Embed Size (px)
Citation preview

CS 414 Review

2
Goals for Today
• Review half the book– Make sure intuition is clear– Ask questions
• For more detailed information– Use past slides, “redo” homework and prelims

3
Operating System: DefinitionDefinition
An Operating System (OS) provides a virtual machine on top of the real hardware, whose interface is more
convenient than the raw hardware interface.
Hardware
Applications
Operating System
OS interface
Physical machine interface
Advantages
Easy to use, simpler to code, more reliable, more secure, …
You can say: “I want to write XYZ into file ABC”

4
What is in an OS?
Operating System Services
Interrupts, Cache, Physical Memory, TLB, Hardware Devices
Generic I/O File System
Memory Management
Process Management
Virtual MemoryNetworking
Naming
Access Control
Windowing & graphics
Windowing & Gfx
Applications
OS Interface
Physical m/c Intf
Device Drivers
ShellsSystem Utils
Quake Sql Server
Logical OS Structure

5
Crossing Protection Boundaries
• User calls OS procedure for “privileged” operations• Calling a kernel mode service from user mode program:
– Using System Calls– System Calls switches execution to kernel mode
User process System Call
TrapMode bit = 0
Save Caller’s state Execute system call Restore state
ReturnMode bit = 1
Resume process
User ModeMode bit = 1
Kernel ModeMode bit = 0

6
What is a process?
• The unit of execution
• The unit of scheduling
• Thread of execution + address space
• Is a program in execution– Sequential, instruction-at-a-time execution of a program.
The same as “job” or “task” or “sequential process”

7
Process State Transitions
New
Ready Running
Exit
Waiting
admitted
interrupt
I/O o
r eve
nt w
aitI/O
or event
completion
dispatch done
Processes hop across states as a result of:
• Actions they perform, e.g. system calls
• Actions performed by OS, e.g. rescheduling
• External actions, e.g. I/O

8
Context Switch
• For a running process– All registers are loaded in CPU and modified
• E.g. Program Counter, Stack Pointer, General Purpose Registers
• When process relinquishes the CPU, the OS– Saves register values to the PCB of that process
• To execute another process, the OS– Loads register values from PCB of that process
Context Switch Process of switching CPU from one process to another Very machine dependent for types of registers

9
Threads and Processes
• Most operating systems therefore support two entities:– the process,
• which defines the address space and general process attributes
– the thread, • which defines a sequential execution stream within a process
• A thread is bound to a single process. – For each process, however, there may be many threads.
• Threads are the unit of scheduling • Processes are containers in which threads execute

10
Schedulers
• Process migrates among several queues– Device queue, job queue, ready queue
• Scheduler selects a process to run from these queues• Long-term scheduler:
– load a job in memory– Runs infrequently
• Short-term scheduler:– Select ready process to run on CPU– Should be fast
• Middle-term scheduler– Reduce multiprogramming or memory consumption
11
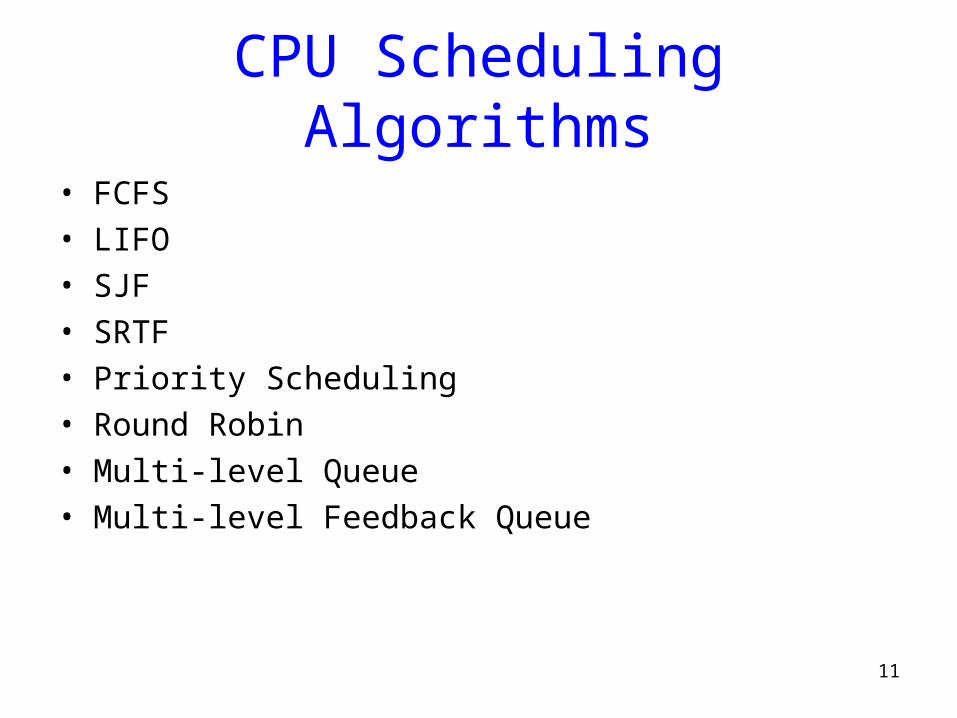
CPU Scheduling Algorithms
• FCFS• LIFO• SJF• SRTF• Priority Scheduling• Round Robin• Multi-level Queue• Multi-level Feedback Queue

12
CPU Scheduling Metrics
• CPU utilization: percentage of time the CPU is not idle• Throughput: completed processes per time unit• Turnaround time: submission to completion• Waiting time: time spent on the ready queue• Response time: response latency

Race conditions• Definition: timing dependent error involving shared state
– Whether it happens depends on how threads scheduled
• Hard to detect:– All possible schedules have to be safe
• Number of possible schedule permutations is huge
• Some bad schedules? Some that will work sometimes?
– they are intermittent
• Timing dependent = small changes can hide bug

14
The Fundamental Issue: Atomicity
• Our atomic operation is not done atomically by machine– E.g. incrementing a variable by one (i++) is three machine
instructions (load, increment, store).– Process can be interrupted between any machine instruction
• Atomic Unit: instruction sequence guaranteed to execute indivisibly– Also called “critical section” (CS)
When 2 processes want to execute their Critical Section,– One process finishes its CS before other is allowed to enter

15
Critical Section Problem
• Problem: Design a protocol for processes to cooperate, such that only one process is in its critical section– How to make multiple instructions seem like one?
Processes progress with non-zero speed, no assumption on clock speed
Used extensively in operating systems:Queues, shared variables, interrupt handlers, etc.
Process 1
Process 2
CS1
Time
CS2

16
Solution StructureShared vars:
Initialization:
Process:. . . . . .
Entry Section
Critical Section
Exit Section
Added to solve the CS problem

17
Solution Requirements
• Mutual Exclusion– Only one process can be in the critical section at any time
• Progress– Decision on who enters CS cannot be indefinitely postponed
• No deadlock
• Bounded Waiting– Bound on #times others can enter CS, while I am waiting
• No livelock
• Also efficient (no extra resources), fair, simple, …

18
Semaphores
• Non-negative integer with atomic increment and decrement• Integer ‘S’ that (besides init) can only be modified by:
– P(S) or S.wait(): decrement or block if already 0– V(S) or S.signal(): increment and wake up process if any
• These operations are atomic
semaphore S;
P(S) { while(S ≤ 0) ; S--;}
V(S) { S++;}

19
Semaphore Types
• Counting Semaphores:– Any integer– Used for synchronization
• Binary Semaphores– Value 0 or 1– Used for mutual exclusion (mutex)
Shared: semaphore S
Init: S = 1;
Process i
P(S);
Critical Section
V(S);

20
Init: S = 1;Init: S = 0;
Mutexes and Synchronizationsemaphore S;
P(S) { while(S ≤ 0) ; S--;}
V(S) { S++;}
Process i
P(S);
Code XYZ
V(S);
Process j
P(S);
Code ABC
V(S);
Deadlock

21
Monitors
• Hoare 1974• Abstract Data Type for handling/defining shared resources• Comprises:
– Shared Private Data• The resource• Cannot be accessed from outside
– Procedures that operate on the data• Gateway to the resource• Can only act on data local to the monitor
– Synchronization primitives• Among threads that access the procedures

22
Synchronization Using Monitors
• Defines Condition Variables:– condition x;– Provides a mechanism to wait for events
• Resources available, any writers
• 3 atomic operations on Condition Variables– x.wait(): release monitor lock, sleep until woken up
condition variables have waiting queues too
– x.notify(): wake one process waiting on condition (if there is one)• No history associated with signal
– x.broadcast(): wake all processes waiting on condition• Useful for resource manager
• Condition variables are not Boolean– If(x) then { } does not make sense

23
Types of Monitors
What happens on notify():• Hoare: signaler immediately gives lock to waiter (theory)
– Condition definitely holds when waiter returns– Easy to reason about the program
• Mesa: signaler keeps lock and processor (practice)– Condition might not hold when waiter returns– Fewer context switches, easy to support broadcast
• Brinch Hansen: signaler must immediately exit monitor– So, notify should be last statement of monitor procedure

24
Deadlocks
Definition:
Deadlock exists among a set of processes if – Every process is waiting for an event – This event can be caused only by another process in the set
• Event is the acquire of release of another resource
One-lane bridge

25
Four Conditions for Deadlock
• Coffman et. al. 1971• Necessary conditions for deadlock to exist:
– Mutual Exclusion• At least one resource must be held is in non-sharable mode
– Hold and wait• There exists a process holding a resource, and waiting for another
– No preemption• Resources cannot be preempted
– Circular wait• There exists a set of processes {P1, P2, … PN}, such that
– P1 is waiting for P2, P2 for P3, …. and PN for P1
All four conditions must hold for deadlock to occur

26
Dealing with Deadlocks
• Proactive Approaches:– Deadlock Prevention
• Negate one of 4 necessary conditions• Prevent deadlock from occurring
– Deadlock Avoidance• Carefully allocate resources based on future knowledge• Deadlocks are prevented
• Reactive Approach:– Deadlock detection and recovery
• Let deadlock happen, then detect and recover from it
• Ignore the problem– Pretend deadlocks will never occur– Ostrich approach

27
Safe State
• A state is said to be safe, if it has a process sequence
{P1, P2,…, Pn}, such that for each Pi,
the resources that Pi can still request can be satisfied by the currently available resources plus the resources held by all Pj, where j < i
• State is safe because OS can definitely avoid deadlock – by blocking any new requests until safe order is executed
• This avoids circular wait condition– Process waits until safe state is guaranteed

28
Banker’s Algorithm
• Decides whether to grant a resource request. • Data structures:
n: integer # of processesm: integer # of resourcesavailable[1..m] available[i] is # of avail resources of type imax[1..n,1..m] max demand of each Pi for each Riallocation[1..n,1..m] current allocation of resource Rj to Pineed[1..n,1..m] max # resource Rj that Pi may still request
let request[i] be vector of # of resource Rj Process Pi wants

29
Basic Algorithm
1. If request[i] > need[i] then error (asked for too much)
2. If request[i] > available[i] then wait (can’t supply it now)
3. Resources are available to satisfy the request
Let’s assume that we satisfy the request. Then we would have:
available = available - request[i]
allocation[i] = allocation [i] + request[i]
need[i] = need [i] - request [i]
Now, check if this would leave us in a safe state:
if yes, grant the request,
if no, then leave the state as is and cause process to wait.

30
Memory Management Issues
• Protection: Errors in process should not affect others• Transparency: Should run despite memory size/location
gcc
virtual address
CPU
Load Store
legal addr?Illegal?
Physicaladdress
Physicalmemoryfault
data
Translation box (MMU)
How to do this mapping?

31
Scheme 1: Load-time Linking
• Link as usual, but keep list of references• At load time: determine the new base address
– Accordingly adjust all references (addition)
• Issues: handling multiple segments, moving in memory
0x1000
static a.out0x3000
0x4000
OS
jump 0x2000 jump 0x5000
0x6000
jump 0x2000

32
Scheme 2: Execution-time Linking
• Use hardware (base + limit reg) to solve the problem– Done for every memory access– Relocation: physical address = logical (virtual) address + base– Protection: is virtual address < limit?
– When process runs, base register = 0x3000, bounds register = 0x2000. Jump addr = 0x2000 + 0x3000 = 0x5000
0x1000
a.out0x3000
0x4000
OS
a.out
jump 0x2000jump 0x2000
0x6000
Base: 0x3000Limit: 0x2000
MMU

33
Segmentation
• Processes have multiple base + limit registers• Processes address space has multiple segments
– Each segment has its own base + limit registers– Add protection bits to every segment
gcc
Text seg r/o
Stack seg r/w
0x1000
0x3000
0x5000
0x6000
Real memory
0x2000
0x8000
0x6000
Base&Limit?
How to do the mapping?

34
Mapping Segments
• Segment Table– An entry for each segment– Is a tuple <base, limit, protection>
• Each memory reference indicates segment and offset
Virtual addr
Seg# offset
3 128
Seg tableProt base len
r 0x1000 512
mem
seg128
+ 0x1000? yesno
fault

35
Fragmentation
• “The inability to use free memory”• External Fragmentation:
– Variable sized pieces many small holes over time
• Internal Fragmentation:– Fixed sized pieces internal waste if entire piece is not used
gcc
emacs
doomstackallocated
Unused (“internal fragmentation”)
ExternalfragmentationWord ??

36
Paging
• Divide memory into fixed size pieces– Called “frames” or “pages”
• Pros: easy, no external fragmentation
gcc
emacs internal frag
Pages typical: 4k-8k

37
Mapping Pages
• If 2m virtual address space, 2n page size (m - n) bits to denote page number, n for offset within page
Translation done using a Page Table
Virtual addr
VPN page offset
3 128 (12bits)
page tableProt VPN PPN
r 3 1
mem
seg128
0x1000((1<<12)|128)
“invalid”
? PPN

38
Paging + Segmentation
• Paged segmentation– Handles very long segments– The segments are paged
• Segmented Paging– When the page table is very big– Segment the page table– Let’s consider System 370 (24-bit address space)
Seg # page # (8 bits) page offset (12 bits)(4 bits)

39
What is virtual memory?
• Each process has illusion of large address space– 232 for 32-bit addressing
• However, physical memory is much smaller• How do we give this illusion to multiple processes?
– Virtual Memory: some addresses reside in disk
page table
Physical memory
disk

40
Virtual Memory
• Load entire process in memory (swapping), run it, exit– Is slow (for big processes)– Wasteful (might not require everything)
• Solutions: partial residency– Paging: only bring in pages, not all pages of process– Demand paging: bring only pages that are required
• Where to fetch page from?– Have a contiguous space in disk: swap file (pagefile.sys)

41
Page Faults
• On a page fault:– OS finds a free frame, or evicts one from memory (which one?)
• Want knowledge of the future?
– Issues disk request to fetch data for page (what to fetch?)
• Just the requested page, or more?
– Block current process, context switch to new process (how?)
• Process might be executing an instruction
– When disk completes, set present bit to 1, and current process in ready queue

42
Page Replacement Algorithms
• Random: Pick any page to eject at random– Used mainly for comparison
• FIFO: The page brought in earliest is evicted– Ignores usage– Suffers from “Belady’s Anomaly”
• Fault rate could increase on increasing number of pages
• E.g. 0 1 2 3 0 1 4 0 1 2 3 4 with frame sizes 3 and 4
• OPT: Belady’s algorithm– Select page not used for longest time
• LRU: Evict page that hasn’t been used the longest– Past could be a good predictor of the future

43
Thrashing
• Processes in system require more memory than is there– Keep throwing out page that will be referenced soon– So, they keep accessing memory that is not there
• Why does it occur?– No good reuse, past != future– There is reuse, but process does not fit– Too many processes in the system

44
Approach 1: Working Set
• Peter Denning, 1968– Defines the locality of a program
pages referenced by process in last T seconds of execution considered to comprise its working set
T: the working set parameter
• Uses:– Caching: size of cache is size of WS– Scheduling: schedule process only if WS in memory– Page replacement: replace non-WS pages

45
Working Sets
• The working set size is num pages in the working set – the number of pages touched in the interval (t, t-Δ).
• The working set size changes with program locality.– during periods of poor locality, you reference more pages.
– Within that period of time, you will have a larger working set size.
• Don’t run process unless working set is in memory.

46
Approach 2: Page Fault Frequency
• thrashing viewed as poor ratio of fetch to work• PFF = page faults / instructions executed • if PFF rises above threshold, process needs more memory
– not enough memory on the system? Swap out.
• if PFF sinks below threshold, memory can be taken away

47
Allocation and deallocation• What happens when you call:
– int *p = (int *)malloc(2500*sizeof(int));• Allocator slices a chunk of the heap and gives it to the program
– free(p);• Deallocator will put back the allocated space to a free list
• Simplest implementation:– Allocation: increment pointer on every allocation– Deallocation: no-op– Problems: lots of fragmentation
heap (free memory)
current free positionallocation

48
Memory Allocator
• What allocator has to do:– Maintain free list, and grant memory to requests– Ideal: no fragmentation and no wasted time
• What allocator cannot do:– Control order of memory requests and frees– A bad placement cannot be revoked
• Main challenge: avoid fragmentation
20 20 2010 10
a
malloc(20)?
b

49
What happens on free?
• Identify size of chunk returned by user• Change sign on both signatures (make +ve)• Combine free adjacent chunks into bigger chunk
– Worst case when there is one free chunk before and after– Recalculate size of new free chunk– Update the signatures
• Don’t really need to erase old signatures

50
Design features
• Which free chunks should service request– Ideally avoid fragmentation… requires future knowledge
• Split free chunks to satisfy smaller requests– Avoids internal fragmentation
• Coalesce free blocks to form larger chunks– Avoids external fragmentation
3020 10 30 30

51
Malloc & OS memory management
• Relocation– OS allows easy relocation (change page table)– Placement decisions permanent at user level
• Size and distribution– OS: small number of large objects– Malloc: huge number of small objects
heap
codedatastack

52
Announcements• Prelims graded
– Mean 76.3 (Median 76), Stddev 8.8, High 93 out of 104!– Mean 73.4 (Median 73.1), Stddev 8.4, High 89.4 out of 100!
• Good job!
• Re-grade policy– Submit written re-grade request to Joy.
• Entire prelim will be re-graded. • We were generous the first time…
– If still unhappy, submit another re-grade request. • Joy will re-grade herself
– If still unhappy, submit a third re-grade request. • I will re-grade. Final grade is law.

53
Grade distribution
Grade Distribution (out of 104 points)
0
1
2
3
4
5
6
7
8
55 60 65 70 75 80 85 90
Score
Frequency

54
Hand back prelims
![USING Intuition - Laura Silva Quesadalaurasilvaquesada.com/wp-content/uploads/2017/03/Intuition-in... · USING Intuition IN BUSINESS [2] Using INTUITION IN Business INTUITION AND](https://img.pdfslide.net/doc/110x75/5ab27fd57f8b9a7e1d8d5a95/using-intuition-laura-silva-ques-intuition-in-business-2-using-intuition-in.jpg)




























