Embed Size (px)
Citation preview
CS61C L32 Caches II (3) Garcia, 2005 © UCB
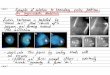
Review: Direct-Mapped Cache
• Cache Location 0 can be occupied by data from:
• Memory location 0, 4, 8, ...
• 4 blocks => any memory location that is multiple of 4
MemoryMemory Address
0123456789ABCDEF
4 Byte Direct Mapped Cache
Cache Index
0123
CS61C L32 Caches II (4) Garcia, 2005 © UCB
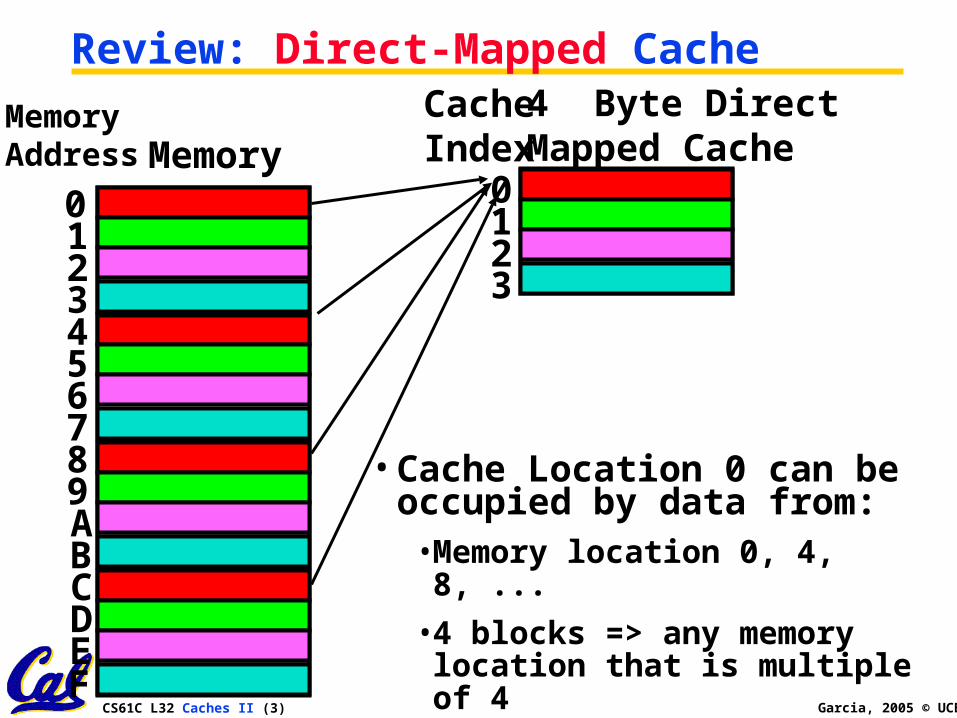
Caching Terminology• When we try to read memory,
3 things can happen:
1. cache hit: cache block is valid and contains proper address, so read desired word
2. cache miss: nothing in cache in appropriate block, so fetch from memory
3. cache miss, block replacement: wrong data is in cache at appropriate block, so discard it and fetch desired data from memory (cache always copy)
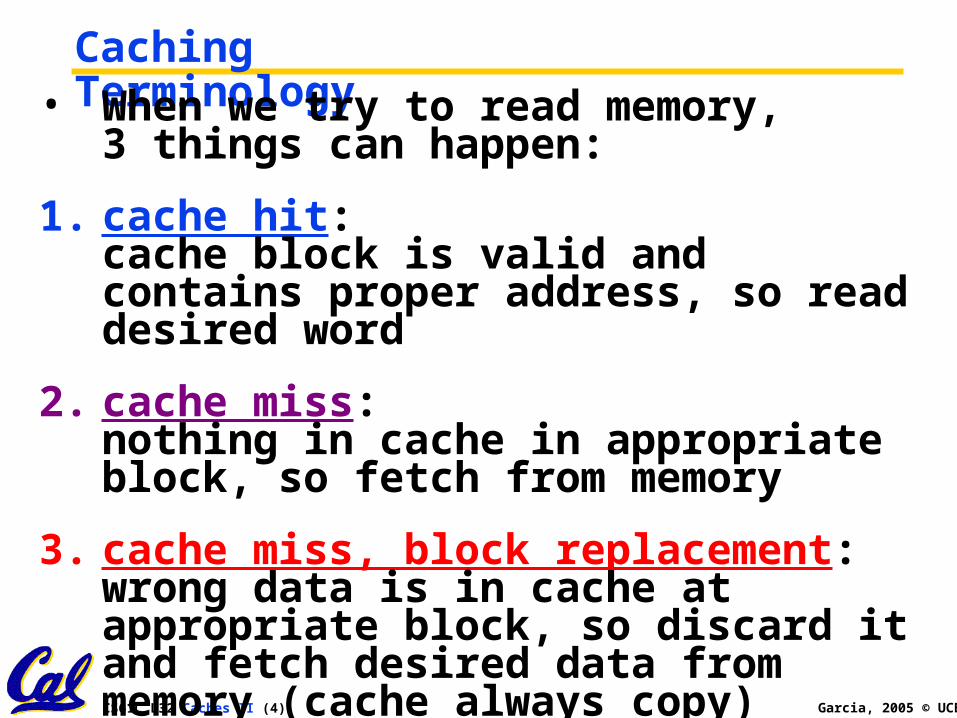
Cache access (Fig 7.7)Address (showing bit positions)
20 10
Byteoffset
Valid Tag DataIndex
0
1
2
1021
1022
1023
Tag
Index
Hit Data
20 32
31 30 13 12 11 2 1 0
1 word = 4bytes
Byteaddressing
Cache 裡真正用來存資料的部分
Cache block 大小:

CS61C L32 Caches II (6) Garcia, 2005 © UCB
Issues with Direct-Mapped•Since multiple memory addresses map to same cache index, how do we tell which one is in there?
•What if we have a block size > 1 byte?
•Answer: divide memory address into three fields
ttttttttttttttttt iiiiiiiiii oooo
tag index byteto check to offsetif have select withincorrect block block block
WIDTHHEIGHT
Tag Index Offset

Use of spatial locality Previous cache design takes advantage
of temporal locality Use spatial locality in cache design
A cache block that is larger than 1 word in length
With a cache miss, we will fetch multiple words that are adjacent
時間上的局部性
空間上的局部性
一次抓多個相鄰的 words

4-word cache (Fig 7.10)Address (showing bit positions)
16 12 Byteoffset
V Tag Data
Hit Data
16 32
4Kentries
16 bits 128 bits
Mux
32 32 32
2
32
Block offsetIndex
Tag
31 16 15 4 32 1 0
4-word blockaddr.

Advantage of multiple-word block (spatial locality)
Ex. access word with byte address 16,24,20
…
…
162024284-word block cache
1-word block cache
16 - cache miss24 - cache miss20 - cache miss
16 – cache miss load 4-word block
24 – cache hit20 – cache hit
memory

Multiple-word cache: write miss
Address (showing bit positions)
16 12 Byteoffset
V Tag Data
Hit Data
16 32
4Kentries
16 bits 128 bits
Mux
32 32 32
2
32
Block offsetIndex
Tag
31 16 15 4 32 1 0
addr. 1-word data01
Reload4-wordblock
1-word data
miss

CS61C L32 Caches II (11) Garcia, 2005 © UCB
Accessing data in a direct mapped cache• Ex.: 16KB of data, direct-mapped, 4 word blocks
• Read 4 addresses1. 0x000000142. 0x0000001C3. 0x000000344. 0x00008014
Address (hex)Value of WordMemory
0000001000000014000000180000001C
abcd
... ...
0000003000000034000000380000003C
efgh
0000801000008014000080180000801C
ijkl
... ...
... ...
... ...

CS61C L32 Caches II (13) Garcia, 2005 © UCB
1. Read 0x00000014
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
00000000
00

CS61C L32 Caches II (14) Garcia, 2005 © UCB
So we read block 1 (0000000001)
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
00000000
00

CS61C L32 Caches II (15) Garcia, 2005 © UCB
No valid data
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
00000000
00

CS61C L32 Caches II (16) Garcia, 2005 © UCB
So load that data into cache, setting tag, valid
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 0100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (17) Garcia, 2005 © UCB
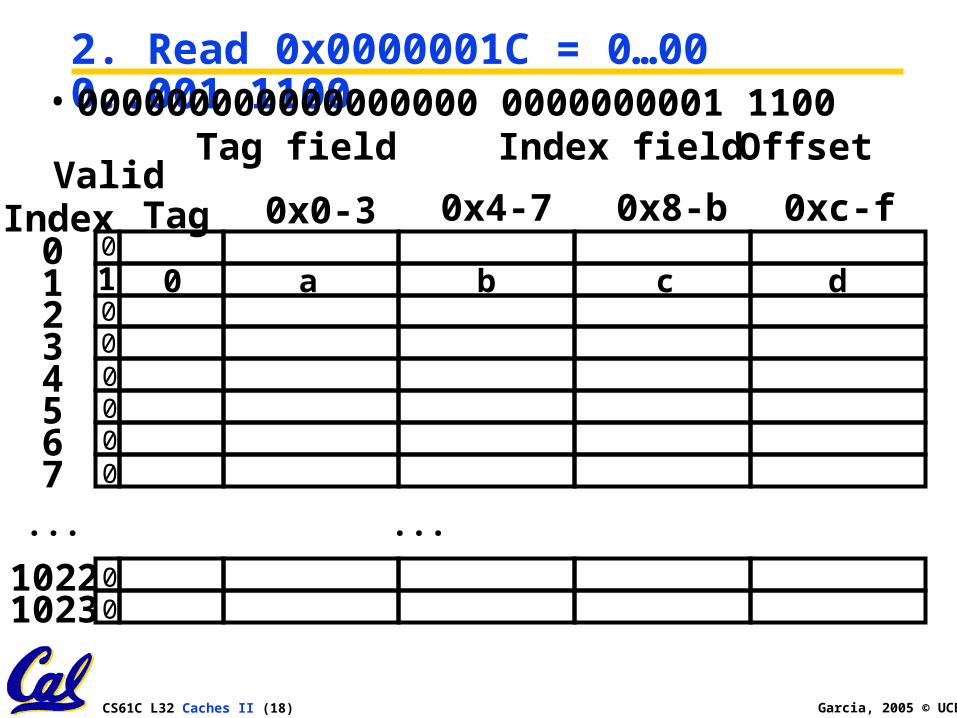
Read from cache at offset, return word b• 000000000000000000 0000000001 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
Index
Tag field Index field Offset
0
000000
00
CS61C L32 Caches II (18) Garcia, 2005 © UCB
2. Read 0x0000001C = 0…00 0..001 1100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (19) Garcia, 2005 © UCB
Index is Valid
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (20) Garcia, 2005 © UCB
Index valid, Tag Matches
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (21) Garcia, 2005 © UCB
Index Valid, Tag Matches, return d
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000001 1100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (22) Garcia, 2005 © UCB
3. Read 0x00000034 = 0…00 0..011 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (23) Garcia, 2005 © UCB
So read block 3
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (24) Garcia, 2005 © UCB
No valid data
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
Index
Tag field Index field Offset
0
000000
00

CS61C L32 Caches II (25) Garcia, 2005 © UCB
Load that cache block, return word f
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000000 0000000011 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (26) Garcia, 2005 © UCB
4. Read 0x00008014 = 0…10 0..001 0100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (27) Garcia, 2005 © UCB
So read Cache Block 1, Data is Valid
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (28) Garcia, 2005 © UCB
Cache Block 1 Tag does not match (0 != 2)
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 0 a b c d
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (29) Garcia, 2005 © UCB
Miss, so replace block 1 with new data & tag
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 2 i j k l
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (30) Garcia, 2005 © UCB
And return word j
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f
01234567
10221023
...
1 2 i j k l
• 000000000000000010 0000000001 0100
1 0 e f g h
Index
Tag field Index field Offset
0
0
0000
00

CS61C L32 Caches II (31) Garcia, 2005 © UCB
Do an example yourself. What happens?• Chose from: Cache: Hit, Miss, Miss w. replace
Values returned: a ,b, c, d, e, ..., k, l• Read address 0x00000030 ? 000000000000000000 0000000011 0000• Read address 0x0000001c ? 000000000000000000 0000000001 1100
...
ValidTag 0x0-3 0x4-7 0x8-b 0xc-f01234567...
1 2 i j k l
1 0 e f g h
Index0
0
0000

Advantage of multiple-word block (spatial locality)
Comparison of miss rateBlock sizein words
program Instructionmiss rate
Datamiss rate
gcc 1 6.1% 2.1%4 2.0% 1.7%
spice 1 1.2% 1.3%4 0.3% 0.6%
Why improvement oninstruction miss is significant?
Instruction references have betterspatial locality
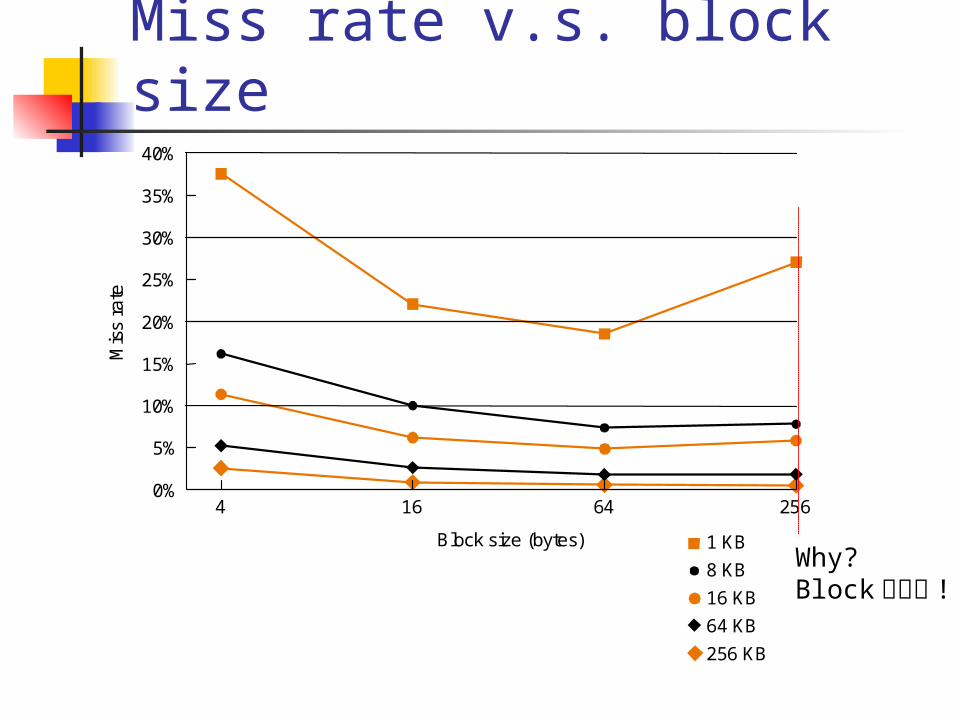
Miss rate v.s. block size
1 KB
8 KB
16 KB
64 KB
256 KB
256
40%
35%
30%
25%
20%
15%
10%
5%
0%
Mis
s ra
te
64164
Block size (bytes)Why?Block 數變少 !

Short conclusion Direct mapped cache
Map a memory word to a cache block Valid bit, tag field
Cache read Hit, read miss, miss penalty
Cache write Write-through Write-back Write miss penalty
Multi-word cache (use spatial locality)

Outline Introduction Basics of caches Measuring cache performance
Set associative cache Multilevel cache
Virtual memory
Make memory system fast

Cache performance How cache affects system
performance?CPU time= ( CPU execution clock cycles ) x clock cycle time
+ Memory-stall clock cycles
cache hit
cache miss
Memory-stall cycles = Read-stall cycles + Write-stall cycles
Read-stall cycles = Program
ReadsX Read miss rate x read miss penalty
Assume read and write miss penalty are the same
Memory-stall cycles = Program
Mem. accessX miss rate x miss penalty

Ex. Calculate cache performance
CPI = 2 without any memory stalls For gcc, instruction cache miss rate=2% data cache miss rate=4% miss penalty = 40 cycles Sol: Set instruction count = I
Instruction miss cycles = I x 2% x 40 = 0.8 x I
Data miss cycles = I x 36% x 4% x 40 = 0.58 x Ipercentage of lw/sw
Memory-stall cycles = 0.8I + 0.58I = 1.38ICPU timestalls
CPU timeperfect cache=
2I + 1.38I2I
=1.69

Why memory is bottleneck for system performance?
In previous example, if we make the processor faster, change CPI from 2 to 1
Memory-stall cycles remains the same=1.38ICPU timestalls
CPU timeperfect cache=
I + 1.38II
=2.38
Percentage of memory stall:
1.383.38
=41%1.382.38
=58%
CPU 變快 (CPI 降低,或 clock rate 提高 )Memory 對系統效能的影響百分比越重

Outline Introduction Basics of caches Measuring cache performance
Set associative cache (reduce miss rate) Multilevel cache
Virtual memory
Make memory system fast

How to improve cache performance ?
Larger cache Set associative cache
Reduce cache miss rate New placement rule other than direct
mapping Multi-level cache
Reduce cache miss penalty
Memory-stall cycles = Program
Mem. accessX miss rate x miss penalty

Flexible placement of blocks
Recall: direct mapped cache One address -> one block in cache
00001 00101 01001 01101 10001 10101 11001 11101
000
Cache
Memory
001
010
011
100
101
110
111
? One address -> more than one block in cache 一個 memory address 可以對應到 cache 中一個以上的 block

Full-associative cache A memory data can be placed in any
block in the cache Disadvantage:
Search all entries in the cache for a match
Using parallel comparators
1
2Tag
Data
Block # 0 1 2 3 4 5 6 7
Search
Direct mapped
1
2Tag
Data
Set # 0 1 2 3
Search
Set associative
1
2Tag
Data
Search
Fully associative記憶體資料可放在 cache 任意位置

Set-associative cache Between direct mapped and full-
associative A memory data can be placed in a set
of blocks in the cache
Disadvantage: Search all entries in the set for a match Parallel comparators
可放在 cache 中某一個集合中
1
2Tag
Data
Block # 0 1 2 3 4 5 6 7
Search
Direct mapped
1
2Tag
Data
Set # 0 1 2 3
Search
Set associative
1
2Tag
Data
Search
Fully associative
(address) modulo (number of sets in cache)
Ex. 12 modulo 4 = 0
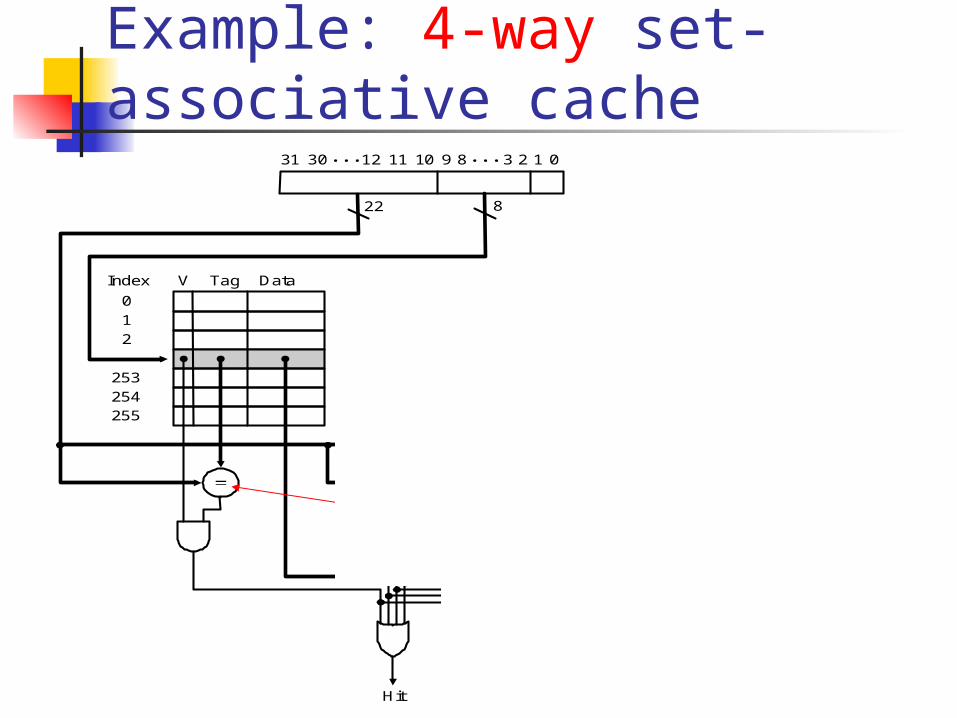
Example: 4-way set-associative cache
Address
22 8
V TagIndex
0
1
2
253
254255
Data V Tag Data V Tag Data V Tag Data
3222
4-to-1 multiplexor
Hit Data
123891011123031 0
Parallelcomparators

Take all schemes as a case of set-associativity
Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data Tag Data
Eight-way set associative (fully associative)
Tag Data Tag Data Tag Data Tag Data
Four-way set associative
Set
0
1
Tag Data
One-way set associative(direct mapped)
Block
0
7
1
2
3
4
5
6
Tag Data
Two-way set associative
Set
0
1
2
3
Tag Data
Ex. 8-block cache

Example: set-associative caches (p. 499)
A cache with 4 blocks Load data with block addresses
0,8,0,6,8one-way set-associative cache (direct mapped)
5 misses

Example: set-associative caches
2-way set-associative cache
4-way set-associative cache
4 misses
3 misses

CS61C L34 Caches IV (48) Garcia © UCB
Block Replacement Policy (1/2)•Direct-Mapped Cache: index completely specifies position which position a block can go in on a miss
•N-Way Set Assoc: index specifies a set, but block can occupy any position within the set on a miss
•Fully Associative: block can be written into any position
•Question: if we have the choice, where should we write an incoming block?

CS61C L34 Caches IV (49) Garcia © UCB
Block Replacement Policy (2/2)
• If there are any locations with valid bit off (empty), then usually write the new block into the first one.
• If all possible locations already have a valid block, we must pick a replacement policy: rule by which we determine which block gets “cached out” on a miss.

CS61C L34 Caches IV (50) Garcia © UCB
Block Replacement Policy: LRU•LRU (Least Recently Used)
• Idea: cache out block which has been accessed (read or write) least recently
• Pro: temporal locality recent past use implies likely future use: in fact, this is a very effective policy
• Con: with 2-way set assoc, easy to keep track (one LRU bit); with 4-way or greater, requires complicated hardware and much time to keep track of this

CS61C L34 Caches IV (51) Garcia © UCB
Block Replacement Example•We have a 2-way set associative cache
with a four word total capacity and one word blocks. We perform the following word accesses (ignore bytes for this problem):
0, 2, 0, 1, 4, 0, 2, 3, 5, 4
How many hits and how many misses will there be for the LRU block replacement policy?

CS61C L34 Caches IV (52) Garcia © UCB
Block Replacement Example: LRU•Addresses 0, 2, 0, 1, 4, 0, ... 0 lru
2
1 lru
loc 0 loc 1
set 0
set 1
0 2lruset 0
set 1
0: miss, bring into set 0 (loc 0)
2: miss, bring into set 0 (loc 1)
0: hit
1: miss, bring into set 1 (loc 0)
4: miss, bring into set 0 (loc 1, replace 2)
0: hit
0set 0
set 1
lrulru
0 2set 0
set 1
lru lru
set 0
set 1
01lru
lru24lru
set 0
set 1
0 41lru
lru lru

Short conclusion Higher degree of associativity
Lower miss rate More hardware cost to search

Outline Introduction Basics of caches Measuring cache performance
Set associative cache Multilevel cache (reduce miss penalty)
Virtual memory
Make memory system fast

Multi-level cache Goal: reduce miss penalty
Memory
CPU
Memory
Size Cost ($/bit)Speed
Smallest
Biggest
Highest
Lowest
Fastest
Slowest Memory
Primary cache (L1)
Secondary cache(L2)
L1 cachemiss
L2 cachemiss
Cache hit
Main memory

Example: Performance of multilevel cache
CPI = 1 without cache miss, clock rate = 500MHz
Primary cache, miss rate=5% Secondary cache, miss rate=2%, access
time=20ns Main memory, access time=200 ns
Total CPI = Base CPI + memory-stall CPI
1 ?

Example: Performance of multilevel cache (cont.)
Total CPI = Base CPI + memory-stall CPI
1 ?
access to main memory=200ns x 500M clock/sec=100clock
access to L2 cache = 20ns x 500M clock/sec =10 clock
Total CPI = 1 + L1 miss penalty + L2 miss penalty = 1 + 5% x 10 + 2% x 100 = 3.5
One-level cache
Two-level cache
Total CPI = 1 + 5% x 100 = 6

Cache Things to Remember• Caches are NOT mandatory:
• Processor performs arithmetic• Memory stores data• Caches simply make data transfers go faster
• Caches speed up due to temporal locality: store data used recently
• Block size > 1 wd spatial locality speedup:Store words next to the ones used recently
• Cache design choices:• size of cache: speed v. capacity• N-way set assoc: choice of N (direct-mapped,
fully-associative just special cases for N)