Embed Size (px)
Citation preview

CUDACUDA
Paulo Ivson Netto Santos
Waldemar Celes Filho
Nov 2007
All you wanted to know about it, but was afraid to ask!

CUDA is aimed at CUDA is aimed at GPGPUGPGPU

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
What is GPGPU ?What is GPGPU ?
General Purpose computation using GPU– Applications other than 3D graphics– GPU accelerates critical path of application
Data parallel algorithms leverage GPU attributes– Large data arrays, streaming throughput– Fine-grain SIMD parallelism– Floating point (FP) computation
Applications – see //GPGPU.org– Game effects (FX) physics, image processing– Physical modeling, computational engineering, matrix
algebra, convolution, correlation, sorting, etc, etc

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Importance of Data ParallelismImportance of Data Parallelism
GPUs are designed for graphics– Highly parallel tasks
Data-parallel processing– GPUs architecture is ALU-heavy
Multiple pipelines, multiple ALUs per pipe
– Large memory latency– HUGE memory bandwidth– Hide memory latency (with more computation)

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CPU vs GPU CPU vs GPU Design Strategies and TacticsDesign Strategies and Tactics
CPU Strategy: Make a few threads run fast– Tactics – minimize latency
Big Cache – build for hit Instruction/Data Prefetch Speculative Execution limited by “perimeter” – communication bandwidth
GPU Strategy: Make many threads run fast– Tactics – maximize throughput
Small Cache – build for miss Parallelism (1000s of threads) Pipelining limited by “area” – compute capability

What a GPU looks like?What a GPU looks like?
from graphics point of view
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
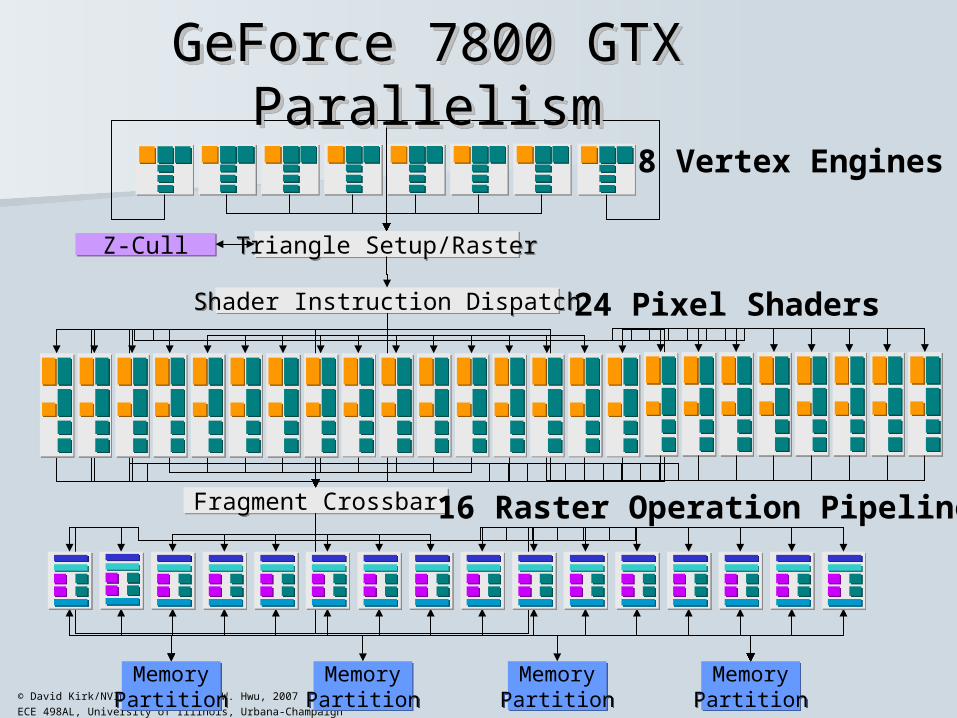
Triangle Setup/RasterTriangle Setup/Raster
Shader Instruction DispatchShader Instruction Dispatch
Fragment CrossbarFragment Crossbar
MemoryPartitionMemoryPartition
MemoryPartitionMemoryPartition
MemoryPartitionMemoryPartition
MemoryPartitionMemoryPartition
Z-CullZ-Cull
8 Vertex Engines
24 Pixel Shaders
16 Raster Operation Pipelines
GeForce 7800 GTX ParallelismGeForce 7800 GTX ParallelismGeForce 7800 GTX ParallelismGeForce 7800 GTX Parallelism

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
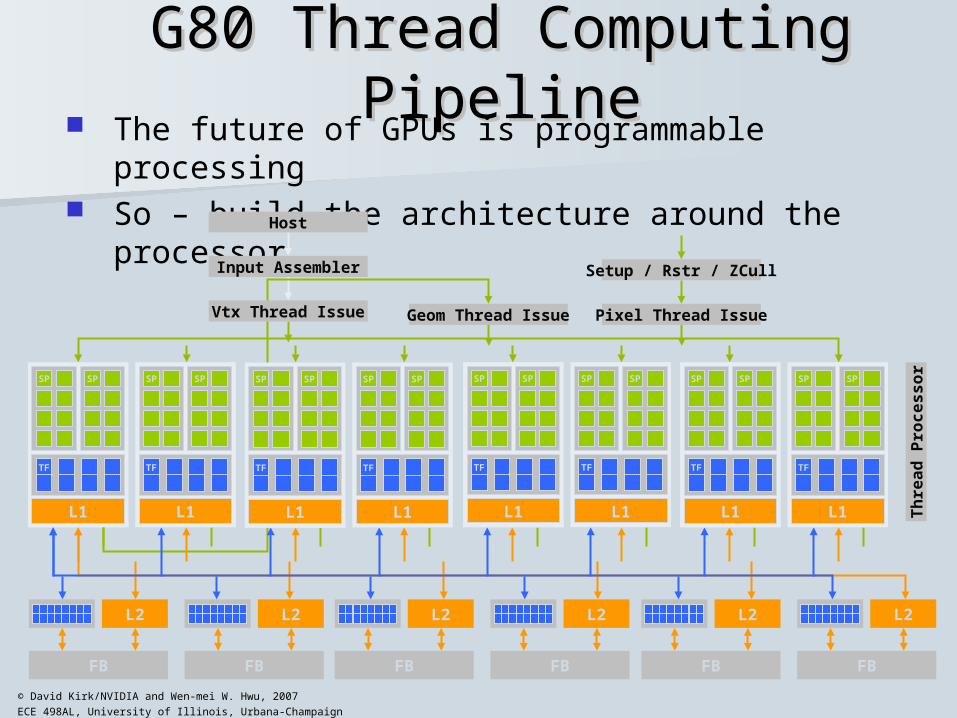
G80 replaces the pipeline modelG80 replaces the pipeline model The future of GPUs is programmable processing So – build the architecture around the processor
L2
FB
SP SP
L1
TF
Th
rea
d P
roc
es
so
r
Vtx Thread Issue
Setup / Rstr / ZCull
Geom Thread Issue Pixel Thread Issue
Data Assembler
Host
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
L2
FB
L2
FB
L2
FB
L2
FB
L2
FB

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Work Distribution for GraphicsWork Distribution for Graphics
Vertices are serially distributed to all the SM’s SPA processes vertices in parallel Vertices are serially gathered from the SM’s
– And sent to Primitive Setup
Pixels are serially distributed in parallel tiles SPA processes pixels in parallel Pixels are sent to ROP/FB
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
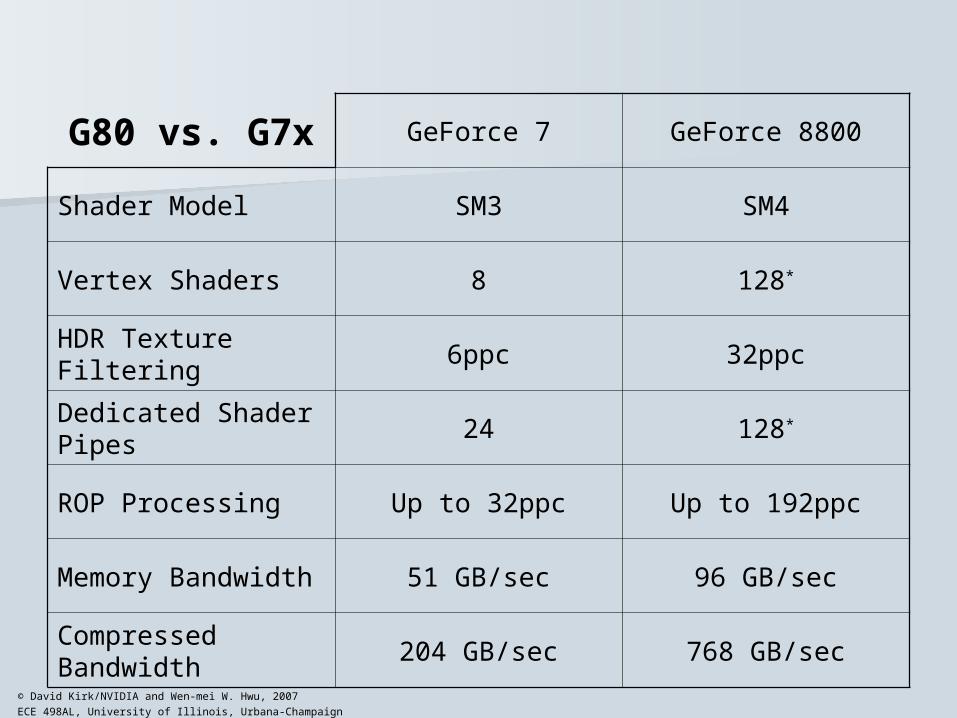
G80 vs. G7x GeForce 7 GeForce 8800
Shader Model SM3 SM4
Vertex Shaders 8 128*
HDR Texture Filtering 6ppc 32ppc
Dedicated Shader Pipes
24 128*
ROP Processing Up to 32ppc Up to 192ppc
Memory Bandwidth 51 GB/sec 96 GB/sec
Compressed Bandwidth
204 GB/sec 768 GB/sec

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Common GPGPU ConstraintsCommon GPGPU Constraints Dealing with graphics API
– Working with the corner cases of the graphics API Addressing modes
– Limited texture size/dimension Shader capabilities
– Limited outputs Instruction sets
– Lack of Integer & bit ops Communication limited
– Between pixels– Scatter a[i] = p

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Just what is CUDA anyway?Just what is CUDA anyway? “Compute Unified Device Architecture” General purpose programming model
– User kicks off batches of threads on the GPU– GPU is viewed as a dedicated super-threaded co-processor
Targeted software stack– Compute oriented drivers, language, and tools
Driver for loading computation programs into GPU– Standalone driver - optimized for computation – Interface designed for compute - graphics free API– Data sharing with OpenGL buffer objects – Guaranteed maximum download & readback speeds– Explicit GPU memory management– Debugging support on the CPU!
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
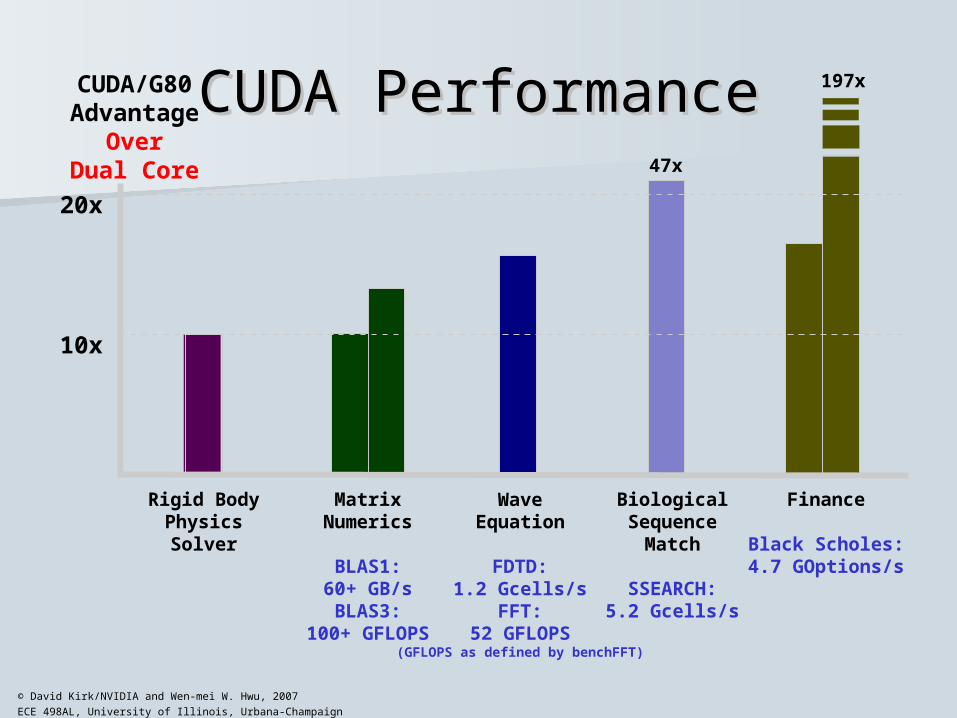
CUDA PerformanceCUDA PerformanceCUDA/G80Advantage
OverDual Core
Rigid BodyPhysicsSolver
10x
20x
47x
197x
MatrixNumerics
BLAS1:60+ GB/sBLAS3:
100+ GFLOPS
WaveEquation
FDTD:1.2 Gcells/s
FFT:52 GFLOPS
(GFLOPS as defined by benchFFT)
BiologicalSequence
Match
SSEARCH:5.2 Gcells/s
Finance
Black Scholes:4.7 GOptions/s

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
GPU: A Highly Multithreaded CoprocessorGPU: A Highly Multithreaded Coprocessor
The GPU is viewed as a compute device that:– Is a coprocessor to the CPU or host– Has its own DRAM (device memory)– Runs many threads in parallel
Identify data-parallel portions of an application Execute them on the device as kernels
– Which run in parallel on many threads Differences between GPU and CPU threads
– GPU threads are extremely lightweight Very little creation overhead
– GPU needs 1000s of threads for full efficiency Multi-core CPU needs only a few
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
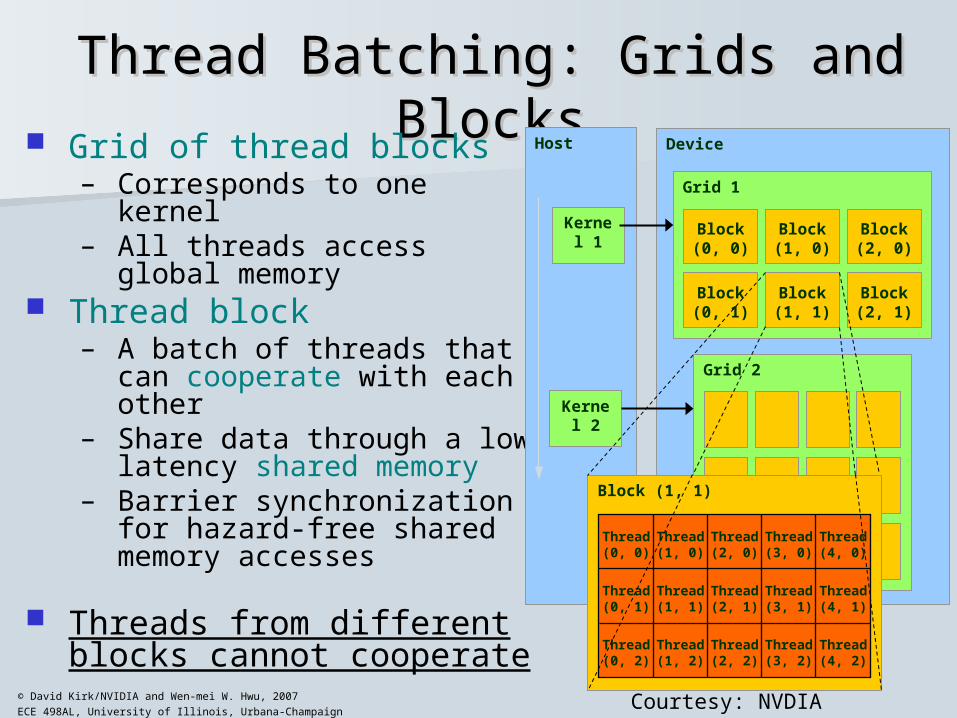
Thread Batching: Grids and BlocksThread Batching: Grids and Blocks Grid of thread blocks
– Corresponds to one kernel– All threads access global
memory Thread block
– A batch of threads that can cooperate with each other
– Share data through a low latency shared memory
– Barrier synchronization for hazard-free shared memory accesses
Threads from different blocks cannot cooperate
Host
Kernel 1
Kernel 2
Device
Grid 1
Block(0, 0)
Block(1, 0)
Block(2, 0)
Block(0, 1)
Block(1, 1)
Block(2, 1)
Grid 2
Block (1, 1)
Thread(0, 1)
Thread(1, 1)
Thread(2, 1)
Thread(3, 1)
Thread(4, 1)
Thread(0, 2)
Thread(1, 2)
Thread(2, 2)
Thread(3, 2)
Thread(4, 2)
Thread(0, 0)
Thread(1, 0)
Thread(2, 0)
Thread(3, 0)
Thread(4, 0)
Courtesy: NVDIA

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Block and Thread IDsBlock and Thread IDs
Threads and blocks have IDs– Each thread can decide
what data to work on– Block ID: 1D or 2D– Thread ID: 1D, 2D, or 3D
Multidimensional data– Image processing– Solving PDEs on volumes– …
Device
Grid 1
Block(0, 0)
Block(1, 0)
Block(2, 0)
Block(0, 1)
Block(1, 1)
Block(2, 1)
Block (1, 1)
Thread(0, 1)
Thread(1, 1)
Thread(2, 1)
Thread(3, 1)
Thread(4, 1)
Thread(0, 2)
Thread(1, 2)
Thread(2, 2)
Thread(3, 2)
Thread(4, 2)
Thread(0, 0)
Thread(1, 0)
Thread(2, 0)
Thread(3, 0)
Thread(4, 0)
Courtesy: NVDIA
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
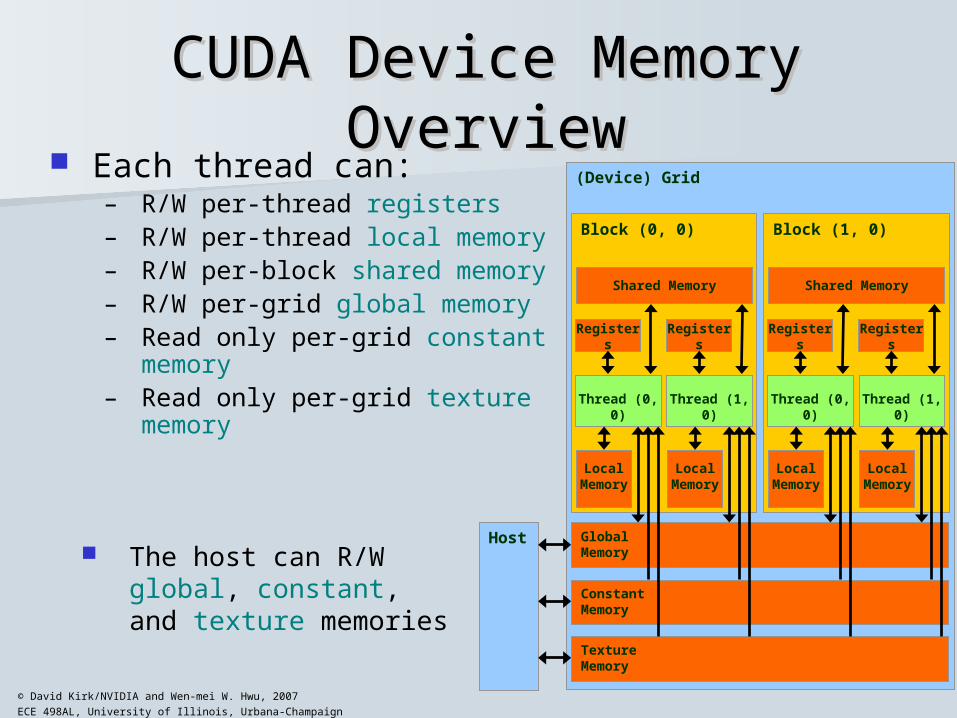
CUDA Device Memory CUDA Device Memory OverviewOverview
Each thread can:– R/W per-thread registers– R/W per-thread local memory– R/W per-block shared memory– R/W per-grid global memory– Read only per-grid constant
memory– Read only per-grid texture
memory
(Device) Grid
ConstantMemory
TextureMemory
GlobalMemory
Block (0, 0)
Shared Memory
LocalMemory
Thread (0, 0)
Registers
LocalMemory
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
LocalMemory
Thread (0, 0)
Registers
LocalMemory
Thread (1, 0)
Registers
Host The host can R/W global,
constant, and texture memories

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Global, Constant, and Texture Global, Constant, and Texture MemoriesMemories
Global memory– Communicating data
between host and device
– Visible to all threads Texture and
Constant memories– Read-only data
initialized by host – Visible to all threads
(Device) Grid
ConstantMemory
TextureMemory
GlobalMemory
Block (0, 0)
Shared Memory
LocalMemory
Thread (0, 0)
Registers
LocalMemory
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
LocalMemory
Thread (0, 0)
Registers
LocalMemory
Thread (1, 0)
Registers
Host
Courtesy: NVDIA

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
A Common Programming PatternA Common Programming Pattern
Local and global memory reside in DRAM– Much slower access than shared memory
Profitable way of performing computation– Block data and computation to take advantage of
fast shared memory– Partition data into data subsets that fit into shared
memory– Handle each data subset with one thread block by:
Loading the subset from global memory to shared memory, using multiple threads to exploit memory-level parallelism
Performing the computation on the subset from shared memory; each thread can efficiently multi-pass over any data element
Copying results from shared memory to global memory

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
A Common Programming PatternA Common Programming Pattern
Texture and Constant memory also reside in device memory (DRAM) – Much slower access than shared memory– But… cached!– Highly efficient access for read-only data
Carefully divide data according to access patterns– R/O no structure constant memory– R/O array structured texture memory– R/W shared within Block shared memory– R/W registers spill to local memory– R/W inputs/results global memory

That’s it!That’s it!

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Or not... so many things still Or not... so many things still missing!missing!
1. How to code?• API, SDK, etc
2. How does it actually work in the GPU? • HW details that make all the difference
3. How to get the best of it?• Tips and tricks to get those GFLOPs!

CUDA APICUDA API

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
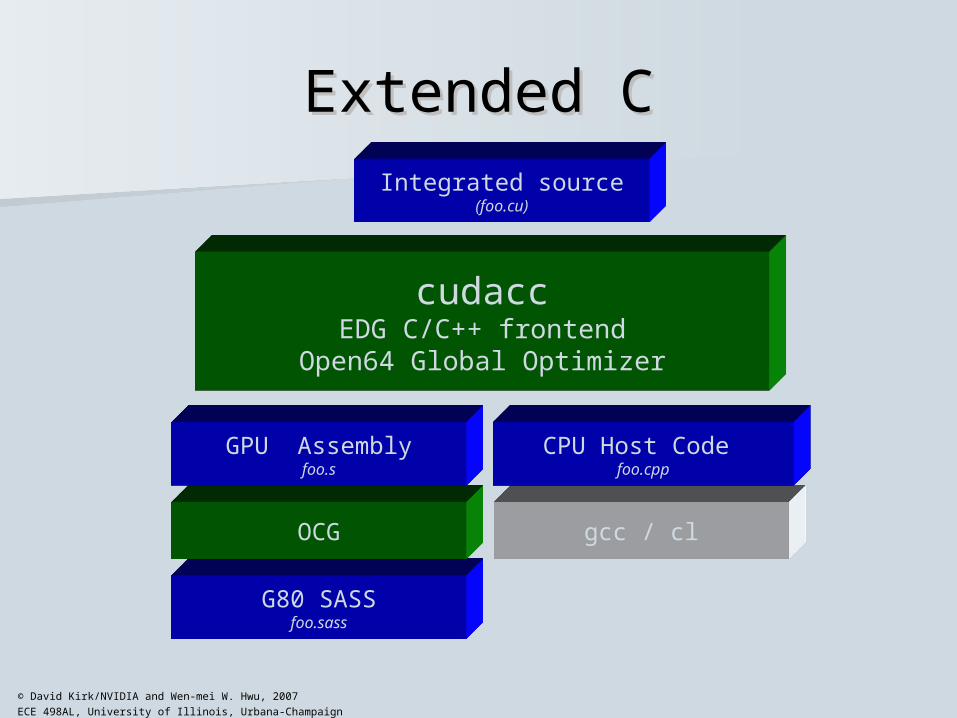
Extended CExtended C Declspecs
– global, device, shared, local, constant
Keywords– threadIdx, blockIdx
Intrinsics– __syncthreads
Runtime API– Memory, symbol,
execution management
Function launch
__device__ float filter[N];
__global__ void convolve (float *image) {
__shared__ float region[M]; ...
region[threadIdx] = image[i]; __syncthreads() ...
image[j] = result;}
// Allocate GPU memoryvoid *myimage = cudaMalloc(bytes)
// 100 blocks, 10 threads per blockconvolve<<<100, 10>>> (myimage);
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
gcc / cl
G80 SASSfoo.sass
OCG
Extended CExtended C
cudaccEDG C/C++ frontend
Open64 Global Optimizer
GPU Assemblyfoo.s
CPU Host Code foo.cpp
Integrated source(foo.cu)
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
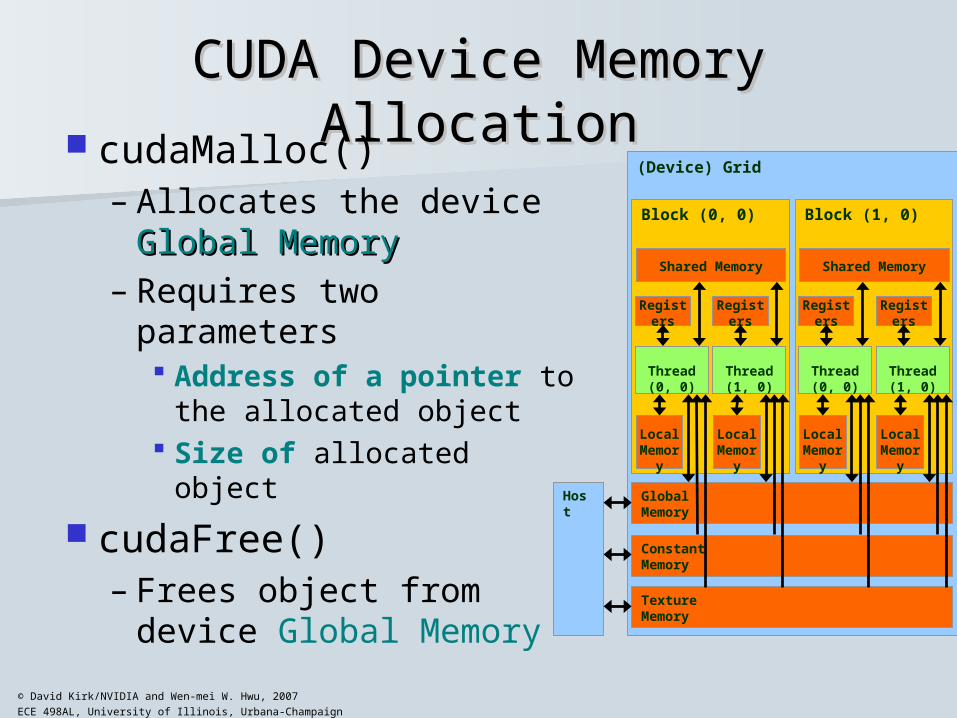
CUDA Device Memory AllocationCUDA Device Memory Allocation cudaMalloc()
– Allocates the device Global MemoryGlobal Memory
– Requires two parameters Address of a pointer to
the allocated object Size of allocated object
cudaFree()– Frees object from device
Global Memory
(Device) Grid
ConstantMemory
TextureMemory
GlobalMemory
Block (0, 0)
Shared Memory
LocalMemor
y
Thread (0, 0)
Registers
LocalMemor
y
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
LocalMemor
y
Thread (0, 0)
Registers
LocalMemor
y
Thread (1, 0)
Registers
Host

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CUDA Device Memory AllocationCUDA Device Memory Allocation
Code example: – Allocate 256 * 256 single precision float array– Use “d” suffix to indicate device data structure
float* elementsd;int size = 256 * 256 * sizeof(float);
cudaMalloc( (void**)&dataOnDevice, size );
cudaFree( dataOnDevice );
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
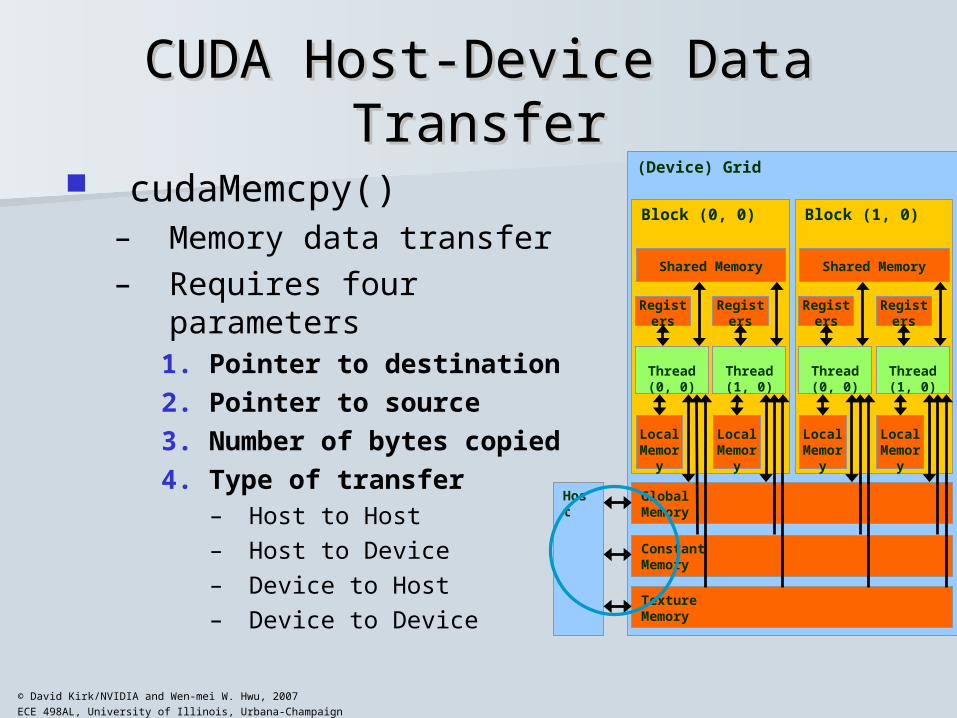
CUDA Host-Device Data TransferCUDA Host-Device Data Transfer
cudaMemcpy()– Memory data transfer– Requires four parameters
1. Pointer to destination
2. Pointer to source
3. Number of bytes copied
4. Type of transfer – Host to Host
– Host to Device
– Device to Host
– Device to Device
(Device) Grid
ConstantMemory
TextureMemory
GlobalMemory
Block (0, 0)
Shared Memory
LocalMemor
y
Thread (0, 0)
Registers
LocalMemor
y
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
LocalMemor
y
Thread (0, 0)
Registers
LocalMemor
y
Thread (1, 0)
Registers
Host

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CUDA Host-Device Data TransferCUDA Host-Device Data Transfer(cont.)(cont.)
Code example: – Transfer a 64 * 64 single precision float array– elements is in host memory– elementsd is in device memory– cudaMemcpyHostToDevice and cudaMemcpyDeviceToHost
are symbolic constants
cudaMemcpy( elementsd, elements, size, cudaMemcpyHostToDevice );
cudaMemcpy( elements, elementsd, size, cudaMemcpyDeviceToHost );

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CUDA Function DeclarationsCUDA Function DeclarationsExecuted
on the:Only callable
from the:
__device__ float DeviceFunc() device device
__global__ void KernelFunc() device host
__host__ float HostFunc() host host
__global__ defines a kernel function– Must return void
__device__ and __host__ can be used together
__host__ is optional

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CUDA Function DeclarationsCUDA Function Declarations
__device__ functions cannot have their address taken
For functions executed on the device:– No recursion
– No static variable declarations inside the function
– No variable number of arguments

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Calling a Kernel – Thread CreationCalling a Kernel – Thread Creation Kernel functions are called with an execution configuration
Calls to a kernel function are asynchronous– But only one kernel active at a time per GPU– Implicit synchronizations
Second kernel launch Memory read backs
– Explicit synchronizations cudaThreadSynchronize()
__global__ void KernelFunc(...);
dim3 DimGrid(100, 50); // 5000 thread blocks dim3 DimBlock(4, 8, 8); // 256 threads per block size_t SharedMemBytes = 64; // 64 bytes of shared memory
KernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...);

Some Additional API Some Additional API FeaturesFeatures
math functions, thread and block ids, etc

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Application Programming InterfaceApplication Programming Interface
The API is an extension to the C programming language
It consists of:– Language extensions
To target portions of the code for execution on the device
– A runtime library split into: A common component providing built-in vector types and
a subset of the C runtime library in both host and device codes
A host component to control and access one or more devices from the host
A device component providing device-specific functions

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Language Extensions:Language Extensions:Built-in VariablesBuilt-in Variables
dim3 gridDim;– Dimensions of the grid in blocks– Grids are at most 2D! gridDim.z is unused
dim3 blockDim;– Dimensions of the block in threads
dim3 blockIdx;– Block index within the grid
dim3 threadIdx;– Thread index within the block

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Common Runtime ComponentCommon Runtime Component
Provides:– Built-in vector types– A subset of the C runtime library supported
in both host and device codes

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Built-in Vector TypesBuilt-in Vector Types
[u]char[1..4], [u]short[1..4], [u]int[1..4], [u]long[1..4], float[1..4]– Structures accessed with x, y, z, w fields:
uint4 param;int y = param.y;
dim3– Based on uint3– Used to specify dimensions

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Mathematical FunctionsMathematical Functions
pow, sqrt, cbrt, hypot exp, exp2, expm1 log, log2, log10, log1p sin, cos, tan, asin, acos, atan, atan2 sinh, cosh, tanh, asinh, acosh, atanh ceil, floor, trunc, round Etc.
– When executed on the host, a given function uses the C runtime implementation if available
– These functions are only supported for scalar types, not vector types

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Host Runtime ComponentHost Runtime Component
Provides functions to deal with:– Device management (including multi-device systems)– Memory management– Error handling
Initializes the first time a runtime function is called
A host thread can invoke a kernel on only one device– Multiple host threads required to run on multiple devices

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Memory ManagementMemory Management
Device memory allocation– cudaMalloc(), cudaFree()
Memory copy from host to device, device to host, device to device– cudaMemcpy(), cudaMemcpy2D(),
cudaMemcpyToSymbol(), cudaMemcpyFromSymbol() Memory addressing
– cudaGetSymbolAddress()– Used to transfer data to constant memory

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Device Mathematical FunctionsDevice Mathematical Functions
Some mathematical functions (e.g. sin(x)) have a less accurate, but faster device-only version (e.g. __sin(x))– __pow– __log, __log2, __log10– __exp– __sin, __cos, __tan

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Device Synchronization FunctionDevice Synchronization Function
void __syncthreads(); Synchronizes all threads in a block Once all threads have reached this point,
execution resumes normally Avoid RAW/WAR/WAW hazards when
accessing shared or global memory Allowed in conditional constructs only if the
conditional is uniform across the entire thread block

Graphics InteroperabilityGraphics Interoperability
one last API bit...

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
OverviewOverview
Interface to exchange data between OpenGL / D3D and CUDA without reading it back to the host
Buffer objects can be mapped into the CUDA address space and then used as global memory– Textures can be accessed by casting them to buffer objects
Data can be accessed as any other global data in the device code
Useful for– Frame post-processing– Visualization– Physical Simulation– …

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
OpenGL InteroperabilityOpenGL Interoperability Mapping GL buffer object to CUDA
cudaError_t cudaGLMapBufferObject( unsigned int bufobj,
void **Ptr, cudaContext_t ctxt = def)
Unmapping GL buffer object from CUDA
cudaError_t cudaGLUnmapBufferObject( unsigned int bufobj, cudaContext_t ctxt = def)

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
OpenGL InteroperabilityOpenGL Interoperability
Example (from simpleGL in the SDK)
float *dptr;cudaGLMapBufferObject( vbo, (void**) &dptr);
dim3 grid( 1, 1, 1);dim3 block( num_threads, 1, 1);kernel<<< grid, block>>>(dptr);
cudaGLUnmapBufferObject( vbo );

Practical Code ExamplePractical Code Example
AKA: breaking the inertia with a simple, illustrative (= useless)
example

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Matrix MultiplicationMatrix Multiplication
Illustrates the basic features of – Global Memory usage– Memory transfer API– Thread allocation– Local, register usage– Thread ID usage– Only example, not efficient!
i.e. Leave shared memory usage for later

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
A Matrix Data TypeA Matrix Data Type
NOT part of CUDA– 2D matrix– single precision float
elements– width * height elements– data elements
allocated and attached to elements
typedef struct { int width; int height; float* elements;} Matrix;
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
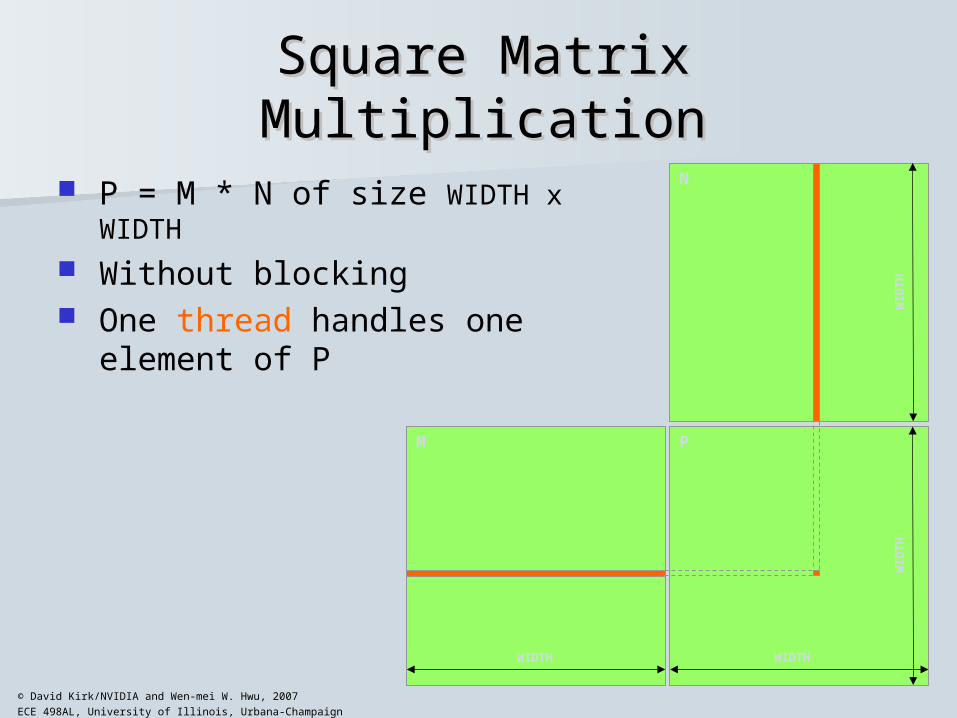
Square Matrix MultiplicationSquare Matrix Multiplication
P = M * N of size WIDTH x WIDTH
Without blocking One thread handles one element
of P
M
N
P
WID
TH
WID
TH
WIDTH WIDTH
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
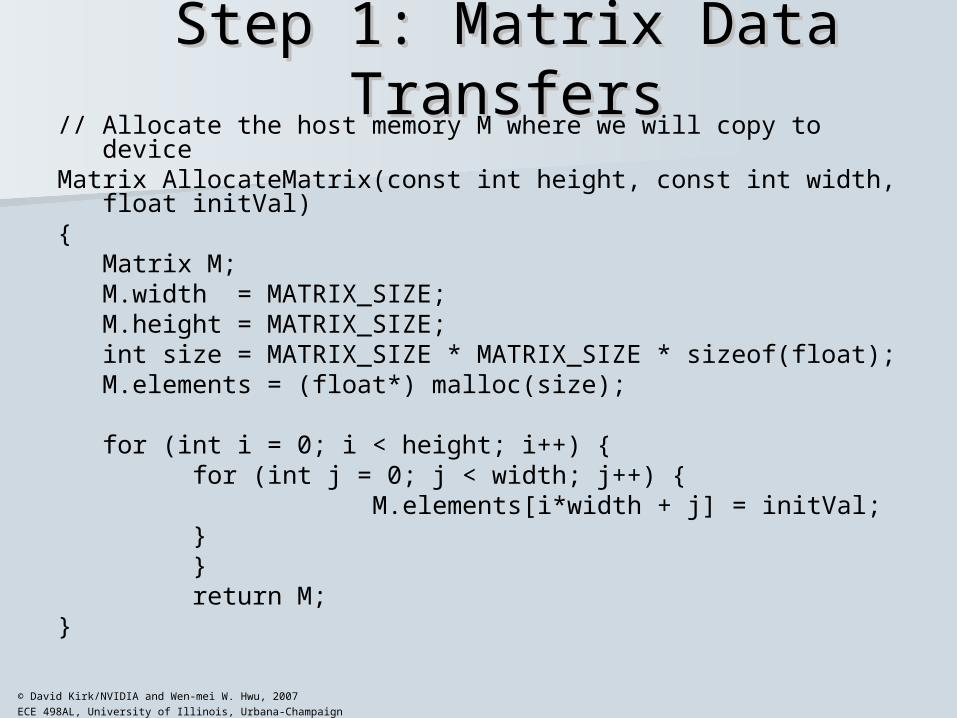
Step 1: Matrix Data TransfersStep 1: Matrix Data Transfers// Allocate the host memory M where we will copy to deviceMatrix AllocateMatrix(const int height, const int width, float initVal){
Matrix M;M.width = MATRIX_SIZE;M.height = MATRIX_SIZE;int size = MATRIX_SIZE * MATRIX_SIZE * sizeof(float);M.elements = (float*) malloc(size); for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) { M.elements[i*width + j] = initVal; } } return M;}

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Step 2: Validation MethodStep 2: Validation Method// Matrix multiplication on the (CPU) host in double precision// For simplicity, we will assume that all dimensions are equal
void MatrixMulOnHost(const Matrix M, const Matrix N, Matrix P){ for (int i = 0; i < M.height; ++i) for (int j = 0; j < N.width; ++j) { double sum = 0; for (int k = 0; k < M.width; ++k) { double a = M.elements[i * M.width + k]; double b = N.elements[k * N.width + j]; sum += a * b; } P.elements[i * N.width + j] = sum; }}
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
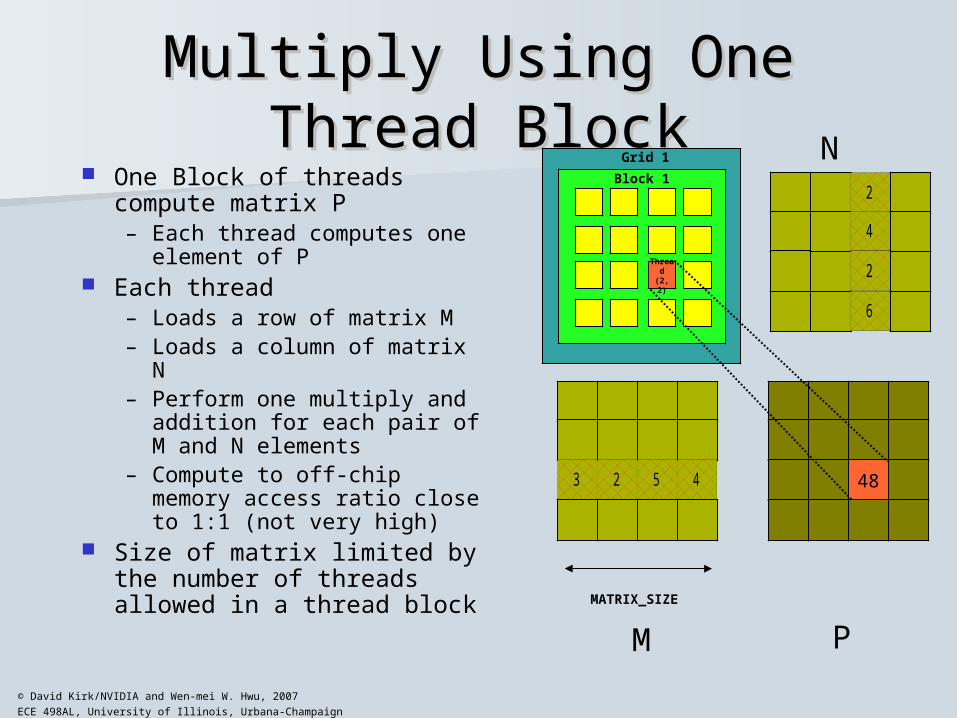
Multiply Using One Thread BlockMultiply Using One Thread Block One Block of threads compute
matrix P– Each thread computes one
element of P Each thread
– Loads a row of matrix M– Loads a column of matrix N– Perform one multiply and
addition for each pair of M and N elements
– Compute to off-chip memory access ratio close to 1:1 (not very high)
Size of matrix limited by the number of threads allowed in a thread block
Grid 1
Block 1
3 2 5 4
2
4
2
6
48
Thread(2, 2)
MATRIX_SIZE
M P
N

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Step 3: Host-side Main CodeStep 3: Host-side Main Code
int main(void) {// Allocate and initialize the matrices Matrix M = AllocateMatrix(MATRIX_SIZE, MATRIX_SIZE, 1); Matrix N = AllocateMatrix(MATRIX_SIZE, MATRIX_SIZE, 1); Matrix P = AllocateMatrix(MATRIX_SIZE, MATRIX_SIZE, 0);
// M * N on the device MatrixMulOnDevice(M, N, P);
// Free matrices FreeMatrix(M); FreeMatrix(N); FreeMatrix(P);return 0;}

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Step 4: Host-side CodeStep 4: Host-side Code
// Matrix multiplication on the devicevoid MatrixMulOnDevice(const Matrix M, const Matrix N, Matrix P){ // Load M and N to the device Matrix Md = AllocateDeviceMatrix(M); CopyToDeviceMatrix(Md, M); Matrix Nd = AllocateDeviceMatrix(N); CopyToDeviceMatrix(Nd, N);
// Allocate P on the device Matrix Pd = AllocateDeviceMatrix(P); CopyToDeviceMatrix(Pd, P); // Clear memory

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Step 4: Host-side Code (cont.)Step 4: Host-side Code (cont.)
// Setup the execution configuration dim3 dimBlock(MATRIX_SIZE, MATRIX_SIZE); dim3 dimGrid(1, 1);
// Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd);
// Read P from the device CopyFromDeviceMatrix(P, Pd);
// Free device matrices FreeDeviceMatrix(Md); FreeDeviceMatrix(Nd); FreeDeviceMatrix(Pd);}

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Step 5: Device-side KernelStep 5: Device-side Kernel
// Matrix multiplication kernel – thread specification__global__ void MatrixMulKernel(Matrix M, Matrix N, Matrix P){ // 2D Thread ID int tx = threadIdx.x; int ty = threadIdx.y;
// Pvalue is used to store the element of the matrix that is computed by the thread float Pvalue = 0;
for (int k = 0; k < MATRIX_SIZE; ++k) { float Melement = M.elements[ty * M.width + k]; float Nelement = N.elements[k * N.width + tx]; Pvalue += Melement * Nelement; } // Write the matrix to device memory; each thread writes one element P.elements[ty * P.width + tx] = Pvalue;}

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Step 3: Some Loose EndsStep 3: Some Loose Ends// Allocate a device matrix of same size as M.Matrix AllocateDeviceMatrix(const Matrix M){ Matrix Mdevice = M; int size = M.width * M.height * sizeof(float); cudaMalloc((void**)&Mdevice.elements, size); return Mdevice;}
// Free a device matrix.void FreeDeviceMatrix(Matrix M) { cudaFree(M.elements);}
void FreeMatrix(Matrix M) { free(M.elements);}

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Step 3: Some Loose EndsStep 3: Some Loose Ends// Copy a host matrix to a device matrix.void CopyToDeviceMatrix(Matrix Mdevice, const Matrix Mhost){ int size = Mhost.width * Mhost.height * sizeof(float); cudaMemcpy(Mdevice.elements, Mhost.elements, size,
cudaMemcpyHostToDevice);}
// Copy a device matrix to a host matrix.void CopyFromDeviceMatrix(Matrix Mhost, const Matrix Mdevice){ int size = Mdevice.width * Mdevice.height * sizeof(float); cudaMemcpy(Mhost.elements, Mdevice.elements, size,
cudaMemcpyDeviceToHost);}

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Performance Results (??)Performance Results (??)
Core 2 Duo 2.4GHz vs 8800 GTS 640MB
Matrix size = 16x16 1 block of 256 threads Host processing time: 0.005550 (ms) Device processing time: 0.398564 (ms)
I told you it was an illustrative example!

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Performance ResultsPerformance Results Of course, we can try cheating and make 12
multiplications in parallel
Matrix size = 16x16 12 blocks of 256 threads each Host processing time: 0.062140 (ms) Device processing time: 0.396850 (ms)
Hmm... since it is still illustrative, lets experiment a little more!

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Matrix Multiplication Matrix Multiplication Shared MemoryShared Memory
__global__ void matrixMulSimpleKernelShared( float* m, float* n, float* p ){
const int tx = threadIdx.x;const int ty = threadIdx.y;float sum = 0;__shared__ float MMs[BLOCK_SIZE][BLOCK_SIZE];__shared__ float NNs[BLOCK_SIZE][BLOCK_SIZE];
MMs[ty][tx] = m[ty*BLOCK_SIZE + tx];NNs[ty][tx] = n[ty*BLOCK_SIZE + tx];
__syncthreads();
for( int k = 0; k < BLOCK_SIZE; ++k ){
sum += MMs[ty][k] * NNs[k][tx];}
p[ty*BLOCK_SIZE + tx] = sum;}
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
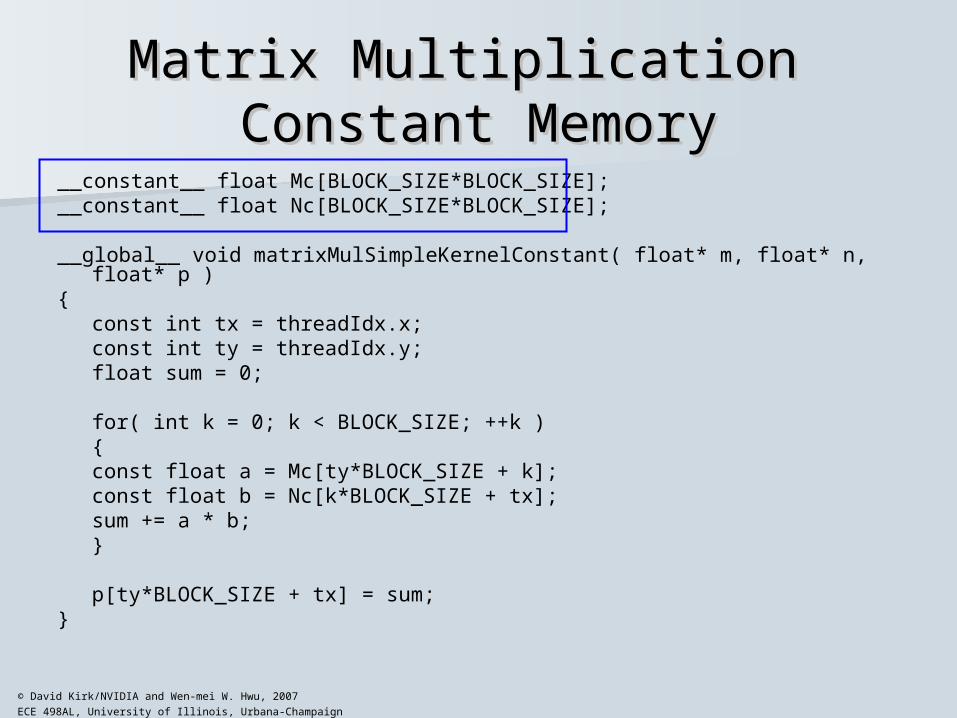
Matrix Multiplication Matrix Multiplication Constant MemoryConstant Memory
__constant__ float Mc[BLOCK_SIZE*BLOCK_SIZE];__constant__ float Nc[BLOCK_SIZE*BLOCK_SIZE];
__global__ void matrixMulSimpleKernelConstant( float* m, float* n, float* p ){
const int tx = threadIdx.x;const int ty = threadIdx.y;float sum = 0;
for( int k = 0; k < BLOCK_SIZE; ++k ){
const float a = Mc[ty*BLOCK_SIZE + k];const float b = Nc[k*BLOCK_SIZE + tx];sum += a * b;
}
p[ty*BLOCK_SIZE + tx] = sum;}

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Matrix Multiplication Matrix Multiplication Constant Memory (host)Constant Memory (host)
int byteTotal = BLOCK_SIZE*BLOCK_SIZE*sizeof(float);
cudaMemcpyToSymbol( Mc, m, byteTotal ) ;
cudaMemcpyToSymbol( Nc, n, byteTotal ) ;
then call kernel

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Matrix Multiplication Matrix Multiplication Texture MemoryTexture Memory
texture<float, 2> texM;texture<float, 2> texN;
__global__ void matrixMulSimpleKernelTexture( float* p ){
const int tx = threadIdx.x;const int ty = threadIdx.y;float sum = 0;
for( int k = 0; k < BLOCK_SIZE; ++k ){
const float a = tex2D( texM, k, ty );const float b = tex2D( texN, tx, k );sum += a * b;
}
p[ty*BLOCK_SIZE + tx] = sum;}

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Matrix Multiplication Matrix Multiplication Texture Memory (host)Texture Memory (host)
// Allocate arrays for texture accesscudaArray* mArray = NULL;cudaArray* nArray = NULL;
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();cudaMallocArray( &mArray, &channelDesc, BLOCK_SIZE, BLOCK_SIZE );cudaMallocArray( &nArray, &channelDesc, BLOCK_SIZE, BLOCK_SIZE );
// Bind the arrays to the texturescudaBindTextureToArray( texM, mArray ) ;cudaBindTextureToArray( texN, nArray ) ;
// Set M texture parameterstexM.addressMode[0] = cudaAddressModeClamp;texM.addressMode[1] = cudaAddressModeClamp;texM.filterMode = cudaFilterModePoint;texM.normalized = false;
// Set N texture parameterstexN.addressMode[0] = cudaAddressModeClamp;texN.addressMode[1] = cudaAddressModeClamp;texN.filterMode = cudaFilterModePoint;texN.normalized = false;
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
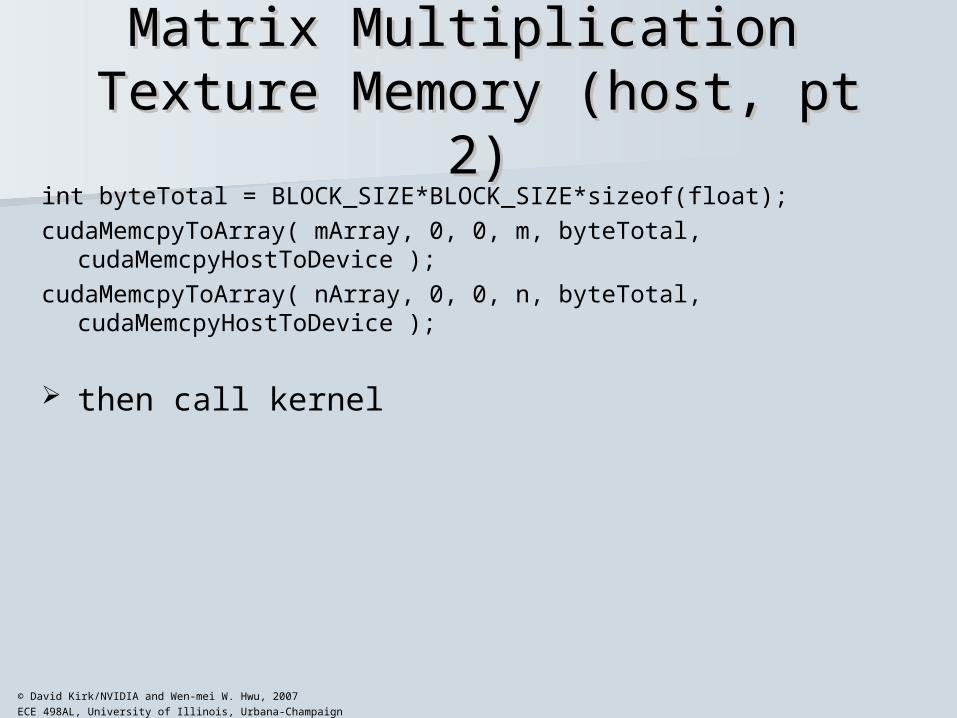
Matrix Multiplication Matrix Multiplication Texture Memory (host, pt 2)Texture Memory (host, pt 2)
int byteTotal = BLOCK_SIZE*BLOCK_SIZE*sizeof(float);
cudaMemcpyToArray( mArray, 0, 0, m, byteTotal, cudaMemcpyHostToDevice );
cudaMemcpyToArray( nArray, 0, 0, n, byteTotal, cudaMemcpyHostToDevice );
then call kernel

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Performance Results?Performance Results?
About the same Constant memory seems faster (about
0.01ms) Not really any difference, still slower than
CPU
We will see the proper way of doing Matrix Multiplication in a few slides!

Useful Information on Useful Information on ToolsTools
like...err... DEBUGGING!

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CompilationCompilation
Any source file containing CUDA language extensions must be compiled with nvcc
nvcc is a compiler driver– Works by invoking all the necessary tools and compilers like
cudacc, g++, cl, ...
nvcc can output:– Either C code
That must then be compiled with the rest of the application using another tool
– Or object code directly

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
LinkingLinking
Any executable with CUDA code requires two dynamic libraries:– The CUDA runtime library (cudart)– The CUDA core library (cuda)

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Debugging Using theDebugging Using theDevice Emulation ModeDevice Emulation Mode
An executable compiled in device emulation mode (nvcc -deviceemu) runs completely on the host using the CUDA runtime– No need of any device and CUDA driver– Each device thread is emulated with a host thread
When running in device emulation mode, one can:– Use host native debug support (breakpoints, inspection, etc.)– Access any device-specific data from host code and vice-
versa– Call any host function from device code (e.g. printf) and vice-
versa– Detect deadlock situations caused by improper usage of
__syncthreads

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Device Emulation Mode PitfallsDevice Emulation Mode Pitfalls Emulated device threads execute sequentially,
so simultaneous accesses of the same memory location by multiple threads could produce different results.
Dereferencing device pointers on the host or host pointers on the device can produce correct results in device emulation mode, but will generate an error in device execution mode
Results of floating-point computations will slightly differ because of:– Different compiler outputs, instruction sets– Use of extended precision for intermediate results
There are various options to force strict single precision on the host

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CUDA SDKCUDA SDK
CUBLAS– Blas level 1, 2 and 3 ready-to-use functions
CUFFT– Discrete Fast Fourier Transform– API similar to popular FFTWin
CUDPP (still beta)– Parallel primitives– Prefix sum, sort, reduction, etc
Full support for clusters running Rocks

HardwareHardware
now, take a breath...
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
G80 Thread Computing PipelineG80 Thread Computing Pipeline The future of GPUs is programmable processing So – build the architecture around the processor
L2
FB
SP SP
L1
TF
Th
rea
d P
roc
es
so
r
Vtx Thread Issue
Setup / Rstr / ZCull
Geom Thread Issue Pixel Thread Issue
Input Assembler
Host
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
SP SP
L1
TF
L2
FB
L2
FB
L2
FB
L2
FB
L2
FB
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
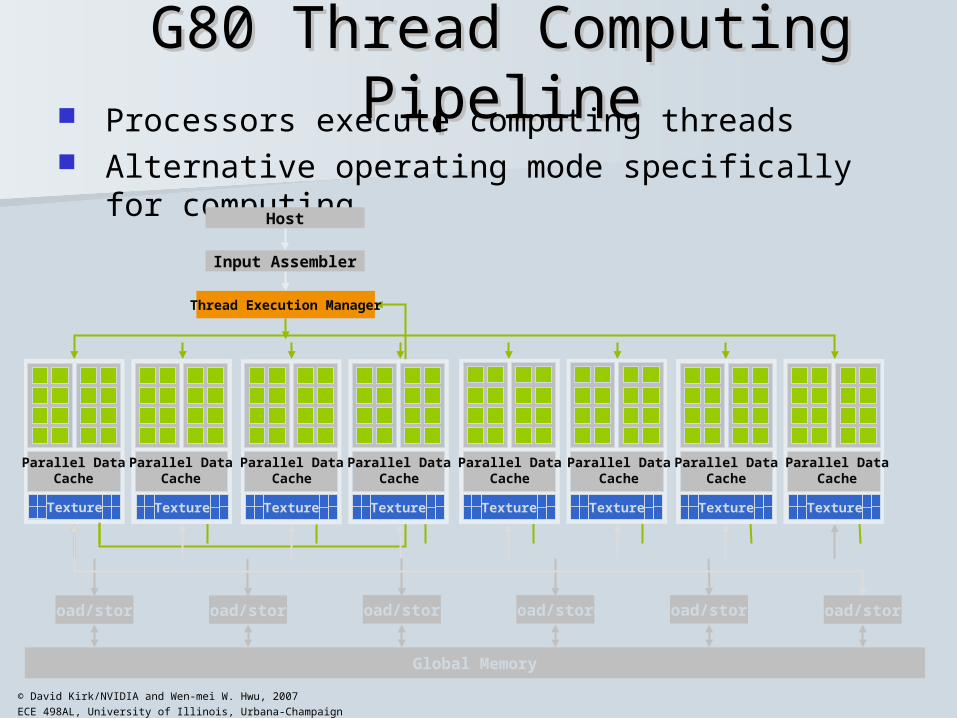
G80 Thread Computing PipelineG80 Thread Computing Pipeline Processors execute computing threads Alternative operating mode specifically for computing
Load/store
Global Memory
Thread Execution Manager
Input Assembler
Host
Texture Texture Texture Texture Texture Texture Texture TextureTexture
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Parallel DataCache
Load/store Load/store Load/store Load/store Load/store

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
GeForce 8800 Series GeForce 8800 Series TechnicalTechnical SpecsSpecs
Maximum number of threads per block: 512 Maximum size of each dimension of a grid: 65,535 Number of streaming multiprocessors (SM):
– GeForce 8800 GTX: 16 @ 1.35 GHz– GeForce 8800 GTS: 12 @ 1.2 GHz
Device memory:– GeForce 8800 GTX: 768 MB– GeForce 8800 GTS: 640 MB
Shared memory per multiprocessor: 16KB divided in 16 banks
Constant memory: 64 KB Warp size: 32 threads (16 Warps/Block)

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
What is the GPU Good at?What is the GPU Good at? Data-parallel processing
– Same computation executed on many data elements in parallel
– Low control flow overhead With high SP floating point arithmetic
intensity
– Many calculations per memory access
– Currently need high floating point to integer ratio

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
What is the GPU Good at?What is the GPU Good at? High floating-point arithmetic intensity
+ Many data elements
= Memory access latency can be hidden
with calculations instead of big caches
Still need to avoid bandwidth saturation!

Drawbacks of (legacy) Drawbacks of (legacy) GPGPU ModelGPGPU Model
how it was done prior to CUDA
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
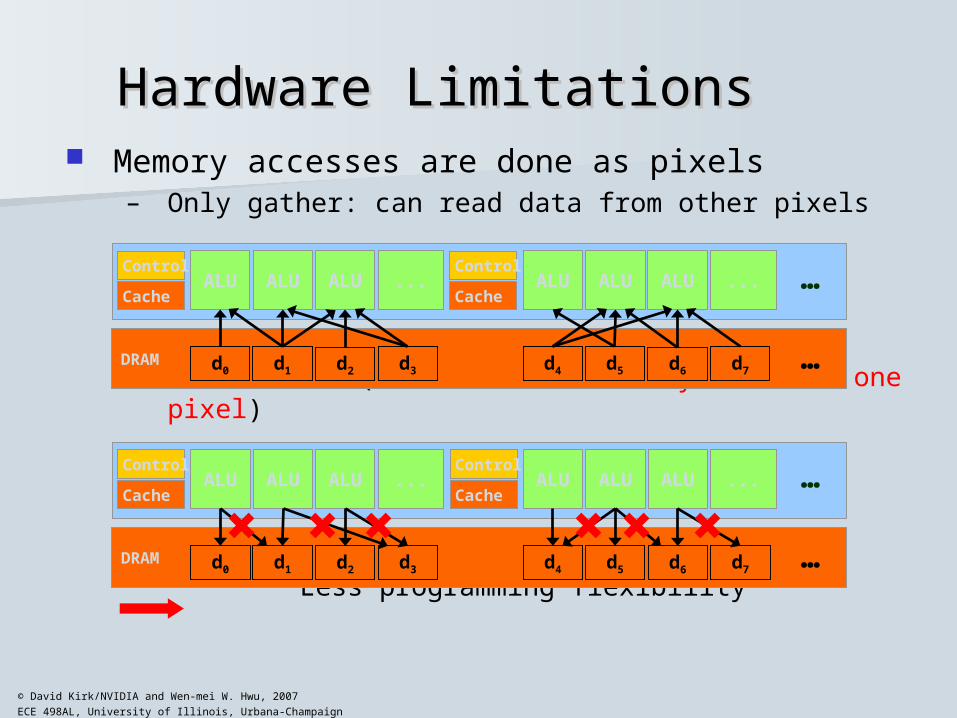
Hardware LimitationsHardware Limitations Memory accesses are done as pixels
– Only gather: can read data from other pixels
– No scatter: (Each shader can only write to one pixel)
Less programming flexibility
DRAM
ALUControl
CacheALU ALU ...
d0 d1 d2 d3
ALUControl
CacheALU ALU ...
d4 d5 d6 d7
…
…
DRAM
ALUControl
CacheALU ALU ...
d0 d1 d2 d3
ALUControl
CacheALU ALU ...
d4 d5 d6 d7
…
…
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
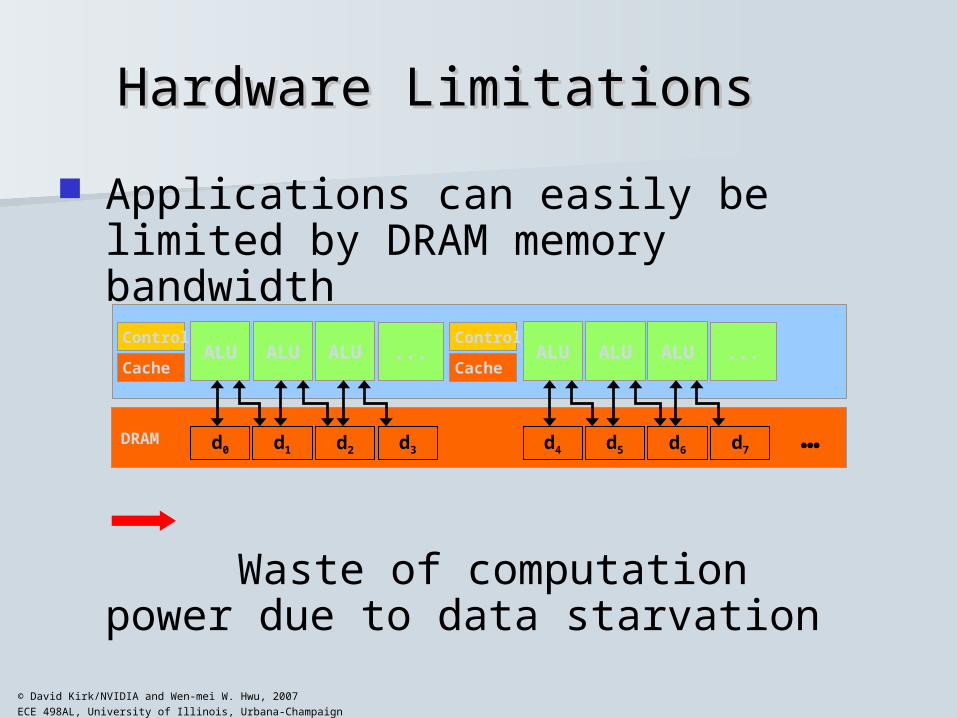
Hardware LimitationsHardware Limitations
Applications can easily be limited by DRAM memory bandwidth
Waste of computation power due to data starvation
DRAM
ALUControl
CacheALU ALU ...
d0 d1 d2 d3
ALUControl
CacheALU ALU ...
d4 d5 d6 d7 …

But with CUDABut with CUDA
what we can do differently
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
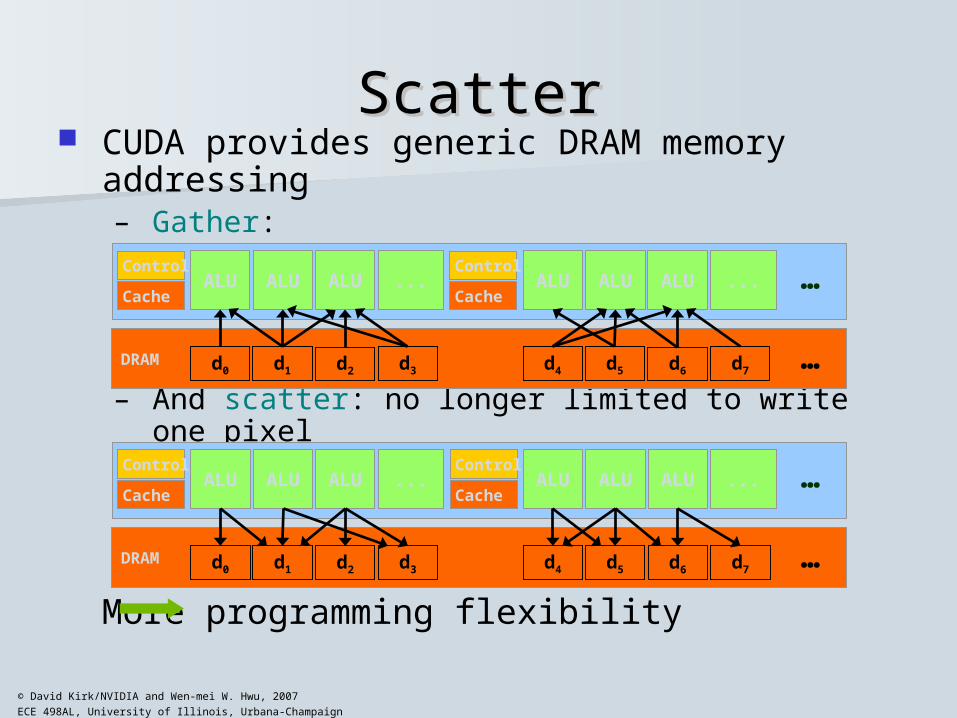
ScatterScatter CUDA provides generic DRAM memory
addressing– Gather:
– And scatter: no longer limited to write one pixel
More programming flexibility
DRAM
ALUControl
CacheALU ALU ...
d0 d1 d2 d3
ALUControl
CacheALU ALU ...
d4 d5 d6 d7
…
…
DRAM
ALUControl
CacheALU ALU ...
d0 d1 d2 d3
ALUControl
CacheALU ALU ...
d4 d5 d6 d7
…
…
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
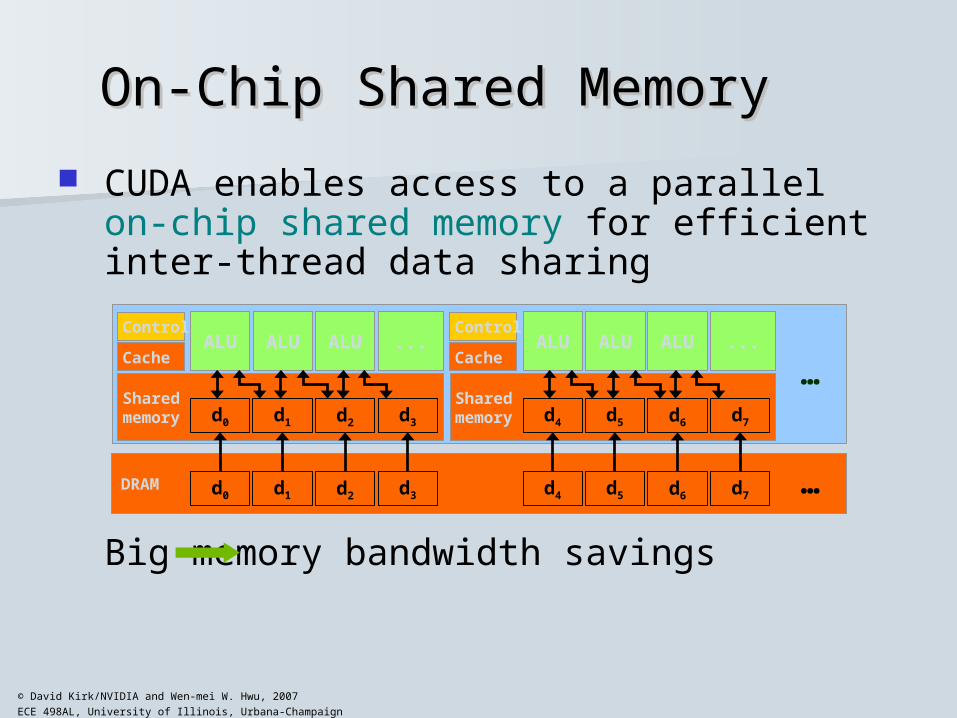
On-Chip Shared MemoryOn-Chip Shared Memory
CUDA enables access to a parallel on-chip shared memory for efficient inter-thread data sharing
Big memory bandwidth savings
DRAM
ALU
Sharedmemory
Control
CacheALU ALU ...
d0 d1 d2 d3
d0 d1 d2 d3
ALU
Sharedmemory
Control
CacheALU ALU ...
d4 d5 d6 d7
d4 d5 d6 d7
…
…

Memory Model & Memory Model & HardwareHardware
how does the CUDA memory model work in the hardware?

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CUDA Memory SpacesCUDA Memory Spaces
Each thread can:– Read/write per-thread registers– Read/write per-thread local memory– Read/write per-block shared
memory– Read/write per-grid global memory– Read only per-grid constant
memory– Read only per-grid texture memory
Grid
ConstantMemory
TextureMemory
GlobalMemory
Block (0, 0)
Shared Memory
LocalMemory
Thread (0, 0)
Registers
LocalMemory
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
LocalMemory
Thread (0, 0)
Registers
LocalMemory
Thread (1, 0)
Registers
Host The host can read/write global, constant, and texture memory
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
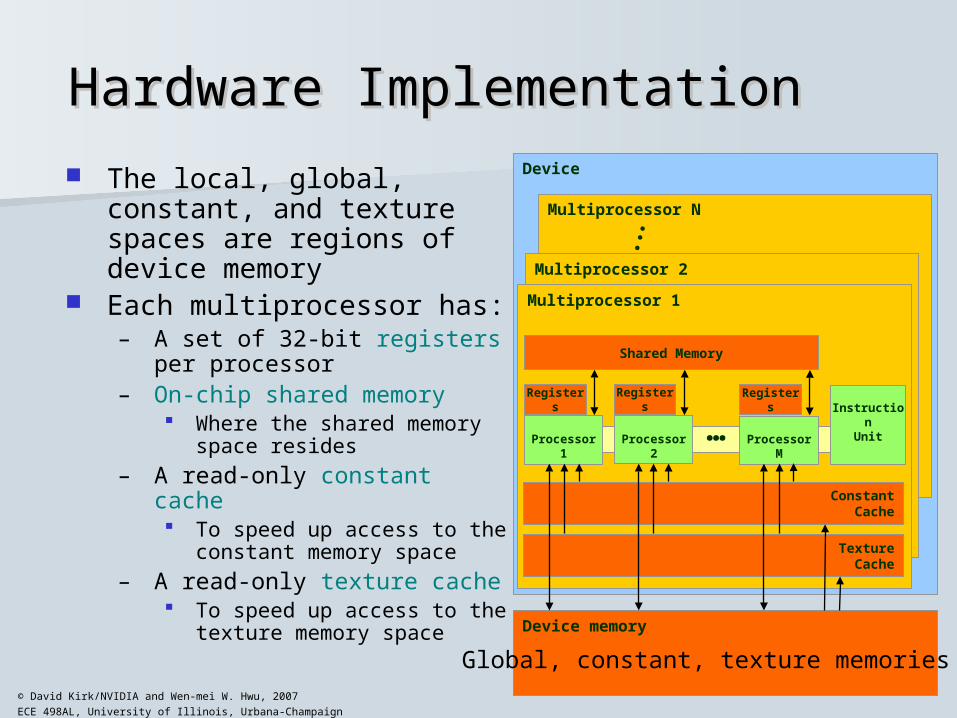
Hardware ImplementationHardware Implementation
The local, global, constant, and texture spaces are regions of device memory
Each multiprocessor has:– A set of 32-bit registers per
processor– On-chip shared memory
Where the shared memory space resides
– A read-only constant cache To speed up access to the
constant memory space
– A read-only texture cache To speed up access to the
texture memory space
Device
Multiprocessor N
Multiprocessor 2
Multiprocessor 1
Device memory
Shared Memory
InstructionUnit
Processor 1
Registers
…Processor 2
Registers
Processor M
Registers
ConstantCache
TextureCache
Global, constant, texture memories
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
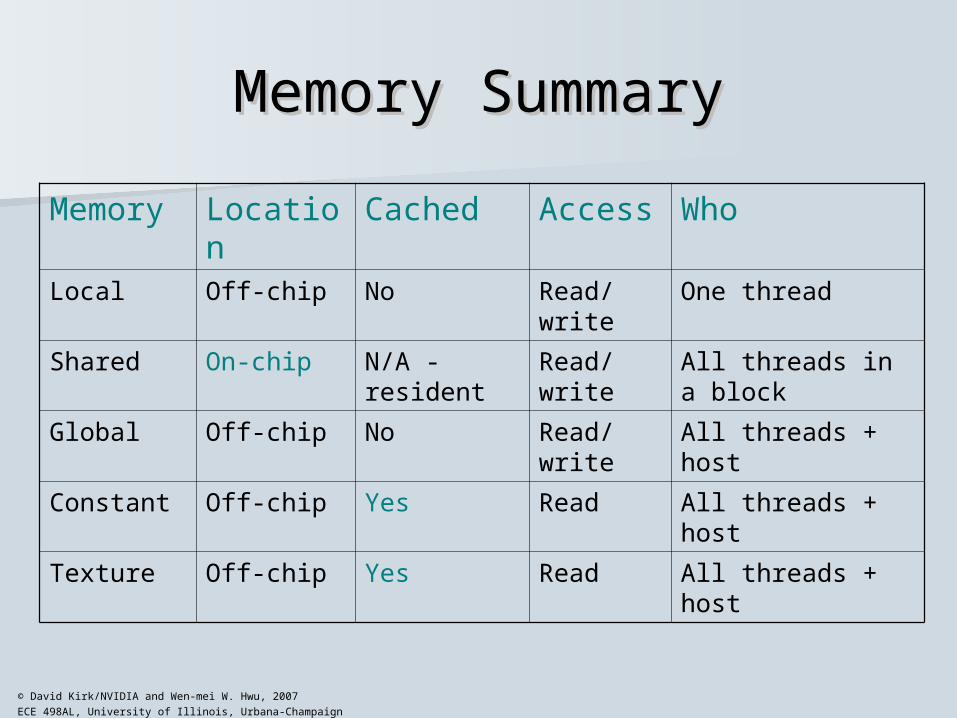
Memory SummaryMemory Summary
Memory Location Cached Access WhoLocal Off-chip No Read/write One thread
Shared On-chip N/A - resident Read/write All threads in a block
Global Off-chip No Read/write All threads + host
Constant Off-chip Yes Read All threads + host
Texture Off-chip Yes Read All threads + host

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Access TimesAccess Times Register
– dedicated HW - single cycle Shared Memory
– dedicated HW - single cycle Local Memory
– DRAM, no cache - *slow* Global Memory
– DRAM, no cache - *slow* Constant Memory
– DRAM, cached, 1…10s…100s of cycles, depending on cache locality
Texture Memory– DRAM, cached, 1…10s…100s of cycles, depending on cache
locality Instruction Memory (invisible)
– DRAM, cached

Processing Model & Processing Model & HardwareHardware
now that we can reach the data, how do we actually process it?

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CUDA: A Set of SIMD CUDA: A Set of SIMD MultiprocessorsMultiprocessors
A set of 16 multiprocessors Each multiprocessor
– A set of 8 processors (32-bit)– Single Instruction Multiple
Data architecture (shared instruction unit)
At each clock cycle– The multiprocessor executes
the same instruction on a group of threads called a warp
The number of threads in a warp is the warp size
Device
Multiprocessor N
Multiprocessor 2
Multiprocessor 1
InstructionUnit
Processor 1 …Processor 2 Processor M

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Threads, Warps, BlocksThreads, Warps, Blocks
There are (up to) 32 threads in a Warp– Only <32 when there are fewer than 32 total threads
There are (up to) 16 Warps in a Block Each Block (and thus, each Warp) executes on a
single SM G80 has 16 SMs At least 16 Blocks required to “fill” the device More is better
– If resources (registers, thread space, shared memory) allow, more than 1 Block can occupy each SM

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Execution Model (review)Execution Model (review)
Each thread block of a grid is split into warps, each gets executed by one multiprocessor (SM)– The way a block is split into warps is always the same
Each warp contains threads of consecutive, increasing thread indices with the first warp containing thread 0
Each thread block is executed by one multiprocessor– So that the shared memory space resides in the on-chip shared
memory A multiprocessor can execute multiple blocks concurrently
– Shared memory and registers are partitioned among the threads of all concurrent blocks
– So, decreasing shared memory usage (per block) and register usage (per thread) increases number of blocks that can run concurrently

Matrix: ReloadedMatrix: Reloaded
a better approach to matrix multiplication

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
M
N
P
WID
TH
WID
TH
WIDTH WIDTH
Recall: Matrix Multiplication Recall: Matrix Multiplication Device-Side Kernel FunctionDevice-Side Kernel Function
for (int k = 0; k < M.width; ++k){ float Melement = M.elements[ty * M.pitch + k]; float Nelement = Nd.elements[k * N.pitch + tx]; Pvalue += Melement * Nelement;}// Write the matrix to device memory;// each thread writes one elementP.elements[ty * P.pitch + tx] = Pvalue;
ty
tx

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Idea: Use Idea: Use Shared MemoryShared Memory to to reusereuse global memory dataglobal memory data
Each input element is read by WIDTH threads Load each element into Shared Memory Several threads use the local version Drastically reduce the memory bandwidth
– Tiled algorithms
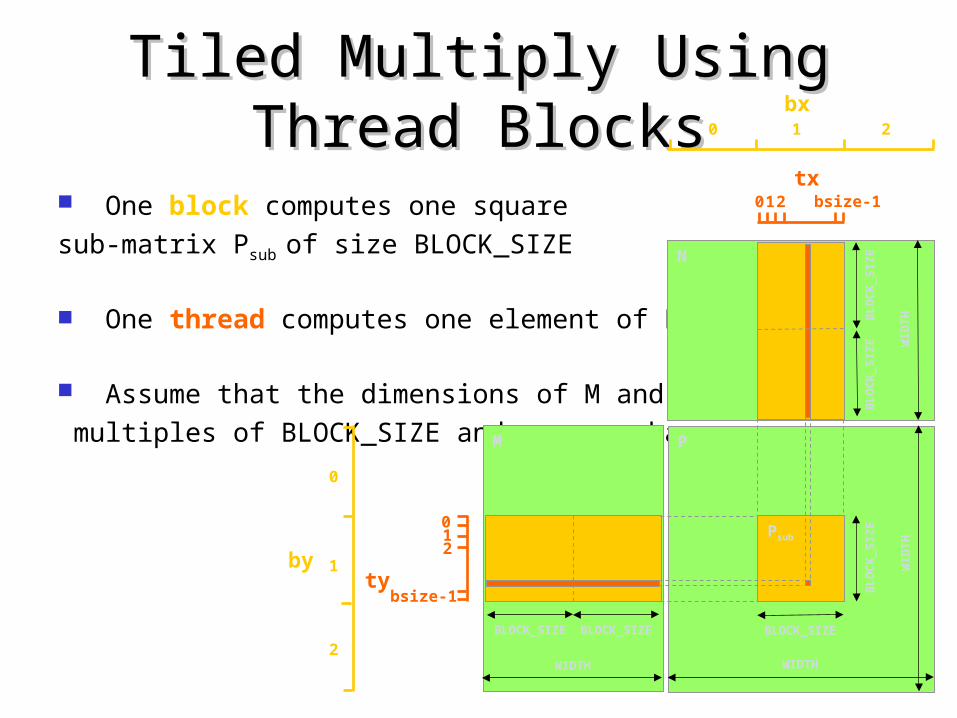
Tiled Multiply Using Thread Tiled Multiply Using Thread BlocksBlocks
One block computes one square
sub-matrix Psub of size BLOCK_SIZE
One thread computes one element of Psub
Assume that the dimensions of M and N are
multiples of BLOCK_SIZE and square shapeM
N
P
Psub
BLOCK_SIZE
WIDTHWIDTH
BLOCK_SIZEBLOCK_SIZE
bx
tx01 bsize-12
0 1 2
byty
210
bsize-1
2
1
0
BL
OC
K_S
IZE
BL
OC
K_S
IZE
BL
OC
K_S
IZE
WID
TH
WID
TH

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Shared Memory UsageShared Memory Usage
Each SMP has 16KB shared memory– Each Thread Block uses 2*256*4B = 2KB of shared
memory. – Potentially up to 8 Thread Blocks actively executing– For BLOCK_SIZE = 16, this allows up to 8*512 =
4,096 pending loads In practice, there will probably be up to half of this due to
scheduling to make use of SPs.
– The next BLOCK_SIZE 32 would lead to 2*32*32*4B= 8KB shared memory usage per Thread Block, allowing only up to 2 Thread Blocks active at the same time

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
First-order Size ConsiderationsFirst-order Size Considerations Each Thread Block should have a minimal of 192
threads– BLOCK_SIZE of 16 gives 16*16 = 256 threads
A minimal of 32 Thread Blocks– A 1024*1024 P Matrix gives 64*64 = 4096 Thread
Blocks
Each thread block perform – 2*256 = 512 float loads from global memory – for 256 * (2*16) = 8,192 mul/add operations– Memory bandwidth no longer a limiting factor

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Kernel Execution ConfigurationKernel Execution Configuration// Setup computation// Matrix size could be 1024dim3 dimBlock( BLOCK_SIZE, BLOCK_SIZE );dim3 dimGrid( MATRIX_SIZE/BLOCK_SIZE, MATRIX_SIZE/BLOCK_SIZE );
// Launch device kernelmatrixMulKernel<<< dimGrid, dimBlock >>>( md, nd, pd );
For very large N and M dimensions, onewill need to add another level of blocking
and execute the second-level blocks sequentially (several kernels);

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Kernel Code: initializationKernel Code: initialization__global__ void matrixMulKernel( float* m, float* n, float* p ){ // Block and thread index int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y;
// Index of the first and last sub-matrix of A processed by the block int mBegin = MATRIX_SIZE * BLOCK_SIZE * by; int mEnd = mBegin + MATRIX_SIZE - 1;
// Step size used to iterate through the sub-matrices of A int mStep = BLOCK_SIZE;
// Index of the first and last sub-matrix of B processed by the block int nBegin = BLOCK_SIZE * bx; int nStep = BLOCK_SIZE * MATRIX_SIZE;
// sum is used to store the element of the block sub-matrix that is computed by the thread float sum = 0;
// Declaration of the shared memory arrays Ms and Ns used to store the sub-matrices of A and B __shared__ float Ms[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Ns[BLOCK_SIZE][BLOCK_SIZE];
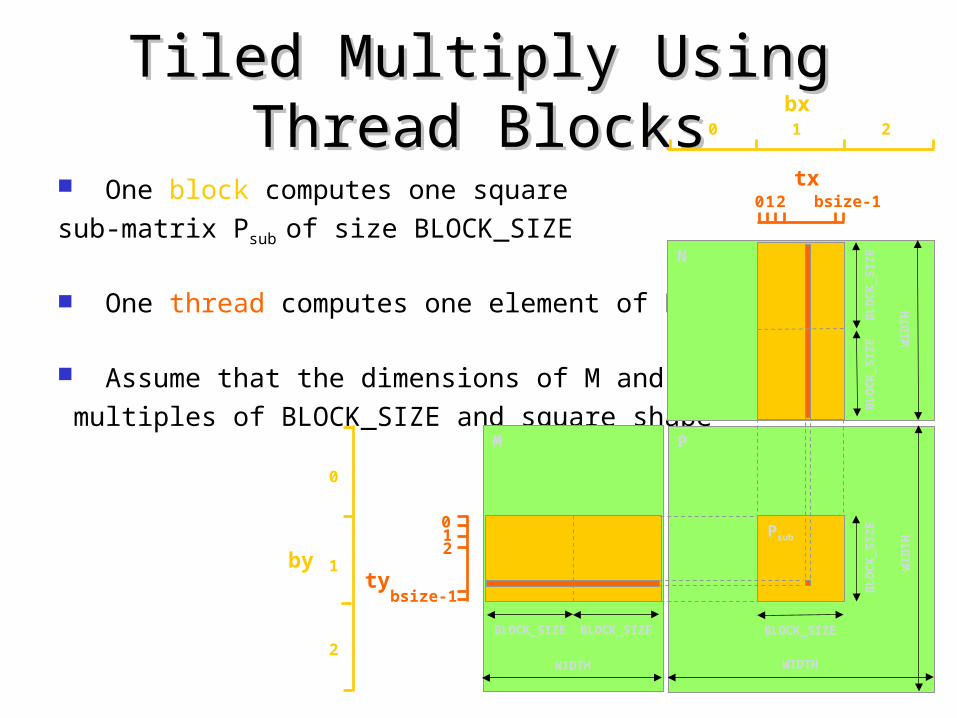
Tiled Multiply Using Thread Tiled Multiply Using Thread BlocksBlocks
One block computes one square
sub-matrix Psub of size BLOCK_SIZE
One thread computes one element of Psub
Assume that the dimensions of M and N are
multiples of BLOCK_SIZE and square shapeM
N
P
Psub
BLOCK_SIZE
WIDTHWIDTH
BLOCK_SIZEBLOCK_SIZE
bx
tx01 bsize-12
0 1 2
byty
210
bsize-1
2
1
0
BL
OC
K_S
IZE
BL
OC
K_S
IZE
BL
OC
K_S
IZE
WID
TH
WID
TH

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Kernel Code: main computationKernel Code: main computation // Loop over all the sub-matrices of A and B required to compute the block sub-matrix for( int a = mBegin, b = nBegin; a <= mEnd; a+=mStep, b+=nStep )
{ // Load the matrices from device memory to shared memory; // each thread loads one element of each matrix MS(ty, tx) = m[a + MATRIX_SIZE * ty + tx]; NS(ty, tx) = n[b + MATRIX_SIZE * ty + tx];
// Synchronize to make sure the matrices are loaded __syncthreads();
// Multiply the two matrices together; each thread computes one element of the block sub-matrix for( int k = 0; k < BLOCK_SIZE; ++k ) sum += MS(ty, k) * NS(k, tx);
// Synchronize to make sure that the preceding computation is done before // loading two new sub-matrices of A and B in the next iteration __syncthreads(); } // Write the block sub-matrix to device memory; each thread writes one element int c = MATRIX_SIZE * BLOCK_SIZE * by + BLOCK_SIZE * bx; p[c + MATRIX_SIZE*ty + tx] = sum;}

This code should run at This code should run at about about 4545 GFLOPS GFLOPS
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
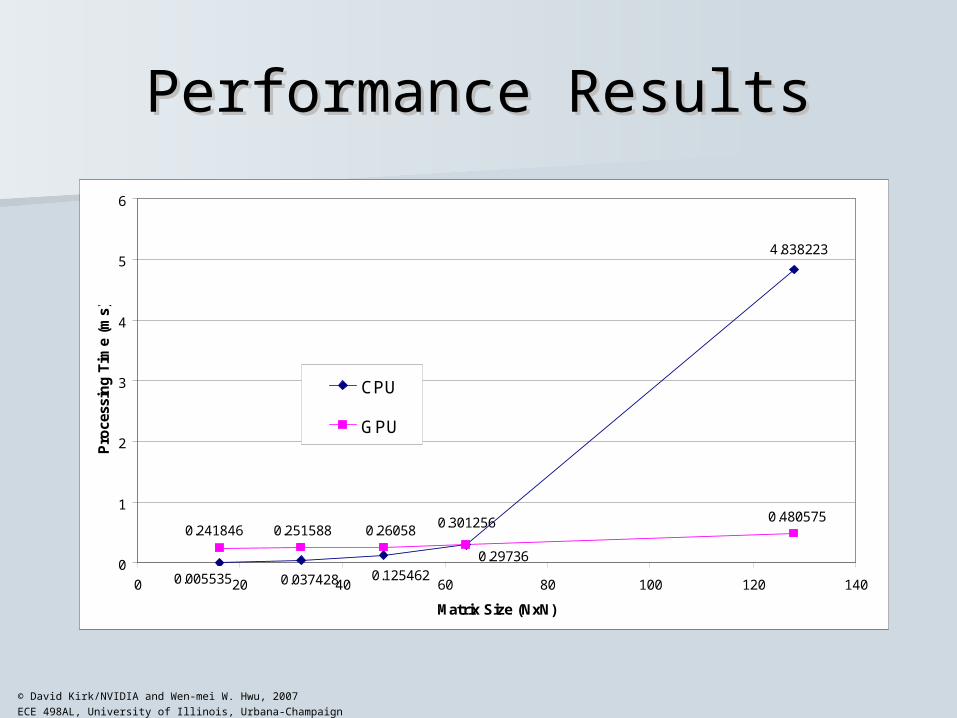
Performance ResultsPerformance Results
4.838223
0.005535 0.037428 0.125462
0.301256 0.4805750.2515880.241846
0.29736
0.26058
0
1
2
3
4
5
6
0 20 40 60 80 100 120 140
Matrix Size (NxN)
Pro
cess
ing
Tim
e (m
s)
CPU
GPU
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Performance ResultsPerformance Results
0
1000
2000
3000
4000
5000
6000
0 200 400 600 800 1000 1200
Matrix Size (NxN)
Pro
cess
ing
Tim
e (m
s)
CPU
GPU
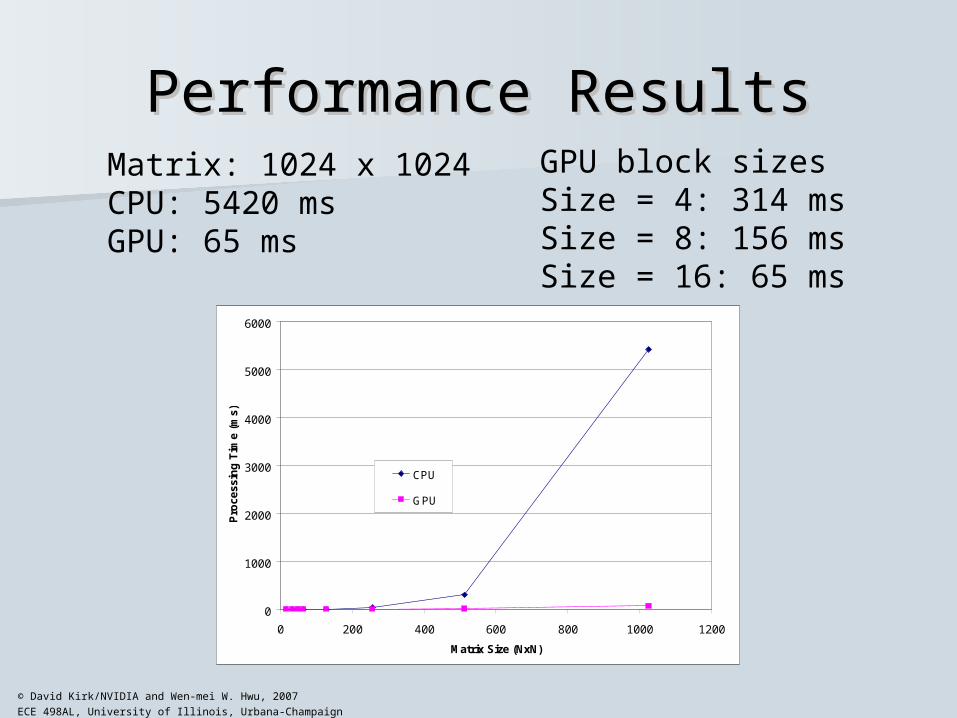
Matrix: 1024 x 1024CPU: 5420 msGPU: 65 ms
GPU block sizesSize = 4: 314 msSize = 8: 156 msSize = 16: 65 ms

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Performance ResultsPerformance Results
Important note: CPU code not optimized! GPU seems almost 100x faster than CPU But
– Even if we can get a 2x speed-up in CPU (!)– GPU would still be about 50x faster!
Do the math!– Fastest Core 2 Duo has peak at ~10 GFLOPs– Previous CUDA code is ~45 GFLOPs

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Matrix Multiplication: VerdictMatrix Multiplication: Verdict
No need to code and optimize this! Use CUBLAS
– CUDA Blas level 1, 2 and 3 library– Ready for use, optimized like hell!

HW ArchitectureHW Architecture
everybody take a deep breath now......
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
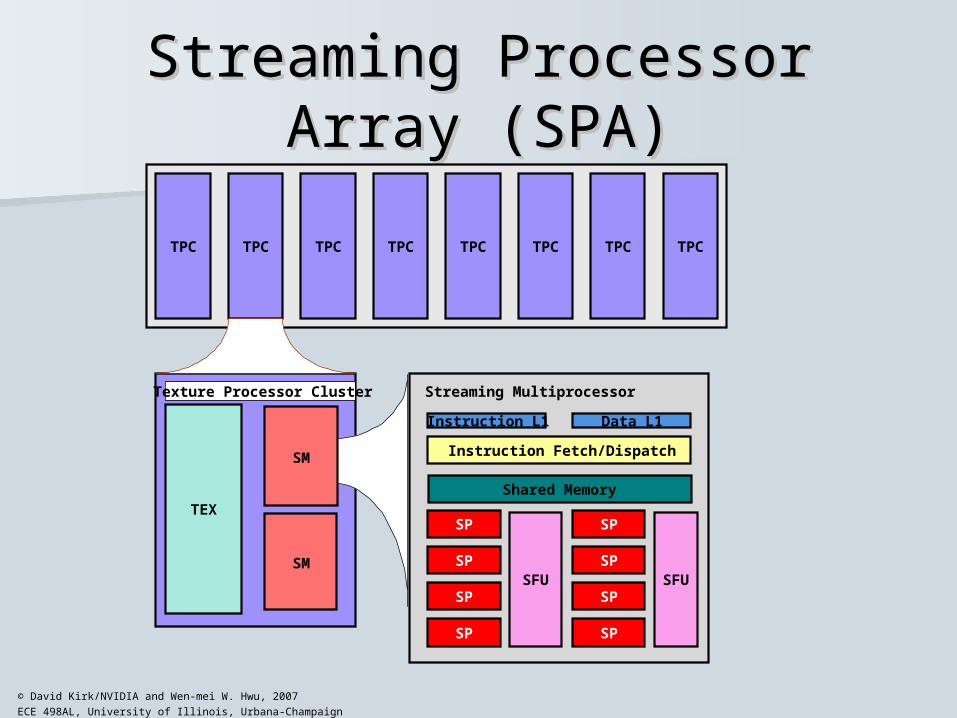
Streaming Processor Array Streaming Processor Array (SPA)(SPA)
TPC TPC TPC TPC TPC TPC TPC TPC
TEX
SM
SP
SP
SP
SP
SFU
SP
SP
SP
SP
SFU
Instruction Fetch/Dispatch
Instruction L1 Data L1
Texture Processor Cluster Streaming Multiprocessor
SM
Shared Memory
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
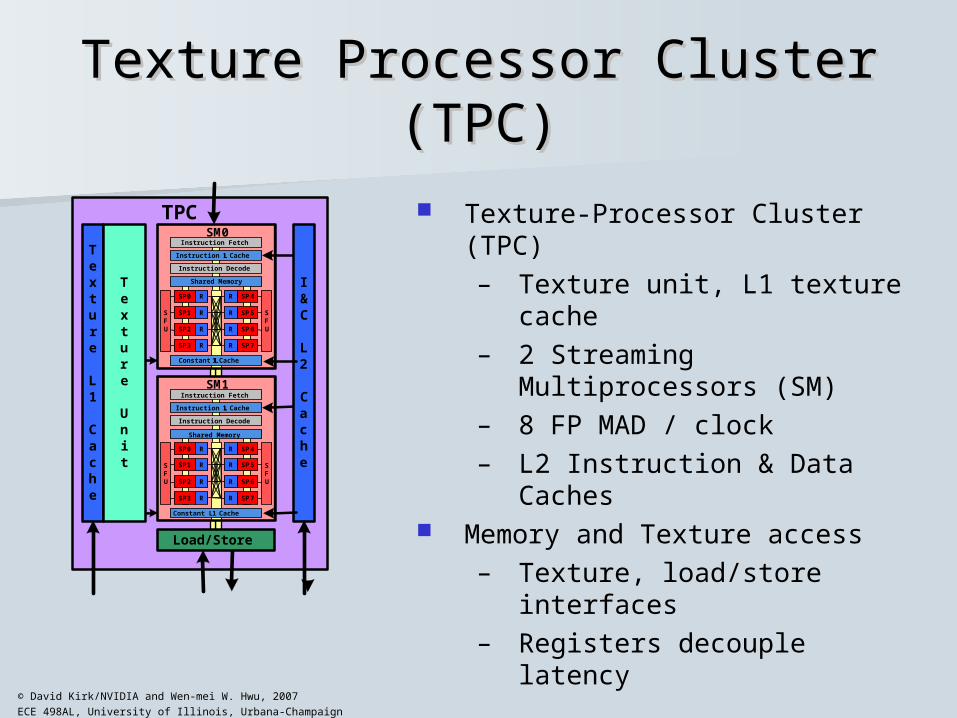
Texture Processor Cluster (TPC)Texture Processor Cluster (TPC)
Texture-Processor Cluster (TPC)– Texture unit, L1 texture cache– 2 Streaming Multiprocessors
(SM)– 8 FP MAD / clock– L2 Instruction & Data Caches
Memory and Texture access– Texture, load/store interfaces– Registers decouple latency
TPC
Texture
L1
Cache
Texture
Unit
Load/Store
SM1
SP0 R
SP1 R
SP2 R
SP3 R
SP4R
SP5R
SP6R
SP7R
Shared Memory
Constant L 1 Cache
SFU
SFU
Instruction Fetch
Instruction L 1 Cache
Instruction Decode
SM0
SP0 R
SP1 R
SP2 R
SP3 R
SP4R
SP5R
SP6R
SP7R
Shared Memory
Constant L1 Cache
SFU
SFU
Instruction Fetch
Instruction L 1 Cache
Instruction Decode
I&C
L2
Cache

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Streaming Multiprocessor (SM)Streaming Multiprocessor (SM)
Streaming Multiprocessor (SM)
– 8 Streaming Processors (SP)– 2 Super Function Units (SFU)
Multi-threaded instruction dispatch– 1 to 768 threads active– SIMD instruction per 16/32
threads– Cover latency of texture/memory
loads Hot clock 1.35 GHz
– 20+ GFLOPS local register file (RFn) 16 KB shared memory DRAM texture and memory access
Streaming Multiprocessor (SM)
Store to
SP0 RF0
SP1 RF1
SP2 RF2
SP3 RF3
SP4RF4
SP5RF5
SP6RF6
SP7RF7
Constant L1 Cache
L1 Fill
Load from Memory
Load Texture
SFU
SFU
Instruction Fetch
Instruction L 1 Cache
Thread / Instruction Dispatch
L1 Fill
Work
Control
Results
Shared Memory
Store to Memory

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Streaming Processor (SP)Streaming Processor (SP)
One scalar ALU– Serves as datapath for 1 thread of a warp– Each SM has 8 SP– Each SM has 2 SFU
Threads– A warp instruction can issue every clock– Need ~8 warps to typically saturate the
MAD/SFU pipes

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
SM Instruction BufferSM Instruction Buffer
Fetch one warp instruction/cycle– from instruction L1 cache – into any instruction buffer slot
Issue one “ready-to-go” warp instruction/cycle– from any warp - instruction buffer slot– operand scoreboarding used to prevent
hazards Issue selection based on round-robin/age
of warp SM broadcasts SIMD instruction to 32
Threads of a Warp
I$L1
MultithreadedInstruction Buffer
RF
C$L1
SharedMem
Operand Select
MAD SFU

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
ScoreboardingScoreboarding
All operands of all instructions in the Instruction Buffer are scoreboarded– prevents hazards– cleared instructions are eligible for issue
Decoupled Memory/Processor pipelines– any thread can continue to issue instructions
until scoreboarding prevents issue– allows Memory/Processor ops to proceed in
shadow of Memory/Processor ops

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
BranchingBranching Conditional branch to label, subroutine call SM schedules each Warp independently SM executes 32 threads of a Warp as a SIMD
instruction– SM enables/disables sets of threads when branches
diverge Synchronization
– Re-converge diverged threads in a Warp Barrier Synchronization
– CUDA uses barrier instruction to synchronize multiple Warps in a Thread Block

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
SM Register FileSM Register File
Register File (RF)– 32 KB– Provides 4 operands/clock
TEX pipe can also read/write RF– 2 SMs share 1 TEX
Load/Store pipe can also read/write RF
I$L1
MultithreadedInstruction Buffer
RF
C$L1
SharedMem
Operand Select
MAD SFU

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
ConstantsConstants
Immediate address constants Indexed address constants Constants stored in memory, and
cached on chip– L1 per SM
I$L1
MultithreadedInstruction Buffer
RF
C$L1
SharedMem
Operand Select
MAD SFU

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Shared MemoryShared Memory
Each SM has 16 KB of Shared Memory– 16 banks of 32bit words
CUDA uses Shared Memory as shared storage visible to all threads in a thread block– read and write access
Not used explicitly for pixel shader programs– we dislike pixels talking to each other
I$L1
MultithreadedInstruction Buffer
RF
C$L1
SharedMem
Operand Select
MAD SFU

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Execution PipesExecution Pipes Scalar MAD pipe
– FMUL,FADD,FMAD– integer ops, conversions– One instruction/clock
Scalar SFU pipe– RCP,RSQ,LG2,EX2,SIN,COS
one instruction/4 clocks– also supports FMUL, MOV
TEX pipe (external to SM, shared by all SM’s in a TPC)
LD/ST pipe– thread register spill to memory, used for
indexable registers– CUDA has both global and local memory
access through LD/ST
I$L1
MultithreadedInstruction Buffer
RF
C$L1
SharedMem
Operand Select
MAD SFU

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Texture (Memory read) Texture (Memory read) Clustering/BatchingClustering/Batching
Use another independent Texture memory read to hide Texture memory latency– Use same thread to help hide own latency
Instead of:– TEX 0 (long latency)– Dependent MATH 0– TEX 1 (long latency)– Dependent MATH 1
Do:– TEX 0 (long latency)– TEX 1 (long latency - hidden)– MATH 0– MATH 1
Compiler handles this!– But, you must have enough non-dependent LDs and Math

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Load/Store (Memory read/write) Load/Store (Memory read/write) Clustering/BatchingClustering/Batching
Use LD to hide LD latency (non-dependent LD ops only)– Use same thread to help hide own latency
Instead of:– LD 0 (long latency)– Dependent MATH 0– LD 1 (long latency)– Dependent MATH 1
Do:– LD 0 (long latency)– LD 1 (long latency - hidden)– MATH 0– MATH 1
Compiler handles this!– But, you must have enough non-dependent LDs and Math

Performance IssuesPerformance Issues
the real gems of how to code efficient algorithms in CUDA
(and G80+ in general!)

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
CUDA Instruction PerformanceCUDA Instruction Performance
Instruction cycles (per warp) = sum of– Operand read cycles– Instruction execution cycles (both memory access and FP)– Result update cycles
Therefore instruction throughput depends on– Nominal instruction throughput– Memory latency– Memory bandwidth

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Maximizing Instruction ThroughputMaximizing Instruction Throughput
Minimize use of low-throughput instructions– Will cover specifics later
Maximize use of high-bandwidth memory– Maximize use of shared memory– Maximize locality and synchrony of cached accesses– Minimize accesses to (uncached) global and local memory– Maximize coalescing of global memory accesses
Optimize performance by overlapping memory accesses with HW computation– High arithmetic intensity programs
i.e. high ratio of math to memory transactions
– Many concurrent threads

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Arithmetic Instruction ThroughputArithmetic Instruction Throughput
int and float add, shift, min, max and float mul, mad: 2 cycles per warp– int multiply (*) is by default 32-bit
requires multiple cycles / warp
– Use __mul24() / __umul24() intrinsics for 2-cycle 24-bit int multiply
Integer divide and modulo are expensive– Compiler will convert literal power-of-2 divides to shifts– Be explicit in cases where compiler can’t tell that divisor is a
power of 2!– Useful trick: foo % n == foo & (n-1) if n is a power of 2

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Arithmetic Instruction ThroughputArithmetic Instruction Throughput
Reciprocal, reciprocal square root, sin/cos, log, exp: 8 cycles per warp– These are the versions prefixed with “__”– Examples:__rcp(), __sin(), __exp()
Other functions are combinations of the above– y / x == rcp(x) * y == 10 cycles per warp– sqrt(x) == rcp(rsqrt(x)) == 16 cycles per warp

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Runtime Math LibraryRuntime Math Library
There are two types of runtime math operations– __func(): direct mapping to hardware ISA
Fast but low accuracy (see prog. guide for details) Examples: __sin(x), __exp(x), __pow(x,y)
– func() : compile to multiple instructions Slower but higher accuracy (5 ulp or less) Examples: sin(x), exp(x), pow(x,y)
The -use_fast_math compiler option forces every func() to compile to __func()

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Inside the HardwareInside the Hardware
Need ~8 warps to typically saturate the MAD/SFU pipes Avoid many SFU calls (RCP,RSQ,SIN,etc) Optimized for FMUL operations SMs share instruction slots by integer ops, loads, stores,
etc and floating point operations– The more floating point you fit, the more flops you get
Keep instruction workload constant: spread fmads, memory fetches, etc

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Make your program float-safe!Make your program float-safe! Future hardware will have double precision support
– G80 is single-precision only– Double precision will have additional performance cost– Careless use of double or undeclared types may run more
slowly on G80+ Important to be float-safe (be explicit whenever you want
single precision) to avoid using double precision where it is not needed– Add ‘f’ specifier on float literals:
foo = bar * 0.123; // double assumed foo = bar * 0.123f; // float explicit
– Use float version of standard library functions foo = sin(bar); // double assumed foo = sinf(bar); // single precision explicit

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Deviations from IEEE-754Deviations from IEEE-754
Addition and Multiplication are IEEE 754 compliant– Maximum 0.5 ulp error
However, often combined into multiply-add (FMAD)– Intermediate result is truncated
Division is non-compliant (2 ulp) Not all rounding modes are supported Denormalized numbers are not supported No mechanism to detect floating-point exceptions

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
GPU Floating Point FeaturesGPU Floating Point FeaturesG80 SSE IBM Altivec Cell SPE
Precision IEEE 754 IEEE 754 IEEE 754 IEEE 754
Rounding modes for FADD and FMUL
Round to nearest and round to zero
All 4 IEEE, round to nearest, zero, inf, -inf
Round to nearest only
Round to zero/truncate only
Denormal handling Flush to zeroSupported,1000’s of cycles
Supported,1000’s of cycles
Flush to zero
NaN support Yes Yes Yes No
Overflow and Infinity support
Yes, only clamps to max norm
Yes Yes No, infinity
Flags No Yes Yes Some
Square root Software only Hardware Software only Software only
Division Software only Hardware Software only Software only
Reciprocal estimate accuracy
24 bit 12 bit 12 bit 12 bit
Reciprocal sqrt estimate accuracy
23 bit 12 bit 12 bit 12 bit
log2(x) and 2^x estimates accuracy
23 bit No 12 bit No

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
How thread blocks are How thread blocks are partitionedpartitioned
Thread blocks are partitioned into warps– Thread IDs within a warp are consecutive and increasing– Warp 0 starts with Thread ID 0
Partitioning is always the same– Thus you can use this knowledge in control flow – (Covered next)
However, DO NOT rely on any ordering between warps– If there are any dependencies between threads, you must
__syncthreads() to get correct results

Branching and Branching and DivergenceDivergence
“This way! No, that way!”

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
SIMD OperationSIMD Operation
The SM is a multithreaded SIMD machine– SIMD allows overhead of fetch-decode-schedule to be amortized
across many threads (the threads of a warp)– Implication is that higher percentage of SM area is computation
units => better perf/area than say a multicore CPU However, only works if threads are truly “coherent” (in
lock step executing the exact same instructions on different data sets)– Branches represent opportunities for thread “divergence”– When threads of a warp diverge, we lose a degree of SIMD– Loss of SIMD increases exponentially for each divergence until
all threads of a warp are executed one-at-a-time– At that point, for a warp size of W, we operate at efficiency 1/W

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Coding for Performance in the Face Coding for Performance in the Face of Branchesof Branches
If you have to branch…– Do it as little as possible– The “divergence distance” in a shader should
be as small as possible The distance between a branch that can diverge
and an instruction which “resyncs” a divergence – a join point
– SM provides means in the ISA to converge a set of threads at some common point

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Control Flow InstructionsControl Flow Instructions
Main performance concern with branching is divergence– Threads within a single warp take different paths– Different execution paths must be serialized
Avoid divergence when branch condition is a function of thread ID– Example with divergence:
If (threadIdx.x > 2) { } Branch granularity < warp size
– Example without divergence: If (threadIdx.x / WARP_SIZE > 2) { } Branch granularity is a whole multiple of warp size

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Instruction Predication in G80Instruction Predication in G80 Comparison instructions set condition codes (CC) Instructions can be predicated to write results only when CC meets
criterion (CC != 0, CC >= 0, etc.)
Compiler tries to predict if a branch condition is likely to produce many divergent warps– If guaranteed not to diverge: only predicates if < 4 instructions– If not guaranteed: only predicates if < 7 instructions
May replace branches with instruction predication
ALL predicated instructions take execution cycles– Those with false conditions don’t write their output
Or invoke memory loads and stores– Saves branch instructions, so can be cheaper than serializing
divergent paths

Memory PerformanceMemory Performance
Memory Bandwith

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Memory InstructionsMemory Instructions Memory instructions take 2 cycles per warp
– Issue global and local memory loads / stores (not cached)– Constant and texture loads (cached)– Shared memory reads / writes
Example__shared__ float shared[];__device__ float global[];shared[threadIdx.x] = global[threadIdx.x];
2 cycles to issue read from global (device) memory, 2 cycles to issue write to shared memory 200-300 cycles to read a float from global (device) memory
– But can be hidden by scheduling independent math instructions or even other loads / stores if there are enough active threads

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Memory BandwidthMemory Bandwidth Effective bandwidth depends on access patterns Minimize device memory accesses
– Much lower bandwidth than on-chip shared memory
Common CUDA kernel structure:1. Load data from global memory to shared memory2. __syncthreads()3. Process the data in shared memory with many threads4. __syncthreads() (if needed)5. Store results from shared memory to global memory
Notes:
– Steps 2-4 may be repeated, looped, etc.
– Step 4 is not necessary if there is no dependence of stored data on other threads

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Global, Local and Shared memoryGlobal, Local and Shared memory
Local and global device memory not cached on GeForce 8800 Series GPUs– High latency, launching more threads hides latency– Important to minimize accesses, optimize
coherence– Coalesce global memory accesses (more later)
Shared memory is on-chip, very high bandwidth– Low latency– Like a user-managed per-multiprocessor cache– But must be careful to avoid bank conflicts (more
later)

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Texture and Constant MemoryTexture and Constant Memory
Texture partition is cached– Uses the texture cache also used for graphics– Optimized for 2D spatial locality– Best performance when threads of a warp read
locations that are close together in 2D
Constant memory is cached– 2 cycles per address read within a single warp
Total cost 2 cycle if all threads in a warp read same address
Total cost 32 cycles if all threads read different addresses

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
RegistersRegisters
Register reads are generally “free” But delays can be caused by
– Register read-after-write dependencies– Register memory bank conflicts
Register bank conflicts are minimized by thread scheduler– No programmer control– No need to pack data into float4 or int4 types

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Data TransfersData Transfers Device memory to host memory bandwidth
much lower than device memory to device bandwidth
Minimize transfers– Intermediate data structures can be allocated,
operated on, and deallocated without ever copying them to host memory
Group transfers– One large transfer much better than many small
ones

Memory PerformanceMemory Performance
Hiding Latencies

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Highlights So FarHighlights So Far
Whenever make memory access– Make as many computations as possible to
hide latency! The same computation executed on many
data elements in parallel– Low control flow overhead
Many calculations per memory access

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Texture (Memory read) Texture (Memory read) Clustering/BatchingClustering/Batching
Use another independent Texture memory read to hide Texture memory latency– Use same thread to help hide own latency
Instead of:– TEX 0 (long latency)– Dependent MATH 0– TEX 1 (long latency)– Dependent MATH 1
Do:– TEX 0 (long latency)– TEX 1 (long latency - hidden)– MATH 0– MATH 1
Compiler handles this!– But, you must have enough non-dependent LDs and Math

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Load/Store (Memory read/write) Load/Store (Memory read/write) Clustering/BatchingClustering/Batching
Use LD to hide LD latency (non-dependent LD ops only)– Use same thread to help hide own latency
Instead of:– LD 0 (long latency)– Dependent MATH 0– LD 1 (long latency)– Dependent MATH 1
Do:– LD 0 (long latency)– LD 1 (long latency - hidden)– MATH 0– MATH 1
Compiler handles this!– But, you must have enough non-dependent LDs and Math

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Load GroupsLoad Groups
FP:LD ratio from 8:1 to 32:1 Need high data re-use for memory operands
– Mimics FP:TEX => FP:LD ratio– Higher ratios imply less memory BW to keep FP units busy– Make use of the local memory as a type of SW-controlled cache
– higher data reuse rates
Larger “LD groups”– Code programs to dispatch multiple loads before the first “use”
of a load result

Memory Access Memory Access StrategiesStrategies
Coalescing Global Memory Access

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Coalesced Loads and StoresCoalesced Loads and Stores __local__ and __device__ are not cached on G80
– Important to minimize accesses, optimize coherence
If per-thread memory accesses for a single warp form a contiguous range of addresses, accesses will be coalesced into a single access– Coalesced accesses are much faster than non-coalesced– Non-coalesced accesses are serialized
Thread N within a warp should access addressBaseAddress + size * N
– size is byte size of each read/written memory block 4, 8, or 16
– BaseAddress is aligned to 16 * size

Memory Access Memory Access StrategiesStrategies
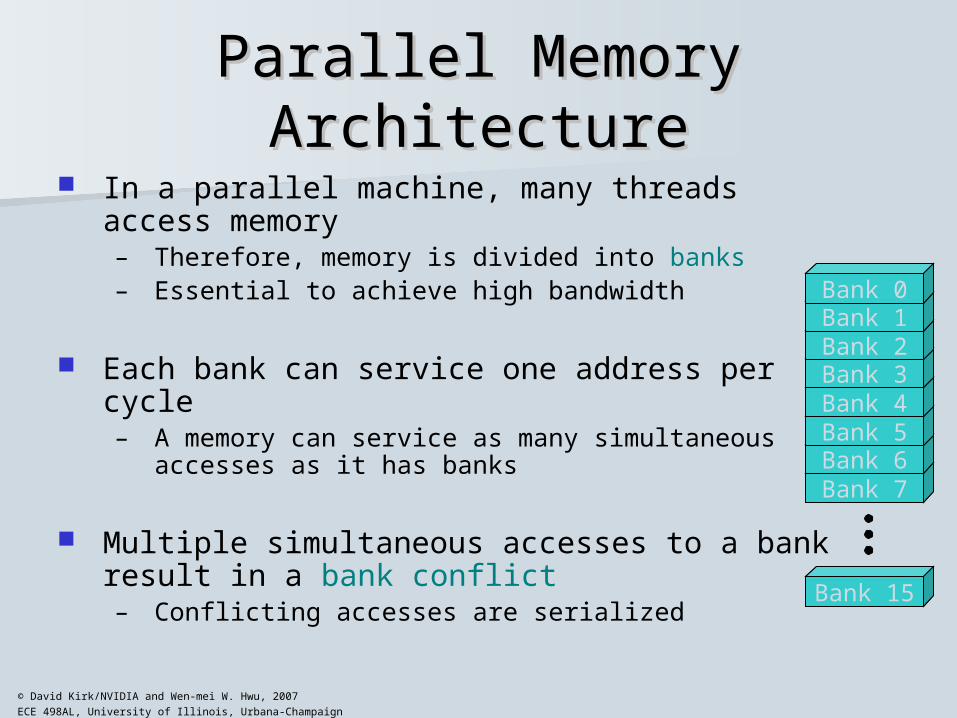
Shared Memory Bank Conflicts
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Parallel Memory ArchitectureParallel Memory Architecture
In a parallel machine, many threads access memory– Therefore, memory is divided into banks– Essential to achieve high bandwidth
Each bank can service one address per cycle– A memory can service as many simultaneous
accesses as it has banks
Multiple simultaneous accesses to a bankresult in a bank conflict – Conflicting accesses are serialized
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
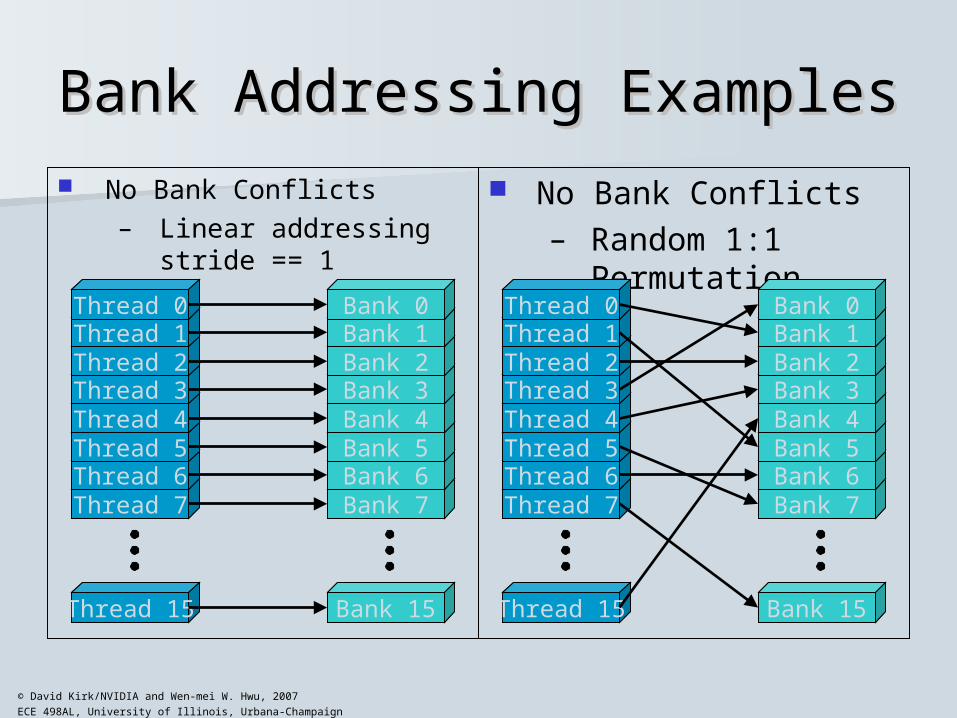
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Bank Addressing ExamplesBank Addressing Examples No Bank Conflicts
– Linear addressing stride == 1
No Bank Conflicts– Random 1:1
Permutation
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0
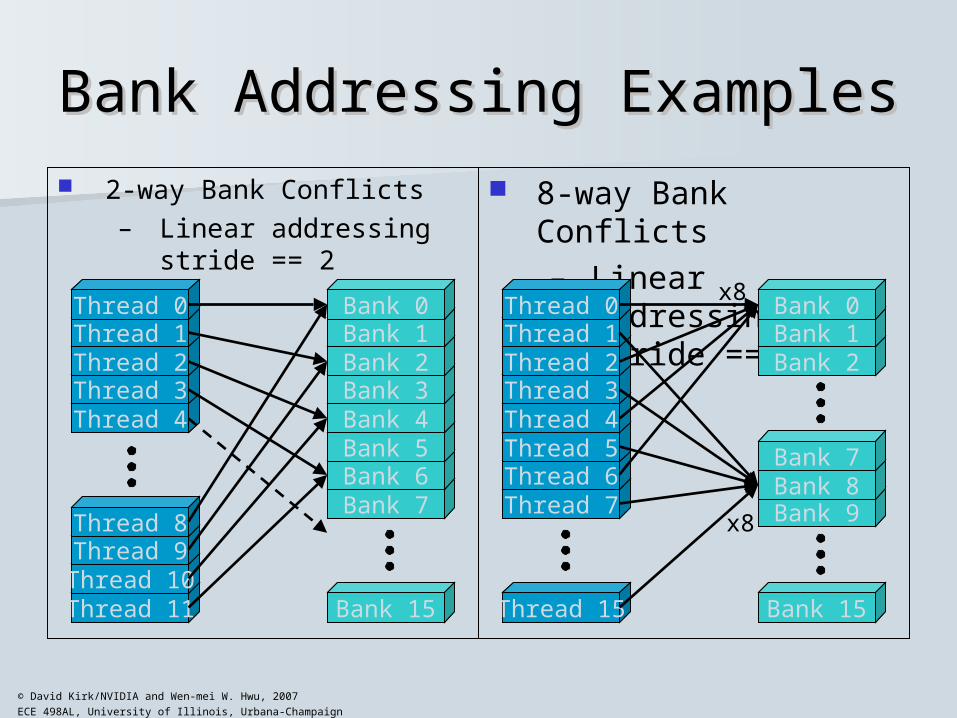
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Bank Addressing ExamplesBank Addressing Examples 2-way Bank Conflicts
– Linear addressing stride == 2
8-way Bank Conflicts– Linear addressing
stride == 8
Thread 11Thread 10Thread 9Thread 8
Thread 4Thread 3Thread 2Thread 1Thread 0
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0
Bank 9Bank 8
Bank 15
Bank 7
Bank 2Bank 1Bank 0
x8
x8

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
How addresses map to banks on G80How addresses map to banks on G80 Each bank has a bandwidth of 32 bits per
clock cycle Successive 32-bit words are assigned to
successive banks G80 has 16 banks
– So bank = address % 16– Same as the size of a half-warp
No bank conflicts between different half-warps, only within a single half-warp

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Shared memory bank conflictsShared memory bank conflicts Shared memory is as fast as registers if there are no
bank conflicts
The fast case:– If all threads of a half-warp access different banks, there is no
bank conflict– If all threads of a half-warp access the identical address, there
is no bank conflict (broadcast) The slow case:
– Bank Conflict: multiple threads in the same half-warp access the same bank
– Must serialize the accesses– Cost = max # of simultaneous accesses to a single bank

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Linear AddressingLinear Addressing Given:
__shared__ float shared[256];
float foo =
shared[baseIndex + s * threadIdx.x];
This is only bank-conflict-free if s shares no common factors with the number of banks – 16 on G80, so s must be odd
Bank 15
Bank 7
Bank 6
Bank 5
Bank 4
Bank 3
Bank 2
Bank 1
Bank 0
Thread 15
Thread 7
Thread 6
Thread 5
Thread 4
Thread 3
Thread 2
Thread 1
Thread 0
Bank 15
Bank 7
Bank 6
Bank 5
Bank 4
Bank 3
Bank 2
Bank 1
Bank 0
Thread 15
Thread 7
Thread 6
Thread 5
Thread 4
Thread 3
Thread 2
Thread 1
Thread 0
s=3
s=1
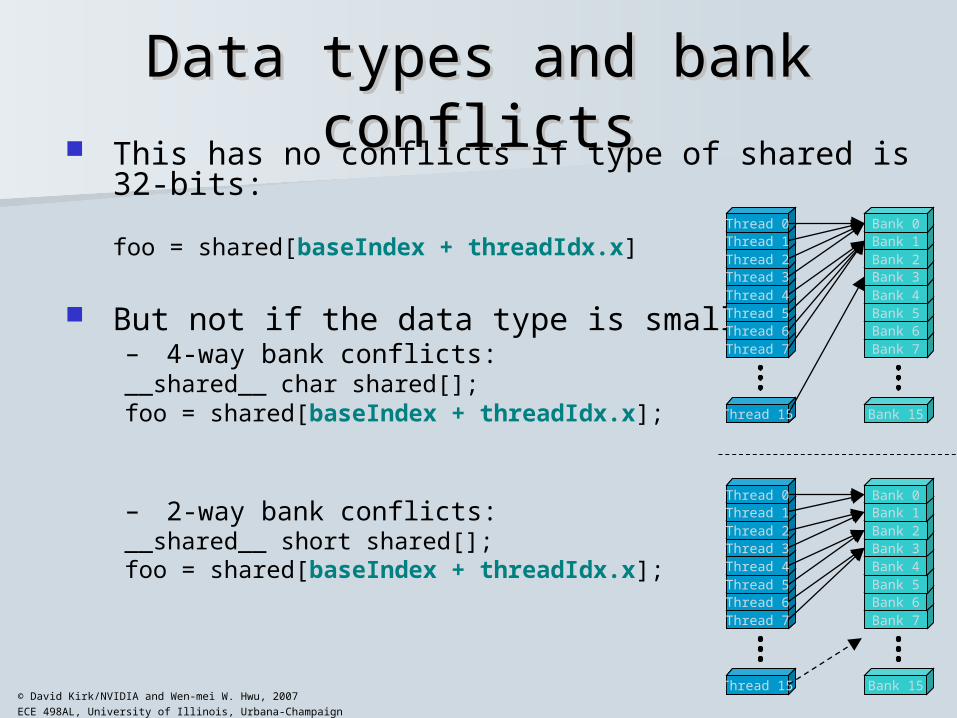
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Data types and bank conflictsData types and bank conflicts This has no conflicts if type of shared is 32-bits:
foo = shared[baseIndex + threadIdx.x]
But not if the data type is smaller– 4-way bank conflicts:__shared__ char shared[];foo = shared[baseIndex + threadIdx.x];
– 2-way bank conflicts:__shared__ short shared[];foo = shared[baseIndex + threadIdx.x];
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Structs and Bank ConflictsStructs and Bank Conflicts Struct assignments compile into as many memory accesses as
there are struct members:
struct vector { float x, y, z; };struct myType {
float f; char c;
};__shared__ struct vector vectors[64];__shared__ struct myType myTypes[64];
This has no bank conflicts; struct size is 3 words– 3 accesses per thread, contiguous banks (no common factor with
16)
struct vector v = vectors[baseIndex + threadIdx.x];
This has 2-way bank conflicts; struct size is 5 bytes (2 accesses per thread)struct myType m = myTypes[baseIndex + threadIdx.x];
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Thread 15
Thread 7Thread 6Thread 5Thread 4Thread 3Thread 2Thread 1Thread 0
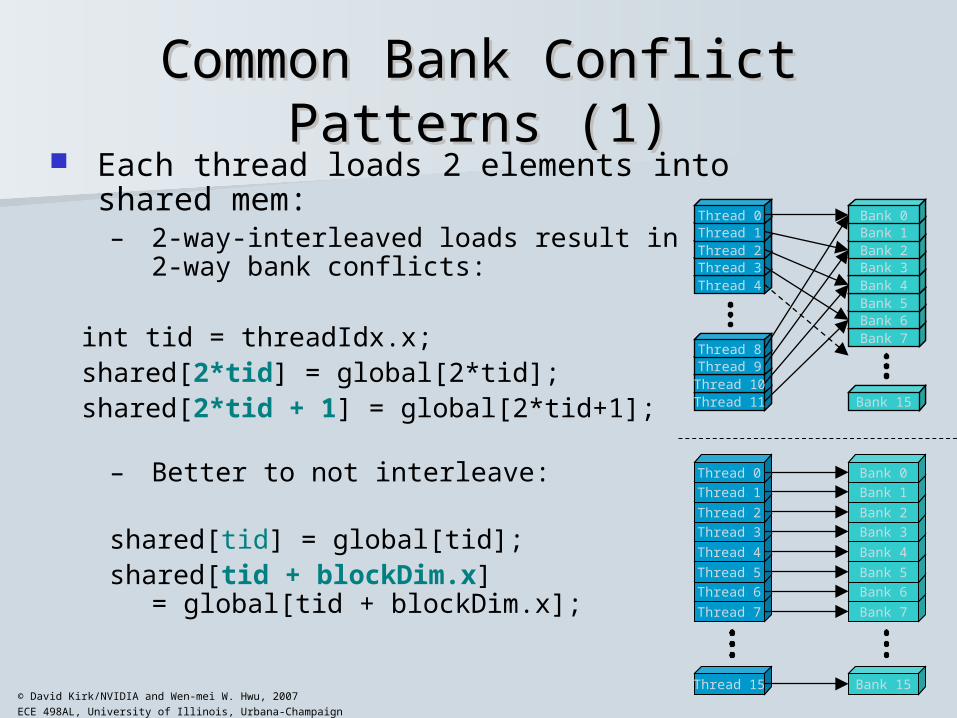
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Common Bank Conflict Patterns (1)Common Bank Conflict Patterns (1) Each thread loads 2 elements into shared
mem:– 2-way-interleaved loads result in
2-way bank conflicts:
int tid = threadIdx.x; shared[2*tid] = global[2*tid]; shared[2*tid + 1] = global[2*tid+1];
– Better to not interleave:
shared[tid] = global[tid];shared[tid + blockDim.x]
= global[tid + blockDim.x];
Thread 11Thread 10Thread 9Thread 8
Thread 4Thread 3Thread 2Thread 1Thread 0
Bank 15
Bank 7Bank 6Bank 5Bank 4Bank 3Bank 2Bank 1Bank 0
Bank 15
Bank 7
Bank 6
Bank 5
Bank 4
Bank 3
Bank 2
Bank 1
Bank 0
Thread 15
Thread 7
Thread 6
Thread 5
Thread 4
Thread 3
Thread 2
Thread 1
Thread 0

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Common Bank Conflict Patterns (2)Common Bank Conflict Patterns (2) Operating on 2D array of floats in
shared memory– e.g. image processing
Example: 16x16 block– Each thread processes a row– So threads in a block access the columns
simultaneously (example: row 1 in purple)– 16-way bank conflicts: rows all start at
bank 0
Solution 1) pad the rows– Add one float to the end of each row
Solution 2) transpose before processing– Suffer bank conflicts during transpose– But possibly save them later
Bank Indices without Padding0 1 2 3 4 5 6 7 150 1 2 3 4 5 6 7 150 1 2 3 4 5 6 7 150 1 2 3 4 5 6 7 150 1 2 3 4 5 6 7 150 1 2 3 4 5 6 7 150 1 2 3 4 5 6 7 150 1 2 3 4 5 6 7 15
0 1 2 3 4 5 6 7 15
0 1 2 3 4 5 6 7 151 2 3 4 5 6 7 8 02 3 4 5 6 7 8 9 13 4 5 6 7 8 9 10 24 5 6 7 8 9 10 11 35 6 7 8 9 10 11 12 46 7 8 9 10 11 12 13 57 8 9 10 11 12 13 14 7
15 0 1 2 3 4 5 6 14
01234568
15
Bank Indices with Padding

Resource Management Resource Management and Occupancyand Occupancy
Scarce Resources

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Performance VariablesPerformance Variables
Shorter programs are overhead limited Longer programs are instruction-rate
limited– Must have enough threads per thread block
– at least 192, more is better– Must have enough thread blocks – at least
32, more is better RF load balancing
– RF space commonly in high demand

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Performance Variables (2)Performance Variables (2)
Compiler quality important for good performance– Minimize register usage in CUDA programs
Reduces spilling to memory
– Interleave non-dependent FP/DATA ops maximizes issue rate
– Cluster non-dependent texture and memory reads decreases program latency

Resource Management Resource Management and Occupancyand Occupancy
Optimizing Threads per Block

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Optimizing threads per blockOptimizing threads per block Given: total threads in a grid
– Choose block size / # blocks to maximize utilization of the device
Enough threads per block to keep machine busy– Cover memory latency
Enough blocks to avoid idle multiprocessors during syncs– If multiple blocks exist that aren’t all waiting at a __syncthreads(),
machine can stay busy Blocks / multiprocessors > 2 increases efficiency
– Blocks stream through machine in pipeline fashion Per-block resources at most half of total available
– Shared memory and registers– So multiple blocks can coexist in a multiprocessor

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Optimizing threads per blockOptimizing threads per block Choose threads per block as a multiple of warp size
– Avoid wasting computation on under-populated warps More threads per block == fewer regs per thread
– Kernel invocations can fail if too many registers are used
Heuristics– Minimum: 64 threads per block
Only if multiple concurrent blocks
– 192 or 256 threads a better choice Usually still enough regs to compile and invoke successfully
– Blocks per grid > 100 to scale to future devices 1000 blocks per grid will scale across multiple generations Of course this depends on problem size

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Optimizing threads per blockOptimizing threads per block
Only up to 8 thread blocks can be active on a multiprocessor– If your block is only of size 8, max active
threads is 8x8=64 (occupancy = 64/768 = 1/12th).
A compute intensive kernel with few threads per block may be faster– 64 threads/block with loop unrolling nearly 2x
faster than 256 threads/block without unrolling

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Parameterize Your ApplicationParameterize Your Application
Parameterization helps adaptation to different GPUs GPUs vary in many ways
– # of multiprocessors– Shared memory size– Register file size– Threads per block– Memory bandwidth
You can even make apps self-tuning (like FFTW)– “Experiment” mode discovers and saves optimal config

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Design EvaluationDesign Evaluation
Key questions to ask– How many threads can be supported?– How many threads are needed?– How are the data structures shared?– Is there enough work in each thread between
synchronizations to make parallel execution worthwhile?

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Design Evaluation Example – Design Evaluation Example – Matrix MultiplicationMatrix Multiplication
Each thread likely need at least 32 FOPS between synchronizations to make parallel processing worthwhile
At least 192 threads are needed in a block to fully utilize the hardware
The M and N sub-blocks of each thread group must fit into 16KB of Shared Memory
The design will likely end up with about 16 ● 16 sub-blocks given all the constraints
The minimal matrix size is around 1K elements in each dimension to make parallel execution worthwhile

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
ConclusionConclusion
CUDA and GeForce 8800 can achieve great results on data-parallel computations if you use a few performance strategies– Optimize for memory locality– Size thread blocks to maximize
multiprocessor utilization and reduce memory stalls
– Ensure memory addresses are coalesced– Avoid shared memory bank conflicts

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
General GuidelinesGeneral Guidelines Blocks count at least double of number of SMs: 16x2=32 Shared memory allocated per block should be at most half of total
available shared memory: 16 / 2 = 8k Threads per block must be a multiple of 64
– Ideally each SM has more than 192 threads– Minimum of 64 threads only if there are lots of concurrent blocks– Usually, 192 or 256 threads per block is good – Maximum is 512 threads per block
Number of blocks per grid at least 100. Maximize arithmetic intensity
– Hide memory access latencies Branches
– May not be worth it if instruction count is 5 or less– Pre-compute values if possible– Avoid branches when result may be pre-determined– Granularity of 16x16 (16x4 is ok)
Make neighboring threads follow same execution path!

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
Possible Performance HotspotsPossible Performance Hotspots(to get 100% occupancy)(to get 100% occupancy)
1. registers <= 10 2. threads/block mod 32 == 0 3. warps/block is a divisor of 24 4. shared mem/block <= 16Kb * (warps/block) / 24 - any alignment constraint? constant memory does not come into it as it is the same for all blocks and then run N * 16 * 24 / (warps/block) blocks, assuming they all execute for the
same time.
Since there are only a few thread counts that satisfy those requirements, maybe we can summarize like this:
Max registers: 10 Threads per Block........Max shared mem (bytes) 96...............................2048 128.............................2730 192.............................4096 256.............................5461 384.............................8192

© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007
ECE 498AL, University of Illinois, Urbana-Champaign
ReferencesReferences
CUDA home page– http://developer.nvidia.com/object/cuda.html
Official CUDA forum– http://forums.nvidia.com/index.php?showforum=62
University of Illinois Parallel Computing Course– http://courses.ece.uiuc.edu/ece498/al/– Presentations– Pod-casts– Nvidia chief scientist David Kirk present at all classes!– Source of inspiration for slides shown






![Estruturas de Dados - facom.ufu.brguliato/disciplinas/PP/modulo2/capitulo02[1].pdf9/8/2005 (c) Marco A. Casanova - PUC-Rio 3 Referências Waldemar Celes, Renato Cerqueira, José Lucas](https://img.pdfslide.net/doc/110x75/5cb9056288c99331688bb614/estruturas-de-dados-facomufubr-guliatodisciplinasppmodulo2capitulo021pdf982005.jpg)













![[Apostila]Estrutura de Dados - Waldemar Celes e José Lucas Rangel](https://img.pdfslide.net/doc/110x75/5571fc5549795991699704d4/apostilaestrutura-de-dados-waldemar-celes-e-jose-lucas-rangel.jpg)








