Embed Size (px)
Citation preview

CSE 100: HUFFMAN CODES

Announcements • PA2 has been posted.
• Checkpoint due: Oct 27th (next Monday) • Final submission due: Nov 3 (Monday following the checkpoint
deadline)

READING QUIZ – NO TALKING – NO NOTES
Q1: What is the definition of an optimal code? A. An assignment of codewords to symbols that
minimizes the average codeword length. B. A mapping between codewords and symbols
that takes the minimum amount of time to construct
C. A mapping between codewords and symbols where the mapping itself can be represented in the smallest amount of space

READING QUIZ – NO TALKING – NO NOTES
Q2: According to your reading, which of the following is NOT a restriction imposed on prospective codes (both in general, and for optimal codes)?
A. Each codeword corresponds to exactly one symbol
B. Decoding should not require look-ahead C. Decoding time should be logarithmic in the
length of the codeword D. The length of a codeword for a given symbol
mj should not exceed the length of a codeword for a less probable symbol mi.

READING QUIZ – NO TALKING – NO NOTES
Q3: What does the entropy of a data source specify?
A. The lower bound on the average code length B. The upper bound on the average code length C. The average code length of optimal codes

READING QUIZ – NO TALKING – NO NOTES
Q4: In the Huffman coding algorithm, how is it decided which two trees to merge?
A. The two smallest trees (i.e., least number of nodes) are merged
B. The trees with the smallest probabilities are merged
C. The trees with the largest probabilities are merged
D. The two largest (i.e., greatest number of nodes) are merged

Variable length codes
Is code B better than code A? A. Yes B. No C. Depends
ssssssssssssssss ssssspppamppam
Symbol Frequency s 0.6 p 0.2 a 0.1 m 0.1
Symbol Codeword s 0 p 1
a 10 m 11
Symbol Codeword s 00 p 01 a 10 m 11
Code A Code B
Text file

Variable length codes
Average length (code A) = 2 bits/symbol Average length (code B) = 0.6 *1 +0.2 *1 + 0.1* 2+ 0.1*2
= 1.2 bits/symbol
ssssssssssssssss ssssspppamppam
Symbol Frequency s 0.6 p 0.2 a 0.1 m 0.1
Symbol Codeword s 0 p 1
a 10 m 11
Symbol Codeword s 00 p 01 a 10 m 11
Code A Code B
Text file

Decoding variable length codes ssssssssssssssss ssssspppamppam
Symbol Frequency s 0.6 p 0.2 a 0.1 m 0.1
Symbol Codeword s 0 p 1
a 10 m 11
Symbol Codeword s 00 p 01 a 10 m 11
Code A Code B
Text file
Decode the binary pattern 0110 using Code B? A. spa B. sms C. Not enough information to decode

Variable length codes
Symbol Codeword s 0 p 1
a 10 m 11
Symbol Codeword s 00 p 01 a 10 m 11
Code A Code B
Variable length codes have to necessarily be prefix codes for correct decoding A prefix code is one where no symbol’s codeword is a prefix of another
Is Code B a prefix code?

Variable length codes
Symbol Codeword s 0 p 1
a 10 m 11
Symbol Codeword s 00 p 01 a 10 m 11
Code A Code B
Is code C better than code A and code B? (Why or why not?) A. Yes B. No
Symbol Codeword s 0
p 10 a 110 m 111
Code C
Symbol Frequency s 0.6 p 0.2 a 0.1 m 0.1

Variable length codes
Symbol Codeword s 0 p 1
a 10 m 11
Symbol Codeword s 00 p 01 a 10 m 11
Code A Code B
Symbol Codeword s 0
p 10 a 110 m 111
Code C
Symbol Frequency s 0.6 p 0.2 a 0.1 m 0.1
Average length (code A) = 2 bits/symbol Average length (code B) = 0.6 *1 +0.2 *1 + 0.1* 2+ 0.1*2
= 1.2 bits/symbol Average length (code C) = 0.6 *1 +0.2 *2 + 0.1* 3+ 0.1*3
= 1.6 bits/symbol
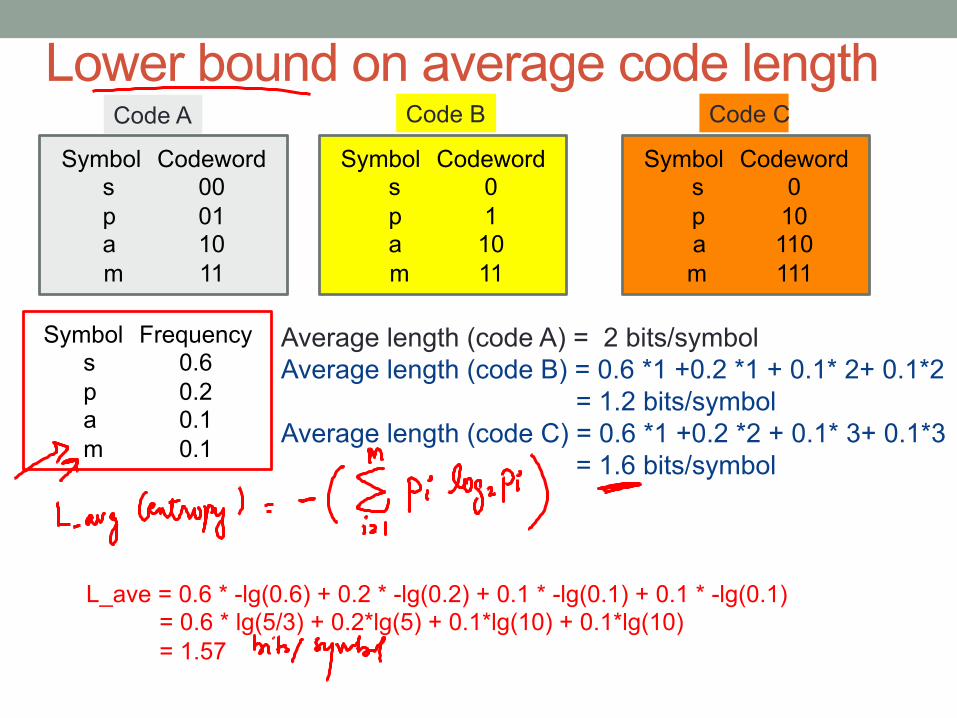
Lower bound on average code length Symbol Codeword
s 0 p 1
a 10 m 11
Symbol Codeword s 00 p 01 a 10 m 11
Code A Code B
Symbol Codeword s 0
p 10 a 110 m 111
Code C
Symbol Frequency s 0.6 p 0.2 a 0.1 m 0.1
Average length (code A) = 2 bits/symbol Average length (code B) = 0.6 *1 +0.2 *1 + 0.1* 2+ 0.1*2
= 1.2 bits/symbol Average length (code C) = 0.6 *1 +0.2 *2 + 0.1* 3+ 0.1*3
= 1.6 bits/symbol
L_ave = 0.6 * -lg(0.6) + 0.2 * -lg(0.2) + 0.1 * -lg(0.1) + 0.1 * -lg(0.1) = 0.6 * lg(5/3) + 0.2*lg(5) + 0.1*lg(10) + 0.1*lg(10) = 1.57

Symbol Frequency S 1.0 P 0.0 A 0.0 M 0.0
What is the theoretical best average length of a coded symbol with these frequencies? A. 0 B. 0.67 C. 1.0 D. 1.57 E. 2.15

Symbol Frequency S 0.25 P 0.25 A 0.25 M 0.25
What is the theoretical best average length of a coded symbol with this frequency distribution? (why?) A. 1 B. 2 C. 3 D. lg(2)
Symbol Codeword s 0
p 10 a 110 m 111
Code C

Problem Definition
Given a frequency distribu2on over M symbols, find the op2mal prefix binary code i.e. one that minimizes the average number of bits per symbol
Le$er freq
s 0.6
p 0.2
a 0.1
m 0.1
map smppam ssampamsmam …
TEXT FILE
Solu2on involves thinking of binary codes as Binary Trees
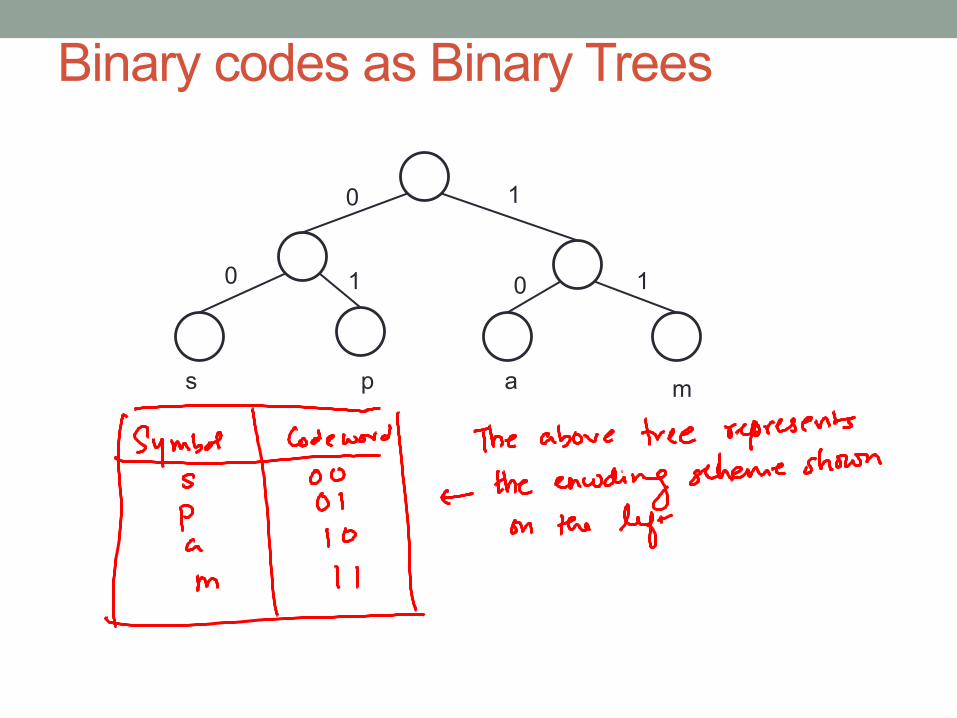
Binary codes as Binary Trees
0 1
0 0 1 1
s p a m
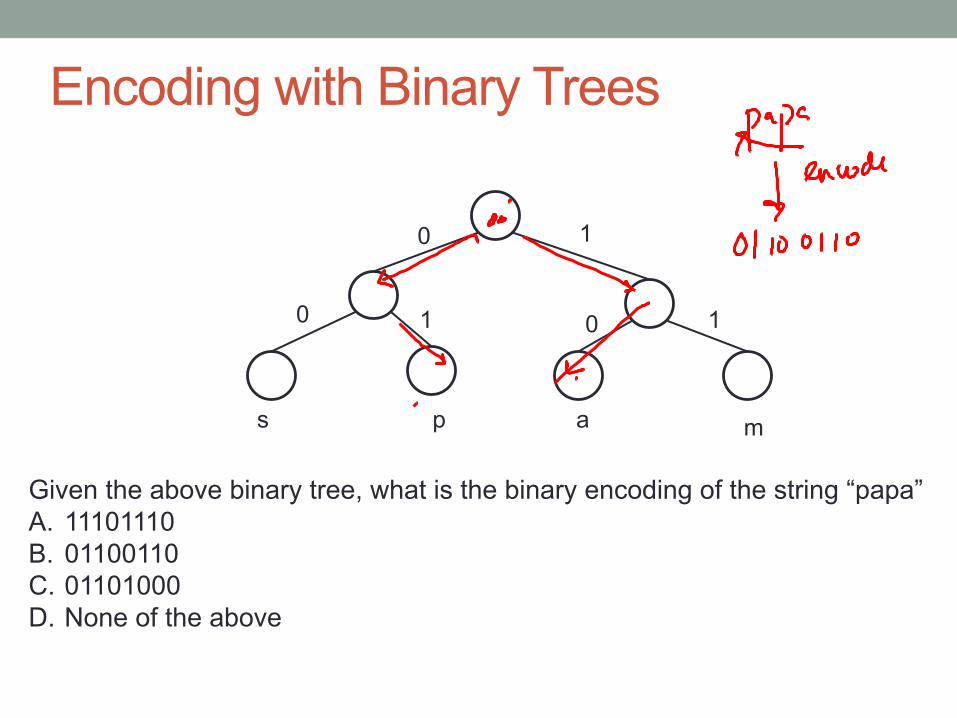
Encoding with Binary Trees
0 1
0 0 1 1
s p a m
Given the above binary tree, what is the binary encoding of the string “papa” A. 11101110 B. 01100110 C. 01101000 D. None of the above
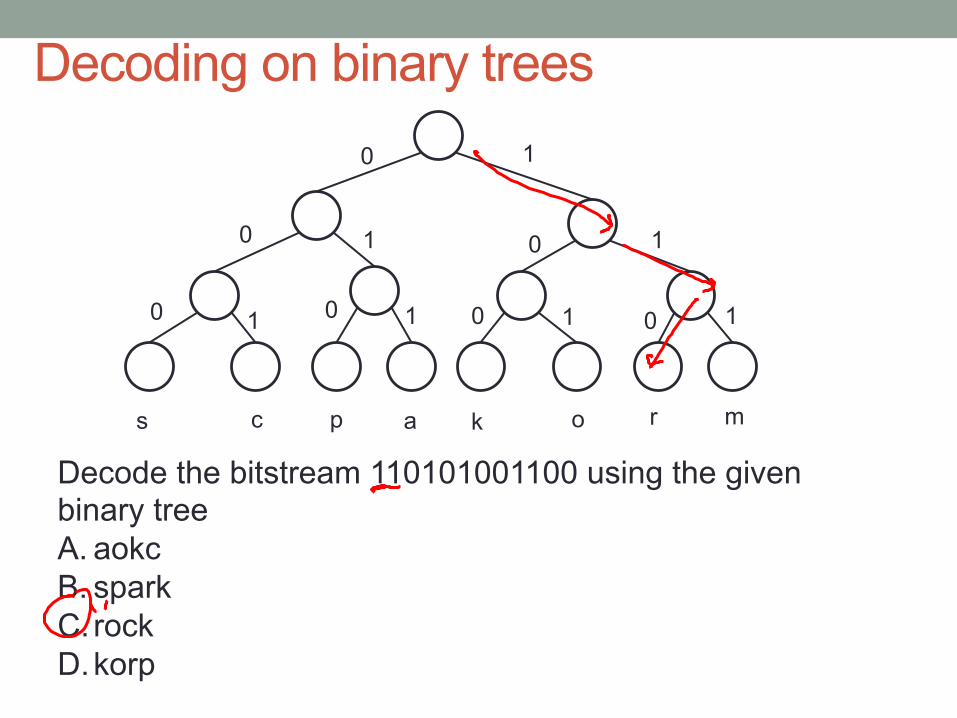
Decoding on binary trees 0 1
0
0
0
0 0 0
1 1
1 1 1 1
s p a m r o c k
Decode the bitstream 110101001100 using the given binary tree A. aokc B. spark C. rock D. korp

Problem Definition (revisited) Input: The frequency (pi) of occurrence of each symbol (Si) Output: Binary tree T that minimizes the following objective function:
L(T ) = pi ⋅Depth(Si in T )i=1:N∑
Solution: Huffman Codes

The David Huffman Story!
Huffman coding is one of the fundamental ideas that people in computer science and data communica2ons are using all the 2me -‐ Donald Knuth
Le$er freq
s 0.6
p 0.2
a 0.1
m 0.1
map smppam ssampamsmam …
TEXT FILE

Not quite Huffman’s algorithm… • The basic idea is to put the frequent items near the root
(short codes) and the less frequent at the leaves. • A simple idea is the top-down approach:
A: 6; B: 4; C: 4; D: 0; E: 0; F: 0; G: 1; H: 2
A B
C
G H
AAAAABBAHHBCBGCCC

Not quite Huffman’s algorithm… • The basic idea is to put the frequent items near the root
(short codes) and the less frequent at the leaves. • A simple idea is the top-down approach:
A: 6; B: 4; C: 4; D: 0; E: 0; F: 0; G: 1; H: 2
A B
C
G H
Pre$y good, but NOT opMmal!

Huffman’s algorithm: Bottom up construction • Build the tree from the bottom up! • Start with a forest of trees, all with just one node
A
6
B
4
C
4
D
0
E
0
F
0
G
1
H
2

Huffman’s algorithm: Bottom up construction • Build the tree from the bottom up! • Start with a forest of trees, all with just one node • Merge trees in the forest two at a time to get a single tree
A
6
B
4
C
4
G
1
H
2
Huffman’s algorithm: Bottom up construction What should be the merge criterion?
A
6
B
4
C
4
G
1
H
2

Huffman’s algorithm: Bottom up construction
• Merging the nodes G and H increases the code length of which of the following symbols:
A
6
B
4
C
4
G H
1 2
A. Symbols A, B and C B. Symbol G C. Symbol H D. Both G and H

Huffman’s algorithm: Bottom up construction
• Choose the two smallest trees in the forest and merge them
A
6
B
4
C
4
G H
T1
1 2

Huffman’s algorithm: Bottom up construction • Choose the two smallest trees in the forest and
merge them
A
6
B
4
C
4
G H
T1
1 2
T1 now represents the meta symbol ‘GH’ What is the count associated with T1?
A. Max(count (G), count (H)) B. (count (G) + count (H))/2 C. (count (G) + count (H))





























