Embed Size (px)
Citation preview

CS 3813Introduction to Formal Languages and Automata
Chapter 6Simplification of Context-free Grammars and Normal Forms
These class notes are based on material from our textbook, An Introduction to Formal Languages and Automata, 4th ed., by Peter Linz, published by Jones and Bartlett Publishers, Inc., Sudbury, MA, 2006. They are intended for classroom use only and are not a substitute for reading the textbook.

Parsing• Given a string w and a grammar G, a parser
finds a derivation of the string w from the grammar G, or else determines that the string is not part of the language
• Thus, a parser solves the membership problem for a language, which is the problem of deciding, for any string w and grammar G, whether w belongs to the language generated by G
• Typically, a parser also constructs a parse tree for the string (which can be used by a compiler for code generation)

Two questions
• Can we solve the membership problem for context-free languages? That is, can we develop a parsing algorithm for any context-free language?
• If so, can we develop an efficient parsing algorithm?
• We saw in the previous chapter that we can, if we place restrictions on the grammar.

Simplified forms and normal forms
Simplified forms can eliminate ambiguity and otherwise “improve” a grammar
What we would like to do is to have all productions in a CFG be in a form such that the string length is strictly non-decreasing. Once the productions are in this form, whenever we find in the process of deriving a string that the derivation string is longer than the input string, we know that the string cannot belong to the language.

Simplified forms and normal forms
Normal forms of context-free grammars are interesting in that, although they are restricted forms, it can be shown that every CFG can be converted to a normal form.
The two types of normal forms that we will look at are Chomsky normal form and Greibach normal form.

The empty string
The empty string often complicates things, so we would like to define (and work with) a subset of a language which accepts the empty string.
Let L be a context-free language and let G’ = (V, T, S, P) be a context free grammar for L – { λ }.
Then we can construct a grammar G that generates L by adding the following to G’:
Create a new Start variable, S0
Add two new production rules to G’:
S0 S
S0 λ

The empty string
Most of the proofs for CFG languages are demonstrated by using λ-free languages. It usually can be shown quite easily that the proof can also be extended to “equivalent” languages for which the only difference is the acceptance of the empty string.
(yes, this is handwaving, but . . .)

Simplified forms
Theorem 6.1: Let G = (V, T, S, P) be a context-free grammar. Suppose that P contains a production rule of the form:
A x1Bx2
Assume that A and B are different variables and that
B y1 | y2 | . . . | yn
is the set of all productions in P which have B as the left side.

Simplified forms
Theorem 6.1: (continued)
Let G’ = (V, T, S, P’) be the grammar in which P’ is constructed by deleting
A x1Bx2
from P, and adding to it
A x1y1x2 | x1y2x2 | . . . | x1ynx2
Then it may be shown that
L(G’) = L(G)
(see the Linz textbook, p. 151, for the proof)

Simplified forms
Example:
A a | aaA | abBc
B abbA | b
Here we can’t eliminate all rules with B on the left side, but we can eliminate it from the right side of any A rules. The equivalent productions would be:
A a | aaA | ababbAc | abbc
B abbA | b

Simplified forms
Example:
Suppose that our complete simplified grammar is:
S A
A a | aaA | ababbAc | abbc
B abbA | b
Since you can’t get to B from S, there is no longer any way that any B rules can play a part in any derivation; they are useless.

Simplified forms
Another example:
Suppose that our grammar is:
S aSb | λ | A
A aA
Notice that the production rule A aA can never be used to produce a sequence of all terminals. It is therefore useless.
The production rule S A is also useless. (Why?) Both of these rules may be deleted without effectively changing the grammar.

Reachable
Definition: A variable A in a CFG grammar G = (V, , S, P)
is reachable if S * xAy for some xy (V T)*.
Reachable variables are variables that appear in strings derivable from S.

Example
S EA
A abA | ab
C EC | Ab
E bC
G EbE | CE | ba
Reachable variables:R0 = {S}R1 = {S, E, A}R2 = {S, E, A, C}R3 = {S, E, A, C}

Useful variables
Definition: Let G = (V, , S, P) be a context-free grammar.
Let A V; then A is live iff there is at least one string w L(G) such that
xAy * w with x, y in (V T)*
Informally, live variables are those from which strings of terminals can be derived. Variables which are not live are said to be dead.

Example
S AB | CD | ADF | CF | EA
A abA |ab
B bB | aD | BF | aF
C cB | EC | Ab
D bB | FFB
E bC | AB
F abbF | baF | bD | BB
G EbE | CE | ba
Live variables:L0={A, G}L1={A, G, C}L2={A, G, C, E}L3={A, G, C, E, S}

Useful variables
Definition 6.1 (modified): A variable A in a CFG grammar G = (V, , S, P) is useful if, for some string w L(G) , there is a derivation of w that takes the form S * xAb* w.
Informally, a variable is useful if it can be used in a derivation of a string in the language L(G).
A variable which is not useful is said to be useless. Variables which are dead are useless.Variables which are not reachable are useless.

Useless variables
So a variable is useless if either:
1. it is not live (i.e., cannot derive a terminal string), or
2. it is not reachable from the start symbol
A production is useless if it involves any useless variables.

Exercise
Example:Given G = ({S, A, B, C}, {a, b}, S, P), with P =
S aS | A | CA aB aaC aCb
eliminate all useless variables and productions.
First, we find any dead variables. It should be obvious that C can never generate a string of all-terminals. C is dead.

Exercise
Delete any productions involving C.
New grammar: S aS | A A aB aa
Next, we check to see if there are any variableswhich cannot be reached from the start symbol.
To do this, we may use a dependency graph.
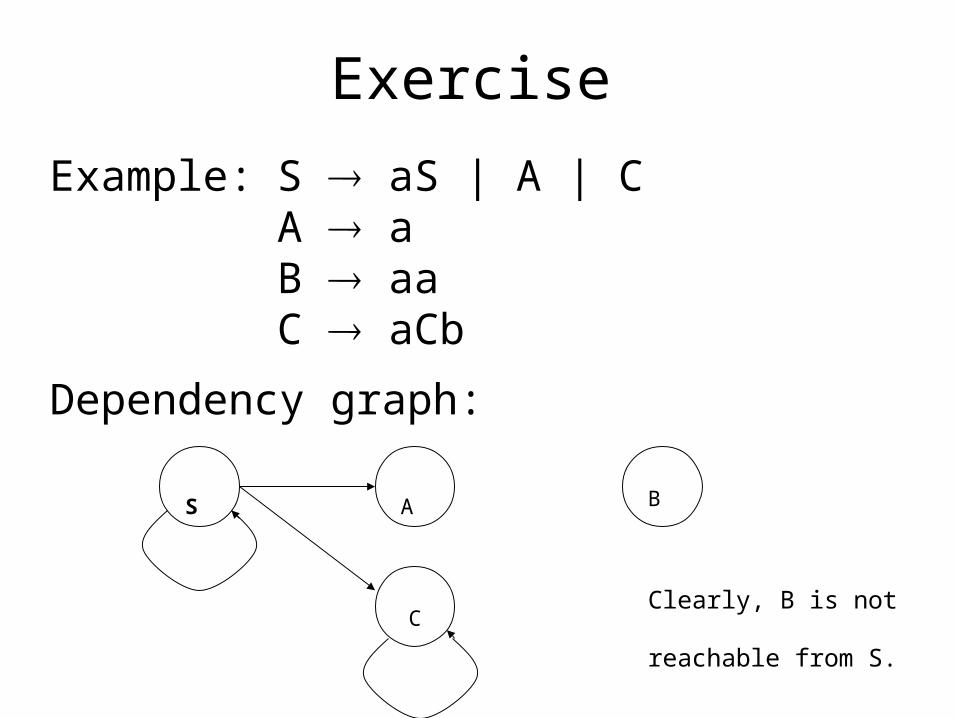
Exercise
Example: S aS | A | CA aB aaC aCb
Dependency graph:
S A
C
B
Clearly, B is not reachable
from S.

Exercise
Delete any productions involving B.
New grammar: S aS | A A a
The only productions that were deleted from the original grammar were useless.
This new grammar generates all and only the strings generated by the original grammar. It is equivalent to the original grammar.

Useless variables
Theorem 6.2: Let G = (V, T, S, P) be a context-free grammar. Then there exists an equivalent grammar G’ = (V’, T’, S, P’) that does not contain any useless variables or productions.
See pp. 155 and 156 in the Linz text for the formal proof.
Note that useless variables may be removed from V to give V’, and any terminals not occurring in any useful production may be removed from T to give T’.

Simplified forms and normal forms
Two undesirable types of productions in a CFG can make the string length in sentential forms not increase:
productions -
these productions are of the form A , and they actually decrease the length of the string
unit productions -
these productions are of the form A B, and they allow rules to be applied to a string without increasing the length of the string and without getting us any closer to the goal of ending up with a string of all terminals

productions
Definition 6.2: Any production of a context-free grammar of the form
A λ
is called a λ-production.
Any variable A for which the derivation A * λ is possible is called null able.

Nullable variables
A nullable variable in a context-free grammar G = (V, , S, P) is defined as follows:
1. Any variable A for which P contains the production A is nullable.
2. If P contains the production A B1B2…Bn and B1B2…Bn are nullable variables, then A is nullable.
3. No other variables in V are nullable.
The nullable variables in V are precisely those variables A for which A * .

The effect of productions
Suppose we are trying to see if our CFG generates the string aabaa, which contains 5 terminal characters. In the process of applying productions, we have generated an intermediate string, aaYbYaa, containing 7 characters. Sinceproductions decrease the length of the string, it might still be possible to generate aabaa from aaYbYaa (if there were a derivation path Y ).

productions
Note that without productions, a grammar would have no way to reduce the number of characters in its intermediate strings. In such a grammar, we could stop processing intermediate strings as soon as they exceeded the length of the target string.

productions
So, given a CFG G without productions, we could determine if a given string x of length |x| belonged to L(G) simply by applying production rules and generating all strings of length |x|. If x had not been generated up to that point, it could not belong to that language.

productions
Given the grammar
S aS1b
S1 aS1b | λ
What is the effect of the production S1 λ?
The effect is to delete S1 from any sentential form occurring on the right-hand side of a production rule.

productions
If we apply the production S1 λ toS aS1b
the resulting production rule isS ab
If we apply the production S1 λ toS1 aS1b
the resulting production rule isS1 ab

productions
Therefore, we can eliminate any λ-productions from this grammar by adding the new productions obtained by substituting λ for S1 wherever S1 appears on the right-hand side of the production rules, and then deleting the λ-production.
When we do this, we obtain the equivalent grammar:
S aS1b | ab
S1 aS1b | ab

productions
Theorem 6.3: Let G be any context-free grammar with λ not in L(G). Then there exists an equivalent grammar G’ having no λ-productions.

Algorithm FindNull
Establish the set N0, which is the set of all variables A in the grammar that go directly to .Now loop: The first time through the loop, add to this set all variables B that go to A. The second time through the loop, add to this set all variables C that go to B. The third time through the loop, add to this set all variables D that go to C. etc. . . . Stop when no new variables were added to the set during the last iteration of the loop.

Example
Let G be the CFG with the productions:
S ABCBCDAA CDB CbC a | D bD |
Here, C and D are nullable because there are production rules C and D .
But A is also nullable, because A CD, and both C and D are nullable.

Algorithm: Eliminate productions
Given a CFG G = (V, S, P) construct a CFG G’= (V, S, P’) with no -productions as follows:
1. Initialize P’ = P2. Find all nullable variables in V, using FindNull.3. For every production A x in P (x {V T}*),
where x contains nullable variables, add to P’ every production that can be obtained from this one by deleting from x one or more of the occurrences in xof nullable variables.
4. Delete all productions from P’. 5. In addition, delete any duplicates and delete
productions of the form A A.

ExampleGiven a context-free grammar with the following production rules, find the nullable variables:S ABCA B | aB C | b | λC AB | DD Cd
N0 = {B}N1 = {B, A}N2 = {B, A, C}N3 = {B, A, C, S}

Example (continued)
S ABCA B | aB C | b | C AB | DD Cd
N = {A, B, C, S}
S ABCS ABC | BC | AC | AB | A | B | C
C AB | DC AB | A | B | D
D CdD Cd | d

Example (continued)
S ABC | AB | AC | BC | A | B | CA B | aB C | bC AB | A | B | DD Cd | d
Note that we have gotten rid of all -productions. However, other beneficial changes can still be made.

Implications of Theorem 6.3:
Let G = (V, , S, P) be any context-fee grammar, and let G’ be the grammar obtained from G by the previous algorithm. Then:
1. G’ has no-productions, and 2. L(G’) = L(G) - {}.3. Moreover, if G is unambiguous, then so is G’.

Unit productions
Definition 6.3: Any production of a context-free grammar of the form
A B,
where A, B V is called a unit-production.

Unit productions
Theorem 6.4: Let G = (V, T, S, P) be any context-free grammar without λ-productions. Then there exists a context-free grammar G’ = (V’, T’, S, P’) that does not have any unit-productions and that is equivalent to G.

Definition of A-derivable variables
The set of “A-derivable variables” is the set of all variables B for which A * .
1. If A B is a production, then B is A-derivable.2. If:
C is A-derivableC B is a productionB A
then B is A-derivable.3. No other variables are A-derivable.

Algorithm: Eliminating Unit Productions
Given a context-free grammar G = (V, S, P) with no -productions, construct a grammar G’= (V, S, P’) having no unit productions as follows:
1. Initialize P’ to be P.2. For each A V, find the set of A-derivable variables.3. For every pair (A, B) such that B is A-derivable, and
every non-unit production B x (where x {V T}+), add the production A x to P’.
4. Delete all unit productions from P’.

Example
Original grammar:S S+T | TT T*F | FF (S) | a
{S -derivable} = {T} {T-derivable} = {F}{S-derivable} ={T, F}
Resulting grammar:S S+T | T*F | (S) | aT T*F | (S) | aF (S) | a

Summary
Theorem 6.5: Let L be a context-free language that does not contain λ. Then there exists a context-free language that generates L and that does not have any useless productions, λ-productions, or unit-productions.
Proof: Find a CFG that generates L. Apply the procedures in theorems 6.2, 6.3, and 6.4. The result is an equivalent CFG that generates L but does not have any useless productions, λ-productions, or unit-productions..

Summary
Note that the procedure specified above must occur in a particular order. The procedure for removing λ-productions can create new unit-productions, and the procedure for eliminating unit-productions must start with a CFG that has no λ-productions. The required sequence is:
1. Remove λ-productions
2. Remove unit productions
3. Remove useless productions

Unit productions
Given a context-free grammar G’ without unitproductions, any production rule must either:
• Convert a non-terminal to a terminal, or
• Replace a non-terminal with at least two other symbols

Simplified forms
What does this mean for us?
Given a grammar G and a language L(G), it means that if you have a string, x, in L(G) and |x| = k, then starting from S there are no more than 2k - 1 steps in the derivation of x.

Chomsky Normal Form
There are other ways to limit the form a grammar can have.
A context-free grammar in Chomsky Normal Form (CNF) has all of its rules restricted so that there are no more than two symbols, either one terminal or two variables, on the right-hand side of a production rule.
This seems very restrictive, but actually every context-free grammar can be converted into Chomsky Normal Form.

Chomsky Normal Form
Definition 6.4: A context-free grammar is in Chomsky Normal Form (CNF) if every production is one of these two types:
A BC
A a
where A, B, and C are variables and a is a terminal symbol.

Chomsky normal form
For languages that include the empty string λ, the rule S λ may also be allowed, where S is the start symbol, as long as S does not occur on the right-hand side of any rule

Chomsky Normal Form
Theorem 6.6: Any context-free grammar G = (V, T, S, P) with λ L(G) has an equivalent grammar G’ = (V’, T’, S, P’) in Chomsky Normal Form.
(Actually, for languages that include the empty string λ, the rule S λ may also be allowed, where S is the start symbol, as long as S does not occur on the right-hand side of any rule.)

Chomsky Normal Form: Proof by construction
Given a CFG grammar G = (V, , S, P), to convert it to Chomsky Normal Form:
1. Eliminate -productions and unit-productions from G, producing a CFG G’= (V, , S, P’), such that L(G’) = L(G) - {}.
2. Convert G’ into G’’ = (V’’, , S, P’’) so that every production is either of the form
A B1B2 … Bk
(where k 2 and each Bi is a variable in V’’), or of the form
A a

Chomsky Normal Form
Basically, what you are doing in step 2 is restricting the right sides of productions to be either single terminals or strings of two or more variables.
What we don’t want is strings of length 2 that have one or more terminals in them. If we have strings like this, for every terminal a appearing in such a string:
1. Add a new variable, Xa and
add a new production, Xa a
2. Replace a by Xa in all the productions where it appears (except those in the form A a).

Chomsky Normal Form (continued)
3. Convert G’’ into G’’’ = (V’’’, , S, P’’’). To do this, replace each production having more than two variables on the right by an equivalent set of productions, each one having exactly two variables on the right. (Create new variables as necessary to accomplish this.)
For example:the production A BCD would be replaced with
A BZ1
Z1 CD
Done!

Example
Original grammar:S AB | abA ABAB | BAB ab | b
After step 2:S AB | XaXb
Xa aXb bA ABAB | BAB XaXb | b

Example
After step 2:S AB | XaXb
Xa aXb bA ABAB | BAB XaXb | b
After step 3:S AB | XaXb
Xa aXb bA AY1 | BAY1 BY2
Y2 ABB XaXb | b

Example
If you recognize thatA ABABhas two copies of thesame pair of variables,you could substitutethe following instead:(but the first procedureworks equally well)
After step 3:S AB | XaXb
Xa aXb bA Y1Y1 | BAY1 ABB XaXb | b

Proof (concluded)
This constitutes a proof by construction that any CFG can be converted to CNF.
Later, this will be used to prove that there are languages which are not context-free.

Greibach Normal Form
Greibach Normal Form is similar to Chomsky Normal Form, except that every production is of the form A ax, where a is a terminal symbol and x is a string of zero or more variables. Note that GNF puts a limit on where terminals and variables can appear – restrictions on their relative positions – rather than on the number of symbols on the right-hand side of the production rules.

Greibach Normal Form
Definition 6.5: A context-free grammar is said to be in Greibach Normal Form if all productions have the form
A axwhere a T and x V*

Greibach Normal Form
Example:
Convert the following grammar into GNF:S abSb | aa
Introduce new variables A and B to stand for a and b respectively, and substitute:
S aBSB | aAA aB b

Greibach Normal Form
Theorem 6.7: Any context-free grammar G = (V, T, S, P) with λ L(G) has an equivalent grammar G’ = (V’, T’, S, P’) in Greibach Normal Form.
It is hard to prove this, and it is hard to construct an easy-to implement algorithm for performing the conversion.

A membership algorithm for CFG’s
The famous linguist Noam Chomsky showed that every context-free grammar can be converted to an equivalent grammar in Chomsky normal form.
Why should you care about this?
The fact that any CFG can be converted to Chomsky normal form lets us develop a parsing algorithm that shows that the membership problem can be solved for context-free languages (CFLs).

Some motivationHere is the idea of the algorithm: For a grammar in Chomsky normal form, any
derivation of a string w has 2n-1 steps, where n is the length of w. (Why?) So, it is only necessary to check derivations of 2n-1 steps to decide whether G generates w.
Of course, this parsing algorithm is inefficient! It would never be used in practice. But it solves the membership problem for CFLs.

The CYK algorithm
The membership algorithm for CFG’s that is usually cited is the CYK algorithm, named for its three developers.
It works by breaking down the problem into a sequence of smaller problems and solving them. Details may be found on pages 172-173 of the Linz textbook.
This algorithm can be shown to run in |w|3 time.

LL grammars• A top-down parser finds a leftmost derivation of a string.
“Top-down” means to start with the start symbol and show how to derive the string from it.
• An LL(k) grammar allows a parser to perform left-to-right scan of the input to find a leftmost derivation, using k symbols of lookahead to select the next rule.
• Many compilers have been written using LL parsers. But LL grammars are not sufficiently general to generate all deterministic CFLs. This led to study of more general deterministic grammars, especially LR grammars.

LR grammars• A bottom-up parser finds a rightmost derivation of a
string. “Bottom-up” means to start with a string and “reduce” it to the start symbol.
• An LR(k) grammar allows a parser to perform left-to-right scan of the input to produce a rightmost derivation, using k symbols of lookahead to select the next rule.
• The class of languages generated by LR(1) grammars is exactly the deterministic CFLs.
• Two subclasses of LR(1) grammars, called SLR(1) (for “simple” LR) and LALR(1) (for “lookahead” LR) are commonly used for programming languages.

Parsing algorithms
• Parsing is an extremely important topic in the design and compilation of programming languages. You will study parsing algorithms based on various LL and LR grammars in a course on compiler design.
• Most of what we have studied in these chapters about regular and context-free languages provides the mathematical foundation for designing good compilers. (It has many other applications as well.)

Efficient parsing
• Programming languages are context-free languages, and parsing is central to any programming language compiler
• Many parsing algorithms for context-free grammars have been developed over the years. Most simulate pushdown automata.
• However, some PDAs cannot be simulated efficiently by computer programs because they are nondeterministic. Efficient parsers simulate deterministic PDAs.

Regular grammar CFG’s
A word is a string of all terminals. A semiword is a string of 0 or more terminals concatenated with exactly one nonterminal on the right. So, for example, abcA is a semiword.
A CFG is called a regular grammar if each of its productions is one of the two forms:Nonterminal semiwordNonterminal word

Regular grammars
All regular languages can be generated by regular grammars. All regular grammars generate regular languages.
Context-free grammars are more powerful than regular grammars. Regular languages are a proper subset of context-free languages, so CFG’s can generate all regular languages (as well as non-regular context-free languages).





























