Embed Size (px)
Citation preview

Cryptographic Approaches To Security and
Privacy Issues In Pervasive Computing
Jihoon Cho
Thesis submitted to the University of Londonfor the degree of Doctor of Philosophy
Information Security GroupDepartment of Mathematics
Royal Holloway, University of London
2013

Declaration
These doctoral studies were conducted under the supervision of Professor Chris J.Mitchell.
The work presented in this thesis is the result of original research carried out bymyself, in collaboration with others, whilst enrolled in the Information SecurityGroup of Royal Holloway, University of London as a candidate for the degree ofDoctor of Philosophy. This work has not been submitted for any other degree oraward in any other university or educational establishment.
Jihoon ChoApril 2013
2

Acknowledgements
During my PhD programme, I had the most unforgettable experiences in my life.I’ve gone through my father’s funeral and got married to a woman. I also lookforward to meeting one amazing person this spring.
My father was my very best friend and great mentor. He was such a generous andlovely person, and I still remember that all his students and fellow teachers senthim away with tears at his retirement. When I left to Waterloo in Canada for mymaster, he was not happy with my plan. He was a bit like Helfgott’s father in thefilm ‘Shine’, who wants his son to stay with him and family. However, he becamesupportive during my PhD programme, and used to encourage me with his greatwisdom and love whenever I faced walls standing against me. He passed away atthe second year of PhD. I had to spend a while until recovering from the shock. Ilost him, but everything of him lives with me.
With my father’s support I could start my PhD, but it was not possible to completemy thesis without another person. I met a girl when I joined an industrial project inKorea during the first year of PhD, and she became my wife in two years. She hasbeen my a source of energy, always praying for me and my study and encouragingme with her lovely smile.
In this acknowledgement, I would like to give thanks to some special people. I greatlyappreciate my supervisor Chris who has guided me with his experience and advice.I am thankful to my ‘Good-Old-Days’ roommates in MC256, Shriram and James.We used to have great discussions on everything, of course, including cryptography.After joining LG Electronics in 2009, my colleagues shared their experiences in thearea of standardisation. Most importantly, Mom, I love you very much. I am whatI am because of you!
I would like to conclude my acknowledgement with all my thanks to God, who ismy Saviour, my Lord, and my King forever!
Seoul, KoreaMarch, 2011
3

Abstract
Technological innovation has enabled tiny devices to participate in pervasive com-puting. Such devices are particularly vulnerable to security and privacy threats,because of their limited computing resources and relatively weak physical security.We investigate possible cryptographic solutions to security and privacy problemsarising in two kinds of emerging pervasive computing networks: Personal Area Net-works (PANs) and the EPCglobal Network.
A number of key management schemes have been proposed for use in PANs, butthese schemes only support key management within a PAN. However, as people areincreasingly equipped with multiple wireless devices, PANs are likely to be intercon-nected to share information or services. We introduce a term, iPANs, to name suchinterconnected PANs. We define system models and design goals for key manage-ment in iPANs, and propose a novel security initialisation scheme for use in iPANs.The proposed scheme achieves desirable security and efficiency properties by makinguse of the unique characteristics of PANs.
The EPCglobal Network is designed to give efficiency and cost savings in and beyondthe supply chain using Radio Frequency Identification (RFID) technology; however,privacy threats affecting such networks are particularly serious. We construct aformal privacy model for RFID systems accurately reflecting adversarial threats andpower. We then give brief privacy analysis for the existing privacy-enhanced RFIDschemes which have received wide attention in the literature. We then construct asecure refresh-based RFID system based on re-encryption techniques, and prove itsprivacy using the defined privacy model. Finally, we show that the proposed schemecan greatly enhance the security and privacy of EPC tags, making the maximumuse of given tag functionalities as specified in the standards.
4

Contents
1 Introduction 141.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.1.1 Security and privacy issues in pervasive computing . . . . . . 141.1.2 Topics in pervasive computing . . . . . . . . . . . . . . . . . 15
1.2 Contributions and Structure . . . . . . . . . . . . . . . . . . . . . . . 16
2 Cryptographic Preliminaries 182.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2 Modern Cryptography . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.1 Cryptographic goals . . . . . . . . . . . . . . . . . . . . . . . 192.2.2 Basic principles . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3 Computational Approach . . . . . . . . . . . . . . . . . . . . . . . . 222.3.1 Computational security . . . . . . . . . . . . . . . . . . . . . 222.3.2 Cryptographic hardness assumptions . . . . . . . . . . . . . . 24
2.4 Secret Key Cryptography . . . . . . . . . . . . . . . . . . . . . . . . 262.4.1 Secret key encryption . . . . . . . . . . . . . . . . . . . . . . 262.4.2 Hash functions . . . . . . . . . . . . . . . . . . . . . . . . . . 272.4.3 Message authentication codes . . . . . . . . . . . . . . . . . . 29
2.5 Public Key Cryptography . . . . . . . . . . . . . . . . . . . . . . . . 312.5.1 Public key encryption . . . . . . . . . . . . . . . . . . . . . . 312.5.2 Digital signature schemes . . . . . . . . . . . . . . . . . . . . 34
2.6 Key Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.6.1 Trusted third parties . . . . . . . . . . . . . . . . . . . . . . . 372.6.2 Key management frameworks . . . . . . . . . . . . . . . . . . 372.6.3 Public key infrastructures . . . . . . . . . . . . . . . . . . . . 392.6.4 Distributed key generation . . . . . . . . . . . . . . . . . . . 40
2.7 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
I Pervasive Computing: Personal Area Networks 46
3 Securing A Personal Area Network 473.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 473.2 Personal Area Networks . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.2.1 A Personal Area Network . . . . . . . . . . . . . . . . . . . . 483.2.2 Security framework of Personal Area Networks . . . . . . . . 50
3.3 Existing Security Schemes . . . . . . . . . . . . . . . . . . . . . . . . 523.3.1 DH key agreement via wireless channels . . . . . . . . . . . . 53
5

CONTENTS
3.3.2 Personal PKIs . . . . . . . . . . . . . . . . . . . . . . . . . . 563.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4 Securing Inter-PANs Communications 594.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.1.1 Interconnected Personal Area Networks . . . . . . . . . . . . 604.1.2 Key management in iPANs . . . . . . . . . . . . . . . . . . . 634.1.3 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.1.4 Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.2 Security Initialisation for iPANs . . . . . . . . . . . . . . . . . . . . . 664.2.1 System models and design goals . . . . . . . . . . . . . . . . 664.2.2 Proposed scheme . . . . . . . . . . . . . . . . . . . . . . . . . 684.2.3 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.3 Further Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 744.3.1 Use of pre-distributed keys . . . . . . . . . . . . . . . . . . . 744.3.2 Revocation and update . . . . . . . . . . . . . . . . . . . . . 754.3.3 Other security issues . . . . . . . . . . . . . . . . . . . . . . . 784.3.4 Generalisation of the proposed scheme . . . . . . . . . . . . . 79
4.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
II Pervasive Computing: Radio Frequency Identification 81
5 Privacy in RFID Systems 825.1 Privacy Issues in RFID Systems . . . . . . . . . . . . . . . . . . . . . 83
5.1.1 Malicious tag readings in RFID systems . . . . . . . . . . . . 835.1.2 Threats in practical scenarios . . . . . . . . . . . . . . . . . . 855.1.3 Privacy as fundamental requirement . . . . . . . . . . . . . . 86
5.2 Defining Privacy of RFID system . . . . . . . . . . . . . . . . . . . . 875.2.1 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . 885.2.2 Defining RFID system . . . . . . . . . . . . . . . . . . . . . . 895.2.3 Defining privacy . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.3 Secret key Cryptographic Solutions . . . . . . . . . . . . . . . . . . . 935.3.1 Protocols based on key search . . . . . . . . . . . . . . . . . . 945.3.2 Use of pre-computed table (OSK/ADO) . . . . . . . . . . . . 955.3.3 Use of time-stamp (YA-TRIP/YA-TRIP∗) . . . . . . . . . . . . 975.3.4 Tree-based approach (MW/MSW) . . . . . . . . . . . . . . . 995.3.5 The Lim-Kwon (LK) scheme . . . . . . . . . . . . . . . . . . . 102
5.4 Public key Cryptographic Solutions . . . . . . . . . . . . . . . . . . . 1065.4.1 Juels-Pappu scheme (JP) . . . . . . . . . . . . . . . . . . . . 1065.4.2 Universal re-encryption (UR) . . . . . . . . . . . . . . . . . . 1115.4.3 Insubvertible encryption (IE) . . . . . . . . . . . . . . . . . . 115
5.5 Lightweight Protocols . . . . . . . . . . . . . . . . . . . . . . . . . . 1175.6 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6 Proposed RFID Systems 1216.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
6

CONTENTS
6.2 Security and privacy in the EPCglobal Network . . . . . . . . . . . . 1236.2.1 The EPCglobal Network . . . . . . . . . . . . . . . . . . . . . 1236.2.2 Gen2 Standards . . . . . . . . . . . . . . . . . . . . . . . . . 1276.2.3 Security and privacy requirements . . . . . . . . . . . . . . . 1356.2.4 Gen2 standard and related variant schemes . . . . . . . . . . 136
6.3 Proposed RFID system . . . . . . . . . . . . . . . . . . . . . . . . . 1406.3.1 Construction of algorithms . . . . . . . . . . . . . . . . . . . 1406.3.2 Privacy analysis . . . . . . . . . . . . . . . . . . . . . . . . . 1436.3.3 Further discussions . . . . . . . . . . . . . . . . . . . . . . . . 145
6.4 Application to the EPCglobal Network . . . . . . . . . . . . . . . . . 1456.4.1 Existing schemes . . . . . . . . . . . . . . . . . . . . . . . . . 1466.4.2 Proposed scheme . . . . . . . . . . . . . . . . . . . . . . . . . 148
6.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
7 Concluding Remarks 1547.1 Main Research Findings . . . . . . . . . . . . . . . . . . . . . . . . . 1547.2 Future Research Directions . . . . . . . . . . . . . . . . . . . . . . . 155
Bibliography 156
7

List of Figures
2.1 Relationships between problems . . . . . . . . . . . . . . . . . . . . . 26
3.1 Example of Connection Handover [47] . . . . . . . . . . . . . . . . . 55
4.1 A Bluetooth scatternet [49] . . . . . . . . . . . . . . . . . . . . . . . 614.2 Three interconnected PANs [49] . . . . . . . . . . . . . . . . . . . . . 614.3 A distributed private key generator (DPKG) . . . . . . . . . . . . . 71
5.1 Potential RFID consumer privacy problems [77] . . . . . . . . . . . . 855.2 The action of tag Ti in the OSK scheme . . . . . . . . . . . . . . . . 955.3 The YA-TRIP Protocol [136] . . . . . . . . . . . . . . . . . . . . . . . 965.4 The YA-TRIP∗ protocol [135] . . . . . . . . . . . . . . . . . . . . . . 985.5 A toy example of the tree of secrets (MSW) . . . . . . . . . . . . . . 1005.6 The LK authentication protocol . . . . . . . . . . . . . . . . . . . . . 1035.7 RFID-enabled banknote data . . . . . . . . . . . . . . . . . . . . . . 1105.8 One round of the HB protocol . . . . . . . . . . . . . . . . . . . . . . 1185.9 One round of the HB+ protocol . . . . . . . . . . . . . . . . . . . . . 119
6.1 The EPCglobal Network architecture framework [71] . . . . . . . . . 1246.2 Electronic Product Code [71] . . . . . . . . . . . . . . . . . . . . . . 1246.3 The EPCglobal Network in action [72] . . . . . . . . . . . . . . . . . 1266.4 Operations between tag and reader [70] . . . . . . . . . . . . . . . . 1286.5 Tag-reader operations and tag state changes [70] . . . . . . . . . . . 1296.6 Example of tag inventory and access [70] . . . . . . . . . . . . . . . . 1306.7 Lock command payload and usage [70] . . . . . . . . . . . . . . . . . 1316.8 The BasicTagAuth protocol [76] . . . . . . . . . . . . . . . . . . . . . 1396.9 Encoding algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . 1416.10 Decoding algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
8

List of Tables
4.1 Comparison of the number of required initial secure channels . . . . . . . 74
6.1 Lock Action-field functionality [70] . . . . . . . . . . . . . . . . . . . 1326.2 The Lock command and response [70] . . . . . . . . . . . . . . . . . 1326.3 The Access command and response [70] . . . . . . . . . . . . . . . . 1346.4 The Write command and response [70] . . . . . . . . . . . . . . . . . 1346.5 Performance of secret key crypto-algorithms [16] . . . . . . . . . . . 1476.6 Security and privacy comparisons of RFID systems . . . . . . . . . . 148
9

Abbreviations
AES Advanced Encryption StandardAODV Ad hoc On-demand Distance VectorCA Certificate AuthorityCCA Chosen Ciphertext AttackCDH Computational Diffie-HellmanCPA Chosen Plaintext AttackCRC Cyclic Redundancy CheckingCRL Certificate Revocation ListDDH Decisional Diffie-HellmanDKG Distributed Key GeneratorDoS Denial of ServiceDL Discrete LogarithmDPKG Distributed Private Key GeneratorDSR Dynamic Source RoutingECDL Elliptic Curve Diffie-HellmanECDSA Elliptic Curve Digital Signature AlgorithmEPC Electronic Product CodeEPCIS EPC Information ServiceGen2 The Class-1 Generation-2 UHF RFID standardGEs Gate EquivalencesGGM Goldreich-Goldwasser-MicaliGPRS General Packet Radio ServicesHF High FrequencyIBC Identity-based CryptographyIBE Identity-based EncryptionIBS Identity-based SignatureIC Integrated CircuitICAO International Civil Aviation OrganisationIE-CCA Indistinguishable Encryption under Chosen Ciphertext AttackIE-CPA Indistinguishable Encryption under Chosen Plaintext AttackIEC International Electrotechnical CommissionIK-CPA Indistinguishability of Keys under Chosen Plaintext AttackiPANs interconnected Personal Area NetworksISM Industrial-Scientific-MedicalISO International Organisation for StandardisationKDC Key Distribution CentreLAN Local Area NetworkLF Low Frequency
10

LPN Learning Parity in the Presence of NoiseLSB Least Significant BitMAC Message Authentication CodeMAC (address) Media Access ControlMOV (Reduction) Menezes-Okamoto-VanstoneMRZ Machine Readable ZoneMSB Most Significant BitNFC Near Field CommunicationONS Object Name ServicesOOB Out-of-BandPAN Personal Area NetworkPDA Personal Digital AssistantPOWF Physical One-Way FunctionPKC Public Key CryptographyPKI Public Key InfrastructurePKG Private Key GeneratorPPT Probabilistic Polynomial-timePRNG Pseudo Random Number GeneratorRE Re-randomisable EncryptionRF Radio FrequencyRFID Radio Frequency IdentificationSSP Secure Simple PairingTA Trusted AuthorityTLS Transport Layer SecurityTPM Trusted Platform ModuleTTP Trusted Third PartyUC Universal ComposabilityUCC Uniform Code CouncilUHF Ultra High FrequencyUMTS Universal Mobile Telecommunications SystemUPC Universal Product CodeUR Universal Re-encryptionURL Universal Resource LocatorUSB Universal Serial BusUSS Universal Semantic SecurityUSSR Universal Semantic Security under Re-encryptionVSS Verifiable Secret SharingWAP Wireless Application ProtocolWLAN Wireless Local Area NetworkWTLS Wireless Transport Layer Security
11

Notation
a⊕ b bitwise XOR of bit strings a, b ∈ {0, 1}l for some l ∈ Za | b b is divisible by aa - b b is not divisible by aab a to the power ba|| b concatenation of strings a and ba ∈R A uniformly random selection of a from a finite set Aa := b defining a value a as a value ba ≈ b a is approximately equal to ba mod p a remainder of a modulo pa ≡ b (modp) a is congruent to b modulo p|a| the length of a bit string a ∈ {0, 1}∗|a| the binary length of a ∈ N‖a‖ the Hamming Weight of vector a‖A‖ the Hamming Weight of matrix Abac the greatest integer less than or equal to adae the smallest integer greater than or equal to a|A| the number of elements in a set A⊥ an error message1n a constant bit string 11 . . . 1 of length nm a plaintext messageak a tag-access keypk a public keysk a secret keyε an arbitrary negligible function〈g〉 a set of all powers of gN a set of positive integersZ a set of integersZq a group {0, 1, . . . , q − 1} under addition modulo qZ∗q the non-zero elements of ZqFp a finite field with p elementsF∗p the non-zero elements of FpDid a PAN device with an identifier id(Qid, did) a public/private key pair for a device Did
Pi a party engaging a secret sharing schemea PKG from each PAN in the km-iPANs scheme
I a set of non-revoked PKGs in revocation schemeQ a set of non-disqualified PKGs in secret sharing schemeG see definition 2.3
12

R a tagT a readere an admissible bilinear pairingE(Fp) an elliptic curve group for an elliptic curve E defined over Fp{0, 1}∗ a set of bit strings of arbitrary length{0, 1}l a set of bit strings of a length l{0, 1}<d a set of bit strings of a length that is less than d{0, 1}≤d a set of bit strings of a length that is less than or equal to d{0, 1}>d a set of bit strings of a length that is greater than d{0, 1}≥d a set of bit strings of a length that is greater than or equal to dO(·) a big O notation which limits behaviour of a function when
the argument tends towards a particular value or infinity
13

Chapter 1
Introduction
Contents
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.1.1 Security and privacy issues in pervasive computing . . . . . 14
1.1.2 Topics in pervasive computing . . . . . . . . . . . . . . . . 15
1.2 Contributions and Structure . . . . . . . . . . . . . . . . . 16
This chapter provides the motivation, contributions, and structure of the thesis.
1.1 Motivation
The term pervasive computing was first introduced by Schechter [125], as a way
of describing the anticipated environment of computing services available anytime,
anywhere, and on demand. In pervasive computing, devices are integrated into
everyday objects and activities, and seamlessly communicate to share and exchange
huge amounts of information. Technological innovation has enabled tiny devices to
participate in pervasive computing; however, such devices are particularly vulnerable
to security and privacy threats.
1.1.1 Security and privacy issues in pervasive computing
The term security includes the notions of confidentiality, integrity, availability, au-
thenticity, etc. A large number of security mechanisms supporting these security
goals have been developed, but these solutions are not all applicable to pervasive
computing systems. Security mechanisms for a pervasive environment should be
capable of handling (i) the diversity of computing resources available to devices,
and (ii) the dynamics including the mobility, ubiquity, and decentralised nature of
pervasive computing systems.
14

1.1 Motivation
Pervasive computing technology is often described as a means of enabling constant
surveillance of large parts of the population, because actions reflected in networked
computing devices may allow personal profiling in great detail and to a high level of
accuracy. Such public concerns are growing, mainly because of the combination of
(i) the ubiquity of tiny computing devices, e.g. RFID tags, and (ii) their invisibility,
i.e. the often uncontrolled wireless communications performed by such devices.
1.1.2 Topics in pervasive computing
We investigate possible cryptographic solutions to security and privacy issues aris-
ing in two pervasive computing systems: Personal Area Networks (PANs) and the
EPCglobal Network.
Personal Area Networks (PANs)
A Personal Area Network (PAN) is a small wireless network that covers a personal
work space, e.g. an office or a meeting room. A PAN only includes those components
owned and controlled by a single user, and the components directly communicating
with each other via a local interface such as Bluetooth or IrDA (Infrared Data
Association). As the population is increasingly equipped with multiple wireless
devices, PANs seem likely to become core elements of pervasive computing. Of
course, PANs may act as stand-alone networks, but it seems likely that they will be
interconnected to share information or services. We call such interconnected PANs
iPANs.
Providing a robust and secure key management scheme for use in PANs remains
a challenging task, in particular because of the unique characteristics of, and con-
straints on, such networks. That is, PAN devices are particularly susceptible to
security and privacy threats because: (i) their computing resources are potentially
limited, and thus often not possible to implement adequate cryptographic primitives;
(ii) they are likely to be exposed to a wide range of physical attacks; and (iii) online
trusted third parties (TTPs) are not always available. A variety of schemes have
been proposed for securing PANs, but these schemes only support key management
within a PAN.
15

1.2 Contributions and Structure
The EPCglobal Network
Radio Frequency Identification (RFID) is a technology for automated identification
of objects or people using radio communications. The EPCglobal Network is a
standards-based technology designed to help realise automated global supply chain
management using RFID technology.
The EPCglobal Network, like every technological innovation, is subject to potential
information security risks. Security issues associated with the components of the
EPCglobal Network other than the RFID system are similar to the concerns arising
in other Internet applications. RFID technology, however, poses unique privacy
and security concerns. In particular, a tag owner cannot physically control the
communications of a tag, since most basic tags respond with their resident data to
any reader queries without first authenticating the readers. Furthermore, tags do not
store any communication history. RFID systems also suffer from threats similar to
those that apply to iPANs. That is, the potentially limited computing capabilities
of RFID tags cause serious security vulnerabilities, since standard cryptographic
primitives are often beyond the capabilities of RFID tags. Also, since such tags will
operate in hostile environments, they may be subject to a range of physical attacks,
including fault induction or power analysis attacks.
Most previously proposed cryptographic solutions to the security and privacy issues
of RFID technology are based on hardware-efficient hash functions or block ciphers.
Such solutions, however, are not applicable to EPC tags1, which cannot support
most cryptographic primitives due to the limitations on their computing powers.
1.2 Contributions and Structure
In Chapter 2, we give the cryptographic preliminary necessary for the subsequent
chapters of the thesis. We first describe the basic principles of modern cryptog-
raphy. After discussing the computational approach to cryptography, we briefly
present secret key and public key cryptography. We then discuss issues related to
cryptographic key management.
1An EPC (Electronic Product Code) tag, the key component in the EPCglobal Network, is anRFID tag that is attached to, or embedded in, items.
16

1.2 Contributions and Structure
The remainder of this thesis is divided into two distinct parts. In Part I, we present
a study of key management schemes for PANs. This part of the thesis consists of
chapters 3 and 4.
In chapter 3, We review previous research security mechanisms designed for use in
PANs, focusing primarily on PAN security initialisation. After defining the notion of
a PAN and giving a PAN security architecture, we present two existing approaches
to PAN security initialisation.
In chapter 4, we propose a novel key management scheme for use both within and
between PANs. We define a term, iPANs, to refer to interconnected PANs. We
define a system model and give the design goals for key management in iPANs,
and propose a security initialisation scheme for iPANs. We then show that the
proposed scheme achieves desirable security and efficiency properties making use of
the unique characteristics of PANs. Some of the research findings in this chapter
have previously been published in [27, 28].
In Part II, we present a comprehensive study of security and privacy issues in
RFID technology, and propose a solution to security and privacy problems in the
EPCglobal Network. This part of the thesis consists of chapters 5–6.
In chapter 5, We discuss privacy issues of RFID technology, and construct a formal
privacy model for RFID systems accurately reflecting adversarial threats and power.
We then give brief privacy analysis for the existing privacy-enhanced RFID schemes
which have received wide attention in the literature.
In chapter 6, we discuss security and privacy issues in the EPCglobal Network. Af-
ter summarising the EPCglobal Network technology, we investigate the security and
privacy issues arising in the RFID system of the EPCglobal Network, i.e. we focus on
those issues exclusive to RFID technology. We also analyse the EPCglobal’s current
approach to such security and privacy concerns. We then propose a refresh-based
RFID system, and analyse its privacy properties. Finally we discuss the application
of the proposed RFID system and existing schemes to the EPCglobal Network. Some
of the research findings in this chapter have previously been published in [29, 30].
In chapter 7, we conclude this thesis, and outline directions for further research.
17

Chapter 2
Cryptographic Preliminaries
Contents
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2 Modern Cryptography . . . . . . . . . . . . . . . . . . . . 19
2.2.1 Cryptographic goals . . . . . . . . . . . . . . . . . . . . . . 19
2.2.2 Basic principles . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.3 Computational Approach . . . . . . . . . . . . . . . . . . . 22
2.3.1 Computational security . . . . . . . . . . . . . . . . . . . . 22
2.3.2 Cryptographic hardness assumptions . . . . . . . . . . . . . 24
2.4 Secret Key Cryptography . . . . . . . . . . . . . . . . . . 26
2.4.1 Secret key encryption . . . . . . . . . . . . . . . . . . . . . 26
2.4.2 Hash functions . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.4.3 Message authentication codes . . . . . . . . . . . . . . . . . 29
2.5 Public Key Cryptography . . . . . . . . . . . . . . . . . . 31
2.5.1 Public key encryption . . . . . . . . . . . . . . . . . . . . . 31
2.5.2 Digital signature schemes . . . . . . . . . . . . . . . . . . . 34
2.6 Key Management . . . . . . . . . . . . . . . . . . . . . . . 36
2.6.1 Trusted third parties . . . . . . . . . . . . . . . . . . . . . . 37
2.6.2 Key management frameworks . . . . . . . . . . . . . . . . . 37
2.6.3 Public key infrastructures . . . . . . . . . . . . . . . . . . . 39
2.6.4 Distributed key generation . . . . . . . . . . . . . . . . . . 40
2.7 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
This chapter provides cryptographic preliminaries necessary for the subsequent chap-
ters of the thesis. We first describe the basic principles of modern cryptography. Af-
ter discussing the computational approach to cryptography, we briefly present secret
key and public key cryptography. We then discuss cryptographic key management
issues.
18

2.1 Introduction
2.1 Introduction
In this chapter, we give a brief overview of the cryptographic primitives relevant to
this thesis. The material in this chapter is mostly derived from three books [35, 82,
102]. The rest of this chapter is organised as follows. In section 2.2, we describe
the goals and basic principles of modern cryptography. In section 2.3, we briefly
introduce computational security, covering cryptographic hardness assumptions and
computational problems. We then describe secret key and public key primitives in
sections 2.4 and 2.5. In section 2.6, we cover key management issues.
2.2 Modern Cryptography
In this section we give five main cryptographic goals, and describe basic principles
of modern cryptography.
2.2.1 Cryptographic goals
The five main goals of cryptography can be defined as follows (ISO 7498-2).
• Authentication: can be subdivided into entity authentication, the corroboration
that the entity at the other end of a communication link is the one claimed,
and data origin authentication, the corroboration that the source of received
data is as claimed.
• Access control: prevents unauthorised use of a resource.
• Data confidentiality: prevents disclosure of data to an unauthorised entity.
• Data integrity: prevents alteration or destruction of data by an unauthorised
entity.
• Non-repudiation: prevents denial by an entity that it has taken a particular
action, such as sending or receiving a message.
19

2.2 Modern Cryptography
Elsewhere in the literature, e.g. ‘Handbook of Applied Cryptography’ [102], the term
identification is used with the same meaning as entity authentication. Most crypto-
graphic protocols require the identities of other entities in the protocol to be assured
before starting cryptographic data processing. By contrast, in some RFID systems,
e.g. the EPCglobal Network, a verifier (i.e. a reader) mostly obtains the identity
declared by a claimant (i.e. a tag) without any corroboration, i.e. without entity
authentication. We thus use the term identification with the following definition in
this thesis: an identification is a process whereby one party (the verifier) obtains the
identity that another party (the claimant) declares.
2.2.2 Basic principles
Classical cryptographic schemes were designed in an ad hoc manner and then eval-
uated on their perceived resistance to known attacks. This ad hoc approach involves
providing informal arguments that any conceivable attack requires a resource level
(e.g. time and space) greater than the fixed resources of a perceived adversary. Hav-
ing survived such analysis, cryptographic primitives or protocols are said to possess
heuristic security. Such claims of security, however, remain open to revision, since
unforeseen attacks always remain a threat.
Modern cryptography to some extent rests on firmer and more scientific foundations
by taking a rigorous approach. The following three principles distinguish modern
cryptography from classical cryptography [82].
“Principle 1 – The first step in solving any cryptographic problem is the formulation of
a rigorous and precise definition of security.”
In order to fully define the security of a cryptographic task, the attack model must
be specified, i.e.
• what is considered to break the scheme, and
• what is assumed regarding the power of adversary : (i) the actions the ad-
versary is assumed to be able to take; and (ii) the adversary’s computational
power.
20

2.2 Modern Cryptography
Any definition of security will thus take the following form: a cryptographic scheme
for a given task is secure if no adversary of a specified power can break the scheme
according to the given definition of security.
“Principle 2 – When the security of a cryptographic construction relies on an unproven
assumption, this assumption must be precisely stated.”
Most modern cryptographic constructions cannot be proven secure unconditionally.
Constructing security proofs for today’s schemes which do not depend on assump-
tions about the inherent difficulty of certain problems would require the resolution
of fundamental questions in the theory of computational complexity, which seem far
from being solved today. Those assumptions must be precisely stated, and they must
be carefully studied. Thus modern cryptography rests on the heuristic assumption
that the more an assumption is examined without it being successfully refuted, the
greater confidence we can have that the assumption is true.
“Principle 3 – Cryptographic constructions should be accompanied by a rigorous proof
of security with respect to a definition formulated according to principle 1, and relative
to an assumption of the form stated as in principle 2.”
Giving an exact definition and a precise assumption is not in itself sufficient; without
a proof that no adversary of the specified power can break the scheme, we have
only our intuition that this is the case. Most proofs in modern cryptography use the
reductionist approach: that is, given a theorem of the form, “Given that assumption X
is true, construction Y is secure according to the given definition,” a proof typically
shows that the problem of breaking construction Y is reduced to the problem of
solving mathematical assumption X.
Remark. For some cryptographic solutions, e.g. complex schemes for key man-
agement, it is difficult to make a precise definition of security, i.e. it is difficult to
give a mathematical statement capturing precisely what constitutes an attack, due
to the complexity of the system. In such cases, we are obliged to use an ad hoc
approach, achieving only heuristic security.
21

2.3 Computational Approach
2.3 Computational Approach
In this section we briefly describe computational security, introducing cryptographic
hardness assumptions and computational problems in a variety of mathematical
settings.
2.3.1 Computational security
Cryptographic schemes are defined to be information-theoretically secure or perfectly
secure when they can be proven mathematically secure (with respect to some partic-
ular definition of security) even against a computationally unlimited adversary. Most
modern cryptographic constructions, however, aim to achieve computational security.
Computational security is weaker than information-theoretic security, incorporating
the following two relaxations:
• security is only preserved against efficient adversaries (algorithms) that run
in a feasible amount of time; and
• adversaries can potentially succeed with some very small probability.
Asymptotic security is one common approach to capturing these notions. This ap-
proach views the running time of an adversary as well as its success probability as
functions of a security parameter n.
Efficient algorithms
Efficient algorithms are defined to be probabilistic algorithms running in time poly-
nomial in the security parameter n. We say that an algorithm with an input of size
n is a polynomial-time algorithm if its worst-case running time is O(nc), for some
constant c. A probabilistic algorithm is one that has the ability to toss coins, i.e. the
algorithm has access to a source of randomness that yields unbiased random bits
that are each independently equal to 1 with probability 1/2.
There are two reasons that in cryptography we consider probabilistic polynomial-time
(PPT) algorithms rather than just deterministic polynomial-time algorithms. First,
22

2.3 Computational Approach
randomness is essential to cryptography, e.g. for generating random keys, and thus
it is also natural to consider a probabilistic adversary. Second, the capability to toss
coins may provide additional power. Since we use the notion of efficient computation
to model a realistic adversary, considering a probabilistic adversary is more desirable.
Negligible success probability
Cryptographic schemes that can be broken with a very small probability of success
are still considered to be secure in modern cryptography. We define the notion
of small probability of success by requiring the the success probability to be smaller
than any inverse-polynomial in n. We call such a probability negligible, and formally
define it as follows.
Definition 2.1 A function f is negligible if, for every polynomial p, there exists an
N such that f(n) < 1/|p(n)| for all n > N .
The following is an equivalent definition.
Definition 2.2 A function f is negligible if, for every constant c > 0, there exists
an N such that f(n) < 1/nc for all n > N .
We typically denote an arbitrary negligible function by ε.
Asymptotic security definition
A definition of asymptotic security then takes the following general form.
A scheme is secure if every probabilistic polynomial-time adversary suc-
ceeds in breaking the scheme with only negligible probability.
The above definition is asymptotic because it is possible that, for small values of n,
an adversary can succeed with high probability.
23

2.3 Computational Approach
2.3.2 Cryptographic hardness assumptions
In this section we introduce a class of cryptographic hardness assumptions regarding
computations in cyclic groups.
Mathematical background
Let G be a finite multiplicative group of order n, and let g ∈ G. The smallest
positive integer t such that gt = 1 is called the order of g; such a t always exists and
must divide n. The set 〈g〉 = {gi| 0 ≤ i ≤ t− 1} of all powers of g is itself a group
under the same operation as G, and is called the cyclic subgroup of G generated by
g. If G has an element g of order n, then G is called a cyclic group and g is called a
generator of G.
Analogous statements are true for additive groups. That is, if G is a finite additive
group of order n and g ∈ G, the order of g is the smallest positive divisor t of n such
that tg = 0, and we write 〈g〉 = {ig| 0 ≤ i ≤ t − 1}. Here, tg denotes the element
obtained by adding together t copies of g.
Menezes, van Oorschot, and Vanstone [101] give more detailed discussions of group
and field.
The discrete logarithm (DL) and Diffie-Hellman (DH) assumptions
We now describe a number of computational problems that can be defined for any
cyclic group. We first define an algorithm that generates cyclic groups as follows.
Definition 2.3 Let G be a polynomial-time algorithm that, on input 1n, outputs a
description of a cyclic group G of order q and a generator g ∈ G.
The notation 1n denotes constant bit string 11 . . . 1 of length n. Given a group-
generating algorithm G, algorithm A, and parameter n, we consider the following
experiment.
24

2.3 Computational Approach
Experiment ExpdlogA,G(n)
1. Run G(1n) to obtain (G, q, g), as in the definition 2.3.
2. Compute h := gx for x ∈R Zq.
3. Given G, q, g, h, A outputs x′ ∈ Zq.
4. The output of the experiment is defined to be 1 if gx′
= h, and 0 otherwise.
The notation Zq denotes the group of integers {0, 1, . . . , q−1} under addition modulo
q, and the notation a ∈R A denotes that a is selected uniformly at random from a
finite set A. The aim of the algorithm A is, given h ∈ G, is to find x′ ∈ Zq such that
gx′
= h (∈ G) in time polynomial in n. We denote ExpdlogA,G(n) = 1 if the output of
the experiment ExpdlogA,G(n) is 1, i.e. A is able to find such a x′. We then have the
following.
Definition 2.4 (DL) We say that the discrete logarithm (DL) problem is hard relative
to G if, for all probabilistic polynomial-time algorithms A, the function Pr[Expdlog
A,G (n) =
1]
is negligible.
The discrete logarithm assumption is then that there exists a group-generating algo-
rithm G for which the discrete logarithm problem is hard for all of the output groups.
We next specify certain closely related problems, called the Diffie-Hellman problems.
In particular we define two particularly important variants of the DH problem: the
computational Diffie-Hellman (CDH) problem and the decisional Diffie-Hellman (DDH)
problem.
Let G be defined as in Definition 2.3. Given two group elements h1 (= gx1) and
h2 (= gx2), define DHg(h1, h2) = gx1x2 . The CDH problem is then to compute
DHg(h1, h2) given h1, h2 ∈R G. The DDH problem is, given h1, h2 ∈R G and a
candidate solution h′ ∈ G, to decide whether or not h′ = DHg(h1, h2). More formally,
given G, the DDH problem is defined as follows.1
Definition 2.5 (DDH) We say that the decisional Diffie-Hellman (DDH) problem is
hard relative to G if, for all probabilistic polynomial-time algorithm A, the function
1We omit a formal description of the CDH problem since it is not used in the remainder of thethesis.
25

2.4 Secret Key Cryptography
Adv-DDH =∣∣∣Pr[A(G, q, g, gx, gy, gz) = 1
]− Pr
[A(G, q, g, gx, gy, gxy) = 1
] ∣∣∣is negligible, where in each case the probabilities are taken over the experiment in
which G(1n) outputs (G, q, g) and x, y, z ∈R Zq are chosen at random.
If the DL problem relative to some G is easy, then so is the CDH problem. It is
not clear, however, whether the hardness of the DL problem necessarily implies the
hardness of CDH problem. Again, if the CDH problem relative to some G is easy,
then so is the DDH problem. The converse does not appear to be true; there are
examples of groups in which the DL and CDH problems are believed to be hard,
even though the DDH problem is easy [82]. The relationships between the problems
is summarised in Figure 2.1.
DL problem is easy =⇒ CDH problem is easy =⇒ DDH problem is easy
Figure 2.1: Relationships between problems
2.4 Secret Key Cryptography
In this section, we briefly describe secret key primitives.
2.4.1 Secret key encryption
We give a definition of computational security for secret key encryption. We first
define the notion of secret key encryption.
Definition 2.6 A secret key encryption scheme is a triple of polynomial-time algo-
rithms (Gen,Enc,Dec) such that:
1. The key generation algorithm Gen takes as input the security parameter 1n and
outputs a key k such that |k| ≥ n. We write k ← Gen(1n).
26

2.4 Secret Key Cryptography
2. The encryption algorithm Enc takes as input k and a plaintext message m ∈{0, 1}∗, and outputs a ciphertext c. We write c← Enc(k,m).
3. The decryption algorithm Dec takes as input a key k and a ciphertext c, and
outputs a message m or a special symbol ⊥ denoting failure. Assuming that
Dec is deterministic, we write m← Dec(k, c).
It is required that, for every n, every k ← Gen(1n), and every m ∈ {0, 1}∗, Dec(k,Enc
(k,m))
= m.
We next define the security notion for a secret key encryption scheme Π = (Gen,Enc,Dec),
i.e. indistinguishability in the presence of an adversary. More specifically, given a secret
key encryption scheme Π and an adversary A, we consider the following experiment.
Experiment ExpeavA,Π(n)
1. A is given input 1n, and outputs a pair of messages (m0,m1) of the same
length.
2. A key k is generated by running Gen(1n), and a random bit b ∈R {0, 1} is
chosen. A ciphertext c← Enc(k,mb) is computed and given to A.
3. A outputs a bit b′.
4. The output of the experiment is defined to be 1 if b′ = b, and 0 otherwise.
A is then said to succeed if ExpeavA,Π(n) = 1. An encryption scheme is said to have
the indistinguishability property if the success probability of any PPT adversary Ais at most negligibly greater than 1/2. It can be defined more formally as follows.
Definition 2.7 A secret key encryption scheme Π=(Gen,Enc,Dec) is indistinguish-
able in the presence of an adversary if, for all probabilistic polynomial-time adversaries
A, the function∣∣Pr[Expeav
A,Π(n) = 1]− 1
2
∣∣ is negligible.
2.4.2 Hash functions
Cryptographic hash functions (hereafter, simply hash functions) are functions that take
arbitrary-length strings and compress them into shorter strings. Hash functions play
a fundamental role in modern cryptography, and can be defined as follows.
27

2.4 Secret Key Cryptography
Definition 2.8 A hash function is a pair of probabilistic polynomial-time algorithms
(Gen,H ) with the following properties:
• Gen is a probabilistic algorithm which takes as input a security parameter 1n
and outputs a key s.
• H takes as input a key s and a string x ∈ {0, 1}∗, and outputs a string Hs(x) ∈{0, 1}l(n), for a polynomial l.
The input value x is a string of arbitrary length, but we assume that there exists
some upper bound on the length of possible input strings. In practice, it is always
the case that hash functions are only defined for strings of bounded length. The
“key” s is not a key in the usual sense of the word. It is not kept secret, and is
rather used to specify (or index) a particular function Hs from a family of hash
functions. We define the following experiment, given a hash function Π = (Gen, H)
and an adversary A.
Experiment ExpcollA,Π(n)
1. A key s is generated by running Gen(1n).
2. The adversary A is given s and outputs x, x′.
3. The output of the experiment is defined to be 1 if x 6= x′ and Hs(x) = Hs(x′).
A hash function is said to be collision resistant if no efficient algorithm can find a
collision in the above experiment except with negligible probability. The formal
definition is as follows.
Definition 2.9 A hash function Π=(Gen,H ) is collision resistant if, for all proba-
bilistic polynomial-time adversaries A, the function Pr[Expcoll
A,Π(n) = 1]
is negligible.
For simplicity and depending on the context, we refer to each of H, Hs, and Π =
(Gen, H) as collision-resistant hash functions.
We now define the notion of security for a hash function. Collision resistance is
a strong security requirement and is quite difficult to achieve, and thus in some
applications we can relax the requirements somewhat. Typically, three security
properties for a hash function are defined.
28

2.4 Secret Key Cryptography
• Collision resistance: This is defined as above.
• Second pre-image resistance: Informally speaking, a hash function is second
pre-image resistant if it is infeasible for a PPT adversary, given a randomly
chosen x, to find x′ ( 6= x) such that Hs(x) = Hs(x′).
• Pre-image resistance: Informally, a hash function is pre-image resistant if it is
infeasible for a PPT adversary, given y (= Hs(x) for a randomly chosen x), to
find a value x′ such that Hs(x′) = y.
It is easy to see that any collision-resistant hash function is second pre-image resis-
tant, i.e. collision resistance implies second pre-image resistance. Collision resistance,
however, does not guarantee pre-image resistance. Furthermore, second pre-image
resistance does not guarantee pre-image resistance, nor does pre-image resistance
guarantee second pre-image resistance [102].
2.4.3 Message authentication codes
In practice, it is often necessary to guarantee message integrity. That is, each com-
municating party should be able to verify that, when it receivers a message, the
message is the exactly message sent by the other party. It is tempting to suggest
that secret key encryption could also provide message authentication, since an ad-
versary cannot possibly modify a ciphertext in a meaningful way. This reasoning is,
however, false (as described in [82]), and thus a separate mechanism is required.
A message authentication code (MAC) is a mechanism enabling communicating par-
ties to check whether or not a message has been tampered with. A MAC can be
used between parties only when they share a secret. We now give a formal definition
of a MAC.
Definition 2.10 (MAC) A message authentication code (MAC ) is a triple of polynomial-
time algorithms (Gen,Mac,Ver) such that:
1. The key generation algorithm Gen takes as input the security parameter 1n and
outputs a key k with |k| ≥ n. We write k ← Gen(1n).
2. The tag generation algorithm Mac takes as input a key k and a message m ∈{0, 1}∗, and outputs a tag t. We write t← Mac(k,m).
29

2.4 Secret Key Cryptography
3. The verification algorithm Ver takes as input a key k, a message m, and a
tag t. It outputs a bit b = 1 if t is valid, and b = 0 otherwise. We write
b← Ver(k,m, t).
It is required that, for every n, every key k ← Gen(1n), and every m ∈ {0, 1}∗,Ver(k,m,Mac(k,m)) = 1.
A MAC can be used in the following way. When two parties wish to communicate
in an authenticated manner, they run Gen(1n) and share a secret k before they
start communication. When one party wants to send a message m to the other, she
computes a MAC tag t← MAC(k,m), and transmits (m, t). Upon receipt of (m, t),
the second party verifies that t is a valid tag on the message m with respect to k
(by checking if Ver(k,m, t) = 1).
A MAC is said to be secure if no PPT adversary is able to generate a valid tag on
any new message that was not previously sent by one of the communicating parties.
The formal security definition requires considering the following experiment for a
message authentication code Π = (Gen,Mac,Ver) and an adversary A.
Experiment ExpforgeA,Π (n)
1. A random key k is generated by running Gen(1n).
2. A is given input 1n and oracle access Mac(k, ·), and eventually outputs a pair
(m, t).
3. The output of the experiment is defined to be 1 if (i) Ver(k,m, t) = 1 and (ii)
m /∈ Q, where Q is the set of queries that A has asked to the oracle.
An oracle Mac(k, ·), given a query m′ ∈ {0, 1}∗ from A, returns t← Mac(k,m′) and
adds m′ to a set Q. As formally defined below, a MAC is said to be secure if no PPT
adversary can succeed in the above experiment with non-negligible probability.
Definition 2.11 A message authentication code Π = (Gen,Mac,Ver) is secure if, for
all probabilistic polynomial-time adversaries A, the function Pr[Expforge
A,Π (n) = 1]
is
negligible.
30

2.5 Public Key Cryptography
2.5 Public Key Cryptography
In this section we briefly describe public key primitives.
2.5.1 Public key encryption
We first review public key encryption schemes, and, as an example, give the ElGamal
encryption scheme that is referred to in Chapter 5 and 6.
Definition and security notions
A public key encryption scheme can be defined as follows.
Definition 2.12 A public key encryption scheme is a triple of polynomial-time algo-
rithms (Gen,Enc,Dec) with the following properties:
1. The key generation algorithm Gen takes as input the security parameter 1n and
outputs a public/private key pair (pk, sk). We write (pk, sk)← Gen(1n).
2. The encryption algorithm Enc takes as input a public key pk and a message m
from some underlying plaintext space (that may depend on pk), and outputs a
ciphertext c. We write c← Enc(pk,m).
3. The decryption algorithm Dec takes as input a private key sk and a cipher-
text c, and outputs a message m or a special symbol ⊥ denoting failure.
We assume without loss of generality that Dec is deterministic, and we write
m← Dec(sk, c).
It is required that, for every n, every (pk, sk) ← Gen(1n), and every message m in
the appropriate underlying plaintext space, Dec(sk,Enc(pk,m)) = m.
We now describe two security notions for public key encryption schemes. First, given
a public key encryption scheme Π = (Gen,Enc,Dec) and an adversary A, we define
the following experiment.
Experiment ExpcpaA,Π(n)
31

2.5 Public Key Cryptography
1. Gen(1n) is run to obtain keys (pk,sk).
2. Given pk, A outputs a pair of messages (m0,m1) of the same length, where
these messages must be in the plaintext space associated with pk.
3. A random bit b is chosen, i.e. b ∈R {0, 1}, and the ciphertext c← Enc(pk,mb)
is given to A.
4. A outputs a bit b′.
5. The output of the experiment is defined to be 1 if b′ = b, and 0 otherwise.
We then have the following.
Definition 2.13 (IND-CPA) A public key encryption scheme Π=(Gen,Enc,Dec) is
indistinguishable under a chosen-plaintext attack (or is CPA secure) if, for all prob-
abilistic polynomial-time adversaries A, the function∣∣∣Pr[Expcpa
A,Π(n) = 1]− 1
2
∣∣∣ is
negligible.
Second, given a public key encryption scheme Π = (Gen,Enc,Dec) and an adversary
A, we define the following experiment.
Experiment ExpccaA,Π(n)
1. Gen(1n) is run to obtain keys (pk,sk).
2. A is given pk and access to a decryption oracle Dec(sk, ·). A outputs a pair of
messages (m0,m1) of the same length, where these messages must be in the
plaintext space associated with pk.
3. A random bit b is chosen, i.e. b ∈R {0, 1}, and the ciphertext c← Enc(pk,mb)
is given to A.
4. A continues to interact with the decryption oracle Dec(sk, ·), but may not
request a decryption of c itself. Finally, A outputs a bit b′.
5. The output of the experiment is defined to be 1 if b′ = b, and 0 otherwise.
We then have the following.
32

2.5 Public Key Cryptography
Definition 2.14 (IND-CCA2) A public key encryption scheme Π=(Gen,Enc,Dec)
is indistinguishable under a chosen-ciphertext attack (or is CCA secure) if, for all
probabilistic polynomial-time adversaries A, the function∣∣Pr[Expcca
A,Π(n) = 1]− 1
2
∣∣is negligible.
Another commonly used means of formalising the above notions is to require that
every adversary behaves the same way whether it sees an encryption of m0 or an
encryption of m1. Since the adversary A outputs a single bit, “behaving the same
way” means that A outputs 1 with almost the same probability in each case. Putting
sec to either cpa or cca, we define the experiments ExpsecA,Π(n, b) to be as above,
except that a fixed bit b is used rather than being randomly chosen.
The following definitions then capture the notion that A cannot determine whether
it is running experiment ExpsecA,Π(n, 0) or experiment Expsec
A,Π(n, 1).
Definition 2.15 For sec ∈ {cpa, cca} we define the advantage of an adversary A to
be
AdvsecA,Π(n) =
∣∣Pr[(Expsec
A,Π(n, 0))
= 1]− Pr[(Expsec
A,Π(n, 1))
= 1]∣∣ .
Definition 2.16 A public key encryption scheme Π = (Gen,Enc,Dec) is CPA secure
(respectively, CCA secure) if the function AdvcpaA,Π(n) (respectively, Advcca
A,Π(n)) is
negligible for all probabilistic polynomial-time adversaries A.
Definition 2.16 can be shown to be equivalent to definitions 2.13 or 2.14 [82].
ElGamal encryption
We describe a well-known public key encryption scheme, namely the ElGamal en-
cryption scheme, and discuss its security.
Definition 2.17 (ElGamal Encryption) Let G be defined as in definition 2.3.
The ElGamal encryption scheme is a triple of algorithms (Gen,Enc,Dec) with the
following properties:
33

2.5 Public Key Cryptography
• Gen: takes as input 1n, and obtains (G, q, g) by running G(1n). It then chooses
a random x ∈R Zq, computes y = gx, and outputs a public/private key pair
(pk,sk), where pk = 〈G, q, g, y〉 and sk = 〈G, q, g, x〉.
• Enc: takes as input a public key pk and a message m ∈ G. It chooses a random
r ∈R Zq and computes c1 = gr and c2 = myr. Finally, it outputs the ciphertext
c = (c1, c2).
• Dec: takes as input a private key sk and a ciphertext c, and outputs m = c2·c−x1 .
It is easy to see that, for every n, every (pk, sk) ← Gen(1n), and every message
m ∈ G, Dec(sk,Enc(pk,m)
)= m. We then have the following result regarding the
security of this scheme [134].
Theorem 2.1 If the DDH problem is hard relative to G, then the ElGamal encryp-
tion scheme has IND-CPA property (i.e. it is CPA secure).
The ElGamal encryption scheme is, however, vulnerable to chosen-ciphertext attack
as a result of the homomorphic property of ElGamal encryption scheme. That is,
for any public key pk and any messages m1 and m2, we have
Enc(pk,m1) · Enc(pk,m2) = Enc(pk,m1m2).2
For example, in the experiment ExpccaA,Π, assume that A receives c = Enc(pk,mb) in
step 3. In step 4, A can send Enc(pk,mb) ·Enc(pk,m1) to the decryption oracle and
obtain mbm1. A is then able to correctly determine b with knowledge of m0 and
m1.
2.5.2 Digital signature schemes
Digital signatures are the public key counterpart of MACs, in that they are used to
ensure the integrity (or authenticity) of transmitted messages. Although typical im-
plementations of digital signature schemes are 2–3 orders of magnitude less efficient
than those of MACs, digital signatures have some advantages.
2The notation Enc(pk,m1)·Enc(pk,m2) means that the sequence of elements should be multipliedcomponent-wise.
34

2.5 Public Key Cryptography
First, use of such a scheme simplifies key management when a sender communicates
with multiple receivers. Instead of establishing distinct shared secrets with each
recipient and computing a separate MAC tag for each secret key, the sender only
needs to compute a single signature which can be verified by all recipients. Second,
digital signatures provide the important security property of non-repudiation, i.e.
once a signer signs a message, he/she cannot later deny having done so.
We next give a formal definition of a digital signature scheme [82].
Definition 2.18 (Signature Scheme) A signature scheme is a triple of three polynomial-
time algorithms (Gen,Sig,Ver) with the following properties:
1. The key-generation algorithm Gen takes as input a security parameter 1n and
outputs a pair of keys (pk, sk), where pk is called the public key and sk is called
the private key. We write (pk, sk)← Gen(1n).
2. The signing algorithm Sig takes as input a private key sk and a message m ∈{0, 1}∗, and outputs a signature σ. We write σ ← Sig(sk,m).
3. The deterministic verification algorithm Ver takes as input a public key pk, a
message m, and a signature σ. It outputs a bit b = 1 if σ is valid, and b = 0
otherwise. We write b← Ver(pk,m, σ).
It is required that, for every n, every (pk, sk) ← Gen(1n), and every message m ∈{0, 1}∗, Ver
(pk,m, Sig(sk,m)
)= 1.
A signature scheme is used in the following way. A sender S runs Gen(1n) to obtain
(pk, sk), and the public key pk is publicised as belonging to S. If S wishes to send
a protected version of message m, S computes σ ← Sig(sk,m) and sends (m,σ). A
receiver with the authentic copy of pk can verify the authenticity of m by checking
whether the signature σ is valid. A signature σ is said to be valid on a message m
if Ver(pk,m, σ) = 1.
We now consider the security of signature schemes, following Goldwasser et al. [61].
An adversary is given a public key and allowed to repeatedly ask for signatures on
multiple messages of his choice. The adversary succeeds if he can output a valid
signature on any message which was not signed previously. The signature scheme
is said to be secure against existential forgery under adaptive chosen-message attack
if the success probability of any PPT adversary is negligible. The formal security
35

2.6 Key Management
definition requires considering the following experiment for a digital signature scheme
Π = (Gen, Sig,Ver) and an adversary A.
Experiment Expe-forgeA,Π (n)
1. Gen(1n) is run to obtain keys (pk,sk).
2. A is given pk and access to an oracle Sig(sk, ·), and eventually outputs a pair
(m,σ).
3. The output of the experiment is defined to be 1 if (i) Ver(pk,m, σ) = 1 and
(ii) m /∈ Q, where Q is the set of queries that A has asked to the oracle.
An oracle Sig(sk, ·), given a query m′ ∈ {0, 1}∗ from A, returns σ ← Sig(sk,m′) and
adds m′ to a set Q. As formally defined below, a digital signature scheme is said
to be existentially unforgeable under an adaptive chosen-message attack if no PPT
adversary can succeed in the above experiment with non-negligible probability.
Definition 2.19 A digital signature scheme Π = (Gen,Sig,Ver) is existentially un-
forgeable under an adaptive chosen-message attack if, for all probabilistic polynomial-
time adversaries A, the function Pr[Expe-forge
A,Π (n) = 1]
is negligible.
2.6 Key Management
Key management covers the roles, techniques, and procedures used to establish
shared secret keys (as used by secret key cryptography) and to provide trustworthy
copies of public keys for public key cryptosystems. We start by briefly describing the
role of trusted third parties in key management. We then review key management
frameworks, and in particular explain the notion of a public key infrastructure.
Finally, we describe distributed key generation schemes which do not involve trusted
third parties.
36

2.6 Key Management
2.6.1 Trusted third parties
A trusted third party (TTP) is an entity in a system that is not under the control of
that system’s security authority and yet is trusted by that security authority to carry
out certain security-related functions [35]. TTPs are often heavily involved in key
management schemes. A TTP can be involved in key generation, key distribution,
or the certification of public keys.
There are several types of TTPs, but they may be classified into two categories in
the context of key management [102]: a TTP is said to be unconditionally trusted if
it is trusted on all matters, i.e. it may have access to the secret and private keys of
users, and functionally trusted if it is assumed to be honest and fair but it does not
have access to the secret or private keys of users.
Dent and Mitchell [35] and Menezes, van Oorschot, and Vanstone [102] give more
detailed discussions of TTPs, covering topics such as requirements, architectures,
and related standards.
2.6.2 Key management frameworks
In this section, we describe basic key management frameworks.
Definitions and basic properties
A key is a sequence of symbols that controls the operation of a cryptographic trans-
formation, and keying material is the data (e.g. keys and initialisation values) nec-
essary to establish and maintain cryptographic keying relationships [35]. Key man-
agement is concerned with all operations related to keys except their actual use by
cryptographic algorithms, and it can be defined as follows [102].
Definition 2.20 Key management is the set of processes and mechanisms which
support key establishment and maintenance of ongoing keying relationships between
parties, including replacing older keys with new keys as necessary.
37

2.6 Key Management
In the above definition, key establishment means any process whereby a shared se-
cret key becomes available to two or more parties for subsequent cryptographic use.
Although there are mathematical security models for certain parts of key manage-
ment systems such as key establishment protocols, it is difficult to define a formal
security model for key management due to the complexity of the whole system. For
this reason, key management principle have been developed as a series of statements
about best practice obtained from practical experience. Dent and Mitchell [35] give
the following main threats on key management systems.
(T1) The unauthorised disclosure of keys.
(T2) The unauthorised modification of keys.
(T3) The misuse of keys, i.e. (a) the use of a key by an unauthorised party, (b) the
use of a key for an unauthorised purpose, or (c) the use of a key whose usage
period has expired.
Finally, we briefly discuss one important key management principle, namely key
separation. This requires that a key should be used for one purpose only, e.g. an
encryption key should never be used with a MAC algorithm. A key hierarchy is a way
of facilitating key separation by adding structure to a set of keys, and by defining
the scope of the use of each key. More specifically, keys are classified in terms of
levels of importance, and keys at one level are only used for protecting keys in the
level directly below, except for the keys at the lowest level. Dent and Mitchell [35]
give more detailed discussions of key management and related standards, such as
ANSI X9.24.
Key management for secret key techniques
A major issue when using secret key cryptography is to establish pairwise secrets.
In a network consisting of n parties, up to(n2
)= n(n−1)
2 pairwise shared secrets
may need to be established. In practice, networks are often large, and thus more
efficient and simple methods of handling this problem are required. One solution
using secret key techniques involves an unconditionally trusted TTP, called a key
distribution centre (KDC). Each entity is only required to share a unique secret key
38

2.6 Key Management
with a KDC, and, when two entities wish to establish a shared secret key, the
necessary secret can be transferred from the KDC to the two entities in encrypted
form.
Key management for public key techniques
The key management problem is rather different for public key techniques. Whereas
secret key cryptography requires shared secrets, the use of public key cryptography
requires a means to provide assurance regarding the validity of public keys.
This can be achieved by using a functionally trusted TTP, called a certification
authority (CA), which issues digitally signed statements (i.e. certificates) binding
public keys to particular entities. More specifically, using a secure signature scheme,
a CA signs a data structure containing an entity’s identity and its public key, after
having verified the identity of the entity. The original data structure, i.e. an entitiy’s
identity and its public key, combined with its signature generated by CA is called a
certificate. Some assurance (the degree of which depends on the CA and the rigour
of its operational procedures) in a public key can be now obtained by any entity
that verifies the certificate using the CA’s public key.
2.6.3 Public key infrastructures
When using a CA, a number of serious issues need to be addressed, including: how
an entity obtains the necessary trusted copy of the CA’s public key; how a CA can
verify the binding between an entity’s identity and its public key; how an entity
decides whether or not to trust a CA; and how a CA can efficiently and securely
revoke certificates when necessary. A public key infrastructure (PKI) includes the set
of policy statements covering such details, and enables the generation and use of
certified public keys in a community accepting the policy rules of the PKI.
The simplest PKI would involve a single CA which issues all the certificates for a
particular PKI. However, use of a single CA can result in a range of problems, and
thus multiple CAs can also be used. To avoid the need for every user of a PKI
to hold trusted copies of the public keys of every CA, CAs can issue certificates
39

2.6 Key Management
for each other’s public keys, resulting in the use of sequences of certificates known
as certificate chains. A multiplicity of CAs can be arranged hierarchically (making
certificate chain construction simple) or in a ‘flat’ peer-to-peer scheme.
In some cases a certificate for an entity’s public key may need to be withdrawn, e.g.
if a user leaves an organisation or a user’s private key is compromised. Handling
these issues can be a non-trivial problem. We briefly discuss two simple approaches.
• Expiry: A certificate can be withdrawn by including an expiry date in the
certificate. For example, a certificate for Bob’s public key pkB might have the
form:
certB := Sig(sk, ‘Bob’s key is pkB’ || expiry date),
where Sig is a signing algorithm (as in definition 2.18) and sk is the private key
of the CA. This approach gives a very coarse-grained solution. For example,
if an employee receives a certificate that expires after one year, then it will
remain valid for up to a year after an employee leaves. Issuing certificates on
a daily basis, however, could be very costly.
• Revocation: A certificate can be withdrawn immediately by a CA explicitly
revoking the certificate. For example, a CA might issue a certificate for Bob’s
public key pkB with the following form:
certB := Sig(sk, ‘Bob’s key is pkB’ || serial number).
A certificate can be immediately revoked by the CA signing a certificate revo-
cation list (CRL) containing the serial numbers of all currently revoked certifi-
cates. This CRL includes the current date, and needs to be made available to
all PKI users.
More detailed discussions of PKI issues can be found in Katz and Lindell [82] and
Menezes, van Oorschot, and Vanstone [102].
2.6.4 Distributed key generation
Pedersen [111] first proposed a solution to the distributed generation of private keys
for threshold cryptosystems, and the variant schemes have subsequently appeared in
40

2.6 Key Management
the literatures [25, 55, 56, 96, 129]. Such schemes involves the n parties choosing the
secret key and distributing it verifiably among themselves, and thus it is infeasible
for a single party to compute or reconstruct the private key. The distributed key
generation schemes can also be used as a building block for other distributed pro-
tocols [48, 55, 68]. For example, Boneh and Franklin [19] propose the use Gennaro
et al.’s scheme [56] to generate a master secret for use of the Distributed Private Key
Generator (DPKG).3 After briefly discussing the generic syntax and security model
of the distributed key generation schemes, we describe example schemes considered
in this thesis afterwards.
System model
We assume that a distributed key generation scheme involves a set of n parties,
denoted by P1,P2, . . . ,Pn. They have secure communication channels between them
and have access to a dedicated broadcast channel. For simplicity, we assume a fully
synchronous communication model, i.e. messages of a given round in the protocol
are sent simultaneously by all the parties, and are delivered simultaneously to their
recipients.
We also define a PPT adversary A, which can corrupt up to t (< n/2) of the n
parties in the system, and may cause the corrupted parties to deviate from the
protocol specification. We assume that an adversary A is static, i.e. it chooses the
corrupted parties at the beginning of the protocol.
Security requirements
Let G be a group of a large prime order q. A distributed key generation protocol is
performed by n parties and generates (i) private outputs x1, x2, . . . , xn, called the
shares of a secret x ∈ Z∗q , and (ii) a public output y ∈ G. The protocol is called
t-secure (or secure with threshold t) if, given an adversary that corrupts at most t
out of n parties in the system, the following requirements are satisfied:
(R1) All subsets of t + 1 shares provided by honest parties define the same unique
secret key x.3See Section 4.1.2 for the details.
41

2.6 Key Management
(R2) All honest parties have the same public value y.
(R3) x is uniformly distributed in Zq, and y depends on x such that y will be
uniformly distributed in G .
(R4) No information regarding x can be learned by an adversary.
Gennaro et al. [56] call R1, R2, and R3 the correctness requirements, and R4 the
secrecy requirement.
Pedersen’s scheme
Pedersen [111] proposed a distributed key generation protocol which distributes a
master secret without relying on a trusted third party. Pedersen’s scheme involves
n parallel executions of Feldman’s scheme [45]. We give the detailed description as
follows.
1. Each party Pi (1 ≤ i ≤ n) chooses a polynomial fi(z) ∈ Zq[z] of degree t, i.e.
fi(z) = ai0 + ai1z + · · ·+ aitzt, where aik ∈R Zq.
2. Each Pi broadcasts wik = gaik mod p for k = 0, 1, . . . , t.
3. Each Pi computes xij = fi(j) mod q for j = 1, . . . , n, and sends xij to Pj via
a secure channel, reserving xii for itself.
4. On receiving xji (1 ≤ j ≤ n, j 6= i), each Pi verifies xji by checking that
gxji =
t∏k=0
(wjk)ik mod p. (2.1)
If this check fails for an index j, Pi broadcasts a complaint against Pj .
(a) If there are complaints against Pj from more than t parties, Pj is dis-
qualified.
(b) Otherwise, i.e. if there are at most t complaints against Pj , Pj reveals
(i.e. broadcasts) the share xji satisfying equation (2.1). If this revealed
share does not satisfy the equation (2.1),4 Pj is disqualified.
The qualified parties then form a set Q.
4This check is performed by all parties.
42

2.6 Key Management
5. Each party Pi computes its share as xi =∑
j∈Q xji mod q. The public value
y (= gx mod p) is computed as y =∏i∈Qwi0 mod p.
The master secret value x is not computed by any party, but is equal to x =∑i∈Q ai0 mod q. If we define the polynomial f(z) =
∑i∈Q fi(z) ∈ Zq[z], it is easy
to see that xi = f(i) mod q for every i ∈ Q, and thus x = f(0) mod q.
Gennaro et al. [56], however, show that an adversary which corrupts a small number
of parties can influence key generation. For example, an adversary can bias the
distribution of a public key y, making its last bit significantly more likely to be 0
than 1. Suppose that an adversary corrupts two parties, say P1 and P2, and all the
other parties are honest, i.e. they correctly follow the protocol specifications. In step
3, P1 sends Pi incorrect shares x1i for i = 3, . . . , t+2, which will result in t complaint
in the subsequent step. One more complaint is now required for the disqualification
of party P1. The adversary computes α =∏ni=1wi0 mod p and β =
∏ni=2wi0 mod p.
If α ends with 0, then P2 does not broadcast a compliant against P1. Otherwise, P2
broadcasts a complaint, and thus P1 is disqualified, in which case the probability
that β ends with 0 is 1/2. Hence, the probability that the public key y ends with 0
is 1/2 + (1/2)2 = 3/4 rather than 1/2, and the security condition R3 of the secret
sharing scheme is not satisfied.
Gennaro et al.’s scheme
Gennaro et al. [56] fixes the above problem and show that the proposed scheme
satisfies the the requirements R1, R2, R3, and R4 with threshold t (< n/2). Let p be
a large prime and g be an element of large prime order q, where q|(p− 1). The g is
an element of a group generated by g. The secret key x can be generated as follows.
1. Each Pi (1 ≤ i ≤ n) chooses two polynomials fi(z), fi(z) ∈ Zq[z] of degree t:
fi(z) = ai0 + ai1z + · · ·+ aitzt and fi(z) = ai0 + ai1z + · · ·+ aitz
t
where aik, aik ∈R Zq (0 ≤ k ≤ t). Each Pi broadcasts wik = gaik gaik mod p for
k = 0, 1, . . . , t.
2. Each Pi computes the pair(xij = fi(j) mod q, xij = fi(j) mod q
)for j =
43

2.6 Key Management
1, . . . , n, and sends (xij , xij) to Pj via a secure channel, reserving (xii, xii) for
itself.
3. On receiving (xji, xji), each Pi verifies it for j = 1, 2, . . . , n by checking that:
gxij gxij =t∏
k=0
(wik)jk mod p. (2.2)
If this check fails for an index j, Pi broadcasts a complaint against Pj .
4. If any Pi receives a complaint from Pj , it broadcasts the pair (xij , xij).
5. A PKG Pi becomes disqualified if:
• there are complaints against Pi from more than t parties; or
• the pair broadcast by Pi in step 4 does not satisfy equation (4.1).
The non-disqualified PKGs then form a set Q.
6. Each Pi computes its share as the following pair:(xi =
∑j∈Q
xji mod q, xi =∑j∈Q
xji mod q).
The master secret value x satisfies x =∑
i∈Q ai0 mod q, and is not available
to any party.
The extraction process for the corresponding public value y = gx mod p can be
performed as follows. Each Pi broadcasts Aik = gaik mod p (k = 0, 1, . . . , t) and
then every Pi verifies the broadcast values by checking whether
gxji =t∏
k=0
ikAik mod p.
If the above check fails for party Pi, then the other parties perform the re-construction
phase, i.e. Pi rebroadcasts the values xij , Aik, and the other parties verify them using
the information xij and wik (see [56, 57] for details). Each Pi from Q can compute
y =∏i∈QAi0 mod p. If we define the polynomial f(z) =
∑i∈Q fi(z) ∈ Zq[z], it is
easy to see that xi = f(i) (∈ Zq) for i ∈ Q, and thus x = f(0) =∑
i∈Q ai0 (∈ Zq) is
the master secret of the system.
44

2.7 Conclusions
2.7 Conclusions
We have introduced the cryptographic primitives and infrastructures used in this
thesis. We discuss some of them in greater detail in subsequent chapters.
45

Part I
Pervasive Computing: PersonalArea Networks
46

Chapter 3
Securing A Personal Area Network
Contents
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.2 Personal Area Networks . . . . . . . . . . . . . . . . . . . 48
3.2.1 A Personal Area Network . . . . . . . . . . . . . . . . . . . 48
3.2.2 Security framework of Personal Area Networks . . . . . . . 50
3.3 Existing Security Schemes . . . . . . . . . . . . . . . . . . 52
3.3.1 DH key agreement via wireless channels . . . . . . . . . . . 53
3.3.2 Personal PKIs . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
We review previous research security mechanisms designed for use in PANs, focus-
ing primarily on PAN security initialisation. After defining the notion of a PAN
and giving a PAN security architecture, we present two existing approaches to PAN
security initialisation.
3.1 Introduction
A Personal Area Network (PAN) is a small wireless network that covers only a personal
work space, e.g. an office or a meeting room. A PAN only includes those components
owned and controlled by a single user, and the components directly communicat-
ing with each other via a local interface such as Bluetooth or IrDA (Infrared Data
Association). Possible deployment scenarios for PANs include smart offices, smart
homes, conference halls, hospitals, public areas, etc. Due to the unique characteris-
tics of a PAN, we could take a different approach to that employed in other wireless
networks, such as using human interface or trust relations within a PAN, in order
to initialise the security contexts of the personal wireless devices.
47

3.2 Personal Area Networks
In this chapter we give a formal definition of a PAN, and introduce a PAN security
framework. We then discuss two different approaches to PAN security initialisation.
The first involves establishing a shared secret between pairs of PAN devices with the
active support of users. Since the PAN components are close to each other and there
is, in most cases, at least one human that controls the components, the necessary
security associations can be created with human assistance. The second approach
uses public key cryptography and involves defining a special device called a Personal
CA as part of a Personal PKI, which maintains the security context within a PAN.
3.2 Personal Area Networks
In this section we give a definition for a PAN, and describe a security framework for
a PAN.
3.2.1 A Personal Area Network
We first define what we mean by a PAN [53, 133].
Definition 3.1 (PAN) A PAN is a collection of fixed, portable, or moving com-
ponents within or entering a Personal Area, which form a Network through local
interfaces. A Personal Area is the space within a sphere around a person (stationary
or in motion), typically having a radius of about 10 metres.
We consider here PANs involving only wireless communications, following the IEEE
standard [133]; however, other authors (see, for example, Gehrmann and Nyberg
[53]) consider PANs using both wired and wireless communications. Wireless con-
nections are expected to be the commonly used means of communications within a
PAN, and, in fact, many PAN devices do not have a wired interface.
We also use the following PAN-specific terminology [53].
• Component (or device): A PAN consists of a collection of components. Each
component is an independent computing unit, and has processing capabili-
ties as well as digital memory. Possible PAN components include computers,
48

3.2 Personal Area Networks
personal digital assistants (PDAs), printers, microphones, headsets, sensors,
mobile phones, smartcards, etc.
• Service: A service is a communication or computing service offered by a com-
ponent either locally, i.e. through a user interface, or remotely to other compo-
nents. Each component maintains a list of services it offers, as well as policies
for access and discovery/advertisement.
• Application: An application is a process running on a component.
• User: A user physically controls and operates a PAN component, complying
with the policies configured in the component. The user of a component might
change, but, at any given time, each component has a single user.
• Owner: Each component has a single owner. By specifying an appropriate
policy, the component owner may allow users other than the owner to use the
component.
• Local interface: Each component has at least one local communication interface
which is suitable for direct connection to other PAN components. A direct con-
nection between every pair of components is not required, but each component
should be able to connect to at least one other PAN component.
• Global network interface: A component may have a global network interface
such as a connection to an IP-backbone or a mobile network.
• Security policy: Each component has a security policy. There are two main
types of security policy: local security policy and remote security policy. A local
security policy specifies which resources of a component a user may access,
and also determines whether or not authorisation for users is required. A
remote security policy determines how to access a component, i.e. it specifies
the relation between the service the component offers and the names of the
PAN components that utilise the service.
In subsequent discussions we often assume that the owner and user of a PAN com-
ponent are the same, but this is not necessarily always the case.
49

3.2 Personal Area Networks
3.2.2 Security framework of Personal Area Networks
We next consider how the security context of personal wireless devices in a PAN
can be initialised. We describe a PAN security architecture, following Gehrmann
and Nyberg [53]. Since the administrator of a PAN may be a non-expert user,
the security initialisation process should be simple and user-friendly. That is, the
number and complexity of interactions should be minimised. We use the Dolev-
Yao threat model [39] to characterise potential adversaries. We assume that the
adversary controls the communication channels; thus an attacker can intercept and
synthesise any message, and is only limited by the constraints of the cryptographic
methods used. We define a security initialisation procedure in a PAN to involve the
following three steps.
• Step 1: Establish an initial secure channel.
• Step 2: Create a security association, i.e. configure cryptographic parameters
for autonomous secure PAN connection establishment.
• Step 3: Configure (default) security policies.
We next discuss each of these three steps in greater detail.
Initial secure channel establishment
In order to create a security association between two PAN components, an initial
secure channel must first be established. Using this initial secure channel, one PAN
component can be sure that it is exchanging information with the intended com-
ponents and that the communication is not being intercepted or modified by any
third party. The provision of an initial secure channel is thus particularly important.
If tampering or eavesdropping is possible during this process, then the security of
all subsequent communications could be compromised. Since wireless interfaces are
potentially insecure, an alternative secure communications channel is required. A
direct wired connection between two components, e.g. using USB or Ethernet, could
provide sufficient protection, but many PAN devices do not have a wired interface.
However, in a PAN the components are close to each other and, in most cases, there
50

3.2 Personal Area Networks
is at least one human that controls the components. We can thus use the human as
a secure channel. That is, a human can be asked to read, check, and/or enter values
into the PAN components.
Another way of establishing a secure channel arises if a component has an optical
reader, e.g. a barcode reader, that could be used to input information to the com-
ponent from a printed slip. In such a case, this reader could be used by a human
administrator to load a public key, a hash of a public key, or a public key certificate
into a component.
Security association creation
The security functions in a PAN, such as those necessary for communication security
or access control, require cryptographic parameters, typically cryptographic keys, to
be established in the PAN components. These parameters include secret keys for
secret key cryptosystems and/or public/private key pairs for public key cryptosys-
tems. Such shared secrets and/or trusted public keys form part of what is known as
a security association. With a security association in place, authentication of other
PAN devices becomes possible. Furthermore, the integrity and/or confidentiality of
the information exchanged over an insecure channel between the components can be
protected.
Security policy configuration
The configuration of security policy must be based on trust relationships between
PAN components. It could cover the case where a new PAN device joins the network,
or where devices from other PANs try to use a service. However, we do not discuss
this topic further here, since the main focus of this chapter is the establishment of
cryptographic keys in a PAN. A detailed discussion of PAN trust models and the
configuration of security policies is given by Gehrmann and Nyberg [53].
51

3.3 Existing Security Schemes
3.3 Existing Security Schemes
In recent years, a wide variety of work has been performed on developing techniques
for security initialisation in decentralised networks. We describe two types of widely
studied security schemes, i.e. key establishment in peer-to-peer networks over a radio
link [11, 26, 41, 47, 52, 53, 92, 98, 131, 132] and key management based on public
key techniques [54, 104].
The first class of solutions involves establishing a shared secret between two
PAN devices with the active involvement of users. Since the PAN components are
close to each other and there is, in most cases, at least one human that controls
the components, the necessary security associations can be created with human
assistance.
For example, if the components possess human interfaces such as a key pad and/or
a display, a human operator could be asked to copy data from one device to the
other, compare the outputs of the two devices, or enter the same data into both
devices. A variety of such solutions exist, with varying requirements on the display
and input capabilities of the devices [26, 41, 52, 53, 92, 98].
Location limited channels can also be used to securely exchange secret information
[11, 47, 132]. That is, security parameters can be exchanged using relatively secure
channels, such as Infrared or NFC (Near Field Communication), prior to or during
performing key establishment protocols using insecure channels. Since such channels
have short communication ranges (typically less than 10cm), users need to locate
two devices in close proximity to create a security association.
The second class of solutions, using public key cryptography, involve defining a
special device called a Personal CA forming part of a Personal PKI [54, 104], respon-
sible for maintaining a security context within a PAN. A PAN user managing its
own local network environment will gain few benefits from employing a centralised
CA, and the user may not want, for privacy reasons, to delegate the CA operation
to a party outside its personal environment. Thus, a more localised PKI can provide
a conventional means of creating security associations in a PAN.
52

3.3 Existing Security Schemes
3.3.1 DH key agreement via wireless channels
The Diffie-Hellman (DH) key agreement protocol [37] provides an efficient way of
creating a security association between two PAN devices. We start by briefly re-
viewing this protocol. Two parties first generate common parameters using a group-
generating algorithm G, as given in definition 2.3. The first party generates x ∈R Zqand computes gx (∈ G). The second party generates y ∈R Zq and computes gy (∈ G).
The two parties exchange the public parameters gx and gy, and calculate the shared
secret key as gxy = (gx)y = (gy)x. Assuming that the DH problem is hard relative to
G, the DH key agreement protocol is known to be secure against a passive adversary
[102].
However, the DH key agreement protocol is vulnerable to an active attack, known
as a man-in-the-middle attack. That is, when two devices attempt to pair with
each other, an adversary device connects to the two devices and relays information
between them, giving the illusion that they are directly connected. In the above
protocol, an adversary generates z ∈R Zq, and exchanges gz with the two devices;
as a result of it establishes separate secret keys, gxz and gyz, with these two devices.
The adversary can then eavesdrop on communications between the two devices, and
is also able to insert or modify information on the connection.
Security using human interface
A variety of approaches have been proposed for verifying the integrity of Diffie-
Hellman (DH) public parameters exchanged between two devices using a human
interface [26, 41, 52, 53, 92, 98].
Maher and Windham [98] present several such methods, one of which involves com-
paring the truncated (four hexadecimal digit) hash values of DH public parameters
in each device. Inspired by the work of Maher and Windham [98], Larsson [92]
proposed the use of a temporary secret shared between the two users. Dohrmann
and Ellison [41] suggest converting hash values to readable words or graphical repre-
sentations. Comparing such words, however, could take as much as 24 seconds, and
potentially limited PAN devices may not have the sophisticated displays necessary
to support such graphical representation.
53

3.3 Existing Security Schemes
Gehrmann, Nyberg, and Mitchell [52, 53] have proposed a series of schemes which
prevent man-in-the-middle attacks requiring the users to type in or compare rela-
tively short strings of digits. These schemes, called the MANA protocols, are designed
to enable wireless devices to authenticate one another via an insecure wireless chan-
nel with the aid of a manual transfer of data between the devices. The manual
transfer refers to one of the following procedures: copying data output from one
device into the other device; comparing the output of two devices; or, entering the
same data into both devices. The MANA protocols have been standardised [46].
Security using location limited channels
The concept of location limited channels has also been proposed to protect against
man-in-the-middle attack on the DH key agreement protocol [11, 47, 132]. Stajano
and Anderson [132] discuss the use of a physical contact as a location limited channel
for transmitting keying materials in plaintext. Balfanz et al. [11] suggest using a
location limited channel, e.g. an infrared link, to exchange pre-authentication data,
and, once such data has been transferred, users switch to a common radio channel
and run a secure key exchange protocol.
Example scheme: Bluetooth SSP
The Bluetooth Alliance Core Specification V2.1 + EDR [130, 131] specifies a secure
pairing procedure called Secure Simple Pairing (SSP), which provides four models
for verifying the integrity of DH public parameters exchanged between two devices.
The Numeric Comparison model makes use of a human interface, and the Out of Band
model uses NFC as a location-limited channel. We next discuss these two models in
greater detail.
The Numeric Comparison model is designed for scenarios, in which both devices have
a six-digit numeric display and an input method that can be used to indicate “yes”
or “no”. A six-digit number is displayed on the displays of both devices, and the user
is asked whether the numbers are the same. If the user enters “yes” on both devices,
the pairing is successful. This process serves two purposes. First, it confirms to
the user that the correct devices are connected with each other; we note that many
54

3.3 Existing Security Schemes
Handover Protocol
Connection Handover Page 5
2 Handover Protocol
2.1 Introduction
This specification defines NDEF messages that enable a Handover Requester to negotiate an
alternative communication carrier with a Handover Selector over the NFC link. As a special case,
it also enables a Handover Requester to retrieve the possible alternative communication carrier(s)
from an NFC Forum Tag, but this has some limitations due to the static nature of information
stored on a Tag. The first case is called “Negotiated Handover” and is described in section 2.2,
while the second case is called “Static Handover” and is described in section 2.3.
The Handover Requester, in the scope of this specification, is defined to be the device that
initiates the handover operation. The Handover Selector device is defined to be the device that is
initially passive and that responds to the Handover Requester. The Handover Selector does not
start any activity such as generating a handover message.
2.2 Negotiated Handover
Negotiated Handover allows two devices to negotiate one or more alternative carriers for further
data exchange. The exemplary use case shown in Figure 1 illustrates how a Handover Requester
uses the embedded NFC Forum Device to exchange connection handover information with the
Handover Selector to finally select a matching alternative carrier. In the example, the application
running on the Handover Requester first announces its alternative carriers (Wi-Fi and Bluetooth
wireless technology) to the Handover Selector, and then receives a carrier selection (Bluetooth
wireless technology) as the only choice and finally performs Bluetooth pairing and data
exchange.
Handover Requester Handover Selector
NFC Forum
Device
Alternative Carrier
(Wi-Fi)
Alternative Carrier
(Bluetooth)
Handover Request ( Wi-Fi | Bluetooth )
NFC Forum
Device
Alternative Carrier
(Wi-Fi)
Alternative Carrier
(Bluetooth)
Data Exchange over Bluetooth
Host Host
Handover Select ( Bluetooth )
Figure 1: Negotiated Handover with Single Selection
If the Handover Selector supports multiple alternative carriers, it might return more than one
selection (see Figure 2). In this case, the Handover Requester is free to choose any of the returned
carriers or even try to simultaneously connect to more than one alternative carrier. However, if
the Handover Requester attempts to choose one of the selected carriers, it should interpret the
order that they are listed in the Handover Select message as a preference indication. In the
example of Figure 2, the Handover Requester has decided against the Handover Selector’s
preference for Wi-Fi and has used Bluetooth wireless technology instead.
Figure 3.1: Example of Connection Handover [47]
devices do not have unique names. Second, it provides protection against man-in-
the-middle attacks. This model looks similar to the PIN entry model adopted in
the Bluetooth Core Specification V2.0 + EDR and in earlier versions. However, the
six-digit number in SSP is not used as an input to the security algorithm; instead it
forms a part of output of the security algorithm.
The Out of Band (OOB) association model is primarily designed for scenarios in
which an OOB channel is used to both discover the correct device and to securely1
exchange (or securely transfer) cryptographic values. A good example of OOB
channel is provided by NFC, where a user(s) places a pair of devices so that they
touch each other; the devices then exchange cryptographic information as well as
discovery information such as Bluetooth addresses. One of the devices uses the
received Bluetooth address to establish a connection with the other device, and the
cryptographic information is used during a subsequent authentication process. Once
the devices have completed their exchange, the user is asked if the device should pair
with the other device; if the user enters “yes”, the pairing procedure is successful.
The above type is standardised in the Connection Handover Specification [47]. SSP is
used to verify the integrity of previously exchanged DH public parameters, and the
Connection Handover exchanges necessary secret information via an NFC channel
prior to a DH exchange using a Bluetooth or Wi-Fi channel. That is, the information
included in the Handover Request/Response is used to prevent a man-in-the-middle
attack on subsequent DH exchanges (see Figure 3.1). More specifically, assume that
two devices are equipped with NFC, Bluetooth, and Wi-Fi communication capa-
bilities. The ‘Handover Requester’ device first sends a Handover Request message,
1The OOB channels are assumed to be secure against passive and active attacks.
55

3.3 Existing Security Schemes
which includes information about the device’s Wi-Fi and Bluetooth capabilities. The
‘Handover Selector’ device then replies with a Handover Select message, which in-
dicates that it will use Bluetooth or Wi-Fi in subsequent communications. The
Handover Request/Select messages include cryptographic secrets as well as the
required configuration parameters.
3.3.2 Personal PKIs
In a conventional public key infrastructure (PKI), a certification authority (CA) issues
a public key certificate. Prior to issuing such a certificate CA is responsible for
checking that
• the user to which certificate is issued has the identity that is specified in the
certificate; and
• the public key to be included in a certificate corresponds to a private key that
the specified certificate subject possesses.
Operation and use of a large scale CA, however, has significant implementation
issues.
• It is costly to implement and maintain a secure certification process for large
numbers of users. Maintenance can be particularly problematic, especially if
it is necessary to generate and distribute frequently updated certificate revo-
cation lists (CRLs) containing the serial numbers of a large number of revoked
certificates.
• A user managing its own local network environment, such as a PAN, will gain
few benefits from employing a centralised CA, and the user may not want, for
privacy reasons, to delegate the CA operation to a party outside its personal
environment [54].
Nevertheless, a more localised PKI can provide an effective means of creating security
associations in a PAN. Gehrmann et al. [54] and Mitchell et al. [104] adapt the notion
of a PKI to a local PAN environment, introducing a concept called the personal PKI,
56

3.3 Existing Security Schemes
and give functional and security requirements for such a PKI [104]. In a personal
PKI, one of the devices in a PAN acts as a personal CA that issues certificates for
all PAN components. As with any other PKI, all PAN components share the public
key of the personal CA, and use certificates issued by the personal CA as a basis for
secure session key establishment and authentication between PAN components.
Security initialisation using a personal CA
We now briefly describe the operational processes of a personal PKI [54]. First,
the personal CA must be initialised, which involves generating a signature key pair.
Other PAN components can be initialised using the following procedure [104].
1. A PAN device generates any necessary key pairs. It also imports authentication
material from its owner, which may require a modest number of keystrokes by
the user.
2. The PAN device is informed of which other device is the personal CA, or
discovers this device by communicating across the PAN.
3. The root public key of the personal CA is passed to the PAN device. This
must be done in such a way that the PAN device can verify the integrity and
origin of the CA public key.
4. The PAN device provides its public key to the personal CA. This must be done
in such a way that the personal CA can verify the integrity and origin of the
public key.
5. The personal CA generates a public key certificate for the mobile device.
6. The newly created public key certificate is passed to the PAN device.
As described above, during initialisation we need a means of verifying the integrity
and origin of the public keys exchanged between the CA and the PAN component.
That is, we require a method for two devices to exchange public keys in an authen-
ticated manner. The Bluetooth SSP, described in Section 3.3.1, could, for example,
be used for this purpose.
57

3.4 Conclusions
Public key status management
Once the PAN devices have been initialised, there is a need for ongoing management
of key pairs and certificates. Three main management functions need to be supported
in a PAN [54, 104].
• Certificate and key pair update, i.e. methods to be used when a PAN device
wishes to use a new key pair or when the certificate for a public key has
expired.
• Key status management, i.e. disseminating information regarding revoked pub-
lic keys across the PAN.
• Trust management, i.e. managing a root public key update or managing the
possible replacement of the personal CA.
We do not discuss key and certificate management issues for a personal PKI further
here; more detailed discussions appear in Gehrmann et al. [54, 104].
3.4 Conclusions
We have investigated security initialisation schemes for PANs, focusing primarily
on the security initialisation process. Personal wireless devices, however, are more
likely to communicate with devices outside the PAN, because of the ubiquity of
such devices and the convergence of communication technology. Inter-PAN secure
communications poses significant additional requirements on the key management
procedures. In the next chapter we propose a novel security initialisation scheme
for use both within and between PANs.
58

Chapter 4
Securing Inter-PANs Communications
Contents
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.1.1 Interconnected Personal Area Networks . . . . . . . . . . . 60
4.1.2 Key management in iPANs . . . . . . . . . . . . . . . . . . 63
4.1.3 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.1.4 Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.2 Security Initialisation for iPANs . . . . . . . . . . . . . . 66
4.2.1 System models and design goals . . . . . . . . . . . . . . . 66
4.2.2 Proposed scheme . . . . . . . . . . . . . . . . . . . . . . . . 68
4.2.3 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.3 Further Discussion . . . . . . . . . . . . . . . . . . . . . . . 74
4.3.1 Use of pre-distributed keys . . . . . . . . . . . . . . . . . . 74
4.3.2 Revocation and update . . . . . . . . . . . . . . . . . . . . 75
4.3.3 Other security issues . . . . . . . . . . . . . . . . . . . . . . 78
4.3.4 Generalisation of the proposed scheme . . . . . . . . . . . . 79
4.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
In this chapter we propose a novel security initialisation scheme for use both within
and between PANs, and show that the proposed scheme achieves desirable security
and efficiency properties making use of the unique characteristics of PANs.
4.1 Introduction
Although a PAN may act as a stand-alone network, PANs are likely to be intercon-
nected to share information or services. We call such interconnected PANs iPANs.
Network nodes exchange routing information in order to establish routes between
nodes. Such information could be a target for an adversary who may inject erroneous
59

4.1 Introduction
routing information in order to disrupt communications in iPANs. Cryptographic
schemes could be used to protect routing information as well as data traffics, but
they require the provision of cryptographic keys, i.e. security initialisation or key
pre-distribution process is required.
In this section we first describe the interconnected Personal Area Networks, iPANs.
We then investigate the candidates for key management schemes, which are po-
tentially suitable for supporting security in iPANs. After discussing related work,
we discuss the advantages of the proposed scheme compared to the conventional
approaches.
4.1.1 Interconnected Personal Area Networks
We next describe how PAN devices communicate, and also how communications in
iPANs is likely to become possible. Bluetooth technologies are potentially a key en-
abler of iPANs, although iPANs could also use a variety of other access technologies,
e.g. wireless LAN (WLAN) interfaces within a PAN, and the IP-backbone (Internet)
or a GPRS/UMTS mobile network between PANs.
Two or more piconets can be connected, forming a scatternet (Figure 4.1), through
a device which is a member of both piconet. A device may be a slave in multiple
piconets, but can be a master in only one piconet. A scatternet can then support
inter-PAN communications. A PAN user may also wish to access a device in another
PAN, where this device is not accessible via a direct connection (e.g. via Bluetooth).
Since a PAN can be IP-based, a PAN user can connect to other PANs via the
IP-backbone network using a LAN access point or GPRS/UMTS mobile network.
Figure 4.2 shows two scenarios of this type, where PANs are connected to an IP-
backbone. The first figure of Figure 4.2 shows the interconnected PANs, where one
PAN serves as a LAN access point for the other two PANs. In the other figure
in Figure 4.2, one PAN serves as an access point to the IP-backbone via a mobile
network.
We now discuss features which the two classes of network have in common.
60
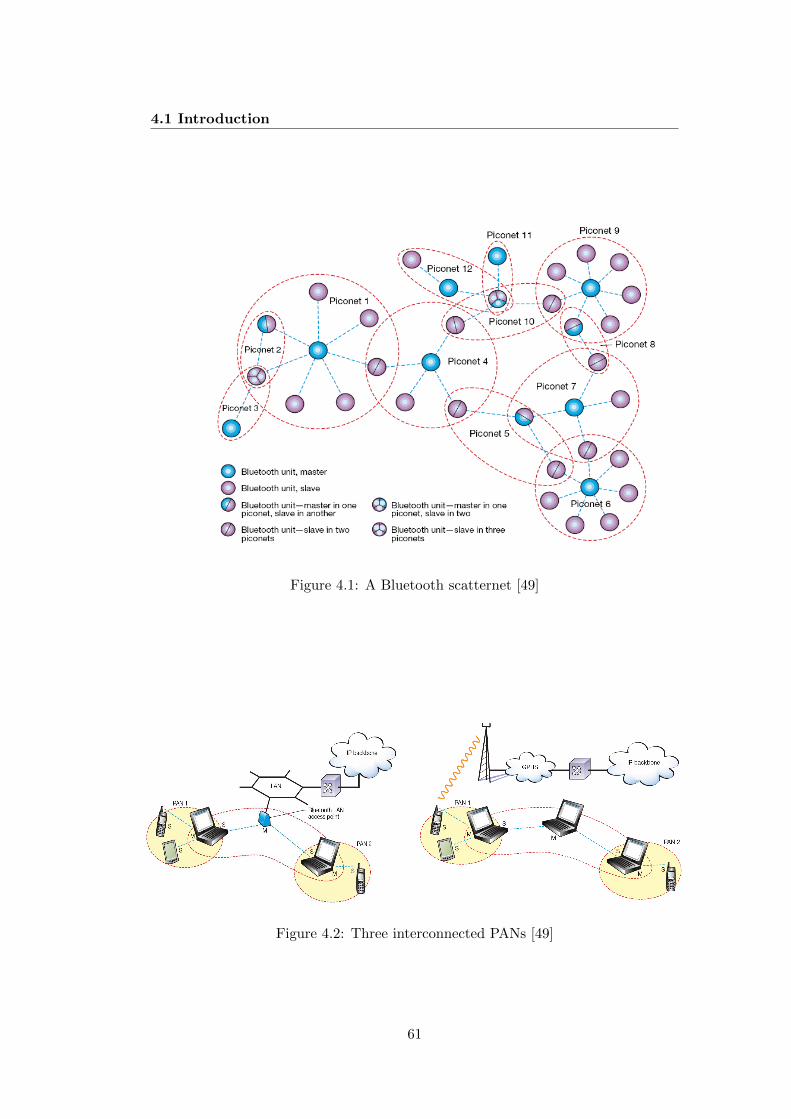
4.1 Introduction
Figure 4.1: A Bluetooth scatternet [49]
Figure 4.2: Three interconnected PANs [49]
61

4.1 Introduction
• Shared physical medium: The wireless communication medium is accessible by
any party with adequate equipment. Adversary is thus able to eavesdrop on
communications and/or modify the transmitted messages.
• Poor physical security: Since network devices are not held in a secure location,
such devices could be easily compromised, e.g. by being stolen or lost. Thus
the insider adversary, who compromises one or more network devices and then
performs attacks using the compromised devices, must be addressed.
• Limited resources: Wireless devices typically have limited computational, mem-
ory, and energy resources, for reasons of cost and portability. Limited compu-
tational capabilities may mean that a device is unable to perform public key
crypto-algorithms. Limited battery power may restrict the energy available
for communications, restricting to the available bandwidth and transmission
range. Security protocols should thus be optimised to minimise use of network
resources, and should also be able to cope with network node failures arising
from battery exhaustion.
• Network topology: Network nodes are potentially mobile and wireless commu-
nication could be error-prone. These network features result in a dynamic
and weakly connected topology. Security protocols should be designed so that
security services remain available even in the presence of dynamic changes in
network topology.
• Self-organisation: Network cannot rely on any form of central administrator,
e.g. an on-line or off-line TTP. This is because such a cental node may not be
accessible by all network nodes, and it could be a target of attack as a single
point of failure [145]. This means that end users are obliged to participate in
setting up security associations.
Apart from the above, iPANs may also have the following characteristics which differ
from those of ad hoc networks.
• Network infrastructure: Ad hoc networks are designed to work in the absence
of a fixed infrastructure, such as an IP-backbone or a mobile network, and all
network nodes must be able to function autonomously. For example, because
of the limited communications range of a single node, data transmission is
62

4.1 Introduction
achieved in a multi-hop fashion, and each node serves as both a host and a
router. This differs from the situation in iPANs, where we assume that external
communications infrastructures, e.g. an IP-backbone or a mobile network, are
likely to be available. Nevertheless, ad hoc networks which are integrated with
conventional fixed networks, such as hybrid ad hoc networks [122] or wireless
mesh networks [1, 22], have been considered. The network infrastructure of
such networks can be regarded as similar to that of iPANs.
• Trust relationships: Unlike in ad hoc networks, all the devices within a PAN
are used and controlled by a single user. Using this fact may enable both
communication and computation efficiency to be significantly increased.
• Hierarchical structure: Ad hoc network protocols often distribute the respon-
sibility of providing network functionality equally across the set of nodes
[103, 145]. In reality, however, networks consist of devices with different com-
putational and communications capabilities. It is thus natural to assign devices
varying roles in providing security services.
As we discussed above, the iPANs share a variety of common features with ad hoc
networks. Thus, key management schemes proposed for use in ad hoc networks
could also be used in iPANs. However, there exist also differences between ad hoc
networks and iPANs, which could make such an approach problematic.
4.1.2 Key management in iPANs
Symmetric cryptography is relatively straightforward to implement in resource-
constrained devices, and necessary shared secrets can be established between any
two devices in a variety of ways, as described in section 3.3. The use of public key
cryptography (PKC), however, is more appropriate for an open environment, such
as iPANs, where parties who have never previously interacted wish to communicate
securely as described in Section 2.6.2. The use of a public key infrastructure (PKI)
(see Section 2.6.3) enables end users to obtain verified public keys, but the identity-
based cryptography (IBC) [18, 31, 127] has potential advantages over a conventional
PKI.
The concept of identity-based cryptography (IBC) was introduced by Shamir [127]
63

4.1 Introduction
in 1984.1 Instead of using a random public/private key pair, Shamir proposed us-
ing a user’s identity, e.g. an email address or IP-address, as that user’s public key
(hence avoiding the need of public key certificate). Such public keys are thus self-
authenticating, and certificates are not required. Furthermore, since identities such
as IP and/or MAC addresses can be propagated in transmitted messages. There is
thus no need to generate and distribute public keys across the network.
One fundamental requirement for an IBC is that it should be infeasible to compute
the private key from the public identity without access to certain global trapdoor
information. For this reason, IBC requires an unconditionally trusted TTP, called
a trusted authority (TA), which computes a user’s private key using a private key
generator (PKG) with the trapdoor information as input. As a means of reducing
the reliance on a single PKG, Boneh and Franklin [18] introduce the concept of a
distributed PKG (DPKG), where private key generation involves multiple PKGs.
The use of a DPKG is desirable in iPANs for the following reasons. A single PKG
could be a point of vulnerability in the network, since iPANs nodes are likely be
vulnerable to various (physical) attacks. Some network nodes may not be able to
communicate with a single PKG because of the limited communications capacity
of personal wireless devices. Furthermore, PAN users are unlikely to delegate secu-
rity operations to an external trusted party for privacy reasons. We thus propose
that the participating PAN users could share key management functionality among
themselves. More specifically, a key management service for iPANs can be realised
by distributing trust to a set of nodes from each PAN.
4.1.3 Related work
Zhou and Haas [145] propose key management scheme in ad hoc networks using
certificates. They propose that a set of network nodes form a distributed CA and
jointly perform key management service. The concept of a personal PKI was intro-
duced in section 3.3.2; this involves one of the PAN devices acting as a personal CA,
which issues and distributes certificates for the other PAN devices. In the setting of
1Although Shamir [127] showed that an identity-based signature (IBS) scheme can be constructedusing the RSA [117] function, he was not able to construct an identity-based encryption (IBE) scheme.Much more recently, in 2001, Boneh and Franklin [18] introduced the first practical and secure IBEscheme, based on Weil parings.
64

4.1 Introduction
iPANs, Personal CAs, one from each PAN, can form a distributed CA, and jointly
sign certificates for devices, using the technique described by Zhou and Haas [145].
The certificates can be transferred from each Personal CA to the PAN devices within
the PAN, using previously established secure channels.
Khalili, Katz, and Arbaugh [87] propose self-organised key pre-distribution schemes
using identity-based cryptography, where all participating network nodes form a
distributed PKG. They assume that there is no prior shared keying material or
trust/security association between PKGs, and describe how to establish these at the
time of network formation using the verifiable secret sharing schemes which does
not involve a trusted third party. However, such a secret sharing scheme known to
the author require secure channels between all network nodes for the distribution of
master secret shares. We also note that they do not address the issue of protecting
the confidentiality and integrity of the private key shares when transferred from
the PKGs to the mobile devices. Providing such a secure channel is a non-trivial
problem.
To address this issue, Deng and Agrawal [34] propose that each PKG encrypts the
share using a requesting mobile device’s temporary public key. Since this temporary
public key is not certified, the adversary can spoof the public key of the requesting
device, and then recover the distributed private key by combining decrypted private
key shares. Both the Deng and Agrawal [34] and the Khalili et al. [87] schemes
require the existence of secure channels between every pair of devices for secure key
pre-distribution, which limits their practicality.
Liu et al. [144] separate non-PKG devices from PKG devices, which together form a
distributed PKG. This scheme, however, requires substantial number of initial secure
channels and only devices with public key functionality can use the key management
service.
4.1.4 Contribution
We propose a security initialisation scheme for use both within and between PANs,
making use of the unique characteristics of iPANs. The proposed scheme for iPANs
has the following distinctive advantages over existing schemes.
65

4.2 Security Initialisation for iPANs
• The proposed scheme greatly reduces the computation and communication
burdens on resource-constrained devices. Unlike identity-based key manage-
ment schemes previously proposed for use in ad hoc networks [34, 87, 144],
which only support devices which can perform public key crypto-algorithms,
the proposed scheme allows resource-constrained devices which only implement
secret key crypto-algorithms to make use of the key management service.
• Previously proposed a distributed key management schemes for ad hoc net-
works [34, 87, 144, 145] assume a priori secure channels between all (or a
substantial number of) participating the nodes, which reduces their applica-
bility. The proposed scheme only requires the existence of a small number of
such channels, relative to the network size.2
In the subsequent sections we describe a security initialisation scheme designed for
iPANs.
4.2 Security Initialisation for iPANs
In this section we give a formal description on the proposed security initialisation
scheme for iPANs, and provide security and efficiency analysis.
4.2.1 System models and design goals
The network scenario involves a limited number, say n, of users with multiple wireless
personal devices who wish to form iPANs to share important information. In this
section we define the system model and the capabilities of a potential adversary, and
specify our design goals.
System definition
We assume that the system, i.e. iPANs, consists of n Personal Area Networks
(PANs), interconnected using scatternets, the IP-backbone, and/or mobile networks,
2See Table 4.1 for the details.
66

4.2 Security Initialisation for iPANs
as discussed in section 4.1.1. Each device has a unique identity, e.g. as provided by
an IP-address and/or a MAC-address.
One3 device from each PAN acts as a PKG for the devices within its PAN. It is rea-
sonable to assume that each device in a PAN trust its PKG, since all devices within
a PAN are under the control of a single user. The following minimum requirements
must be satisfied for such a PKG.
• It should be computationally more powerful than other devices in the PAN.
It must be capable of performing public key cryptography, while other PAN
devices are assumed to be capable of performing secret key cryptography.
• It should have secure communication channels to all devices in its PAN. Such
secure channels can be established using several schemes described in section
3.3.
• It should have a communication channel to the PKGs of at least dn/2e of the
other PANs.
Such a set of n PKGs form a distributed private key generator (DPKG).
Adversary
Since the objective is devising a secure key management scheme, we only consider
attacks against the key management scheme itself. We consider two kinds of attacks;
compromise attacks and disruption attacks. If an adversary compromises a device,
it has complete control over it, including learning its secret information and being
able to change its intended behaviour. An adversary could also disrupt the system
by making the compromised device affect the intended communication process.
We assume that an adversary cannot compromise an unlimited number of nodes,
so that honest devices are always in the majority. Specifically, we assume that an
adversary can corrupt up to t of the n PKG devices for any value of t < n/2. We
assume that the adversarial computational power is a probabilistic polynomial time.
Our adversary is static, i.e. it chooses the corrupted network nodes at the beginning
of the protocol.
3More than one device may act as PKGs within a PAN, as discussed in section 4.3.3.
67

4.2 Security Initialisation for iPANs
Design goals
Given the above system model and adversary types, we propose a security initiali-
sation scheme, with the following security and efficiency requirements.
• Secrecy: The system master secret should be not disclosed to any party, and
any information regarding the private key of a PAN device should not be
learned by any party except for the PKG device within the same PAN.
• Correctness: Each PAN device should be equipped with the correct private key
corresponding to its identifier, given the system parameter and master secret.
• Efficiency: The scheme should be efficient in terms of storage, computation,
and communication, since PAN devices are often resource-constrained. In
many cases, a wireless personal devices will be battery-operated, and devices
such as RFID tags will even have no battery.
• Minimal initial secure channels: A priori initial secure channels are often as-
sumed in key management schemes for ad hoc networks. Provision of such
channels, however, is never simple in an ad hoc network, and, in some cases,
a manual process is the only option. For practicality, the number of initial
secure channels relative to the number of network nodes should be minimised.
In the subsequent sections we propose a security initailisation scheme for iPANs,
which has been designed to meet the above requirements.
4.2.2 Proposed scheme
The security intialisation process involves distributing a master secret amongst n
PKGs, and provides each network node with a public/private key pair. An adversary
is assumed to be able to compromise at most t PKGs during network setup (i.e.
during the security initialisation process). It is important to note that all secret
sharing schemes require some kind of a priori security association, i.e. an initial
secure channel, between the participating parties, and the proposed scheme requires
n(n− 1)/2 initial secure channels (between all the n PKGs).
68

4.2 Security Initialisation for iPANs
System parameters
The group G1 of order q has a generator P , and the group G2 is of order q. The
bilinear map e : G1 × G1 → G2 is the modified Weil pairing [18]. We also define a
hash function h : {0, 1}∗ → G∗1, as defined by Boneh and Franklin [18]. Since it is
difficult to construct hash functions mapping directly from {0, 1}∗ to G∗1, Boneh and
Franklin [18] show that it suffices to have a hash function h : {0, 1}∗ → B (⊂ {0, 1}∗)and a deterministic encoding function to map from B to G∗1.
The parameters t and n need to be chosen to achieve an appropriate tradeoff between
security and robustness. In particular, for a fixed n, a larger t means that adversaries
need to compromise more PKGs (i.e. the system is more secure), but they only need
to disrupt fewer PKGs (i.e. the system is less robust). It has been suggested to set
t = bn2 c [36, 128].
Distributing master secret
A set of n PKGs, Pi (1 ≤ i ≤ n), jointly generate a master secret and distribute the
shares amongst the set using the Gennaro et al.’s scheme [56] (described in Section
2.6.4).4
1. Each Pi (1 ≤ i ≤ n) chooses two polynomials fi(z), fi(z) ∈ Zq[z] of degree t:
fi(z) = ai0 + ai1z + · · ·+ aitzt and fi(z) = ai0 + ai1z + · · ·+ aitz
t
where aik, aik ∈R Zq (0 ≤ k ≤ t). Each Pi broadcastsWik = aikP+aikP (∈ G1)
for k = 0, 1, . . . , t, where P (= lP ∈ G1 for some l ∈ Z∗q) and l are not known
to any Pi.
2. Each Pi computes the pair(sij = fi(j) mod q, sij = fi(j) mod q
)for j =
1, . . . , n, and sends (sij , sij) to Pj via a secure channel, reserving (sii, sii) for
itself.
4We use Gennaro et al’s scheme to generate a master secret for the distributed private keygenerator (DPKG) as suggested by Boneh and Franklin [18]. When Gennaro et al’s scheme is fullyadopted, i.e. the public output is also generated (see Section 2.6.4), such a key pair can be used forthe threshold cryptosystems for PKG devices [56].
69

4.2 Security Initialisation for iPANs
3. On receiving (sji, sji), each Pi verifies it for j = 1, 2, . . . , n by checking that:
sjiP + sjiP =t∑
k=0
ikWik (∈ G1). (4.1)
If this check fails for an index j, Pi broadcasts a complaint against Pj .
4. If any Pi receives a complaint from Pj , it broadcasts the pair (sij , sij).
5. A PKG Pi becomes disqualified if:
• there are complaints against Pi from more than t parties; or
• the pair broadcast by Pi in step 4 does not satisfy equation (4.1).
The non-disqualified PKGs then form a set Q.
6. Each Pi computes its share as the following pair:(si =
∑j∈Q
sji mod q, si =∑j∈Q
sji mod q).
The master secret value s satisfies s =∑
i∈Q ai0 mod q, and is not available to any
party. If we define the polynomial f(z) =∑
i∈Q fi(z) ∈ Zq[z], it is easy to see that
si = f(i) (∈ Zq) for i ∈ Q, and thus s = f(0) =∑
i∈Q ai0 (∈ Zq) is the master secret
of the system. Any disqualified PKG, i.e. any PKG Pj such that j /∈ Q, is excluded
from use of the key management service along with the PAN that includes Pj .
Private key extraction and secure transfer
Once the master secret is shared between the n PKGs, they can jointly generate the
private keys for iPANs network nodes.
Any set of at least t+1 PKGs can jointly perform private key extraction. We denote
by Did the PAN device with identifier id ∈ {0, 1}∗. A PKG in the same PAN as Did,
denoted by P, can extract the private key for Did using the following procedure.
1. Did sends P its identifier id along with a private key extraction request, together
with any information required by the key issuance policy.
70

4.2 Security Initialisation for iPANs
Distributed Private Key Generator
PAN1
PKG2......
PKG3 PKGn
PAN2 PAN3 PANn
denotes the PKG device in each PAN. Such n PKGs form the Distributed Private KeyA node Generator. A PAN device with an identifier ID, denoted by
PKG1
1. private key
3. securely transfer private keycorresponding to ID
request for identifier ID
ID
2. jointly extract the privatekey
, requests a private key extraction to
the PKG3 wihtin its PAN. The PKG3 jointly extracts the private key with other PKGs, and finally securely transfers it to .
Figure 4.3: A distributed private key generator (DPKG)
2. P relays the request information to t (or more5) other PKGs: P1,P2,. . . ,Pt,say.
3. Each Pi (1 ≤ i ≤ t) replies with a private key share d(i)id = siQid (∈ G1) via a
secure channel, where Qid = h(ID) and ID = id || expiry-date. Assuming that
s0 is P’s share of the master secret, P also computes the share d(0)id = s0Qid.
4. On receiving t private key shares d(i)id (1 ≤ i ≤ t), P computes Did’s private
key as did =∑t
k=0 λisiQid (∈ G1), where the λi’s are the appropriate Lagrange
coefficients for the polynomial f(z) [19].
It is straightforward to see that P is able to compute its private key with the help
of t other PKGs. Once a private key has been computed by P, it must be securely
transferred to the requesting PAN device Did. This secure channel must provide data
origin authentication as well as confidentiality. Such a channel can be established
using Bluetooth SSP or the MANA protocols as described in section 3.3.
5Bearing in mind the error-prone nature of wireless links, sending the request information togreater than t other PKGs will reduce the risk of P not receiving enough private key shares.
71

4.2 Security Initialisation for iPANs
4.2.3 Analysis
We give an analysis on how the security initialisation scheme satisfies the design
goals, i.e. secrecy, correctness, efficiency, and minimal initial secure channels.
Secrecy and correctness
The master secret distribution makes use of the Gennaro et al.’s scheme [56] de-
scribed in Section 2.6.4. The Gennaro et al. [56] prove that their scheme satisfies
the followings: (i) all subset of t+ 1 master secret shares provided by honest parties
define the same unique master secret; and (ii) no information regarding the master
secret can be learned by the adversary. The proposed scheme thus satisfies the the
secrecy and correctness requirements for the process of master secret distribution.
We now discuss the private key extraction and transfer process. Any information
regarding the private key of a PAN device belonging to the honest, i.e. not corrupted,
PKG devices, is never learned by the adversary, because it is infeasible to compute
the private key from less than t+1 private key shares and the computed private key
is transferred to the requesting device in encrypted form. It is, of course, possible
for an adversary to learn the private key of a device belonging to a PAN with a
compromised PKG.
Given each node’s public key, the private key is computed from the correct t + 1
private key shares and the correctness of the private key shares is verified by the
PKG device on behalf of the requesting PAN device, using the fact that the DDH
problem is easy in G1 [18]. More specifically, P first computes Ui for each Pi as
follows.6
6We note that a pair (si, Ui) can be used as a private/public key pair, e.g. for Schnorr’s signaturescheme [126] or Hashed ElGamal [40], a variant of the ElGamal encryption scheme, as proposedby Saxena [124]. In this case, these cryptographic schemes could be viewed as examples of IBC(without using pairings), since a node can send an encrypted message and verify signatures withthe knowledge of the identifier of a particular node and the public system parameters. However,unlike other identity-based schemes, these schemes become insecure once more than t PKGs arecompromised. These schemes would be appropriate for a private network with a relatively smallsize. We note that using the secret shares in multiple schemes would violate the principle of keyseparation and may jeopardise the security of the schemes, depending on how they interact [102].
72

4.2 Security Initialisation for iPANs
Ui := siP =∑
i∈Q ai0P +∑
i∈Q ai1iP + · · ·+∑
i∈Q aititP ,
=∑
i∈QAi0 +∑
i∈Q iAi1 + · · ·+∑
i∈Q itAit (∈ G1),
(4.2)
The identifier i and the values Aik (i ∈ Q and k = 0, 1, . . . , t) are public values. The
private key share d(i)id can then be verified by checking whether
e(d(i)id , P ) = e(Qid, Ui) in G2. (4.3)
Equation (4.3) holds because
e(d(i)id , P ) = e(siQid, P ) = e(Qid, P )si = e(Qid, siP ) = e(Qid, Ui) in G2.
If equation (4.3) does not hold, P discards the private key share d(i)id and broadcasts
a complaint against Pi.
Finally, the authenticity and integrity of transferred private key is guaranteed by
the secure channel established by using the schemes described in Section 3.3.
Efficiency
By delegating private key extraction to a PKG device in the same PAN, both the
computations and communications that non-PKG devices need to perform are de-
creased. As a result, a PAN device will only need to contact its PKG instead
of communicating with t PKGs for private key generation, as required by other
identity-based DPKG proposals for ad hoc networks [34, 87, 144]. Indeed, personal
wireless devices, which generally have a local communications interface with limited
capacity, will not necessarily be able to connect to as many as t PKGs. Finally,
observe that the overall energy efficiency of the novel scheme is significantly greater
than that of rival schemes, because wireless transmission of a bit can require over
1,000 times more energy than a single 32-bit computation [144].7
7Transmitting a sufficiently powerful signal or decoding a received spread-spectrum signal in-volves considerable energy consumption, equivalent to that used by several thousand cycles a CPU;see, e.g. http://xbow.com
73

4.3 Further Discussion
Table 4.1: Comparison of the number of required initial secure channels
Deng et al. [34] Khalili et al. [87] Liu et al. [144] Proposed scheme
Number ofinitial securechannels
O(m2) O(m2) O(n2) +O(mn)O(m) or
O(n2) +O(m)
∗ The value m denotes the number of network nodes in an iPAN, and n denotes the number ofPKG devices (clearly m ≥ n).
Minimal initial secure channels
Finally, the proposed scheme is potentially efficient in its use of secure channels
during initialisation, as shown in Table 4.1. The related work quoted in this table,
[34, 87, 144], is discussed in section 4.1.3.
4.3 Further Discussion
In this section we briefly describe the example use case of pre-distributed key pairs,
and discuss the subsequent key management process after security initialisation in
iPANs.
4.3.1 Use of pre-distributed keys
Any two network nodes, with identifiers ida and idb say, can agree a shared secret
key without any communication [121]:
Kab = e(dida , Qidb) = e(Qida , Qidb)s
= e(Qidb , Qida)s = e(didb , Qida) = Kba ∈ G2(4.4)
where didi and Qidi are the private/public keys respectively of the network node with
identifier idi.
In fact, the nodes only need to compute Kab (or Kba) once and can cache the result,
obviating the need for an expensive pairing computation which (after the initial
key computation) makes the system as efficient as would be the case if secret key
74

4.3 Further Discussion
cryptography was used for key establishment. A PAN device could ask its PKG
to compute the shared secret on its behalf if pairing computations are beyond its
computing capabilities. The shared secrets can be used as long-term shared secrets
between a pair of network nodes.
The iPAN devices, however, subject to physical attacks which would compromise
secure data stored in the devices. The use of the non-interactive key establishment
protocols between PAN devices is thus vulnerable to attacks in which the attacker
corrupts the devices, extracts the keys, and then retroactively reads communications
between the devices which had occurred before the devices were corrupted.
The concept of the forward security [38] protects against the threats of this kind by
ensuring that the security of past uses of keys is not compromised by the exposure
of the currently stored keys. Bellare and Yee [13] dicuss a comprehensive treatment
of forward-security in the context of shared-key based cryptographic primitives, as
a practical means to mitigate the damage caused by key exposure, showing how
forward-secure message authentication schemes and symmetric encryption schemes
can be built based on standard schemes.
Since implementing full PKI functionality in constrained devices appears likely to
be problematic, a number of authors have considered how TLS might be modified
to use shared secrets, especially in mobile environments. These methods typically
avoid expensive public-key operations involving the exchange of certificates in the
TLS handshake, while providing an equivalent level of security using shared secret
secret keys. Gutmann [63] suggests seeding the TLS session cache with the shared
key and using session resumption functionality without changing the TLS protocol.
Eronen and Tschofenig [42] propose three sets of new ciphersuites for the TLS pro-
tocol to support authentication based on shared secrets. In particular, the first set
of ciphersuites uses only symmetric algorithms and is thus suited to performance-
constrained devices.
4.3.2 Revocation and update
We have proposed a security initialisation scheme for iPANs, but the subsequent key
management should be provided. In this section we briefly discuss such process, i.e.
75

4.3 Further Discussion
key revocation and update.
Revocation
Cryptographic schemes themselves cannot protect against attacks from compromised
but non-revoked network nodes, i.e. an internal adversary [84]. To minimise the
possible damage from compromised nodes, the public keys of such nodes should be
revoked immediately the problem becomes known. It is not sufficient to associate
an expiry date with a public key to support key revocation (as described in [18]) in
iPANs, since the public keys of malicious or compromised devices may need to be
revoked prior to their expiry.
In the key revocation we briefly described here, PKGs are given the right to generate
an accusation of misbehaviour against any iPAN node. If a non-PKG device detects
misbehaviour by another network node, then the device reports the misbehaviour
to its PKG. The PKG generates a signed accuasation against a device, Did say,
by computing Sig(sk, id), where id = id||revoke request||t and Sig is the signing
algorithm in Definition 2.18. The value t denotes the time when the signature is
generated. The PKG then propagates the signed accusation to the other PKG
devices. For the generation and verification of the signed accusations, each PKG
may use the private/public key pair provided in the initial secure channels8 with
any appropriate secure signature schemes [102].
On receiving an accusation, a PKG discards it if the PKG issuing the accusation
has been revoked. Otherwise, the PKG adds the accusation to its accusation list.
If the number of accusations against an iPAN device reaches a revoke threshold r
during the predefined period, the device is deemed to be revoked. To prevent an
adversary from attempting to revoke an honest PKG, the value r should be no less
than t + 1 (i.e. r ≥ t + 1)9. The list of the revoked devices is propagated within a
PAN by a PKG device using the secure channels. The choice for the threshold r is a
trade-off between false-accusation tolerance and compromise detectability. A larger
choice for r will give a greater tolerance to false accusations, but a reduced ability
8The security initialisation process assumes that there exist the initial secure channels betweenPKGs (see Section 4.2.1).
9The adversary is assumed to be able to compromise up to t PKGs as described in the securityinitialisation phase (see Section 4.2.2).
76

4.3 Further Discussion
to detect compromised nodes. The reasonable choice of the revoke threshold value
would be r = t+ 1.
We note that naive broadcast of a signed accusation, however, may be insecure, since
it could alert the accused network node to temporarily behave normally, as pointed
out by Zhang et al. [144]. By misbehaving selectively, the misbehaving device could
keep the number of accusations below the threshold r. To avoid this possibility, the
signed accusation may be sent to the other PKG devices in the encrypted form.
We note that it requires considerable computation and communication activities
to participate the revocation process. Such activities, however, are performed by
the PKG devices, and the other resource-constrained PAN devices can detect the
revoked devices using the list received from its PKG device. The revocation scheme
also provides a greater efficiency in storage. PKG devices should maintain the list
of any received signed accusations, but the other PAN devices only have to store the
list of identifiers whose keys have been revoked.
Update
We first describe the share update process, and then how a network node updates
its public/private key pair. We also describe how the share update technique could
be used to support membership update, i.e. when an existing PAN leaves or a new
PAN joins an iPAN.
Share update: Herzberg et al. [68] proposed a share update technique called proac-
tive secret sharing to cope with a mobile adversary of the type defined in section 4.2.1.
The idea is to refresh the shares at the beginning of each time period in such a way
that: (i) the updated shares are independent of the shares in the previous time pe-
riod; and (ii) the master secret remains the same. Assume that each Pi has a share
si of a master secret s, i.e. f(i) = si and f(0) = s, as in section 4.2.2. All the PKGs
Pi (i ∈ I) can engage in proactive secret sharing as follows.
• The PKGs Pi (i ∈ I) jointly generate g(z) =∑t
k=0 bkzk ∈R Zq[z] such that
b0 = 0 (∈ Zq), by performing the Pedersen’s DPKG (see Section 2.6.4) scheme,
i.e. they compute a new master secret equal to 0 (∈ Zq).
77

4.3 Further Discussion
• Each Pi then updates its share to si+g(i) mod q, where si is its old share. The
value g(i) can be computed locally at each Pi, as described in section 2.6.4.
The previous polynomial f(z) is now implicitly updated to f(z) + g(z), but the
master secret remains the same since g(0) = 0 (∈ Zq).
Key update: In line with generally accepted key management principles, key
pairs should be updated periodically. The key management scheme defined here
enables this by including the expiry date within public keys, as originally proposed
in [18, 19]. When the public key of a node expires, a new public key can be auto-
matically computed by any entity in the network, i.e. the previous public key h(ID)
is updated to h(ID′), where ID = id||expiry-date and ID′ = id||expiry-date +
predetermined period. The corresponding private key can be extracted using the
method described in section 4.2.2.
Membership update: To accommodate PANs joining and leaving iPANs, any
necessary changes of configuration, such as from use of an (n, t) threshold scheme to
an (n′, t) scheme, will need to be securely managed. When a PAN leaves iPANs, the
remaining PKGs must perform the share refreshing process without the involvement
of the PKG device in the leaving PAN. As a result, the leaving PKG will be excluded
from any future key management procedures. The public keys of all nodes in the
leaving PAN will need to be revoked; to achieve this the leaving PKG could broadcast
the list of pairs (idi, σi), where idi is the identifier of device in its PAN and σi is
a signature on idi|| revoke-request. On the other hand, when a new PAN joins
an iPAN, the PKG device in the joining PAN must perform the share refreshing
procedure with the existing PKGs. The private keys for the other PAN devices can
then be generated as described in section 4.2.2.
4.3.3 Other security issues
A fundamental assumption for the use of IBC is that the PKG is secure. This is a
reasonable assumption, because it is typically reasonable to assume that the PKG
can be kept physically secure. This is, however, not the case in an iPAN; a PKG
device could be compromised (e.g. mobile phones are prone to theft) or simply be
78

4.3 Further Discussion
unavailable (e.g. a laptop or a mobile phone might be switched off).
The proposed scheme (i.e. use of a DPKG) is resilient to failures of one or more
PKGs, and also tolerant of faulty or malicious behaviour by up to t PGKs. However,
a PKG in a PAN represents a single point of failure for the communications of the
other devices within this PAN. To avoid this issue, two or more devices10 in the
same PAN could act as PKGs. One device would be nominated as the primary
PKG, and the others as secondary PKGs. All such PKGs would participate in the
master secret sharing protocols as defined in section 4.2.2, and each PKG would be
assigned a different share. Assuming that all the PKGs in a PAN are known to the
PAN devices, one of the secondary PKGs can replace the primary PKG in the event
of the failure of the primary PKG.
Commonly discussed routing protocols, such as AODV [112] and DSR [74], allows ad-
versaries to locate PKGs easily by eavesdropping on identifiers sent in data packets.
Zhang et al. [144] point out that an adversary could launch a pinpoint compromise
or disruption attack given knowledge of the identity of a PKG. Such an attack could
be prevented by using the MASK [143] routing protocol, which uses dynamically
changing pseudonyms in the routing process without disclosing the real identities of
packet sources, packet destinations, and all intermediate nodes.
4.3.4 Generalisation of the proposed scheme
The proposed scheme can be applied to an ad hoc network. An ad hoc network is a
network formed without any central administration, which consists of (mobile) nodes
that use a wireless interface to send data packets [49]. So far, ad hoc packet-radio
network have been mainly considered as military applications, where decentralised
configurations are usually required. However, as capacity of personal wireless devices
increases in the commercial sectors, the needs of ad hoc networking of such devices
are rising. Furthermore, ad hoc network in commercial sectors are more likely to
form iPANs, because a single (master) user could deploy more than two wireless
devices to maximise the resources within the ad hoc network. The proposed scheme
can be applied to any ad hoc network which can be divided into a collection of
10Such devices should be computationally powerful and physically secure by comparison withother devices in the PAN.
79

4.4 Conclusions
smaller sub-networks, where a certain degree of trust exists between devices within
each sub-networks.
4.4 Conclusions
Since personal wireless devices are becoming ubiquitous, the need for secure commu-
nications within and between PANs is becoming increasingly common. Providing
robust and secure key management scheme remains a challenging task, in partic-
ular because of the unique characteristics of, and constraints on, such networks.
Whilst it is possible to employ existing key management schemes for ad hoc net-
works to secure intra/inter-PAN communication, we have proposed a novel scheme
which achieves a greater degree of security and efficiency by taking advantage of the
unique characteristics of PANs.11
11See Section 4.1.1 for the details of the unique characteristics of iPANs
80

Part II
Pervasive Computing: RadioFrequency Identification
81

Chapter 5
Privacy in RFID Systems
Contents
5.1 Privacy Issues in RFID Systems . . . . . . . . . . . . . . 83
5.1.1 Malicious tag readings in RFID systems . . . . . . . . . . . 83
5.1.2 Threats in practical scenarios . . . . . . . . . . . . . . . . . 85
5.1.3 Privacy as fundamental requirement . . . . . . . . . . . . . 86
5.2 Defining Privacy of RFID system . . . . . . . . . . . . . . 87
5.2.1 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.2.2 Defining RFID system . . . . . . . . . . . . . . . . . . . . . 89
5.2.3 Defining privacy . . . . . . . . . . . . . . . . . . . . . . . . 90
5.3 Secret key Cryptographic Solutions . . . . . . . . . . . . 93
5.3.1 Protocols based on key search . . . . . . . . . . . . . . . . . 94
5.3.2 Use of pre-computed table (OSK/ADO) . . . . . . . . . . . 95
5.3.3 Use of time-stamp (YA-TRIP/YA-TRIP∗) . . . . . . . . . . . 97
5.3.4 Tree-based approach (MW/MSW) . . . . . . . . . . . . . . 99
5.3.5 The Lim-Kwon (LK) scheme . . . . . . . . . . . . . . . . . . 102
5.4 Public key Cryptographic Solutions . . . . . . . . . . . . 106
5.4.1 Juels-Pappu scheme (JP) . . . . . . . . . . . . . . . . . . . 106
5.4.2 Universal re-encryption (UR) . . . . . . . . . . . . . . . . . 111
5.4.3 Insubvertible encryption (IE) . . . . . . . . . . . . . . . . . 115
5.5 Lightweight Protocols . . . . . . . . . . . . . . . . . . . . . 117
5.6 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
We discuss privacy issues of RFID technology, and construct a formal privacy model
for RFID systems accurately reflecting adversarial threats and power. We then give
brief privacy analysis for the existing privacy-enhanced RFID schemes which have
received wide attention in the literature.
82

5.1 Privacy Issues in RFID Systems
5.1 Privacy Issues in RFID Systems
Radio Frequency Identification (RFID) is a technology for automated identification
of objects or people using radio communications. An RFID system consists of tags
and readers. A Radio Signal Transponder, commonly known as an RFID tag or
simply a tag, consists of a chip containing identity information and an antenna
for wireless data transmission. Such a tag is typically attached to an object, and
transmits resident data when the tag passes through a radio frequency (RF) field
generated by a compatible reader.
The use of radio identification technology dates back at least to the second world
war, when the British attached transponders to aircraft to differentiate their own
planes from others [118]. Only recently, however, has such a technology been se-
riously considered for commercial applications. Use of this technology has been
pioneered by large organisations, such as WalMart, Proctor & Gamble, and the
United States Department of Defense, who have attempted to implement RFID
technology in their supply chains [77]. A combination of falling tag costs and global
RFID standardisation makes rapid growth in adoption likely in the near future.
RFID technology, however, poses unique privacy and security concerns. In partic-
ular, the owner of a tag cannot physically control tag communications because: (i)
radio communications are non-contact and non-line-of-sight, (ii) the tag itself typ-
ically does not maintain any history of past readings, and (iii) the tag does not
possess a human interface. The potentially limited computing capabilities of RFID
tags render security threats more serious, since standard cryptographic primitives
are beyond the capabilities of most RFID tags. Also, because of their small size,
people can carry RFID tags without their consent or even knowledge. Furthermore,
since such tags will operate in hostile environments, they may be subject to a variety
of physical attacks [138], including fault induction and power analysis attacks [17].
5.1.1 Malicious tag readings in RFID systems
Unauthorised tag reading is probably the most serious security and privacy threat
to an RFID system, since it could either directly infringe privacy and/or security,
or facilitate further malicious activities such as tag cloning. We divide unauthorised
83

5.1 Privacy Issues in RFID Systems
tag reading into two types, i.e. passive and active attacks. An unauthorised reader in
the field could surreptitiously listen to tag-reader communications. Alternatively, it
could actively attempt to read tags, since passive tags send their identifiers without
further security verification to an interrogating reader.
Tag-read ranges are an important factor when discussing security and privacy issues.
The standards specify a range of frequency bands, along with nominal read ranges,
for passive tags [77]. LF (Low-Frequency) tags operate at 124–135 kHz and have
nominal read ranges up to half a metre; HF (High-Frequency) tags operate at 13.56
MHz and have read ranges up to a metre or more; Ultra High-Frequency (UHF) tags
operate at 860–960 MHz (sometimes 2.45 GHz) and have read ranges up to tens of
metres. The following issues also affect reading ranges.
Forward link vs. reverse link in a passive attack
Since passive tags communicate using backscattering energy sent by readers, a very
high energy signal is used on the forward link from readers to tags; tags respond by
backscattering a very small portion of that energy on the reverse link. As a result,
the high power forward link can be read up to hundreds, or even thousands, of
metres away, depending on the regulations, antenna, and environment. The reverse
link, on the other hand, can be typically observed only within tens of metres [70].
Sending tag-sensitive information on the forward link should thus be avoided.
Nominal read ranges vs. rogue read ranges in an active attack
The read ranges for the reverse link can be further sub-divided. The nominal read
range indicates the maximum distance at which tags can be scanned reliably by a
normally operating reader, i.e. a reader with an ordinary antenna and power output.
A rogue reader, however, may be equipped with more a sensitive antenna and could
generate power beyond the legal limits. Such a rogue read range could be up to five
times the nominal read range [86].
84

5.1 Privacy Issues in RFID Systems
Figure 5.1: Potential RFID consumer privacy problems [77]
5.1.2 Threats in practical scenarios
Indeed, RFID technology has already raised privacy concerns in a range of practical
scenarios as follows.
EPC tags: The EPCglobal Network [71] is a standards-based approach designed
to help realise automated global supply chain management. An EPC (Electronic
Product Code) tag is the key component in the EPCglobal Network. The EPC tag is
an RFID tag, which is attached to, or embedded in, items. EPC tags may eventually
replace conventional barcodes for the items used in supply chains, but they will
introduce serious privacy issues. For example, mobile RFID devices [88, 89, 110],
i.e. tag readers embedded within a mobile phone and capable of communicating with
the EPCglobal Network via a mobile service provider, are being developed. Such
devices, when combined with the network of fixed tag readers, would significantly
increase threats of unauthorised tag reading. Figure 5.1 illustrates the potential
privacy threats arising from unauthorised tag reading. We further discuss privacy
issues on EPC tags in the following chapter.
Banknotes: The European Central Bank planned to embed RFID tags in ban-
85

5.1 Privacy Issues in RFID Systems
knotes as an anti-counterfeiting measurement.1 Juels and Pappu [79] proposed a
practical cryptographic banknote protection scheme using both Optical and RFID
systems. However, Avoine [6] demonstrated that the Juel-Pappu scheme [79] severely
compromises the privacy of banknotes bearers.
Libraries: Some libraries have implemented RFID systems to facilitate book check-
out and inventory control. This may be the first major deployment of item-level
tagging, where each individual item is given its own tag. Molnar and Wagner [106]
discuss privacy issues for RFID-enabled library users.
e-Passports: The International Civil Aviation Organization (ICAO) has published
a guideline for RFID-enabeld passports, so called the e-Passport [78]. An Integrated
Circuit (IC) embedded in the cover pages of an e-Passport contains: a copy of the
Machine Readable Zone (MRZ)2, a digital facial image, and other optional biometric
data for the passport holder. RFID technology is used to read the information stored
in the e-Passport. The security and privacy threats of e-Passport have been widely
discussed [8, 66, 78, 90].
Human-implantable chips: The possible use of VeriChip3, a human-implantable
RFID tag, has fuelled major privacy concerns arising from possible physical tracking
of individuals. Its proposed uses include in healthcare and emergencies, as well as
security applications such as physical access control. Halamka et al. [64] show that
Verichip is vulnerable to a simple cloning attack, and also suggest that, for bearer
safety, such tags should be exclusively used for identification and not authentication.
5.1.3 Privacy as fundamental requirement
Privacy, in particular, seems to be a fundamental property required in all RFID
systems, since, if industry fails to address privacy concerns, RFID technology is
likely to be deployed in environments in which legislation will limit its operation.
There is also likely to be public resistance to deployment as described below.
1See http://www.eetimes.com/story/OEG20011219S00162The MRZ is the set of optically-readable encoded lines at the bottom of the first page of a
passport, and includes information such as document type, full name, passport number, nationality,date of birth, and gender.
3See http://www.verichipcorp.com
86

5.2 Defining Privacy of RFID system
The European Union has created a working group4 to protect consumer privacy
in connection with personal data gathered using RFID technology. In the United
States, several states have initiated RFID privacy legislation [77]. Consumer privacy
advocates have mounted campaigns against RFID deployment by retailers. For ex-
ample, in 2003 a boycott caused Benetton to abandon RFID plans for its products.5
In the same year, a group of privacy organisations signed a position statement on
the use of RFID technology in consumer products.6
Malicious tag reading is not just a consumer privacy concern; it also poses a security
threat to the supply chain. For example, identifying individual tagged items could
make it easier for competitors to learn about a company’s stock turnover rates in
its supply chains. This threat is potentially even more serious in a military supply
chain,7 e.g. because enemy forces might learn about troop movements by monitoring
RFID communications.
5.2 Defining Privacy of RFID system
It is important to note that the cryptographic security models only capture the
security properties of the application layer communications protocols used between
tags and readers. Avoine and Oechslin [10] point out that there are multilayer
privacy issues; for example, if a tag has a distinct radio fingerprint (e.g. due to its
use of a different underlying standard at the communication/physical layer), then
the most secure cryptographic privacy-preserving identification protocol running at
the application layer may be of no use.
Several privacy models of RFID systems have been proposed in the literature [4, 7,
23, 75, 80, 137], but most privacy models fail to cover all major attack scenarios,
threats to the system, possible platforms, and attack strategies. We define a security
model for privacy in RFID systems, which captures multiple security levels in many
different categories.
4See http://ec.europa.eu/justice home/fsj/privacy.5See http://www.boycottbenetton.com.6See http://www.privacyrights.org/ar/RFIDposition.htm.7The Department of Defence in the United States has ordered that all shipments to its armed
forces be equipped with RFID tags [77].
87

5.2 Defining Privacy of RFID system
5.2.1 Related work
The definition of privacy used in the existing RFID systems varies depending on the
system components and the adversarial capabilities, but the fundamental property is
summarised as follows: An adversary should not be able to link two different sessions
involving the same tag.
In most cryptographic security models, an adversary is assumed to have more-or-less
unfettered access to system components. Such access, however, will be a sporadic
event in most RFID systems, since, in order to scan a tag, an adversary must
have physical proximity to the tag. Moreover, because most inexpensive RFID tags
cannot perform standard cryptographic functions, they cannot provide a meaningful
level of security against too strong an adversary. This provides an additional motive
to consider security models involving a less powerful adversary as the security model
described below.
Juels [75] points out the inevitable computational limitations of low-cost RFID tags,
describes likely attack scenarios in real-world settings, and provides a practical for-
malisation of minimal security requirements for a low-cost RFID tag. More specifi-
cally, the minimalist security model assumes that an adversary can read a given tag
only a specified number of times; once this number is reached, the tag is assumed
to interact with a valid reader outside the eavesdropping range of the adversary. Le
et al. [93] define that a refresh-based RFID system is said to provide privacy if the
adversary cannot link two reads of the same tag if the tag has been refreshed outside
the eavesdropping range of the adversary between the two read events. Juels and
Weis [80] focus on a strong privacy requirement for an RFID system in which secret
key cryptographic operations are assumed to be possible in an RFID tag, but they
exclude the adversarial capability of corrupting a certain class of tags, i.e. the two
tags that the adversary is challenged to distinguish in the privacy experiment.
Security, however, is not a binary state, so the security model may have many levels
in many different categories of RFID systems. Vaudenay [137] presents a security
model by defining adversaries with a range of strengths and introducing the eight
levels of privacy; each level of privacy considers the adversary with different strength.
88

5.2 Defining Privacy of RFID system
5.2.2 Defining RFID system
An RFID system consists of the following two entities.
• A tag, denoted by T , is a passive transponder; tags have no on-board power
source and are powered from an interrogating reader. Such use of an external
power source limits communication range of tags up to only few metres. A tag
also has limited size of storage and computational capabilities.
• A reader, denoted by R, consists of one or more transceivers and a back-end
server. The transceivers send the captured data from a tags to the back-end
server in order to determine if such tags are legitimate, i.e. if tags are registered
in the database DR, and further identify the legitimate tags, i.e. recover tag
identifiers id’s.
An RFID system consists of a set P of polynomial-time algorithms of the following
types.
• Setup-Reader takes as input a security parameter 1n, and returns the system
parameter parm and a key KR. We write R(parm,KR)← Setup-Reader(1n).
• Setup-Tag takes as inputs parm, a key KR, and a tag identifier id. It returns
a tag-specific secret KT and the initial state S of a tag. The pair (id,KT ) is
stored in DR, and S in a tag T . KT is not necessarily stored in the tag, but the
initial state S may be defined to include KT . We write (R(id,KT ), T (S)) ←Setup-Tag(id).
• Protocol is a polynomial-time interactive protocol between a tag and a reader.
A reader initiates the protocol, and it ends with a tape output. We write
output← Protocol(R, T ).
We now give a formal definition of an RFID system.
Definition 5.1 (RFID system) An RFID system consists of a tuple (T ,R,P), as
defined above, satisfying the following viability condition. That is, for the following
experiment
89

5.2 Defining Privacy of RFID system
R(parm,KR)← Setup-Reader(1n);
(R(id,KT ), T (S))← Setup-Tag(id);
output← Protocol(R, T ).
we have output = id.
5.2.3 Defining privacy
Providing rigorous definition of the notions of privacy in an RFID system involves
constructing a formal model that characterises the capabilities of potential adver-
saries. Such a model typically takes the form of an experiment, which intermediates
in communications between an adversary and a runtime environment, also called a
challenger, which contains the system components. In an RFID system, the system
components are tags and readers.
We now define the notion of privacy required in RFID systems based on the notion
of indistinguishability. Following the security model of Vaudenay [137], we define
the multiple levels of privacy depending on the adversarial capability of corrupting
the tags and the availability of side channels. We, however, further generalise the
existing privacy model by reflecting the fact that the adversarial access to the system
components would be a sporadic event in RFID systems. More specifically, we
describe the types and capabilities of adversary as follows.
• Accessibility to tag internal states: Adversary may be able to recover the
internal states of tags, including the tag secrets, and such a capability is char-
acterised by the Corrupt query.
• Accessibility to side channels: Adversary may be able to access the side
channels such as the result of RFID protocols, e.g. whether the interrogated
tags are successfully identified or not, and this could greatly affect tag privacy
as discussed in the following sections. Such a capability is characterised by the
Result query.
• Pervasiveness of adversary: In order to either scan a tag or listen to messages
from a reader, an adversary must be in physical proximity to the tag or the
reader. The most powerful adversary may listen to tag-reader communication
90

5.2 Defining Privacy of RFID system
or send messages to tags and reader anytime. Otherwise, a tag may be assumed
to have communication with a reader outside the eavesdropping range of the
adversary between every two consecutive adversarial access to the tag. There
may be a certain upper limit on the number that the adversary is allowed to
access tags during the lifetime of tags. An adversary may be assumed to have
an access to a tag once in a particular length of time. We characterise such a
adversarial capability by defining the access types.
Reflecting the adversarial capabilities described above, we now construct a formal
privacy model.
Definition 5.2 (Adversary) An adversary A is a probabilistic polynomial-time
(PPT ) algorithm, which can make the following types of oracle queries:
- Create-Tag(id): creates a tag T with a tag identifier id using Setup-Tag(id),
and (id,KT ) is added to the database of the backend server.
- Launch(protocol)→ π: makes a reader initiate the protocol instance π.
- Send-Reader(m,π) → m′: sends a message m to a reader for a protocol in-
stance π, and receives the answer m′.
- Send-Tag(m,π, T )→ m′: sends a message m to a tag for a protocol instance
π, and receives the answer m′.
- Execute(protocol, T )→ (π, trasncript): performs one Lauch query and succes-
sive use of Send-Reader and Send-Tag to execute a complete protocol between
the reader and the tag T . It returns the transcript of the protocol, i.e. the list
of successive protocol messages.
- Result(π) → x: at the end of execution of π, returns 1 if the tag has been
successfully identified and 0 otherwise.
- Corrupt(T ): returns the current state S of T .
The adversaries are classified by the capability of using the oracle queries. The weak
adversary cannot use Corrupt query. The destructive adversary cannot use T again
after the Corrupt(T ) query. The strong adversary, however, still has an access to
91

5.2 Defining Privacy of RFID system
the queries involving T after the Corrupt(T ) query. The wide adversary has access
to the Result query, but the narrow adversary does not.
Apart from the adversarial capabilities to use the particular oracle queries, we also
define three access types of adversary. The universal adversary make queries involving
any tag anytime during the experiment. The discrete adversary, prior to making
any query, should send the Execute query, where the transcript is not given to the
adversary. The discrete-τ adversary cannot make more than one oracle query during
the time interval τ .
We next define the experiments given the RFID system and the adversary Aδ, where
the parameter δ denotes the adversarial capability of using oracle queries and the
access type.
Experiment ExpprivacyAδ,RFID(n, ω, b)
Learning Stage:
(1) A single reader or two readers are set up.
(2) Aδ makes the allowed oracles queries, without exceeding ω overall queries.
Challenge Stage:
(3) Aδ outputs two tags, T0 and T1 say, and one of the tags, Tb say, is selected.
(4) Aδ makes the allowed oracle queries involving T b depending on their access
types, without exceeding overall ω queries.
(5) Aδ outputs a guess bit d ∈ {0, 1}.
The variable ω is polynomial in the security parameter n. Most RFID schemes
assume a single reader within the system, but some schemes aim to provide privacy
of tags which have been set up by different readers [2, 27, 28, 62]. Privacy of such
schemes can be analysed by setting up two readers as in step (1) and investigating if
the given adversary can distinguish the two tags which have been set up by different
readers.
92

5.3 Secret key Cryptographic Solutions
In step (3) the adversary cannot output the tags which have been set up by the
corrupted readers. In step (4) the universal adversary can make any allowed or-
acle queries after T b is selected. The discrete adversary should first make the
Execute(protocol, T b) query without the transcript given, before making the al-
lowed oracle queries. Finally, the discrete-τ adversary cannot make more than one
oracle query during the time interval τ .
We define privacy to mean that every adversary behaves in the same way in the
privacy experiment regardless of whether it interacts with T0 or T1 in the challenge
stage. Since the adversary Aδ outputs a single bit, “behaving in the same way”
means that it outputs “1” with almost the same probability in both cases. For the
privacy experiment defined above, the advantage of Aδ can be defined as
AdvprivacyAδ,RFID(n, ω) =
∣∣∣Pr[Expprivacy
Aδ,RFID(n, ω, 1) = 1]− Pr
[Expprivacy
Aδ,RFID(n, ω, 0) = 1]∣∣∣ .
The following definition captures the notion that the adversary Aδ cannot deter-
mine whether it is running the experiment ExpprivacyAδ,RFID(n, ω, 0) or the experiment
ExpprivacyAδ,RFID(n, ω, 1).
Definition 5.3 ((δ, ω)-privacy) An RFID system is said to provide (δ, ω)-privacy if
the function AdvprivacyAδ,RFID(n, ω) is negligible, where δ ∈ {x, y, z}, x ∈ {universal,
discrete, discrete-τ}, y ∈ {wide, narrow}, and z ∈ {strong, destructive,weak}.
We note that, if the system provides universal privacy, it also provides discrete
and descrete-τ privacy; wide privacy means narrow privacy; strong privacy means
destructive privacy, which in turns means weak privacy.
5.3 Secret key Cryptographic Solutions
Since inexpensive RFID tags cannot perform public key cryptography, most privacy-
enhancing RFID schemes have proposed to use secret key cryptography. A technique
known as key search8 has been most widely discussed in the literature, as surveyed
8The term key means bit-strings that are used by the tags to prove their identity. They arenot keys in the classical cryptographic definition, in that they do not control the operation of acommonly-accepted cryptographic primitive (see Section 2.6.2).
93

5.3 Secret key Cryptographic Solutions
by Avoine [5]. In this section we first discuss the general idea of RFID security
protocols based on key search, and then describe the variants of key-search RFID
schemes which aim to enhance security and efficiency.
5.3.1 Protocols based on key search
In privacy-enhanced RFID schemes, we need to find a means for a tag to identify
itself to a reader without revealing its identifier in cleartext. In order to achieve this
property using secret key cryptography, the majority of published privacy-preserving
RFID protocols use a method called key search, first discussed by Weis et al. [140].
A tag and a reader share a tag-specific key k, and perform a protocol as follows.
Given a pseudo-random function f , a tag chooses a random number r, computes
s = f(k, r), and sends (r, s) to a reader. A reader is then able to identify a tag by
finding a key k∗ such that s = f(k∗, r). The value r should be different at every
session so that the output s would be different from session to session.
It is easy to see that the scheme cannot achieve strong privacy, since the adversary
can determine the value b in the challenge stage after recovering the keys stored in
T 0 and T 1 in the learning stage. The scheme satisfies (universal, wide, destructive,
ω)-privacy, provided that the a pseudo-random function f is a random oracle. This
can be proven by showing that Aδ gains no knowledge from its interaction with
T b. More specifically, a simulator Sim for T b can be constructed in the experiment
ExpprivacyAδ,RFID(n, ω, b) such that (a) Sim does not have knowledge of the value b or any
key k, and (b) Aδ’s interaction with Sim would be computationally indistinguishable
from the one with T b. The probability that the adversary distinguishes Sim from
T b can be shown to be p(n)/2n, where p is a polynomial in the security parameter
n. The detailed security proof can be found in Weis et al. [140].
A potential issue associated with key search is the computation/storage cost for the
reader, which is a linear function of the number of tags in the system. Based on Weis
et al. [140], several variants of key-search RFID scheme have been proposed in the
literature [5], aiming to enhance privacy and/or efficiency. Such improvement makes
use of the following methods; (a) use of pre-computed table, (b) use of time-stamp,
(c) use of tree-architecture, and (d) randomised internal secret update.
94

5.3 Secret key Cryptographic Solutions
H HH
G G
sji sj+1i
aji aj+1i
Figure 5.2: The action of tag Ti in the OSK scheme
In the following sections, we describe such variant schemes along with brief privacy
analysis. The strategy of the formal security proof for such schemes is similar to
Weis et al. [140], and we rather focus on analysing how security and/or efficiency
improvements specifically affected privacy levels compared to the original key-search
RFID scheme [140].
5.3.2 Use of pre-computed table (OSK/ADO)
Ohkubo, Suzuki, and Kinoshita (OSK) [108] propose a simple privacy-preserving tag
identification scheme. Suppose the set of tag is {Ti}1≤i≤n. Suppose that a tag Tiwith identifier idi is initialised with a secret s1
i , and let H and G be independent
one-way hash functions. As shown in Figure 5.2, in the j-th transaction with a
reader, Ti replies to a reader query with aji = G(sji ), and then updates its secret sji
to sj+1i = H(sji ). A reader determines idi using a pre-computed table containing
{aji , (idi, j)}1≤i≤n,1≤j≤m for rapid lookup, where n is the number of tags and m is a
fixed upper bound on the number of times a tag can be queried before it needs to
be re-initialised.
Hellman [67] studied the problem of searching for secret keys for symmetric ciphers.
He considered the resource requirements for an attacker seeking to recover a secret
key k from a ciphertext c = ek(m) on a predetermined message m. He showed
how to reduce the computational effort involved in searching for a key from O(n) to
O(n2/3) by constructing a pre-computed table known as a Helllman table, where n
is the size of a key space.
Avoine, Dysli, and Oescslin (ADO) [7, 9] observe that the problem of table searching
95

5.3 Secret key Cryptographic Solutions
Protocol: YA-TRIP
1. R −→ T : Tr
2. T : if Tr ≤ Tt or Tr > Tmax, Hr ← PRNGji ;
3. else, Tt ← Tr and Hr ← HMAC(ki, Tt)
4. T −→ R : Hr
5. R : s← TableLookup(Tr, Hr)
Figure 5.3: The YA-TRIP Protocol [136]
task for readers in RFID systems using a key search approach is similar to the prob-
lem breaking keys, i.e. a reader needs to be able to determine the secret key ki of a
tag Ti, in order to authenticate Ti. They thus apply a variant of the Hellman tech-
nique to the OSK scheme, yielding a scheme with considerably reduced complexity
of server table searching.
The OSK/ADO schemes are conjectured to provide (universal, narrow, destructive,
ω)-privacy if G is a random oracle and H is collision-resistant. Ohkubo et al. [108]
discuss that the schemes could provide privacy since it is infeasible to link aji and
aj+1i because of the assumed pre-image resistance of G. We, however, point out that
the OSK/ADO schemes fail to provide privacy if the hash function H is not collision-
resistant. For example, once two collided hash chains are found, e.g. {sji}∞j=1 and
{sji′}∞j=1 say, and one of the chains is used in the system, privacy of the tag using
the chain is not guaranteed.
As Weis et al. [140], the OSK/ADO schemes cannot satisfy privacy against strong
adversary, since, once the adversary obtains the internal state sji for T i in the learn-
ing stage, it is possible to compute the all valid future aji . The OSK/ADO schemes,
however, also fail to provide wide privacy, since the adversary is able to determine
the value b exploiting the upper bound m described by Juels and Weis [80]. The
adversary may send the Execute(protocol, T ) query m times to exhaust T ’s valid
outputs, and submits T and any other tag in the challenge stage. By sending
Execute(protocol, Tb) and Result query, the adversary determine whether T is T bor not.
96

5.3 Secret key Cryptographic Solutions
5.3.3 Use of time-stamp (YA-TRIP/YA-TRIP∗)
A number of schemes have been proposed which use monotonically increasing time-
stamps, thus facilitating efficient key search via a pre-computed table for each time-
stamp [33, 135, 136]. The YA-TRIP (Yet Another Trivial RFID Identification Pro-
tocol) scheme [136] was the first proposed protocol of this type (see Figure 5.3).
A reader R pre-computes a table containing entries of the form {ki,MAC(ki, Tr)}i,rfor all tag keys ki and time-stamps Tr (for a pre-specified range of values r). The
choice of the interval between time-stamps is thus an important factor in determining
the table size. A relatively long interval, e.g. of an hour, would decrease the cost
of computation and storage for a reader, but tags could only be identified once in
any hour. On the other hand, a short interval, e.g. of a few seconds, would be more
realistic, but increases the maintenance cost at the reader.
Each tag Ti is initialised with the triple (ki, T0, Tmax), where ki serves as both a
tag identifier and a secret key for Ti, and T0 and Tmax are the initial and final
possible time-stamps, respectively. We use Tt to denote the current time-stamp
stored in Ti. PRNG is a pseudo-random number generator which could, for example,
be constructed using a cryptographic hash function, and PRNGji denotes the j-th
invocation of PRNG in tag Ti.
To authenticate a tag Ti, a reader R sends it the current time-stamp Tr. Ti responds
with MAC(ki, Tr) if Tt < Tr ≤ Tmax, i.e. Ti ensures that that Tr is a fresh and
valid time-stamp before computing and sending a response. Otherwise, Ti responds
with PRNGji . The algorithm TableLookup(Tr, Hr) returns ki if there exists an entry(ki,MAC(ki, Tr)
)such that Hr = MAC(ki, Tr); otherwise, it returns ⊥. Tr is not
tag-specific and could be the real (current) time value.
However, tags do not have an internal clock, and thus can only check the validity
of Tr by means of a comparison with the most recently received time-stamp. This
causes significant security vulnerabilities as pointed out by Tsudik [135].
• YA-TRIP does not provide tag authentication,9 since an adversary could easily
impersonate a tag by querying it in advance to obtain pairs (Tr, Hr).
9Tsudik [136] first proposes this protocol as YA-TRAP, and later re-names it as YA-TRIP in [135].
97

5.3 Secret key Cryptographic Solutions
Protocol: YA-TRIP∗
1. R −→ T : Tr, wr
2. T : γ ← Tr − Tt; δ ← bTr/intc − bTt/intc;
3. if γ ≤ 0 or Tr > Tmax or Hδ(wr) 6= wt, then Hr ← PRNGji
3′. else, Tt ← Tr; wt ← wr; Hr ← MAC(ki, Tt)
4 & 5 are the same as YA-TRIP
Figure 5.4: The YA-TRIP∗ protocol [135]
• YA-TRIP is vulnerable to an obvious Denial of Service (DoS) attack; an ad-
versary could send a tag T ′r such that T ′r � Tr or T ′r ≈ Tmax, and thereby
incapacitate it either temporarily or permanently.
To mitigate the above DoS attack, Tsudik [135] introduced a modified version of
the YA-TRIP scheme, which we refer to as the YA-TRIP∗ scheme (see Figure 5.4).
The YA-TRIP∗ scheme incorporates a hash chain {wi}zi=0, such that wj = H(wj+1)
for j = 0, 1, . . . , z − 1, where z = Tmax/int for the time interval int between values
wj . Each tag now stores the triple (Tt, wt, ki). The choice of the length of the time
interval int has a direct effect on the degree of vulnerability to a DoS attack. That
is, an adversary can disable tags for at most int, by intercepting (Tr, wr) and sending
(T ′r, wr), where T ′r is the maximum time-stamp such that bT ′r/intc = bTr/intc. Too
small a choice for int, however, will impose an excessive computational burden on
both reader and tags.
The YA-TRIP provides (universal, narrow, destructive, ω)-privacy if the underlying
MAC function is a random oracle. The scheme fails to provide wide privacy similarly
to the OSK/ADO schemes, since the adversary is able to mark a tag by querying
Tmax. The tag sets Tt ← Tmax, and outputs random values for all future queries. The
reader would be reject this marked tag in all future sessions, allowing the adversary
to distinguish such a tag from unmarked tags.
On the other hand, the YA-TRIP∗ provides either (universal, narrow, destructive,
ω)-privacy or (discrete-2int, wide, destructive, ω)-privacy. That is, the scheme
provides privacy against the wide adversary, if the adversary cannot access a tag
more than once during the time interval 2×int. By adopting the hash chain for
reader authentication, the attack of marking the target tags only works during the
98

5.3 Secret key Cryptographic Solutions
time internal int.
5.3.4 Tree-based approach (MW/MSW)
Molnar and Wagner (MW) [106] propose an RFID system in which each tag contains
multiple secret keys. These keys are arranged hierarchically as defined by a tree T ,
where every node other than the root is associated with a unique key and each tag
is assigned to a unique leaf. Each tag stores the keys associated with each of the
nodes on the path from the root to its leaf. A reader can authenticate a tag using
its stored secret keys.
That is, the reader runs several rounds of an authentication protocol, e.g. the pro-
tocol of Weis et al. [140], where the tag uses a different shared key in each round,
starting with the key for the root of a tree T and successively using keys on the path
to the leaf corresponding to the tag. This means that, in each round, the reader only
needs to search through the keys immediately adjacent (in T ) to the key used in the
previous round, thereby significantly reducing the size of the key search performed
by the reader.
For example, if T has depth d and branching factor b, then each tag contains d
keys and the scheme can accommodate up to bd tags in total. The reader is able
to authenticate a tag after searching through at most db keys. The brute-force key
search, however, would require a reader to search the complete space of bd tag keys.
Molnar, Soppera, and Wagner (MSW) [105] further develop the MW scheme, in-
troducing the notion of time-limited delegation. Unlike the MW scheme, the MSW
scheme uses a binary tree of secrets with depth d = d1 + d2, as shown in Figure
5.5. The nodes at each of the first d1 levels of the tree are assigned secrets that are
chosen uniformly at random by the Trusted Centre (TC), and each node at depth
d1 corresponds to a unique tag. The next d2 levels of the tree contains node secrets
that are derived from the secret stored in the node at depth d1 (e.g. the secret x in
the case of the tag T1 in Figure 5.5) using the Goldreich-Goldwasser-Micali (GGM)
construction [59], and each tag keeps a counter c that identifies a leaf at level d in
the tree. We give a formal description below.
99

5.3 Secret key Cryptographic Solutions
G00(x)(T 1
1 )G01(x)(T 2
1 )G10(x)(T 3
1 )G11(x)(T 4
1 )
G0(x) G1(x)
x(T1)
10
0 1 0 1
T 11 T 2
1 T 31 T 4
1
T1 T2 T3 T4
s′
d1
d2
d
The nodes connected with solid edges correspond to secrets shared between tags T1, . . . , T4and the TC, while the nodes with dashed edges correspond to secrets which are generatedusing the GGM construction from the secret at their immediate parent. On each read,a tag increases its counter and updates its state to use the secrets in the next leaf. Forexample, a tag T1 first uses the secrets from the root to the leaf T 1
1 , and when queried nextit uses the secrets from the root to the leaf T 2
1 . If a reader is delegated to identify a tagT1 during the interval [1, 2], it is provided with the secret G0(x) associated with node s′.This reader can then identify tag T1 only twice using the secrets G0(G0(x)) = G00(x) andG1(G0(x)) = G01(x).
Figure 5.5: A toy example of the tree of secrets (MSW)
Let {0, 1}l be a set of binary strings of length l. A node s of depth e is labelled with
a binary string of length e defined by the unique path form the root to that node.
For example, in Figure 5.5 the node s′ is labelled with 000. A value h(s) denotes
the key associated with node s. The TC defines a function h : {0, 1}≤d → {0, 1}k
for a security parameter k as follows:
• h : {0, 1}≤d1 → {0, 1}k is chosen uniformly at random; and
• h : {0, 1}>d1 → {0, 1}k is defined as h(s||b) = Gb(h(s)) for all s ∈ {0, 1}≥d1
and b ∈ {0, 1},
where G : {0, 1}k → {0, 1}2k is a pseudo-random number generator, and G0(s)
and G1(s) are the k MSBs and k LSBs of G(s), respectively. By using the GGM
construction [59], both tags and the TC can reduce key storage space, i.e. they only
need to store keys up to d1 levels in the tree.
A tag responds to a reader query by generating a random number r and sending the
100

5.3 Secret key Cryptographic Solutions
following pair of values back to the reader(r, p)
=(r, (p1, p2, . . . , pd)
)=(r, (Fh(c1..1)(r), Fh(c1..2)(r), . . . , Fh(c1..d)(r))
). (5.1)
F denotes a pseudo-random function, and c1..i (1 ≤ i ≤ d) denotes the sequence of
nodes on the path in the tree of secrets from the root to the tag’s current leaf T c.Finally, the tag increases its counter c, i.e. it sets c ← c+ 1. Note that each leaf is
assigned with a counter c such that 1 ≤ c ≤ 2d, and that each tag can update its
counter at most 2d2 − 1 times.
On receipt of (r, p), the reader can conduct a depth-first search to find a path in the
tree that matches p, as in the MW scheme. That is, at node s with a depth i, the
reader can check whether the left child s||0 or the right child s||1 matches an entry
pi+1 by checking whether Fh(s||0)(r) = pi+1 or Fh(s||1)(r) = pi+1.
The MSW scheme also enables delegation of the ability to identify a tag for a limited
period of time, i.e. for a specific number of read operations. Suppose that the TC
decides to delegate the right to access tag T to a reader R for the interval [L,R],
where 1 ≤ L ≤ R ≤ 2d. The TC then sends R the secret h(s∗) of the node
s∗ ∈ {0, 1}≥d1 , where s∗||00 · · · 0 of depth d has a counter L and s∗||11 · · · 1 of depth
d has a counter R. It is straightforward to verify that, for any node s of depth d
satisfying that its counter is within [L,R], there exists an s∗ such that s∗ is a prefix
of s. R is thus able to compute the secrets h(s) for |s∗| ≤ |s| ≤ d using the GGM
construction, where |s| and |s∗| denote the bit-lengths of s and s∗, respectively.
Also, given (r, p) as a tag response, a reader can identify the tag R−L+ 1 times by
checking the entries p|s|, . . . , pd−1, pd of p.
Such a delegation can be useful in a variety of scenarios. For example, hand-held
readers may be given temporary scanning privileges within systems with intermittent
connectivity. In the strict sense, the scheme does not provide transfer of ownership,
but enables the distribution of access control rights by the TC.
There is a price to be paid for the efficiency of key search in tree-based approach.
First, tags must store dlogb ne keys, where n is the number of tags and b is the
branching factor, and must also perform dlogb ne protocol executions. Furthermore,
since the tree structure creates an overlap among the sets of keys, compromising one
tag or a small number of tags can lead to significant privacy infringements for other
tags, as analysed in [7, 107].
101

5.3 Secret key Cryptographic Solutions
More specifically, the MW/MSW schemes fails to provide destructive privacy, conjec-
tured to only satisfying (universal, wide, weak, ω)-privacy if the underlying pseudo-
random functions are random oracles. We give a simple example that the destructive
adversary wins the privacy experiment ExpprivacyAδ,MSW
. The adversary corrupts a tag
T ∗ and then tries to find two tags, T0 and T1, where one of the two tags, T0 say, has
the same c1 as T ∗ and the other tag, T1 say, does not. Finding such tags become
possible because T ∗ and T0 will respond with same p1 given the same r in the equa-
tion (5.1). By selecting T0 and T1 in the step (3) of ExpprivacyAδ,RFID, the adversary is
able to output the correct guess bit d.
5.3.5 The Lim-Kwon (LK) scheme
Lim and Kwon (LK) [97] propose a modified version of the OSK scheme, realising tag
authentication, forward secrecy, and secure ownership transfer. In the LK scheme,
forward secrecy and secure ownership transfer become possible by evolving the tag
secrets during every protocol execution. More specifically, they use the term refresh
to mean probabilistic evolution, and update to mean deterministic evolution. If
the protocol is successfully completed, the tag and backend database refresh the
tag secret probabilistically using exchanged random numbers; otherwise, the tag
updates its secret deterministically, as in the OSK scheme. The ‘refresh’ process
makes secure ownership transfer possible. The LK scheme’s use of a pre-computed
table is more efficient than that of the OSK scheme, as described below.
Parameters. We first define the parameters used in the scheme: m denotes the
maximum number of allowable authentication failures between two valid sessions;
n denotes the length of the backward key chain used for server authentication; l
denotes the bit-length of a tag secret; l1 denotes the bit-length of random challenges;
l2 denotes the bit-length of the tag secret transmitted in clear when the server
identifies a tag (l2 ≤ l). The following functions are used in the protocol:
• f : {0, 1}l × {0, 1}2l2 → {0, 1}2l1 , which is used to generate authenticators;
• g : {0, 1}l → {0, 1}l, which is used to generate the forward key chain;
• h : {0, 1}2l1 → {0, 1}2l1 , which is used to generate the backward key chain;
102

5.3 Secret key Cryptographic Solutions
READERTAG
Initialised with (si, wi,T , ci)
Pre-computed table for TiDold [i] = (si, {tji}
m−1j=0 , ui, ni, wi,T , wi,R)
Dnew[i] = (si, {tji}m−1j=0 , ui, ni, wi,T , wi,R)
r1 ∈R {0, 1}l1r1ti ← ext(si, l2);
r2 ∈R {0, 1}l1 ;
σ1 ← ext(f(si, r1||r2), l1)
wi,R ← f(si, r2||r1)⊕ σ2;
if h(wi,R) = wi,T ,
refresh (si, wi,T , ci)
otherwise, update (si, wi,T , ci)
ti, r1, r2, σ1
σ2
find s′i = sji using ti
if ext(f(s′i, r1||r2), l1) = σ1,
σ2 ← f(s′i, r2||r1)⊕ wi,R;
update Dold[i] and Dnew[i]
Figure 5.6: The LK authentication protocol
• ext(x, l∗) denotes a simple extract function that returns l∗ bits of x, e.g. x
mod 2l∗.
The functions f , g, and h are pseudo-random functions and can be constructed from
a single lightweight block cipher [97].
Initialisation. Tag Ti is initialised by a reader R in the following way.
• R chooses a secret si ∈R {0, 1}l for Ti, and computes {sji}m−1j=1 and {tji}
m−1j=1 ,
where s0i = si, s
ji = g(sj−1
i ), and tji = ext(sji , l2).
• R also chooses ui ∈R {0, 1}l1 for each Ti, and computes a hash chain {wji }n−1j=0 ,
of length n, where wni = ui and wji = h(wj+1i ) for 0 ≤ j < n.
• Ti stores (si, wi,T ), where wi,T = w0i , and initialises the failure counter ci to 0.
• Rmakes the following entries for Ti in its tag database, D[i] = Dold[i]∪Dnew[i];
Dold[i] is initially empty and Dnew[i] =(si, {tji}
m−1j=0 , ui, ni, wi,T , wi,R
), where
wi,R = w1i and ni = n. Note that wi,T = h(wi,R).
Protocol. The protocol is summarised in Figure 5.6. Rmaintains two tag databases
Dold[i] and Dnew[i]. The retention of old tag data prevents Ti becoming desynchro-
nised if it does not receive the last protocol message σ2, e.g. because of a commu-
103

5.3 Secret key Cryptographic Solutions
nication failure. The authentication protocol is performed between Ti and R as
follows.
1. R chooses r1 ∈R {0, 1}l1 and sends it to Ti.
2. Ti chooses r2 ∈R {0, 1}l1 , computes ti ← ext(si, l2) and σ1 ← ext(f(si, r1||r2), l1),
and send (ti, r1, r2, σ1) to R.
3. R searches its database to find an entry containing ti. If no match is found,
R responds with σ2 =⊥ (denoting ‘failure’) and stops; otherwise, i.e. if there
exists D[i] containing(si, {tji}
m−1j=0 , ui, ni, wi,T , wi,S
)such that tji = ti for some
j, R computes s′i = gj(si) and checks that ext(f(s′i, r1||r2), l1) = σ1. If this
checks fails, R responds with σ2 =⊥ and stops; otherwise, i.e. if the check
succeeds, R computes σ2 ← f(s′i, (r2||r1))⊕wi,R, sends σ2 to Ti, and updates
D[i] as follows:
(a) Dold[i] is updated to(si, {tji}
m−1j=0 , ui, ni, wi,T , wi,R
), where si = g(s′i),
tki = ext(gk(si), l2) for 0 ≤ k ≤ m − 1, and ui ← ui, ni ← ni, wi,T ←wi,T , wi,R ← wi,R.
(b) Dnew[i] is updated to(si, {tji}
m−1j=0 , ui, ni, wi,T , wi,R
), where si ← g(s′i ⊕
(wi,R||r1||r2)), tji = ext(gj(si), l2) for 0 ≤ k ≤ m − 1, ni ← ni − 1,
wi,T ← wi,R and wi,R ← hni(ui), and ui and ni are unchanged.
4. Ti computes w′i,R = σ2 ⊕ f(si, r2||r1) and checks whether h(w′i,R) = wi,T .
If the check succeeds, then Ti sets ci = 0 and refreshes (si, wi,T ) as follows:
wi,T ← w′i,R and si ← g(si ⊕ (wi,T ||r1||r2)). If the check fails, then: if ci < m
then Ti increments the failure counter, i.e. sets ci ← ci + 1 and updates si as
si ← g(si);10 alternatively, if ci ≥ m then R does nothing.
The LK scheme provides either (universal, wide, destructive, m)-privacy or (diescrete,
wide, strong, m)-privacy if the underlying pseudo-random functions are random
oracles. We observe that the scheme fails to provide privacy if the adversary can
make more than m oracle queries, since the tag does not update the secret si once
the tag reaches the upper bound for the authentication failures; in such a case a tag
10Once si is updated, the tag will emit the updated ti in the subsequent session, where ti =ext(si, l2) and si is the updated version.
104

5.3 Secret key Cryptographic Solutions
will emit a static identifier ti. To minimise the probability of the described privacy
infringes, a relatively large m could be used in practice.
The parameter m determines the size of the pre-computed table held by the reader,
like the upper bound m in the OSK scheme. The size of the parameter m in the
LK scheme, however, can typically be considerably smaller than the corresponding
parameter in the OSK scheme. This is because m in the LK scheme is an upper
bound on the number of permitted protocol failures between two successful protocol
executions for a tag, whereas m in the OSK scheme defines the maximum number
of protocol executions in the entire tag life cycle.
Differently from the previous key-search schemes, the LK scheme provides strong
privacy given that the adversarial access type is discrete. This is because the protocol
provides a measure of protection even if the tag secret (si, wi,T ) is compromised.
Such secret becomes useless when the compromised tag engages the successful run
of protocol outside the eavesdropping range of the adversary; the tag refreshes the
internal secrets, i.e. wi,T ← w′i,R and si ← g(si ⊕ (wi,T ||r1||r2)). That is, the
adversary cannot determine the updated value wi,T provided that the constructed
hash function h satisfies the one-wayness, and also the updated value si because the
adversary has no knowledge of the values r1 and r2.
Apart from privacy, Lim and Kown [97] claim that the protocol provides a mea-
sure of strong authentication and secure ownership transfer. A compromised tag
secret could be used to construct a counterfeit tag. Suppose that a fake tag Tiis constructed by equipping it with the secret (si, wi,T ). The fake tag Ti becomes
useless as soon as the genuine tag Ti engages in the protocol with R causing the
secret to be refreshed. Unfortunately, it is also true that the genuine tag Ti will
become permanently desynchronised if the fake tag Ti engages in the protocol with
the reader.
Ownership of a tag Ti can be securely transferred from A to B in the following way.
The reader information for the tag, i.e. Di (= Dold[i] ∪ Dnew[i]), is sent to B via
a secure channel, and B performs the above protocol with Ti in an environment in
which A cannot eavesdrop upon the exchanged messages. As a result, the secret key
in Ti and the secret tag record Di held by B will both be refreshed. The previous
owner then can no longer identify Ti.
105

5.4 Public key Cryptographic Solutions
5.4 Public key Cryptographic Solutions
Use of public key cryptography can securely address privacy issues in RFID systems
as discussed in the literatures [85, 91, 99, 100, 141]. Unfortunately, implementing
public-key primitives is beyond the computational capability of passive RFID tags.
External agents, however, could refresh the pseudonym resident in a tag frequently
enough to ensure privacy.
A number of refresh-based approaches have been proposed which support the use of
public key primitives in an RFID system, where a tag delegates expensive crypto-
graphic operations to a reader. Such refresh-based approaches have been discussed
by a number of authors [2, 62, 79], in which public key encryption is used to sup-
port refresh techniques, i.e. tags store data in encrypted form which is subsequently
refreshed (i.e. re-encrypted) by more powerful readers without requiring any cryp-
tographic functionality in a tag.
In this section we describe Juels and Pappu (JP) [79], which first proposed to use
public key encryption as a refresh technique in RFID systems. We then investigate
other refresh-based schemes of Golle et al. [62] and Ateniese et al. [2], which suggest
the methods of refreshing ciphertexts when multiple public keys are used in the
system.
5.4.1 Juels-Pappu scheme (JP)
The European Central Bank planned to embed RFID tags into banknotes in order
to prevent forgeries, and to also provide tracking mechanism for use by law enforce-
ment agencies.11 Embedding a tag in a banknote, however, may infringe individual
privacy when improperly deployed [79]. To address this issue Juels and Pappu [79]
proposed a cryptographic banknote protection scheme, which both protects against
counterfeiting and enables banknote tracking by a law enforcement agency, whilst
protecting the privacy of banknote bearers.
More specifically, Juels and Pappu [79] first proposed use of the refresh approach
to enhance privacy of RFID-enabled banknotes. The authors proposed storing an
11See http://www.eetimes.com/story/OEG20011219S0016.
106

5.4 Public key Cryptographic Solutions
encrypted version of a banknote’s serial number in an RFID tag embedded in the
banknote. To prevent tracking, the ciphertext is periodically re-encrypted by read-
ers programmed with the public key system, thereby rendering multiple interactions
with the same RFID tag unlinkable. Juels and Pappu also proposed that the ban-
knote should carry optical write-access keys, to prevent unauthorised writing to a
tag. Thus a reader must scan this optical key before re-encrypting a ciphertext.
‘Re-encryption’ here means transforming a ciphertext c into a new unlinkable ci-
phertext c′ using a public key pk, without changing the underlying plaintext, i.e. c
and c′ decrypt to the same plaintext under the system private key sk. This is dif-
ferent from other uses of the term re-encryption, such as proxy re-encryption, which
involves generating a new ciphertext that is an encrypted version of the original
plaintext under a different public key.
We now describe Juels and Pappu’s scheme [79], and first describe the entities in-
volved.
• Central bank (B): The central bank creates banknotes and wishes to prevent
banknote forgery.
• Law enforcement agency (L): This agency wishes to trace flows of banknotes,
and in addition wishes to efficiently detect counterfeit banknotes with high
assurance.
• Merchant (M): The merchant is an entity that handles banknotes, accepting
them for payment and possibly anonymising them to help protect client pri-
vacy. Most merchants will comply with requirements of the law enforcement
agency by reporting irregularities in banknote data and helping to protect
client privacy; however, some merchants may attempt to compromise the pri-
vacy of their clients.
• Consumers (C): The consumers are banknote bearers, and they may wish to
protect their privacy. They may attempt to corrupt the information stored in
the banknote in order to avoid tracing by L.
Juels and Pappu [79] next define the RFID-enabled banknote scheme.
107

5.4 Public key Cryptographic Solutions
Definition 5.4 (JP Scheme) Suppose that PE=(EKG,Enc,Dec) is a public key en-
cryption scheme, as in definition 2.12, and DS=(SKG,Sig,Ver) is a digital signature
scheme, as in definition 2.18.12 The JP scheme consists of the following procedures.
• Setup: Given a security parameter τ , a central bank B and a law enforcement
agency L generate their own public/private key pairs (PKB, SKB) ← SKG(τ)
and (PKL, SKL) ← EKG(τ), respectively. The public keys, i.e. PKB and
PKL, and a collision-resistant hash function h : {0, 1}∗ → {0, 1}k are pub-
lished, where k is chosen appropriately.
• Banknote creation: For every banknote i, B selects a unique serial number Si
and computes the signature Σi = Sig(SKB, Si||Di), where Di is the denomina-
tion (value) of the banknote. B then generates an access key Ai = h(Σi), and
prints Si and Σi as an optical barcode on the banknote.13 B then generates a
random number ri ∈R {0, 1}l for an appropriately chosen l, and computes
Ci = Enc(PKL,Σi||Si; ri),
where ri is written into the δ-cell memory and Ci is written into the γ-cell
memory, as indicated in Figure 5.7.
• Banknote verification and anonymisation: On receiving a banknote i, a merchant
M first verifies the stored data and then re-encrypts it, using the following
procedure.
1. M reads the data Si and Σi printed on the banknote, and computes Ai =
h(Σi).
2. M reads Ci from γ-cell, and keyed-reads ri from δ-cell using Ai.
3. M checks if Ci = Enc(PKL,Σi||Si; ri).
4. M chooses a random number r′i and key-writes it into δ-cell.
5. M computes C ′i = Enc(PKL,Σi||Si; r′i) and keyed-writes it into γ-cell.
If any of the above steps fails, then the merchant reports to L.
12We use notations EKG and SKG to denote key generation algorithms for public key encryptionscheme and digital signature scheme, respectively.
13Juels and Pappu [79] state that the access key Ai should be derived by hashing Σi rather thanSi, in order to avoid an attack in which an adversary computes the access-key by guessing the serialnumber without needing to see the banknote.
108

5.4 Public key Cryptographic Solutions
• Banknote tracking: L obtains a ciphertext Ci by reading γ-cell in the banknote,
and recovers the plaintext by computing Σi||Si = Dec(SKL, Ci). L then checks
if Σi is a valid signature on Si by seeing Ver(PKB,Σi, Si||Di) = 1. If Σi is
valid, then L obtains the banknote serial number Si.
While the security of a conventional banknote relies on visible features (possibly
including features only visible under an ultraviolet source), Juels and Pappu use
both optical and electronic features, summarised as in Figure 5.7. Optical data is
encoded in a human-readable form and/or in a machine-readable two-dimensional
barcode. Electronic data is stored in an RFID tag, whose memory consists of two
types of cell; universally-readable/keyed-writable γ-cell and keyed-readable/keyed-
writable δ-cell (see Figure 5.7).14
Given the entities and definition of the scheme, Juels and Pappu [79] describe the
security goal of the proposed scheme as follows.
• Consumer privacy : Only the law enforcement agency L should be able to track
banknotes; even central bank B should not be able to track banknotes.
• Strong tracking : The law enforcement agency L should be able to identify and
track a banknote even without visually inspecting it.
• Forgery resistance: A forger should not be able to create a new banknote with
a previously unseen serial number; the forger should also not be able to alter
the denomination of a banknote.
• Fraud detection: If invalid information is written to the RFID tag in a ban-
knote, this should be readily detectable by a merchant M.
For the specific construction of the JP scheme, which we call the Juels-Pappu scheme,
Juels and Pappu choose ElGamal encryption scheme [40] and the Boneh-Shacham-
Lynn signature scheme [20] as cryptographic algorithms. Let ElGmal encryption
is defined as a tuple (Gen,Enc,Dec), as in definition 2.17, where for r ∈R Zq and
PKL = y,
Enc(PKL,m; r) = (myr, gr).
14The terms keyed-read/write mean that the reader could read or write into the tag only if sendingthe correct keys along with the read/write commands.
109

5.4 Public key Cryptographic Solutions
RFID Tag
γ-cell δ-cell(universally-readable/keyed-writable) (keyed-readable/keyed-writable)
C = Enc(PKL,Σ||S; r) r
Optical
S Σ = Sig(SKB, S||D)
Figure 5.7: RFID-enabled banknote data
Since ElGamal encryption scheme is not CCA secure, Juels and Pappu propose to
use the secure integration method of Fujisaki and Okamoto [51].15
More specifically, for r ∈R Zq, Juels and Pappu define
Enc∗(PKL,m; r) =(Enc(PKL, r;h1(r||m)), h2(r)⊕m
),
where h1 and h2 are hash functions from {0, 1}∗ to {0, 1}n (n = |m|).
The JP scheme, however, cannot satisfy any type of privacy defined in the Definition
5.3 as discussed by Avoine [6]. First, the static access key could be used to track
it when each banknote has a unique access key. This is because the adversary can
readily obtain a tag-access key by making the Send-Tag query and a banknote tag
will only respond if the access-key sent by a reader is valid. An adversary could thus
track the banknote with a particular access key, by attempting to read the δ-cell
memory of any banknote.
Even if such access keys are not unique across banknotes, the adversary can distin-
guish every banknote by making data recovery attack [6]. The adversary can readily
obtain a random number r for each banknote by making the Execute query. In such
a case, the integration method of Fujisaki and Okamoto becomes insecure, since,
given
Enc∗(PKL,m; r) = (ω1, ω2, ω3) =(ryh1(r||m), gh1(r||m), h2(r)⊕m
),
the adversary can recover the plaintext by simply computing m := ω3⊕h2(r), since
m = Σ||S.
15Although the authors propose to use a specific method, any IND-CCA2 secure public key en-cryption scheme could be used.
110

5.4 Public key Cryptographic Solutions
5.4.2 Universal re-encryption (UR)
While a single key pair may suffice for the RFID-enabled banknote scheme, multiple
public keys are likely to be necessary in other RFID systems. In such a scenario,
in order to randomise the ciphertext within an RFID tag, it is necessary to know
under which public key the ciphertext has been encrypted. However, including a
public key on a tag along with the ciphertext would itself permit a certain degree of
tracking and profiling, because the public key could be used as a static identifier. To
solve this anonymity problem, Golle et al. [62] introduced a cryptographic technique
known as universal re-encryption, which permits re-encryption without any need to
know which public key was used to encrypt the ciphertext.
The universal re-encryption makes use of the ElGamal encryption scheme. Let
ElGmal encryption be defined as a tuple (Gen,Enc,Dec), as in definition 2.17. The
output of an encryption operation for a message m consists of a pair made up of an
ElGamal encryption of m together with an ElGamal encryption of 1. That is, the
output of the encryption operation is:(Enc(y,m),Enc(y, 1)
)=((myk0 , gk0), (yk1 , gk1)
),
for the public/private key pair (G, q, g, y) and (G, q, g, x). Universal re-encryption
then operates as follows. Randomly choose r′ = (k′0, k′1) ∈R Z∗q × Z∗q , randomise
Enc(y, 1) by computing Enc′(y, 1) = (yk1k′1 , gk1k
′1), and then use Enc(y, 1) to conceal
Enc(y,m), exploiting the homomorphic property of ElGamal. That is, compute
Enc′(y,m) = (myk0yk1k′0 , gk0gk1k
′0) = (myk0+k1k′0 , gk0+k1k′0).
The re-encrypted ciphertext is then the pair(Enc′(y,m),Enc′(y, 1)
), where Enc′(y,m)
decrypts to the message m using the private key x.
Definitions
We now give the definition of Golle et al.’s universal re-encryption scheme [62], which
we call the UR scheme.
Definition 5.5 (UR Scheme) The UR scheme is a tuple of polynomial-time algo-
rithms (UK,UE,UD,URe) with the following properties:
111

5.4 Public key Cryptographic Solutions
• The key generation algorithm UK takes as input a security parameter 1τ , and
returns a public/private key pair (pk, sk). We write (pk, sk)← UK(1τ ).
• The encryption algorithm UE takes as input a public key pk and a plaintext m,
and returns a ciphertext c. We write c← UE(pk,m).
• The decryption algorithm UD takes as input a secret key sk and a ciphertext
c, and outputs a message m or a special symbol ⊥ denoting failure. We write
m← UD(sk, c).
• The re-encryption algorithm URe takes as input the public parameter and a
ciphertext c, and returns c′ such that both c and c′ decrypt to the same plaintext
m. We write c′ ← URe(c).
In order to model the security of the UR scheme, Golle et al. [62] also introduce a new
security concept, universal semantic security under re-encryption (USSR). Given the
UR = (UG,UK,UE,URe,UD) scheme and an adversary B, we consider the following
experiment.
Experiment Exp ussrUR,B(τ)
1. UK(1τ ) is run to obtain key pairs (pki, ski) for i = 0, 1.
2. Given (pk0, pk1), B outputs ciphertexts (c0, c1).16
3. A random bit b ∈R {0, 1} is chosen, and a ciphertext c′ ← URe(c) is computed.
Finally, the ciphertext c′ is given to B.
4. B outputs a bit b′.
5. The output of the experiment is defined to be 1 if b′ = b, and 0 otherwise.
Golle et al. give the following definition [62].
Definition 5.6 (USSR) We say that the UR scheme has universal semantic security
under re-encryption (USSR) if, for any probabilistic polynomial-time adversary B, a
function∣∣Pr[Expussr
B,UR(τ) = 1]− 12
∣∣ is negligible.
Golle et al. [62] construct the example scheme of the UR scheme using ElGamal
encryption scheme as follows.
16The corresponding plaintexts must be in the plaintext space associated with the public keys.
112

5.4 Public key Cryptographic Solutions
Definition 5.7 (GJJS Scheme) The scheme is a tuple of polynomial-time algo-
rithms (UK,UE,UD,URe) with the following properties:
• The key generation algorithm UK takes as input a security parameter 1τ , and
returns a public/private key pair (pk, sk) =((G, q, g, y), (G, q, g, x)
), where
x ∈R Z∗q and y = gx. We write (pk, sk)← UK(1τ ).
• The encryption algorithm UE takes as input a public key pk and a plaintext
m ∈ G, and returns a ciphertext
c =((α0, β0), (α1, β1)
)=((myk0 , gk0), (yk1 , gk1)
),
where r = (k0, k1) ∈R Z∗q × Z∗q. We write c← UE(pk,m).
• The decryption algorithm UD takes as input a secret key sk and a ciphertext
c =(
(α0, β0) , (α1, β1)). It first checks whether αk, βk ∈ G for k = 0, 1; if not,
it returns a special symbol ⊥ indicating that the ciphertext is invalid. It then
checks whether α1/βx1 = 1. If so, the algorithm outputs m := α0/β
x0 ; otherwise
the decryption fails and the output is ⊥. We write m← UD(sk, c).
• The re-encryption algorithm URe takes as input (G, p, g) and a ciphertext c, and
returns
c′ =((α′0, β
′0), (α′1, β
′1))
=((α0α
k′01 , β0β
k′01 ), (α
k′11 , β
k′11 )),
where r′ = (k′0, k′1) ∈R Z∗q×Z∗q is an randomly chosen pair of values. We write
c′ ← URe(c).
Application to RFID systems
Golle et al. [62] propose using the GJJS scheme to enhance privacy of RFID tags.
Each tag stores a ciphertext c that is an encrypted version of its identifier id under
some public key pk of its owner, i.e. c ← UE(pk, id). Since tags themselves are not
capable of performing the re-encryption process, more powerful computing agents,
such as readers, re-encrypt the ciphertexts c stored in tags.
In practice, when a customer has bought a number of items with RFID tags attached
in the market, readers in the shop or public area can re-encrypt the ciphertexts
113

5.4 Public key Cryptographic Solutions
in tags as a public service to prevent unauthorised tracking of the tags. More
specifically, a reader obtains c from the tag, re-encrypts it to c′, i.e. c′ ← URe(I, c),
and writes c′ to the tag. Re-encryption can be performed without knowledge of the
underlying public key pk, and thus a reader is able to randomise any tag that have
been encrypted (or re-encrypted) using the shared system parameter.
Privacy analysis
The USSR security property plays an essential role to enhance privacy against passive
eavesdropping adversary. That is, even though an adversary knows the currently
stored ciphertext and the associated identifier of a tag, the adversary cannot identify
the tag any longer once the ciphertext is re-encrypted using the GJJS scheme.
Golle et al.’s scheme, however, is not secure against active adversary,17 thus not sat-
isfying any type of privacy in the Definition 5.3. Golle et al. [62] identify basic vul-
nerability. On seeing a ciphertext c =((α, β), (α′, β′)
)stored in a tag, an adversary
could re-write the ciphertext c′ =((α, β), (1, 1)
)to the tag. It is straightforward to
verify that such a ciphertext will not change after subsequent re-encryptions. They
thus suggest that readers should always check whether a ciphertext read from tags
has this degenerate form.
Even such a security method is performed in readers, the adversary is still able to
trace tags as pointed out by Siato et al. [120]. Suppose an adversary generates a
public/private key pair (y = gx, x) ∈ G × Z∗q . The adversary then constructs the
following ciphertext c and writes it to a target tag T :
c =((myk0 , gk0), (yk1 , gk1)
),
where m is the adversary’s chosen message and (k0, k1) ∈R Z∗q × Z∗q . It follows that
even after the ciphertext c in T has been re-encrypted, the adversary can recognise
T by decrypting the ciphertext resident in T using its private key. More specifically,
even if the ciphertext c in T is re-encrypted to
c′ =((α0, β0), (α1, β1)
)=((myk0 yk1k
′0 , gk0gk1k
′0), (yk1k
′1 , gk1k
′1)),
where (k′0, k′1) ∈R Z∗q ×Z∗q , an adversary can still recognise T by decrypting c′ using
the private key x, i.e. by checking whether α0/βx0 = m and α1/β
x1 = 1.
17Active adversary can write into tags the data that is selected by the adversary.
114

5.4 Public key Cryptographic Solutions
5.4.3 Insubvertible encryption (IE)
As described in previous section, Golle et al.’s universal re-encryption allows an
adversary to mark RFID tags so that they can be recognised later even after they
have been re-encrypted [120]. To address this limitation, Ateniese, Camenisch, and
Medeiros [2] proposed the notion of an insubvertible encryption scheme, which uses a
special type of universal re-encryption technique. Ateniese et al. [2] propose storing
a (ciphertext, certificate) pair in an RFID tag, where the ciphertext is an encrypted
version of the tag identifier under the public key of the tag issuer, and a certificate
is a signature on the issuer’s public key. Their scheme permits such a pair to be
randomised with only the system parameter, but without any keying material, and
the certificate ensures that the ciphertext can only be decrypted by the tag issuer.
Definition
We give the definition of Ateniese et al.’s insubvertible encryption scheme [2], which
we call the IE scheme.
Definition 5.8 The IE scheme is a tuple of polynomial-time algorithms with the
following properties:
• GenerateCAKey generates a public/private signature key pair (CPK, CSK) for a
certification authority C.
• GenerateKey generates a public/private key pair (pk, sk) for a reader R.
• RegisterPublicKey takes as input a public key pk and the private key CSK of a
certificate authority C, and generates a certificate u on pk.
• InitiateTag takes as input the identifier m of a tag T and the pair (pk, u), and
encrypts the pair (m,u) using the public key pk, generating a ciphertext d that
is written to the tag T .
• ReadAndDecrypt takes as input the ciphertext d for a tag T and the pair
(CPK, sk), and determines the identifier of T : If d is the output of the de-
cryption of (u,m) and u corresponds to sk, output m; otherwise, return ⊥.
• ReadAndRandomise takes as input d and CPK, and randomises d to d′.
115

5.4 Public key Cryptographic Solutions
Ateniese et al. [2] construct an example scheme of the IE scheme to prevent the
malicious writing attack described in section 5.4.2. Let E(Fp) be an elliptic curve
defined over the field Fp of low embedding degree, and let G1 be a large subgroup
of prime order q in E(Fp). Suppose also that its embedding degree l be the smallest
integer such that a pairing e : G1×G2 → GT (= Fpl) exists, where G2 is a subgroup
of E(Fpl). Let g be a generator of G1, and g be a generator of G2. As previously,
we use multiplicative group notation, instead of the additive notation often used in
elliptic curve settings.
The certification authority C first generates a public/private key pair (CPK, CSK),
where CPK = (gs, gt) and CSK = (s, t) ∈R Fq × Fq. The reader R then generates
a public/secret key pair (pk, sk) = (y, x), where x ∈R Fp and y = gx ∈ G1, and Cissues a certificate u = (a1, a2, a3, a4, a5) = (a, at, as+xst, ax, axt) ∈ G5
1 for the public
key y, where w ∈R Fq, a = gw ∈ G1, and
e(a1, gt) = e(a2, g), e(a4, g
t) = e(a5, g)
and e(a3, g) = e(a1a5, gs).
}(∗)
The reader R then initiates a tag T with identifier m by writing it the value
d = (u, c) ∈ G71, where r ∈R Fq, u ← (ar1, a
r2, a
r3, a
r4, a
r5) ∈ G5
1, and c = (c1, c2) =
(gk,myk) ∈ G21 for k ∈R Fq.
R can identify T in the following way. R first verifies the certificate u by checking (i)
the equations in (∗) and (ii) whether ax1 = a4 (∈ G1) to ensure that u is a certificate
for its own public key y. R then returns m← c2/cx1 (∈ G1) if u is valid, and x←⊥
otherwise.
Any reader can then verify and randomise T in the following way. R′ verifies the
certificate u by checking the equations in (∗), and writes d′ to T , where
• d′ ← ρ, where ρ is a dummy value, if u is invalid,
• d′ ← (av1, av2, a
v3, a
v4, a
v5, a
z1c1, a
z4c2) ∈ G7
1 for v, z ∈R Fq, otherwise.
The above process enhances tag privacy by either writing into dummy value when the
certificate is not valid, or randomising the ciphertext otherwise. We note that the
randomising process applies the principle of Golle et al.’s universal re-encryption
116

5.5 Lightweight Protocols
[62]. Specifically, we note that a1 = gw and a4 = yw for some w ∈ Fq, where y
is the public key for which the certificate is issued. We thus have the following:
(az1c1, az4c2) = (gwzgk, ywzmyk) = (gw
′,myw
′) for w′ = wz + k.
Privacy analysis
Ateniese et al. [2] define the notion of privacy to mean that if a tag has been read
and randomised by an honest reader, it cannot be tracked by an adversary. This
security definition is equivalent to (discrete, wide, strong, ω)-privacy.
Ateniese et al. [2] prove privacy of the scheme using the Universal Composability
(UC)/Reactive Simulatability frameworks [24, 113]. They first provide a rigorous spec-
ification of the ideal functionality of the IE scheme (the ideal world scenario), where
an ideal world adversary S cannot break privacy. They then propose a specific con-
struction of the IE scheme (the real world scenario). They finally show that the
inputs/outputs of all parties, including adversaries in the real and ideal world, are
identically distributed, and thus a real world adversary A cannot break privacy, as
an ideal world adversary S cannot by definition of the ideal functionality.
The IE scheme, however, is vulnerable against insider attack. When any legitimate
subscriber tries to track some target tags owned by other subscribers by writing
into the tags its certificate and the ciphertext which is encrypted under its public
key. The randomising process, of course, cannot prevent its malicious tracking, and,
even seriously, it is not possible to identify the insider attacker. This is because,
the certificate contains the public key with its randomised version. Ateniese et al.
[2] state that such a threat is mitigated in practice by the need for subscribers to
maintain their reputation within the system. However, in supply chains, which is
the main application of the IE scheme, the most serious adversary is the insiders,
e.g. competitor suppliers or superstores.
5.5 Lightweight Protocols
There has been a considerable volume of work devoted to designing cryptographic
mechanisms with particularly small computational requirements. Juels and Weis
117

5.5 Lightweight Protocols
READER (secret x)TAG (secret x)
Check a · x = z
zCompute z ← a · x⊕ ν
a Choose a ∈R {0, 1}k
ν ∈ {0, 1|Prob(ν = 1) = η}
Figure 5.8: One round of the HB protocol
[81, 139] propose two versions of lightweight authentication protocols, called the
HB/HB+ protocols, whose security can be reduced to a problem called Learning
Parity in the Presence of Noise (LPN). These protocols have been widely discussed as
seen in other variants [21, 50, 65, 83, 95, 109, 142].
The LPN problem requires an adversary to recover a k-bit secret vector x after
being given a number of bits of the form bi = ai ·x⊕νi with unknown noise bits νi’s,
where νi is equal to 1 with probability η ∈ (0, 1/2). The LPN problem is known to
be NP-hard [14] and is formally defined as follows. We write ‖x‖ and ‖A‖ to denote
the Hamming Weight of a vector x and matrix A, respectively.
Definition 5.9 (LPN Problem) Let A be a random q × k binary matrix, x be a
random k-bit vector, η ∈ (0, 1/2) be a constant noise parameter, and ν be a random
q-bit vector such that ‖ν‖ ≤ ηq. Given A, η, and z = (A · x)⊕ ν, find a k-bit vector
x′ such that ‖(A · x′)⊕ z‖ ≤ νq.
The HB protocol (see Figure 5.8) is a tag authentication protocol. The message
exchange is repeated r times, and the tag is deemed authenticated if the check, i.e.
whether a · x = z, fails at most ηr times. The HB protocol is secure against a
passive adversary under the LPN hardness assumption, but not secure against an
active attack [81]. An active adversary could challenge a tag with a chosen value of
a, such as e.g. ||a|| = 1, multiple times, and thereby recover the value a · x. Once
k linearly independent values a haven been collected, the adversary can recover x
using Gaussian elimination [3].
The HB+ protocol (see Figure 5.9) is a somewhat more sophisticated protocol de-
signed to prevent the extraction of tag secrets by the type of attacks described
118

5.6 Conclusions
READER (secret x, y)TAG (secret x, y)
Check a · x⊕ b · y = z
zCompute z ← a · x⊕ b · y ⊕ ν
Choose b ∈R {0, 1}k
a
b
Choose a ∈R {0, 1}k
ν ∈ {0, 1|Prob(ν = 1) = η}
Figure 5.9: One round of the HB+ protocol
above. The secret key shared between a tag and a reader consists of a pair (x, y) of
k-bit vectors. The HB+ protocols is repeated r times, and the tag is deemed to be
successfully authenticated if the check, i.e. whether a · x⊕ b · y = z, fails at most ηr
times.
The HB+ protocol provides (universal, narrow, destructive, ω)-privacy under the
LPN hardness assumption [58, 81]. In particular, Gilbert et al. [58] has discussed
that HB+ is vulnerable to a wide adversary, showing that each “accept” or “reject”
outcome from a reader reveals one bit of secret information.
Specifically, suppose that an adversary intercepts the second message a and instead
sends a ⊕ δ to a tag, where the k-bit vector δ is chosen so that ‖δ‖ = 1 (i.e. δ
has a single non-zero bit). The same vector δ is used in each of the r rounds of the
protocol. If the authentication is successful, δ ·x = 0 with overwhelming probability;
otherwise, δ · x = 1 with overwhelming probability. Acceptance or rejection by the
reader thereby reveals one bit of secret key x, and a k-bit secret vector x can be
recovered after k instances of this attack.
5.6 Conclusions
In this chapter we gave a formal privacy definition, and discussed the existing RFID
schemes which have received very wide attention in the literature. In the following
chapter we discuss EPC tags which seem likely to be used in the majority of RFID
application, mostly affecting consumer privacy as well as supply chain security. We
119

5.6 Conclusions
then propose a privacy-enhancing RFID scheme, and discuss the feasibility of the
practical deployment of the proposed scheme and existing schemes to the EPC tags.
120

Chapter 6
Proposed RFID Systems
Contents
6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . 122
6.2 Security and privacy in the EPCglobal Network . . . . . 123
6.2.1 The EPCglobal Network . . . . . . . . . . . . . . . . . . . . 123
6.2.2 Gen2 Standards . . . . . . . . . . . . . . . . . . . . . . . . 127
6.2.3 Security and privacy requirements . . . . . . . . . . . . . . 135
6.2.4 Gen2 standard and related variant schemes . . . . . . . . . 136
6.3 Proposed RFID system . . . . . . . . . . . . . . . . . . . . 140
6.3.1 Construction of algorithms . . . . . . . . . . . . . . . . . . 140
6.3.2 Privacy analysis . . . . . . . . . . . . . . . . . . . . . . . . 143
6.3.3 Further discussions . . . . . . . . . . . . . . . . . . . . . . . 145
6.4 Application to the EPCglobal Network . . . . . . . . . . 145
6.4.1 Existing schemes . . . . . . . . . . . . . . . . . . . . . . . . 146
6.4.2 Proposed scheme . . . . . . . . . . . . . . . . . . . . . . . . 148
6.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
We describe the EPCglobal Network and its associated RFID system, which looks set
to become the most widely deployed RFID system in the near future. We define the
security requirements arising from threats that arise from the RFID systems within
the EPCglobal Network. We then construct an example of a refresh-based RFID
system, and analyse its security and privacy properties. Finally, we investigate the
applicability of the proposed system to the EPCglobal Network.
121

6.1 Introduction
6.1 Introduction
The EPCglobal Network [71] is a standard-based approach designed to help realise
automated global supply chain management. EPCglobal1, a subscriber-driven or-
ganisation, is leading the development of the EPCglobal Network. The EPCglobal
Network uses RFID technology to obtain information for individual objects, and
uses Internet technology to create a network for sharing the information captured
from tags among authorised trading partners.
An EPC (Electronic Product Code) tag is the key component in the EPCglobal
Network. The EPC tag is an RFID tag, which is attached to, or embedded in, items.
These technologies could usefully be extended to consumers beyond the supply chain
to maximise the benefits of RFID technology. However, security and privacy threats
for such applications are potentially serious.
In a privacy-enhanced RFID system, an RFID tag identifies itself to an autho-
rised reader using a sequence of pseudonyms, and these pseudonyms should appear
random to any entity other than the authorised reader. EPC tags, however, are in-
capable of either computing or storing such a sequence of pseudonyms. The refresh-
based RFID schemes discussed in section 5.4 could be used to ensure privacy of EPC
tags, delegating expensive computations to external transceivers.
In section 6.2 we briefly describe the EPCglobal Network [71] and its associated
RFID standard, and define security and privacy requirements. In section 6.3 we
then propose a refresh-based RFID system which complies with the underlying RFID
standard, and analyse privacy of the proposed scheme using the privacy model de-
fined in the previous chapter. Finally, in section 6.4, we investigate the feasibility
of practical deployment of the proposed scheme and the existing schemes to the
EPCglobal Network [71].
1http://www.epcglobalinc.org
122

6.2 Security and privacy in the EPCglobal Network
6.2 Security and privacy in the EPCglobal Network
We briefly describe the EPCglobal Network and the standard of its associated RFID
system, and then investigate the security and privacy issues for the RFID system.
6.2.1 The EPCglobal Network
Efficiency gains in supply chain management can deliver significant savings to busi-
nesses, and RFID technology has been introduced as a way of achieving this. EPC
tags provide two attractive features by comparison with conventional barcodes:
• Automation: EPC tags can transmit information to RFID readers via RF
without requiring line-of-sight or physical contact. This feature reduces the
need for potentially costly manual intervention in the scanning process.
• Unique Identification: While a barcode typically specifies the type of a prod-
uct, an EPC tag assigns a unique serial number to individual items. This
unique identifier associated with an object can be used as a pointer to a
database containing a detailed history of the object.
The EPCglobal Network then provides two fundamental capabilities to support sup-
ply chain management [73]. It allows companies both to know where a product is
at any time within the supply chain (tracking), and to see exactly where a product
has been throughout the entire supply chain process (tracing).
We now briefly describe the architecture, components, functionality, and implemen-
tation of the EPCglobal Network.
Architecture framework
As illustrated in Figure 6.1, the EPCglobal architecture framework [71] describes
the activities carried out by EPCglobal subscribers and the role that components of
the EPCglobal architecture framework play in facilitating those activities. It also
123

6.2 Security and privacy in the EPCglobal Network
EPCglobal Subscriber
EPCglobal Core Servicesand other shared services
shared service interaction
peer-to-peer exchange of data about EPCs
exchange of physical objects with EPCs
EPC Information Services (EPCIS)EPCglobal Subscriber
Objects
EPC Middleware
RFID System
Object Name Service (ONS)
EPCIS Discovery
Tag Data
EPC iden-tificationstandards
EPC infra-structurestandards
EPC dataexchagestandards
= Interface and Data Standards
Subscriber Authentication
Figure 6.1: The EPCglobal Network architecture framework [71]
Electronic Product Code
01 . 000A89 . 00013F . 000134GQEHeader EPC Manager Object Class Serial Number
Figure 6.2: Electronic Product Code [71]
defines three broad standards, each supported by a group of minor standards. We
first describe the three main groups of standards.
• The Electronic Product Code (EPC) data exchange standards provide a
means for subscribers to share data about EPCs within defined user groups,
or with the general public, in order to enable sharing of information about the
movement of physical objects through the network.
• The EPC Infrastructure standards define interface standards for subscribers’
internal systems to enable them to share EPC data.
• The EPC identification standards are designed to ensure that, when one sub-
scriber delivers a physical object to another subscriber, the recipient will be
able to determine the EPC of the object and interpret it properly.
The EPCglobal Network consists of the following components [71], which are used to
realise its three major activities, i.e. shared service interaction, peer-to-peer exchange
124

6.2 Security and privacy in the EPCglobal Network
of data about EPCs, and exchange of physical objects with EPCs, as shown in Figure
6.1.
• Electronic Product Codes: EPCs are analogous to the Universal Product
Codes (UPCs) used in bar codes. Unlike UPCs, however, EPCs uniquely
identify individual product items via a serial number, as shown in Figure 6.2.
The EPC Manager, which is typically a manufacturer in the supply chain, is
an organisation that is granted the right to use one or more blocks of EPCs
within a designated coding scheme, in order to independently assign EPCs to
physical objects or other entities. We make a distinction between an EPC and
an EPC tag. An EPC tag is an RFID device attached to an object, while an
EPC is a bit string stored in an EPC tag.
• RFID System: The RFID system consists of tags and readers. EPCs are
stored on the tags, which are applied to cases, pallets, and/or individual items.
Readers communicate with tags via radio, and deliver the captured EPCs to
the local business information systems using the EPC Middleware.
• EPC Middleware: This is a subscriber’s internal infrastructure, including the
readers, data collection software, and enterprise applications. It manages the
captured tag information by communicating with EPCIS and other informa-
tion systems at the business site.
• EPC Information Services (EPCIS): This is a data repository which stores
EPC information about unique items. Each company has its own EPCIS, and
designates which trading partners have access to its EPCIS.
• Discovery Services: This is a collective term for the Object Name Service
(ONS) and the EPCIS Discovery Service. The ONS is a simple lookup service
that, given an EPC as input, outputs the address (in the form of a Uniform Re-
source Locator (URL)) of EPCIS which issued the EPC. The EPCIS Discovery
Service provides a directory of the EPCISs of the parties which participated
in the supply chain for a particular EPC.
125

6.2 Security and privacy in the EPCglobal Network
ONS
Manufacturer
EPCIS
Distributor
EPCIS
Retailer
EPCIS
Authorised partners in the supply chain
Discovery Services
12 6
7
54
3 8
EPCIS Discovery
9
Figure 6.3: The EPCglobal Network in action [72]
The EPCglobal Network in action
The EPCglobal Network enables information to be disseminated across the entire
supply chain. As shown in Figure 6.3, it involves the following steps.
1. A product is first given a tag that includes an EPC.
2. The information on this particular product is added to the manufacturer’s
EPCIS.
3. The location of this information is passed to the Discovery Services.
4-5. When the product leaves the manufacturer’s premises, the EPCIS is updated
with the departure information of the product.
6-7. The arrival of the product is registered with the distributor’s EPCIS, and the
location information of the product is updated with the Discovery Services.
8-9. A retailer asks the ONS for the location of the manufacturer’s EPCIS in order
to obtain the product information, and also asks the EPCIS Discovery Service
to obtain the history of the whereabouts of the arrived product.
A more detailed description is given in [72].
126

6.2 Security and privacy in the EPCglobal Network
Implementation
Adoption of EPCglobal Network technology is still at an early stage. Companies
in the Fast Moving Consumer Goods (FMCG) industry are currently testing the
components in the EPCglobal Network at the pallet and case level [69]. Item-level
tagging, however, is expected to only be implemented on a large scale when tag cost
drops to $0.05 and the standards are well established [77].
6.2.2 Gen2 Standards
The Auto-ID centre first developed the EPCglobal Network as a way of bringing
the benefits of RFID technology to the global supply chain. The original Class-1
Generation-1 RFID standard (Gen1 standard) was developed by a small number of
commercial companies, and was not an open standard. The Auto-ID center also
started the development of the Class-1 Generation-2 (Gen2 standard), eventually
transferring the responsibility for its further development to EPCglobal, which was
formed by EAN International and the Uniform Code Council (UCC).
In this section we describe the standard of RFID systems for the EPCglobal Network,
known as the Class-1 Generation-2 UHF (860–960 MHz) RFID standard (ISO/IEC
18000-6C) [70].
Memory
The memory of EPC tags is logically separated into four distinct banks, as shown
Figure 6.4. The memory banks are defined as follows.
• EPC memory contains a CRC-16, Protocol-Control (PC) bits, and a code (e.g.
an EPC) that identifies the object to which the tag is or will be attached. A
CRC-16 is a cyclic-redundancy check, and it conforms with ISO/IEC 13239.
The PC bits contain an EPC length field, which supports up to 416 bits of
EPC length.
• User memory allows to store user-specific data.
127
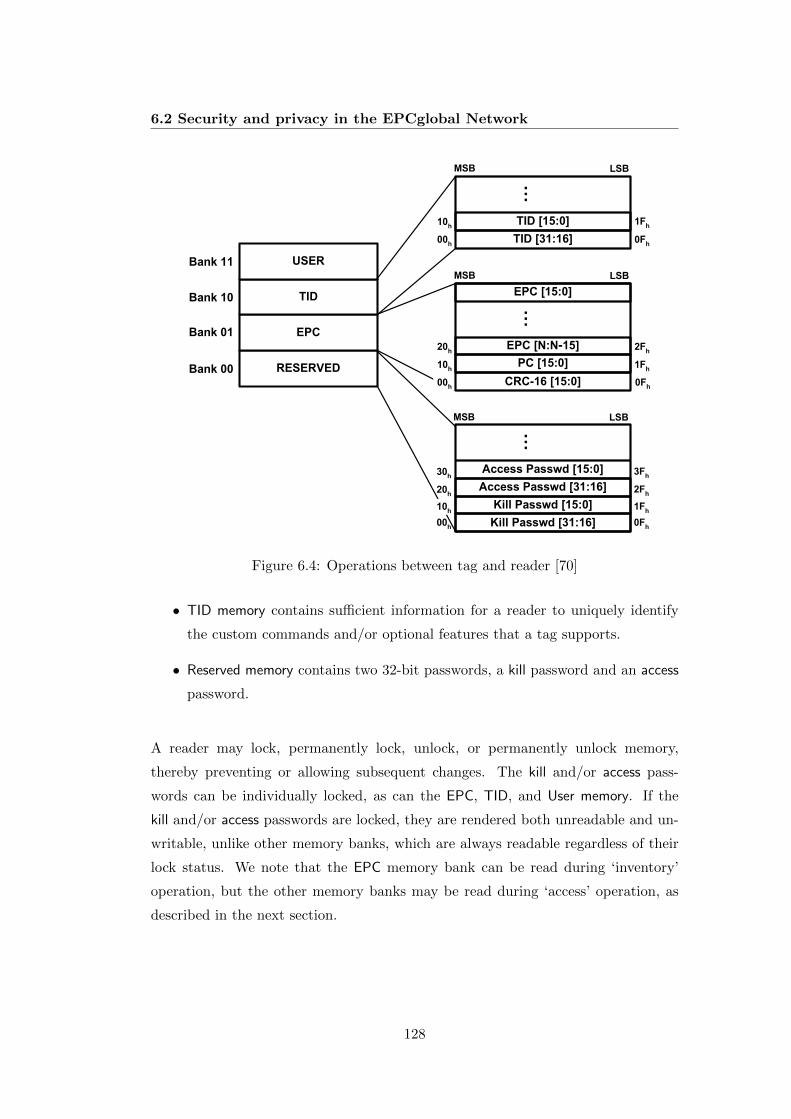
6.2 Security and privacy in the EPCglobal Network
6.3.2 Tag selection, inventory, and access Tag selection, inventory, and access may be viewed as the lowest level in the data link layer of a layered network communication system.
6.3.2.1 Tag memory
Tag memory shall be logically separated into four distinct banks, each of which may comprise zero or more mem-ory words. A logical memory map is shown in Figure 6.17. The memory banks are:
a) Reserved memory shall contain the kill and access passwords. The kill password shall be stored at memory addresses 00h to 1Fh; the access password shall be stored at memory addresses 20h to 3Fh. If a Tag does not implement the kill and/or access password(s), the Tag shall act as though it had zero-valued password(s) that are permanently read/write locked (see 6.3.2.10.3.5), and the corresponding memory locations in Reserved memory need not exist.
b) EPC memory shall contain a CRC-16 at memory addresses 00h to 0Fh, Protocol-Control (PC) bits at memory addresses 10h to 1Fh, and a code (such as an EPC, and hereafter referred to as an EPC) that identifies the object to which the tag is or will be attached beginning at address 20h. As detailed in 6.3.2.1.4, the PC is subdivided into an EPC length field in memory locations 10h to 14h, RFU bits in mem-ory locations 15h and 16h, and a Numbering System Identifier (NSI) in memory locations 17h to 1Fh. The CRC-16, PC, and EPC shall be stored MSB first (the EPC’s MSB is stored in location 20h).
c) TID memory shall contain an 8-bit ISO/IEC 15963 allocation class identifier (111000102 for EPCglobal) at memory locations 00h to 07h. TID memory shall contain sufficient identifying information above 07h for an Interrogator to uniquely identify the custom commands and/or optional features that a Tag supports. For Tags whose ISO/IEC 15963 allocation class identifier is 111000102, this identifying information shall com-prise a 12-bit Tag mask-designer identifier (free to members of EPCglobal) at memory locations 08h to 13h and a 12-bit Tag model number at memory locations 14h to 1Fh. Tags may contain Tag- and vendor-specific data (for example, a Tag serial number) in TID memory above 1Fh.
d) User memory allows user-specific data storage. The memory organization is user-defined.
The logical addressing of all memory banks shall begin at zero (00h). The physical memory map is vendor-specific. Commands that access memory have a MemBank parameter that selects the bank, and an address parameter, specified using the EBV format described in Annex A, to select a particular memory location within that bank.
00h
00h
10h
20h
0Fh
1Fh
2Fh
MSB LSBBank 11
Bank 10
Bank 01
Bank 00 RESERVED
EPC
TID
USER
CRC-16 [15:0]
EPC [15:0]
EPC [N:N-15]
…
20h
0Fh
1Fh
2Fh
MSB LSB
30h 3Fh
10h
Access Passwd [15:0]
Kill Passwd [15:0]Access Passwd [31:16]
Kill Passwd [31:16]
…00h
10h
0Fh
1Fh
MSB LSB
TID [31:16]TID [15:0]
…
PC [15:0]
Figure 6.17 – Logical memory map
© 2004, EPCglobal Inc. Page 35 of 94 31 January 2005 Figure 6.4: Operations between tag and reader [70]
• TID memory contains sufficient information for a reader to uniquely identify
the custom commands and/or optional features that a tag supports.
• Reserved memory contains two 32-bit passwords, a kill password and an access
password.
A reader may lock, permanently lock, unlock, or permanently unlock memory,
thereby preventing or allowing subsequent changes. The kill and/or access pass-
words can be individually locked, as can the EPC, TID, and User memory. If the
kill and/or access passwords are locked, they are rendered both unreadable and un-
writable, unlike other memory banks, which are always readable regardless of their
lock status. We note that the EPC memory bank can be read during ‘inventory’
operation, but the other memory banks may be read during ‘access’ operation, as
described in the next section.
128

6.2 Security and privacy in the EPCglobal Network
Select
Access
Inventory
ReadyArbitrate
ReplyAcknowleged
OpenSecured
Killed
Reader TagState
Figure 6.5: Tag-reader operations and tag state changes [70]
Air interface
We now describe the air interface between a tag and a reader, following ‘Specification
for RFID Air Interface by EPCglobal’ [70]. Readers manage tag populations using
the three basic operations, while tags implement the states, as shown in Figure 6.5.
The operations are defined in three steps: select, inventory, and access.
In the select process a reader selects a particular tag population prior to use of the
inventory process. It involves issuing multiple identical Select commands to select
the tags matching user-defined criteria.
In the inventory process a reader uniquely identifies, using commands of Query,
QueryAdjust, QueryRep, ACK, and NAC. Upon receiving a Query participating tags
pick a random value in (0, 2Q − 1), inclusive, and load this value into their slot
counter. The slot counter parameter Q is an integer in (0, 15), inclusive. If tags pick
a zero, they transition to the ready state and reply immediately; otherwise, they
transition to the arbitrary state, and await a QueryAdjust/QueryRep command.
Assuming that a single tag replies, the query-response protocol proceeds between a
tag T and a reader R as follows.
(a) Upon receiving a Query from R, T backscatters a randomly generated 16-bit
RN16, and enters the reply state.
(b) R acknowledges T by sending an ACK, which is the same as the received RN16.
(c) On receiving ACK, T checks that RN16 = ACK; if so, T backscatters its PC,
EPC, and CRC-16.
129

6.2 Security and privacy in the EPCglobal Network
Annex E (informative)
Example of Tag inventory and access
E.1 Example inventory and access of a single Tag Figure E.1 shows the steps by which an Interrogator inventories and accesses a single Tag.
Interrogator issues Req_RNcontaining same RN16
INTERROGATOR TAG
Interrogator accesses Tag.Each access command useshandle as a parameter
Tag verifies handle. Tag ignorescommand if handle does not match
5
6
7
8
Interrogator acknowledgesTag by issuing ACK withsame RN16
3
Two possible outcomes:1) Valid RN16: Tag responds with {PC, EPC}2) Invalid RN16: No reply
4
Interrogator issues a Query,QueryAdjust, or QueryRep1
Two possible outcomes:1) Slot = 0: Tag responds with RN162) Slot <> 0: No reply
2
Query/Adjust/Rep
ACK(RN16)
RN16
{PC, EPC}
Req_RN(RN16)
handle
command(handle)
NOTES: -- CRC-16 not shown in transitions -- See command/reply tables for command details
Two possible outcomes:1) Valid RN16: Tag responds with {handle}2) Invalid RN16: No reply
Figure E.1 – Example of Tag inventory and access
© 2004, EPCglobal Inc. Page 85 of 94 31 January 2005
Figure 6.6: Example of tag inventory and access [70]
After acknowledging T , R may issue a QueryAdjust/QueryRep command, causing
T to transition to the ready state. If T fails to receive ACK within a pre-defined
timeout, or receives ACK with an erroneous RN16 in step (c), T transitions to the
arbitrary state. T in the arbitrary or ready state that receives a QueryAdjust first
adjusts Q and picks a random value in (0, 2Q − 1), inclusive, and loads this value
into its slot counter. T in the arbitrary state that receives a QueryRep decrements its
slot counter, and transitions to the reply state and backscatters RN16 when its slot
counter reaches a zero. At any point, R may issue a NAK to cause T to transition to
the arbitrary state.
When multiple tags reply in step (a), a reader can resolve an RN16 from one of
the tags by detecting and resolving collisions at the waveform level. Unresolved
tags receive erroneous RN16 and return to the arbitrary state. Also, two or more
readers can independently inventory the common tag population. The more detailed
description can be found in the Gen2 standard [70].
After acknowledging a tag, a reader may choose to access it during the access process.
The specification defines mandatory commands such as Req RN, Read, Write, Kill,
130

6.2 Security and privacy in the EPCglobal Network
Table 6.38 – Lock command
Command Payload RN CRC-16
# of bits 8 20 16 16
description 11000101 Mask and Action Fields handle
Table 6.39 – Tag reply to a Lock command
Header RN CRC-16
# of bits 1 16 16
description 0 handle
0 1 2 3 4 5 6 7 8 9
KillMask
AccessMask
EPCMask
TIDMask
10 11 12 13 14 15 16 17
UserMask
KillAction
AccessAction
EPCAction
TIDAction
UserAction
18 19
Masks and Associated Action Fields
pwdread/write
permalock
pwdread/write
permalock
pwdwrite
permalock
pwdwrite
permalock
pwdwrite
permalock
0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
Mask
Action
Kill pwd Access pwd EPC memory TID memory User memory
Lock-Command Payload
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
Figure 6.24 – Lock payload and usage
Table 6.40 – Lock Action-field functionality
pwd-write permalock Description
0 0 Associated memory bank is writeable from either the open or secured states.
0 1 Associated memory bank is permanently writeable from either the open or secured states and may never be locked.
1 0 Associated memory bank is writeable from the secured state but not from the open state.
1 1 Associated memory bank is not writeable from any state.
pwd-read/write permalock Description
0 0 Associated password location is readable and writeable from either the open or securedstates.
0 1 Associated password location is permanently readable and writeable from either the openor secured states and may never be locked.
1 0 Associated password location is readable and writeable from the secured state but not from the open state.
1 1 Associated password location is not readable or writeable from any state.
© 2004, EPCglobal Inc. Page 62 of 94 31 January 2005
Figure 6.7: Lock command payload and usage [70]
and Lock, and optional commands such as Access, BlockWrite, and BlockErase.
A reader R and a tag T in the acknowledge state start access process as follows.
(a) R issues a Req RN to T .
(b) T generates and stores a new RN16, which is called a handle, and backscatters
the handle. T transitions to the open state if its access password is nonzero;
otherwise, it transitions to the secured state.
R may now issue further access commands, or may terminate the access sequence
by issuing a Query, QueryAdjust, QueryRep, or NAK. All access commands issued
to T in the open or secured states include the tag’s handle, which the tag verifies
prior to executing the received access commands. This handle is fixed for the entire
duration of an access sequence.
We particularly describe a set of commands, Lock, Write, and Access. The de-
scription of the other commands used in access operation can be found in the Gen2
standard [70].
A reader uses the Lock command in order to:
• lock individual passwords (i.e. kill and access passwords), thereby preventing
or allowing subsequent reads and/or writes of that password;
131
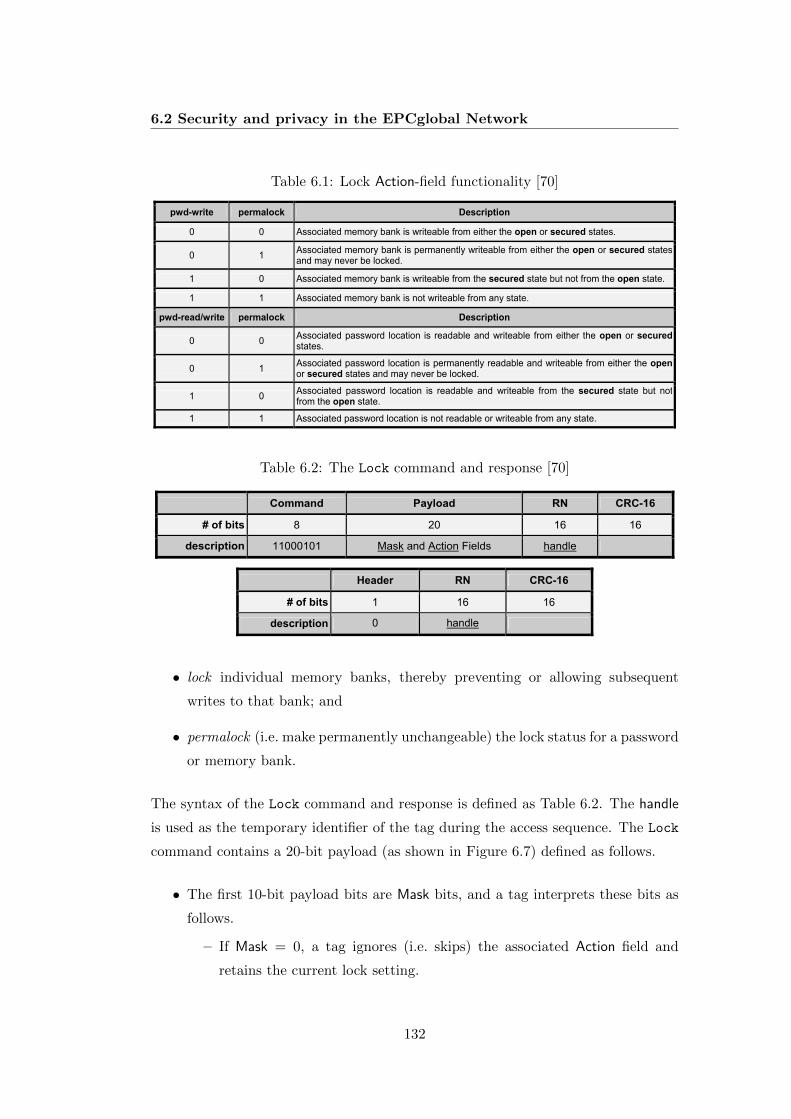
6.2 Security and privacy in the EPCglobal Network
Table 6.1: Lock Action-field functionality [70]
Table 6.38 – Lock command
Command Payload RN CRC-16
# of bits 8 20 16 16
description 11000101 Mask and Action Fields handle
Table 6.39 – Tag reply to a Lock command
Header RN CRC-16
# of bits 1 16 16
description 0 handle
0 1 2 3 4 5 6 7 8 9
KillMask
AccessMask
EPCMask
TIDMask
10 11 12 13 14 15 16 17
UserMask
KillAction
AccessAction
EPCAction
TIDAction
UserAction
18 19
Masks and Associated Action Fields
pwdread/write
permalock
pwdread/write
permalock
pwdwrite
permalock
pwdwrite
permalock
pwdwrite
permalock
0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
Mask
Action
Kill pwd Access pwd EPC memory TID memory User memory
Lock-Command Payload
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
Figure 6.24 – Lock payload and usage
Table 6.40 – Lock Action-field functionality
pwd-write permalock Description
0 0 Associated memory bank is writeable from either the open or secured states.
0 1 Associated memory bank is permanently writeable from either the open or secured states and may never be locked.
1 0 Associated memory bank is writeable from the secured state but not from the open state.
1 1 Associated memory bank is not writeable from any state.
pwd-read/write permalock Description
0 0 Associated password location is readable and writeable from either the open or securedstates.
0 1 Associated password location is permanently readable and writeable from either the openor secured states and may never be locked.
1 0 Associated password location is readable and writeable from the secured state but not from the open state.
1 1 Associated password location is not readable or writeable from any state.
© 2004, EPCglobal Inc. Page 62 of 94 31 January 2005
Table 6.2: The Lock command and response [70]Table 6.38 – Lock command
Command Payload RN CRC-16
# of bits 8 20 16 16
description 11000101 Mask and Action Fields handle
Table 6.39 – Tag reply to a Lock command
Header RN CRC-16
# of bits 1 16 16
description 0 handle
0 1 2 3 4 5 6 7 8 9
KillMask
AccessMask
EPCMask
TIDMask
10 11 12 13 14 15 16 17
UserMask
KillAction
AccessAction
EPCAction
TIDAction
UserAction
18 19
Masks and Associated Action Fields
pwdread/write
permalock
pwdread/write
permalock
pwdwrite
permalock
pwdwrite
permalock
pwdwrite
permalock
0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
Mask
Action
Kill pwd Access pwd EPC memory TID memory User memory
Lock-Command Payload
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
Figure 6.24 – Lock payload and usage
Table 6.40 – Lock Action-field functionality
pwd-write permalock Description
0 0 Associated memory bank is writeable from either the open or secured states.
0 1 Associated memory bank is permanently writeable from either the open or secured states and may never be locked.
1 0 Associated memory bank is writeable from the secured state but not from the open state.
1 1 Associated memory bank is not writeable from any state.
pwd-read/write permalock Description
0 0 Associated password location is readable and writeable from either the open or securedstates.
0 1 Associated password location is permanently readable and writeable from either the openor secured states and may never be locked.
1 0 Associated password location is readable and writeable from the secured state but not from the open state.
1 1 Associated password location is not readable or writeable from any state.
© 2004, EPCglobal Inc. Page 62 of 94 31 January 2005
Table 6.38 – Lock command
Command Payload RN CRC-16
# of bits 8 20 16 16
description 11000101 Mask and Action Fields handle
Table 6.39 – Tag reply to a Lock command
Header RN CRC-16
# of bits 1 16 16
description 0 handle
0 1 2 3 4 5 6 7 8 9
KillMask
AccessMask
EPCMask
TIDMask
10 11 12 13 14 15 16 17
UserMask
KillAction
AccessAction
EPCAction
TIDAction
UserAction
18 19
Masks and Associated Action Fields
pwdread/write
permalock
pwdread/write
permalock
pwdwrite
permalock
pwdwrite
permalock
pwdwrite
permalock
0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
Mask
Action
Kill pwd Access pwd EPC memory TID memory User memory
Lock-Command Payload
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
skip/write
Figure 6.24 – Lock payload and usage
Table 6.40 – Lock Action-field functionality
pwd-write permalock Description
0 0 Associated memory bank is writeable from either the open or secured states.
0 1 Associated memory bank is permanently writeable from either the open or secured states and may never be locked.
1 0 Associated memory bank is writeable from the secured state but not from the open state.
1 1 Associated memory bank is not writeable from any state.
pwd-read/write permalock Description
0 0 Associated password location is readable and writeable from either the open or securedstates.
0 1 Associated password location is permanently readable and writeable from either the openor secured states and may never be locked.
1 0 Associated password location is readable and writeable from the secured state but not from the open state.
1 1 Associated password location is not readable or writeable from any state.
© 2004, EPCglobal Inc. Page 62 of 94 31 January 2005
• lock individual memory banks, thereby preventing or allowing subsequent
writes to that bank; and
• permalock (i.e. make permanently unchangeable) the lock status for a password
or memory bank.
The syntax of the Lock command and response is defined as Table 6.2. The handle
is used as the temporary identifier of the tag during the access sequence. The Lock
command contains a 20-bit payload (as shown in Figure 6.7) defined as follows.
• The first 10-bit payload bits are Mask bits, and a tag interprets these bits as
follows.
– If Mask = 0, a tag ignores (i.e. skips) the associated Action field and
retains the current lock setting.
132

6.2 Security and privacy in the EPCglobal Network
– If Mask = 1, a tag implements the associated Action field and overwrites
the current lock setting.
• The last 10 payload bits are Action bits, and are defined as in Table 6.1.
Permalock bits, once they have been set, cannot be changed. Depending the success
of Lock command operation, a tag replies by backscattering its handle if the opera-
tion has been successful; otherwise, the tag backscatters an error code. If a reader
does not observe any reply within 20ms, it assumes that the lock operation has not
been successful.
We next describe the use of the Write and Access commands. When a reader Rsends these commands, it sends a 16-bit word (either data or half-passwords) to a
tag T at a time, using a technique called cover-coding to prevent sensitive words
from being transmitted in cleartext in high-power forward link. The sequence is
defined as follows.
(a) R issues a Req RN, to which T responds by backscattering a new RN16. Tstores this RN16.
(b) R generates and transmits a ciphertext that is a bit-wise XOR of a 16-bit word
(to be transmitted) with the received RN16.
(c) T decrypts the received ciphertext string by performing a bit-wise XOR of the
received 16-bit ciphertext with the stored RN16.
R must not use re-use an RN16 for cover-coding, and it shall first issue Req RN for
sending another data. The handle is not used for cover-coding. We give an example
of tag inventory and access operations in Figure 6.6.2 We now describe the Write
and Access commands more in detail.
The Access command is used to cause a tag with a non-zero access password to
transition form the open state to the secured state.3 The syntax of the Access
command and response is defined as Table 6.3. Since the Access command contains
a half-password (i.e. 16 bits), a reader issues two Access commands using the cover-
coding technique described above, and a tag incorporates the necessary logic to
successively accept two 16-bit sub-portions of a 32-bit access password.
2The Gen2 standard uses a term interrogator to denote a reader.3A tag with a zero access password is never in the open state as described earlier in this section.
133
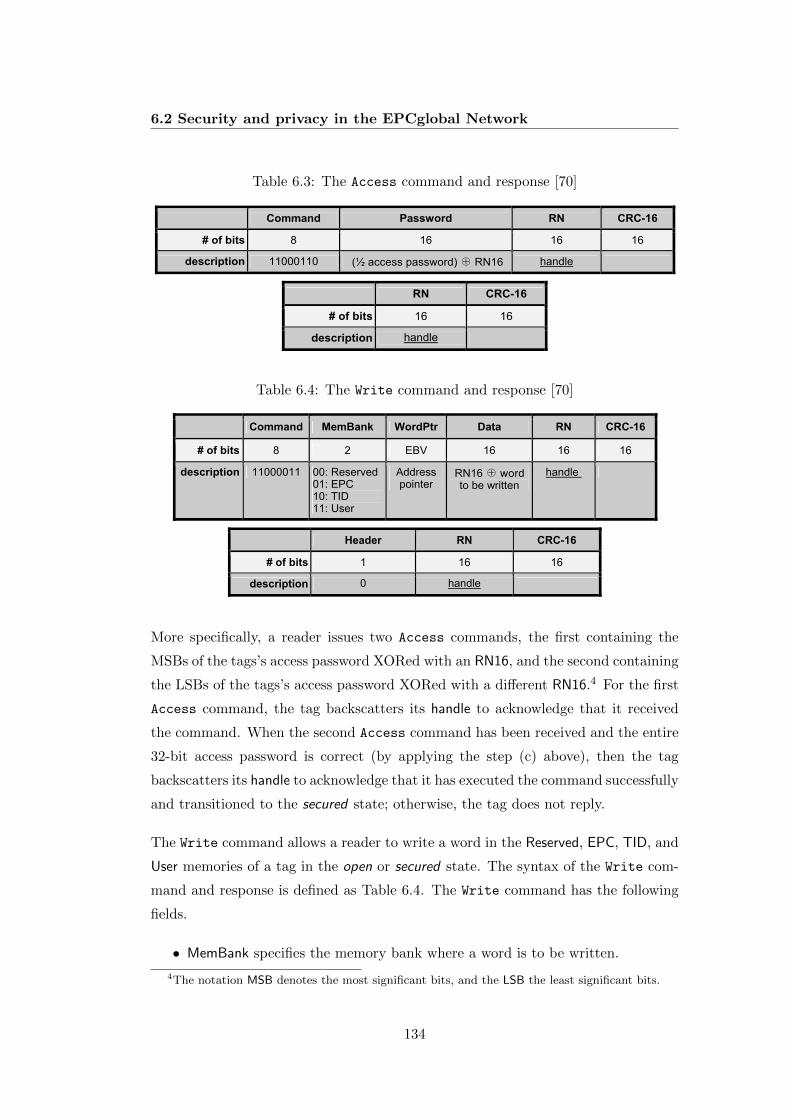
6.2 Security and privacy in the EPCglobal Network
Table 6.3: The Access command and response [70]
6.3.2.10.3.6 Access (optional)
Interrogators and Tags may implement an Access command; if they do, the command shall be as shown in Table 6.41. Access causes a Tag with a nonzero-valued access password to transition from the open to the securedstate (a Tag with a zero-valued access password is never in the open state — see Figure 6.19) or, if the Tag isalready in the secured state, to remain in secured.
To access a Tag, an Interrogator shall follow the multi-step procedure outlined in Figure 6.25. Briefly, an Interro-gator issues two Access commands, the first containing the 16 MSBs of the Tag’s access password EXORed with an RN16, and the second containing the 16 LSBs of the Tag’s access password EXORed with a different RN16.Each EXOR operation shall be performed MSB first (i.e. the MSB of each half-password shall be EXORed with the MSB of its respective RN16). Just prior to issuing each Access command the Interrogator first issues a Req_RN to obtain a new RN16.
Tags shall incorporate the necessary logic to successively accept two 16-bit subportions of a 32-bit access pass-word. Interrogators shall not intersperse commands other than Req_RN between the two successive Access commands. If a Tag, after receiving a first Access, receives any command other than Req_RN before the secondAccess, it shall return to arbitrate, unless the intervening command is a Query, in which case the Tag shall exe-cute the Query (inverting its inventoried flag if the session parameter in the Query matches the prior session).
An Access shall be prepended with a frame-sync (see 6.3.1.2.8).
The Tag reply to an Access command shall be as shown in Table 6.42. If the Access is the first in the sequence, then the Tag backscatters its handle to acknowledge that it received the command. If the Access is the second inthe sequence and the entire received 32-bit access password is correct, then the Tag backscatters its handle toacknowledge that it has executed the command successfully and has transitioned to the secured state; otherwise the Tag does not reply. The reply includes a CRC-16 calculated over the handle.
Table 6.41 – Access command
Command Password RN CRC-16
# of bits 8 16 16 16
description 11000110 (! access password) ⊕ RN16 handle
Table 6.42 – Tag reply to an Access command
RN CRC-16
# of bits 16 16
description handle
© 2004, EPCglobal Inc. Page 63 of 94 31 January 2005
6.3.2.10.3.6 Access (optional)
Interrogators and Tags may implement an Access command; if they do, the command shall be as shown in Table 6.41. Access causes a Tag with a nonzero-valued access password to transition from the open to the secured state (a Tag with a zero-valued access password is never in the open state — see Figure 6.19) or, if the Tag is already in the secured state, to remain in secured.
To access a Tag, an Interrogator shall follow the multi-step procedure outlined in Figure 6.25. Briefly, an Interro-gator issues two Access commands, the first containing the 16 MSBs of the Tag’s access password EXORed with an RN16, and the second containing the 16 LSBs of the Tag’s access password EXORed with a different RN16. Each EXOR operation shall be performed MSB first (i.e. the MSB of each half-password shall be EXORed with the MSB of its respective RN16). Just prior to issuing each Access command the Interrogator first issues a Req_RN to obtain a new RN16.
Tags shall incorporate the necessary logic to successively accept two 16-bit subportions of a 32-bit access pass-word. Interrogators shall not intersperse commands other than Req_RN between the two successive Access commands. If a Tag, after receiving a first Access, receives any command other than Req_RN before the second Access, it shall return to arbitrate, unless the intervening command is a Query, in which case the Tag shall exe-cute the Query (inverting its inventoried flag if the session parameter in the Query matches the prior session).
An Access shall be prepended with a frame-sync (see 6.3.1.2.8).
The Tag reply to an Access command shall be as shown in Table 6.42. If the Access is the first in the sequence, then the Tag backscatters its handle to acknowledge that it received the command. If the Access is the second in the sequence and the entire received 32-bit access password is correct, then the Tag backscatters its handle to acknowledge that it has executed the command successfully and has transitioned to the secured state; otherwise the Tag does not reply. The reply includes a CRC-16 calculated over the handle.
Table 6.41 – Access command
Command Password RN CRC-16
# of bits 8 16 16 16
description 11000110 (! access password) RN16 handle
Table 6.42 – Tag reply to an Access command
RN CRC-16
# of bits 16 16
description handle
© 2004, EPCglobal Inc. Page 63 of 94 31 January 2005
Table 6.4: The Write command and response [70]
6.3.2.10.3.3 Write (mandatory)
Interrogators and Tags shall implement the Write command shown in Table 6.33. Write allows an Interrogator towrite a word in a Tag’s Reserved, EPC, TID, or User memory. Write has the following fields:
MemBank specifies whether the Write occurs in Reserved, EPC, TID, or User memory. WordPtr specifies the word address for the memory write, where words are 16 bits in length. For example, WordPtr = 00h specifies the first 16-bit memory word, WordPtr = 01h specifies the second 16-bit memoryword, etc. WordPtr uses EBV formatting (see Annex A). Data contains a 16-bit word to be written. Before each and every Write the Interrogator shall first issue aReq_RN command; the Tag responds by backscattering a new RN16. The Interrogator shall cover-codethe data by EXORing it with this new RN16 prior to transmission.
The Write command also includes the Tag’s handle and a CRC-16. The CRC-16 is calculated over the first com-mand-code bit to the last handle bit.
If a Tag in the open or secured states receives a Write with a valid CRC-16 but an invalid handle, or it receives a Write before which the immediately preceding command was not a Req_RN, it shall ignore the Write and remainin its current state.
A Write shall be prepended with a frame-sync (see 6.3.1.2.8).
After issuing a Write an Interrogator shall transmit CW for the lesser of TREPLY or 20ms, where TREPLY is the timebetween the Interrogator’s Write command and the Tag’s backscattered reply. An Interrogator may observe sev-eral possible outcomes from a Write, depending on the success or failure of the Tag’s memory-write operation:
The Write succeeds: After completing the Write a Tag shall backscatter the reply shown in Table 6.34 and Figure 6.22 comprising a header (a 0-bit), the Tag’s handle, and a CRC-16 calculated over the 0-bit and handle. If the Interrogator observes this reply within 20 ms then the Write completed successfully. The Tag encounters an error: The Tag shall backscatter an error code during the CW period rather than the reply shown in Table 6.34 (see Annex I for error-code definitions and for the reply format). The Write does not succeed: If the Interrogator does not observe a reply within 20ms then the Write did not complete successfully. The Interrogator may issue a Req_RN command (containing the Tag’s handle) to verify that the Tag is still in the Interrogator’s field, and may reissue the Write command.
Upon receiving a valid Write command a Tag shall write the commanded Data into memory. The Tag’s reply to a successful Write shall use the extended preamble shown in Figure 6.11 or Figure 6.15, as appropriate (i.e. a Tag shall reply as if TRext=1 regardless of the TRext value in the Query that initiated the round).
Table 6.33 – Write command
Command MemBank WordPtr Data RN CRC-16
# of bits 8 2 EBV 16 16 16
description 11000011 00: Reserved 01: EPC 10: TID 11: User
Address pointer
RN16 ⊕ wordto be written
handle
Table 6.34 – Tag reply to a successful Wr te command i
Header RN CRC-16
# of bits 1 16 16
description 0 handle
Write, Kill, Lock, BlockWrite, BlockErase {0, handle, CRC-16}CW
TREPLY
Preamble
Interrogator command Tag response
Figure 6.22 – Successful Wri e sequence t
© 2004, EPCglobal Inc. Page 57 of 94 31 January 2005
6.3.2.10.3.3 Write (mandatory)
Interrogators and Tags shall implement the Write command shown in Table 6.33. Write allows an Interrogator to write a word in a Tag’s Reserved, EPC, TID, or User memory. Write has the following fields:
MemBank specifies whether the Write occurs in Reserved, EPC, TID, or User memory. WordPtr specifies the word address for the memory write, where words are 16 bits in length. For example, WordPtr = 00h specifies the first 16-bit memory word, WordPtr = 01h specifies the second 16-bit memory word, etc. WordPtr uses EBV formatting (see Annex A). Data contains a 16-bit word to be written. Before each and every Write the Interrogator shall first issue a Req_RN command; the Tag responds by backscattering a new RN16. The Interrogator shall cover-code the data by EXORing it with this new RN16 prior to transmission.
The Write command also includes the Tag’s handle and a CRC-16. The CRC-16 is calculated over the first com-mand-code bit to the last handle bit.
If a Tag in the open or secured states receives a Write with a valid CRC-16 but an invalid handle, or it receives a Write before which the immediately preceding command was not a Req_RN, it shall ignore the Write and remain in its current state.
A Write shall be prepended with a frame-sync (see 6.3.1.2.8).
After issuing a Write an Interrogator shall transmit CW for the lesser of TREPLY or 20ms, where TREPLY is the time between the Interrogator’s Write command and the Tag’s backscattered reply. An Interrogator may observe sev-eral possible outcomes from a Write, depending on the success or failure of the Tag’s memory-write operation:
The Write succeeds: After completing the Write a Tag shall backscatter the reply shown in Table 6.34 and Figure 6.22 comprising a header (a 0-bit), the Tag’s handle, and a CRC-16 calculated over the 0-bit and handle. If the Interrogator observes this reply within 20 ms then the Write completed successfully. The Tag encounters an error: The Tag shall backscatter an error code during the CW period rather than the reply shown in Table 6.34 (see Annex I for error-code definitions and for the reply format). The Write does not succeed: If the Interrogator does not observe a reply within 20ms then the Write did not complete successfully. The Interrogator may issue a Req_RN command (containing the Tag’s handle) to verify that the Tag is still in the Interrogator’s field, and may reissue the Write command.
Upon receiving a valid Write command a Tag shall write the commanded Data into memory. The Tag’s reply to a successful Write shall use the extended preamble shown in Figure 6.11 or Figure 6.15, as appropriate (i.e. a Tag shall reply as if TRext=1 regardless of the TRext value in the Query that initiated the round).
Table 6.33 – Write command
Command MemBank WordPtr Data RN CRC-16
# of bits 8 2 EBV 16 16 16
description 11000011 00: Reserved 01: EPC 10: TID 11: User
Address pointer
RN16 wordto be written
handle
Table 6.34 – Tag reply to a successful Wr te command i
Header RN CRC-16
# of bits 1 16 16
description 0 handle
Write, Kill, Lock, BlockWrite, BlockErase {0, handle, CRC-16}CW
TREPLY
Preamble
Interrogator command Tag response
Figure 6.22 – Successful Wri e sequence t
© 2004, EPCglobal Inc. Page 57 of 94 31 January 2005
More specifically, a reader issues two Access commands, the first containing the
MSBs of the tags’s access password XORed with an RN16, and the second containing
the LSBs of the tags’s access password XORed with a different RN16.4 For the first
Access command, the tag backscatters its handle to acknowledge that it received
the command. When the second Access command has been received and the entire
32-bit access password is correct (by applying the step (c) above), then the tag
backscatters its handle to acknowledge that it has executed the command successfully
and transitioned to the secured state; otherwise, the tag does not reply.
The Write command allows a reader to write a word in the Reserved, EPC, TID, and
User memories of a tag in the open or secured state. The syntax of the Write com-
mand and response is defined as Table 6.4. The Write command has the following
fields.
• MemBank specifies the memory bank where a word is to be written.
4The notation MSB denotes the most significant bits, and the LSB the least significant bits.
134

6.2 Security and privacy in the EPCglobal Network
• WordPtr specifies the 16-bit word address for the memory write. For example,
WordPtr = 00h means the first 16-bit memory word, WordPtr = 01h means the
second 16-bit memory word, etc.
• Data contains a 16-bit word to be written.
Depending the success of Write command operation, the tag backscatteres its handle
if the operation has been successful; otherwise, the tag backscatters an error code.
If the reader does not observe any reply within 20ms, it means that the operation
has not been successful.
6.2.3 Security and privacy requirements
In this section we discuss security and privacy requirements in the EPCglobal Net-
work. Since security issues for many components of the EPCglobal Network, other
than the RFID system, are similar to those arising in other Internet applications, we
only assess the corresponding security and privacy properties required in the RFID
system.
Privacy is most important requirement for the deployment of the EPCglobal net-
work. An EPC stored in a tag can permit surreptitious inventorying of an object
the tag is attached to. This is because the field ‘EPC manager’ in an EPC repre-
sents the manufacturer, and the ‘object class’ is typically a product code. A reader
could surreptitiously harvest personal information such as: the type of medication a
person is carrying, clothing size, accessory preference, etc. Also, by surreptitiously
scanning tagged items, an organisation could learn about stock turnover rates in the
supply chains of its competitors. Confidentiality or data privacy is thus required.
Requirement 6.1 (Confidentiality (or Data Privacy)) Reading EPC tags
should not give any product information of the tagged item to the unauthorised en-
tities.
A unique tag identifier, such as an EPC or other tag-specific string, can be used
to track an object or a person carrying a tag in terms of both time and space.
The collected information can be merged and linked to create a personal profile, or
generate critical information about inbound and outbound flows to/from a corpo-
135

6.2 Security and privacy in the EPCglobal Network
rate warehouse. In a military supply chain, enemy forces could learn about troop
movements by monitoring RFID communications. Anonymity or location privacy of
objects/people carrying tags is thus required.
Requirement 6.2 (Anonymity (or Location Privacy)) It should be infeasible
for unauthorised entities to have knowledge of the whereabout of the products attached
with EPC tags.
While identification of items is the main purpose of using RFID technology in the
supply chain, authentication5 is also required for certain items, such as expensive
products or drugs. Drug counterfeiting is a particularly serious issue [77]; confirming
the authenticity of drug supplies is challenging because of the complexity of modern
supply chains, i.e. it is difficult to ensure the provenance of delivered items. Tag
authenticity is thus required.
Requirement 6.3 (Authenticity) Once an EPC has been programmed into a
specific tag by the EPCglobal Network, only should this tag be able to claim that it
possesses that specific EPC value.
A Denial of Service (DoS) attack could result in a permanent or temporary loss of
the ability of a reader to communicate with a tag. Like any system using wireless
communications, RFID systems can be easily disturbed by RF jamming, but this is
not an issue specific to RFID systems. We thus only consider DoS attacks arising
in the application layer. Availability is thus required.
Requirement 6.4 (Availability) An authorised reader within reading range of an
EPC tag should have uninterrupted access to that tag.
6.2.4 Gen2 standard and related variant schemes
In this section we give security and privacy analysis for Gen2 standard [70] to be
used for RFID system of the EPCglobal Network.
5The authentication of an item is performed by authenticating the tag which is attached to theitem.
136

6.2 Security and privacy in the EPCglobal Network
Privacy
The EPCglobal Network addresses confidentiality and anonymity in the following
ways [69, 70, 71]. An EPC is simply an identifier for a specific object, and no other
information is contained in it. The information associated with an EPC is only
accessible to authorised subscribers, and data is transferred between subscribers via
secure channels, i.e. making the networks virtually private. At the point of sale,
RFID tags are permanently deactivated (killed) to ensure consumer privacy; when a
tag receives the kill command, it renders itself permanently inoperable. To prevent
inadvertent or malicious disabling of tags, the Gen2 standards requires readers to
use a tag-specific 32-bit password.
However, the use of the kill command at the point of sale blocks a range of post-
purchase applications of RFID technology, including their use in smart appliances
and receiptless return of goods [77], as described below.
• The EPCglobal Network could provide benefits to customers if the network
could be extended to smart home systems; such a system could retrieve de-
tailed product information from the EPCglobal Network using the EPC as an
identifier. For example, a washing machine could select an appropriate wash
cycle and temperature to avoid damage to delicate fabrics by reading a tag
in a garment, or a refrigerator might warn its owner when a tagged item of
foodstuff has expired.
• People who are physically or mentally impaired might benefit from RFID-
enabled smart home systems [114]. For example, a voice-enabled aid to a blind
person could recognise the content of an object by reading the embedded tag.
• Customers could return an item without the need for the sales receipt, since a
tag could act as an index into the database payment records and help retailers
track defective or contaminated items.
Although killing tags at the point of sale may provide consumer privacy, it fails
to address security issues for corporate supply chains; since EPC tags emit static
identifiers, they are vulnerable to malicious tracking by competitors. As described
in Section 6.2.3, unauthorised reading in military supply chains is a particularly
serious threat, and killing tags cannot address this.
137

6.2 Security and privacy in the EPCglobal Network
Authenticity
The EPCglobal Network expects RFID technology to help combat counterfeiting
[72], e.g. the authenticity of drug shipments could be checked by using the electronic
pedigree provided by Discovery Services. EPC tags, however, may provide only very
limited assurance of authenticity, as described below.
A cloning attack involves a counterfeit tag attempting to convince a reader that it
is exchanging information with a genuine tag. Since EPC tags emit their resident
EPC to any querying reader, an adversary could easily learn the data resident in a
tag by simply scanning it. Furthermore, field-programmable EPC tags are available
today,6 and readers typically have no way of checking the validity of the EPCs they
scan. These features make EPC tags vulnerable to elementary cloning attacks.
Juels [76] describes a simple way of using the kill functionality in EPC tags to achieve
limited counterfeit resistance. The kill password is normally used to authenticate a
reader to a tag, i.e. a kill password is used as a means to enable a tag to authenticate
a reader prior to self-deactivation. However, the unique kill password shared between
a tag and a reader can also be used to enable a reader to authenticate a tag.
More specifically, when an EPC tag receives a kill command including a valid kill
password, but the received power is insufficient, it remains operational and emits an
error code. Juels thus suggests that, given that it possesses this functionality, a tag
could be modified to emit “yes” or “no” indicating the validity of a kill password.
Such a protocol, however, has basic vulnerability; any cloned tag, which is not
compliant with the Gen2 standard, could simply accept any password, in which case
the protocol will always output “valid”.
To address the problem described above, Juels [76] proposes the modified protocol,
called BasicTagAuth (see Figure 6.8). The protocol uses spurious passwords, which
functions similarly to winnowing as introduced by Rivest [116].7 The number % is a
security parameter that defines the number of spurious passwords to be generated
(line 4). The function GenPWSet generates a set of % − 1 spurious passwords uni-
formly at random, and inserts the correct password ki in a random position j (line
6See http://www.ti.com/rfid/docs/manuals/pdfSpecs/epc inlay.pdf.7Rivest suggests inserting false packets into a data stream to achieve confidentiality; a receiver
can extract the transmitted message by picking out the correct ones.
138

6.2 Security and privacy in the EPCglobal Network
Protocol: BasicTagAuth
1. T −→ R : id
2. R : if id = idx for some 1 ≤ x ≤ n, then i← x;
3. else output “unknown tag” and halt
4. R : (j, {P (1)i , . . . , P
(%)i })← GenPWSet(i)[%];
5. λ← “valid”;
6. for k = 1 to % do
7. R −→ T : PW-test(P(k)i )
8. T −→ R : b
9. R : if b = 1 and k 6= j, then λ← “invalid”
10. if b = 0 and k = j, then λ← “invalid”
11. R : output λ
Figure 6.8: The BasicTagAuth protocol [76]
4).
The BasicTagAuth protocol, however, is vulnerable to the adversary who obtains the
tag identifier id and the true password P(p)i by either passively or actively as follows
[76]. The adversary first
(i) eavesdrops on the BasicTagAuth protocol run and thus obtains id and P(p)i ; or
(ii) obtains id by sending the target tag a read-query, interacts with the reader
and obtains the password set {P (k)i }
%k=1, and, finally, actively tests the keys in
the set on the tag to determine P(p)i .
It is then impossible to detect such counterfeit tags from genuine tags.
Availability
As described in Section 6.2.2, Gen2 standard [70] implements an access control for
tag-writing and tag-deactivation using tag-specific passwords. If such an access
control is not present, e.g. an access password is set to be zero, the rewritable tag
139

6.3 Proposed RFID system
memory, such as the EPC memory, could be manipulated by an adversary so that
the tag becomes permanently desynchronised with the authorised reader(s). That
is, an adversary may attempt to write into the EPC memory a garbage value, in
which case the tag is not recognised by a reader in the subsequent communications.
6.3 Proposed RFID system
We now construct a refresh-based RFID system, namely what we call the RFID-R
system, and give privacy analysis using the privacy model in Definition 5.3.
6.3.1 Construction of algorithms
We first define an encoding scheme and then a set of algorithms for RFID system.
Encoding scheme
Following Ateniese et al. [2], we present an encoding scheme which maps bit-strings
of fixed length b into elements of an elliptic curve group. Let E be an elliptic
curve such that E(Fp) contains a cyclic subgroup of large prime order, q say. Let
MAC = (m-Gen,Mac,Ver) be a secure message authentication code, as in definition
2.10. The MAC length will be denoted by t,8 and we also require a w-bit counter ct,
where w = blog2 qc− b− t− 1. Unlike the scheme of Ateniese et al. [2], the encoding
scheme presented here makes use of the counter ct for authentication purposes.
The encoding algorithm Encode-to-Group is shown in Figure 6.9. The input to
Encode-to-Group, is a b-bit tag identifier id and a key KMAC (← m-Gen(1n′)). Given a
b-bit identifier id and a w-bit ct, the algorithm first computesM ← id||ct||Mac(KMAC, id||ct).Since |M | = blog2 qc − 1 ≤ blog2 pc − 1,9 M may be interpreted as the binary repre-
sentation of an integer X smaller than p, and thus as a unique value in Fp.8A reasonable choice for t would be in the range 64–128 bits, depending on the security require-
ments.9The notation |M | denotes the bit length of M .
140

6.3 Proposed RFID system
Algorithm: Encode-to-Group (KMAC, id, ct)
1. while ct < 2w do;
2. m← id||ct; m← Mac(KMAC,m); M ← m||m;
3. X ← O2I(M);
4. if there exists Y such that E(X,Y ) = 0, then
5. P ← (X,Y ); return (P, ct) and stop;
6. else, increment ct
7. return ⊥
Figure 6.9: Encoding algorithm
Exploiting this fact, the function O2I maps octet-strings (byte strings) to numbers
in Fp, i.e. maps M to X. Regarding X as the x-coordinate of a point in E(Fp), the
algorithm checks whether there exists a value Y satisfying the equation E(X,Y ) mod
p = 0. This equation has either two solutions or none. If two solutions exist, then
the algorithm chooses one in a systematic manner, e.g. it could choose the smaller
integer. If no solution is found, the algorithm increments ct and repeats the above
process.10 Finally, the algorithm outputs a point P = (X,Y ) and the current counter
value ct.
Algorithm: Decode-from-Group (KMAC, P )
1. X ← X-coordinate(P );
2. M ← I2O(X); id||ct||m←M ;
3. b← Ver(KMAC, id||ct, m);
4. if b = 1, return (id, ct); else, return ⊥
Figure 6.10: Decoding algorithm
The Decode-from-Group algorithm, shown in Figure 6.10, can be used to invert the
Encode-to-Group encoding operation. Given input of a key KMAC and a point P ,
the algorithm processes P ’s x-coordinate X using the X-coordinate function. Using
the function I2O that maps numbers in Fp to octet-strings, the binary represen-
tation of X is recovered, and then parsed as id||ct||m. If m is a valid MAC, i.e.
Ver(KMAC, id||ct, m) = 1, then the algorithm returns id and ct. If this check fails,
10Since approximately 50% of the values in a finite field possess a square root, the probabilitythat the encoding will fail is 2−2w .
141

6.3 Proposed RFID system
the algorithm returns the error message ⊥.
Algorithms
We first define two basic protocols between R and T . R reads a pseudonym, i.e. the
encrypted version of the tag identifier, resident in T by performing the Tag-Read
protocol. R updates a pseudonym in T by performing the Tag-Write(c, ak) protocol.
This has the effect of causing T to replace its existing pseudonym with the value c
only if ak is equal to the tag-access key stored in T . R and T may also perform the
Tag-Write(c) protocol, when T does not enforce access control for tag writing.
We use multiplicative group notation instead of the additive notation often used in
elliptic curve settings. The algorithms of the RFID-R system we define here make use
of the ElGamal encryption scheme PE = (e-Gen,Enc,Dec), as given in definition 2.17,
and a message authentication code MAC=(m-Gen,Mac,Ver), as given in definition
2.10. We construct the algorithms of RFID-R system using the notations defined in
Section 5.2.2.
• Setup-Reader takes as input a security parameter 1n and returns the system pa-
rameter parm and a master key KR = (KPE,KMAC), where KPE = (pk, sk)←e-Gen(1n), KMAC ← m-Gen(1n
′), and n′ = l(n) for some polynomial l. We
write R(parm,KR)← Setup-Reader(1n).
• Setup-Tag is a two-party protocol conducted by T and R. It takes as inputs
(parm,KR) and a tag identifier id ∈ {0, 1}b. R initialises T as follows.
R : ct← 00 · · · 0 (w bits);
(P, ct)← Encode-to-Group(KMAC, id, ct);
c← Enc(pk, P );
R ←→ T : Tag-Write(c)
We write (R(id,KT ), T (c))← Setup-Tag(id), where KT = KR.
• Idt-Tag is two-party protocol conducted by T and R. It takes as inputs
(parm,KR) and a ciphertext c = (α, β). R determines the identifier of T .
142

6.3 Proposed RFID system
R ←→ T : Tag-Read
R : P ← Dec(sk, c);
if ⊥← Decode-from-Group(KMAC, P ),
then output← unknown tag; return output and halt
else (i.e. if (id, ct)← Decode-from-Group(KMAC, P ))
output← id; return output
We write output ← Idt-Tag(R(parm,KR), T (c)).
• Ref-Tag is two-party protocol conducted by T and R. It takes as input
(parm, pk) and a ciphertext c = (α, β). R refreshes the pseudonym stored
in T in the following way.
R ←→ T : Tag-Read
R : c′ ← (α(pk)k′, βgk
′) for k′ ∈R Z∗q
R ←→ T : Tag-Write(c′)
We write T (c′)← Ref-Tag(R(parm, pk), T (c)).
In the Setup-Tag algorithm, a tag identifier id is encoded after concatenated with its
MAC value, which can be generated with the knowledge of KMAC. This ensures that
R will be able to correctly identify T which has been setup by itself. We assume
that the reader and tag perform both the Idt-Tag and Ref-Tag for privacy-enhanced
tag identification, but two protocols can be used separately for its own purpose.
6.3.2 Privacy analysis
It is straightforward to see that the proposed RFID-R scheme fails to provide privacy
against the wide adversary. This is because such a adversary can distinguish the
tag T b by writing a garbage value into one of the tags T 0 and T 1 in the privacy
experiment. We now prove that the proposed RFID-R scheme satisfies (discrete,
narrow, strong, ω)-privacy.
Theorem 6.1 The RFID-R system provides (discrete, narrow, strong, ω)-privacy if
the DDH is hard relative to G.
143

6.3 Proposed RFID system
Proof. We provide a sketch of proof as below. Suppose that a simulator, SIM0 say,
performs all its actions as in privacy experiment ExpprivacyAδ,RFID-R
and the advantage of
the adversary Aδ is ε.
We then construct a simulator, SIM1 say, that performs all its actions as in SIM0
except for the production of the final ciphertext; it is replaced with a random value.
We now show that the advantage of Aδ in SIM1 is at most ε+ Adv-DDH.11 We first
need to address how SIM1 knows which ciphertext would be the last ciphertext to
be requested. Since the adversary can send at most ω queries, there has to be qe
queries which require the production of ciphertext. SIM1 can thus set to replace
with a random value the qe-th ciphertext that has to be produced. The queries that
require to produce ciphetexts are Create-Tag, Send-Reader, and Execute.
First, the adversary can distinguish with the probability at most Adv-DDH between a
random number and a ciphertext created from a tag identifier when the Create-Tag
is queried, due to the fact that the security of underlying ElGamal encryption scheme
can be reduced to the DDH problem [134]. The Execute query is a set of other oracle
queries, where Send-Reader is only query that requires to produce ciphertexts using
the Ref-Tag algorithm. When the ciphertext is replaced with a random number, the
adversary can distinguish between them with the probability at most Adv-DDH.
Since Ref-Tag outputs c′ = (myk+k′ , gk+k′) given c = (myk, gk) as an input, where
k′ ∈R Z∗q , the adversary has the same advantage as when it is challenged when the
ciphertext is produced using the Create-Tag query. We note that the Result query
is not allowed to the given type of adversary, and the Corrupt query simply reveals
the ciphertext stored in a tag.
We next construct a simulator, SIM2 say, that performs all its actions as in SIM1
except for the production of the next-to-last ciphertext; it is replaced with a random
value. As described above, we can show that the advantage of Aδ in SIM2 is at most
ε+ 2Adv-DDH.
All the ciphertexts can be eventually replaced with random values, in which case the
adversary never receives a ciphertext that depends on a tag identifier. Furthermore,
the discrete type of adversary always gets two different random numbers for two
consecutive reads of the same tag. The adversary thus has no advantage in SIMqe.
11See Definition 2.5 for Adv-DDH.
144

6.4 Application to the EPCglobal Network
We now see that ε+ qe · Adv-DDH is negligible and thus ε is negligible. �
The security of the MAC scheme does not affect the privacy of the RFID-R scheme.
That is, even if unsecure MAC scheme is used, the privacy of the RFID-R scheme is
preserved. By using secure MAC scheme, a reader can determine if an interrogated
tag has been issued by itself by checking m (see Figure 6.10). The use of MAC
scheme will be further discussed in Section 6.4.
6.3.3 Further discussions
Secret key encryption scheme, e.g. AES-CTR, may also be used as a refresh-based
RFID system, which could deliver a significant reduction in computation cost for
the reader and the reduced size of ciphertexts to be stored in the tags.
Public key encryption schemes, however, give the following advantages when used
as refresh-based RFID schemes. That is, the keys used for identification and refresh
can be separately managed. The private key used for identification remains in the
central server, and the public key used for refresh process can be transferred to
the third party or a stand-alone transceiver which is entitled to enhance privacy of
tags. For example, items tagged with RFID tags can be frequently refreshed by
transceivers using the public key during transport.
On the other hand, the secret key should not be known to the third party when
using secret key encryption scheme. When such a key is transferred to a stand-alone
transceiver, the secret key could be compromised because the transceivers might
be often deployed in the hostile environments. Even though the secret key only
remains in the central server, the connectivity may be not always guaranteed between
the server and transceivers, and the central server could be the communication
bottleneck.
6.4 Application to the EPCglobal Network
A key issue is whether or not RFID tags in the EPCglobal Network can perform
onboard cryptographic operations, in order to enhance privcy. The main obstacle
145

6.4 Application to the EPCglobal Network
to providing such functionality is cost; EPC tags are likely to be deployed on a
very large scale once the unit price drops to $0.05 [77]. In this case, Moore’s law
will not necessarily deliver the increases in computing power necessary to enable
cryptographic functionality, since commercial pressures will push the industry to
use one-cent tags when they become available, rather than continuing to pay five
cents per tag and adding advanced security features.
The Gen2 standard [70] specifies the physical and logical requirements for the RFID
system used in the EPCglobal Network. Given their small size, the most inexpensive
EPC tags are likely to only have between 250 to 1,000 gates available for security
features [123]. Another estimate indicates that no more than 2,000 gate equivalents
(GEs) are available for security functionality in general EPC tags [81]. In this section
we investigate the applicability of the discussed RFID scheme to the EPCglobal
Network.
6.4.1 Existing schemes
The key-search based schemes described in Section 5.3 use either hash functions or
secret key encryption algorithms, since these functions can be readily used to produce
other necessary crypto-fuctions, such as message authentication codes (MACs) or
pseudorandom number generators (PRNGs). In particular, an on-tag hash function
is often assumed in RFID security protocols, perhaps because the high throughput
possible for dedicated hash functions suggests that hash functions could be imple-
mented even on very computationally limited platforms such as RFID tags. However,
current hash functions are not suitable for implementation on low-cost basic tags,
as shown in [16, 44].
Even one of the most compact dedicated hash functions, namely MD4, requires as
many as 7350 GEs for 80-bit security.12 Thus, since current dedicated hash functions
are either too complex or broken, it would be desirable to consider hash functions
built from compact block ciphers. Bogdanov et al. [16] investigate the performance
of a variety of hash functions based on direct application of the most compact
block cipher known to the author (the block cipher present), and the results are
summarised in Table 6.5. Replacing present with a different block cipher is likely
12MD4 is, however, considered broken by the vast majority of the cryptographic community.
146

6.4 Application to the EPCglobal Network
Table 6.5: Performance of secret key crypto-algorithms [16]
Block Key Block Cycles Throughput Logic Areaciphers size size per block (Kbps) process GEs
PRESENT-80 [15] 80 64 32 200 0.18µm 1570PRESENT-80 [119] 80 64 563 11.4 0.18µm 1075DES [94] 56 64 144 44.4 0.18µm 2309PRESENT-128 [15] 128 64 32 200 0.18µm 1886AES-128 [43] 128 128 1032 12.4 0.35µm 3400
Hash Output Data path Cycles Throughput Logic Areafunctions size size per block (Kbps) process GEs
MD4 [44] 128 32 456 112.28 0.13µm 7350MD5 [44] 128 32 612 83.66 0.13µm 8400SHA-1 [44] 160 32 1274 40.19 0.35µm 8120SHA-256[44] 256 32 1128 45.39 0.35µm 10868
H-PRESENT-128 [16] 128 128 32 200 0.18µm 4256H-PRESENT-128 [16] 128 8 559 11.45 0.18µm 2330C-PRESENT-128 [16] 192 192 108 59.26 0.18µm 8048C-PRESENT-128 [16] 192 12 3338 1.9 0.18µm 4600
to increase the space required for an implementation.
Table 6.5 shows that, with today’s technology, compact block ciphers are more
efficient than hash functions in RFID implementations. Furthermore, when using
hash functions in a security protocol, care should be taken regarding the security
properties required for hash functions; a hash function with an n-bit output can
offer a 2n-bit security level for pre-image and second pre-image resistance, and a
2n/2-bit security level for collision resistance.
Even though compact block ciphers such as present-8013 could be implemented
on EPC tags, the use of secret key cryptographic primitives in RFID systems often
requires an (optimised) exhaustive key search by the reader, and this could be not
appropriate for potentially large-scale RFID applications such as the EPCglobal
Network. Furthermore, the use of all the RFID schemes discussed in Section 5.3 and
Section 5.5 in the EPC tags require the significant changes of the current standard
[70].
The previously proposed refresh-based schemes, i.e. Golle et al. [62] and Ateniese et
al. [2], comply to the Gen2 standard [70], i.e. the encrypted version of the EPC can
13This block cipher is designed to have a 64-bit block size and 80-bit key length.
147

6.4 Application to the EPCglobal Network
Table 6.6: Security and privacy comparisons of RFID systems
Class-1 Gen-2 Golle et al.’s Ateniese et al.’s The RFID-RStandard [70] UR scheme [62] IE scheme [2] system
Data Privacy X O O OLocation Privacy X X 4 O
Authenticity 4 X X OAvailability O X X O
The notations X, 4, and O denote no protection, partial protection, and full-protection, respec-tively. Privacy is only satisfied against the discrete adversary. Gelle et al. and Ateniese et al.sacrifice authenticity and availability in order to enable randomisation of tag pseudonyms by anytransceivers with the underlying system parameters, i.e. without knowledge of private/public keypairs; neither the Gen2 standard nor our proposed scheme cannot provide this property.
be written into the EPC partition and the access password can be set to be zero to
allow any reader to refresh the encrypted EPC. Golle et al.’s scheme, however, cannot
provide location privacy as described in section 5.4.2, and Ateniese et al.’s scheme
also fails to provide location privacy against insider attackers, e.g. competitors in
supply chains, which are practically most serious adversary as discussed in Section
5.4.3.
6.4.2 Proposed scheme
In this section we investigate the compatibility of the proposed scheme to Gen2
standard [70], and then discuss how the RFID-R scheme uses and extends the core
set of features of the Gen2 standard [70] to satisfy privacy and security requirements
discussed in Section 6.2.3. We summarise the comparison between the proposed
scheme, Gen2 standard, and existing refresh-based RFID systems in Table 6.6.
Compatibility to Gen2 standard
Similarly to other refresh-based RFID schemes [2, 62], the tag identifier id corre-
sponds to the EPC, and the encrypted version of EPC can be written into the EPC
partition of the tag storage instead of EPC. Given that 80-bit security appears to
be a reasonable target for RFID tag applications,14 the RFID-R system can use an
14This security level is adopted by the eSTREAM project, details of which are available athttp://www.ecrypt. eu.org/stream.
148

6.4 Application to the EPCglobal Network
underlying finite field Fp with |p| = 192 or F2m with |m| = 163.15 The result of such
a choice would mean that the length of an encrypted EPC would be less than 416
bits, which the Gen2 standard sets as the maximum length for an EPC. The tag-
access key ak corresponds to the access password of the standard, which is stored
in the Reserved partition of tag storage. The Tag-Read and Tag-Write protocols, two
basic building blocks of the protocols of the RFID-R system, corresponds to the pro-
tocol used during inventory process and the combination of the Access and Write
commands in the access process, respectively.
Example use case of the RFID-R scheme
Unlikely previous refresh-based RFID schemes [2, 62], we suggest to implement
access control for tag-writing to enhance authenticity and availability. Otherwise,
an adversary could maliciously write into tags garbage values making attacked tags
permanently desynchronised from readers. The tag-specific access keys could also
be used for tag authentication discussed in Section 6.2.
Naive introduction of such tag-specific access key, however, directly infringes privacy.
If the association between a tag identifier id (or an item bearing the tag) and a
tag-access key ak is compromised, an adversary could trace the associated tag by
broadcasting the tag-access key and, if any tag responds, that tag can be identified
as the owner of the tag identifier id.
We thus suggest to use the RFID-R scheme in order to enhance security and privacy
of EPC tags as follows. The EPC partition is configured to be universally readable
and keyed writable, i.e. pwd-write field set to 1 (see Table 6.1), and the Reserved
partition is configured to be keyed readable/writable, i.e. pwd-read/write field set to
be 1 (see Table 6.1). The central database maintains the list of (EPC, ak), and the
tag-identification process can be implemented as follows.
The reader identifies the tag using the Idt-Tag protocol and recovers (EPC, ak). The
reader then refreshes the interrogated tag using Ref-Tag algorithm with the following
extension. Instead of performing the Tag-Write(c′), a reader could authenticate a
tag by testing whether the tag can be successfully written using its tag-access key,
15See http://csrc.nist.gov/groups/ST/toolkit/documents/dss/NISTReCur.pdf.
149

6.4 Application to the EPCglobal Network
i.e. performing Tag-Write(c′, ak) and checking if c′ is successfully written. However,
in order to detect an attack in which a cloned tag always indicates that the wiring
process has been successful, the reader may send the tag a series of write instruc-
tions, one of which contains the correct tag-access key and the rest of which involve
invalid tag-access keys, as described in Section 6.2. Finally, if the tag is successfully
authenticated, the reader writes into the Reserved partition the tag-access key ak′
which is newly generated uniformly at random. After receiving from the tag the
acknowledgement that writing of ak′ has been successful, the reader also updates
(EPC, ak′) in the database.
For a large number of write instructions, i.e. the number of spurious passwords, the
protocol can be time-consuming; however, small number, even % = 2, would suffice
to detect the casual introduction of cloned tags (see Figure 6.8). For example, as
described in section 6.2.3, drug counterfeiting is a particularly serious issue in supply
chains [77]. The detection of a single counterfeit tag among the tags associated with
a batch of drugs would be sufficient to cast doubt about the provenance of the entire
batch.
Privacy analysis
Confidentiality (or data privacy), as defined in Requirement 6.1, is guaranteed
through the universal semantic security (USS) property of the underlying ElGa-
mal encryption scheme. That is, if an EPC is encrypted using the ElGamal scheme,
then the USS property guarantees that no information about the EPC can be learned
by an adversary.
With respect to anonymity (or location privacy), as in Requirement 6.2, the adver-
sary should be able to link either a tag-access key or the encrypted version of EPC
between two reads of the same tag. Since the tag-access key is always randomly
generated, the adversary is now left to link two ciphertexts. This, however, is not
possible as shown in Section 6.3.2.
It is, however, clear that tags can be tracked between refreshes, since the tags store
universally-readable static values. This issue is inherent to refresh-based RFID sys-
tems. Such threats, however, can be mitigated in practice. Correlations between
inbound/outbound flows in supply chains could reveal sensitive information that
150

6.4 Application to the EPCglobal Network
compromises corporate privacy; however, the tracing of tags at an isolated loca-
tion poses relatively little threat. A certain level of corporate location privacy can
be provided by refreshing ciphertexts in tags before they leave the supply chain
premises.16 For individual location privacy, personal mobile RFID devices can re-
duce the risk of malicious tracing by refreshing tags frequently, with the precise
refresh rate depending on the user’s security policy.
When the RFID-R system is applied to the EPCglobal Network, we assume that an
adversary cannot gain access to a decryption oracle query for a chosen ciphertext.
To see why this is true, we first observe that we can reasonably assume that an
authorised entity only has access to the decryption algorithm Dec (see Section 6.3).
Now suppose that an adversary is somehow able to make a decryption oracle query
with a chosen ciphertext. However, if the submitted ciphertext has not been con-
structed by the legitimate issuer, i.e. the tag owner, the output from the Idt-Tag
algorithm will be an error message. This is because, when a ciphertext is decrypted,
the plaintext should contain a valid MAC value.
Authenticity
In any refresh-based RFID system it is always possible to perform a cloning attack
by obtaining tag pseudonyms from target tags either passively or actively and then
writing these pseudonyms into field-programmable tags. It is then impossible to
detect such counterfeit tags, since readers deem a tag to be legitimate as long as the
pseudonym resident in a tag is valid.
We thus introduced a tag-authentication scheme using the technique proposed by
Juels [76]. Our proposed protocol, however, provides a robust mechanism for de-
tecting counterfeit tags produced by an attack of the type described by Juels [76].
Suppose that an adversary obtains the pseudonym c and the tag-access key ak of T ,
e.g. by eavesdropping on the Ref-Tag algorithm performed between the tag T and a
reader. The adversary can now produce a counterfeit tag T by writing c and ak into
it. However, once the genuine tag T performs the suggested authentication protocol,
16RFID tags using ultra high frequency (UHF) communications are likely to be used for item-leveltagging in supply chains, and the radio signal for such tags cannot penetrate metal. Thus leakage ofinformation regarding inbound/outbound flows can be greatly reduced if items are carried in metalcontainers.
151

6.5 Conclusion
the access key stored in T becomes invalid. It is, of course, possible that the genuine
tag T could be deemed to be a cloned tag if T performs the authentication protocol
first. However, whenever a tag is identified as having been cloned, R could choose to
classify as tainted the decrypted identifier from the pseudonym stored in the cloned
tag, and then track the tags having this tainted identifier.
We point out that the proposed authentication scheme is not a standard challenge-
response authentication protocol. Specifically, the proposed authentication mech-
anism cannot prevent the tag counterfeiting attacks, i.e. not fully satisfying Re-
quirement 6.3, but can only detect that such attacks have been attempted. The
proposed scheme thus would fail to satisfy the security definitions designed for au-
thentication. Nevertheless, for inexpensive tags incapable of implementing such
standard challenge-response authentication protocols, the proposed algorithm pro-
vides a pragmatic approach to enhancing tag authenticity.
Availability
As the Gen2 standard [70], our proposed scheme provides availability, as in Require-
ment 6.4, by implementing access-control for tag writing and thus preventing an
adversary from maliciously writing into tags garbage values for permanent desyn-
chronisation with the reader. The proposed scheme, however, provides a more robust
level of protection even when the database of subscribers is compromised. That is,
with the compromised list of EPC and its access/kill passwords the adversary could
maliciously write into the tags the garbage values or even permanently deactivate
the tags by simply reading the EPC from the tag and searching the correspond-
ing passwords from the compromised database. With the proposed scheme, since
EPCs are now stored as an encrypted form, an adversary cannot determine which
access/kill passwords to use.
6.5 Conclusion
EPC tags are likely to become very widely used in the very near future, despite
the fact that current tags have very limited computational capabilities and hence
152

6.5 Conclusion
cannot implement strong cryptographic primitives. Hence, there is a need to achieve
the optimum level of security and privacy possible realisable with the capabilities of
current tags. The proposed RFID system is directed at this endeavour.
153

Chapter 7
Concluding Remarks
Contents
7.1 Main Research Findings . . . . . . . . . . . . . . . . . . . 154
7.2 Future Research Directions . . . . . . . . . . . . . . . . . 155
In this chapter we describe main findings in this thesis and outline some possible
directions for further research.
7.1 Main Research Findings
We have studied security and privacy issues in two classes of pervasive networks,
namely Personal Area Networks and RFID-enabled EPCglobal Networks.
A number of key management schemes have been proposed for use in PANs, but these
schemes only support key management within a PAN. We defined system models
and design goals for key management within and between PANs, and proposed a
novel security initialisation scheme for use in such networks. The proposed scheme
achieves desirable security and efficiency properties by making use of the unique
characteristics of iPANs.
We also constructed a formal privacy model for RFID systems accurately reflecting
adversarial threats and power. We then gave brief privacy analysis for the existing
privacy-enhanced RFID schemes which have received wide attention in the literature.
We then constructed a secure refresh-based RFID system based on re-encryption
techniques, and proved its privacy using the defined privacy model. Finally, we
showed that the proposed scheme can greatly enhance the security and privacy of
EPC tags, making the maximum use of given tag functionalities as specified in the
154

7.2 Future Research Directions
standards.
7.2 Future Research Directions
More networks seamlessly connect to other networks in pervasive computing, rather
than existing as isolated networks. As society is becoming more densely connected,
new research opportunities are arising to investigate the provision of security and
privacy in future networks.
In this connection the EU has launched a number of research projects on the Future
Internet [32, 115], aiming to overcome the current limitations of the Internet and
to provide emerging integration services accommodating various types of devices.
Clearly, security, privacy, and trust must be included in all aspects of the design and
development of the Future Internet.
Since 2007, the EU’s FP7 (7th Framework Programme) has supported a range of
projects on the Future Internet [32]. Trustworthy ICT is a security project under
the work programme Pervasive and Trusted Network and Service Infrastructures,
and focuses on trustworthy network/services infrastructure, standardisation, and
authentication models. More recently, the EU Future Internet PPP (Public Private
Partnership) project started with the active involvement of industry [115]. This
project focuses on delivering transparent application services on a common consol-
idated platform. Such applications include Smart Grid, Intelligent Transportation,
e-Health, and m-commerce. The PPP project covers the development of a strat-
egy for security provisioning, where the infrastructure must deliver optimal levels of
security, privacy, and trust that match the dynamic context of the Future Internet.
However, while it is widely recognised that the future Internet requires built-in
security mechanisms, the appropriate adversary model is far less clear. That is, while
the current problems are relatively well known, it is not obvious which threats the
Future Internet might face. Thus identifying the adversarial model and anticipating
the emerging threats is a fundamentally important first step in building a secure
Future Internet. Only when the community has a solid understanding of the threats
in the Future Internet can appropriate countermeasures be designed.
155

Bibliography
[1] I. F. Akyildiz, X. Wang, and W. Wang. Wireless mesh networks: a survey.
Computer Networks, 47(4):445–487, 2005.
[2] G. Ateniese, J. Camenisch, and B. Medeiros. Untraceable RFID tags via
insubvertible encryption. In V. Atluri, C. Meadows, and A. Juels, editors,
Proceedings of the 12th ACM Conference on Computer and Communications
Security (CCS 2005), pages 92–101. ACM, 2005.
[3] K. A. Atkinson, editor. An Introduction to Numerical Analysis (2nd ed.). John
Wiley & Sons, New York, 1989.
[4] G. Avoine. Adversarial model for radio frequency identification. Cryptology
ePrint Archive, Report 2005/049, 2005, Available at http://eprint.iacr.org/
2005/049.
[5] G. Avoine. RFID security & privacy lounge. Available at http://www.avoine.
net/rfid/.
[6] G. Avoine. Privacy issues in RFID banknotes protection schemes. In J-J
Quisquater, P. Paradinas, Y. Deswarte, and A. A. E. Kalam, editors, Proceed-
ings of 6th International Conference on Smart Card Research and Advanced
Applications (CARDIS 2004), pages 33–48. Kluwer, 2004.
[7] G. Avoine, E. Dysli, and P. Oechslin. Reducing time complexity in RFID
systems. In B. Preneel and S. E. Tavares, editors, Proceedings of 12th Interna-
tional Workshop on Selected Areas in Cryptography (SAC 2005), volume 3897
of LNCS, pages 291–306. Springer, 2006.
[8] G. Avoine, K. Kalach, and J-J Quisquater. ePassport: Securing international
contacts with contactless chips. In G. Tsudik, editor, Financial Cryptography
2008, volume 5143 of LNCS, pages 141–155. Springer, 2008.
156

BIBLIOGRAPHY
[9] G. Avoine and P. Oechslin. A scalable and provably secure hash-based RFID
protocol. Proceedings of third IEEE International Conference on Pervasive
Computing and Communications Workshops (PerComW05), pages 110–114.
IEEE Computer Society, 2005.
[10] G. Avoine and P. Oechslin. RFID traceability: A multilayer problem. In A. S.
Patrick and M. Yung, editors, Financial Cryptography 2005, volume 3570 of
LNCS, pages 125–140. Springer, 2005.
[11] D. Balfanz, D. K. Smetters, P. Stewart, and H. C. Wong. Talking to strangers:
Authentication in ad-hoc wireless networks. In Proceedings of the Network and
Distributed System Security Symposium (NDSS 2002). The Internet Society,
2002.
[12] M. Bellare, A. Boldyreva, A. Desai, and D. Pointcheval. Key-privacy in public-
key encryption. In C. Boyd, editor, Proceedings of Advances in Cryptology —
ASIACRYPT 2001, volume 2248 of LNCS, pages 566–582. Springer, 2001.
[13] M. Bellare and B. Yee. Forward-security in private-key cryptography. In
J. Marc, editor, Proceedings of the 2003 RSA conference on The cryptogra-
phers’ track (CT-RSA’03), volume 2612 of LNCS, pages 1–18. Springer, 2003.
[14] E. R. Berlekamp, R. J. McEliece, and V. Tilborg. On the inherent intractabil-
ity of certain coding problems. IEEE Transactions on Information Theory,
24:384–386, 1978.
[15] A. Bogdanov, L. R. Knudsen, G. Leander, C. Paar, A. Poschmann, M. J. B.
Robshaw, Y. Seurin, and C. Vikkelsoe. PRESENT: An ultra-lightweight block
cipher. In P. Paillier and I. Verbauwhede, editors, Proceedings of 9th Interna-
tional Workshop on Cryptographic Hardware and Embedded Systems (CHES
2007), volume 4727 of LNCS, pages 450–466. Springer, 2007.
[16] A. Bogdanov, G. Leander, C. Paar, and A. Poschmann. Hash functions and
RFID tags: Mind the gap. In E. Oswald and P. Rohatgi, editors, Proceedings
of 10th International Workshop on Cryptographic Hardware and Embedded
Systems (CHES 2008), volume 5154 of LNCS, pages 283–299. Springer, 2008.
[17] D. Boneh, R. A. DeMillo, and R. J. Lipton. On the importance of checking
cryptographic protocols for faults (extended abstract). In W. Fumy, editor,
157

BIBLIOGRAPHY
Proceedings of Advances in Cryptology — EUROCRYPT 1997, volume 1233
of LNCS, pages 37–51. Springer, 1997.
[18] D. Boneh and M. K. Franklin. Identity-based encryption from the Weil pairing.
In Joe Kilian, editor, Proceedings of Advances in Cryptology — CRYPTO
2001, volume 2139 of LNCS, pages 213–229. Springer, 2001.
[19] D. Boneh and M. K. Franklin. Identity-based encryption from the Weil pairing.
SIAM J. Comput., 32(3):586–615, 2003.
[20] D. Boneh, B. Lynn, and H. Shacham. Short signatures from the Weil pairing.
In C. Boyd, editor, Proceedings of Advances in Cryptology - ASIACRYPT
2001, volume 2248 of LNCS, pages 514 – 532. Springer, 2001.
[21] J. Bringer, H. Chabanne, and E. Dottax. HB++: a Lightweight Authenti-
cation Protocol Secure against Some Attacks. Proceedings of Second Interna-
tional Workshop on Security, Privacy and Trust in Pervasive and Ubiquitous
Computing (SecPerU 2006), pages 28–33, IEEE Computer Society, 2006.
[22] R. Bruno, M. Conti, and E. Gregori. Mesh networks: commodity multihop ad
hoc networks. IEEE Communications Magazine, 43(3):123–131, 2005.
[23] M. Burmester, T. Le, and B. Medeiros. Provably secure ubiquitous systems:
Universally composable RFID authentication protocols. Proceedings of Sec-
ond International Conference on Security and Privacy in Communication Net-
works (SecureComm), pages 1–9, IEEE Computer Society, 2006.
[24] R. Canetti. Universally composable security: A new paradigm for crypto-
graphic protocols. Proceedings of 42nd Annual Symposium on Foundations
of Computer Science (FOCS 2001), pages 136–145, IEEE Computer Society,
2001.
[25] M. Cerecedo, T. Matsumoto, and H. Imai. Efficient and secure multiparty
generation of digital signatures based on discrete logarithms. IEICE Trans.
Fundamentals, E76-A(4):532–545, 1993.
[26] M. Cagalj, S. Capkun, and J. P. Hubaux. Key agreement in peer-to-peer
wireless networks. Proceedings of the IEEE, 94(2):467–478, 2006.
[27] J. Cho. Bootstrapping security in personal area networks. Journal of Infor-
mation Assurance and Security, 2(4):303–310, December 2008.
158

BIBLIOGRAPHY
[28] J. Cho. Practical and robust self-keying scheme for personal area networks.
Proceedings of 2th IEEE International Conference on Digital Information
Management (ICDIM 2007), pages 493–499, IEEE, 2007.
[29] J. Cho. On refresh-based tag identification schemes. Proceedings of 6th IEEE
Consumer Communications and Networking Conference (CCNC 2009), pages
1–5, IEEE, 2009.
[30] J. Cho. Strengthening Class1 Gen2 RFID tags. Proceedings of 6th IEEE
International Conference on Mobile Ad-hoc and Sensor Systems (MASS 2009),
pages 818–824, IEEE Computer Society, 2009.
[31] C. Cocks. An identity based encryption scheme based on quadratic residues.
In B. Honary, editor, Proceedings of 8th IMA International Conference on
Cryptography and Coding, volume 2260 of LNCS, pages 360–363. Springer,
2001.
[32] European Commission. FP7 (7th Framework Programme). Available at
http://www.future-internet.eu.
[33] M. Conti, R. D. Pietro, L. V. Mancini, and A. Spognardi. RIPP-FS: An RFID
Identification, Privacy Preserving Protocol with Forward Secrecy. Proceedings
of 4Fifth Annual IEEE International Conference on Pervasive Computing and
Communications (PerCom 2007), pages 229–234, IEEE Computer Society,
2007.
[34] H. Deng and D. P. Agrawal. TIDS: Threshold and identity-based security
scheme for wireless ad hoc networks. Ad Hoc Networks, 2(3):291–307, 2004.
[35] A. W. Dent and C. J. Mitchell, editors. User’s Guide To Cryptography And
Standards. Artech House, Inc., Norwood. MA. USA, 2004.
[36] Y. Desmedt and Y. Frankel. Threshold cryptosystems. In G. Brassard, editor,
Proceedings of Advances in Cryptology - CRYPTO ’89, volume 435 of LNCS,
pages 307–315. Springer, 1990.
[37] W. Diffie and M. Hellman. New directions in cryptography. IEEE Transactions
in Information Theory, 22(6):644–654, November 1976.
[38] W. Diffie, P. C. van Oorschot, and M. J. Wiener. Authentication and authen-
ticated key exchanges. Designs, Codes and Cryptography, 2(2), June 1992.
159

BIBLIOGRAPHY
[39] D. Dolev and A. C. Yao. On the security of public key protocols. Proceedings
of the IEEE 22nd Annual Symposium on Foundations of Computer Science,
pages 350–357, IEEE, 1981.
[40] T. ElGamal. A public key cryptosystem and a signature scheme based on
discrete logarithms. IEEE Transactions on Information Theory, 31(4):469–
472, 1985.
[41] C. M. Ellison and S. Dohrmann. Public-key support for group collaboration.
ACM Transactions on Information and System Security, 6(4):547–565, 2003.
[42] P. Eronen and H. Tschofenig. Pre-shared key ciphersuites for Transport Layer
Security (TLS). RFC 4279, December 2005.
[43] M. Feldhofer, S. Dominikus, and J. Wolkerstorfer. Strong authentication for
RFID systems using the AES algorithm. In M. Joye and J-J Quisquater,
editors, Proceedings of 6th International Workshop Cryptographic Hardware
and Embedded Systems (CHES 2004), volume 3156 of LNCS, pages 357–370.
Springer, 2004.
[44] M. Feldhofer and C. Rechberger. A case against currently used hash func-
tions in RFID protocols. In R. Meersman, Z. Tari, and P. Herrero, editors,
Prceedings of On the Move to Meaningful Internet Systems 2006 (OTM 2006
Workshop), volume 4277 of LNCS, pages 372–381. Springer, 2006.
[45] P. Feldman. A practical scheme for non-interactive verifiable secret sharing.
Proceedings of 28th Annual Symposium on Foundations of Computer Science
(FOCS), pages 427–437, IEEE, 1987.
[46] International Organization for Standardization. ISO/IEC 1st CD 9798-6, In-
formation technology — Security techniques — Entity authentication — Part
6: Mechanisms using manual data transfer. December, 2003.
[47] NFC Forum. Connection Handover Technical Specification. Available at
http://www.nfc-forum.org/specs/spec list/.
[48] Y. Frankel, P. Gemmell, P. Mackenzie, and M. Yung. Optimal resilience proac-
tive public-key cryptosystems. Proceedings of 38nd Annual Symposium on
Foundations of Computer Science (FOCS 1997), pages 384–393, IEEE Com-
puter Society, 1997.
160

BIBLIOGRAPHY
[49] M. Frodigh, P. Johansson, and P. Larsson. Wireless ad hoc networking —
the art of networking without a network (Ericsson Review). Available at
http://www.ericsson.com/ericsson/corpinfo/publications/ review/2000 04/
124.shtml, April 2000.
[50] D. Frumkin and A. Shamir. Un-Trusted-HB: Security Vulnerabilities of
Trusted-HB. Workshop on RFID Security – RFIDSec’09, July 2009.
[51] E. Fujisaki and T. Okamoto. Secure integration of asymmetric and symmetric
encryption scheme.
[52] C. Gehrmann, C. J. Mitchell, and K. Nyberg. Manual authentication for
wireless devices. Cryptobytes, 7(1):29–37, Spring 2004.
[53] C. Gehrmann and K. Nyberg. Securty in personal area networks. In C. J.
Mitchell, editor, Security for Mobility, chapter 9, pages 191–230. IEE, London,
2004.
[54] C. Gehrmann, K. Nyberg, and C. Mitchell. The personal CA — PKI for a Per-
sonal Area Network. Proceedings of IST Mobile & Wireless Communications
Summit 2002, pages 31–35, June 2002.
[55] R. Gennaro, S. Jarecki, H. Krawczyk, and T. Rabin. Robust threshold DSS
signatures. In U. Maurer, editor, Proceedings of Advances in Cryptology —
EUROCRYPT ’96, volume 1070 of LNCS, pages 353–371. Springer, 1996.
[56] R. Gennaro, S. Jarecki, H. Krawczyk, and T. Rabin. Secure distributed key
generation for discrete-log based cryptosystem. In J. Stern, editor, Proceed-
ings of Advances in Cryptology — EUROCRYPT ’99, LNCS, pages 295–310.
Springer, 1999.
[57] R. Gennaro, S. Jarecki, H. Krawczyk, and T. Rabin. Secure distributed
key generation for discrete-log based cryptosystems. Journal of Cryptology,
20(1):51–83, Winter 2007.
[58] H. Gilbert, M. Robshaw, and H. Sibert. Active attack against HB+: a provably
secure lightweight authentication protocol. Electronics Letters, 41(21):1169–
1170, 2005.
[59] O. Goldreich, S. Goldwasser, and S. Micali. How to construct random func-
tions. Journal of the ACM, 33(4):792–807, 1986.
161

BIBLIOGRAPHY
[60] S. Goldwasser and S. Micali. Probabilistic encryption. Journal of Computer
and System Sciences, 28(2):270–299, 1984.
[61] S. Goldwasser, S. Micali, and R. Rivest. A digital signature scheme se-
cure against adaptive chosen-message attacks. SIAM Journal of Computing,
17(2):281–308, 1988.
[62] P. Golle, M. Jakobsson, A. Juels, and P. F. Syverson. Universal re-encryption
for mixnets. In T. Okamoto, editor, Proceedings of Topics in Cryptology —
CT-RSA 2004, volume 2964 of LNCS, pages 163–178. Springer, 2004.
[63] P. Gutmann. Use of shared keys in the TLS protocol. Internet draft (expired),
draft-ietf-tls-sharedkeys-02, October 2003.
[64] J. Halamka, A. Juels, A. Stubblefield, and J. Westhues. The security im-
plications of VeriChip cloning. Journal of the American Medical Informatics
Association (JAMIA), 13(5):601–607, November 2006.
[65] T. Halevi, N. Saxena, and S. Halevi. Using HB Family of Protocols for Privacy-
Preserving Authentication of RFID Tags in a Population. Workshop on RFID
Security – RFIDSec’09, July 2009.
[66] M. Halvac and T. Rosa. A Note on the Relay Attacks on e-Passports: The
Case of Czech e-Passports. Cryptology ePrint Archive, Report 2007/244, 2007.
[67] M. Hellman. A cryptographic time-memory tradeoff. IEEE Transactions on
Information Theory, IT-26:401–406, 1980.
[68] A. Herzberg, S. Jarecki, H. Krawczyk, and M. Yung. Proactive secret sharing
or: How to cope with perpetual leakage. In D. Coppersmith, editor, Proceed-
ings of Advances in Cryptology — CRYPTO ’95, volume 963 of LNCS, pages
339–352. Springer, 1995.
[69] EPCglobal Inc. The EPCglobal Network: Overview of design, benefits, and
security. Available at http://www.epcglobalinc.org/about/media centre/ Net-
work Security Final.pdf, September 2004.
[70] EPCglobal Inc. Specification for RFID air interface. Available at http://www.
epcglobalinc.org/standards/uhfc1g2/uhfc1g2 1 1 0-standard-20071017.pdf,
December 2005.
162

BIBLIOGRAPHY
[71] EPCglobal Inc. The EPCglobal architecture framework. Available at http://
www.epcglobalinc.org/standards/architecture/architecture 1 2-framework-
20070910.pdf, September 2007.
[72] VeriSign Inc. The EPCglobal Network: Ehancing the supply chains. Available
at http://www.verisign.com/stellent/groups/public/documents/white paper
/002109.pdf, June 2005.
[73] VeriSign Inc. The EPCglobal Network: Maximizing the business benifits of
RFID. Available at http://www.verisign.com/static/014025.pdf, June 2005.
[74] D. Johnson and D. Maltz. Dynamic sourcee routing in ad hoc wireless net-
works. In T. Imielinski and H. Korth, editors, Ad Hoc Wireless Networks.
Kluwer Academic Publishers, New York, 1996.
[75] A. Juels. Minimalist cryptography for low-cost RFID tags. In C. Blundo and
S. Cimato, editors, Proceedings of 4th International Conference on Security in
Communication Networks (SCN 2004), volume 3352 of LNCS, pages 149–164.
Springer, 2005.
[76] A. Juels. Strengthening EPC tags against cloning. In M. Jakobsson and
R. Poovendran, editors, Proceedings of the ACM Workshop on Wireless Secu-
rity (WiSe 2005), pages 67–76. ACM, 2005.
[77] A. Juels. RFID security and privacy: A research survey. IEEE Journal on
Selected Areas in Communications, 24(2):381–394, 2006.
[78] A. Juels, D. Molnar, and D. Wagner. Security and privacy issues in e-passports.
Proceedings of First International Conference on Security and Privacy for
Emerging Areas in Communications Networks (SecureComm 2005), pages 74–
88, IEEE Computer Society, 2005.
[79] A. Juels and R. Pappu. Squealing Euros: Privacy protection in RFID-enabled
banknotes. In R. N. Wright, editor, Financial Cryptography 2003, volume 2742
of LNCS, pages 103–121. Springer, 2003.
[80] A. Juels and S. Weis. Defining strong privacy for RFID. Proceedings of Inter-
national Conference on Pervasive Computing and Communications (PerCom
2007), pages 342–347. IEEE Computer Society, 2007.
163

BIBLIOGRAPHY
[81] A. Juels and S. A. Weis. Authenticating pervasive devices with human proto-
cols. In V. Shoup, editor, Proceedings of Advances in Cryptology — CRYPTO
2005, volume 3621 of LNCS, pages 293–308. Springer, 2005.
[82] J. Katz and Y. Lindell. Introduction to Modern Cryptogaphy. Champman &
Hall/CRC, 2008.
[83] J. Katz and J. Shin. Parallel and concurrent security of the HB and HB+
protocols. In S. Vaudenay, editor, Proceedings of Advances in Cryptology -
EUROCRYPT 2006, volume 4004 of LNCS, pages 73–87. Springer, 2006.
[84] J. Katz and J. Shin. Modelling insider attacks on group key exchange protocols.
Proceedings of the 12th ACM Conference on Computer and Communications
Security (CCS 2005), pages 180–189, ACM, 2005.
[85] S. V. Kaya, E. Savas, A. Levi, and O. Ercetin. Public key cryptography
based privacy preserving multi-context RFID infrastructure. Ad Hoc Networks,
7(1):136–152, 2009.
[86] Z. Kfir and A. Wool. Picking virtual pockets using relay attacks on contactless
smartcard. Proceedings of First International Conference on Security and Pri-
vacy for Emerging Areas in Communications Networks (SecureComm 2005),
pages 47–58. IEEE Computer Society, 2005.
[87] A. Khalili, J. Katz, and W. A. Arbaugh. Toward secure key distribution in
truly ad-hoc networks. Proceedings of IEEE Security and Assurance in Ad-
Hoc Networks at International Symposium on Applications and the Internet
(SAINT ’03), pages 342–346. IEEE, 2003.
[88] I. Kim, E. Choi, and D. Lee. Secure mobile RFID system against privacy and
security problems. Proceedings of Third International Workshop onSecurity,
Privacy and Trust in Pervasive and Ubiquitous Computing (SecPerU 2007),
pages 67–72. IEEE Computer Society, 2007.
[89] D. M. Konidala and K. Kim. Mobile RFID applications and security chal-
lenges. In M. Rhee and B. Lee, editors, Proceedings of 9th International Con-
ference on Information Security and Cryptology (ICISC 2006), volume 4296
of LNCS, pages 194–205. Springer, 2006.
164

BIBLIOGRAPHY
[90] E. Kosta, M. Meints, M. Hensen, and M. Gasson. An analysis of security and
privacy issues relating to RFID enabled ePassports. In H. Venter, M. Eloff,
L. Labuschagne, J. Eloff, and R. Von Solms, editors, IFIP International Fed-
eration for Information Processing, New approaches for Security, Privacy and
Trust in Complex Environments, pages 467–472. Springer, 2007.
[91] S. Kumar and C. Paar. Are standards compliant elliptic curve cryptosystems
feasible on RFID. Workshop on RFID Security (RFIDSec06), 2006. Available
at http://events.iaik.tugraz.at/RFIDSec06.
[92] J. Larsson. Private communication with M. Jakobsson.
[93] T. V. Le, M. Burmester, and B. Medeiros. Universally composable and
forward-secure RFID authentication and authenticated key exchange. In
F. Bao and S. Miller, editors, Proceedings of the 2007 ACM Symposium on In-
formation, Computer and Communications Security (ASIACCS 2007), pages
242–252. ACM, 2007.
[94] G. Leander, C. Paar, A. Poschmann, and K. Schramm. New lightweight DES
variants. In A. Biryukov, editor, Proceedings of the 14th International Work-
shop on Fast Software Encryption (FSE 2007), volume 4593 of LNCS, pages
196–210. Springer, 2007.
[95] X. Leng, K. Mayes, and K. Markantonakis. HB-MP+ protocol: An improve-
ment on the HB-MP protocol. IEEE International Conference on RFID, pages
118–124, April 2008.
[96] C. Li, T. Hwang, and N. Lee. (t, n) threshold signature schemes based on dis-
crete logarithm. In R. Rueppel, editor, Proceedings of Advances in Cryptology
— EUROCRYPT ’94, volume 950 of LNCS, pages 191–200. Springer, 1994.
[97] C. Lim and T. Kwon. Strong and robust RFID authentication enabling perfect
ownership transfer. In P. Ning, S. Qing, and N. Li, editors, Proceedings of
8th International Conference on Information and Communications Security
(ICICS 2006), volume 4307 of LNCS, pages 1–20. Springer, 2006.
[98] D. P. Maher and N. H. Windham. Secure communication method and appa-
ratus. United States Patent, No. 5450493, Sep. 1995.
165

BIBLIOGRAPHY
[99] S. Martinez, M. Valls, C. Roig, F. Gine, and J. Miret. An elliptic curve and
zero knowledge based forward secure RFID protocol. Workshop on RFID
Security (RFIDSec07), 2007. Available at http://rfidsec07.etsit.uma.es/.
[100] M. McLoone and M. J. B. Robshaw. Public key cryptography and RFID tags.
In M. Abe, editor, Proceedings of Topics of Cryptology — CT-RSA 2007,
volume 4377 of LNCS, pages 372–384. Springer, 2007.
[101] A. Menezes, T. Okamoto, and S. A. Vanstone. Reducing elliptic curve log-
arithms to logarithms in a finite field. IEEE Transactions on Information
Theory, 39(5):1639–1646, 1993.
[102] A. J. Menezes, P. C. Oorschot, and S. A. Vanstone. Handbook of Applied
Cryptography. CRC Press, 2001. Available at http://www.cacr.math.uwater-
loo.ca/hac/.
[103] J. V. D. Merwe, D. Dawoud, and S. McDonald. A survey on peer-to-peer key
management for mobile ad hoc networks. ACM Computing Surveys, 39(1):Ar-
ticle No. 1, 2007.
[104] C. J. Mitchell and R. Schaffelhofer. The personal PKI. In C. J. Mitchell,
editor, Security for Mobility, chapter 3, pages 35–60. IEE, London, 2004.
[105] D. Molnar, A. Soppera, and D. Wagner. A scalable, delegatable pseudonym
protocol enabling ownership transfer of RFID tags. In B. Preneel and S. E.
Tavares, editors, 12th International Workshop On Selected Areas in Cryptog-
raphy (SAC 2005), volume 3897 of LNCS, pages 276–290. Springer, 2006.
[106] D. Molnar and D. Wagner. Privacy and security in library RFID: issues, prac-
tices, and architectures. In V. Atluri, B. Pfitzmann, and P. D. McDaniel,
editors, Proceedings of 11th ACM Conference on Computer and Communica-
tions Security (CCS 2004), pages 210–219. ACM, 2004.
[107] K. Nohl and D. Evans. Quantifying information leakage in tree-based hash
protocols (short paper). In P. Ning, S. Qing, and N. Li, editors, Proceedings
of 8th International Conference on Information and Communications Security
(ICICS 2006), volume 4307 of LNCS, pages 228–237. Springer, 2006.
166

BIBLIOGRAPHY
[108] M. Ohkubo, K. Suzuki, and S. Kinoshita. Cryptographic approach
to privacy-friendly tags. In RFID Privacy Workshop, available at
http://www.rfidprivacy.org/papers/ohkubo.pdf, 2003.
[109] K. Ouafi, R. Overbeck, and S. Vaudenay. On the security of HB# against
a man-in-the-middle attack. In J. Pieprzyk, editor, Proceedings of Advances
in Cryptology - ASIACRYPT 2008, volume 5350 of LNCS, pages 108–124.
Springer, 2008.
[110] N. Park, Y. Song, D. Won, and H. Kim. Multilateral approaches to the mobile
RFID security problem using web service. In Y. Zhang, G. Yu, E. Bertino, and
G. Xu, editors, Proceedings of 10th Asia-Pacific Web Conference on Progress
in WWW Research and Development (APWeb 2008), volume 4976 of LNCS,
pages 331–341. Springer, 2008.
[111] T. P. Pedersen. A threshold cryptosystem without a trusted party (extended
abstract). In D. W. Davies, editor, Proceedings of Advances in Cryptology -
EUROCRYPT ’91, volume 547 of LNCS, pages 522–526. Springer, 1991.
[112] C. Perkins, E. Belding-Royer, and S. Das. Ad hoc on-demand distance vector
(AODV) routing. RFC 3561, July 2003.
[113] B. Pfitzmann and M. Waidner. Composition and integrity preservation of
secure reactive systems. Proceedings of the 7th ACM Conference on Computer
and Communications Security (CCS 2000), pages 245–254, ACM, 2000.
[114] M. Philipose, K. P. Fishkin, D. Fox, H. Kautz, D. Patterson, and M. Perkowitz.
Guide: Towards understanding daily life via auto-identification and statistical
analysis. Proceedings of the International Workshop on Ubiquitous Comput-
ing for Pervasive Healthcare Applications (Ubihealth 2003), Springer Verlage,
2003.
[115] European Future Internet Portal. White paper on the Future Internet PPP
Definition. Available at http://www.future-internet.eu.
[116] R. L. Rivest. Chaffing and winnowing: Confidentiality without encryption.
CryptoBytes, 4(1):12–17, 1998.
167

BIBLIOGRAPHY
[117] R. L. Rivest, A. Shamir, and L. M. Adleman. A method for obtaining dig-
ital signatures and public-key cryptosystems. Communications of the ACM,
21(2):120–126, 1978.
[118] C. M. Roberts. Radio Frequency Identification (RFID). Computers & Security,
25(1):18–26, 2006.
[119] C. Rolfes, A. Poschmann, G. Leander, and C. Paar. Ultra-lightweight im-
plementations for smart devices — security for 1000 gate equivalents. In
G. Grimaud and F-X Standaert, editors, Proceedings of 8th IFIP WG 8.8/11.2
International Conferenc on Smart Card Research and Advanced Applications
(CARDIS 2008), volume 5189 of LNCS, pages 89–103. Springer, 2008.
[120] J. Saito, J. Ryou, and K. Sakurai. Enhancing privacy of universal re-encryption
scheme for RFID tags. In L. T. Yang, M. Guo, G. R. Gao, and N. K. Jha,
editors, Proceedings of International Conference on Embedded and Ubiquitous
Computing (EUC 2004), volume 3207 of LNCS, pages 879–890. Springer, 2004.
[121] R. Sakai, K. Ohgishi, and M. Kasahara. Cryptosystems based on pairing.
Proceedings of the 2000 Symposium on Cryptography and Information Security
(SCIS 2000), pages 26–28, January 2000.
[122] N. B. Salem, L. Buttyan, J. P. Hubaux, and M. Jakobsson. Node cooperation in
hybrid ad hoc networks. IEEE Transactions on Mobile Computing, 5(4):365–
376, 2006.
[123] S. E. Sarma, S. A. Weis, and D. W. Engels. Radio Frequency Identification:
Security risks and challenges. CryptoBytes, 6(1):2–9, 2003.
[124] N. Saxena. Public key cryptography sans certificates in ad hoc networks. In
J. Zhou, editor, Proceedings of 4th International Conference on Applied Cryp-
tography and Network Security (ACNS 2006), volume 3989 of LNCS, pages
375–389. Springer-Verlag, 2006.
[125] B. Schechter. Seeing the light: IBM’s vision of life beyond the PC. IBM
research, No. 2, 2000.
[126] C-P Schnorr. Efficient signature generation by smart cards. Journal of Cryp-
tology, 4(3):161–174, 1991.
168

BIBLIOGRAPHY
[127] A. Shamir. Identity-based cryptosystems and signature schemes. In G. R.
Blakley and D. Chaum, editors, Proceedings of Advances in Cryptology —
CRYPTO ’84, volume 196 of LNCS, pages 47–53. Springer, 1985.
[128] Adi Shamir. How to share a secret. Commun. ACM, 22(11):612–613, 1979.
[129] V. Shoup and R. Gennaro. Securing threshold cryptosystems against chosen
ciphertext attack. In K. Nyberg, editor, Proceedings of Advances in Cryptology
— EUROCRYPT ’98, volume 1403 of LNCS, pages 1–16. Springer, 1998.
[130] Bluetooth SIG. Core specification version 2.1 + edr. Available at http://www.
bluetooth.com/English/Technology/Works/Pages/Core Specification v21 ED
R.aspx.
[131] Bluetooth SIG. Secure simple pairing whitepaper (2006-08-03). Available
at http://www.bluetooth.com/NR/rdonlyres/0A0B3F36-D15F-4470-85A6-
F2CCFA26F70F/0/SimplePairing WP V10r00.pdf.
[132] F. Stajano and R. J. Anderson. The resurrecting duckling: Security issues
for ad-hoc wireless networks. In B. Christianson, B. Crispo, J. A. Malcolm,
and M. Roe, editors, Proceedings of 7th International Workshop on Security
Protocols, volume 1796 of LNCS, pages 172–194. Springer, 2000.
[133] IEEE standard 802.15.1. IEEE Standard for Information technology —
Telecommunications and information exchange between systems — Local
and metropolitan area networks – Specific requirements Part 15.1: Wireless
Medium Access Control (MAC) and Physical Layer (PHY) Specifications for
Wireless Personal Area Networks (WPANs).
[134] Y. Tsiounis and M. Yung. On the security of ElGamal based encryption. In
H. Imai and Y. Zheng, editors, Proceedings of First International Workshop
on Practice and Theory in Public Key Cryptography (PKC 1998), volume 1431
of LNCS, pages 117–134. Springer, 1998.
[135] G. Tsudik. A Family of Dunces: Trivial RFID Identification and Authentica-
tion Protocols. In N. Borisov and P. Golle, editors, Proceedings of 7th Inter-
national Symposium in Privacy Enhancing Technologies (PEC 2007), volume
4776 of LNCS, pages 45–61. Springer, 2007.
169

BIBLIOGRAPHY
[136] G. Tsudik. YA-TRAP: Yet Another Trivial RFID Authentication Protocol.
Proceedings of 4th IEEE Conference on Pervasive Computing and Communi-
cations Workshops (PerCom 2006), pages 640–643, IEEE Computer Society,
2006.
[137] S. Vaudenay. On privacy models for RFID. In K. Kurosawa, editor, Proceedings
in Advances in Cryptology - ASIACRYPT 2007, volume 4833 of LNCS, pages
68–87. Springer, 2007.
[138] S. H. Weingart. Physical security devices for computer subsystems: A survey
of attacks and defences. In C. K. Koc and C. Paar, editors, Proceedings of 9th
International Workshop on Cryptographic Hardware and Embedded Systems
(CHES 2000), volume 1965 of LNCS, pages 302–317. Springer, 2000.
[139] S. A. Weis. Security parallels between people and pervasive devices. Proceed-
ings of 3rd IEEE Conference on Pervasive Computing and Communications
Workshops (PerCom 2005), pages 105–109, IEEE Computer Society, 2005.
[140] S. A. Weis, S. E. Sarma, R. L. Rivest, and D. W. Engels. Security and pri-
vacy aspects of low-cost radio frequency identification systems. In D. Hutter,
G. Muller, W. Stephan, and M. Ullmann, editors, First International Confer-
ence on Security in Pervasive Computing (SPC 2003), volume 2802 of LNCS,
pages 201–212. Springer, 2004.
[141] J. Wolkerstorfer. Is elliptic-curve cryptography suitable to secure RFID tags?
ECRYPT Workshop on RFID and Lightweight Crypto, 2005. Available at
http://events.iaik.tugraz.at/RFIDandLightweightCrypto05.
[142] B. Yoon. HB-MP++ protocol: An ultra light-weight authentication protocol
for RFID system. In IEEE International Conference on RFID – RFID 2009.
IEEE, April 2009.
[143] Y. Zhang, W. Liu, W. Lou, and Y. Fang. Anonymous communications in
mobile ad hoc networks. Proceedings of 24th Annual Joint Conference of
the IEEE Computer and Communications Societies (INFOCOM 2005), pages
1940–1951.
[144] Y. Zhang, W. Liu, W. Lou, and Y. Fang. Securing mobile ad hoc networks
with certificateless public keys. IEEE Transactions on Dependable and Secure
Computing, 3(4):386–399, 2006.
170

BIBLIOGRAPHY
[145] L. Zhou and Z. J. Haas. Securing ad hoc networks. IEEE Network, 13(6):24–
30, 1999.
171



![An Effective Lightweight Cryptographic Algorithm to Secure ... · cryptographic standards to small devices [3]. Many conventional cryptographic algorithms, was optimized for desktop](https://img.pdfslide.net/doc/110x75/5eba52c083012c62a6160c7f/an-effective-lightweight-cryptographic-algorithm-to-secure-cryptographic-standards.jpg)

























