Embed Size (px)
Citation preview

CS61C:GreatIdeasinComputerArchitecture(MachineStructures)Warehouse-ScaleComputing,
MapReduce,andSparkInstructors:
KrsteAsanović &RandyH.Katzhttp://inst.eecs.berkeley.edu/~cs61c/
11/8/17 Fall2017 -- Lecture#21 1
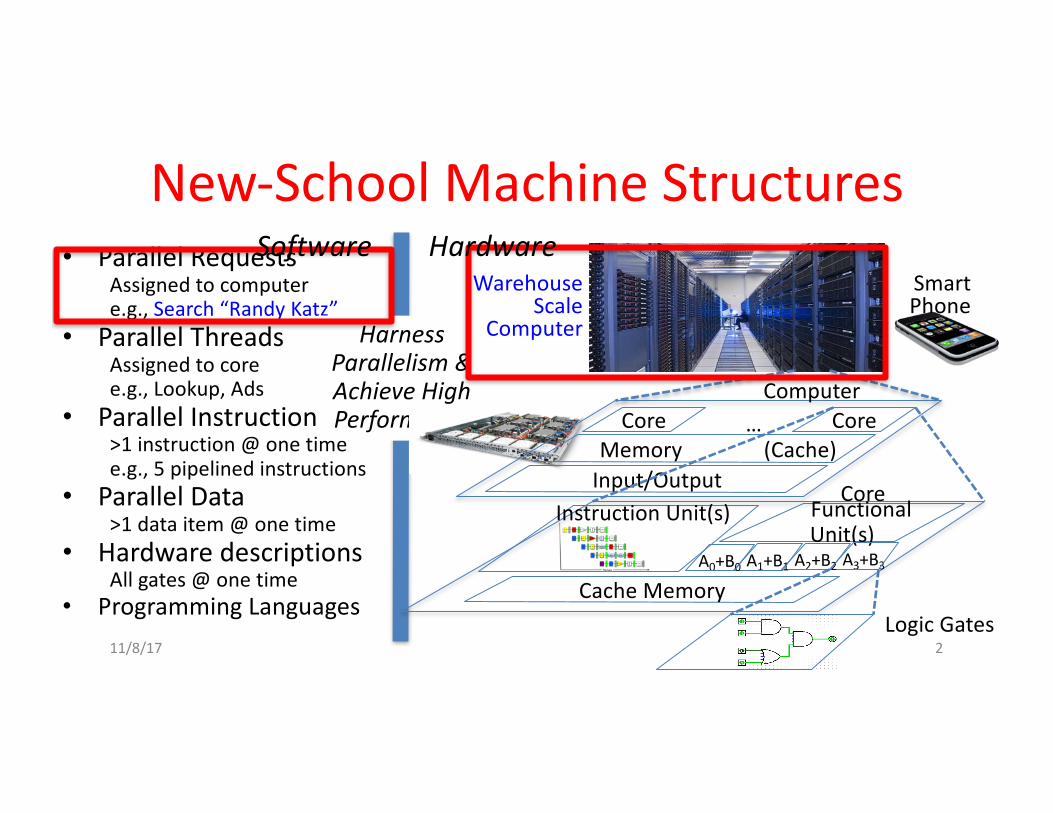
New-SchoolMachineStructures• ParallelRequests
Assignedtocomputere.g.,Search“RandyKatz”
• ParallelThreadsAssignedtocoree.g.,Lookup,Ads
• ParallelInstructions>[email protected].,5pipelinedinstructions
• ParallelData>1dataitem@onetime
• HardwaredescriptionsAllgates@onetime
• ProgrammingLanguages
SmartPhone
WarehouseScale
ComputerHarnessParallelism&AchieveHighPerformance
LogicGates
Core Core…Memory(Cache)Input/Output
Computer
CacheMemory
CoreInstructionUnit(s) Functional
Unit(s)A3+B3A2+B2A1+B1A0+B0
SoftwareHardware
11/8/17 2

Agenda• Warehouse-ScaleComputing• CloudComputing• Request-LevelParallelism
(RLP)• Map-ReduceDataParallelism• And,inConclusion…
11/8/17 3

Agenda• Warehouse-ScaleComputing• CloudComputing• RequestLevelParallelism
(RLP)• Map-ReduceDataParallelism• And,inConclusion…
11/8/17 4

Google’sWSCs
511/8/17
Ex:InOregon
11/8/17 Fall2016 -- Lecture#21 5
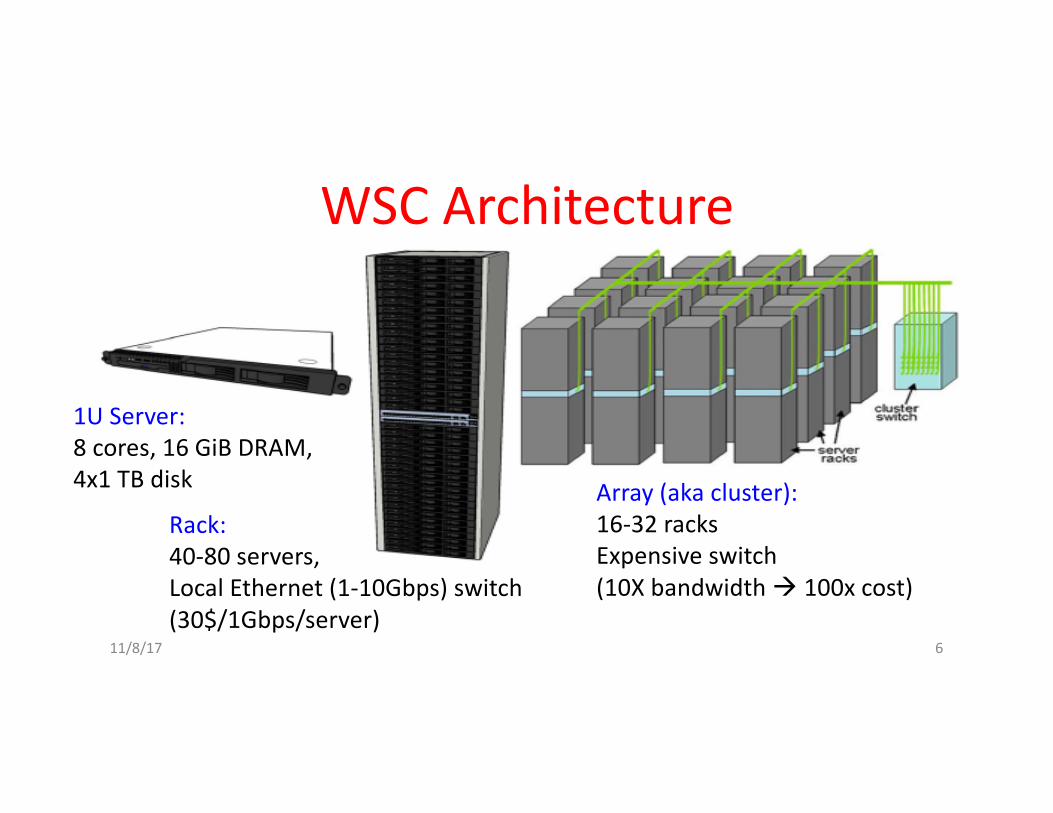
WSCArchitecture
1UServer:8cores,16GiB DRAM,4x1TBdisk
Rack:40-80servers,LocalEthernet(1-10Gbps)switch(30$/1Gbps/server)
Array(akacluster):16-32racksExpensiveswitch(10Xbandwidthà 100xcost)
11/8/17 6
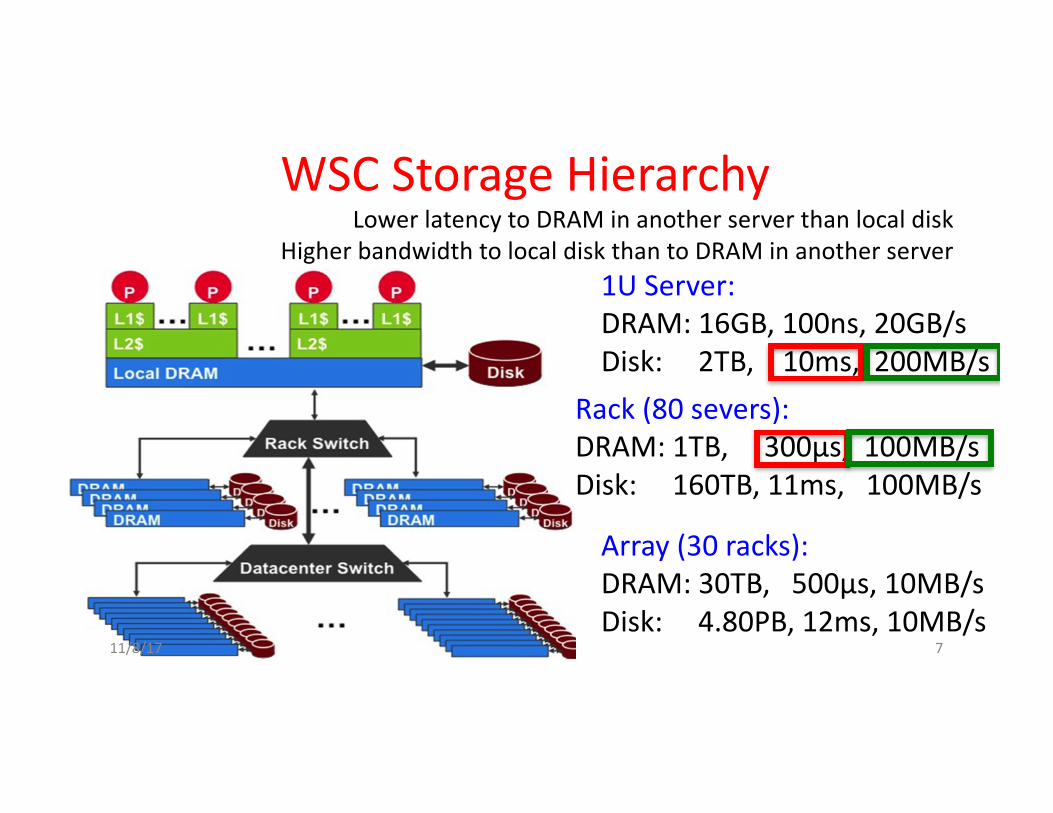
WSCStorageHierarchy
1UServer:DRAM:16GB,100ns,20GB/sDisk:2TB,10ms,200MB/s
Rack(80severs):DRAM:1TB,300µs,100MB/sDisk:160TB,11ms,100MB/s
Array(30racks):DRAM:30TB,500µs,10MB/sDisk:4.80PB,12ms,10MB/s
LowerlatencytoDRAMinanotherserverthanlocaldiskHigherbandwidthtolocaldiskthantoDRAMinanotherserver
11/8/17 7

GoogleServerInternalsGoogleServer
11/8/17 8


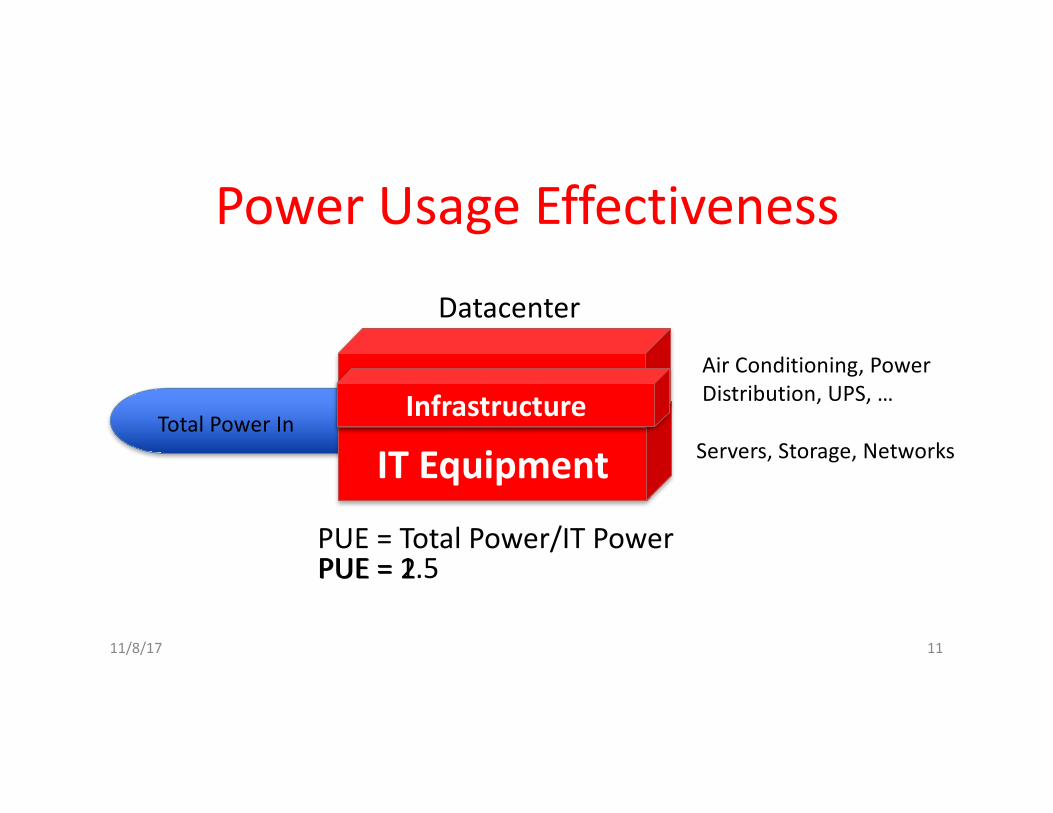
PowerUsageEffectiveness• Energyefficiency
– PrimaryconcerninthedesignofWSC– Importantcomponentofthetotalcostofownership
• PowerUsageEffectiveness(PUE):
– PowerefficiencymeasureforWSC– Notconsideringefficiencyofservers,networking– Perfection=1.0– GoogleWSC’sPUE=1.2
TotalBuildingPowerITequipmentPower
11/8/17 10
PowerUsageEffectiveness
11/8/17 11
ITEquipmentTotalPowerIn
Datacenter
Servers,Storage,Networks
AirConditioning,PowerDistribution,UPS,…
PUE=TotalPower/ITPower
Infrastructure
PUE=2
Infrastructure
PUE=1.5
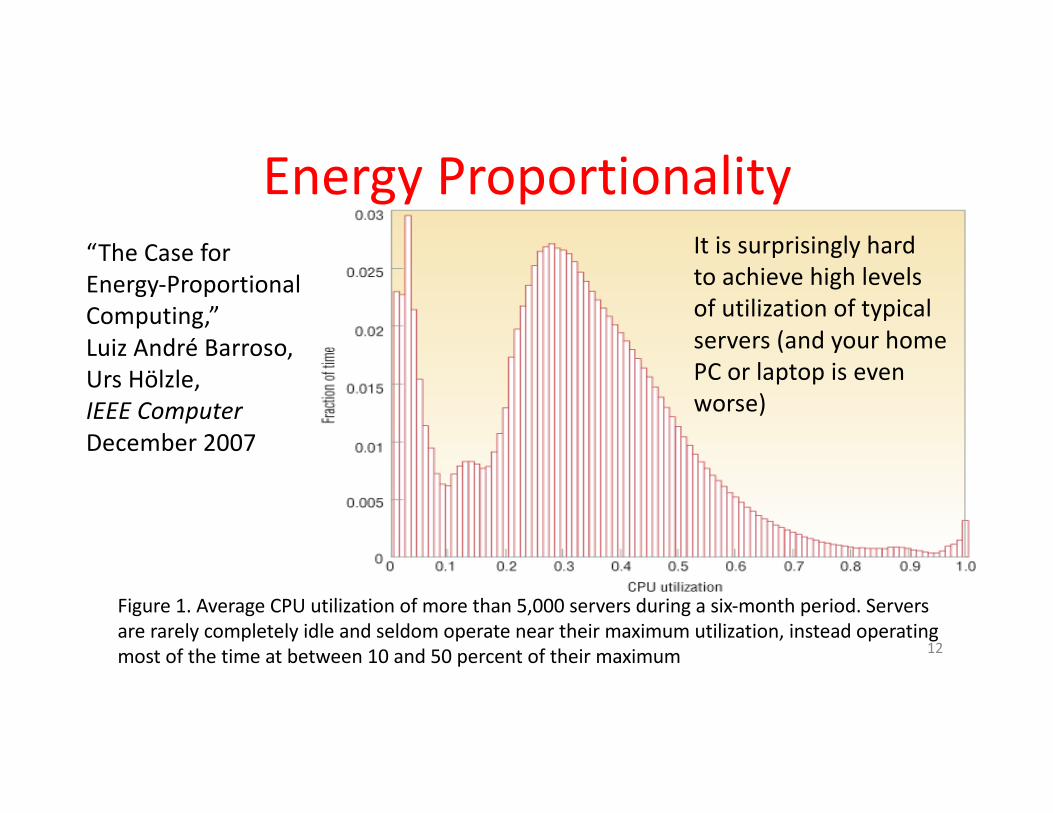
EnergyProportionality
12
Figure1.AverageCPUutilizationofmorethan5,000serversduringasix-monthperiod.Serversarerarelycompletelyidleandseldomoperateneartheirmaximumutilization,insteadoperatingmostofthetimeatbetween10and50percentoftheirmaximum
Itissurprisinglyhardtoachievehighlevelsofutilizationoftypicalservers(andyourhomePCorlaptopisevenworse)
“TheCaseforEnergy-ProportionalComputing,”LuizAndréBarroso,UrsHölzle,IEEEComputerDecember2007
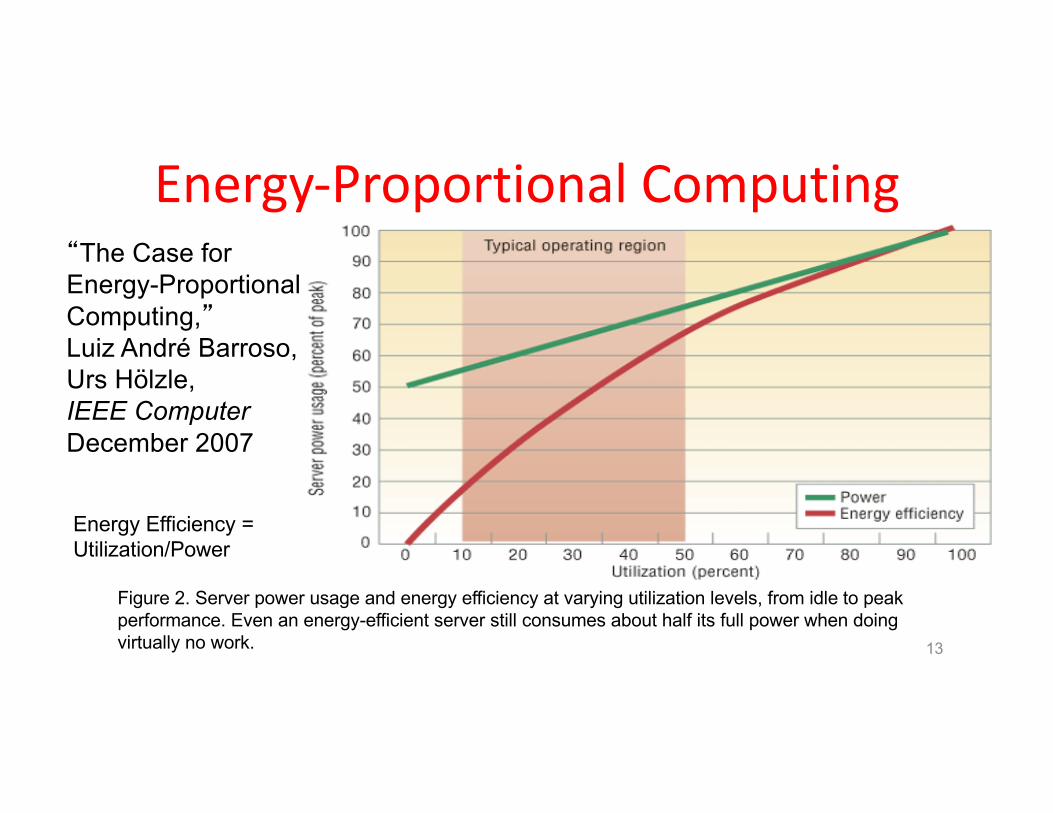
Energy-ProportionalComputing
13
Figure 2. Server power usage and energy efficiency at varying utilization levels, from idle to peak performance. Even an energy-efficient server still consumes about half its full power when doing virtually no work.
“The Case for Energy-Proportional Computing,”Luiz André Barroso,Urs Hölzle,IEEE ComputerDecember 2007
Energy Efficiency =Utilization/Power
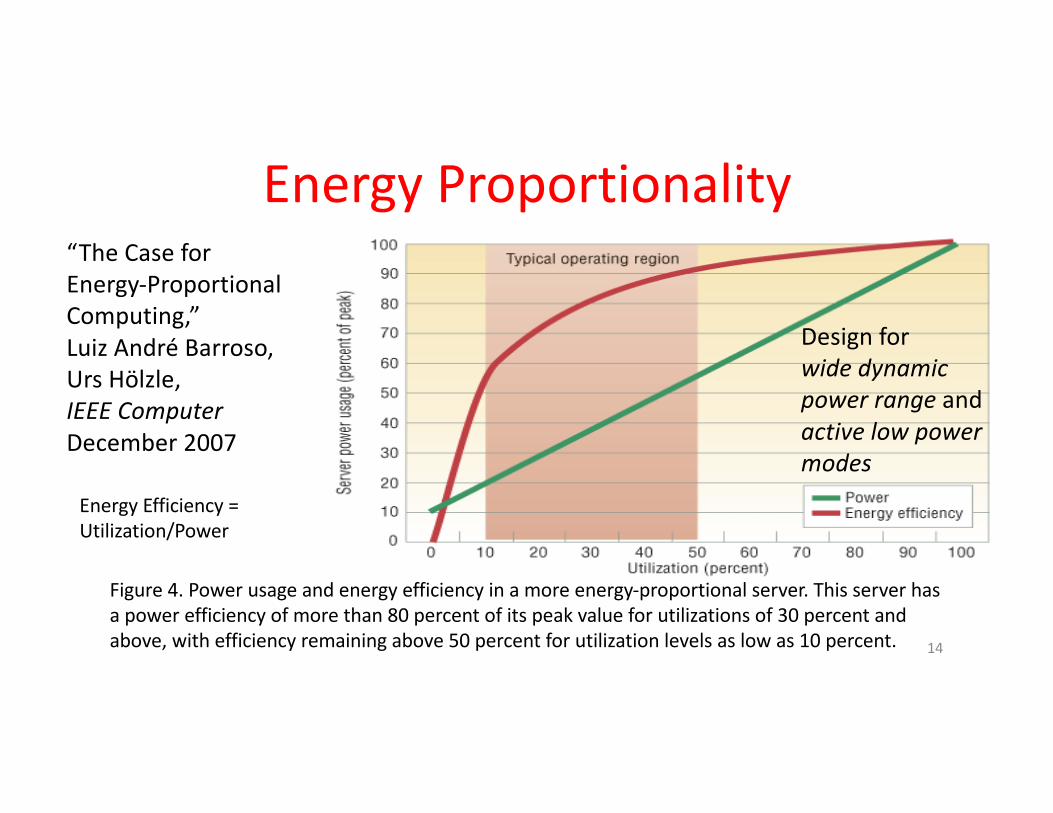
EnergyProportionality
14
Figure4.Powerusageandenergyefficiencyinamoreenergy-proportionalserver.Thisserverhasapowerefficiencyofmorethan80percentofitspeakvalueforutilizationsof30percentandabove,withefficiencyremainingabove50percentforutilizationlevelsaslowas10percent.
“TheCaseforEnergy-ProportionalComputing,”Luiz AndréBarroso,Urs Hölzle,IEEEComputerDecember2007
Designforwidedynamicpowerrange andactivelowpowermodes
EnergyEfficiency=Utilization/Power

Agenda• WarehouseScaleComputing• CloudComputing• RequestLevelParallelism(RLP)• Map-ReduceDataParallelism• And,inConclusion…
11/8/17 15
ScaledCommunities,Processing,andData
11/8/17 16
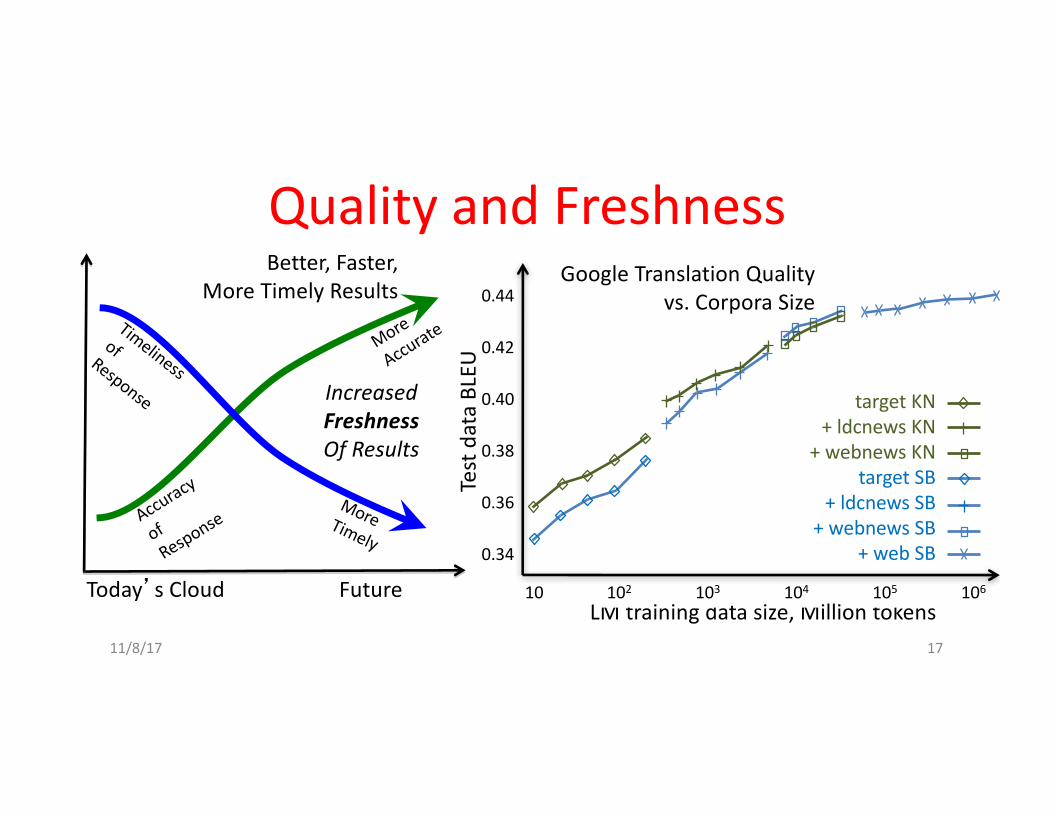
QualityandFreshness
11/8/17 17
IncreasedFreshnessOfResults
Today’sCloudFuture
Better,Faster,MoreTimelyResults
GoogleTranslationQualityvs.CorporaSize
LMtrainingdatasize,Milliontokens
targetKN+ldcnewsKN
+webnewsKNtargetSB
+ldcnewsSB+webnewsSB
+webSB
0.44
0.34
0.40
0.42
0.38
0.36
10 106105104103102
TestdataBLEU

CloudDistinguishedby…• Sharedplatformwithillusionofisolation
– Collocationwithothertenants– ExploitstechnologyofVMsandhypervisors(nextlectures!)– Atbest“fair”allocationofresources,butnottrueisolation
• Attractionoflow-costcycles– Economiesofscaledrivingmovetoconsolidation– Statisticalmultiplexingtoachievehighutilization/efficiencyofresources
• Elasticservice− Payforwhatyouneed,getmorewhenyouneedit− Butnoperformanceguarantees:assumesuncorrelateddemandfor
resources
11/8/17 18
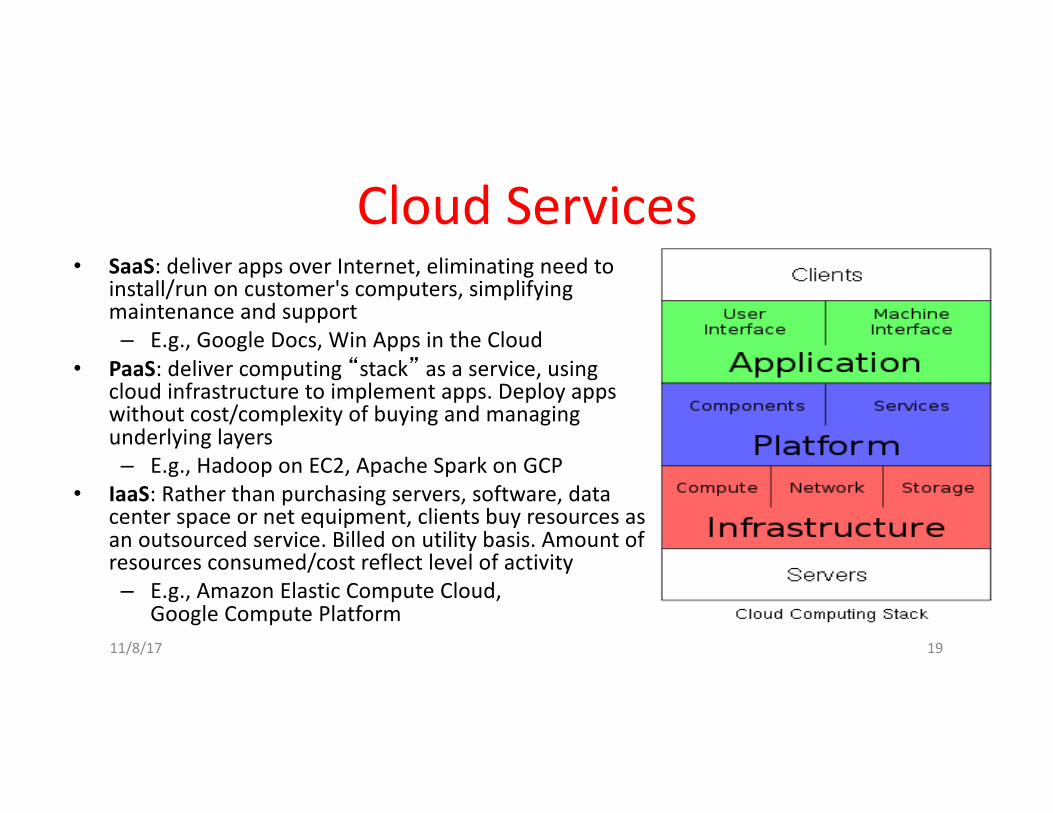
CloudServices• SaaS:deliverappsoverInternet,eliminatingneedto
install/runoncustomer'scomputers,simplifyingmaintenanceandsupport– E.g.,GoogleDocs,WinAppsintheCloud
• PaaS:delivercomputing“stack” asaservice,usingcloudinfrastructuretoimplementapps.Deployappswithoutcost/complexityofbuyingandmanagingunderlyinglayers– E.g.,Hadoop onEC2,ApacheSparkonGCP
• IaaS:Ratherthanpurchasingservers,software,datacenterspaceornetequipment,clientsbuyresourcesasanoutsourcedservice.Billedonutilitybasis.Amountofresourcesconsumed/costreflectlevelofactivity– E.g.,AmazonElasticComputeCloud,
GoogleComputePlatform11/8/17 19

Agenda• WarehouseScaleComputing• CloudComputing• Request-LevelParallelism
(RLP)• Map-ReduceDataParallelism• And,inConclusion…
11/8/17 20

Request-LevelParallelism(RLP)• Hundredsofthousandsofrequestspersecond
– PopularInternetserviceslikewebsearch,socialnetworking,…– Suchrequestsarelargelyindependent
• Ofteninvolveread-mostlydatabases• Rarelyinvolveread-writesharingorsynchronizationacrossrequests
• Computationeasilypartitionedacrossdifferentrequestsandevenwithinarequest
11/8/17 21
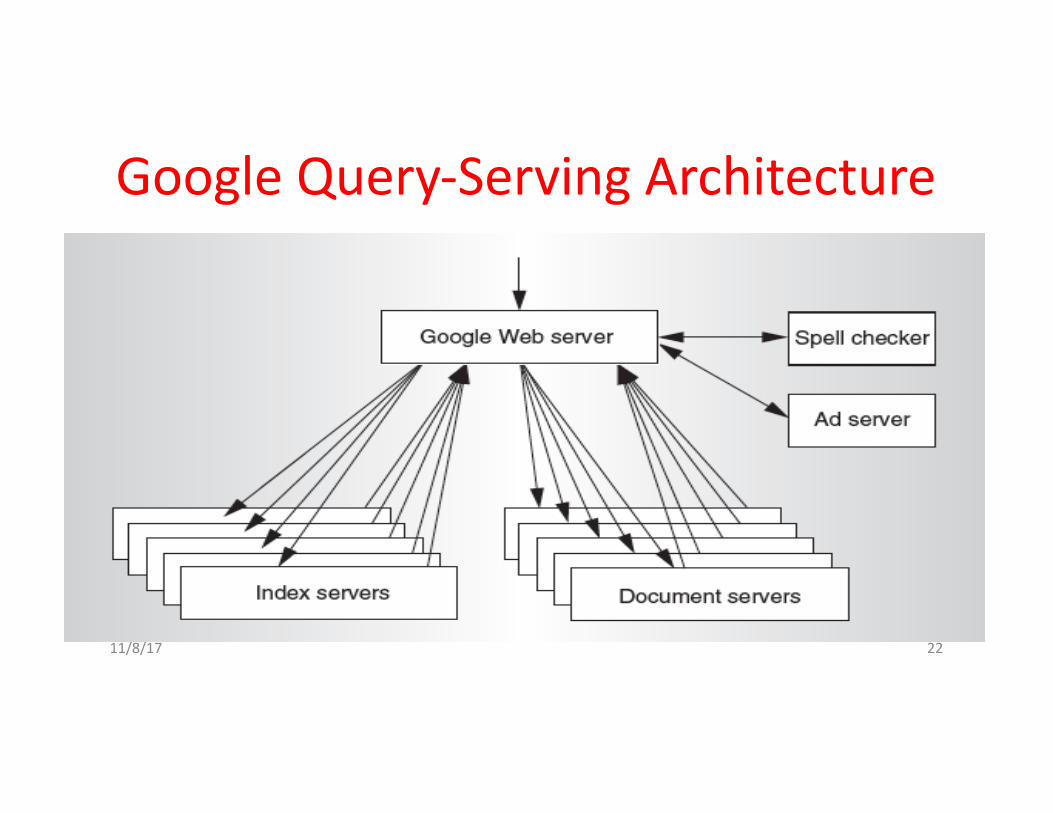
GoogleQuery-ServingArchitecture
11/8/17 22
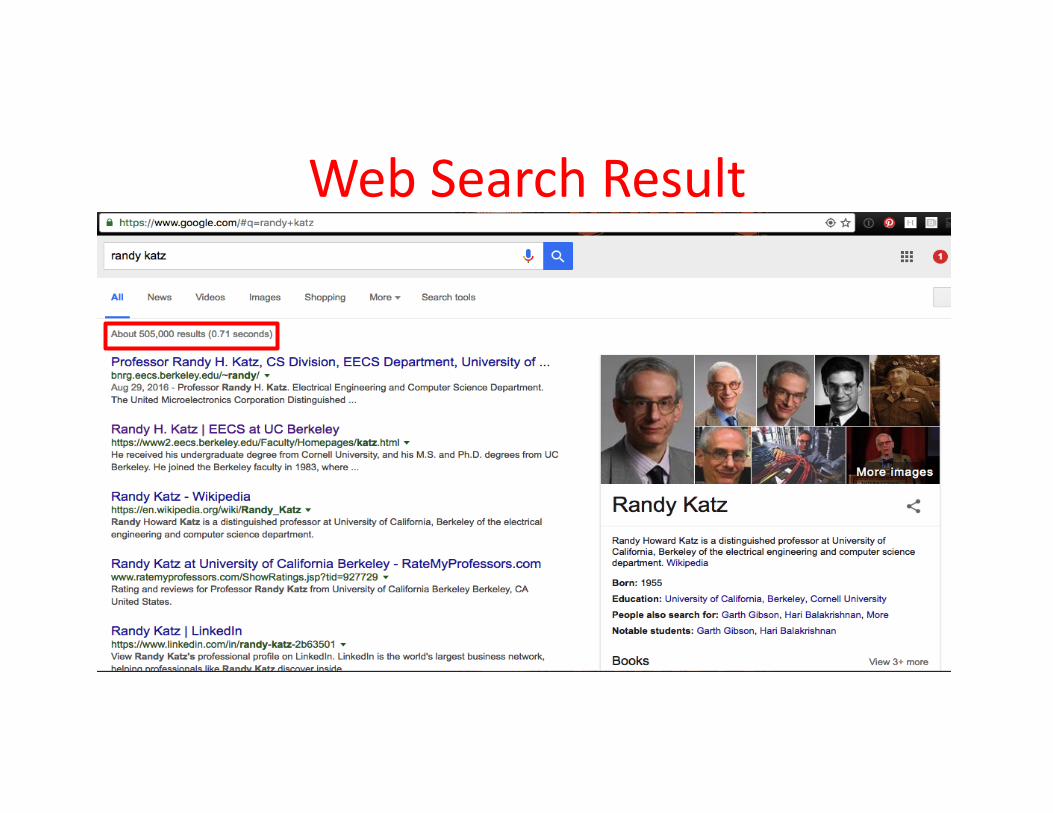
WebSearchResult
11/8/17 23

AnatomyofaWebSearch(1/3)• Google“RandyKatz”
1. Directrequestto“closest”GoogleWarehouse-ScaleComputer2. Front-endloadbalancerdirectsrequesttooneofmanyclustersof
serverswithinWSC3. Withincluster,selectoneofmanyGoogleWebServers(GWS)to
handletherequestandcomposetheresponsepages4. GWScommunicateswithIndexServerstofinddocumentsthat
containthesearchwords,“Randy”,“Katz”,useslocationofsearchaswell
5. Returndocumentlistwithassociatedrelevancescore
11/8/17 24

AnatomyofaWebSearch(2/3)• Inparallel,
– Adsystem:booksbyKatzatAmazon.com– ImagesofRandyKatz
• Usedocids (documentIDs)toaccessindexeddocuments• Composethepage
– Resultdocumentextracts(withkeywordincontext)orderedbyrelevancescore
– Sponsoredlinks(alongthetop)andadvertisements(alongthesides)
11/8/17 25

AnatomyofaWebSearch(3/3)• Implementationstrategy
– Randomlydistributetheentries– Makemanycopiesofdata(aka“replicas”)– Loadbalancerequestsacrossreplicas
• Redundantcopiesofindicesanddocuments– Breaksuphotspots,e.g.,“JustinBieber”– Increasesopportunitiesforrequest-levelparallelism– Makesthesystemmoretolerantoffailures
11/8/17 26

Administrivia
11/8/17 27
• Project3:Performancehasbeenreleased!– DueMonday,November20– Competeinaperformancecontext(Proj5)forextracredit!
• HW5wasreleased;dueWednesdayNov15• Regraderequestsareopen
– DuethisFriday(Nov10)– PleaseconsultthesolutionsandGradeScope rubricfirst

Agenda• WarehouseScaleComputing• CloudComputing• RequestLevelParallelism(RLP)• Map-ReduceDataParallelism• And,inConclusion…
11/8/17 Fall2016 -- Lecture#21 28

Data-LevelParallelism(DLP)• SIMD
– Supportsdata-levelparallelisminasinglemachine– Additionalinstructions&hardware(e.g.,AVX)e.g.,Matrixmultiplicationinmemory
• DLPonWSC– Supportsdata-levelparallelismacrossmultiplemachines– MapReduce &scalablefilesystems
11/8/17 29

ProblemStatement• Howprocesslargeamountsofrawdata(crawled
documents,requestlogs,…)everydaytocomputederiveddata(invertedindices,pagepopularity,…)whencomputationconceptuallysimplebutinputdatalargeanddistributedacross100sto1000sofserverssothatfinishinreasonabletime?
• Challenge:Parallelizecomputation,distributedata,toleratefaultswithoutobscuringsimplecomputationwithcomplexcodetodealwithissues
11/8/17 30

Solution:MapReduce• Simpledata-parallelprogrammingmodel and
implementation forprocessinglargedatasets• Usersspecifythecomputationintermsof
– amap function,and– areduce function
• Underlyingruntimesystem– Automaticallyparallelize thecomputationacrosslargescaleclusters
ofmachines– Handlesmachinefailure– Schedule inter-machinecommunicationtomakeefficientuseofthe
networks
11/8/17 31
JeffreyDeanandSanjayGhemawat,“MapReduce:SimplifiedDataProcessingonLargeClusters,”6th USENIXSymposiumonOperatingSystemsDesignandImplementation,2004.(optionalreading,linkedoncoursehomepage– adigestibleCSpaperatthe61Clevel)
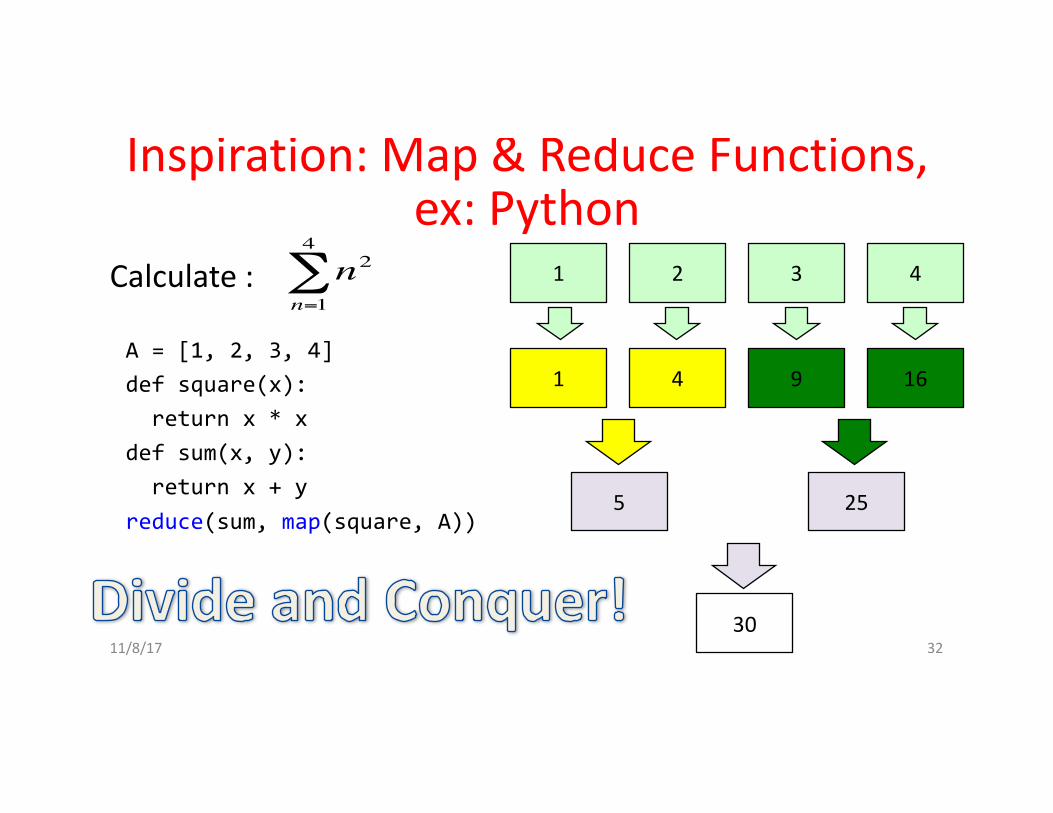
Inspiration:Map&ReduceFunctions,ex:Python
Calculate: n2n=1
4
∑
A = [1, 2, 3, 4]def square(x):
return x * xdef sum(x, y):
return x + yreduce(sum, map(square, A))
1 2 3 4
1 4 9 16
5 25
3011/8/17 32

• Map:(in_key, in_value) à list(interm_key, interm_val)map(in_key, in_val):// DO WORK HEREemit(interm_key,interm_val)
– Slicedatainto“shards”or“splits”anddistributetoworkers– Computesetofintermediatekey/valuepairs
• Reduce:(interm_key, list(interm_value)) à list(out_value)reduce(interm_key, list(interm_val)): // DO WORK HEREemit(out_key, out_val)
– Combinesallintermediatevaluesforaparticularkey– Producesasetofmergedoutputvalues(usuallyjustone)
MapReduce ProgrammingModel
11/8/17 33
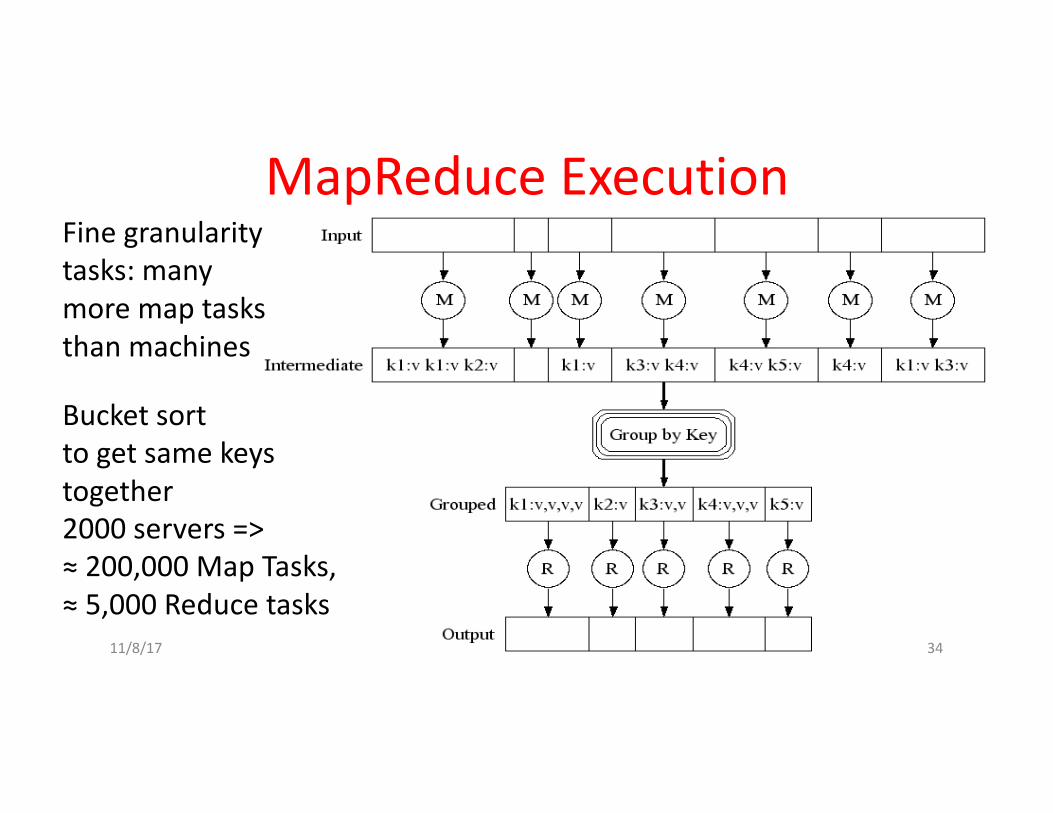
MapReduceExecutionFinegranularitytasks:manymoremaptasksthanmachines
2000servers=>≈200,000MapTasks,≈5,000Reducetasks
Bucketsorttogetsamekeystogether
11/8/17 34
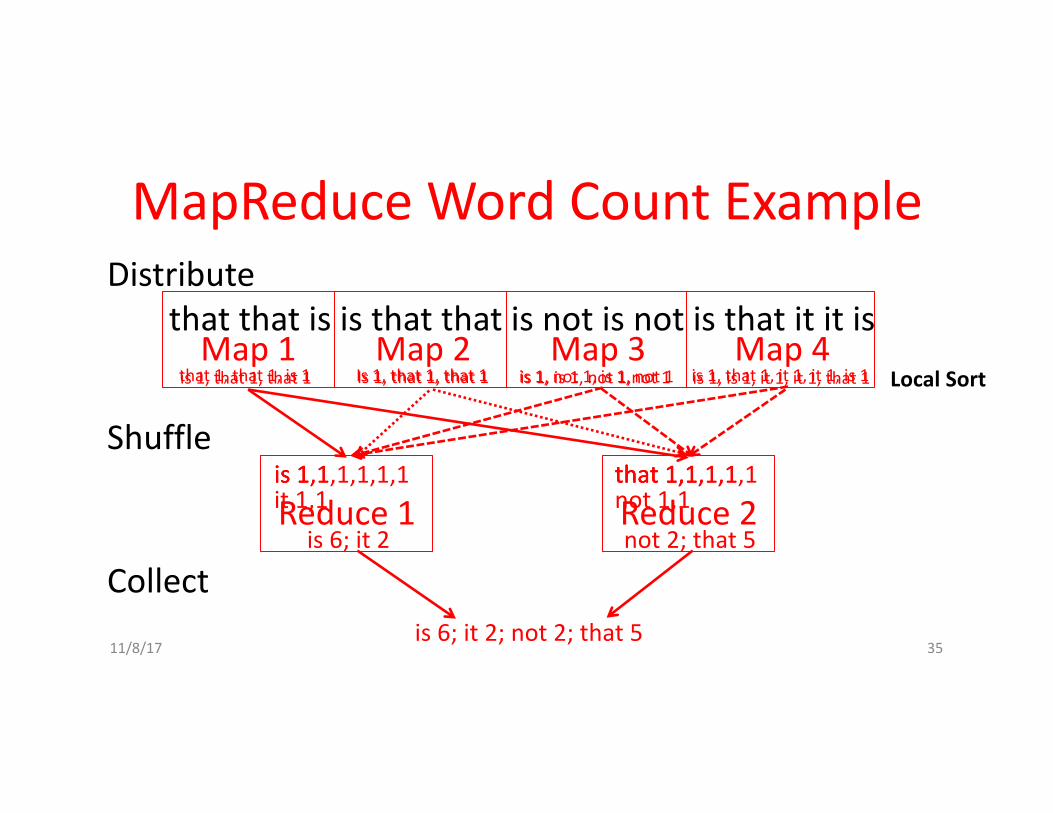
MapReduce WordCountExample
11/8/17 35
thatthatisisthatthatisnotisnotisthatititisis1,that1,that1 Is1,that1,that1 is1,is1,not1,not1 is1,is1,it1,it1,that1Map1 Map2 Map3 Map4
Reduce1 Reduce2is1 that1,1is1,1 that1,1,1,1is1,1,1,1,1,1it1,1
that1,1,1,1,1not1,1
is6;it2 not2;that5
Shuffle
Collectis6;it2;not2;that5
Distribute
that1,that1,is1 Is1,that1,that1 is1,not1,is1,not1 is1,that1,it1,it1,is1 LocalSort

User-writtenMap functionreadsthedocumentdataandparsesthewords.Foreachword,itwritesthe(key,value)pairof(word,1).Thewordistreatedastheintermediatekeyandtheassociatedvalueof1meansthatwesawthewordonce.
Map phase:(docname,doccontents)à list(word,count)// “I do I learn” à [(“I”,1),(“do”,1),(“I”,1),(“learn”,1)]map(key, value):for each word w in value:emit(w, 1)
MapReduce WordCountExampleTaskofcountingthenumberofoccurrencesofeach
wordinalargecollectionofdocuments
11/8/17 36

IntermediatedataisthensortedbyMapReduce bykeysandtheuser’sReducefunctioniscalledforeachuniquekey.Inthiscase,Reduceiscalledwithalistofa"1"foreachoccurrenceofthewordthatwasparsedfromthedocument.Thefunctionaddsthemuptogenerateatotalwordcountforthatword.
Reducephase:(word,list(counts))à (word,count_sum)// (“I”, [1,1]) à (“I”,2)reduce(key, values): result = 0for each v in values:result += v
emit(key, result)
MapReduce WordCountExampleTaskofcountingthenumberofoccurrencesofeach
wordinalargecollectionofdocuments.
37

Fall2016 -- Lecture#21 38

TheCombiner(Optional)• Onemissingpieceforourfirstexample:
– Manytimes,theoutputofasinglemappercanbe“compressed”tosaveonbandwidthandtodistributework(usuallymoremaptasksthanreducetasks)
– Toimplementthis,wehavethecombiner:combiner(interm_key,list(interm_val)):
// DO WORK (usually like reducer)emit(interm_key2, interm_val2)
39
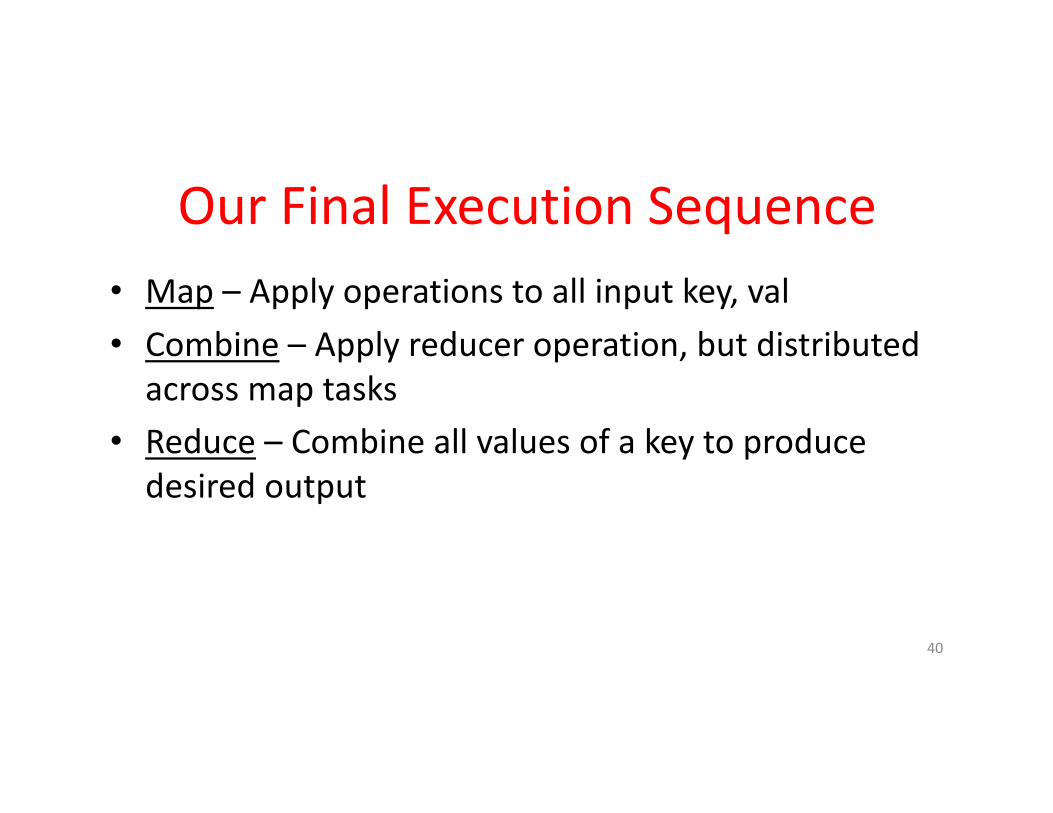
OurFinalExecutionSequence• Map – Applyoperationstoallinputkey,val• Combine – Applyreduceroperation,butdistributedacrossmaptasks
• Reduce – Combineallvaluesofakeytoproducedesiredoutput
40

MapReduceProcessingExample:CountWordOccurrences
• PseudoCode:foreachwordininput,generate<key=word,value=1>• Reducesumsallcountsemittedforaparticularwordacrossallmappers
map(String input_key, String input_value):// input_key: document name// input_value: document contentsfor each word w in input_value:EmitIntermediate(w, "1"); // Produce count of words
combiner: (same as below reducer)reduce(String output_key, Iterator intermediate_values):// output_key: a word// intermediate_values: a list of countsint result = 0;for each v in intermediate_values:result += ParseInt(v); // get integer from key-value
Emit(output_key, result);41
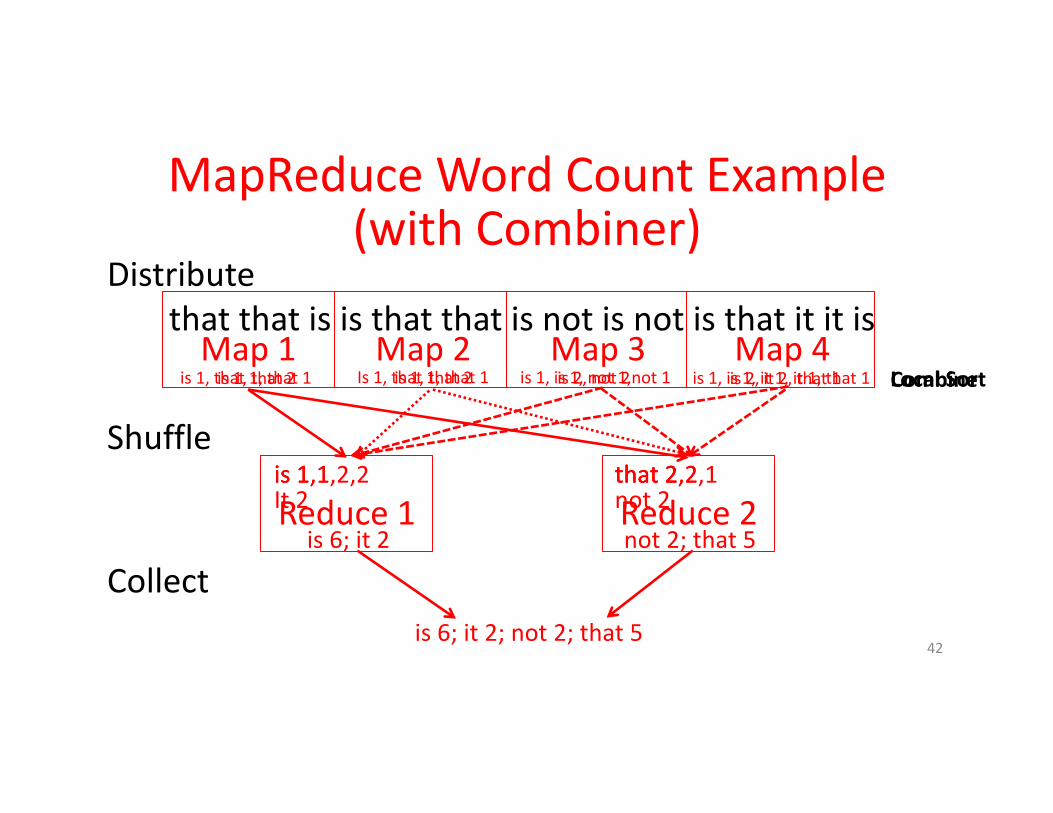
MapReduce WordCountExample(withCombiner)
42
thatthatisisthatthatisnotisnotisthatititisis1,that1,that1 Is1,that1,that1 is1,is1,not1,not1 is1,is1,it1,it1,that1Map1 Map2 Map3 Map4
Reduce1 Reduce2is1 that2is1,1 that2,2is1,1,2,2It2
that2,2,1not2
is6;it2 not2;that5
Shuffle
Collectis6;it2;not2;that5
Distribute
LocalSortis1,that2 is1,that2 is2,not2 is2,it2,that1 Combine
11/8/17 Fall2016 -- Lecture#2 43
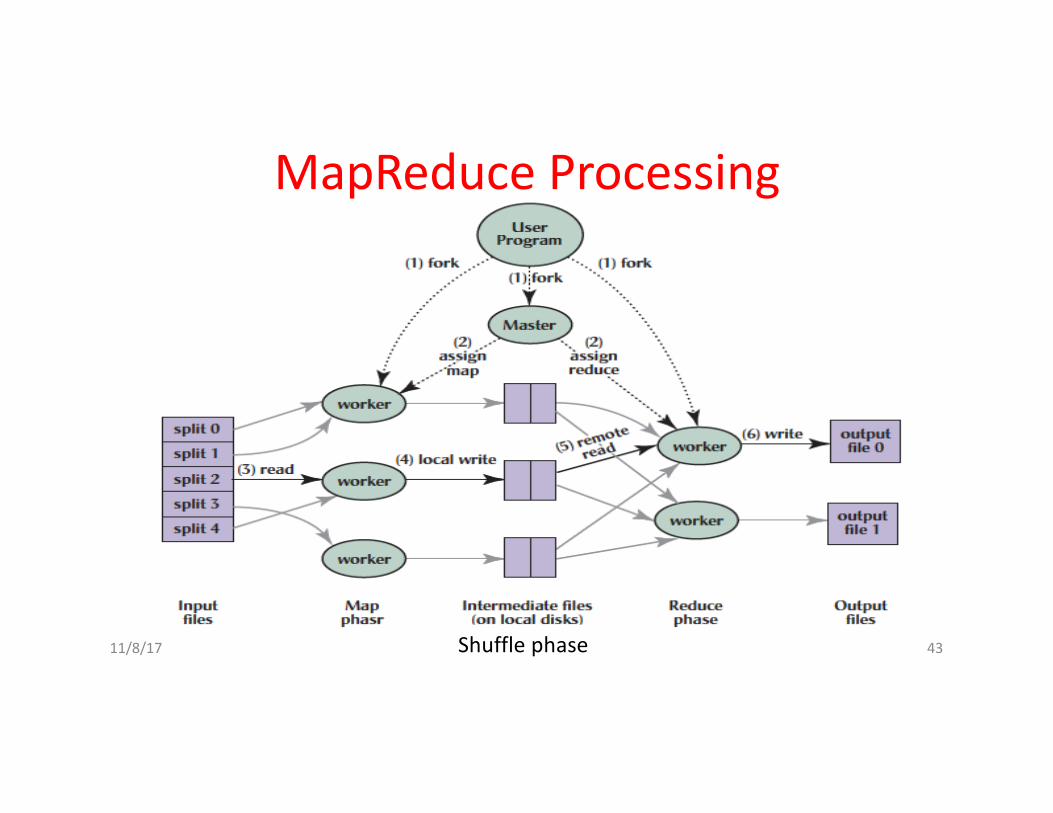
MapReduceProcessing
Shufflephase
MapReduceProcessing
11/8/17 Fall2016 -- Lecture#2 44
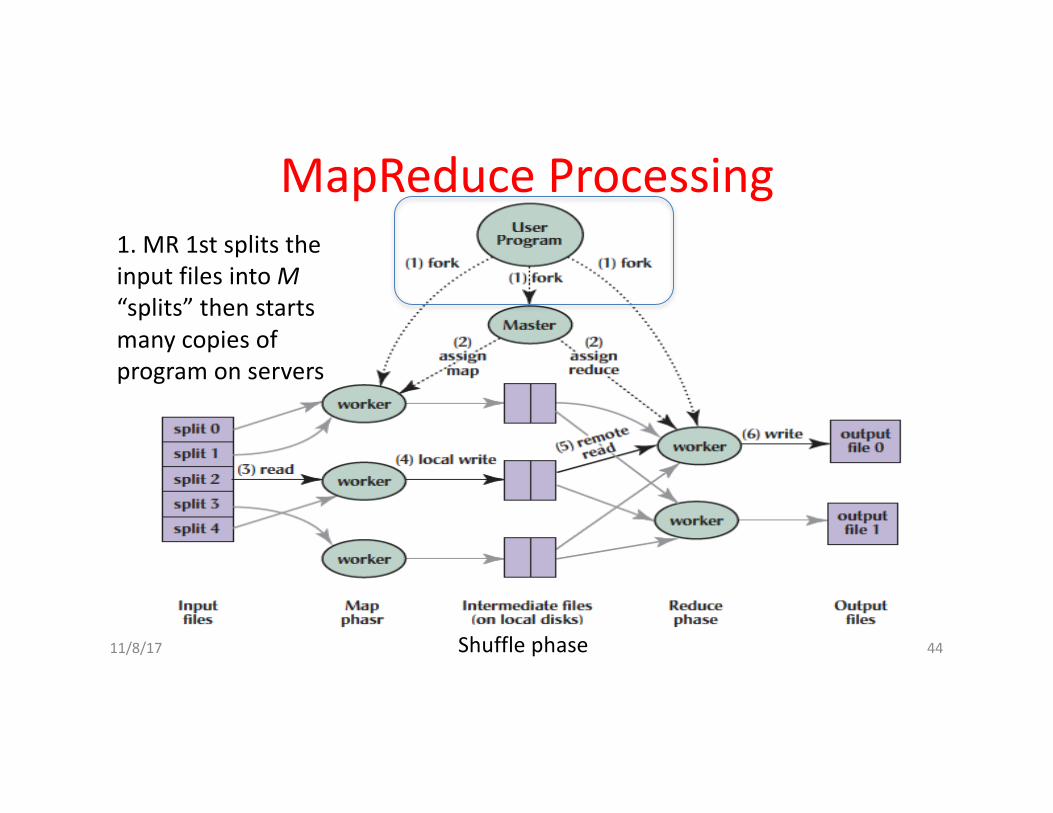
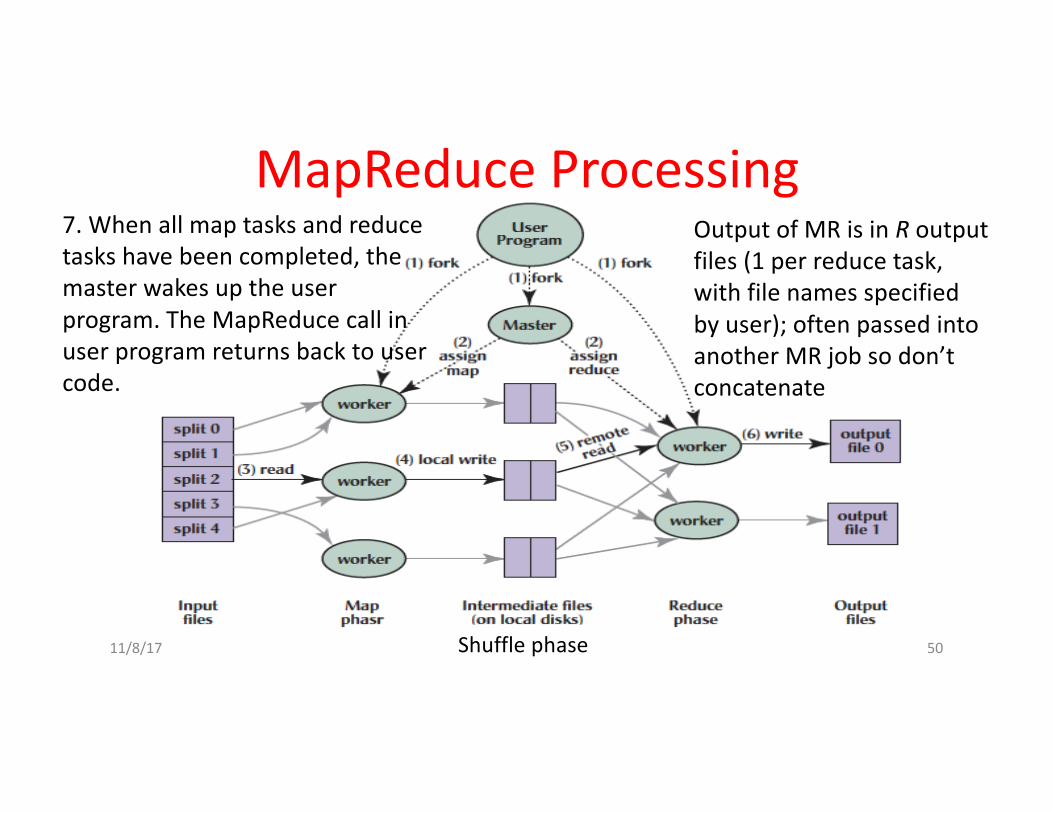
1.MR1stsplitstheinputfilesintoM“splits”thenstartsmanycopiesofprogramonservers
Shufflephase
MapReduceProcessing
11/8/17 Fall2016 -- Lecture#2 45
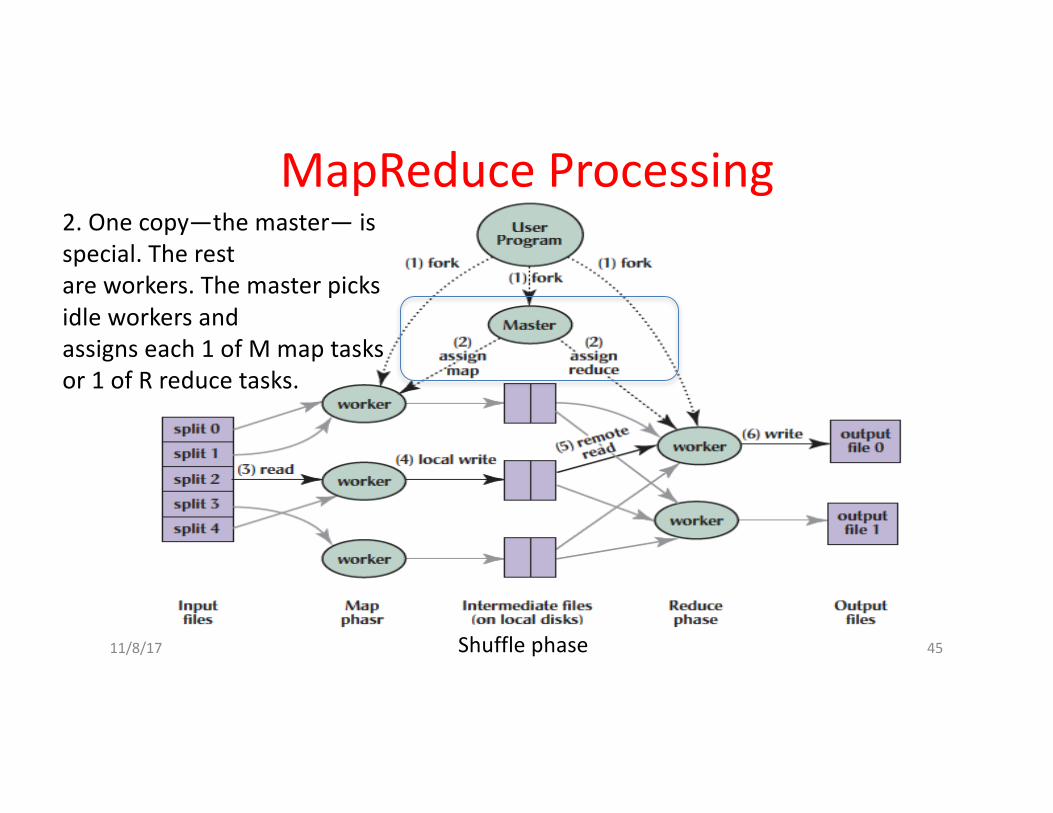
2.Onecopy—themaster— isspecial.Therestareworkers.Themasterpicksidleworkersandassignseach1ofMmaptasksor1ofRreducetasks.
Shufflephase
MapReduceProcessing
11/8/17 Fall2016 -- Lecture#2 46
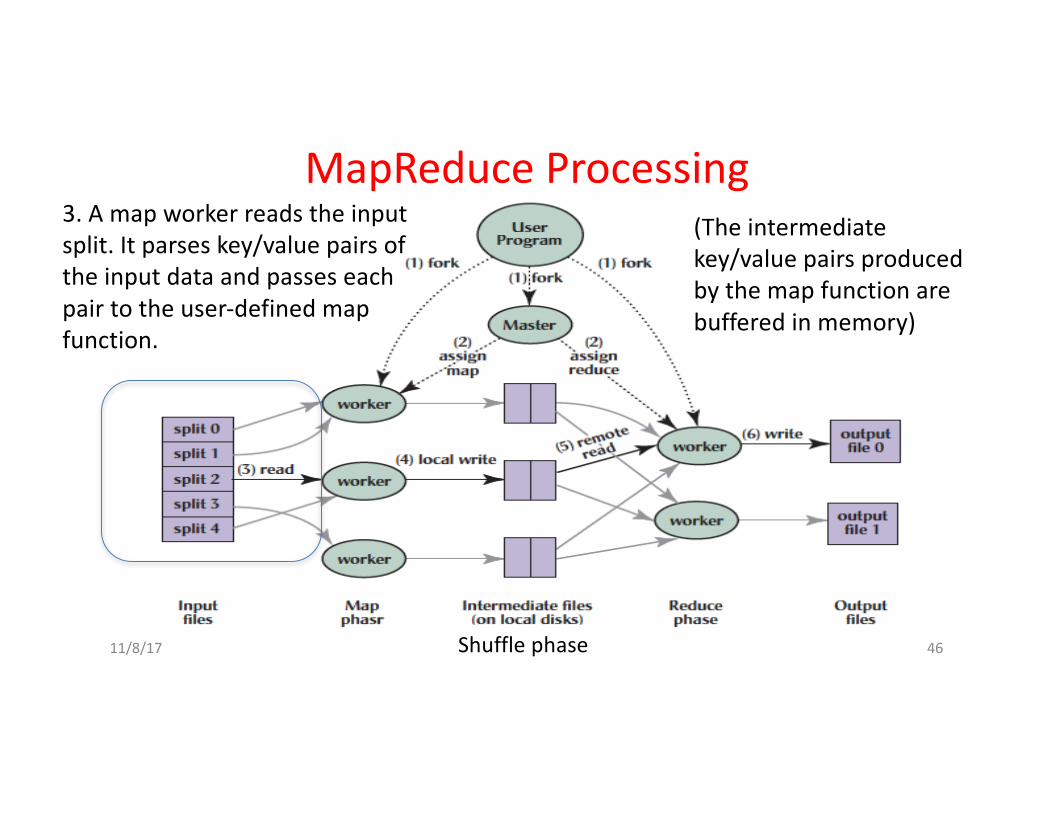
3.Amapworkerreadstheinputsplit.Itparseskey/valuepairsoftheinputdataandpasseseachpairtotheuser-definedmapfunction.
(Theintermediatekey/valuepairsproducedbythemapfunctionarebufferedinmemory)
Shufflephase
MapReduceProcessing
11/8/17 Fall2016 -- Lecture#2 47
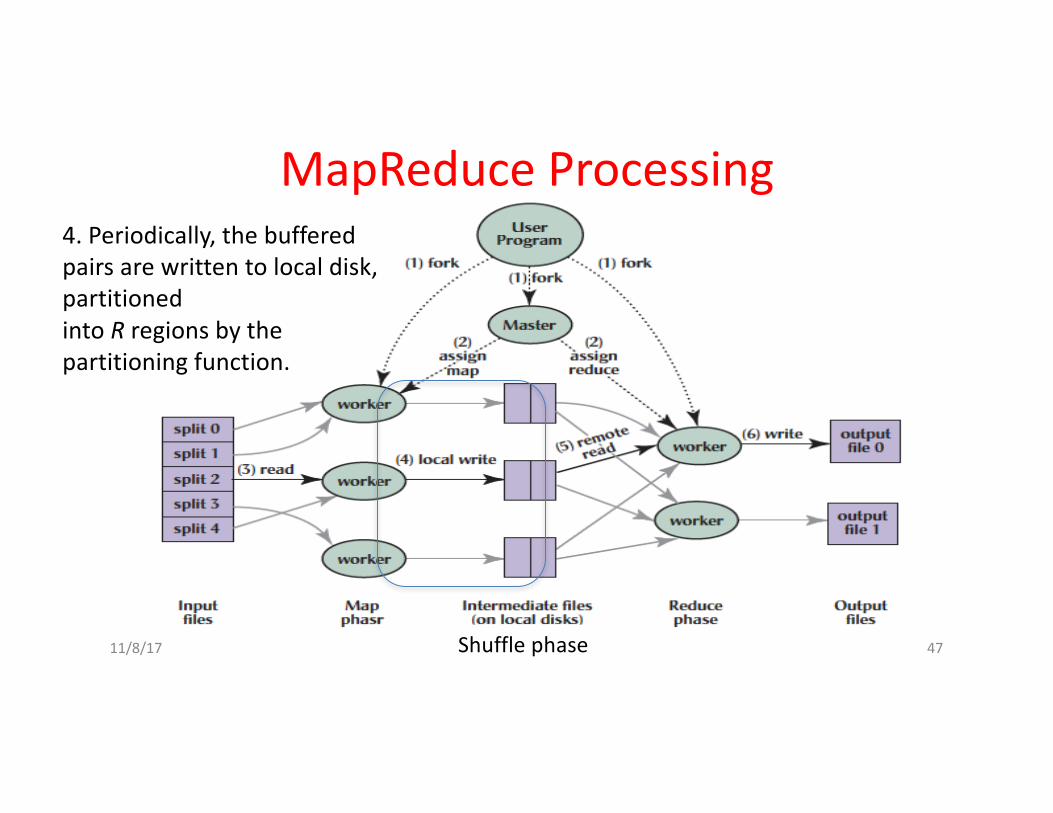
4.Periodically,thebufferedpairsarewrittentolocaldisk,partitionedintoRregionsbythepartitioningfunction.
Shufflephase
MapReduceProcessing
11/8/17 Fall2016 -- Lecture#2 48
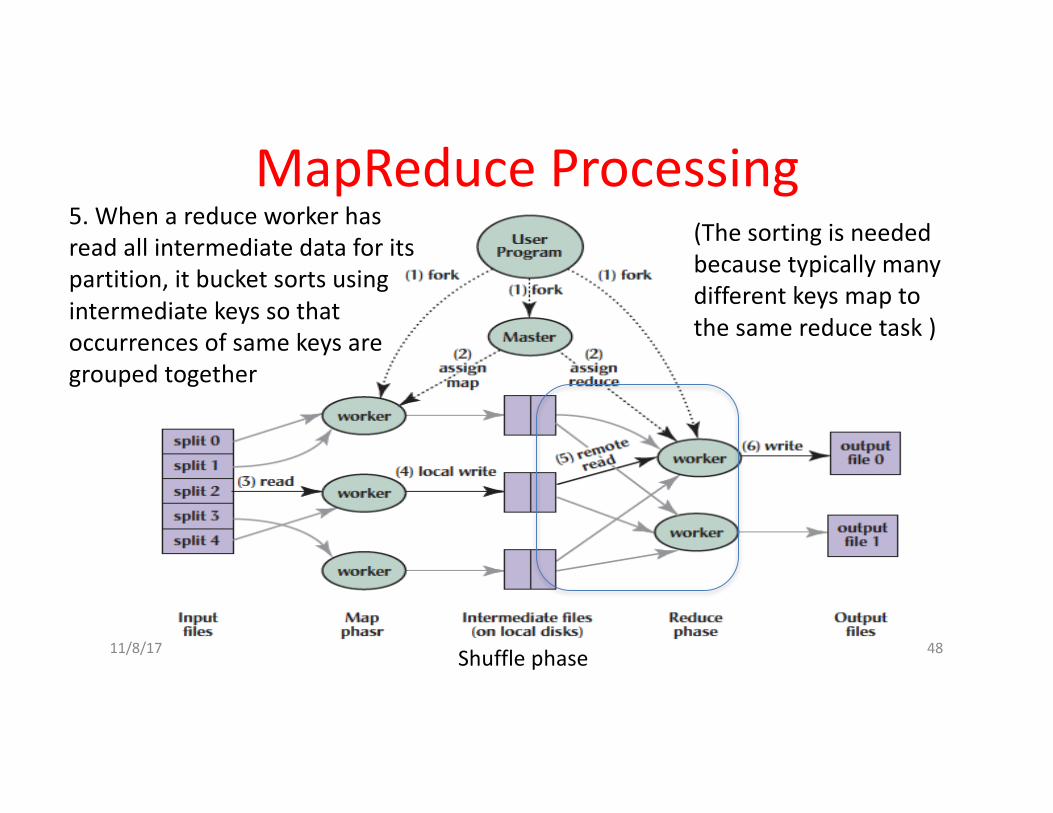
5.Whenareduceworkerhasreadallintermediatedataforitspartition,itbucketsortsusingintermediatekeyssothatoccurrencesofsamekeysaregroupedtogether
(Thesortingisneededbecausetypicallymanydifferentkeysmaptothesamereducetask)
Shufflephase
MapReduceProcessing
11/8/17 Fall2016 -- Lecture#2 49
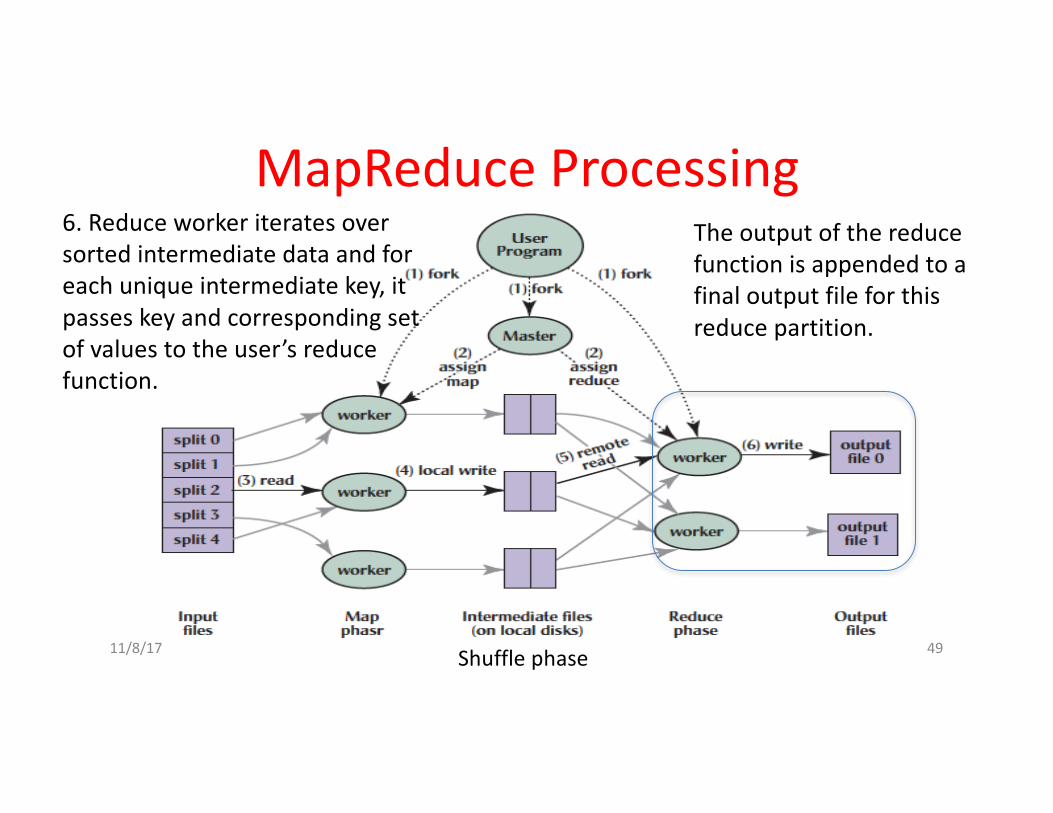
6.Reduceworkeriteratesoversortedintermediatedataandforeachuniqueintermediatekey,itpasseskeyandcorrespondingsetofvaluestotheuser’sreducefunction.
Theoutputofthereducefunctionisappendedtoafinaloutputfileforthisreducepartition.
Shufflephase
MapReduceProcessing
11/8/17 Fall2016 -- Lecture#2 50
7.Whenallmaptasksandreducetaskshavebeencompleted,themasterwakesuptheuserprogram.TheMapReduce callinuserprogramreturnsbacktousercode.
OutputofMRisinRoutputfiles(1perreducetask,withfilenamesspecifiedbyuser);oftenpassedintoanotherMRjobsodon’tconcatenate
Shufflephase

BigDataFrameworks:Hadoop &Spark• ApacheHadoop
– Open-sourceMapReduce Framework– Hadoop DistributedFileSystem(HDFS)– MapReduce JavaAPIs
• ApacheSpark– Fastandgeneralengineforlarge-scale
dataprocessing.– OriginallydevelopedintheAMPlabatUCBerkeley– RunningonHDFS– ProvidesJava,Scala,PythonAPIsfor
• Database• Machinelearning• Graphalgorithm11/8/17 51

WordCount inHadoop’s JavaAPI
52

// RDD: primary abstraction of a distributed collection of itemsfile = sc.textFile(“hdfs://…”)// Two kinds of operations: // Actions: RDD à Value// Transformations: RDD à RDD// e.g. flatMap, Map, reduceByKeyfile.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a + b)
WordCountinSpark’sPythonAPI
53
Seehttp://spark.apache.org/examples.html
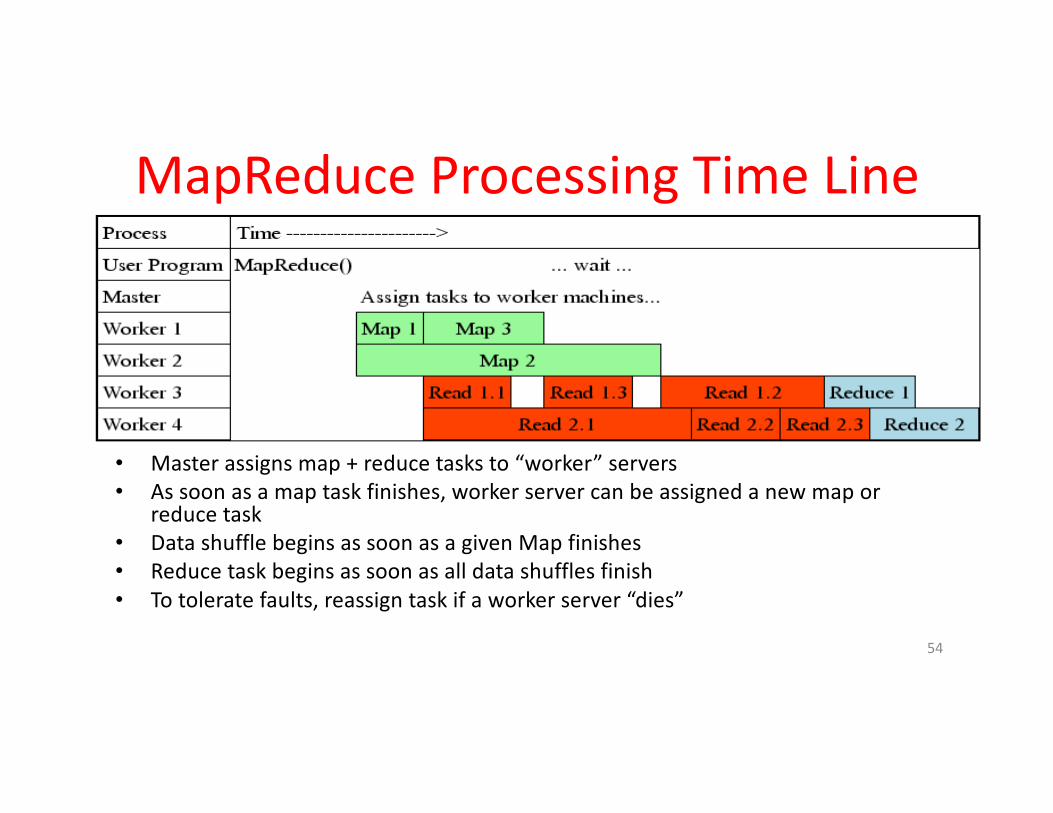
MapReduceProcessingTimeLine
• Masterassignsmap+reducetasksto“worker”servers• Assoonasamaptaskfinishes,workerservercanbeassignedanewmapor
reducetask• DatashufflebeginsassoonasagivenMapfinishes• Reducetaskbeginsassoonasalldatashufflesfinish• Totoleratefaults,reassigntaskifaworkerserver“dies”
54

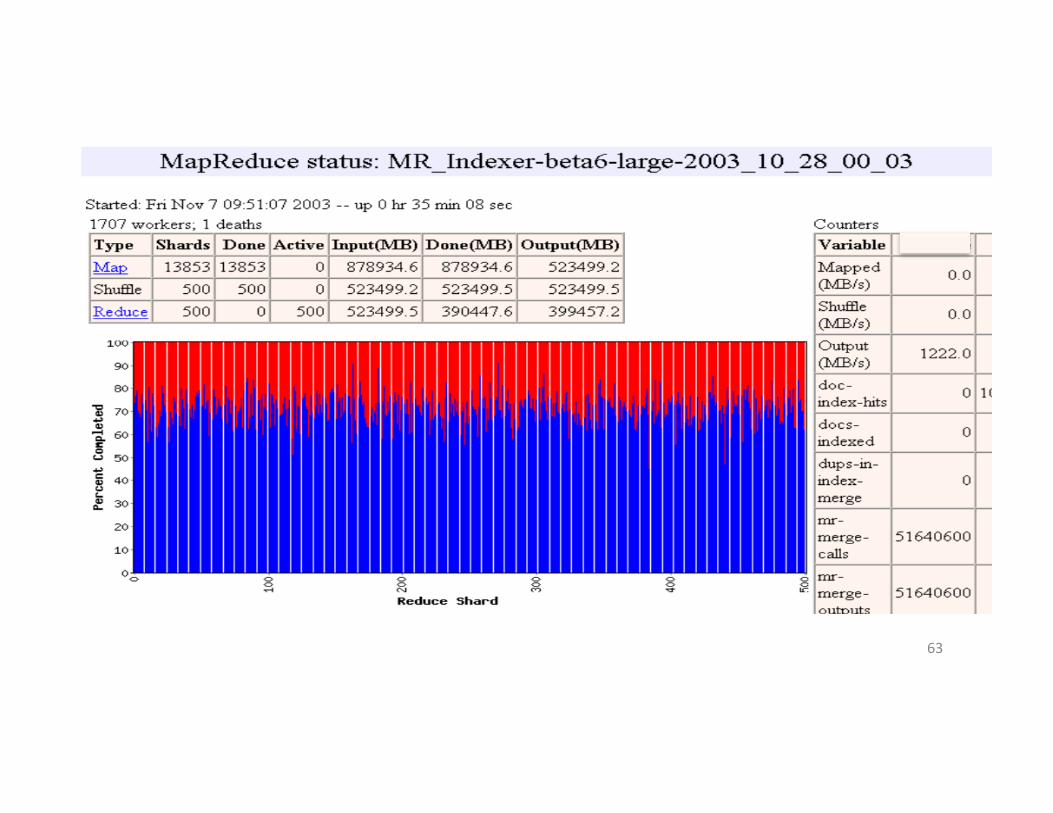
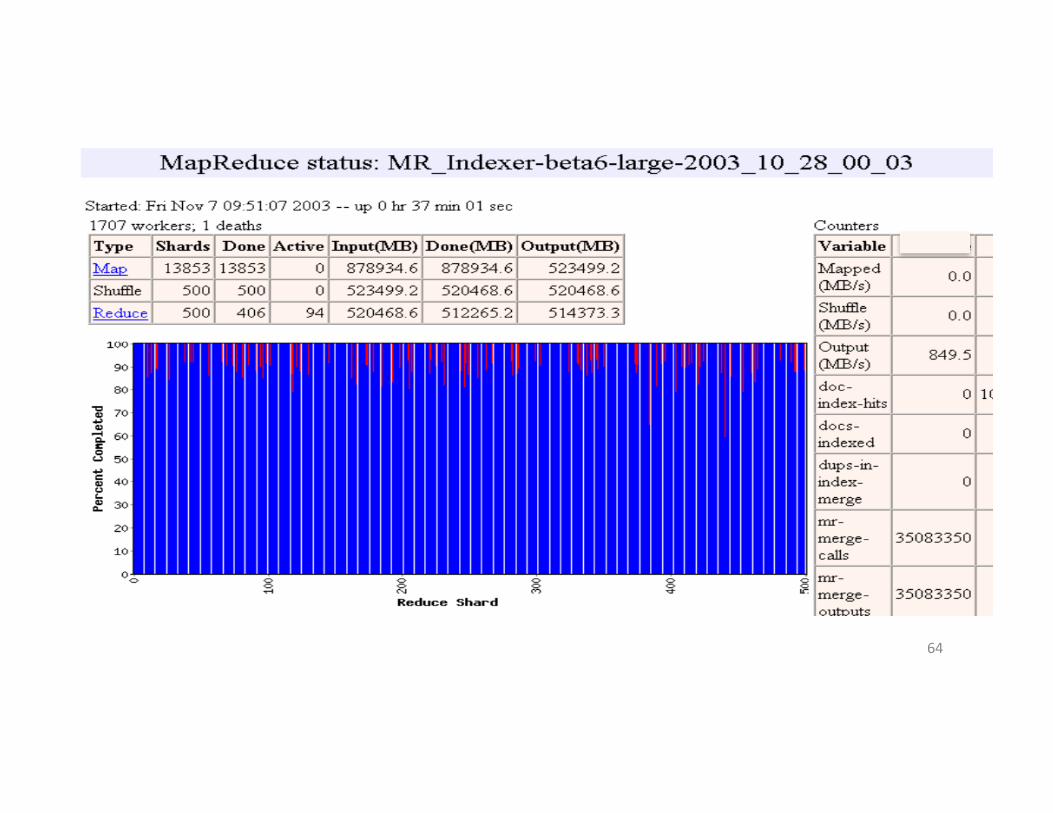
ShowMapReduceJobRunning• ~41minutestotal
– ~29minutesforMaptasks&Shuffletasks– ~12minutesforReducetasks– 1707workerserversused
• Map(Green)tasks read0.8TB,write0.5TB• Shuffle(Red)tasks read0.5TB,write0.5TB• Reduce(Blue)tasks read0.5TB,write0.5TB
55

56

57

58

59

60

61

62
63
64

65

66

And,inConclusion...• Warehouse-ScaleComputers(WSCs)
– Newclassofcomputers– Scalability,energyefficiency,highfailurerate
• CloudComputing– BenefitsofWSCcomputingforthirdparties– “Elastic”payasyougoresourceallocation
• Request-LevelParallelism– Highrequestvolume,eachlargelyindependentofother– Usereplicationforbetterrequestthroughput,availability
• MapReduce DataParallelism– Map:Dividelargedatasetintopiecesforindependentparallelprocessing– Reduce:Combineandprocessintermediateresultstoobtainfinalresult– Hadoop,Spark
67


















![The course Image Formation: Outlinecseweb.ucsd.edu/classes/fa17/cse252A-a/lec3.pdf · 2017. 10. 25. · MS Comprehensive Exam [Pending] CS252A, Fall 2017 Computer Vision I The course](https://img.pdfslide.net/doc/110x75/6119e76ba575b277f1076af6/the-course-image-formation-2017-10-25-ms-comprehensive-exam-pending-cs252a.jpg)










