Embed Size (px)
Citation preview

Copyright 2005, Data Mining Research Lab, The Ohio State University
Cache-conscious Frequent Pattern Mining on a Modern Processor
Amol Ghoting, Gregory Buehrer, and Srinivasan Parthasarathy
Data Mining Research Laboratory, CSEThe Ohio State University
Daehyun Kim, Anthony Nguyen, Yen-Kuang Chen, and Pradeep Dubey
Intel Corporation

Copyright 2005, Data Mining Research Lab, The Ohio State University
Roadmap
• Motivation and Contributions• Background• Performance characterization• Cache-conscious optimizations• Related work• Conclusions
Copyright 2005, Data Mining Research Lab, The Ohio State University
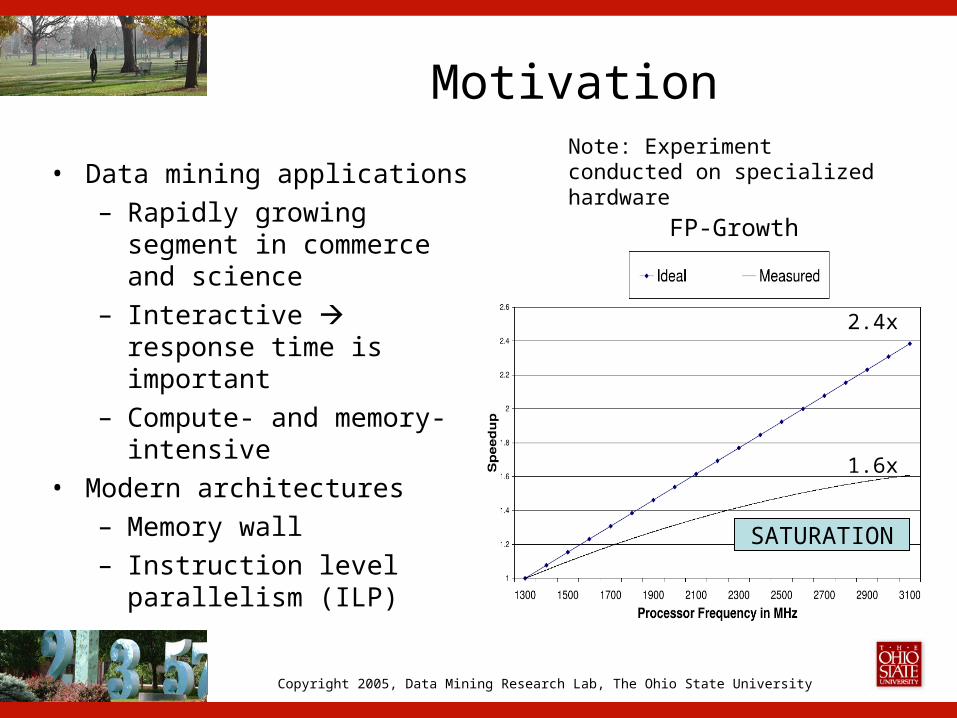
Motivation
• Data mining applications– Rapidly growing segment
in commerce and science– Interactive response
time is important– Compute- and memory-
intensive• Modern architectures
– Memory wall– Instruction level
parallelism (ILP)
FP-Growth
Note: Experiment conducted on specialized hardware
SATURATION
2.4x
1.6x

Copyright 2005, Data Mining Research Lab, The Ohio State University
Contributions
• We characterize the performance and memory access behavior of three state-of-the-art frequent pattern mining algorithms
• We improve the performance of the three frequent pattern mining algorithms– Cache-conscious prefix tree
• Spatial locality + hardware pre-fetching• Path tiling to improve temporal locality• Co-scheduling to improve ILP on a
simultaneous multi-threaded (SMT) processor

Copyright 2005, Data Mining Research Lab, The Ohio State University
Roadmap
• Motivation and Contributions• Background• Performance characterization• Cache-conscious optimizations• Related work• Conclusions

Copyright 2005, Data Mining Research Lab, The Ohio State University
• Finds groups of items that co-occur frequently in a transactional data set
• Example:
• Minimum support = 2• Frequent patterns:
– Size 1: (milk), (bread), (eggs), (sugar)– Size 2: (milk & bread), (milk & eggs), (sugar & eggs)– Size 3: None
• Search space traversal: breadth-first or depth-first
Frequent pattern mining (1)
Customer 1: milk bread cereal
Customer 2: milk bread eggs sugar
Customer 3: milk bread butter
Customer 4: eggs sugar

Copyright 2005, Data Mining Research Lab, The Ohio State University
Frequent pattern mining (2)
• Algorithms under study– FP-Growth (based on the pattern-growth
method)• Winner of the 2003 Frequent Itemset Mining
Implementations (FIMI) evaluation– Genmax (depth-first search space traversal)
• Maximal pattern miner– Apriori (breadth-first search space traversal)
• All algorithms use a prefix tree as a data set representation

Copyright 2005, Data Mining Research Lab, The Ohio State University
Roadmap
• Motivation and Contributions• Background• Performance characterization• Cache-conscious optimizations• Related work• Conclusions

Copyright 2005, Data Mining Research Lab, The Ohio State University
Setup
• Intel Xeon processor– At 2Ghz with 4GB of main memory– 4-way 8KB L1 data cache– 8-way 512KB L2 cache on chip– 8-way 2MB L3 cache
• Intel VTune Performance Analyzers to collect performance data• Implementations
– FIMI repository• FP-Growth (Gosta Grahne and Jianfei Zhu)• Genmax (Gosta Grahne and Jianfei Zhu)• Apriori (Christian Borgelt)
– Custom memory managers
Copyright 2005, Data Mining Research Lab, The Ohio State University
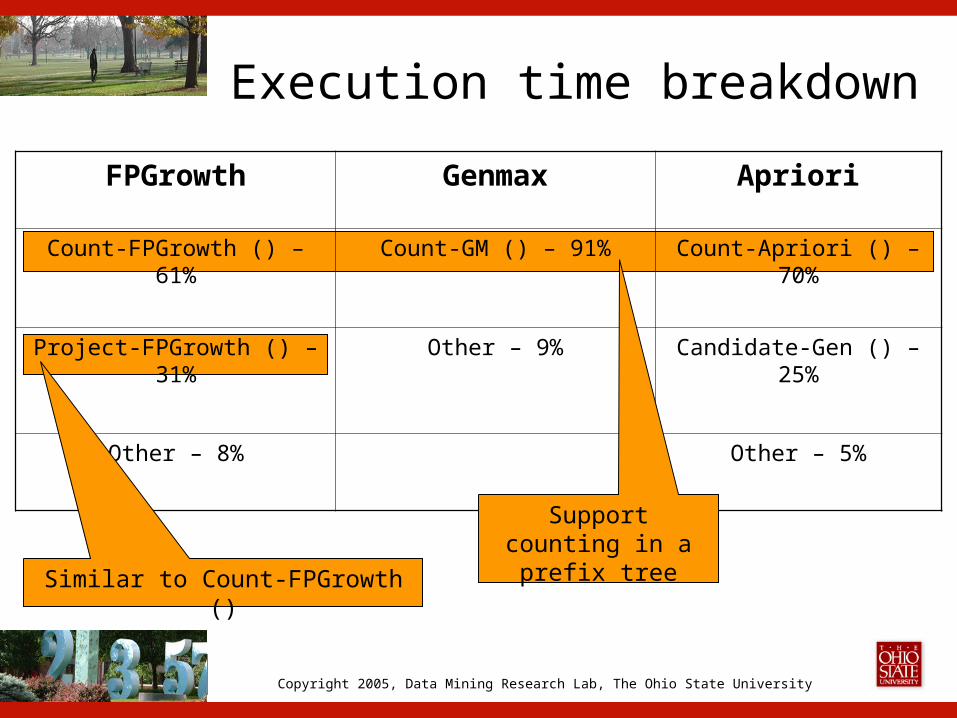
Execution time breakdown
FPGrowth Genmax Apriori
Count-FPGrowth () – 61% Count-GM () – 91% Count-Apriori () – 70%
Project-FPGrowth () – 31% Other – 9% Candidate-Gen () – 25%
Other – 8% Other – 5%
Support counting in a prefix tree
Similar to Count-FPGrowth ()
Copyright 2005, Data Mining Research Lab, The Ohio State University
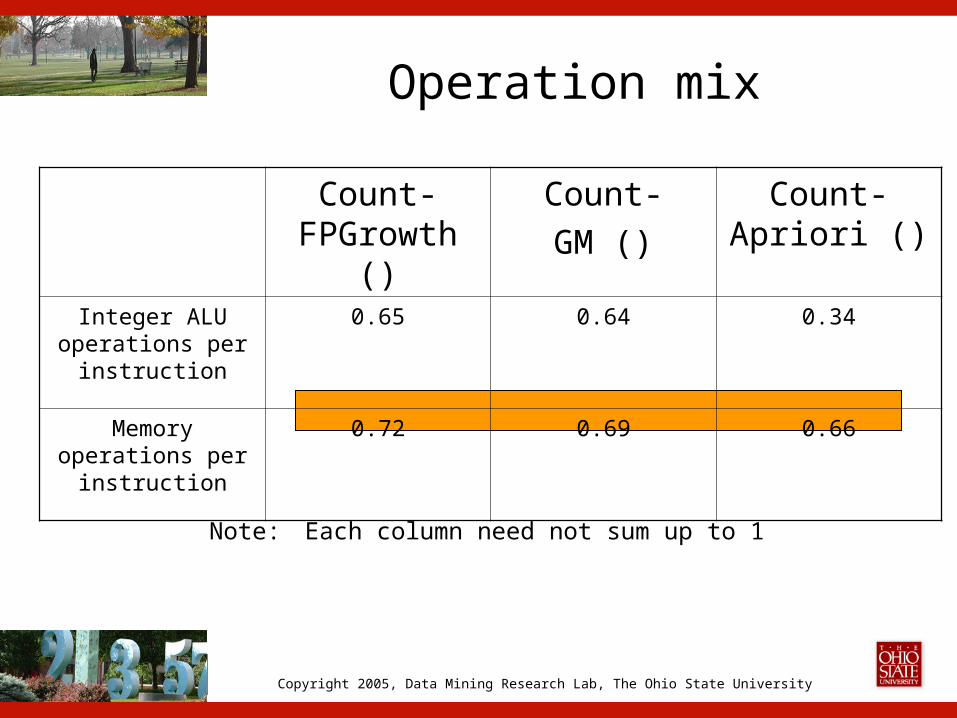
Operation mix
Count-FPGrowth ()
Count-GM ()
Count-Apriori ()
Integer ALU operations per
instruction
0.65 0.64 0.34
Memory operations per
instruction
0.72 0.69 0.66
Note: Each column need not sum up to 1
Copyright 2005, Data Mining Research Lab, The Ohio State University
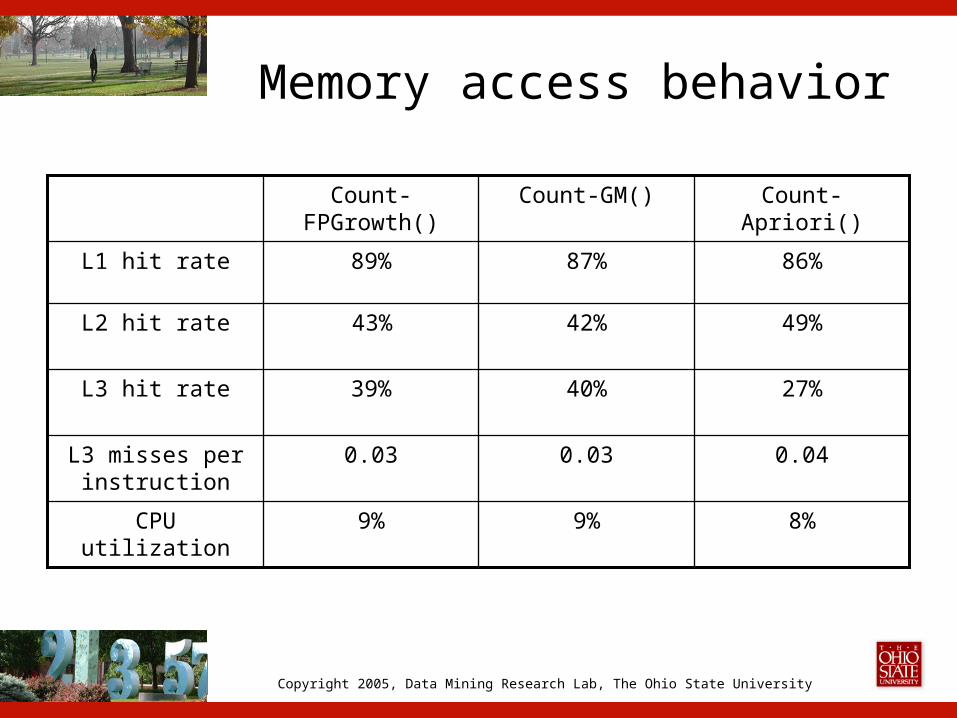
Memory access behavior
8%9%9%CPU utilization
0.040.030.03L3 misses per instruction
27%40%39%L3 hit rate
49%42%43%L2 hit rate
86%87%89%L1 hit rate
Count-Apriori()Count-GM()Count-FPGrowth()

Copyright 2005, Data Mining Research Lab, The Ohio State University
Roadmap
• Motivation and Contributions• Background• Performance characterization• Cache-conscious optimizations• Related work• Conclusions
Copyright 2005, Data Mining Research Lab, The Ohio State University
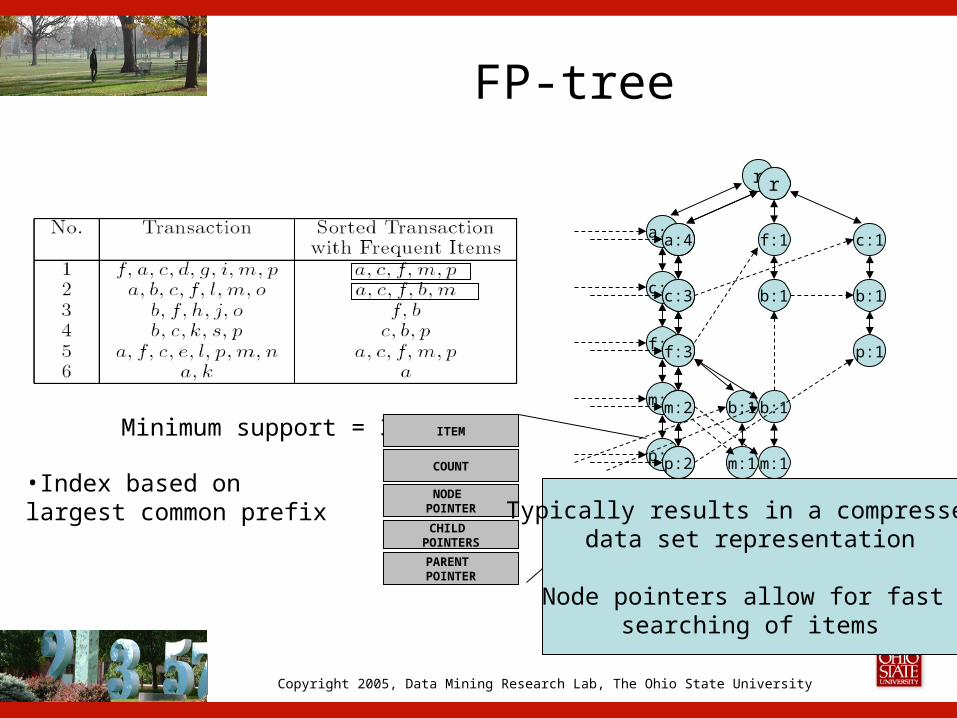
FP-tree
Minimum support = 3
a:1
p:1
c:1
f:1
m:1
r
COUNT
ITEM
NODE POINTER
CHILD POINTERS
PARENT POINTER
a:2
p:1
c:2
f:2
m:1
r
b:1
m:1
a:4
p:2
c:3
f:3
m:2
c:1
b:1
p:1
f:1
b:1
b:1
r
m:1•Index based on largest common prefix Typically results in a compressed
data set representation
Node pointers allow for fast searching of items
Copyright 2005, Data Mining Research Lab, The Ohio State University
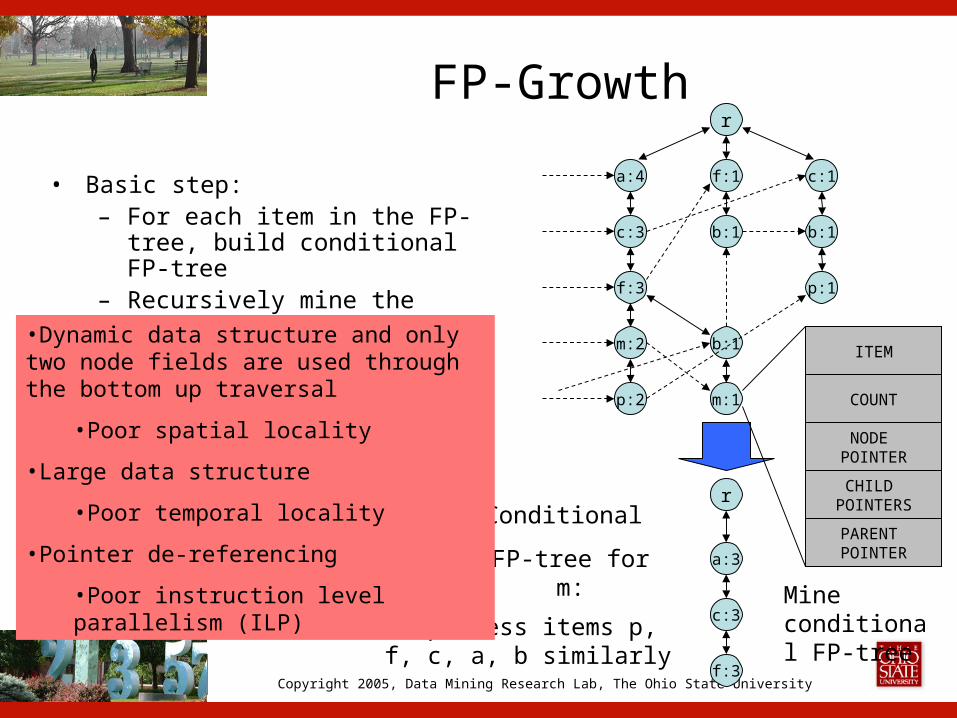
FP-Growth
• Basic step:– For each item in the FP-tree,
build conditional FP-tree– Recursively mine the
conditional FP-tree
a:4
p:2
c:3
f:3
m:2
c:1
b:1
p:1
f:1
b:1
b:1
r
m:1
r
a:3
c:3
f:3
Conditional
FP-tree for m:
COUNT
ITEM
NODE POINTER
CHILD POINTERS
PARENT POINTER
Mine conditional FP-tree
We process items p, f, c, a, b similarly
•Dynamic data structure and only two node fields are used through the bottom up traversal
•Poor spatial locality
•Large data structure
•Poor temporal locality
•Pointer de-referencing
•Poor instruction level parallelism (ILP)
Copyright 2005, Data Mining Research Lab, The Ohio State University
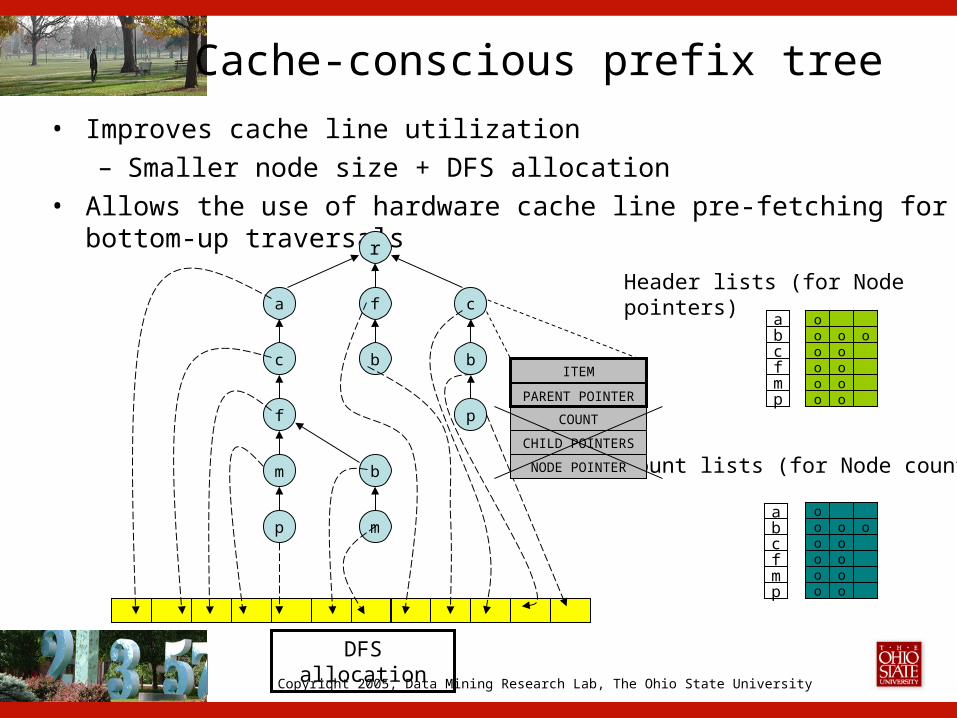
Cache-conscious prefix tree• Improves cache line utilization
– Smaller node size + DFS allocation• Allows the use of hardware cache line pre-fetching for bottom-
up traversals
a
p
c
f
m
c
b
p
f
b
b
r
m
ITEM
oo o o
oooooooo
Header lists (for Node pointers)
oo o o
oooooooo
Count lists (for Node counts)
DFS allocation
abcfmp
abcfmp
COUNT
CHILD POINTERS
NODE POINTER
PARENT POINTER
Copyright 2005, Data Mining Research Lab, The Ohio State University
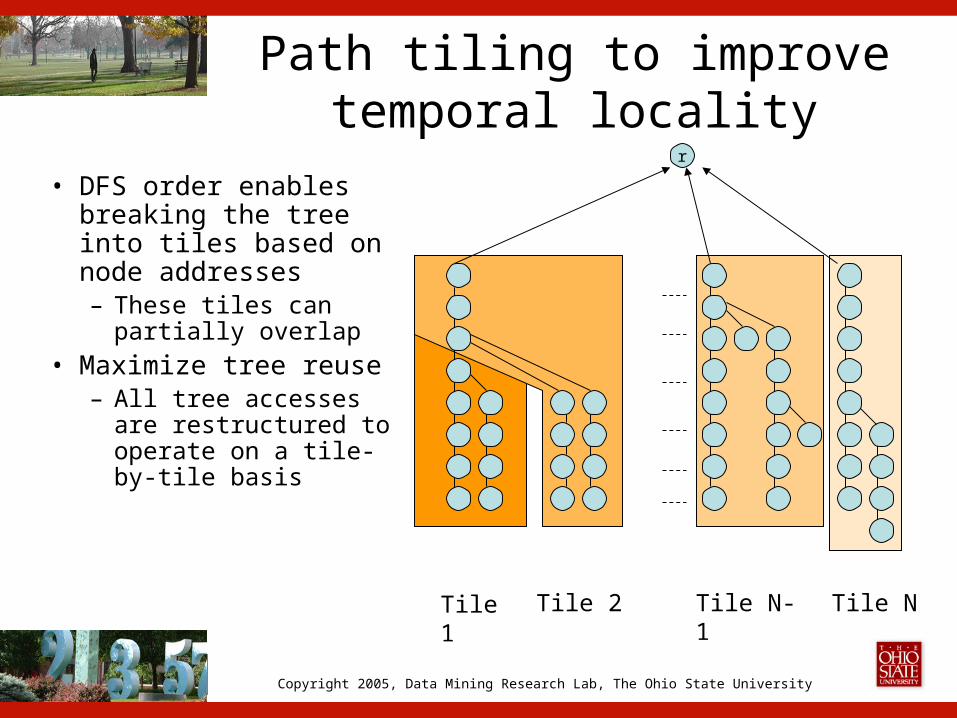
Path tiling to improve temporal locality
• DFS order enables breaking the tree into tiles based on node addresses– These tiles can
partially overlap• Maximize tree reuse
– All tree accesses are restructured to operate on a tile-by-tile basis
r
Tile 1 Tile 2 Tile NTile N-1
Copyright 2005, Data Mining Research Lab, The Ohio State University
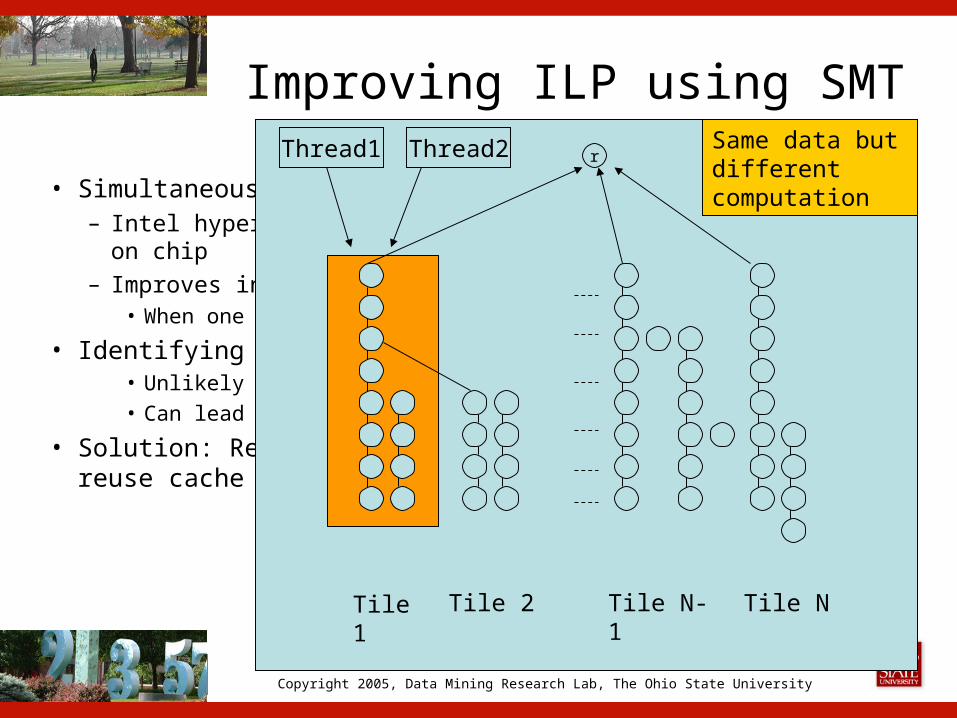
Improving ILP using SMT
• Simultaneous multi-threading (SMT) – Intel hyper-threading (HT) maintains two hardware contexts on
chip– Improves instruction level parallelism (ILP)
• When one thread waits, the other thread can use CPU resources
• Identifying independent threads is not good enough• Unlikely to hide long cache miss latency• Can lead to cache interference (conflicts)
• Solution: Restructure multi-threaded computation to reuse cache on a tile-by-tile basis
r
Tile 1 Tile 2 Tile NTile N-1
Thread1 Thread2 Same data but different computation
Copyright 2005, Data Mining Research Lab, The Ohio State University
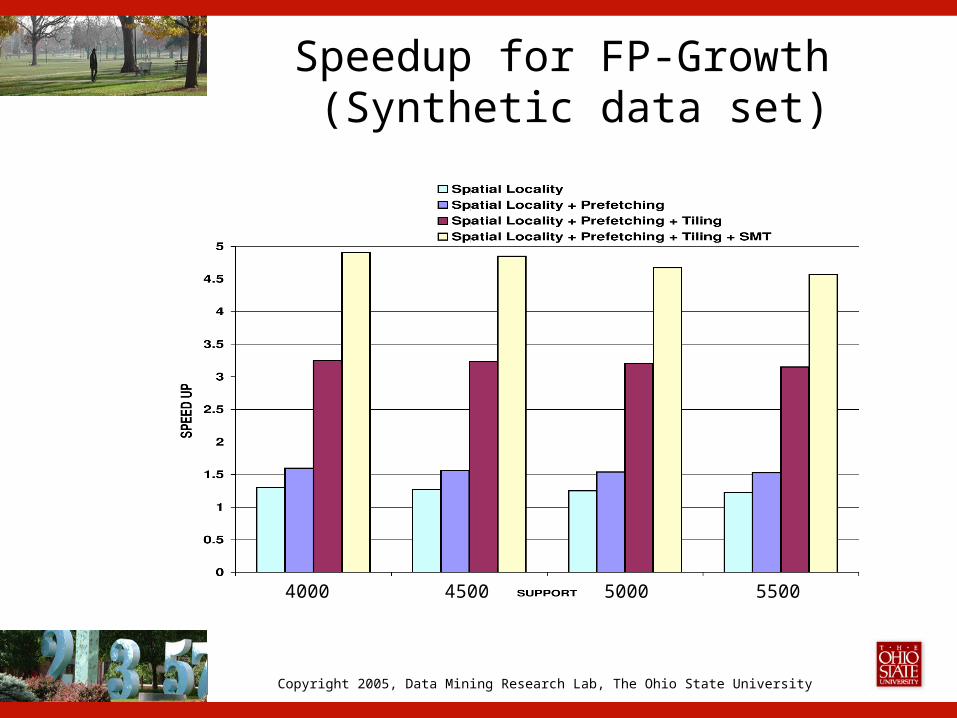
Speedup for FP-Growth (Synthetic data set)
4000 4500 5000 5500
Copyright 2005, Data Mining Research Lab, The Ohio State University
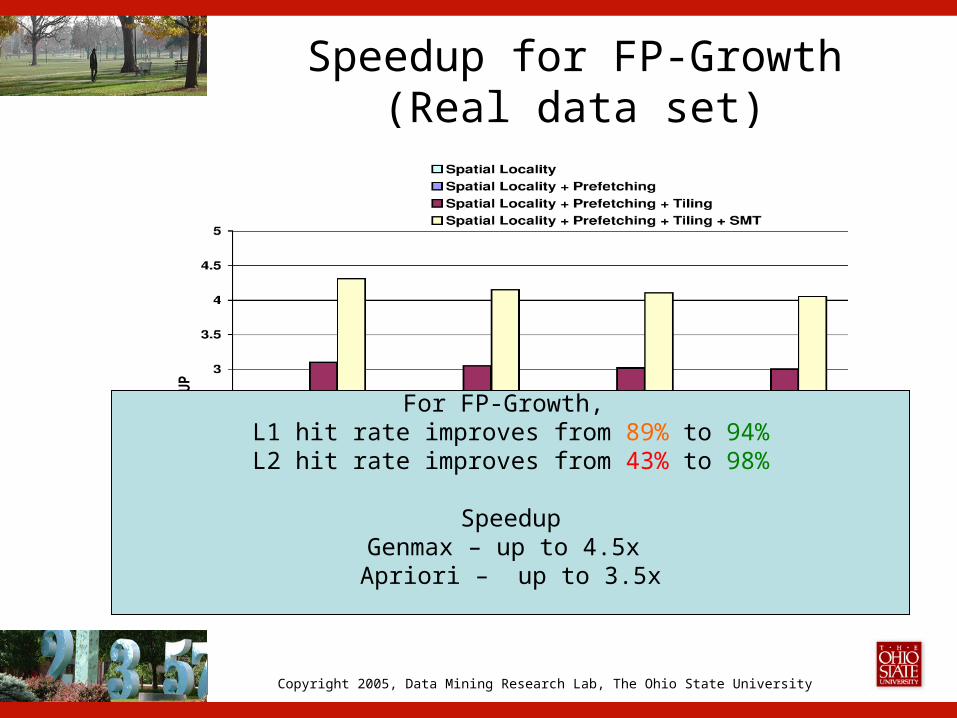
Speedup for FP-Growth(Real data set)
50000 58350 66650 75000
For FP-Growth, L1 hit rate improves from 89% to 94%L2 hit rate improves from 43% to 98%
SpeedupGenmax – up to 4.5x Apriori – up to 3.5x

Copyright 2005, Data Mining Research Lab, The Ohio State University
Roadmap
• Motivation and Contributions• Background• Performance characterization• Cache-conscious optimizations• Related work• Conclusions

Copyright 2005, Data Mining Research Lab, The Ohio State University
Related work (1)
• Data mining algorithms– Characterizations
• Self organizing maps– Kim et al. [WWC99]
• C4.5– Bradford and Fortes [WWC98]
• Sequence mining, graph mining, outlier detection, clustering, and decision tree induction
– Ghoting et al. [DAMON05]– Memory placement techniques for association rule
mining• Considered the effects of memory pooling and coarse
grained spatial locality on association rule mining algorithms in a serial and parallel setting
– Parthasarathy et al. [SIGKDD98,KAIS01]

Copyright 2005, Data Mining Research Lab, The Ohio State University
Related work (2)
• Data base algorithms– DBMS on modern hardware
• Ailamaki et al. [VLDB99,VLDB2001] – Cache sensitive search trees and B+-trees
• Rao and Ross [VLDB99,SIGMOD00]– Prefetching for B+-trees and Hash-Join
• Chen et al. [SIGMOD00,ICDE04]

Copyright 2005, Data Mining Research Lab, The Ohio State University
Ongoing and future work
• Algorithm re-design for next generation architectures – e.g. graph mining on multi-core architectures
• Cache-conscious optimizations for other data mining and bioinformatics applications on modern architectures– e.g. classification algorithms, graph mining
• Out-of-core algorithm designs• Microprocessor design targeted at data
mining algorithms

Copyright 2005, Data Mining Research Lab, The Ohio State University
Conclusions
• Characterized the performance of three popular frequent pattern mining algorithms
• Proposed a tile-able cache-conscious prefix tree– Improves spatial locality and allows for cache line pre-fetching– Path tiling improves temporal locality
• Proposed novel thread-based decomposition for improving ILP by utilizing SMT– Overall, up to 4.8-fold speedup
• Effective algorithm design in data mining needs to take into account modern architectural designs.

Copyright 2005, Data Mining Research Lab, The Ohio State University
Thanks
• We would like to acknowledge the following grants– NSF: CAREER-IIS-0347662– NSF: NGS-CNS-0406386– NSF: RI-CNS-0403342– DOE: ECPI-DE-FG02-04ER25611





























