Embed Size (px)
Citation preview

CS4025:
Advanced Information Extraction

CS4025, Department of Computing Science, University of Aberdeen
2
Overview
• Overview of aspects of IE and General Architecture for Text Engineering (GATE)
• Examples

CS4025, Department of Computing Science, University of Aberdeen
3
Main Point
• Context: Textual material is expressed in natural language. We understand the structure and the meaning of textual material, but it is unstructured information for a machine.
• Problem: How to structure the information to support processing – information extraction for queries, reasoning, and further machine processing?
• Solution: Annotate the data with semantic mark ups using natural language processing systems. Makes data machine readable.

CS4025, Department of Computing Science, University of Aberdeen
4
Problems for Annotation
• Annotate large legacy corpora.
• Address growth of corpora.
• Distribution of information.
• Reduce number of human annotators and tedious work.
• Make annotation systematic, automatic, and consistent.
• Annotate fine-grained information: names, locations, addresses, organisations, actions, relations amongst terms.

CS4025, Department of Computing Science, University of Aberdeen
5
An Approach
• Knowledge heavy, using lists, rules, and processes. Labour and knowledge intensive. Transparent.
• Decompose large complex problems into smaller, manageable problems for which we can create solutions.
• Make implicit information explicit by adding machine readable annotations.
• Software engineering approach.
CS4025, Department of Computing Science, University of Aberdeen
6
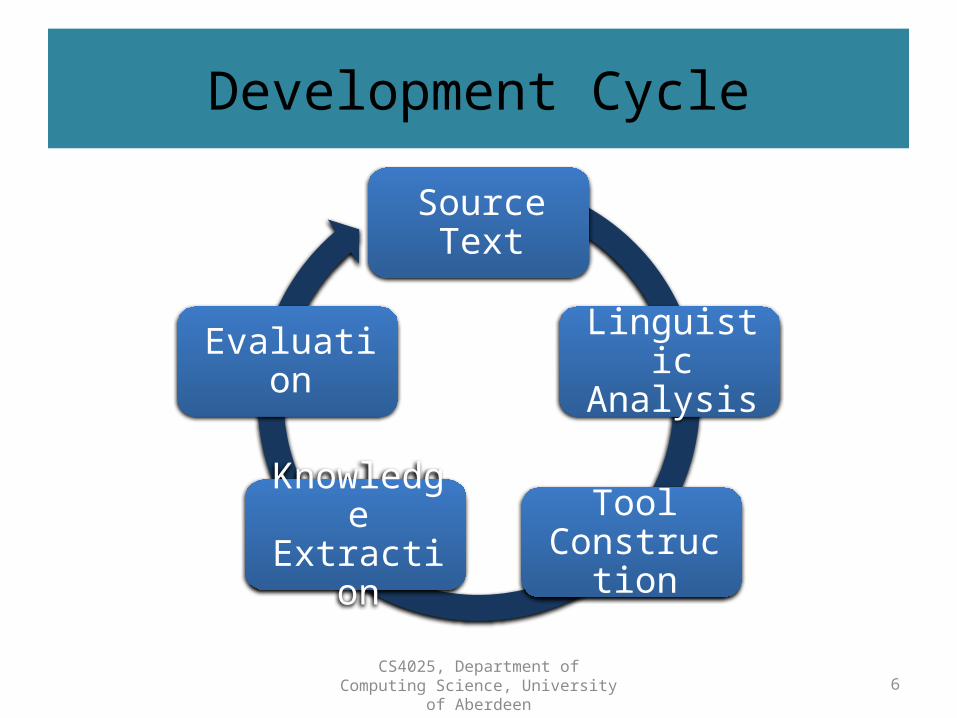
Development Cycle
Source Text
Linguistic Analysis
Tool Construction
Knowledge Extraction
Evaluation

CS4025, Department of Computing Science, University of Aberdeen
7
Computational Linguistic Cascade I
• Sentence segmentation - divide text into sentences.
• Tokenisation - words identified by spaces between them.
• Lemmatisation – homogenise 'run', 'ran', 'runs' to 'run'.
• Part of speech tagging - noun, verb, adjective....
• Morphological analysis - singular/plural, tense, nominalisation, ...
• Shallow syntactic parsing/chunking - noun phrase, verb phrase, subordinate clause, ....
• Identification of relevant terms and constructions.

CS4025, Department of Computing Science, University of Aberdeen
8
Computational Linguistic Cascade II
• Named entity recognition - the entities in the text.
• Dependency analysis - subordinate clauses, pronominal anaphora,...
• Relationship recognition – X is president of Y; A hit B with a car and killed B.
• Enrichment - add lexical semantic information to verbs or nouns.
• Each step guided by pattern matching and rule application.

CS4025, Department of Computing Science, University of Aberdeen
9
GATE
• General Architecture for Text Engineering (GATE) - open source framework which supports plug-in NLP components to process a corpus of text.
• GATE Training Courses 2014http://gate.ac.uk/wiki/TrainingCourseJune2014/
• A GUI to work with the tools.• A Java library to develop further applications.• Components and sequences of processes, each process
feeding the next in a “pipeline”.• Annotated text output or other sorts of output.

CS4025, Department of Computing Science, University of Aberdeen
10
Methodology I
• Form the corpus of text.• Identify terminology and sort into 'classes'. Maybe use a
spreadsheet for development.• Put sorted terminology into gazetteer lists (GAZ).• Create JAPE rules to 'reveal' the terminology.• Run the pipeline.• Examine results either 'in situ' or query with semantic search.• Refine/revise lists, rules, and queries.• Add further GATE processing modules as needed.

CS4025, Department of Computing Science, University of Aberdeen
11
Methodology II
CS4025, Department of Computing Science, University of Aberdeen
12
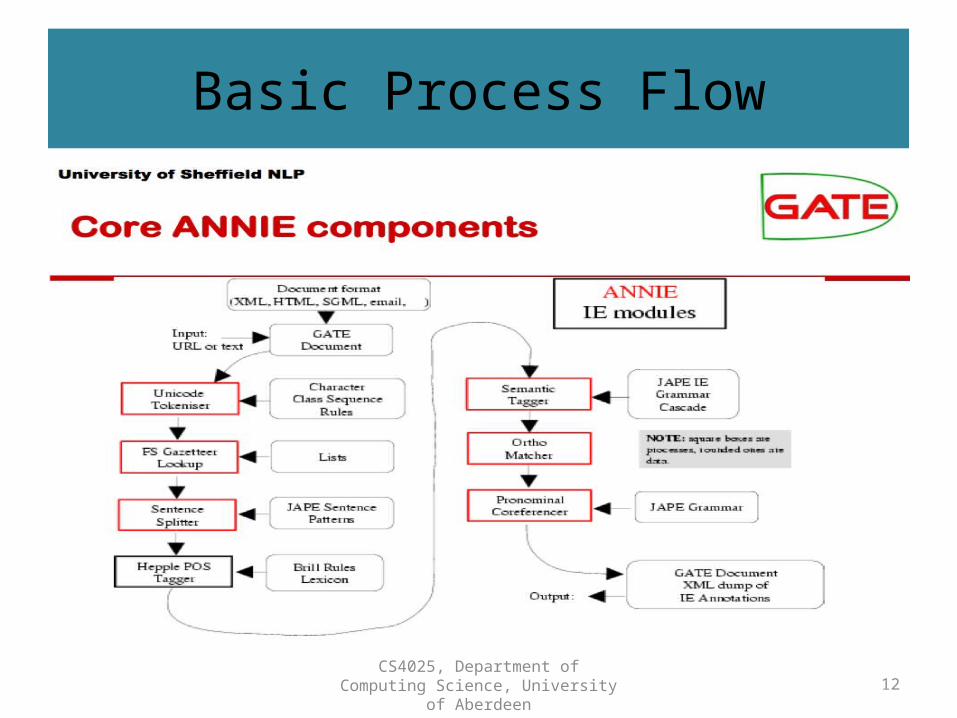
Basic Process Flow

CS4025, Department of Computing Science, University of Aberdeen
13
Example Process Flow

CS4025, Department of Computing Science, University of Aberdeen
14
Gazetteers
• Gazetteers are lookup lists that add features - when a string in the text is located in a lookup list, annotate the string in the text with the feature. Conceptual covers.
• Feature: list of items...
• Obligation: ought, must, obliged, obligation....• Exception: unless, except, but, apart from....• Verbs according to thematic roles: lists of verbs and their
associated roles, e.g. run has an agent (Bill ran), rise has a theme (The wind blew).
• Easy to change.

CS4025, Department of Computing Science, University of Aberdeen
15
JAPES
• JAPE Rules (finite state transduction rules) create overt annotations and reuse other annotations (e.g. Parser Output):
• Easy to change.

CS4025, Department of Computing Science, University of Aberdeen
16
Example 1Psychology

CS4025, Department of Computing Science, University of Aberdeen
17
Corpus

CS4025, Department of Computing Science, University of Aberdeen
18
Terminology
CS4025, Department of Computing Science, University of Aberdeen
19
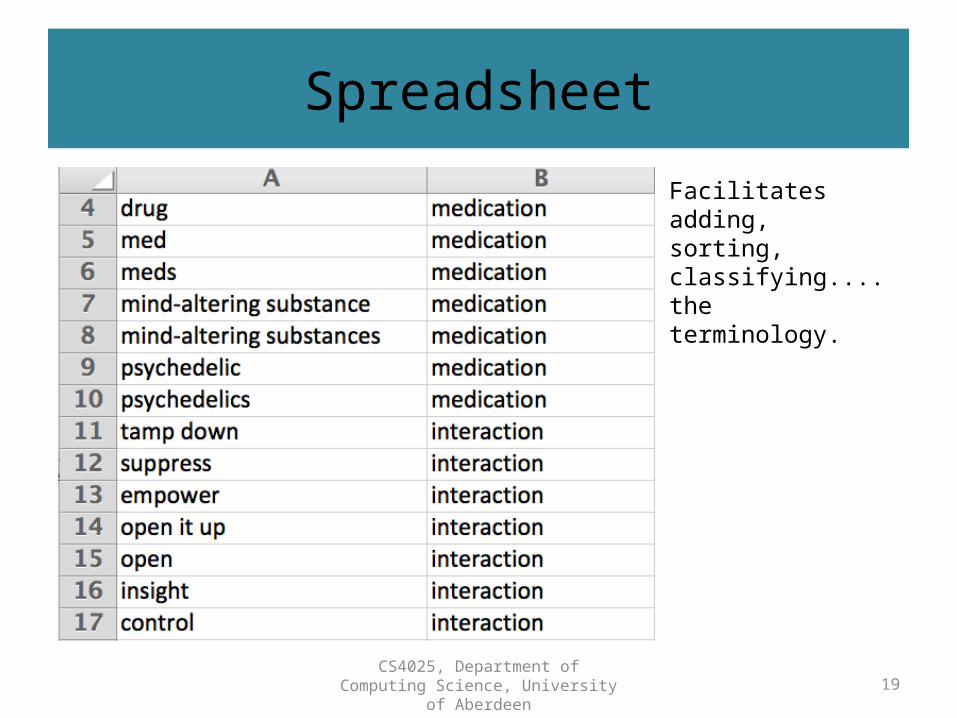
Spreadsheet
Facilitates adding, sorting, classifying.... the terminology.

CS4025, Department of Computing Science, University of Aberdeen
20
GAZ

CS4025, Department of Computing Science, University of Aberdeen
21
JAPE

CS4025, Department of Computing Science, University of Aberdeen
22
Pipeline

CS4025, Department of Computing Science, University of Aberdeen
23
Results in situ

CS4025, Department of Computing Science, University of Aberdeen
24
Results with ANNIC (one)

CS4025, Department of Computing Science, University of Aberdeen
25
Results with ANNIC (more)

CS4025, Department of Computing Science, University of Aberdeen
26
Other Modules (POS, Sentiment, etc.)

CS4025, Department of Computing Science, University of Aberdeen
27
Example 2Rule Extraction from Regulations

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
28
• Identify and extract rules from regulations using a rule-based, bottom-up, linguistically expressive, open-source, verifiable tool.
• Fine-grained structure to identify rule structure, nouns with their thematic roles, exceptions, and lists.
• Carry out an experiment on a portion of a regulation, demonstrating the feasibility of the approach and tools.
• Results (start to be) useful for knowledge acquisition and engineering.
• Towards computational semantics of natural language.
Main Points
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
29
Use Cases
• Legislation and regulations have rules that must be identified to:
• create and maintain up to date rule books that are used in compliance management, where a company must comply with the rules. (ComplianceTrack)
• create logic programs that, given input of ground facts, can generate determinations, e.g. whether an individual is due a benefit from the government or owes taxes. (Oracle)
• exchange machine readable rules. (LegalRuleML)
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
30
However....
• The knowledge engineering bottleneck:
It is knowledge, time, and labour intensive to identify, organise, and formalise rules which are expressed in natural language into rules that can be automatically processed.
• Solution - apply Natural Language Processing tools.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
31
Research Material
US Code of Federal Regulations, US Food and Drug Administration, Department of Health and Human Services regulation for blood banks on testing requirements for communicable disease agents in human blood, Title 21 part 610 section 40. 4 page document of 1,777 words.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
32
Why Not Parse and Be Done?
• Applied the Stanford Parser, and it outputs:
• parses – sequences of words that form a grammatical phrase;
• dependencies – relationships between phrases, e.g. subject of verb;
• alternative parses.
• It failed to parse the whole text. Succeeds on portions, but still lots of issues.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
33
Whazza Problem?
• long, complex sentences;• alternative parses;• lists with punctuation;• references with punctuation;• embedded clauses (...that....; ...to be....);• diathesis (e.g. active-passive) and thematic roles (e.g. agent):
You must test the blood; the blood must be tested by you.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
34
Proposition
• Define and target a more specific task.
• Work with simpler materials and build up from there.
• Develop a knowledge-based system to identify and extract information.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
35
Target Model
Deontic rules:
Conditional rules:
Start with this. In future work, add punctuation, negation, temporal phrases, generics, Hohfeldian relations, tense in conditionals, references, and so on....06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
36
Methodology - Materials
Given the problems of working with the source material directly, the data is systematically decomposed into less complex forms:
• Source – original materials, unparseable.• Source Sections – sections of source material, parseable,
but complex and inaccurate.• Source Derived – edited confounding issues such as long
conjunctive sentences, embeddings, and references. Created a Gold Standard in which we annotated the 'correct' elements and parses.
• Testing Data – simplified materials focusing on elements of the model.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
37
Source Derived
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
38
Gold Standard
The Gold Standard encodes knowledge.06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
39
Testing Data
A. B.
C.
D.
06/09/2013
Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
40
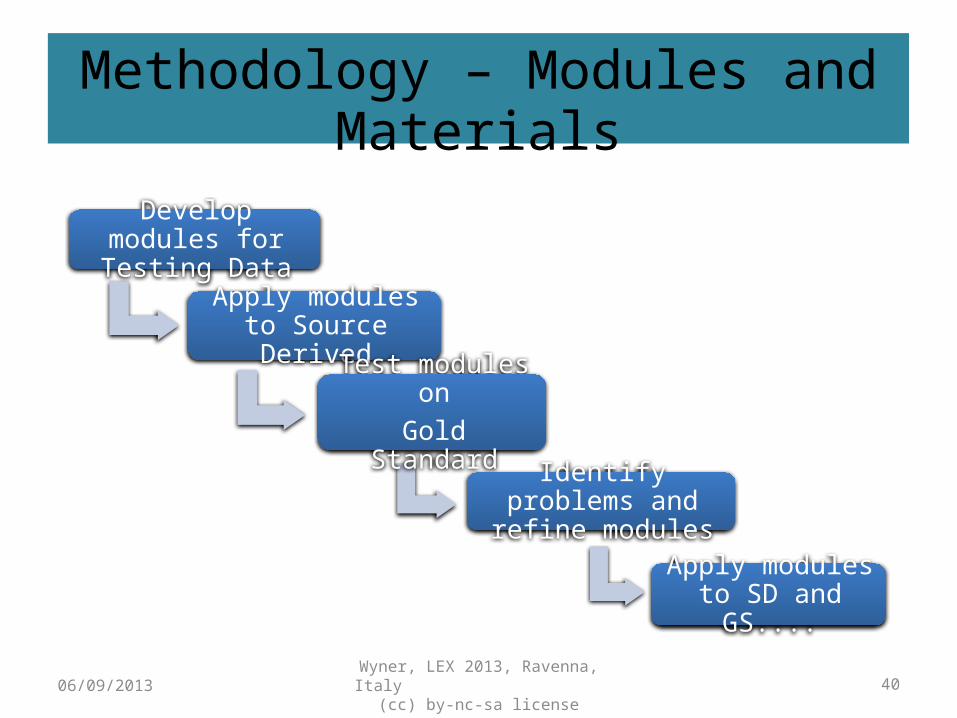
Methodology – Modules and Materials
Develop modules for Testing Data
Apply modules to Source Derived
Test modules onGold Standard
Identify problems and refine modules
Apply modules to SD and GS....
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
41
General Architecture for Text Engineering
NLP pipeline
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
42
General Architecture for Text Engineering
• Gazetteers are lookup lists that add features - when a string in the text is located in a lookup list, annotate the string in the text with the feature. Conceptual covers.
• Feature: list of items...
• Obligation: ought, must, obliged, obligation....• Exception: unless, except, but, apart from....• Verbs according to thematic roles: lists of verbs and
their associated roles, e.g. run has an agent (Bill ran), rise has a theme (The wind blew).
• Easy to change.06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
43
General Architecture for Text Engineering
• JAPE Rules (finite state transduction rules) create overt annotations and reuse other annotations (e.g. Parser Output):
• Easy to change.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
44
General Architecture for Text Engineering
• Have Gazetteer lists and JAPE rules for:
• lists in various forms;• exception phrases in various forms;• conditionals in various forms;• deontic terms;• associating grammatical roles (e.g. subject and object)
with thematic roles (agent and theme) in various forms.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
45
Sample Outputs
Consequence, list structure, and conjuncts of the antecedent.
Exception, agent NP, deontic concept, active main verb, theme.06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
46
Sample Output
Theme, deontic modal, passive verb, agent with complex relative clause.
06/09/2013

Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
47
Sample Output - Overall
06/09/2013
Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
48
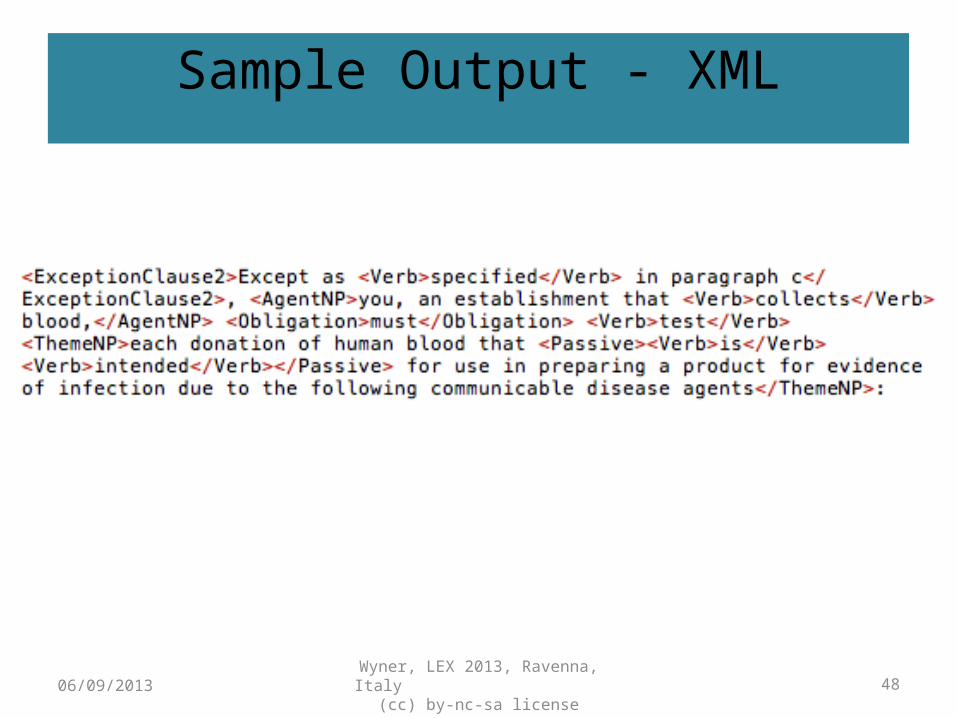
Sample Output - XML
06/09/2013
Wyner, LEX 2013, Ravenna, Italy (cc) by-nc-sa license
49
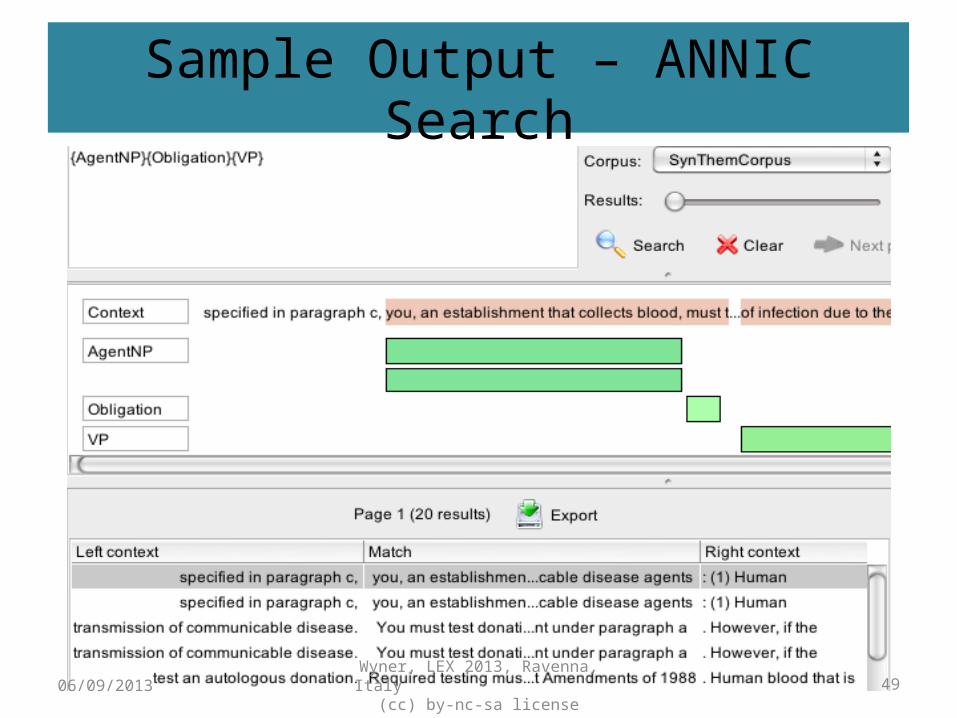
Sample Output – ANNIC Search
06/09/2013


























![The Aberdeen Democrat. (Aberdeen, S.D.), 1905-03-17, [p ]](https://img.pdfslide.net/doc/110x75/616d0ff553a9be267648fc3d/the-aberdeen-democrat-aberdeen-sd-1905-03-17-p-.jpg)

