.072521 /tk/1997/k0302.xml /article[1]/bdy[1]/sec[3]/ss1[1]26.992224 /co/2000/ry037.xml /article[1]/bdy[1]/sec[5]/ss1[1]
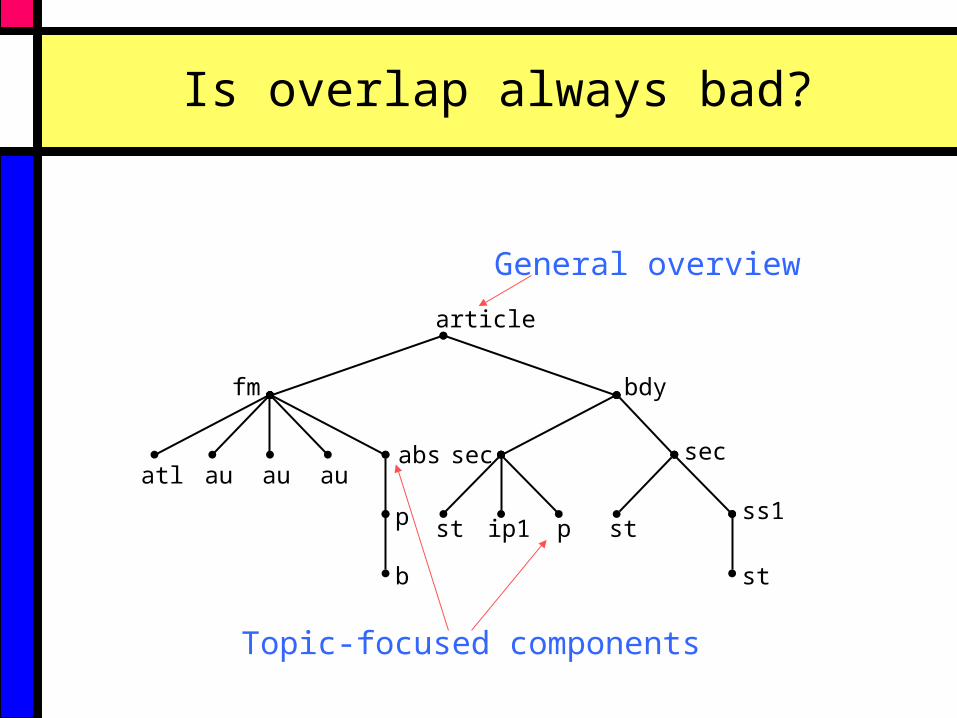
Is overlap always bad?
General overview
Topic-focused components
article
fm bdy
atl au au auabs
p
b
sec
st ip1 p
sec
stss1
st

Overview
• Baseline retrieval method
• Evaluation methodology
• Re-ranking algorithm

Baseline Retrieval Method
• Treat each component as a separate document.
• Rank using Okapi BM25.
• Tune retrieval parameters to task and collection.

Okapi BM25
Given a query Q, a component x is scored:
where:D = number of documents in the collectionDt = number of documents containing tqt = frequency that t occurs in the queryxt = frequency that t occurs in xK = k1((1 – b) + b·lx/lavg)lx = length of xlavg = average document length
Σ qt(k1 + 1) xt
K + xt
D – Dt + 0.5Dt + 0.5( )log
t є Q
k1 = 10.0b = 0.80

Overview
• Baseline retrieval method
• Evaluation methodology
• Re-ranking algorithm

XML Evaluation - INEX 2004
• Third year of the “INitiative for the Evaluation of XML retrieval” (INEX).
• Encourages research into XML information retrieval technology (similar to TREC).
• Over 50 participating groups.

INEX 2004 Content-Only Retrieval Task
• Test collection of articles taken from IEEE journals between 1995 and 2002.
• 40 “adhoc” queries:–text index compression– software quality– new fortran 90 compiler
• Each group could submit up to three runs consisting of the top 1500 components for each query.

Relevance Assessment
• INEX uses two dimensions for relevance– exhaustivity: the degree to which a
component covers a topic– specificity: the degree to which a
component is focused on a topic
• A four-point scale is used in both dimensions (eg. a (3,3) component is highly exhaustive and highly specific)

INEX 2004 Evaluation Metrics
• Mean average precision (MAP)
• XML cumulated gain (XCG)
• Various quantization functions:– strict quantization - (3,3) elements only
– generalized quantization
– specificity-oriented generalization

Overview
• Baseline retrieval method
• Evaluation methodology
• Re-ranking algorithm

Controlling Overlap
Starting with a component ranking generated by the baseline method, elements are re-ranked to control overlap.
Scores of those components containing or contained within higher ranking components are iteratively adjusted.
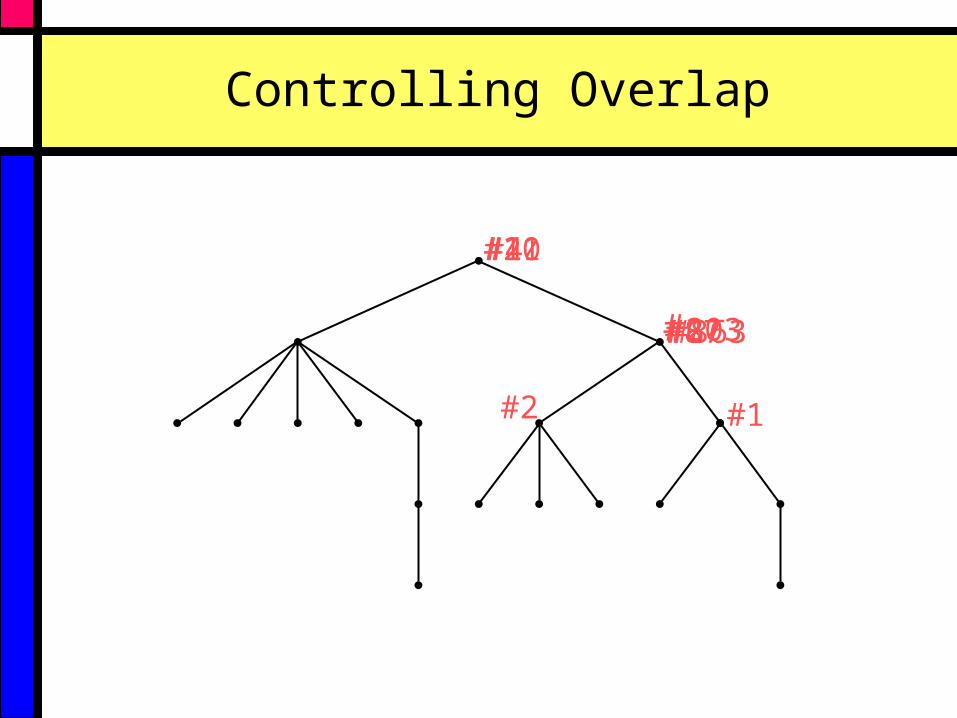
Controlling Overlap
#1#2
#4
#6
#10
#87#203
#21
#863

Re-ranking Algorithm
1. Report the highest ranking component.
2. Adjust the scores of the unreported components.
3. Repeat steps 1 and 2 until the top m components have been reported.

Adjusting Scores
xt = frequency that t occurs in component x
Σ qt(k1 + 1) xt
K + xt
D – Dt + 0.5Dt + 0.5( )log
t є Q
ft = frequency that t occurs in xgt = frequency that t has been reported in
subcomponents of x
xt = ft – α·gt

Adjusting Scores (α = 0.5)
ft = 6gt = 0xt = 6
ft = 13gt = 0xt = 13
#1
ft = 13gt = 6xt = 10

Re-ranking Algorithm
1. Maintain tree nodes in a priority queue ordered by score.
2. Report component at front of queue.
3. Propagate adjustments up and down the tree re-ordering nodes in the queue.
4. Repeat steps 2 and 3 until the top m components have been reported.
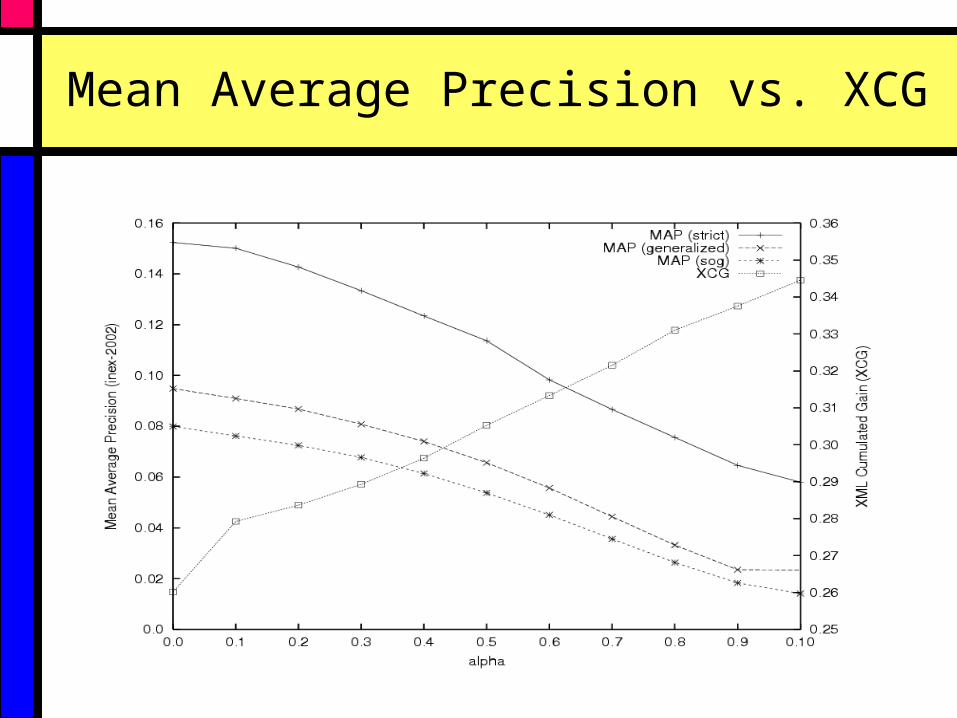
Mean Average Precision vs. XCG

Extended Re-Ranking Algorithm
• One parameter (α) not sufficient.
• Reported in descendant (α) vs. ancestor (β).
• Number of times term reported in ancestor: 1 = β0 ≥ β1 ≥ β2 ≥ … ≥ βn = 0
xt = βi·( ft – α·gt )

Concluding Comments
• Overlap isn’t always bad
• Overlap should be controlled not eliminated
• Current and future work:– Modifying k1 to reflect term frequency adjustments
– More appropriate evaluation methodology
– Learning α, βi

Questions?
Controlling Overlap in
Content-Oriented XML Retrieval
Charles L. A. ClarkeSchool of Computer Science
University of WaterlooWaterloo, Canada





























