Embed Size (px)
Citation preview

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
Richard Futrell work with Kyle Mahowald and Ted Gibson
22 September 2016

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Quantitative Syntax with Dependency Corpora • Dependency Length Minimization • Comparison to Random Baselines • Grammar and Usage • Residue of Dependency Length Minimization • Conclusion

Quantitative Syntax and Functional Typology
• This work is about using crosslinguistic dependency corpora to do quantitative syntax.
• It’s also about communicative functional typology, which posits that languages have developed structures that make utterances easy to use in communication.
• Such theories make predictions at the level of the utterance, since they predict that the average utterance will have desirable properties. • So quantitative corpus syntax is a natural way to test
communicative hypotheses for language universals. • This talk explores the hypothesis that there is a universal
pressure to minimize dependency lengths, which leads to easier parsing and generation of sentences.

Preview of Dependency Length Results
• We find that dependency length of real utterances is shorter than in linguistically motivated random baselines.
• We develop models of grammatical dependency tree linearizations. In almost all languages, dependency length in real utterances is shorter than random grammatical reorderings of those utterances.
• We explore crosslinguistic variation in dependency length and find it is non-uniform. Explaining these results is a challenge for functional typology.
bn
grc
got trja
caes
xclga huhrno
zhen
fa
plruda fi
etde
nlsk
cu
pt
hi
id
orv
arhe
taelsv
frcs
la
eu ko
bgsl
itro
bngrc
gottr
ja
caes
xclgahu
hrno
zh
en
fa
pl
ruda fi
et
de
nl
sk
cu
pt
hi
id
orv
arhe
taelsv
fr
cs
la
euko
bg
sl
itro
bn
grc
got
tr
ja
caes
xclga
hu
hr
no
zh
en
fa
pl
ruda fi
et
de
nl
sk
cu
pt
hi
id
orv
ar he
tael
sv
fr
cs
la
eu
ko
bg
sl
it
ro
10 15 20
20
30
40
50
60
0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00Proportion head final
Dep
ende
ncy
leng
th
Ancient Greek Basque Bulgarian Church Slavonic Croatian Czech
Danish Dutch English Estonian Finnish French
German Gothic Hebrew Hindi Hungarian Indonesian
Irish Italian Japanese Latin Modern Greek Norwegian (Bokmål)
Persian Portuguese Romanian Slovenian Spanish Swedish
40
60
80
100
40
60
80
100
40
60
80
100
40
60
80
100
40
60
80
100
15 20 25 30 15 20 25 30 15 20 25 30 15 20 25 30 15 20 25 30 15 20 25 30Sentence length
Dep
ende
ncy
leng
th realfree random
rand_proj_lin_hdr_lic
rand_proj_lin_hdr_mle
rand_proj_lin_perplex
real

Data Sources• There has been a recent effort in the NLP community to develop
standardized dependency corpora of many languages for use in training parsers.
• Results: • Universal Dependencies: Hand-parsed or -corrected corpora
of 35+ languages, modern and ancient (Nivre et al., 2015) • HamleDT: Automatic conversion of hand-parsed corpora to
Universal Dependencies style. (Zeman et al., 2012, 2014) • Google Universal Treebank: A predecessor to UD, which still
has some languages which UD doesn’t (McDonald et al., 2013)
• PROIEL: Texts in Indo-European classical languages (Haug and Jøhndal, 2008).
• Corpora vary in their public availability but most are easy to get.
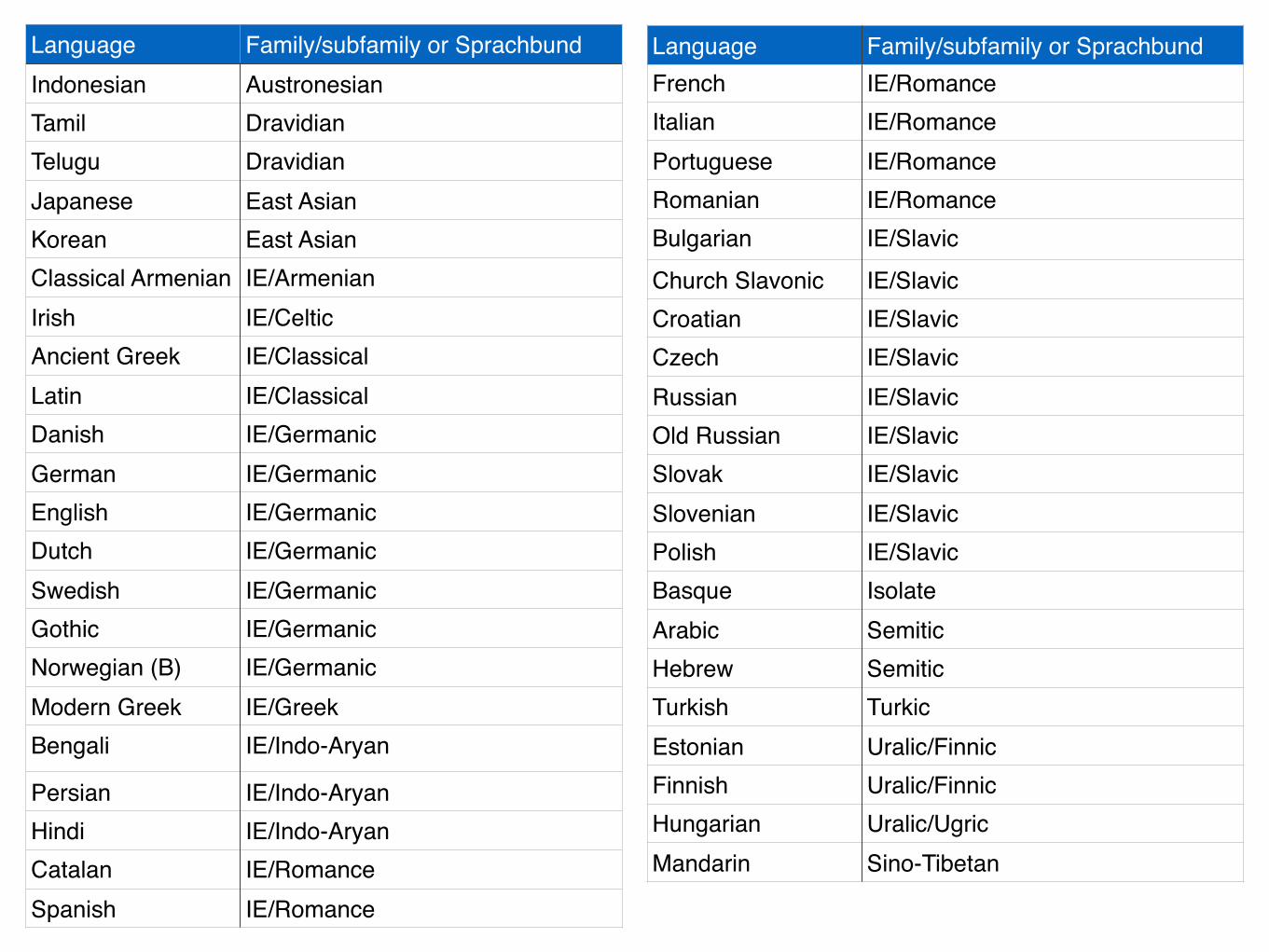
Language Family/subfamily or SprachbundIndonesian AustronesianTamil DravidianTelugu DravidianJapanese East AsianKorean East AsianClassical Armenian IE/ArmenianIrish IE/CelticAncient Greek IE/ClassicalLatin IE/ClassicalDanish IE/GermanicGerman IE/GermanicEnglish IE/GermanicDutch IE/GermanicSwedish IE/GermanicGothic IE/GermanicNorwegian (B) IE/GermanicModern Greek IE/GreekBengali IE/Indo-Aryan
Persian IE/Indo-AryanHindi IE/Indo-AryanCatalan IE/RomanceSpanish IE/Romance
French IE/RomanceItalian IE/RomancePortuguese IE/RomanceRomanian IE/RomanceBulgarian IE/SlavicChurch Slavonic IE/SlavicCroatian IE/SlavicCzech IE/SlavicRussian IE/SlavicOld Russian IE/SlavicSlovak IE/SlavicSlovenian IE/SlavicPolish IE/SlavicBasque IsolateArabic SemiticHebrew SemiticTurkish TurkicEstonian Uralic/FinnicFinnish Uralic/FinnicHungarian Uralic/UgricMandarin Sino-Tibetan
Language Family/subfamily or Sprachbund

Universal Dependencies Annotation
PRON VERB ADP DET NOUN ADP DET NOUN
(Sentence 99 in the English UD dev set)
• Sentences annotated with dependency tree, dependency arc labels, wordforms, and Google Universal POS tags.
• For most but not all languages, all of these levels of annotation are available.
• Data sources are newspapers, novels (inc. some translated novels), blog posts, and some spoken language.

Universal Dependencies Annotation
(Sentence 99 in the English UD dev set)
• Some of the annotation decisions are surprising from the perspective of purely syntactic dependencies.
PRON VERB ADP DET NOUN ADP DET NOUN

Universal Dependencies Annotation
• In order to parse English uniformly with languages that would have item with a case marker and no adposition, UD parses prepositional phrases with the noun as the head and the preposition as a dependent.
• Similarly, complementizers are dependents of verbs, auxiliary verbs are dependents of content verbs, and predicates are heads of copula verbs (!).
• The dependencies in their raw from thus reflect grammatical relations more than syntactic dependencies (de Marneffe and Manning, 2008; de Marneffe et al., 2014; Nivre, 2015).

Universal Dependencies Annotation
• Fortunately, it is often possible to convert UD dependencies automatically into syntactic dependencies. • And for HamleDT corpora and other non-UD corpora, Prague-
style syntactic dependencies are often available. • We prefer syntactic dependencies for dependency length studies.
PRON VERB ADP DET NOUN ADP DET NOUNPRON VERB ADP DET NOUN ADP DET NOUN

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Quantitative Syntax with Dependency Corpora • Dependency Length Minimization • Comparison to Random Baselines • Grammar and Usage • Residue of Dependency Length Minimization • Conclusion

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Dependency Length Minimization • As an empirical phenomenon • As a typological theory • Cognitive motivations
Dependency Length Minimization as an Empirical Phenomenon: Weight Preferences
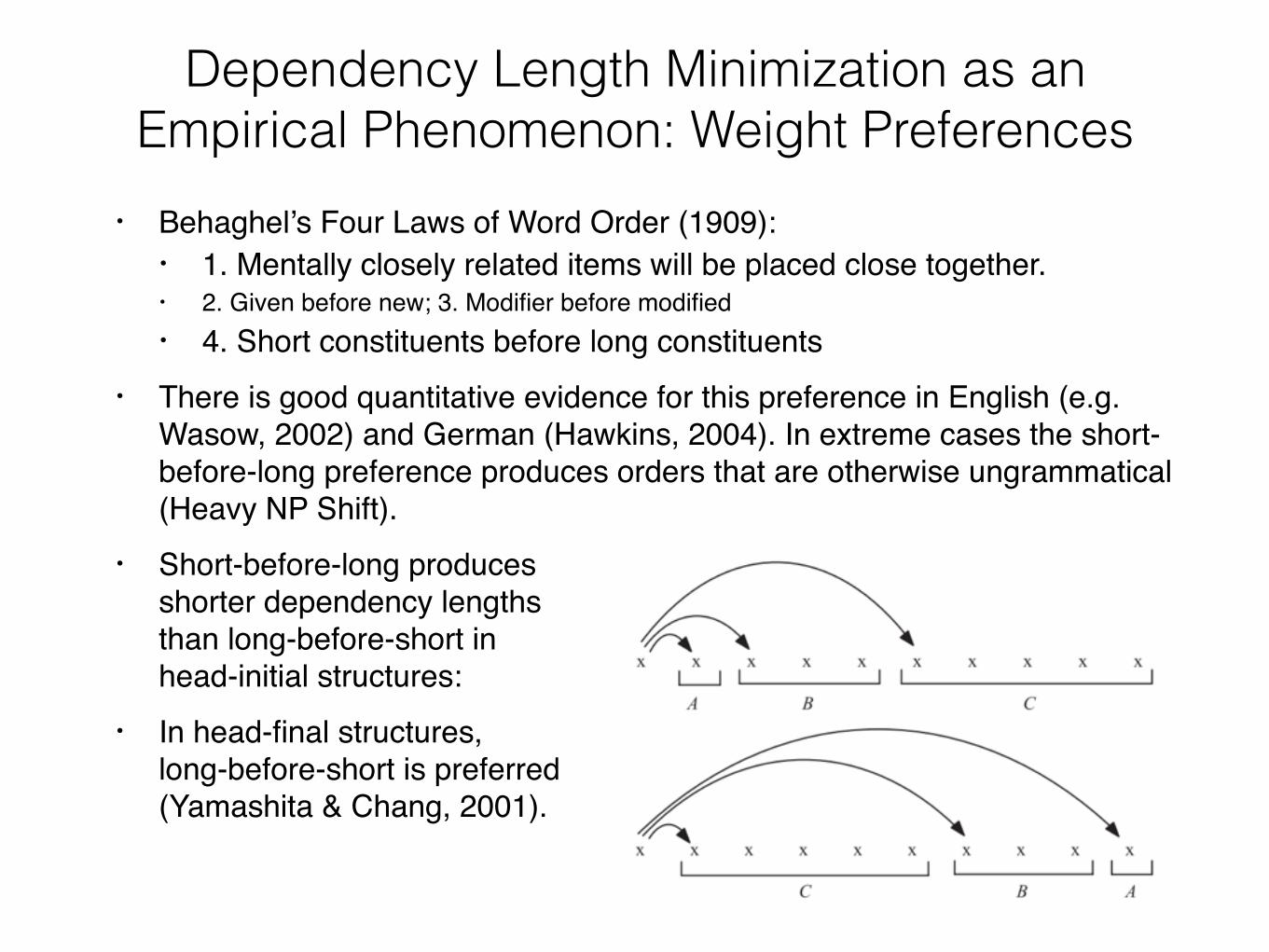
• Behaghel’s Four Laws of Word Order (1909):• 1. Mentally closely related items will be placed close together.• 2. Given before new; 3. Modifier before modified• 4. Short constituents before long constituents
• There is good quantitative evidence for this preference in English (e.g. Wasow, 2002) and German (Hawkins, 2004). In extreme cases the short-before-long preference produces orders that are otherwise ungrammatical (Heavy NP Shift).
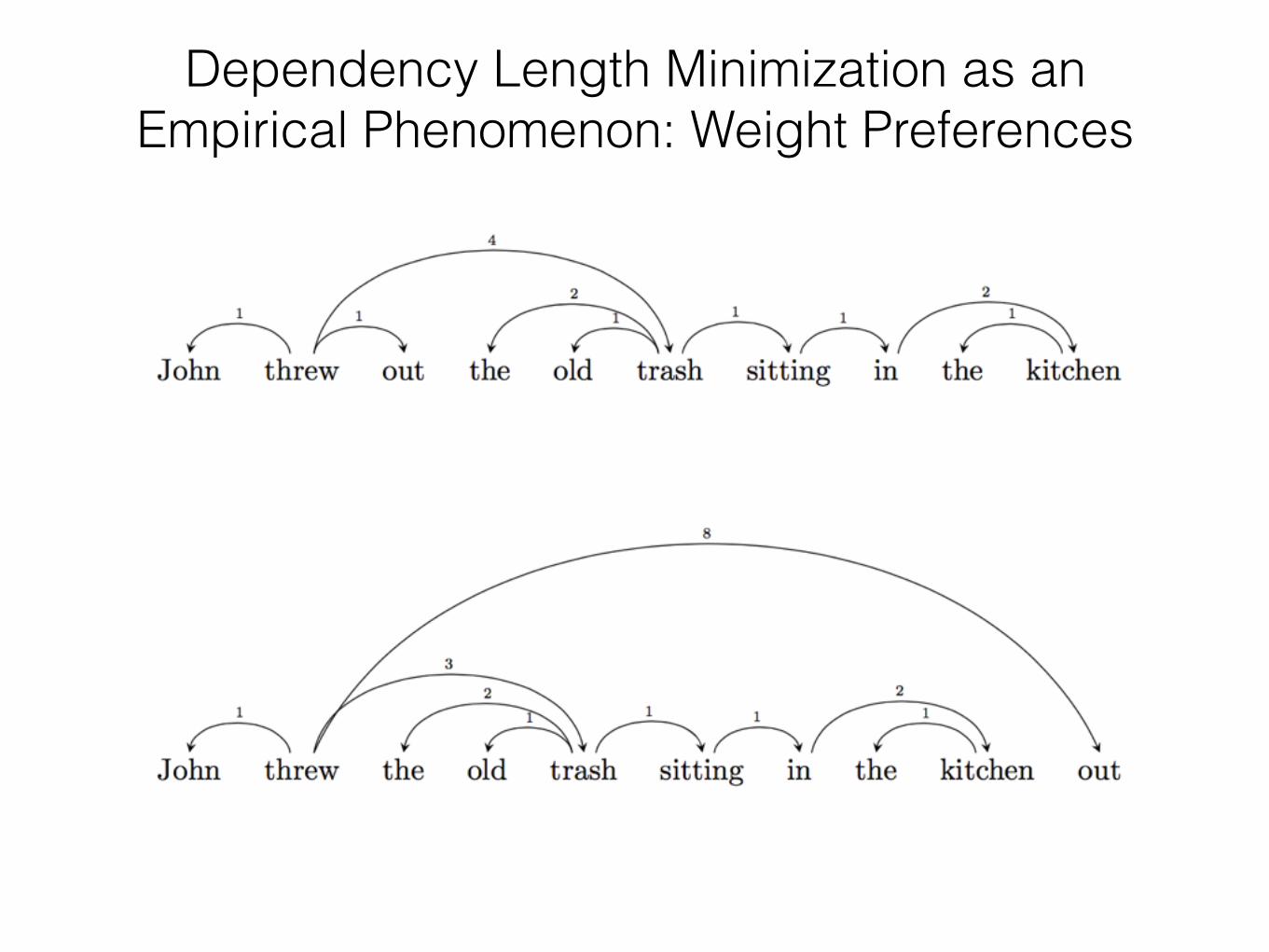
• Short-before-long producesshorter dependency lengthsthan long-before-short in head-initial structures:
• In head-final structures, long-before-short is preferred (Yamashita & Chang, 2001).
Dependency Length Minimization as an Empirical Phenomenon: Weight Preferences

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Dependency Length Minimization • As an empirical phenomenon • As a typological theory • Cognitive motivations

Dependency Length Minimization as a Typological Theory
• In addition to explaining order preferences within utterances, a pressure to minimize dependency lengths can explain word order universals (Hawkins, 1991, 1994): • When dependency trees have low arity, DLM is achieved by
consistent head direction:
• Possible explanation for harmonic orders (Greenberg 1963, Vennemann, 1973): • OV order is correlated with Noun-Adposition, Adjective-Noun,
Determiner-Noun, etc.: consistently head final. • VO order is correlated with Adposition-Noun, Noun-Adjective,
Noun-Determiner, etc.: consistently head initial.
as opposed to

• For higher-arity trees, a (projective) grammar should arrange phrases outward from a head in order of increasing average length (Gildea & Temperley, 2007).
• Consistent with Dryer’s (1992) observations that exceptions to harmonic orders are usually for short constituents such as determiners.
as opposed to or
Dependency Length Minimization as a Typological Theory

Dependency Length Minimization as a Typological Theory
• DLM has been advanced as an explanation for the prevalence of projective dependencies — corresponding to context-freeness — in language (Ferrer i Cancho, 2004). in nova fert animus mūtātas dīcere formas corpora
subject
object
object
adjmodpmod
pobj adjmod
[in [nova[mūtātas[formas corpora]]]]]]fert[animus [dīcere
subjectpmod
objectobject adjmod
pobj
adjmod

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Dependency Length Minimization • As an empirical phenomenon • As a typological theory • Cognitive motivations

Motivation for Dependency Length Minimization
• When parsing a sentence incrementally, dependency length is the lower bound on the amount of time you have to hold a word in memory (Abney & Johnson, 1991).
• Making a syntactic connection between the current word and a previous word might be hard if the previous word has been in memory for a long time, because of decay of memory representations (DLT integration cost: Gibson, 1999, 2000) or similarity-based interference (Vasishth & Lewis, 2006).• Reading time evidence for integration cost in controlled
experiments (Grodner & Gibson, 2005) (but corpus evidence is mixed: see Demberg & Keller, 2008).
• Short dependencies means a smaller domain to search for the head of a phrase (Hawkins, 1994).

Motivation for Dependency Length Minimization
• Convergent predictions from multiple theories predicting easier processing when dependency length is minimized.
• In current work we are agnostic to the precise motivation for DLM.

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Quantitative Syntax with Dependency Corpora • Dependency Length Minimization • Comparison to Random Baselines • Grammar and Usage • Residue of Dependency Length Minimization • Conclusion

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Comparison to Random Baselines • Motivation and Methodology • Free Order Projective Baseline • Fixed Order Projective Baseline • Consistent Head Direction Projective Baseline

DLM is an appealing theory, but…
• But there are other explanations for the putative typological effects of DLM: • Consistent head direction might have to do with simplicity
of grammar. • Projectivity might be motivated by parsing complexity.
• If actual utterances do not have shorter dependency length than what one would expect from these (and other) independently motivated constraints, • then the evidence for DLM as the functional pressure
explaining these constraints is weakened. • Our research question: Do real utterances in many
languages have word orders that minimize dependency length, compared to what one would expect under these constraints?

Random Reorderings as a Baseline
• Do the recently available parsed corpora of 40+ languages show evidence that dependency lengths are shorter than what we would expect under independently motivated constraints?
• Methodology: Comparison of attested orders to random reorderings of the same dependency trees with various constraints. • Methodology of Gildea & Temperley (2007, 2010), Park &
Levy (2009), Hawkins (1999), Gildea & Jaeger (ms) • Similar approach: comparison to random tree structures (Liu,
2008; Ferrer i Cancho and Liu, 2015; Lu, Xu, and Liu, 2015) • Measure dependency length as number of words intervening
between head and dependent + 1.

Why Random Reorderings?
Tree structures / content expressed
Word order rules and preferences
Dependency length
• Our approach is to hold tree structure constant and study whether word orders are optimized given those tree structures.
• Allows us to isolate the specific effect of DLM on word order.
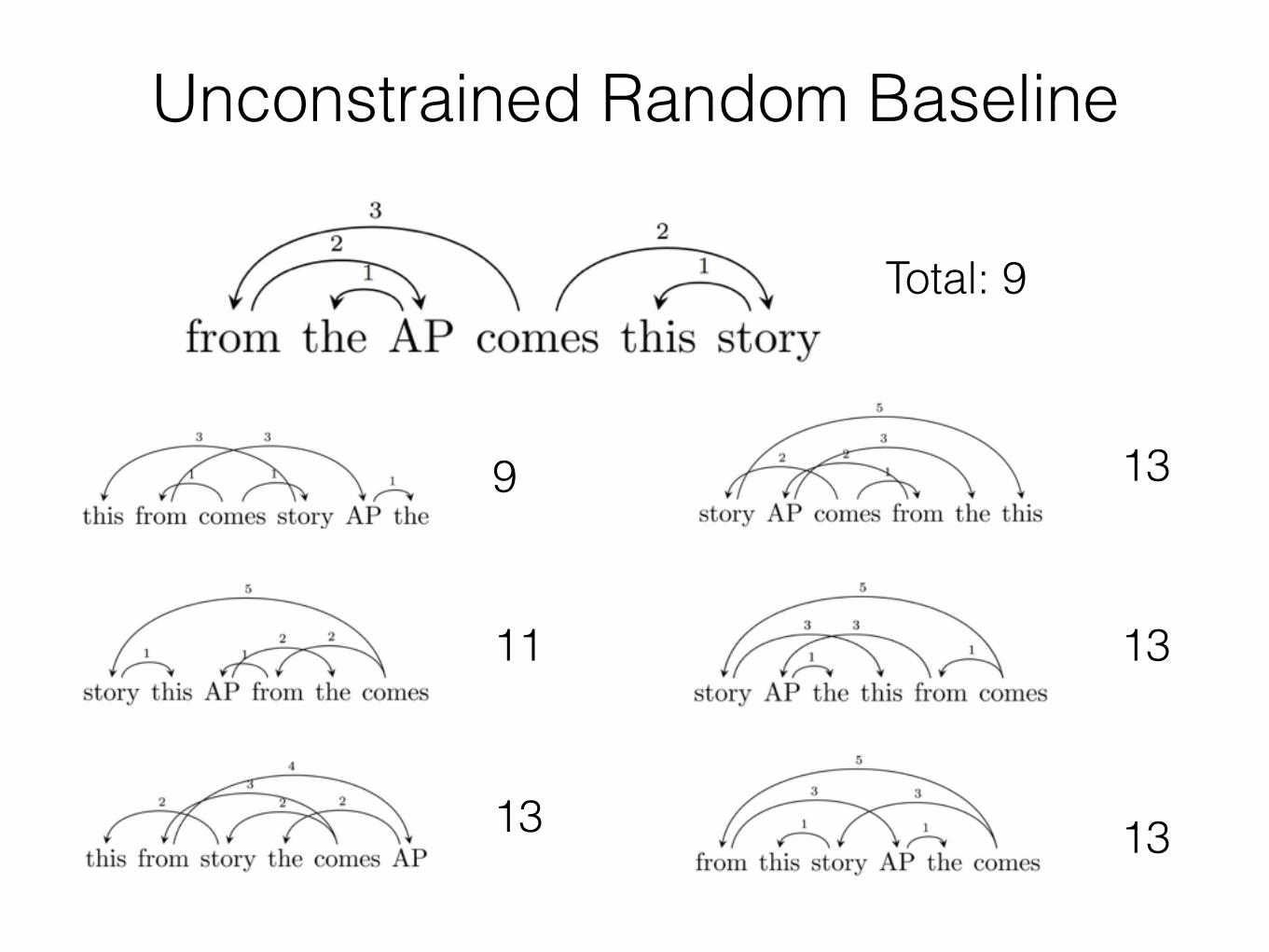
Unconstrained Random Baseline
Total: 9
9
11
13
13
13
13

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Comparison to Random Baselines • Motivation and Methodology • Free Order Projective Baseline • Fixed Order Projective Baseline • Consistent Head Direction Projective Baseline
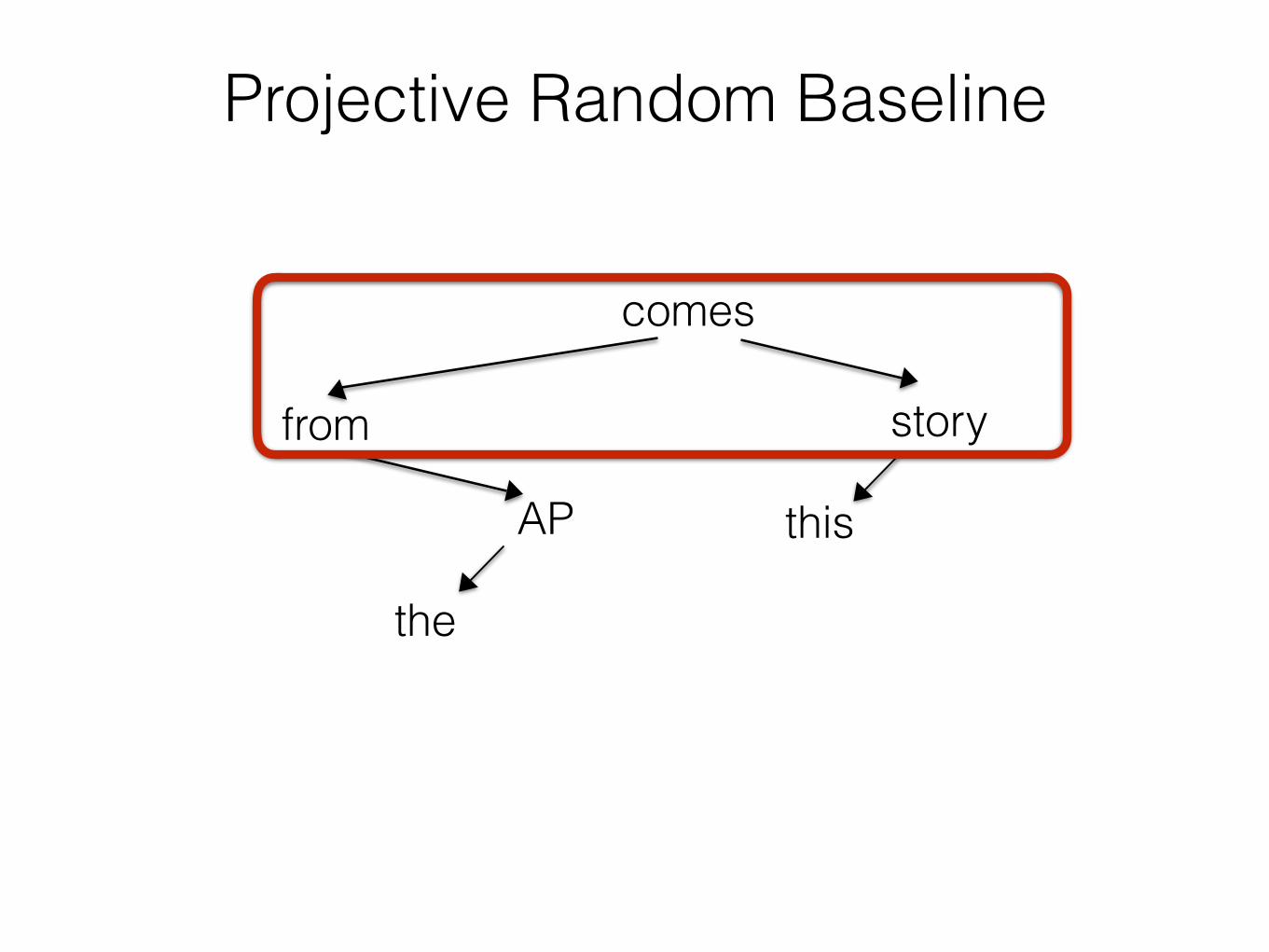
Projective Random Baseline
comes
story
this
from
the
AP
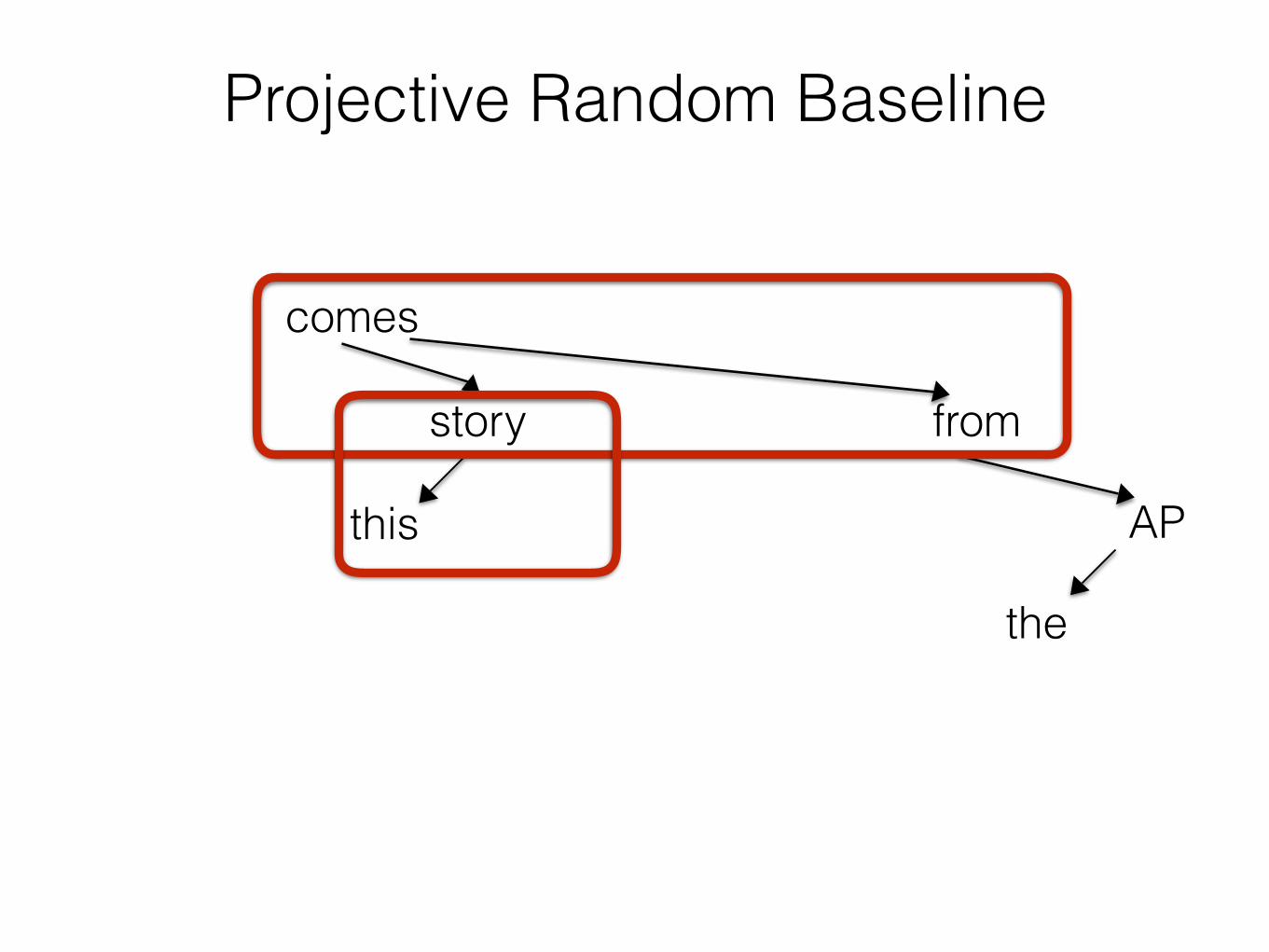
Projective Random Baseline
comes
story
this
from
the
AP
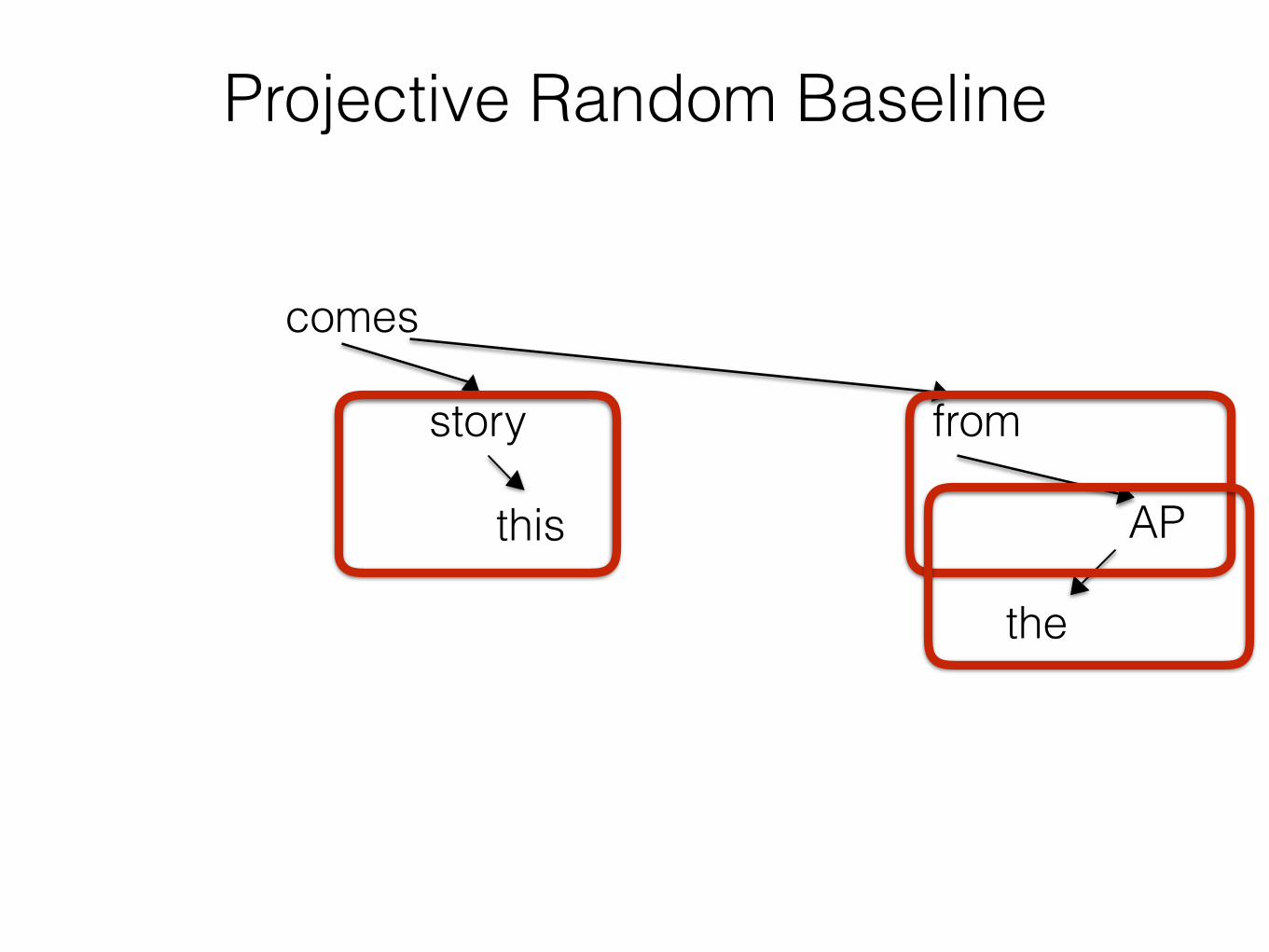
Projective Random Baseline
comes
story from
the
APthis
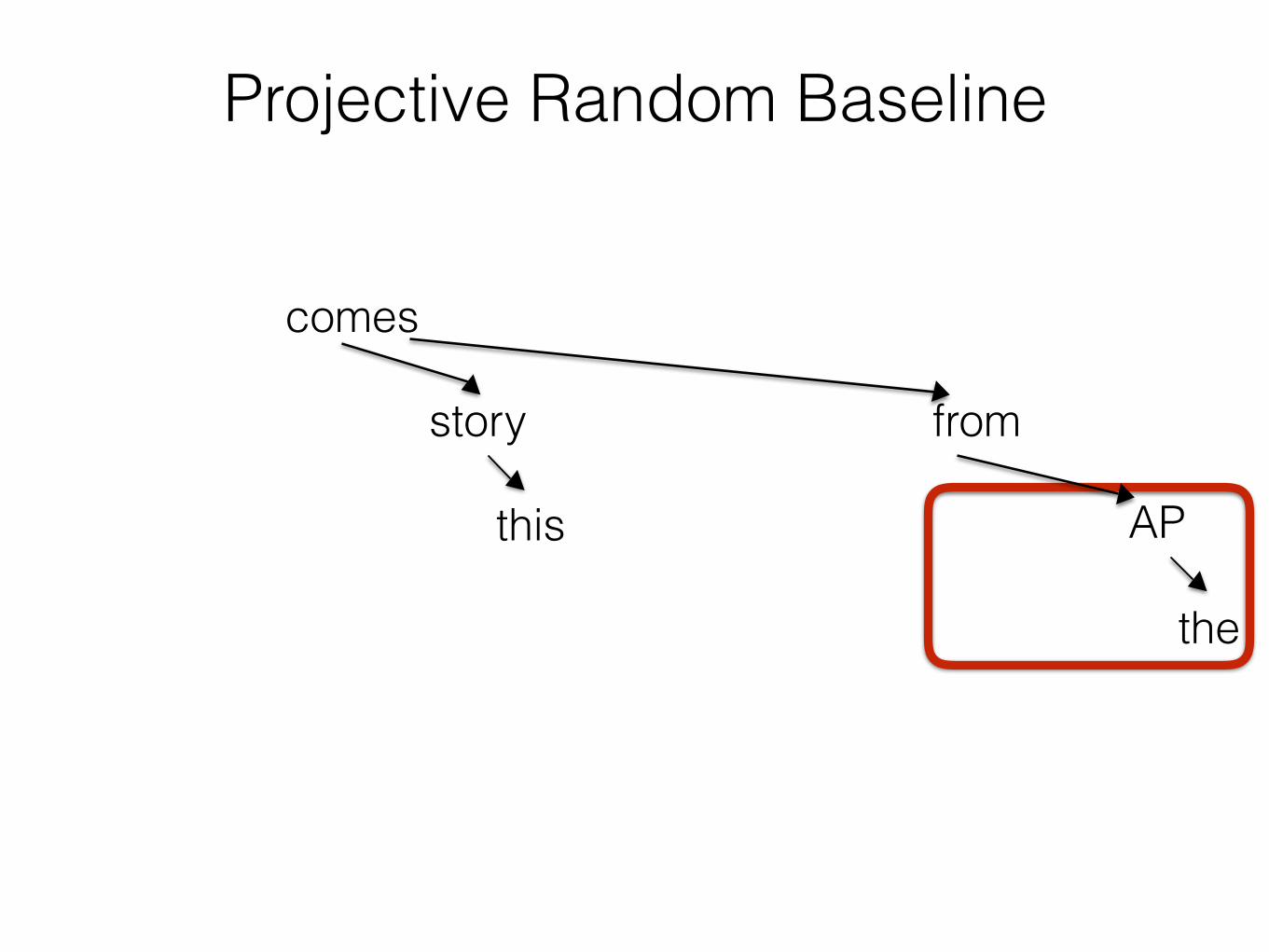
Projective Random Baseline
comes
fromstory
this
the
AP
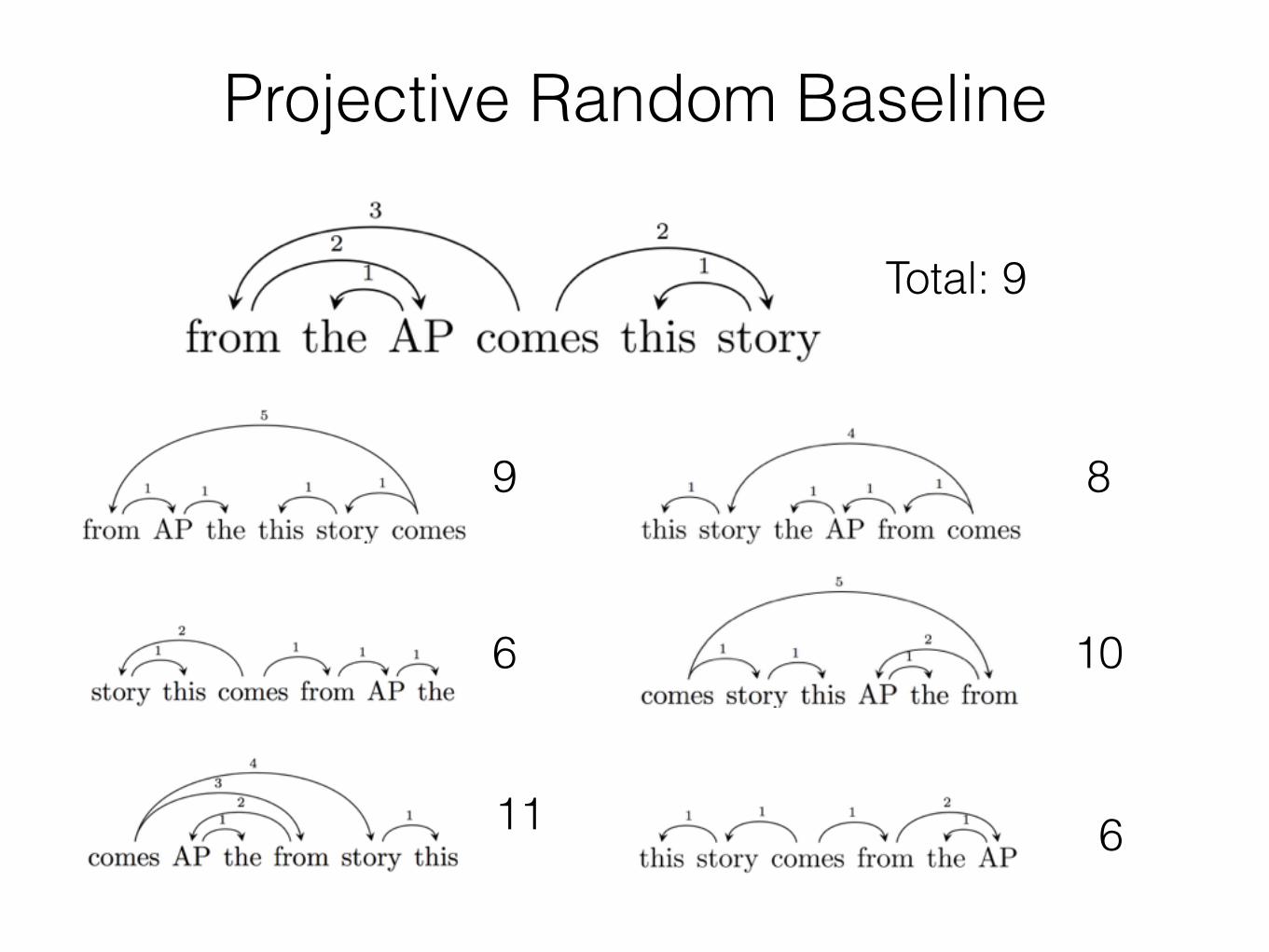
Projective Random Baseline
Total: 9
9
6
11
8
10
6
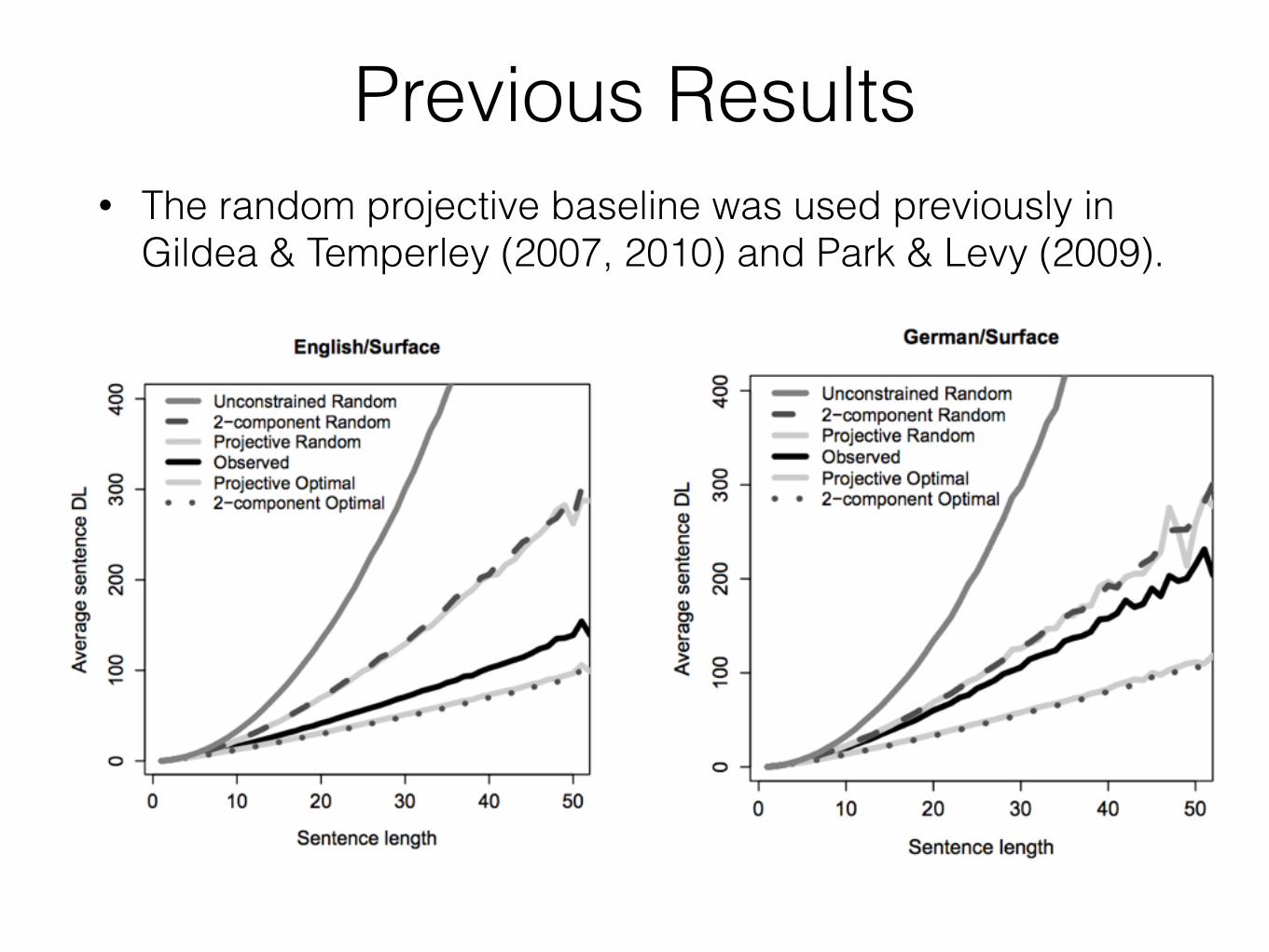
Previous Results• The random projective baseline was used previously in
Gildea & Temperley (2007, 2010) and Park & Levy (2009).
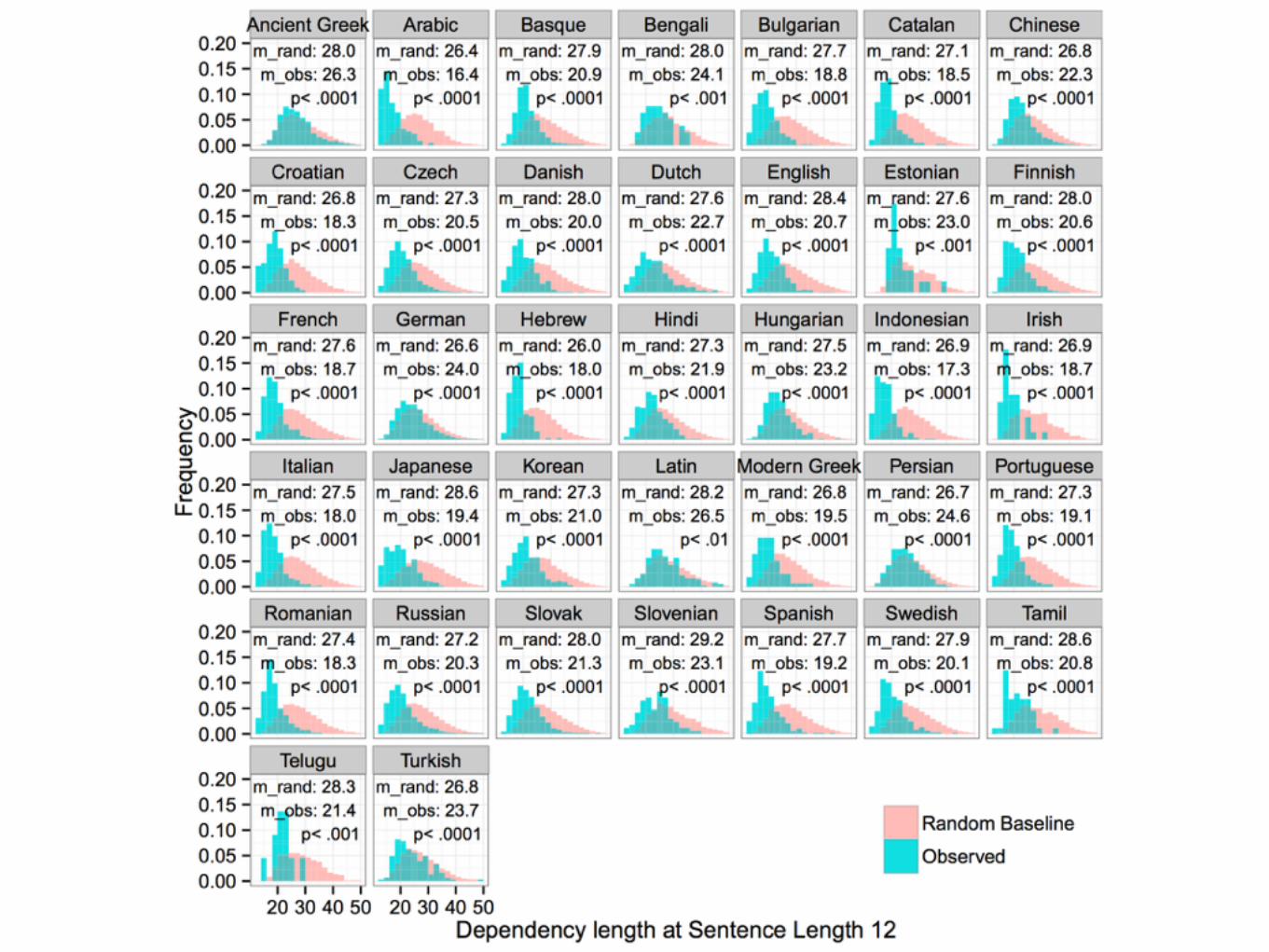

Statistical Model• To test the significance of the effect that real dependency lengths are
shorter than the random baseline, we fit a mixed effects regression for each language.
• For each sentence, predict dependency length of each linearized tree given:• (1) Sentence length (squared),• (2) Whether the linearization is real [0] or random [1],• (3) Random slope of (2) conditional on sentence identity.
• The coefficient for (1) is the dependency length growth rate for real sentence.
• The interaction of (1) and (2) is the difference in dependency length growth rate for baseline linearizations as opposed to attested linearizations. This interaction is the coefficient of interest.
• The interaction of (1) and (2) is significantly positive in all languages (p < 0.001).

Conclusions So Far• Observed dependency length is not explained by
projectivity alone.

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Comparison to Random Baselines • Motivation and Methodology • Free Order Projective Baseline • Fixed Order Projective Baseline • Consistent Head Direction Projective Baseline

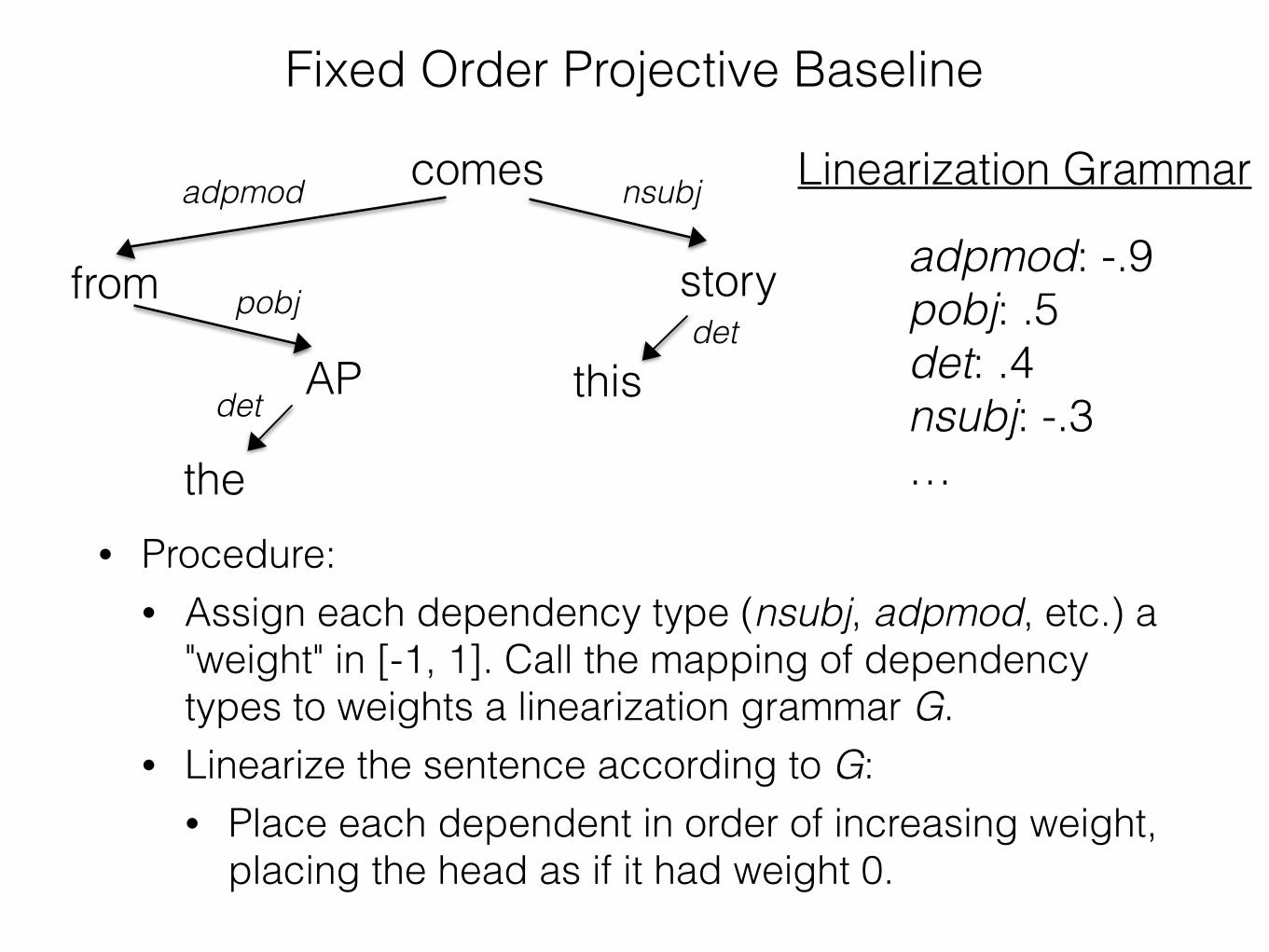
Fixed Order Projective Baseline
• The previous baseline simulated languages with no word order restrictions beyond projectivity. • Speakers speaking random languages randomly.
• Here we simulate random linearization grammars with fixed word order for given dependency types. • Speakers speaking random languages deterministically. • E.g., languages in which subjects always come before
verbs, or adjectives always come before nouns, etc. • Might affect dependency length because head
direction will be more consistent within utterances.
Fixed Order Projective Baseline
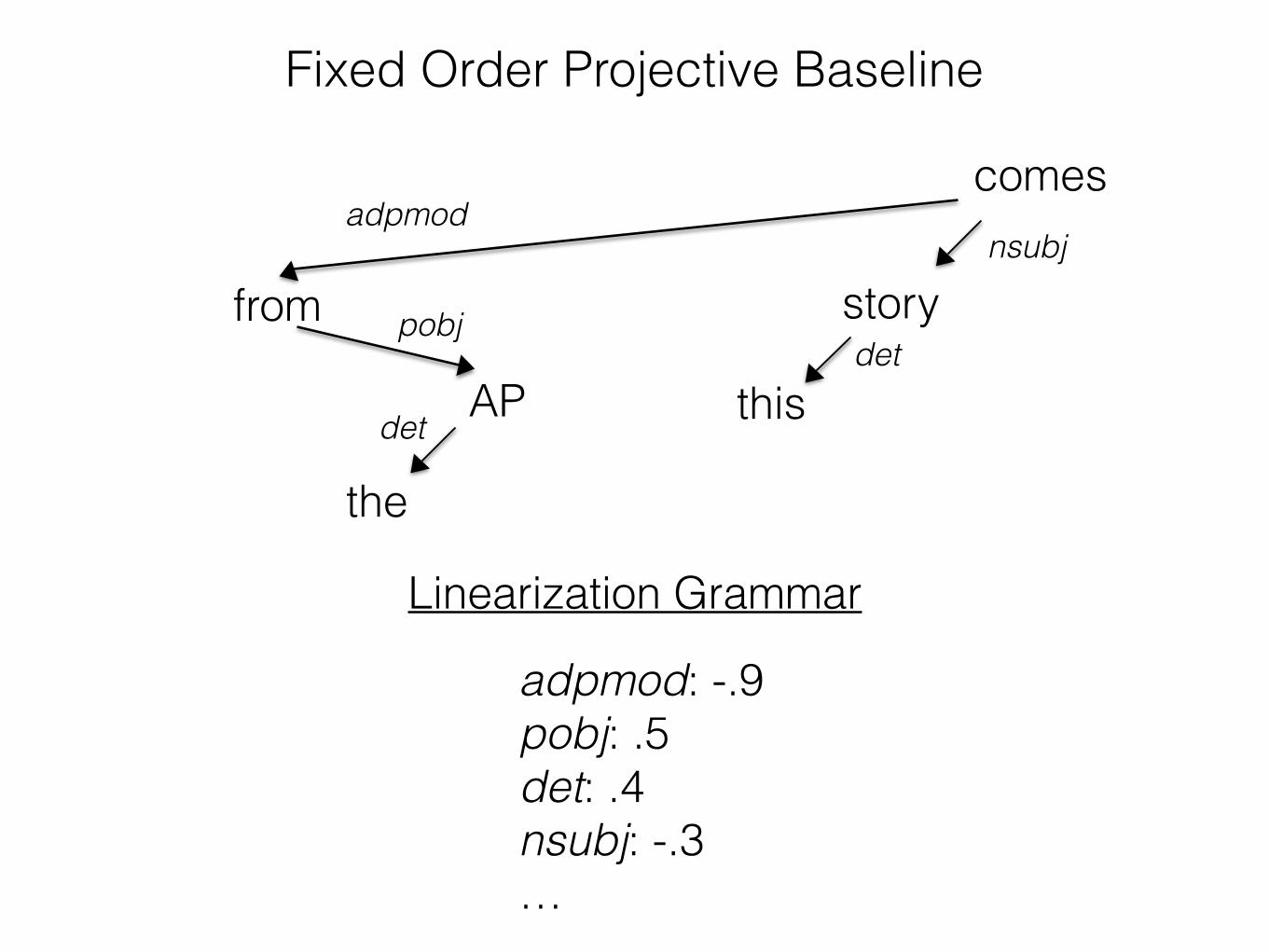
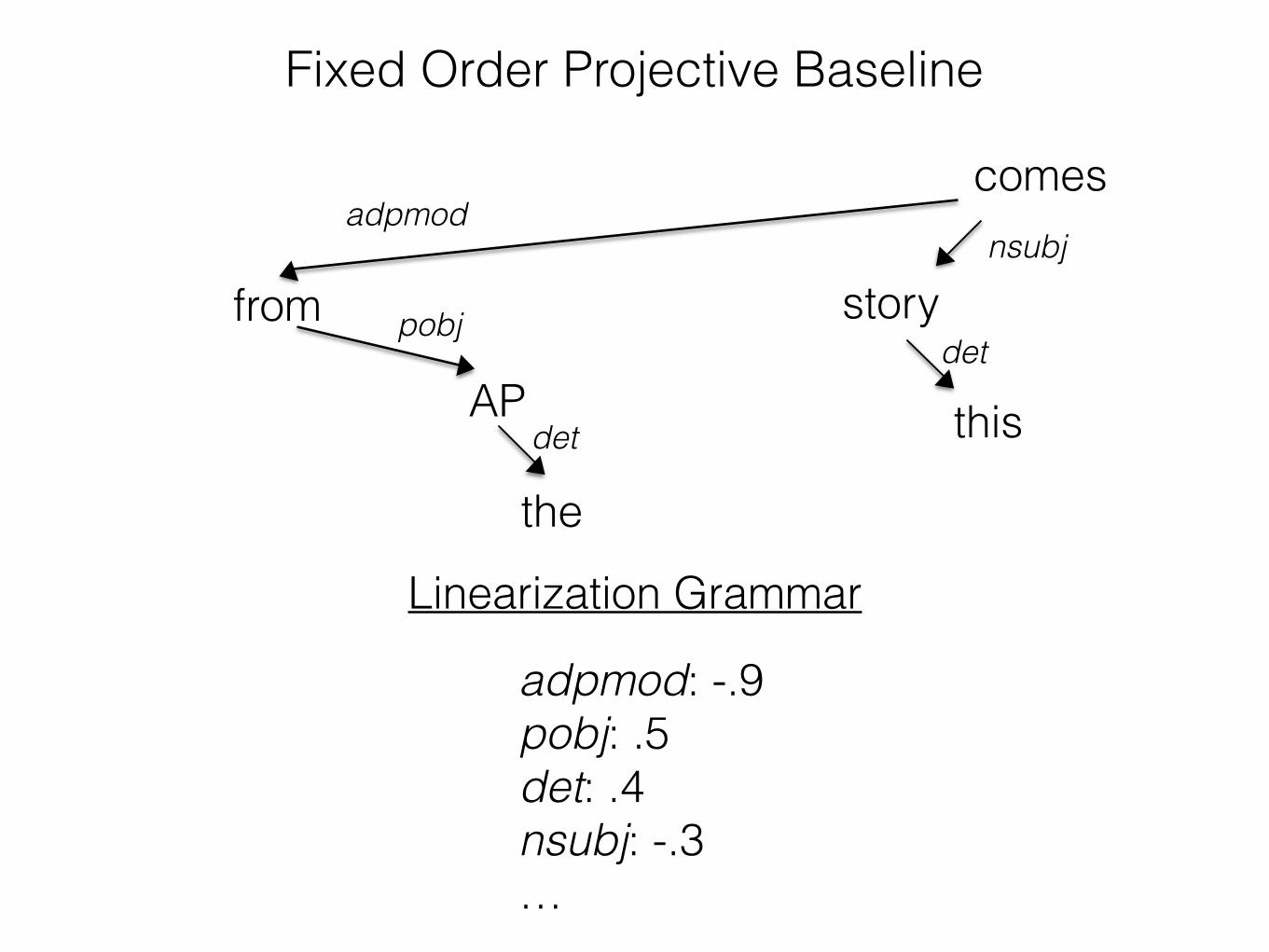
• Procedure: • Assign each dependency type (nsubj, adpmod, etc.) a
"weight" in [-1, 1]. Call the mapping of dependency types to weights a linearization grammar G.
• Linearize the sentence according to G: • Place each dependent in order of increasing weight,
placing the head as if it had weight 0.
comesadpmod
the
AP
from pobj
det
nsubj
this
storydet
Linearization Grammar
adpmod: -.9pobj: .5 det: .4 nsubj: -.3 …

Fixed Order Projective Baseline
comesadpmod
the
AP
from pobj
det
nsubj
this
storydet
Linearization Grammar
adpmod: -.9pobj: .5 det: .4 nsubj: -.3 …

Fixed Order Projective Baseline
comesadpmod
the
AP
from pobj
det
nsubj
this
storydet
Linearization Grammar
adpmod: -.9pobj: .5 det: .4 nsubj: -.3 …
Fixed Order Projective Baseline
comesadpmod
AP
from pobj
thedet
nsubj
story
thisdet
Linearization Grammar
adpmod: -.9pobj: .5 det: .4 nsubj: -.3 …
Fixed Order Projective Baseline
comesadpmod
the
AP
from pobj
det
nsubj
this
story
Linearization Grammar
adpmod: -.9pobj: .5 det: .4 nsubj: -.3 …
det
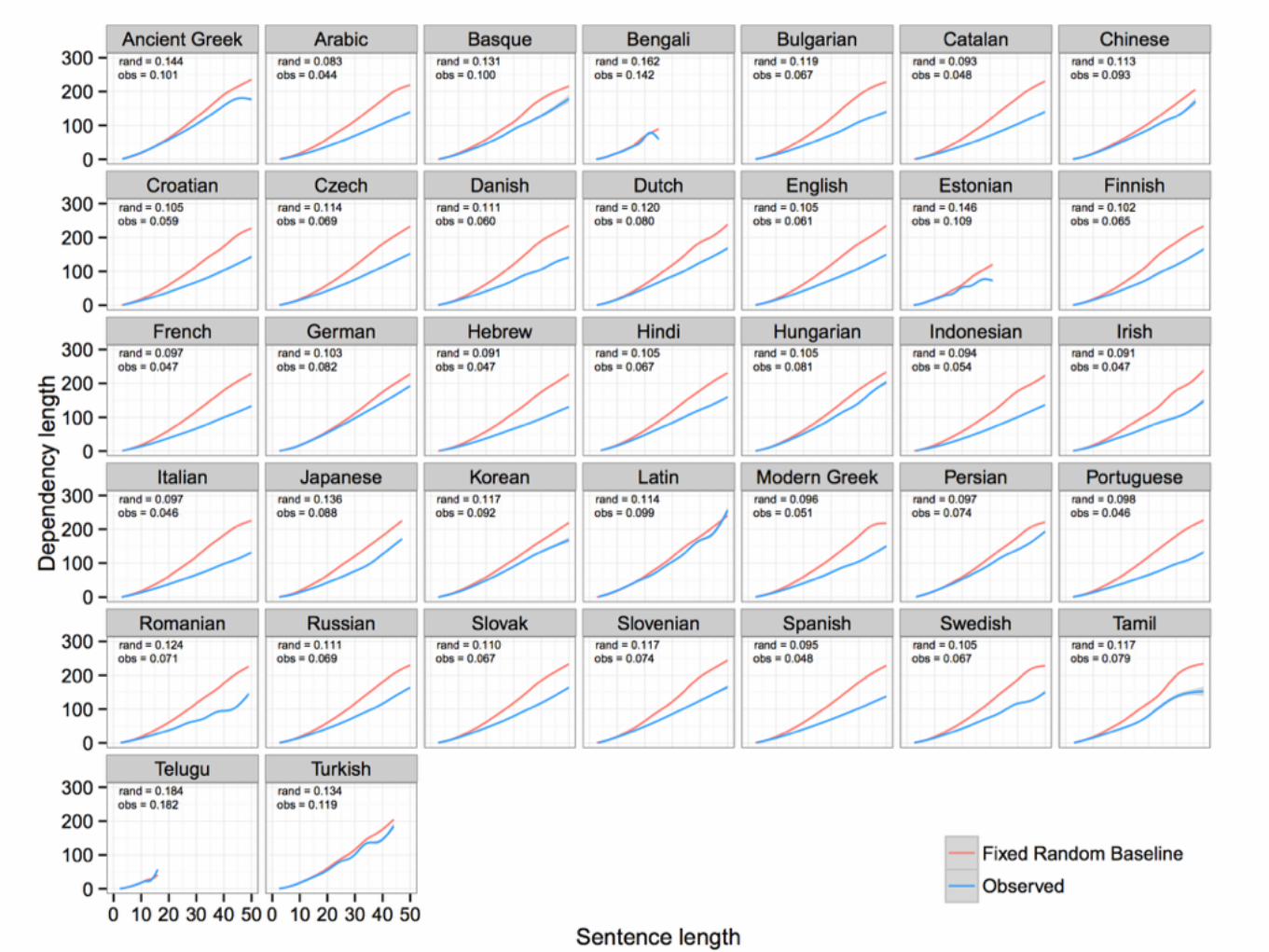

Conclusions So Far• Observed dependency length is not explained by
projectivity alone. • Observed dependency length is not explained by
projectivity in conjunction with fixed word order.

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Comparison to Random Baselines • Motivation and Methodology • Free Order Projective Baseline • Fixed Order Projective Baseline • Consistent Head Direction Projective Baseline

Consistent Head Direction Projective Baseline
• Could observed dependency length be explained by a combination of (1) projectivity and (2) consistent head direction?
• Let’s compare to random projective reorderings with consistent head direction.
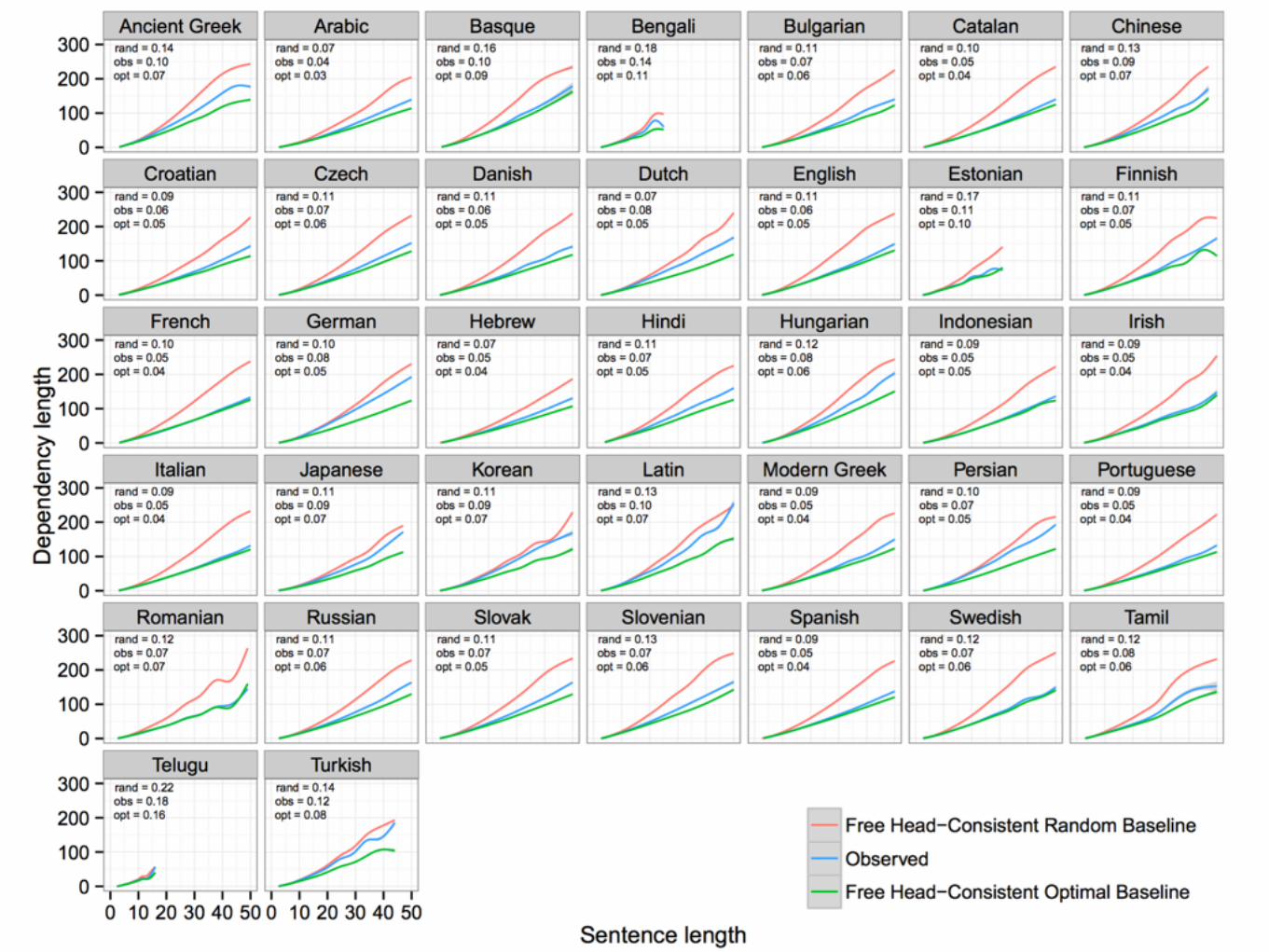

Conclusions So Far• Observed dependency length is not explained by
projectivity alone. • Observed dependency length is not explained by
projectivity in conjunction with fixed word order.• Observed dependency length is not explained by a
pressure for consistency in head direction. • For strongly head-initial and head-final languages, this
implies the existence of short-before-long or long-before-short order preferences.
• Overall, dependency length minimization effects are not explained by various alternative principles—evidence that dependency length minimization is a pressure in itself.

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Quantitative Syntax with Dependency Corpora • Dependency Length Minimization • Comparison to Random Baselines • Grammar and Usage • Residue of Dependency Length Minimization • Conclusion

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Grammar and Usage • Relevance to Dependency Length Minimization • Modeling Grammatical Orders • Results
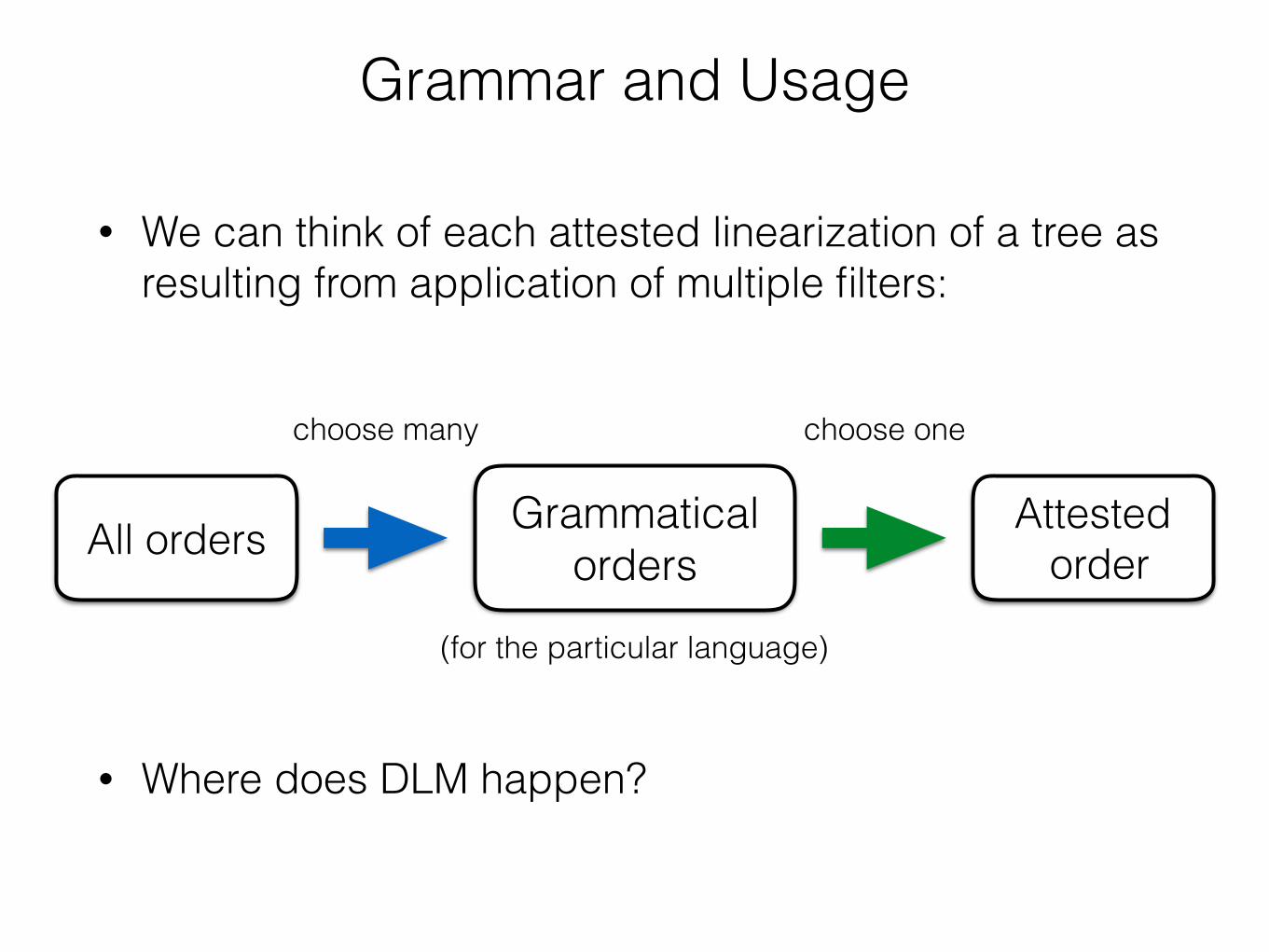
Grammar and Usage
• We can think of each attested linearization of a tree as resulting from application of multiple filters:
All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
• Where does DLM happen?
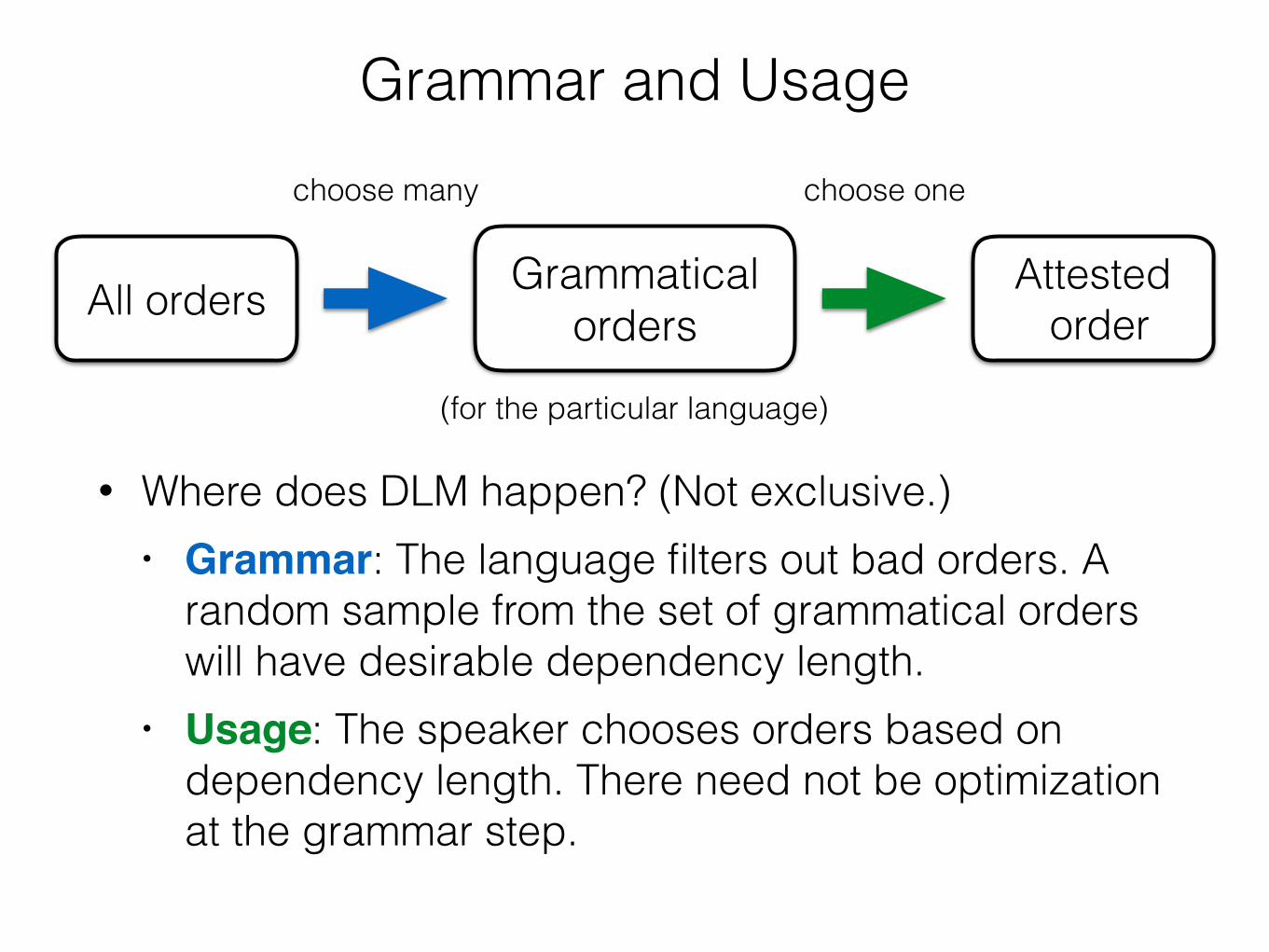
All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
• Where does DLM happen? (Not exclusive.) • Grammar: The language filters out bad orders. A
random sample from the set of grammatical orders will have desirable dependency length.
• Usage: The speaker chooses orders based on dependency length. There need not be optimization at the grammar step.
Grammar and Usage

All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
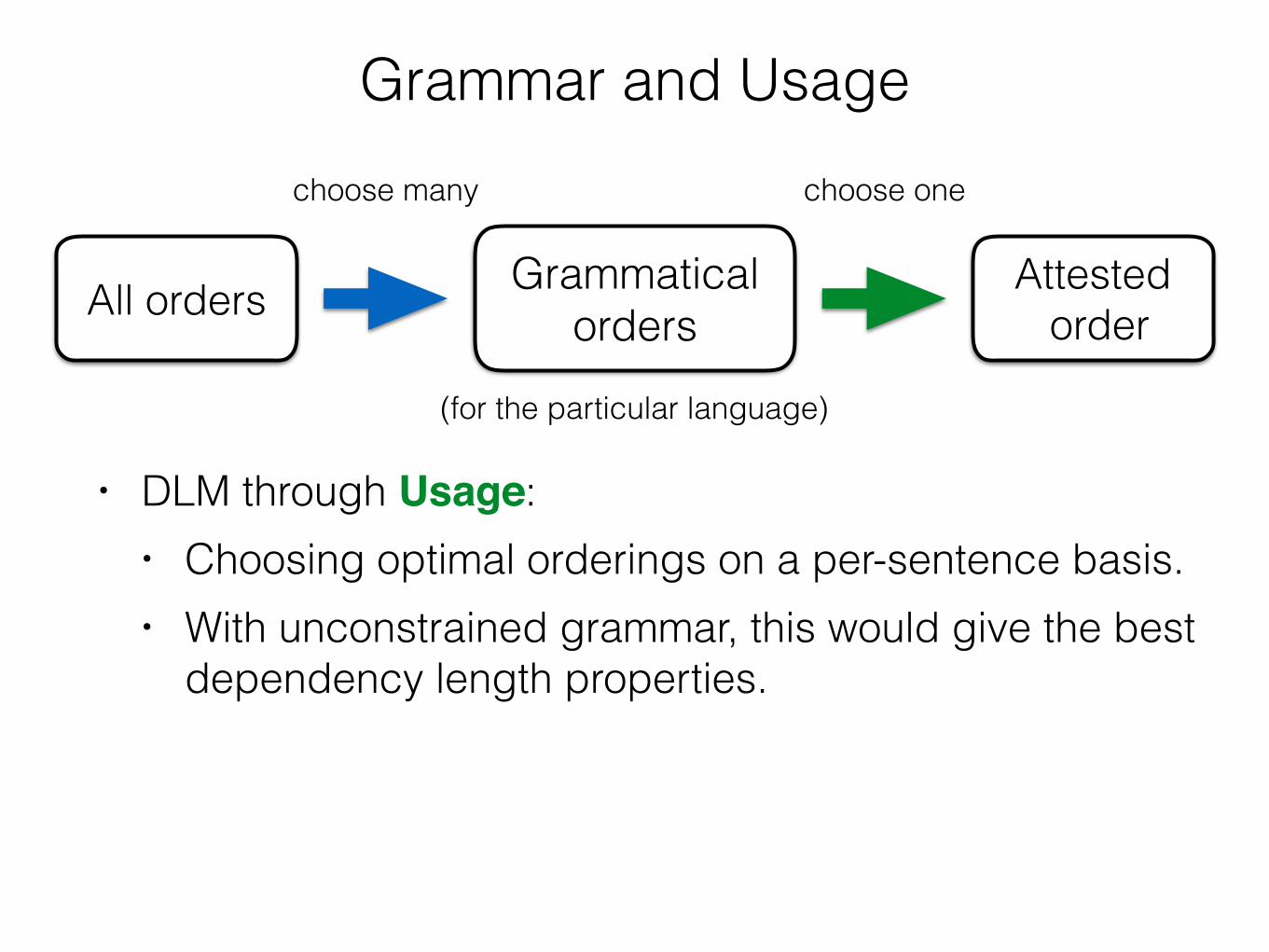
• DLM through Usage:
Grammar and Usage
All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
• DLM through Usage: • Choosing optimal orderings on a per-sentence basis. • With unconstrained grammar, this would give the best
dependency length properties.
Grammar and Usage
All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
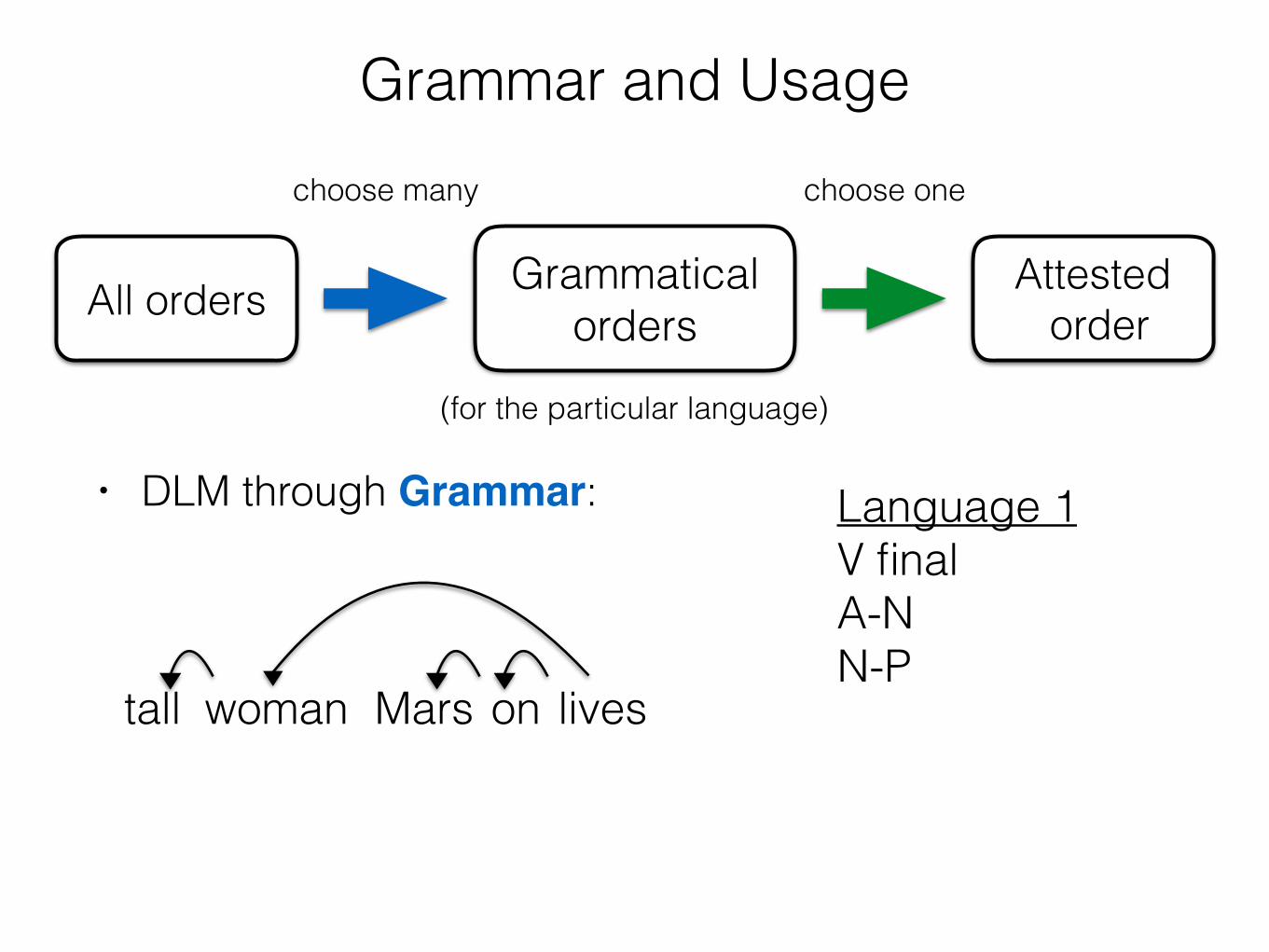
• DLM through Grammar:
Grammar and Usage
livesMars ontall woman
Language 1 V final A-N N-P

All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
• DLM through Grammar:
Grammar and Usage
livesMars on tall woman
Language 1 V final A-N N-P
All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
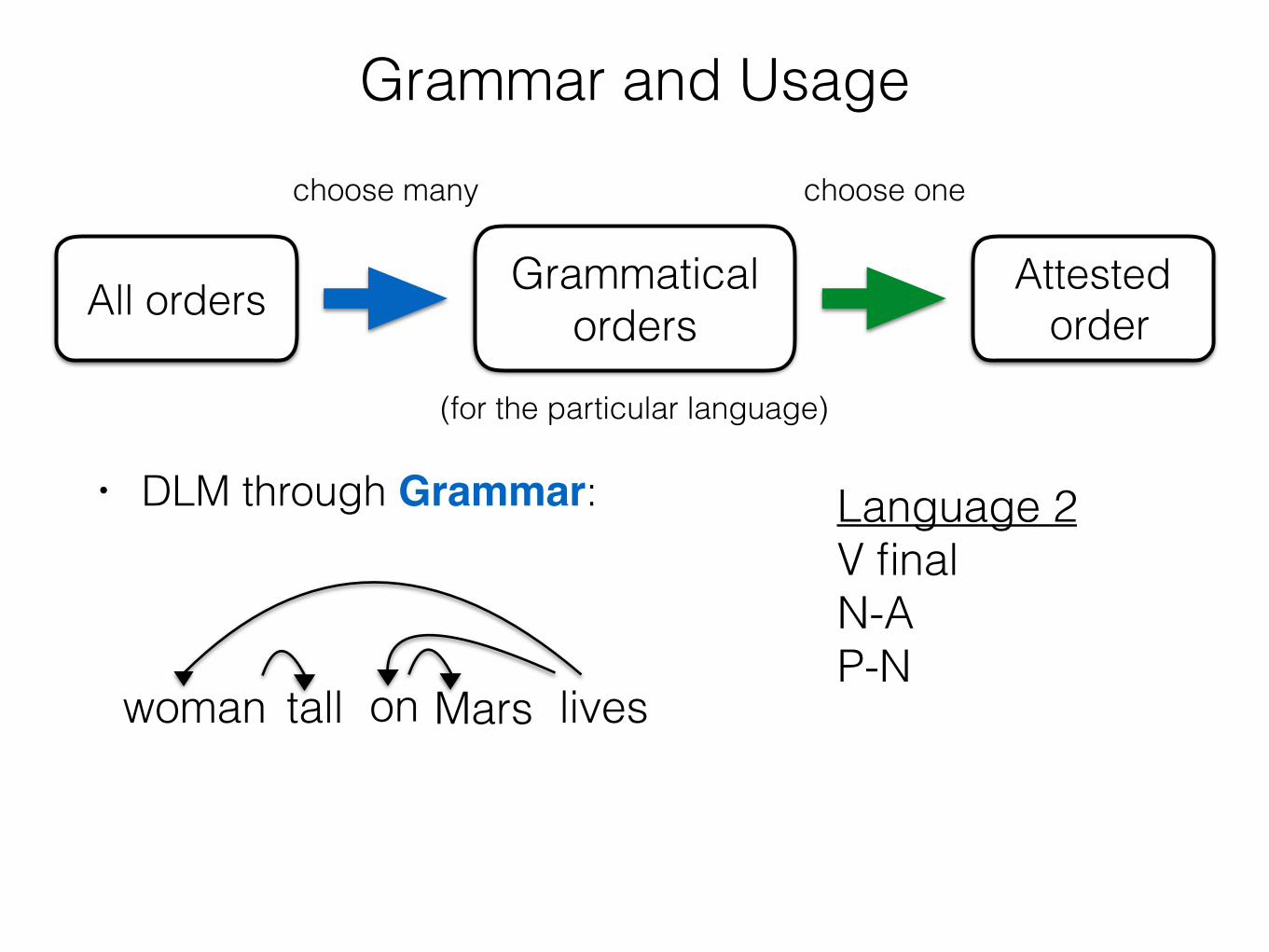
• DLM through Grammar:
Grammar and Usage
livestallwoman Marson
Language 2 V final N-A P-N

All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
• DLM through Grammar:
Grammar and Usage
livesMarson tallwoman
Language 2 V final N-A P-N

All orders Grammatical orders
(for the particular language)
choose many choose one
Attested order
• DLM through Grammar: • For certain sentences,
Language 1 is better on average than Language 2.
Grammar and Usage
Language 1 V final A-N N-P
Language 2 V final N-A P-N

Total: 9
9
6
11
8
10
6
Random Grammatical Reorderings
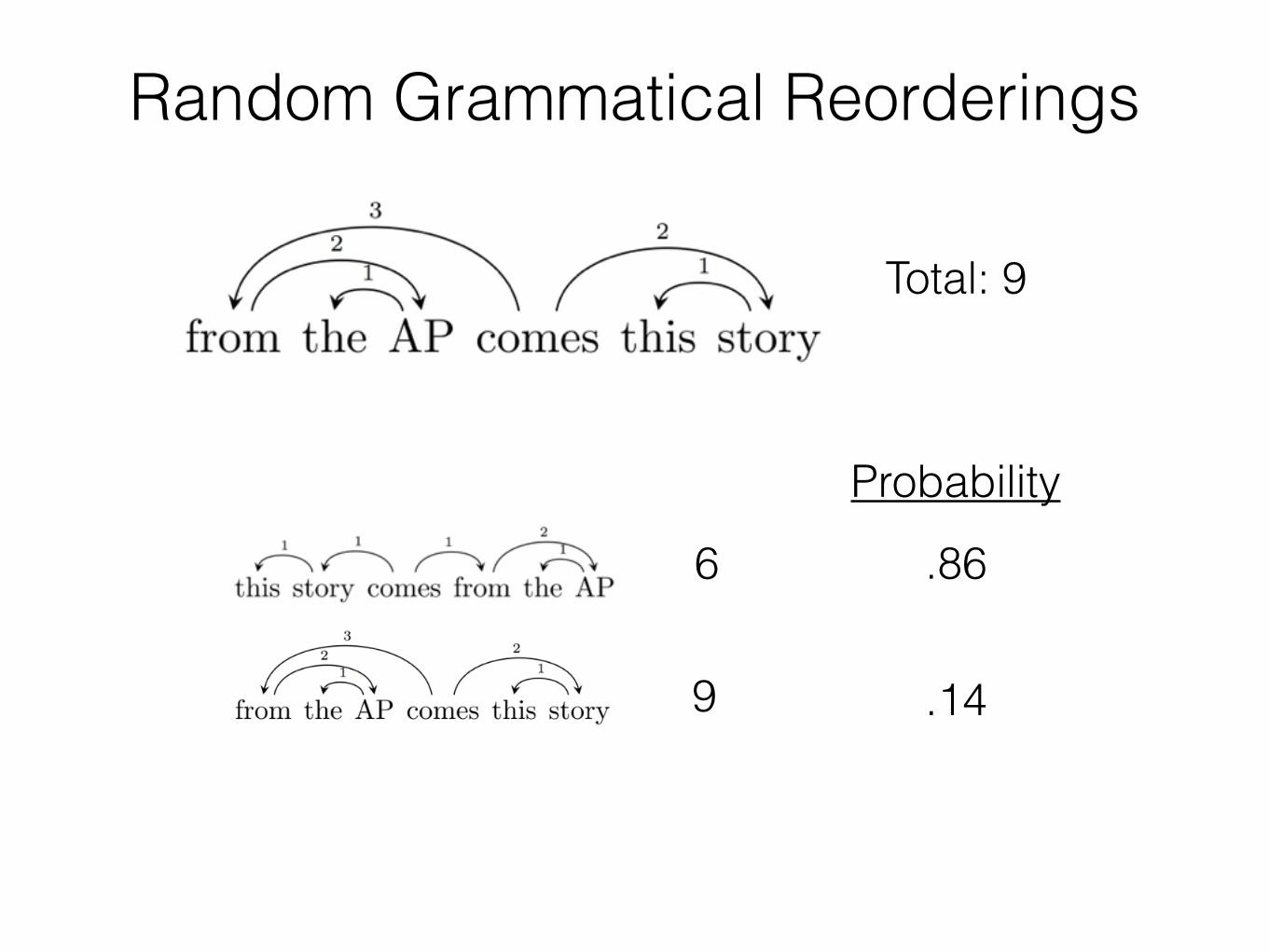
Random Grammatical Reorderings
Total: 9
6
9
Probability
.86
.14

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Grammar and Usage • Relevance to Dependency Length Minimization • Modeling Grammatical Orders • Results

Linearization Models• We want to be able to induce from corpora a
model of the possible grammatical linearizations of a given dependency tree.
• Task: Given an unordered dependency tree U, find the probability distribution over ordered dependency trees T with the same structure as U.
• This is a known task in NLP, as part of natural language generation pipelines (Belz et al., 2011; Rajkumar & White, 2014).
• For more details on models and their evaluation, see Futrell & Gibson (2015, EMNLP).
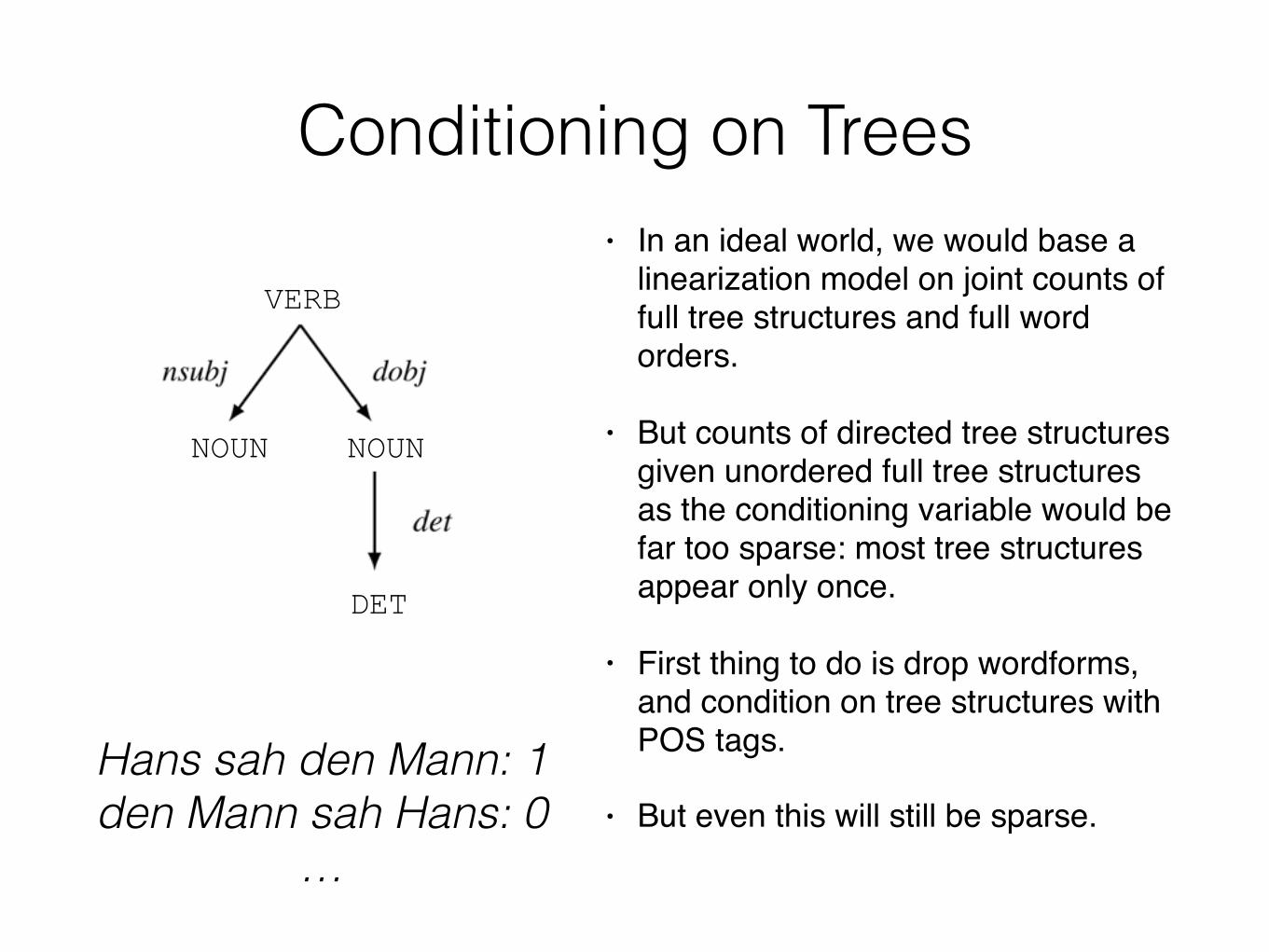
Conditioning on Trees• In an ideal world, we would base a
linearization model on joint counts of full tree structures and full word orders.
• But counts of directed tree structures given unordered full tree structures as the conditioning variable would be far too sparse: most tree structures appear only once.
• First thing to do is drop wordforms, and condition on tree structures with POS tags.
• But even this will still be sparse.Hans sah den Mann: 1 den Mann sah Hans: 0
…
VERB
NOUN NOUN
DET
VERB
NOUN NOUN
DET
Breaking Trees Apart• So, we get conditional counts of orders
of local subtrees.
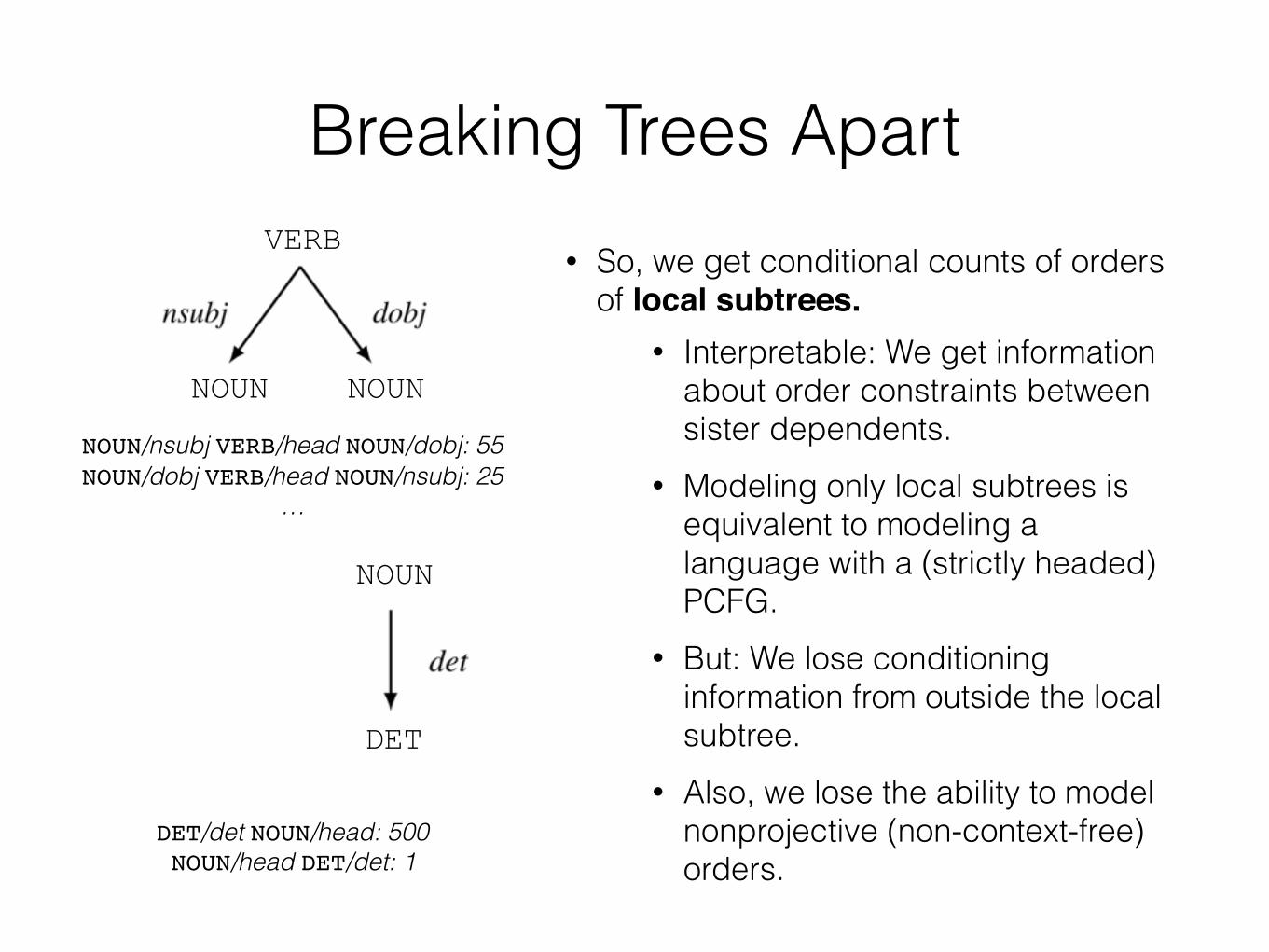
Breaking Trees Apart• So, we get conditional counts of orders
of local subtrees.• Interpretable: We get information
about order constraints between sister dependents.
• Modeling only local subtrees is equivalent to modeling a language with a (strictly headed) PCFG.
• But: We lose conditioning information from outside the local subtree.
• Also, we lose the ability to model nonprojective (non-context-free) orders.
VERB
NOUN NOUN
NOUN
DET
NOUN/nsubj VERB/head NOUN/dobj: 55 NOUN/dobj VERB/head NOUN/nsubj: 25
…
DET/det NOUN/head: 500 NOUN/head DET/det: 1

What’s in a Tree?• Then another question is: what
aspects of the local subtrees do we condition on?
• POS tags for head and dependents, and relation types?
• Or maybe don’t consider the POS of the head?
• Or maybe don’t consider the POS of the dependents?
VERB
NOUN
NOUN NOUN
DET
NOUN/nsubj VERB/head NOUN/dobj: 55 NOUN/dobj VERB/head NOUN/nsubj: 25
…
DET/det NOUN/head: 500 NOUN/head DET/det: 1
NOUN/nsubj X/head NOUN/dobj: 135 NOUN/dobj X/head NOUN/nsubj: 115
…
DET/det X/head: 1000 X/head DET/det: 4
X/nsubj X/head X/dobj: 235 X/dobj X/head X/nsubj: 193
…
X/det X/head: 1251 X/head X/det: 5

Linearization Models
• To strike a balance between accuracy and data sparsity, we combine models that condition on more and less context to form a backoff distribution.
• We can also smooth the model by considering N-gram probabilities of orders within local subtrees.
• Backoff weights determined by Baum-Welch algorithm.

Linearization Models from Generative Dependency Models
• We want a model of ordered trees T conditional on unordered trees U.• We can derive these models from head-outward generative models
that generate T from scratch (Eisner, 1996; Klein and Manning, 2004).• Basic form of these models:
comes
this
story
the
AP
from today# #
"From the AP comes this story today."
##
#
# # # #
#

Linearization Models from Generative Dependency Models
• In these models, dependency trees are generated from a set of N-gram models conditional on head word and direction.
• So if we want a model of ordered trees conditional on unordered trees, we just need a model of ordered sequences conditional on unordered sequences generated by an N-gram model.
p(ABC)p(ABC | {A, B, C})
permutations of wDynamic programming


Evaluating Linearization Models• We have a large parameter space for linearization
models. We evaluate different parameters in three ways: • 1. Test Set Perplexity: Which model setting gives the
highest probability to unseen trees in dependency corpora?
• 2. Acceptability: Ask people how natural the reordered sentences sound on a scale of 1 to 5.
• 3. Same meaning: Ask people whether the reordered sentence means the same thing as the original sentence.
• The last two evaluations were done on Mechanical Turk for English models only.

Best Models• The best model for perplexity is the one with the most smoothing.
• The best models for acceptability and same meaning are more conservative models based on POS N-grams within local subtrees. • For English, best acceptability is 3.8 / 5 on average. (Original
sentences are 4.7 / 5 on average.) • For English, the best model produces orders with the same
meaning as the original 85% of the time (close to the state of the art).
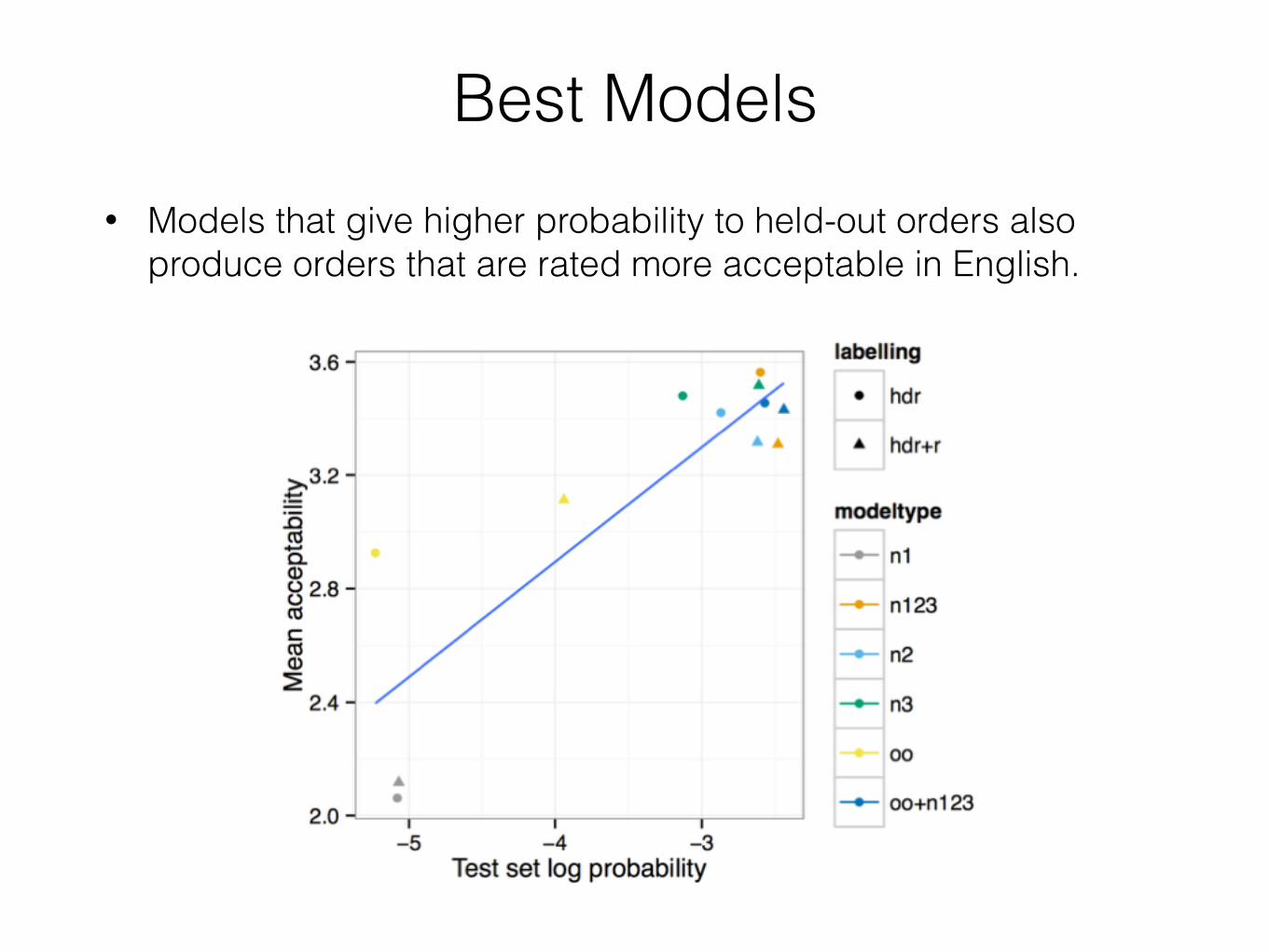
Best Models• Models that give higher probability to held-out orders also
produce orders that are rated more acceptable in English.

Models to Run• For dependency length experiments, we
compare attested dependency length to random linearizations under three models: • 1. The model that selects uniformly among
attested orders for local subtrees, conditional on POS tags for head and dependent.
• 2. The model with the best perplexity score (highly smoothed).
• 3. The model with the best same-meaning rating for English (more conservative).

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Grammar and Usage • Relevance to Dependency Length Minimization • Modeling Grammatical Orders • Results
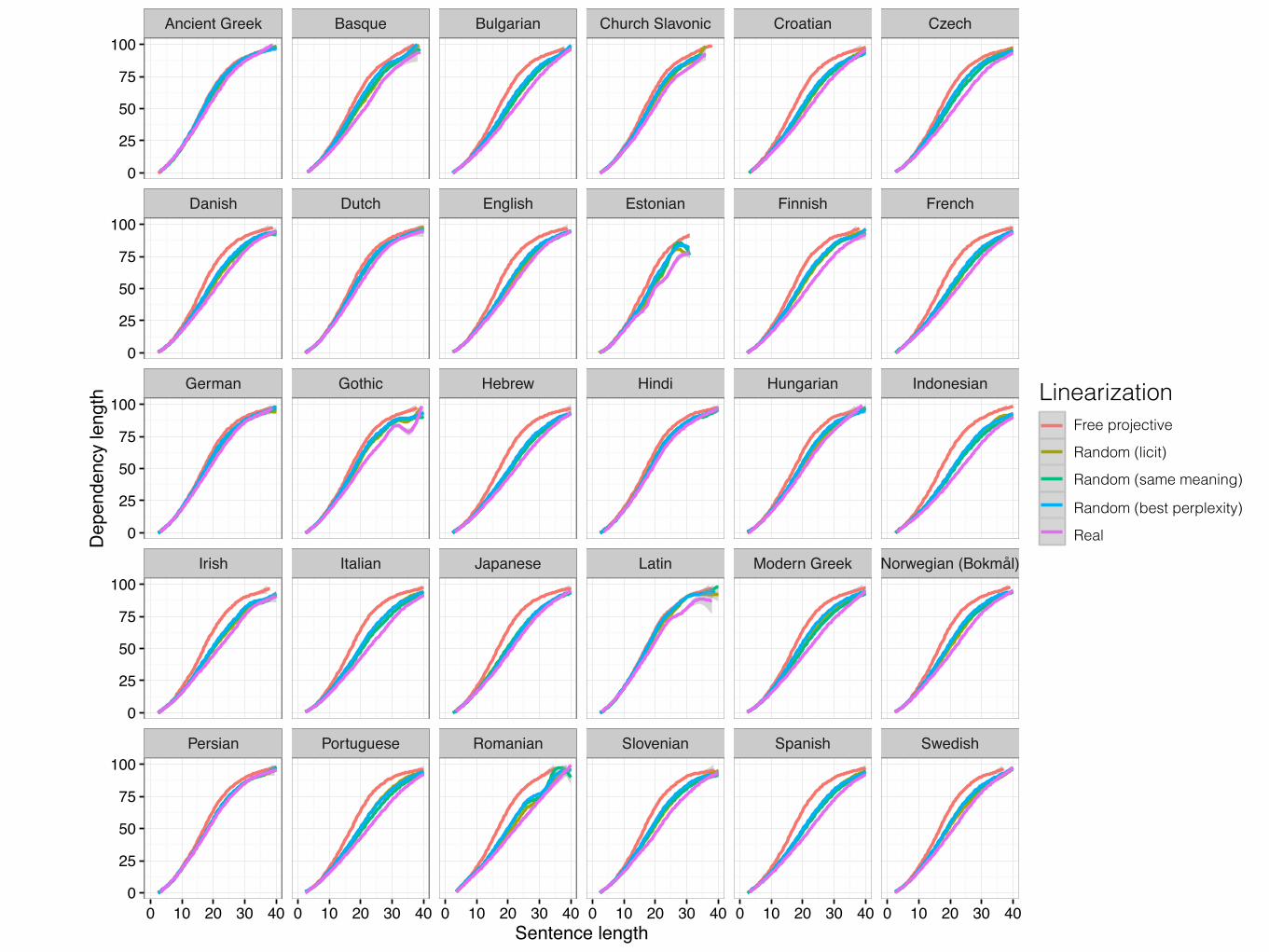
Ancient Greek Basque Bulgarian Church Slavonic Croatian Czech
Danish Dutch English Estonian Finnish French
German Gothic Hebrew Hindi Hungarian Indonesian
Irish Italian Japanese Latin Modern Greek Norwegian (Bokmål)
Persian Portuguese Romanian Slovenian Spanish Swedish
0
25
50
75
100
0
25
50
75
100
0
25
50
75
100
0
25
50
75
100
0
25
50
75
100
0 10 20 30 40 0 10 20 30 40 0 10 20 30 40 0 10 20 30 40 0 10 20 30 40 0 10 20 30 40Sentence length
Dep
ende
ncy
leng
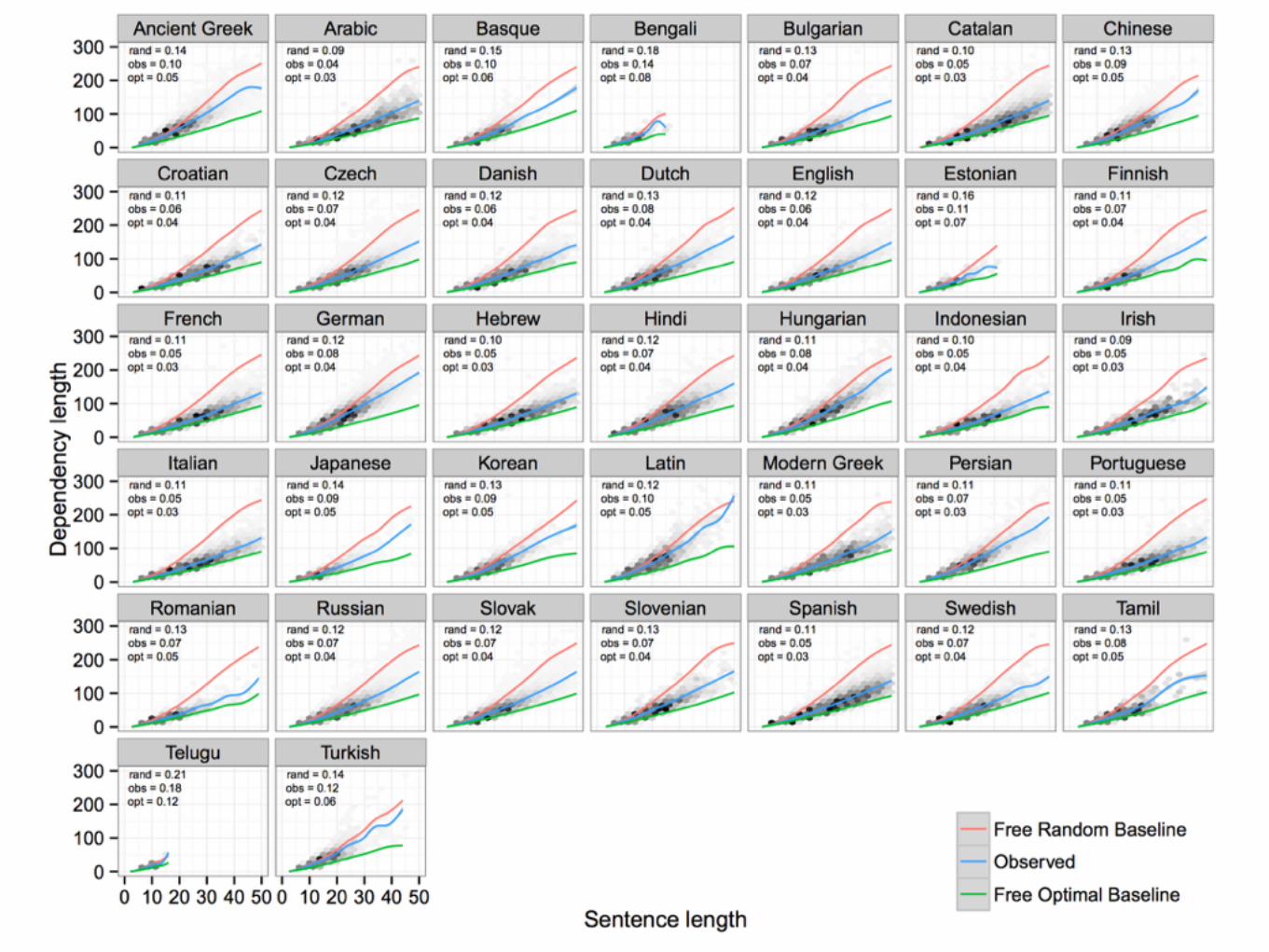
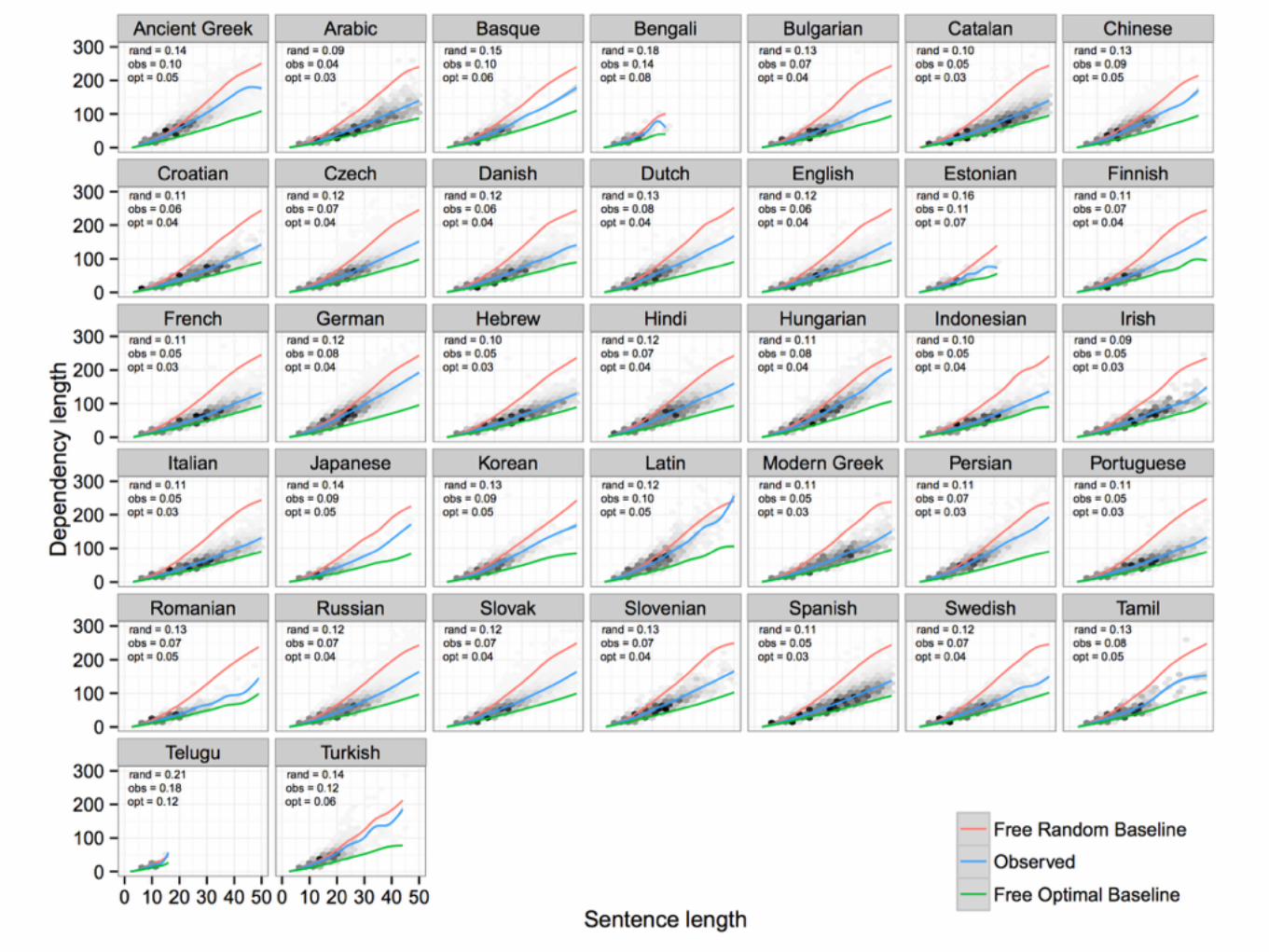
th realfree randomrand_proj_lin_hdr_licrand_proj_lin_hdr_mlerand_proj_lin_perplexreal
LinearizationFree projective
Random (licit)
Random (same meaning)
Random (best perplexity)
Real
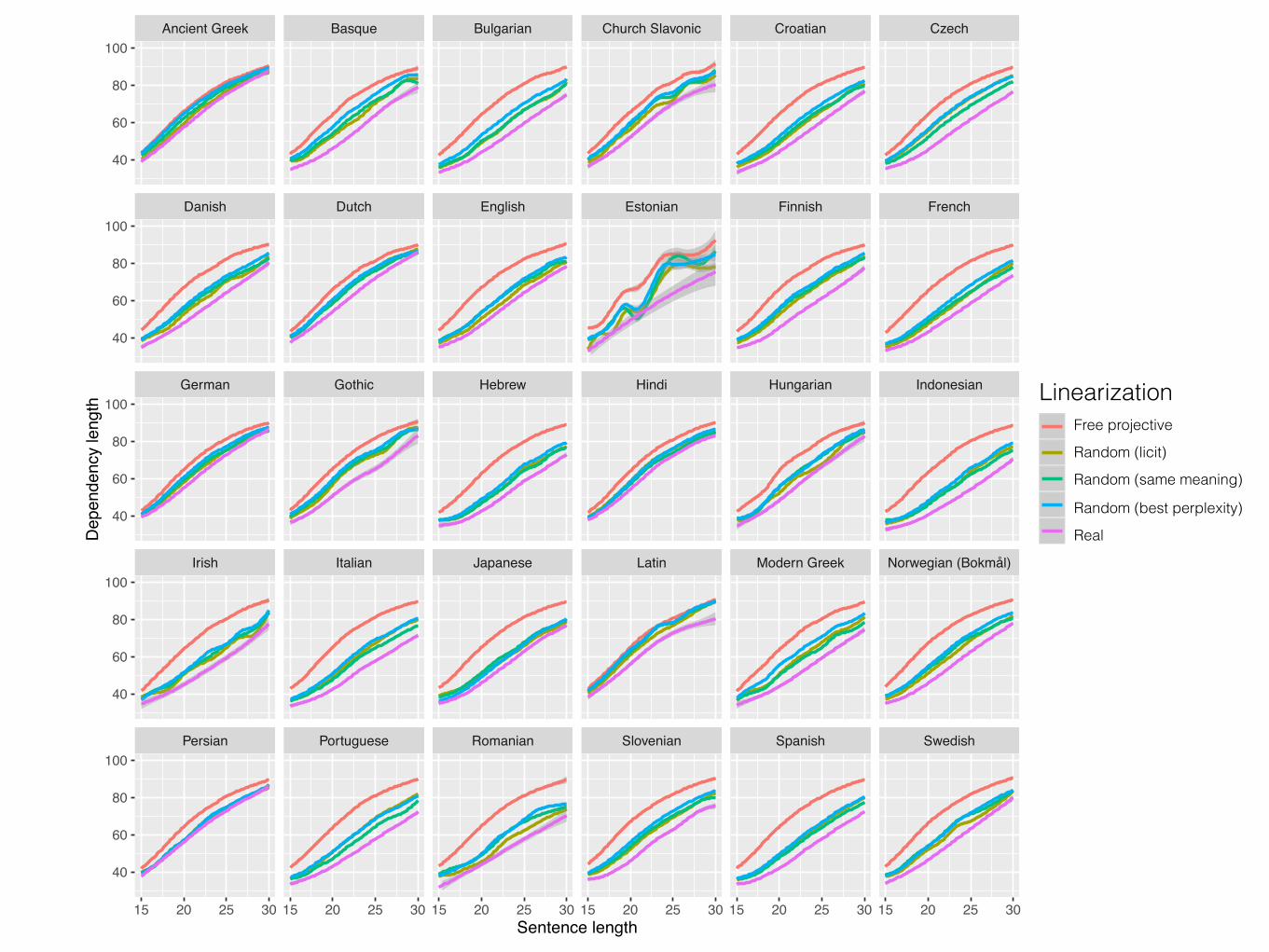
Ancient Greek Basque Bulgarian Church Slavonic Croatian Czech
Danish Dutch English Estonian Finnish French
German Gothic Hebrew Hindi Hungarian Indonesian
Irish Italian Japanese Latin Modern Greek Norwegian (Bokmål)
Persian Portuguese Romanian Slovenian Spanish Swedish
40
60
80
100
40
60
80
100
40
60
80
100
40
60
80
100
40
60
80
100
15 20 25 30 15 20 25 30 15 20 25 30 15 20 25 30 15 20 25 30 15 20 25 30Sentence length
Dep
ende
ncy
leng
th realfree random
rand_proj_lin_hdr_lic
rand_proj_lin_hdr_mle
rand_proj_lin_perplex
real
LinearizationFree projective
Random (licit)
Random (same meaning)
Random (best perplexity)
Real

Conclusions• Dependency length of real utterances is shorter than
random grammatical linearizations under these models. • We would like to conclude that this means:
• (1) There is a universal pressure in usage for DLM, • (2) Grammars are optimized so that the average
utterance will have short dependency length. • However, our conclusions are only as strong as our
linearization models. • We only consider projective reorderings within local
subtrees. • The models are based on limited data and may miss
certain licit orders.

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Quantitative Syntax with Dependency Corpora • Dependency Length Minimization • Comparison to Random Baselines • Grammar and Usage • Residue of Dependency Length Minimization • Conclusion

Residue of DLM
• We have studied dependency length with the hypothesis that there is a universal pressure for dependency lengths to be short, and that this affects grammar and usage.
• But having controlled for various baselines, there remains residual variance between languages in dependency length.
• No new baselines in this part, rather we ask the question: What linguistic properties determine whether a language has short or long dependencies?
• We do not have formal explanations for these findings, but offer some directions for explaining them.
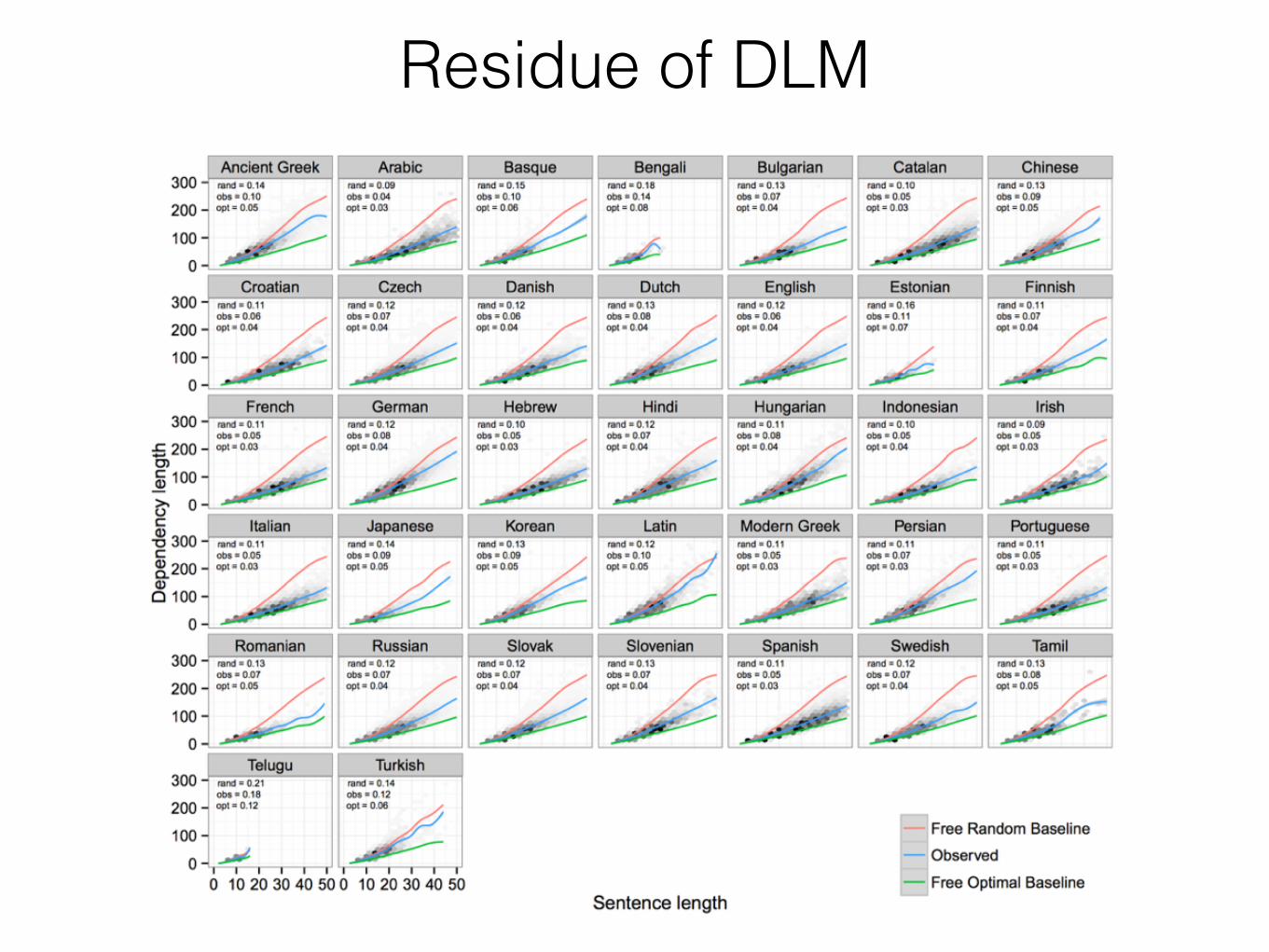
Residue of DLM

Head-Finality• We see relatively long dependency length for strongly head-final languages such
as Japanese, Korean, Tamil, Turkish.• Comparing dependency length at fixed sentence lengths to the proportion of
head-final dependencies in a corpus, we find correlations of dependency length with head finality:
bn
grc
got trja
caes
xclga huhrno
zhen
fa
plruda fi
etde
nlsk
cu
pt
hi
id
orv
arhe
taelsv
frcs
la
eu ko
bgsl
itro
bngrc
gottr
ja
caes
xclgahu
hrno
zh
en
fa
pl
ruda fi
et
de
nl
sk
cu
pt
hi
id
orv
arhe
taelsv
fr
cs
la
euko
bg
sl
itro
bn
grc
got
tr
ja
caes
xclga
hu
hr
no
zh
en
fa
pl
ruda fi
et
de
nl
sk
cu
pt
hi
id
orv
ar he
tael
sv
fr
cs
la
eu
ko
bg
sl
it
ro
10 15 20
20
30
40
50
60
0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00Proportion head final
Dep
ende
ncy
leng
th

ar bg cs cu da de
el en es et eu fa
fi fr ga got grc he
hi hr hu id it ja
la nl no pl pt ro
sl sv ta
0.00.20.40.6
0.00.20.40.6
0.00.20.40.6
0.00.20.40.6
0.00.20.40.6
0.00.20.40.6
1 2 1 2 1 2Position
Weight

ar bg cs cu da de
el en es et eu fa
fi fr ga got grc he
hi hr hu id it ja
la nl no pl pt ro
sl sv ta
0.00.20.40.6
0.00.20.40.6
0.00.20.40.6
0.00.20.40.6
0.00.20.40.6
0.00.20.40.6
−2.5 −2.0 −1.5 −1.0 −0.5−2.5 −2.0 −1.5 −1.0 −0.5−2.5 −2.0 −1.5 −1.0 −0.5Position
Weight

ar bg cs cu da de
el en es et eu fa
fi fr ga got grc he
hi hr hu id it ja
la nl no pl pt ro
sl sv ta
0.0
0.2
0.4
0.6
0.0
0.2
0.4
0.6
0.0
0.2
0.4
0.6
0.0
0.2
0.4
0.6
0.0
0.2
0.4
0.6
0.0
0.2
0.4
0.6
1 2 3 1 2 3 1 2 3Position
Weight

ar bg cs cu da de
el en es et eu fa
fi fr ga got grc he
hi hr hu id it ja
la nl no pl pt ro
sl sv ta
0.00.10.20.30.4
0.00.10.20.30.4
0.00.10.20.30.4
0.00.10.20.30.4
0.00.10.20.30.4
0.00.10.20.30.4
−3 −2 −1 −3 −2 −1 −3 −2 −1Position
Weight

Dependency Length and Head-Finality
• Under the integration cost theories of processing difficulty, where there is difficulty for linking a word to another word that has been in memory for a long time, we expect no asymmetry between head final and head initial dependencies.
• But integration cost effects are typically not observed in head-final constructions where many modifiers precede the head (Konieczny, 2000; Vasishth & Lewis, 2006; Levy, 2008).
• Perhaps head-final dependencies incur less processing cost, so there is less pressure to minimize the distances of the dependencies.

Back to this figure
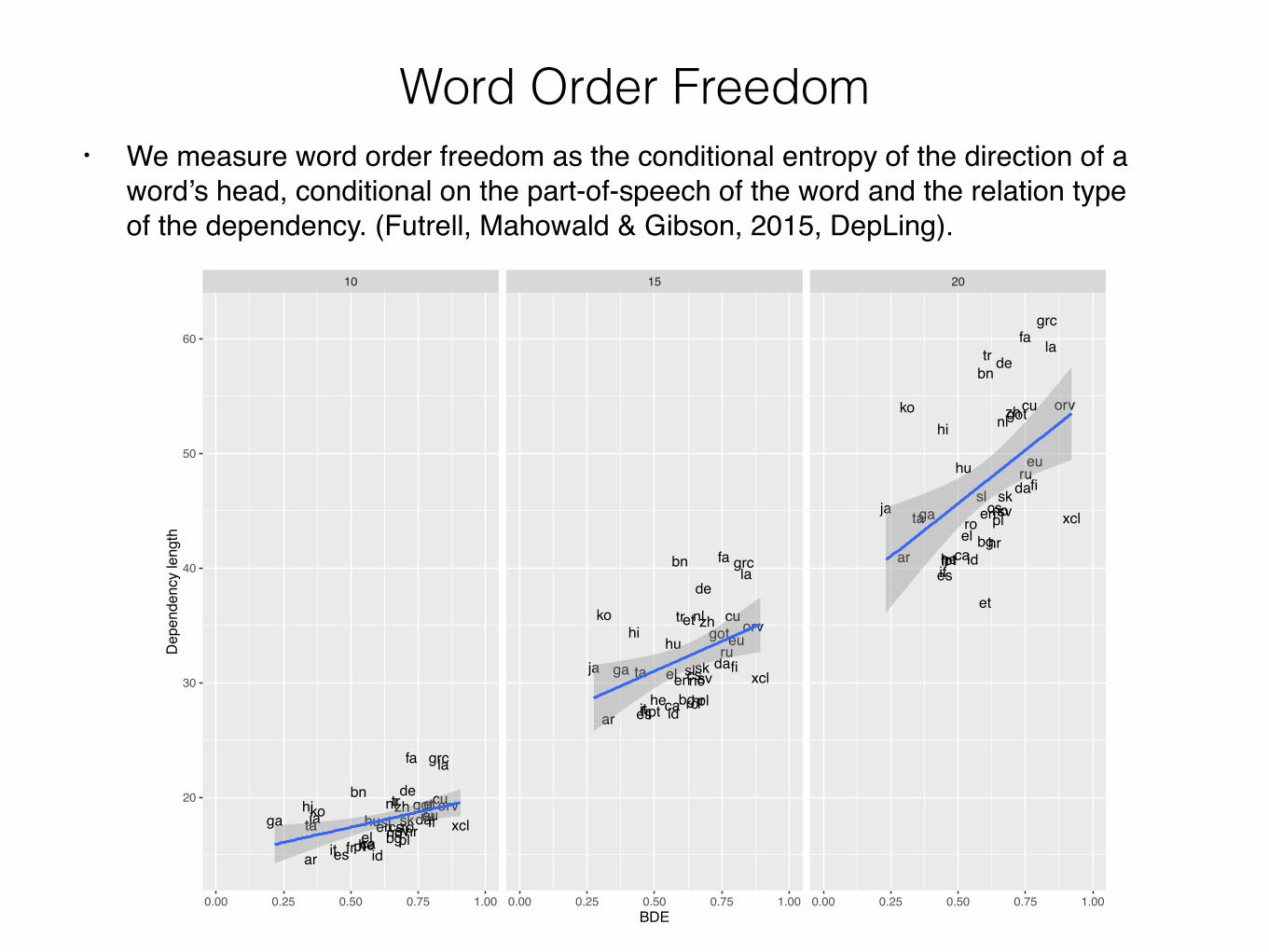
Word Order Freedom• We measure word order freedom as the conditional entropy of the direction of a
word’s head, conditional on the part-of-speech of the word and the relation type of the dependency. (Futrell, Mahowald & Gibson, 2015, DepLing).
bn
grc
gottrja
caes
xclga hu hrnozh
en
fa
plrudafiet
denl
skcu
pt
hi
id
orv
arhe
tael sv
frcs
la
euko
bgsl
itro
bn grc
gottr
ja
caes
xclgahu
hrno
zh
en
fa
pl
rudafi
et
de
nl
sk
cu
pt
hi
id
orv
arhe
ta el sv
fr
cs
la
euko
bg
sl
it ro
bn
grc
got
tr
ja
caes
xclga
hu
hr
no
zh
en
fa
pl
rudafi
et
de
nl
sk
cu
pt
hi
id
orv
ar he
tael
sv
fr
cs
la
eu
ko
bg
sl
it
ro
10 15 20
20
30
40
50
60
0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00 0.00 0.25 0.50 0.75 1.00BDE
Dep
ende
ncy
leng
th

Dependency Length and Word Order Freedom
• In languages with a high degree of freedom in whether the head of a word is to its right or left, we find longer dependencies.
• One would think that speakers of languages with lots of word order freedom would use that freedom to select the orders that highly minimize dependency length.
• On the other hand, such languages typically have complex morphology.
• If the difficulty of processing long dependencies is due to similarity-based interference (Lewis & Vasishth, 2006), then words with more distinctive morphology will be less confusable and retrieving them from memory will be easier. • So we might expect morphologically complex languages to
have longer dependencies: long dependencies incur less processing difficulty in such languages.
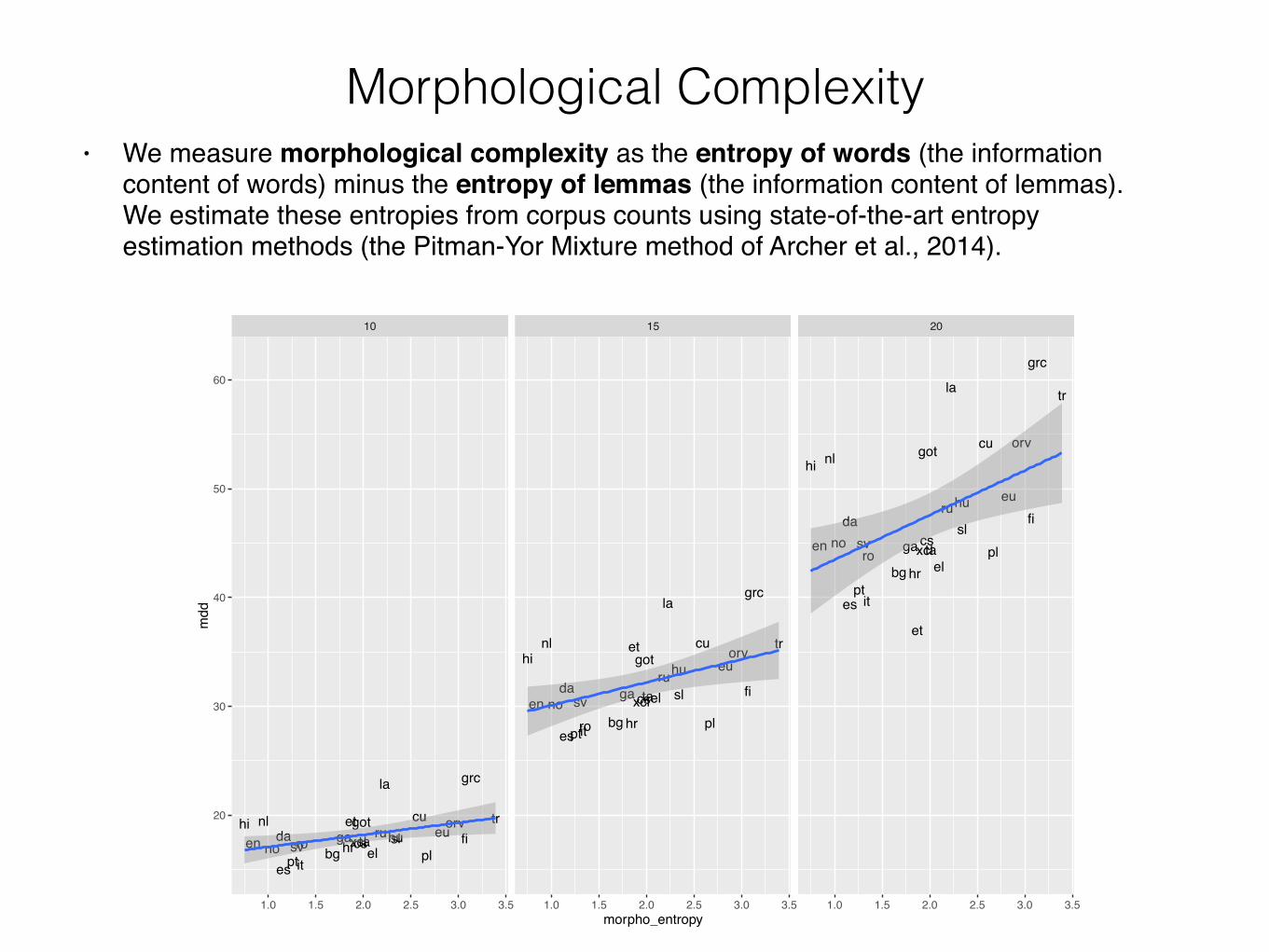
Morphological Complexity• We measure morphological complexity as the entropy of words (the information
content of words) minus the entropy of lemmas (the information content of lemmas). We estimate these entropies from corpus counts using state-of-the-art entropy estimation methods (the Pitman-Yor Mixture method of Archer et al., 2014).
grc
got tr
es
xclga huhrnoen
plruda fi
etnl cu
pt
hi orvtaelsv cs
la
eubg
sl
itro
grc
gottr
es
xclgahu
hrnoen
pl
ruda fi
etnl cu
pt
hi orv
taelsv cs
la
eu
bg
sl
itro
grc
got
tr
es
xclga
hu
hr
noen pl
ruda fi
et
nlcu
pt
hiorv
tael
sv cs
la
eu
bg
sl
it
ro
10 15 20
20
30
40
50
60
1.0 1.5 2.0 2.5 3.0 3.5 1.0 1.5 2.0 2.5 3.0 3.5 1.0 1.5 2.0 2.5 3.0 3.5morpho_entropy
mdd

Dependency Length and Morphology
• Consistent with the concept that languages with more informative morphology will have create less difficulty in processing long dependencies, we find longer dependency lengths in such languages.
• Real formalization of this notion would require a processing model that integrates morphological complexity and dependency length, and a way to find orders that minimize parsing difficulty under such a model.

Crosslinguistic Quantitative Syntax: Dependency Length and Beyond
• Quantitative Syntax with Dependency Corpora • Dependency Length Minimization • Comparison to Random Baselines • Grammar and Usage • Residue of Dependency Length Minimization • Conclusion

Conclusion
• We have provided large-scale corpus evidence for dependency length minimization beyond what is explained by projectivity, fixedness of word order, and consistency of head direction.• Evidence for dependency length minimization as a
principle that is independent of those other constraints, or which subsumes those constraints.

• We have shown that attested utterances have shorter dependency length than random grammatical reorderings of those utterances, and that the random grammatical reorderings have shorter dependency length than under random grammars.• Evidence for universal DLM in grammar and usage.
Conclusion

• We have shown residual covariance of dependency length with other linguistic features.• Suggests that DLM is not enough — we need other,
more detailed theories to explain the quantitative distribution of dependency lengths.
Conclusion

• Thanks to Tim O’Donnell, Roger Levy, Kristina Gulordava, Paola Merlo, Ramon Ferrer i Cancho, Christian Bentz, and Timothy Osborne for helpful discussions.
• This work was supported by NSF Doctoral Dissertation Improvement Grant #1551543 to Richard Futrell, an NDSEG fellowship to Kyle Mahowald, and NSF grant #6932627 to Ted Gibson.
Thanks all!

This talk is based on these papers
• Futrell, Mahowald & Gibson (2015). Large-scale evidence of dependency length minimization in 37 languages. PNAS.
• Futrell, Mahowald & Gibson (2015). Quantifying word order freedom in dependency corpora. Proceedings of DepLing.
• Futrell & Gibson (2015). Experiments with generative models for dependency tree linearization. Proceedings of EMNLP.
(but a lot of it isn’t published yet!)





























