Embed Size (px)
Citation preview

CSE 490/590, Spring 2011
CSE 490/590 Computer Architecture
ISAs and MIPS
Steve KoComputer Sciences and Engineering
University at Buffalo

CSE 490/590, Spring 2011 2
Last Time…• Computer Architecture >> ISAs and RTL• Comp. Arch. shaped by technology and applications• Computer Architecture brings a quantitative approach
to the table– 5 quantitative principles of design
• The current performance trend shows that – Latency lags behind bandwidth

CSE 490/590, Spring 2011 3
Instruction Set Architecture (ISA)
• The contract between software and hardware• Typically described by giving all the programmer-
visible state (registers + memory) plus the semantics of the instructions that operate on that state
• IBM 360 was first line of machines to separate ISA from implementation (aka. microarchitecture)
• Many implementations possible for a given ISA– E.g., today you can buy AMD or Intel processors that run the x86-
64 ISA.– E.g.2: many cellphones use the ARM ISA with implementations
from many different companies including TI, Qualcomm, Samsung, Marvell, etc.
– E.g.3., the Soviets build code-compatible clones of the IBM360, as did Amdhal after he left IBM.

CSE 490/590, Spring 2011 4
ISA to Microarchitecture Mapping• ISA often designed with particular microarchitectural style
in mind, e.g.,– CISC microcoded– RISC hardwired, pipelined– VLIW fixed-latency in-order parallel pipelines– JVM software interpretation
• But can be implemented with any microarchitectural style– Intel Nehalem: hardwired pipelined CISC (x86)
machine (with some microcode support)– Intel could implement a dynamically scheduled out-
of-order VLIW Itanium (IA-64) processor– ARM Jazelle: A hardware JVM processor
CSE 490/590, Spring 2011 5
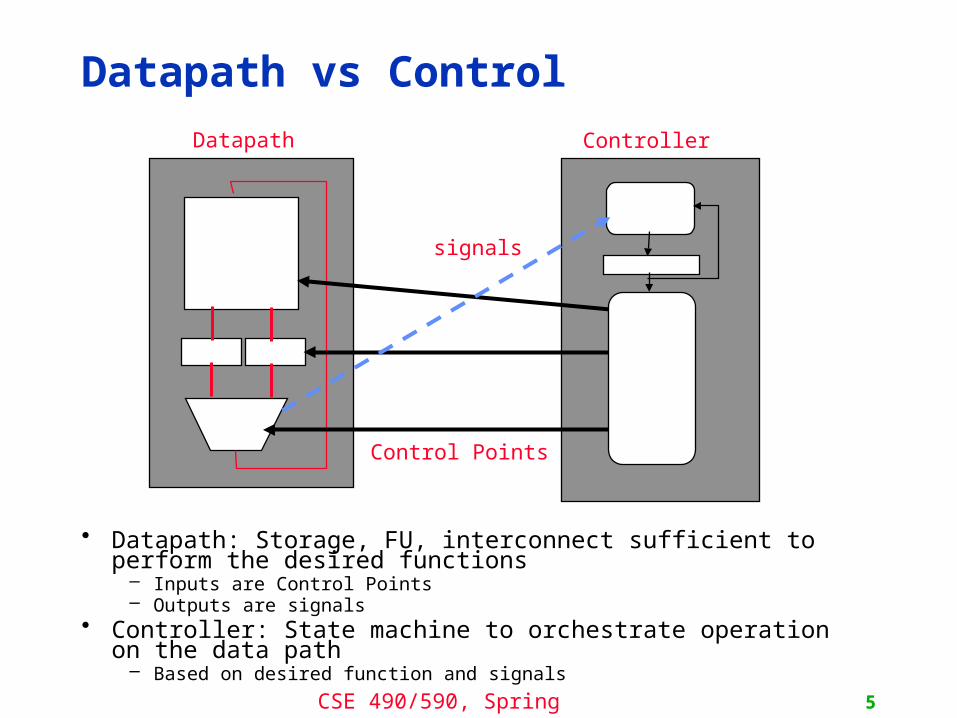
Datapath vs Control
• Datapath: Storage, FU, interconnect sufficient to perform the desired functions
– Inputs are Control Points– Outputs are signals
• Controller: State machine to orchestrate operation on the data path– Based on desired function and signals
Datapath Controller
Control Points
signals
CSE 490/590, Spring 2011 6
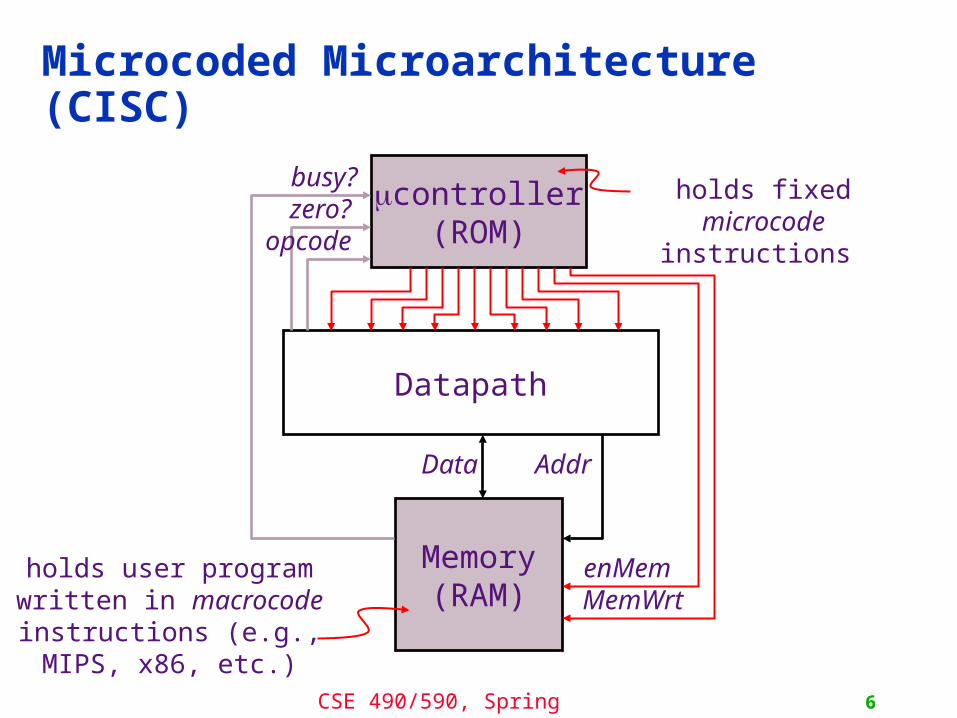
Microcoded Microarchitecture (CISC)
Memory(RAM)
Datapath
mcontroller(ROM)
AddrData
zero?busy?
opcode
enMemMemWrt
holds fixedmicrocode instructions
holds user program written in macrocode
instructions (e.g., MIPS, x86, etc.)
CSE 490/590, Spring 2011
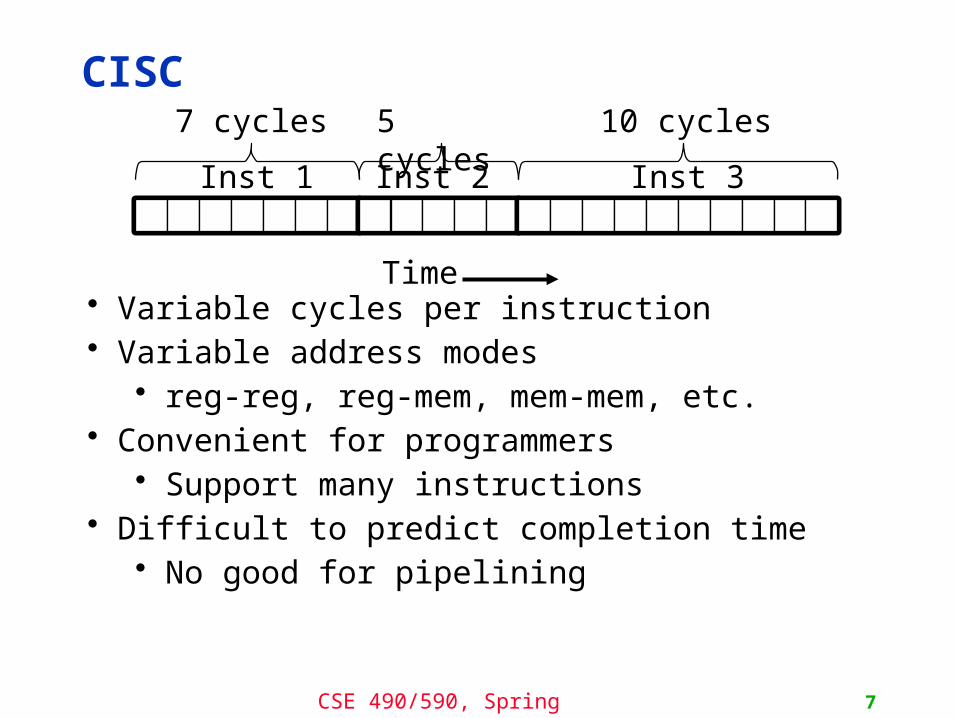
Inst 3
CISC
7
7 cycles
Inst 1 Inst 2
5 cycles 10 cycles
Time• Variable cycles per instruction• Variable address modes
• reg-reg, reg-mem, mem-mem, etc.• Convenient for programmers
• Support many instructions• Difficult to predict completion time
• No good for pipelining
CSE 490/590, Spring 2011 8
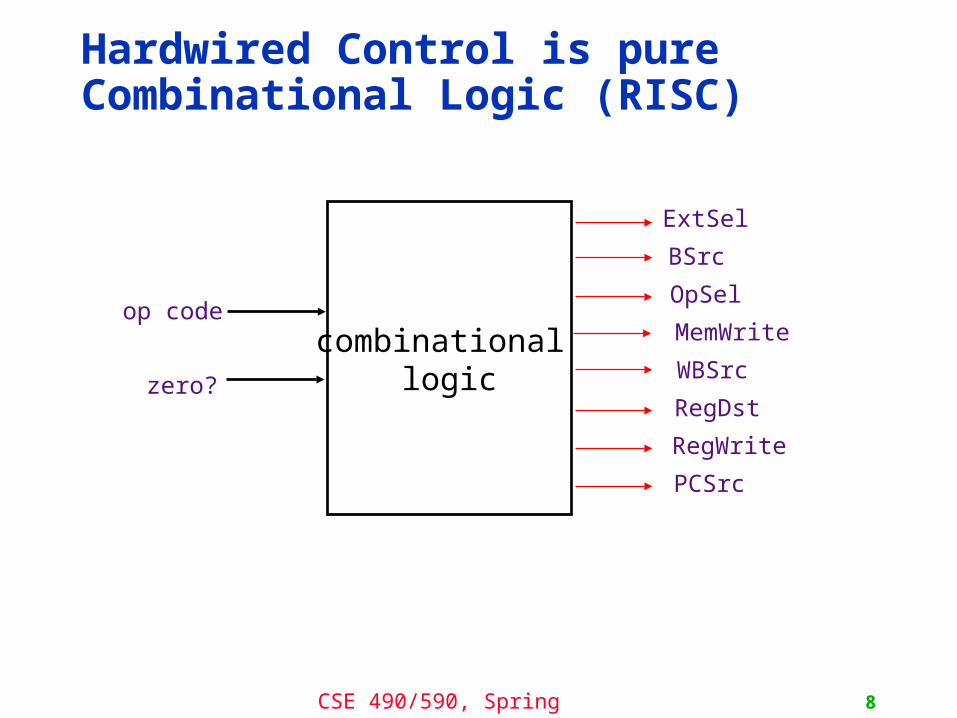
Hardwired Control is pure Combinational Logic (RISC)
combinational logic
op code
zero?
ExtSel
BSrc
OpSel
MemWrite
WBSrc
RegDst
RegWrite
PCSrc

CSE 490/590, Spring 2011 9
A "Typical" RISC ISA
• 32-bit fixed format instruction (3 formats)• 32 32-bit GPR (R0 contains zero, DP take pair)• 3-address, reg-reg arithmetic instruction• Single address mode for load/store:
base + displacement– no indirection
• Simple branch conditions• Delayed branch• Designed for use by compilers & pipelining
see: SPARC, MIPS, HP PA-Risc, DEC Alpha, IBM PowerPC, CDC 6600, CDC 7600, Cray-1, Cray-2, Cray-3

CSE 490/590, Spring 2011 10
Example: MIPS
Op
31 26 01516202125
Rs1 Rd immediate
Op
31 26 025
Op
31 26 01516202125
Rs1 Rs2
target
Rd Opx
Register-Register
561011
Register-Immediate
Op
31 26 01516202125
Rs1 Rs2/Opx immediate
Branch
Jump / Call
CSE 490/590, Spring 2011
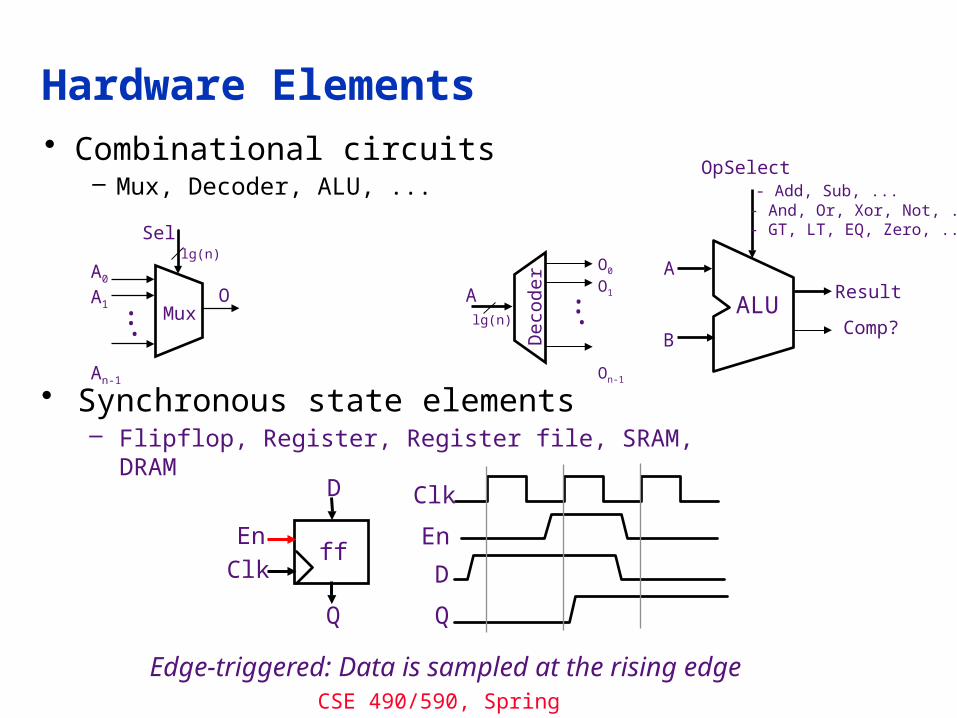
Hardware Elements• Combinational circuits
– Mux, Decoder, ALU, ...
• Synchronous state elements– Flipflop, Register, Register file, SRAM, DRAM
Edge-triggered: Data is sampled at the rising edge
Clk
D
Q
Enff
Q
D
Clk
En
OpSelect - Add, Sub, ... - And, Or, Xor, Not, ... - GT, LT, EQ, Zero, ...
Result
Comp?
A
B
ALU
Sel
OA0
A1
An-1
Mux...
lg(n)
A
Deco
der
...
O0
O1
On-1
lg(n)
CSE 490/590, Spring 2011 12
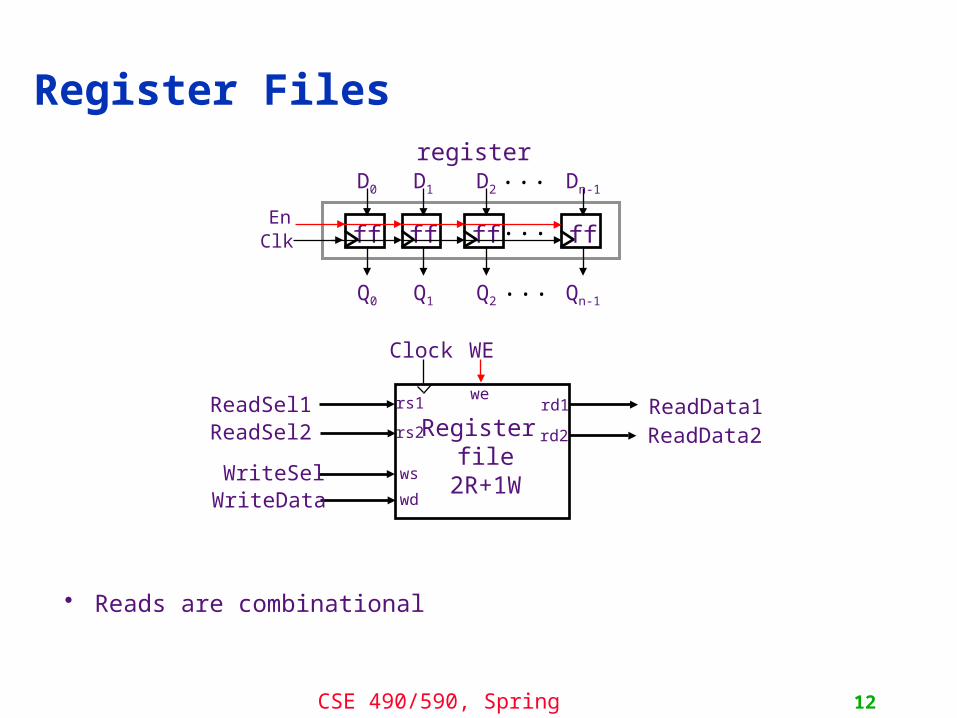
Register Files
ReadData1ReadSel1ReadSel2
WriteSel
Register file
2R+1W
ReadData2
WriteData
WEClock
rd1rs1
rs2
ws
wd
rd2
we
• Reads are combinational
ff
Q0
D0
ClkEn
ff
Q1
D1
ff
Q2
D2
ff
Qn-1
Dn-1
...
...
...
register
CSE 490/590, Spring 2011 13
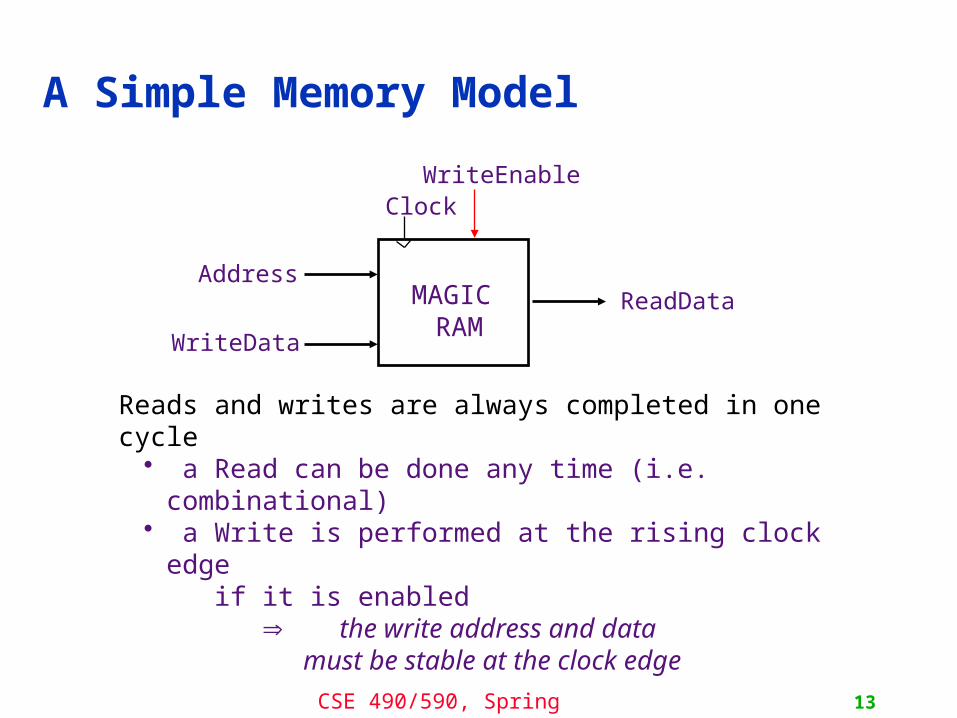
A Simple Memory Model
MAGIC RAM
ReadData
WriteData
Address
WriteEnableClock
Reads and writes are always completed in one cycle• a Read can be done any time (i.e. combinational)• a Write is performed at the rising clock edge
if it is enabled the write address and data must be stable at the clock edge
CSE 490/590, Spring 2011 14
CSE 490/590 Administrivia
• Please check the web page: http://www.cse.buffalo.edu/~stevko/courses/cse490/spring11
• Don’t forget– Recitations start from this week.– Please purchase a BASYS2 board (100K) as soon as possible.– Projects should be done individually.
• Please read the syllabus webpage.• I have no idea how fast/slow I’m going.
– Please stop me if too fast!

CSE 490/590, Spring 2011 15
Implementing MIPS:
Single-cycle per instructiondatapath & control logic

CSE 490/590, Spring 2011 16
The MIPS ISAProcessor State
32 32-bit GPRs, R0 always contains a 032 single precision FPRs, may also be viewed as
16 double precision FPRsFP status register, used for FP compares & exceptionsPC, the program countersome other special registers
Data types8-bit byte, 16-bit half word 32-bit word for integers32-bit word for single precision floating point64-bit word for double precision floating point
Load/Store style instruction setdata addressing modes- immediate & indexedbranch addressing modes- PC relative & register indirectByte addressable memory- big endian mode
All instructions are 32 bits

CSE 490/590, Spring 2011 17
Example: MIPS
Op
31 26 01516202125
Rs1 Rd immediate
Op
31 26 025
Op
31 26 01516202125
Rs1 Rs2
target
Rd Opx
Register-Register
561011
Register-Immediate
Op
31 26 01516202125
Rs1 Rs2/Opx immediate
Branch
Jump / Call

CSE 490/590, Spring 2011 18
Instruction Execution
Execution of an instruction involves
1. instruction fetch2. decode and register fetch3. ALU operation4. memory operation (optional)5. write back
and the computation of the address of the next instruction
CSE 490/590, Spring 2011 19
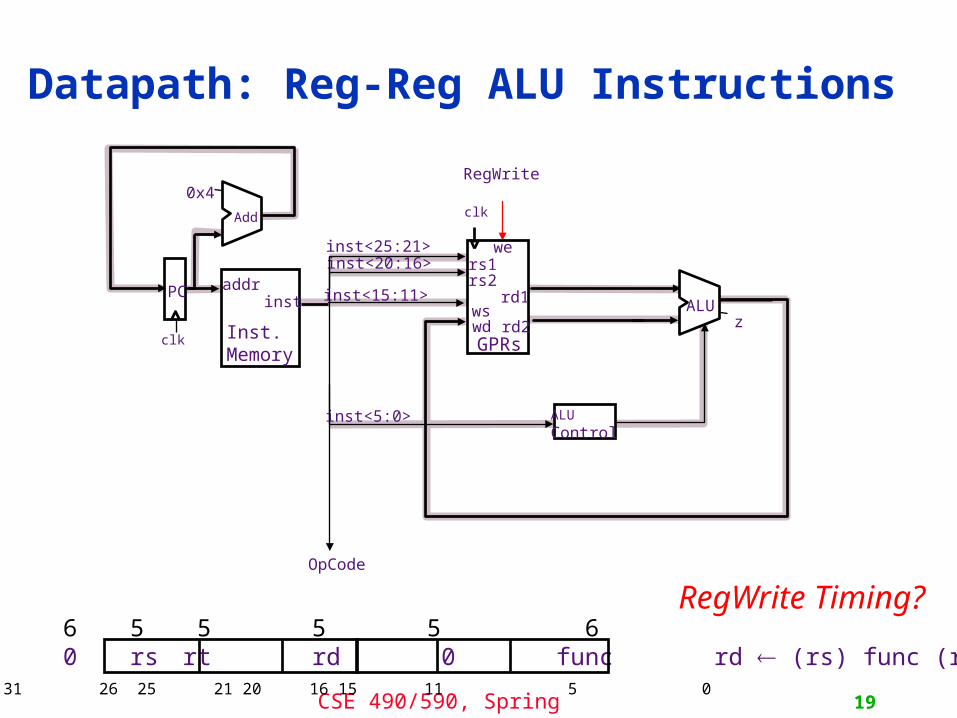
Datapath: Reg-Reg ALU Instructions
RegWrite Timing? 6 5 5 5 5 6 0 rs rt rd 0 func rd (rs) func (rt)
31 26 25 21 20 16 15 11 5 0
0x4
Add
clk
addrinst
Inst.Memory
PC
inst<25:21>inst<20:16>
inst<15:11>
inst<5:0>
OpCode
zALU
ALU
Control
RegWrite
clk
rd1
GPRs
rs1rs2
wswd rd2
we
CSE 490/590, Spring 2011 20
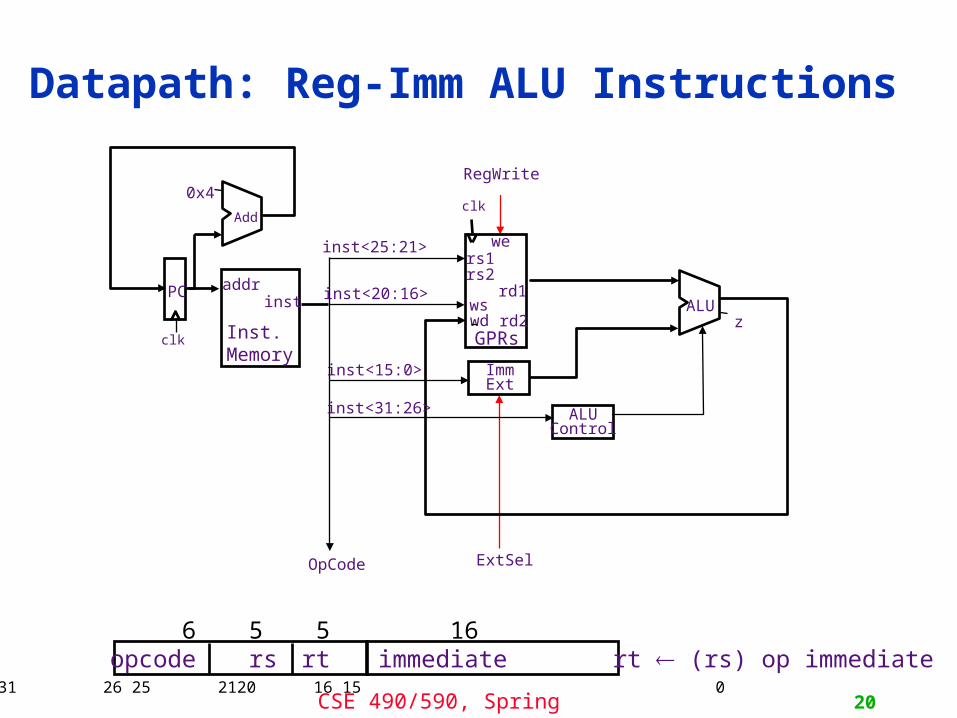
Datapath: Reg-Imm ALU Instructions
6 5 5 16opcode rs rt immediate rt (rs) op immediate31 26 25 2120 16 15 0
ImmExt
ExtSel
inst<15:0>
OpCode
0x4
Add
clk
addrinst
Inst.Memory
PC
zALU
RegWrite
clk
rd1
GPRs
rs1rs2
wswd rd2
weinst<25:21>
inst<20:16>
inst<31:26> ALUControl
CSE 490/590, Spring 2011 21
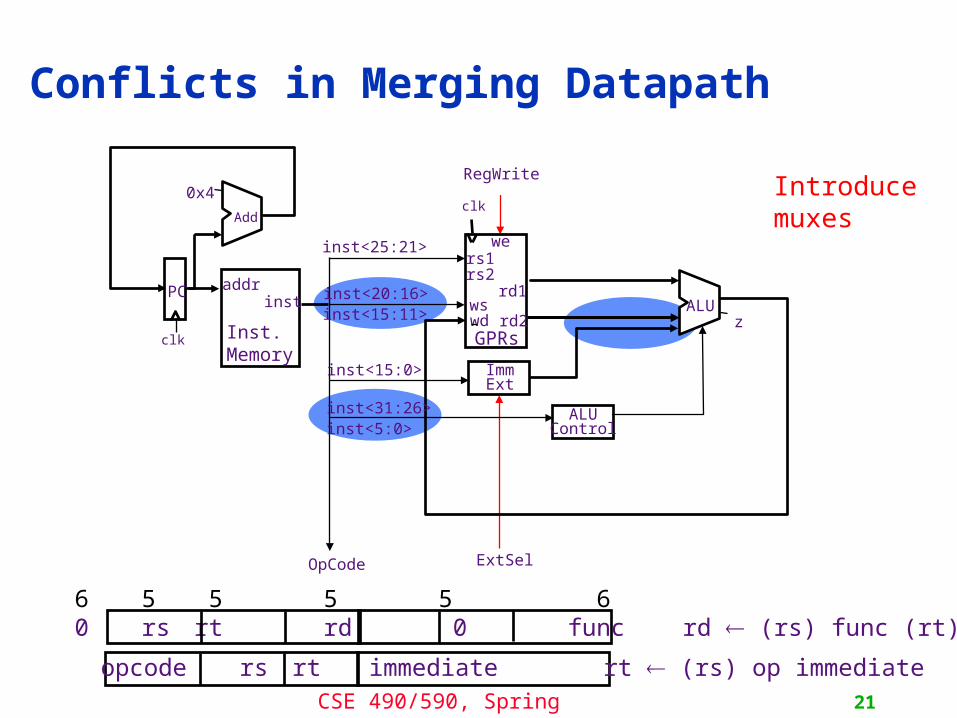
Conflicts in Merging Datapath
ImmExt
ExtSelOpCode
0x4
Add
clk
addrinst
Inst.Memory
PC
zALU
RegWrite
clk
rd1
GPRs
rs1rs2
wswd rd2
weinst<25:21>
inst<20:16>
inst<15:0>
inst<31:26> ALUControl
inst<15:11>
inst<5:0>
opcode rs rt immediate rt (rs) op immediate
6 5 5 5 5 6 0 rs rt rd 0 func rd (rs) func (rt)
Introducemuxes
CSE 490/590, Spring 2011 22
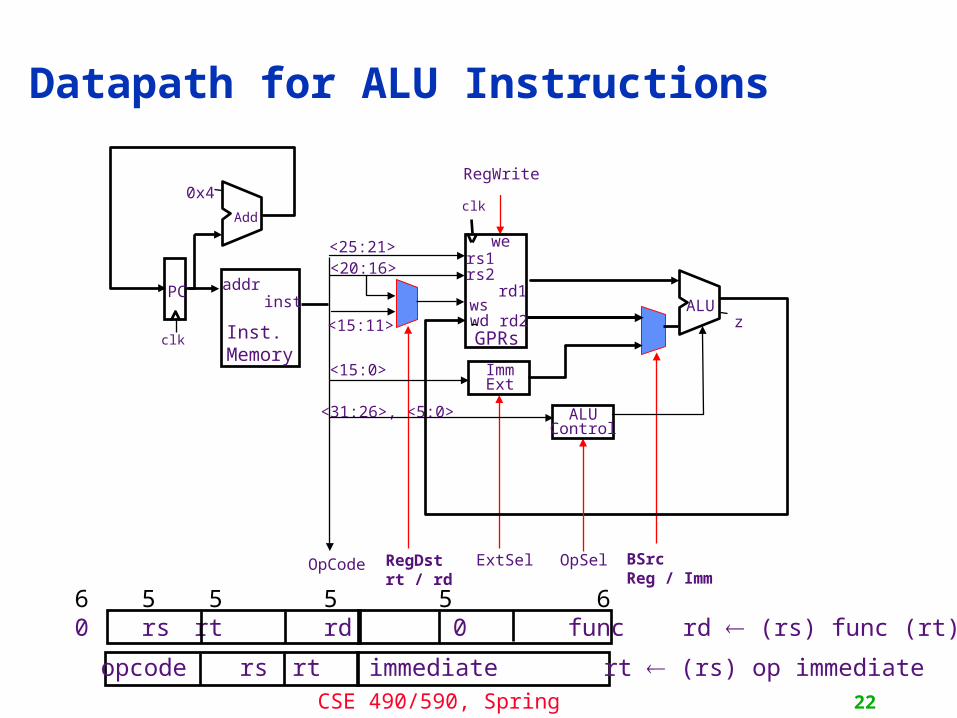
Datapath for ALU Instructions
<31:26>, <5:0>
opcode rs rt immediate rt (rs) op immediate
6 5 5 5 5 6 0 rs rt rd 0 func rd (rs) func (rt)
BSrcReg / Imm
RegDstrt / rd
ImmExt
ExtSelOpCode
0x4
Add
clk
addrinst
Inst.Memory
PC
zALU
RegWrite
clk
rd1
GPRs
rs1rs2
wswd rd2
we<25:21><20:16>
<15:0>
OpSel
ALUControl
<15:11>

CSE 490/590, Spring 2011 23
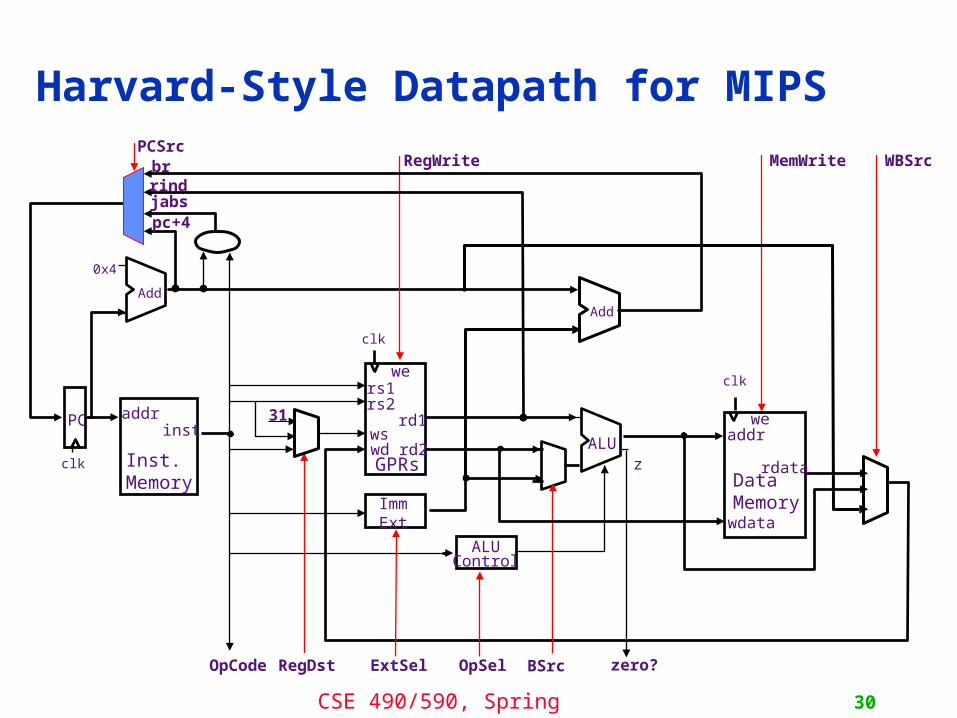
Datapath for Memory InstructionsShould program and data memory be separate?
Harvard style: separate (Aiken and Mark 1 influence)- read-only program memory
- read/write data memory
- Note:Somehow there must be a way to load theprogram memory
Princeton style: the same (von Neumann’s influence)- single read/write memory for program and data
- Note: A Load or Store instruction requires accessing the memory more than once during its execution
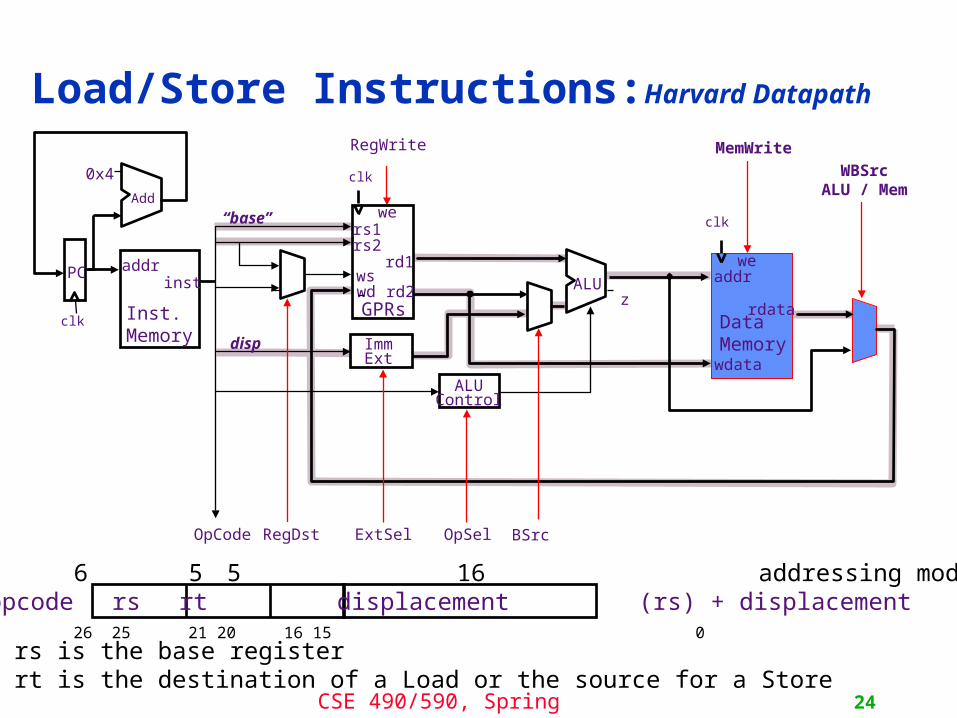
CSE 490/590, Spring 2011 24
Load/Store Instructions:Harvard Datapath
WBSrcALU / Mem
rs is the base registerrt is the destination of a Load or the source for a Store
6 5 5 16 addressing modeopcode rs rt displacement (rs) + displacement31 26 25 21 20 16 15 0
RegDst BSrc
“base”
disp
ExtSelOpCode OpSel
ALUControl
zALU
0x4
Add
clk
addrinst
Inst.Memory
PC
RegWrite
clk
rd1
GPRs
rs1rs2
wswd rd2
we
ImmExt
clk
MemWrite
addr
wdata
rdataData Memory
we

CSE 490/590, Spring 2011 25
MIPS Control Instructions
Conditional (on GPR) PC-relative branch
Unconditional register-indirect jumps
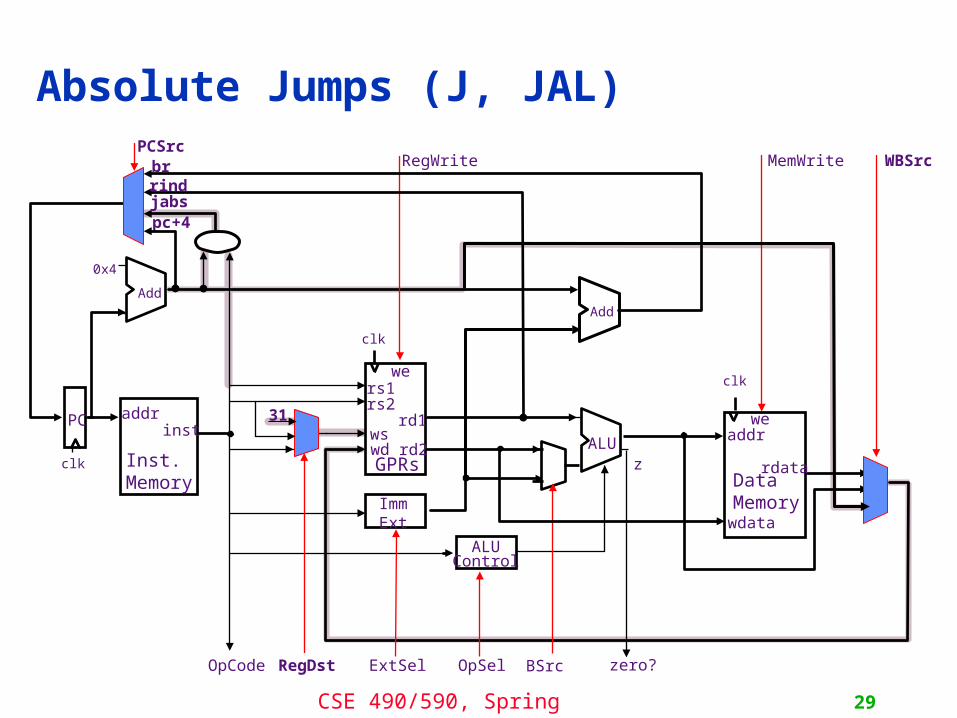
Unconditional absolute jumps
• PC-relative branches add offset4 to PC+4 to calculate the target address (offset is in words): 128 KB range
• Absolute jumps append target4 to PC<31:28> to calculate the target address: 256 MB range
• jump-&-link stores PC+4 into the link register (R31)• All Control Transfers are delayed by 1 instruction
we will worry about the branch delay slot later
6 5 5 16opcode rs offset BEQZ, BNEZ
6 26opcode target J, JAL
6 5 5 16opcode rs JR, JALR
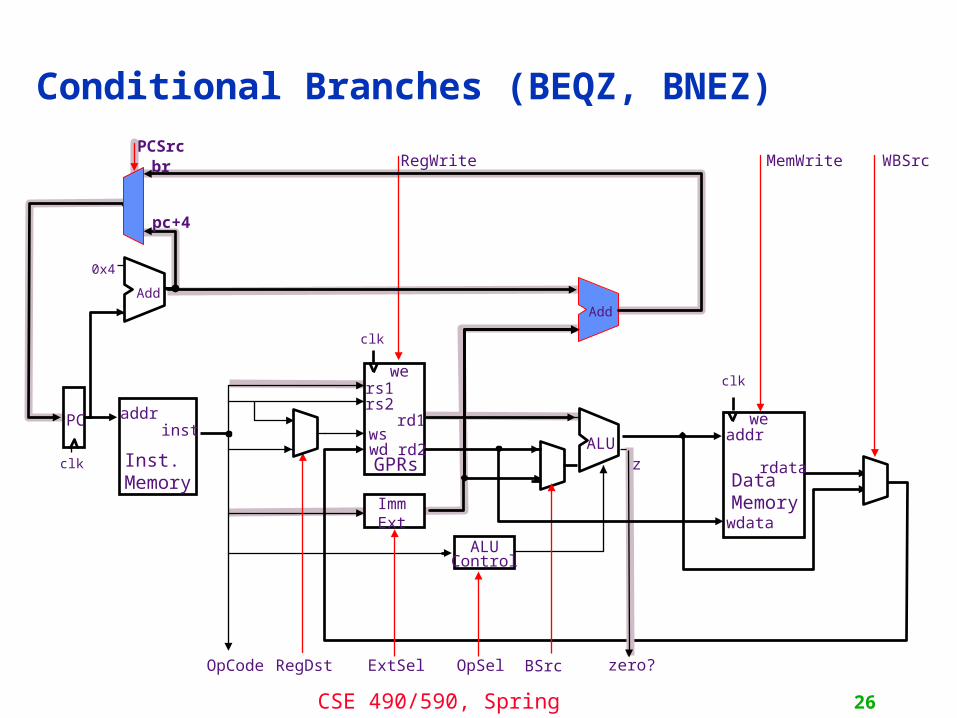
CSE 490/590, Spring 2011 26
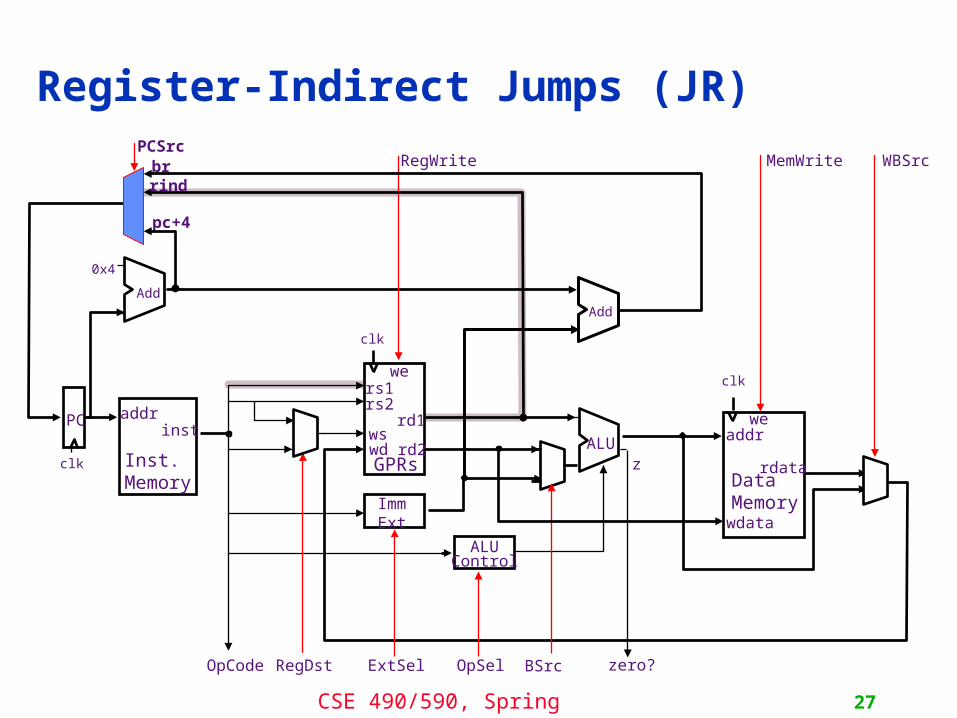
Conditional Branches (BEQZ, BNEZ)
0x4
Add
PCSrc
clk
WBSrcMemWrite
addr
wdata
rdataData Memory
we
RegDst BSrcExtSelOpCode
z
OpSel
clk
zero?
clk
addrinst
Inst.Memory
PC rd1
GPRs
rs1rs2
wswd rd2
we
ImmExt
ALU
ALUControl
Add
br
pc+4
RegWrite
CSE 490/590, Spring 2011 27
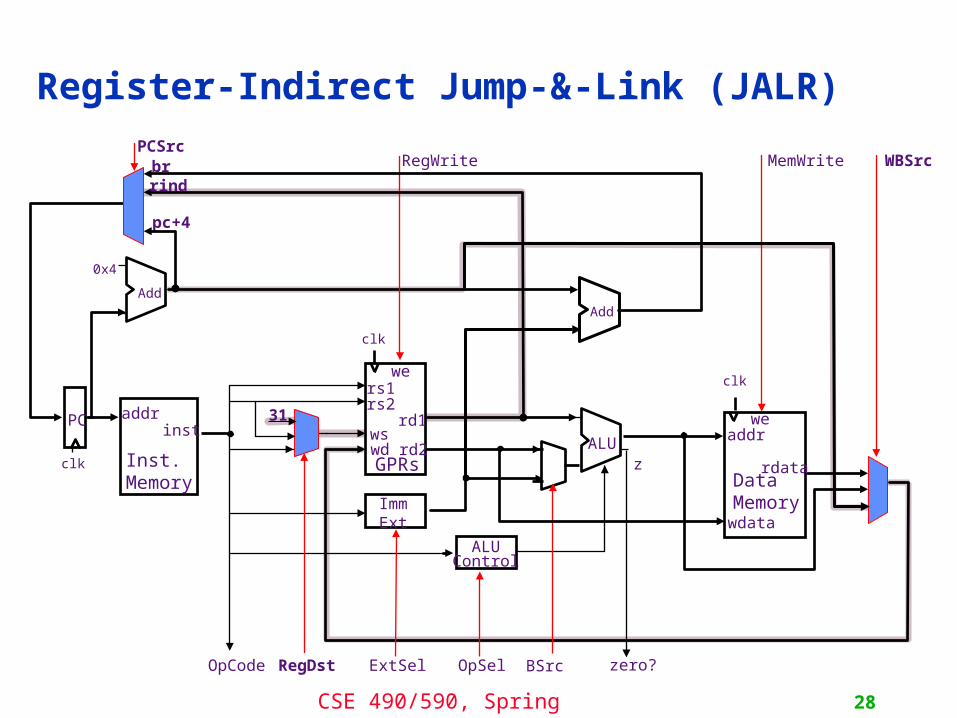
Register-Indirect Jumps (JR)
0x4
RegWrite
Add
Add
clk
WBSrcMemWrite
addr
wdata
rdataData Memory
we
RegDst BSrcExtSelOpCode
z
OpSel
clk
zero?
clk
addrinst
Inst.Memory
PC rd1
GPRs
rs1rs2
wswd rd2
we
ImmExt
ALU
ALUControl
PCSrcbr
pc+4
rind
CSE 490/590, Spring 2011 28
Register-Indirect Jump-&-Link (JALR)
0x4
RegWrite
Add
Add
clk
WBSrcMemWrite
addr
wdata
rdataData Memory
we
RegDst BSrcExtSelOpCode
z
OpSel
clk
zero?
clk
addrinst
Inst.Memory
PC rd1
GPRs
rs1rs2
wswd rd2
we
ImmExt
ALU
ALUControl
31
PCSrcbr
pc+4
rind
CSE 490/590, Spring 2011 29
Absolute Jumps (J, JAL)
0x4
RegWrite
Add
Add
clk
WBSrcMemWrite
addr
wdata
rdataData Memory
we
RegDst BSrcExtSelOpCode
z
OpSel
clk
zero?
clk
addrinst
Inst.Memory
PC rd1
GPRs
rs1rs2
wswd rd2
we
ImmExt
ALU
ALUControl
31
PCSrcbr
pc+4
rindjabs
CSE 490/590, Spring 2011 30
Harvard-Style Datapath for MIPS
0x4
RegWrite
Add
Add
clk
WBSrcMemWrite
addr
wdata
rdataData Memory
we
RegDst BSrcExtSelOpCode
z
OpSel
clk
zero?
clk
addrinst
Inst.Memory
PC rd1
GPRs
rs1rs2
wswd rd2
we
ImmExt
ALU
ALUControl
31
PCSrcbrrindjabspc+4

CSE 490/590, Spring 2011 31
Single-Cycle Hardwired Control:Harvard architecture
We will assume • clock period is sufficiently long for all of
the following steps to be “completed”:
1. instruction fetch2. decode and register fetch3. ALU operation4. data fetch if required5. register write-back setup time
tC > tIFetch + tRFetch + tALU+ tDMem+ tRWB
• At the rising edge of the following clock, the PC, the register file and the memory are updated
CSE 490/590, Spring 2011 32
An Ideal Pipeline
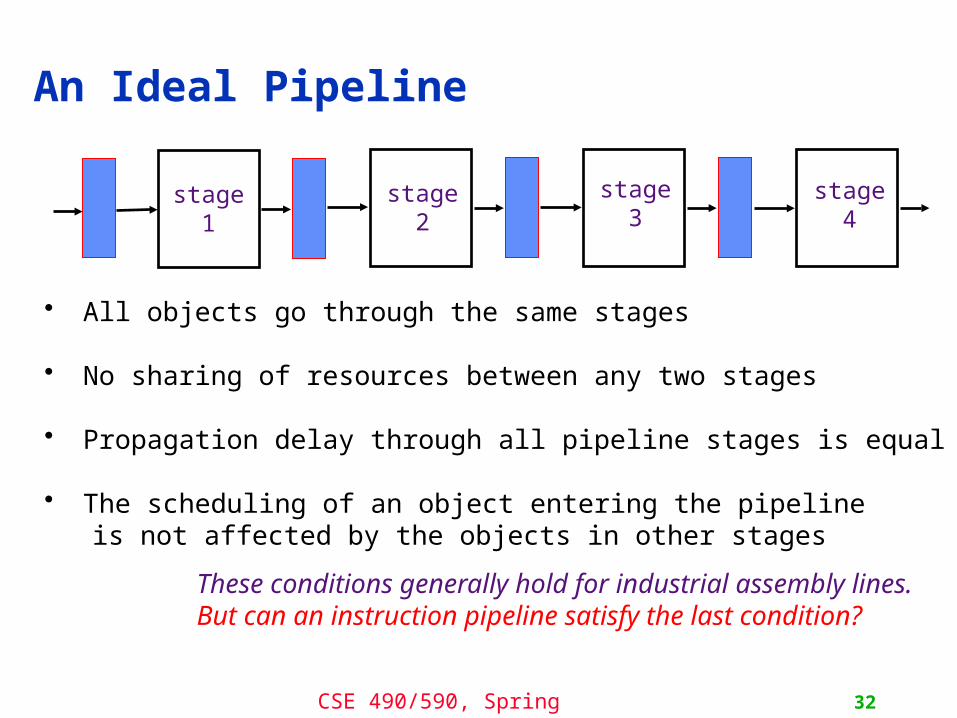
• All objects go through the same stages
• No sharing of resources between any two stages
• Propagation delay through all pipeline stages is equal
• The scheduling of an object entering the pipeline is not affected by the objects in other stages
stage1
stage2
stage3
stage4
These conditions generally hold for industrial assembly lines. But can an instruction pipeline satisfy the last condition?

CSE 490/590, Spring 2011 33
Acknowledgements
• These slides heavily contain material developed and copyright by
– Krste Asanovic (MIT/UCB)– David Patterson (UCB)
• And also by:– Arvind (MIT)– Joel Emer (Intel/MIT)– James Hoe (CMU)– John Kubiatowicz (UCB)
• MIT material derived from course 6.823• UCB material derived from course CS252





























