Embed Size (px)
DESCRIPTION
This work is licensed under a Creative Commons Attribution-Share Alike 3.0 Unported License . CS 479, section 1: Natural Language Processing. Lecture # 36: Alignment and Metrics. Thanks to Dan Klein of UC Berkeley and Uli Germann of ISI for many of the materials used in this lecture. - PowerPoint PPT Presentation
Citation preview

CS 479, section 1:Natural Language Processing
Lecture #36: Alignment and Metrics
This work is licensed under a Creative Commons Attribution-Share Alike 3.0 Unported License.
Thanks to Dan Klein of UC Berkeley and Uli Germann of ISI for many of the materials used in this lecture.

Announcements Check the schedule
Plan enough time to succeed! Don’t get or stay blocked. Get your questions answered early. Get the help you need to keep moving forward. No late work accepted after the last day of instruction.
Project Report: Early: Friday Due: Monday
Reading Report #14 Phrase-based MT paper Due: next Wednesday(online again)

Objectives Consider additional models for statistical word
alignment
See how our alignment models capture real phrases
Understand how to actually score a word-level alignment with a word alignment model
Discuss how to evaluate alignment quality

Quiz
Why do we use parallel corpora (bitexts)?
What is the hidden (unknown) variable in building translation models?
What was the main idea behind IBM Model 1?
Model 2?

Recall This Example
Des tremblements de terre ont à nouveau touché le Japon jeudi 4 novembre.
On Tuesday Nov. 4, earthquakes rocked Japan once again
What else is going on here that we haven’t tried to model?

Models Summary IBM Model 1: word alignment IBM Model 2: word alignment, with global position
(order) model HMM Model: word alignment, with local position IBM Model 3: adds model of fertility to model 2, deficient
IBM Model 4: adds relative ordering to model 3, deficient
IBM Model 5: fixes deficiency of Model 4

Context
Given a source language sentence, The search algorithm must propose possible
translations (target language sentences) along with corresponding alignments
Let’s pretend we’re in the midst of a search and scoring a single hypothesis
How do we use our models to compute such a score?

Example: How to score Spanish source sentence:
“Maria no daba una bofetada a la bruja verde” Here denotes “foreign” sentence.
During the search, we propose a possible English translation:“Mary did not slap the green witch”
We consider one possible alignment What is the score, according to model 5?
i.e., what is ?

Example: How to score
Mary not slap slap slap the green witch n(3|slap)
P(NULL)
t(la|the)
d(j|i)Maria no daba una bofetada a la bruja verde
Mary not slap slap slap NULL the green witch
Maria no daba una bofetada a la verde bruja
[Al-Onaizan and Knight, 1998]
Mary did not slap the green witchExamples from Local Models

Example: How to score
Mary not slap slap slap the green witch n(3|slap)
P(NULL)
t(la|the)
d(j|i)Maria no daba una bofetada a la bruja verde
Mary not slap slap slap NULL the green witch
Maria no daba una bofetada a la verde bruja
[Al-Onaizan and Knight, 1998]
Mary did not slap the green witch

Cascaded Training
Standard practice for training: Initialize one model with the previous (simpler)
model Proceed with EM
Typical order: 1, (2 | HMM), 3, 4, 5

Insight into these models

Examples: Translation and Fertility

Example: Idioms
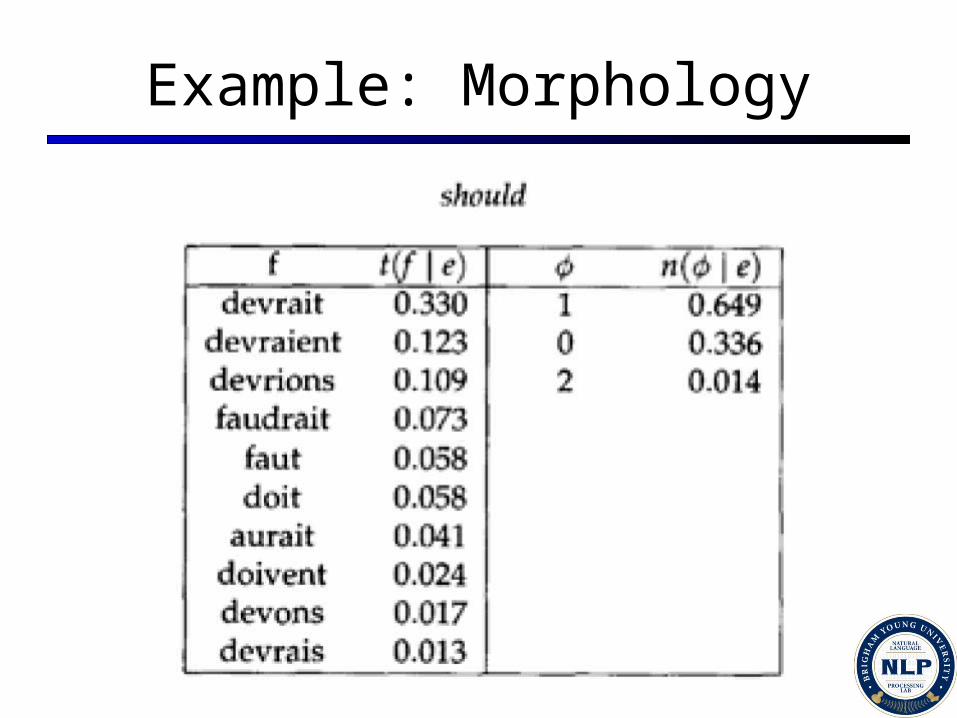
Example: Morphology

Example: WSD Word sense disambiguation:
Word-based MT systems rarely have a WSD step Why not?

Choosing an Alignment

Choosing an Alignment

Efficiency of Choosing Best Alignment

Evaluating TMs
How do we measure TM quality?
Measure quality of the alignments produced Metric: AER

Alignment Error Rate
/ Actual

AER
Easy to measure
Problems? Hard to know what the gold alignments should be May not correlate with translation quality
like perplexity and speech reco. accuracy in LMs
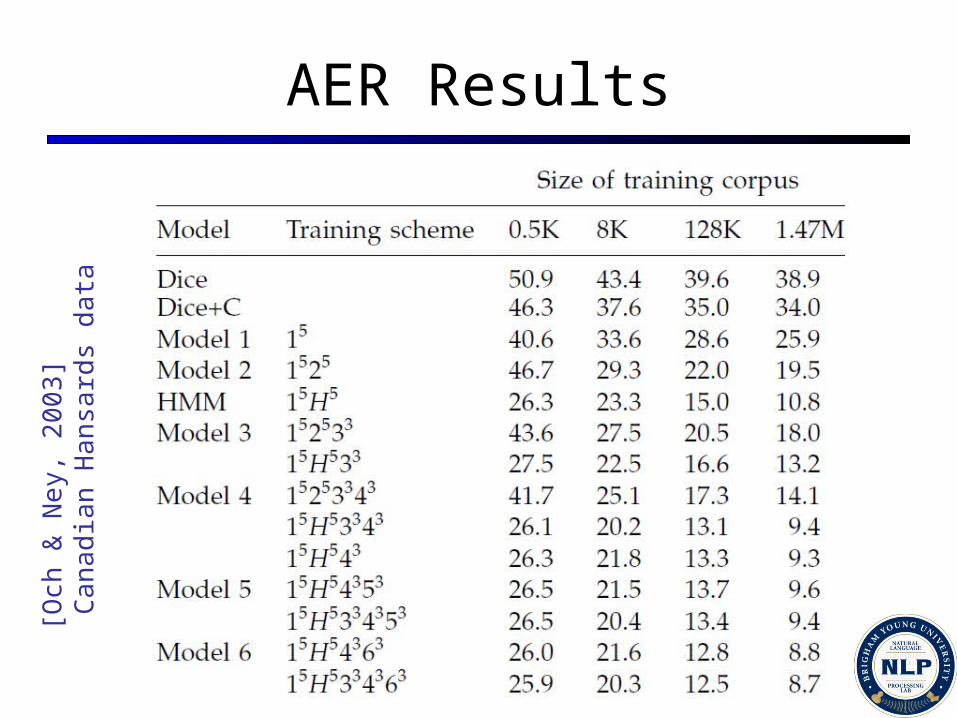
AER Results[O
ch &
Ney
, 200
3] C
anad
ian
Hans
ards
dat
a

Next
Decoding
Complexity of Decoding
Evaluating Translation





























