Embed Size (px)
Citation preview

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Gesture Recognition Using 3D Appearance and Motion Features
Guangqi Ye, Jason J. Corso, Gregory D. Hager
Computational Interaction and Robotics Lab
The Johns Hopkins University
Baltimore, MD

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Analogy Between Gesture and Speech

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
4DT Platform Previous work: J. Corso, D. Burschka, G. Hager,
The 4DT: Unencumbered HCI With VICs. CVPRHCI, 2003.
Geometrically and photometrically calibrated Known background

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Video Preprocessing
Acquisition
Rectification
Background Subtraction
Color Calibration

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
System Framework
Image Preprocessing
Coarse Stereo Matching
Appearance/Motion Extraction
Feature Clustering
Gesture Recognition

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Visual Feature Capturing: 3D Volume
Consider limited 3D space around object Block-based coarse stereo matching

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Motion Computation
Motion by differencing of stereo volume
kiii VV=M

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Unsupervised Learning of Feature Set
VQ: K-means approach Choice of cluster number based on
distortion analysis

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Temporal Gesture Modeling
6-state discrete forward HMMs
Multilayer Neural Network Aligning all sequences to have equal length 3-layers, 50 hidden nodes

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Experiment: Gesture Vocabulary
Push
Toggle

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Gesture Vocabulary
Swipe Left
Swipe Right

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Gesture Vocabulary
Twist
Twist
Clockwise
Anti-clockwise

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Different Feature Data Sets
Appearance volume 5x5x5=125 10x10x10=1000
Motion volume Concatenation of appearance and motion
e.g.,(125-appearance, 1000-d motion)
Combination of clustering result of appearance and motion
Form a 2-d vector of cluster identity e.g., (3, 2)

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Gesture Recognition
Training: >100 sequences for each gesture Test: >70 sequences for each gesture
Combination achieves best results
Feature Set Clusters HMM NN
Appearance 8 99.5 99.5 100.0 98.8
Motion 15 98.4 98.1 97.7 86.3
Concatenation 18 98.9 99.0 98.9 87.7
Combination 8*15=120 100.0 100.0 100.0 96.6

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Real-time Implementation Demo

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Conclusion Novel approach to extract 3D appearance
and motion cues without tracking
VQ clustering to learn gesteme
Modeling dynamic gestures using HMM, NN
Real-time implementation on 4DT
Extensive experiments achieve high recognition accuracy

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Thanks

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
3D Appearance Volume Comprehensive color normalization Coarse disparity map Consider local images
of m x n patches, perform pair-wise image matching between patches
Disparity search range [0, ( p-1 ) * w ] Dimensionality 3D volume m*n*p
10,10,10, pz,ny,mx
I,IMatch=V yz,+xryx,lzy,x,
CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
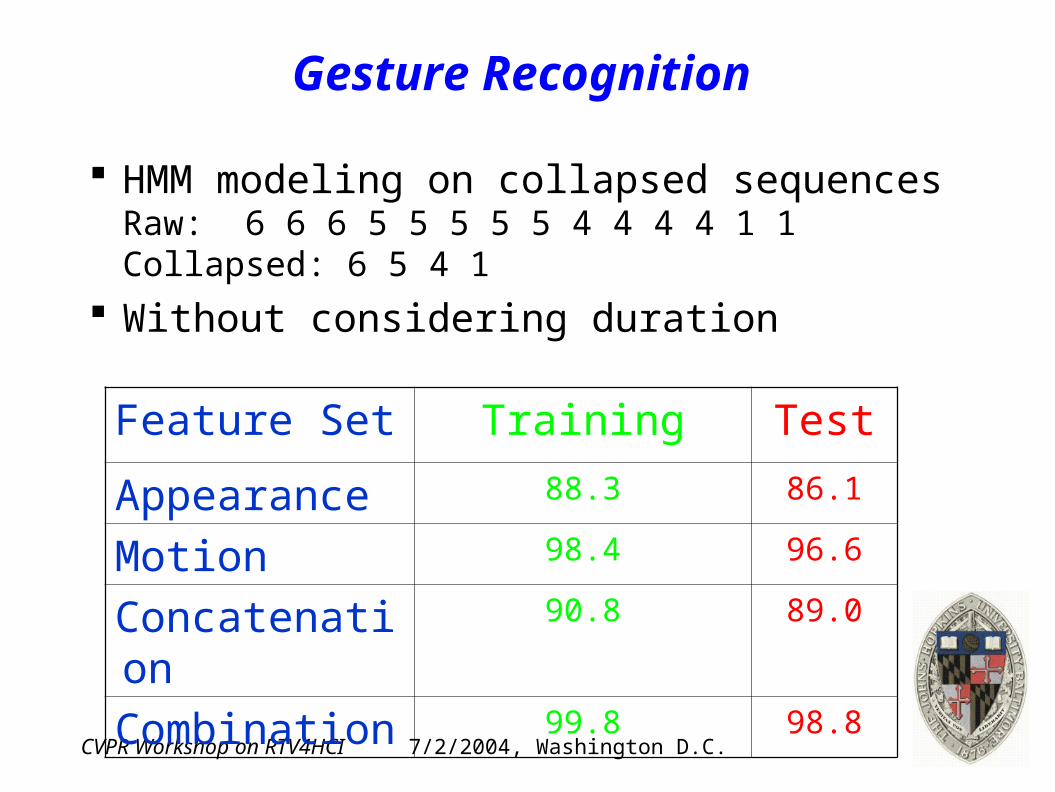
Gesture Recognition
HMM modeling on collapsed sequencesRaw: 6 6 6 5 5 5 5 5 4 4 4 4 1 1Collapsed: 6 5 4 1
Without considering duration
Feature Set Training Test
Appearance 88.3 86.1
Motion 98.4 96.6
Concatenation 90.8 89.0
Combination 99.8 98.8

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
4DT Platform
Gestures in visual HCI: popular choice
Manipulative gesture modeling without tracking Difficulty of reliable tracking of hand Complexity of hand modeling
3D data acquisitionLimitation of 2D cues for modeling handStereo matching Special sensors

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.
Properties of 4DT
Known background & object properties

CVPR Workshop on RTV4HCI 7/2/2004, Washington D.C.




























