Embed Size (px)
Citation preview

CS 582 / CMPE 481Distributed Systems
Spring 2004 - 2005
Shahab Baqai

Administrative Information• Lecture TR at 1015 – 1130 hours• Homeworks Maybe
– selected paper(s) review.– Usually due in 1 week.
• Project– Three projects– 2 extra days for emergencies
• Exams– Mid-Term Exam ~ 11th lecture– Final Exam
• Web page – http://suraj.lums.edu.pk/~cs582s04 • Evaluation:
– HW/Quizzes 10 %– Project 30 %– Mid & Final 60 %
W04

Academic IntegrityPermitted Collaboration:
– encouraged and allowed at all times
Examples• Discussion of material covered during lecture / handouts• Discussion of the requirements of an assignment• Discussion of the use of tools or development environments• Discussion of general approaches to solving problems• Discussion of general techniques of coding or debugging• Discussion between a student & a TA or instructor

Academic IntegrityCollaboration Requiring Citation:
– must be able to explain the solution – properly credit contribution, just like citing a reference in
a paper
Examples
• Discussing the “key” to a problem
• Discussing the design of a programming project
• Assistance in debugging code
• Sharing advice for testing
• Research from alternative sources

Academic IntegrityNon-permitted Collaboration:
– submissions must represent original, independent work
Examples
• Copying solutions from others
• Using work from past quarters
• Studying another student's solution
• Debugging code for someone else
• Cut & paste of solution/code from Internet

Overview
• The course will focus on the principles underlying modern distributed systems such as networking, naming, security, synchronization, concurrency, fault tolerance, etc. along with case studies.
• Text and reference books– [CDK]
Distributed Systems - Concept and Design, G. Coulouris, J, Dollimore, and T. Kindberg, Addison-Wesley, 3rd Edition, 2001.
– [DS] Distributed Systems – Principles and Paradigms, A. Tanenbaum and M. van Steen, Prentice Hall, 2002.

Syllabus• Introduction• Communications• Naming• Security• Distributed File Systems• Synchronization• Concurrency Control• Distributed Transactions• Replication & Consistency• Fault Tolerance• Advanced topic: Distributed Multimedia Systems

Class Overview
• Definition and Motivation of Distributed Systems
• Properties of Distributed Systems
• Challenges of Distributed Systems
• Design Principles of Distributed Systems
• Distributed System Architecture and Model

Introduction• A system is:
– an autonomous whole– an owner of a set of resources– something that can perform information processing– something that may be able to communicate with other systems
• A distributed system– a system– is composed of other systems– requires explicit communication among the components– its components have a common goal set
• Asynchronous system– Concurrency– No global clock– Independent failures

Definition(s) of a Distributed SystemA distributed system is:• one in which hardware or software components at networked
computers communicate and coordinate their actions only by passing messages [CDK]
• collection of independent computers that appears to its users as a single coherent system. [DS]
• several computers doing something together; multiple components, interconnections and shared state [Schroeder]
• fundamental properties are fault tolerance and parallelism [Mullender]• one that stops you from getting any work done when a machine
you’ve never heard of crashes [Lamport]• A set of communicating autonomous entities functioning together to
achieve a common goal [Cheriton]• Collection of computer nodes connected by a network running
software that makes it function as one system.
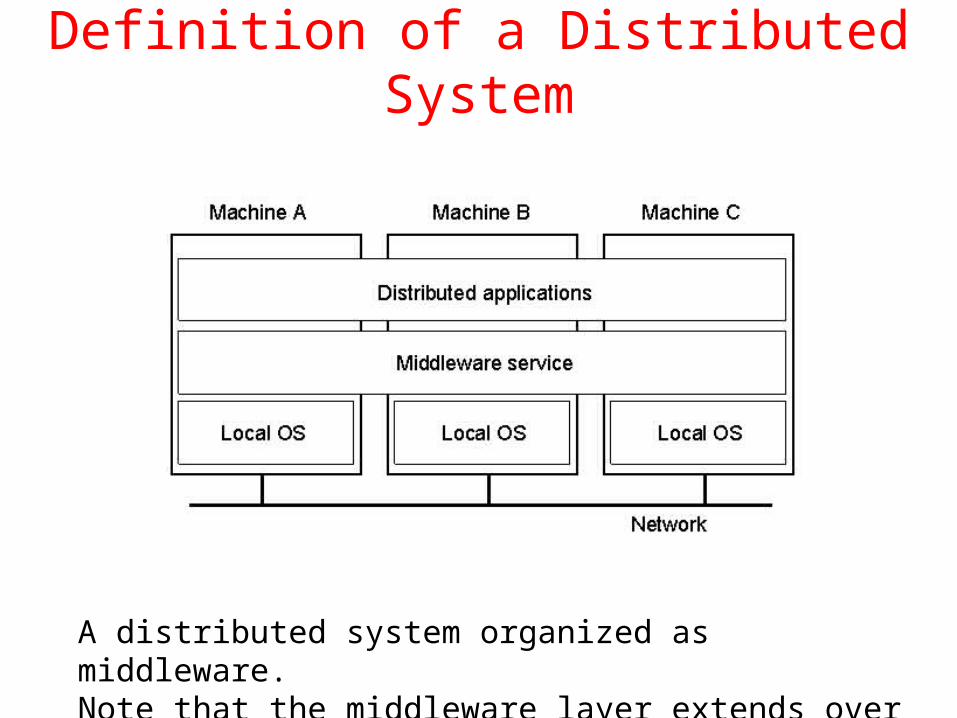
Definition of a Distributed System
A distributed system organized as middleware.Note that the middleware layer extends over multiple machines.
1.1

Why Build Distributed Systems?• inherently distributed
– people, information, etc.• performance/cost
– users requires more CPU cycles: e.g. interactive UI– network bandwidth growth >> CPU clock speed– concurrency
• Modularity– standard interfaces– DCE, CORBA, and COM are examples
• expandability– incremental growth
• Availability– partial failure– load sharing
• Scalability– Ideally no limit– no qualitative change as the system scales– careful design required to scale to very large numbers of components:e.g. naming, addressing, etc.
• Reliability– Failsafe– Recovery – roll back

Examples of Distributed Systems• Internet
– Heterogeneity– Scalability– Fault tolerance
• Intranet– Security– Availability– Resource sharing
• Mobile and ubiquitous computing– Location & hand-off management– Service discovery & integration management– Disconnected operation support– Security

Properties of Distributed Systems• Fundamental property of distributed systems
– Separation
• Derived properties– Isolation property– Explicit communication property– Location property– Heterogeneity property– Multiple authority property– Concurrency property– Incremental change property– Partial failure property

Properties of Distributed Systems (cont.)• Isolation property
– explicit access & potential for control over accessibility of components
• Explicit communications property– components have disjoint storage: explicit
communications between components– communication mechanism between components
• Location property– components are potentially separable– requires explicit communications– possibility of relocation - location change

Properties of Distributed Systems (cont.)• Heterogeneity property
– implication of diverse implementation technology usage
– mechanism to accommodate heterogeneous components
• Multiple authority property– implication of multiple autonomous management or control
authorities
– mechanism to make systems consistent
– multiple security domains
• Concurrency property– timely parallel activity to occur
– Synchronization
– modeling of relative and temporal event ordering

Properties of Distributed Systems (cont.)• Incremental change property (extensibility)
– potential to add or remove components
• Partial failure property– potential to continue after failure of individual property– failure recovery and fault modeling

Challenges of Distributed Systems• Heterogeneity
• Openness
• Scalability
• Concurrency
• Security
• Distribution Transparency

Challenges of Distributed Systems (cont.)• Heterogeneity
– Applies to • Networks
– interfaces, protocols
• Hardware– data representation
• Operating systems– system calls
• Programming languages– data representation
– Support for heterogeneity• Middleware
– DCE, CORBA, DCOM
• Virtual machine/mobile code– Java

Challenges of Distributed Systems (cont.)• Openness
– Criteria to determine the extensibility or re-configurability of a system
• Be able to interact with services from other components, regardless of heterogeneity of the underlying environment
– Key factors to openness: coherence• public interfaces to key functions• uniform communication mechanism and public interfaces for access to
shared resources• conformance test of components to integrate
– Implementing openness• provide only mechanisms, not policies• Examples
– level of consistency for client-cached data– operations for mobile code download– network QoS requirement adjustment– level of security

Challenges of Distributed Systems (cont.)• Scalability
– Said to be scalable if a system• remains effective in the presence of a significant increase in the number of
resources & users [CDK]• can handle the addition of users and resources without suffering a noticeable
loss of performance or increase in administrative complexity [Neuman]
– Scalability components [Neuman]• size scalability• geographic scalability• administrative scalability
– Design considerations for scalability• cost of physical resources• performance loss• software resource shortage• performance bottleneck

Challenges of Distributed Systems (cont.)• Scalability (cont.)
– Techniques for scaling• Distribution
– distribute data and computations across multiple sites
• Replication– replicate data to multiple sites
• caching– make copies available locally
– Scalability trade-offs• consistency vs. global synchronization

Challenges of Distributed Systems (cont.)• Failure handling
– A system is considered faulty once its behavior is no longer consistent with its specification [Schneider]
• partial failure property
– Failure handling techniques• Fault detection:
– omission failure, timing failure (performance failure), response failure, crash failure
• Fault masking– retransmission, checksum, roll-back
• Fault tolerance– can detect a fault and either fail predictably or mask the fault from users
• Recovery from failures– roll-back
• Redundancy– k-resilience

Challenges of Distributed Systems (cont.)• Concurrency
– Concurrent access to a shared resource may cause inconsistency of the resource
– Inconsistency examples• lost updates
– two transactions concurrently perform an update operation
• inconsistent retrievals– performing retrieval operation before or during an update operation
– To avoid possible problems due to concurrent access, operations of related transactions must be serialized (one-at-a-time)

Challenges of Distributed Systems (cont.)• Security
– Authentication• verification of source
– Authorization• access rights to the resource
– Encryption and decryption• public vs. private key

Challenges of Distributed Systems (cont.)• Distribution transparency
– abstraction concepts/mechanisms to make distributed systems appear as if they are a single united system by concealing properties derived from separation
• Various forms of distribution transparency– Access transparency– Location transparency– Replication transparency– Concurrency transparency– Migration/Mobility transparency– Failure transparency– Performance transparency– Scaling transparency

Distribution transparency• Access transparency
– hiding the use of explicit communications• no difference in access between local and remote data
• access may be restricted by controls in support of some policy
• generic functions: communications and security mechanisms
Logical Shared Resource
A B C D

Distribution transparency (cont.)• Location transparency
– hiding the details of topology in a system• bindings between objects are independent of the routes
connecting them• data is identified by logical or functional names rather than
addresses• generic functions: naming, addressing, and routing
Logical Shared Resource
A B C D
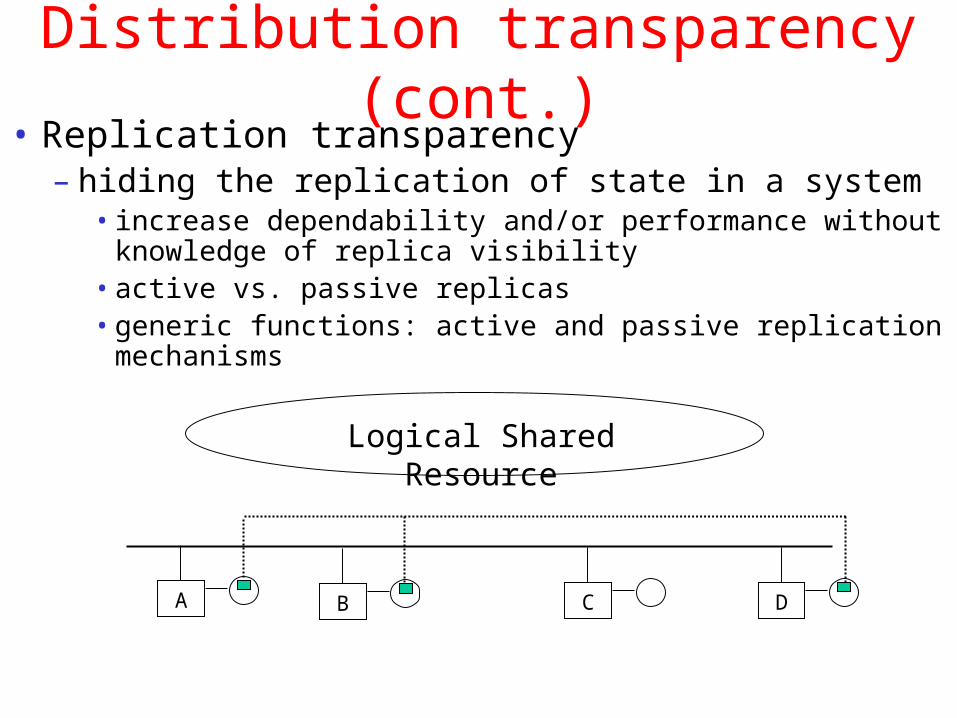
Distribution transparency (cont.)• Replication transparency
– hiding the replication of state in a system• increase dependability and/or performance without knowledge
of replica visibility• active vs. passive replicas• generic functions: active and passive replication mechanisms
Logical Shared Resource
A B C D
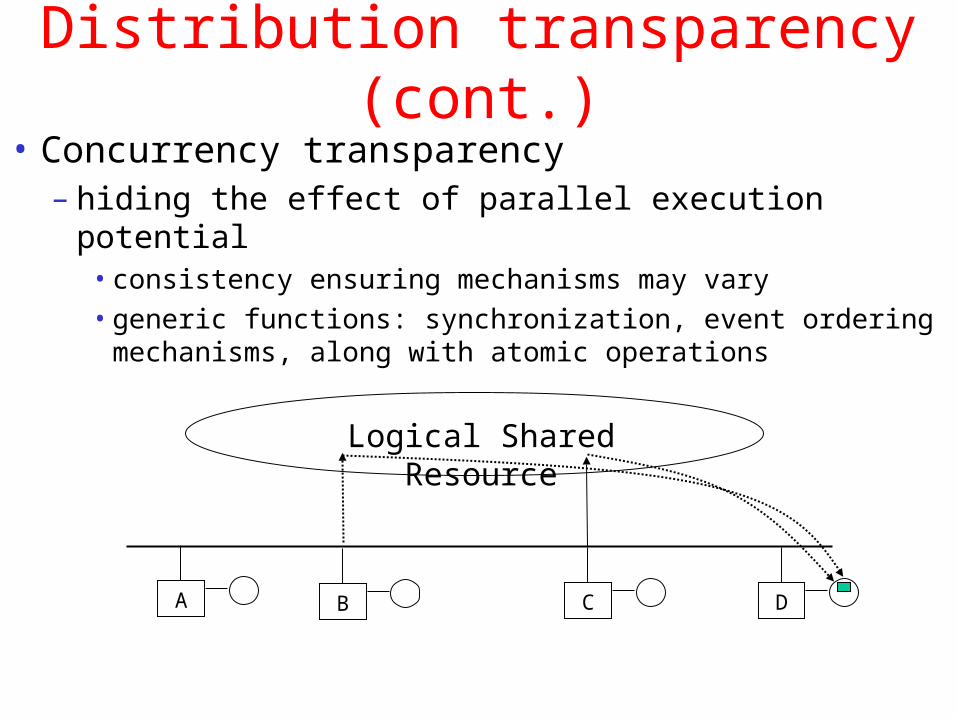
Distribution transparency (cont.)
• Concurrency transparency– hiding the effect of parallel execution potential
• consistency ensuring mechanisms may vary
• generic functions: synchronization, event ordering mechanisms, along with atomic operations
Logical Shared Resource
A B C D
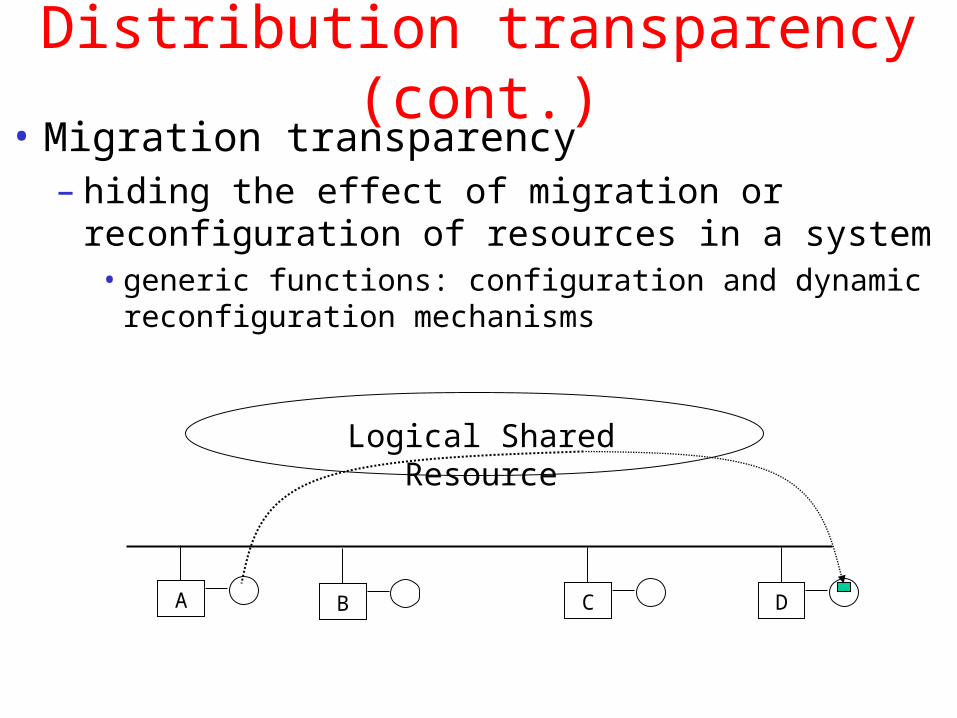
Distribution transparency (cont.)• Migration transparency
– hiding the effect of migration or reconfiguration of resources in a system
• generic functions: configuration and dynamic reconfiguration mechanisms
Logical Shared Resource
A B C D
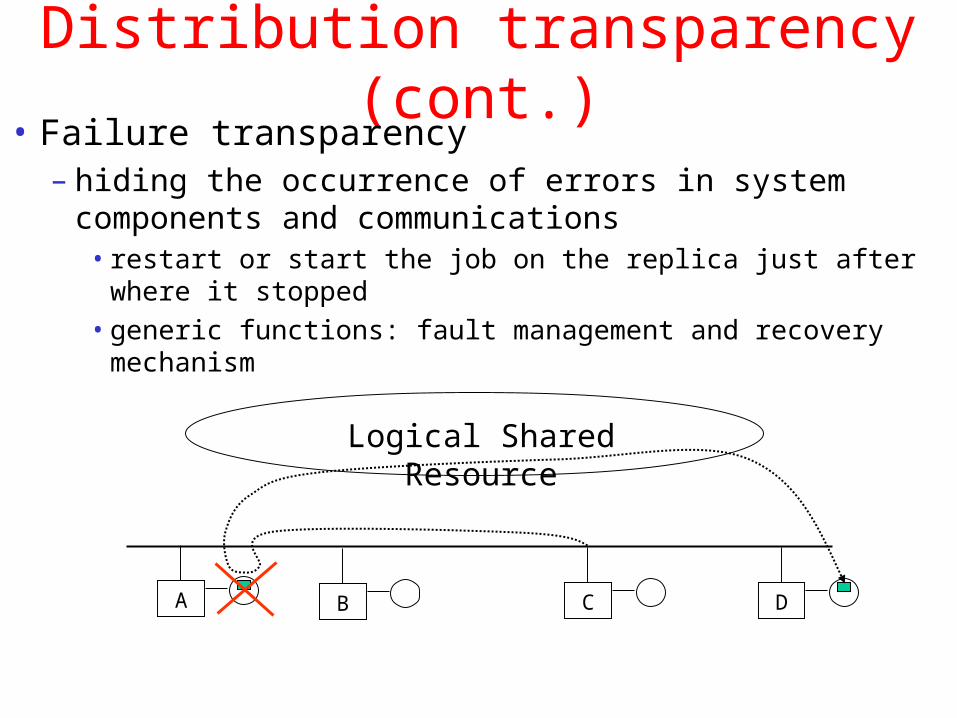
Distribution transparency (cont.)• Failure transparency
– hiding the occurrence of errors in system components and communications
• restart or start the job on the replica just after where it stopped
• generic functions: fault management and recovery mechanism
Logical Shared Resource
A B C D
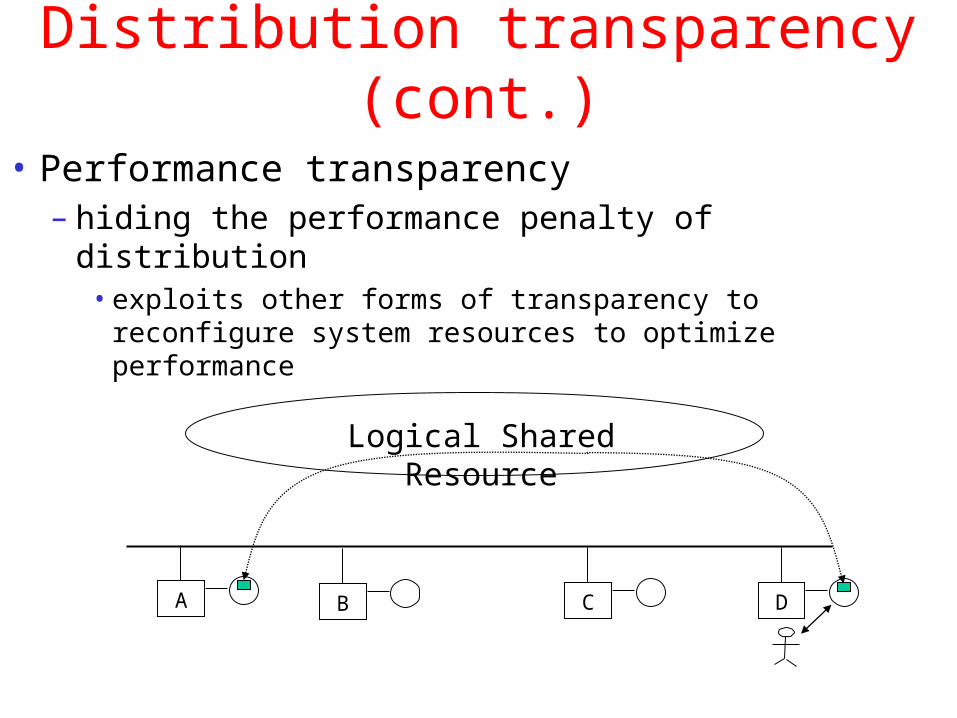
Distribution transparency (cont.)
• Performance transparency– hiding the performance penalty of distribution
• exploits other forms of transparency to reconfigure system resources to optimize performance
Logical Shared Resource
A B C D

Distribution transparency (cont.)• Scaling transparency
– hiding the effect of changes in system size• allows the resizing of a distributed system to be independent of
its structures and algorithms
Logical Shared Resource
A B C D
E F G H

Considerations in Distributed System Design
• Widely varying modes of use– Workload– Connectivity– Timeliness
• Wide range of system environments– Heterogeneity– Performance– Scalability
• Internal Problems– Synchronization– Failure
• External Threats– Security

Distributed Systems Design Principles • Replicate to increase availability
– replication and consistency vs. availability
• Tradeoff availability and consistency– network name service vs. bank transaction
• Cache hints if possible– vital technique for high-performance distributed system
design and implementation
• Stashing to allow autonomous operation– conceal the temporal disconnection from networks
• Exploit locality with caches– cache coherence protocols

Distributed Systems Design Principles• Use timeout for revocation
– resource locking, validity of cache, etc.
• Use a standard remote invocation mechanism• Trust only programs on physically secure machines• Use encryption for authentication and data security• Try to prove distributed algorithms
– formal specification of operations
• Capabilities might be useful– authentication and access right embedded in the client’s
request
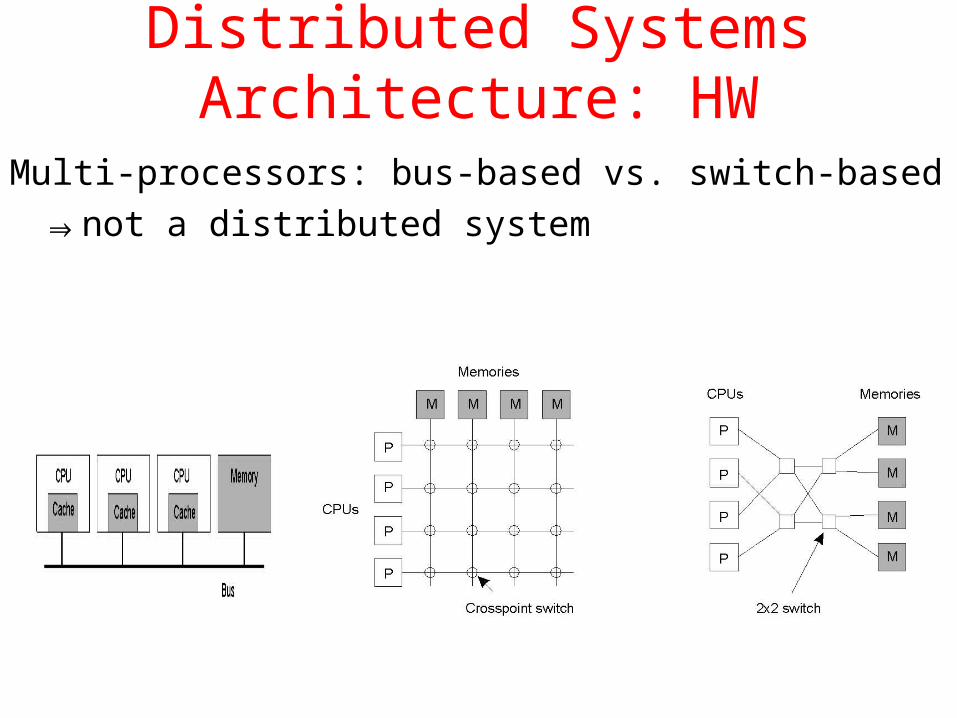
Distributed Systems Architecture: HW
Multi-processors: bus-based vs. switch-based
⇒not a distributed system

Distributed Systems Architecture: HW (cont.)
• Multi-computers– homogeneous systems
• bus-based vs. switch-based
– heterogeneous systems• node heterogeneity
• network heterogeneity
⇒ distributed systems hide heterogeneity
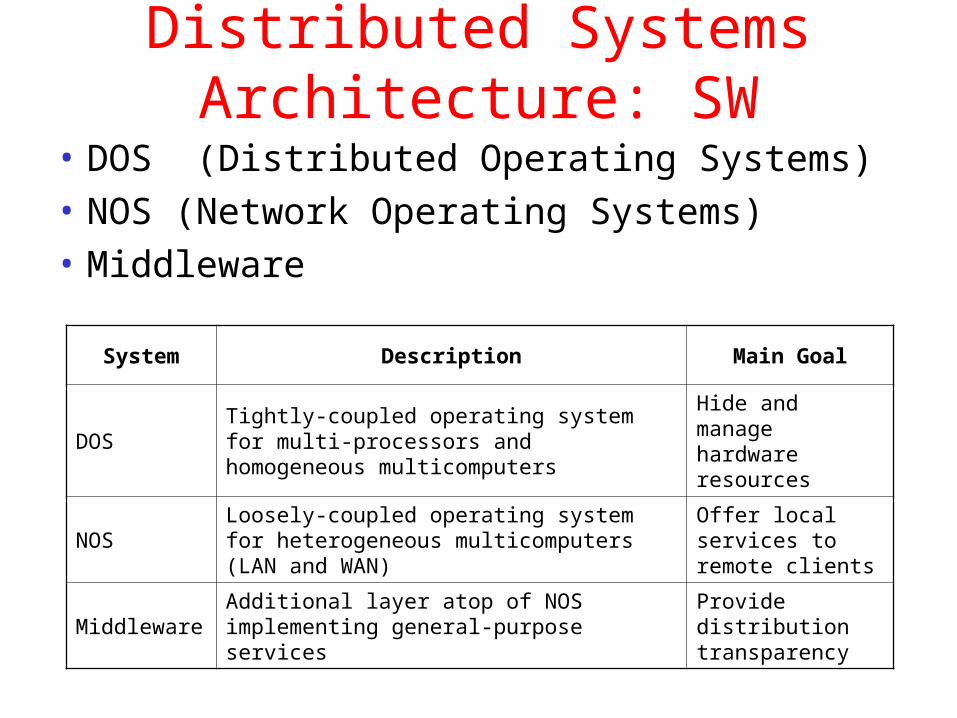
Distributed Systems Architecture: SW
• DOS (Distributed Operating Systems)
• NOS (Network Operating Systems)
• MiddlewareSystem Description Main Goal
DOSTightly-coupled operating system for multi-processors and homogeneous multicomputers
Hide and manage hardware resources
NOSLoosely-coupled operating system for heterogeneous multicomputers (LAN and WAN)
Offer local services to remote clients
MiddlewareAdditional layer atop of NOS implementing general-purpose services
Provide distribution transparency
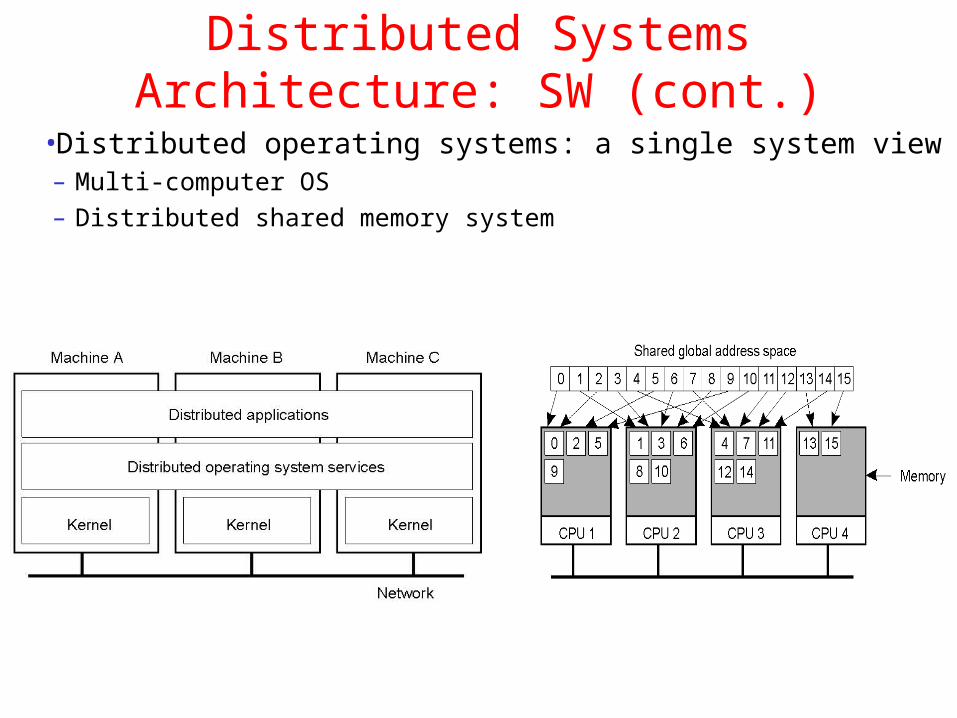
Distributed Systems Architecture: SW (cont.)
•Distributed operating systems: a single system view– Multi-computer OS
– Distributed shared memory system
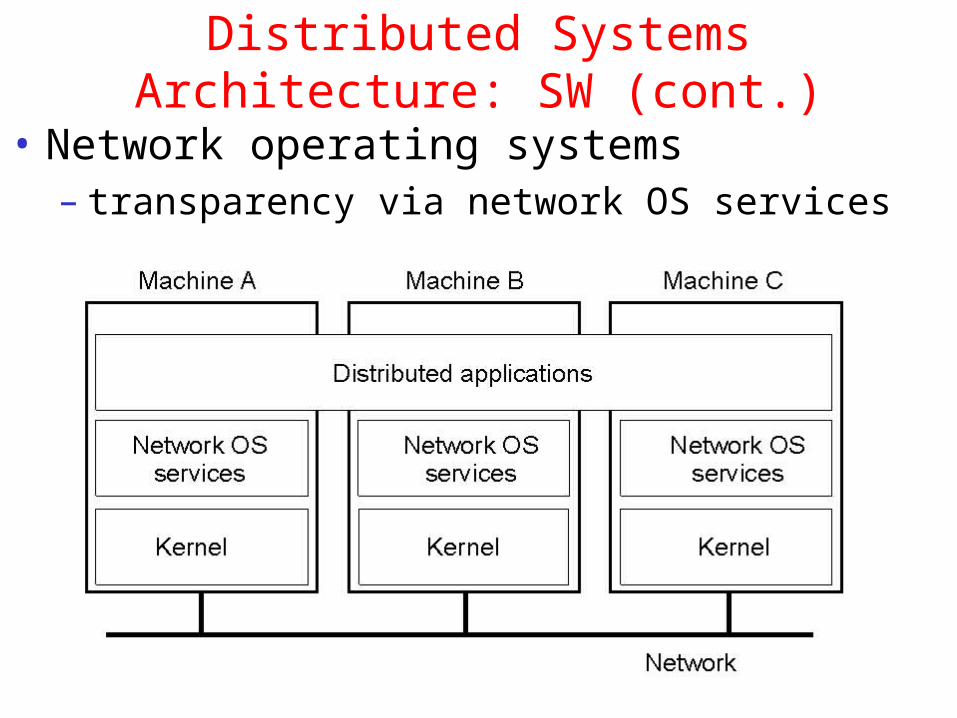
Distributed Systems Architecture: SW (cont.)
• Network operating systems– transparency via network OS services
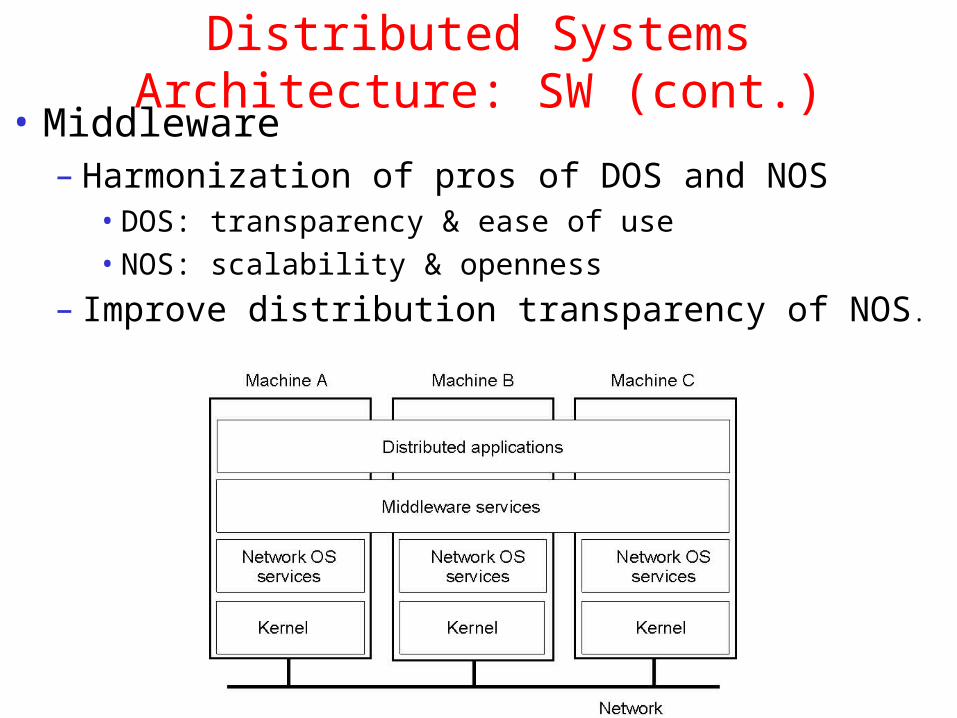
Distributed Systems Architecture: SW (cont.)• Middleware
– Harmonization of pros of DOS and NOS• DOS: transparency & ease of use
• NOS: scalability & openness
– Improve distribution transparency of NOS.
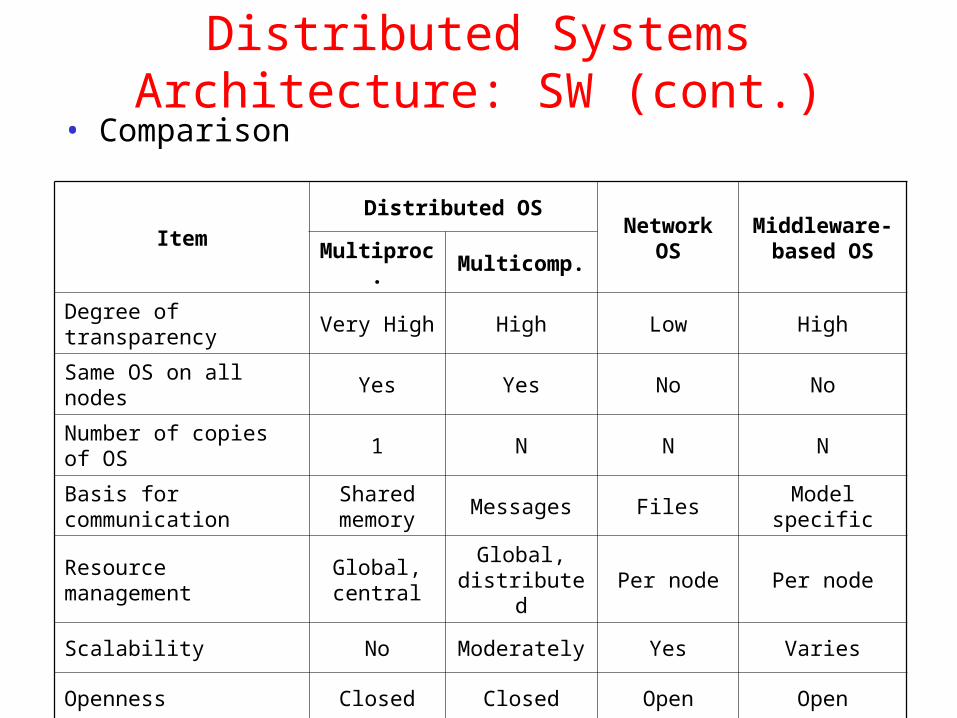
Distributed Systems Architecture: SW (cont.)• Comparison
ItemDistributed OS
Network OS
Middleware-based OSMultiproc
.Multicomp.
Degree of transparency
Very High High Low High
Same OS on all nodes Yes Yes No No
Number of copies of OS
1 N N N
Basis for communication
Shared memory
Messages FilesModel
specific
Resource management
Global, central
Global, distributed
Per node Per node
Scalability No Moderately Yes Varies
Openness Closed Closed Open Open

Distributed Systems Architecture: SW (cont.)
• Client-Server Model– Client : a process wishing to access the resources on a different computer– Server : a process managing the shared resources which is allowed to a client
• HTTP server vs. Web browser
• Services provided by multiple servers– Functional distribution– Replication
• Proxy servers and caches– Increase availability and performance of the service
• Peer processes– Processes without any distinction between clients and servers– Distribution of control and load
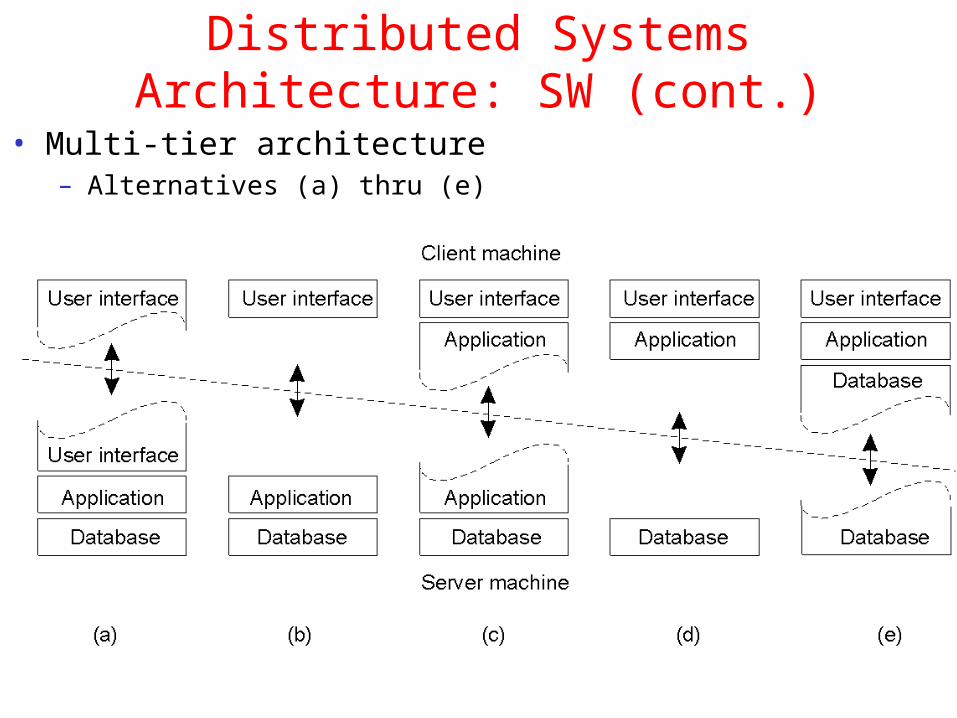
Distributed Systems Architecture: SW (cont.)
• Multi-tier architecture– Alternatives (a) thru (e)

Variations of Client-Server Model• Mobile code
– Code at the client downloaded to the server• e.g., Applets
• Mobile agents– Executing program (code and data) that goes from one computer to
another in a network carrying out a task• e.g., worm program (Xerox PARC)
• Network computers– Applications are run locally but the files are managed by a remote
file server• e.g., NFS
• Thin clients– executing windows-based user interface on local computer while
application executes on compute server• e.g., X11 Server

Variations of Client-Server Model (cont.)
• Mobile devices– capable of wireless networking
• e.g. personal digital assistants (PDAs)
• Spontaneous networking– the form of distribution that integrates mobile devices
and other devices into a given network– Key features
• easy connection to a local network– A device brought into a new network environments is transparently
reconfigured to obtain connectivity there
• easy integration with local services– automatic discovery of available services with no special configuration– discovery services

Variations of Client-Server Model (cont.)• Spontaneous networking (cont.)
– Issues• supporting convenient connection and integration
• limited connectivity– how the system can support the user so that they can continue to work while
disconnected
• security and privacy– track of users’ location
– Discovery services• to accept and store details of services that are available on the network and
to respond to queries from clients about them
• Interfaces of discovery services– registration service : accept registration requests from servers, stores properties
in database of currently available services
– lookup service : match requested services with available servers

Fundamental Models of Distributed Systems
• Main consideration points– Interaction
• Communication and coordination
– Failure• Classification of faults and tolerance methods
– Security• Classification of attacks and protection mechanisms

Interaction Model• Process interaction in a distributed system
– Separation transparency over a communication subsystem– two factors
• Communication performance– Latency– Bandwidth– Jitter
• Clock synchronization– Adjust clock drifts via either physical clock or logical clock
• Two variants of interaction model– synchronous distributed systems
• Bounded time on process execution, message delivery, and clock drift• Use timeout for detecting failures
– asynchronous distributed systems• no bounds on process execution, message delivery, and clock drift

Interaction Model (cont.)• Event ordering
– Example• X sends a message ‘Meeting’(m1)
• Y reads ‘Meeting’ and then replies ‘Re: Meeting’(m2)
• Z reads ‘Meeting’(m1) and ‘Re: Meeting’(m2) and then replies ‘Re:Meeting’(m3)
• A sees m3, m1, and m2 in wrong order (due to independent delay)send
receive
send
receive
m1 m2
2
1
3
4X
Y
Z
Physical time
Am3
receive receive
send
receive receive receivet1 t2 t3
receive
receive
m2
m1

Interaction Model (cont.)• Event ordering (cont.)
– using physical time• not feasible in real since perfect clock synchronization is
impossible
– using logical time [Lamport78]• execution of a distributed system can be described in terms of
events and their ordering despite the lack of accurate clocks• event ordering rules (partial ordering relation)
– if e1 and e2 happen in the same process, and e2 happens after e1, then e1→e2
» Y receives m1 before sending m2 (logical time 2 and 3)– if e1 is the sending of a message and e2 is the receiving of the message,
then e1→e2
» X sends m1 before Y receives m1 (logical time 1 and 2)» Y sends m2 before X receives m2 (logical time 3 and 4)

Failure Model• Omission failures
– fail to perform actions a process or communication channel is supposed to do
– process omission failures• crash: halt and remain halted• a process crash is fail-stop if other processes can detect certainly that the
process has crashed– detection by timeout in synchronous systems– cf. asynchronous systems
– communication omission failures• fail to transport a message from a sender’s outgoing buffer to a receiver’s
incoming buffer• possible causes
– buffer overflow and/or transmission error• Derived failures
– send-omission failure– channel failures– receive-omission failures

Failure Model (cont.)• Arbitrary failures
– the term arbitrary or Byzantine to describe the worst possible failure semantics (cf. omission and timing failures are called benign)
• a process arbitrarily omits intended steps or takes unintended steps
– set or return wrong values
– can’t detect by timeout
• communication arbitrary failures
• message contents corruption or delivery of non-existent messages and duplicate messages
– detect by checksums or sequence numbers

Failure Model (cont.)• Timing failures
– applicable only in synchronous systems• time limits are set on process execution, message delivery, and
clock drift rate
– clock failures• exceeding the bounds on clock drift rate
– performance failures• exceeding the bounds on the interval between two processing
steps or message transmission

Failure Model (cont.)• Masking failures
– by hiding failures or by converting them into a more acceptable type of failures (e.g., checksums)
• retransmission - masking communication omission failures
• replication - masking process crashes
– reliable communication (masking communication omission failures)
• validity: any message is eventually delivered
• integrity: the identical message is delivered exactly once– duplicate checking by sequence number
– security measures against spurious message and replaying or tampering with messages

Security Model• Protecting objects
– access right allows a specified principal to perform a specified operation of an object
• principal: authority (user or process) on which a invocation/result is issued
• Securing processes and channels– to identify/defeat security threats to processes
’interaction by message exchange– identifying security threats
• threats to processes: message source spoofing
• threats to channels: message copying, altering, replaying

Security Model (cont.)• Protection mechanisms
– encryption scrambles a message to hide its contents by using secret keys shared only by processes involved
– message authentication proves the identities of senders• an encrypted part included in a message
– secure channel• reliable knowledge of the identity of the principal behind a invocation/result• privacy and integrity (protection against tampering)• prevention of message replaying or reordering (physical or logical time stamp)• e.g.: Virtual Private Networks (VPN), Secure Sockets Layer (SSL) protocol
• Other possible threats– denial of service: interfering with the activities of authorized users
• making excessive, invalid invocations or transmission -> resource overloading,• e.g., “pings” to cnn.com
– mobile code• e.g., email worm as a Trojan horse