Embed Size (px)
Citation preview

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.1
CS 152Computer Architecture and Engineering
Lecture 26
The Final ChapterA whirlwind retrospective on the term
0
May 12, 2003
John Kubiatowicz (www.cs.berkeley.edu/~kubitron)
lecture slides: http://inst.eecs.berkeley.edu/~cs152/

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.2
What IS Quantum Computing?

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.3
Can we Use Quantum Mechanics to Compute?
• Weird properties of quantum mechanics?– You’ve already seen one: tunneling of electrons through
insulators to make TMJ RAM– Quantization: Only certain values or orbits are good
• Remember orbitals from chemistry???
– Superposition: Schizophrenic physical elements don’t quite know whether they are one thing or another
• All existing digital abstractions try to eliminate QM– Transistors/Gates designed with classical behavior– Binary abstraction: a “1” is a “1” and a “0” is a “0”
• Quantum Computing: Use of Quantization and Superposition to compute.
• Interesting results:– Shor’s algorithm: factors in polynomial time!– Grover’s algorithm: Finds items in unsorted database in time
proportional to square-root of n.

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.4
Quantization: Use of “Spin”
• Particles like Protons have an intrinsic “Spin” when defined with respect to an external magnetic field
• Quantum effect gives “1” and “0”:– Either spin is “UP” or “DOWN” nothing between
North
South
Spin ½ particle:(Proton/Electron)
Representation: |0> or |1>
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.5
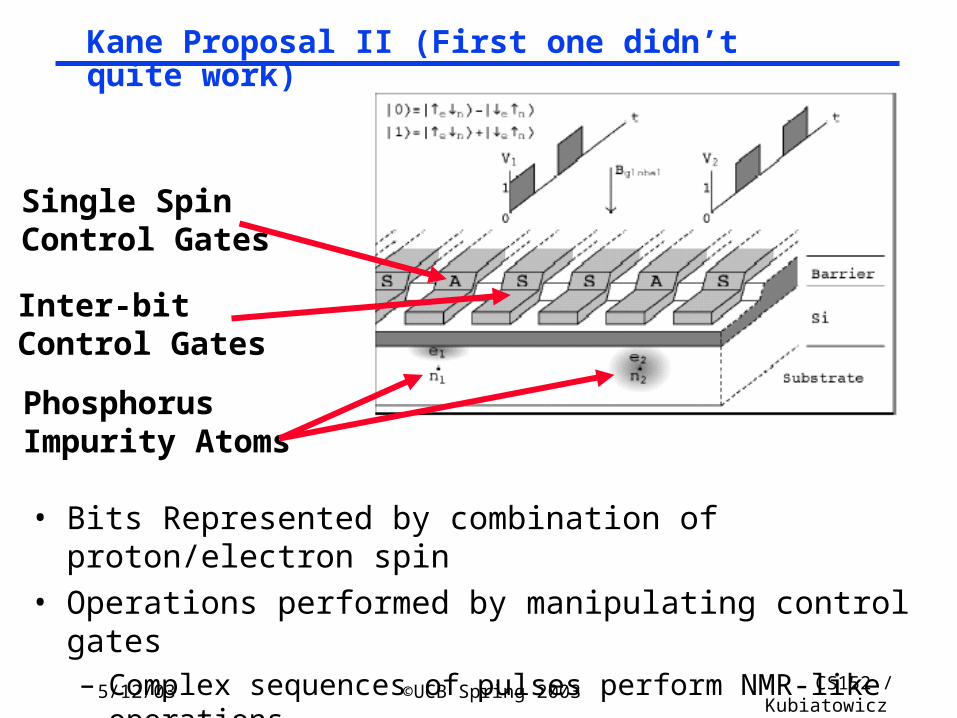
Kane Proposal II (First one didn’t quite work)
• Bits Represented by combination of proton/electron spin• Operations performed by manipulating control gates
– Complex sequences of pulses perform NMR-like operations
• Temperature < 1° Kelvin!
PhosphorusImpurity Atoms
Single SpinControl Gates
Inter-bit Control Gates

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.6
Now add Superposition!
• The bit can be in a combination of “1” and “0”:– Written as: = C0|0> + C1|1>
– The C’s are complex numbers!
– Important Constraint: |C0|2 + |C1|2 =1
• If measure bit to see what looks like, – With probability |C0|2 we will find |0> (say “UP”)
– With probability |C1|2 we will find |1> (say “DOWN”)
• Is this a real effect? Options:– This is just statistical – given a large number of protons, a
fraction of them (|C0|2 ) are “UP” and the rest are down.
– This is a real effect, and the proton is really both things until you try to look at it
• Reality: second choice! There are experiments to prove it!

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.7
Implications: A register can have many values
• Implications of superposition:– An n-bit register can have 2n values simultaneously!
– 3-bit example:
= C000|000>+ C001|001>+ C010|010>+ C011|011>+
C100|100>+ C101|101>+ C110|110>+ C111|111>
• Probabilities of measuring all bits are set by coefficients:
– So, prob of getting |000> is |C000|2, etc.
– Suppose we measure only one bit (first):
• We get a “0” with probability: P0=|C000|2+ |C001|2+ |C010|2+ |C011|2
Result: = (C000|000>+ C001|001>+ C010|010>+ C011|011>)
• We get a “1” with probability: P1=|C100|2+ |C101|2+ |C110|2+ |C111|2
Result: = (C100|100>+ C101|101>+ C110|110>+ C111|111>)
0
1
P
1
1
P
• Problem: Don’t want environment to measure before ready!– Solution: Quantum Error Correction Codes!
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.8
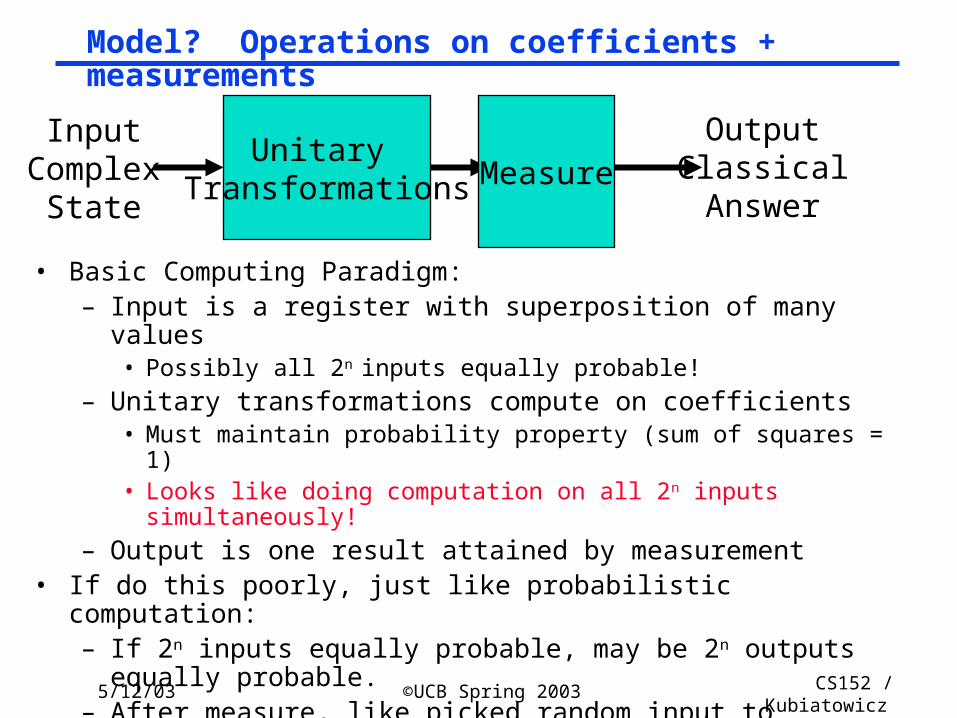
Model? Operations on coefficients + measurements
• Basic Computing Paradigm:– Input is a register with superposition of many values
• Possibly all 2n inputs equally probable!
– Unitary transformations compute on coefficients• Must maintain probability property (sum of squares = 1)• Looks like doing computation on all 2n inputs simultaneously!
– Output is one result attained by measurement• If do this poorly, just like probabilistic computation:
– If 2n inputs equally probable, may be 2n outputs equally probable.– After measure, like picked random input to classical function!– All interesting results have some form of “fourier transform”
computation being done in unitary transformation
Unitary Transformations
InputComplex
StateMeasure
OutputClassicalAnswer

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.9
Some Issues in building quantum computer• What are the bits and how do we manipulate them?
– NMR computation: use “cup of liquid”. • Use nuclear spins (special protons on complex molecules).• Manipulate with radio-frequencies• IBM Has produced a 7-bit computer
– Silicon options (more scalable)• Impurity Phosphorus in silicon• Manipulate through electrons (including measurement)• Still serious noise/fabrication issues
– Other options:• Optical (Phases of photons represent bits)• Single electrons trapped in magnetic fields
• How do we prevent the environment from “Measuring”?– Make spins as insulated from environment as possible– Quantum Error Correction!
• Where do we get “clean” bits (I.e. unsuperposed |0> or |1>)?– Entropy exchange unit:
• Radiates heat to environment (entropy)• Produces clean bits (COLD) to enter into device
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.10
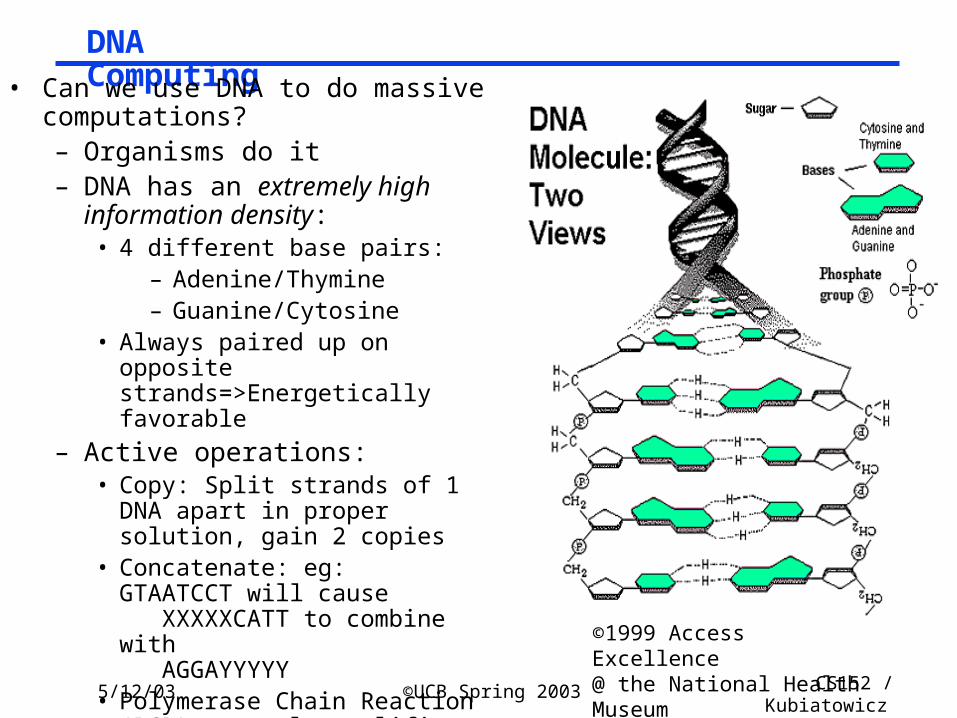
DNA Computing• Can we use DNA to do massive
computations?– Organisms do it– DNA has an extremely high
information density:• 4 different base pairs:
– Adenine/Thymine– Guanine/Cytosine
• Always paired up on opposite strands=>Energetically favorable
– Active operations:• Copy: Split strands of 1 DNA apart in
proper solution, gain 2 copies• Concatenate: eg:
GTAATCCT will cause XXXXXCATT to combine with AGGAYYYYY
• Polymerase Chain Reaction (PCR): greatly amplifies region of molecule between two marker molecules
©1999 Access Excellence @ the National Health Museum

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.11
DNA Computing and the Hamiltonian Path• Given a set of cities and costs
between them (possibly directedpaths):– Find shortest path
– Simpler: find single path that visits all cities
• DNA Computing example is latter version:– Every city represented by unique 20 base-pair strand
– Every path between cities represented by complementary pairs: 10 pairs from source city, 10 pairs from destination
– Shorter example: AAGT for city 1, TTCG for city 2Path 1->2: CAAAWill build: AAGTTTCG
..CAAA..– Dump “city molecules” and “path molecules” into testtube.
Select and amplify paths of right length. Analyze for result.
– Been done for 6 cities! (Adleman, ~1998!)
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.12
Where have we been?
CS152Spring ‘99
µProc60%/yr.(2X/1.5yr)
DRAM9%/yr.(2X/10 yrs)
1
10
100
1000
19
80 1
98
1 19
83 1
98
4 19
85 1
98
6 19
87 1
98
8 19
89 1
99
0 19
91 1
99
2 19
93 1
99
4 19
95 1
99
6 19
97 1
99
8 19
99 2
00
0
DRAM
CPU
19
82
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
Time
“Moore’s Law”
34-b it A LU
LO register(16x2 bits)
Load
HI
Cle
arH
I
Load
LO
M ultiplicandRegister
S h iftA ll
LoadM p
Extra
2 bits
3 232
LO [1 :0 ]
Result[H I] Result[LO]
32 32
Prev
LO[1]
Booth
Encoder E N C [0 ]
E N C [2 ]
"LO
[0]"
Con trolLog ic
InputM ultiplier
32
S ub /A dd
2
34
34
32
InputM ultiplicand
32=>34sig nEx
34
34x2 M U X
32=>34sig nEx
<<13 4
E N C [1 ]
M ulti x2 /x1
2
2HI register(16x2 bits)
2
01
3 4 ArithmeticSingle/multicycleDatapaths
IFetchDcd Exec Mem WB
IFetchDcd Exec Mem WB
IFetchDcd Exec Mem WB
IFetchDcd Exec Mem WB
Pipelining
Memory Systems
I/O
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.13
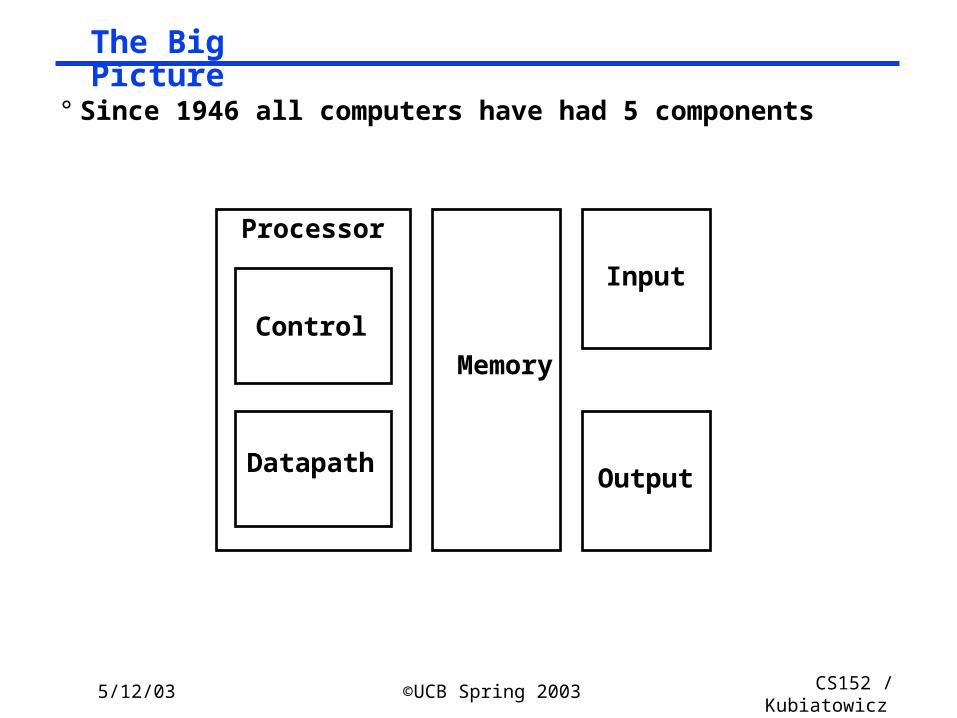
The Big Picture
Control
Datapath
Memory
Processor
Input
Output
° Since 1946 all computers have had 5 components
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
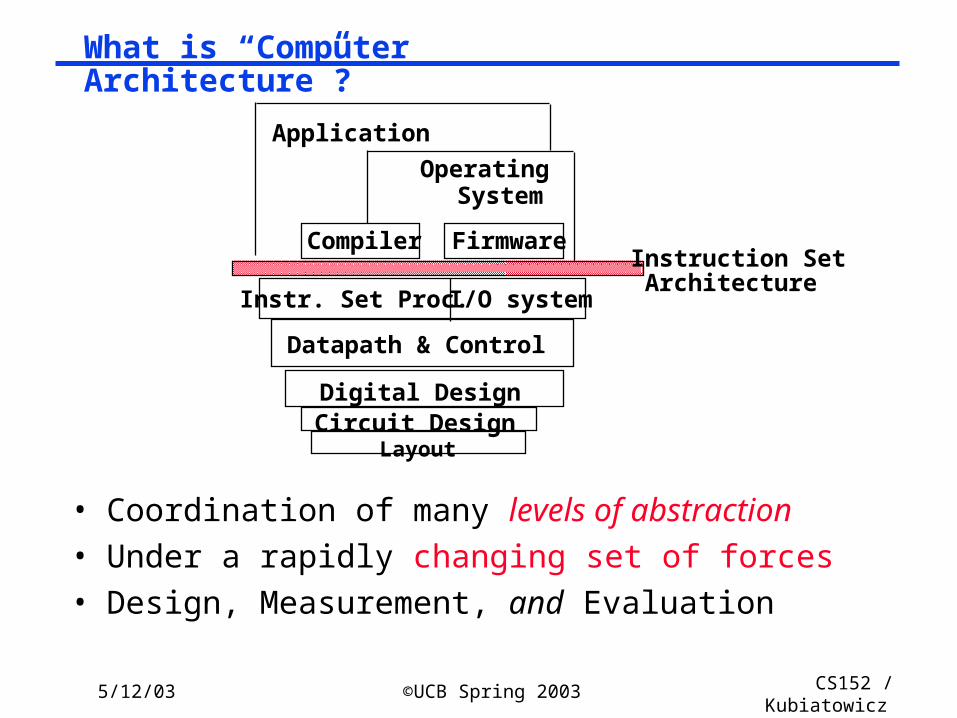
Lec26.14
What is “Computer Architecture”?
I/O systemInstr. Set Proc.
Compiler
OperatingSystem
Application
Digital DesignCircuit Design
Instruction Set Architecture
Firmware
• Coordination of many levels of abstraction• Under a rapidly changing set of forces• Design, Measurement, and Evaluation
Datapath & Control
Layout
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.15
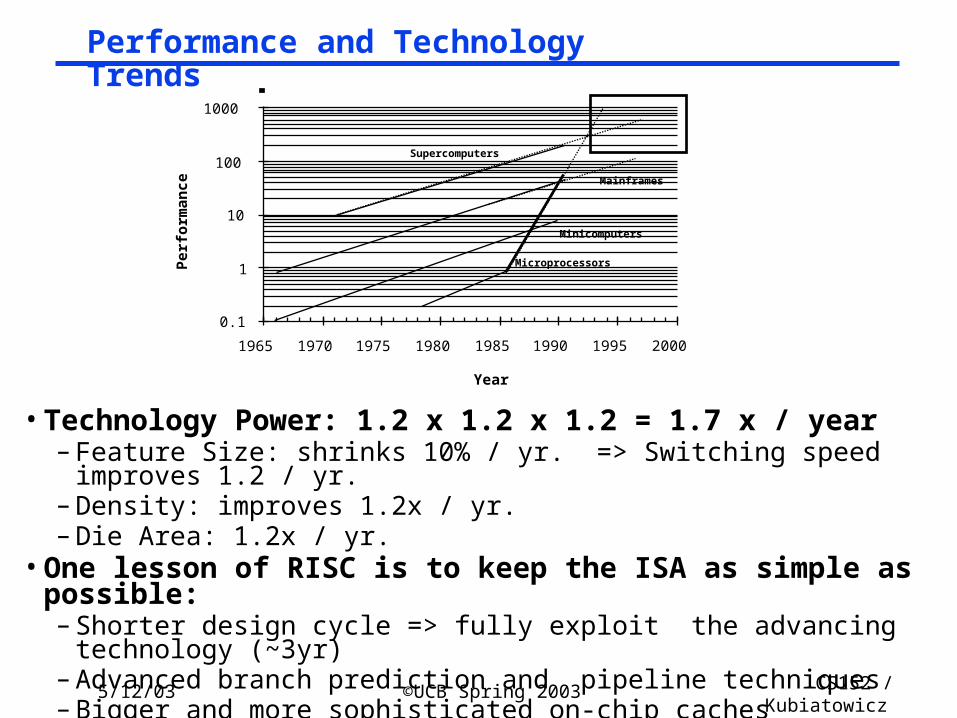
Year
Perf
orm
an
ce
0.1
1
10
100
1000
1965 1970 1975 1980 1985 1990 1995 2000
Microprocessors
Minicomputers
Mainframes
Supercomputers
• Technology Power: 1.2 x 1.2 x 1.2 = 1.7 x / year– Feature Size: shrinks 10% / yr. => Switching speed improves 1.2 / yr.– Density: improves 1.2x / yr.– Die Area: 1.2x / yr.
• One lesson of RISC is to keep the ISA as simple as possible:– Shorter design cycle => fully exploit the advancing technology (~3yr)– Advanced branch prediction and pipeline techniques– Bigger and more sophisticated on-chip caches
Performance and Technology Trends

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.16
• Processor– logic capacity: about 30% per year
– clock rate: about 20% per year
– Performance: about 50-60% per year (2x in 18 months)
• Memory– DRAM capacity: about 60% per year (4x every 3 years)
– Memory speed: about 10% per year
– Cost per bit: improves about 25% per year
• Disk– capacity: about 60% per year
Examples of “Moore’s Law’s”

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.17
0
50
100
150
200
250
300
350
1982 1984 1986 1988 1990 1992 1994
Year
Per
form
ance
RISC
Intel x86
35%/yr
RISCintroduction
Processor Performance
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.18
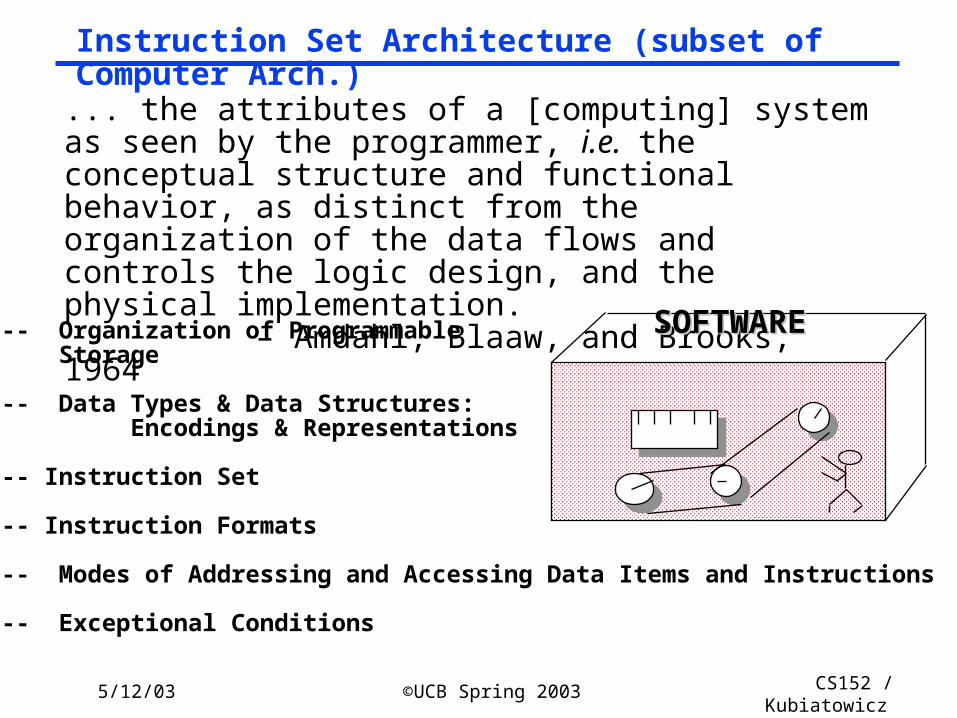
Instruction Set Architecture (subset of Computer Arch.)
... the attributes of a [computing] system as seen by the programmer, i.e. the conceptual structure and functional behavior, as distinct from the organization of the data flows and controls the logic design, and the physical implementation. – Amdahl, Blaaw, and Brooks, 1964
SOFTWARESOFTWARE-- Organization of Programmable Storage
-- Data Types & Data Structures: Encodings & Representations
-- Instruction Set
-- Instruction Formats
-- Modes of Addressing and Accessing Data Items and Instructions
-- Exceptional Conditions
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.19
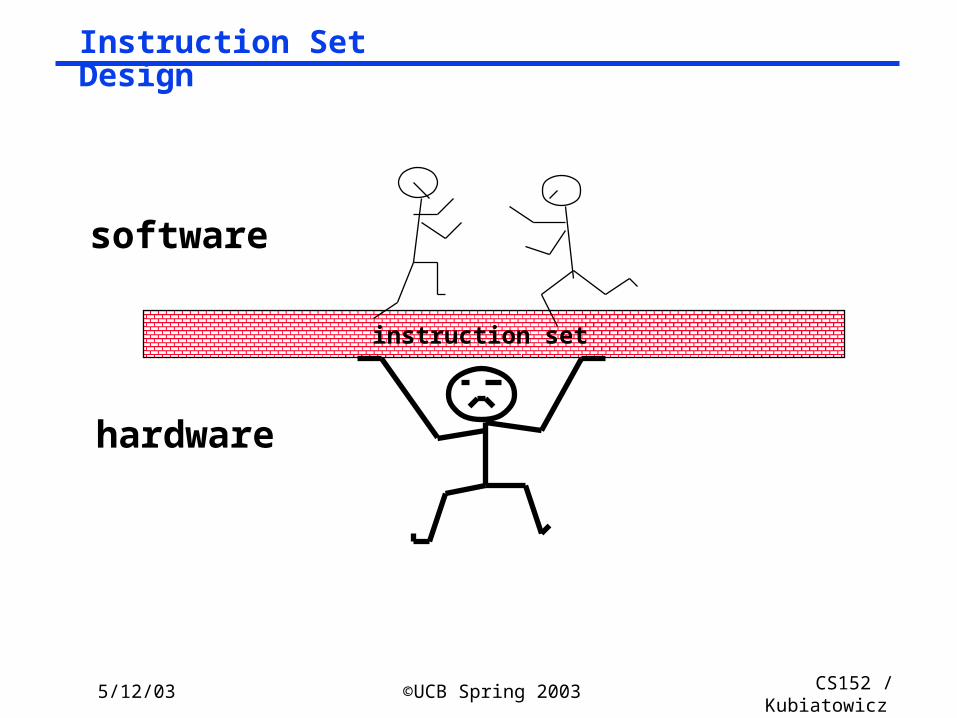
Instruction Set Design
instruction set
software
hardware
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.20
Hierarchical Design to manage complexity
Top Down vs. Bottom Up vs. Successive Refinement
Importance of Design Representations:
Block Diagrams
Decomposition into Bit Slices
Truth Tables, K-Maps
Circuit Diagrams
Other Descriptions: state diagrams, timing diagrams, reg xfer, . . .
Optimization Criteria:
Gate Count
[Package Count]
Logic Levels
Fan-in/Fan-outPower
topdown
bottom up
AreaDelay
mux designmeets at TT
Cost Design timePin Out
Summary of the Design Process

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.21
Measurement and Evaluation
Architecture is an iterative process -- searching the space of possible designs -- at all levels of computer systems
Good IdeasGood Ideas
Mediocre IdeasBad Ideas
Cost /PerformanceAnalysis
Design
Analysis
CreativityYou must be willing to throw out Bad Ideas!!
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.22
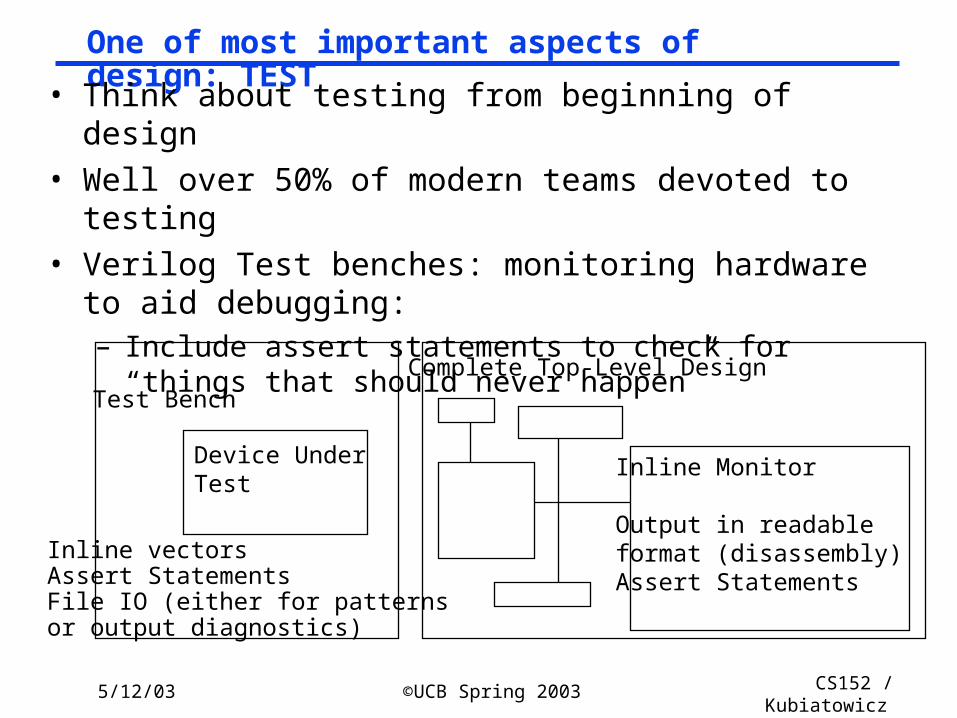
One of most important aspects of design: TEST
• Think about testing from beginning of design• Well over 50% of modern teams devoted to testing• Verilog Test benches: monitoring hardware to aid
debugging:– Include assert statements to check for “things that should
never happen”
Test Bench
Device UnderTest
Inline vectorsAssert StatementsFile IO (either for patternsor output diagnostics)
Inline Monitor
Output in readableformat (disassembly)Assert Statements
Complete Top-Level Design
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.23
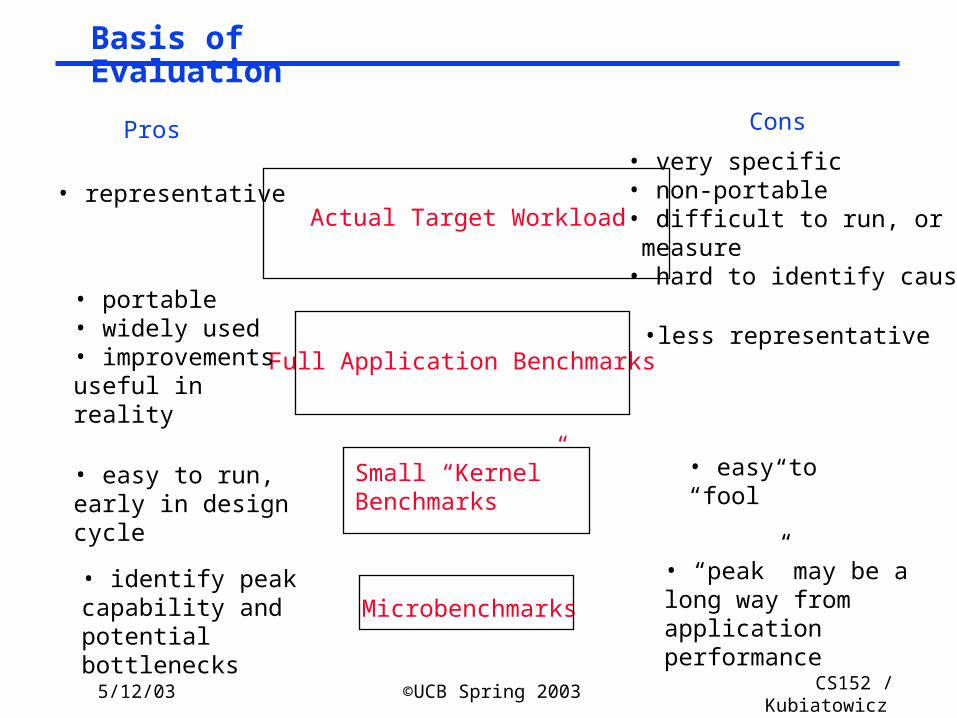
Basis of Evaluation
Actual Target Workload
Full Application Benchmarks
Small “Kernel” Benchmarks
Microbenchmarks
Pros Cons
• representative• very specific• non-portable• difficult to run, or measure• hard to identify cause
• portable• widely used• improvements useful in reality
• easy to run, early in design cycle
• identify peak capability and potential bottlenecks
•less representative
• easy to “fool”
• “peak” may be a long way from application performance

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.24
Speedup due to enhancement E:
ExTime w/o E Performance w/ E
Speedup(E) = -------------------- = ---------------------
ExTime w/ E Performance w/o E
Suppose that enhancement E accelerates a fraction F of the task
by a factor S and the remainder of the task is unaffected then,
ExTime(with E) = ((1-F) + F/S) X ExTime(without E)
Speedup(with E) = 1 (1-F) + F/S
Amdahl's Law

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.25
° Time is the measure of computer performance!
° Remember Amdahl’s Law: Speedup is limited by unimproved part of program
° Good products created when have:
• Good benchmarks
• Good ways to summarize performance
° If NOT good benchmarks and summary, then choice between 1) improving product for real programs 2) changing product to get more sales (sales almost always wins)
CPU time = Seconds = Instructions x Cycles x Seconds
Program Program Instruction Cycle
CPU time = Seconds = Instructions x Cycles x Seconds
Program Program Instruction Cycle
Performance Evaluation Summary
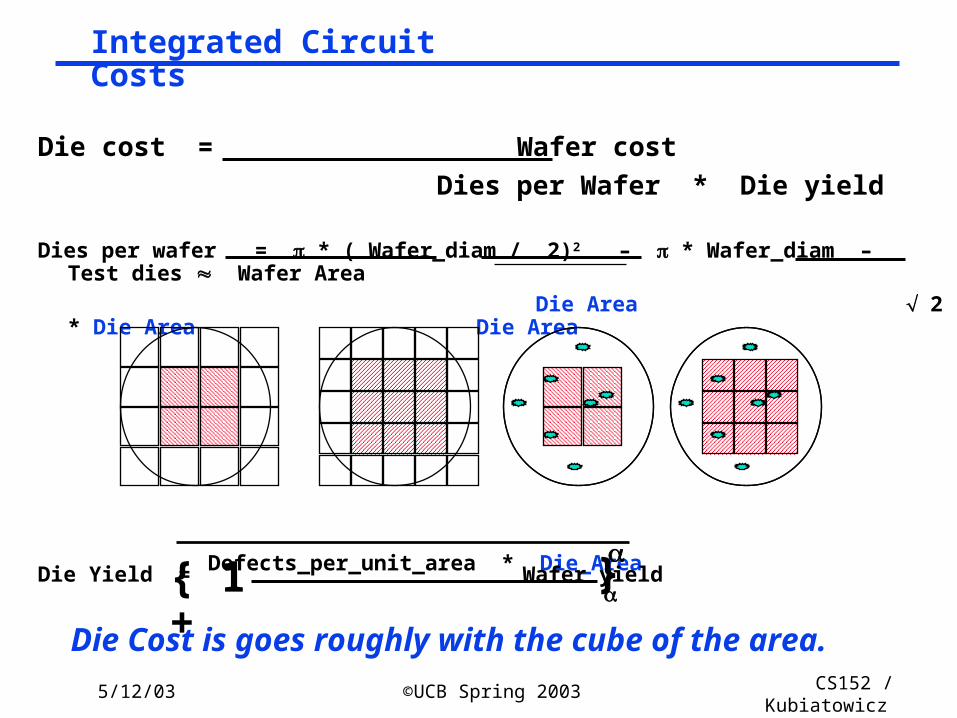
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.26
Defects_per_unit_area * Die_Area
}
Integrated Circuit Costs
Die Cost is goes roughly with the cube of the area.
{ 1+
Die cost = Wafer cost
Dies per Wafer * Die yield
Dies per wafer = * ( Wafer_diam / 2)2 – * Wafer_diam – Test dies Wafer Area
Die Area 2 * Die Area Die Area
Die Yield = Wafer yield

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.27
Computer Arithmetic
• Bits have no inherent meaning: operations determine whether really ASCII characters, integers, floating point numbers
• Hardware algorithms for arithmetic:–Carry lookahead/carry save addition–Multiplication and divide.–Booth algorithms
• Divide uses same hardware as multiply (Hi & Lo registers in MIPS)
• Floating point follows paper & pencil method of scientific notation
–using integer algorithms for multiply/divide of significands
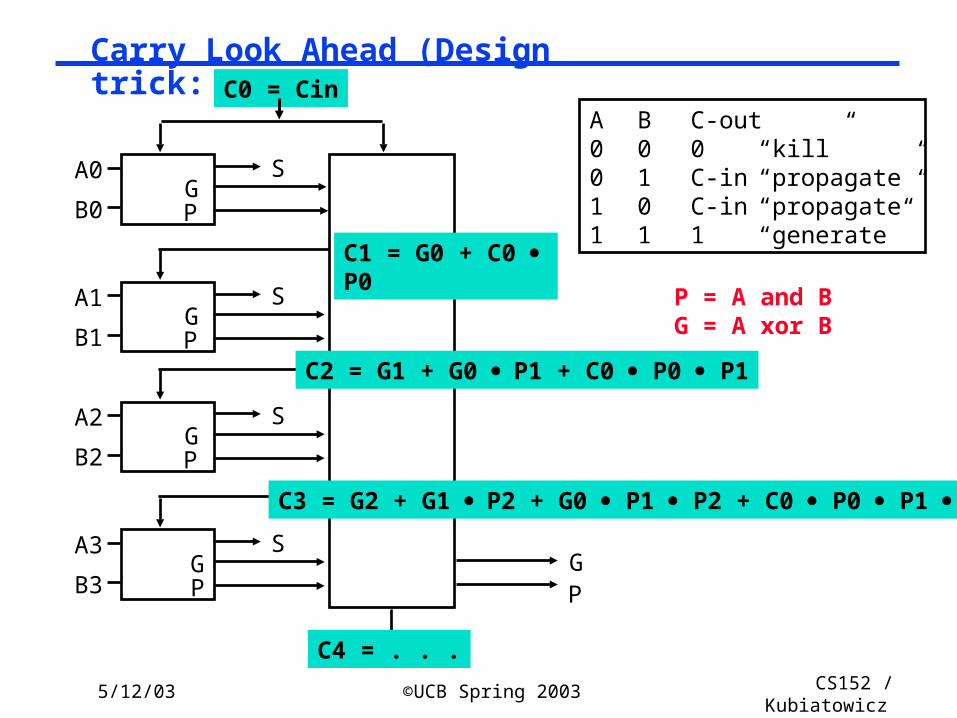
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.28
Carry Look Ahead (Design trick: peek)
A B C-out0 0 0 “kill”0 1 C-in “propagate”1 0 C-in “propagate”1 1 1 “generate”
P = A and BG = A xor B
A0
B0
A1
B1
A2
B2
A3
B3
S
S
S
S
GP
GP
GP
GP
C0 = Cin
C1 = G0 + C0 P0
C2 = G1 + G0 P1 + C0 P0 P1
C3 = G2 + G1 P2 + G0 P1 P2 + C0 P0 P1 P2
G
C4 = . . .
P

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.29
MULTIPLY HARDWARE Version 3
• 32-bit Multiplicand reg, 32-bit ALU, 64-bit Product reg (shift right), (0-bit Multiplier reg)
Product (Multiplier)
Multiplicand
32-bit ALU
WriteControl
32 bits
64 bits
Shift Right“HI” “LO”
Divide can use same hardware!
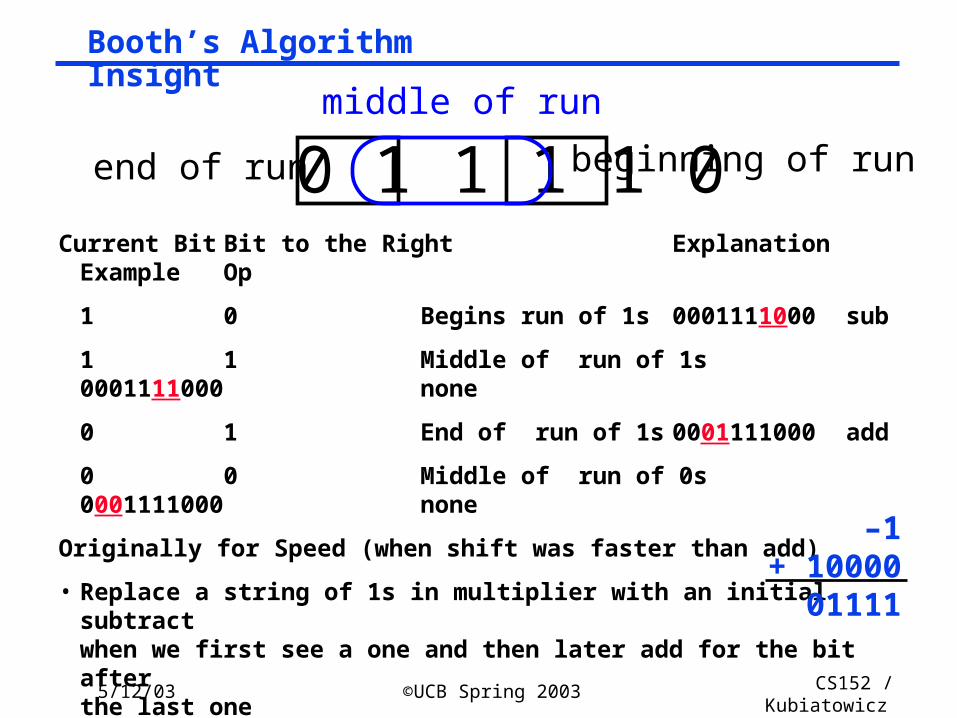
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.30
Booth’s Algorithm Insight
Current Bit Bit to the Right Explanation Example Op
1 0 Begins run of 1s 0001111000 sub
1 1 Middle of run of 1s 0001111000none
0 1 End of run of 1s 0001111000 add
0 0 Middle of run of 0s 0001111000none
Originally for Speed (when shift was faster than add)
• Replace a string of 1s in multiplier with an initial subtract when we first see a one and then later add for the bit afterthe last one
0 1 1 1 1 0beginning of runend of run
middle of run
–1+ 1000001111

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.31
Pentium Bug
• Pentium: Difference between bugs that board designers must know about and bugs that potentially affect all users
–$200,000 cost in June to repair design–$400,000,000 loss in December in profits to replace bad
parts–How much to repair Intel’s reputation?–Make public complete description of bugs in later
category? • What is technologist’s and company’s responsibility to disclose
bugs?

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.32
Administrivia
• Oral reports Thursday: – 1:00 – 4:00 in 306 Soda
– Remember: talk is 15 minutes + 5 minutes questions• Don’t bring more than 8 slides!!!• Practice! Your final project grade will depend partially on
your oral report.• Everyone should participate in talk
– Sheet on my door
– Everyone should show up for at least part of this
– Plan on cheering on your classmates (ask good questions)
• Finally:– 5pm go over to lab to run mystery programs.
– Reports submitted via Web site by Friday at midnight
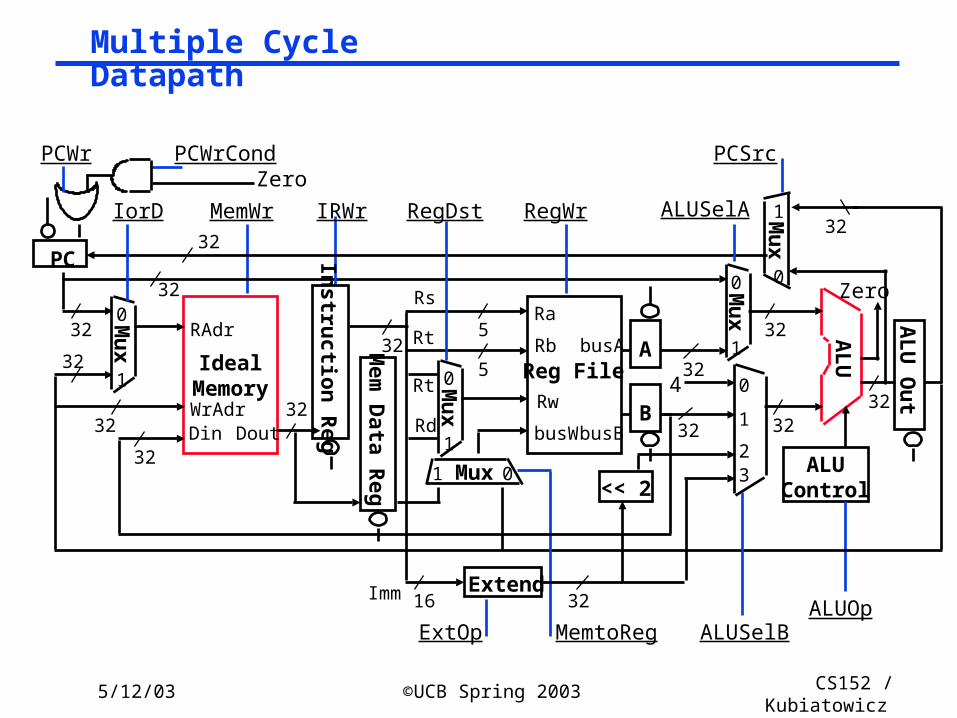
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.33
Multiple Cycle Datapath
IdealMemoryWrAdrDin
RAdr
32
32
32Dout
MemWr
32
AL
U
3232
ALUOp
ALUControl
32
IRWr
Instru
ction R
eg
32
Reg File
Ra
Rw
busW
Rb5
5
32busA
32busB
RegWr
Rs
Rt
Mu
x
0
1
Rt
Rd
PCWr
ALUSelA
Mux 01
RegDst
Mu
x
0
1
32
PC
MemtoReg
Extend
ExtOp
Mu
x
0
132
0
1
23
4
16Imm 32
<< 2
ALUSelB
Mu
x1
0
32
Zero
ZeroPCWrCond PCSrc
32
IorD
Mem
Data R
eg
AL
U O
ut
B
A

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.34
Control: Hardware vs. Microprogrammed
° Control may be designed using one of several initial representations. The choice of sequence control, and how logic is represented, can then be determined independently; the control can then be implemented with one of several methods using a structured logic technique.
Initial Representation Finite State Diagram Microprogram
Sequencing Control Explicit Next State Microprogram counter Function + Dispatch ROMs
Logic Representation Logic Equations Truth Tables
Implementation Technique PLA ROM“hardwired control” “microprogrammed control”
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.35
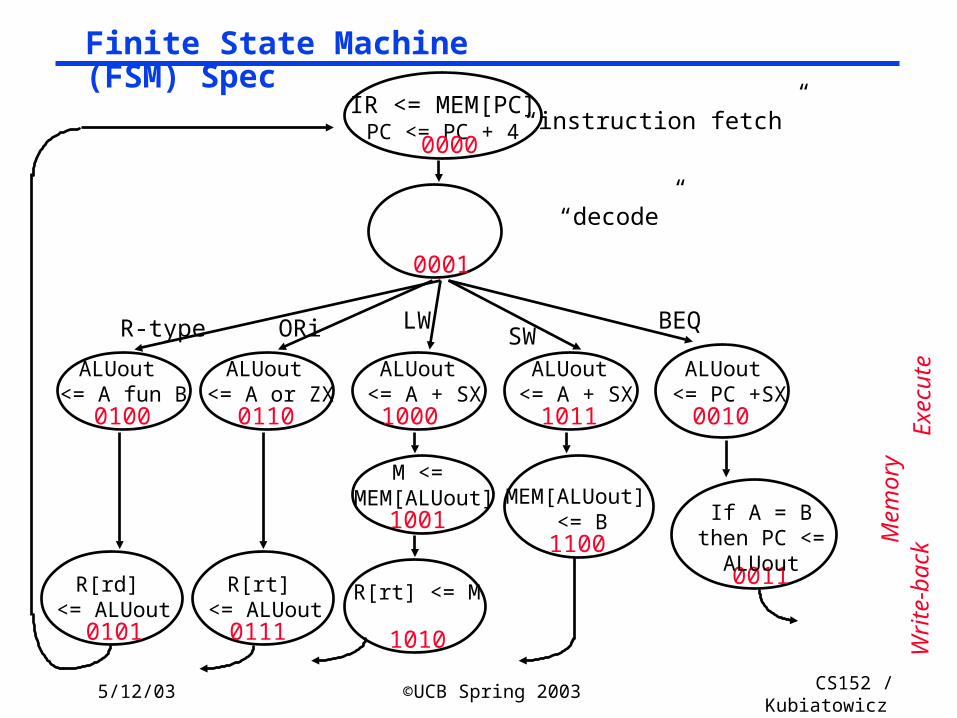
Finite State Machine (FSM) Spec
IR <= MEM[PC]PC <= PC + 4
R-type
ALUout <= A fun B
R[rd] <= ALUout
ALUout <= A or ZX
R[rt] <= ALUout
ORi
ALUout <= A + SX
R[rt] <= M
M <= MEM[ALUout]
LW
ALUout <= A + SX
MEM[ALUout] <= B
SW
“instruction fetch”
“decode”
Exe
cute
Mem
ory
Writ
e-ba
ck
0000
0001
0100
0101
0110
0111
1000
1001
1010
1011
1100
BEQ
0010
0011
If A = B then PC <= ALUout
ALUout <= PC +SX
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.36
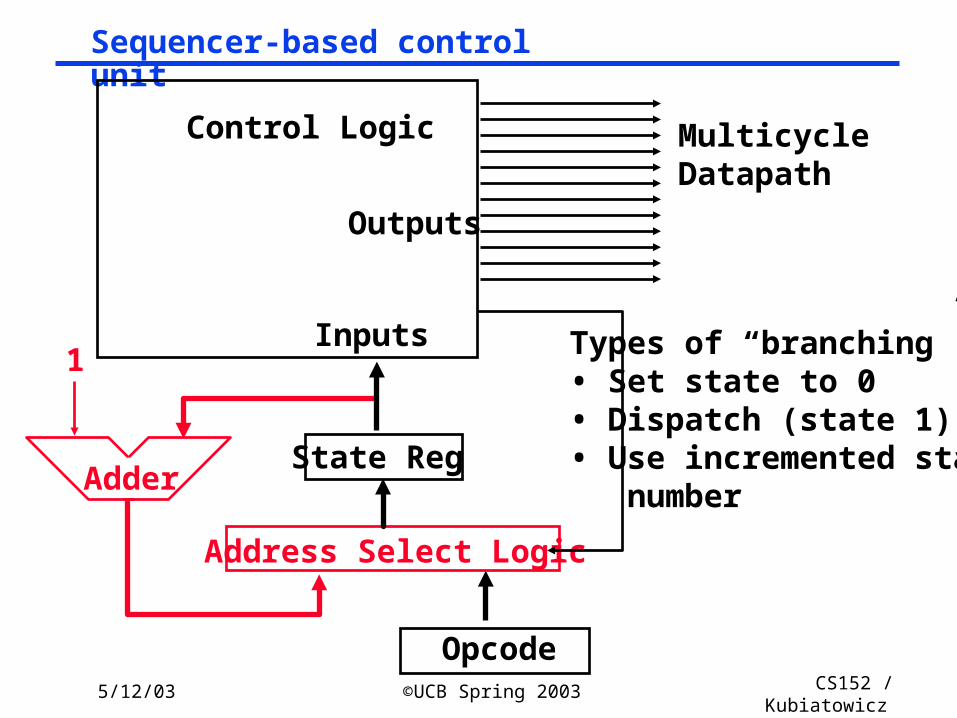
Sequencer-based control unit
Opcode
State Reg
Inputs
Outputs
Control Logic MulticycleDatapath
1
Address Select Logic
Adder
Types of “branching”• Set state to 0• Dispatch (state 1)• Use incremented state number
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.37
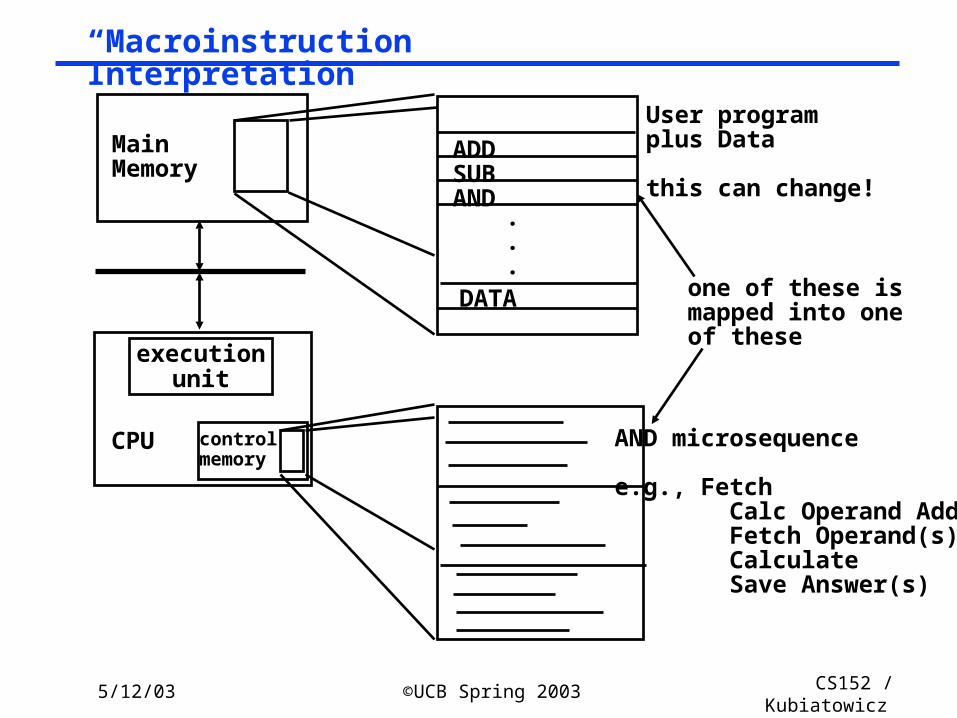
“Macroinstruction” Interpretation
MainMemory
executionunit
controlmemory
CPU
ADDSUBAND
DATA
.
.
.
User program plus Data
this can change!
AND microsequence
e.g., Fetch Calc Operand Addr Fetch Operand(s) Calculate Save Answer(s)
one of these ismapped into oneof these
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.38
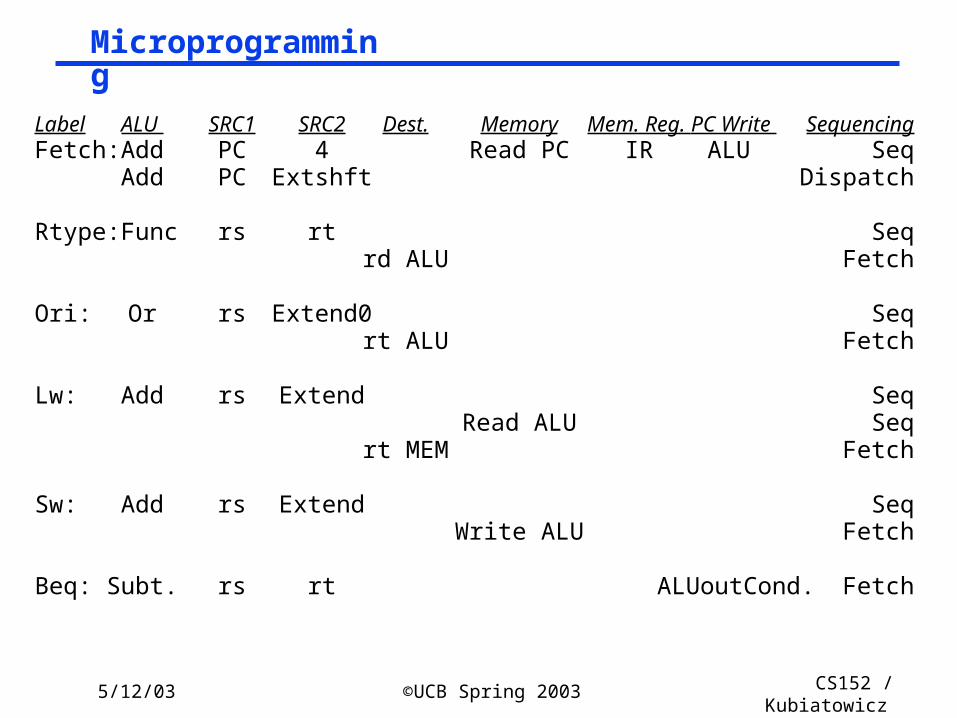
Microprogramming
Label ALU SRC1 SRC2 Dest. Memory Mem. Reg. PC Write SequencingFetch: Add PC 4 Read PC IR ALU Seq
Add PC Extshft Dispatch
Rtype: Func rs rt Seqrd ALU Fetch
Ori: Or rs Extend0 Seqrt ALU Fetch
Lw: Add rs Extend SeqRead ALU Seq
rt MEM Fetch
Sw: Add rs Extend SeqWrite ALU Fetch
Beq: Subt. rs rt ALUoutCond. Fetch
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.39
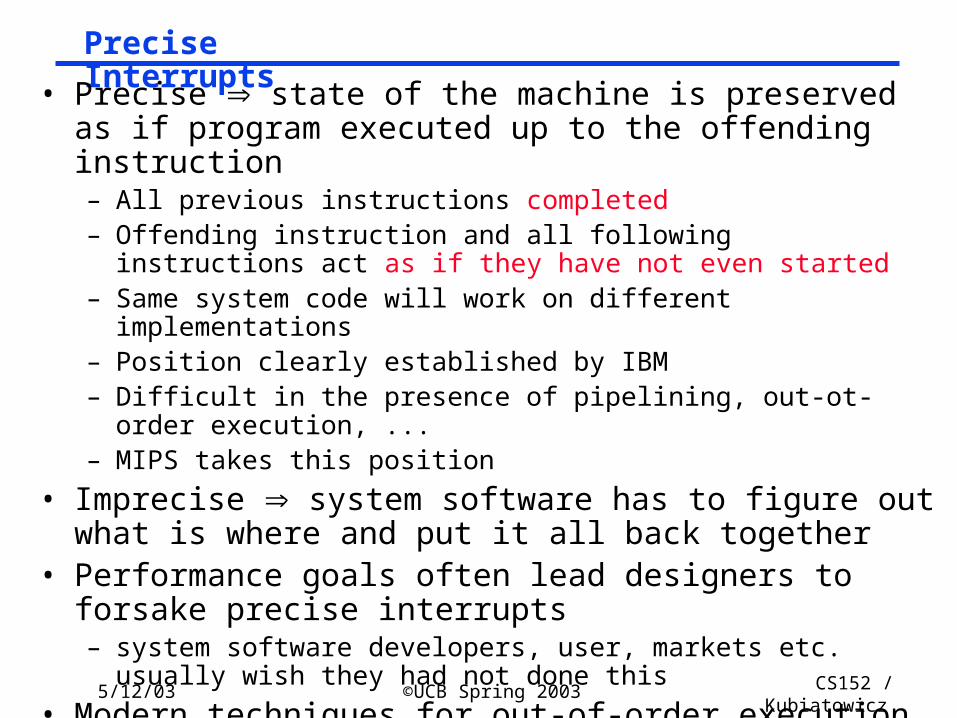
Precise Interrupts
• Precise state of the machine is preserved as if program executed up to the offending instruction– All previous instructions completed– Offending instruction and all following instructions act as if they have
not even started– Same system code will work on different implementations – Position clearly established by IBM– Difficult in the presence of pipelining, out-ot-order execution, ...– MIPS takes this position
• Imprecise system software has to figure out what is where and put it all back together
• Performance goals often lead designers to forsake precise interrupts– system software developers, user, markets etc. usually wish they had
not done this
• Modern techniques for out-of-order execution and branch prediction help implement precise interrupts
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.40
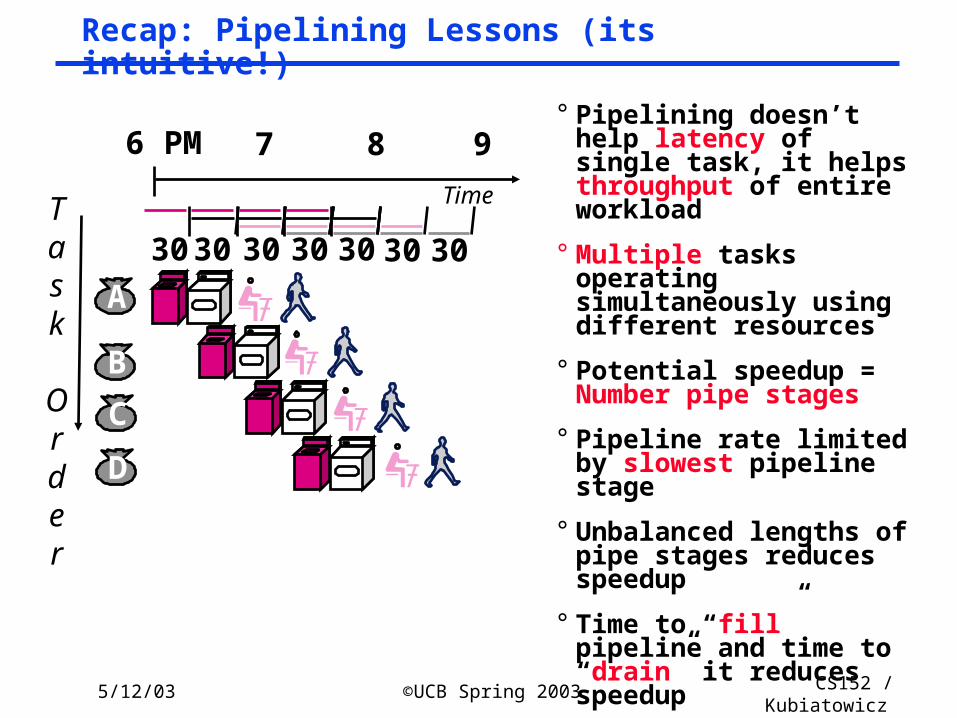
Recap: Pipelining Lessons (its intuitive!)
° Pipelining doesn’t help latency of single task, it helps throughput of entire workload
° Multiple tasks operating simultaneously using different resources
° Potential speedup = Number pipe stages
° Pipeline rate limited by slowest pipeline stage
° Unbalanced lengths of pipe stages reduces speedup
° Time to “fill” pipeline and time to “drain” it reduces speedup
° Stall for Dependences
6 PM 7 8 9
Time
B
C
D
A
303030 3030 3030Task
Order
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.41
Instr.
Order
Time (clock cycles)
Inst 0
Inst 1
Inst 2
Inst 4
Inst 3
AL
UIm Reg Dm Reg
AL
UIm Reg Dm Reg
AL
UIm Reg Dm RegA
LUIm Reg Dm Reg
AL
UIm Reg Dm Reg
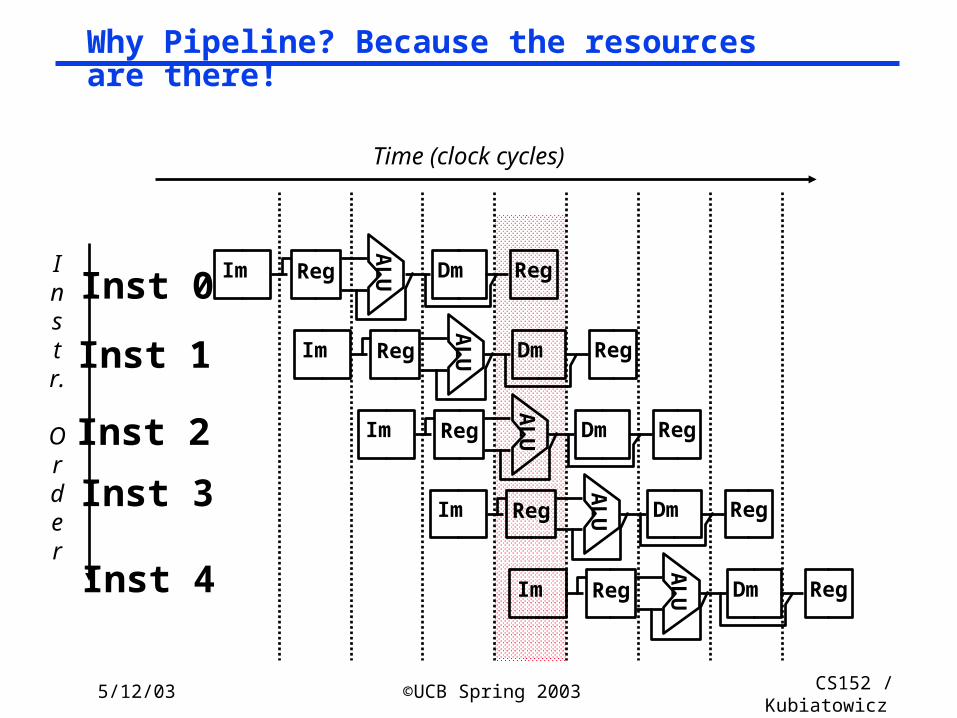
Why Pipeline? Because the resources are there!

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.42
• Yes: Pipeline Hazards– structural hazards: attempt to use the same resource two
different ways at the same time• E.g., combined washer/dryer would be a structural hazard or
folder busy doing something else (watching TV)– data hazards: attempt to use item before it is ready
• E.g., one sock of pair in dryer and one in washer; can’t fold until get sock from washer through dryer
• instruction depends on result of prior instruction still in the pipeline
– control hazards: attempt to make a decision before condition is evaulated• E.g., washing football uniforms and need to get proper
detergent level; need to see after dryer before next load in• branch instructions
• Can always resolve hazards by waiting– pipeline control must detect the hazard– take action (or delay action) to resolve hazards
Can pipelining get us into trouble?
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.43
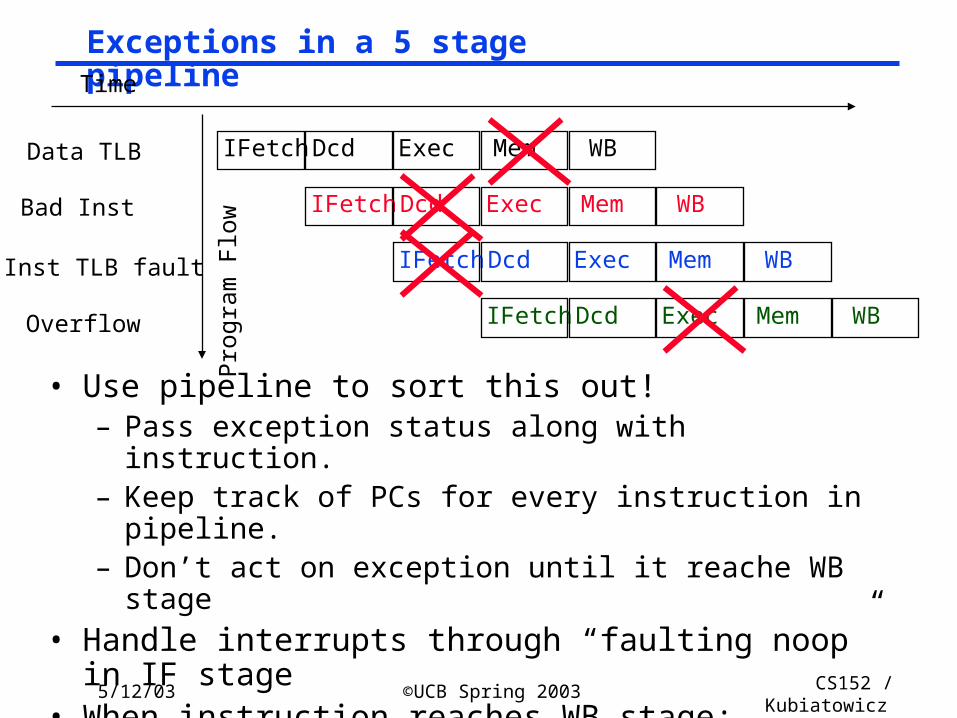
Exceptions in a 5 stage pipeline
• Use pipeline to sort this out!– Pass exception status along with instruction.– Keep track of PCs for every instruction in pipeline.– Don’t act on exception until it reache WB stage
• Handle interrupts through “faulting noop” in IF stage• When instruction reaches WB stage:
– Save PC EPC, Interrupt vector addr PC– Turn all instructions in earlier stages into noops!
Pro
gram
Flo
w
Time
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
Data TLB
Bad Inst
Inst TLB fault
Overflow

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.44
Data Stationary Control
• The Main Control generates the control signals during Reg/Dec– Control signals for Exec (ExtOp, ALUSrc, ...) are used 1 cycle later
– Control signals for Mem (MemWr Branch) are used 2 cycles later
– Control signals for Wr (MemtoReg MemWr) are used 3 cycles later
IF/ID
Register
ID/E
x Register
Ex/M
em R
egister
Mem
/Wr R
egister
Reg/Dec Exec Mem
ExtOp
ALUOp
RegDst
ALUSrc
Branch
MemWr
MemtoReg
RegWr
MainControl
ExtOp
ALUOp
RegDst
ALUSrc
MemtoReg
RegWr
MemtoReg
RegWr
MemtoReg
RegWr
Branch
MemWr
Branch
MemWr
Wr

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.45
° Simple 5-stage pipeline: F D E M W° Pipelines pass control information down the pipe just
as data moves down pipe
° Resolve data hazards through forwarding.
° Forwarding/Stalls handled by local control
° Exceptions stop the pipeline
° MIPS I instruction set architecture made pipeline visible (delayed branch, delayed load)
° More performance from deeper pipelines, parallelism
° You built a complete 5-stage pipeline in the lab!
Pipeline Summary
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
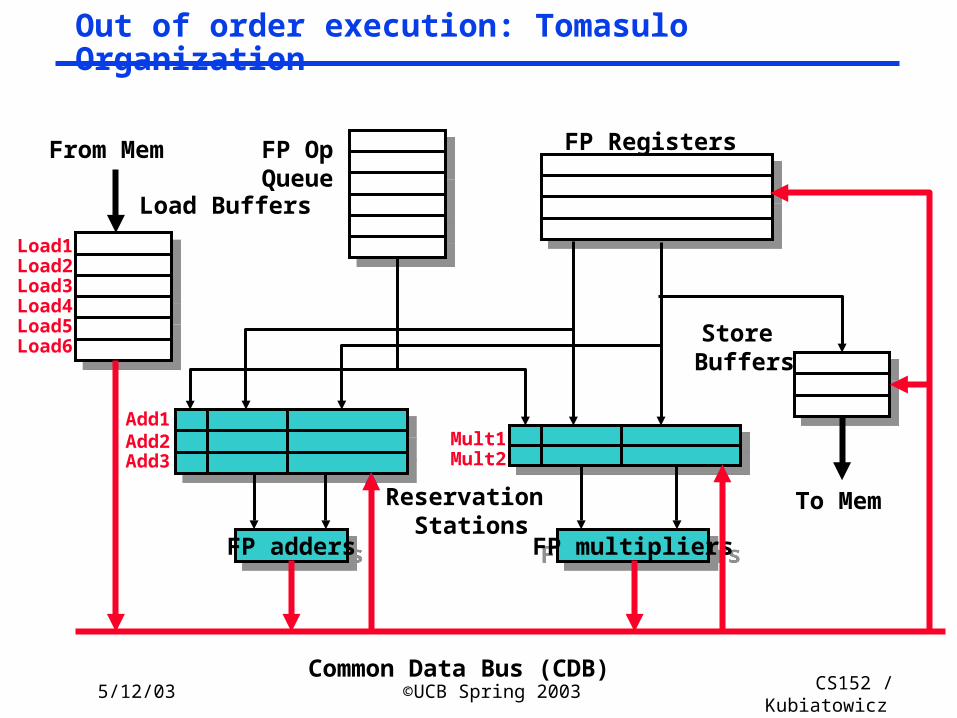
Lec26.46
Out of order execution: Tomasulo Organization
FP addersFP adders
Add1Add2Add3
FP multipliersFP multipliers
Mult1Mult2
From Mem FP Registers
Reservation Stations
Common Data Bus (CDB)
To Mem
FP OpQueue
Load Buffers
Store Buffers
Load1Load2Load3Load4Load5Load6
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.47
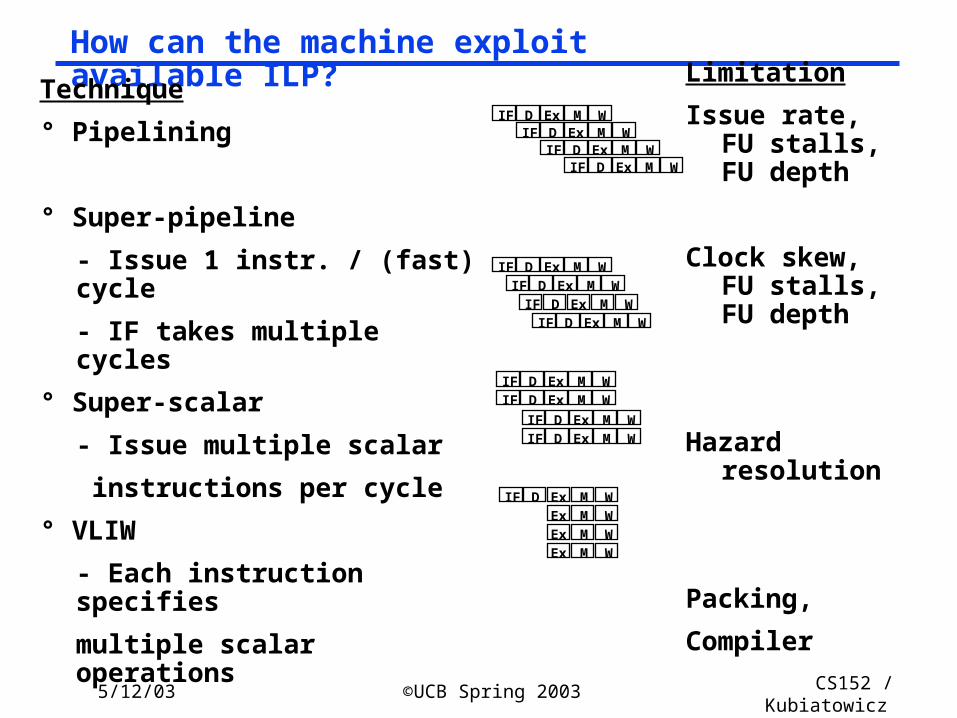
How can the machine exploit available ILP?Technique
° Pipelining
° Super-pipeline
- Issue 1 instr. / (fast) cycle
- IF takes multiple cycles
° Super-scalar
- Issue multiple scalar
instructions per cycle
° VLIW
- Each instruction specifies
multiple scalar operations
Limitation
Issue rate, FU stalls, FU depth
Clock skew, FU stalls, FU depth
Hazard resolution
Packing,
Compiler
IF D Ex M W
IF D Ex M W
IF D Ex M W
IF D Ex M W
IF D Ex M WIF D Ex M W
IF D Ex M WIF D Ex M W
IF D Ex M W
IF D Ex M W
IF D Ex M W
IF D Ex M W
IF D Ex M W
Ex M W
Ex M W
Ex M W
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.48
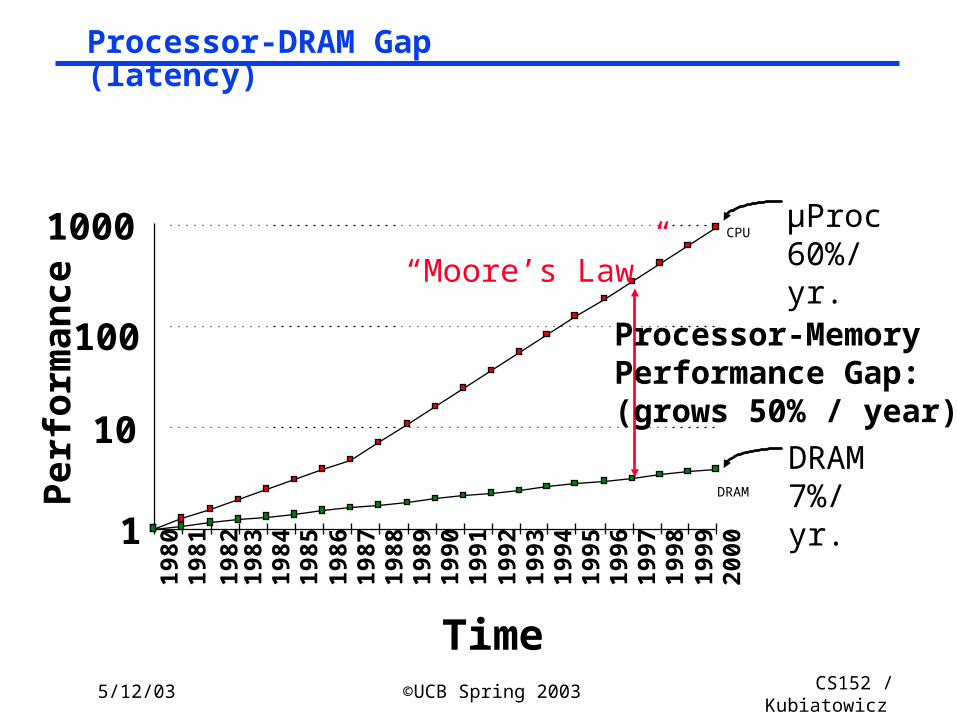
µProc60%/yr.
DRAM7%/yr.
1
10
100
1000
198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU198
2
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
Time
“Moore’s Law”
Processor-DRAM Gap (latency)
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.49
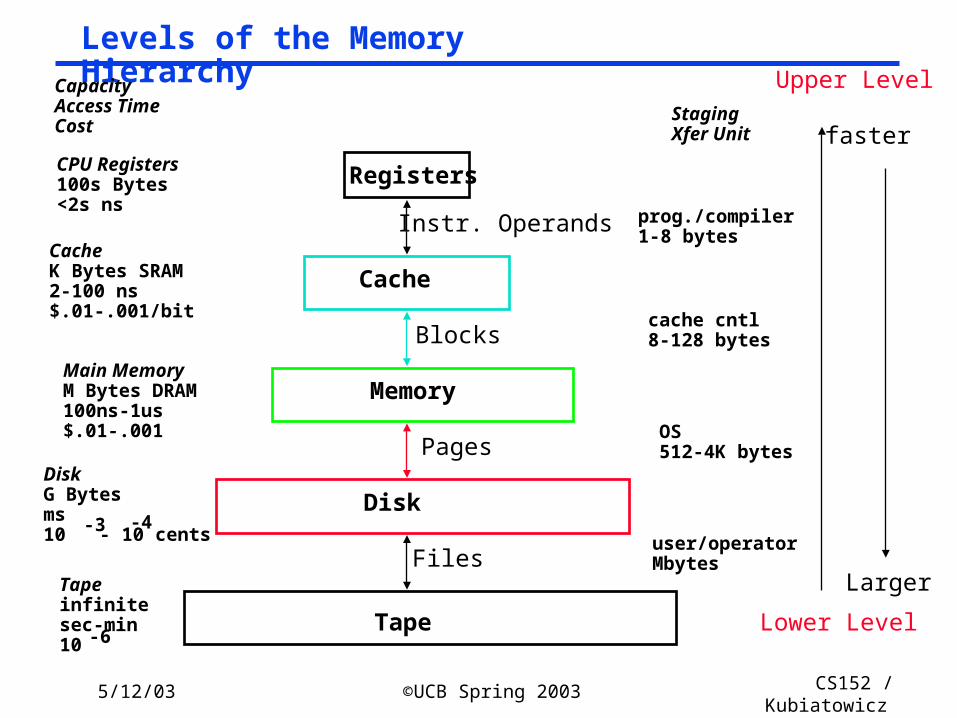
Levels of the Memory Hierarchy
CPU Registers100s Bytes<2s ns
CacheK Bytes SRAM2-100 ns$.01-.001/bit
Main MemoryM Bytes DRAM100ns-1us$.01-.001
DiskG Bytesms10 - 10 cents-3 -4
CapacityAccess TimeCost
Tapeinfinitesec-min10-6
Registers
Cache
Memory
Disk
Tape
Instr. Operands
Blocks
Pages
Files
StagingXfer Unit
prog./compiler1-8 bytes
cache cntl8-128 bytes
OS512-4K bytes
user/operatorMbytes
Upper Level
Lower Level
faster
Larger

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.50
Memory Hierarchy
° The Principle of Locality:• Program access a relatively small portion of the address
space at any instant of time.- Temporal Locality: Locality in Time- Spatial Locality: Locality in Space
° Three Major Categories of Cache Misses:• Compulsory Misses: sad facts of life. Example: cold start
misses.• Conflict Misses: increase cache size and/or associativity.• Capacity Misses: increase cache size
° Virtual Memory invented as another level of the hierarchy–Today VM allows many processes to share single memory
without having to swap all processes to disk, protection more important
–TLBs are important for fast translation/checking
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.51
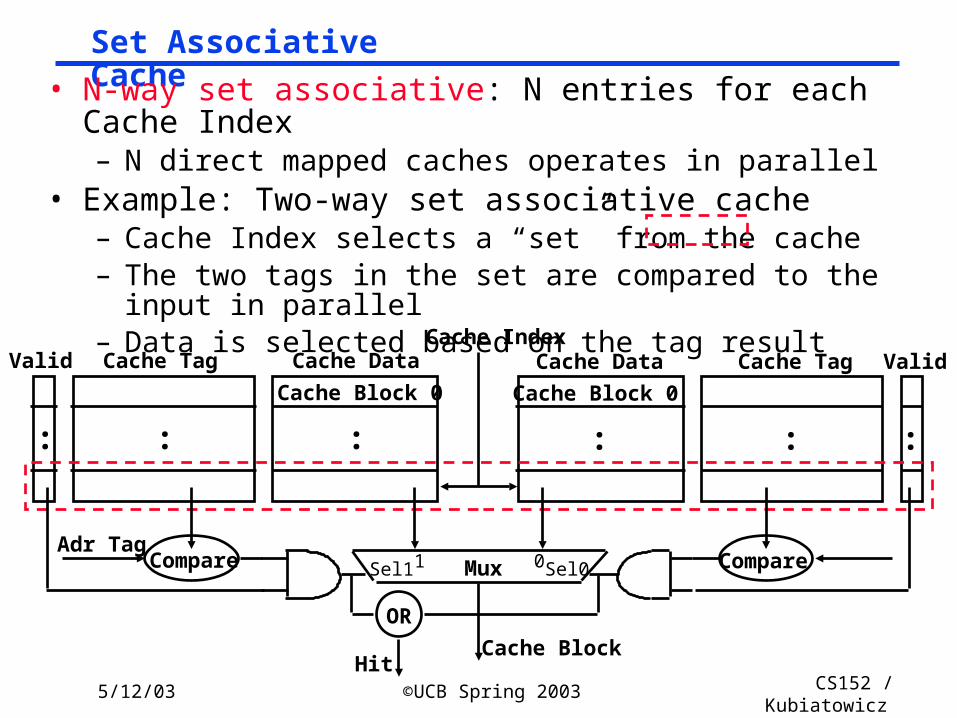
Set Associative Cache
• N-way set associative: N entries for each Cache Index– N direct mapped caches operates in parallel
• Example: Two-way set associative cache– Cache Index selects a “set” from the cache– The two tags in the set are compared to the input in
parallel– Data is selected based on the tag result
Cache Data
Cache Block 0
Cache TagValid
:: :
Cache Data
Cache Block 0
Cache Tag Valid
: ::
Cache Index
Mux 01Sel1 Sel0
Cache Block
CompareAdr Tag
Compare
OR
Hit
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.52
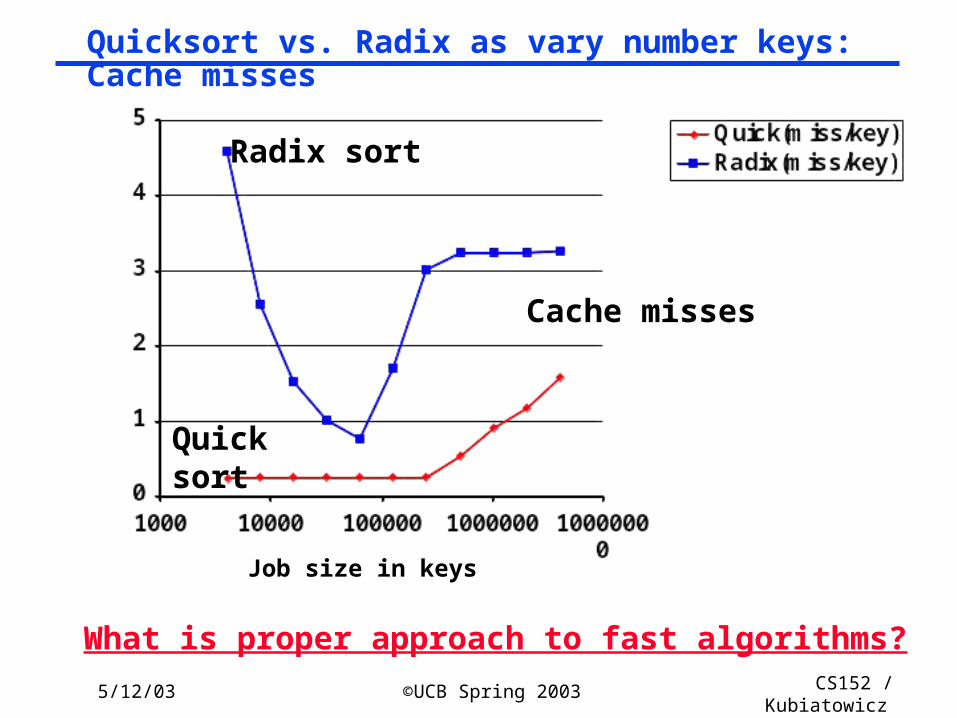
Cache misses
Job size in keys
Radix sort
Quicksort
What is proper approach to fast algorithms?
Quicksort vs. Radix as vary number keys: Cache misses
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.53
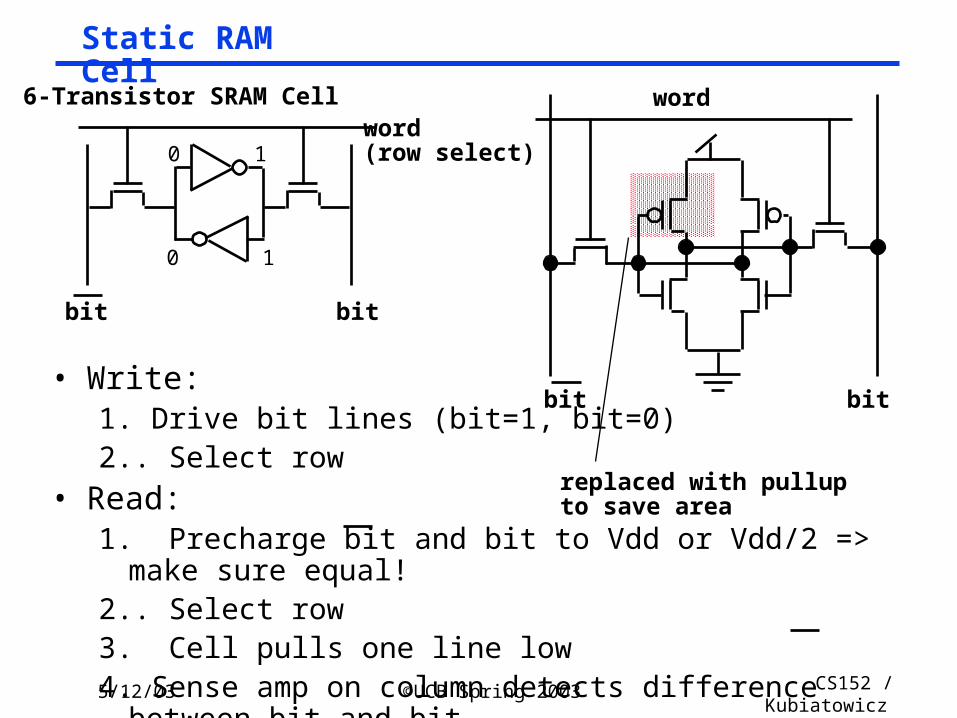
Static RAM Cell
6-Transistor SRAM Cell
bit bit
word(row select)
bit bit
word
• Write:1. Drive bit lines (bit=1, bit=0)2.. Select row
• Read:1. Precharge bit and bit to Vdd or Vdd/2 => make sure equal!2.. Select row3. Cell pulls one line low4. Sense amp on column detects difference between bit and bit
replaced with pullupto save area
10
0 1
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.54
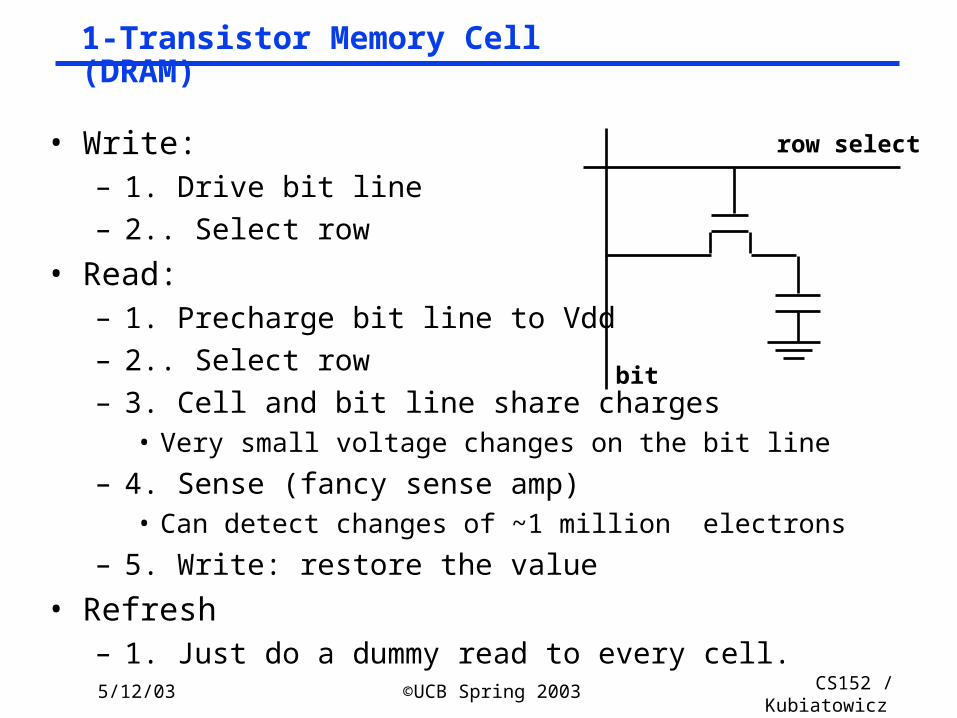
1-Transistor Memory Cell (DRAM)
• Write:– 1. Drive bit line
– 2.. Select row
• Read:– 1. Precharge bit line to Vdd
– 2.. Select row
– 3. Cell and bit line share charges• Very small voltage changes on the bit line
– 4. Sense (fancy sense amp)• Can detect changes of ~1 million electrons
– 5. Write: restore the value
• Refresh– 1. Just do a dummy read to every cell.
row select
bit
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.55
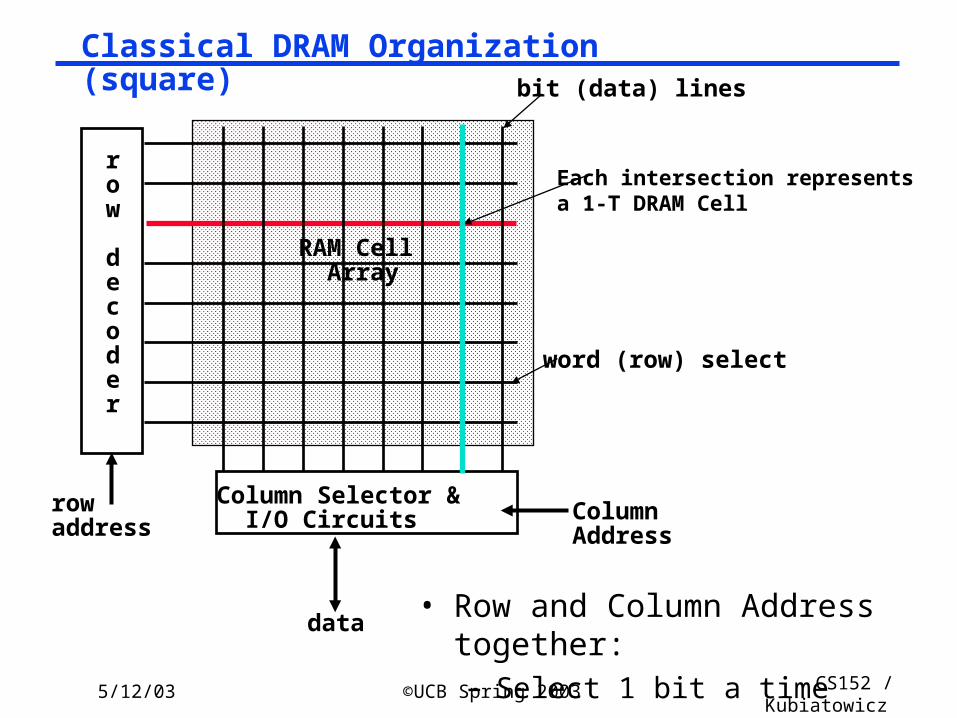
Classical DRAM Organization (square)
row
decoder
rowaddress
Column Selector & I/O Circuits Column
Address
data
RAM Cell Array
word (row) select
bit (data) lines
• Row and Column Address together: – Select 1 bit a time
Each intersection representsa 1-T DRAM Cell
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.56
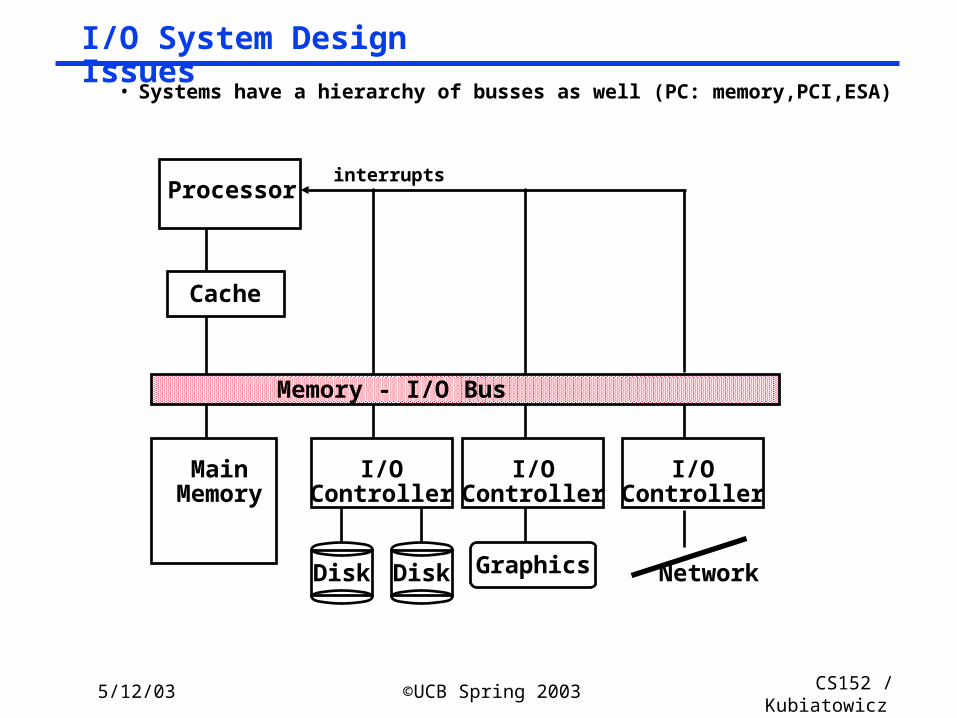
I/O System Design Issues
Processor
Cache
Memory - I/O Bus
MainMemory
I/OController
Disk Disk
I/OController
I/OController
Graphics Network
interrupts
• Systems have a hierarchy of busses as well (PC: memory,PCI,ESA)
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.57
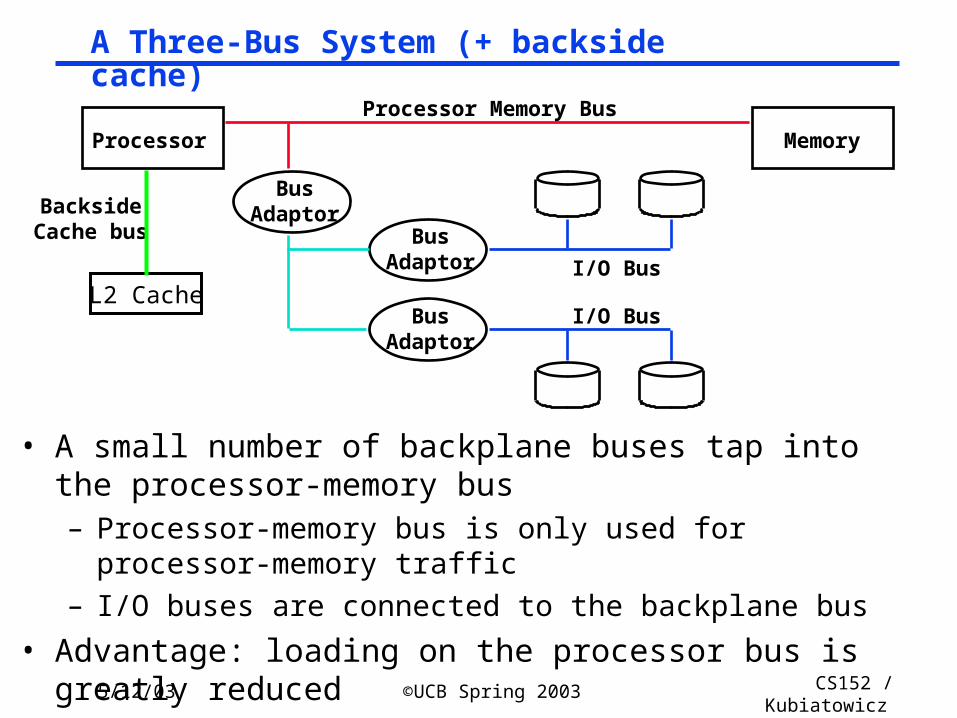
A Three-Bus System (+ backside cache)
• A small number of backplane buses tap into the processor-memory bus– Processor-memory bus is only used for processor-memory
traffic
– I/O buses are connected to the backplane bus
• Advantage: loading on the processor bus is greatly reduced
Processor Memory
Processor Memory Bus
BusAdaptor
BusAdaptor
BusAdaptor
I/O Bus
BacksideCache bus
I/O BusL2 Cache
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.58
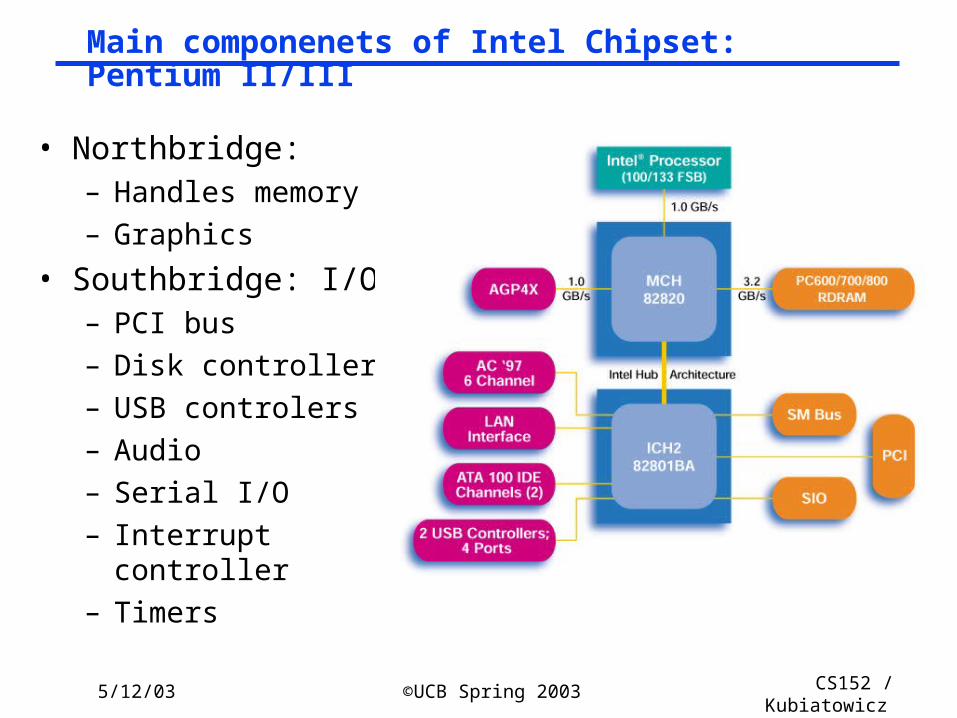
Main componenets of Intel Chipset: Pentium II/III
• Northbridge:– Handles memory
– Graphics
• Southbridge: I/O– PCI bus
– Disk controllers
– USB controlers
– Audio
– Serial I/O
– Interrupt controller
– Timers
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.59
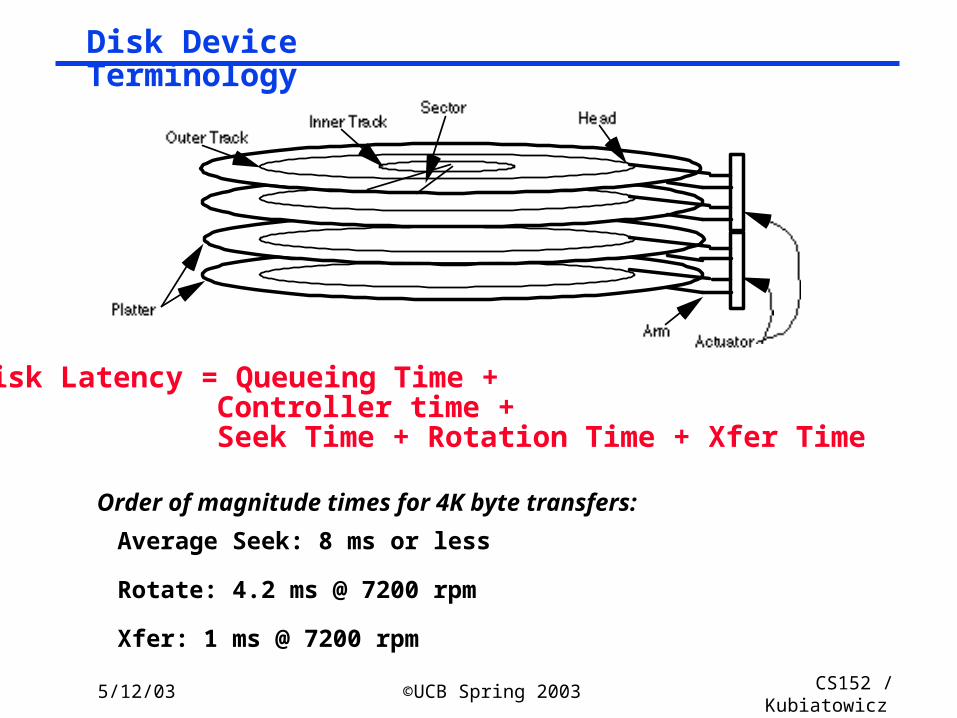
Disk Latency = Queueing Time + Controller time + Seek Time + Rotation Time + Xfer Time
Order of magnitude times for 4K byte transfers:
Average Seek: 8 ms or less
Rotate: 4.2 ms @ 7200 rpm
Xfer: 1 ms @ 7200 rpm
Disk Device Terminology
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.60
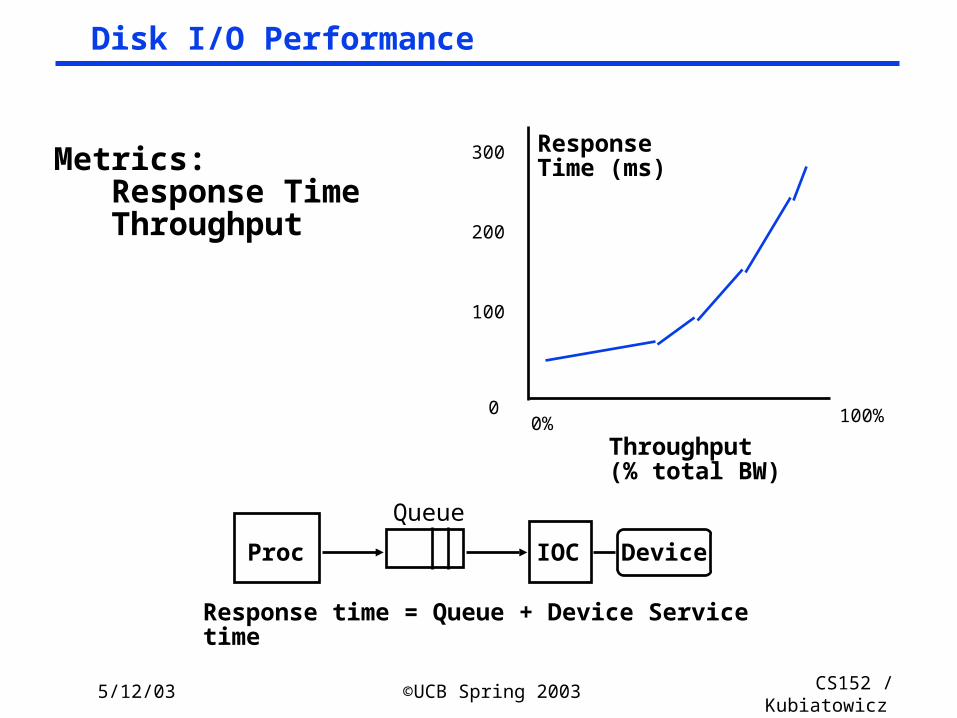
Disk I/O Performance
Response time = Queue + Device Service time
100%
ResponseTime (ms)
Throughput (% total BW)
0
100
200
300
0%
Proc
Queue
IOC Device
Metrics: Response Time Throughput
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.61
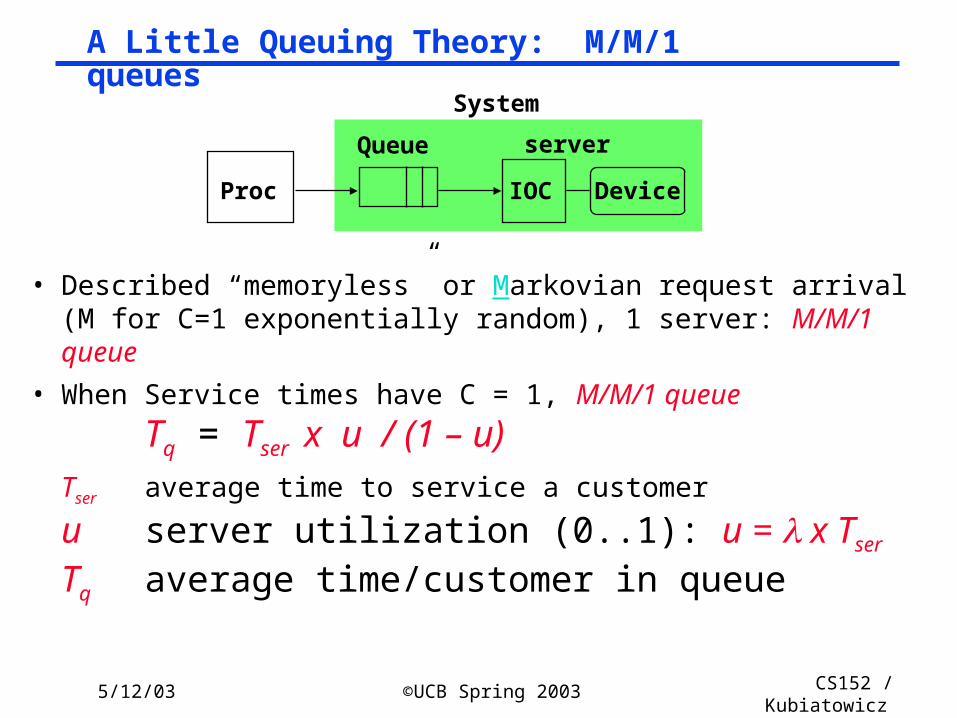
• Described “memoryless” or Markovian request arrival (M for C=1 exponentially random), 1 server: M/M/1 queue
• When Service times have C = 1, M/M/1 queue
Tq = Tser x u / (1 – u) Tser average time to service a customer
u server utilization (0..1): u = x Tser
Tq average time/customer in queue
A Little Queuing Theory: M/M/1 queues
Proc IOC Device
Queue server
System

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.62
Computers in the news: Tunneling Magnetic Junction

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.63
What does the future hold?
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.64
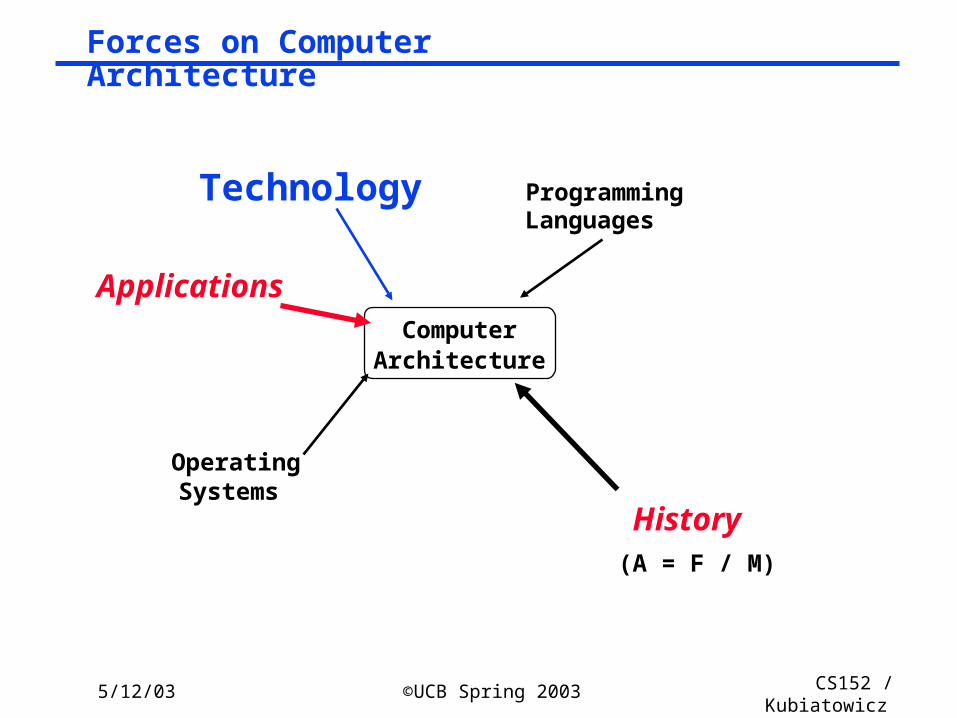
ComputerArchitecture
Technology ProgrammingLanguages
OperatingSystems
History
Applications
(A = F / M)
Forces on Computer Architecture

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.65
Today: building materials prevalent
• Originally: worried about squeezing the last ounce of performance from limited resources
• Today: worried about an abundance (embarrassment) of riches?– Billions of transistors on a chip (17nm Yeah!)
– Microprocessor Report articles wondering if all the lessons of RISC are now irrelevant
• Moore’s laws: exponential growth of everything– Transistors, Performance, Disk Space, Memory Size
• So, what matters any more????

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.66
° Fast, cheap, highly integrated “computers-on-a-chip”• IDT R4640, NEC VR4300, StrongARM, Superchips
• Devices everywhere!
° Micromechanical Devices (MEMS)• Integrated sensors everywhere
° Ubiquituous access to fast networks
• Network is everywhere!• ISDN, Cable Modems, ATM, Metrocom (wireless) . .
° Platform independent programming languages• Java, JavaScript, Visual Basic Script
° Lightweight Operating Systems• GEOS, NCOS, RISCOS
° ???
Key Technologies

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.67
• Complexity: – more than 50% of design teams now for verification
• Power– Processor designs hampered in performance to keep from
melting– Why 3 or 4 orders of magnitude difference in power consumption
between custom hardware and general Von Neuman architectures?
• Energy– Portable devices
• Scalability, Reliability, Maintainability– How to keep services up 24x7?
• Performance (“Cost conscious”)– how to get performance without a lot of power, complexity, etc.
• Security?– What are the consequences of distributed info to privacy?– What are moral implications of ubiquitous sensors???
Issues for Research
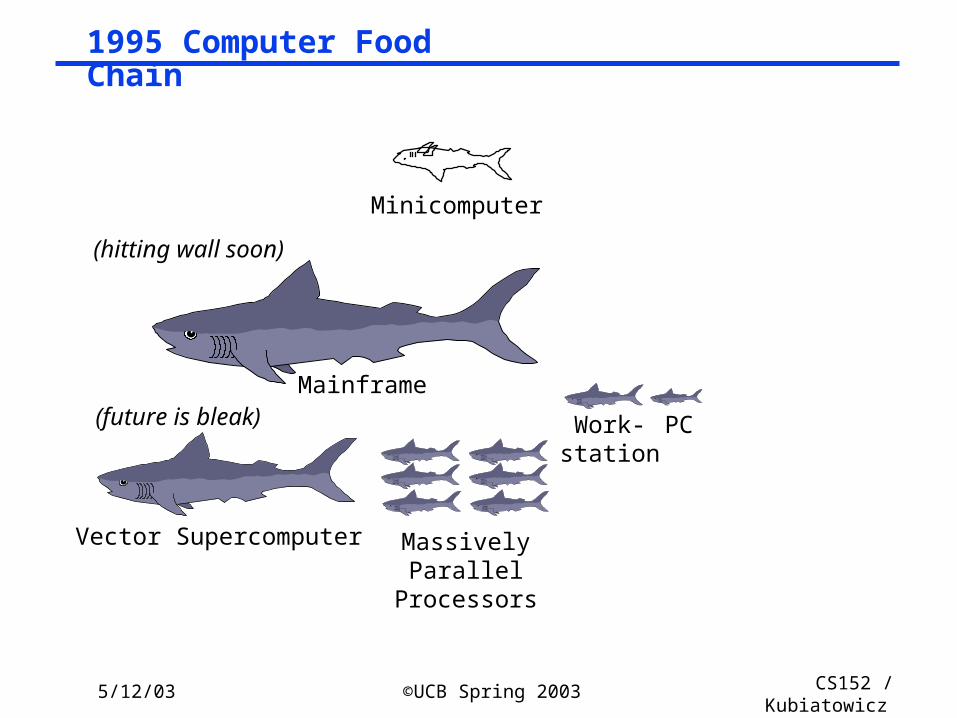
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.68
PCWork-station
Mainframe
Vector Supercomputer Massively Parallel Processors
Minicomputer
(hitting wall soon)
(future is bleak)
1995 Computer Food Chain
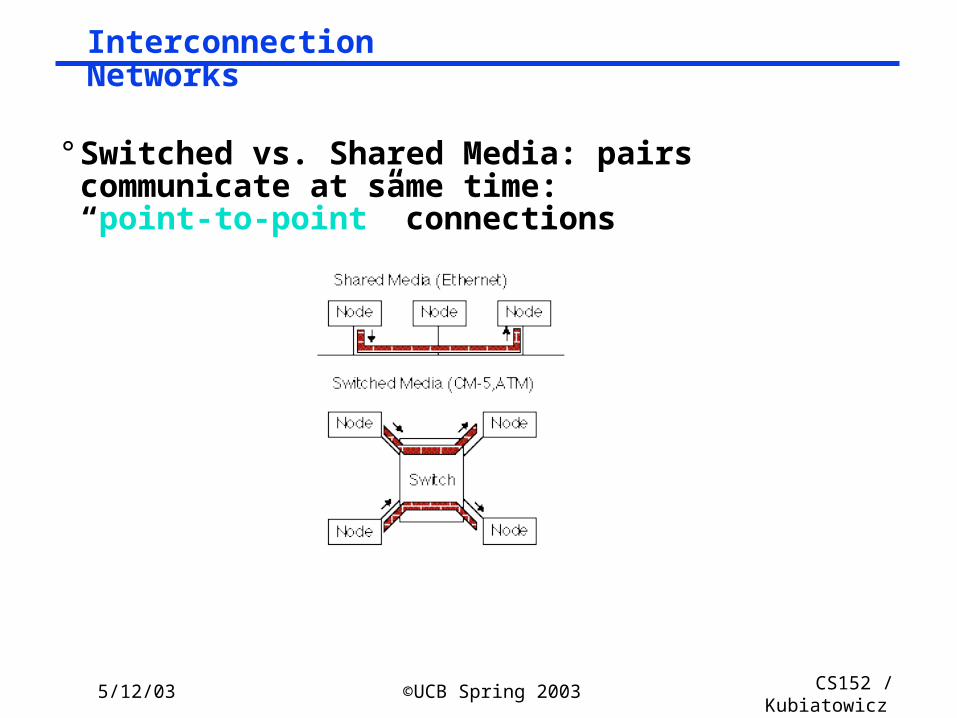
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.69
° Switched vs. Shared Media: pairs communicate at same time: “point-to-point” connections
Interconnection Networks
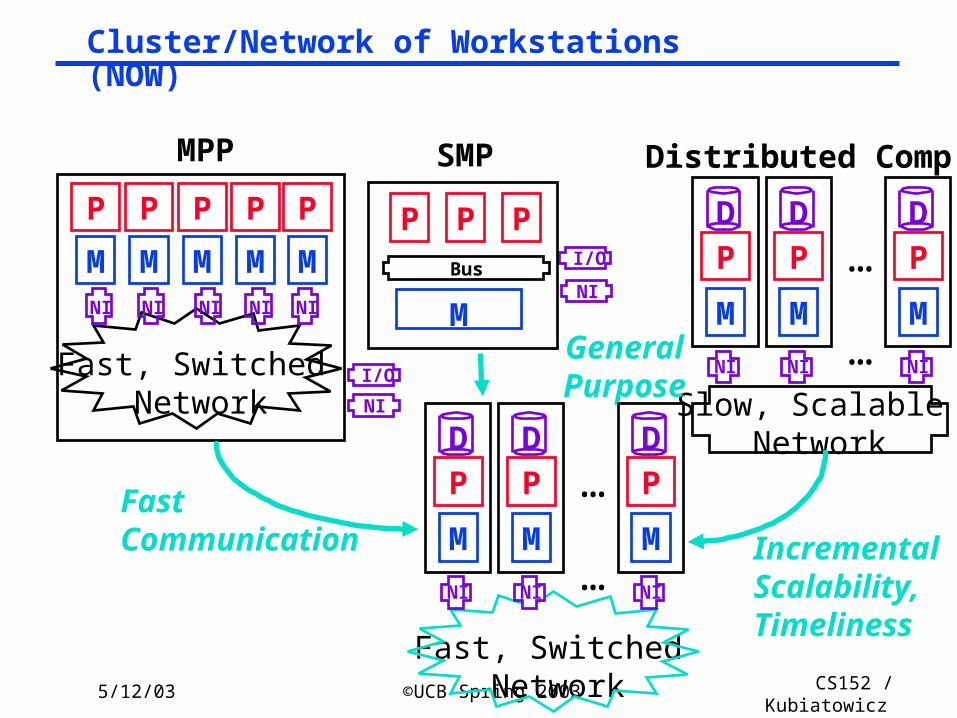
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.70
P
M
P
M
P
M
P
M
I/O
NI
Fast, Switched Network
P
MNININININI
Fast Communication
Slow, Scalable Network
…
…
P
M
NI
D
P
M
NI
D
P
M
NI
D
Distributed Comp.MPP
P P P
M
SMP
I/OBus
NI
General Purpose
Incremental Scalability,Timeliness
Fast, Switched Network
…
…
P
M
NI
D
P
M
NI
D
P
M
NI
D
Cluster/Network of Workstations (NOW)

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.71
2005 Computer Food Chain?
PortableComputers
Mainframe Vector Supercomputer
Networks of Workstations/PCs
MinicomputerMassively Parallel Processors

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.72
• IRAM motivation ( 2000 to 2005)– 256 Mbit/1Gbit DRAMs in near future (128 MByte)– Current CPUs starved for memory BW– On chip memory BW = SQRT(Size)/RAS or 80 GB/sec– 1% of Gbit DRAM = 10M transistors for µprocessor– Even in DRAM process, a 10M trans. CPU is attractive– Package could be network interface vs. Addr./Data pins– Embedded computers are increasingly important
• Why not re-examine computer design based on separation of memory and processor?– Compact code & data?– Vector instructions?– Operating systems? Compilers? Data Structures?
Intelligent DRAM (IRAM)
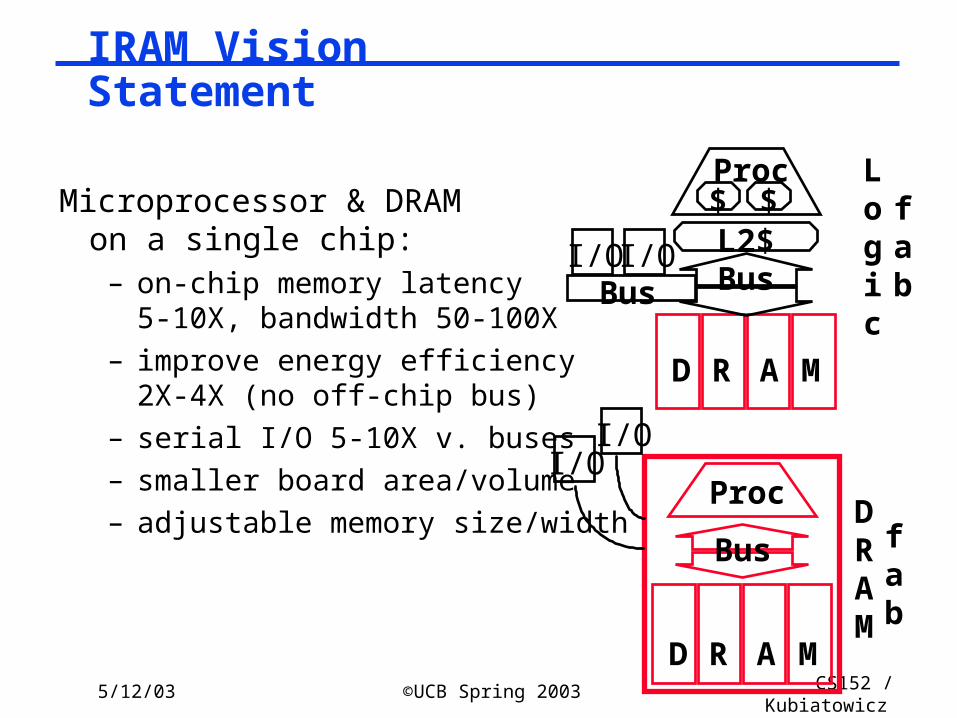
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.73
Microprocessor & DRAM on a single chip:
– on-chip memory latency 5-10X, bandwidth 50-100X
– improve energy efficiency 2X-4X (no off-chip bus)
– serial I/O 5-10X v. buses
– smaller board area/volume
– adjustable memory size/width DRAM
fab
Proc
Bus
D R A M
$ $Proc
L2$
Logic
fabBus
D R A M
I/OI/O
I/OI/O
Bus
IRAM Vision Statement
5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.74
Global-Scale Persistent Storage
OceanStore: The Oceanic Data Utility

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.75
• Consumers of data move, change from one device to another, work in cafes, cars, airplanes, the office, etc.
• Properties REQUIRED for OceanStore:– Strong Security: data must be encrypted whenever in the
infrastructure; resistance to monitoring
– Coherence: too much data for naïve users to keep coherent “by hand”
– Automatic replica management and optimization: huge quantities of data cannot be managed manually
– Simple and automatic recovery from disasters: probability of failure increases with size of system
– Utility model: world-scale system requires cooperation across administrative boundaries
Ubiquitous Devices Ubiquitous Storage

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.76
Pac Bell
Sprint
IBMAT&T
CanadianOceanStore
• Service provided by confederation of companies– Monthly fee paid to one service provider– Companies buy and sell capacity from each other
IBM
Utility-based Infrastructure

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.77
Introspective Computing
• Biological Analogs for computer systems:– Continuous adaptation
– Insensitivity to design flaws• Both hardware and software• Necessary if can never be
sure that all componentsare working properly…
• Examples:– ISTORE -- applies introspective
computing to disk storage
– DynaComp -- applies introspectivecomputing at chip level• Compiler always running and part of execution!
Compute
Monitor
Adapt

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.78
° multiprocessors on a chip?
° complete systems on a chip?
• memory + processor + I/O
° computers in your credit card?
° networking in your kitchen? car?
° eye tracking input devices?
° Wearable computers
° Intelligent books (made from paper!)
and why not

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.79
Learned from Cal/CS152?

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.80
CS152: So what's in it for me? (from 1st lecture)
° In-depth understanding of the inner-workings of modern computers, their evolution, and trade-offs present at the hardware/software boundary.
• Insight into fast/slow operations that are easy/hard to implementation hardware
° Experience with the design process in the context of a large complex (hardware) design.
• Functional Spec --> Control & Datapath --> Physical implementation
• Modern CAD tools
° Designer's "Intellectual" toolbox.

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.81
Simulate Industrial Environment (from 1st lecture)
° Project teams must have at least 4 members• Managers have value
° Communicate with colleagues (team members)• What have you done?
• What answers you need from others?
• You must document your work!!!
• Everyone must keep an on-line notebook
° Communicate with supervisor (TAs)• How is the team’s plan?
• Short progress reports are required:
- What is the team’s game plan?
- What is each member’s responsibility?

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.82
So let’s thanks those TAs

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.83
Summary: Things we Hope You Learned from 152
° Keep it simple and make it work:• Fully test everything individually & then together;
break when together• Retest everything whenever you make any changes• Last minute changes are big “no nos”
° Group dynamics. Communication is the key to success:
• Be open with others of your expectations & your problems (e.g., trip)• Everybody should be there on design meetings when key decisions
are made and jobs are assigned
° Planning is very important (“plan your life; live your plan”):
• Promise what you can deliver; deliver more than you promise• Murphy’s Law: things DO break at the last minute
- DON’T make your plan based on the best case scenarios- Freeze your design and don’t make last minute changes
° Never give up! It is not over until you give up (“Bear won’t die”)

5/12/03 ©UCB Spring 2003 CS152 / Kubiatowicz
Lec26.84
The End!





























