Embed Size (px)
Citation preview

1
1. INTRODUCTION
In the running world, there is growing demand for the software systems to recognize characters in
computer world when information is scanned through paper documents. As we know that we have a
number of newspapers and books which are in printed format related to different subjects. In these days
there is a huge demand in “storing the information available in these paper documents in to a computer
storage disk and then later reusing this information by searching process, to avoid damages or losses”.
One simple way to store information in these paper documents in to computer system is to first scan the
documents and then store them as IMAGES. But to reuse this information it is very difficult to read the
individual contents and searching the contents form these documents line-by-line and word-by-word. The
reason for this difficulty is the font characteristics of the characters in paper documents are different to
font of the characters in computer system. As a result, computer is unable to recognize the characters
while reading them. This concept of storing the contents of paper documents in computer storage place
and then reading and searching the content is called DOCUMENT PROCESSING. Sometimes in this
document processing we need to process the information that is related to languages other than the
English in the world. For this document processing we need an application software system named
CHARACTER RECOGNITION SYSTEM. This process is also called CHARACTER RECOGNITION
AND CONVERSION (CRC).
Thus our need is to develop character recognition software system to perform Document Image
Analysis which transforms documents in paper format to electronic format. For this process there are
various techniques in the world. We’ve chosen Character Recognition and Conversion.
HISTORY OF OCR
Early optical character recognition may be traced to technologies involving telegraphy
and creating reading devices for the blind. In 1914, Emanuel Goldberg developed a machine that
read characters and converted them into standard telegraph code. Concurrently, Edmund Fournier
d'Albe developed the Optophone, a handheld scanner that when moved across a printed page,
produced tones that corresponded to specific letters or characters.
In the late 1920s and into the 1930s Emanuel Goldberg developed what he called a "Statistical
Machine" for searching microfilm archives using an optical code recognition system. In 1931 he
was granted USA Patent number 1,838,389 for the invention. The patent was acquired by IBM.
With the advent of smart-phones and smart-glasses, OCR can be used in internet connected
mobile device applications that extract text captured using the device's camera. These devices
that do not have OCR functionality built-in to the operating system will typically use an
OCR API to extract the text from the image file captured and provided by the device. The OCR
API returns the extracted text, along with information about the location of the detected text in
the original image back to the device app for further processing (such as text-to-speech) or
display.

2
TYPES OF OCR
Optical character recognition (OCR) – targets typewritten text, one glyph or character at a time.
Optical word recognition – targets typewritten text, one word at a time (for languages that use a space as
a word divider). (Usually just called "OCR".)
Intelligent character recognition (ICR) – also targets handwritten printscript or cursive text one glyph or
character at a time, usually involving machine learning.
Intelligent word recognition (IWR) – also targets handwritten printscript or cursive text, one word at a
time. This is especially useful for languages where glyphs are not separated in cursive script.
OCR is generally an "offline" process, which analyses a static document. Handwriting movement analysis can
be used as input to handwriting recognition.[13] Instead of merely using the shapes of glyphs and words, this
technique is able to capture motions, such as the order in which segments are drawn, the direction, and the
pattern of putting the pen down and lifting it. This additional information can make the end-to-end process
more accurate. This technology is also known as "on-line character recognition", "dynamic character
recognition", "real-time character recognition", and "intelligent character recognition".
1.1 PURPOSE
The main purpose of Character Recognition and Conversion is to perform document
processing of electronic document formats converted from paper formats more effectively and
efficiently. This improves the accuracy of recognizing the characters during document
processing compared to various existing available character recognition methods. Here Character
Recognition technique derives the meaning of the characters, their font properties from their bit-
mapped images.
The primary objective is to speed up the process of character recognition in document
processing. As a result the system can process huge number of documents with-in less time
and hence saves the time.
It aims to recognize multiple heterogeneous characters that belong to different universal
languages with different font properties and alignments.

3
1.2 PROJECT SCOPE
The scope of our project Character Recognition and Conversion on a grid infrastructure is to
provide an efficient and enhanced software tool for the users to perform Document Image
Analysis, document processing by reading and recognizing the characters in research, academic,
governmental and business organizations that are having large pool of documented, scanned
images. Irrespective of the size of documents and the type of characters in documents, the
product is recognizing them, searching them and processing them faster according to the needs
of the environment.
1.3 Technology Used
The exact mechanisms that allow humans to recognize objects are yet to be understood,
but the three basic principles are already well known by scientists – integrity, purposefulness and
adaptability (IPA). These principles allows to replicate natural or human-like recognition.
Let’s take a look on how OCR recognizes text. First, the program analyses the structure
of document image. It divides the page into elements such as blocks of texts, tables, images, etc.
The lines are divided into words and then - into characters. Once the characters have been
singled out, the program compares them with a set of pattern images. It advances numerous
hypotheses about what this character is. Basing on these hypotheses the program analyses
different variants of breaking of lines into words and words into characters. After processing
huge number of such probabilistic hypotheses, the program finally takes the decision, presenting
you the recognized text.
1.4 How to use?
Using OCR is easy: the process generally consists of three stages: Open (Scan) the
document, Recognize it and then Save in a convenient format (DOC, RTF, XLS, PDF, HTML,
TXT etc.) or export data directly to one of Office applications such as Microsoft Word, Excel or
Adobe Acrobat.

4
2. FEASIBILITY STUDY
A feasibility study is a high-level capsule version of the entire System analysis and Design
Process. The study begins by classifying the problem definition. Feasibility is to determine if it’s worth
doing. Once an acceptance problem definition has been generated, the analyst develops a logical model of
the system. A search for alternatives is analyzed carefully. There are 3 parts in feasibility study.
2.1 TECHNICAL FEASIBILITY
Evaluating the technical feasibility is the trickiest part of a feasibility study. This is because, at
this point in time, not too many detailed design of the system, making it difficult to access issues like
performance, costs on (on account of the kind of technology to be deployed) etc. A number of issues have
to be considered while doing a technical analysis. Understand the different technologies involved in the
proposed system before commencing the project we have to be very clear about what are the technologies
that are to be required for the development of the new system. Find out whether the organization currently
possesses the required technologies. Is the required technology available with the organization?
2.2 OPERATIONAL FEASIBILITY
Proposed project is beneficial only if it can be turned into information systems that will meet
the organizations operating requirements. Simply stated, this test of feasibility asks if the system will
work when it is developed and installed. Are there major barriers to Implementation? Here are
questions that will help test the operational feasibility of a project:
Is there sufficient support for the project from management from users? If the current system is well
liked and used to the extent that persons will not be able to see reasons for change, there may be
resistance.
Are the current business methods acceptable to the user? If they are not, Users may welcome a
change that will bring about a more operational and useful systems.
Have the user been involved in the planning and development of the project?
Early involvement reduces the chances of resistance to the system and in general and increases the
likelihood of successful project.
Since the proposed system was to help reduce the hardships encountered. In the existing manual
system, the new system was considered to be operational feasible.

5
2.3 ECONOMIC FEASIBILITY
Economic feasibility attempts to weigh the costs of developing and implementing a new system,
against the benefits that would accrue from having the new system in place. This feasibility study gives
the top management the economic justification for the new system. A simple economic analysis which
gives the actual comparison of costs and benefits are much more meaningful in this case. In addition, this
proves to be a useful point of reference to compare actual costs as the project progresses. There could be
various types of intangible benefits on account of automation. These could include increased customer
satisfaction, improvement in product quality better decision making timeliness of information, expediting
activities, improved accuracy of operations, better documentation and record keeping, faster retrieval of
information, better employee morale.

6
3. SOFTWARE USED
The software used in Character Recognition and Conversion (CRC) is MATLAB.
MATLAB (Matrix Laboratory) is a high-level language and interactive environment that enables
to you to perform computationally intensive faster than with traditional programming languages such as
C, C++ and Fortran.
MATLAB consists of 4 components such as;
Workspace
Command Window
Command History
File Editor Window
Workspace displays all the defined variables.
Command Window is used to execute commands in the MATLAB environment.
Command History displays record of the commands used.
File Editor Window defines your function.
3.1 Operating System
Windows 7 and higher versions
3.2 Hardware Requirement Specification
Processor: Intel core 2 dual or higher
RAM: 2GB
Memory Required: 5GB or higher

7
4. SOFTWARE DESIGN
4.1 DATA FLOW DIAGRAM
The DFD is also called as bubble chart. A data-flow diagram (DFD) is a graphical
representation of the "flow" of data through an information system. DFD’s can also be used for the
visualization of data processing.
Figure 4.1: Level 0 DFD
Figure 4.2: Level 1 DFD

8
Figure 4.3: Level 2 DFD

9
5. CODING
5.1. Code for Creating Template %Letter clc; close all; A=imread('letters_numbers\A.bmp');B=imread('letters_numbers\B.bmp'); C=imread('letters_numbers\C.bmp');D=imread('letters_numbers\D.bmp'); E=imread('letters_numbers\E.bmp');F=imread('letters_numbers\F.bmp'); G=imread('letters_numbers\G.bmp');H=imread('letters_numbers\H.bmp'); I=imread('letters_numbers\I.bmp');J=imread('letters_numbers\J.bmp'); K=imread('letters_numbers\K.bmp');L=imread('letters_numbers\L.bmp'); M=imread('letters_numbers\M.bmp');N=imread('letters_numbers\N.bmp'); O=imread('letters_numbers\O.bmp');P=imread('letters_numbers\P.bmp'); Q=imread('letters_numbers\Q.bmp');R=imread('letters_numbers\R.bmp'); S=imread('letters_numbers\S.bmp');T=imread('letters_numbers\T.bmp'); U=imread('letters_numbers\U.bmp');V=imread('letters_numbers\V.bmp'); W=imread('letters_numbers\W.bmp');X=imread('letters_numbers\X.bmp'); Y=imread('letters_numbers\Y.bmp');Z=imread('letters_numbers\Z.bmp'); %lower case letters a=imread('letters_numbers\a.png');b=imread('letters_numbers\b.png'); c=imread('letters_numbers\c.png');d=imread('letters_numbers\d.png'); e=imread('letters_numbers\e.png');f=imread('letters_numbers\f.png'); g=imread('letters_numbers\g.png');h=imread('letters_numbers\h.png'); i=imread('letters_numbers\i.png');j=imread('letters_numbers\j.png'); k=imread('letters_numbers\k.png');l=imread('letters_numbers\l.png'); m=imread('letters_numbers\m.png');n=imread('letters_numbers\n.png'); o=imread('letters_numbers\o.png');p=imread('letters_numbers\p.png'); q=imread('letters_numbers\q.png');r=imread('letters_numbers\r.png'); s=imread('letters_numbers\s.png');t=imread('letters_numbers\t.png'); u=imread('letters_numbers\u.png');v=imread('letters_numbers\v.png'); w=imread('letters_numbers\w.png');x=imread('letters_numbers\x.png'); y=imread('letters_numbers\y.png');z=imread('letters_numbers\z.png');
%Number one=imread('letters_numbers\1.bmp'); two=imread('letters_numbers\2.bmp'); three=imread('letters_numbers\3.bmp');four=imread('letters_numbers\4.bmp'); five=imread('letters_numbers\5.bmp'); six=imread('letters_numbers\6.bmp'); seven=imread('letters_numbers\7.bmp');eight=imread('letters_numbers\8.bmp'); nine=imread('letters_numbers\9.bmp'); zero=imread('letters_numbers\0.bmp'); %*-*-*-*-*-*-*-*-*-*-*- letter=[A B C D E F G H I J K L M... N O P Q R S T U V W X Y Z]; number=[one two three four five... six seven eight nine zero];
lowercase = [a b c d e f g h i j k ... l m n o p q r s t u v w x y z]; character=[letter number lowercase]; templates=mat2cell(character,42,[24 24 24 24 24 24 24 ...

10
24 24 24 24 24 24 24 ... 24 24 24 24 24 24 24 ... 24 24 24 24 24 24 24 ... 24 24 24 24 24 24 24 24 ... 24 24 24 24 24 24 24 24 ... 24 24 24 24 24 24 24 24 ... 24 24 24 24 24 24 24 24 ... 24 24]); save ('templates','templates') clear all
5.2. Read Lines
%function lines% % function [fl re]=lines_crop(im_texto) % Divide text in lines % im_texto->input image; fl->first line; re->remain line % Example: %clc; %im_texto=imread('blackwhite.jpg'); %figure,imshow(im_texto) %title('after bwareaopen') %im_texto = bwareaopen(im_texto,60); %figure,imshow(im_texto); %title('after bwareaopen') %[fl re]=lines(im_texto); %subplot(3,1,1);imshow(im_texto);title('INPUT IMAGE') %subplot(3,1,2);imshow(fl);title('FIRST LINE') %subplot(3,1,3);imshow(re);title('REMAIN LINES') im_texto=clip(im_texto); num_filas=size(im_texto,1); for s=1:num_filas if sum(im_texto(s,:))==0 nm=im_texto(1:s-1, :); % First line matrix %pause(1); rm=im_texto(s:end, :);% Remain line matrix %pause(1); fl = clip(nm); pause(1); re=clip(rm); %*-*-*Uncomment lines below to see the result*-*-*-*- %subplot(2,1,1);imshow(fl); %subplot(2,1,2);imshow(re); break else fl=im_texto;%Only one line. re=[ ]; end end %subplot(3,1,1);imshow(im_texto);title('INPUT IMAGE') %subplot(3,1,2);imshow(fl);title('FIRST LINE') %subplot(3,1,3);imshow(re);title('REMAIN LINES')
function img_out=clip(img_in)

11
[f c]=find(img_in); img_out=img_in(min(f):max(f),min(c):max(c));
5.3. Read Letters in a Line
%function lines% %function letter_in_a_line function [fl re space]=letter_crop(im_texto) % Divide letters in lines
im_texto=clip(im_texto); num_filas=size(im_texto,2);
%figure,imshow(im_texto); %title('line sent in the function letter'); for s=1:num_filas s; sum_col = sum(im_texto(:,s)); if sum_col==0 k = 'true'; nm=im_texto(:,1:s-1); % First letter matrix %figure,imshow(nm); %title('first letter in the function letter_in_a_line'); %pause(1); rm=im_texto(:,s:end);% Remaining line matrix %figure,imshow(rm); %title('remaining letters in the function letter_in_a_line'); %pause(1); fl = clip(nm); %pause(1); re=clip(rm); space = size(rm,2)-size(re,2); %*-*-*Uncomment lines below to see the result*-*-*-*- %subplot(2,1,1);imshow(fl); %subplot(2,1,2);imshow(re); break else fl=im_texto;%Only one line. re=[ ]; space = 0; end end
function img_out=clip(img_in) [f c]=find(img_in); img_out=img_in(min(f):max(f),min(c):max(c));

12
5.4. Recognize letters
%function read_letter function letter=read_letter(imagn,num_letras) % Computes the correlation between template and input image % and its output is a string containing the letter. % Size of 'imagn' must be 42 x 24 pixels % Example: % imagn=imread('D.bmp'); % letter=read_letter(imagn) %load templates global templates comp=[ ];
for n=1:num_letras
sem=corr2(templates{1,n},imagn); comp=[comp sem];
%pause(1) end
vd=find(comp==max(comp)); %*-*-*-*-*-*-*-*-*-*-*-*-*- if vd==1 letter='A'; elseif vd==2 letter='B'; elseif vd==3 letter='C'; elseif vd==4 letter='D'; elseif vd==5 letter='E'; elseif vd==6 letter='F'; elseif vd==7 letter='G'; elseif vd==8 letter='H'; elseif vd==9 letter='I'; elseif vd==10 letter='J'; elseif vd==11 letter='K'; elseif vd==12 letter='L'; elseif vd==13 letter='M'; elseif vd==14 letter='N'; elseif vd==15 letter='O'; elseif vd==16

13
letter='P'; elseif vd==17 letter='Q'; elseif vd==18 letter='R'; elseif vd==19 letter='S'; elseif vd==20 letter='T'; elseif vd==21 letter='U'; elseif vd==22 letter='V'; elseif vd==23 letter='W'; elseif vd==24 letter='X'; elseif vd==25 letter='Y'; elseif vd==26 letter='Z'; %*-*-*-*-* elseif vd==27 letter='1'; elseif vd==28 letter='2'; elseif vd==29 letter='3'; elseif vd==30 letter='4'; elseif vd==31 letter='5'; elseif vd==32 letter='6'; elseif vd==33 letter='7'; elseif vd==34 letter='8'; elseif vd==35 letter='9'; elseif vd==36 letter='0'; %******** elseif vd==37 letter='a'; elseif vd==38 letter='b'; elseif vd==39 letter='c'; elseif vd==40 letter='d'; elseif vd==41 letter='e'; elseif vd==42 letter='f'; elseif vd==43 letter='g';

14
elseif vd==44 letter='h'; elseif vd==45 letter='i'; elseif vd==46 letter='j'; elseif vd==47 letter='k'; elseif vd==48 letter='l'; elseif vd==49 letter='m'; elseif vd==50 letter='n'; elseif vd==51 letter='o'; elseif vd==52 letter='p'; elseif vd==53 letter='q'; elseif vd==54 letter='r'; elseif vd==55 letter='s'; elseif vd==56 letter='t'; elseif vd==57 letter='u'; elseif vd==58 letter='v'; elseif vd==59 letter='w'; elseif vd==60 letter='x'; elseif vd==61 letter='y'; elseif vd==62 letter='z'; else letter='l'; %*-*-*-*-* end
5.5. Convert recognized letters to text format
% PRINCIPAL PROGRAM warning off %#ok<WNOFF> % Clear all clc, close all, clear all % Read image imagen=imread('testcheck1.jpg'); % Show image imagen1 = imagen;

15
figure,imshow(imagen1); title('INPUT IMAGE WITH NOISE') % Convert to gray scale if size(imagen,3)==3 %RGB image imagen=rgb2gray(imagen); end % Convert to BW threshold = graythresh(imagen);
imagen =~im2bw(imagen,threshold); imagen2 = imagen; %figure,imshow(imagen2); % title('before bwareaopen') % Remove all object containing fewer than 15 pixels imagen = bwareaopen(imagen,15); imagen3 = imagen; %figure,imshow(imagen3); %title('after bwareaopen') %Storage matrix word from image word=[ ]; re=imagen; %Opens text.txt as file for write fid = fopen('text.txt', 'wt'); % Load templates load templates global templates % Compute the number of letters in template file num_letras=size(templates,2); while 1 %Fcn 'lines_crop' separate lines in text [fl re]=lines_crop(re); %fl= first line, re= remaining image imgn=fl; n=0; %Uncomment line below to see lines one by one %figure,imshow(fl);pause(2) %-----------------------------------------------------------------
spacevector = []; % to compute the total spaces betweeen % adjacent letter rc = fl;
while 1 %Fcn 'letter_crop' separate letters in a line [fc rc space]=letter_crop(rc); %fc = first letter in the line %rc = remaining cropped line %space = space between the letter % cropped and the next letter %uncomment below line to see letters one by one %figure,imshow(fc);pause(0.5) img_r = imresize(fc,[42 24]); %resize letter so that correlation %can be performed n = n + 1; spacevector(n)=space;
%Fcn 'read_letter' correlates the cropped letter with the images %given in the folder 'letters_numbers' letter = read_letter(img_r,num_letras);

16
%letter concatenation word = [word letter];
if isempty(rc) %breaks loop when there are no more characters break; end end
%-------------------------------------------------------------------
% max_space = max(spacevector); no_spaces = 0;
for x= 1:n %loop to introduce space at requisite locations if spacevector(x+no_spaces)> (0.75 * max_space) no_spaces = no_spaces + 1; for m = x:n word(n+x-m+no_spaces)=word(n+x-m+no_spaces-1); end word(x+no_spaces) = ' '; spacevector = [0 spacevector]; end end
%fprintf(fid,'%s\n',lower(word));%Write 'word' in text file (lower) fprintf(fid,'%s\n',word);%Write 'word' in text file (upper) % Clear 'word' variable word=[ ]; %*When the sentences finish, breaks the loop if isempty(re) %See variable 're' in Fcn 'lines' break end end fclose(fid); %Open 'text.txt' file winopen('text.txt') clear all

17
6. SAMPLE TESTING
During the process of execution, it selects a file from a directory using a dialog box.
Figure 6.1: Select an Image Dialog box
The image which has been selected will be displayed in the processing platform.
Figure 6.2: Show Image with error

18
The processed image will be displayed as a text in notepad.
Figure 6.3: Text generation in a textbox

19
7. PERFORMANCE TESTING
There are many types of tastings which can be performed in the software. One of the testing is
black box testing.
7.1 Black Box Testing In this type of testing the product design to perform is already known. The only thing to check
here is the input and its corresponding output. Out of millions of inputs we have consider only
four inputs.
Figure 7.1: Conversion of text from a single line image to text format
Figure 7.2: Conversion of text from a multi-line image to text format

20
Figure 7.3: Conversion of text from a colored background image to text format
Figure 7.4: Conversion of text from a lower case letter format
Figure 7.5: Conversion of text from a lower case letter and upper case letter format

21
Figure 7.6: Conversion of text from a distorted image to text format
22
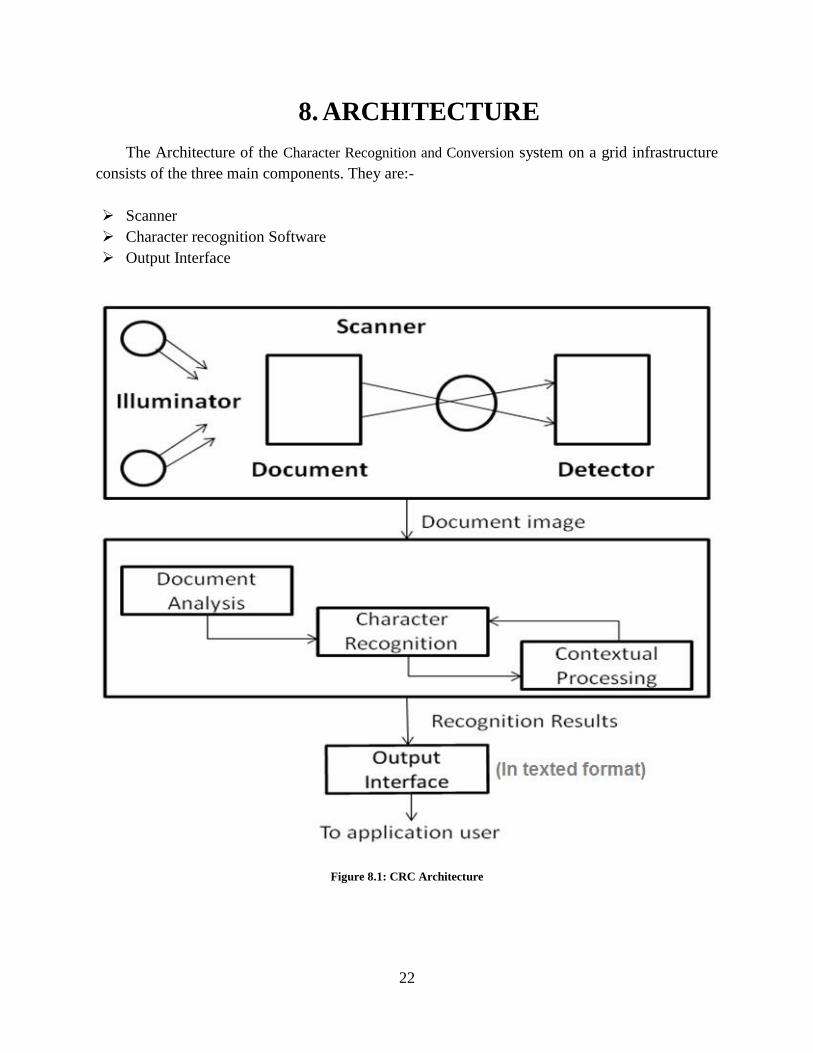
8. ARCHITECTURE
The Architecture of the Character Recognition and Conversion system on a grid infrastructure
consists of the three main components. They are:-
Scanner
Character recognition Software
Output Interface
Figure 8.1: CRC Architecture

23
9. APPLICATION
Language Conversion
Along with English, there are varieties of languages which can be converted into user readable
format. By language translation software which uses DIA as its main functioning software.
Automatic Number Plate Recognition
Automatic number plate recognition is a mass surveillance method that uses optical
character recognition on images to read vehicle registration plates. They can use existing closed-
circuit television or road-rule enforcement cameras, or ones specifically designed for the task.
They are used by various police forces and as a method of electronic toll collection on pay-per-
use roads and cataloging the movements of traffic or individuals.
Data Entry for Business Documents
It is widely used as a form of data entry from printed paper data records, whether
passport documents, invoices, bank statements, computerized receipts, business cards, mail,
printouts of static-data, or any suitable documentation.
More applications,
More quickly make textual versions of printed documents
Make electronic images of printed documents searchable
Automatic insurance documents key information extraction
Converting handwriting in real time to control a computer
Assistive technology for blind and visually impaired users

24
10. CONCLUSION
It is a powerful tool to recognize characters into electronic formats. As mentions earlier it can be used for
many purposes. However, the limited availability of capital could restrict the growth of this technology.
But if given proper enhancement it can be used for a variety of other purposes like, retinal scan,
recognition of new font and characters and can be used for storing large documents in electronic format
like one’s certificates and belongings.

25
11. References
1. http://in.mathworks.com/help/vision/examples/recognize-text-using-optical-character-
recognition-ocr.html (6th Jan 2016, 19.14)
2. https://en.wikipedia.org/wiki/Optical_character_recognition(21st May 2016, 21.38)
3. http://www.advancedsourcecode.com/characterrecognition.asp(22nd may 2016, 22.13)
4. http://in.mathworks.com/help/vision/ref/ocr.html(21st May 2016, 20.46)
5. https://www.google.co.in/url?sa=t&rct=j&q=&esrc=s&source=web&cd=4&cad=rja&uact=
8&sqi=2&ved=0ahUKEwjx34-
Op5nKAhWPGI4KHSX3ALgQtwIILjAD&url=https%3A%2F%2Fwww.youtube.com%2
Fwatch%3Fv%3D8Qjzkk-
h0p4&usg=AFQjCNEnGN163uiWbcciPic8ORNN6RHBRQ&bvm=bv.110151844,d.c2E(20t
h May 2016, 12.34)
6. Software Engineering, 9th Edition, IAN SOMMERVILLE
7. http://in.mathworks.com/help/matlab/predefined-dialog-boxes.html(20th May 2016, 15.45)
8. in.mathworks.com/help/matlab/ref/uigetpref.html(20th May 2016, 16.10)
9. http://in.mathworks.com/help/matlab/predefined-dialog-boxes.html(20th May 2016, 16.15)
10. http://in.mathworks.com/videos/creating-a-gui-with-guide-68979.html(21st May 2016, 8. 25)
11. http://in.mathworks.com/help/search.html?qdoc=use+a+selected+image+taken+by+uigetfile
&submitsearch= (21st May 2016, 8.45)
12. http://www.mathworks.com/matlabcentral/fileexchange/view_license?file_info_id=18169(21
st May 2016, 9.00)
13. http://www.mathworks.com/matlabcentral/fileexchange/18169-optical-character-
recognition--ocr-(21st May 2016, 10.30)
14. http://www.mathworks.com/matlabcentral/fileexchange/31322-optical-character-
recognition-lower-case-and-space-included-(21st May 2016, 11.00)
15. https://sourceforge.net/directory/os:windows/?q=character%20recognition%20using%20m
atlab(21st May 2016, 11.30)
16. http://www.caam.rice.edu/~timwar/CAAM210/OCR.html(21st May 2016, 12.00)
17. http://in.mathworks.com/help/vision/ref/ocr.html(21st May 2016, 12.15)
18. http://in.mathworks.com/help/vision/examples/recognize-text-using-optical-character-
recognition-ocr.html(22nd May 2016, 12.30)
19. http://www.springer.com/us/book/9781848003293(22nd May 2016, 16.00)
20. http://in.mathworks.com/help/images/(22nd May 2016, 16.15)





























